NL2SQL进阶系列(3):Data-Copilot、Chat2DB、Vanna Text2SQL优化框架开源应用实践详解[Text2SQL]
NL2SQL进阶系列(3):Data-Copilot、Chat2DB、Vanna Text2SQL优化框架开源应用实践详解[Text2SQL]
NL2SQL基础系列(1):业界顶尖排行榜、权威测评数据集及LLM大模型(Spider vs BIRD)全面对比优劣分析[Text2SQL、Text2DSL]
NL2SQL基础系列(2):主流大模型与微调方法精选集,Text2SQL经典算法技术回顾七年发展脉络梳理
NL2SQL进阶系列(1):DB-GPT-Hub、SQLcoder、Text2SQL开源应用实践详解
NL2SQL进阶系列(2):DAIL-SQL、DB-GPT开源应用实践详解[Text2SQL]
NL2SQL进阶系列(3):Data-Copilot、Chat2DB、Vanna Text2SQL优化框架开源应用实践详解[Text2SQL]
☆☆NL2SQL进阶系列(4):ConvAI、DIN-SQL、C3-浙大、DAIL-SQL-阿里等16个业界开源应用实践详解[Text2SQL]
☆☆NL2SQL进阶系列(5):论文解读业界前沿方案(DIN-SQL、C3-SQL、DAIL-SQL、SQL-PaLM)、新一代数据集BIRD-SQL解读
NL2SQL实践系列(1):深入解析Prompt工程在text2sql中的应用技巧
NL2SQL实践系列(2):2024最新模型实战效果(Chat2DB-GLM、书生·浦语2、InternLM2-SQL等)以及工业级案例教学
NL2SQL任务的目标是将用户对某个数据库的自然语言问题转化为相应的SQL查询。随着LLM的发展,使用LLM进行NL2SQL已成为一种新的范式。在这一过程中,如何利用提示工程来发掘LLM的NL2SQL能力显得尤为重要。
1.Data-Copilot
链接:https://github.com/zwq2018/Data-Copilot
demo链接:https://huggingface.co/spaces/zwq2018/Data-Copilot
论文链接:https://arxiv.org/pdf/2306.07209.pdf
1.1 相关介绍
摘要:
金融、气象、能源等各行各业每天都会生成大量的异构数据。人们急切需要一个工具来有效地管理、处理和展示这些数据。DataCopilot 通过部署大语言模型 (LLMs) 来自主地管理和处理海量数据,即它连接不同领域(股票、基金、公司、经济和实时新闻)的丰富数据,满足多样化的用户查询, 计算, 预测, 可视化等需求。只需要输入文字告诉 DataCopilot 你想看啥数据,无需繁琐的操作,无需自己编写代码, DataCopilot 自主地将原始数据转化为最符合用户意图的可视化结果,因为它可以自主地帮你找数据, 处理数据, 分析数据, 画图, 无需人类协助。
许多研究已经探索了 LLMs 的潜力。例如 Sheet-Copilot、Visual ChatGPT、Audio GPT 利用 LLMs 调用视觉,语音等领域工具进行数据分析、视频编辑和语音转换。从数据科学的角度来看,表格、可视化和音频都可以被视为一种形式的数据,所有这些任务都可以被看作是与数据相关的任务. 因此,一个问题出现了:在通用数据的背景下,LLMs 能否构建自动化的数据科学工作流来处理各种与数据相关的任务?为了实现这一目标,需要解决几个挑战:
(1)从数据角度看:直接使用 LLMs 读取和处理海量数据不仅不切实际,而且存在数据泄露的潜在风险。
(2)从模型角度看:LLMs 不擅长处理数值计算,可能没有合适的可调用外部工具来满足多样化的用户需求,从而限制了 LLMs 的利用率。
(3)从任务角度看:尽管 LLMs 展示了强大的少样本能力,但许多与数据相关的任务是复杂的,需要结合多个操作,如数据检索、计算和表格操作,并且结果需要以图像、表格和文本等多种格式呈现,这些都超出了当前 LLMs 的能力。
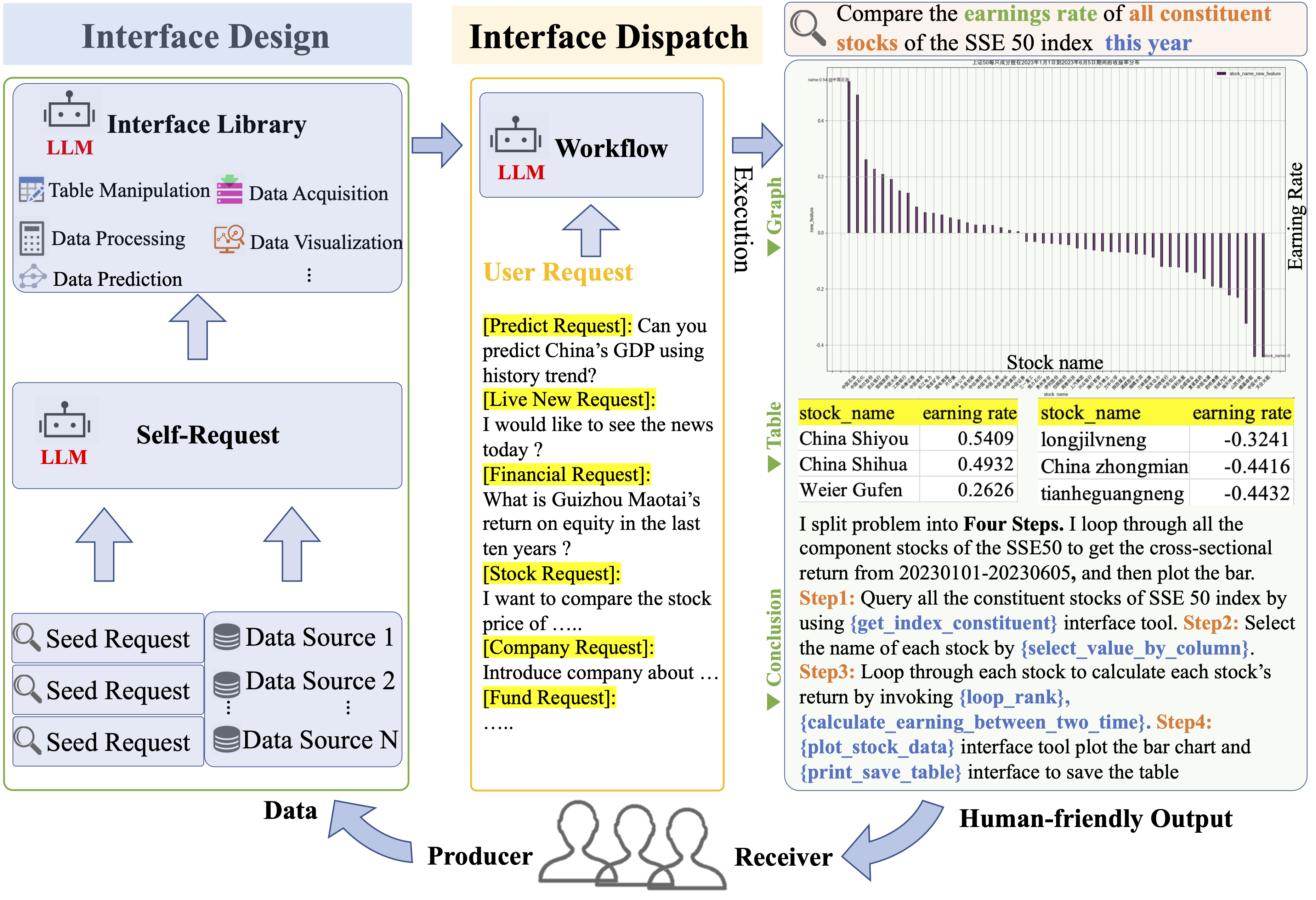
Data-Copilot 是一个基于 LLM 的系统,用于处理与数据相关的任务,连接了数十亿条数据和多样化的用户需求。它独立设计接口工具,以高效地管理、调用、处理和可视化数据。在接收到复杂请求时,Data-Copilot 会自主调用这些自设计的接口,构建一个工作流程来满足用户的意图。在没有人类协助的情况下,它能够熟练地将来自不同来源、不同格式的原始数据转化为人性化的输出,如图形、表格和文本。
-
主要贡献
- 设计了一个通用系统 DataCopilot,它将不同领域的数据源和多样化的用户需求连接起来,通过将 LLM 集成到整个流程中,减少了繁琐的劳动和专业知识。
- Data-Copilot 可以自主管理、处理、分析、预测和可视化数据。当接收到请求时,它将原始数据转化为最符合用户意图的信息性结果。
- 作为设计者和调度者,Data-Copilot 包含两个阶段:离线接口设计 (设计者) 和在线接口调度(调度者)。
- 构建了中国金融市场的 Data-Copilot Demo
-
主要方法
Data-Copilot 是一个通用的大语言模型系统,具有接口设计和接口调度两个主要阶段。
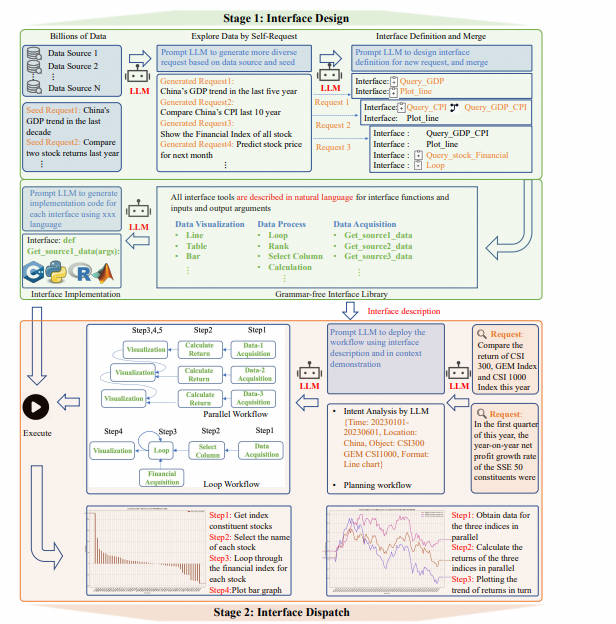
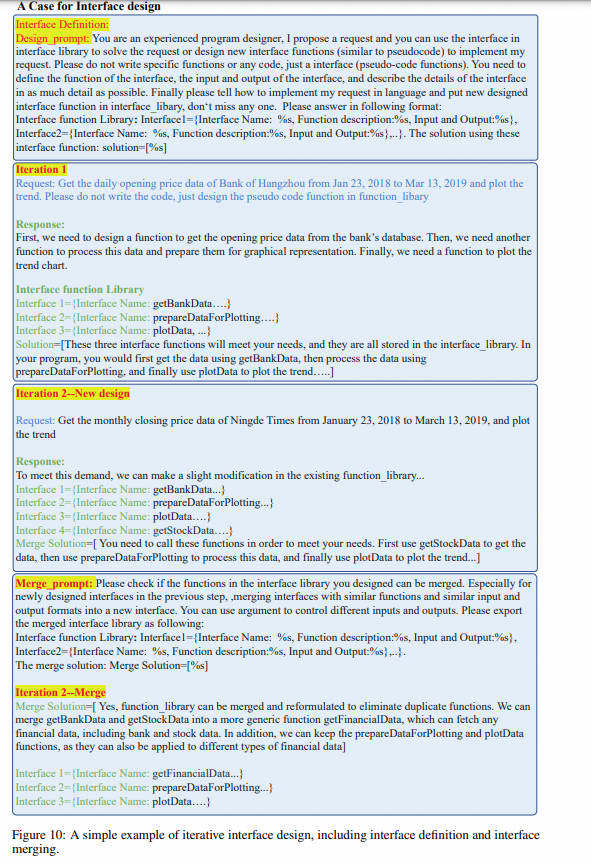
接口设计:我们设计了一个 self-request 的过程,使 LLM 能够自主地从少量种子请求生成足够的请求。然后,LLM 根据生成的请求进行迭代式的设计和优化接口。这些接口使用自然语言描述,使它们易于扩展和在不同平台之间转移。
接口调度:在接收到用户请求后,LLM 根据自设计的接口描述和 in context demonstration 来规划和调用接口工具, 部署一个满足用户需求的工作流,并以多种形式呈现结果给用户。
总体而言,Data-Copilot 通过自动生成请求和自主设计接口的方式,实现了高度自动化的数据处理和可视化,满足用户的需求并以多种形式向用户展示结果。
1 - 接口设计
如图所示, 首先要实现数据管理,第一步需要接口工具。
Data-Copilot 会自己设计了大量接口作为数据管理的工具,其中接口是由自然语言(功能描述)和代码(实现)组成的模块,负责数据获取、处理等任务。
- 首先,LLM 通过一些种子请求并自主生成大量请求 (explore data by self-request)。
