pandas 数据子集的获取
有时数据读入后并不是对整体数据进行分析,而是数据中的部分子集,例如,对于地铁乘客量可能只关心某些时间段的流量,对于商品的交易可能只需要分析某些颜色的价格变动,对于医疗诊断数据可能只对某个年龄段的人群感兴趣等。所以,该如何根据特定的条件实现数据子集的获取将是本节的主要内容。
通常,在pandas模块中实现数据框子集的获取可以使用iloc,loc和ix三种‘方法’,这三种方法既可以对数据进行筛选,也可以实现变量的挑选,它们的语法可以表示
成【row_select,cols_select】.
iloc只能通过行号和列号进行数据筛选,我们可以将iloc中的‘i’理解为“integer”,即只能向【rows_select,cols_select】指定整数列表。该索引方式与数组的索引方式类似,都是从0开始,可以间隔取号,对于切片仍然无法取到上限。
loc要比iloc灵活一些,读者可以将loc中的“1”理解为“label”,即可以向【rows_select,col_select】指定具体的行标签和列标签。注意,这里是标签不再是索引。而且,还可以将rows_select指定为具体的筛选条件,在iloc中是无法做到的。
ix是iloc和loc的混合,读者可以将ix理解为“mix”,该方法吸收了iloc和loc的优点,市数据库子集的获取更加灵活。(此方法忽略,最新的模块好像已经去掉了,编译的时候警告,待再验证)
如下用具体的代码来说明iloc和loc二者之间的差异:
import pandas as pd
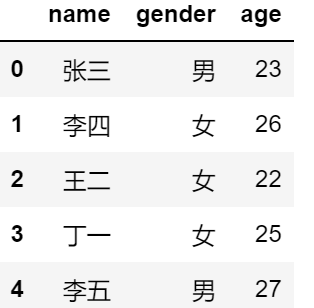
df1 = pd.DataFrame({'name':['张三','李四','王二','丁一','李五'],
'gender':['男','女','女','女','男'],
'age':[23,26,22,25,27]},columns = ['name','gender','age'])
df1
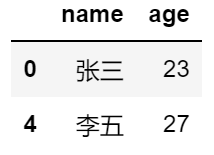
#去除数据集的中间三行(所有女性),并且返回姓名和年龄两列
df1.iloc[1:4,[0,2]]
df1.loc[1:3,['name','age']]
# df1.ix[1:3,[0,2]]
out:

再继续研究,将员工的姓名用做行标签
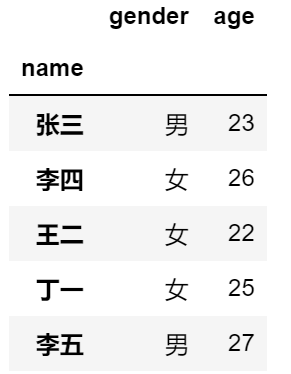
#将员工的姓名用作行标签
df2 = df1.set_index('name')
df2
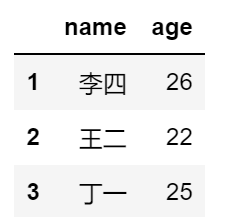
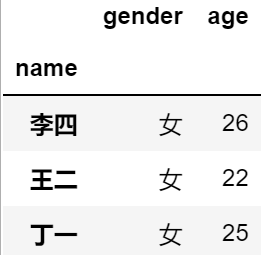
#同样取出数据集的中间三行
df2.iloc[1:4,:]
df2.loc[['李四','王二','丁一'],:]
out:

很显然,在实际的学习和工作中,观测行的筛选很少是通过写入具体的行索引或行标签,而是对某些列做条件筛选,进而获得目标数据.例如,在上面的df1数据集中,如何返回所有男性的姓名和年龄,代码如下:
df1.loc[df1.gender == '男',['name','age']]
out: