Docker是如何实现容器隔离的
Docker如何实现隔离
Linxu内核实现Namespace的主要目的是为了实现轻量化的虚拟化,就是为了支持容器
查看隔离
Docker每一个容器中有独立的IP、端口、路由,共有六项隔离
我们通过一个简单的Apache来查看Docker有哪六项隔离
[root@localhost ~]# yum -y install httpd
[root@localhost ~]# systemctl start httpd
[root@localhost ~]# netstat -anpt | grep 80
tcp6 0 0 :::80 :::* LISTEN 68305/httpd 可以看到关于80端口的pid是68305,这是重点,接下来就要去看68305这个pid中有哪些东西
这写pid的相关目录都在/proc目录中,也理解为在内存中运行的内容
[root@localhost ~]# ls /proc
1 10524 10676 1286 289 484 67448 861 cgroups modules
10 10529 10701 1289 29 485 67589 862 cmdline mounts
10042 10535 10727 1293 290 49 67590 863 consoles mpt
101 10552 10730 13 314 50 67591 864 cpuinfo mtrr
10112 10562 10735 1301 316 51 67628 865 crypto net
10117 10570 10742 1307 317 53 677 867 devices pagetypeinfo
10120 10581 10745 1308 318 569 68058 868 diskstats partitions
....所有正在运行的进程id号都会在这里以目录的形式体现,同样刚才启动的80端口的pid68305也在这里,如果要看该程序占用多大,查看目录相关pid目录的大小即可
其中的ns目录就是namespace的缩写
[root@localhost ~]# cd /proc/68305/ns/
[root@localhost ns]# ll
total 0
lrwxrwxrwx. 1 root root 0 Mar 25 09:06 ipc -> ipc:[4026531839]
lrwxrwxrwx. 1 root root 0 Mar 25 09:06 mnt -> mnt:[4026532505]
lrwxrwxrwx. 1 root root 0 Mar 25 09:06 net -> net:[4026531956]
lrwxrwxrwx. 1 root root 0 Mar 25 09:06 pid -> pid:[4026531836]
lrwxrwxrwx. 1 root root 0 Mar 25 09:06 user -> user:[4026531837]
lrwxrwxrwx. 1 root root 0 Mar 25 09:06 uts -> uts:[4026531838]ns目录中的六项内容,就是namespace的隔离数据包,每个程序的空间都要保持唯一性,否则就会产生冲突
我们通过另一个随机程序的隔离机制来查看,当两个程序的每一项后面的数字相同时,表示存在冲突,也就是他们在同一个空间内,但是观察发现,只有mnt是不冲突的
[root@localhost ns]# ll ../../20/ns/
total 0
lrwxrwxrwx. 1 root root 0 Mar 25 09:09 ipc -> ipc:[4026531839]
lrwxrwxrwx. 1 root root 0 Mar 25 09:09 mnt -> mnt:[4026531840]
lrwxrwxrwx. 1 root root 0 Mar 25 09:09 net -> net:[4026531956]
lrwxrwxrwx. 1 root root 0 Mar 25 09:09 pid -> pid:[4026531836]
lrwxrwxrwx. 1 root root 0 Mar 25 09:09 user -> user:[4026531837]
lrwxrwxrwx. 1 root root 0 Mar 25 09:09 uts -> uts:[4026531838]mnt:是挂载点和文件系统的隔离,也就是程序所在的根目录不同,也就是在不同的mnt命名空间
六项隔离
Linux的namespace是在内核版本3.8以后引进的,如果内核是之前的也就代表不支持虚拟化
编写一个C语言的脚本来启动一个进程模拟命名空间
[root@localhost ~]# vim example.c
# 添加
#define _GNU_SOURCE
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#define STACK_SIZE (1024 * 1024)
static char child_stack[STACK_SIZE];
char* const child_args[] = {
"/bin/bash",
NULL
};
int child_main(void* args) {
printf("在子进程中!\n");
execv(child_args[0], child_args);
return 1;
}
int main() {
printf("程序开始: \n");
int child_pid = clone(child_main, child_stack + STACK_SIZE, SIGCHLD, NULL);
waitpid(child_pid, NULL, 0);
printf("已退出\n");
return 0;
}编译该脚本
gcc -Wall example.c -o test.o将编译后的脚本程序运行起来
./test.o验证该进程是否好用
可以看到运行脚本后多了一个终端test.o,执行ps命令之后,查看到执行的ps是在test.o的bash环境里面执行的,其实就是我们在c脚本程序中让他开启了一个子进程bash
当exit退出test.o,再次执行时,发现只有一个bash了,也就是我们最开始使用的环境
[root@localhost ~]# ./test.o
程序开始:
在子进程中!
