


机器学习二 逻辑回归作业
作业在这,http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2016/Lecture/hw2.pdf 是区分spam的。

57维特征,2分类问题。采用逻辑回归方法。但是上述数据集在kaggle中没法下载,于是只能用替代的方法了,下了breast-cancer-wisconsin数据集。
链接在这http://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data
9个特征,标签分别为2/4 第一个为序号,没有表头,一共699个数据,但有些数据有缺失? 采取丢弃
不说了,上代码,看看怎么弄。
第一步: 读取原始数据集,并去除数据缺失的数据,并将标签变为0/1

1 # -*- coding: utf-8 -*-
2 __author__ = 'Administrator'
3
4 import csv
5 import cv2
6 import sys
7 import numpy as np
8 import math
9 import random
10
11 filename = 'F:/台湾机器学习/data/2/data.csv'
12 ufilename = unicode(filename , "utf8") #这一块主要是因为汉字路径 也就是python调用open打开文件时,其路径必须要转换为utf-8格式
13 list=[]
14 result=[]
15 row=0
16 colum=0;
17 with open(ufilename, 'r') as f:
18 data = f.readlines() #dat中所有字符串读入data
19 for line in data:
20 odom = line.split(',') #将单个数据分隔开存好
21 colum=len(odom)
22 if '?'in odom:
23 print(odom)
24 else:
25 lists= map(int, odom[1:11])#第一个开始开始数据 一直取10个数
26 if lists[9]==2:
27 lists[9]=0
28 else:
29 lists[9]=1
30 list.append(lists)
31 # print odom
32 row=row+1
33
34 print("原始数据是:{0}行 :{1}列 的数据".format(row, colum))
35 print("有{0}个训练数据".format(len(list)))
第二步: 随机划分数据集为训练和测试集,并且保存到csv文件中, 默认是583个训练 100个测试
1 #保存为训练集和测试集合
2 #输出最后的测试结果
3
4 l=[]
5 csvfile = file('F:\\csv_train.csv', 'wb')
6 writer = csv.writer(csvfile)
7 #n=input('你想选几个?')
8 n=583
9 while n>len(list) or n<=len(list)/2:
10 print '数据集选择错误'
11 n=input('请重新输入一个合适的的数:')
12
13 print(list[0])
14 while n!=len(l):
15 x=random.randint(0,len(list)-1)
16 if x in l:
17 continue
18 else:
19 print(x)
20 l.append(x)
21 print(list[x]) #tuple不能赋值进行修改
22 writer.writerow(list[x]) #必须是row 没有s
23 csvfile.close()
24 print l
25 csvfiletest = file('F:\\csv_test.csv', 'wb')
26 writer = csv.writer(csvfiletest)
27 for i in range(len(list)):
28 if i in l:
29 continue
30 else:
31 writer.writerow(list[i]) #必须是row 没有s
32 csvfile.close()
第三步: 读取训练集开始训练:
1 # -*- coding:UTF-8 -*-
2 __author__ = 'tao'
3
4 import csv
5 import cv2
6 import sys
7 import numpy as np
8 import math
9 from sklearn.linear_model import LogisticRegression
10
11 filename = 'F:/台湾机器学习/data/2/csv_train.csv'
