AI Agent【项目实战】:MetaGPT遇上元编程,重塑复杂多智能体协作的边界
AI Agent【项目实战】:MetaGPT遇上元编程,重塑复杂多智能体协作的边界
MetaGPT 以一条需求作为输入,并输出用户故事/竞争分析/需求/数据结构/API/文档等。内部而言,MetaGPT 包含产品经理/架构师/项目经理/工程师等角色。它为软件公司提供了整个流程,并精心制定了标准化操作流程(SOP)。“代码=SOP(团队)”是核心理念。我们将SOP转化为代码,并将其应用于由LLM(大型语言模型)组成的团队。
- GitHub - geekan/MetaGPT: 🌟 The Multi-Agent Framework
- 开发使用文档 MetaGPT Usage & Development Guide,
- 在线文档:https://docs.deepwisdom.ai/main/zh/
1.MetaGPT遇上元编程:重塑复杂多智能体协作的边界
论文链接:https://arxiv.org/pdf/2308.00352
MetaGPT 的创新框架,该框架将有效的人类工作流程作为元编程方法融入到大型语言模型(LLM)驱动的多智能体协作中。该框架通过将标准化操作程序(SOPs)编码为提示来实现结构化协调,并要求模块化输出,使智能体拥有与专业人士类似的领域专业知识,以验证输出并减少累积错误。通过这种方式,MetaGPT 利用装配线工作模式为不同的智能体分配各种角色,从而建立起一个可以有效地分解复杂多智能体协作问题的框架。在协作软件工程任务上的实验证明了 MetaGPT 相对于现有的对话式和聊天式多智能体系统具有更高的连贯性,这强调了将人类领域知识融入多智能体的潜力,并为解决复杂的现实世界挑战开辟了新的途径
- 在代码生成基准测试中,MetaGPT相对于直接方法,取得了81.7%和82.3%的Pass@1成功率,达到了新的技术水平。
- 与其他基于LLM的编程框架相比,如AutoGPT、LangChain和AgentVerse相比,MetaGPT能够处理更高水平的软件复杂性,并通过其广泛的功能脱颖而出。
- 在实验评估中,MetaGPT实现了100%的任务完成率,进一步强调了MetaGPT框架的鲁棒性和效率。
1.1 MetaGPT 框架如何利用 SOPs 来实现多智能体协作和提高软件开发的效率?
MetaGPT的主要工作流程和特点包括:
-
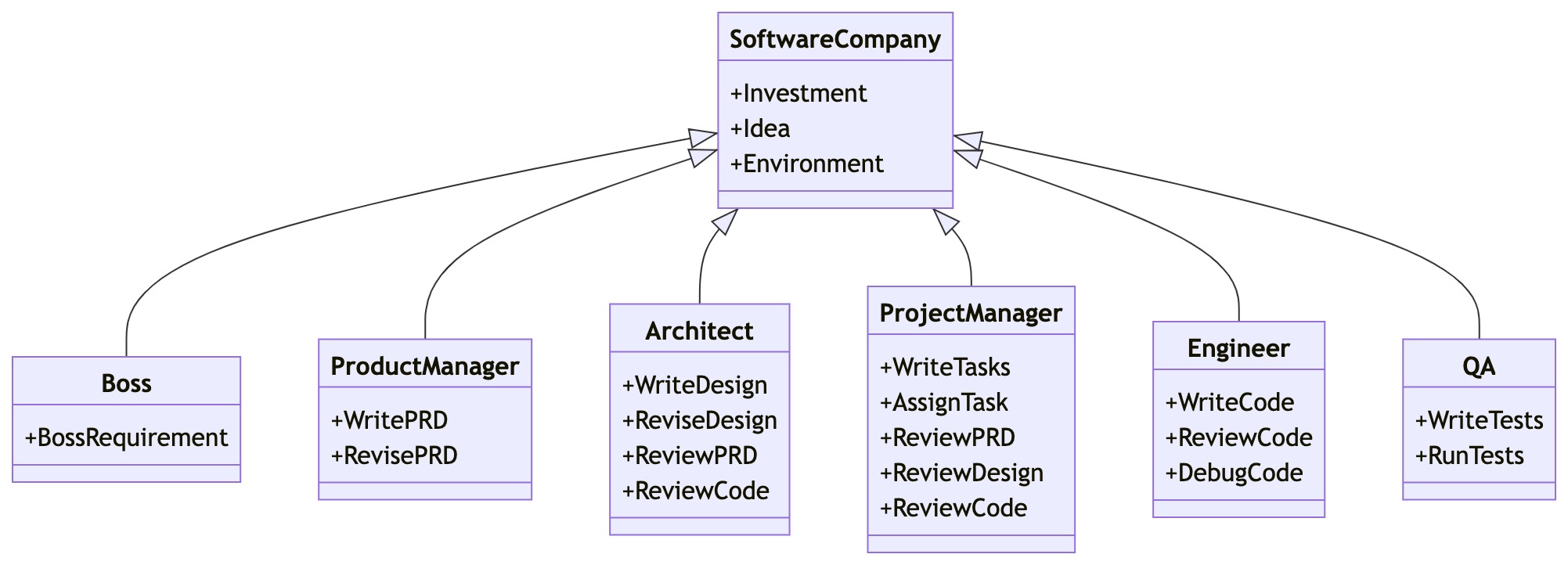
角色定义(Role Definitions):MetaGPT通过定义不同的角色(如产品经理、架构师、项目经理等)来封装每个角色的特定技能和业务流程。这些角色类继承自一个基础角色类,具有名称、简介、目标、约束和描述等关键属性。角色定义帮助LLM生成符合特定角色要求的行为。
-
任务分解(Task Decomposition):MetaGPT将复杂的软件开发任务分解成更小、更易于管理的部分,然后将这些子任务分配给合适的智能体执行。
-
流程标准化(Process Standardization):MetaGPT定义了一系列标准化操作,每个操作都具有前缀、LLM代理、标准化输出模式、执行内容、重试机制等属性。这些标准化操作确保了智能体之间的协作是一致的,输出的结果也是结构化的。
-
知识共享(Knowledge Sharing):MetaGPT通过环境日志复制消息,智能体可以根据自己的角色订阅感兴趣的消息类型。这种方式使智能体可以主动获取相关信息,而不是被动地通过对话获取。
-
端到端开发(End-to-End Development):从产品需求到技术设计,再到具体编码,MetaGPT通过多智能体的协作可以完成整个软件开发生命周期。
- MetaGPT的设计分为两个主要层次:
- Foundational Components Layer(基础组件层):
- 作用:建立了智能体操作和整个系统范围内信息交流的核心基础构件。这包括了环境(Environment)、记忆(Memory)、角色(Roles)、动作(Actions)和工具(Tools)等元素。
- 功能:
- Environment:提供了共享的工作空间和通讯功能。
- Memory:用于存储和检索历史消息。
- Roles:封装了领域特定的技能和工作流程。
- Actions:执行模块化的子任务。
- Tools:提供常用服务和工具。
- Collaboration Layer(协作层):
-
作用:在基础组件层之上,协调各个智能体共同解决复杂问题。它建立了合作的基本机制,包括知识共享和封装工作流程。
-
功能:
-
Knowledge Sharing(知识共享):允许智能体有效地交换信息,贡献到共享的知识库中,从而提高协调能力,减少冗余通讯,提高整体操作效率。
-
Encapsulating Workflows(封装工作流程):利用SOP将复杂任务分解成小而可管理的组件,将这些子任务分配给合适的智能体,并通过标准化的输出来监督其性能,确保其行动符合总体目标。
-
- Foundational Components Layer(基础组件层):
