
python-re


1. 基本使用:
|
|
输出
|
|
#re
#pattern = re.compile() #生成pattern对象
#pattern.match #pattern.search
#pattern.find str1 = "itest python"
pa = re.compile(r"itest")
#加r代表是原字符串,不加r容易将\n等进行转义。 print (type(pa)) print (help(pa)) print(pa.match(str1))
print(pa.match(str1).group())
print (pa.match(str1).span()) #获取原字符串 print (pa.match(str1).string) #获取实例 print (pa.match(str1).re) #忽略大小写
pa = re.compile(r"itest",re.I)
ma = pa.match("Itest python") print ("ma:", ma.group()) ma1 = pa.match("ITEST python") print("mal:", ma1.group()) ma2 = pa.match("itest python") print ("ma2:", ma2.group()) #groups
pa = re.compile(r"(itest)",re.I)
ma_group = pa.match("Itest python").group() print ("ma_group:", ma_group) ma_groups = pa.match("Itest python").groups()
print ("ma_groups:", ma_groups) |
<class 're.Pattern'>
None
<re.Match object; span=(0, 5), match='itest'> itest (0, 5) itest python re.compile('itest') ma: Itest
mal: ITEST ma2: itest ma_group: Itest
ma_groups: ('Itest',) |
2. 基本语法
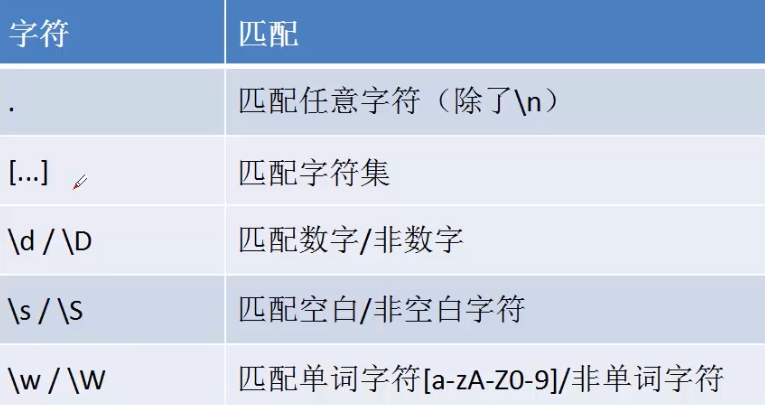
| 输出 | |
|
ma = re.match(r"{..}", "{ad}d")
print (re.match(r"{[abc]}", "{a}").group())
print (re.match(r"{[a-z]}", "{d}").group()) print (re.match(r"{[a-zA-Z]}", "{A}").group())
print (re.match(r"{[a-zA-Z0-9]}", "{8}").group())
print (re.match(r"{[\w]}", "{8}").group())
print (re.match(r"{[\w]}", "{}").group())
print (re.match(r"{[\W]}", "{ }").group())
print (re.match(r"\[[\w]\]",'[a]').group())
print (re.match(r"{[abc]+}", "{ab}").group())
|
ma: {ad}
{a}
{8}
'NoneType' object has no attribute 'group'
{ }
[a]
{ab} |

| 输出 | |
|
print (re.match(r'[A-Z][a-z]*', 'Aadddd dd').group())
print (re.match(r"[1-9]?[0-9]",'09').group())
print (re.search(r"[1-9]?[0-9]",'09').group())
print (re.match(r"[a-zA-Z0-9]{6,10}@163.com",'adc123@163.com').group()) print (re.match(r"[a-zA-Z0-9]{6,10}@163.com",'adc12345@163.com').group())
print (re.match(r"[0-9][a-z]*",'1bc').group())
print (re.match(r"[0-9][a-z]*?",'1bc').group())
print (re.match(r"[0-9][a-z]+?",'1bc').group())
print (re.match(r"[0-9][a-z]??",'1bc').group())
|
Aadddd
0
1bc |

print (re.match(r"^[a-zA-Z0-9_]*$", "jadsjkjs2222((").group()) 指定字符串里面只能有字符,数字和下划线

| 输出 | |
|
print (re.match(r"^[1-9]?\d$",'99').group())
print (re.match(r"[\w]{6,10}@(163|126).com",'adc123@163.com').group())
print (re.match(r"[\w]{6,10}@(163|126).com",'adc123@126.com').group())
print (re.match(r"[\w]{6,10}@(163|126|qq).com",'adc123@qq.com').group())
|
99
adc123@163.com |
(?:\w+\.)* 以句点结尾的字符串,如:gooogle. , 但是这些匹配不会保存下来供后续的使用和数据检索
(?#comment) 此处不做匹配, 只是作为注释用
(?=.com) 如果一个字符串后面跟着“.com”才做匹配
(?!.com) 如果一个字符串后面不是跟着“.com”才做匹配
(?<=800-) 如果字符串之前为800-才做匹配
(?<!192\.168\.) 如果一个字符串之前不是 “192.168” 才做匹配操作, 假定用于过滤一组c类ip地址
(?(1)y|x) 如果匹配组 1(\1)存在,就与y匹配,否则和x匹配

 浙公网安备 33010602011771号
浙公网安备 33010602011771号