快递单信息抽取【三】--五条标注数据提高准确率,仅需五条标注样本,快速完成快递单信息任务
相关文章:
1.快递单中抽取关键信息【一】----基于BiGRU+CR+预训练的词向量优化
2.快递单信息抽取【二】基于ERNIE1.0至ErnieGram + CRF预训练模型
3.快递单信息抽取【三】–五条标注数据提高准确率,仅需五条标注样本,快速完成快递单信息任务
1)PaddleNLP通用信息抽取技术UIE【一】产业应用实例:信息抽取{实体关系抽取、中文分词、精准实体标。情感分析等}、文本纠错、问答系统、闲聊机器人、定制训练
2)PaddleNLP–UIE(二)–小样本快速提升性能(含doccona标注)
!强烈推荐:数据标注平台doccano----简介、安装、使用、踩坑记录
本项目链接:
https://aistudio.baidu.com/aistudio/projectdetail/4160432?contributionType=1
五条标注数据搞定快递单信息抽取
本项目将演示如何通过五条标注样本进行模型微调,快速且准确抽取快递单中的姓名、电话、省、市、区、详细地址等内容,形成结构化信息。辅助物流行业从业者进行有效信息的提取,从而降低客户填单的成本。
1. 任务介绍
如何从物流信息中抽取想要的关键信息呢?我们首先要定义好需要抽取哪些字段。
比如现在拿到一个快递单,可以作为我们的模型输入,例如“张三18625584663广东省深圳市南山区学府路东百度国际大厦”,那么序列标注模型的目的就是识别出其中的“张三”为人名,“18625584663”为电话名,“广东省深圳市南山区百度国际大厦”分别是『省、市、区、街道』4 级地址)。
这是一个典型的命名实体识别(Named Entity Recognition,NER)场景,各实体类型及相应符号表示见下表:
| 抽取实体/字段 | 抽取结果 |
|---|---|
| 姓名 | 张三 |
| 电话 | 15209XX1921 |
| 省份 | 广东省 |
| 城市 | 深圳市 |
| 县区 | 南山区 |
| 详细地址 | 百度国际大厦 |
2. 方案设计
2.1 UIE基于Prompt统一建模
Universal Information Extraction (UIE):Yaojie Lu等人提出了开放域信息抽取的统一框架,这一框架在实体抽取、关系抽取、事件抽取、情感分析等任务上都有着良好的泛化效果。
PaddleNLP基于这篇工作的prompt设计思想,提供了以ERNIE为底座的信息抽取模型,用于关键信息抽取。同时,针对不同场景,支持通过构造小样本数据来优化模型效果,快速适配特定的关键信息配置。
 ## 2.2 UIE的优势
## 2.2 UIE的优势
-
