关于乱码问题的一些思考
前言
从长沙辞职跑到深圳,找房子找工作适应新的工作环境超级忙。之前一直没时间好好写博客,今天难得有空就上来写点东西吧!
都9102年了,没想到还能有那么多乱码问题。之前的工作基本上前后端统一编码就完事了;话不多说,既然遇到了就干脆搞搞明白吧!
编码解码概述
我们都知道计算机不能直接存储字母,数字,图片,符号等,计算机能处理和工作的唯一单位是"比特位(bit)",一个比特位通常只有 0 和 1。利用比特位序列来代表字母,数字,图片,符号等,我们就需要一个存储规则,不同的比特序列代表不同的字符,这就是所谓的"编码"。反之,将存储在计算机中的比特位序列(或者叫二进制序列)解析显示出来成对应的字母,数字,图片和符号,称为"解码",如同密码学中的加密和解密,下面将详细解释编码解码过程中涉及到的一些术语:
字符集合(Character set):是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等,简单理解就是一个字库,与计算机以及编码无关。
字符编码集(Coded character set):是一组字符对应的编码(即数字),为字符集合中的每一个字符给予一个数字,如 Unicode 为每一个字符分配一个唯一的码点与之一一对应。
字符编码(Character Encoding):简单理解就是一个映射关系,将字符集对应的码点映射为一个个二进制序列,从而使得计算机可以存储和处理。常见的编码方式有 ASCII 编码、ISO-8859-1(不支持中文)、GBK、GB2312(中国编码,支持中文)、UTF-8 等等
字符解码(Character Decoding): 根据一定规则,将二进制序列映射成对应的正确字符串,即二进制序列-->字符串,个人将其理解为"翻译"。
字符集(Charset):包括编码字符集和字符编码,如 ASCII 字符集、ISO-8859-X、GB2312 字符集(简中)、BIG5 字符集(繁中)、GB18030 字符集、Shift-JIS 等,即下文中提到的字符集。
| 字符集 | 编码 | 详解 |
|---|---|---|
| ASCII | ASCII 编码 | ASCII字符集:主要包括控制字符(回车键、退格、换行键等);可显示字符(英文大小写字符、阿拉伯数字和西文符号。ASCII 编码:用一个字节的低 7 位表示,0~31 是控制字符如换行回车删除等;32~126 是打印字符;ASCII的最大缺点是只能解决了部份西欧语言的显示问题,但对更多其他语言依然无能为力。 |
| I 字 ISO-8859-X(常用的 ISO-8859-1) | ISO-8859-1 编码 ISO-8859-2 编码 … ISO-8859-15 编码 | ISO-8859-X 字符集:扩展的 ASCII 字符集,包括 ISO-8859-1 ~ ISO-8859-15,涵盖了大多数西欧语言字符和希腊语。ISO-8859-1 编码:用 8 位表示一个字符,总共能表示 256 个字符,但还是单字节编码,不能对双字节如中日韩等进行编码。 |
| GBXXXX | GB2312 编码 | GB2312 编码 :双字节编码,每个汉字及符号以两个字节来表示。第一个字节称为"高位字节"(也称"区字节)",第二个字节称为"低位字节"(也称"位字节")。总的编码范围是 A1-F7,其中从 A1-A9 是符号区,总共包含 682 个符号,从 B0-F7 是汉字区。对于人名、古汉语等方面出现的罕用字,GB2312 不能处理,这导致了后来GBK及GB 18030汉字字符集的出现。 |
