regression


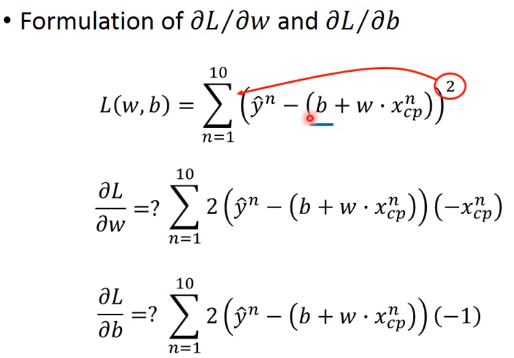


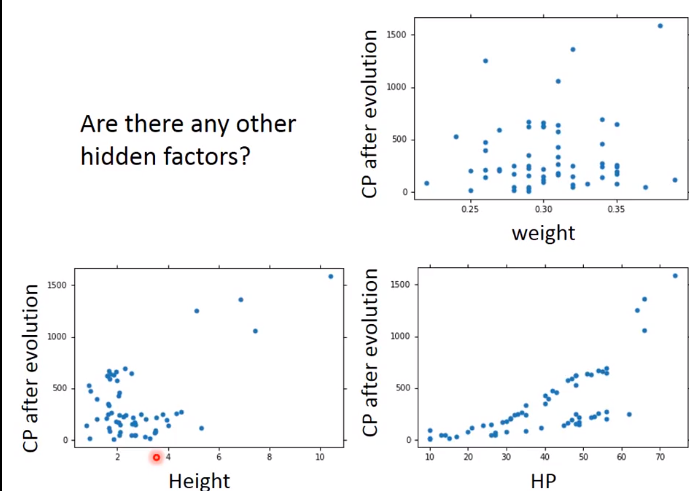
这个模型不好,因为隐藏因素:物种
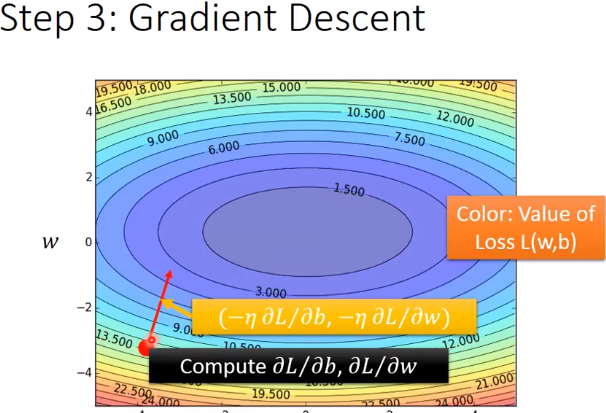
优化这个模型

