Data Pump Export 数据泵导出
目录对象
- 数据泵必须在 服务端 执行;使用数据泵,需要先创建目录对象,并且需要为数据库用户授予使用该 directory 的权限
- 当你创建一个 directory 时,会自动获得该 directory 的 READ / WRITE / EXECUTE 权限,你也可以将这些权限授给其他用户或角色
SELECT * FROM dba_directories; 查询已有的目录
CREATE OR REPLACE DIRECTORY exp_dir AS '/oratmp'; 自定义目录对象
GRANT READ,WRITE ON DIRECTORY dir_dump TO u1; 授予 u1 用户对该目录的读写权限
DROP DIRECTORY exp_dir; 删除目录
隐含参数 trace
- 可以通过在 Export DataPump(expdp)或 Import DataPump(impdp)的TRACE 参数中指定7位十六进制掩码来启用跟踪;前三位启用对特定数据泵组件的跟踪,而最后四位数通常为:0300
- 可以省略前导零,并且为 TRACE 参数指定的值不区分大小写
- 在为 TRACE 参数指定值时需要记住一些规则:
- 不要指定多于 7个十六进制数字
- 不要指定典型的十六进制规范字符 前导 0x
- 不要将十六进制值转换为十进制值;
- 省略任何前导零(不强制要求);
- 值不区分大小写
- 使用 TRACE 参数时,如果数据泵作业与非特权用户一起运行,则可能会发生错误,例如:
expdp scott/tiger DIRECTORY=my_dir DUMPFILE=expdp_s.dmp LOGFILE=expdp_s.log TABLES=emp TRACE=480300
Export: Release 10.2.0.3.0 - Production on Friday, 19 October, 2007 13:46:33
Copyright (c) 2003, 2005, Oracle. All rights reserved.
Connected to: Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 - Production
With the Partitioning, Oracle Label Security, OLAP and Data Mining Scoring Engine options
ORA-31631: privileges are required
- 要解决此问题,请确保使用 expdp 或 impdp 连接到数据库的用户是特权用户(即具有DBA 角色、 EXP_FULL_DATABASE 或 IMP_FULL_DATABASE 角色),例如:
-- run this Data Pump job with TRACE as a privileged user:
expdp system/manager DIRECTORY=my_dir DUMPFILE=expdp_s.dmp LOGFILE=expdp_s.log TABLES=scott.emp TRACE=480300
-- or:
-- make user SCOTT a privileged user:
CONNECT / AS SYSDBA
GRANT exp_full_database TO scott;
expdp scott/tiger DIRECTORY=my_dir DUMPFILE=expdp_s.dmp LOGFILE=expdp_s.log TABLES=emp TRACE=480300
- 数据泵作业期间发生的大多数错误可以通过为主控制进程(MCP)和工作进程创建一个跟踪文件来诊断,例如:
-- To run a Data Pump job with standard tracing:
-- This results in two trace files in BACKGROUND_DUMP_DEST:
-- Master Process trace file: <SID>_dm<number>_<process_id>.trc
-- Worker Process trace file: <SID>_dw<number>_<process_id>.trc
expdp system/manager DIRECTORY=my_dir DUMPFILE=expdp_s.dmp LOGFILE=expdp_s.log SCHEMAS=scott TRACE=480300
