NL2SQL技术方案系列(1):NL2API、NL2SQL技术路径选择;LLM选型与Prompt工程技巧,揭秘项目落地优化之道
NL2SQL技术方案系列(1):NL2API、NL2SQL技术路径选择;LLM选型与Prompt工程技巧,揭秘项目落地优化之道
NL2SQL基础系列(1):业界顶尖排行榜、权威测评数据集及LLM大模型(Spider vs BIRD)全面对比优劣分析[Text2SQL、Text2DSL]
NL2SQL基础系列(2):主流大模型与微调方法精选集,Text2SQL经典算法技术回顾七年发展脉络梳理
NL2SQL进阶系列(1):DB-GPT-Hub、SQLcoder、Text2SQL开源应用实践详解
NL2SQL进阶系列(2):DAIL-SQL、DB-GPT开源应用实践详解[Text2SQL]
NL2SQL进阶系列(3):Data-Copilot、Chat2DB、Vanna Text2SQL优化框架开源应用实践详解[Text2SQL]
☆☆NL2SQL进阶系列(4):ConvAI、DIN-SQL、C3-浙大、DAIL-SQL-阿里等16个业界开源应用实践详解[Text2SQL]
☆☆NL2SQL进阶系列(5):论文解读业界前沿方案(DIN-SQL、C3-SQL、DAIL-SQL、SQL-PaLM)、新一代数据集BIRD-SQL解读
NL2SQL实践系列(1):深入解析Prompt工程在text2sql中的应用技巧
NL2SQL实践系列(2):2024最新模型实战效果(Chat2DB-GLM、书生·浦语2、InternLM2-SQL等)以及工业级案例教学
1.大模型之NL2SQL、数据智能分析简介
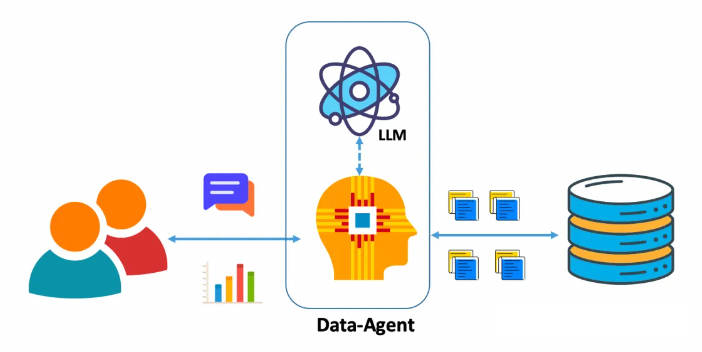
NL2SQL任务的目标是将用户对某个数据库的自然语言问题转化为相应的SQL查询。随着LLM的发展,使用LLM进行NL2SQL已成为一种新的范式。在这一过程中,如何利用提示工程来发掘LLM的NL2SQL能力显得尤为重要。
现状:大语言模型虽然在不断的迭代过程中越来越强大,但类似商业智能这样的企业级应用要远比分析一个 Excel 文件、总结一个 PDF 文件的问题要复杂的多:
-
数据结构复杂:企业信息系统的数据结构复杂性远远超过几个简单的 Excel 文件,一个大型企业应用可能存在几百上千个数据实体,所以在实际应用中,大型 BI 系统会在前端经过汇聚、简化与抽象成新的语义层,方便理解。
-
数据量较大:分析类应用以海量历史数据为主,即使一些数据在分析之前会经过多级汇总处理。这决定了无法在企业应用中把数据简单的脱机成文件进行分析处理。
-
分析需求复杂:企业应用的数据分析需求涵盖及时查询、到各个维度的报表与指标展现、数据的上下钻、潜在信息的挖掘等,很多需求有较复杂的后端处理逻辑。
这些特点决定了,当前大语言模型在企业数据分析中的应用无法完全的取代目前所有的或者部分的分析工具。其合适的定位或许是:作为现有数据分析手段的一种有效补充,在部分需求场景下,给经营决策人员提供一种更易于使用与交互的分析工具。
具体的应用场景包括:
-
及时数据查询。提供对运营或统计数据的简单自定义查询,当然你只需要使用自然语言。
-
传统 BI 工具能力的升级。很多传统 BI 工具会定义一个抽象的语义层,其本身的意义之一就是为了让数据分析对业务人员更友好。而大模型天然具有强大的语义理解能力,因此将传统 BI 中的一些功能进化到基于自然语言的交互式分析,是非常水到渠成的。
-
简单的数据挖掘与洞察。在某些场景下的交互式数据挖掘与洞察,可以利用大语言模型的 Code 生成能力与算法实现对数据隐藏模式的发现。
1.1 三种基础技术方案介绍
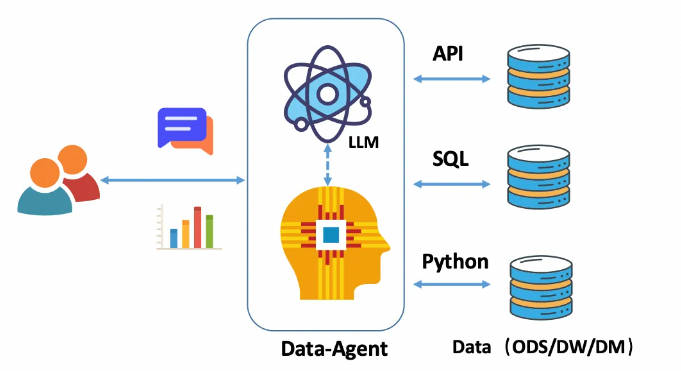
-
自然语言转数据分析的 API,text2API
类似现有的一些 BI 工具会基于自己的语义层开放出独立的 API 用于扩展应用,因此如果把自然语言转成对这些数据分析 API 的调用,是一种很自然的实现方式。当然完全也可以自己实现这个 API 层。
这个方案的特点是受到 API 层的制约,在后面我们会分析。
-
自然语言转关系数据库 SQL,text2SQL
这也是目前最受关注的一种大模型能力(本质上也是一种特殊的 text2code)。由于 SQL 是一种相对标准化的数据库查询语言,且完全由数据库自身来解释执行,因此把自然语言转成 SQL 是最简单合理、实现路径最短的一种解决方案。
-
自然语言转数据分析的语言代码,即 text2Code
即代码解释器方案。简单的说,就是让 AI 自己编写代码(通常是 Python)然后自动在本地或者沙箱中运行后获得分析结果。当然目前的 Code Interpreter 大多是针对本地数据的分析处理(如 csv 文件),因此在面对企业应用中的数据库内数据时,需要在使用场景上做特别考虑。
2.方案一:text2API
用下图来表示 text2API 这种方案的大致架构:
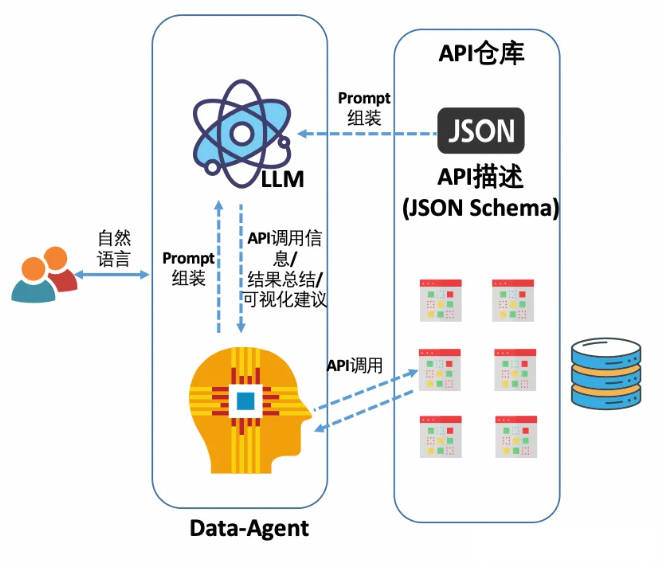
基本流程
-
首先你需要定义良好的数据分析 API 接口(如现有 BI 系统的开放 API),这个需要根据各自的业务情况进行充分设计与实现,形成 API 的使用 “说明书”(JSON Schema 描述,也就是 Agent 里面的 Tools 工具描述)。
-
使用者输入自然语言,系统借助 LLM 将使用者的输入问题转化为对 API 工具的调用,包括 API 的名称与提取的参数。
-
根据 LLM 的响应调用指定的 API,取得返回的数据。根据情况需要,在一些场景下可能还需要将返回的数据再附加到用户输入,再次交给 LLM,由 LLM 来输出最终响应给客户的分析结果。
2.1问题一:Text2API 的实现探讨
如何实现大语言模型的 text2API 能力?由于这是私有企业应用的定制 API,无法借助于一些已经对互联网公开 API 训练过的一些 text2Tool 模型。
- 一般需要借助提示工程来让大语言模型为你实现这种转换,比如类似这样的 Prompt:
"""
请遵循如下要求与约束:
1.参考以下的工具列表,找到需要使用的工具,并输出以下JSON格式内容用来使用工具。注意要确保下面内容在输出结果中只出现一次:
{"api_calls":[{"name":name of tool,"args":{"arg1":value1,"arg2":value2...}}]}
2.请根据工具的定义与参数描述来生成调用文本, 参考案例如下:
工具列表:
[
{
"name": "get_current_weather",
"description": "获取给定位置的当前天气信息",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "需要查询天气的城市"