[root@localhost ~]# ps
PID TTY TIME CMD
68102 pts/3 00:00:01 bash
68651 pts/3 00:00:00 test.o
68652 pts/3 00:00:00 bash
68695 pts/3 00:00:00 ps
[root@localhost ~]# exit
exit
已退出
[root@localhost ~]# ps
PID TTY TIME CMD
68102 pts/3 00:00:01 bash
68697 pts/3 00:00:00 ps这个程序中的子进程bash和原始bash是对称空间的关系
UTS:主机和域名
提供了主机名和域名的隔离,每个容器都有自己的主机名和域名,可以理解为一个独立的节点,并不是一个进程
修改c脚本来实现UTS的隔离,在脚本中我们子进程的bash设置了一个主机名为Changed Name,希望在执行程序进入子进程后,它的主机名是我们设置的这个,又添加了CLONE_NEWUTS,用来克隆一个当前空间来启动一个UTS空间
[root@localhost ~]# vim example.c
#define _GNU_SOURCE
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#define STACK_SIZE (1024 * 1024)
static char child_stack[STACK_SIZE];
char* const child_args[] = {
"/bin/bash",
NULL
};
int child_main(void* args) {
printf("在子进程中!\n");
sethostname("Changed Name", 12);
execv(child_args[0], child_args);
return 1;
}
int main() {
printf("程序开始: \n");
int child_pid = clone(child_main, child_stack + STACK_SIZE, CLONE_NEWUTS | SIGCHLD, NULL);
waitpid(child_pid, NULL, 0);
printf("已退出\n");
return 0;
}编译修改后的脚本
gcc -Wall example.c -o uts.o运行成功后是这样的,运行之前的主机名是localhost,之后就是我们在脚本中设置的一样Changed Name
[root@localhost ~]# ./uts.o
程序开始:
在子进程中!
[root@Changed Name ~]# 现在这台电脑里就有两个主机名
查看进程也可以看到有两个/bin/bash环境在运行
[root@Changed Name ~]# ps -ef | grep bash
root 973 1 0 06:25 ? 00:00:00 /bin/bash /usr/sbin/ksmtuned
root 68102 68098 0 08:53 pts/3 00:00:01 -bash
root 70128 70127 0 09:52 pts/3 00:00:00 /bin/bash
root 70181 70128 0 09:54 pts/3 00:00:00 grep --color=auto bashIPC:信号量、消息列队、共享内存
容器当中进程间通讯,使用消息列队,共享内存等,和虚拟机不同的是容器内的进程通讯对宿主机来说实际上是具有相同的pid的,因此需要一个标识符来区别,因此需要在 IPC 资源申请时加入命名空间信息,每个 IPC 资源有一个唯一的 32 位 id。
IPC命名空间包含了系统中的标识符和实现消息列队的系统文件,所以在同一个ipc命名空间的进程彼此间是可以感知或者可见的,其他的ipc命名空间互不可见
ipcs -q用来查看当前的列队
ipcs查看计算机中所有的列队
由于一开始已经启动过httpd,所以可以看到关于apache的进程信息,最下方显示的Semaphore Arrays就是信号量数组,apache的信息都在同一个信号量组
[root@localhost ~]# ipcs
------ Message Queues --------
key msqid owner perms used-bytes messages
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x00000000 524288 root 777 16384 1 dest
0x00000000 1015814 root 777 3932160 2 dest
0x13143901 1966090 root 600 1000 6
------ Semaphore Arrays --------
key semid owner perms nsems
0x00000000 131072 apache 600 1
0x00000000 163841 apache 600 1
0x00000000 196610 apache 600 1
0x00000000 229379 apache 600 1
0x00000000 262148 apache 600 1 当还没有进行IPC隔离时,进入刚才的uts.o的子进程中,也会看到apache的信号量组
在不同空间中实际是不应该存在相同的ipc信号量的
[root@localhost ~]# ./uts.o
程序开始:
在子进程中!