-
可以显式地指定数据泵组件,以获取该组件的详细 trace 信息:
-
跟踪数据泵组件的组合是可能的,例如:
-
对于初始数据泵跟踪,值 480300 足够。当指定值 480300 时,我们将追踪主控制进程(MCP)和工作进程(DW);创建数据泵跟踪文件时,我们建议使用值 480300,除非 Oracle Support 要求不同的跟踪级别
一、数据泵导出介绍
- 数据泵导出是将数据和元数据卸载到操作系统文件集合(称为 dump 文件集)的工具,dump 文件集只能使用数据泵导入工具(impdp)导入
- dump 文件集可以被导入到同一系统,亦可以移动到另一系统进行加载
- dump 文件集由一或多个磁盘文件组成,包含表数据、数据库对象元数据、控制信息的。文件以专有的二进制格式编写。在导入操作期间,Data Pump Import 程序使用这些文件来定位 dump 文件集中的每个数据库对象
二、数据泵导出界面
- 使用 expdp 命令调用数据泵导出程序。导出操作的特征由指定的导出参数决定,可以在命令行或参数文件中指定这些参数
- 1)命令行界面:可以直接在命令行中指定大部分导出参数
- 2)参数文件界面:允许参数文件中指定命令行参数。唯一的例外是 PARFILE 参数,因为参数文件不能嵌套。如果使用值需要引号的参数,建议使用参数文件
- 3)交互命令界面:停止终端的日志记录并显示 Export 提示,从中可以输入各种命令,其中一些命令特定于交互式命令模式。在使用命令行或参数文件界面启动的导出操作期间,按 Ctrl + C 启用此模式。当 attach 到正在执行或停止的作业时,也会启用交互式命令模式
三、数据泵导出模式
- 1)全库导出:使用 FULL 参数指定,该模式下,整个数据库被卸载、该模式需要你具有 DATAPUMP_EXP_FULL_DATABASE 角色
- 2)Schema 导出:使用 SCHEMAS 参数指定 ,这是默认的导出模式。如果你具有 DATAPUMP_EXP_FULL_DATABASE 角色,那么你可以指定一个 shema 列表,包括 schema 定义,以及授予这些 schema 的系统权限;如果你不具有 DATAPUMP_EXP_FULL_DATABASE 角色,那你只能导出自己的 schema
SYS schema 不可以作为一个导出作业的源 schema - 3)表模式:使用 TABLES 参数指定,在表模式下,只卸载一组表、分区以及它们所依赖的对象
- 4)表空间模式:使用 TABLESPACES参数指定。在表空间模式下,仅卸载指定的一组表空间中所包含的表;如果一个表被卸载,那么它所依赖的对象也被卸载;对象的元数据和数据都被卸载。特权用户获取所有表,非特权用户只能获取在自己 schema 中的表
四、导出命令行模式下可用的参数
指定导出参数
- 对于可以指定多个值的参数,可以使用逗号或空格分隔这些值,例如:
TABLES=employees, jobs或TABLES=employees jobs - 对于输入的每一个参数来说,必须指定等号(=)和值,例如,在下面的命令行中,即使 NOLOGFILE 是一个有效的参数,它也会被解释为 DUMPFILE 参数的另一个 dump 文件名
expdp DIRECTORY=dpumpdir DUMPFILE=test.dmp NOLOGFILE TABLES=employees
- 该命令会生成两个 dump 文件:test.dmp 和 nologfile.dmp
- 为了避免该现象,指定 NOLOGFILE=YES 或 NOLOGFILE=NO
在数据泵命令行上使用引号
- 某些操作系统会将引号作为特殊字符处理,因此不会将它们传递给应用程序,除非它们前面带有转义字符,例如反斜杠(\)。在命令行和参数文件中都是如此。一些操作系统可能需要在包含特殊字符的整个参数值的命令行上附加一组单引号或双引号
- 假设在参数文件中指定 TABLES 参数,如下所示:
TABLES = \"MixedCaseTableName \"
- 如果要在命令行中指定,某些操作系统将要求将其使用单引号括起来,如下所示:
TABLES =' \"MixedCaseTableName \" '
- 为了避免在命令行上提供额外的引号,Oracle 建议使用参数文件。另外请注意,如果使用参数文件,并且指定的参数值没有引号作为字符串中的第一个字符(例如TABLES=scott."EmP"),则在某些系统上可能不需要使用转义字符
ACCESS_METHOD
- 默认: AUTOMATIC
