【深度学习项目一】全连接神经网络实现mnist数字识别
相关文章:
【深度学习项目一】全连接神经网络实现mnist数字识别
【深度学习项目二】卷积神经网络LeNet实现minst数字识别
【深度学习项目三】ResNet50多分类任务【十二生肖分类】
『深度学习项目四』基于ResNet101人脸特征点检测
项目链接:https://aistudio.baidu.com/aistudio/projectdetail/1926913
1.深度学习开发的万能公式
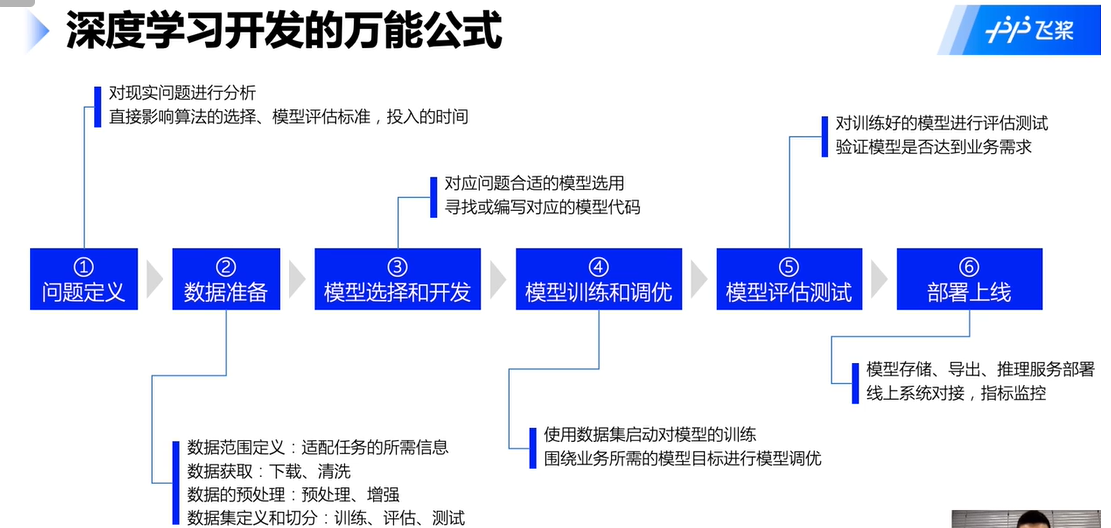
模式流程:

import paddle
import numpy as np
import matplotlib.pyplot as plt
2 数据准备
2.1 数据加载和预处理
import paddle.vision.transforms as T
# 数据的加载和预处理
transform = T.Normalize(mean=[127.5], std=[127.5]) #里面数值是根据数据集进行设置的
#像素值分布0-255组成图片,差值比较大会影响loss,影响性能,归一化到【-1,1】【0,1】梯度下降
#图像归一化处理,支持两种方式: 1. 用统一的均值和标准差值对图像的每个通道进行归一化处理; 2. 对每个通道指定不同的均值和标准差值进行归一化处理。
#如有问题可以参考官网API文档例程
# 训练数据集
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
# 评估数据集
eval_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
print('训练集样本量: {},验证集样本量: {}'.format(len(train_dataset), len(eval_dataset)))
训练集样本量: 60000,验证集样本量: 10000
2.2 数据集查看
print('图片:')
print(type(train_dataset[0][0]))
print(train_dataset[0][0])
print('标签:')
print(type(train_dataset[0][1]))
print(train_dataset[0][1])
# 可视化展示
plt.figure()
plt.imshow(train_dataset[0][0].reshape([28,28]), cmap=plt.cm.binary) #单通道图片
plt.show()
#numpy ndarray,归一化后的图像。

3. 模型选择和开发
3.1 模型组网
在网络构建模块,飞桨高层API与基础API保持完全的一致,都使用paddle.nn下的API进行组网。这也是尽可能的减少需要暴露的概念,从而提升框架的易学性。飞桨框架 paddle.nn 目录下包含了所有与模型组网相关的API,如卷积相关的 Conv1D、Conv2D、Conv3D,循环神经网络相关的 RNN、LSTM、GRU 等。
对于组网方式,飞桨框架统一支持 Sequential 或 SubClass 的方式进行模型的组建。我们根据实际的使用场景,来选择最合适的组网方式。如针对顺序的线性网络结构我们可以直接使用 Sequential ,相比于 SubClass ,Sequential 可以快速的完成组网。 如果是一些比较复杂的网络结构,我们可以使用 SubClass 定义的方式来进行模型代码编写,在 init 构造函数中进行 Layer 的声明,在 forward 中使用声明的 Layer 变量进行前向计算。通过这种方式,我们可以组建更灵活的网络结构。