12 ufilename = unicode(filename , "utf8") #这一块主要是因为汉字路径 也就是python调用open打开文件时,其路径必须要转换为utf-8格式
13 list=[]
14 result=[]
15 row=0
16 colum=0;
17 with open(ufilename, 'r') as f:
18 data = f.readlines() #dat中所有字符串读入data
19 for line in data:
20 odom = line.split(',') #将单个数据分隔开存好
21 colum=len(odom)
22 lists= map(int, odom[0:9])#第三个开始开始数据 一直取9个数
23 results= map(int, odom[9:10])#取第10个数
24 list.append(lists)
25 result.append(results)
26 # print odom
27 row=row+1
28
29 print("原始数据是:{0}行 :{1}列 的数据".format(row, colum))
30 print("有{0}个训练数据".format(len(list)))
31
32
33 #y=w0*x0+w1*x1+w2*x2+w3*x3+w4*x4+w5*x5+w6*x6+w7*x7+w8*x8+b0
34 #z=1/(1+exp(y))
35 #
36 alpha=0.01
37 b_0=np.random.rand(1,1)
38 th = np.random.rand(1,9);
39 print(th)
40 b_0=np.array([[0]])
41
42 th= np.array([[1, 1, 1, 1, 1, 1, 1 ,1, 1]])
43 print(th)
44
45 L =[]
46 batch=100
47 for k in range(2000):
48 length = len(list)
49 jtheta = 0
50 total = 0
51 sum_total = 0
52 count=0
53 error =0
54 for j in range(batch): #batch
55 # print("当前序号{0}训练数据".format(id))
56 xset= np.array(list[j+count*batch]) #一行 X数值
57 yset= np.array(result[j+count*batch]) # 要估计值
58 z=1.0/(1+math.exp((np.dot(th,xset)+b_0)*(-1)))
59 total = total+z- yset
60 error= error +(-1)*(yset*math.log(z,math.e)+(1-yset)*(1-math.log(z,math.e)))
61 # print( "当前误差{0}".format(b_0 +np.dot(th,xset)- yset))
62 b_0 = b_0 - 1.0*alpha/batch*(total)
63 th = th - 1.0*alpha/batch*(total)*xset
64 L.append(error)
65 count = count +1
66 if(count>=len(list)/batch):
67 break;
68 if(j==batch-1):
69 print " %10.5f %10.5f %10.5f %10.5f %10.5f %10.5f %10.5f %10.5f %10.5f %10.5f \n" %(b_0,th[0][0],th[0][1],th[0][2],th[0][3],th[0][4],th[0][5],th[0][6],th[0][7],th[0][8])
70
71 #
72 print("-训练得到的权值如下--")
73 print" %10.5f %10.5f %10.5f %10.5f %10.5f %10.5f %10.5f %10.5f %10.5f %10.5f \n" %(b_0,th[0][0],th[0][1],th[0][2],th[0][3],th[0][4],th[0][5],th[0][6],th[0][7],th[0][8])
第四部:测试
#测试训练集
count=0;
for k in range(len(list)):
xset = np.array(list[k])
nptresult= np.array(result[k])
# print(xset)
# print("预测数据{0}".format( b_0 + th_0 * xset[0]+ th_1 * xset[1]+ th_2 * xset[2]+ th_3 * xset[3]+ th_4 * xset[4]+ th_5 * xset[5]+ th_6 * xset[6]+ th_7 * xset[7]+ th_8 * xset[8]))
# print("真实数据{0}".format(nptresult))
z=1.0/(1+math.exp((np.dot(th,xset)+b_0)*(-1)))