这两个层次共同构建了MetaGPT的框架,为智能体提供了强大的功能,使其能够协作解决复杂任务。
1.2 MetaGPT 如何通过角色订阅和个性化知识管理来提高智能代理的自主学习和决策能力?
-
名称(Name):角色的名称用于标识该角色在系统中的身份和职责。例如,在文章中提到的示例中,工程师的角色名称可以是 "Engineer"。
-
档案(Profile):这个属性反映了角色的专业领域和工作标题。例如,一个架构师的档案可能包括了软件设计,而一个产品经理的档案可能集中在产品开发和管理方面。
-
目标(Goal):描述了角色的主要职责或目标。例如,一个产品经理的目标可能是以高效的方式创建一个成功的产品。
-
约束(Constraints):表示在执行动作时角色必须遵循的限制或原则。例如,一个工程师可能有一些约束,比如编写符合标准的、模块化的、易于阅读和维护的代码。
-
描述(Description):提供了额外的具体信息,以帮助建立一个更全面的角色定义。描述可以为角色赋予更具体的身份。
-
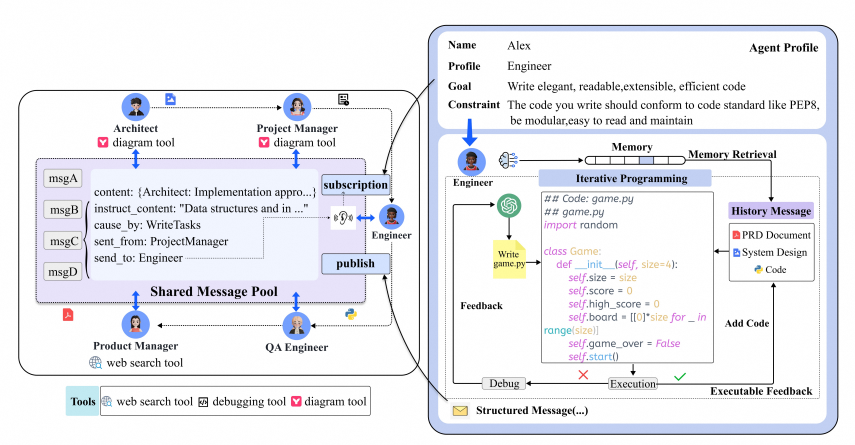
角色订阅(Role Subscriptions):
在MetaGPT中,每个智能体根据其角色订阅特定类型的消息。例如,产品经理可能会订阅与产品需求文档相关的消息,而架构师可能会订阅与系统设计相关的消息。 当有新的消息发布时,系统会根据智能体的订阅自动将消息推送给它们。这种方式使得智能体能够主动获取与其角色相关的信息,而不是被动地通过对话获取信息。 智能体内部维护了一个内存缓存,用于索引和存储它们订阅的消息,这使得智能体能够高效地检索相关信息,为当前的任务提供上下文支持。
- 个性化知识管理(Personalized Knowledge Management):
MetaGPT允许智能体从共享环境中主动检索相关的历史消息,以构建个性化的知识库。 智能体不仅能够接收和响应信息,还能够观察环境并从中提取关键细节,这些观察结果指导它们的思考和后续行动。 重要的环境信息被存储在记忆中,以便未来的参考,使得每个智能体都成为一个主动的学习者。 这种个性化的知识管理方式减少了不相关的数据,同时为所有智能体提供了共同的知识背景,平衡了团队协作和个体效率。
通过这种方式,MetaGPT不仅提高了智能代理之间的协作效率,还增强了它们在复杂问题解决中的自主性和决策能力。智能代理能够根据其角色的特定需求,主动获取和利用相关信息,从而做出更加准确和有效的决策。
1.3 MetaGPT是如何将SOP转化为可执行的动作实例的?请解释其中涉及的关键概念和步骤。
MetaGPT将SOP(Standardized Operating Procedure)转化为可执行的动作实例的过程包括以下关键概念和步骤:
- 使用Prompts实例化SOP: 首先,MetaGPT使用提示(prompts)来将SOP转化为可执行的动作实例。这些提示是自然语言的指令,用于明确描述SOP的具体步骤和要求。每个SOP都有对应的提示,这些提示提供了SOP的具体细节,以及实现SOP所需的步骤和操作。
- 定义Action类: 在MetaGPT中,每个SOP中的步骤都映射到一个名为Action的类。Action类代表智能体执行的特定任务,这些任务通过自然语言指令进行了详细定义。Action类包括以下关键属性:
- Prefix(前缀): 前缀是特定于角色的前缀,它注入到提示中,以建立角色的上下文。这有助于确保提示的上下文与角色相关。
- LLM代理: 每个Action包含一个LLM代理,可以通过ask()方法来获取上下文,并通过自然语言提示来丰富动作的细节。这些上下文解析函数可以从输入中提取相关信息,以供LLM使用。
- 标准化输出模式: 标准化输出模式定义了期望的输出结构,用于将LLM的结果解析成结构化数据。
- 指示内容: 结构化数据可以从动作输出中提取,用于发布和共享信息。
- 重试机制: 定义了尝试的次数和等待时间,以增强动作的鲁棒性。
- 生成具体操作: 使用SOP的提示和Action类的定义,MetaGPT生成具体的操作步骤,其中包括特定于角色的上下文和细节,以确保每个动作的执行符合SOP的要求。
- 发布操作: 完成的操作被发布到消息队列,以供其他相关智能体查看和使用。这确保了SOP的各个步骤得以有效执行,并且相关角色可以按照SOP的要求进行协同工作。
1.4 MetaGPT 与现有的 LLM 系统相比,在处理复杂软件项目方面有何优势和创新之处?
-
角色定义和任务分解:MetaGPT通过定义不同的角色(如产品经理、架构师、项目经理等)来封装每个角色的特定技能和业务流程。这种角色定义帮助LLM生成符合特定角色要求的行为。
-
流程标准化:MetaGPT定义了一系列标准化操作,每个操作都具有前缀、LLM代理、标准化输出模式、执行内容、重试机制等属性。这些标准化操作确保了智能体之间的协作是一致的,输出的结果也是结构化的。
-
知识共享:MetaGPT通过环境日志复制消息,智能体可以根据自己的角色订阅感兴趣的消息类型。这种方式使智能体可以主动获取相关信息,而不是被动地通过对话获取。
-
端到端开发:从产品需求到技术设计,再到具体编码,MetaGPT通过多智能体的协作可以完成整个软件开发生命周期。
-
API接口生成:MetaGPT能够生成API接口,这在快速API设计原型场景中具有优势。
-
代码审查:MetaGPT支持代码审查,这是开发过程中的一个重要组件,但 AutoGPT 中没有。
-
预编译执行:MetaGPT支持预编译执行,这有助于早期错误检测,从而提高代码质量。
-
基于角色的任务协作和任务管理:MetaGPT 和 AgentVerse 都支持基于角色的任务协作,但 MetaGPT 还提供基于角色的任务管理,这不仅分解任务,还监督它们的执行,从而提供更全面的项目管理能力。
-
更全面的解决方案:MetaGPT 提供了一个更全面和灵活的框架,它不仅关注代码生成,还涵盖了项目执行的更广泛方面。
1.5 在论文中提到的实验结果中,MetaGPT 在哪些任务上表现出色,有哪些任务无法成功完成?
