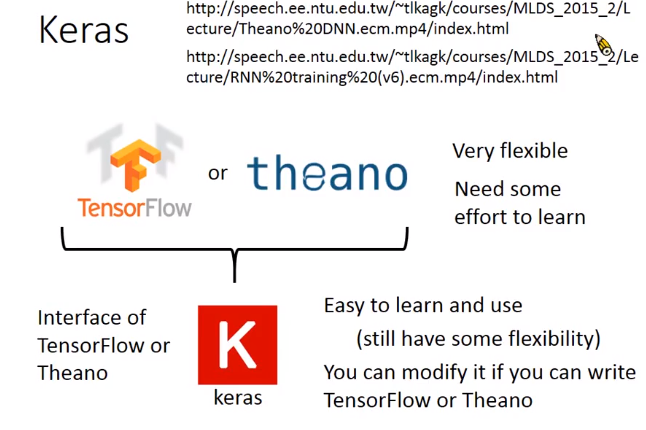
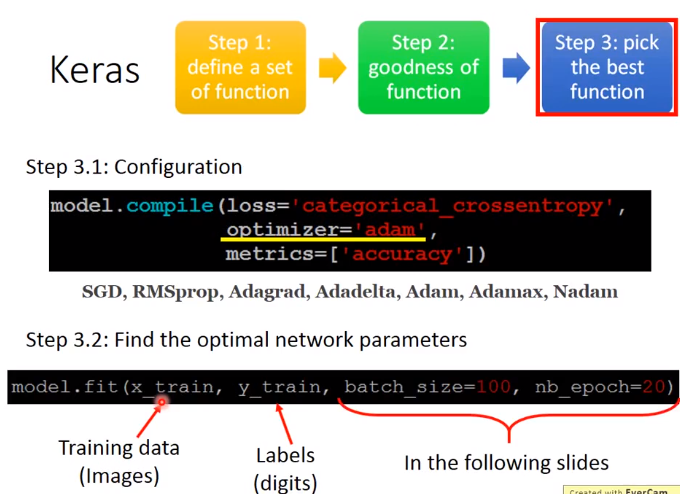
Keras
分3步进行
Mini_batch
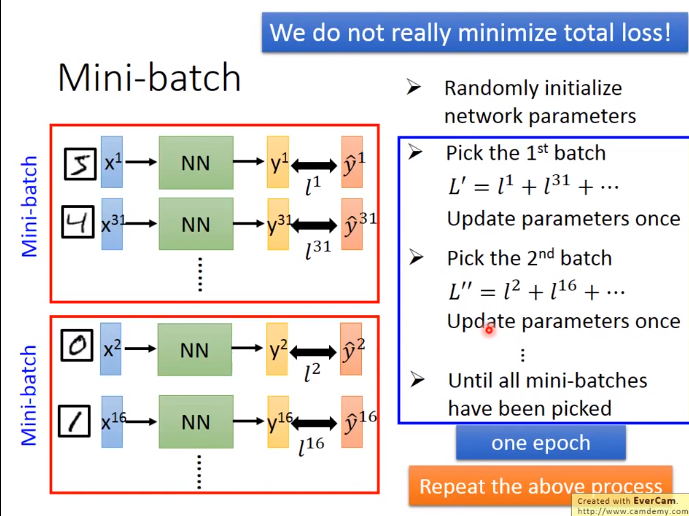
为什么要Mini_batch
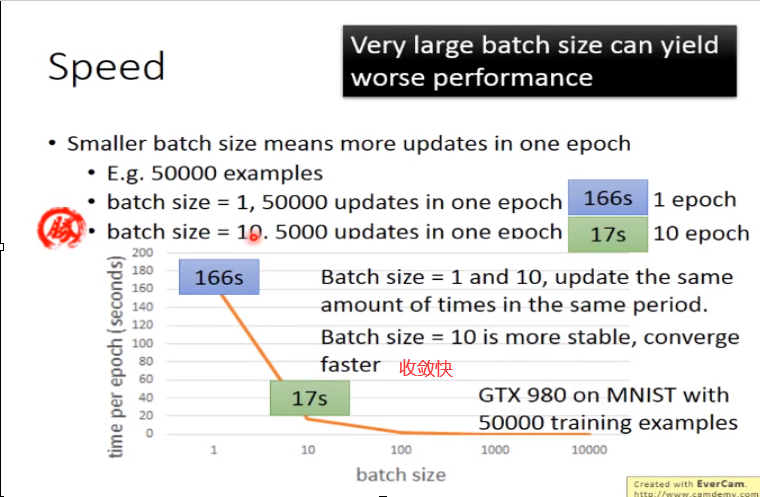
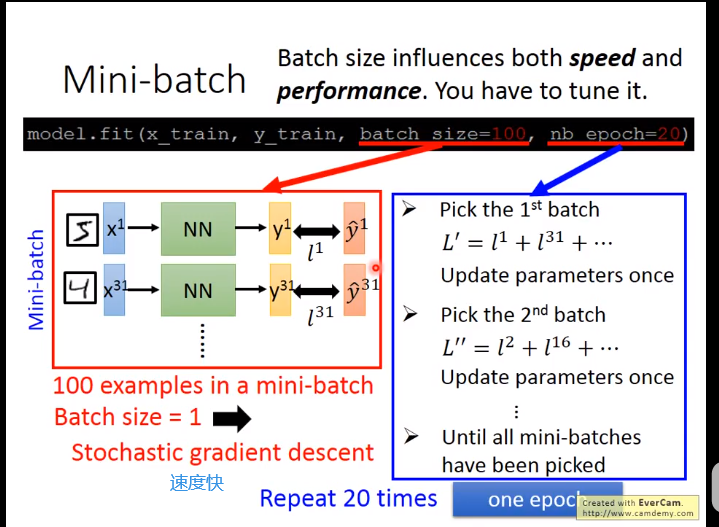
166s 放到size=10,其实相当于10 epoch(也就是说也会50000updates)
batch_size大的时候,用了平行运算(算10个examples 时间和1 example时间差不多)所以更快
但是不能设置的太大,会卡住
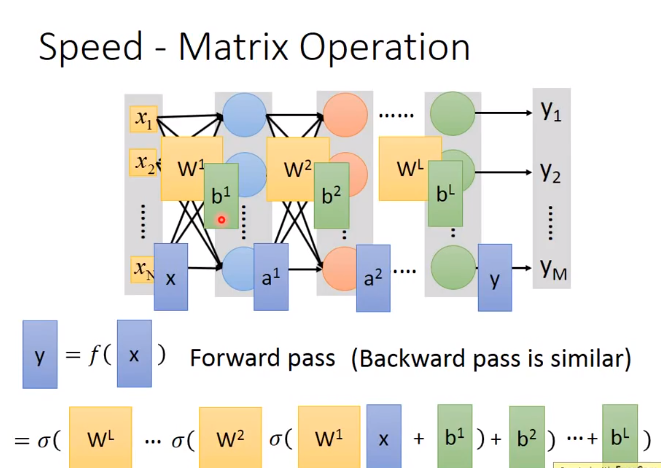

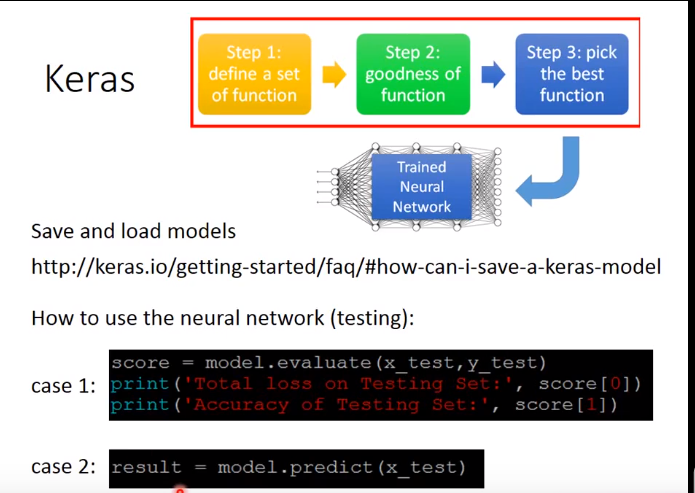


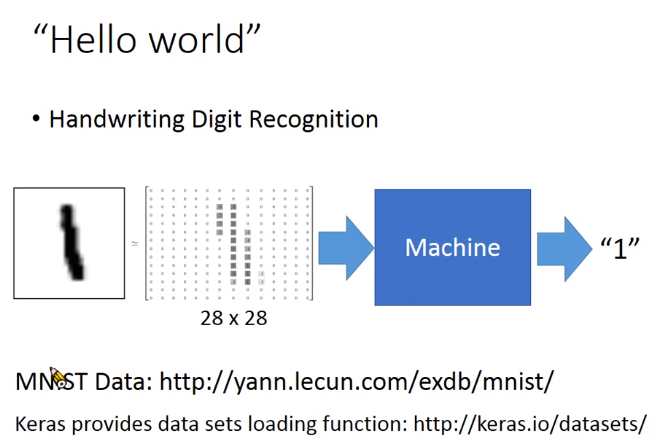
下面介绍一个基于Keras的手写数字识别的项目
初始代码
deep learning这么潮的东西,实现起来也很简单。首先是load_data进行数据载入处理。
import numpy as np
from keras.models import Sequential
from keras.layers.core import Dense,Dropout,Activation
from keras.optimizers import SGD,Adam
from keras.utils import np_utils
from keras.datasets import mnist
def load_data():
(x_train,y_train),(x_test,y_test)=mnist.load_data()
number=10000
x_train=x_train[0:number]
y_train=y_train[0:number]
x_train=x_train.reshape(number,28*28)
x_test=x_test.reshape(x_test.shape[0],28*28)
x_train=x_train.astype('float32')
x_test=x_test.astype('float32')
y_train=np_utils.to_categorical(y_train,10)
y_test=np_utils.to_categorical(y_test,10)
x_train=x_train