| GBK 编码 | GBK 编码:在 GB2312-80 标准基础上的内码扩展规范,使用了双字节编码方案,其编码范围从 8140 至 FEFE(剔除 xx7F),共 23940 个码位,共收录了 21003 个汉字,完全兼容 GB2312-80 标准,支持国际标准 ISO/IEC10646-1 和国家标准GB13000-1 中的全部中日韩汉字,并包含了 BIG5 编码中的所有汉字 | |
| GB18030 编码 | GB18030-2005编码:是我国自主研制的以汉字为主并包含多种我国少数民族文字(如藏、蒙古、傣、彝、朝鲜、维吾尔文等)的超大型中文编码字符集强制性标准,其中收入汉字 70000 余个,解决了中文、日文、朝鲜语等的编码,兼容 GBK。采用变长字节表示即单字节、双字节和四字节三种方式对字符编码。 | |
| Big5 | Big5 编码 | Big5 编码: 适用于台湾、香港地区的一个繁体字编码方案。使用了双八码存储方法,以两个字节来安放一个字,第一个字节称为"高位字节",第二个字节称为"低位字节" |
| Unicode | UTF-8 | UTF-8:采用变长字节 (1 ASCII, 2 希腊字母, 3 汉字, 4 平面符号) 表示,在网络传输中即使错了一个字节,不影响其他字节;存储效率比较高,适用于拉丁字符较多的场合以节省空间,UTF-8 没有字节顺序问题,所以 UTF-8 适合传输和通信。 |
| UTF-16 | UTF-16:从先前的固定宽度的 16 位编码(UCS-2)发展而来的,能够对 Unicode 的所有 1,112,064 个有效 code point 进行编码。 其编码方式是可变长度的,因为 code point 是用一个或两个 16 位代码单元编码的。在 UTF-16 文件的开头,会放置一个 U+FEFF 字符作为 Byte Order Mark(BOM):UTF-16LE(小端序)以 FF FE 代表,UTF-16BE(大端序)以 FE FF 代表,以显示这个文字档案是以 UTF-16 编码。UTF-16 比起 UTF-8,好处在于大部分字符都以固定长度的字节 (2 字节) 储存,但 UTF-16 却无法兼容于 ASCII 编码,实际使用也比较少。 | |
| UTF-32 | UTF-32 (或 UCS-4):对每一个 Unicode 码点使用 4 字节进行编码,其它的 Unicode 编码方式则使用不定长度编码。就空间而言,UTF-32 是非常没有效率的。尤其非基本多文种平面的字符在大部分文件中通常很罕见,以致于它们通常被认为不存在占用空间大小的讨论,使得 UTF-32 通常会是其它编码的二到四倍。虽然每一个码位使用固定长定的字节看似方便,它并不如其它 Unicode 编码使用得广泛。 |
表的几点说明
1.UTF-16 与 UCS-2 的关系:UTF-16 可看成是 UCS-2 的父集。在没有辅助平面字符(surrogate code points)前,UTF-16 与 UCS-2 所指的是同样的意思。但当引入辅助平面字符后,就称为 UTF-16 了。现在若有软件声称自己支持 UCS-2 编码,那其实是暗指它不能支持在 UTF-16 中超过 2 位元组的字集。对于小于 0x10000 的 UCS 码,UTF-16 编码就等于 UCS 码。
2.为什么中文默认使用 GB1832 而不使用 UTF-8?因为 GB1832 对绝大多数中文采用双字节编码,而 UTF-8 要用三字节,GB11832 大大节省了存储空间。
