解读未知:文本识别算法的突破与实际应用
解读未知:文本识别算法的突破与实际应用
1.文本识别算法理论
- 背景介绍
文本识别是OCR(Optical Character Recognition)的一个子任务,其任务为识别一个固定区域的的文本内容。在OCR的两阶段方法里,它接在文本检测后面,将图像信息转换为文字信息。
具体地,模型输入一张定位好的文本行,由模型预测出图片中的文字内容和置信度,可视化结果如下图所示:


文本识别的应用场景很多,有文档识别、路标识别、车牌识别、工业编号识别等等,根据实际场景可以把文本识别任务分为两个大类:规则文本识别和不规则文本识别。
-
规则文本识别:主要指印刷字体、扫描文本等,认为文本大致处在水平线位置
-
不规则文本识别: 往往出现在自然场景中,且由于文本曲率、方向、变形等方面差异巨大,文字往往不在水平位置,存在弯曲、遮挡、模糊等问题。
下图展示的是 IC15 和 IC13 的数据样式,它们分别代表了不规则文本和规则文本。可以看出不规则文本往往存在扭曲、模糊、字体差异大等问题,更贴近真实场景,也存在更大的挑战性。
因此目前各大算法都试图在不规则数据集上获得更高的指标。


不同的识别算法在对比能力时,往往也在这两大类公开数据集上比较。对比多个维度上的效果,目前较为通用的英文评估集合分类如下:
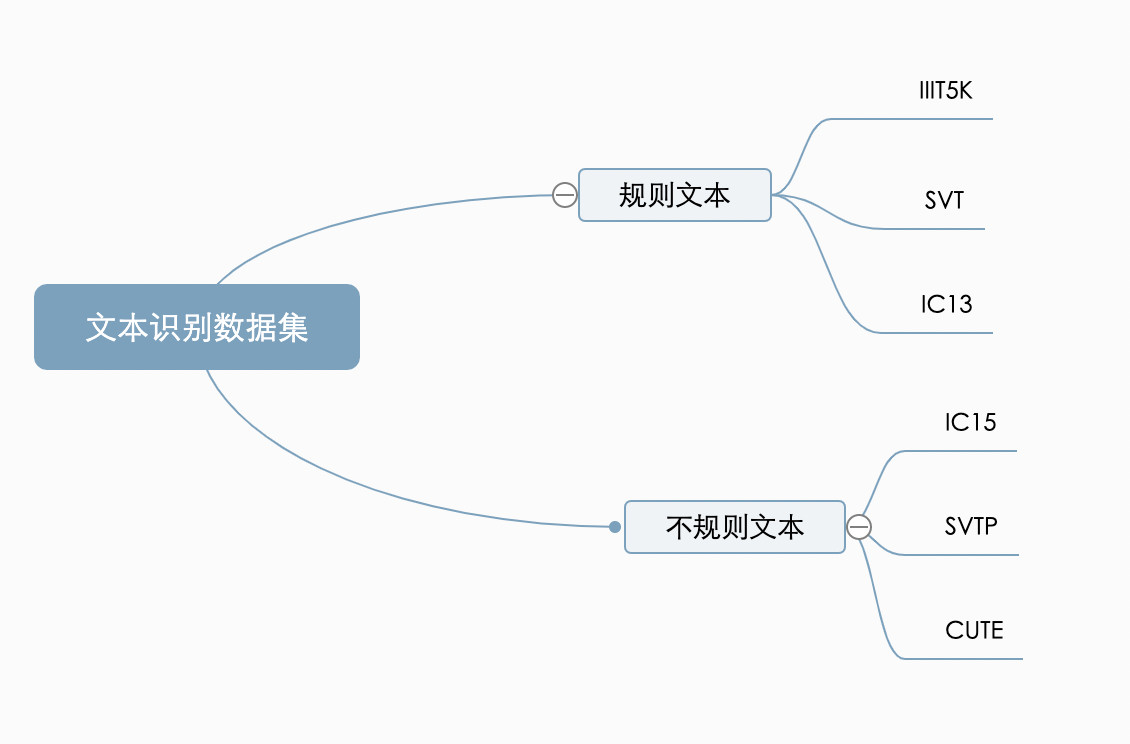
1.1 文本识别算法分类
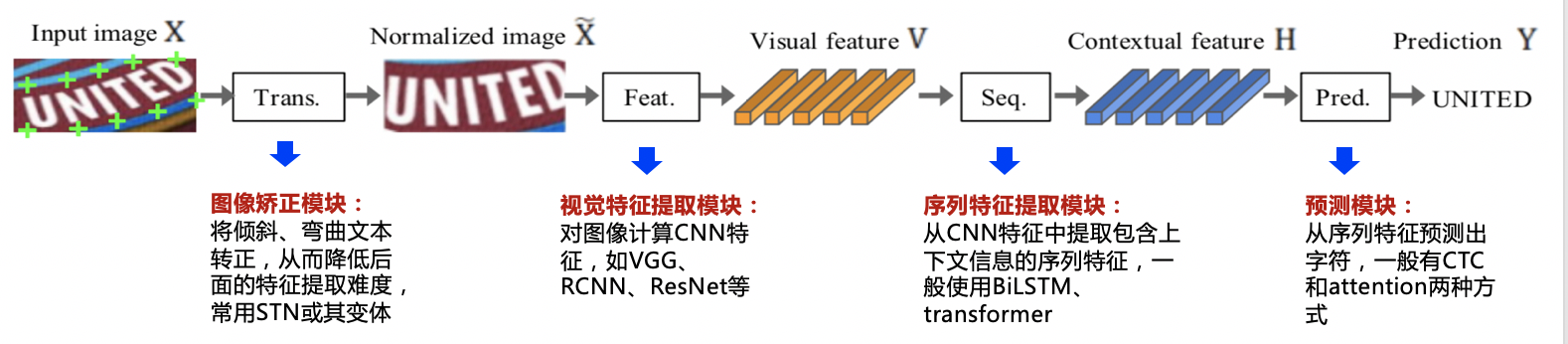
在传统的文本识别方法中,任务分为3个步骤,即图像预处理、字符分割和字符识别。需要对特定场景进行建模,一旦场景变化就会失效。面对复杂的文字背景和场景变动,基于深度学习的方法具有更优的表现。
多数现有的识别算法可用如下统一框架表示,算法流程被划分为4个阶段:
我们整理了主流的算法类别和主要论文,参考下表:
| 算法类别 | 主要思路 | 主要论文 |
|---|---|---|
| 传统算法 | 滑动窗口、字符提取、动态规划 | - |
| ctc | 基于ctc的方法,序列不对齐,更快速识别 | CRNN, Rosetta |
| Attention | 基于attention的方法,应用于非常规文本 | RARE, DAN, PREN |
| Transformer | 基于transformer的方法 | SRN, NRTR, Master, ABINet |
| 校正 | 校正模块学习文本边界并校正成水平方向 | RARE, ASTER, SAR |
| 分割 | 基于分割的方法,提取字符位置再做分类 | Text Scanner, Mask TextSpotter |
1.1.1 规则文本识别
