【五】强化学习之Sarsa、Qlearing详细讲解----PaddlePaddlle【PARL】框架{飞桨}
相关文章:
【一】飞桨paddle【GPU、CPU】安装以及环境配置+python入门教学
代码链接:码云:https://gitee.com/dingding962285595/parl_work ;github:https://github.com/PaddlePaddle/PARL
1.TD更新:
 会找到能获取reward最大的路径。
会找到能获取reward最大的路径。
对应数学公式:

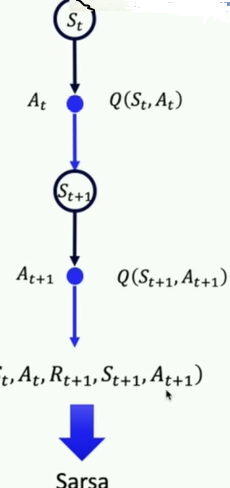
对应流程:

下一步Q值更新当前Q值。
软更新方式,设置权重a每次更新一点点,类似学习率。这样最后Q值都会逼近目标值。

2.Sarsa

部分代码:
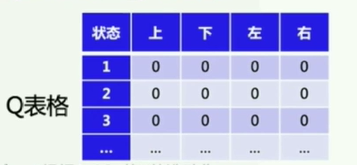
建立的Q表格
初始化Q表格:四列n行
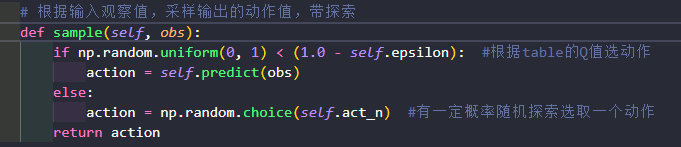
Agent是和环境environment交互的主体。predict()方法:输入观察值observation(或者说状态state),输出动作值sample()方法:再predict()方法基础上使用ε-greedy增加探索learn()方法:输入训练数据,完成一轮Q表格的更新
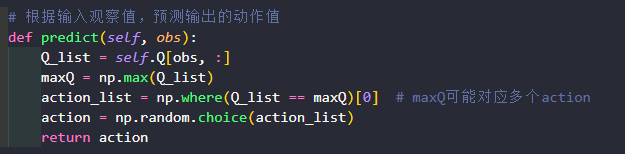
提取出状态s的这一行,然后得到最大Q值的下标。
当对应Q值存在多个动作时,避免每次都获取第一个动作,np.where从最大q值里随机挑选一个动作。
对应代码最后两行
如果 done 为true 则为episode最后一个状态,下一个时刻就没有状态了;
run_episode():agent在一个episode中训练的过程,使用agent.sample()与环境交互,使用agent.learn()训练Q表格。test_episode():agent在一个episode中测试效果,评估目前的agent能在一个episode中拿到多少总reward。
测试一下算法效果
跑一个episode 只取动作最优的,每个step都延迟了0.5s,动态图显示会稍微慢点的。
得到的结果发现在到达终点过程中距离悬崖远远的,因为程序中有个探索的过程,如果离得太近,下一步会掉下悬崖,重新开始拿到reward-100
reward计算







3.Qlearning
Q-learning也是采用Q表格的方式存储Q值(状态动作价值),决策部分与Sarsa是一样的,采用ε-greedy方式增加探索。Q-learning跟Sarsa不一样的地方是更新Q表格的方式。
Sarsa是on-policy的更新方式,先做出动作再更新。Q-learning是off-policy的更新方式,更新learn()时无需获取下一步实际做出的动作next_action,并假设下一步动作是取最大Q值的动作。Q-learning的更新公式为:
两者区别在于target不同,Qlearing默认下下一个动作为最优的策略,不受探索的影响。
除了learn其余代码都一样
效果比sarsa好






4.策略结果比较:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号