- 然后,LLM 为这些请求设计相应的接口(interface definition: 只包括描述和参数),并在每次迭代中逐步优化接口设计 (interface merge)。
- 最后,我们利用 LLM 强大的代码生成能力为接口库中的每个接口生成具体的代码 (interface implementation)。
这个过程将接口的设计与具体的实现分离开来,创建了一套多功能的接口工具,可以满足大多数请求。
2 - 接口调度
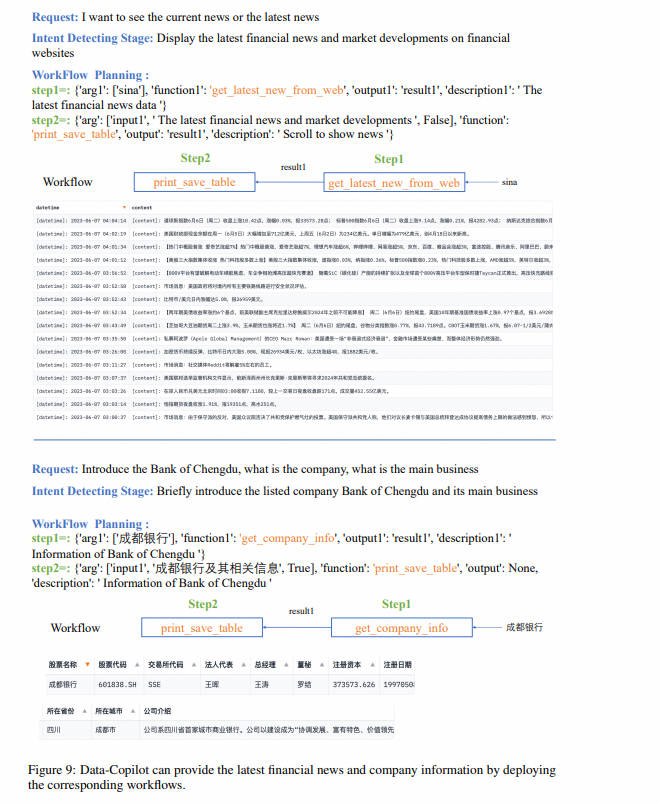
在前一个阶段,我们获取了用于数据获取、处理和可视化的各种通用接口工具。每个接口都有清晰明确的功能描述。如图 2 所示的两个示例,Data-Copilot 通过实时请求中的规划和调用不同的接口,形成了从数据到多种形式结果的工作流程。
- Data-Copilot 首先进行意图分析来准确理解用户的请求。
- 一旦准确理解了用户的意图,Data-Copilot 将规划一个合理的工作流程来处理用户的请求。我们指示 LLM 生成一个固定格式的 JSON,代表调度的每个步骤,例如 step={"arg":"","function":"", "output":"","description":""}。
在接口描述和示例的指导下,Data-Copilot 在每个步骤内以顺序或并行的方式精心安排接口的调度。
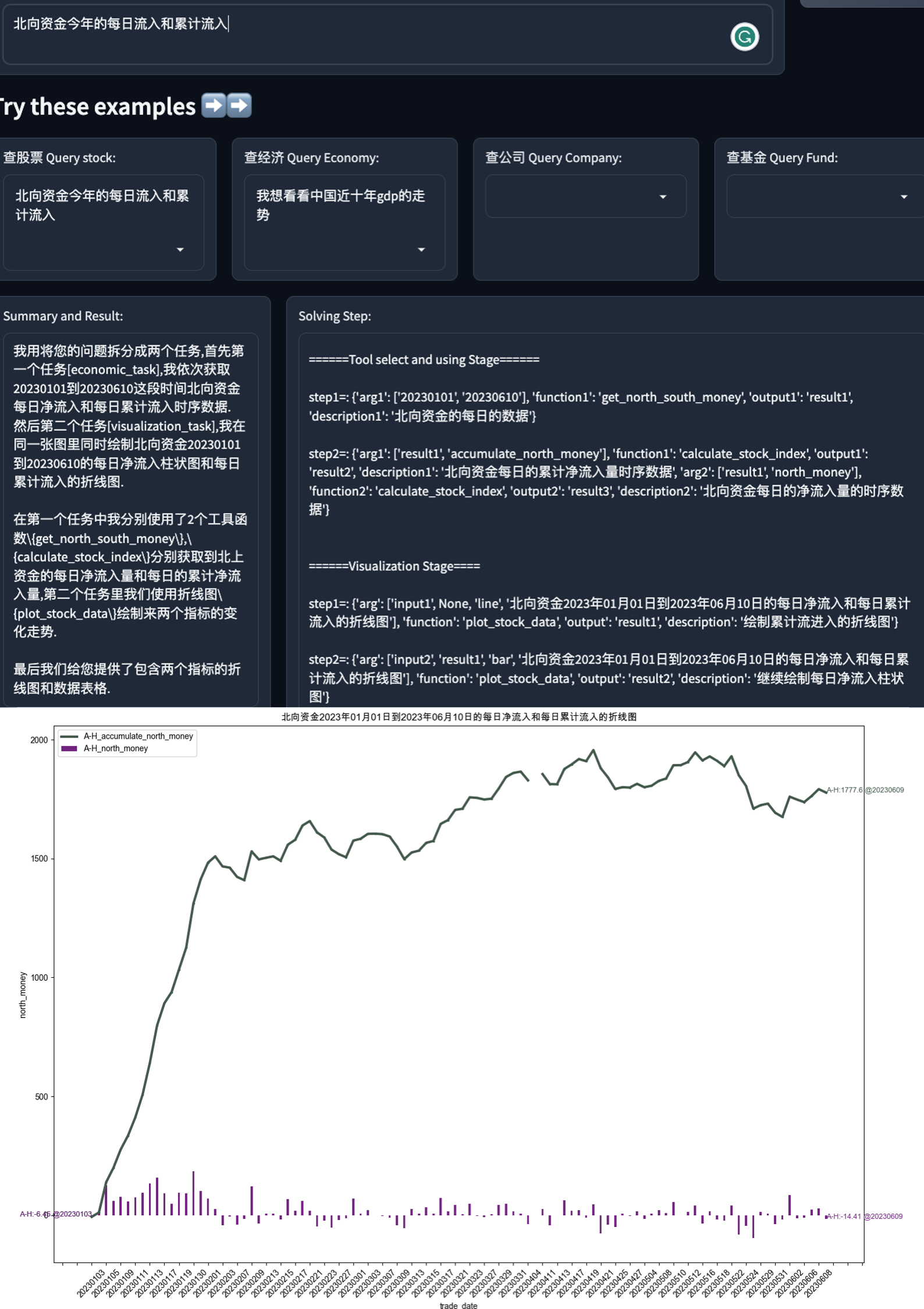
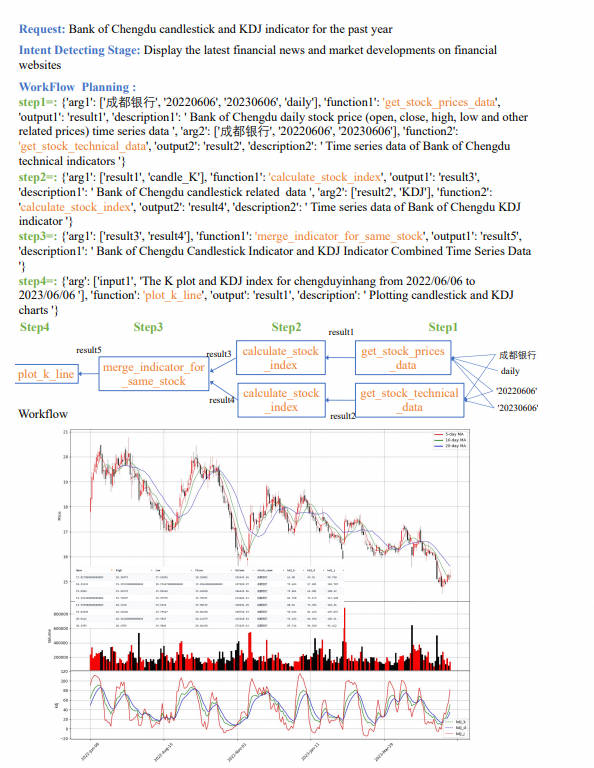
如下图例子:
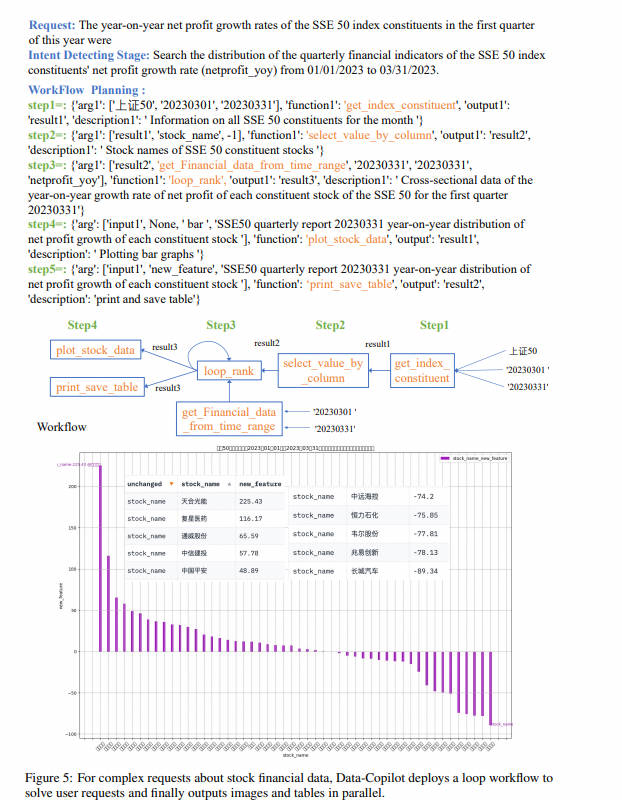
今年一季度上证 50 指数的所有成分股的净利润增长率同比是多少
Data-Copilot 自主设计了工作流如下:
针对这个复杂的问题,Data-Copilot 采用了 loop_rank 这个接口来实现多次循环查询
最后该工作流并执行后结果如下:横坐标是每只成分股的股票名字,纵坐标是一季度的净利润同比增长率
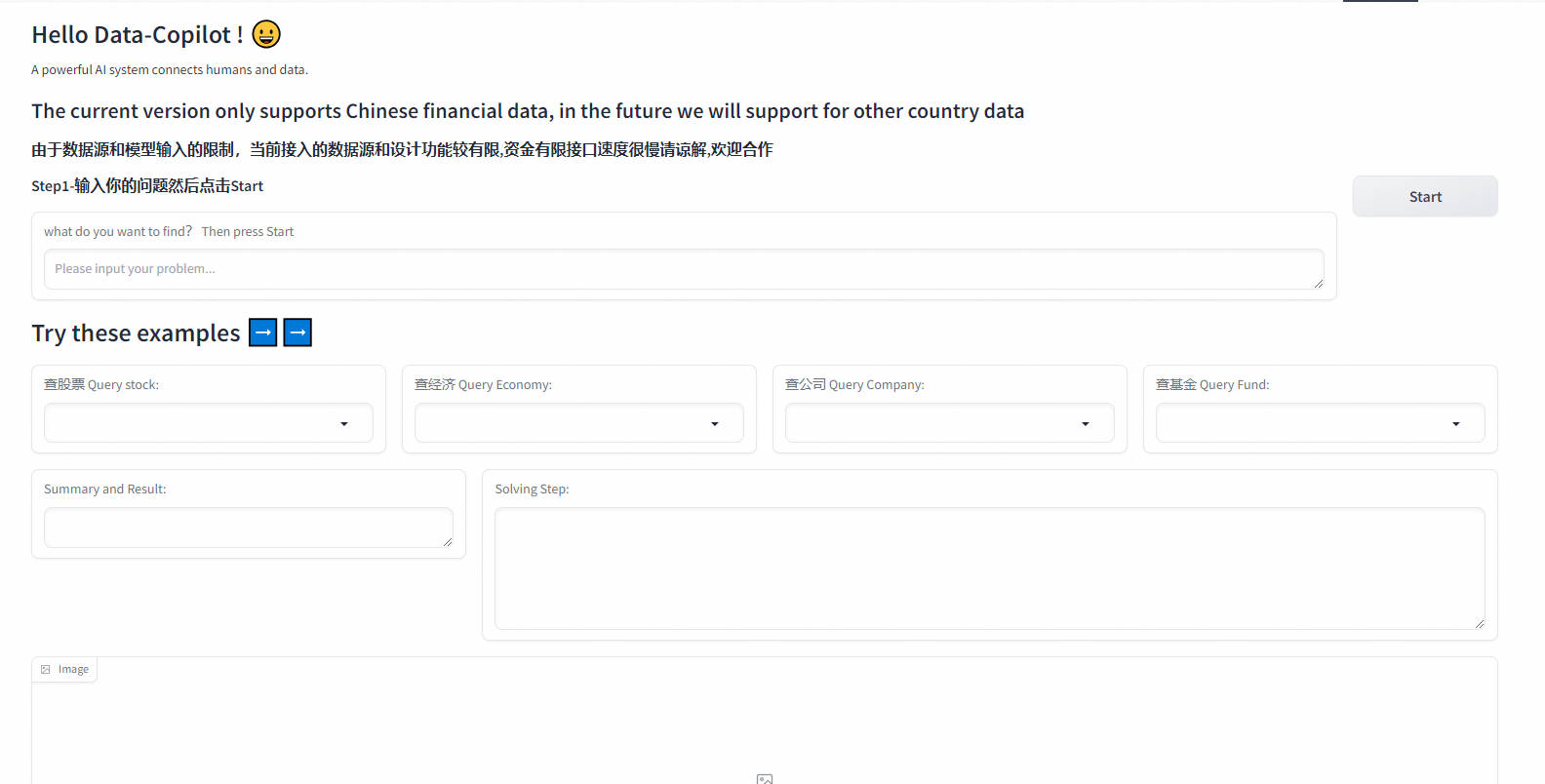
1.2 如何使用
在Spaces中打开 它可以访问中国股票、基金和一些经济数据。但由于gpt3.5的输入令牌长度只有4k,目前的数据访问量仍然相对较小。未来,Data-Copilot将支持更多来自国外金融市场的数据。
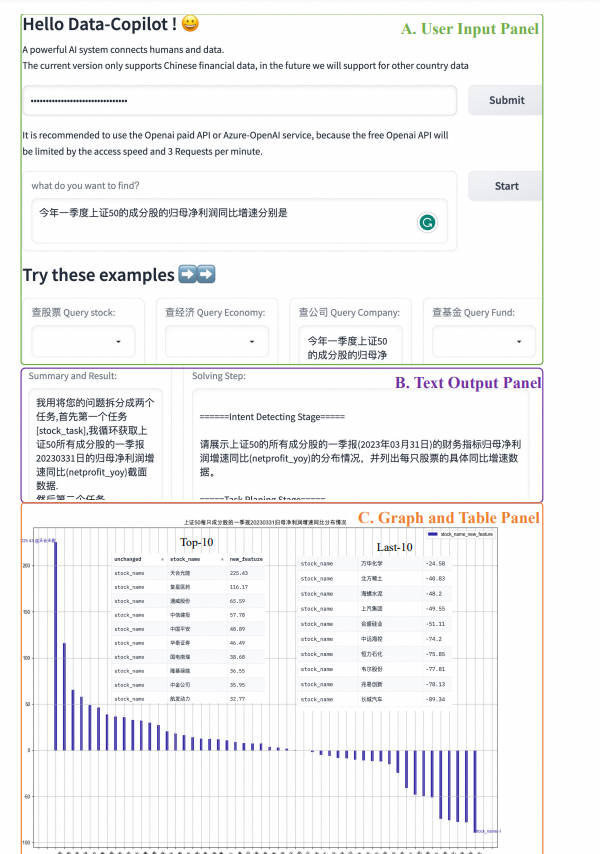
步骤1:输入你的Openai或Openai-Azure密钥,请尽量使用Openai的付费API。如果你打算使用Azure的服务,请记得除了密钥外,还要输入api-base和engine。
步骤2:点击“确定”按钮提交
步骤3:在文本框中输入你想要查询的请求,或者直接从示例框中选择一个问题,它会自动出现在文本框中。
步骤4:点击“开始”按钮提交请求
步骤5:Data-Copilot将在“解决步骤”中显示中间调度过程,并在最后呈现文本(摘要和结果)、图像和表格。
1.3 效果展示
用户问题: 预测下面四个季度的中国季度 GDP
部署工作流:获取历史 GDP 数据 ----> 采用线性回归模型预测未来 -----> 输出表格

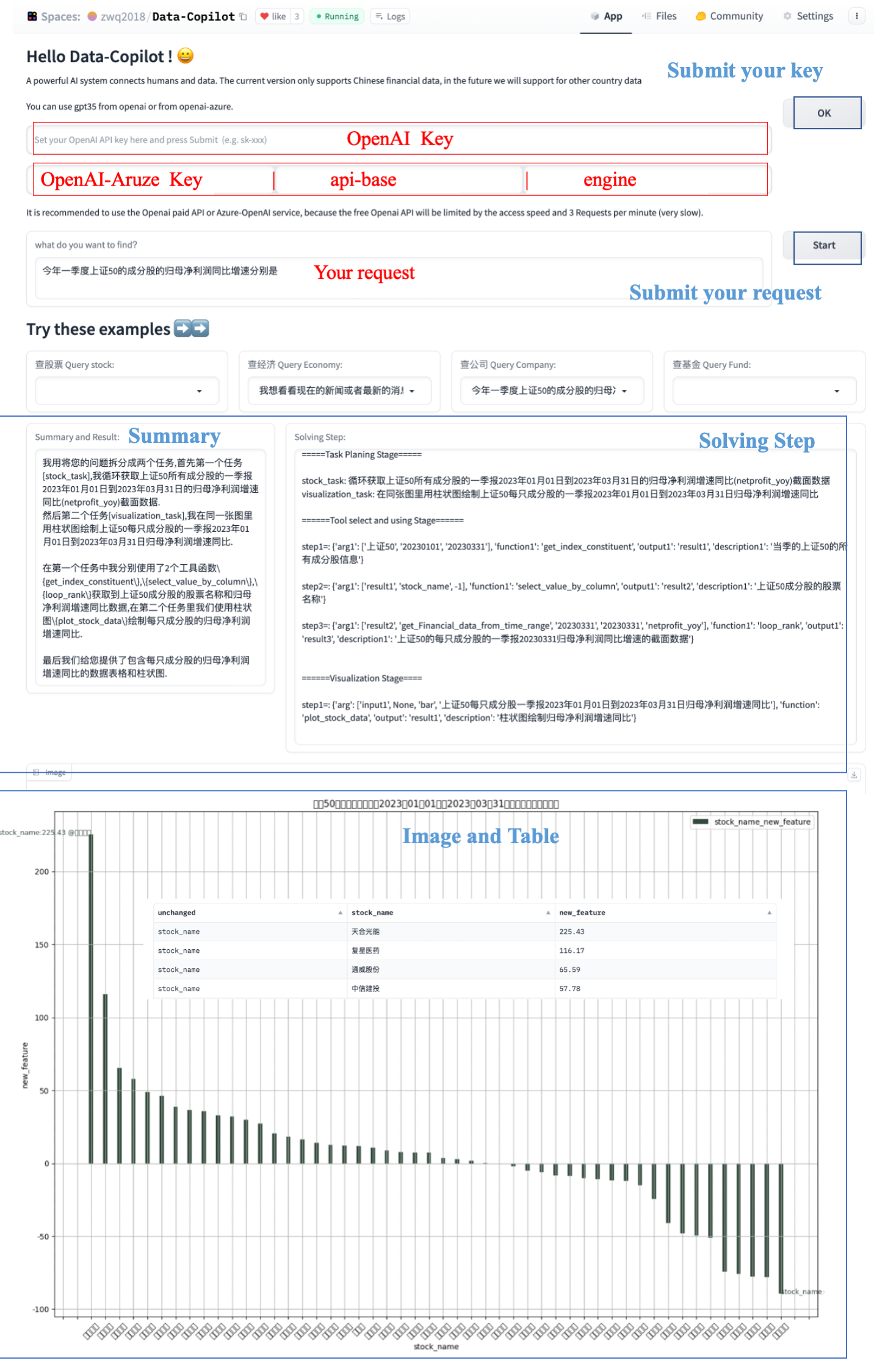
