pandas-缺失值处理
缺失值是指数据集中的某些观测存在遗漏的指标值,缺失值的存在同样会影响到数据分析和挖掘的结果。
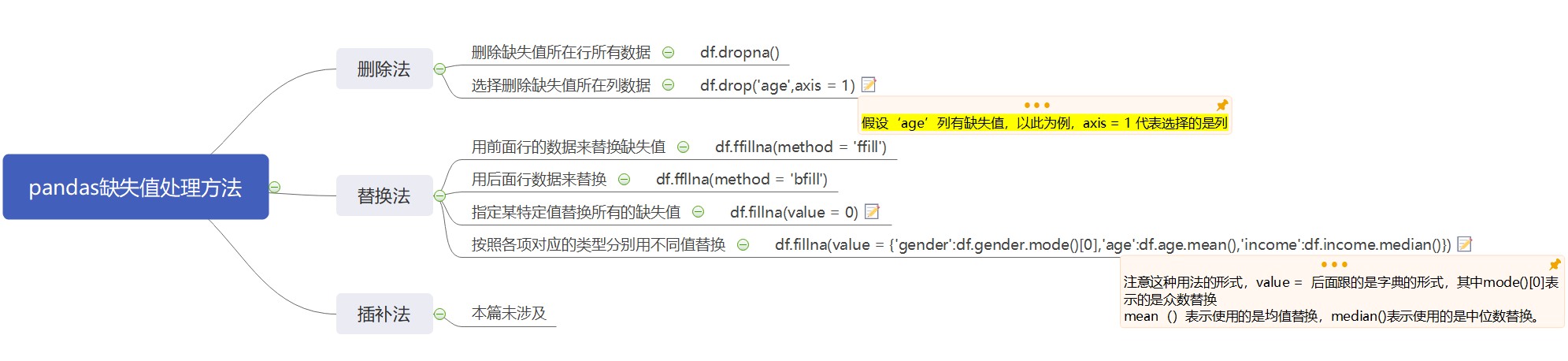
一般而言,当遇到缺失值是可以采三种方法处置:删除法,替换法和插补法。
1.删除法使用情况:当确实的观测比例非常低是,如5%以内,可以直接删除这些缺失的变量。
2.替换法:用某种直接替换缺失值,例如,对连续变量而言,可以使用均值或中位数替换,对于离散型变量,可以使用众数替换。
3.插补法:是指根据其他非确实的变量或观测来预测缺失值,常用的插补法有回归插补法,K近邻法,拉格朗日插补法等。
下面我们介绍两种比较常见的缺失值处理方法,删除法和替换法
例:
原数据:
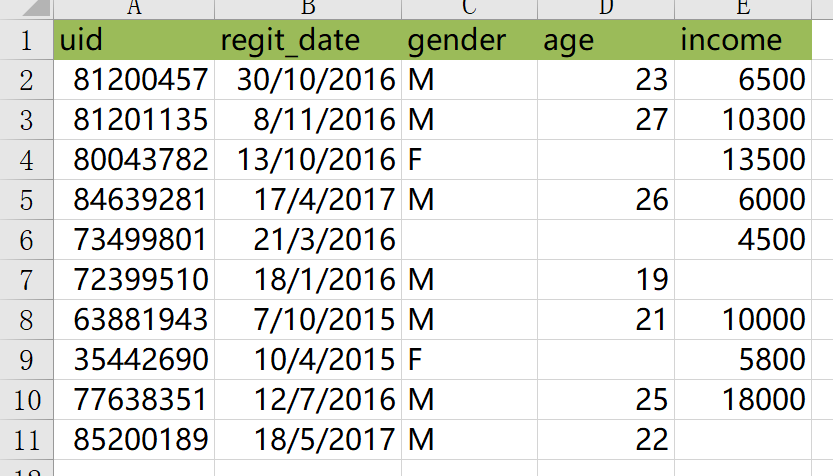
从表中可以看出,该数据集存在4条缺失观测,行号分别是4,6,7和9,11。接下来我们要做的是如何判断数据集是否存在缺失值(尽管记录少的时候可以清楚地发现)
import pandas as pd
df= pd.read_excel(r'd:/data_test05.xlsx')
print('数据集中是否存在缺失值:\n',any(df.isnull()))
OUT:
True
删除操作:
df.dropna() #删除缺失值所在的行
df.drop('age',axis = 1) #选择某具体的列删除
