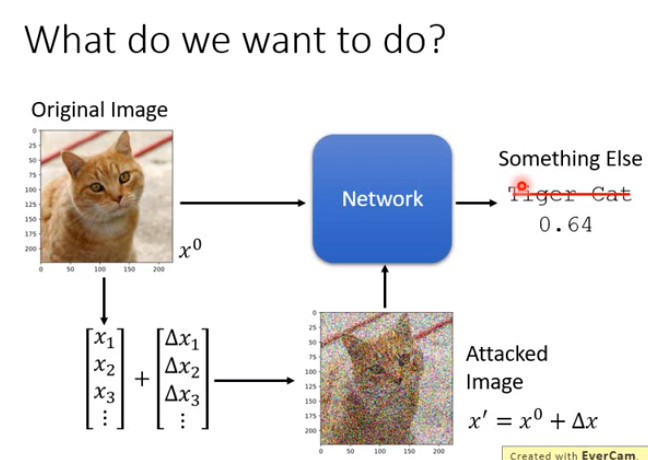
Attack ML Models

Attack
-
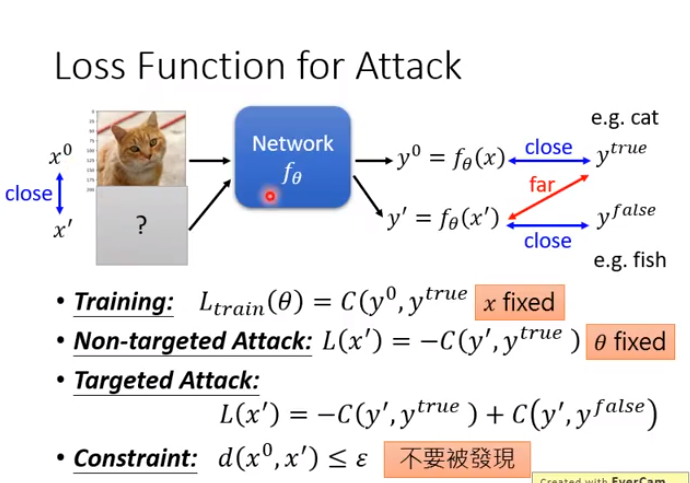
Training的Loss:固定x,修改θ,使y0接近ytrue.
-
Non-targeted Attack的Loss:固定θ,修改x,使y‘远离ytrue.
-
Targeted Attack的Loss:固定θ,修改x,使y‘远离ytrue且接近yfalse.
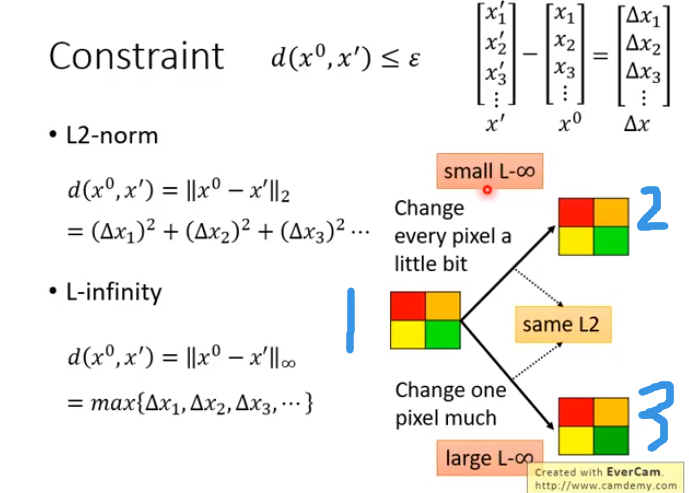
4个pixel,(RGB每个3dim)12个dim
从人类感知来看,1和2更相似,但L2-norm是一样的,那么L2-norm不能很好的表示d(,)
1,2的L-inf小些,1,3的L-inf大些.因此取决于人类感知,一般采用L-infinity

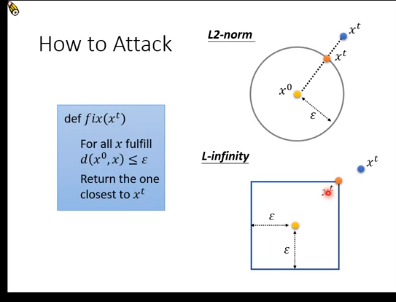
fix(xt)函数

1.00认为右图为Star Fish

50*2者的差值得到右上角的图片


Attack Approaches
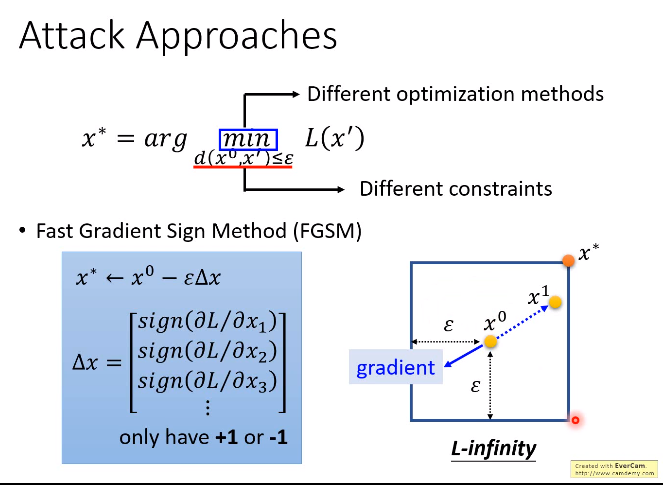
FGSM:只需要做一次update
当x>0,sign(x)=1;当x=0,sign(x)=0; 当x<0, sign(x)=-1
不同的对抗攻击方法,区别一般在于采用不同的距离限制方式与不同的优化策略.
FGSM是一种常见的对抗攻击方法,它的原理是计算出分类函数loss的梯度,
然后用sign函数将其指向四个角的方向之一,再乘上ε使其落在角上,x0减去一次该值就得到最终的x*,位于四个角其中之一.