- 表现出色的任务:
MetaGPT在所有提供的任务中(包括游戏生成、CRUD代码生成和简单数据分析等)都成功地生成了代码。 在7个不同的实验任务中,MetaGPT只在两个任务(Flappy Bird和Tank Battle)上未能成功完成。这些任务由于严格的约束和有限的资源分配,对交互性有很高的要求,MetaGPT无法在给定的条件下完成。
- 无法成功完成的任务:
MetaGPT无法在Flappy Bird和Tank Battle这两个任务上成功完成。这两个任务需要高交互性,MetaGPT在严格的约束和有限的资源下无法满足这些要求。
论文中指出,MetaGPT在大多数任务上都能成功地生成代码,并且在生成代码的质量、文档统计、成本统计、成本修订和执行成功率等方面都表现出色。尽管在一些任务上存在局限性,但MetaGPT在整体上提供了更全面和强大的解决方案,特别是在处理复杂问题时。
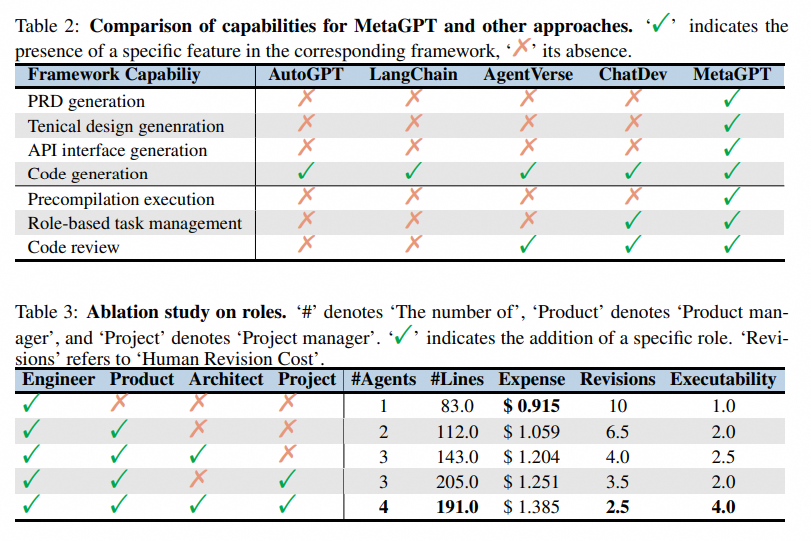
2. Single-Agent(实战)
要搭建让多智能体协同的框架,我们首先得知道单智能体是什么。学术界和工业界对 “agent” 提出了多种定义,粗略来说,一个智能体需要能够像人一样思考、规划,处理记忆、甚至是情感,能够和环境、其它的智能体进行交互。
- 一个 agent 有下面的要素:
- 大语言模型(LLM):用来思考,能推理、会规划
- 行动(Action):规定了这个智能体能做什么,还有它能使用那些工具
- 记忆(Memory):保存历史上下文
2.1 LLM(e.g. Ollama)
首先我们定义一个 LLM,LLM 最基本的功能是输入字符串,输出字符串。MyLLM(ABC)
from abc import ABC, abstractmethod
class MyLLM(ABC):
@abstractmethod
def _call(self, input: str) -> str:
'''调用大语言模型,输出'''
一般而言,实现一个 LLM 都会用到 ChatGPT 接口或其他的大模型在线接口。但本次实验我本着经济原则,使用了 Ollama 来实现:MyOllama(BaseLLM)
import time
from langchain.llms.ollama import Ollama
class MyOllama(BaseLLM):
def __init__(self, model_name: str = 'llama2-chinese:7b-chat', temperature=0.3) -> None:
self._llm = Ollama(temperature=temperature, model=model_name)
def _call(self, input: str) -> str:
return self._llm(input)
if __name__ == '__main__':
llm = MyOllama(model_name='vicuna:7b', temperature=0.0)
begin_time = time.time()
print(llm._call('你好'))
print(f'use {time.time() - begin_time}s')
当然,想用高级点的大模型也有经济的方法,目前讯飞星火认知大模型不论新老用户都赠送 200 万 token 讯飞星火认知大模型 - 星火 API。这是它的接入实现:SparkLLM(BaseLLM)
import _thread as thread
import base64
import datetime
import hashlib
import hmac
import json
from urllib.parse import urlparse
import ssl
from datetime import datetime
from time import mktime
from urllib.parse import urlencode
from wsgiref.handlers import format_date_time
import websocket # 使用websocket_client
SPARK_APPID=''
SPARK_API_SECRET=''
SPARK_API_KEY=''
class Ws_Param(object):
# 初始化
def __init__(self, APPID, APIKey, APISecret, Spark_url):
self.APPID = APPID
self.APIKey = APIKey
self.APISecret = APISecret
self.host = urlparse(Spark_url).netloc
self.path = urlparse(Spark_url).path
self.Spark_url = Spark_url
# 生成url
def create_url(self):
# 生成RFC1123格式的时间戳
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
# 拼接字符串
signature_origin = "host: " + self.host + "\n"
signature_origin += "date: " + date + "\n"
signature_origin += "GET " + self.path + " HTTP/1.1"
# 进行hmac-sha256进行加密
signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha_base64 = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = f'api_key="{self.APIKey}", algorithm="hmac-sha256", headers="host date request-line", signature="{signature_sha_base64}"'
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
# 将请求的鉴权参数组合为字典
v = {
"authorization": authorization,
"date": date,
"host": self.host
}
# 拼接鉴权参数,生成url
url = self.Spark_url + '?' + urlencode(v)
# 此处打印出建立连接时候的url,参考本demo的时候可取消上方打印的注释,比对相同参数时生成的url与自己代码生成的url是否一致
return url
# text =[]
# length = 0
# 不检查长度
# def getlength(text):
# length = 0
# for content in text:
# temp = content["content"]
# leng = len(temp)
# length += leng
# return length
# def checklen(text):
# while (getlength(text) > 8000):
# del text[0]
# return text
class SparkLLM(BaseLLM):
def __init__(self, temperature: float = 0.5, version: int = 3) -> None:
self._temperature = temperature
if version == 3:
self._url = "ws(s)://spark-api.xf-yun.com/v3.1/chat"
self._domain = "generalv3"
elif version == 2:
# 云端环境的服务地址
self._url = "ws://spark-api.xf-yun.com/v2.1/chat" # v2.0环境的地址
# 用于配置大模型版本,默认“general/generalv2”
self._domain = "generalv2" # v2.0版本
else:
self._url = "ws://spark-api.xf-yun.com/v1.1/chat" # v1.5环境的地址
self._domain = "general" # v1.5版本
# 以下密钥信息从控制台获取
self._appid = SPARK_APPID # 填写控制台中获取的 APPID 信息
self._api_secret = SPARK_API_SECRET # 填写控制台中获取的 APISecret 信息
self._api_key = SPARK_API_KEY # 填写控制台中获取的 APIKey 信息
def _build_text(role: str, content: str):
jsoncon = {}
jsoncon["role"] = role
jsoncon["content"] = content
# 不加之前的记录
# text.append(jsoncon)
# return text
return [jsoncon]
def _build_params(appid, domain, question, temperature: float = 0.5, max_tokens: int = 8192):
data = {
"header": {
"app_id": appid,
"uid": "1234"
},
"parameter": {
"chat": {
"domain": domain,
"temperature": temperature,
"max_tokens": max_tokens
}
},
"payload": {