x_test=x_test
x_train=x_train/255
x_test=x_test/255
return (x_train,y_train),(x_test,y_test)
(x_train,y_train),(x_test,y_test)=load_data()
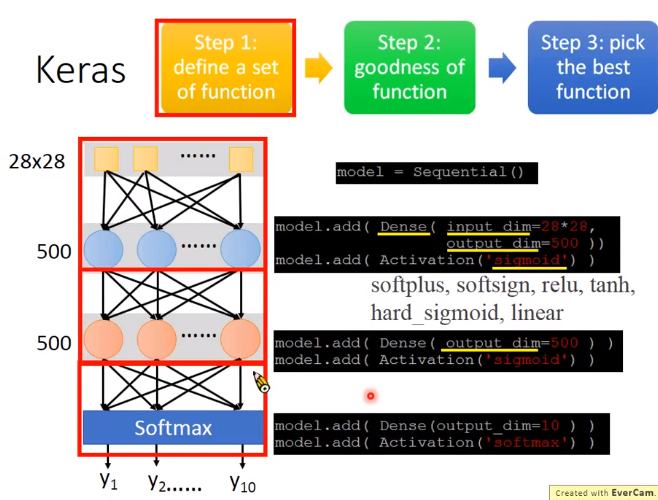
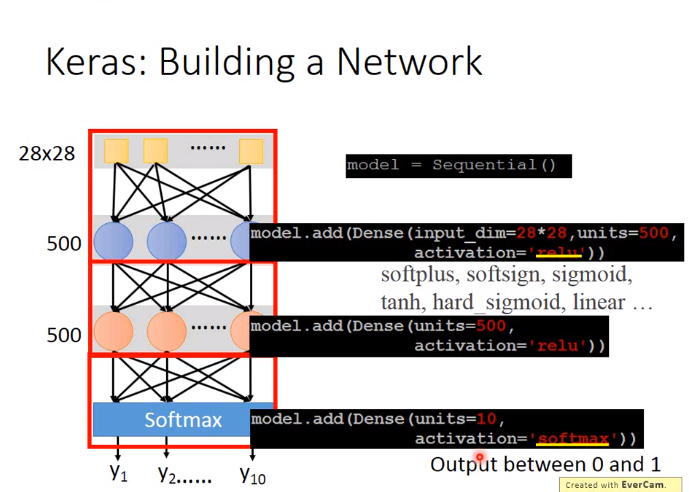
model=Sequential()
model.add(Dense(input_dim=28*28,units=633,activation='sigmoid'))
model.add(Dense(units=633,activation='sigmoid'))
model.add(Dense(units=633,activation='sigmoid'))
model.add(Dense(units=10,activation='softmax'))
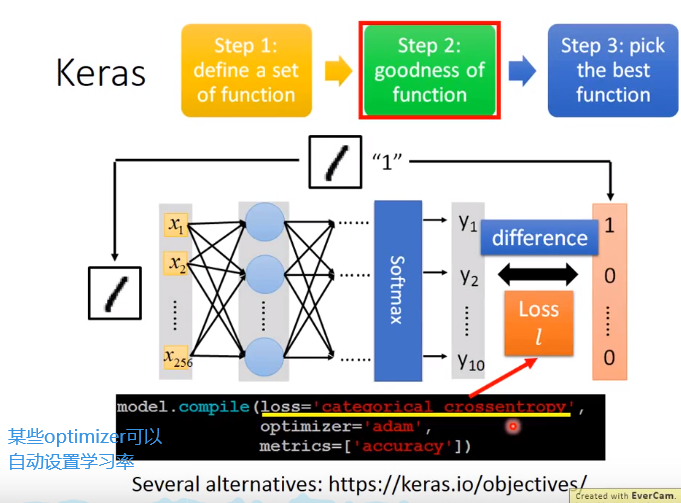
model.compile(loss='mse',optimizer=SGD(lr=0.1),metrics=['accuracy'])
model.fit(x_train,y_train,batch_size=100,epochs=20)
result= model.evaluate(x_test,y_test)
print('TEST ACC:',result[1])
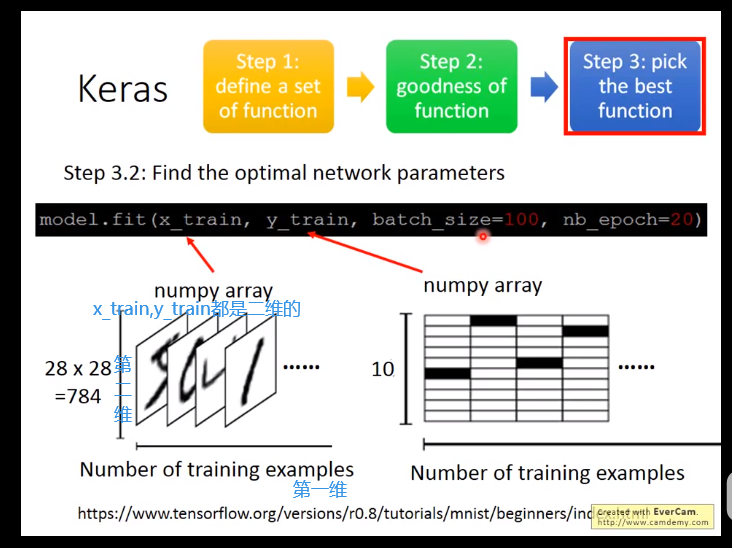
其中x_train是一个二维的向量,x_train.shape=(10000,784),这个是什么意思呢,就告诉我们现在train data一共有一万笔,
每笔由一个784维的vector所表示。y_train也是一个二维向量,y_train.shape=(10000,10),其中只有一维的数字是1,其余的为0。
结果如下图 正确率只有11.35%,感觉不太行,调一下参数~
但是访问'https://s3.amazonaws.com/img-datasets/mnist.npz'时由于被阻止无法完成数据集下载
那么可以先下载好数据集mnist.npz放到某个目录下,(我放在了E://PycharmProjects//Keras//mnist)直接获取即可。下面时mnist.npz的下载链接
链接: https://pan.baidu.com/s/1AGwxxIh2fcNWayjOBsv8TQ 提取码: fnes
同时还需要修改下load_data()
