JAVA I/O
- 序列化: 将数据结构或对象转换成二进制字节流的过程
- 反序列化:将在序列化过程中所生成的二进制字节流转换成数据结构或者对象的过程
对于 Java 这种面向对象编程语言来说,我们序列化的都是对象(Object)也就是实例化后的类(Class),但是在 C++这种半面向对象的语言中,struct(结构体)定义的是数据结构类型,而 class 对应的是对象类型
:序列化的主要目的是通过网络传输对象或者说是将对象存储到文件系统、数据库、内存中。
Java 序列化中如果有些字段不想进行序列化,怎么办?
对于不想进行序列化的变量,使用 transient 关键字修饰。
transient 关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复。
关于 transient 还有几点注意:
transient只能修饰变量,不能修饰类和方法。transient修饰的变量,在反序列化后变量值将会被置成类型的默认值。例如,如果是修饰int类型,那么反序列后结果就是0。static变量因为不属于任何对象(Object),所以无论有没有transient关键字修饰,均不会被序列化。
i/o
I/O(Input/Outpu) 即输入/输出 。
从计算机结构的视角来看的话, I/O 描述了计算机系统与外部设备之间通信的过程。
从应用程序的视角来看的话,我们的应用程序对操作系统的内核发起 IO 调用(系统调用),操作系统负责的内核执行具体的 IO 操作。也就是说,我们的应用程序实际上只是发起了 IO 操作的调用而已,具体 IO 的执行是由操作系统的内核来完成的。
当应用程序发起 I/O 调用后,会经历两个步骤:
- 内核等待 I/O 设备准备好数据
- 内核将数据从内核空间拷贝到用户空间。
IO 模型
UNIX 系统下, IO 模型一共有 5 种: 同步阻塞 I/O、同步非阻塞 I/O、I/O 多路复用、信号驱动 I/O 和异步 I/O。
Java 中 3 种常见 IO 模型
同步阻塞 IO 模型 BIO
同步阻塞 IO 模型中,应用程序发起 read 调用后,会一直阻塞,直到内核把数据拷贝到用户空间。在客户端连接数量不高的情况下,是没问题的。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的
同步非阻塞 I/O NIO
Java 中的 NIO ,有一个非常重要的选择器 ( Selector ) 的概念,也可以被称为 多路复用器。通过它,只需要一个线程便可以管理多个客户端连接。当客户端数据到了之后,才会为其服务
同步阻塞 IO 模型,同步非阻塞 IO 模型确实有了很大改进。通过轮询操作,避免了一直阻塞 应用程序不断进行 I/O 系统调用轮询数据是否已经准备好的过程是十分消耗 CPU 资源的。这个时候,I/O 多路复用模型 就上场
IO 多路复用模型
IO 多路复用模型中,线程首先发起 select 调用,询问内核数据是否准备就绪,等内核把数据准备好了,用户线程再发起 read 调用。read 调用的过程(数据从内核空间 -> 用户空间)还是阻塞的。
目前支持 IO 多路复用的系统调用,有 select,epoll 等等。select 系统调用,目前几乎在所有的操作系统上都有支持。
- select 调用 :内核提供的系统调用,它支持一次查询多个系统调用的可用状态。几乎所有的操作系统都支持。
- epoll 调用 :linux 2.6 内核,属于 select 调用的增强版本,优化了 IO 的执行效率。
IO 多路复用模型,通过减少无效的系统调用,减少了对 CPU 资源的消耗。
异步 IO
异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
分类

Java IO 流的 40 多个类都是从如下 4 个抽象类基类中派生出来的。
- InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。
- OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
既然有了字节流,为什么还要有字符流
字符流是由 Java 虚拟机将字节流转换得到的,这个过程还算是非常耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。
所以, I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好
节点流
字符流 字符 读取文本文件 ,哪怕是汉字也可以,但是字节流读汉字会乱码
字节流 字节 读取 图片视频文件
综上 建议: 对于文本文件 (.txt .java .cpp等)用字符流读
对于非文本文件 用字节流读
字符流
import java.io.*; import java.util.*; public class Fileduchu { public static void testFileReader1() { FileReader fr = null; try { File file = new File("a.txt"); fr = new FileReader(file); int data; // fr.read 返回读入的一个字符,如果达到文件末尾返回-1 while ((data = fr.read()) != -1) { System.out.print((char) data); } } catch (Exception e) { e.printStackTrace(); // TODO: handle exception } finally { try { if (fr != null) fr.close(); } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } } } public static void testFileReader2() { FileReader fr = null; try { File file = new File("a.txt"); fr = new FileReader(file); char buf[] = new char[5]; int len; // read(char[]buf ):返回每次读入的buf数组中的字符个数,如果达到文件末尾返回-1 while ((len = fr.read(buf)) != -1) { for (char x : buf) { System.out.print(x); } } } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } } public static void main(String[] args) { testFileReader1();// helloworld123 testFileReader2();// helloworld123ld } }
明显
testFileReader2();// helloworld123ld 不对
原因
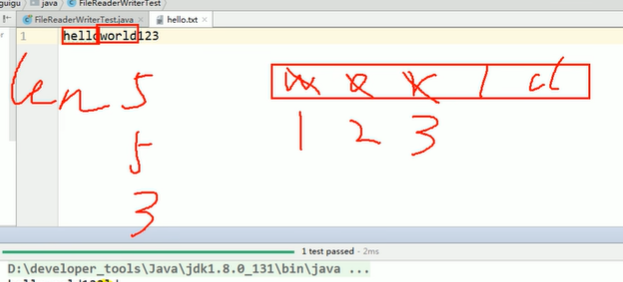
修改 testFileReader2();
for (int i = 0; i < len; i++) { System.out.print(buf[i]); }
helloworld123
文本文件读取和复制