文本识别的主流算法有两种,分别是基于 CTC (Conectionist Temporal Classification) 的算法和 Sequence2Sequence 算法,区别主要在解码阶段。
基于 CTC 的算法是将编码产生的序列接入 CTC 进行解码;基于 Sequence2Sequence 的方法则是把序列接入循环神经网络(Recurrent Neural Network, RNN)模块进行循环解码,两种方式都验证有效也是主流的两大做法。
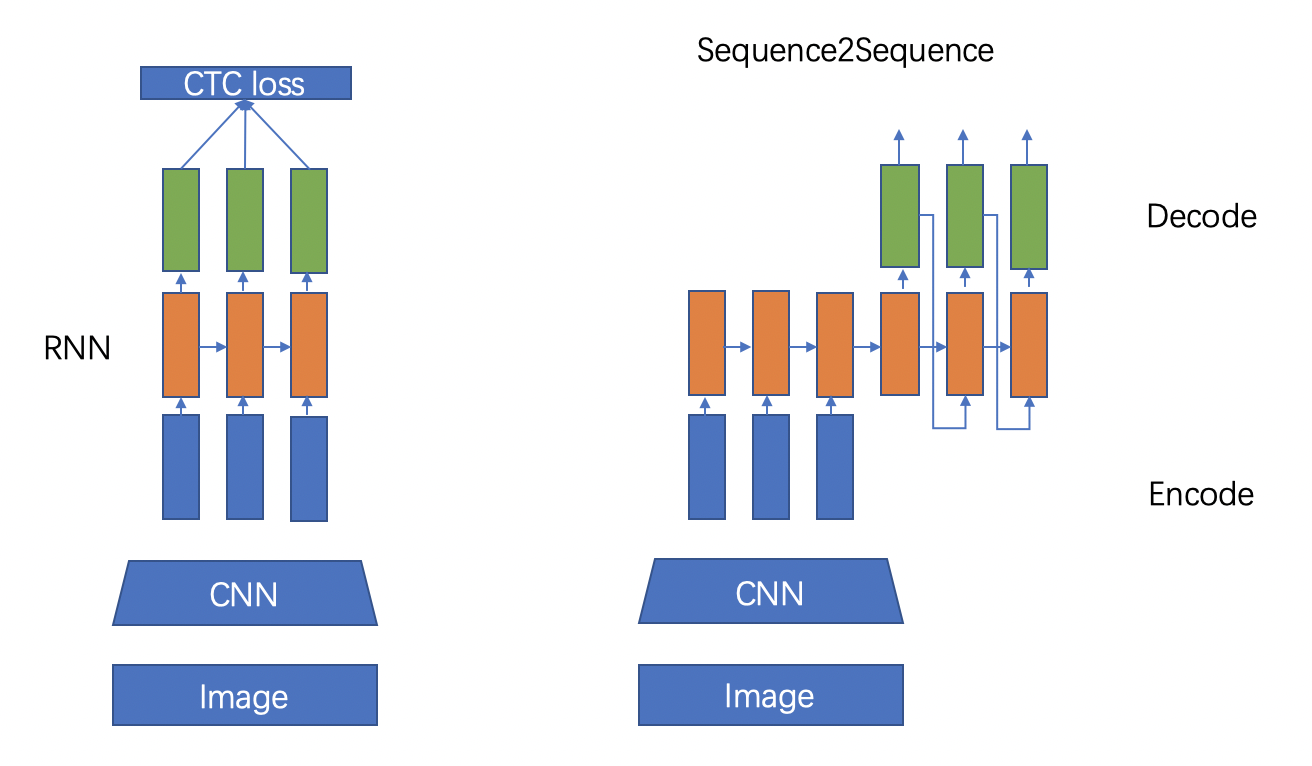
基于CTC的算法
基于 CTC 最典型的算法是CRNN (Convolutional Recurrent Neural Network)[1],它的特征提取部分使用主流的卷积结构,常用的有ResNet、MobileNet、VGG等。由于文本识别任务的特殊性,输入数据中存在大量的上下文信息,卷积神经网络的卷积核特性使其更关注于局部信息,缺乏长依赖的建模能力,因此仅使用卷积网络很难挖掘到文本之间的上下文联系。为了解决这一问题,CRNN文本识别算法引入了双向 LSTM(Long Short-Term Memory) 用来增强上下文建模,通过实验证明双向LSTM模块可以有效的提取出图片中的上下文信息。最终将输出的特征序列输入到CTC模块,直接解码序列结果。该结构被验证有效,并广泛应用在文本识别任务中。Rosetta[2]是FaceBook提出的识别网络,由全卷积模型和CTC组成。Gao Y[3]等人使用CNN卷积替代LSTM,参数更少,性能提升精度持平。
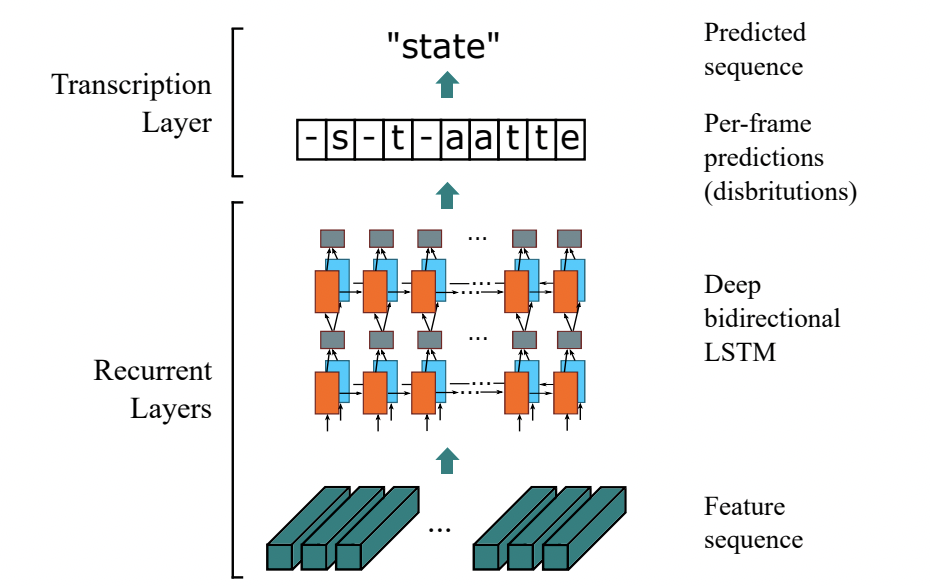
Sequence2Sequence 算法
Sequence2Sequence 算法是由编码器 Encoder 把所有的输入序列都编码成一个统一的语义向量,然后再由解码器Decoder解码。在解码器Decoder解码的过程中,不断地将前一个时刻的输出作为后一个时刻的输入,循环解码,直到输出停止符为止。一般编码器是一个RNN,对于每个输入的词,编码器输出向量和隐藏状态,并将隐藏状态用于下一个输入的单词,循环得到语义向量;解码器是另一个RNN,它接收编码器输出向量并输出一系列字以创建转换。受到 Sequence2Sequence 在翻译领域的启发, Shi[4]提出了一种基于注意的编解码框架来识别文本,通过这种方式,rnn能够从训练数据中学习隐藏在字符串中的字符级语言模型。
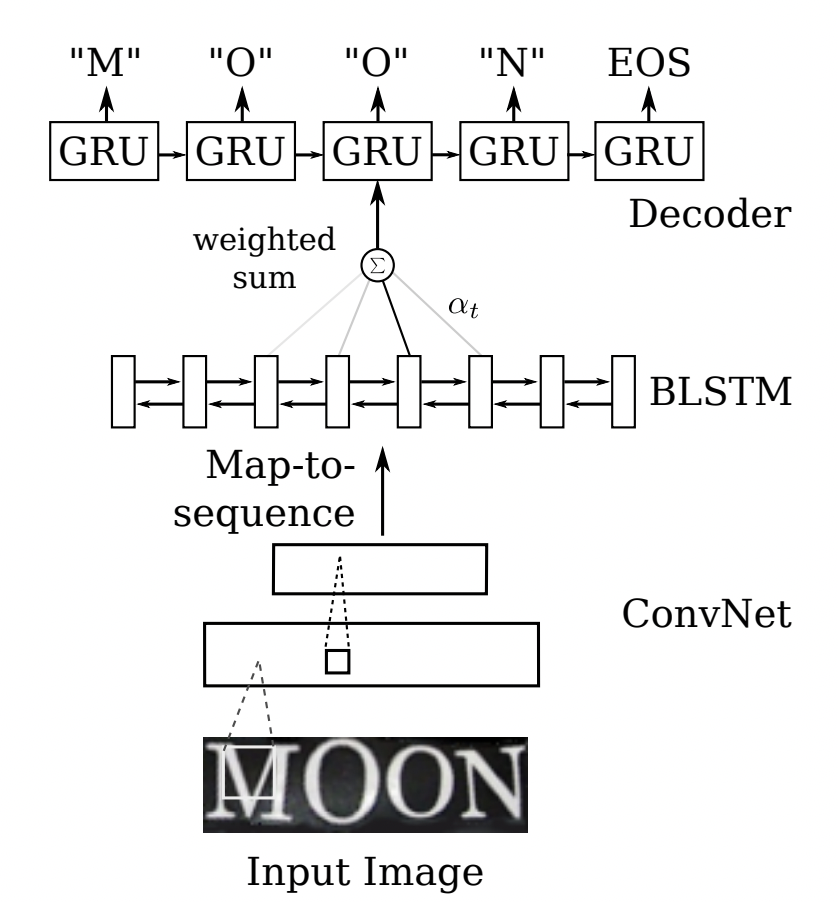
以上两个算法在规则文本上都有很不错的效果,但由于网络设计的局限性,这类方法很难解决弯曲和旋转的不规则文本识别任务。为了解决这类问题,部分算法研究人员在以上两类算法的基础上提出了一系列改进算法。
