线性回归
线性回归变量选择方法
- 输入(回归)(Enter (Regression))
- 一种变量选择过程,其中一个块中的所有变量在一个步骤中输入。
- Stepwise(逐步)
- 在每一步,不在方程中的具有 F 的概率最小的自变量(对因变量贡献最大)被选入(如果该概率足够小)。对于已在回归方程中的变量,如果它们的 F 概率变得足够大,那么移去这些变量。如果不再有变量符合包含或移去的条件,那么该方法终止。
- 删除(R)
- 一种变量选择过程,其中在单步中移去一个块中的所有变量。
- 向后去除 (Backward Elimination)
- 一种变量选择过程,在该过程中将所有变量输入到方程中,然后按顺序移去。会考虑将与因变量之间的部分相关性最小的变量第一个移去。如果它满足消除条件,那么将其移去。移去第一个变量之后,会考虑下一个将方程的剩余变量中具有最小的部分相关性的变量移去。直到方程中没有满足消除条件的变量,过程才结束。
- 向前选择 (Forward Selection)
- 一个逐步变量选择过程,在该过程中将变量顺序输入到模型中。第一个考虑要选入到方程中的变量是与因变量之间具有最大的正或负的相关性的变量。只要在该变量满足选入条件时才将它选入到方程中。选入了第一个变量之后,接下来考虑不在方程中的具有最大的部分相关性的自变量。当无满足选入条件的变量时,过程结束。
输出中的显著性值基于与单个模型的拟合。所以,当使用步进法(逐步式、向前或向后)时,显著性值通常无效。
无论指定什么进入方法,所有变量都必须符合容差条件才能进入方程。缺省的容差水平为 0.0001。另外,如果某个变量会导致另一已在模型中的变量的容差下降到容差条件以下,那么该变量不进入方程。
所有被选自变量将被添加到单个回归模型中。不过,您可以为不同的变量子集指定不同的进入方法。例如,您可以使用逐步式选择将一个变量块输入到回归模型中,而使用向前选择输入第二个变量块。要将第二个变量块添加到回归模型中,请单击“添加 (+)”控件。
设置规则
设置选择变量的值
- 从菜单中选择:
- 在“线性回归”对话框中,选择一个选择变量。
- 定义选择规则,以选择个案子集进行分析。选定的变量名将出现在左边。
- 从下拉列表中选择关系。可用的关系有等于、不等于、小于、小于等于、大于以及大于等于。对于字符串变量,可用关系为等于。
- 输入值或字符串。
线性回归统计
可用的统计包括:
- 回归系数
- 估计
- 显示回归系数 B、B 的标准误差、标准化系数 Beta、B 的 t 值以及 t 的双尾显著性水平。