- 目的:指示导出使用特定的方法卸载数据
ACCESS_METHOD = [AUTOMATIC | DIRECT_PATH | EXTERNAL_TABLE]
- 如果默认的方法不适用,可以使用该参数指定其他方式。Oracle 建议尽可能使用默认选项(AUTOMATIC),因为它允许 Data Pump 自动选择最有效的方法
- 限制:如果还指定了 NETWORK_LINK 参数,则不支持直接路径模式
expdp hr DIRECTORY = dpump_dir1 DUMPFILE = expdat.dmp SCHEMAS = hr ACCESS_METHOD = EXTERNAL_TABLE
ATTACH
- 默认值:当前在用户 schema 中的作业,如果只用一个
- 目的:连接到现有导出作业的客户端会话并自动将您置于交互式命令界面。导出会显示所连接的作业的描述,并显示
"Export" 提示
ATTACH [= [ schema_name. ] job_name ]
- schema_name 是可选的。要指定除自己以外的 schema,您必须具有该DATAPUMP_EXP_FULL_DATABASE角色
- job_name 是可选的, 如果 schema 中只有一个导出作业,并且该作业是 active 的
- 要连接到已停止的作业,必须提供作业名称。要查看数据泵作业名称列表,可以查询 DBA_DATAPUMP_JOBS 或 USER_DATAPUMP_JOBS 视图
- 限制
- 指定 ATTACH 参数时,可以在命令行中指定的唯一数据泵参数是ENCRYPTION_PASSWORD
- 如果附加到的作业最初是使用加密密码初启动的,则在附加到作业时,必须再次在命令行中输入 ENCRYPTION_PASSWORD 参数以重新指定该密码。唯一的例外是如果作业最初是用 ENCRYPTION=ENCRYPTED_COLUMNS_ONLY 参数启动的。在这种情况下,附加到作业时不需要加密密码
- 除非已经在运行,否则您无法附加到另一个 schema 中的作业
- 如果作业的 dump 文件集或主表已被删除,则附加操作会失败
- 以任何方式更改主表都将导致不可预测的结果
- 示例:它假定该作业 hr.export_job 已经存在
expdp hr ATTACH = hr.export_job
CONTENT
- 默认: ALL
- 目的:指定导出操作要过滤什么数据:仅数据、仅元数据、或都有
CONTENT = [ALL | DATA_ONLY | METADATA_ONLY]
- ALL 卸载数据和元数据。这是默认值
- DATA_ONLY 仅卸载表行数据,没有数据库对象定义被卸载
- METADATA_ONLY 仅卸载数据库对象定义, 没有表行数据被卸载。请注意,如果指定 CONTENT=METADATA_ONLY,那么随后导入 dump 文件时,导入后从 dump 文件导入的索引或表的统计信息将被锁定
- 限制:该 CONTENT=METADATA_ONLY 参数不能与TRANSPORT_TABLESPACES(可传输表空间模式)参数或 QUERY 参数一起使用
- 示例:
> expdp hr DIRECTORY = dpump_dir1 DUMPFILE = hr.dmp CONTENT = METADATA_ONLY
此命令将执行 schema 模式导出,仅卸载与 hr 用户关联的元数据
DIRECTORY
- 默认: DATA_PUMP_DIR
- 目的:指定导出可以写入 dump 文件集和日志文件的默认位置
DIRECTORY = directory_object
- directory_object 是数据库目录对象的名称(而不是实际目录的文件路径)
- 安装数据库后,特权用户可以访问名为 DATA_PUMP_DIR 的默认目录对象。具有访问默认目录对象的用户根本不需要使用 DIRECTORY参数
- 在 DUMPFILE 或 LOGFILE 参数上指定的目录对象将覆盖为 DIRECTORY 参数指定的对象
- 示例:
expdp hr DIRECTORY = dpump_dir1 DUMPFILE = employees.dmp CONTENT = METADATA_ONLY
employees.dmp 文件将被写入与 dpump_dir1 目录对象相关联的路径
DUMPFILE
- 默认值:expdat.dmp
- 目的:指定 dump 文件的名称、目录对象
DUMPFILE = [ directory_object:] file_name [ , ...]