使用简单:用户可以使用自然语言自定义抽取目标,无需训练即可统一抽取输入文本中的对应信息。实现开箱即用,并满足各类信息抽取需求。
-
降本增效:以往的信息抽取技术需要大量标注数据才能保证信息抽取的效果,为了提高开发过程中的开发效率,减少不必要的重复工作时间,开放域信息抽取可以实现零样本(zero-shot)或者少样本(few-shot)抽取,大幅度降低标注数据依赖,在降低成本的同时,还提升了效果。
-
效果领先:开放域信息抽取在多种场景,多种任务上,均有不俗的表现。
2.3 应用场景示例
- 医疗场景-专病结构化
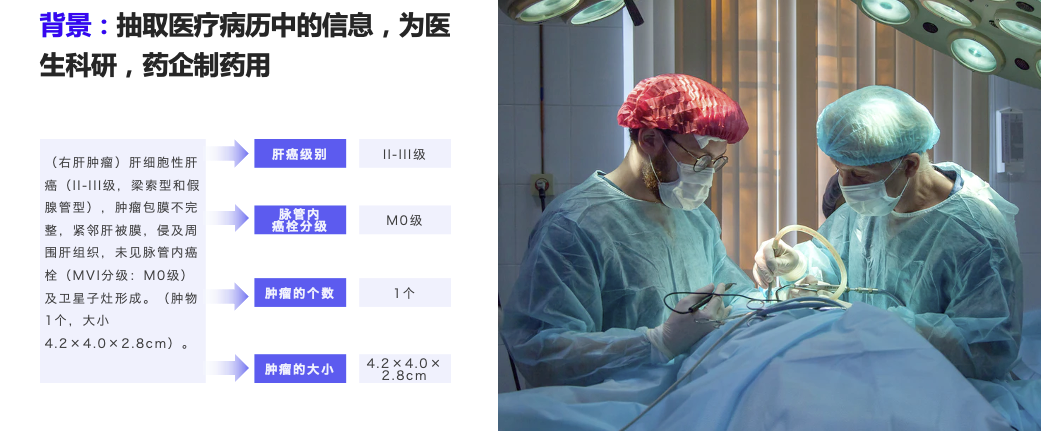
- 金融场景-收入证明、招股书抽取
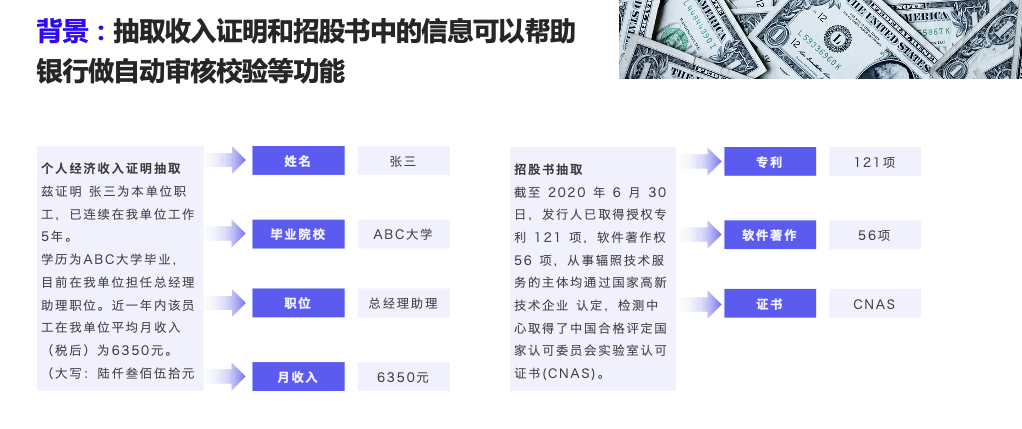
3. 环境准备
! pip install --upgrade paddlenlp -i https://mirror.baidu.com/pypi/simple
! pip show paddlenlp
4. 开箱即用
from paddlenlp import Taskflow
schema = ["姓名", "省份", "城市", "县区"]
ie = Taskflow("information_extraction", schema=schema)
ie("北京市海淀区上地十街10号18888888888张三")
[{'姓名': [{'text': '张三',
'start': 24,
'end': 26,
'probability': 0.9659838994810457}],
'城市': [{'text': '北京市',
'start': 0,
'end': 3,
'probability': 0.9992708589150467}],
'县区': [{'text': '海淀区',
'start': 3,
'end': 6,
'probability': 0.9997972338090335}]}]
- Taskflow UIE更多使用方式解锁:Taskflow UIE使用文档
5. 轻定制功能
对于『电话』、『详细地址』这些非通用性实体类型标签,推荐使用PaddleNLP提供的轻定制功能(数据标注-训练-部署全流程工具)。
我们标注5条数据试试效果。
5.1 数据标注
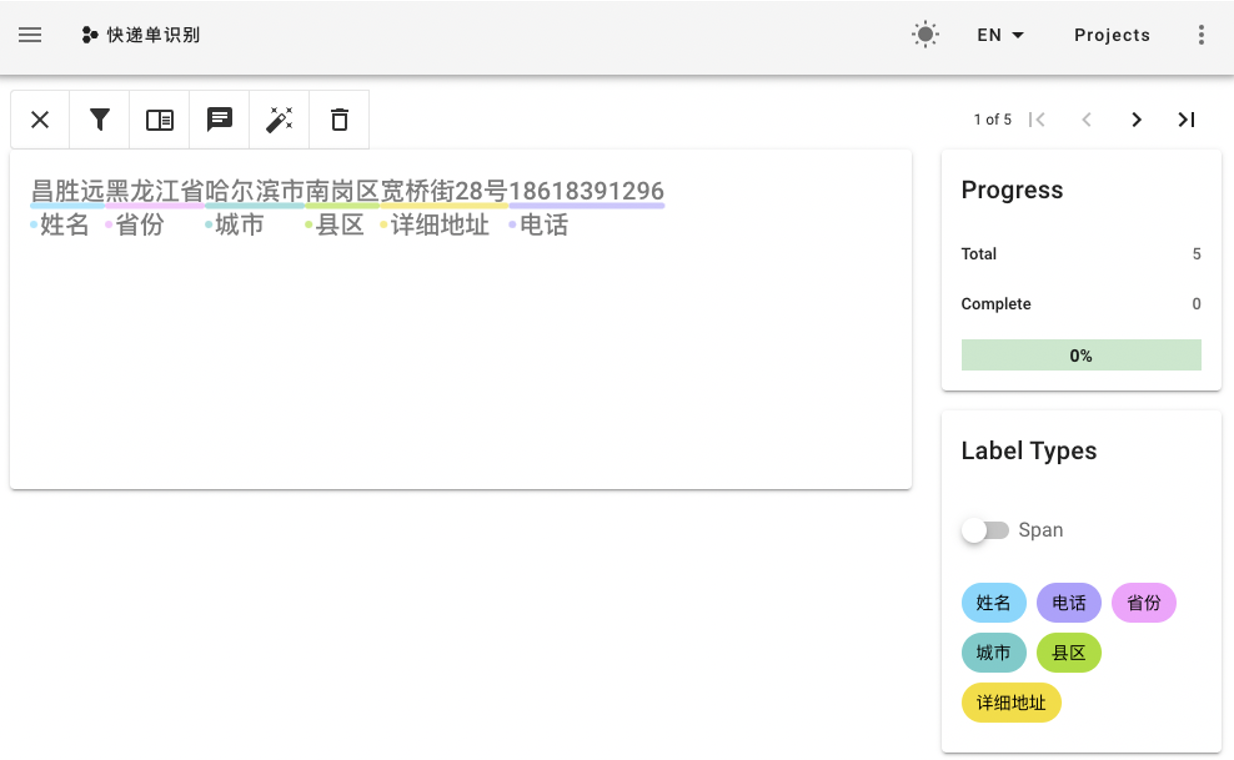
我们推荐使用数据标注平台doccano 进行数据标注,本案例也打通了从标注到训练的通道,即doccano导出数据后可通过doccano.py脚本轻松将数据转换为输入模型时需要的形式,实现无缝衔接。为达到这个目的,您需要按以下标注规则在doccano平台上标注数据:
Step 1. 本地安装doccano(请勿在AI Studio内部运行,本地测试环境python=3.8)
$ pip install doccano
Step 2. 初始化数据库和账户(用户名和密码可替换为自定义值)
$ doccano init
$ doccano createuser --username my_admin_name --password my_password
Step 3. 启动doccano
- 在一个窗口启动doccano的WebServer,保持窗口
$ doccano webserver --port 8000
- 在另一个窗口启动doccano的任务队列
$ doccano task
Step 4. 运行doccano来标注实体和关系
-
打开浏览器(推荐Chrome),在地址栏中输入
http://0.0.0.0:8000/后回车即得以下界面。
![]()
-
登陆账户。点击右上角的
LOGIN,输入Step 2中设置的用户名和密码登陆。 -
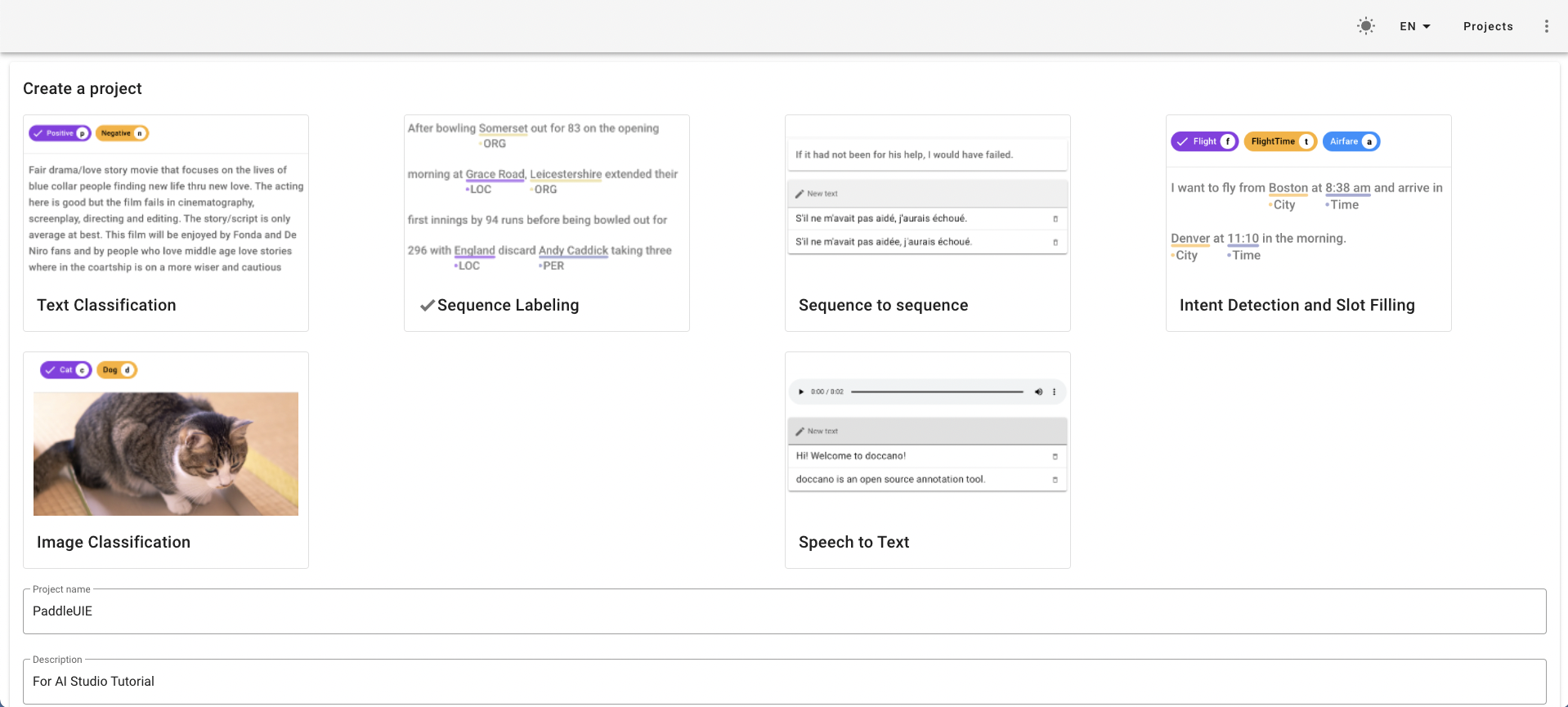
创建项目。点击左上角的
CREATE,跳转至以下界面。- 勾选序列标注(
Sequence Labeling) - 填写项目名称(
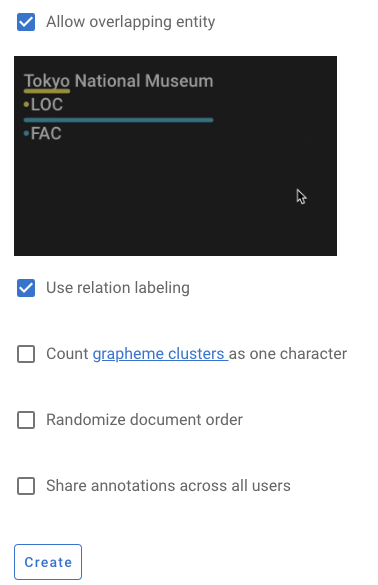
Project name)等必要信息 - 勾选允许实体重叠(
Allow overlapping entity)、使用关系标注(Use relation labeling) - 创建完成后,项目首页视频提供了从数据导入到导出的七个步骤的详细说明。
![]()
![]()
- 勾选序列标注(
-
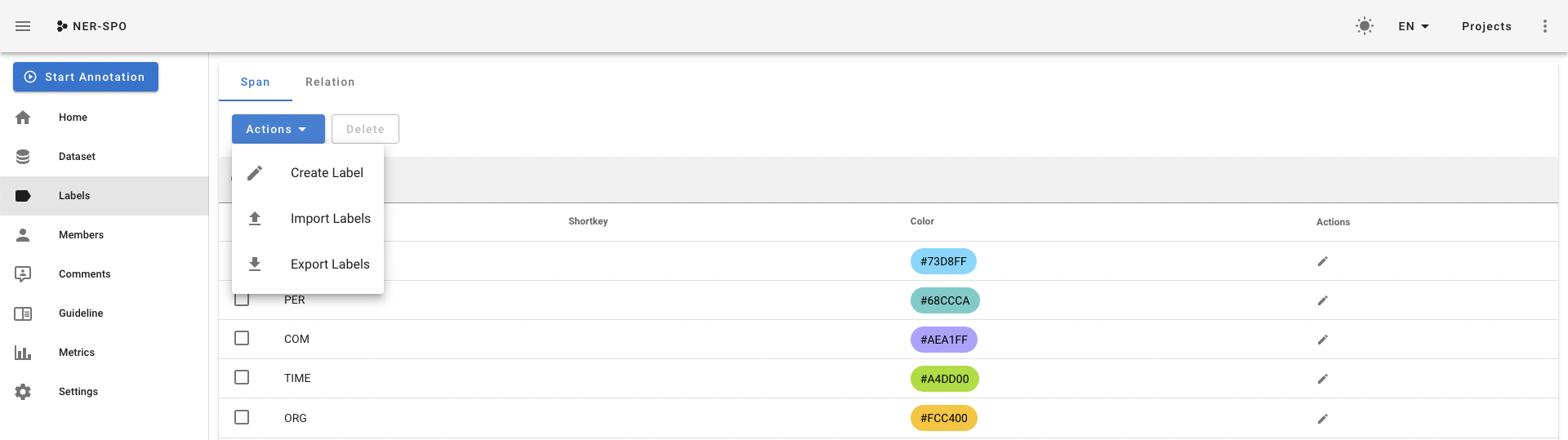
设置标签。在Labels一栏点击
Actions,Create Label手动设置或者Import Labels从文件导入。- 最上边Span表示实体标签,Relation表示关系标签,需要分别设置。
![]()
- 最上边Span表示实体标签,Relation表示关系标签,需要分别设置。
-
导入数据。在Datasets一栏点击
Actions、Import Dataset从文件导入文本数据。- 根据文件格式(File format)给出的示例,选择适合的格式导入自定义数据文件。
- 导入成功后即跳转至数据列表。
-
标注数据。点击每条数据最右边的
Annotate按钮开始标记。标记页面右侧的标签类型(Label Types)开关可在实体标签和关系标签之间切换。- 实体标注:直接用鼠标选取文本即可标注实体。
