classification
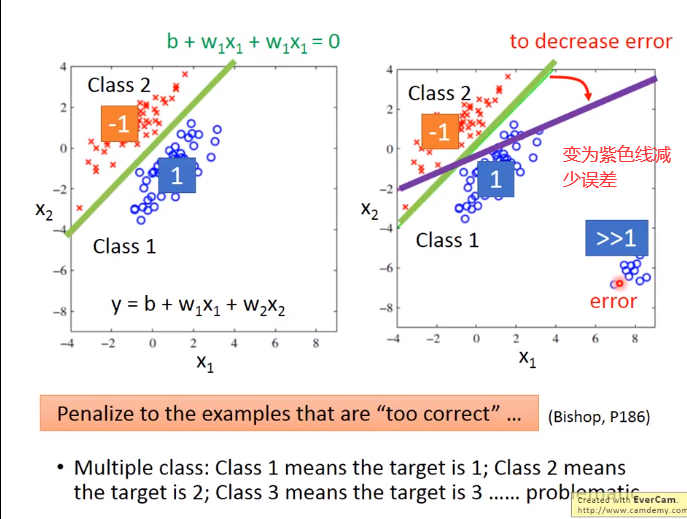
这样会认为class 1 ,class 2 接近,有某种关系
但实际没有,那么multiple class 没有好的结果
理想的方法


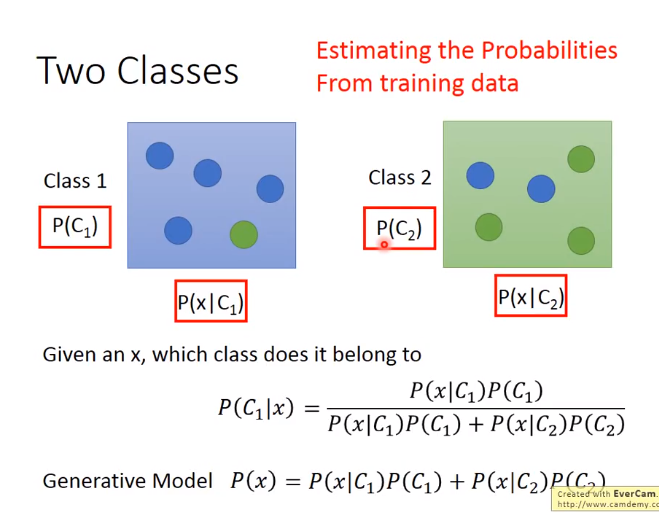
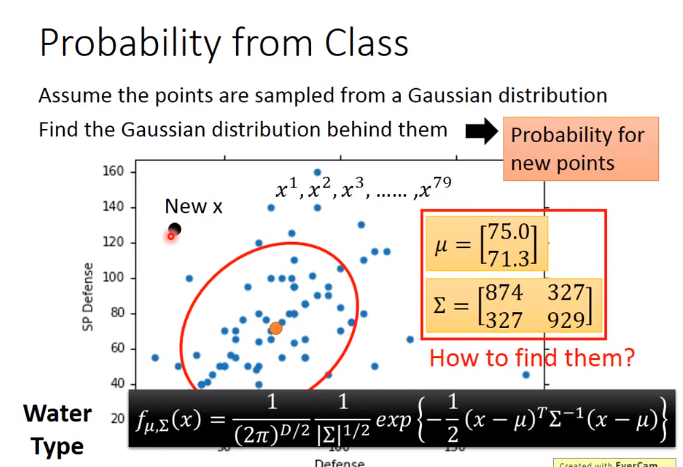
下面计算各个概率