[root@Changed Name ~]# ipcs
------ Message Queues --------
key msqid owner perms used-bytes messages
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x00000000 524288 root 777 16384 1 dest
0x00000000 1015814 root 777 3932160 2 dest
0x13143901 1966090 root 600 1000 6
------ Semaphore Arrays --------
key semid owner perms nsems
0x00000000 131072 apache 600 1
0x00000000 163841 apache 600 1
0x00000000 196610 apache 600 1
0x00000000 229379 apache 600 1
0x00000000 262148 apache 600 1 修改c脚本,增加ipc信号量的隔离CLONE_NEWIPC
[root@localhost ~]# vim example.c
#define _GNU_SOURCE
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#define STACK_SIZE (1024 * 1024)
static char child_stack[STACK_SIZE];
char* const child_args[] = {
"/bin/bash",
NULL
};
int child_main(void* args) {
printf("在子进程中!\n");
sethostname("Changed Name", 12);
execv(child_args[0], child_args);
return 1;
}
int main() {
printf("程序开始: \n");
int child_pid = clone(child_main, child_stack + STACK_SIZE, CLONE_NEWIPC | CLONE_NEWUTS | SIGCHLD, NULL);
waitpid(child_pid, NULL, 0);
printf("已退出\n");
return 0;
}编译输出为ipc.o
gcc -Wall example.c -o ipc.o现在执行ipc.o进入另一个空间后,再次查看ipcs,这时已经与他相对的空间的ipc已经隔离开了
[root@localhost ~]# ./ipc.o
程序开始:
在子进程中!
[root@Changed Name ~]# ipcs
------ Message Queues --------
key msqid owner perms used-bytes messages
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
------ Semaphore Arrays --------
key semid owner perms nsems 然后可以在这个空间中创建一个属于它自己的列队
[root@Changed Name ~]# ipcmk -Q
Message queue id: 0
[root@Changed Name ~]# ipcmk -Q
Message queue id: 32769
[root@Changed Name ~]# ipcmk -Q
Message queue id: 65538
[root@Changed Name ~]# ipcmk -Q
Message queue id: 98307
[root@Changed Name ~]# ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
0xea398e26 0 root 644 0 0
0xf7fe5f0c 32769 root 644 0 0
0xc1cc43e6 65538 root 644 0 0
0x47762e70 98307 root 644 0 0 然后在验证物理机的环境中有没有这些创建的队列
[root@Changed Name ~]# exit
exit
已退出
[root@localhost ~]# ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages 生产环境中大部分会去使用消息列队去替代ipc,但是docker要用到这个ipc隔离机制
Docker的BUG—PID
pid隔离非常使用,对进程pid编号进行重新编号,不同空间中的进程可以有相同的pid号,内核为所有的pid命名空间维护各树状结构,最顶层是root的命名空间,在它之下创建的命名空间被称为child命名空间,不同的pid命名空间形成了等级体系,所有的父节点可以看到子节点中的进程,并通过信号的方式对子节点的进程产生影响,反过来说,子节点不能对父节点产生任何影响。
结论:每个pid命名空间的第一个进程pid,一定是1
当一个系统中查看pid时,会看到第一个进程pid就是1,在linux中,第一个进程是init进程,版本不同,可能有的是systemd进程,在linux中运行的所有进程都都是init的子进程
ps -aux查看所有进程,查看第一个进程
pstree查看进程树,可以清晰的看到进程之间的关系,最上面的就是systemd或者init进程衍生了所有的进程,一个命名空间中的父进程不会影响物理机或者和它对等空间的父进程
在没有pid命名空间隔离之前,进入一个新的空间,echo $$查看进行当前shell的进程号
[root@localhost ~]# ./ipc.o
程序开始:
在子进程中!