1.1.2 不规则文本识别
- 不规则文本识别算法可以被分为4大类:基于校正的方法;基于 Attention 的方法;基于分割的方法;基于 Transformer 的方法。
基于校正的方法
基于校正的方法利用一些视觉变换模块,将非规则的文本尽量转换为规则文本,然后使用常规方法进行识别。
RARE[4]模型首先提出了对不规则文本的校正方案,整个网络分为两个主要部分:一个空间变换网络STN(Spatial Transformer Network) 和一个基于Sequence2Squence的识别网络。其中STN就是校正模块,不规则文本图像进入STN,通过TPS(Thin-Plate-Spline)变换成一个水平方向的图像,该变换可以一定程度上校正弯曲、透射变换的文本,校正后送入序列识别网络进行解码。
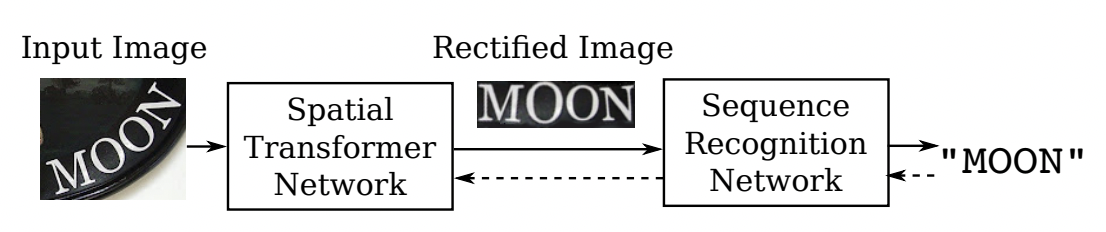
RARE论文指出,该方法在不规则文本数据集上有较大的优势,特别比较了CUTE80和SVTP这两个数据集,相较CRNN高出5个百分点以上,证明了校正模块的有效性。基于此[6]同样结合了空间变换网络(STN)和基于注意的序列识别网络的文本识别系统。
基于校正的方法有较好的迁移性,除了RARE这类基于Attention的方法外,STAR-Net[5]将校正模块应用到基于CTC的算法上,相比传统CRNN也有很好的提升。
基于Attention的方法
基于 Attention 的方法主要关注的是序列之间各部分的相关性,该方法最早在机器翻译领域提出,认为在文本翻译的过程中当前词的结果主要由某几个单词影响的,因此需要给有决定性的单词更大的权重。在文本识别领域也是如此,将编码后的序列解码时,每一步都选择恰当的context来生成下一个状态,这样有利于得到更准确的结果。
R^2AM [7] 首次将 Attention 引入文本识别领域,该模型首先将输入图像通过递归卷积层提取编码后的图像特征,然后利用隐式学习到的字符级语言统计信息通过递归神经网络解码输出字符。在解码过程中引入了Attention 机制实现了软特征选择,以更好地利用图像特征,这一有选择性的处理方式更符合人类的直觉。
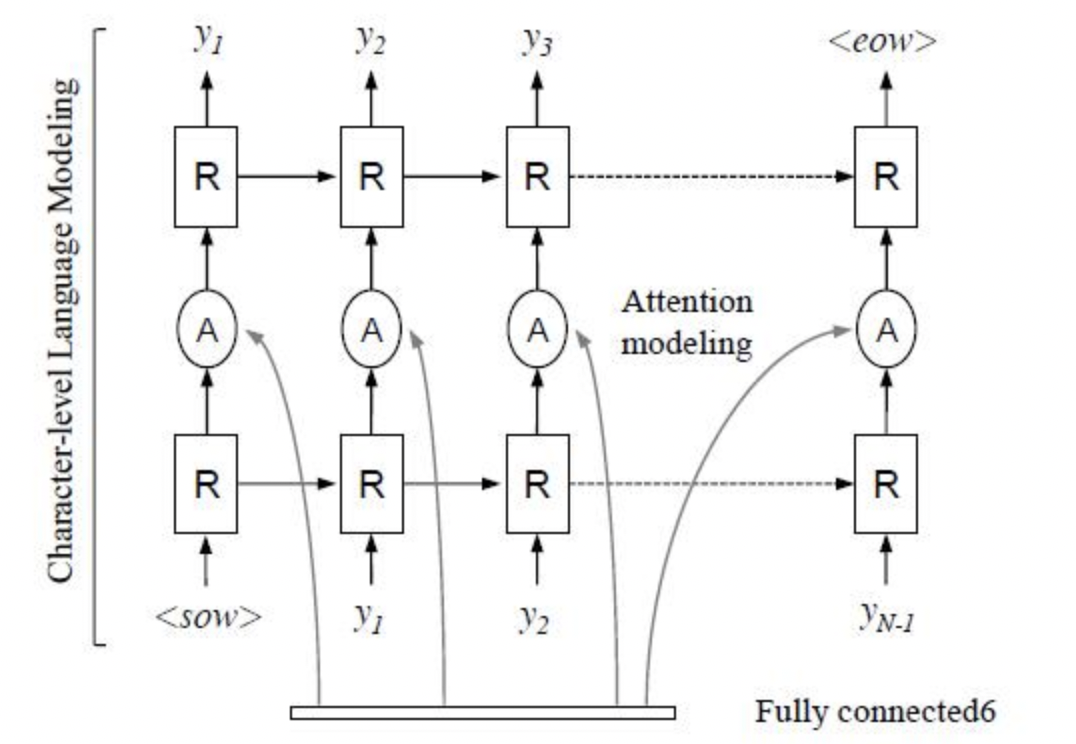
后续有大量算法在Attention领域进行探索和更新,例如SAR[8]将1D attention拓展到2D attention上,校正模块提到的RARE也是基于Attention的方法。实验证明基于Attention的方法相比CTC的方法有很好的精度提升。

基于分割的方法
