数据降维+PCA(主成分 分析法)
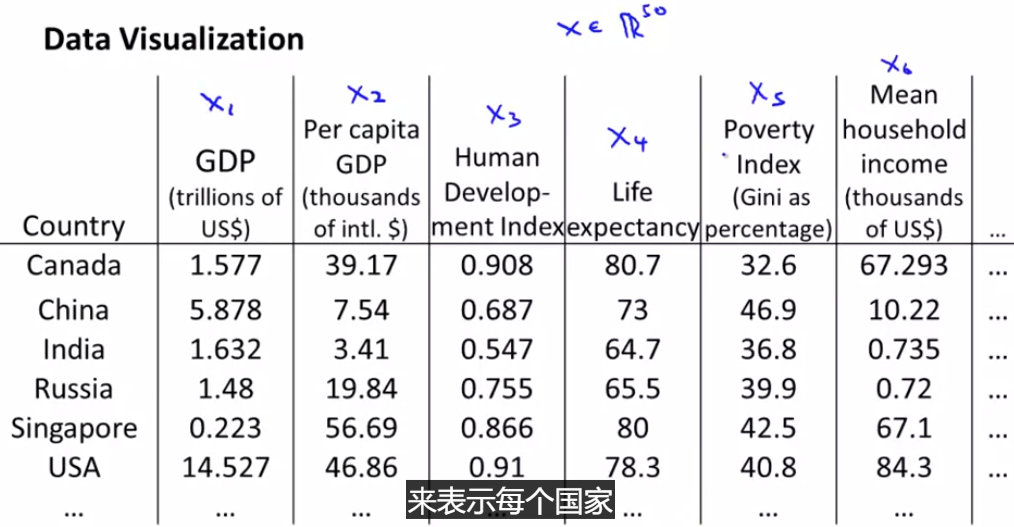
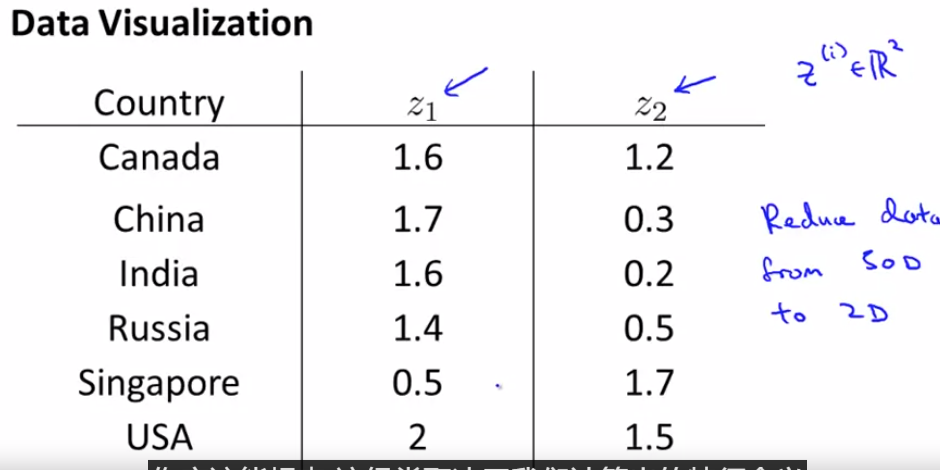
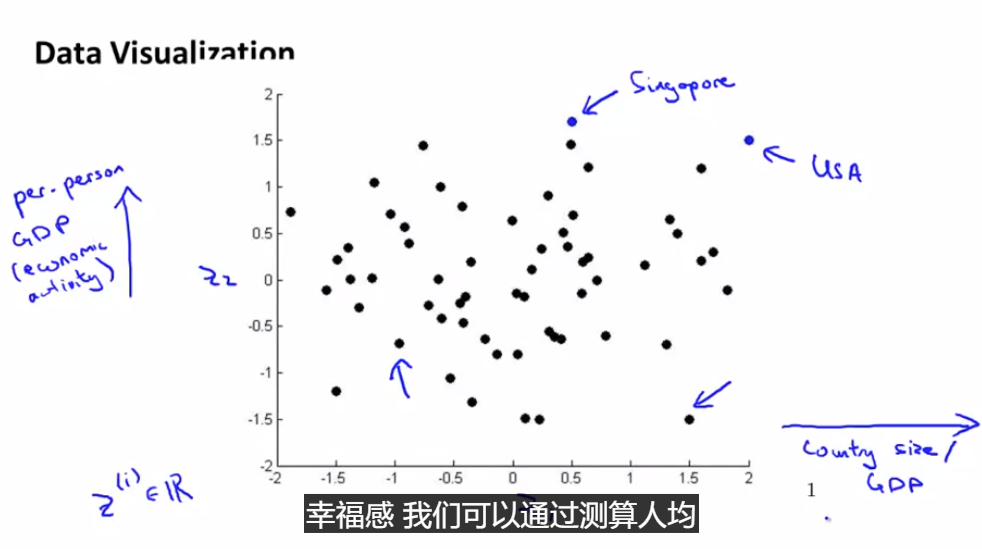
维数约减 (dimensionality reduction)