ANSI 编码:各个国家和地区独立制定的既兼容 ASCII 编码又彼此之间不兼容的字符编码,微软统称为 ANSI 编码。在 Windows 系统中,ANSI 编码一般代表系统默认的编码方式,并且不是确定的某一种特定编码方式,比如在英文 Windows 操作系统中,ANSI 指的是 ISO-8859-1;简体中文操作系统中 ANSI 编码默认指的是 GB 系列编码(GB2312、GBK、GB18030)等;在繁体中文操作系统中 ANSI 编码默认指的是 BIG5;在日文操作系统中 ANSI 编码默认指的是 Shift JIS 等等,并且默认的 ANSI 编码可以通过设置系统 Locale 更改。
UCS(Universal Character Set):称作通用字符集,是由 ISO 制定的 ISO 10646(或称 ISO/IEC 10646)标准所定义的标准字符集。包括了其他所有字符集。它保证了与其他字符集的双向兼容,即,如果你将任何文本字符串翻译到 UCS 格式,然后再翻译回原编码,你不会丢失任何信息。
UTF(UCS Transformation Format/Unicode transformation format): UCS 转换格式/Unicode 转换格式。
BOM(Byte Order Mark):字节顺序标记,出现在文本文件头部,Unicode 编码标准中用于标识文件是采用哪种格式的编码,其 Unicode 码点为 U+FEFF。维基百科详细解释点击这里
Code Point:称作码点或码位,是组成编码空间(或代码页)的数值。例如,ASCII 码包含 128 个码点,范围是 0 到 7F(16 进制);ISO-8859-1 包含 256 个码点,范围是 0 到 FF;而 Unicode 包含 1,114,112 个码点,范围是 0 到 10FFFF。Unicode 码空间划分为17 个 Unicode 字符平面(基本多文种平面,16 个辅助平面),每个平面有 65,536(= 216)个码点。因此 Unicode 码空间总计是 17 x 65,536 = 1,114,112。
乱码产生原因概述
乱码产生的根源一般情况下可以归结为三方面即:编码引起的乱码、解码引起的乱码以及缺少某种字体库引起的乱码(这种情况需要用户安装对应的字体库),其中大部分乱码问题是由不合适的解码方式造成的,如图下图所示:
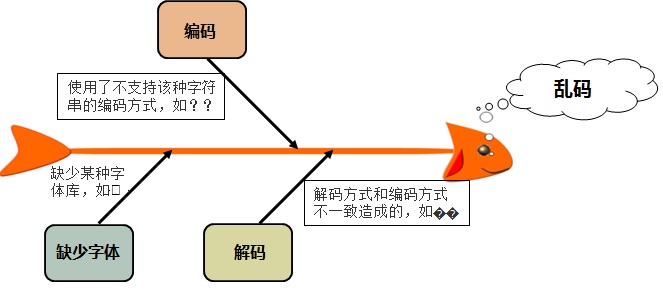
编码引起的乱码分析
在不支持中文的编码如( ISO-8859-1)的环境下输入中文字符。会出现乱码情况,我们用十六进制查看器可以看到(ISO-8859-1)编码环境下"你好"对应的的十六进制数为"3F3F"
这是因为中文和中文符号经过不支持中文的 ISO-8859-1 编码时,将不在字符集范围内的字符统一用 3F 表示,3F 对应的字符为问号"?"
解决办法 : 这种情况下形成的乱码是不可逆的,只有更改环境的字符编码为支持中文的字符编码才能编码乱码问题。
解码引起的乱码分析
比如在GBK环境下编码的文本内容,使用UTF-8解码方式打开后,会发现文本内容全是乱码。
解决办法:使用正确的解码方式打开原文本,这种乱码是可逆的。(请注意,这里的可逆指的是使用正确的解码方式打开原文本,而不是已经是乱码了的utf-8文本)
缺少字体库引起的乱码
从二进制字节序列转换成对应字符集中的码点,然后码点通过查找字体库找到对应的字符,最后通过点阵的方式显示在屏幕上。这里的方框是因为所查找的字体库缺少该码点对应的字符,或者根本没有安装该字体库,从而字符库中找不到的字符都以方框代替。
解决办法:安装码点对应的字体库即可
tip:乱码中的?为不在解码所用的字符集编码中时显示的内容,空白方框为找不到码点对于字符时所显示的内容. 问号为字节丢失,是没有任何办法通过这串乱码还原源文本的。
以上都是乱码之所以形成的原因,已经在有源文本时,如何显示正确的文本内容的解决办法。但是很多情况下,我们可能需要对已经形成的乱码字符串进行逆向还原成源文本内容的操作,那这种时候有没有办法呢?