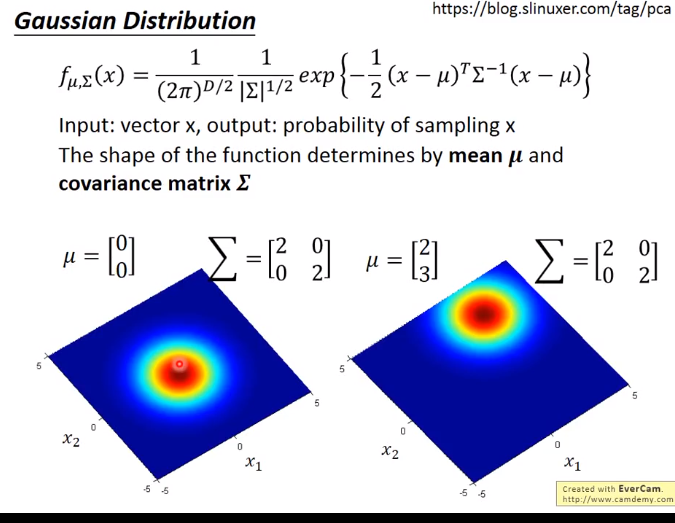
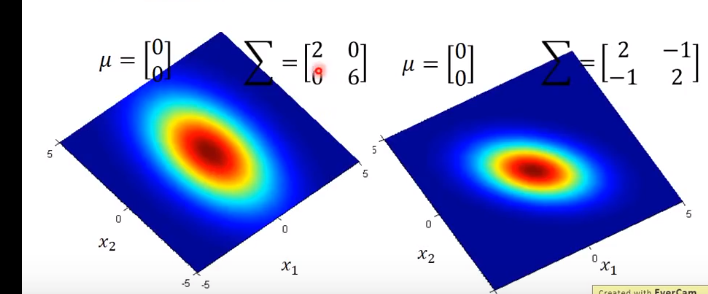
D:维度。下面的D=2
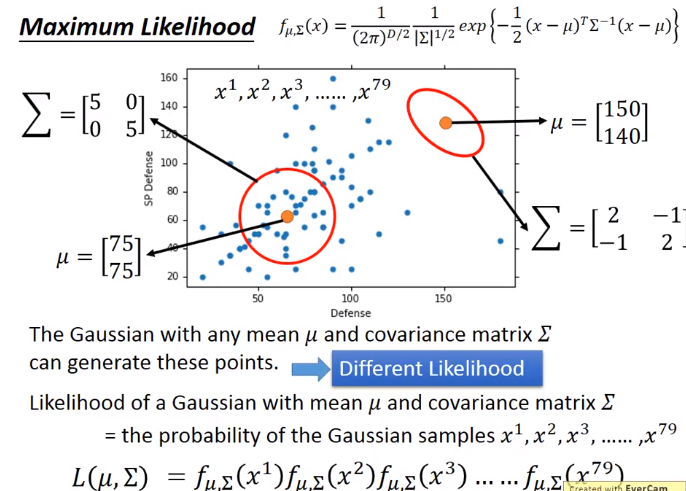
最大似然估计
每一个高斯分布都有可能产生这79个点


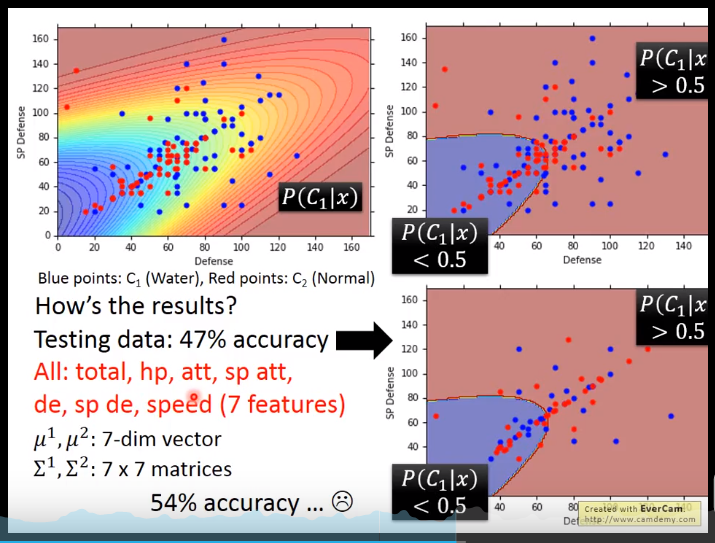
上面标明,结果不好。那么进行修改model
协方差矩阵与feature size 的平方成正比
model参数多,variance 就会大,那么容易过拟合
故意用一个协方差矩阵,则需要less feature
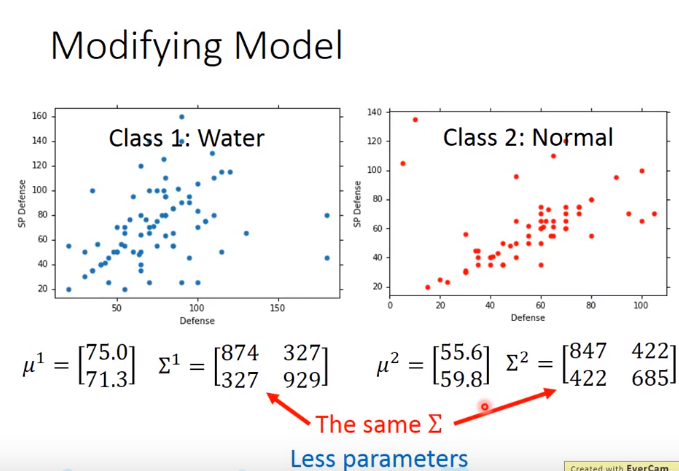

u1,u2的计算和之前算的一样,如u1 : x1......x79的均值
修改后准确率提高了
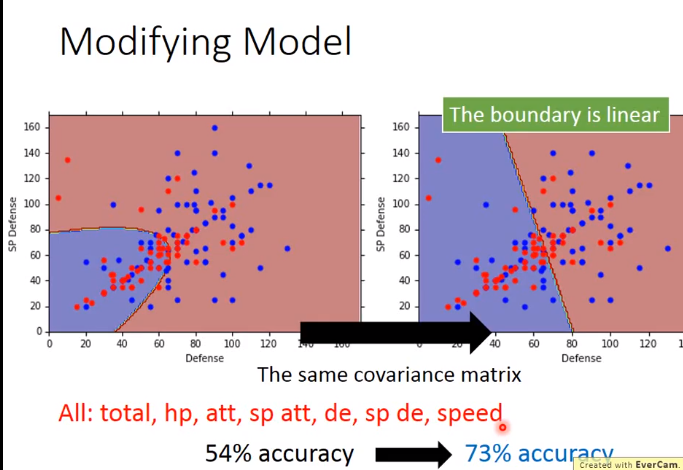
总结需要下面3步


Sigmod 函数

下面是数学公式变形

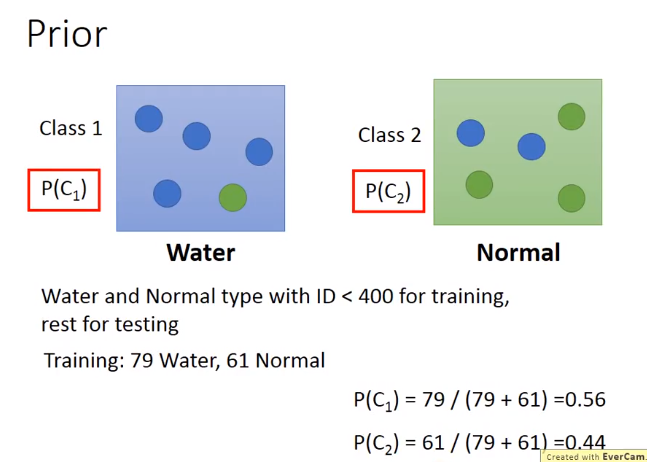
N1:class 1 占有的数目


其实z=wx+b
w:vector b:const


 浙公网安备 33010602011771号
浙公网安备 33010602011771号