关于飞桨UIE等模型预测推理时间很久的问题分析以及解决,蒸馏剪枝部署问题解决
1.关于飞桨UIE等模型预测推理时间很久的问题分析以及解决
1.1.原因分析
用uie做实体识别,Taskflow预测的时间与schema内的实体类别数量成正比,schema里面有多少个实体类别
实体识别中每次取一个类别作为prompt与原文本拼接作为模型的输入,所以schema中有多个实体类别时会预测多次。
1.2.解决方案
1.使用tiny系列模型进行提速
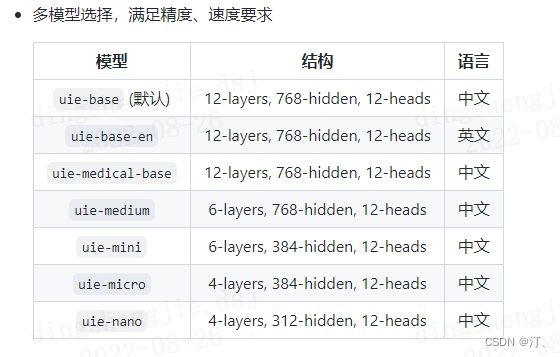
- 更多配置
from paddlenlp import Taskflow
ie = Taskflow('information_extraction',
schema="",
batch_size=1,
model='uie-base',
position_prob=0.5,
precision='fp16')schema:定义任务抽取目标,可参考开箱即用中不同任务的调用示例进行配置。batch_size:批处理大小,请结合机器情况进行调整,默认为1。model:选择任务使用的模型,默认为uie-base,可选有uie-base,uie-medium,uie-mini,uie-micro,uie-nano和uie-medical-base,uie-base-en。position_prob:模型对于span的起始位置/终止位置的结果概率在0~1之间,返回结果去掉小于这个阈值的结果,默认为0.5,span的最终概率输出为起始位置概率和终止位置概率的乘积。precision:选择模型精度,默认为fp32,可选有fp16和fp32。fp16推理速度更快。如果选择fp16,请先确保机器正确安装NVIDIA相关驱动和基础软件,确保CUDA>=11.2,cuDNN>=8.1.1,初次使用需按照提示安装相关依赖。其次,需要确保GPU设备的CUDA计算能力(CUDA Compute Capability)大于7.0,典型的设备包括V100、T4、A10、A100、GTX 20系列和30系列显卡等。更多关于CUDA Compute Capability和精度支持情况请参考NVIDIA文档:GPU硬件与支持精度对照表。
参考链接:https://github.com/PaddlePaddle/PaddleNLP/issues/3022
2. 问题:在使用PaddleSlim进行剪枝后,生成的是静态图,有什么办法可以再加载进模型进行训练,或者像正常训练完model一样进行预测
裁剪后的模型会导出为静态图模型,无法再通过动态图的方式加载再训练。预测的话可以在静态图下或者使用PaddleInference进行预测,这样可以直接加载.pdmodel, .pdiparams进行推理。预测可以参考
PaddleNLP/model_zoo/ernie-3.0/deploy/python at develop · PaddlePaddle/PaddleNLP · GitHub

 浙公网安备 33010602011771号
浙公网安备 33010602011771号