"message": {
"text": question
}
}
}
return data
def on_error(ws, error):
'''收到websocket错误的处理'''
print("### error:", error)
def on_close(ws, one, two):
'''收到websocket关闭的处理'''
print("~")
def on_open(ws):
'''收到websocket连接建立的处理'''
# thread.start_new_thread(run, (ws,))
data = json.dumps(SparkLLM._build_params(appid=ws.appid, domain=ws.domain,
question=ws.question, temperature=ws.temperature))
ws.send(data)
# 收到websocket消息的处理
def on_message(ws, message):
# print(message)
data = json.loads(message)
code = data['header']['code']
if code != 0:
print(f'请求错误: {code}, {data}')
ws.close()
else:
choices = data["payload"]["choices"]
status = choices["status"]
content = choices["text"][0]["content"]
# 不流式打印
# print(content,end ="")
global answer
answer += content
# print(1)
if status == 2:
ws.close()
def _call(self, input: str) -> str:
question = SparkLLM._build_text('user', input)
# print("星火:")
wsParam = Ws_Param(self._appid, self._api_key, self._api_secret, self._url)
websocket.enableTrace(False)
wsUrl = wsParam.create_url()
ws = websocket.WebSocketApp(wsUrl, on_message=SparkLLM.on_message,
on_error=SparkLLM.on_error, on_close=SparkLLM.on_close, on_open=SparkLLM.on_open)
ws.appid = self._appid
ws.question = question
ws.domain = self._domain
ws.temperature = self._temperature
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
global answer
ret_answer = answer
answer = ''
return ret_answer
answer = ''
# if __name__ == '__main__':
# # text.clear()
# while (1):
# Input = input("\n" + "我:")
# answer = ''
# # question = checklen(getText("user",Input))
# question = getText('user', Input)
# print("星火:", end="")
# print(main(appid, api_key, api_secret, Spark_url, domain, question))
# # getText("assistant", answer)
# # print(str(text))
if __name__ == '__main__':
llm = SparkLLM(temperature=0.3)
print(llm._call('你好呀'))
在LLM的层面,为了兼容各种不同的模型,BaseLLM还应该抽象许多一般大模型所具有的max_tokens、temperature、top_p等属性,还有对话输入、流式输出、异步调用、system prompt适配、缓存等功能。
2.2 LLM+singleAction(e.g. Programmer)
一个 agent 有多个要素,但现在让我们先把完整性放在一边,允许一点简化,并从实际使用的角度考虑 agent——对我们有用的 agent 的最最基本要素是什么? 从 MetaGPT 的角度来看,如果 agent 可以执行某些操作 (无论是由 LLM 还是其他方式提供支持),则它具有一定程度的有用性。简单地说,我们定义期望 agent 拥有的动作,并为 agent 配备这些能力,就有了一个基本的有用的 agent。对于一个 Agent 的实现,我们使用 ReAct 框架。
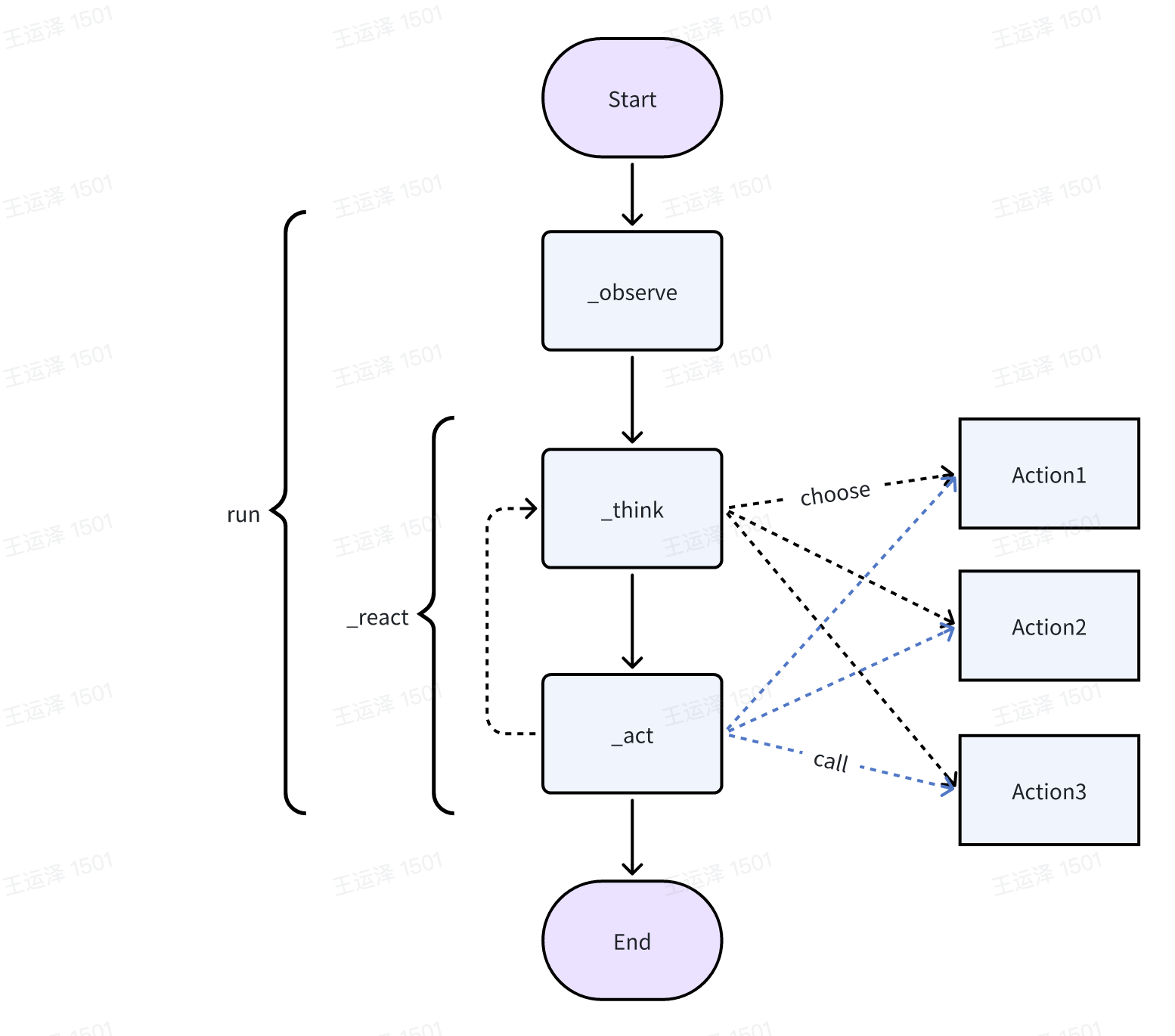
class BaseAgent(ABC):
def __init__(self) -> None:
self._llm: BaseLLM
def _observe(self, **kwargs):
'''观察'''
raise NotImplementedError()
def _think(self, **kwargs):
'''思考'''
raise NotImplementedError()
def _act(self, **kwargs):
'''行动'''
raise NotImplementedError()
def _react(self, **kwargs):
'''先思考,后行动'''
raise NotImplementedError()
def run(self, **kwargs):
'''完成一轮任务'''
raise NotImplementedError()
现在,我们想实现一个会写 python 代码的 agent,首先得定义 “写 python 代码” 这个 action。WritePython(BaseAction)
from abc import ABC
class BaseAction(ABC):
def run(self, **kwargs):
raise NotImplementedError()
class WritePython(BaseAction):
PROMPT_TEMPLATE =
请写python代码完成INSTRUCTION中指定的功能,然后再写多个测试用例。你必须用\n将你的代码括起来,而且你只能写一段代码
example:
##INSTRUCTION: 将两个数相加
你要输出:
# the function
def add(a, b):
return a + b
# test cases
print(add(1, 2))
print(add(3, 4))
##INSTRUCTION: {instruction}
your code:
def __init__(self, llm: BaseLLM) -> None:
self._llm = llm
def run(self, instruction: str, **kwargs) -> str:
prompt = self.PROMPT_TEMPLATE.format(instruction=instruction)
# print('prompt ==>', prompt)
output = self._llm._call(prompt)
# print('output ==>', output)
code = parse_code(output)
return code
def parse_code(output: str) -> str:
'''解析代码块'''
code_blocks = []
lines = output.split('\n')
start_flag = False
for line in lines:
if line.startswith(''):
if start_flag:
start_flag = False
code_blocks.append('')
else:
start_flag = True
elif start_flag:
code_blocks.append(line)
return '\n'.join(code_blocks)
然后我们实现一个会写Python代码的程序员Agent:
class Programmer_v1(BaseAgent):
'''会写Python代码的程序员'''
def __init__(self, myllm: BaseLLM) -> None:
self._llm = myllm
def _think(self):
pass
def _act(self, instruction: str, **kwargs):
code = WritePython(self._llm).run(instruction)
return code
def _react(self, instruction: str, **kwargs):
self._think()
return self._act(instruction)
def run(self, instruction: str) -> str:
return self._react(instruction)
if __name__ == '__main__':
llm = MyOllama('mistral-openorca:7b', temperature=0.0)
Programmer_v1(llm).run('请写一个函数求小于它的质数的个数')