- directory_object 是可选的,如果已经使用 DIRECTORY 参数建立了一个。如果在此处提供一个值,那么它必须是已经存在并且可以访问的目录对象
- 可以提供多个 file_name,使用逗号分隔,或者使用多个 DUMPFILE 参数。如果文件名没有扩展名,则导出会使用默认文件扩展名 .dmp。文件名可以包含一个替换变量(%U),这意味着可能会生成多个文件。替换变量在结果文件名中扩展为从 01 开始并以 99 结尾的2位固定宽度递增整数。如果文件名中包含两个替换变量,则两者都将同时递增。例如,exp%Uaa%U.dmp 将解析为 exp01aa01.dmp,exp02aa02.dmp,等等
- 如果指定了 FILESIZE 参数,那么每个 dump 文件的最大值将不会超过此大小并且不能扩展。如果 dump 文件集需要更多空间,并且提供了带有替换变量(%U)的模板,如果设备上有空间,则会自动创建一个新的 dump 文件,该参数大小由参数 FILESIZE指定
- 限制:任何与已存在的 dump 文件名匹配的 dump 文件名将会生成错误,并且已存在的文件将不会被覆盖;可以通过指定导出参数 REUSE_DUMPFILES=YES 来覆盖此行为
- 示例:
expdp hr SCHEMAS = hr DIRECTORY = dpump_dir1 DUMPFILE = dpump_dir2:exp1.dmp, exp2%U.dmp PARALLEL = 3
- exp1.dmp 文件将被写入与 dpump_dir2 相关联的路径,因为 dpump_dir2被指定为转储文件名的一部分,因此覆盖了使用DIRECTORY 参数指定的目录对象。因为三个并行进程将给予给这项作业,转储文件命名为 exp201.dmp,并 会根据指定的替代变量 exp2%U.dmp 来创建 exp202.dmp 。因为没有为它们指定目录,所以它们将被写入DIRECTORY参数指定的目录对象 dpump_dir1 所关联的路径
ESTIMATE
- 默认: BLOCKS
- 目的:指定将用于估算导出作业中的每个表将占用多少磁盘空间(以字节为单位)的方法。估计值会打印在日志文件中,并显示在客户端的标准输出设备上。估计仅用于表行数据,它不包括元数据
ESTIMATE = [BLOCKS | STATISTICS]
- BLOCKS 通过将源对象使用的数据库块的数量乘以适当的块大小来计算估计值
- STATISTICS 使用每个表的统计量计算估计。为了使这种方法尽可能准确,所有的表都应该被分析了(可以使用 ANALYZE 语句或 DBMS_STATS 包进行表分析)
- 限制:
- 如果数据泵导出作业涉及压缩表,则当使用 ESTIMATE=BLOCKS 时,估计的压缩表大小是不准确的。这是因为大小估计不会映射以压缩形式存储的数据。要获得压缩表的更准确的大小估计,请使用 ESTIMATE=STATISTICS
- 如果使用 QUERY或REMAP_DATA参数,估计可能也不准确
- 示例:
expdp hr TABLES = employees ESTIMATE = STATISTICS DIRECTORY = dpump_dir1 DUMPFILE = estimate_stat.dmp
ESTIMATE_ONLY
- 默认: NO
- 目的:估计导出作业将消耗的空间,而不实际执行导出操作
ESTIMATE_ONLY = [YES | NO]
- 如果 ESTIMATE_ONLY= YES,则估计将被消耗的空间,但并不实际执行导出操作而退出
- 限制:该参数不能与QUERY参数结合使用
- 示例:使用该参数确定导出 HR 用户需要多少空间
expdp hr ESTIMATE_ONLY = YES NOLOGFILE = YES SCHEMAS = HR