if z>=0.5:
lgresult=1;
else:
lgresult=0;
if lgresult == nptresult:
continue
else:
count = count+1;
print("第几个{0}出错".format(k))
print(count)
print("训练数据集的正确率为{0}".format(1-1.0*count/len(list)))
import matplotlib.pyplot as plt
plt.plot(range(len(L)), L, 'r')
plt.xlabel('index')
plt.ylabel('error')
plt.title('line_regression & gradient decrease')
plt.legend()
plt.show()
## 采用模型
# lr = LogisticRegression()
# lr.fit(list,result)
# count=0
# for k in range(len(list)):
# xset = np.array(list[k])
# nptresult= np.array(result[k])
# ly_y_predict= lr.predict(xset)
# if ly_y_predict == nptresult:
# continue
# else:
# count = count+1;
# print("第几个{0}出错".format(k))
# print(count)
# print("采用sk模型训练数据集的正确率为{0}".format(1-1.0*count/len(list)))
#
# print 'accuragy',lr.score(list,result)
#读取测试集数据
testfilename = 'F:/台湾机器学习/data/2/csv_test.csv'
utestfilename = unicode(testfilename , "utf8") #这一块主要是因为汉字路径 也就是python调用open打开文件时,其路径必须要转换为utf-8格式
testlist=[]
testresult=[]
testrow=0
testcolum=0;
with open(utestfilename, 'r') as f:
testdata = f.readlines() #dat中所有字符串读入data
for line in testdata:
odom = line.split(',') #将单个数据分隔开存好
testcolum=len(odom)
testlists= map(int, odom[0:9])#第三个开始开始数据 一直取9个数
testlist.append(testlists)
testresults= map(int, odom[9:10])#取第10个数
testresult.append(testresults)
# print odom
testrow=testrow+1
print("测试数据是:{0}行 :{1}列 的数据".format(testrow, testcolum))
print("有{0}个测试数据".format(len(testlist)))
# #我的模型读取测试数据
tcount=0
for k in range(len(testlist)):
xset = np.array(testlist[k])
nptresult= np.array(testresult[k])
z= 1.0/(1+math.exp((np.dot(th,xset)+b_0)*(-1)))
lgresult=0
if z>=0.5:
lgresult=1;
else:
lgresult=0;
if lgresult == nptresult:
continue
else:
tcount = tcount+1;
print("第几个{0}出错".format(k))
print(tcount)
print("测试数据集的正确率为{0}".format(1-1.0*tcount/len(testlist)))
# #模型读取测试数据
# tcount=0
# for k in range(len(testlist)):
# xset = np.array(testlist[k])
# nptresult= np.array(testresult[k])
# ly_y_predict= lr.predict(xset)
# if ly_y_predict == nptresult:
# continue
# else:
# tcount = tcount+1;
# print("第几个{0}出错".format(k))
# print(tcount)
# print("采用sk测试数据集的正确率为{0}".format(1-1.0*tcount/len(testlist)))
损失函数下降图像:

测试数据集正确率:86%左右 。
可是用sklearn自己带的模型是 96%
囧。。。。想想办法刷刷数据,这个程序设计到 从读取CSV文件中随机的划分训练集和测试集合。通过计算出损失函数利用matplot绘图
逻辑回归(Logistic Regression)
从本质上讲:机器学习就是一个模型对外界的刺激(训练样本)做出反应,趋利避害(评价标准)。
1. 什么是逻辑回归?
许多人对线性回归都比较熟悉,但知道逻辑回归的人可能就要少的多。从大的类别上来说,逻辑回归是一种有监督的统计学习方法,主要用于对样本进行分类。
在线性回归模型中,输出一般是连续的,例如
,对于每一个输入的x,都有一个对应的y输出。模型的定义域和值域都可以是[-∞, +∞]。但是对于逻辑回归,输入可以是连续的[-∞, +∞],但输出一般是离散的,即只有有限多个输出值。例如,其值域可以只有两个值{0, 1},这两个值可以表示对样本的某种分类,高/低、患病/健康、阴性/阳性等,这就是最常见的二分类逻辑回归。因此,从整体上来说,通过逻辑回归模型,我们将在整个实数范围上的x映射到了有限个点上,这样就实现了对x的分类。因为每次拿过来一个x,经过逻辑回归分析,就可以将它归入某一类y中。
逻辑回归与线性回归的关系
逻辑回归也被称为广义线性回归模型,它与线性回归模型的形式基本上相同,都具有 ax+b,其中a和b是待求参数,其区别在于他们的因变量不同,多重线性回归直接将ax+b作为因变量,即y = ax+b,而logistic回归则通过函数S将ax+b对应到一个隐状态p,p = S(ax+b),然后根据p与1-p的大小决定因变量的值。这里的函数S就是Sigmoid函数
将t换成ax+b,可以得到逻辑回归模型的参数形式:
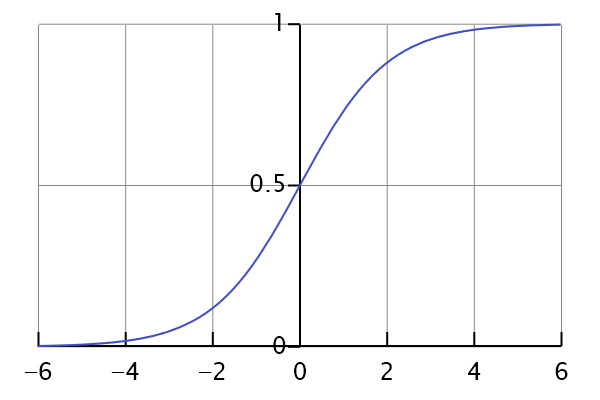
图1:sigmoid函数的图像
通过函数S的作用,我们可以将输出的值限制在区间[0, 1]上,p(x)则可以用来表示概率p(y=1|x),即当一个x发生时,y被分到1那一组的概率。可是,等等,我们上面说y只有两种取值,但是这里却出现了一个区间[0, 1],这是什么鬼??其实在真实情况下,我们最终得到的y的值是在[0, 1]这个区间上的一个数,然后我们可以选择一个阈值,通常是0.5,当y>0.5时,就将这个x归到1这一类,如果y<0.5就将x归到0这一类。但是阈值是可以调整的,比如说一个比较保守的人,可能将阈值设为0.9,也就是说有超过90%的把握,才相信这个x属于1这一类。了解一个算法,最好的办法就是自己从头实现一次。下面是逻辑回归的具体实现。
逻辑回归模型的代价函数
逻辑回归一般使用交叉熵作为代价函数。关于代价函数的具体细节,请参考代价函数,这里只给出交叉熵公式:
m:训练样本的个数;
hθ(x):用参数θ和x预测出来的y值;
y:原训练样本中的y值,也就是标准答案
上角标(i):第i个样本
2. 数据准备
下面的数据来自《机器学习实战》中的示例:

-0.017612 14.053064 0 -1.395634 4.662541 1 -0.752157 6.538620 0 -1.322371 7.152853 0 0.423363 11.054677 0 0.406704 7.067335 1 0.667394 12.741452 0 -2.460150 6.866805 1 0.569411 9.548755 0 -0.026632 10.427743 0
上面的数据一共是3列10行,其中前两列为x1和x2的值,第3列表示y的值;10行表示取了10个样本点。我们可以将这些数据当做训练模型参数的训练样本。
见到训练样本就可以比较直观的理解算法的输入,以及我们如何利用这些数据来训练逻辑回归分类器,进而用训练好的模型来预测新的样本(检测样本)。
从逻辑回归的参数形式,式子(1)我们可以看到逻辑回归模型中有两个待定参数a(x的系数)和b(常数项),我们现在给出来的数据有两个特征x1, x2,因此整个模型就增加了一项:ax1 + cx2 + b。为了形式上的统一,我们使用带下标的a表示不同的参数(a0表示常数项b并作x0的参数<x0=1>,a1、a2分别表示x1和x2的参数),就可以得到:
这样统一起来后,就可以使用矩阵表示了(比起前面展开的线性表示方式,用矩阵表示模型和参数更加简便,而且矩阵运算的速度也更快):
将上面的式子带入到(1)式,我们就可以得到逻辑回归的另一种表示形式了:
此时,可以很清楚的看到,我们后面的行动都是为了确定一个合适的a(一个参数向量),使得对于一个新来的X(也是一个向量),我们可以尽可能准确的给出一个y值,0或者1.
注:数据是二维的,也就是说这组观察样本中有两个自变量,即两个特征(feature)。
3. 训练分类器
就像上面说的,训练分类器的过程,就是根据已经知道的数据(训练样本)确定一个使得代价函数的值最小的a(参数向量/回归系数)的过程。逻辑回归模型属于有监督的学习方法,上面示例数据中的第3列其实是训练样本提供的"标准答案"。也就是说,这些数据是已经分好类的(两类,0或者1)。在训练阶段,我们要做的就是利用训练样本和(2)式中的模型,估计一个比较合适的参数a,使得仅通过前面两列数据(观察值/测量值)就可以估计一个值h(a),这个值越接近标准答案y,说明我们的模型预测的越准确。
下面是估计回归系数a的值的过程,还是借鉴了《机器学习实战》中的代码,做了少量修改:
其中计算参数梯度,即代价函数对每个参数的偏导数(下面代码中的第36-38行),的详细推导过程可以参考这里
1 ''' 2 Created on Oct 27, 2010 3 Logistic Regression Working Module 4 @author: Peter 5 ''' 6 from numpy import * 7 import os 8 9 path = 'D:\MechineLearning\MLiA_SourceCode\machinelearninginaction\Ch05' 10 training_sample = 'trainingSample.txt' 11 testing_sample = 'testingSample.txt' 12 13 # 从文件中读入训练样本的数据,同上面给出的示例数据 14 # 下面第20行代码中的1.0表示x0
= 1 15 def loadDataSet(p, file_n): 16 dataMat = []; labelMat = [] 17 fr = open(os.path.join(p, file_n)) 18 for line in fr.readlines(): 19 lineArr = line.strip().split() 20 dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) # 三个特征x0, x1, x2 21 labelMat.append(int(lineArr[2])) # 标准答案y 22 return dataMat,labelMat 23 24 def sigmoid(inX): 25 return 1.0/(1+exp(-inX)) 26 27 # 梯度下降法求回归系数a,由于样本量少,我将迭代次数改成了1000次 28 def gradAscent(dataMatIn, classLabels): 29 dataMatrix = mat(dataMatIn) #convert to NumPy matrix 30 labelMat = mat(classLabels).transpose() #convert to NumPy matrix 31 m,n = shape(dataMatrix) 32 alpha = 0.001 # 学习率 33 maxCycles = 1000 34 weights = ones((n,1)) 35 for k in range(maxCycles): # heavy on matrix operations 36 h = sigmoid(dataMatrix*weights) # 模型预测值, 90 x 1 37 error = h - labelMat # 真实值与预测值之间的误差, 90 x 1 38 temp = dataMatrix.transpose()* error # 交叉熵代价函数对所有参数的偏导数, 3 x 1 39 weights = weights - alpha * temp # 更新权重 40 return weights 41 42 # 下面是我自己写的测试函数 43 def test_logistic_regression(): 44 dataArr, labelMat = loadDataSet(path, training_sample) # 读入训练样本中的原始数据 45 A = gradAscent(dataArr, labelMat) # 回归系数a的值 46 h = sigmoid(mat(dataArr)*A) #预测结果h(a)的值 47 print(dataArr, labelMat) 48 print(A) 49 print(h) 50 # plotBestFit(A) 51 52 test_logistic_regression()
上面代码的输出如下:
- 一个元组,包含两个数组:第一个数组是所有的训练样本中的观察值,也就是X,包括x0, x1, x2;第二个数组是每组观察值对应的标准答案y。
([[1.0, -0.017612, 14.053064], [1.0, -1.395634, 4.662541], [1.0, -0.752157, 6.53862], [1.0, -1.322371, 7.152853], [1.0, 0.423363, 11.054677], [1.0, 0.406704, 7.067335], [1.0, 0.667394, 12.741452], [1.0, -2.46015, 6.866805], [1.0, 0.569411, 9.548755], [1.0, -0.026632, 10.427743]], [0, 1, 0, 0, 0, 1, 0, 1, 0, 0])
- 本次预测出来的回归系数a,包括a0, a1, a2
[[ 1.39174871] [-0.5227482 ] [-0.33100373]]
- 根据回归系数a和(2)式中的模型预测出来的h(a)。这里预测得到的结果都是区间(0, 1)上的实数。
[[ 0.03730313] [ 0.64060602] [ 0.40627881] [ 0.4293251 ] [ 0.07665396] [ 0.23863652] [ 0.0401329 ] [ 0.59985228] [ 0.11238742] [ 0.11446212]]
标准答案是{0, 1},如何将预测到的结果与标准答案y进行比较呢?取0.5作为阈值,大于该值的样本就划分到1这一组,小于等于该值的样本就划分到0这一组,这样就可以将数据分为两类。检查一下结果可以看到,我们现在分出来的1这一类中包括原来y=1的两个样本,另一类包括原来y=0的所有样本和一个y=1的样本(分错了)。鉴于我们选择取的样本比较少(只有10个),这样的效果其实还算非常不错的!