基于分割的方法是将文本行的各字符作为独立个体,相比与对整个文本行做矫正后识别,识别分割出的单个字符更加容易。它试图从输入的文本图像中定位每个字符的位置,并应用字符分类器来获得这些识别结果,将复杂的全局问题简化成了局部问题解决,在不规则文本场景下有比较不错的效果。然而这种方法需要字符级别的标注,数据获取上存在一定的难度。Lyu[9]等人提出了一种用于单词识别的实例分词模型,该模型在其识别部分使用了基于 FCN(Fully Convolutional Network) 的方法。[10]从二维角度考虑文本识别问题,设计了一个字符注意FCN来解决文本识别问题,当文本弯曲或严重扭曲时,该方法对规则文本和非规则文本都具有较优的定位结果。

基于Transformer的方法
随着 Transformer 的快速发展,分类和检测领域都验证了 Transformer 在视觉任务中的有效性。如规则文本识别部分所说,CNN在长依赖建模上存在局限性,Transformer 结构恰好解决了这一问题,它可以在特征提取器中关注全局信息,并且可以替换额外的上下文建模模块(LSTM)。
一部分文本识别算法使用 Transformer 的 Encoder 结构和卷积共同提取序列特征,Encoder 由多个 MultiHeadAttentionLayer 和 Positionwise Feedforward Layer 堆叠而成的block组成。MulitHeadAttention 中的 self-attention 利用矩阵乘法模拟了RNN的时序计算,打破了RNN中时序长时依赖的障碍。也有一部分算法使用 Transformer 的 Decoder 模块解码,相比传统RNN可获得更强的语义信息,同时并行计算具有更高的效率。
SRN[11] 算法将Transformer的Encoder模块接在ResNet50后,增强了2D视觉特征。并提出了一个并行注意力模块,将读取顺序用作查询,使得计算与时间无关,最终并行输出所有时间步长的对齐视觉特征。此外SRN还利用Transformer的Eecoder作为语义模块,将图片的视觉信息和语义信息做融合,在遮挡、模糊等不规则文本上有较大的收益。
NRTR[12] 使用了完整的Transformer结构对输入图片进行编码和解码,只使用了简单的几个卷积层做高层特征提取,在文本识别上验证了Transformer结构的有效性。
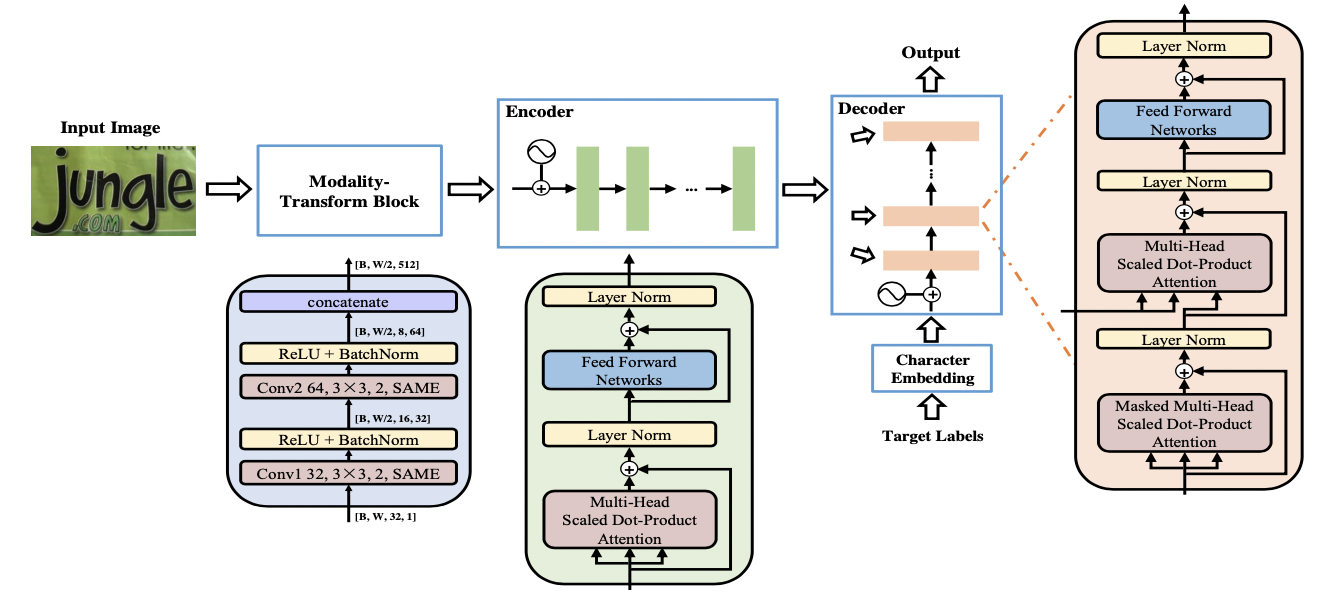
SRACN[13]使用Transformer的解码器替换LSTM,再一次验证了并行训练的高效性和精度优势。
1.2 小结
本节主要介绍了文本识别相关的理论知识和主流算法,包括基于CTC的方法、基于Sequence2Sequence的方法以及基于分割的方法,并分别列举了经典论文的思路和贡献。下一节将基于CRNN算法进行实践课程讲解,从组网到优化完成整个训练过程,
2.文本识别实战