def load_data():
path = 'E://PycharmProjects//Keras//mnist//mnist.npz'
f = np.load(path)
x_train, y_train = f['x_train'], f['y_train']
x_test, y_test = f['x_test'], f['y_test']
f.close()
# (x_train,y_train),(x_test,y_test)=mnist.load_data()
number=10000
x_train=x_train[0:number]
y_train=y_train[0:number]
x_train=x_train.reshape(number,28*28)
x_test=x_test.reshape(x_test.shape[0],28*28)
x_train=x_train.astype('float32')
x_test=x_test.astype('float32')
y_train=np_utils.to_categorical(y_train,10)
y_test=np_utils.to_categorical(y_test,10)
x_train=x_train
x_test=x_test
x_train=x_train/255
x_test=x_test/255
return (x_train,y_train),(x_test,y_test)
输出的结果为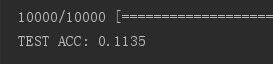
下面从几个方面优化
隐层神经元个数
model.add(Dense(input_dim=28*28,units=689,activation='sigmoid'))
model.add(Dense(units=689,activation='sigmoid'))
model.add(Dense(units=689,activation='sigmoid'))
model.add(Dense(units=10,activation='softmax'))
深度
deep learning 就是很deep的样子,那么才三层,用for添加10层
model.add(Dense(input_dim=28*28,units=689,activation='sigmoid'))
model.add(Dense(units=689,activation='sigmoid'))
model.add(Dense(units=689,activation='sigmoid'))
for _ in range(10):
