

scikit-learn学习手记_1
安装
法1: 在终端输入
pip install scikit-learn
补充:
pip uninstall scikit-learn #卸载 pip install -U scikit-learn #升级
法2: Anaconda环境下,可以使用conda
conda install scimitar-learn
简介
scikit-learn是基于python语言的机器学习库,广泛应用于数据统计分析和机器学习建模等数据科学领域。它具有各种分类,回归和聚类算法,包括支持向量机,随机森林,梯度提升,k均值和DBSCAN,可以实现数据预处理、分类、回归、降维、模型选择等常用的机器学习算法, Scikit-learn与许多其他Python库很好地集成在一起,例如matplotlib和plotly用于绘图,NumPy用于数组矢量化,pandas数据帧,SciPy等。
六个任务模块和一个引入模块
- 有监督学习的分类任务
- 有监督学习的回归任务
- 无监督学习的聚类任务
- 无监督学习的数据降维任务
- 数据预处理任务
- 模型选择任务
- 数据引入
具体流程
自带数据集
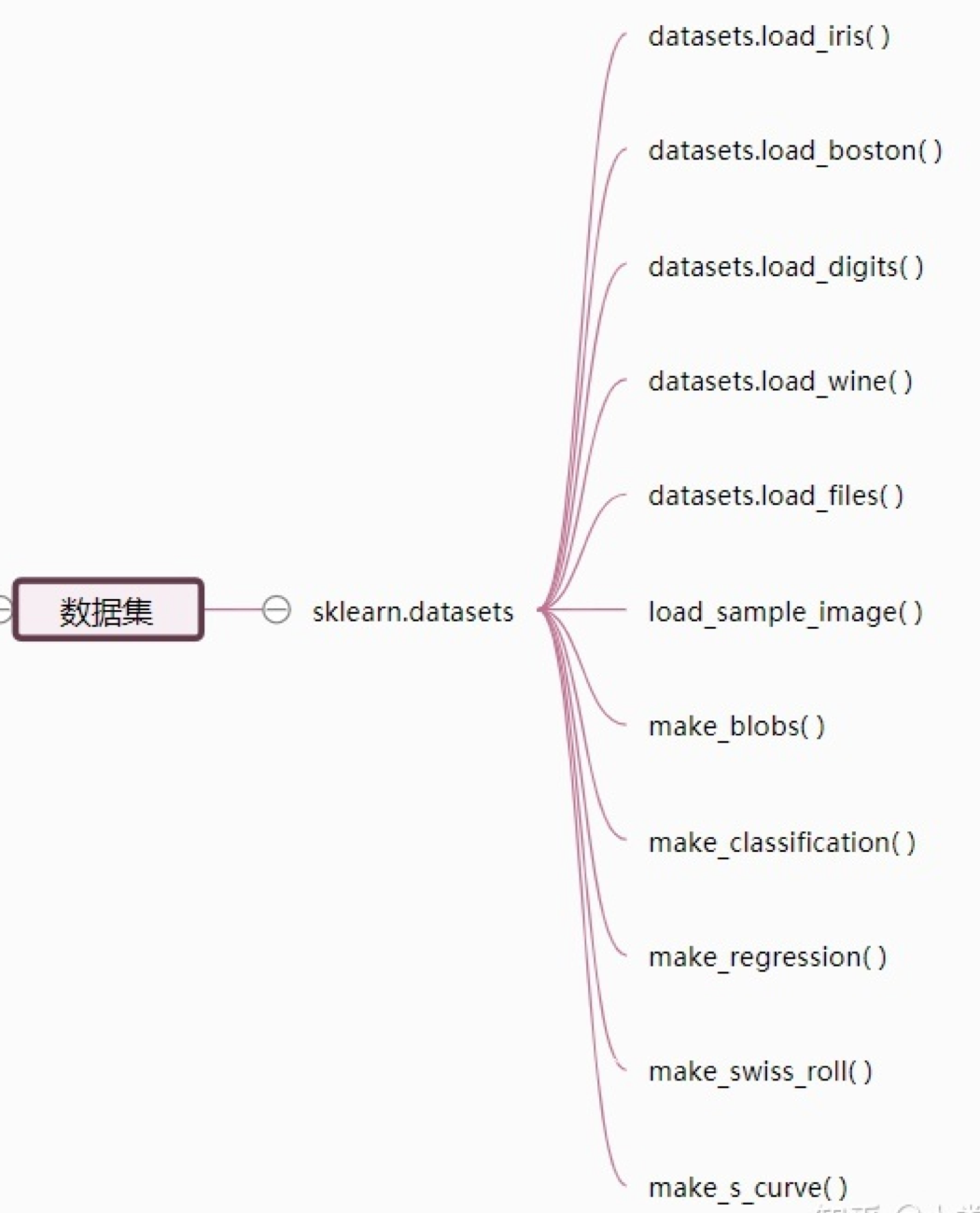
引入数据集的方法
小数据:load_dataname()
大数据:fetch_dataname()
构造随机数据:make_dataname()
#引入数据法一 from sklearn import datasets iris=datasets.load_iris() iris.keys() #法二 from sklearn.datasets import load_iris iris=load_iris() iris.keys() iris.target_names
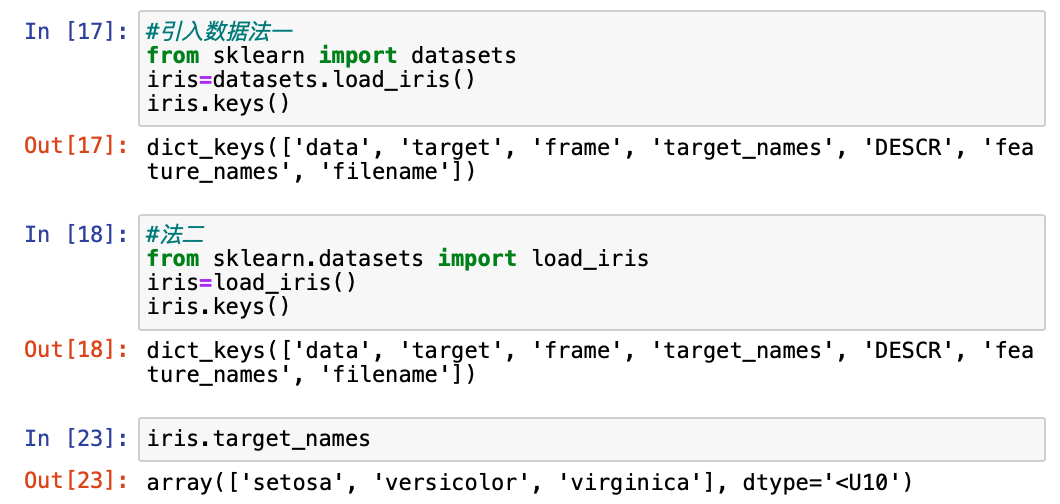
键里的名词解释
data:特征值 (数组)
target:标签值 (数组)
target_names:标签 (列表)
DESCR:数据集描述
feature_names:特征 (列表)
filename:iris.csv 文件路径
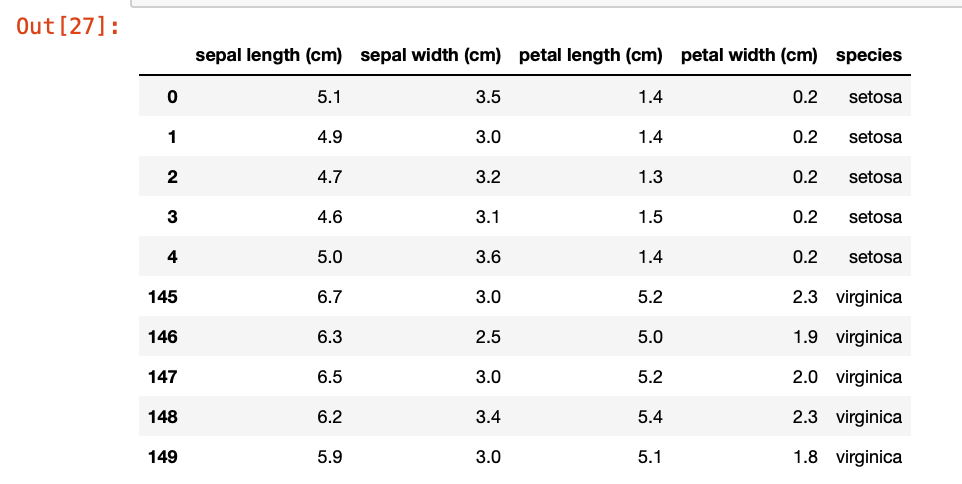
将数据集转化成DataFrame
import pandas as pd iris_data = pd.DataFrame(iris.data,columns=iris.feature_names)#feature_name:特征列表 iris_data['species'] = iris.target_names[iris.target] iris_data.head(5).append(iris_data.tail(5))
'
可视化seaborn
seaborn是python中的一个可视化库,是对matplotlib进行二次封装而成,既然是基于matplotlib,所以seaborn的很多图表接口和参数设置与其很是接近
import seaborn as sns sns.pairplot(iris_data, hue='species', palette='husl')


 浙公网安备 33010602011771号
浙公网安备 33010602011771号