}
},
"required": ["location"]
}
}
],
用户输入:查询北京的天气
返回调用JSON文本:
{"api_calls":[{"name":"get_current_weather","args":{"location":"Beijing"}}]}
3.如果无法理解用户意图,请回复“我无法理解您的意图”。
4.请根据用户问题与上下文来推理与提取本次工具调用需要的参数内容。
5.直接输出上述的JSON结果,不要有多余解释。
上下文:
{context}
工具列表:
{tools}
用户问题:
{question}
"""
在借助 LLM 把自然语言转化为 API 的调用及参数后,通过对输出的解析,我们就可以调用对应的 API 取得结果。当然,实际使用时需要对 Prompt 进行细致的调优与反复测试来验证准确率与稳定性。
2.2 问题二:企业的 APIs 过多的问题
在大型的企业 BI 应用系统中,数据分析的需求可能非常复杂,即使只考虑部分的需求实现,其潜在的 API 数量也可能非常庞大。由于在大语言模型的无状态特征,每次我们在输入用户问题时,理论上需要携带全部的 API 规格说明。这就可能导致上下文超出模型的最大允许 tokens。
- 一种可能的解决方案是:
借助于向量数据库的语义搜索能力对所有的工具即 APIs 进行一次过滤,在每次需要 LLM 进行 text2API 的转换时,只携带与用户问题相关的 API Schema,这样可以大大减少输入的 tokens 与上下文大小。
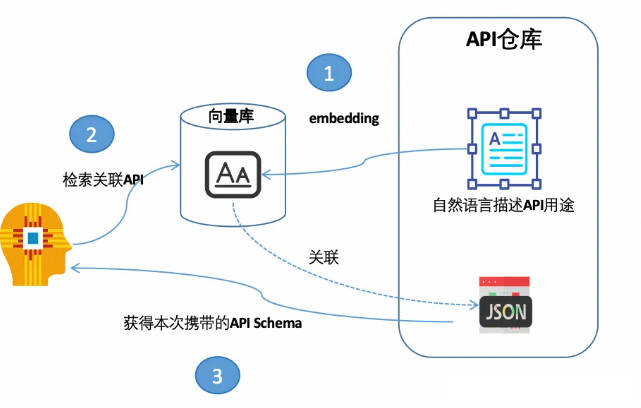
大致过程为:
-
对所有的工具即 API 的功能描述做嵌入存储到向量数据库
-
根据用户输入问题进行语义搜索,获取到相关的 API 描述
-
借助检索到 chunk 的元数据关联获取需要携带的 API Schema
-
在发送给大模型的提示中仅携带关联的 API Schema,从而节省上下文长度
text2API 总结
text2API 方案本质上是在传统的数据分析系统之上增加一层自然语言的 UI,核心的数据分析功能需要自行设计 API 来实现。所以这种方案的好处是:
核心的分析逻辑不依赖于大模型(在 API 中),因此更可控。对于一些包含了复杂分析逻辑的任务(涉及不同的数据源、较多的逻辑判断和数据实体等),或者分析逻辑经常变化的任务,可以把内部的复杂性对大模型屏蔽,从而减少对输出稳定性的影响。
而这种方案的不足是:
-
**核心分析逻辑 API 实现,需要极高的业务理解与抽象能力。
** -
灵活性与扩展能力差,受限于已经实现与开放的 API 库。
因此,可以认为这种方案更适合用在输入输出结构上较简单(决定了 API 更简洁),但是内部数据处理与分析逻辑较复杂的任务。
3.方案二 NL2SQL
text2SQL 的实现原理非常简单,其核心就在于如何把自然语言组装成 Prompt,并交给 LLM 转化成 SQL。我们不妨看一下 OpenAI 公司在官网给出的一个标准的 chatGPT 做自然语言转 SQL 的例子:
System
/*系统指令*/
Given the following SQL tables, your job is to write queries given a user’s request.