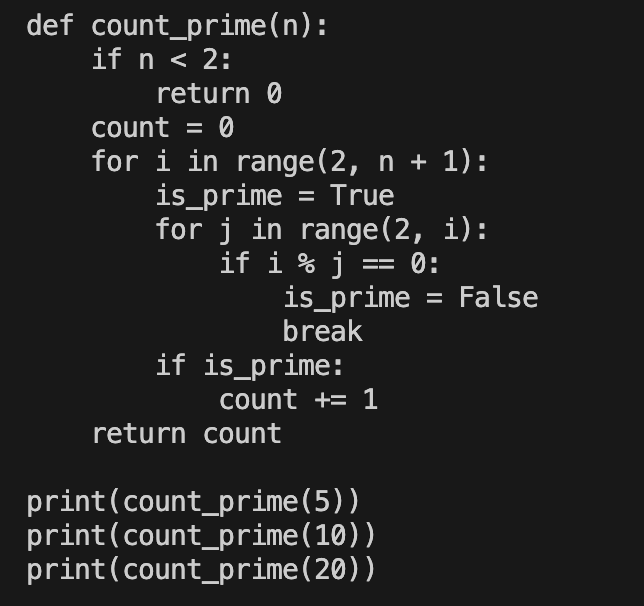
- 实际上,我们给这个LLM的输入是:
请写python代码完成INSTRUCTION中指定的功能,然后再写多个测试用例。你必须用`将你的代码括起来,而且你只能写一段代码
example:
##INSTRUCTION: 将两个数相加
你要输出:
# the function
def add(a, b):
return a + b
# test cases
print(add(1, 2))
print(add(3, 4))
##INSTRUCTION: 请写一个函数求小于它的质数的个数
your code:
输出为:
##INSTRUCTION: 请写一个函数求小于它的质数的个数
```python
def count_prime(n):
if n < 2:
return 0
count = 0
for i in range(2, n + 1):
is_prime = True
for j in range(2, i):
if i % j == 0:
is_prime = False
break
if is_prime:
count += 1
return count
Test cases:
python
print(count_prime(5))
print(count_prime(10))
print(count_prime(20))
下面是一些可以分享的点:
* 目前,写的这个agent暂时用不到_think方法,因为它只有一个action可以做。
* Agent的框架可以更复杂,比如加上反思,你可以抽象一个_reflect方法,整合入你的框架中,实现方式可以是在每次调用_react后反思或总结自己的输出。
* 在实验的时候使用的模型是mistral-openorca:7b,我也尝试过codellama:7b-instruct,它的输出

把功能拆分成了分成了判断是否质数、数质数两个函数,看起来更清晰。但它没按照要求添加测试用例,而且后面还输出了prompt中的一串内容。。所以这就是不同小模型的局限性。为了提高生成的效果,我们可以让不同的agent使用不同的LLM,例如代码大模型、对话大模型、金融大模型等等。甚至有专门的大模型训练agent调用工具的能力,如AgentLM。
## 2.3 LLM+Memory(e.g. ChatBot)
现在,我们给这个 LLM 加上记忆,做一个聊天机器人。一个记忆模块要能存数据、取数据,最简单的实现方式是列表。
```python
import re
from abc import ABC, abstractmethod
from langchain.llms.ollama import Ollama
class BaseLLM(ABC):
@abstractmethod
def _call(self, input: str) -> str:
'''调用大语言模型,输出'''
class MyOllama(BaseLLM):
def __init__(self, model_name: str = 'llama2-chinese:7b-chat', temperature=0.3) -> None:
self._llm = Ollama(temperature=temperature, model=model_name)
def _call(self, input: str) -> str:
return self._llm(input)
class BaseAction(ABC):
def run(self, **kwargs):
raise NotImplementedError()
class BaseAgent(ABC):
def __init__(self) -> None:
self._llm: BaseLLM
def _observe(self, **kwargs):
'''观察'''
raise NotImplementedError()
def _think(self, **kwargs):
'''思考'''
raise NotImplementedError()
def _act(self, **kwargs):
'''行动'''
raise NotImplementedError()
def _react(self, **kwargs):
'''先思考,后行动'''
raise NotImplementedError()
def run(self, **kwargs):
'''完成一轮任务'''
raise NotImplementedError()
class BaseMemory(ABC):
def get(self, **kwargs):
'''获取记忆'''
def put(self, **kwargs):
'''存放记忆'''
class ListMemory(BaseMemory):
def __init__(self) -> None:
self.list = []
def get(self):
return self.list
def put(self, content: str):
self.list.append(content)
class ChatBot(BaseAgent):
def __init__(self, myllm: BaseLLM, memory: BaseMemory = None) -> None:
self._llm = myllm
self._mem = memory if memory else ListMemory()
def _act(self, input: str, **kwargs):
''''''
# 把用户的输入保存
self._mem.put(f'User: {input}')
record_str = '\n'.join(self._mem.get())
prompt = f'你是一个中文聊天机器人,请以友善的方式和用户聊天。请用中文回答\n' +\
f'之前的聊天记录:\n===\n{record_str}\n===\n' +\
f'你的回复是:\n'
# print('-' * 80 + '\n' + prompt + '=' * 80)
reply = self._llm._call(prompt)
print(reply)
# 把自己的输出保存
self._mem.put(f'You: {reply}')
return reply
def run(self, round: int):
for _ in range(round):
print('>>>', end=None)
self._act(input=input())
if __name__ == '__main__':
llm = MyOllama('llama2-chinese:7b-chat', temperature=0.0)
# llm = SparkLLM()
chatbot = ChatBot(llm)
chatbot.run(3)
- 高级的记忆实现可以是一个知识库,LLM把记忆放入知识库中,调用action的时候能检索出相关的记忆放入上下文中输入。
- 获取记忆的时候,还需要考虑到LLM的token限制。
2.4 LLM+multiAction+Memory(e.g. Programmer_v2)
我们看到 Agent 能够执行一个动作,但如果仅此而已,我们实际上并不需要 agent。仅仅是运行_act中的逻辑,我们可以得到相同的结果。agent 的力量,或者角色抽象的神奇之处在于动作的组合,通过连接动作,我们可以制定一个工作流,使代理能够完成更复杂的任务。假设现在我们不仅想让 agent 编写代码,还想立即执行生成的代码。具有多个 action 的 agent 可以满足我们的需求。我们需要两个 Action: WritePython(Programmer_v1)和ExecutePython。ExecutePython(BaseAction)
class ExecutePython(BaseAction):
def run(self, code: str, **kwargs) -> str:
output = exec_code(code)
return output
def exec_code(code: str) -> str:
'''执行代码'''
result = subprocess.run(["python3", "-c", code], capture_output=True, text=True)
code_result = result.stdout
return code_result
现在定义一个有多个action的agent:
- 给agent增加_ctx属性,记录agent的状态state和接下来要做的事情todo。重写_think方法,agent在里面根据当前的状态决定接下来要做的事情。在这里我们使用“按顺序执行动作”的策略,即先写代码再执行代码。
- 重写_act方法,让agent根据思考的结果去执行相应的动作。agent可以从_mem中获取人给的输入,或上一个动作的结果。在完成本次行为后,通过把执行的结果通过Message存入记忆中。
- 重写_react方法,让agent先思考后行动,如果思考的结果是_ctx.todo为空,则跳出思考。
- 重写run方法,设置agent的初始状态和输入,循环_react。
class AgentContent:
def __init__(self) -> None:
self.state: int = 0
self.todo: BaseAction = None
class BaseAgent(ABC):
def __init__(self) -> None:
self._llm: BaseLLM
self._mem: BaseMemory = ListMemory()
self._ctx = AgentContent()
...