2.1. 数据准备
- 准备数据集
PaddleOCR 支持两种数据格式:
lmdb用于训练以lmdb格式存储的数据集(LMDBDataSet);通用数据用于训练以文本文件存储的数据集(SimpleDataSet);
训练数据的默认存储路径是 PaddleOCR/train_data,如果您的磁盘上已有数据集,只需创建软链接至数据集目录:
#linux and mac os
ln -sf <path/to/dataset> <path/to/paddle_ocr>/train_data/dataset
#windows
mklink /d <path/to/paddle_ocr>/train_data/dataset <path/to/dataset>
- 自定义数据集
下面以通用数据集为例, 介绍如何准备数据集:
- 训练集
建议将训练图片放入同一个文件夹,并用一个txt文件(rec_gt_train.txt)记录图片路径和标签,txt文件里的内容如下:
注意: txt文件中默认请将图片路径和图片标签用 \t 分割,如用其他方式分割将造成训练报错。
" 图像文件名 图像标注信息 "
train_data/rec/train/word_001.jpg 简单可依赖
train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
...
最终训练集应有如下文件结构:
|-train_data
|-rec
|- rec_gt_train.txt
|- train
|- word_001.png
|- word_002.jpg
|- word_003.jpg
| ...
除上述单张图像为一行格式之外,PaddleOCR也支持对离线增广后的数据进行训练,为了防止相同样本在同一个batch中被多次采样,我们可以将相同标签对应的图片路径写在一行中,以列表的形式给出,在训练中,PaddleOCR会随机选择列表中的一张图片进行训练。对应地,标注文件的格式如下。
["11.jpg", "12.jpg"] 简单可依赖
["21.jpg", "22.jpg", "23.jpg"] 用科技让复杂的世界更简单
3.jpg ocr
上述示例标注文件中,"11.jpg"和"12.jpg"的标签相同,都是简单可依赖,在训练的时候,对于该行标注,会随机选择其中的一张图片进行训练。
- 验证集
同训练集类似,验证集也需要提供一个包含所有图片的文件夹(test)和一个rec_gt_test.txt,验证集的结构如下所示:
|-train_data
|-rec
|- rec_gt_test.txt
|- test
|- word_001.jpg
|- word_002.jpg
|- word_003.jpg
| ...
