【三】强化学习之PaddlePaddlle-Notebook、&pdb、ipdb 调试---及PARL框架
相关文章:
【一】飞桨paddle【GPU、CPU】安装以及环境配置+python入门教学
1.AI Studio基本操作-Notebook篇
--------云端运行程序
当进入自己项目的详情页面时, 用户可以选择"运行"项目, 也就是准备项目环境.
同样的, 当不想继续时, 可以此页面点击"停止"以终止项目.


1.1 多代码编辑
Notebook支持多文件编辑, 支持.py, .json, .txt, .log等格式的在线编辑, 支持部分图片类型文件的在线预览.
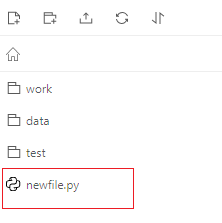
上传文件的体积是30MB. 如果需要引用更大体积的文件, 请使用数据集功能.
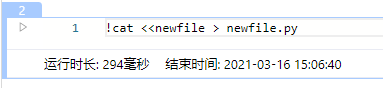
用户也可以使用命令, !cat <<newfile > newfile.py 在项目空间内直接创建文件, 之后双击进行编辑. 如上图所示:
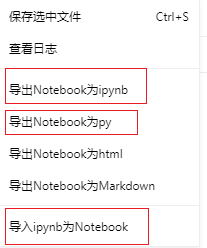
1.2 上传Notebook
可以用自己的ipynb文件取代当前默认的Notebook(前提是格式合法)
1.3 Notebook快捷键
快捷键分成两种状态下的. 一个是命令模式, 一个是编辑模式


1.4 Notebook中使用Shell命令
通过在Shell命令前添加! (感叹号), 就可以执行部分Shell命令. 包括诸如 !pip install这样的命令. 不过, !apt-get这种可能引发用户进一步操作的命令是不支持的.
例子如下:
# 查看当前挂载的数据集目录
!ls /home/aistudio/data/#显示当前路径
!pwd使用pip来安装自己需要的package (但不支持apt-get)
例如
!pip install jupyterthemes查看当前环境中安装的package
!pip list --format=columns1.5 持久化安装
如果需要进行持久化安装, 需要使用持久化路径, 如下方代码示例:
!mkdir /home/aistudio/xxx
!pip install beautifulsoup4 -t /home/aistudio/xxx同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可:
import sys
sys.path.append('/home/aistudio/xxx')# 查看当前挂载的数据集目录, 该目录下的变更重启环境后会自动还原
# View dataset directory. This directory will be recovered automatically after resetting environment.
!ls /home/aistudio/data
# 查看工作区文件, 该目录下的变更将会持久保存. 请及时清理不必要的文件, 避免加载过慢.
# View personal work directory. All changes under this directory will be kept even after reset. Please clean unnecessary files in time to speed up environment loading.
!ls /home/aistudio/work
# 如果需要进行持久化安装, 需要使用持久化路径, 如下方代码示例:
# If a persistence installation is required, you need to use the persistence path as the following:
!mkdir /home/aistudio/external-libraries
!pip install beautifulsoup4 -t /home/aistudio/external-libraries
# 同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可:
# Also add the following code, so that every time the environment (kernel) starts, just run the following code:
import sys
sys.path.append('/home/aistudio/external-libraries')1.6 使用git命令来同步代码 (暂时需要Paddle 1.4.1以上)
%cd work/!git clone https://github.com/PaddlePaddle/Paddle.git #Paddle官方模型可以看到同步后work目录下出现一个PaddleDetection文件夹---------[不过会因为时延,下载失败]

也可以活用Git命令进行本地代码管理.
注意: Paddle的Git体积过大, 同步会非常迟缓. 建议使用浏览器插件, 对指定目录进行下载, 然后上传至AI Studio的项目空间中. Chrome版
通过以下命令克隆最新的PaddleDetection代码库。
! git clone https://github.com/PaddlePaddle/PaddleDetection
如果因为网络问题clone较慢,可以:
通过github加速通道clone
!git clone https://hub.fastgit.org/PaddlePaddle/PaddleDetection.git
选择使用码云上的托管
!git clone https://gitee.com/paddlepaddle/PaddleDetection
注:码云托管代码可能无法实时同步本github项目更新,存在3~5天延时,请优先从github上克隆。
使用本项目提供的代码库,存放路径work/PaddleDetection.zip这里采用项目提供代码库:
! ls ~/work/PaddleDetection.zip
%cd ~/work/
! unzip -o PaddleDetection.zip1.7 Magic命令
Magic命令是Notebook的高级用法了. 可以运行一些特殊的指令. Magic 命令的前面带有一个或两个百分号(% 或 %%),分别代表行 Magic 命令和单元格 Magic 命令。行 Magic 命令仅应用于编写 Magic 命令时所在的行,而单元格 Magic 命令应用于整个单元格。
举个例子:
#显示全部可用的Magic命令
%lsmagic