[root@Changed Name ~]# echo $$
70752
[root@localhost ~]# echo $$
68102虽然pid不是紧跟在宿主机的后面,但是也会在宿主机的pid号周围
修改c脚本代码,增加pid命名空间的隔离
[root@localhost ~]# vim example.c
#define _GNU_SOURCE
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#define STACK_SIZE (1024 * 1024)
static char child_stack[STACK_SIZE];
char* const child_args[] = {
"/bin/bash",
NULL
};
int child_main(void* args) {
printf("在子进程中!\n");
sethostname("Changed Name", 12);
execv(child_args[0], child_args);
return 1;
}
int main() {
printf("程序开始: \n");
int child_pid = clone(child_main, child_stack + STACK_SIZE, CLONE_NEWPID | CLONE_NEWIPC | CLONE_NEWUTS | SIGCHLD, NULL);
waitpid(child_pid, NULL, 0);
printf("已退出\n");
return 0;
}编译输出为pid.o
gcc -Wall example.c -o pid.o运行程序,再去查看当前shell的pid编号,变为了1,但是物理机的还是没有改变的
[root@localhost ~]# ./pid.o
程序开始:
在子进程中!
[root@Changed Name ~]# echo $$
1
[root@Changed Name ~]# exit
exit
已退出
[root@localhost ~]# echo $$
68102mnt:挂载点和文件系统
上一步对pid命名空间进行了隔离,但是进入空间中查看进程时ps -aux,还是可以看到宿主机的所有进程,这是因为没有对文件系统进行隔离
ps和top之类的命令是直接调用宿主机的/proc目录进行查看的
无论在宿主机还是一个命名空间中,查看proc目录中的内容是相同的。
[root@localhost ~]# ls /proc
1 10524 10676 1286 289 484 67591 861 cgroups modules
10 10529 10701 1289 29 485 67628 862 cmdline mounts
10042 10535 10727 1293 290 49 677 863 consoles mpt
101 10552 10730 13 314 50 68058 864 cpuinfo mtrr
10112 10562 10735 1301 316 51 68098 865 crypto net
10117 10570 10742 1307 317 53 68102 867 devices pagetypeinfo
10120 10581 10745 1308 318 569 68305 868 diskstats partitions
1013 10586 10746 14 320 583 68306 869 dma sched_debug
...
[root@localhost ~]# ./pid.o
程序开始:
在子进程中!
[root@Changed Name ~]# ls /proc
1 10524 10676 1286 289 484 67591 861 cgroups modules
10 10529 10701 1289 29 485 67628 862 cmdline mounts
10042 10535 10727 1293 290 49 677 863 consoles mpt
101 10552 10730 13 314 50 68058 864 cpuinfo mtrr
10112 10562 10735 1301 316 51 68098 865 crypto net
10117 10570 10742 1307 317 53 68102 867 devices pagetypeinfo
10120 10581 10745 1308 318 569 68305 868 diskstats partitions
1013 10586 10746 14 320 583 68306 869 dma sched_debug