替换操作:
df.fillna(method = 'ffill') #用前一行的数据来替换空白 助记词:front
df.fillna(method = 'bfill') #用后一行数据来替换空内容 助记词:backward fill填充
df.fillna(value = 0) #指定用某个值来填充所有的空白内容 该方法慎用,典型的以点概面的方式,很容易造成数据混乱
df.fillna(value = {'gender':df.gender.mode()[0],'age':df.age.mean(), #这里面gender 使用的是众数替换,age 使用均值替换,income 使用中位数替换
'income':df.income.median()}) #value = 后面用的是字典, mode()[0] 因为众数可能存在多个,所以mode()返回的其 #实是一个序列,mode(0)表示,取第一个众数。参考摘选的补充说明:
**** 如上代码并没有实际改变df数据框的结果,因为dropna,drop和fillna方法并没有使inplace参数设置为True。因此我们在实际工作中,先预览处理效果,然后再把inplace参数设置为True,进而真正地改变你所处理的数据集:
补充说明:
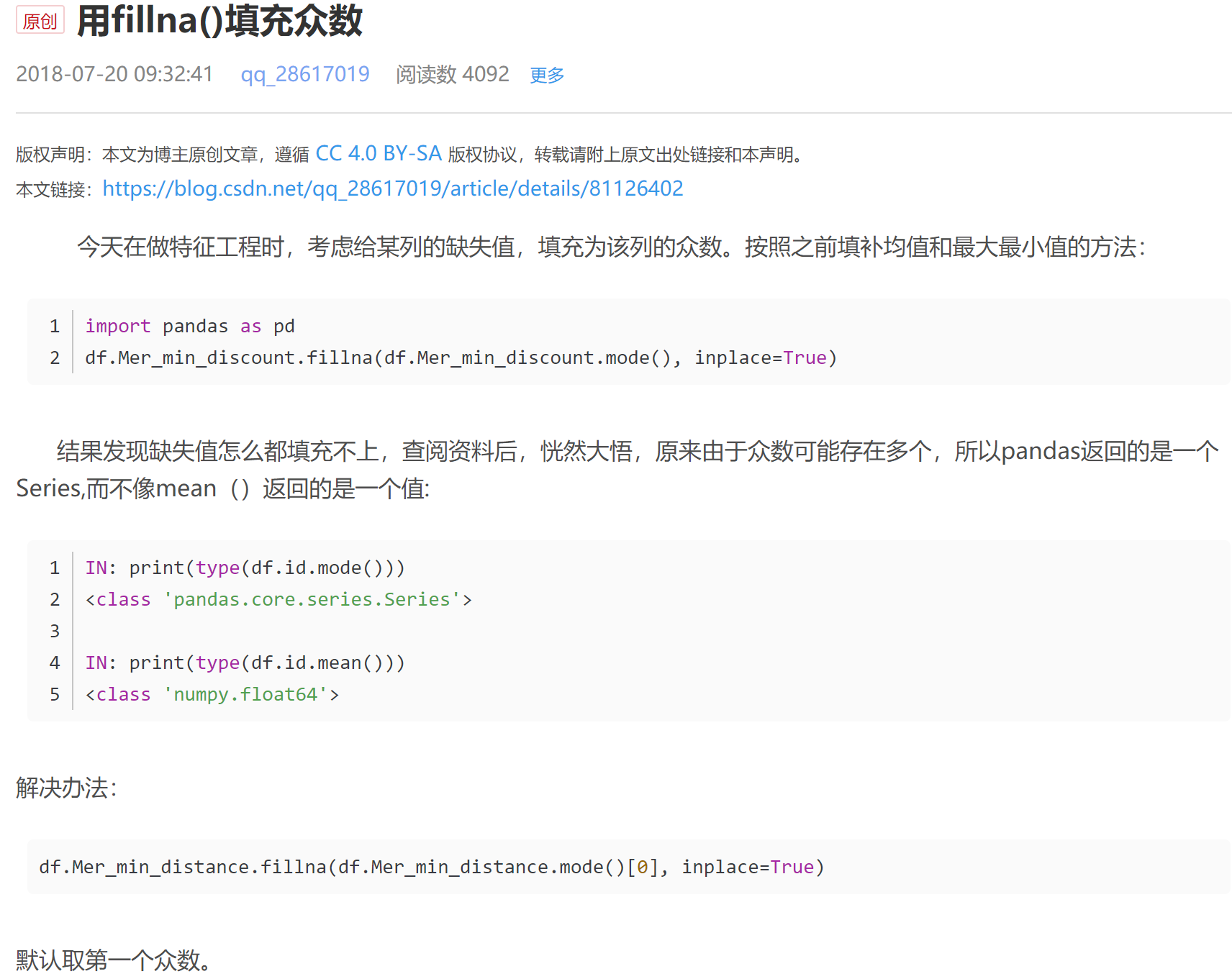
本篇涉及内容小结: