
Redis-基础篇
本文为针对黑马课程redis所总结笔记。
基础知识
| SQL | NoSQL | |
|---|---|---|
| 数据结构 | 结构化 | 非结构化 |
| 数据关联 | 关联的 | 无关联的 |
| 查询方式 | SQL查询 | 非SQL |
| 事务特性 | ACID | Base |
| 存储方式 | 磁盘 | 内存 |
| 扩展性 | 垂直 | 水平 |
| 使用场景 | 数据结构稳定 相关业务对数据安全性、一致性要求高 |
数据结构不稳定 对一致性、安全性要求不高、对性能要求高 |
redis是一个基于内存的键值型NoSQL数据库。key一般是String类型,value的类型是多样的。上表是SQL数据库和NoSQL数据库的区别。
特征:
- 键值型
- 单线程,核心每个命令具备原子性
- 低延迟,速度快:基于内存、IO多路复用、良好的编码
- 支持数据持久化(定期从内存备份到硬盘中)
- 支持主从集群、分片集群
- 支持多语言客户端
安装:在linux环境下,下载命令
- 首先安装linux虚拟机,输入ifconfig,查看ip地址。然后使用mobaXterm新建session,输入ip地址和用户名,连接linux。
- 然后安装radis所需要的gcc依赖,
yum install -y gcc tcl。(使用管理员模式,su root) - 将redis安装包上传到/usr/local/src/目录,因为此目录一般情况放置安装文件。
- 然后
cd /usr/local/src/,解压缩tar -xzf redis-6.2.6.tar.gz - 进入redis目录,
cd redis-6.2.6,运行编译命令make && make install。 - 默认安装路径在/usr/local/bin/目录下,因为该目录已经默认配置到环境变量。
- 在任意位置输入命令均可以启动radis。
其中:
- redis-cli:是redis提供的命令行客户端。命令格式为
redis-cli [options] [commands]
常见options:-h ip,指定要连接的redis节点的ip地址,默认是127.0.0.1。-p 6379,指定要连接的redis节点的端口,默认是6379。-a yeah,指定redis的访问密码。但是使用-a password这种方法并不安全,因此可以在运行redis-cli后使用AUTH -password连接redis。 - redis-server:是redis的服务端启动脚本
- redis-sentinel:是redis的哨兵启动脚本
配置:修改配置文件
安装完成后,在任意目录输入redis-server命令即可启动Redis。但是这种启动输入前台启动,会阻塞整个会话窗口。因此通过修改配置文件,使其改为后台启动。
- 备份配置文件,配置文件为/usr/local/src/redis-6.2.6下的redis.conf。使用
cp redis.conf redis.conf.bck备份文件。 - 按下述内容修改redis.conf的配置
- 进入redis安装目录,启动
redis-server redis.conf - 使用
ps -ef | grep redis,可以看到后台已经启动的redis。
# 允许访问的地址,默认是127.0.0.1,会导致只能在本地访问。修改为0.0.0.0则可以在任意IP访问,生产环境不要设置为0.0.0.0
bind 0.0.0.0
# 守护进程,修改为yes后即可后台运行
daemonize yes
# 密码,设置后访问Redis必须输入密码
requirepass yeah
# 监听的端口
port 6379
# 工作目录,默认是当前目录,也就是运行redis-server时的命令,日志.持久化等文件会保存在这个目录
dir .
# 数据库数量,设置为1,代表只使用1个库,默认有16个库,编号0~15
databases 1
# 设置redis能够使用的最大内存
maxmemory 512mb
# 日志文件,默认为空,不记录日志,可以指定日志文件名
logfile "redis.log"
设置开机自启:
首先,新建一个系统服务文件:vi /etc/systemd/system/redis.service
内容如下:
[Unit]
Description=redis-server
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/bin/redis-server /usr/local/src/redis-6.2.6/redis.conf
PrivateTmp=true
[Install]
WantedBy=multi-user.target
然后重载系统服务:systemctl daemon-reload
设置redis开机自启:systemctl enable redis
现在,我们可以用下面这组命令来操作redis了:
# 启动
systemctl start redis
# 停止
systemctl stop redis
# 重启
systemctl restart redis
# 查看状态
systemctl status redis
常见命令:官网查询
通用命令:
- KEYS:查看符合模板的所有key,不建议在生产环境设备上使用,因为在key过多的情况下,效率不高。
keys pattern - DEL:删除key,返回值num代表删除的key的数量。
del [key ...] - EXISTS:判断key是否存在。
- EXPIRE:给一个key设置有效期seconds,因为内存很宝贵,对于一些数据,应该适当设置过期时间。
expire key seconds - TTL:查看key的剩余有效期。返回为-1,表示永久有效。返回为-2,表示该key已过期。
- help:查看一个命令的具体用法。
help [command]
String类型:
不管是哪种格式,底层都是字节数组形式存储,只不过编码方式不同。字符串类型最大空间不能超过512M。
String类型的常见命令:
- SET:添加或者修改已经存在的一个String类型的键值对
- GET:根据key获取String类型的value
- MSET:批量添加多个String类型的键值对
- MGET:根据多个key获取多个String类型的value
- INCR:让一个整型的key自增1。
- INCRBY:让一个整型的key自增并指定步长,例如:incrby num 2 让num值自增2
- INCRBYFLOAT:让一个浮点类型的数字自增并指定步长
组合命令 - SETNX:添加一个String类型的键值对,前提是这个key不存在,否则不执行。set + nx
- SETEX:添加一个String类型的键值对,并且指定有效期。set + expire
hash类型:
key的层级结构:[项目名]:[业务名]:[类型]:[id] value。因为redis没有类似mysql的table的概念,因此通过层级结构的存储,则可以区分不同类型的key。
比如
| KEY | VALUE |
|---|---|
| heima:user:1 | |
| heima:product:1 |
存入的层级结构是yeah下面分支的两个不同的类型user和product
string结构是将对象序列化为json字符串后存储,当需要修改对象某个字段时很不方便。因此hash结构可以将对象中的每个字段独立存储,可以针对单个字段做CRUD。
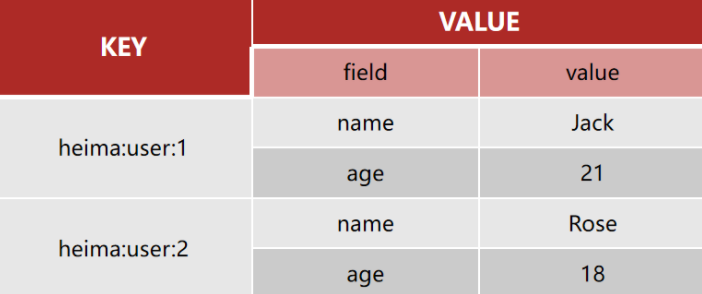
Hash类型的常见命令
- HSET key field value:添加或者修改hash类型key的field的值
- HGET key field:获取一个hash类型key的field的值
- HMSET:批量添加多个hash类型key的field的值
- HMGET:批量获取多个hash类型key的field的值
- HGETALL:获取一个hash类型的key中的所有的field和value
- HKEYS:获取一个hash类型的key中的所有的field
- HVALS:获取一个hash类型的key中所有的value
- HINCRBY:让一个hash类型key的字段值自增并指定步长
- HSETNX:添加一个hash类型的key的field值,前提是这个field不存在,否则不执行
List类型:
与java的linkedlist类似,可以看作一个双向链表结构。因此有有序、元素可重复、插入删除快、查询速度一般的特点。
List的常见命令有:
- LPUSH key element ... :向列表左侧插入一个或多个元素
- LPOP key:移除并返回列表左侧的第一个元素,没有则返回nil
- RPUSH key element ... :向列表右侧插入一个或多个元素
- RPOP key:移除并返回列表右侧的第一个元素
- LRANGE key star end:返回一段角标范围内的所有元素
- BLPOP和BRPOP:与LPOP和RPOP类似,只不过在没有元素时等待指定时间,而不是直接返回nil
Set类型
与java的hashset类似,可以看作是一个value为null的hashmap。因此有无序、元素不可重复、查找快、支持交并差集等功能的特点。
Set类型的常见命令
-
SADD key member ... :向set中添加一个或多个元素
-
SREM key member ... : 移除set中的指定元素
-
SCARD key: 返回set中元素的个数
-
SISMEMBER key member:判断一个元素是否存在于set中
-
SMEMBERS:获取set中的所有元素
-
SINTER key1 key2 ... :求key1与key2的交集
-
SDIFF key1 key2 ... :求key1与key2的差集
-
SUNION key1 key2 ..:求key1和key2的并集
SortedSet类型
是一个可排序的set集合,与java的treeset有些类似,但底层数据机构差别很大。sortedset中每个元素都带有一个score属性,可以基于score属性对元素排序,底层实现是一个跳表加哈希表。因此有可排序、元素不重复、查询速度快的特点。经常被用作实现排行榜这样的功能。
SortedSet的常见命令有:
- ZADD key score member:添加一个或多个元素到sorted set ,如果已经存在则更新其score值
- ZREM key member:删除sorted set中的一个指定元素
- ZSCORE key member : 获取sorted set中的指定元素的score值
- ZRANK key member:获取sorted set 中的指定元素的排名
- ZCARD key:获取sorted set中的元素个数
- ZCOUNT key min max:统计score值在给定范围内的所有元素的个数
- ZINCRBY key increment member:让sorted set中的指定元素自增,步长为指定的increment值
- ZRANGE key min max:按照score排序后,获取指定排名范围内的元素
- ZRANGEBYSCORE key min max:按照score排序后,获取指定score范围内的元素
- ZDIFF.ZINTER.ZUNION:求差集.交集.并集
上述所有命令默认都是升序,如果需要降序则在命令的Z后面添加REV即可。member是hash结构的filed。
Jedis-redis 的java客户端
- 新建maven项目,添加jedis依赖:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.7.0</version>
</dependency>
- 在test中,新建jedisTest.java,建立连接:
public class jedisTest {
private Jedis jedis;
//建立连接
@BeforeEach
void setUp(){
jedis=new Jedis("192.168.233.128",6379);
jedis.auth("yeah");
jedis.select(0);
}
@Test
void testString(){
String result=jedis.set("name","yeah");
System.out.println(result);
String name=jedis.get("name");
System.out.println(name);
}
//释放资源
@AfterEach
void tearDown(){
if(jedis!=null){
jedis.close();
}
}
}
- 运行testString函数。
稀奇古怪的bug:如果运行出错,判断是否是ip地址端口号填错、是否虚拟机防火墙未关。
SpringDataRedis
数据序列化器
- 引入spring-boot-starter-data-redis依赖
- 配置main/resources/application.yaml文件
- 编写测试代码
@ Test
void testString() {
redisTemplate.opsForValue().set("name","rose");
Object name=redisTemplate.opsForValue().get("name");
System.out.println(name);
}
RedisTemplate可以接收任意Object作为值写入redis,只不过将Object序列化为字节形式,默认采用JDK序列化,因此redis数据库中显示为:\xac\xed\x00\x05t\x00\x04name "\xac\xed\x00\x05t\x00\x04rose"
该方法的缺点是:可读性差、内存占用较大。
自定义序列化:
因此必须改变RedisTemplate的序列化方式。在这里使用GenericJackson2JsonRedisSerializer序列化value,因为value有可能是一个对象,所以通过其对对象序列化;用RedisSerializer.string()序列化key。因此需要导入jackson的依赖。
稀奇古怪的bug:而使用spring4.X时,jackson的版本要高点,比如2.13.5,否则报错。
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String,Object> redisTemplate(RedisConnectionFactory connectionFactory){
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(connectionFactory);
GenericJackson2JsonRedisSerializer jsonRedisSerializer=new GenericJackson2JsonRedisSerializer();
template.setKeySerializer(RedisSerializer.string());
template.setHashKeySerializer(RedisSerializer.string());
template.setValueSerializer(RedisSerializer.string());
template.setValueSerializer(jsonRedisSerializer);
template.setHashValueSerializer(jsonRedisSerializer);
return template;
}
}
为了在反序列化时知道对象的类型,JSON序列化器会将类的class类型写入json结果中,存入Redis,会带来额外的内存开销。
使用StringRedisTemplate:
为了节省空间,我们并不会使用JSON序列化器来处理value。因此统一使用String序列化器,要求只能存储String类型的key和value。当需要存储Java对象时,手动完成对象的序列化和反序列化。
mapper是spring中常用的序列化工具。
String json = mapper.writeValueAsString(obj);//序列化
UObject obj = mapper.readValue(json,UObject.class);//反序列化
本文作者:梅落南山
本文链接:https://www.cnblogs.com/ting65536/p/17677731.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步