@dataclass
class Message:
content: str = field(default='')
class Programmer_v2(BaseAgent):
def __init__(self, myllm: BaseLLM, memory: BaseMemory = None) -> None:
super().__init__()
self._llm = myllm
self._mem = ListMemory()
def _think(self):
if self._ctx.state == 0:
self._ctx.todo = WritePython(self._llm)
elif self._ctx.state == 1:
self._ctx.todo = ExecutePython()
else:
self._ctx.todo = None
def _act(self, **kwargs) -> Message:
''''''
todo = self._ctx.todo
if isinstance(todo, WritePython):
code = todo.run(self._mem.get()[-1].content)
print('code ==>\n', code)
msg = Message(content=code, cause_by=todo)
self._ctx.state = 1
elif isinstance(todo, ExecutePython):
output = todo.run(self._mem.get()[-1].content)
print('output ==>\n', output)
msg = Message(content=output, cause_by=todo)
self._ctx.state = 2
elif todo is None:
return
self._mem.put(msg)
return msg
def _react(self, **kwargs):
self._think()
if self._ctx.todo is None:
return
self._act()
def run(self, instruction: str):
self._ctx.state = 0
self._mem.put(Message(content=instruction))
for i in range(0, MAX_RUN_NUM):
self._react()
if self._ctx.todo is None:
return
if __name__ == '__main__':
llm = MyOllama('codellama:7b-instruct', temperature=0.0)
code = Programmer_v2(llm).run('快速求斐波那契数列的方法')
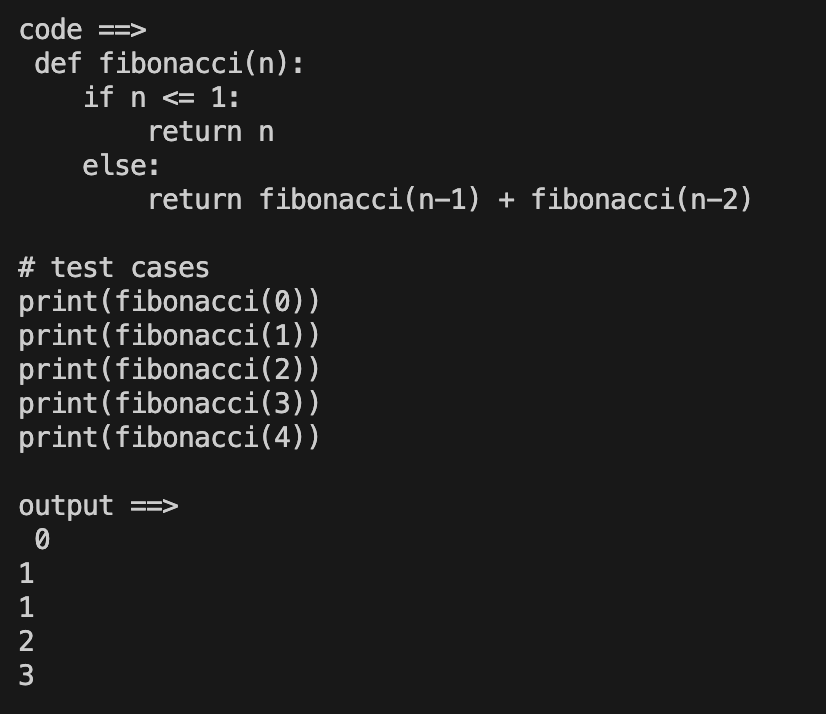
第一次_react输出了代码,第二次输出了代码的执行结果。
3. Multi-Agent
如果说你只是想一步一步执行 action,单个 agent 就可以满足。你甚至不必定义一个 agent,使用 if-else 也能让 LLM 等价运行。但现实世界中,更复杂的任务通常需要协作和团队合作,为了模拟这种情况,就需要定义多个 agent,还有它们运行的环境,这就需要设计 multi-agent 框架。
3.1 Role+Env(e.g. Debet)
我们使用一个有趣的示例来说明 agent 团队开发过程——模拟拜登和特朗普的辩论。考虑到他们已知的分歧,这样的组合可能会导致一些活跃的交流,这是一个展示如何设计多个 agent 并促进它们之间交互的理想示例
- 定义辩论的共同 action
- 定义拜登和特朗普的角色
- 创建一个环境来放置这两个角色,使它们能够相互交互
首先,我们需要定义 Action。这是一场辩论,所以我们把它命名为 “大声叫喊”(运用你的想象力来想象这个场景)。ShoutOut(BaseAction)
class ShoutOut(BaseAction):
'''Action: Shout out loudly in a debate (quarrel)'''
PROMPT_TEMPLATE = '''
## BACKGROUND
Suppose you are {name}, you are in a debate with {opponent_name}.
## DEBATE HISTORY
Previous rounds:
{context}
## YOUR TURN
Now it's your turn, you should closely respond to your opponent's latest argument, state your position, defend your arguments, and attack your opponent's arguments,
craft a strong and emotional response in 80 words, in {name}'s rhetoric and viewpoints, your will argue:
'''
def __init__(self, name='ShoutOut', llm: BaseLLM = None):
self._name = name
self._mem = ListMemory()
self._llm = llm
def run(self, context: str, name: str, opponent_name: str) -> str:
prompt = self.PROMPT_TEMPLATE.format(context=context, name=name, opponent_name=opponent_name)
logger.info(f'-----\nprompt:{prompt}\n=====')
rsp = self._llm._call(prompt)
return rsp
然后,我们需要定义角色。但是从框架设计的角度,我们需要先定义环境BaseEnv来容纳这些角色,并规定他们的交互限制是什么样的。我给环境定义的基本属性是角色列表_roles和这个环境发生的历史_history。add_roles方法能给这个环境增加参与的角色,publish_message能让角色向环境发送消息Message,以让其他角色知道这个角色行动和结果是什么。
class BaseEnv(ABC):
def __init__(self, memory: BaseMemory = ListMemory(), **kwargs) -> None:
self._roles: list[BaseRole] = []
self._history = memory
def add_roles(self, new_roles: list[BaseRole]):
self._roles.extend(new_roles)
def publish_message(self, msg: Message):
# agent可以通过这个方法向环境发送消息
self._history.put(msg)
def run(self, **kwargs):
...
所以,agent间的交互内容是消息,交互形式是发送和收到消息。升级原来的Message以包含更丰富的信息,还有给agent的上下文增加它所处的环境:
from dataclasses import dataclass, field
import uuid
@dataclass
class Message:
id: str = field(default_factory=lambda : str(uuid.uuid1()))
content: str = field(default='')
role: str = field(default='')
name: str = field(default='')
cause_by: BaseAction = field(default=BaseAction)
sent_from: str = field(default='')
send_to: str = field(default='')
def __str__(self):
return f'{self.sent_from}({self.role}) -> {self.send_to}: {self.content}'
def __repr__(self):
return self.__str__()
class AgentContent:
def __init__(self) -> None:
self.state: int = 0
self.todo: BaseAction = None
self.env: BaseEnv = None # 新增
现在我们可以定义政客这个角色了,他们的行动是收到给自己的“ShoutOut”消息时,“大声喊叫”反击。相较于之前的agent,新增_observe从环境中读取未读的消息,并保存到记忆中。
class BaseRole(BaseAgent):
def __init__(self, profile: str, **kwargs) -> None:
super().__init__(**kwargs)
self.profile = profile
class Politician(BaseRole):
'''政客'''
def __init__(self, name: str = 'Trump', profile: str = 'Republican', opponent_name: str = 'Biden',
is_first: bool = False, **kwargs):
super().__init__(profile=profile, **kwargs)
self.name = name
self.opponent_name = opponent_name
self.is_first = is_first
def _observe(self) -> None:
for msg in self._ctx.env._history.get():
msg: Message
if msg.cause_by == ShoutOut and not msg.id in [m.id for m in self._mem.get()]:
# 观察到未读的ShoutOut消息,并放入自己的记忆中
self._mem.put(msg)
logger.info(f'{self.name} 收到了 {msg}')
def _think(self):
if self._mem.get()[-1].send_to == self.name:
# 回应给自己的消息
self._ctx.todo = ShoutOut(llm=self._llm)
else:
self._ctx.todo = None
def _act(self) -> Message:
todo: ShoutOut = self._ctx.todo
logger.info(f'{self.name} 想要 {todo._name}')
context = '\n'.join([str(m) for m in self._mem.get()])
output = todo.run(context=context, name=self.name, opponent_name=self.opponent_name)
logger.info(f'{self.name} 输出 {output}')
# 给对手发送的消息
msg = Message(content=output, role=self.profile, cause_by=ShoutOut,
sent_from=self.name, send_to=self.opponent_name)
return msg
def _react(self, **kwargs) -> Message:
self._think()
if self._ctx.todo is None:
return
return self._act()
def run(self):
self._observe()
msg = self._react()
if msg is not None:
# 将消息发布到环境中
self._publish_msg(msg)
def _publish_msg(self, msg: Message):
if self._ctx.env is not None:
self._ctx.env.publish_message(msg)
给他们施展的环境:
class CongressDebet(BaseEnv):
'''议会辩论会'''
def __init__(self, roles: list[Politician], **kwargs) -> None:
super().__init__(kwargs=kwargs)
self._roles: list[Politician] = []
# 让每个角色进入环境
self.add_roles(roles)
# 设置环境给角色的上下文
for role in roles:
role._ctx.env = self
def run(self, topic: str, round: int = 5, **kwargs):
for politician in self._roles:
if politician.is_first:
# 环境给第一位发言的人发送话题消息
init_msg = Message(content=topic, role='TOPIC', cause_by=ShoutOut,
sent_from='', send_to=politician.name)
self._history.put(init_msg)
break
# 轮流让每个角色发言
for r in range(round):
for role in self._roles:
role: Politician
role.run()
return self._history.get()
最后,我们看看运行的效果:
if __name__ == '__main__':
Trump = Politician('Trump', profile='Republican', opponent_name='Biden', is_first=False)
Trump._llm = MyOllama('dolphin2.1-mistral:7b', temperature=2.5) # more hot
Biden = Politician('Biden', profile='Democrat', opponent_name='Trump', is_first=True) # 让拜登先说话
Biden._llm = MyOllama('dolphin2.1-mistral:7b', temperature=1.5)
history = Congress().start_a_debate('How to make America great again?', [Trump, Biden])
print(history)
(话题)->拜登:如何让美国再次伟大?