/*数据库内表结构*/
CREATE TABLE Orders (
OrderID int,
CustomerID int,
OrderDate datetime,
OrderTime varchar(8),
PRIMARY KEY (OrderID)
);
...此处省略其他表...
/*问题*/
Write a SQL query which computes the average total order value for all orders on 2023-04-01.
确实,这个看似复杂的任务仅需一个简洁的“咒语”即可完成。实际应用时,或许需针对所用的大模型微调,但不论形式如何变化,text2SQL的Prompt主要由几个核心部分构成。
-
指令(Instruction):比如,“你是一个 SQL 生成专家。请参考如下的表格结构,直接输出 SQL 语句,不要多余的解释。”
-
数据结构(Table Schema):类似于语言翻译中的 “词汇表”。即需要使用的数据库表结构,由于大模型无法直接访问数据库,你需要把数据的结构组装进入 Prompt,这通常包括表名、列名、列的类型、列的含义、主外键信息。
-
用户问题(Questions):自然语言表达的问题,比如,“统计上个月的平均订单额”。
-
参考样例(Few-shot):这是一个可选项,当然也是提示工程的常见技巧。即指导大模型生成本次 SQL 的参考样例。
-
其他提示(Tips):其他你认为有必要的指示。比如要求生成的 SQL 中不允许出现的表达式,或者要求列名必须用 “table.column" 的形式等。
3.1 NL2SQL会遇到的难点
实现text2SQL的原型固然简单,但在实际运用中,其表现往往难以达到预期。核心问题在于,当前AI模型生成SQL的准确性远逊于人类工程师。深度学习模型的预测本身就存在置信度问题,无法确保绝对可靠,这一挑战在大语言模型中同样显著。此外,输出的不确定性已成为阻碍大模型在关键企业系统广泛应用的最大障碍。
除了模型自身的知识能力以外,还有一些客观原因:
-
自然语言表达本身的歧义性,而 SQL 是一种精确编程语言。因此在实际应用中,可能会出现无法理解,或者错误理解的情况。比如,“谁是这个月最厉害的销售”,那么 AI 是理解成订单数量最多,还是订单金额最大呢?
-
尽管你可以通过 Prompt 输入数据结构信息帮助 AI 模型来理解,但有时候 AI 可能会由于缺乏外部行业知识导致错误。比如,“分析去年的整体客户流失率?”,那么如果 AI 缺乏对 “客户流失率” 的理解,自然就会出错或者编造。
Text2SQL 的方案在企业应用中还会面临两个严重的挑战:
3.1.1 可以运行但结果错误