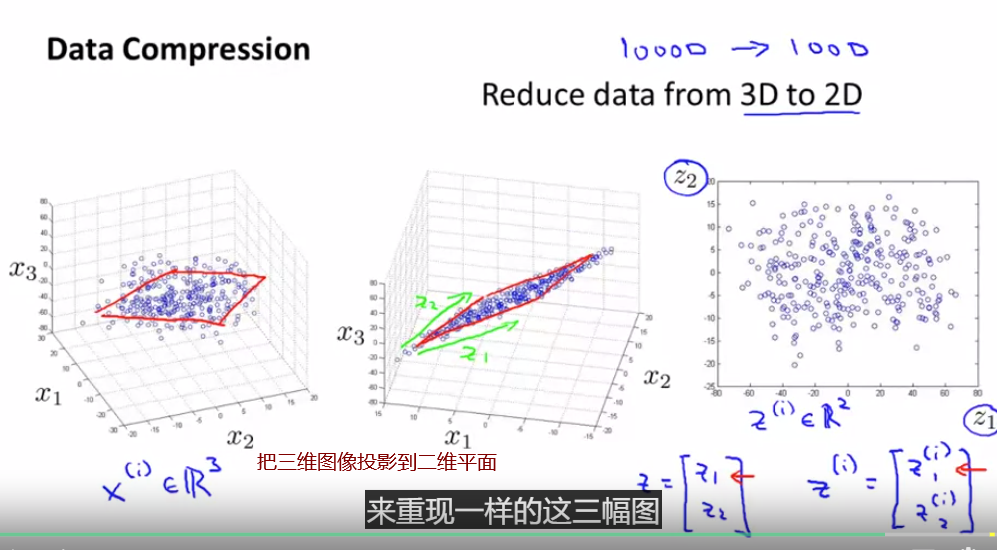





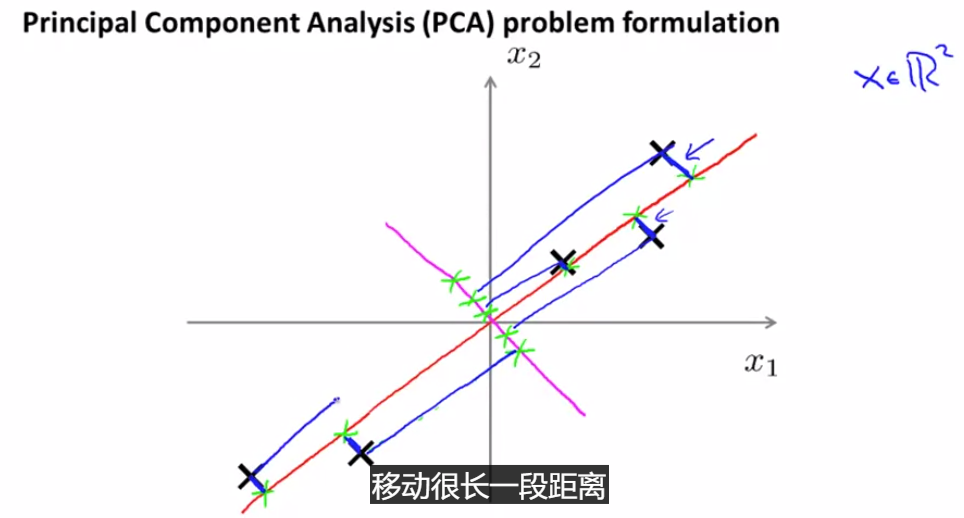
PCA:寻找一个低维的面,这里把所有的点投影到一条直线上,让原点和投影点的距离平方和最小
这些蓝色线段的长度 时常被叫做 投影误差
在应用PCA之前 通常的做法是 先进行均值归一化和 特征规范化 使得 特征 x1 和 x2 均值为0
