模块(序列化(json&pickle)+XML+requests)
一、序列化模块
Python中用于序列化的两个模块:
- json 跨平台跨语言的数据传输格式,用于【字符串】和 【python基本数据类型】 间进行转换
- pickle python内置的数据传输格式,多用于二进制形式,用于【python特有的类型】 和 【python基本数据类型】间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
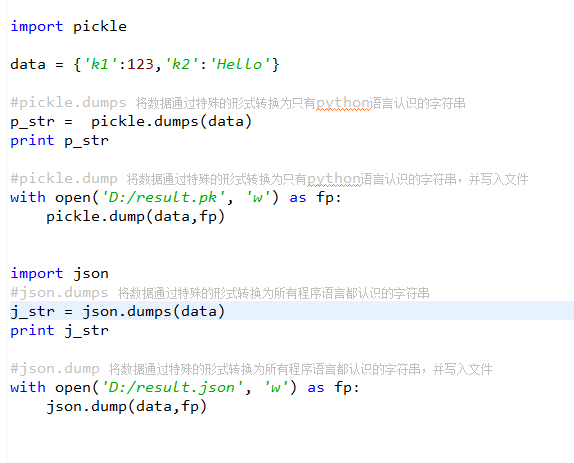
#pickle.dumps将数据通过特殊的形式转换为只有python能识别的字符串 import pickle data={'k1':123,'k2':'hello'} p_str=pickle.dumps(data) print(p_str) ------->b'\x80\x03}q\x00(X\x02\x00\x00\x00k2q\x01X\x05\x00\x00\x00helloq\x02X\x02\x00\x00\x00k1q\x03K{u.' s = pickle.loads(p_str) print(s) -------->{'k2': 'hello', 'k1': 123} #pickle.dump将数据通过特殊的形式转换为只有python认识的字符串,并写入文件 with open('db','w') as fp: pickle.dump(data,fp) json实例 #json.loads()#将字符串转换成python基本数据类型,注:里面一定要是双引号,外面是单引号 import json s='{"name":"tina","age":"18"}' l='[1,2,3,4]' r=json.loads(l) w=json.loads(s) print(r,type(r)) print(w,type(w)) ############执行结果如下:########### [1, 2, 3, 4] <class 'list'> {'age': '18', 'name': 'tina'} <class 'dict'> #json.dumps()将python的基本数据类型转换成字符串 a={"name":"tina","age":"18"} b=json.dumps(a) print(b,type(b)) #############执行结果如下:########## {"age": "18", "name": "tina"} <class 'str'> #不带s的是对文件进行操作 dic = {'k1':123,'k2':345} a=json.dump(dic,open('db','w')) print(a,type(a)) #读内容 #字符串转换成字典 r=json.load(open('db','r')) print(r,type(r)) #############执行结果如下:########## 写入db文件中的内容即为dict {'k2': 345, 'k1': 123} <class 'dict'>
二、XML
JSON跨平台跨语言的数据传输格式
XML实现不同语言或程序之间进行数据交换的协议
返回的都是字符串,只是不同表现形式的字符串
XML文件格式如下:
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2023</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria" />
<neighbor direction="W" name="Switzerland" />
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2026</year>
<gdppc>59900</gdppc>
<neighbor direction="N" name="Malaysia" />
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2026</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica" />
<neighbor direction="E" name="Colombia" />
</country>
</data>
1、解析XML
from xml.etree import ElementTree as ET #打开文件,读取文件内容 str_xml = open('first.xml','r').read() #将文件内容解析成XML格式,root是文件tree的根节点 root=ET.XML(str_xml) print(root.tag) #打印根节点的标签,结果为data print(root) #<Element 'data' at 0x00000057EDD566D8>
方法二: from xml.etree import ElementTree as ET #直接解析XML文件 tree = ET.parse('first.xml') #获取XML文件的根节点 root=tree.getroot() print(root) #<Element 'data' at 0x0000008708517318> print(root.tag) #data #返回结果是一样的
@@@@@@@@@小练习@@@@@@@@ from xml.etree import ElementTree as tina TT = tina.parse('first.xml') print(TT.getroot().tag) #data
2、操作XML
XML格式类型是节点嵌套节点,对于每一个节点均有以下功能,以便对当前节点进行操作:
 功能源码总览
功能源码总览具体用法举例说明:
(1)遍历XML文档的所有内容
eg1(2) 遍历XML中指定的节点

from xml.etree import ElementTree as ET ############ 解析方式一 ############ """ # 打开文件,读取XML内容 str_xml = open('xo.xml', 'r').read() # 将字符串解析成xml特殊对象,root代指xml文件的根节点 root = ET.XML(str_xml) """ ############ 解析方式二 ############ # 直接解析xml文件 tree = ET.parse("xo.xml") # 获取xml文件的根节点 root = tree.getroot() ### 操作 # 顶层标签 print(root.tag) # 遍历XML中所有的year节点 for node in root.iter('year'): # 节点的标签名称和内容 print(node.tag, node.text)