import java.util.*; import java.io.*; public class Filechu { public static void FileWriter1() { FileWriter fw = null; try { File file = new File("a1.txt");// 如果a1.txt 不存在 会自定生成 fw = new FileWriter(file, false);// 第二个参数 : true 表示会在a1.txt末尾追加(如果a1.txt已经存在) // 。false 不在原有文件追加 覆盖原文件 fw.write("000\n"); fw.write("153631111"); } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } finally { try { if (fw != null) { fw.close(); } } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } } } public static void filecopy() { File srcfile = new File("a.txt"); File dstFile = new File("ad.txt"); FileReader fr = null; FileWriter fw = null; try { fr = new FileReader(srcfile); fw = new FileWriter(dstFile); char buf[] = new char[5]; int len; while ((len = fr.read(buf)) != -1) { fw.write(buf, 0, len); } } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } finally { if (fr != null) { try { fr.close(); } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } } if (fw != null) { try { fw.close(); } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } } } } public static void main(String[] args) { // FileWriter1(); filecopy(); } }
FileInputStream 不能读取文本文件
import java.util.*; import java.io.*; public class Fileinputs { public static void filese() { File file = new File("a.txt"); FileInputStream fileins = null; try { fileins = new FileInputStream(file); byte buf[] = new byte[5]; int len; while ((len = fileins.read(buf)) != -1) { String str = new String(buf, 0, len); System.out.println(str); } } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } finally { try { if (fileins != null) { fileins.close(); } } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } } } public static void main(String[] args) { filese(); } }
hello
world
123
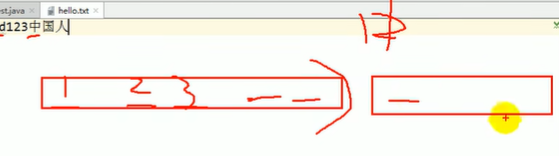
所以当a.txt :helloworld123中国人
读取结果:helloworld123涓浗?汉
用字符流来读就没问题
非文本文件的读取和复制
import java.util.*; import java.io.*; public class Fileinputs { public static void filese() { File file = new File("a.txt"); FileInputStream fileins = null; try { fileins = new FileInputStream(file); byte buf[] = new byte[5]; int len; while ((len = fileins.read(buf)) != -1) { String str = new String(buf, 0, len); System.out.print(str); } } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } finally { try { if (fileins != null) { fileins.close(); } } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } } } public static void filetucopy(String srcpath, String dstpath) { File srcfile = new File(srcpath); File dstfile = new File(dstpath); FileInputStream fileins = null; FileOutputStream fileout = null; try { fileins = new FileInputStream(srcfile); fileout = new FileOutputStream(dstfile); byte buf[] = new byte[1024]; int len; while ((len = fileins.read(buf)) != -1) { fileout.write(buf, 0, len); } } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } finally { if (fileins != null) { try { fileins.close(); } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } } if (fileout != null) { try { fileout.close(); } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } } } } public static void main(String[] args) { String srcpath = "E:\\home\\work\\qiuzhaozhunbei\\code\\IO\\01.7z"; String dstpath = "E:\\home\\work\\qiuzhaozhunbei\\code\\IO\\02.7z"; long timesta = System.currentTimeMillis(); filetucopy(srcpath, dstpath); long timeend = System.currentTimeMillis(); System.out.println(timeend - timesta);// 696 } }
缓冲流

缓冲流 字节型 复制 非文本文件