我想看看最近三年宁德时代和贵州茅台的市盈率
部署工作流
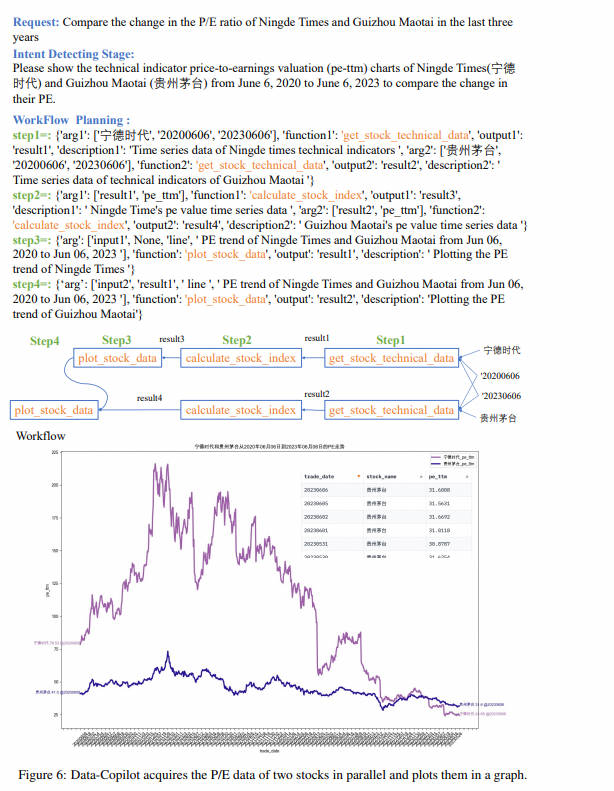
用户问题: 基金经理周海栋管理的基金今年的收益率怎么样
成都银行过去一年的KDJ指标
迭代界面设计的一个简单示例,包括接口定义和接口合并。
界面调度阶段的提示和演示设计

2. Chat2DB
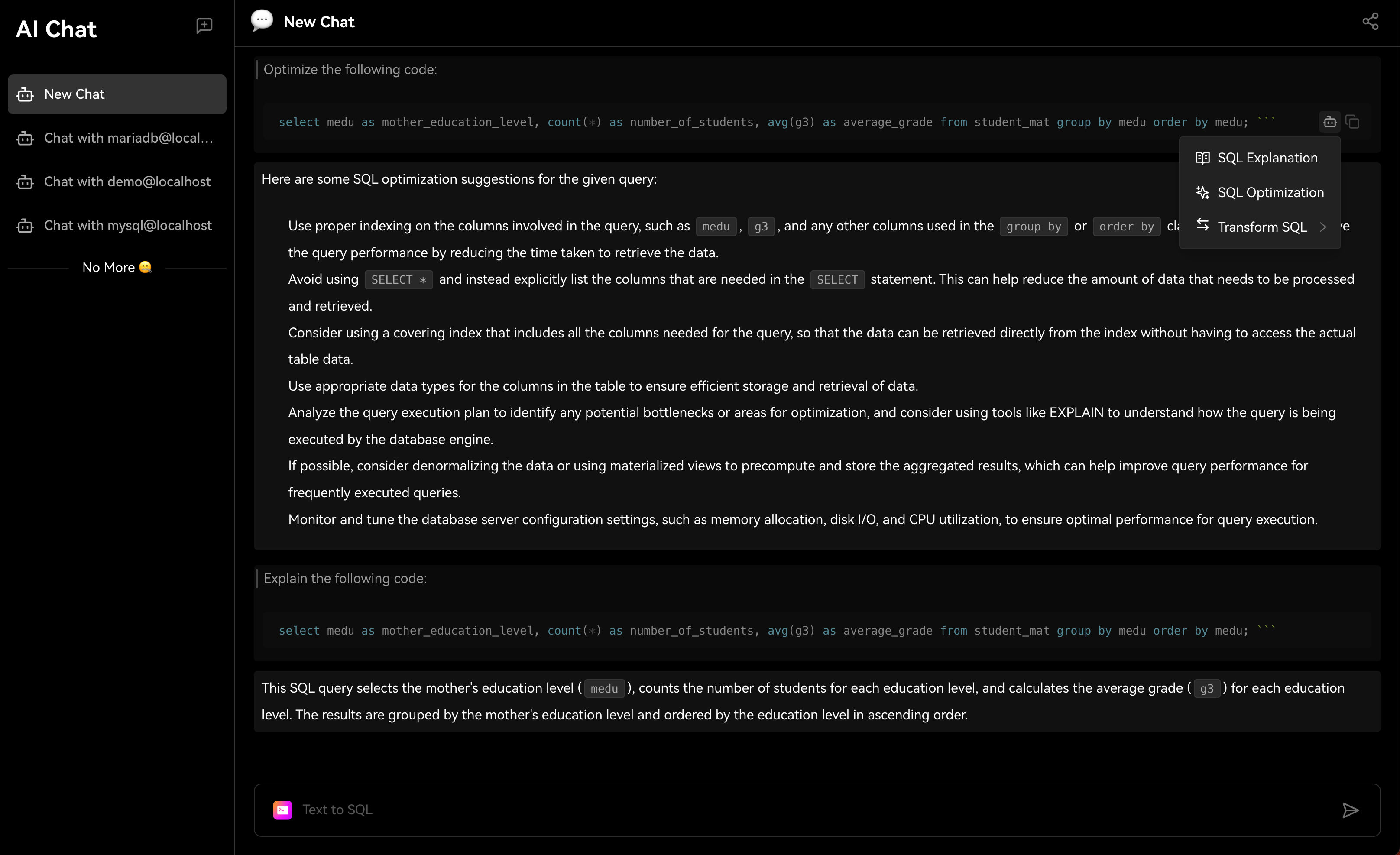
Chat2DB是一个人工智能的数据管理、开发和分析工具。其核心是AIGC(人工智能生成代码)能力。它可以将自然语言转换为SQL,将SQL转换为自然语言,还可以自动生成报表,大大提高人员效率。通过一个产品,可以实现数据管理、数据开发和数据分析的功能。即使那些不懂SQL的人也可以使用快速查询业务数据和生成报告的功能。
当你使用Chat2DB时,你会发现它的AI功能非常强大。当你做任何操作时,它都会给你一些建议。这些建议都是基于Chat2DB的AI模型进行分析的。这会帮助你把工作做得更好。当你在做数据库开发时,他会帮你直接用自然语言生成SQL,给你SQL优化建议,帮你分析SQL的性能,帮你分析SQL的执行计划,还可以帮你快速生成SQL测试数据,生成系统。代码等等。当你做数据分析的时候,他可以直接帮你生成报告,帮你分析数据,帮你生成数据报告等等。
官方链接:https://github.com/chat2db/Chat2DB/blob/main/README_CN.md
手册链接:https://docs.chat2db-ai.com/docs/start-guide/getting-started
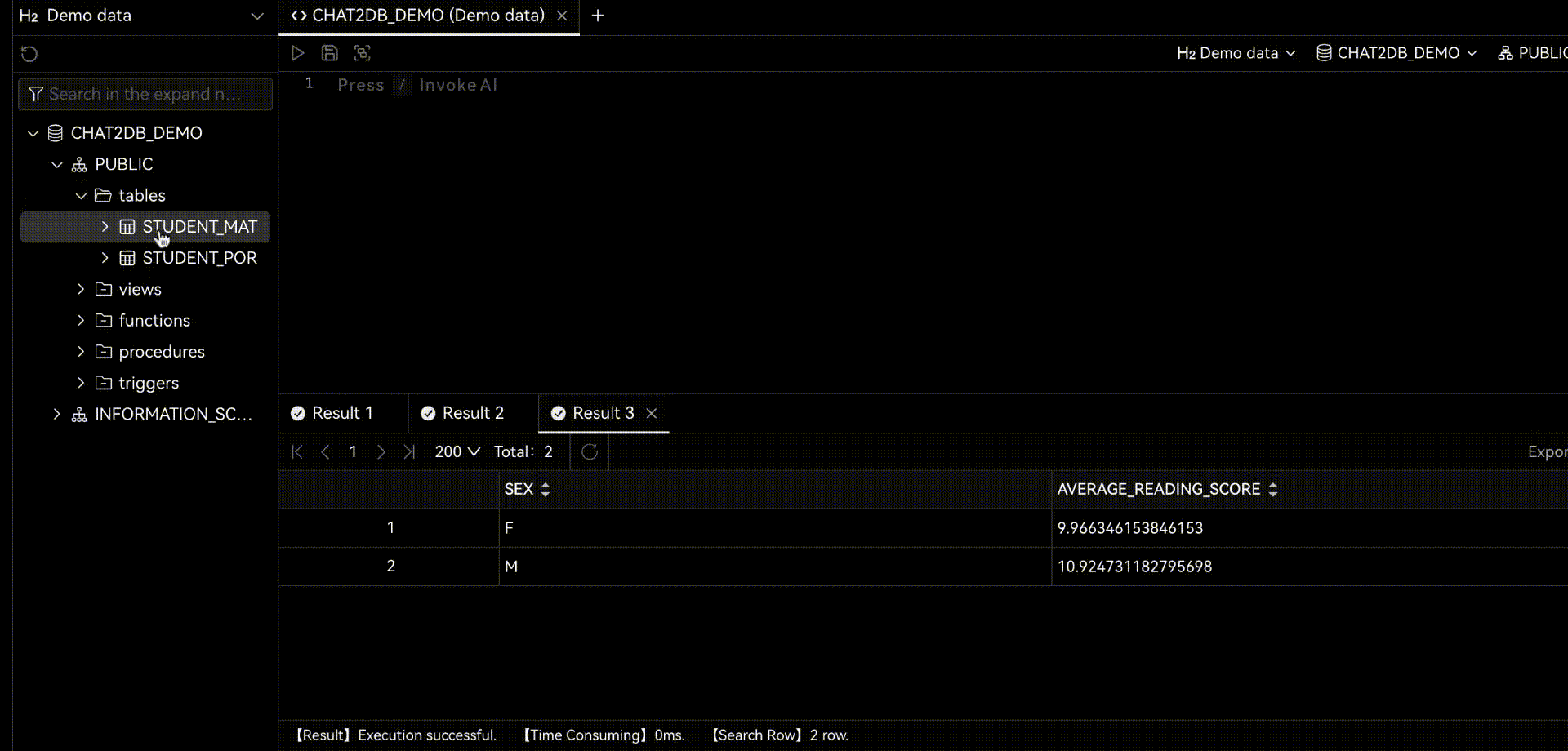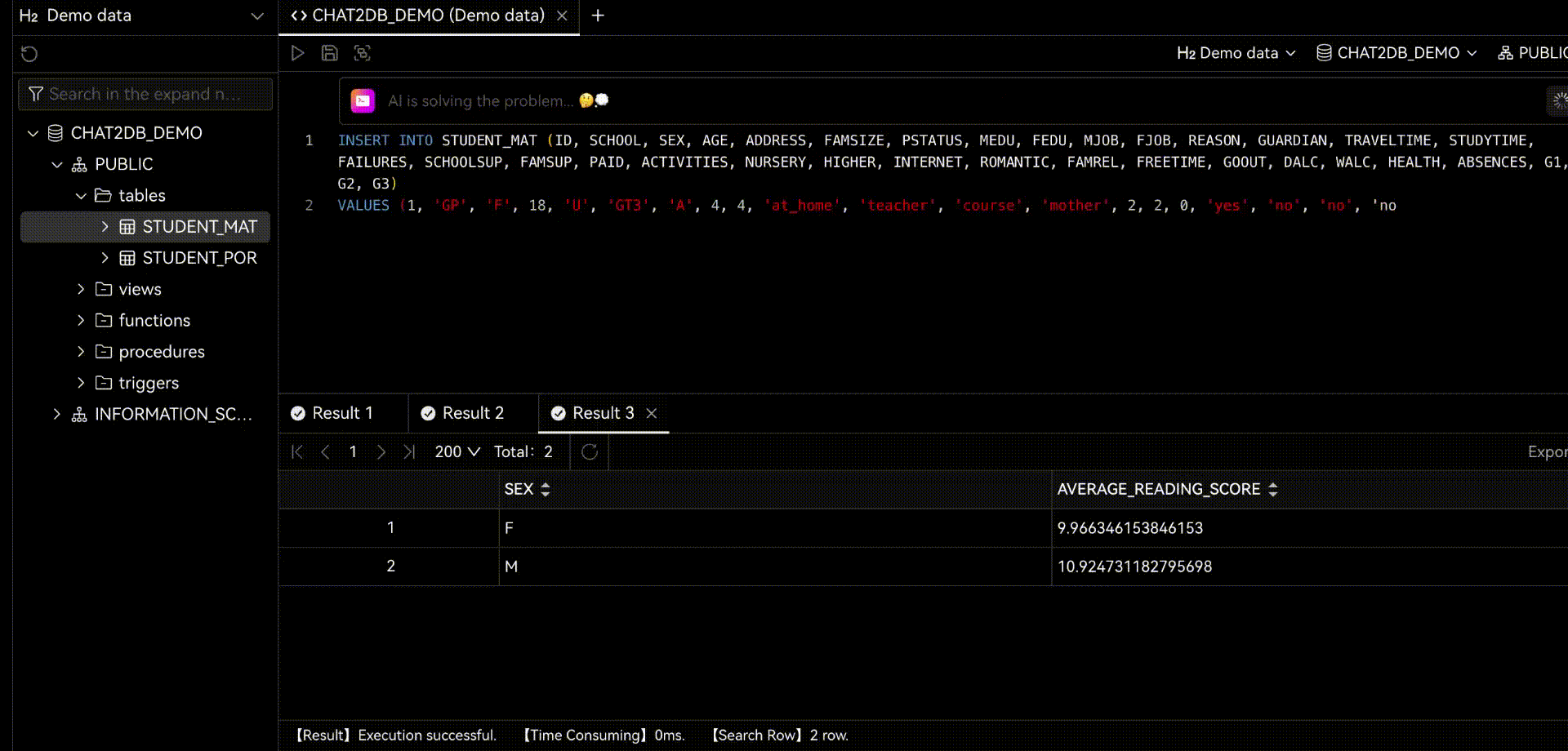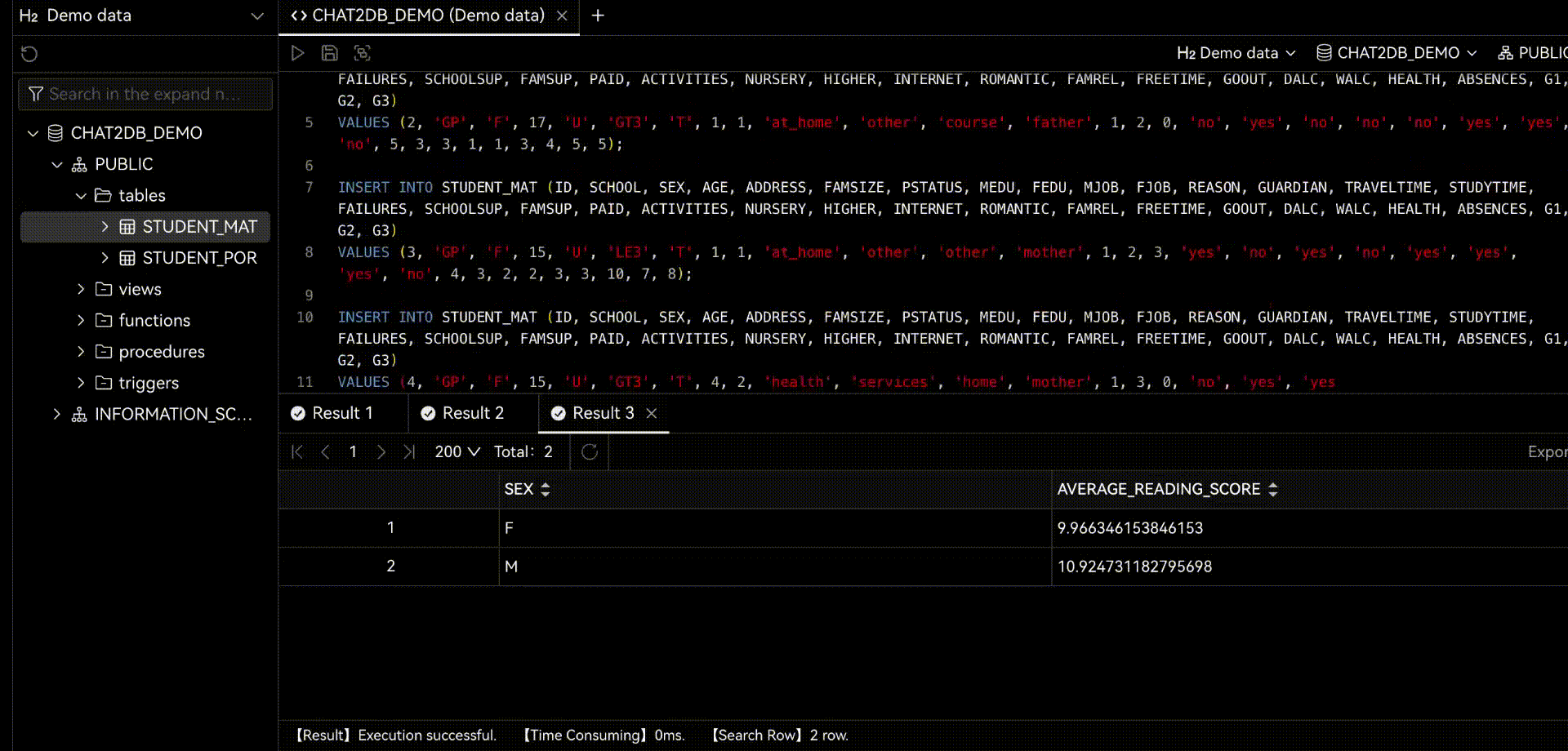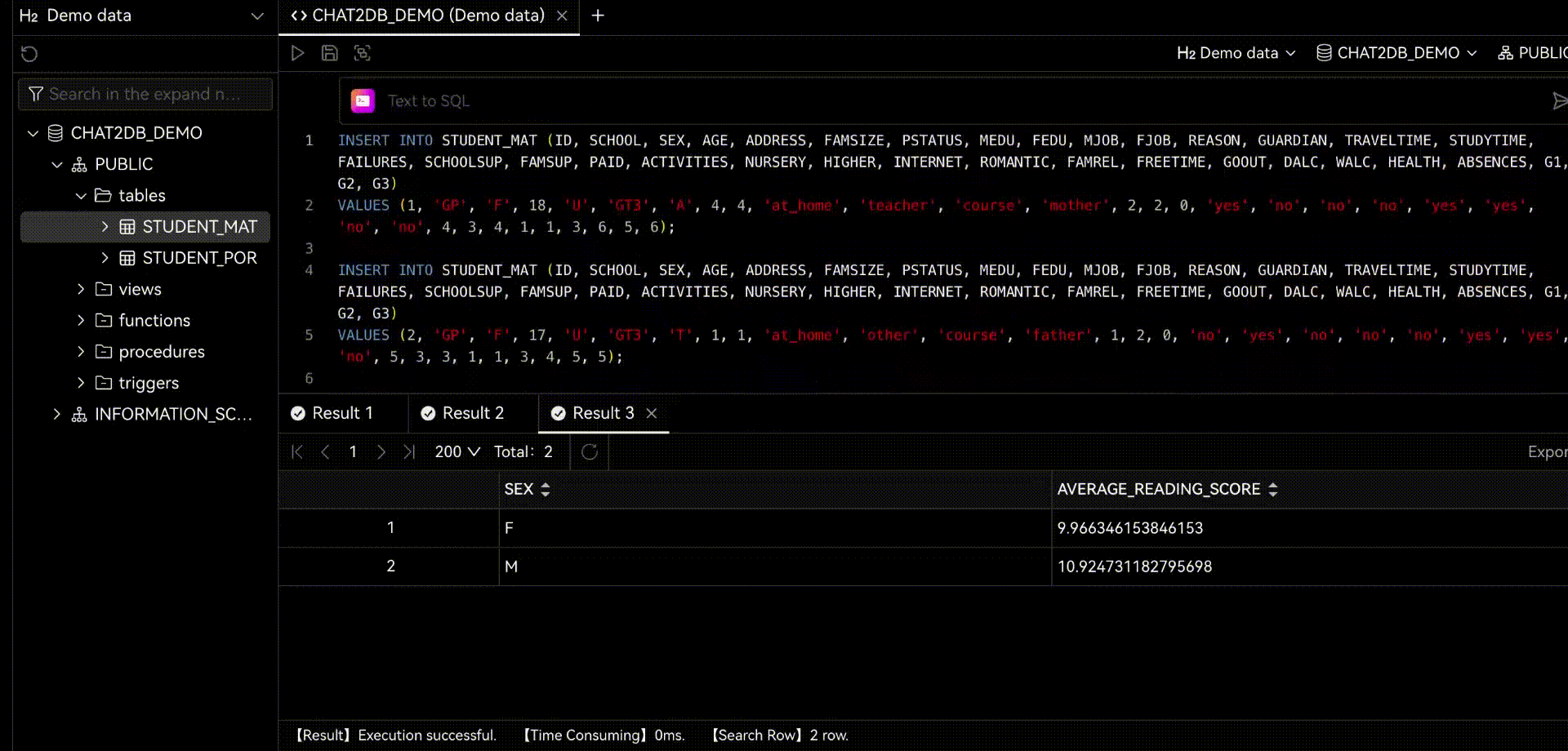
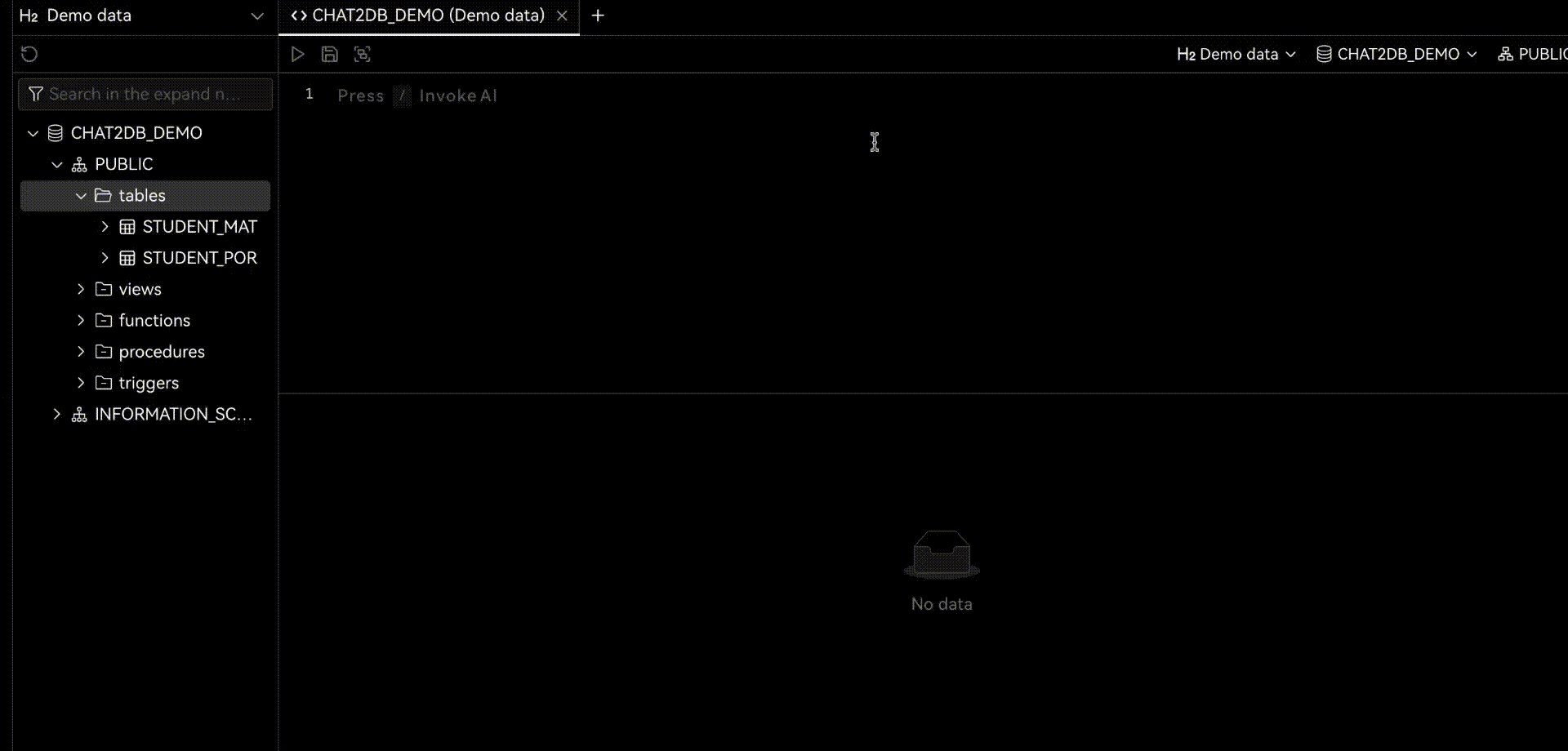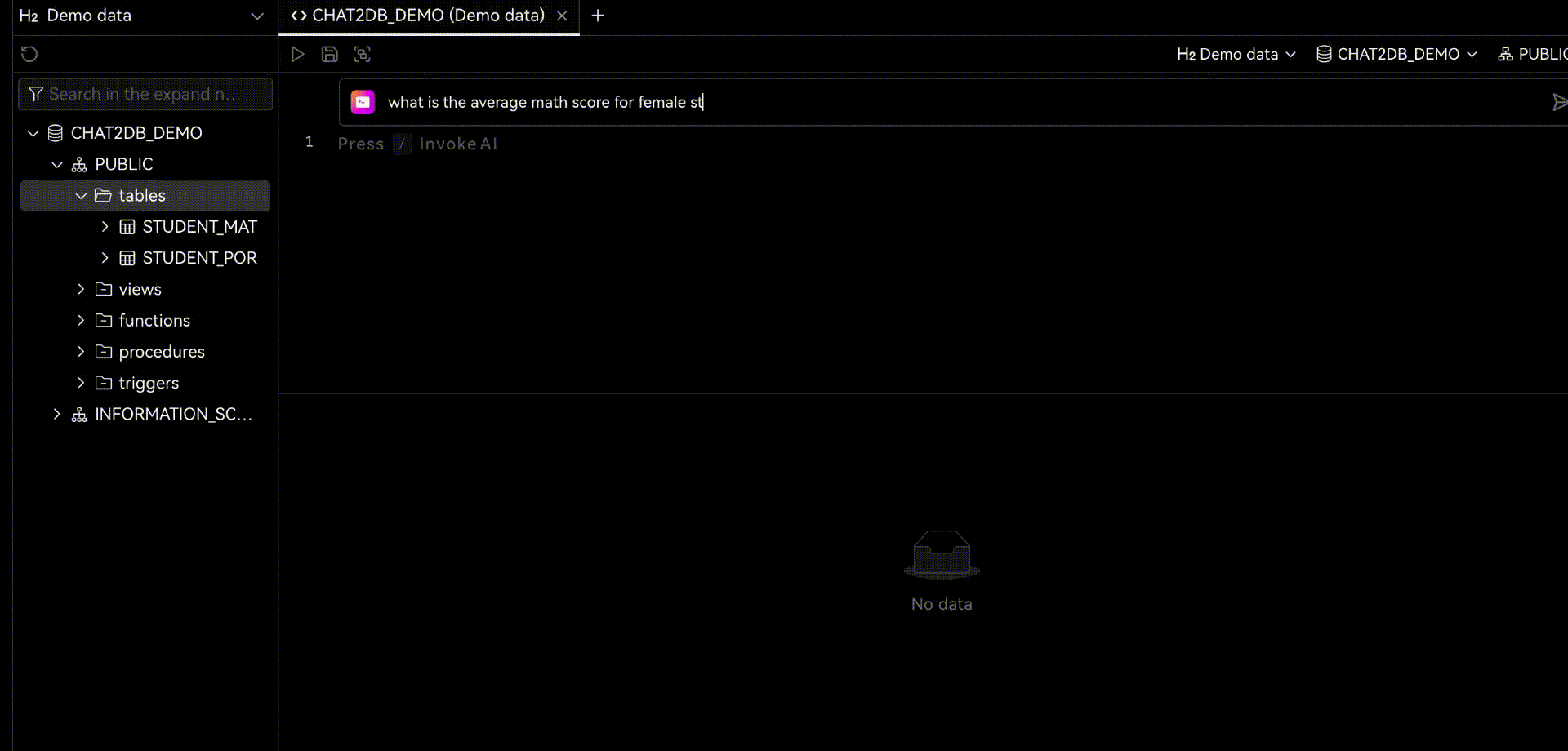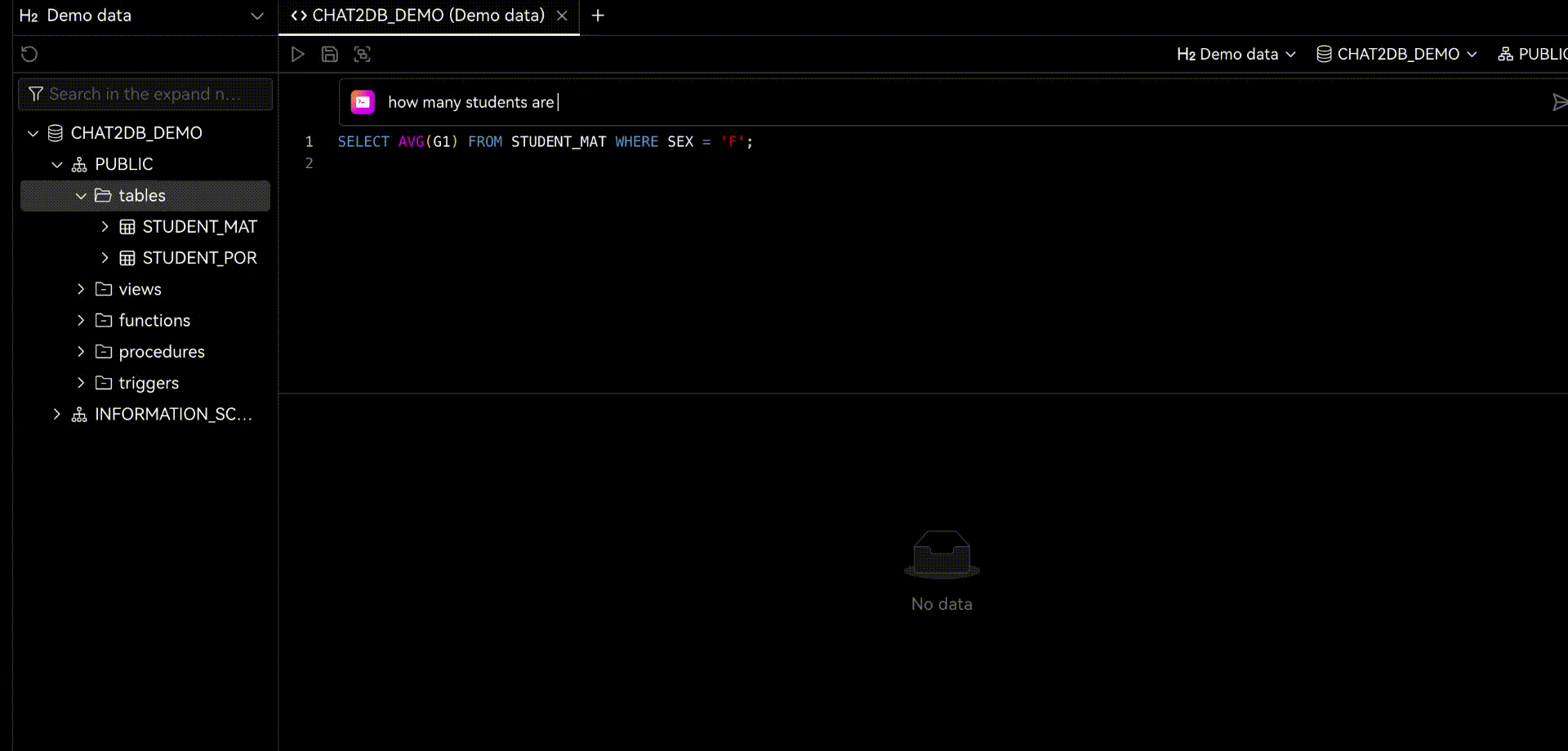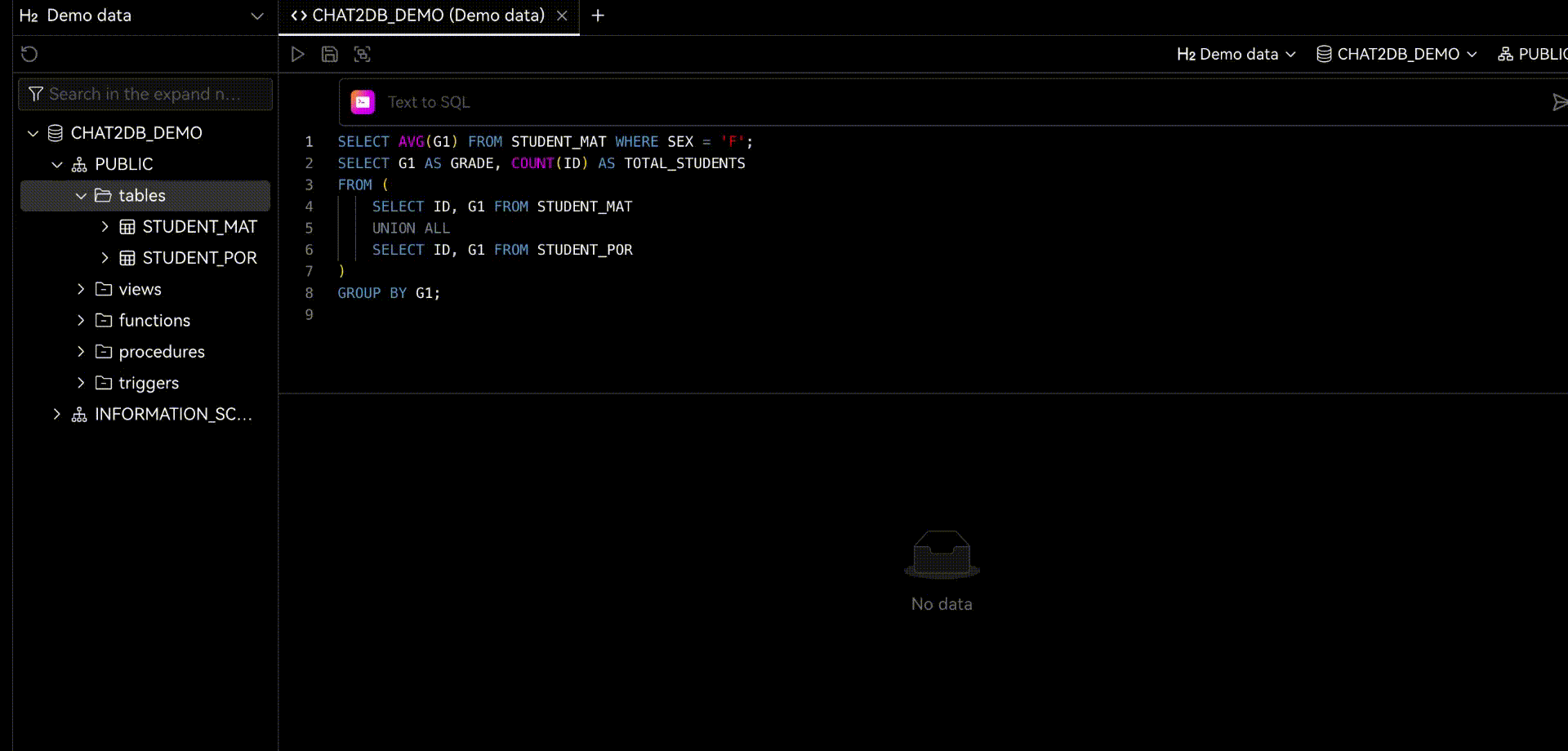
2.1 Chat2DB-GLM
Chat2DB-GLM是Chat2DB开源项目的组成部分,旨在提供一个高效的途径,将自然语言查询转换为结构化的SQL语句。此次开源的Chat2DB-SQL-7B模型,拥有7B参数,基于CodeLlama进行了精心微调。这一模型专为自然语言转SQL任务设计,支持多种SQL语言,并且具有高达16k的上下文长度处理能力。
Chat2DB-SQL-7B模型支持广泛的SQL语言,包括但不限于Mysql、Postgres、Sqlite,以及其他通用的SQL语言。这一跨语言支持能力确保了模型的广泛适用性和灵活性。
2.2 模型效果
Chat2DB-SQL-7B模型在多个语言和SQL关键部分上都展现出了优异的性能。以下是模型在不同的SQL关键部分的表现概览,以通用SQL为例,基于spider数据集进行的评测结果展示了模型在处理SQL各个关键部分和各类SQL函数(如日期函数、字符串函数等)上的能力。