用这条品红色直线 来投影数据 是一个非常糟糕的方向
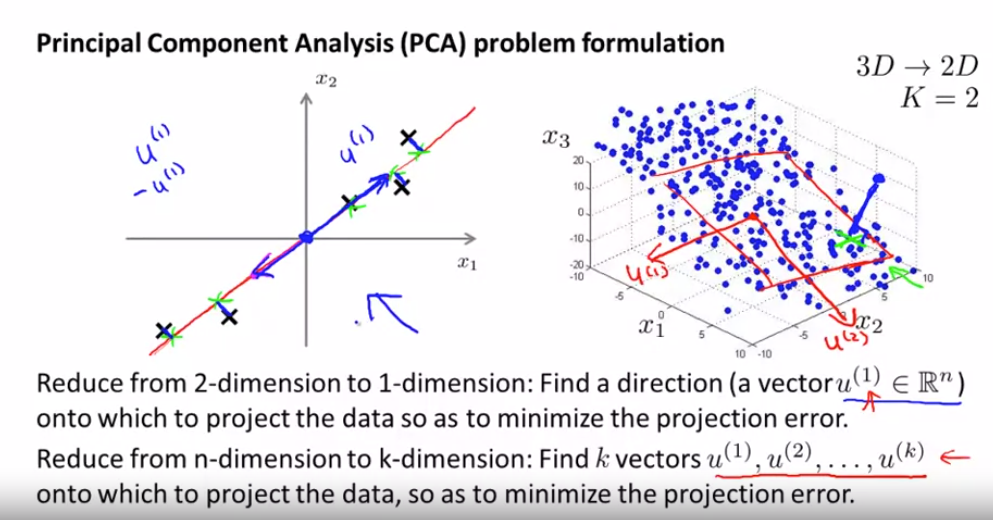
我们将寻找一组向量 u(1) u(2) 也许 一直到 u(k) 我们将要做的是 将数据投影到 这 k 个向量展开的线性子空间上
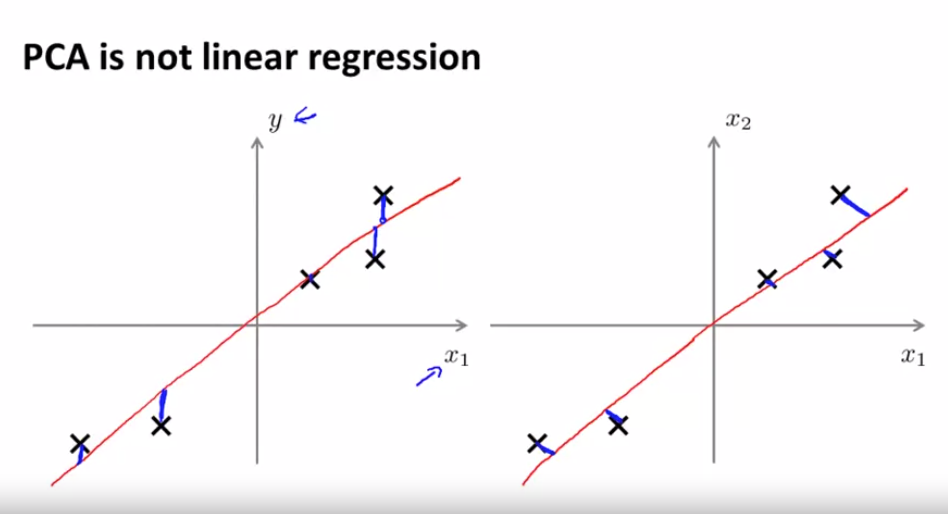
左侧为线性回归,右侧为PCA(蓝色线段不同)