- 关系标注:首先点击待标注的关系标签,接着依次点击相应的头尾实体可完成关系标注。
-
导出数据。在Datasets一栏点击
Actions、Export Dataset导出已标注的数据。
5.2 将标注数据转化成UIE训练所需数据
- 将doccano平台的标注数据保存在
./data/目录。对于快递单信息抽取的场景,可以直接下载标注好的数据。
! wget https://paddlenlp.bj.bcebos.com/model_zoo/uie/waybill.jsonl
! mv waybill.jsonl ./data/
! python doccano.py --doccano_file ./data/waybill.jsonl --splits 1 0 0
可配置参数说明
doccano_file: 从doccano导出的数据标注文件。save_dir: 训练数据的保存目录,默认存储在data目录下。negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative_ratio * 正例数量。该参数只对训练集有效,默认为5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。splits: 划分数据集时训练集、验证集所占的比例。默认为[0.8, 0.1, 0.1]表示按照8:1:1的比例将数据划分为训练集、验证集和测试集。task_type: 选择任务类型,可选有抽取和分类两种类型的任务。options: 指定分类任务的类别标签,该参数只对分类类型任务有效。prompt_prefix: 声明分类任务的prompt前缀信息,该参数只对分类类型任务有效。is_shuffle: 是否对数据集进行随机打散,默认为True。seed: 随机种子,默认为1000.
5.3 一键微调
因为是轻量级定制,即训练集数量较少时,通常将训练集直接作为验证集
- 执行以下脚本进行一键微调
对finetune.py文件保存逻辑,进行修改,只保留最好模型,减少储存
! python finetune.py \
--train_path ./data/train.txt \
--dev_path ./data/train.txt \
--save_dir ./checkpoint \
--model uie-base \
--learning_rate 1e-5 \
--batch_size 16 \
--max_seq_len 512 \
--num_epochs 10 \
--seed 1000 \
--logging_steps 10 \
--valid_steps 10