from xml.etree import ElementTree as tina TT = tina.parse('first.xml') # print(TT.getroot().tag) # for i in TT.getroot():#在跟节点下遍历孩子标签及属性 # print(i.tag,i.attrib) # for j in i:#在孩子节点下遍历孙子标签及属性 # print(j.tag,j.attrib) #返回结果也是呈树状的,有点像之前三级联动的小练习 for node in TT.getroot().iter('year'): #遍历XML中所有的year节点,类似于Windows中文件夹中全局搜索 print(node.tag,node.text) @@@@@@非注释部分的执行结果如下:@@@@@@@ year 2025 year 2028 year 2028
(3)修改节点内容
由于修改节点时,都是在内存中进行,不会影响文件中的内容,所以,如果想要修改,则需要重新将内存中的内容写入到文件。
解析字符串方式打开,修改,保存解析文件方式打开,修改,保存(4)删除节点
解析字符串方式打开,删除,保存解析文件方式打开,删除,保存
3、创建XML文档
from xml.etree import ElementTree as ET # 创建根节点 root = ET.Element("famliy") # 创建节点大儿子 son1 = ET.Element('son', {'name': '儿1'}) # 创建小儿子 son2 = ET.Element('son', {"name": '儿2'}) # 在大儿子中创建两个孙子 grandson1 = ET.Element('grandson', {'name': '儿11'}) grandson2 = ET.Element('grandson', {'name': '儿12'}) son1.append(grandson1) son1.append(grandson2) # 把儿子添加到根节点中 root.append(son1) root.append(son1) tree = ET.ElementTree(root) tree.write('oooo.xml',encoding='utf-8', short_empty_elements=False) 创建方式(一)
创建方式二创建方式三
由于原生保存的XML时默认无缩进,如果要设置缩进的话,需要修改保存方式:
from xml.etree import ElementTree as ET from xml.dom import minidom def prettify(elem): """将节点转换成字符串,并添加缩进。 """ rough_string = ET.tostring(elem, 'utf-8') reparsed = minidom.parseString(rough_string) return reparsed.toprettyxml(indent="\t") # 创建根节点 root = ET.Element("famliy") # 创建大儿子 # son1 = ET.Element('son', {'name': '儿1'}) son1 = root.makeelement('son', {'name': '儿1'}) # 创建小儿子 # son2 = ET.Element('son', {"name": '儿2'}) son2 = root.makeelement('son', {"name": '儿2'}) # 在大儿子中创建两个孙子 # grandson1 = ET.Element('grandson', {'name': '儿11'}) grandson1 = son1.makeelement('grandson', {'name': '儿11'}) # grandson2 = ET.Element('grandson', {'name': '儿12'}) grandson2 = son1.makeelement('grandson', {'name': '儿12'}) son1.append(grandson1) son1.append(grandson2) # 把儿子添加到根节点中 root.append(son1) root.append(son1) raw_str = prettify(root) f = open("xxxoo.xml",'w',encoding='utf-8') f.write(raw_str) f.close()
4、命名空间
详细介绍,猛击这里
from xml.etree import ElementTree as ET ET.register_namespace('com',"http://www.company.com") #some name # build a tree structure root = ET.Element("{http://www.company.com}STUFF") body = ET.SubElement(root, "{http://www.company.com}MORE_STUFF", attrib={"{http://www.company.com}hhh": "123"}) body.text = "STUFF EVERYWHERE!" # wrap it in an ElementTree instance, and save as XML tree = ET.ElementTree(root) tree.write("page.xml", xml_declaration=True, encoding='utf-8', method="xml") 命名空间
三、requests模块
requests是使用Apache2 Licensed许可证的基于python开发的HTTP库,其在python内置模块的基础上进行了高度的封装,从而使pythoner在进行网络请求时,变得更容易,使用requests可以轻而易举的完成浏览器可有的任何操作。requests模块是第三方开发库里的模块,调用前要先下载安装该模块。
1、安装模块
pip3 install requests
2、使用模块