FILESIZE
- 默认值:(0 相当于最大大小为16 TB)
- 目的:指定每个转储文件的最大大小。如果转储文件集的任何成员达到大小,那么该文件将被关闭,并尝试创建一个新文件,如果文件名中包含一个替换变量,或者已将其他转储文件添加到作业中
FILESIZE = integer [B | KB | MB | GB | TB]
- 字节是默认值。生成的文件的实际大小可能略微向下舍入,以匹配转储文件中使用的内部块的大小
- 限制:文件的最小值是默认数据泵块大小的十倍,为4千字节;文件的最大值为16 TB
- 示例:将转储文件的大小设置为3兆字节
expdp hr DIRECTORY = dpump_dir1 DUMPFILE = hr_3m.dmp FILESIZE = 3MB
- 如果3兆字节不足以容纳所有导出的数据,则会显示以下错误,并且该作业将停止:
ORA-39095: Dump file space has been exhausted: Unable to allocate 217088 bytes
- 无法分配的实际字节数可能会有所不同。此外,此数字并不表示完成整个导出操作所需的空间量。它只表示当作业用完转储文件空间时,当前正在导出的对象的大小。可以通过附加到停止的作业,使用 ADD_FILE 命令添加一个或多个文件,然后重新启动操作来纠正此情况
交互式命令模式下可用的命令
- 在交互式命令模式下,当前作业将继续运行,但登录终端已暂停,并显示导出提示符(Export>)
- 要启动交互式命令模式,请执行以下操作之一:
- 从连接的客户端,按Ctrl + C
- 从正在运行作业的终端以外的终端,使用 ATTACH 参数附加到作业
![]()
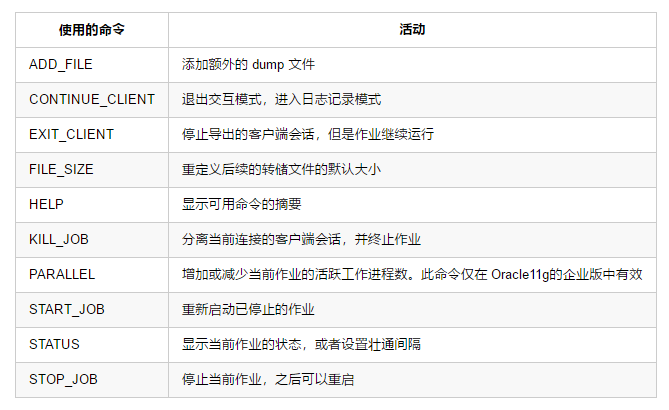
ADD_FILE
- 目的:添加文件或替代变量到 dump文件集
ADD_FILE = [ directory_object:] file_name [ , ...]
- 每个文件名可以有一个不同的目录对象。如果没有指定目录对象,则使用默认的
- file_name 不得包含任何目录路径信息。但是,它可以包括一个替换变量,%U它表示可以按照给定的文件名模板生成多个文件
- 要添加的文件的大小由 FILESIZE 参数决定
- 示例:将两个转储文件添加到转储文件集。没有为 hr2.dmp 指定目录对象,因此使用默认目录对象。为名为 hr3.dmp 的转储文件指定了目录对象 dpump_dir2
Export > ADD_FILE = hr2.dmp,dpump_dir2:hr3.dmp
CONTINUE_CLIENT
- 目的: 从交互式命令模式到日志记录模式
CONTINUE_CLIENT
- 在记录模式下,状态会持续输出到终端。如果该作业目前已停止,则CONTINUE_CLIENT 还会使客户端尝试启动该作业
- 示例
Export> CONTINUE_CLIENT
EXIT_CLIENT
- 目的:停止导出客户端会话,退出 Export,并停止日志记录到终端,但使当前作业运行
- 因为 EXIT_CLIENT 使作业运行,之后可以附加到该作业。要查看作业的状态,可以监控作业的日志文件,也可以查询 USER_DATAPUMP_JOBS、V$SESSION_LONGOPS视图
- 示例
Export> EXIT_CLIENT
FILE_SIZE
- 目的:重新定义后续转储文件的最大大小
- 其他介绍同 命令模式
HELP
- 显示有关交互式命令模式下可用命令的信息
- 示例
Export> HELP
KILL_JOB
- 目的:分离所有当前连接的客户端会话,然后终止当前作业。它退出 Export 并返回到终端提示符