- 对于线性的网络模型,我们只需要按网络模型的结构顺序,一层一层的加到Sequential 后面即可,非常快速就可以完成模型的组建。
- 上述的SubClass 组网的结果与Sequential 组网的结果完全一致,可以明显看出,使用SubClass 组网会比使用Sequential 更复杂一些。不过,这带来的是网络模型结构的灵活性。我们可以设计不同的网络模型结构来应对不同的场景。
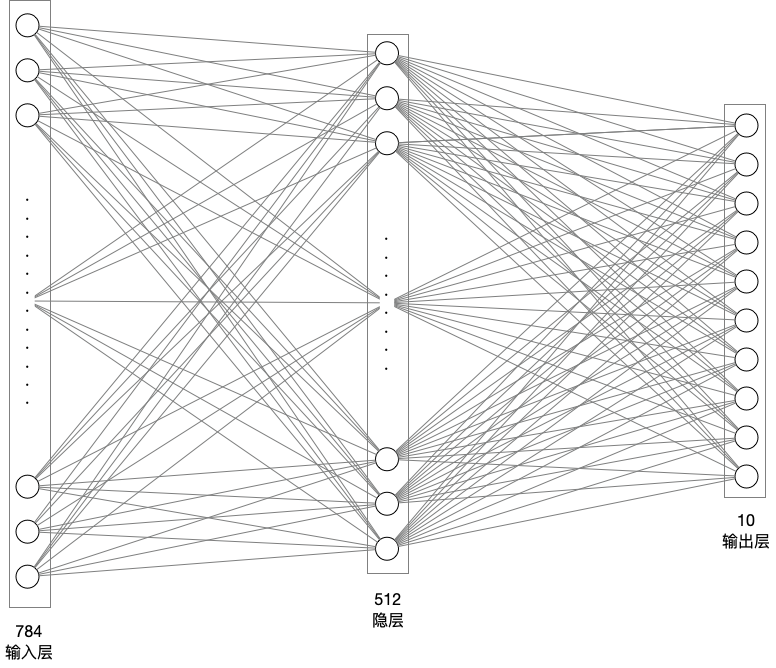
# 模型网络结构搭建,线性全连接,1个隐藏层
network = paddle.nn.Sequential(
paddle.nn.Flatten(), # 拉平,将 (28, 28) => (784) 1维数组
paddle.nn.Linear(784, 512), # 隐层:线性变换层
paddle.nn.ReLU(), # 激活函数--保持梯度
paddle.nn.Linear(512, 10) # 输出层
)
3.2 模型网络结构可视化
# 模型封装
model = paddle.Model(network)
# 模型可视化 检验创建模型对错
model.summary((1, 28, 28))
Layer (type) Input Shape Output Shape Param #
===========================================================================
Flatten-1 [[1, 28, 28]] [1, 784] 0
Linear-1 [[1, 784]] [1, 512] 401,920
ReLU-1 [[1, 512]] [1, 512] 0
Linear-2 [[1, 512]] [1, 10] 5,130
===========================================================================
Total params: 407,050
Trainable params: 407,050
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.01
Params size (MB): 1.55
Estimated Total Size (MB): 1.57
---------------------------------------------------------------------------
{'total_params': 407050, 'trainable_params': 407050}

# 配置优化器、损失函数、评估指标
model.prepare(paddle.optimizer.Adam(learning_rate=0.001, parameters=network.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
#softmax已经直接在调用函数中写进去了
# 启动模型全流程训练
model.fit(train_dataset, # 训练数据集
eval_dataset, # 评估数据集 ,同时判断训练的好坏是否存在过拟合欠拟合
epochs=5, # 训练的总轮次,所有数据集训练次数
batch_size=64, # 训练使用的分批大小
verbose=1) # 日志展示形式 1:每条显示 0:不显示
The loss value printed in the log is the current step, and the metric is the average value of previous step.
Epoch 1/5
step 20/938 [..............................] - loss: 0.6511 - acc: 0.6156 - ETA: 14s - 15ms/ste
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
return (isinstance(seq, collections.Sequence) and
step 30/938 [..............................] - loss: 0.4588 - acc: 0.6885 - ETA: 12s - 13ms/step
step 40/938 [>.............................] - loss: 0.5677 - acc: 0.7301 - ETA: 11s - 13ms/step
step 938/938 [==============================] - loss: 0.2502 - acc: 0.9135 - 12ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 0.0397 - acc: 0.9527 - 8ms/step
Eval samples: 10000
Epoch 2/5
step 938/938 [==============================] - loss: 0.0424 - acc: 0.9600 - 19ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 0.0038 - acc: 0.9628 - 8ms/step
Eval samples: 10000
Epoch 3/5
step 938/938 [==============================] - loss: 0.0244 - acc: 0.9687 - 19ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 0.0068 - acc: 0.9687 - 8ms/step
Eval samples: 10000
Epoch 4/5
step 938/938 [==============================] - loss: 0.0076 - acc: 0.9740 - 20ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 0.0055 - acc: 0.9614 - 8ms/step
Eval samples: 10000
Epoch 5/5
step 938/938 [==============================] - loss: 0.0781 - acc: 0.9770 - 19ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 0.0024 - acc: 0.9756 - 8ms/step
5. 模型评估测试