即正常的完成了任务,但实际结果是错误的。由于 text2SQL 是直接输出用于数据库访问的语句,理论上来说,只要不存在基本的语法错误,就可以执行成功,即使转换的 SQL 在语义上是错误的!这与 text2API 的区别在于:API 由于有很严格的结构化输入输出规范与校验,因此如果模型转换错误,很大概率会导致 API 调用的异常,使用者能够获得错误反馈(当然也存在 “假象” 的可能)。
比如这样一个问题,LLM 的两个输出都可以正常执行,但是第二个显然是错误的。而且这样的错误对于使用者来说,很可能是难以察觉的:

这个问题其实来自于 text2SQL 输出正确性的评估困难。这种 text2SQL 输出语义准确性衡量的复杂性本质上来自于这样一个事实:判断 AI 输出的一段代码是否正确,要比判断一个选择题答案是否正确,或者一段字符串的相似度要复杂的多。
下面这个来自于 text2SQL 模型的输出评估工具 TestSuiteEval 中的例子:

其中 Gold 代表正确答案,predicted1 和 2 代表模型的两个输出,这里正确的是 predicted2,错误的是 predicted1,我们来看两种评估方法:
-
如果用 SQL 执行结果来判断:Predicted1 的结果和正确 SQL 的结果很可能一样,但实际上 Predicted1 的 SQL 是错误的。
-
如果直接对比输出的 SQL:由于 Predicted2 和正确的 SQL 不完全一致,你可能判断它是错误的,但其实 Predicted2 的 SQL 在这个场景下是正确的。
这就是评估 text2SQL 模型输出正确性的复杂所在:你既不能用输出 SQL 的执行结果来判断,也不能简单的把输出 SQL 与标准答案对比来判断。
3.1.2 企业应用的特点会加大错误输出的概率
企业应用分析场景的一些特点:
-
真实企业应用数据库的结构要远比测试应用复杂。
-
真实企业应用的分析逻辑会更复杂。在企业应用即使有几百行的一个 SQL 统计语句为了生成一个报表也不用奇怪。
-
真实企业应用不仅有正确性的要求,还有效率即响应性能的要求,特别对于大型的数据仓库。
那么大语言模型在应对这些问题时是否有很好的解决方案呢?遗憾的是,从当前的一些模型测试结果看,让大语言模型能够在这些场景下完全胜任,达到人类工程师的精度是不现实的。但是我们可以在几个方面考虑其优化,以实现在部分场景下的优先可用。
-
**选择或者微调合适的大模型
** -
提示词工程优化
-
应用场景的限制与设计
4.优化一:选择合适的大模型
- 更多分析见:
NL2SQL基础系列(1):业界顶尖排行榜、权威测评数据集及LLM大模型(Spider vs BIRD)全面对比优劣分析[Text2SQL、Text2DSL]
NL2SQL基础系列(2):主流大模型与微调方法精选集,Text2SQL经典算法技术回顾七年发展脉络梳理
4.1 开源大模型对比
- 【Spider 基准测试】