4. 结果展示
上面已经求出了一组回归系数,它确定了不同类别数据之间的分割线。可以利用X内部(x1与x2之间的关系)的关系画出该分割线,从而更直观的感受到分类的效果。
添加下面一段代码:
1 # 分类效果展示,参数weights就是回归系数
2 def plotBestFit(weights):
3 import matplotlib.pyplot as plt
4 dataMat,labelMat=loadDataSet(path, training_sample)
5 dataArr = array(dataMat)
6 n = shape(dataArr)[0]
7 xcord1 = []; ycord1 = []
8 xcord2 = []; ycord2 = []
9 for i in range(n):
10 if int(labelMat[i])== 1:
11 xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
12 else:
13 xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
14 fig = plt.figure()
15 ax = fig.add_subplot(111)
16 ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
17 ax.scatter(xcord2, ycord2, s=30, c='green')
18 x = arange(-3.0, 3.0, 0.1)
19 y = (-weights[0]-weights[1]*x)/weights[2] # x2 = f(x1)
20 ax.plot(x.reshape(1, -1), y.reshape(1, -1))
21 plt.xlabel('X1'); plt.ylabel('X2');
22 plt.show()
将上面的test_logistic_regression()函数中的最后一句注释去掉,调用plotBestFit函数就可以看到分类的效果了。
这里说明一下上面代码中的第19行,这里设置了sigmoid函数的取值为1/2,也就是说取阈值为0.5来划分最后预测的结果。这样可以得到
,即−aTX=0−aTX=0,可以推出x2=(−a0x0−a1x1)/a2x2=(−a0x0−a1x1)/a2,同第19行,也就是说这里的yy实际上是x1x1,而xx是x1x1。因此下图表示的是x1x1与x2x2之间的关系。