- 数据下载
- ICDAR2015
若您本地没有数据集,可以在官网下载 ICDAR2015 数据,用于快速验证。也可以参考DTRB ,下载 benchmark 所需的lmdb格式数据集。
如果你使用的是icdar2015的公开数据集,PaddleOCR 提供了一份用于训练 ICDAR2015 数据集的标签文件,通过以下方式下载:
#训练集标签
wget -P ./train_data/ic15_data https://paddleocr.bj.bcebos.com/dataset/rec_gt_train.txt
#测试集标签
wget -P ./train_data/ic15_data https://paddleocr.bj.bcebos.com/dataset/rec_gt_test.txt
PaddleOCR 也提供了数据格式转换脚本,可以将ICDAR官网 label 转换为PaddleOCR支持的数据格式。 数据转换工具在 ppocr/utils/gen_label.py, 这里以训练集为例:
#将官网下载的标签文件转换为 rec_gt_label.txt
python gen_label.py --mode="rec" --input_path="{path/of/origin/label}" --output_label="rec_gt_label.txt"
数据样式格式如下,(a)为原始图片,(b)为每张图片对应的 Ground Truth 文本文件:

- 多语言数据集
多语言模型的训练数据集均为100w的合成数据,使用了开源合成工具 text_renderer ,少量的字体可以通过下面两种方式下载。
-
百度网盘 提取码:frgi
-
字典
最后需要提供一个字典({word_dict_name}.txt),使模型在训练时,可以将所有出现的字符映射为字典的索引。
因此字典需要包含所有希望被正确识别的字符,{word_dict_name}.txt需要写成如下格式,并以 utf-8 编码格式保存:
l
d
a
d
r
n
word_dict.txt 每行有一个单字,将字符与数字索引映射在一起,“and” 将被映射成 [2 5 1]
- 内置字典
PaddleOCR内置了一部分字典,可以按需使用。
ppocr/utils/ppocr_keys_v1.txt 是一个包含6623个字符的中文字典
ppocr/utils/ic15_dict.txt 是一个包含36个字符的英文字典
ppocr/utils/dict/french_dict.txt 是一个包含118个字符的法文字典
ppocr/utils/dict/japan_dict.txt 是一个包含4399个字符的日文字典
ppocr/utils/dict/korean_dict.txt 是一个包含3636个字符的韩文字典
ppocr/utils/dict/german_dict.txt 是一个包含131个字符的德文字典
ppocr/utils/en_dict.txt 是一个包含96个字符的英文字典
目前的多语言模型仍处在demo阶段,会持续优化模型并补充语种,非常欢迎您为我们提供其他语言的字典和字体,
如您愿意可将字典文件提交至 dict,我们会在Repo中感谢您。
- 自定义字典
如需自定义dic文件,请在 configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml 中添加 character_dict_path 字段, 指向您的字典路径。
- 添加空格类别
如果希望支持识别"空格"类别, 请将yml文件中的 use_space_char 字段设置为 True。
- 数据增强
PaddleOCR提供了多种数据增强方式,默认配置文件中已经添加了数据增广。
默认的扰动方式有:颜色空间转换(cvtColor)、模糊(blur)、抖动(jitter)、噪声(Gasuss noise)、随机切割(random crop)、透视(perspective)、颜色反转(reverse)、TIA数据增广。
训练过程中每种扰动方式以40%的概率被选择,具体代码实现请参考:rec_img_aug.py
由于OpenCV的兼容性问题,扰动操作暂时只支持Linux
2.2 开始训练
PaddleOCR提供了训练脚本、评估脚本和预测脚本,本节将以 PP-OCRv3 英文识别模型为例:
- 启动训练
首先下载pretrain model,您可以下载训练好的模型在 icdar2015 数据上进行finetune
cd PaddleOCR/
#下载英文PP-OCRv3的预训练模型
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_train.tar
#解压模型参数
cd pretrain_models
tar -xf en_PP-OCRv3_rec_train.tar && rm -rf en_PP-OCRv3_rec_train.tar
开始训练:
如果您安装的是cpu版本,请将配置文件中的 use_gpu 字段修改为false
#GPU训练 支持单卡,多卡训练
#训练icdar15英文数据 训练日志会自动保存为 "{save_model_dir}" 下的train.log
#单卡训练(训练周期长,不建议)
python3 tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy
#多卡训练,通过--gpus参数指定卡号
python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy
正常启动训练后,会看到以下log输出:
[2022/02/22 07:58:05] root INFO: epoch: [1/800], iter: 10, lr: 0.000000, loss: 0.754281, acc: 0.000000, norm_edit_dis: 0.000008, reader_cost: 0.55541 s, batch_cost: 0.91654 s, samples: 1408, ips: 153.62133
[2022/02/22 07:58:13] root INFO: epoch: [1/800], iter: 20, lr: 0.000001, loss: 0.924677, acc: 0.000000, norm_edit_dis: 0.000008, reader_cost: 0.00236 s, batch_cost: 0.28528 s, samples: 1280, ips: 448.68599
[2022/02/22 07:58:23] root INFO: epoch: [1/800], iter: 30, lr: 0.000002, loss: 0.967231, acc: 0.000000, norm_edit_dis: 0.000008, reader_cost: 0.14527 s, batch_cost: 0.42714 s, samples: 1280, ips: 299.66507
[2022/02/22 07:58:31] root INFO: epoch: [1/800], iter: 40, lr: 0.000003, loss: 0.895318, acc: 0.000000, norm_edit_dis: 0.000008, reader_cost: 0.00173 s, batch_cost: 0.27719 s, samples: 1280, ips: 461.77252
log 中自动打印如下信息:
| 字段 | 含义 |
|---|---|
| epoch | 当前迭代轮次 |
| iter | 当前迭代次数 |
| lr | 当前学习率 |
| loss | 当前损失函数 |
| acc | 当前batch的准确率 |
| norm_edit_dis | 当前 batch 的编辑距离 |
| reader_cost | 当前 batch 数据处理耗时 |
| batch_cost | 当前 batch 总耗时 |
| samples | 当前 batch 内的样本数 |
| ips | 每秒处理图片的数量 |
PaddleOCR支持训练和评估交替进行, 可以在 configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml 中修改 eval_batch_step 设置评估频率,默认每500个iter评估一次。评估过程中默认将最佳acc模型,保存为 output/en_PP-OCRv3_rec/best_accuracy 。
如果验证集很大,测试将会比较耗时,建议减少评估次数,或训练完再进行评估。
提示: 可通过 -c 参数选择 configs/rec/ 路径下的多种模型配置进行训练,PaddleOCR支持的识别算法可以参考前沿算法列表:
训练中文数据,推荐使用ch_PP-OCRv3_rec_distillation.yml,如您希望尝试其他算法在中文数据集上的效果,请参考下列说明修改配置文件:
以 ch_PP-OCRv3_rec_distillation.yml 为例:
Global:
...