无参数,直接访问网站,拿数据 import requests response = requests.get("http://www.weather.com.cn/adat/sk/101010500.html") response.encoding='utf-8' result = response.text print(result)
###################执行结果如下:#####################
{"weatherinfo":
{"city":"怀柔",
"cityid":"101010500",
"temp":"9",
"WD":"南风",
"WS":"1级",
"SD":"29%",
"WSE":"1",
"time":"10:25",
"isRadar":"1",
"Radar":"JC_RADAR_AZ9010_JB",
"njd":"暂无实况","qy":"1007"}
}
有参数,参数用params=变量名传入,结果中会先将参数打印在头部
import requests payload={'k1':'value1','k2':'value2'} ret=requests.get("http://www.weather.com.cn/adat/sk/101010500.html",params=payload) ret.encoding='utf-8' print(ret.url) print(ret.text) ###############执行结果如下:################ http://www.weather.com.cn/adat/sk/101010500.html?k1=value1&k2=value2 {"weatherinfo": {"city":"怀柔", "cityid":"101010500", "temp":"9", "WD":"南风", "WS":"级", "SD":"29%", "WSE":"1", "time":"10:25", "isRadar":"1", "Radar":"JC_RADAR_AZ9010_JB", "njd":"暂无实况", "qy":"1007"} }
# 1、基本POST实例 import requests payload = {'key1': 'value1', 'key2': 'value2'} ret = requests.post("http://httpbin.org/post", data=payload) print(ret.text) # 2、发送请求头和数据实例 import requests import json url = 'https://api.github.com/some/endpoint' payload = {'some': 'data'} headers = {'content-type': 'application/json'} ret = requests.post(url, data=json.dumps(payload), headers=headers) print(ret.text) print(ret.cookies)#cookies验证,比如登录后服务器会发送一串XX码保存在客户端内存中或硬盘中,即为cookies POST请求
更多requests模块相关的文档见:http://cn.python-requests.org/zh_CN/latest/
3、用requests模块发送HTTP请求,请求结束后解析XML的实例
import urllib import requests from xml.etree import ElementTree as ET # 使用内置模块urllib发送HTTP请求,或者XML格式内容 """ f = urllib.request.urlopen('http://www.webxml.com.cn//webservices/qqOnlineWebService.asmx/qqCheckOnline?qqCode=424662508') result = f.read().decode('utf-8') """ @@显然使用内置urllib模块的方式比较繁琐,所以请选择忘记,并选择用下面的requests模块来发送HTTP请求。@@ # 使用第三方模块requests发送HTTP请求,或者XML格式内容 r = requests.get('http://www.webxml.com.cn//webservices/qqOnlineWebService.asmx/qqCheckOnline?qqCode=424662508') result = r.text # 解析XML格式内容 node = ET.XML(result)#这里的ET.XML在此篇二、XML模块中有详解 # 获取内容 if node.text == "Y": print("在线") else: print("离线")
import urllib import requests from xml.etree import ElementTree as ET # 使用内置模块urllib发送HTTP请求,或者XML格式内容 """ f = urllib.request.urlopen('http://www.webxml.com.cn/WebServices/TrainTimeWebService.asmx/getDetailInfoByTrainCode?TrainCode=G666&UserID=') result = f.read().decode('utf-8') """ # 使用第三方模块requests发送HTTP请求,或者XML格式内容 r = requests.get('http://www.webxml.com.cn/WebServices/TrainTimeWebService.asmx/getDetailInfoByTrainCode?TrainCode=G666&UserID=') result = r.text # 解析XML格式内容 root = ET.XML(result) for node in root.iter('TrainDetailInfo'): print(node.find('TrainStation').text,node.find('StartTime').text,node.tag,node.attrib)
注:更多接口猛击这里
四、总结
1、json数据传输时用的
2、XML一种文件表现形式,形似树
3、requests模块就是程序媛们访问网站或者API接口拿数据时用的,记住requests比urllib好用,然后记住requests.get(),requests.post()就行了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号