Spider 是一个被广泛用于评估 text2SQL 模型与任务的数据集。你可以在官方网站直接下载这个数据集,然后用来评估你选择或者训练的模型。这个数据集包含了 1 万多个自然语言的问题和相关的 SQL 语句,以及用来运行这些 SQL 的 200 多个数据库,横跨了 100 多个应用领域。你甚至可以把模型和测试代码提交给官方,官方会在一个不公开的测试集上测试你的模型,并公开结果排名。
目前 Spider 公开的官方最新测试结果,注意 Model 部分不仅列出了大模型,也包括可能的提示工程技术(比如 DAIL-SQL,参考下一部分):
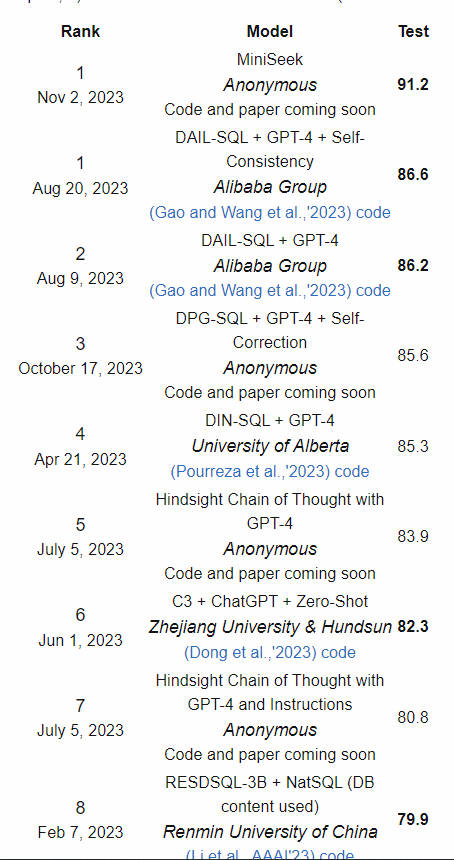
- 【BIRD 基准测试】
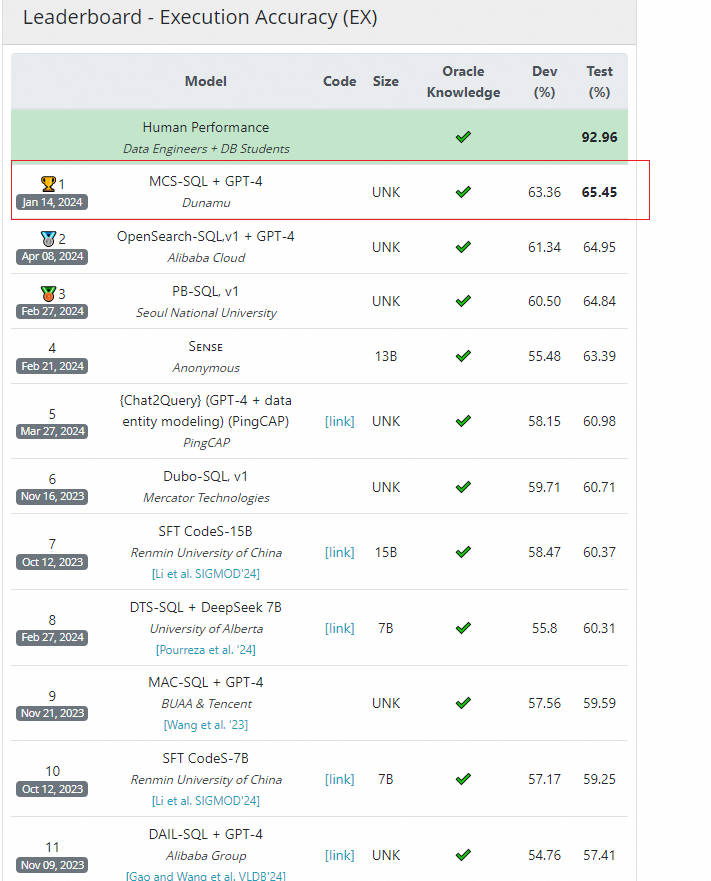
BIRD 是阿里达摩院联合香港大学一起推出的针对 text2SQL 的测试数据集。其作用与 Spider 类似,但是相对于 Spider 更专注于学术研究,BIRD 则更加考虑了真实应用中的数据库中信息的复杂性,且考虑了模型生成的 SQL 运行效率。BIRD 也包含了约 12000 多个自然语言与 SQL,涵盖了约 37 个专业领域的 90 多个数据库。与 Spider 类似,你也可以提交测试代码与模型给官方获得官方测试结果。最新排名如下:
注意到,在这个相对复杂的测试数据集下,大模型的最高分也只有 65.45,离人类能力的 92.96 分还有相当的距离!
4.2 微调模型
- 详细参考:
NL2SQL进阶系列(1):DB-GPT-Hub、SQLcoder、Text2SQL开源应用实践详解
NL2SQL进阶系列(2):DAIL-SQL、DB-GPT开源应用实践详解[Text2SQL]
NL2SQL进阶系列(3):Data-Copilot、Chat2DB、Vanna Text2SQL优化框架开源应用实践详解[Text2SQL]
-
DB-GPT-Hub
-
SQLCoder
-
更多内容请参考
NL2SQL技术方案系列(1):NL2API、NL2SQL技术路径选择;LLM选型与Prompt工程技巧,揭秘项目落地优化之道
5.优化二:提示工程
- 更多内容参考
☆☆NL2SQL进阶系列(4):ConvAI、DIN-SQL、C3-浙大、DAIL-SQL-阿里等16个业界开源应用实践详解[Text2SQL]
NL2SQL实践系列(1):深入解析Prompt工程在text2sql中的应用技巧
NL2SQL实践系列(2):2024最新模型实战效果(Chat2DB-GLM、书生·浦语2、InternLM2-SQL等)以及工业级案例教学
5.1 DAIN-SQL
5.2 C3-SQL
6. 优化三:应用场景
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
- 更多内容请参考
NL2SQL技术方案系列(1):NL2API、NL2SQL技术路径选择;LLM选型与Prompt工程技巧,揭秘项目落地优化之道

 浙公网安备 33010602011771号
浙公网安备 33010602011771号