- 使用 KILL_JOB 终止的作业无法重新启动。所有连接的客户端(包括发出KILL_JOB 命令的客户端)都会收到警告,指示该作业正在被当前用户终止,然后被分离。所有客户端被分离后,作业的进程结构将停止,主表和转储文件将被删除,日志文件不被删除
- 示例
Export> KILL_JOB
PARALLEL
- 目的:增加或减少当前作业的活跃进程(工作和并行 slaves)的数量
PARALLEL = integer
- PARALLEL 可用作命令行参数和交互命令模式参数。你可以根据需要设置并行进程数。如果有足够的文件和资源,增加将立即生效。在现有进程完成当前任务之前,减少不会生效。如果值降低,则工作进程将空闲,但不会删除,直到作业退出
START_JOB
- 目的:启动 ATTACH 到的当前作业
- START_JOB 命令重新启动附加到的当前作业(该作业当前无法执行)。在意外故障或发出STOP_JOB命令后,重新启动作业,而没有数据丢失或损坏,前提是转储文件集和主表没有以任何方式进行更改
- 以可传输表空间模式完成的导出不可重新启动
STATUS
- 目的:显示作业的累积状态,当前操作的描述以及预估的完成百分比。它还允许你重置日志记录模式下状态的显示间隔
STATUS [= integer ]
- 可以选择指定在日志记录模式下状态的显示频率(以秒为单位)。如果没有输入值,或者使用默认值0,则周期状态显示被关闭,状态只显示一次
- 此状态信息仅写入到标准输出设备,而不是日志文件
- 示例:显示当前作业状态,并将日志记录模式的显示间隔更改为五分钟(300秒)
Export> STATUS = 300
STOP_JOB
- 目的:立即停止当前作业,或在有序关闭后停止作业,退出 Export 提示界面
STOP_JOB [= IMMEDIATE]
- 如果主表和转储文件集在 STOP_JOB 命令发出时或发出后不受干扰,则之后可以附加到该作业并使用 START_JOB 重新启动
- 要执行有序的关闭,使用 STOP_JOB(不带任何关联值),将发出需要确认的警告。在工作进程完成当前任务之后,有序关闭会停止该作业
- 要执行立即关闭,指定 STOP_JOB= IMMEDIATE,将发出需要确认的警告。所有连接的客户端,包括发出 STOP_JOB 命令的客户端都会收到一条警告,指示该作业正被当前用户停止,并且它们将被分离。所有客户端分离后,该作业的进程结构会立即停止运行。也就是说,主进程不会等待工作进程完成当前的任务。指定STOP_JOB=IMMEDIATE ,不存在损坏或丢失数据的风险。但是,某些在关机时未完成的任务可能在重启动时需要重做
使用交互模式停止并重新连接到作业
- 1)执行全库导出
expdp hr FULL=YES DUMPFILE=dpump_dir1:full1%U.dmp, dpump_dir2:full2%U.dmp FILESIZE=2G PARALLEL=3 LOGFILE=dpump_dir1:expfull.log JOB_NAME=expfull
- 2)导出正在运行时,按 Ctrl + C,这将启动数据泵导出的交互模式;在 Export 提示符下,发出以下命令停止作业:作业处于停止状态并退出客户端
Export> STOP_JOB=IMMEDIATE
Are you sure you wish to stop this job ([y]/n): y
- 3)输入以下命令重新连接刚刚停止的作业
Export> expdp hr ATTACH = EXPFULL
- 显示作业状态后,可以发出 CONTINUE_CLIENT 命令恢复日志记录模式并重新启动 expfull 作业
Export> CONTINUE_CLIENT
- 消息显示该作业已重新打开,并将处理状态输出到客户端

 浙公网安备 33010602011771号
浙公网安备 33010602011771号