| 语言 | select | where | group | order | function | total |
|---|---|---|---|---|---|---|
| Generic SQL | 91.5 | 83.7 | 80.5 | 98.2 | 96.2 | 77.3 |
Chat2DB-SQL-7B主要针对语言MySql、PostgreSQL和通用SQL进行了微调。尽管对于其他SQL语言,此模型仍可提供基本的转换能力,但在处理特定语言的特殊函数(如日期函数、字符串函数等)时,可能会出现误差。随着数据集的变化,模型的性能也可能会有所不同。
请注意,此模型主要供学术研究和学习目的使用。虽然我们努力确保模型输出的准确性,但不保证其在生产环境中的表现。使用此模型所产生的任何潜在损失,本项目及其贡献者概不负责。我们鼓励用户在使用模型时,应谨慎评估其在特定用例中的适用性。
2.3 模型推理
您可以通过transformers加载模型,参考如下样例代码段使用Chat2DB-SQL-7B模型,模型表现会随着prompt不同而有所不同,请尽量使用以下样例中的prompt范式。以下代码块中的model_path可以替换成你的本地模型路径。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
model_path = "Chat2DB/Chat2DB-SQL-7B" # 此处可换成模型的本地路径
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto",trust_remote_code=True, torch_dtype=torch.float16,use_cache=True)
pipe = pipeline( "text-generation",model=model,tokenizer=tokenizer,return_full_text=False,max_new_tokens=100)
prompt = "### Database Schema\n\n['CREATE TABLE \"stadium\" (\\n\"Stadium_ID\" int,\\n\"Location\" text,\\n\"Name\" text,\\n\"Capacity\" int,\\n\"Highest\" int,\\n\"Lowest\" int,\\n\"Average\" int,\\nPRIMARY KEY (\"Stadium_ID\")\\n);', 'CREATE TABLE \"singer\" (\\n\"Singer_ID\" int,\\n\"Name\" text,\\n\"Country\" text,\\n\"Song_Name\" text,\\n\"Song_release_year\" text,\\n\"Age\" int,\\n\"Is_male\" bool,\\nPRIMARY KEY (\"Singer_ID\")\\n);', 'CREATE TABLE \"concert\" (\\n\"concert_ID\" int,\\n\"concert_Name\" text,\\n\"Theme\" text,\\n\"Stadium_ID\" text,\\n\"Year\" text,\\nPRIMARY KEY (\"concert_ID\"),\\nFOREIGN KEY (\"Stadium_ID\") REFERENCES \"stadium\"(\"Stadium_ID\")\\n);', 'CREATE TABLE \"singer_in_concert\" (\\n\"concert_ID\" int,\\n\"Singer_ID\" text,\\nPRIMARY KEY (\"concert_ID\",\"Singer_ID\"),\\nFOREIGN KEY (\"concert_ID\") REFERENCES \"concert\"(\"concert_ID\"),\\nFOREIGN KEY (\"Singer_ID\") REFERENCES \"singer\"(\"Singer_ID\")\\n);']\n\n\n### Task \n\n基于提供的database schema信息,How many singers do we have?[SQL]\n"
response = pipe(prompt)[0]["generated_text"]
print(response)
- 硬件要求
| 模型 | 最低GPU显存(推理) | 最低GPU显存(高效参数微调) |
|---|---|---|
| Chat2DB-SQL-7B | 14GB | 20GB |
- 模型下载
- huggingface:Chat2DB-SQL-7B
- modelscope:Chat2DB-SQL-7B
3.Vanna Text2SQL优化框架
-
基于Python语言。可通过PyPi包vanna在自己项目中直接使用
-
RAG框架。很多人了解RAG最典型的应用是私有知识库问答,通过Prompt注入私有知识以提高LLM回答的准确性。但RAG本身是一种Prompt增强方案,完全可以用于其他LLM应用场景。比如之前我们介绍过的在构建Tools Agent时,利用RAG方案可以减少注入到Prompt中的APIs信息的数量,以减少上下文窗口的占用,节约Tokens。Vanna则是通过RAG方案对输入LLM的Prompt进行优化,以最大限度提高自然语言转换SQL的准确率,提高数据分析结果的可信度。
3.1 Vanna 工作原理
官方链接:https://github.com/vanna-ai/vanna
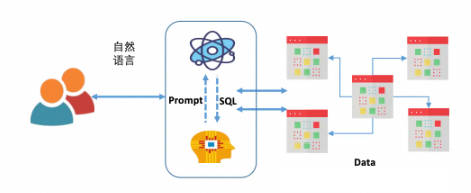
借助 LLM 实现一个最简单的、基于 Text2SQL 的数据库对话机器人本身原理是比较简单的:
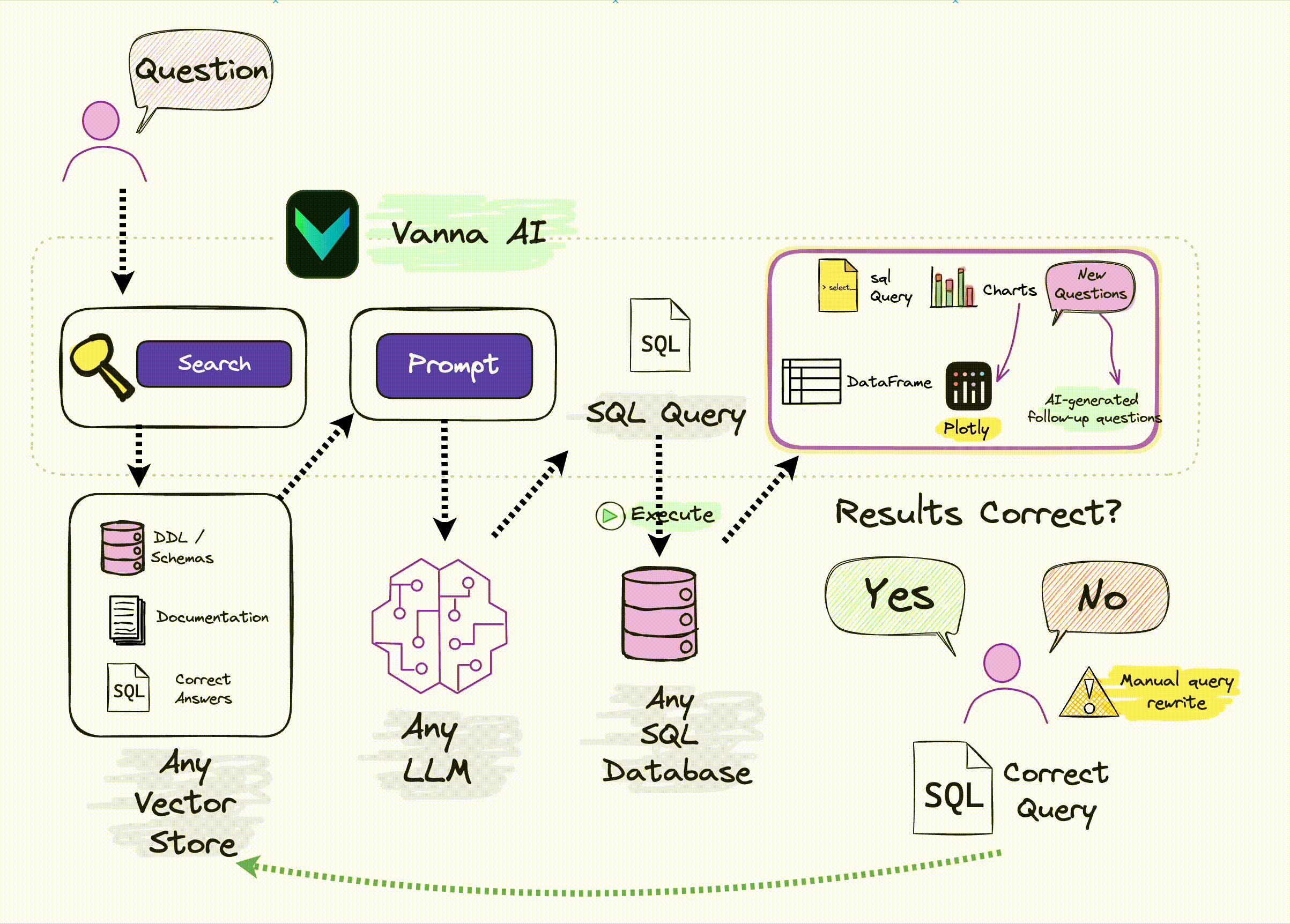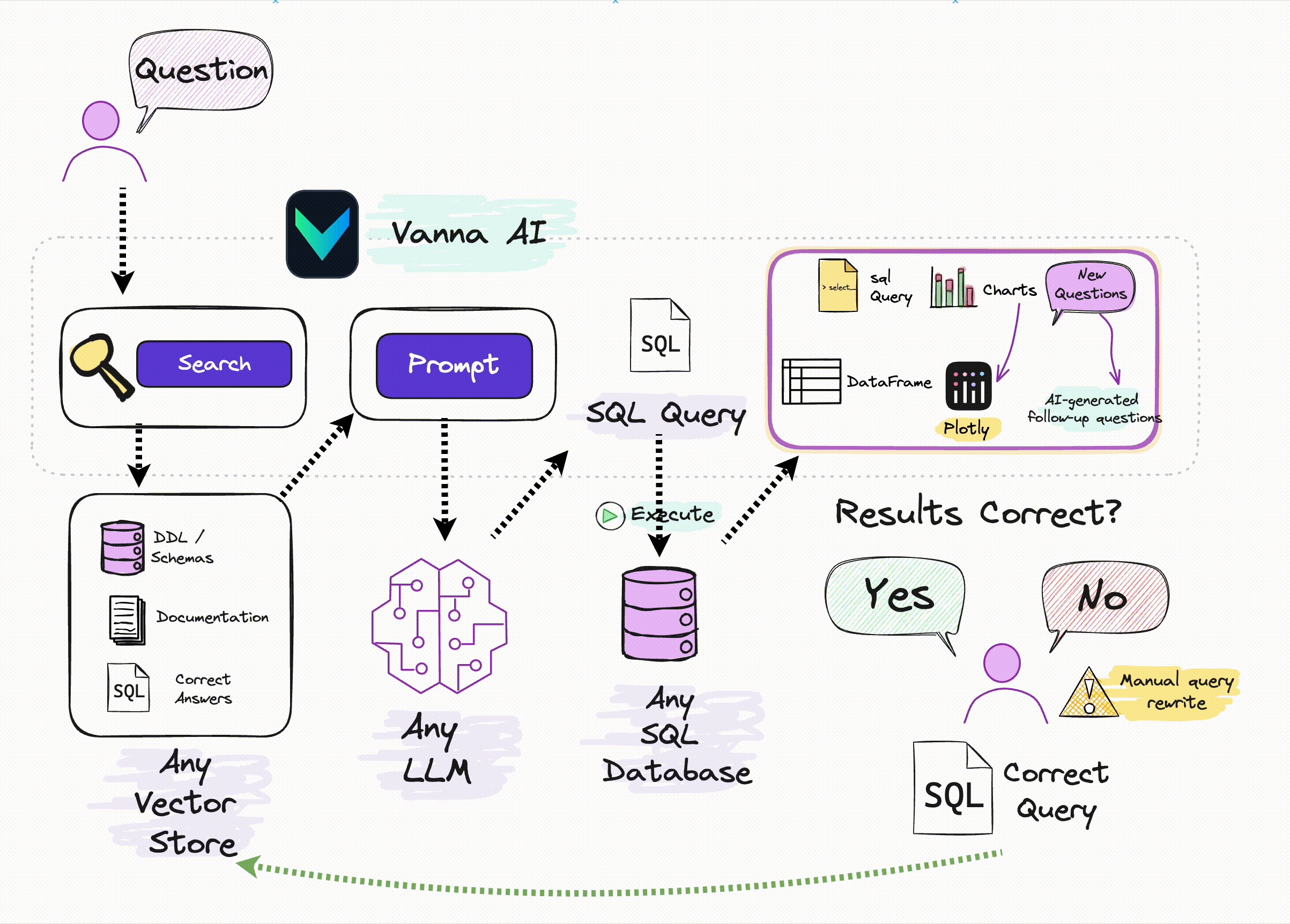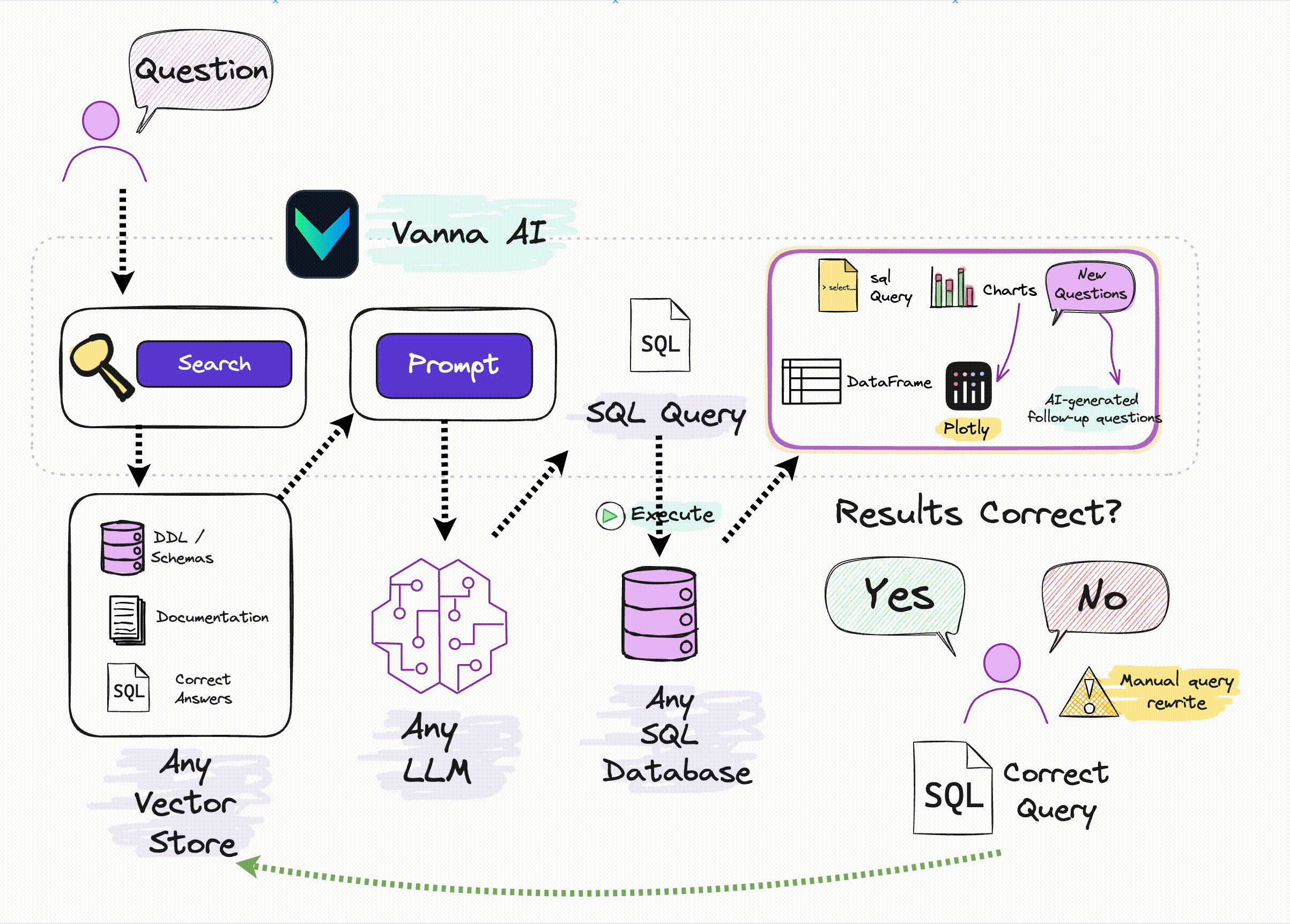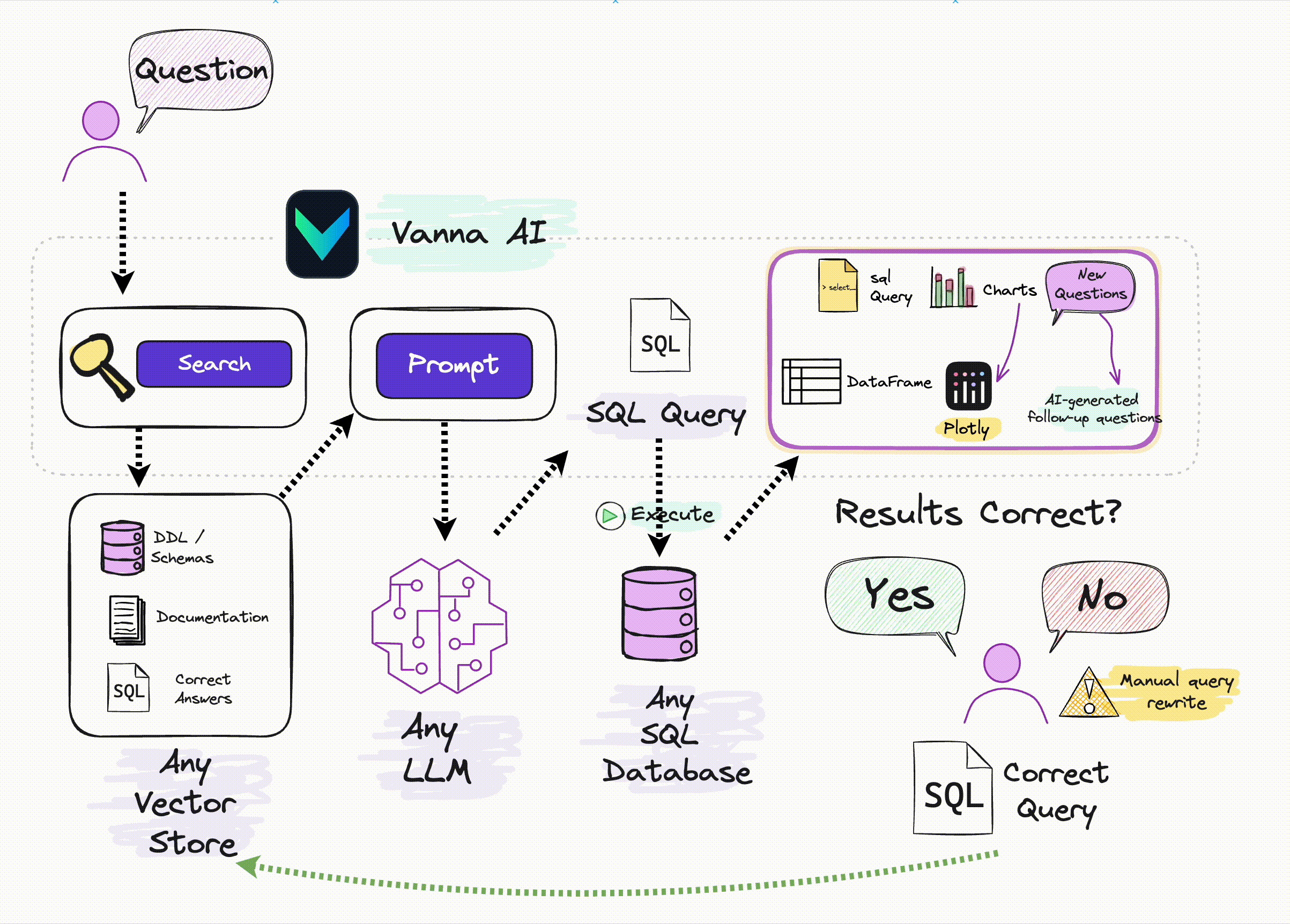