- 回归系数(regression coefficient)在回归方程中表示自变量x 对因变量y 影响大小的参数。回归系数越大表示x 对y 影响越大,正回归系数表示y 随x 增大而增大,负回归系数表示y 随x增大而减小。例如回归方程式Y=bX+a中,斜率b称为回归系数,表示X每变动一单位,平均而言,Y将变动b单位。
- 标准回归系数,是指消除了因变量和自变量所取单位的影响之后的回归系数,其绝对值的大小直接反映了自变量对因变量的影响程度。标准化回归系数的比较结果只是适用于某一特定环境的,而不是绝对正确的,它可能因时因地而变化。
![]()
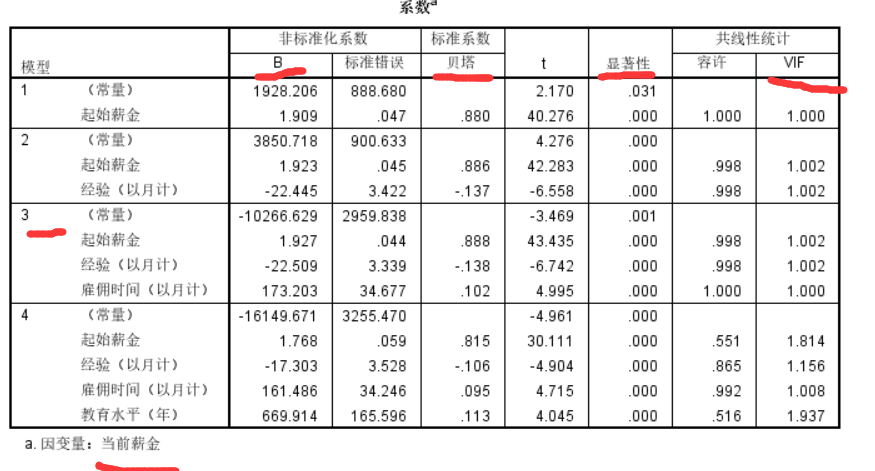
贝塔是标准化后的,因此有可比性,这里可以看到起始薪资的标准系数最大。
显著性都<0.05,都通过了显著性检验
共线性统计:VIF都较小(小于10)说明基本不存在多重共线性
通过非标准化系数就可以写出回归方程:当前薪金=起始薪金*1.927+经验*(-22.509)+雇佣时间*173.203-10266.629(以模型3为例)
- 置信区间
- 显示对于每个回归系数或协方差矩阵具有指定置信度级别的置信区间。
- 协方差矩阵
- 显示回归系数的方差-协方差矩阵,其中对角线以外为协方差,对角线为方差。还显示相关性矩阵。
- 变量分析
- 模型拟合度
- 列出输入到模型中的变量以及从模型中除去的变量,并显示以下拟合优度统计:复 R、R 2 和调整 R 2、估计的标准误差以及方差分析表。
- R 方变化
- 由于添加或删除自变量而产生的 R 2 统计变化。如果与某个变量相关联的 R 2 变化很大,那么意味着该变量是因变量的一个良好的预测变量。
![]()
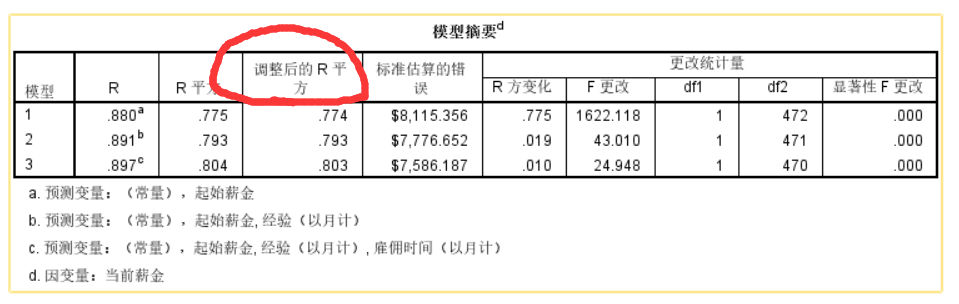
- R²是复相关系数,可以理解为这个系数值越大(R2越接近1说明回归拟合效果更好),自变量对因变量的解释就越大,(上图模型3最好)一般的回归分析里面,只需要关注R²和调整的R²就可以了,是用来说明自变量的解释效果
- 描述性
- 提供分析中的有效个案数、平均值以及每个变量的标准差。还显示具有单尾显著性水平的相关性矩阵以及每个相关系数的个案数。
- 部分相关 (Part Correlation) 和偏相关 (Partial Correlation)
- 部分相关:
- 从自变量中移除模型中其他自变量的线性效应后,因变量和该自变量之间的相关性。当变量添加到方程时,它与 R 方的更改有关。有时称为半部分相关。
- 偏相关
-
对于两个变量,在移去由于它们与其他变量之间的相互关联引起的相关性之后,这两个变量之间剩余的相关性。从因变量和自变量中移除模型中其他自变量的线性效应后,该因变量和自变量之间的相关性。
- 共线性诊断