model.add(Dense(units=689,activation='sigmoid'))
model.add(Dense(units=10,activation='softmax'))
但是修改后我多次运行了代码,可结果没有改变
总结
- deep learning 并不是越deep越好
- 关于deep learning 的实践,还是需要基于理论基础,而不是参数随便调来调去,所以继续跟着课程好好学。
优化
1.调节units
model.add(Dense(input_dim=28*28,units=633,activation='sigmoid'))
model.add(Dense(units=633,activation='sigmoid'))
model.add(Dense(units=633,activation='sigmoid'))
model.add(Dense(units=10,activation='softmax'))
TEST ACC: 0.1135
首先先看你在train data的performer,如果它在train data上做得好,那么可能是过拟合,如果在train data上做得不好...
result1 = model.evaluate(x_train,y_train)
print('TRAIN ACC:',result1[1])
TRAIN ACC: 0.1127
train data acc 也是差的,就说明train没有train好,并不是overfiting
2.loss function
model.compile(loss='categorical_crossentropy',optimizer=SGD(lr=0.1),metrics=['accuracy'])
TRAIN ACC: 0.8639
TEST ACC: 0.8426
ACC明显提高
3.batch_size
model.fit(x_train,y_train,batch_size=1000,epochs=20)
8288/10000 [=======================>......] - ETA: 0s
8896/10000 [=========================>....] - ETA: 0s
9504/10000 [===========================>..] - ETA: 0s
10000/10000 [==============================] - 1s 93us/step
TEST ACC: 0.1135
ACC基本没有变化,但是耗时减少了
4.deep layer 再加10层