可配置参数说明:
train_path: 训练集文件路径。dev_path: 验证集文件路径。save_dir: 模型存储路径,默认为./checkpoint。learning_rate: 学习率,默认为1e-5。batch_size: 批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数,默认为16。max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。num_epochs: 训练轮数,默认为100。model: 选择模型,程序会基于选择的模型进行模型微调,可选有uie-base和uie-tiny,默认为uie-base。seed: 随机种子,默认为1000.logging_steps: 日志打印的间隔steps数,默认10。valid_steps: evaluate的间隔steps数,默认100。device: 选用什么设备进行训练,可选cpu或gpu。
5.3 推理部署
- 执行以下代码高性能部署快递单识别定制版本UIE模型
from paddlenlp import Taskflow
schema = ["姓名", "电话", "省份", "城市", "县区", "详细地址"]
ie = Taskflow("information_extraction", schema=schema, task_path="./checkpoint/model_best")
ie("北京市海淀区上地十街10号18888888888张三")
[{'姓名': [{'text': '张三',
'start': 24,
'end': 26,
'probability': 0.9993427274729783}],
'电话': [{'text': '18888888888',
'start': 13,
'end': 24,
'probability': 0.9902358279724055}],
'城市': [{'text': '北京市',
'start': 0,
'end': 3,
'probability': 0.99967702117047}],
'县区': [{'text': '海淀区',
'start': 3,
'end': 6,
'probability': 0.9998499188335472}],
'详细地址': [{'text': '上地十街10号',
'start': 6,
'end': 13,
'probability': 0.9594372662315109}]}]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号