%matplotlib inline
%config InlineBackend.figure_format = 'retina'
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(0,1,300)
for w in range(2,6,2):
plt.plot(x, np.sin(np.pi*x)*np.sin(2*w*np.pi*x)) 
这里需要注意的是, 当前技术架构局限, 一个Cell里面只能输出一张图片. 如果输出多张图片, 可能会有显示异常的问题
%env:设置环境变量
使用该命令, 可以在不必重启Kernel的情况下管理notebook的环境变量
# Running %env without any arguments
# lists all environment variables
# The line below sets the environment
# variable OMP_NUM_THREADS
%env OMP_NUM_THREADS=4%run: 运行python代码
使用%run 可以运行.py格式的python代码
当然是用!python也是可以的
我在项目空间中上传了一个.py文件, 里面只有一行print代码. 我们执行一下看看.
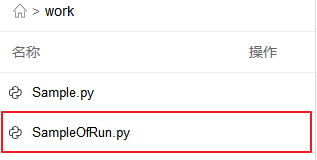
%run work/SampleOfRun.py
It's a demo code written in file SampleOfRun.py
!python work/SampleOfRun.py
It's a demo code written in file SampleOfRun.py%%writefile and %pycat: 导出cell内容/显示外部脚本的内容
AI Studio当前支持一定格式文件的预览和处理, 如果您的格式比较特殊, 尚未支持的话, 不妨试试这两个命令.
%%writefile magic可以把cell的内容保存到外部文件里。 而%pycat则可把外部文件展示在Cell中
%%writefile SaveToPythonCode.py
from math import sqrt
for i in range(2,10):
flag=1
k=int(sqrt(i))
for j in range(2,k+1):
if i%j==0:
flag=0
break
if(flag):
print(i)Writing SaveToPythonCode.py 因为没有指定路径, 所以文件被保存到了根目录下. 但至少it works.
我们再来尝试从中读文件内容
%pycat SaveToPythonCode.py更多Magic命令可以点击这里查询 Magic命令
关于变量监控
你可以通过修改内核选项ast_note_interactivity,使得Jupyter对独占一行的所有变量或者语句都自动显示,这样你就可以马上看到多个语句的运行结果了。
!pip install pydataset
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
from pydataset import data
quakes = data('quakes')
quakes.head()
quakes.tail()

2.project Debug:
2.1 Python代码执行与调试
Notebook执行Python代码的原理和传统IDE略有不同.
- 传统IDE, 当点击Run按钮时, 编译器/解释器开始构建一个进程. 用户通过单步执行/设置断点进行代码调试和变量监控. 当代码出错, 或用户点击Stop按钮时, 进程被杀死, 资源回收.
- 而Notebook, 一旦启动, 就是开始创建一个"进程"(kernel). 每一个Cell, 都是一个天然的断点. 当代码出错, 或用户点击Stop按钮时, "进程"通常也不会被杀死.因此如果代码陷入死循环等情况, 需要用户手动关闭并重启该"进程".
Notebook的Cell是可以随意颠倒顺序来执行的. 这点和传统IDE有很大不同.,作为前端的Notebook, 与后端的进程(kernel), 建立有一个Session. 未来本平台将支持terminal功能. 也就可以同时支持多个Session来控制kernel.
变量监控
因为Notebook的Cell是可以随意颠倒顺序来执行的, 因此本平台自带"变量监控"和"运行历史". 方便用户了解当前代码运行状态.
通过重启环境并清空输出, 可以消除已生成的变量监控.
![]()
2.2 pdb&ipdb调试使用方法
- pdb为python程序实现了一个交互式调试环境。它包括一些特性,可以暂停程序,查看变量值,以及逐步监视程序执行,从而能了解程序具体做了什么,并查找逻辑中存在的bug
- ipdb是pdb的扩展版本,在pdb的基础上添加了如下功能:
·可以使用tab(提示)补全代码的功能
· 调试不再是黑白的,l命令可以输出带颜色的代码(将变量、命令、函数名等区分开,提高代码可读性)
****pdb 和 ipdb同时安装 优先级是ipdb,并且兼容pdb
2.2.1 pdb
安装
pip install pdb -i https://pypi.tuna.tsinghua.edu.cn/simpleimport pdb
pdb.set_trace()##设置断点例子如下:
import pdb
##import ipdb
import sys
def add(num1=0, num2=0):
return int(num1) + int(num2)
def sub(num1=0, num2=0):
return int(num1) - int(num2)
def main():
#Assuming our inputs are valid numbers
num1 = 33
num2 = 44
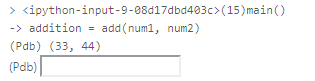
pdb.set_trace() # <-- 这个表示添加断点
addition = add(num1, num2)
print (addition)
subtraction = sub(num1, num2)
print (subtraction)
if __name__ == '__main__':
main()一旦开始运行, 会出现交互框
如下图所示:
在这个输入框里敲入命令, 即可开始调试.
常见指令:
- 通过命令where(简写w)可以得出正在执行哪一行,以及程序的调用栈的位置。
- 通过直接输入变量i可以看到当前的值。 如:num1 num2 --------→p num1,num2
--------→
- 通过list(简写l)可以看周围的代码默认是上5行、下5行。另外命令longlist(简写ll)可以输出当前的函数的源码。如果需要看整个类的源码可以通过source+类名获取源码。
- step(简称s):函数单步执行,如果遇到函数会进入函数内部继续调试,如果不需要进入函数体只是一步一步执行,此时就要用下面的next了。
- next(简称n):单步执行命令,不会进入函数体,但是向之前说的那个如果遇到了一个for循环10次还好如果是10000次呢,此时就要用到下面的命令了。
- until:该命令类型next,只不过它会继续执行,直到执行到同一个函数中行号大于当前值的一行,也就是说可以用until跳出循环末尾。当然until也可以指定一个比当前行号大的值,调到指定位置。
- 如果你想在任何时候退出,你可以使用q。正在执行的程序被中止。
- u也就是up ,回到上一层的帧栈 (对应的就是 d ) ,这在你进入到了一个exception的捕捉过程中的时候相当有用…
- display var var是我们要跟踪的变量,这样每次var变化的时候就会自动print出来 想取消就用undisplay var即可
- bt/where 或者简写成 w 查看层叠帧栈
- source function 查看 function的源代码 类似的还有pdoc var 查看var的文档(变量和函数都可以,有点像dir(var)命令)
- pinfo var命令,可以看到var声明的源代码地址 ll命令也可以
- j(jump)修改CPU的下一条指令,会忽略中间的代码不去执行,也可以往回跳,
例子如下:


 --------→
--------→ 
import pdb
class Myobj():
def foo(self,num):
print(f"当前的数字是:{num}")
pdb.set_trace()
for i in range(num):
print(f"当前循环的数字:{i}")
print("over")
if __name__ == '__main__':
m=Myobj()
m.foo(4)
![]()
可以发现执行until把整个循环走了一遍,然后到下一行也就是
print("over")return:return也可以绕开一段代码的捷径,只不过它会继续执行,直至函数准备执行一个return语句,然后会暂停,使得在函数返回之前可以看到返回值.一个没什么实际用途的例子,不过可以很好地演示这个效果
import pdb lst=[] class Myobj(): def foo(self,num): print(f"当前的数字是:{num}") pdb.set_trace() for i in range(num): print(f"当前循环的数字:{i}") lst.append(i) return lst if __name__ == '__main__': m=Myobj() m.foo(4)



断点相关:
break(简称b): 当然随着代码的增长即使使用return和until或者next都很费时间,此时就要考虑在指定位置设置断点的方式了,如果要在文件的一个特定行设置断点,可以使用break lineno,然后通过下面的continue(简写c)命令调到下一个断点。
我们还可以指定在某个函数中设置断点比如:break Myobj().foo
除此之外还可以执行其他文件设置断点,也可以相当于sys.path上将某个文件的相对路径。如果只执行break命令可以看到哪些地方有断点,包括哪个文件行号等信息。
disable:可以指定上面break之后显示的断点,执行后可以发现之前Enb栏有yes变为false。此时输入l可以看到打断点的为会有B标识。如果想彻底删除就需要执行clear命令了。
设置断点如下: 删除断点
![]()
clear:彻底删除一个断点,使用方式clear id号,类型disable
tbreak:临时断点,程序第一次执行到临时断点时会自动清除。不用再去手动删除了。