...与其他的命名空间不同的是,为了实现一个稳定安全的容器,pid命名空间还需要进行一些额外的工作,才能确保其中进程运行顺利
pid为1的进程,用来维护命名空间中的所有进程,进行资源的监控和回收
内核也赋予了1号进程特殊的权利,叫信号屏蔽,如果进程中没有写处理某个信号的代码逻辑,那么1号进程在同一个命名空间下的所有进程都会被屏蔽。
Docker一旦启动,就有进程在运行,不存在不包括任何进程的Docker
如果想在pid命名空间中只想要看到该命名空间内运行的pid进程,则需要挂载proc目录到命名空间
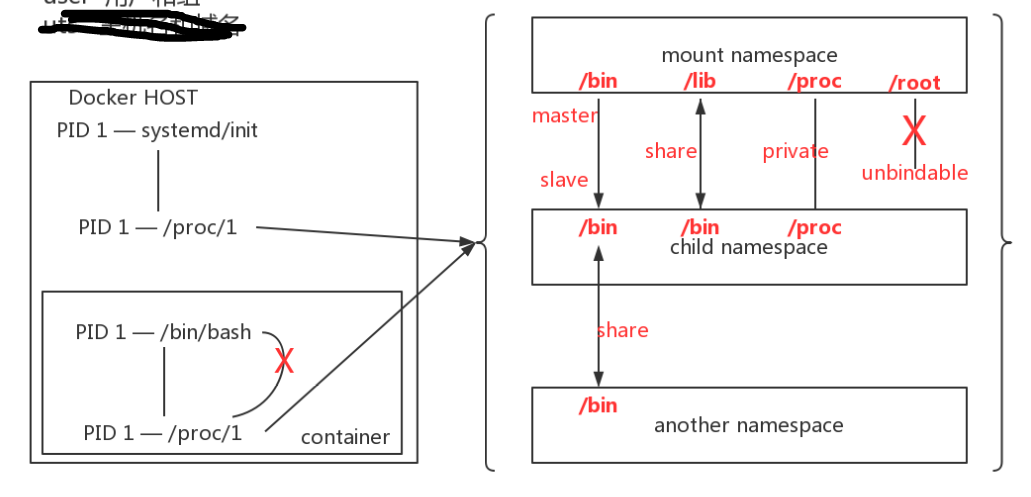
如图所示,物理机中的1号进程是
init,而容器中的1号进程是/bin/bash,他俩的proc目录需要同步,需要使用mnt命名空间来实现我们传统的挂载,属于共享式(share)的挂载,无论是挂载点还是挂载源,改变任何一个都会想另一个点去同步
现在就是不需要两端去同步写数据,需要有一个主从的概念,一端写入,另外一端可以看到,但是不会传播给另外一端
mount支持的挂载操作如下:
Supported operations:
mount --make-shared mountpoint # 默认使用
mount --make-slave mountpoint # 有主从结构,master挂载到从,master写,slave看,适用于只读
mount --make-private mountpoint # 私有挂载,各自是各自的,互补影响,经常用来挂载proc目录,适用于隔离
mount --make-unbindable mountpoint # 不能被二次挂载,如:root目录mount是历史上第一个命名空间,它的标识比较特殊,CLONE_NEWNS,隔离之后不同的mnt命名空间中的文件结构都会发生变化,也不会互相影响
cat /proc/68305/mounts # 可以查看到所有挂载到当前命名空间的文件系统
# 查看命名空间中文件系统的挂载状态,包括了,什么东西挂载了哪个目录上
cat /proc/68305/mountstats 进程在创建新的mnt命名空间的时候,会把当前的文件系统结构复制给新的命名空间,新的命名空间中的所有mount操作都值影响自己命名空间中的文件系统,严格的实现了文件系统隔离
实现/proc/文件系统的隔离挂载,需要在物理机和命名空间中都进行隔离挂载
[root@localhost ~]# vim example.c
#define _GNU_SOURCE
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#define STACK_SIZE (1024 * 1024)
static char child_stack[STACK_SIZE];
char* const child_args[] = {
"/bin/bash",
NULL
};
int child_main(void* args) {
printf("在子进程中!\n");
sethostname("Changed Name", 12);
execv(child_args[0], child_args);
return 1;
}
int main() {
printf("程序开始: \n");
int child_pid = clone(child_main, child_stack + STACK_SIZE, CLONE_NEWNS | CLONE_NEWPID | CLONE_NEWIPC | CLONE_NEWUTS | SIGCHLD, NULL);
waitpid(child_pid, NULL, 0);
printf("已退出\n");
return 0;
}编译输出为mount.o
gcc -Wall example.c -o mount.o执行mount.o,进入mnt命名空间
[root@localhost ~]# ./mount.o
[root@Changed Name ~]# mount --make-private -t proc proc /proc
[root@Changed Name ~]# ls /proc # 发现已经和刚才做mnt隔离之前不一样了
1 cpuinfo fs kmsg mounts self timer_stats
33 crypto interrupts kpagecount mpt slabinfo tty
acpi devices iomem kpageflags mtrr softirqs uptime
asound diskstats ioports loadavg net stat version
buddyinfo dma irq locks pagetypeinfo swaps vmallocinfo