这里的关键在于:如果不在大模型层进行优化(比如针对 SQL 进行微调),那么唯一的优化手段只有 Prompt,在之前文章中提到的一些技术研究报告很多都是基于 Prompt 优化,但都相对较复杂。Vanna 则是借助了相对简单也更易理解的 RAG 方法,通过检索增强来构建 Prompt,以提高 SQL 生成的准确率:
来源:Vanna.ai 官方图片
从这张图可以了解到,Vanna 的关键原理为:
借助数据库的 DDL 语句、元数据(数据库内关于自身数据的描述信息)、相关文档说明、参考样例 SQL 等训练一个 RAG 的 “模型”(embedding + 向量库);并在收到用户自然语言描述的问题时,从 RAG 模型中通过语义检索出相关的内容,进而组装进入 Prompt,然后交给 LLM 生成 SQL。
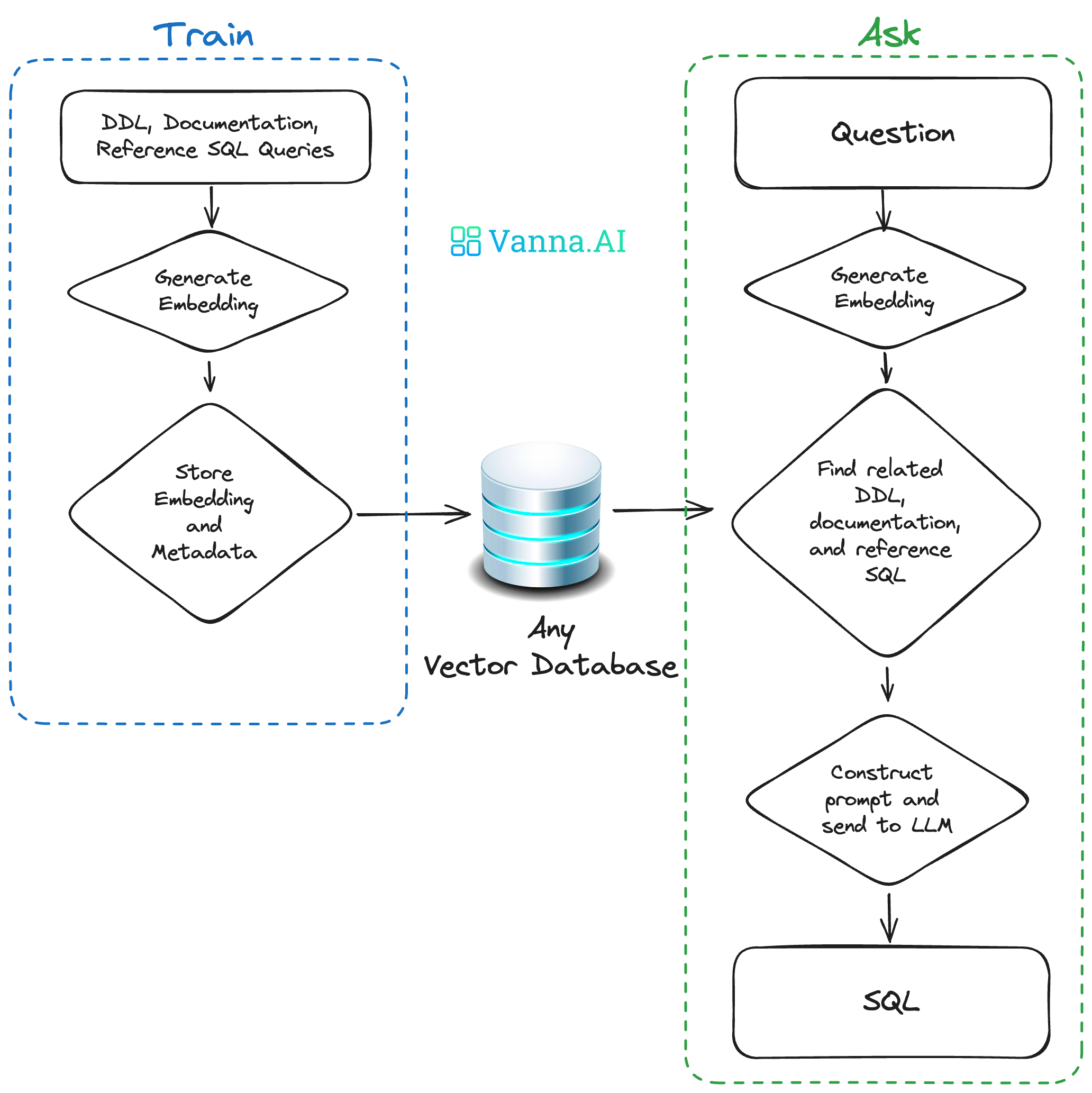
因此,使用 Vanna 的基本步骤分为两步:
第一步:在你的数据上训练一个 RAG“模型”
把 DDL/Schemas 描述、文档、参考 SQL 等交给 Vanna 训练一个用于 RAG 检索的 “模型”(向量库)。
Vanna 的 RAG 模型训练,支持以下几种方式:
1. DDL 语句
DDL 有助于 Vanna 了解你的数据库表结构信息。
vn.train(ddl="CREATE TABLE my_table (id INT, name TEXT)")
2. 文档内容
可以是你的企业、应用、数据库相关的任何文档内容,只要有助于 Vanna 正确生成 SQL 即可,比如对你行业特有名词的解释、特殊指标的计算方式等。
vn.train(documentation="Our business defines XYZ as ABC")
3. SQL 或者 SQL 问答对
即 SQL 的样例,这显然有助于大模型学习针对您数据库的知识,特别是有助于理解提出问题的上下文,可以大大提高 sql 生成正确性。
vn.train(question="What is the average age of our customers?",sql="SELECT AVG(age) FROM customers")
4. 训练计划(plan)
这是 vanna 提供的一种针对大型数据库自动训练的简易方法。借助 RDBMS 本身的数据库内元数据信息来训练 RAG model,从而了解到库内的表结构、列名、关系、备注等有用信息。
df_information_schema=vn.run_sql("SELECT * FROM INFORMATION_SCHEMA.COLUMNS")
plan=vn.get_training_plan_generic(df_information_schema)
vn.train(plan=plan)
第二步:提出 “问题”,获得回答
RAG 模型训练完成后,可以用自然语言直接提问。Vanna 会利用 RAG 与 LLM 生成 SQL,并自动运行后返回结果。
3.2 vanna 的扩展与定制化
从上述的 vanna 原理介绍可以知道,其相关的三个主要基础设施为:
-
Database,即需要进行查询的关系型数据库
-
VectorDB,即需要存放 RAG“模型” 的向量库
-
LLM,即需要使用的大语言模型,用来执行 Text2SQL 任务
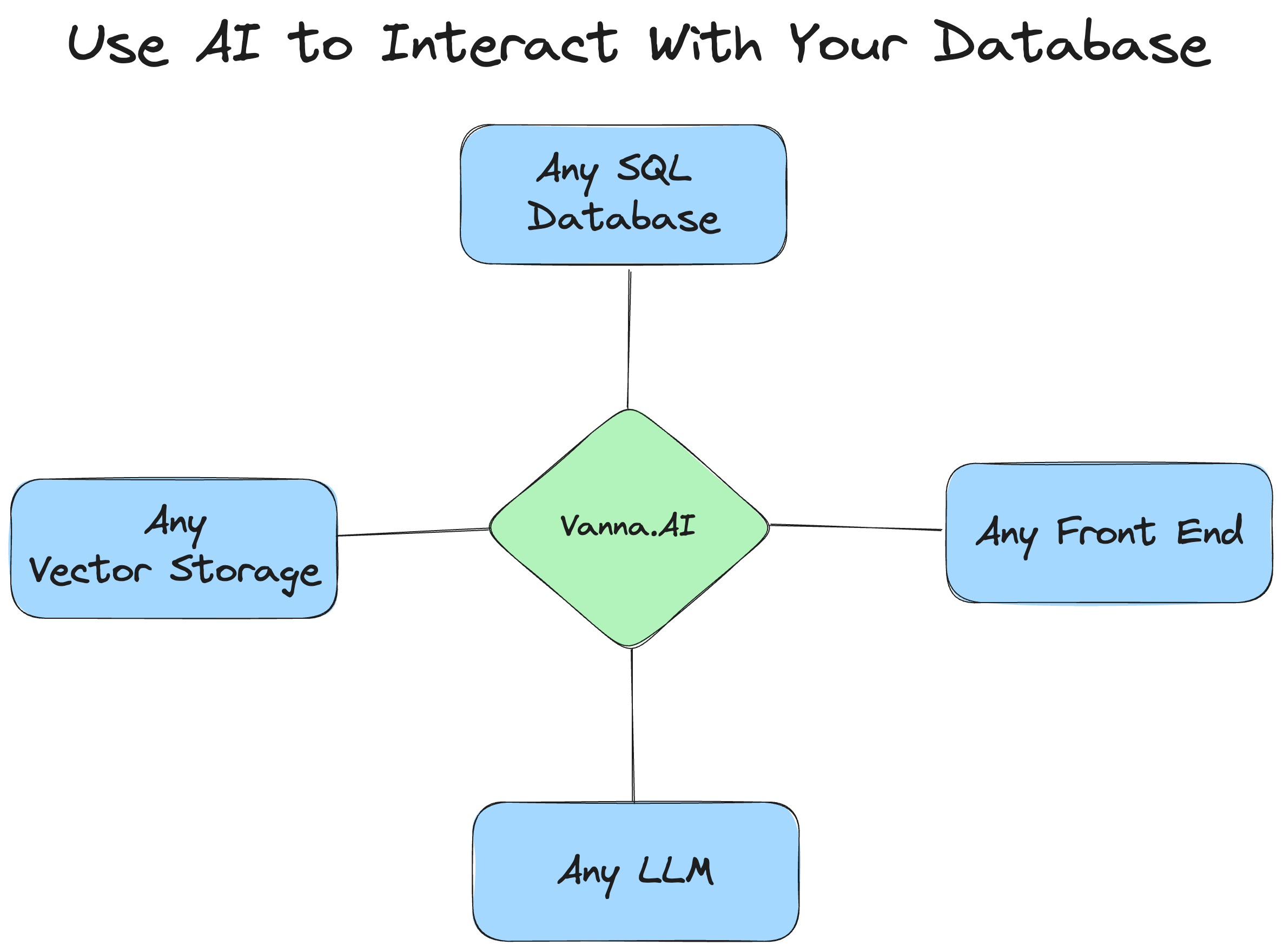