for _ in range(10): model.add(Dense(units=689,activation='sigmoid'))
结果没有改善
5.activition function
我们把sigmoid都改为relu,发现现在train的accuracy就爬起来了,train的acc已经将近100分了,test 上也可以得到
TRAIN ACC: 0.9151
TEST ACC: 0.9029
6.normalize
现在的图片是有进行normalize,每个pixel我们用一个0-1之间的值进行表示,那么我们不进行normalize,把255拿掉会怎样呢?
把normalize 注释掉
# x_train=x_train/255 进行normalize
#x_test=x_test/255
0黑,255是白。在这两种情况下,无论饱和度、色调、亮度如何变化,都只有黑白色。
灰度图侧是在亮度不为零,饱和度和色调为零的情况下,修改红、蓝、绿色的配比而得出的颜色。彩色图侧是饱和度、色调、亮度不为零,再搭配红、蓝、绿不同的配比得出的颜色。
几乎没变化
689 normalize 11.35%
689 没有normalize 33.38%
这种小小的地方,只是有没有做normalizion,其实对你的结果会有关键性影响。
7.optimizer
把SGD改为Adam,然后再跑一次
SGD(lr=0.1) 11.35% 100us/step
model.compile(loss='mse',optimizer='adam',metrics=['accuracy'])
'adam'(有引号,不要写lr) 94.12%
8.dropout 防止overfitting
model=Sequential()
model.add(Dense(input_dim=28*28,units=689,activation='relu'))
model.add(Dropout(0.7))
model.add(Dense(units=689,activation='relu'))
model.add(Dropout(0.7))
model.add(Dense(units=689,activation='relu'))
model.add(Dropout(0.7))
model.add(Dense(units=10,activation='softmax'))
dropout之前
TRAIN ACC: 0.9151
TEST ACC: 0.9029
after dropout
TRAIN ACC: 0.605
TEST ACC: 0.5996

 浙公网安备 33010602011771号
浙公网安备 33010602011771号