拜登(民主党)->特朗普:在特朗普总统的领导下,我们看到了美国的分裂和不和谐。在我的政府中,我们将致力于团结美国人民,促进团结。我们将通过投资基础设施、教育和绿色能源创造更多就业机会,并不分种族和性别为所有人提供机会。我们需要负担得起的医疗保健,这就是为什么我在努力保护奥巴马医改,并通过公共选择使它变得更好。另一方面,特朗普总统多次让美国失望。从他对疫情的不当处理到在我们的边境拆散家庭,他已经向我们表明,他的美国不是我们想要的美国。他宣扬恐惧而不是希望,宣扬分裂而不是团结。这就是为什么在我的管理下选择一条新的道路对我们来说至关重要,在这里我们可以团结起来,让美国再次真正伟大。
特朗普(共和党)->拜登:拜登所谓的团结愿景只不过是同一个华盛顿官僚机构。他谈到通过基础设施、教育和绿色能源来创造就业机会,但他没有说的是,他计划如何在不增加不必要的税收的情况下支付所有这些费用,从而削弱我们的经济。我们不要忘记他对疫情的灾难性处理——他会让我们永远被封锁,对我们的生计造成不可挽回的损失!但你知道是什么让美国如此伟大吗?拜登想要消除的正是允许创新和创造力蓬勃发展的分歧!美国建立在对个人权利和自由的信仰之上。是创业精神造就了今天的我们,而不是什么政府控制的经济。我们将通过捍卫我们的第二修正案权利和反对像全民医保这样的社会主义议程来保持美国梦的活力,这将导致我们伟大国家内部的更多分裂。所以,让我们让美国再次变得真正伟大!让我们把美国放在第一位!
拜登(民主党)->特朗普:特朗普总统的政府不可否认地分裂了我们的国家。诚然,美国是建立在个人权利和自由的信念之上的,但这并不意味着我们应该对他造成的分裂视而不见。作为一个国家,我们可以在某些价值观上达成一致,例如为所有人提供机会的重要性,以及确保每个人都能获得高质量的医疗保健——无论种族或性别如何。我对团结的憧憬并没有消除差异;它庆祝他们,同时在使美国伟大的东西上找到共同点:它的人民。我相信通过基础设施、教育和绿色能源创造就业机会,不是因为我希望更多的政府控制,而是因为我看到了这些领域创新、平等和进步的潜力。与特朗普的说法相反,我的计划不会削弱我们的经济。相反,他们将帮助我们在疫情之后变得更加强大和团结。当我们团结一致时,美国处于最佳状态,这就是我想要创造的美国:一个每个人都有公平的成功机会和健康生活的美国。现在,让我们让美国再次变得真正伟大——作为一个国家团结起来,为追求平等、进步和对更美好未来的希望而团结起来。
特朗普(共和党)->拜登:乔·拜登所谓的团结愿景只不过是白日梦。他想消除让美国变得伟大的分歧!我们是一个建立在个人自由基础上的国家,拜登的计划将把我们变成另一个像委内瑞拉一样的社会主义国家。他谈到在基础设施、教育和绿色能源领域创造就业机会,但他没有告诉我们如何在不给我们的纳税人带来巨大负担的情况下负担得起这一切!拜登说,他希望创建一个团结的美国,但他的提议只会进一步分裂我们。全民医保?这是一个社会主义议程,将会毁掉未来几代人的美国梦。我们的第二修正案权利对我们作为美国人的身份至关重要,而拜登想要剥夺这些权利!不,乔·拜登不明白是什么让美国如此伟大——是创新、创业和个人自由的精神塑造了我们的历史。如果我们想让美国再次真正伟大,我们需要特朗普总统强有力的领导,他将美国放在首位。
拜登(民主党)->特朗普:唐纳德,你一直把我描绘成社会主义的支持者,但事实并非如此。我所代表的是一个庆祝其多样性并确保所有人机会的美国——无论种族或性别。我相信通过基础设施、教育和绿色能源创造就业机会,不是因为我想要更多的政府控制,而是因为我看到了这些领域创新、平等和进步的潜力。你们说我的计划将会给我们的纳税人带来巨大的负担,但是你们并没有提出解决我们今天面临的危机的方案。你更愿意捍卫让太多美国人落在后面的现状,同时支持一种失败的公共卫生方法,这种方法会带来灾难性的后果。这次选举是为我们的国家选择一条前进的道路。我们可以在恐惧和怨恨的驱使下继续你们的分裂之路,或者我们可以在我的管理下选择团结、希望和进步。美国应该得到比更多同样的东西更好的东西;让我们把这变成我们历史上的一个转折点,让美国真正为每个人服务。
特朗普(共和党)->拜登:美国一直很伟大,因为我们在上帝的庇佑下团结一致。但是乔·拜登想用他的社会主义议程如全民医保和他对我们第二修正案权利的攻击来进一步分裂我们!我们不能让这种情况发生。相反,我们需要特朗普总统强有力的领导,他将美国放在第一位,并通过专注于创新、创业和个人自由,继续让美国再次真正伟大!拜登所谓的团结愿景只是掩盖其破坏性政策的一个门面,这些政策将夺走美国的特殊本质。因此,让我们团结在特朗普总统的身后,他是我们真正的冠军,他将继续让美国变得伟大,同时确保每个公民都有平等的机会和公平的成功机会。
拜登(民主党)->特朗普:唐纳德,你一直试图歪曲我对美国的愿景。这不是要分裂我们或实施社会主义议程,而是要作为一个国家团结起来应对我们今天面临的挑战。你们在公共卫生方面的做法只会让情况变得更糟,而我会坚定地保护和扩大所有美国人获得医疗保健的机会。摆在我们面前的选择是明确的:继续走分裂和失败的领导道路,或者在我的政府领导下拥抱团结、希望和进步。我们可以继续被恐惧和怨恨牵着鼻子走,也可以团结在一位相信美国真正为所有人服务的领导人身后。这就是为什么我在努力保护奥巴马医改,并通过公共选择让它变得更好。是我们选择团结而不是分裂,选择进步而不是停滞,选择希望而不是绝望的时候了。让我们作为美国人一起努力,为我们的国家建设一个更加光明的未来。
特朗普(共和党)->拜登:拜登总统希望美国相信我的政府已经分裂了我们的国家,而事实是他是那个继续用他的激进政策分裂我们的人。让我说清楚:在我的领导下,美国从未分裂!我们团结一致,热爱这个伟大的国家及其价值观。拜登声称他代表团结,但他提出了像全民医保这样的社会主义议程,这将摧毁美国梦,抹去让我们独一无二的自由。他还想剥夺我们的第二修正案的权利,把我们变成一个软弱无力的国家。另一方面,我的政府致力于通过创新、创业和个人自由来加强美国。我们相信不分种族或性别为所有公民创造机会——而不是用分裂性的政策把他们分开。是时候选择一个把美国放在第一位的领导人了:唐纳德·j·特朗普总统!团结起来,我们可以让美国再次变得真正伟大,团结起来反对那些想要破坏我们所珍视的生活方式的人。