- 由于一个自变量是其他自变量的线性函数时所引起的共线性(或多重共线性)是不被期望的。显示已标度的非中心化叉积矩阵的特征值、条件指数和方差-分解比例,以及各个变量的方差膨胀因子 (VIF) 和容差。
![]()
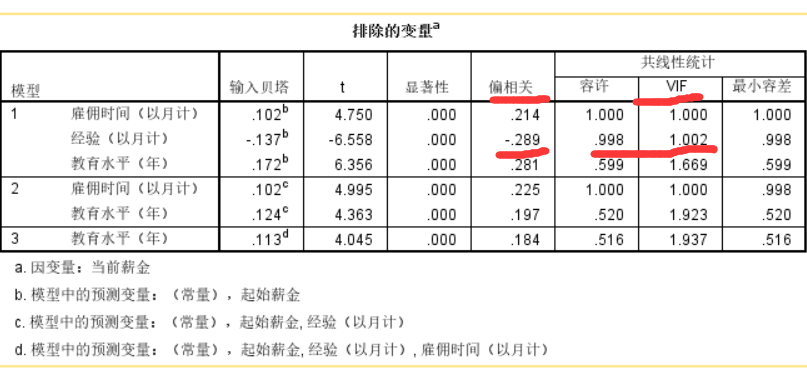
在模型1的排除变量表里面经验的偏相关最大,且此时的VIF=1.002不大即不存在共线,因此在模型2中经验被引入。
- 残差
- 显示残差的序列相关性的 Durbin-Watson 检验,以及满足选择标准(n 倍标准差以外的离群值)的个案的个案诊断信息。
请求回归统计
此功能需要 Statistics Base Edition。
- 从菜单中选择:
- 在“线性回归”对话框中,单击统计。
- 选择所需的统计。
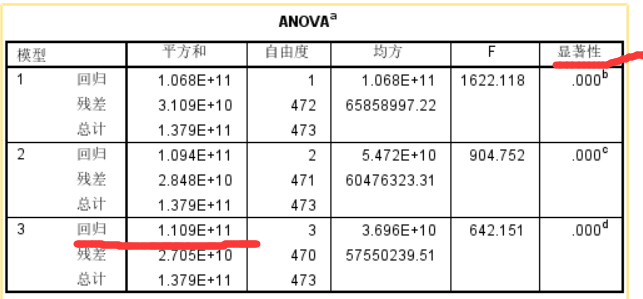
在模型3中,回归占了总计的绝大部分,说明线性模型解释了总平方和的绝大部分,说明模型拟合效果较好
图
图可以帮助验证正态性、线性相关度和方差相等的假设。对于检测离群值、异常实测值和有影响的个案,图也是有用的。将它们保存为新变量之后,在数据编辑器中可以使用预测值、残差和其他诊断信息来构造含有自变量的图。以下图是可用的:
散点图。您可以对下列各项中的任意两项进行绘图:因变量、标准化预测值、标准化残差、剔除残差、调整预测值、Student 化残差或者 Student 化剔除残差。针对标准化预测值绘制标准化残差,以检查线性相关度和等方差性。
源变量列表。列出因变量 (DEPENDNT) 及以下预测变量和残差变量:标准化预测值 (*ZPRED)、标准化残差 (*ZRESID)、剔除残差 (*DRESID)、调整的预测值 (*ADJPRED)、Student 化的残差 (*SRESID) 以及 Student 化的已删除残差 (*SDRESID)。
- 标准化残差图
- 您可以获取标准化残差的直方图以及正态概率图,将标准化残差的分布与正态分布进行比较。
- 产生所有部分图
- 当根据其余自变量分别对两个变量进行回归时,显示每个自变量残差和因变量残差的散点图。要生成部分图,方程中必须至少有两个自变量。
如果请求了任意图,那么将显示标准化预测值和标准化残差(*ZPRED 和 *ZRESID)的汇总统计。
获取回归图
此功能需要 Statistics Base Edition。
- 从菜单中选择:
- 在“线性回归”对话框中,单击图。
- 对于散点图,选择一个垂直 (y) 轴变量和一个水平 (x) 轴变量。要请求其他散点图,请单击“添加 (+)”控件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号