#添加自定义字典,如修改字典请将路径指向新字典
character_dict_path: ppocr/utils/ppocr_keys_v1.txt
...
#识别空格
use_space_char: True
Optimizer:
...
#添加学习率衰减策略
lr:
name: Cosine
learning_rate: 0.001
...
...
Train:
dataset:
#数据集格式,支持LMDBDataSet以及SimpleDataSet
name: SimpleDataSet
#数据集路径
data_dir: ./train_data/
# 训练集标签文件
label_file_list: ["./train_data/train_list.txt"]
transforms:
...
- RecResizeImg:
# 修改 image_shape 以适应长文本
image_shape: [3, 48, 320]
...
loader:
...
# 单卡训练的batch_size
batch_size_per_card: 256
...
Eval:
dataset:
#数据集格式,支持LMDBDataSet以及SimpleDataSet
name: SimpleDataSet
#数据集路径
data_dir: ./train_data
# 验证集标签文件
label_file_list: ["./train_data/val_list.txt"]
transforms:
...
- RecResizeImg:
# 修改 image_shape 以适应长文本
image_shape: [3, 48, 320]
...
loader:
# 单卡验证的batch_size
batch_size_per_card: 256
...
注意,预测/评估时的配置文件请务必与训练一致。
2.2. 断点训练
如果训练程序中断,如果希望加载训练中断的模型从而恢复训练,可以通过指定Global.checkpoints指定要加载的模型路径:
python3 tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.checkpoints=./your/trained/model
注意:Global.checkpoints的优先级高于Global.pretrained_model的优先级,即同时指定两个参数时,优先加载Global.checkpoints指定的模型,如果Global.checkpoints指定的模型路径有误,会加载Global.pretrained_model指定的模型。
2.3. 更换Backbone 训练
PaddleOCR将网络划分为四部分,分别在ppocr/modeling下。 进入网络的数据将按照顺序(transforms->backbones->necks->heads)依次通过这四个部分。
├── architectures # 网络的组网代码
├── transforms # 网络的图像变换模块
├── backbones # 网络的特征提取模块
├── necks # 网络的特征增强模块
└── heads # 网络的输出模块
如果要更换的Backbone 在PaddleOCR中有对应实现,直接修改配置yml文件中Backbone部分的参数即可。
如果要使用新的Backbone,更换backbones的例子如下:
- 在 ppocr/modeling/backbones 文件夹下新建文件,如my_backbone.py。
- 在 my_backbone.py 文件内添加相关代码,示例代码如下:
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
class MyBackbone(nn.Layer):
def __init__(self, *args, **kwargs):
super(MyBackbone, self).__init__()
# your init code
self.conv = nn.xxxx
def forward(self, inputs):
# your network forward
y = self.conv(inputs)
return y
- 在 ppocr/modeling/backbones/_init_.py文件内导入添加的
MyBackbone模块,然后修改配置文件中Backbone进行配置即可使用,格式如下:
Backbone:
name: MyBackbone
args1: args1
注意:如果要更换网络的其他模块,可以参考文档。
2.4. 混合精度训练
如果您想进一步加快训练速度,可以使用自动混合精度训练, 以单机单卡为例,命令如下:
python3 tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml \
-o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy \
Global.use_amp=True Global.scale_loss=1024.0 Global.use_dynamic_loss_scaling=True
2.5. 分布式训练
多机多卡训练时,通过 --ips 参数设置使用的机器IP地址,通过 --gpus 参数设置使用的GPU ID:
python3 -m paddle.distributed.launch --ips="xx.xx.xx.xx,xx.xx.xx.xx" --gpus '0,1,2,3' tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml \
-o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy
注意: (1)采用多机多卡训练时,需要替换上面命令中的ips值为您机器的地址,机器之间需要能够相互ping通;(2)训练时需要在多个机器上分别启动命令。查看机器ip地址的命令为ifconfig;(3)更多关于分布式训练的性能优势等信息,请参考:分布式训练教程。
2.6. 知识蒸馏训练
PaddleOCR支持了基于知识蒸馏的文本识别模型训练过程,更多内容可以参考知识蒸馏说明文档。
2.7. 多语言模型训练
PaddleOCR目前已支持80种(除中文外)语种识别,configs/rec/multi_languages 路径下提供了一个多语言的配置文件模版: rec_multi_language_lite_train.yml。
按语系划分,目前PaddleOCR支持的语种有:
| 配置文件 | 算法名称 | backbone | trans | seq | pred | language |
|---|---|---|---|---|---|---|
| rec_chinese_cht_lite_train.yml | CRNN | Mobilenet_v3 small 0.5 | None | BiLSTM | ctc | 中文繁体 |
| rec_en_lite_train.yml | CRNN | Mobilenet_v3 small 0.5 | None | BiLSTM | ctc | 英语(区分大小写) |
| rec_french_lite_train.yml | CRNN | Mobilenet_v3 small 0.5 | None | BiLSTM | ctc | 法语 |
| rec_ger_lite_train.yml | CRNN | Mobilenet_v3 small 0.5 | None | BiLSTM | ctc | 德语 |
| rec_japan_lite_train.yml | CRNN | Mobilenet_v3 small 0.5 | None | BiLSTM | ctc | 日语 |
| rec_korean_lite_train.yml | CRNN | Mobilenet_v3 small 0.5 | None | BiLSTM | ctc | 韩语 |
| rec_latin_lite_train.yml | CRNN | Mobilenet_v3 small 0.5 | None | BiLSTM | ctc | 拉丁字母 |
| rec_arabic_lite_train.yml | CRNN | Mobilenet_v3 small 0.5 | None | BiLSTM | ctc | 阿拉伯字母 |
| rec_cyrillic_lite_train.yml | CRNN | Mobilenet_v3 small 0.5 | None | BiLSTM | ctc | 斯拉夫字母 |
| rec_devanagari_lite_train.yml | CRNN | Mobilenet_v3 small 0.5 | None | BiLSTM | ctc | 梵文字母 |
更多支持语种请参考: 多语言模型
如您希望在现有模型效果的基础上调优,请参考下列说明修改配置文件:
以 rec_french_lite_train 为例:
Global:
...