bus driver kallsyms mdstat partitions sys vmstat
cgroups execdomains kcore meminfo sched_debug sysrq-trigger zoneinfo
cmdline fb keys misc schedstat sysvipc
consoles filesystems key-users modules scsi timer_list然后使用ps查看进程,也只剩下了两个,1号进程为/bin/bash
[root@Changed Name ~]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 116752 3340 pts/3 S 11:31 0:00 /bin/bash
root 34 0.0 0.0 155372 1844 pts/3 R+ 11:35 0:00 ps aux退出查看物理机
[root@Changed Name ~]# exit
exit
已退出
[root@localhost ~]# ls /proc/
ls: cannot read symbolic link /proc/self: No such file or directory
acpi devices iomem kpageflags mtrr softirqs uptime
asound diskstats ioports loadavg net stat version
buddyinfo dma irq locks pagetypeinfo swaps vmallocinfo
bus driver kallsyms mdstat partitions sys vmstat
cgroups execdomains kcore meminfo sched_debug sysrq-trigger zoneinfo
cmdline fb keys misc schedstat sysvipc
consoles filesystems key-users modules scsi timer_list
cpuinfo fs kmsg mounts self timer_stats
crypto interrupts kpagecount mpt slabinfo tty发现proc目录的内容和命名空间中一样,被命名空间所影响了,所以物理机也需要变为隔离挂载
[root@localhost ~]# mount --make-private -t proc proc /proc
[root@localhost ~]# ls /proc
1 10505 10652 10891 21 448 644 70002 870 devices mpt
10 10514 10659 10912 22 449 645 70625 882 diskstats mtrr
10042 10518 10662 10971 23 46 656 70937 884 dma net
101 10524 10669 11 24 460 65815 71085 888 driver pagetypeinfo
10112 10529 10673 11030 25 461 66 71324 892 execdomains partitions
10117 10535 10674 11039 26 474 66041 71384 895 fb sched_debug
...这个时候命名空间内还是会被影响,还需要再进一次,隔离挂载就好
[root@localhost ~]# ./mount.o
程序开始:
在子进程中!
[root@Changed Name ~]# ls /proc
1 10524 10676 1286 289 484 68102 861 cgroups modules
10 10529 10701 1289 29 485 68305 862 cmdline mounts
10042 10535 10727 1293 290 49 68306 863 consoles mpt
101 10552 10730 13 314 50 68307 864 cpuinfo mtrr
10112 10562 10735 1301 316 51 68308 865 crypto net
10117 10570 10742 1307 317 53 68309 867 devices pagetypeinfo
10120 10581 10745 1308 318 569 68310 868 diskstats partitions
1013 10586 10746 14 320 583 7 869 dma sched_debug
...