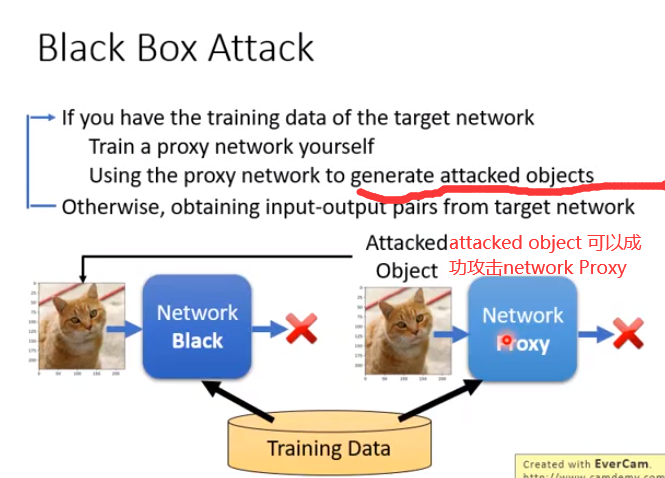
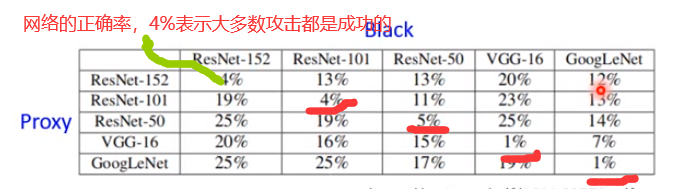

universal adversarial attack 普遍对抗攻击

把带有方块的图片夹到噪声上,再放到imageNet Classifier就可以进行方块数目识别
Defense

Passive Defense
使用Filter

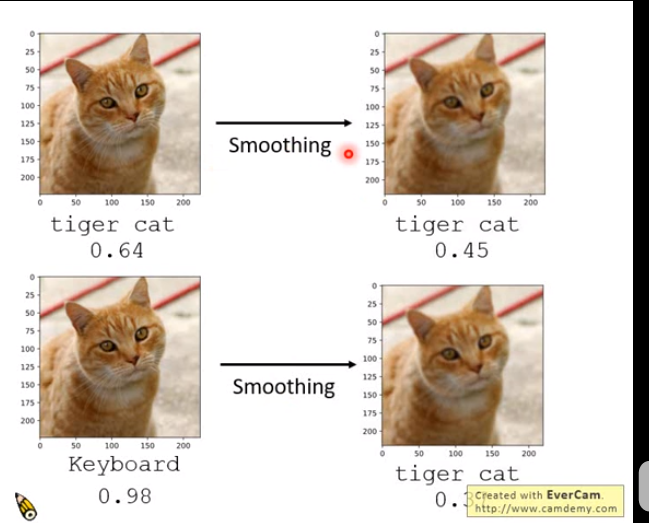
只有某几种方向的信号能让攻击成功,加入Smoothing后不会影响tiget cat,
但是Smoothing把信号改变了,那么攻击也就失效
-
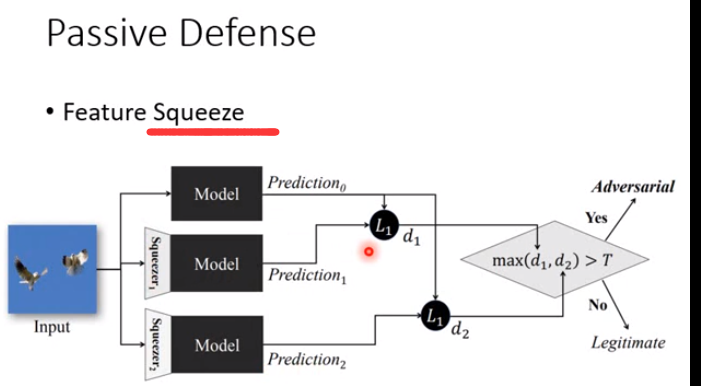
Feature Squeeze中的Squeeze即一个filter,该方法将原图像与通过多种filter后的图像预测结果进行比较,若其中有某个预测结果相差超过阈值,就认为该图像被修改过.
Randomization at Inference Phase对图像采用随机的、微小的改变,例如缩放、填充等,对改编后的图片进行分类.
但是如果你的修改被泄露,那么defense可能失败

Proactive Defene

为什么要T次循环?
一次循环后把之前的漏洞补了,但是可能出现新的漏洞,需要继续补
补漏洞:现在adversarial input 对应的label 就是原来训练集input的label,就失去了攻击的意义.
你找漏洞的算法被泄露了,那么别人可以根据其他算法进行攻击,那么又会出现漏洞

 浙公网安备 33010602011771号
浙公网安备 33010602011771号