# 添加自定义字典,如修改字典请将路径指向新字典
character_dict_path: ./ppocr/utils/dict/french_dict.txt
...
# 识别空格
use_space_char: True
...
Train:
dataset:
# 数据集格式,支持LMDBDataSet以及SimpleDataSet
name: SimpleDataSet
# 数据集路径
data_dir: ./train_data/
# 训练集标签文件
label_file_list: ["./train_data/french_train.txt"]
...
Eval:
dataset:
# 数据集格式,支持LMDBDataSet以及SimpleDataSet
name: SimpleDataSet
# 数据集路径
data_dir: ./train_data
# 验证集标签文件
label_file_list: ["./train_data/french_val.txt"]
...
2.8. 其他训练环境
-
Windows GPU/CPU
在Windows平台上与Linux平台略有不同:
Windows平台只支持单卡的训练与预测,指定GPU进行训练set CUDA_VISIBLE_DEVICES=0
在Windows平台,DataLoader只支持单进程模式,因此需要设置num_workers为0; -
macOS
不支持GPU模式,需要在配置文件中设置use_gpu为False,其余训练评估预测命令与Linux GPU完全相同。 -
Linux DCU
DCU设备上运行需要设置环境变量export HIP_VISIBLE_DEVICES=0,1,2,3,其余训练评估预测命令与Linux GPU完全相同。
2.9 模型微调
实际使用过程中,建议加载官方提供的预训练模型,在自己的数据集中进行微调,关于识别模型的微调方法,请参考:模型微调教程。
2.10 模型评估与预测
- 指标评估
训练中模型参数默认保存在Global.save_model_dir目录下。在评估指标时,需要设置Global.checkpoints指向保存的参数文件。评估数据集可以通过 configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml 修改Eval中的 label_file_path 设置。
#GPU 评估, Global.checkpoints 为待测权重
python3 -m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.checkpoints={path/to/weights}/best_accuracy
- 测试识别效果
使用 PaddleOCR 训练好的模型,可以通过以下脚本进行快速预测。
默认预测图片存储在 infer_img 里,通过 -o Global.checkpoints 加载训练好的参数文件:
根据配置文件中设置的 save_model_dir 和 save_epoch_step 字段,会有以下几种参数被保存下来:
output/rec/
├── best_accuracy.pdopt
├── best_accuracy.pdparams
├── best_accuracy.states
├── config.yml
├── iter_epoch_3.pdopt
├── iter_epoch_3.pdparams
├── iter_epoch_3.states
├── latest.pdopt
├── latest.pdparams
├── latest.states
└── train.log
其中 best_accuracy.* 是评估集上的最优模型;iter_epoch_x.* 是以 save_epoch_step 为间隔保存下来的模型;latest.* 是最后一个epoch的模型。
#预测英文结果
python3 tools/infer_rec.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.pretrained_model={path/to/weights}/best_accuracy Global.infer_img=doc/imgs_words/en/word_1.png
预测图片:

得到输入图像的预测结果:
infer_img: doc/imgs_words/en/word_1.png
result: ('joint', 0.9998967)
预测使用的配置文件必须与训练一致,如您通过 python3 tools/train.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml 完成了中文模型的训练,
您可以使用如下命令进行中文模型预测。
#预测中文结果
python3 tools/infer_rec.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml -o Global.pretrained_model={path/to/weights}/best_accuracy Global.infer_img=doc/imgs_words/ch/word_1.jpg
预测图片:

得到输入图像的预测结果:
infer_img: doc/imgs_words/ch/word_1.jpg
result: ('韩国小馆', 0.997218)
- 模型导出与预测
inference 模型(paddle.jit.save保存的模型)
一般是模型训练,把模型结构和模型参数保存在文件中的固化模型,多用于预测部署场景。
训练过程中保存的模型是checkpoints模型,保存的只有模型的参数,多用于恢复训练等。
与checkpoints模型相比,inference 模型会额外保存模型的结构信息,在预测部署、加速推理上性能优越,灵活方便,适合于实际系统集成。
识别模型转inference模型与检测的方式相同,如下:
#-c 后面设置训练算法的yml配置文件
#-o 配置可选参数
#Global.pretrained_model 参数设置待转换的训练模型地址,不用添加文件后缀 .pdmodel,.pdopt或.pdparams。
#Global.save_inference_dir参数设置转换的模型将保存的地址。
python3 tools/export_model.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy Global.save_inference_dir=./inference/en_PP-OCRv3_rec/
注意:如果您是在自己的数据集上训练的模型,并且调整了中文字符的字典文件,请注意修改配置文件中的character_dict_path为自定义字典文件。
转换成功后,在目录下有三个文件:
inference/en_PP-OCRv3_rec/
├── inference.pdiparams # 识别inference模型的参数文件
├── inference.pdiparams.info # 识别inference模型的参数信息,可忽略
└── inference.pdmodel # 识别inference模型的program文件
-
自定义模型推理
如果训练时修改了文本的字典,在使用inference模型预测时,需要通过
--rec_char_dict_path指定使用的字典路径,更多关于推理超参数的配置与解释,请参考:模型推理超参数解释教程。python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words_en/word_336.png" --rec_model_dir="./your inference model" --rec_image_shape="3, 48, 320" --rec_char_dict_path="your text dict path"
3. FAQ
Q1: 训练模型转inference 模型之后预测效果不一致?
A:此类问题出现较多,问题多是trained model预测时候的预处理、后处理参数和inference model预测的时候的预处理、后处理参数不一致导致的。可以对比训练使用的配置文件中的预处理、后处理和预测时是否存在差异。
参考链接:
https://aistudio.baidu.com/education/group/info/25207
https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.7
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号