# 再次进行隔离挂载
[root@Changed Name ~]# mount --make-private -t proc proc /proc
[root@Changed Name ~]# ls /proc
1 cpuinfo fs kmsg mounts self timer_stats
33 crypto interrupts kpagecount mpt slabinfo tty
acpi devices iomem kpageflags mtrr softirqs uptime
asound diskstats ioports loadavg net stat version
buddyinfo dma irq locks pagetypeinfo swaps vmallocinfo
bus driver kallsyms mdstat partitions sys vmstat
cgroups execdomains kcore meminfo sched_debug sysrq-trigger zoneinfo
cmdline fb keys misc schedstat sysvipc
consoles filesystems key-users modules scsi timer_list
# 退出后查看物理机的proc目录,已经完全不影响了
[root@Changed Name ~]# exit
exit
已退出
[root@localhost ~]# ls /proc
1 10505 10652 10891 21 448 644 70002 882 diskstats mtrr
10 10514 10659 10912 22 449 645 70625 884 dma net
10042 10518 10662 10971 23 46 656 71085 888 driver pagetypeinfo
101 10524 10669 11 24 460 65815 71451 892 execdomains partitions
10112 10529 10673 11030 25 461 66 71463 895 fb sched_debugNET:网络隔离
当物理机已经运行一个apache进程时,再进入命名空间去运行一个apache,会报出端口被占用的错误,就需要进行网络隔离
NET网络隔离包括了设备,ipv4/ipv6协议栈,防火墙,路由表、端口、socket等。
物理的网络设备最多存在一个net命名空间中,可以通过虚拟网络端对端,
不同的net命名空间创建通道,达到网络通讯的目的
如果有多块网卡,可以将网卡分配给新建net命名空间,当net命名空间被释放时,所有的内部进程都会中止,物理网卡就会返回到root的命名空间中

不同的net命名空间会通过物理机的网桥实现路由转发功能
使用代码建立net命名空间时较为复杂,所以接下来使用命令来测试
创建network namespace
# 创建test_ns的network命名空间
[root@localhost ~]# ip netns add test_ns
# 查看test_ns中的网卡,只有一个lo网卡,且状态为DOWN
[root@localhost ~]# ip netns exec test_ns ip link list
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# lo的DOWN状态下是无法进行iso封装数据的
[root@localhost ~]# ip netns exec test_ns ping 127.0.0.1
connect: Network is unreachable
# 开启lo网卡
[root@localhost ~]# ip netns exec test_ns ip link set dev lo up
[root@localhost ~]# ip netns exec test_ns ping 127.0.0.1
PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.161 ms创建网络设备对为命名空间添加网卡
[root@localhost ~]# ip link add veth0 type veth peer name veth1
[root@localhost ~]# ip a # 宿主机的网卡编号是全局的,无论哪个空间编号不会重复
12: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 3a:3e:0e:0a:1f:bf brd ff:ff:ff:ff:ff:ff
13: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 56:83:20:7a:c5:3a brd ff:ff:ff:ff:ff:ff
[root@localhost ~]# ip link set veth1 netns test_ns # 将veth1放入test_ns命名空间
[root@localhost ~]# ip netns exec test_ns ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
12: veth1@if13: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether be:a8:bd:76:bd:71 brd ff:ff:ff:ff:ff:ff link-netnsid 0配置ip地址
# 为test_ns中的veth1配置ip为10.1.1.1,并启动
[root@localhost ~]# ip netns exec test_ns ifconfig veth1 10.1.1.1/24 up
# 网络设备对的另一个配置ip,作为和网络命名空间网桥地址
[root@localhost ~]# ifconfig veth0 10.1.1.2/24
[root@localhost ~]# ping 10.1.1.1
[root@localhost ~]# ip netns exec test_ns ping 10.1.1.2
[root@localhost ~]# ip netns # 查看现有的网络命名空间
test_ns (id: 1)路由表隔离查看
[root@localhost ~]# ip netns exec test_ns route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.1.1.0 0.0.0.0 255.255.255.0 U 0 0 0 veth1
[root@localhost ~]# route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default gateway 0.0.0.0 UG 100 0 0 ens33
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
192.168.1.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33