import java.util.*; import java.io.*; public class Bufferinputs { public static void buffrtincopy(String srcpath, String dstpath) { File srcfile = new File(srcpath); File dstFile = new File(dstpath); FileInputStream fins = null; FileOutputStream fouts = null; BufferedInputStream bufins = null; BufferedOutputStream bufouts = null; try { fins = new FileInputStream(srcfile); fouts = new FileOutputStream(dstFile); bufins = new BufferedInputStream(fins);// 对应FileInputStream ,FileReader 不行 bufouts = new BufferedOutputStream(fouts); byte buf[] = new byte[1024]; int len; while ((len = bufins.read(buf)) != -1) { bufouts.write(buf, 0, len); } } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } finally { // 这里的关闭要有顺序,先关闭外层的 bufins和bufouts。再关闭内层的fins和fouts // 但是 bufins和bufouts一旦关闭,fins和fouts会自动关闭 if (bufins != null) { try { bufins.close(); } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } } if (bufouts != null) { try { bufouts.close(); } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } } } } public static void main(String[] args) { String srcpath = "E:\\home\\work\\qiuzhaozhunbei\\code\\IO\\01.7z"; String dstpath = "E:\\home\\work\\qiuzhaozhunbei\\code\\IO\\03.7z"; long timesta = System.currentTimeMillis(); buffrtincopy(srcpath, dstpath); long timeend = System.currentTimeMillis(); System.out.println(timeend - timesta);// 78 } }
System.out.println(timeend - timesta);// 78
同时在非文本文件的读取和复制中
System.out.println(timeend - timesta);// 696
696>78 对比时要注意
byte buf[] = new byte[1024]; 都是1024 ,也就是要相等
说明缓冲流可以提升读取效率
提升效率的原因:内部提供了一个缓冲区缓冲流 字符型 复制 文本文件
import java.util.*; import java.io.*; public class Bufferinputs { public static void buffrtincopywen(String srcpath, String dstpath) { File srcfile = new File(srcpath); File dstFile = new File(dstpath); FileReader fins = null; FileWriter fouts = null; BufferedReader bufins = null; BufferedWriter bufouts = null; try { fins = new FileReader(srcfile); fouts = new FileWriter(dstFile); bufins = new BufferedReader(fins);// bufouts = new BufferedWriter(fouts); char buf[] = new char[1024]; int len; // 方式1 // while ((len = bufins.read(buf)) != -1) { // bufouts.write(buf, 0, len); //会自动换行 // } // 方式2 String data; while ((data = bufins.readLine()) != null) { bufouts.write(data);// 不会自动换行 bufouts.newLine(); } } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } finally { // 这里的关闭要有顺序,先关闭外层的 bufins和bufouts。再关闭内层的fins和fouts // 但是 bufins和bufouts一旦关闭,fins和fouts会自动关闭 if (bufins != null) { try { bufins.close(); } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } } if (bufouts != null) { try { bufouts.close(); } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } } } } public static void main(String[] args) { String srcpath = "E:\\home\\work\\qiuzhaozhunbei\\code\\IO\\a.txt"; String dstpath = "E:\\home\\work\\qiuzhaozhunbei\\code\\IO\\a2.txt"; long timesta = System.currentTimeMillis(); buffrtincopywen(srcpath, dstpath); long timeend = System.currentTimeMillis(); System.out.println(timeend - timesta);// 78 } }
转换流

import java.util.*; import java.io.*; public class inputreader { public static void zhuan() { File file = new File("a.txt"); FileInputStream fins = null; InputStreamReader inrea = null; try { fins = new FileInputStream(file); inrea = new InputStreamReader(fins, "UTF-8"); //解决字符乱码问题 char buf[] = new char[1024]; int len; while ((len = inrea.read(buf)) != -1) { String str = new String(buf, 0, len); System.out.println(str); } } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } finally { if (fins != null) { try { fins.close(); } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } } if (inrea != null) { try { inrea.close(); } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } } } } public static void main(String[] args) { zhuan(); } }
总结
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号