Pandas 简介
学习目标:
- 大致了解 pandas 库的
DataFrame和Series数据结构 - 存取和处理
DataFrame和Series中的数据 - 将 CSV 数据导入 pandas 库的
DataFrame - 对
DataFrame重建索引来随机打乱数据
基本概念
以下行导入了 pandas API 并输出了相应的 API 版本:
from __future__ import print_function
import pandas as pd
%matplotlib inline
pd.__version__
创建 Series 的一种方法是构建 Series 对象。例如:
pd.Series(['San Francisco', 'San Jose', 'Sacramento'])
您可以将映射 string 列名称的 dict 传递到它们各自的 Series,从而创建DataFrame对象。如果 Series 在长度上不一致,系统会用特殊的 NA/NaN 值填充缺失的值。例如:
city_names = pd.Series(['San Francisco', 'San Jose', 'Sacramento'])
population = pd.Series([852469, 1015785, 485199]
pd.DataFrame({ 'City name': city_names, 'Population': population })

但是在大多数情况下,您需要将整个文件加载到 DataFrame 中。下面的示例加载了一个包含加利福尼亚州住房数据的文件。请运行以下单元格以加载数据,并创建特征定义:
california_housing_dataframe = pd.read_csv
("https://download.mlcc.google.cn/mledu-datasets/california_housing_train.csv", sep=",")
california_housing_dataframe.describe()
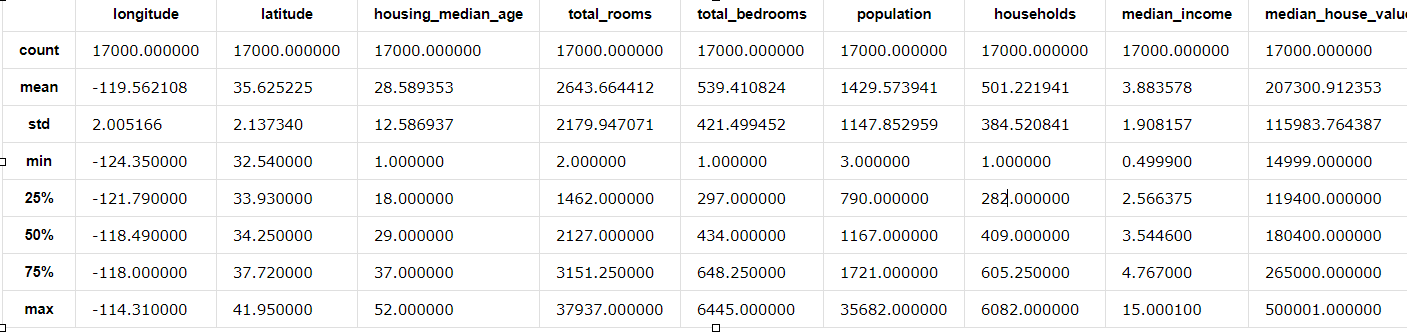
上面的示例使用 DataFrame.describe 来显示关于 DataFrame 的有趣统计信息。另一个实用函数是 DataFrame.head,它显示 DataFrame 的前几个记录:
california_housing_dataframe.head()

pandas 的另一个强大功能是绘制图表。例如,借助 DataFrame.hist,您可以快速了解一个列中值的分布:
california_housing_dataframe.hist('housing_median_age')

访问数据
您可以使用熟悉的 Python dict/list 指令访问 DataFrame 数据:
cities = pd.DataFrame({ 'City name': city_names, 'Population': population })
print(type(cities['City name']))
cities['City name']
print(type(cities['City name'][1]))
cities['City name'][1]
print(type(cities[0:2]))
cities[0:2]

此外,pandas 针对高级索引和选择提供了极其丰富的 API(数量过多,此处无法逐一列出)。
操控数据
您可以向 Series 应用 Python 的基本运算指令。例如:
population / 1000.
NumPy 是一种用于进行科学计算的常用工具包。pandas Series 可用作大多数 NumPy 函数的参数:
import numpy as np
np.log(population)
population.apply(lambda val: val > 1000000)
DataFrames 的修改方式也非常简单。例如,以下代码向现有 DataFrame 添加了两个 Series:
cities['Area square miles'] = pd.Series([46.87, 176.53, 97.92])
cities['Population density'] = cities['Population'] / cities['Area square miles']
cities
练习 1
通过添加一个新的布尔值列(当且仅当以下两项均为 True 时为 True)修改 cities 表格:
- 城市以圣人命名。
- 城市面积大于 50 平方英里。
注意:布尔值 Series 是使用“按位”而非传统布尔值“运算符”组合的。例如,执行逻辑与时,应使用 &,而不是 and。
提示:"San" 在西班牙语中意为 "saint"。
# Your code here
cities['Zong he'] = cities['City name'].apply(lambda nam:nam.startswith('San')) & (cities['Area square miles']>50)
cities
索引
Series 和 DataFrame 对象也定义了 index 属性,该属性会向每个 Series 项或 DataFrame 行赋一个标识符值。
默认情况下,在构造时,pandas 会赋可反映源数据顺序的索引值。索引值在创建后是稳定的;也就是说,它们不会因为数据重新排序而发生改变。
city_names.index
cities.index
调用 DataFrame.reindex 以手动重新排列各行的顺序。例如,以下方式与按城市名称排序具有相同的效果:
cities.reindex([2, 0, 1])
重建索引是一种随机排列 DataFrame 的绝佳方式。在下面的示例中,我们会取用类似数组的索引,然后将其传递至 NumPy 的 random.permutation 函数,该函数会随机排列其值的位置。
如果使用此重新随机排列的数组调用 reindex,会导致 DataFrame 行以同样的方式随机排列。 尝试多次运行以下单元格!
cities.reindex(np.random.permutation(cities.index))
有关详情,请参阅索引文档。
练习 2
reindex 方法允许使用未包含在原始 DataFrame 索引值中的索引值。请试一下,看看如果使用此类值会发生什么!您认为允许此类值的原因是什么?
# Your code here
cities.reindex([3,1,2])
解决方案
点击下方,查看解决方案。
如果您的 reindex 输入数组包含原始 DataFrame 索引值中没有的值,reindex 会为此类“丢失的”索引添加新行,并在所有对应列中填充 NaN 值:
cities.reindex([0, 4, 5, 2])
这种行为是可取的,因为索引通常是从实际数据中提取的字符串(请参阅 pandas reindex 文档,查看索引值是浏览器名称的示例)。
在这种情况下,如果允许出现“丢失的”索引,您将可以轻松使用外部列表重建索引,因为您不必担心会将输入清理掉。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号