条件断点:
可以对断点应用一些规则,以便其仅当条件满足时才执行。与手动启用和禁用断点相比,使用条件断点可以更好地控制调试器暂停程序的方式。条件断点可以通过两种方式设置。第一种方法是指定使用break设置断点时的条件。使用方法是代码行号加表达式。看一个应用例子
import pdb lst = [] class Myobj(): pdb.set_trace() def foo(self, num): print(f"当前的数字是:{num}") if __name__ == '__main__': m = Myobj() [m.foo(i) for i in range(10)]
- .break 10,num>5,是指在第10行打断点,然后条件是num>5的时候,通过后面输出break可以看到具体的断点信息,很明显看到我们的断点条件
stop only if num>5

如果表达式的计算结果为true,则执行将在断点处停止。除此之外,还可以使用条件命令将条件应用于现有断点。参数是断点id和表达式。

忽略断点
如果在循环的过程中想忽略前几条结果,比如这里忽略前3个,就可以使用ignore.
使用方法是:
ignore 断点id 忽略次数。
如果在运行之前不想忽略了可以使用下面命令,如果已经运行continue了的话就没效果了。
ignore 断点id 0监视变量
display:有时候我们需要实时观察一个变量的变化,这个时候dispaly就是最好的帮手,如果想移出可以使用undisplay。

改变工作流
jump:jump命令在运行时改变程序的流程,而不修改代码。 它可以向前跳过以避免运行某些代码,也可以向后跳转以再次运行它。
import pdb def f(n): pdb.set_trace() result = [] j = 0 for i in range(n): j = i * n + j j += n result.append(j) return result if __name__ == '__main__': print(f(5))向前跳
向前跳转会将执行点移动到当前位置之后,而不会执行期间任何语句。
![]()
可以看到jump作用是跳转到指定行,对应的中断行的值不会被使用
不使用jump如下:
前跳jump 原理是,终端点计算是运行,但是在弹出result时候不记录
向后跳
跳转还可以将程序执行移动到已经执行的语句中,以便再次运行它。
不允许的jump方式
1.跳入和跳出某些流控制语句,无法判断什么时候进入。
2.跳转可以用来输入函数,但是不给参数,代码也不能工作。
3.跳转不会进入for循环或try:except语句等块的中间。
4.finally块中的代码必须全部执行,因此跳转不会离开该块。
5.最基本的限制是跳转被限制在调用堆栈的底部框架上。 向上移动堆栈以检查变量后,此时无法更改执行流程。



2.2.2 ipdb
#如发现环境中未安装, 可以运行下方代码来安装ipdb
!pip install ipdb -i https://pypi.tuna.tsinghua.edu.cn/simpleipdb常用指令~~~和pdb相似
- ENTER (重复上次命令)
- c (继续)
- l (查找当前位于哪里)
- s (进入子程序,如果当前有一个函数调用,那么 s 会进入被调用的函数体)
- n(ext) 让程序运行下一行,如果当前语句有一个函数调用,用 n 是不会进入被调用的函数体中的
- r (运行直到子程序结束)
- !<python 命令>
- h (帮助)
- a(rgs) 打印当前函数的参数
- j(ump) 让程序跳转到指定的行数
- l(ist) 可以列出当前将要运行的代码块
- p(rint) 最有用的命令之一,打印某个变量
- q(uit) 退出调试
- r(eturn) 继续执行,直到函数体返回
使断点全局失效/生效
import ipdb
ipdb.set_trace() #在你想要开始调试的地方写下这行就可以
- 如果单次想要让断点失效,但是又不想手动一个一个删除ipdb.set_trace()怎么办?
def f():
pass
ipdb.set_trace=f
利用函数覆盖
如果调试到一半又想要使用ipdb.set_trace()的功能怎么办
reload ipdb 或者 del ipdb
想要监视某个变量的特殊情况
- condition BreakPointIndex expr
- 在那个出错的地方加上ipdb的set_trace
比如说,想看xx小于0的时候是怎么个情况,就在它上次报错的后面加上:
if xx<0:
import ipdb
ipdb.set_trace()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号