sj 表示特征 j 的某个量度范围 因此它可以表示最大值减最小值 或者更普遍地 它可以表示特征 j 的标准差


covariance matrix :协方差矩阵
eigenvectors :特征向量
svd 表示奇异值分解 (singular value decomposition)

这个矩阵的维度 应该是 k × n 这里 x 的维度 应该是 n × 1 因此这两个相乘 维度应该是 k × 1 因此 z 是 k 维的 向量


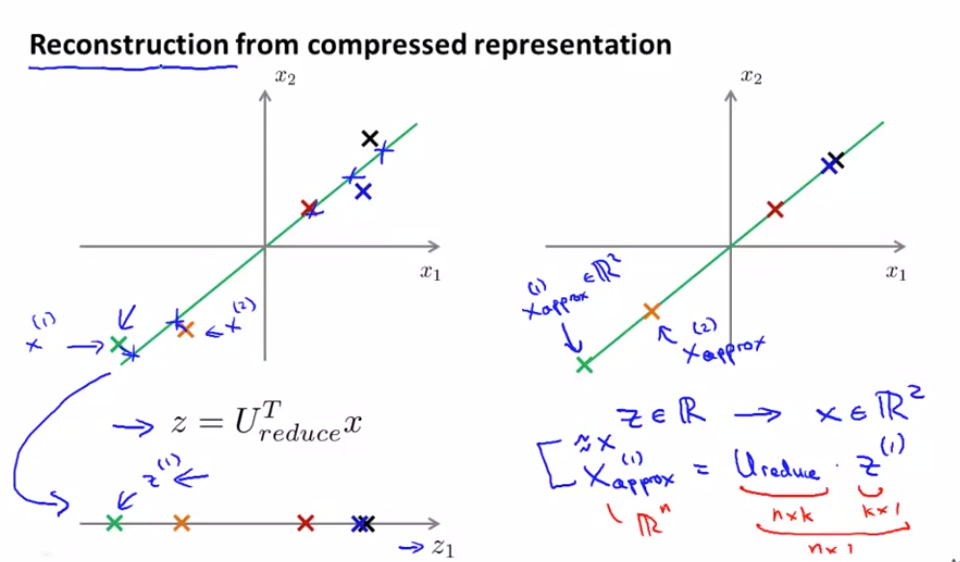



PCA 所做的是 尽量最小化平均平方映射误差 (Average Squared Projection Error)
因此 PCA 就是要将这个量最小化 就是我正在写的这个 它是原始数据x 它是原始数据x 和映射值 x_approx(i) 之间的差
数据的总变差 (Total Variation) 它是这些样本x(i)的 长度的平方的均值 它的意思是 “平均来看 我的训练样本 距离零向量多远?
一个常见的 选择K值的经验法则是 选择能够使得它们之间的比例 小于等于0.01
我们希望在平均均方误差与训练集方差的比例尽可能小的情况下选择尽可能小的𝑘值。如果我们希望这个比例小于1%,就意味着原本数据的偏差有99%都保留下来了,如果
我们选择保留95%的偏差,便能非常显著地降低模型中特征的维度了。
我们可以先令𝑘 = 1,然后进行主要成分分析,获得𝑈𝑟𝑒𝑑𝑢𝑐𝑒和𝑧,然后计算比例是否小于1%。如果不是的话再令𝑘 = 2,如此类推,直到找到可以使得比例小于1%的最小𝑘 值(原因
是各个特征之间通常情况存在某种相关性)。还有一些更好的方式来选择𝑘,当我们在Octave 中调用“svd”函数的时候,我们获得三
个参数:[U, S, V] = svd(sigma)。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号