Vanna 的设计具备了很好的扩展性与个性化能力,能够支持任意数据库、向量数据库与大模型。
【自定义 LLM 与向量库】
默认情况下,Vanna 支持使用其在线 LLM 服务(对接 OpenAI)与向量库,可以无需对这两个进行任何设置,即可使用。因此使用 Vanna 最简单的原型只需要五行代码:
import vanna
from vanna.remote import VannaDefault
vn = VannaDefault(model='model_name', api_key='api_key')
vn.connect_to_sqlite('https://vanna.ai/Chinook.sqlite')
vn.ask("What are the top 10 albums by sales?")
注意使用 Vanna.AI 的在线 LLM 与向量库服务,需要首先到 https://vanna.ai/ 去申请账号,具体请参考下一部分实测。
如果需要使用自己本地的 LLM 或者向量库,比如使用自己的 OpenAI 账号与 ChromaDB 向量库,则可以扩展出自己的 Vanna 对象,并传入个性化配置即可。
from vanna.openai.openai_chat import OpenAI_Chat
from vanna.chromadb.chromadb_vector import ChromaDB_VectorStore
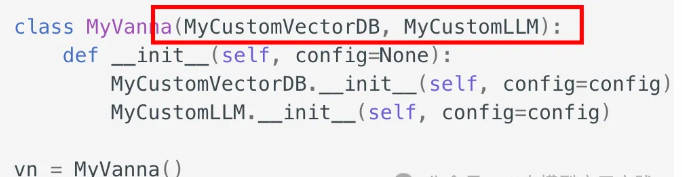
class MyVanna(ChromaDB_VectorStore, OpenAI_Chat):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
OpenAI_Chat.__init__(self, config=config)
vn = MyVanna(config={'api_key': 'sk-...', 'model': 'gpt-4-...'})
当然这里的 OpenAI_Chat 和 ChromaDB_VectorStore 是 Vanna 已经内置支持的 LLM 和 VectorDB。如果你需要支持没有内置支持的 LLM 和 vectorDB,则需要首先扩展出自己的 LLM 类与 VectorDB 类,实现必要的方法(具体可参考官方文档),然后再扩展出自己的 Vanna 对象:
【自定义关系型数据库】
Vanna 默认支持 Postgres,SQL Server,Duck DB,SQLite 等关系型数据库,可直接对这一类数据库进行自动访问,实现数据对话机器人。但如果需要连接自己企业的其他数据库,比如企业内部的 Mysql 或者 Oracle,自需要定义一个个性化的 run_sql 方法,并返回一个 Pandas Dataframe 即可。具体可参考下方的实测代码。
- 参考链接
Vanna:10分钟快速构建基于大模型与RAG的SQL数据库对话机器人 :https://mp.weixin.qq.com/s/-dQYHcK_Ji_jNydgBJxEGw
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号