192.168.122.0 0.0.0.0 255.255.255.0 U 0 0 0 virbr0防火墙隔离查看
# net命名空间防火墙列表
[root@localhost ~]# ip netns exec test_ns iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
# 宿主机防火墙列表
[root@localhost ~]# iptables -L
# 由于太多就不复制了删除网络命名空间
[root@localhost ~]# ip netns delete test_ns # 删除网络命名空间演示容器中的1号进程不能去启动其他进错误
这就是经过pid隔离以后引出的大bug
命名空间中的pid为1的程序为/bin/bash,它是没有权限去管理其他的进程的,但前面说到,id为1的进程可以管理所有的进程,这个时候需要去做什么。
容器还存在一个bug,不能运行yum所使用的东西
如:运行一个容器
[root@localhost ~]# docker run -it --rm centos /bin/bash
[root@68dfc0967784 /]# yum -y install httpd
[root@68dfc0967784 /]# systemctl start httpd
Failed to get D-Bus connection: Operation not permitted在启动httpd时报错,没有操作权限,就是说明容器中的1号进程bash是无法启动其他进程的
我们要做到让它可以去管理这些进程
[root@68dfc0967784 /]# ll /sbin/init # 链接到1号物理机父进程
lrwxrwxrwx. 1 root root 22 Oct 1 01:15 /sbin/init -> ../lib/systemd/systemd
[root@68dfc0967784 /]# exit
exit方法一
给容器提权:--privileged运行/sbin/init环境,当操作完之后,建议立即退出容器,时间长会占用权限,使系统锁定。
[root@localhost ~]# docker run -d --rm --name test --privileged centos /sbin/init
eea69300721c847ca67d3961ca222f75565b920b70459be01a050649c85d36d0
[root@localhost ~]# docker exec -it test /bin/bash
[root@eea69300721c /]# yum -y install httpd
[root@eea69300721c /]# systemctl start httpd
[root@eea69300721c /]# exit
exit方法二
这个才是正确的用法
[root@localhost ~]# docker run -itd --name sshd centos /bin/bash
cd3c512d6cd959263b1c94e19781d7213831aad714a2e962ade7c0adc28c510e
[root@localhost ~]# docker exec -it sshd /bin/bash
[root@cd3c512d6cd9 /]# yum -y install openssh-server openssh-clients password iproute net-tools
[root@cd3c512d6cd9 /]# passwd root # 设置root密码
[root@cd3c512d6cd9 /]# cat /usr/lib/systemd/system/sshd.service
# 找到以下
ExecStart=/usr/sbin/sshd -D $OPTIONS
# /usr/sbin/sshd -D这个用来启动yum安装的服务,几乎所有yum安装的都有这个
[root@5c46b791e8d2 /]# /usr/sbin/sshd -D
# 执行之后发现报错,找不到3个密钥文件
Could not load host key: /etc/ssh/ssh_host_rsa_key
Could not load host key: /etc/ssh/ssh_host_ecdsa_key
Could not load host key: /etc/ssh/ssh_host_ed25519_key
sshd: no hostkeys available -- exiting.
# 生成密钥,分别存放到它要找到三个路径中
[root@cd3c512d6cd9 /]# ssh-keygen -q -t rsa -b 2048 -f /etc/ssh/ssh_host_rsa_key -N ''
[root@cd3c512d6cd9 /]# ssh-keygen -q -t ecdsa -f /etc/ssh/ssh_host_ecdsa_key -N ''
[root@cd3c512d6cd9 /]# ssh-keygen -q -t dsa -f /etc/ssh/ssh_host_ed25519_key -N ''
# 可以通过cat去查看这三个密钥
[root@cd3c512d6cd9 /]# vi /etc/ssh/sshd_config
# 修此文件是得ssh以进程方式运行
# 这是pam模块使用sshd,容器中没有这个模块,所以需要注释
# UsePAM no
# 解开以下注释并修改值为no
UsePrivilegeSeparation sandbox //将sandbox改为no
# 以下解开注释,允许超级用户登录
PermitRootLogin yes
[root@5c46b791e8d2 /]# /usr/sbin/sshd -D &
[root@5c46b791e8d2 /]# exit
exit然后就可以通过ssh来管理docker的容器了
[root@192 ~]# ssh root@172.17.0.2
The authenticity of host '172.17.0.2 (172.17.0.2)' can't be established.
ECDSA key fingerprint is SHA256:8M08usrRzTfDZjM9cfZhM+DAMn8d4O6/xW3ULlpM17o.
ECDSA key fingerprint is MD5:8b:72:3b:0f:15:ac:f4:8f:24:f0:ed:fa:40:12:c3:ae.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '172.17.0.2' (ECDSA) to the list of known hosts.
root@172.17.0.2's password:
[root@5c46b791e8d2 ~]# pid隔离后引发的两个bug
- 容器中的1号pid不能去管理其他进程,容器提权解决
- pid隔离后,进入命名空间还是可以看到物理机的所有进程,私有挂载文件系统解决

 浙公网安备 33010602011771号
浙公网安备 33010602011771号