5.1 模型评估
# 模型评估,根据prepare接口配置的loss和metric进行返回
result = model.evaluate(eval_dataset, verbose=1)
print(result)
#得到最后的精度指标
5.2 模型预测
5.2.1 批量预测
使用model.predict接口来完成对大量数据集的批量预测。
评估完后只能看到loss和acc,还需要给真实图片进行检验
# 进行预测操作
result = model.predict(eval_dataset)
# 定义画图方法
def show_img(img, predict):
plt.figure()
plt.title('predict: {}'.format(predict))
plt.imshow(img.reshape([28, 28]), cmap=plt.cm.binary)
plt.show()
# 抽样展示
indexs = [2, 15, 38, 211]
for idx in indexs:
show_img(eval_dataset[idx][0], np.argmax(result[0][idx]))
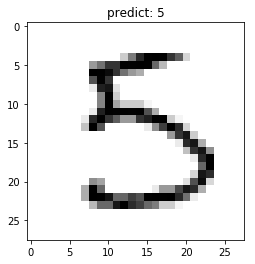

5.2.2 单张图片预测
采用model.predict_batch来进行单张或少量多张图片的预测。
# 读取单张图片
image = eval_dataset[501][0]
# 单张图片预测
result = model.predict_batch([image]) #numpy形式数据
print(result)
print(np.argmax(result))
#是个数组,在这个数组里找最大值,最大值对应的下标就是预测值0--9
# 可视化结果
show_img(image, np.argmax(result))
#np.argmax找到下标
[array([[ -6.519223 , -10.6420555 , -1.3091288 , 0.15322888,
-4.734633 , -4.65111 , -16.480547 , -0.9590389 ,
-4.847525 , 11.187076 ]], dtype=float32)]
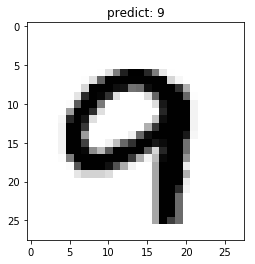
6. 部署上线
6.1 保存模型

保存用于后续继续调优训练的模型
model.save('mnist')
#后续可以加载进来继续训练,避免错过最优模型,在最优模型上继续调优
6.2 继续调优训练
from paddle.static import InputSpec
# 模型封装,为了后面保存预测模型,这里传入了inputs参数
model_2 = paddle.Model(network, inputs=[InputSpec(shape=[-1, 28, 28], dtype='float32', name='image')])
#预测模型部署的时候需要知道输入模型的形状;-1表示batchsize大小,-1表示灵活的 后续可以再设值
# 加载之前保存的阶段训练模型
model_2.load('mnist')
# 模型配置
model_2.prepare(paddle.optimizer.Adam(learning_rate=0.001, parameters=network.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
#CrossEntropyLoss分类,
# 模型全流程训练
model_2.fit(train_dataset,
eval_dataset,
epochs=2,
batch_size=64,
verbose=1)
#继续调优训练epochs=2可以少一点了
The loss value printed in the log is the current step, and the metric is the average value of previous step.
Epoch 1/2
step 938/938 [==============================] - loss: 0.1485 - acc: 0.9785 - 10ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 9.0207e-04 - acc: 0.9709 - 9ms/step
Eval samples: 10000
Epoch 2/2
step 938/938 [==============================] - loss: 0.0094 - acc: 0.9820 - 13ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 1.1729e-04 - acc: 0.9752 - 8ms/step
Eval samples: 10000
6.3 保存预测模型
# 保存用于后续推理部署的模型
model_2.save('infer/mnist', training=False)
#training=False保存部署模型了,不在调优!
总结
这次采用全连接神经网络实现了数字识别得到了较高的准确率,不过也存在很多问题,我将会在项目二更进一步进行改进模型提高准确率!
项目链接:https://aistudio.baidu.com/aistudio/projectdetail/1926913

 浙公网安备 33010602011771号
浙公网安备 33010602011771号