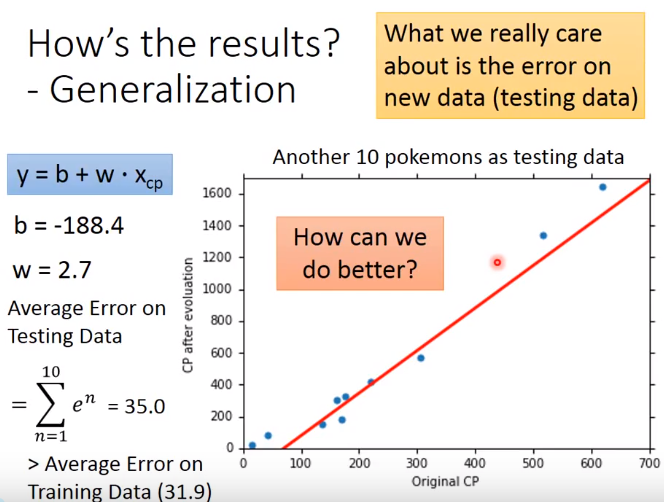
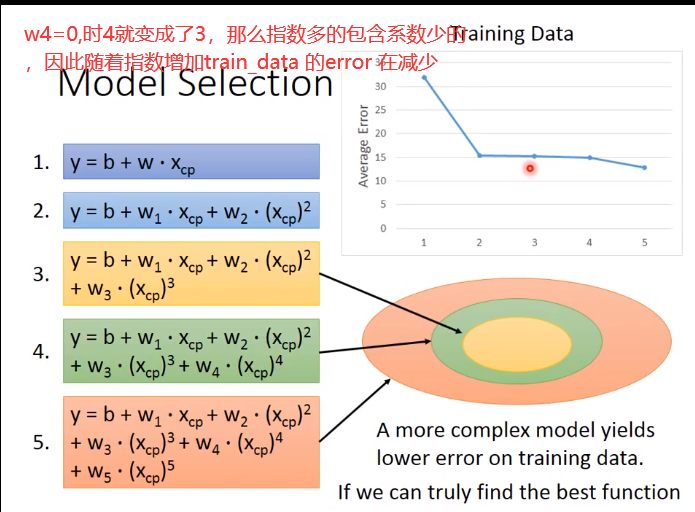
不同物种的对应的error线也是不一样的,那么error会更小,fit的更好
当然还和其他的因素有关:不同物种在进化时的情况不同(如红色线),其次有些值略高或略低于直线(产生进化后CP值时有加rand)
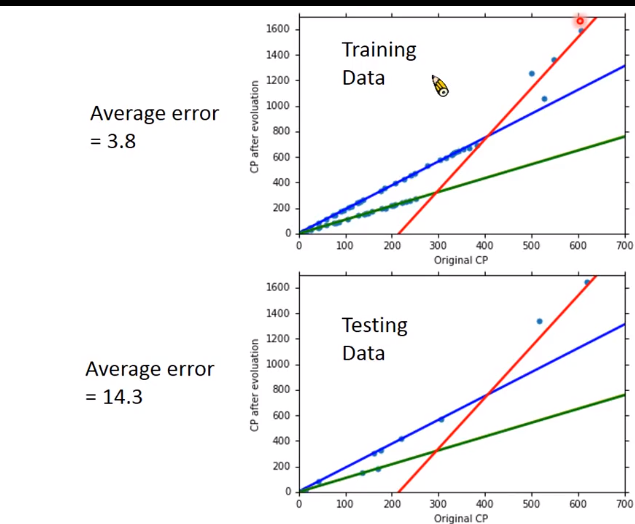
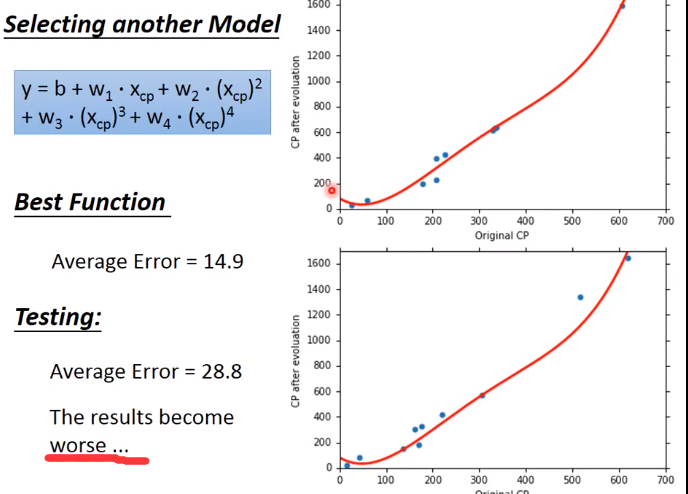
此时可以构造更复杂的模型,把想到的因素都考虑进去,此时会fit的很好
得到的train_error很小,但是会过拟合

过拟合了,怎么办呢?
regularization
smooth:此处表示output对输入x的变化不敏感,我们喜欢更平滑的funct
wi越小,那么输入变化对输出影响越小(wi*dea(xi)越小)


lam越大function 越平滑
b(bias)只会让图像上下移动,对平滑程度没影响,那么regularization不需要考虑bias

 浙公网安备 33010602011771号
浙公网安备 33010602011771号