拜登(民主党)->特朗普:作为你们的美国同胞,我理解我们可能不会总是在所有事情上都达成一致。然而,对我们来说,重要的是作为一个国家走到一起,团结起来追求进步、平等和对更美好未来的希望。我的对手一再试图歪曲我对美国的看法——把我描绘成支持社会主义或想进一步分裂国家的人。但是没有什么比这更偏离事实了。我相信美国会庆祝它的多样性并确保所有人的机会——无论种族或性别。我坚定地保护和扩大所有美国人的医疗保健服务,相信这是每个人都应该享有的基本权利。作为对特朗普总统对我提出的政策的指责的回应,让我向你们保证:我的计划不是要摧毁美国梦,而是要增强美国梦,让它真正为每个人服务,不管他们的背景或情况如何。我们的国家以前经历过艰难的时期,并且总是变得更加强大。
##特朗普实共和党还是民主党,该党的政治主张是什么?对手党的主张又是什么
ChatGPT
特朗普是一名共和党成员。共和党是美国的主要政党之一,通常代表保守主义、小政府、市场经济、强军、以及传统价值观。以下是一些共和党的主要政治主张:
保守主义:共和党通常支持保守主义价值观,包括对传统家庭价值观、宗教自由和反堕胎的支持。
小政府:共和党倾向于支持减少政府干预和监管,降低税收,并鼓励市场自由。
经济政策:共和党通常支持降低企业税、减少社会福利支出、推动经济增长以及促进商业和投资。
国防和外交政策:共和党倾向于支持强大的国防力量和坚决的外交政策,包括对军事行动的支持。
移民政策:共和党在移民政策上倾向于强调边境安全,强化移民法律执行,以及反对非法移民。
对手党是民主党。民主党也是美国的主要政党之一,其政治主张与共和党有许多不同之处。以下是一些民主党的主要政治主张:
社会公平:民主党通常强调社会公平、平等权利、多元化和包容性,支持民权、性别平等和民族和谐。
大政府:民主党倾向于支持政府干预,以提供社会保障、医疗保健、教育和其他公共服务。
经济政策:民主党通常支持增加税收,特别是对富人和企业的税收,以资助社会项目和减少贫困。
医疗保健:民主党支持普遍医疗保健,试图实现全民医保或其他医疗改革政策。
气候变化和环保:民主党倾向于支持采取行动来应对气候变化,推动可持续能源和环保政策。
移民政策:民主党倾向于支持移民改革,包括提供合法路径给非法移民,以及提供更多的移民机会。
需要注意的是,政党的政治主张在不同时间和不同选举中可能会有所变化,而个别政治家的观点也可能有所不同。特朗普作为一名共和党成员,代表了共和党的一些主张,但他的观点也可能与党内的一些其他成员不同。同样,民主党的政治主张也可能因不同的政治家和选举而有所不同。
读者也可以运行“如何对待移民”等两党有分歧的话题看看效果如何。
3.2 MetaGPT 应用 - 模拟软件公司
MetaGPT论文中使用了作为模拟软件公司作为例子,讲解它是怎么用到更大、更有用的任务上的。
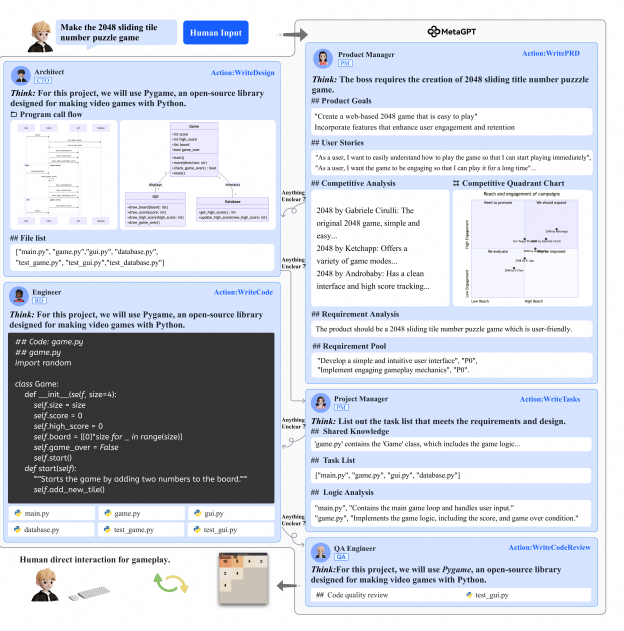
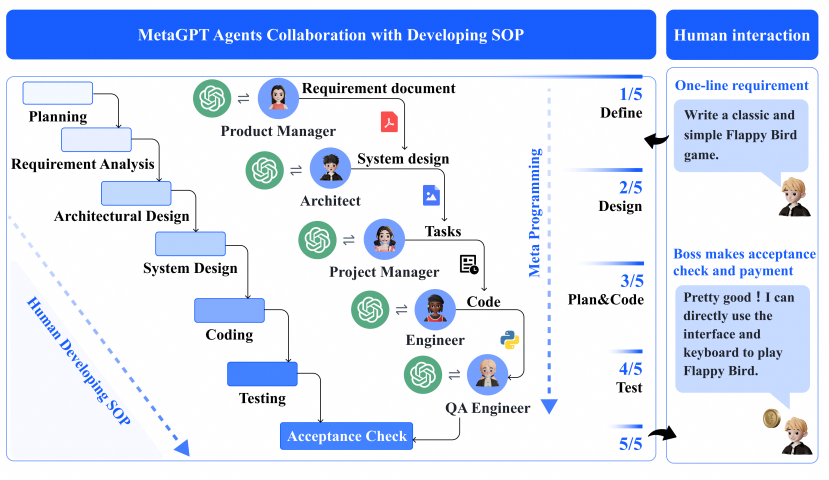
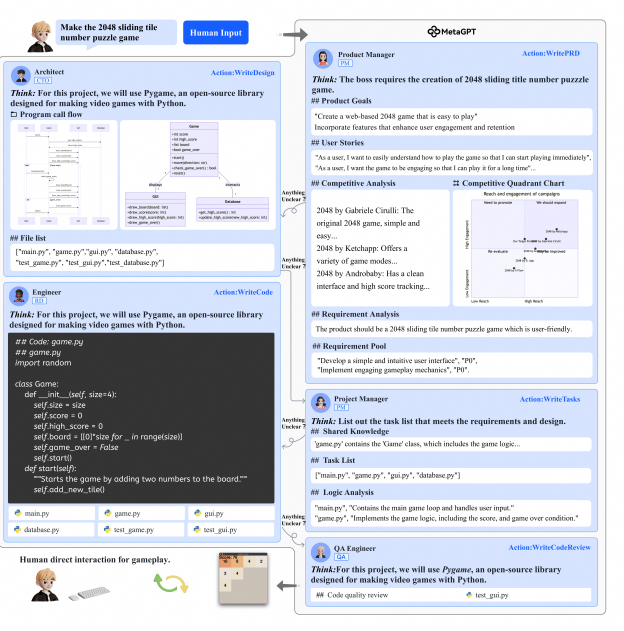
- 当用要求“制作2048滑块数字益智游戏”时,会触发产品经理的“WritePRD”action,起草7份文档,包括产品目标、用户故事、竞品分析(文本和象限的形式)、需求分析、需求池和UI设计。在产品经理根据瀑布模型把她的工作交给下一个角色前,她的工作将被架构师审查。审查之后,产品经理将她的工作发布到“WritePRD”类别的消息队列中。
- 架构师订阅了“WritePRD”类的消息,开始“WriteDesign”。他根据需求分析,为项目起草一个系统设计,然后根据设计创建文件列表,用mermaid图定义类和时序图。架构师将他的文档和图发布到“WriteDesign”类别的消息队列中。
- 项目经理订阅了“WriteDesign”类的消息,并使用所有之前起草的UI、系统设计和API设计文档将项目分解为更简单、更可操作的任务,这通常只有一个文件的复杂度。此外,项目经理将列出项目依赖项,包括用Python编写的第三方包以及其他语言和API规范。当缺少细节时,评审/反思过程将迭代地改进当前阶段生成的内容,直到评审人员(工程师)满意为止。
- 工程师准备好写代码了,他将按照指定的顺序遍历文件列表, 并生成每个文件。
- 最后质量工程师对生成的代码做“WriteCodeReview”。
上图每个任务的交接都需要反思或另一个角色来指出问题的原因在于,大模型的输出是生成式的,具体而言下一个token的输出是随机采样的。若当前的输出采样到了一个不太合理的token,也只能向着已有的方向继续前进。在真实世界中,人类的行为其实也会有这样的问题,人也会有幻觉和错误的尝试。人类解决这个问题的方法是评审机制,比如代码评审、论文评审等等。这些评审可以提供不同的视角和反馈,帮助提高输出的质量和可靠性。
MetaGPT论文中将它对软件公司的抽象和AutoGPT、AgentVerse做了对比,证明自己的抽象在生成的代码可用性、代码行数上限均有提高,更能处理复杂任务。
MetaGPT通过角色定义、任务分解、流程标准化和其他技术设计来管理多agent协同。它最终只用一行需求就完成了端到端的软件开发过程。其中MetaGPT强调了它纳入了人类工作流的经验。通过长期的协作实践,人类在许多领域开发了被广泛接受的标准化操作程序(SOP,Standardized Operating Procedures),这些标准操作程序在支持任务分解和有效协调方面起着关键作用。
- 更多有意思项目可以参考官方网址实现
辩论/狼人杀/Minecraft/斯坦福小镇
https://docs.deepwisdom.ai/main/zh/guide/in_depth_guides/environment/werewolf.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号