实践出真知
网上很多关于乱码还原的解决办法,都是很片面甚至是误导性的。逆向转码是提到最多的,如下:
假定errStr是原本为gbk编码格式的字符串,但是使用utf-8进行解码从而形成了乱码。错误示范,并不能还原乱码
String str = new String(errStr.getBytes(StandardCharsets.UTF_8), "GBK");
逆向转码乍一看有道理,但真的经得起推敲吗?
实验一
假定乱码场景为:原本为gbk编码的字符串错误的使用了utf-8进行解码形成了乱码。现需要把这个乱码进行还原
按照网上很多人说的乱码还原的解决办法,即逆向转码就能解决。事实真的如此吗?
public static void main(String[] args) throws UnsupportedEncodingException {
String unicodeStr = "这是一串原本为GBK编码格式的字符串";
// gbks 为GBK编码格式
byte[] gbks = unicodeStr.getBytes("GBK");
// 解码验证 GBK解码方式不乱码而UTF8乱码则说明是GBK
String errStr = new String(gbks, StandardCharsets.UTF_8);
System.out.println(errStr);
String rightStr = new String(gbks, "GBK");
System.out.println(rightStr);
// 将原本为GBK编码格式 的乱码字符串 还原
// 乱码字符串进行还原
byte[] errBytes = errStr.getBytes(StandardCharsets.UTF_8);
String str = new String(errStr.getBytes(StandardCharsets.UTF_8), "GBK");
System.out.println(str);
}
控制台输出:
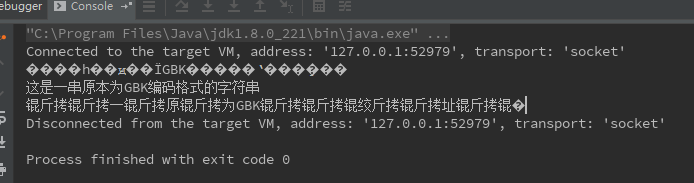
很显然一串原本为GBK编码格式的当使用了utf8解码而形成了乱码。当使用逆向转码试图还原乱码时形成了新的乱码。
事实上如果乱码中出现了问号,则表示这部分已经丢失了,是没有办法还原了的。即这串乱码是不可逆的。
实验二
假定乱码场景为:原本为utf8编码的字符串错误的使用了gbk进行解码形成了乱码。现需要把这个乱码进行还原
public static void main(String[] args) throws UnsupportedEncodingException {
String unicodeStr = "这是一串原本为UTF-8编码格式的字符串";
// gbks 为GBK编码格式
byte[] utf8s = unicodeStr.getBytes(StandardCharsets.UTF_8);
// 解码验证 utf8解码方式不乱码而gbk乱码则说明是utf8
String rightStr = new String(utf8s, StandardCharsets.UTF_8);
System.out.println(rightStr);
String errStr = new String(utf8s, "GBK");
System.out.println(errStr);
// 将原本为utf8编码格式 的乱码字符串 还原
// 乱码字符串进行还原
byte[] gbks = errStr.getBytes("GBK");
String str = new String(errStr.getBytes("GBK"), StandardCharsets.UTF_8);
System.out.println(str);
}
控制台输出:
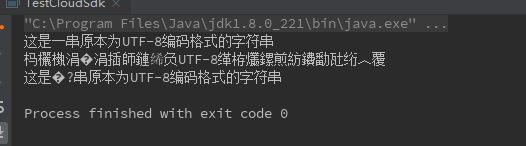
当原本为utf8的字符串错误的使用了gbk解码后形成的乱码。经过逆向转码,是可以部分还原的,但是依然不能百分百还原!这里也可以很清晰的看到乱码中的?问号部分就是字节丢失,无法还原的;
最后
总结: 乱码问题的关键在于从源头抓起,统一编码,使用正确的解码方式进行解码。对已经形成的乱码文本是没有办法保证百分百还原的。
就是在形成乱码的那一步遏制,使用正确的解码方式,而不是乱码已经形成了再去想办法还原
❀❀❀END❀❀❀

 浙公网安备 33010602011771号
浙公网安备 33010602011771号