分类效果图如下:
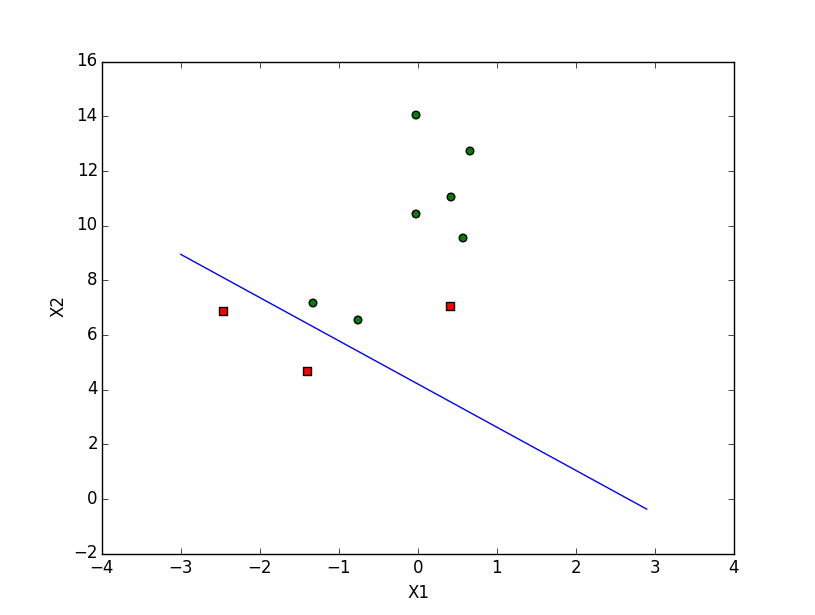
三个红色的点是原来y=1y=1的样本,有一个分错了。这里相当于将所有的数据用二维坐标(x1, x2)表示了出来,而且根据回归参数画出的线将这些点一分为二。如果有新的样本,不知道在哪一类,只用将该点画在图上,看它在这条直线的哪一边就可以分类了。
下面是使用90个训练样本得到的结果:
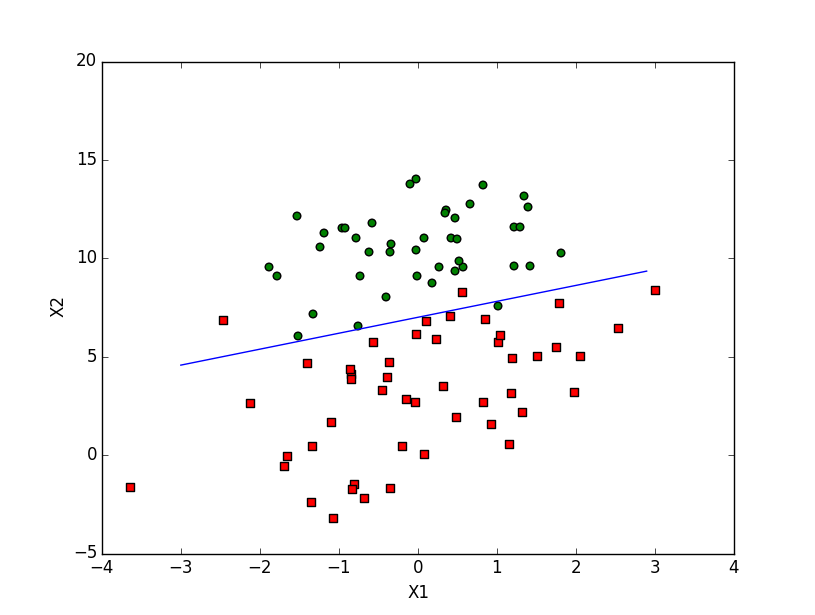
可以看出一个非常明显的规律是,y=1y=1的这一类样本(红色的点)具有更小的x2x2值,当x2x2相近时则具有更大的x1x1值。
此时计算出来的回归系数a为:
[[ 5.262118 ] [ 0.60847797] [-0.75168429]]
5. 预测新样本
添加一个预测函数,如下:
直接将上面计算出来的回归系数a拿来使用,测试数据其实也是《机器学习实战》这本书中的训练数据,我拆成了两份,前面90行用来做训练数据,后面10行用来当测试数据。
1 def predict_test_sample(): 2 A = [5.262118, 0.60847797, -0.75168429] # 上面计算出来的回归系数a 3 dataArr, labelMat = loadDataSet(path, testing_sample) 4 h_test = sigmoid(mat(dataArr) * mat(A).transpose()) # 将读入的数据和A转化成numpy中的矩阵 5 print(h_test) # 预测的结果
调用上面的函数,可以得到以下结果,即h(a):
[[ 0.99714035] [ 0.04035907] [ 0.12535895] [ 0.99048731] [ 0.98075409] [ 0.97708653] [ 0.09004989] [ 0.97884487] [ 0.28594188] [ 0.00359693]]
下面是我们的测试数据(原来的训练样本后十行的数据,包括标准答案y):
0.089392 -0.715300 1 1.825662 12.693808 0 0.197445 9.744638 0 0.126117 0.922311 1 -0.679797 1.220530 1 0.677983 2.556666 1 0.761349 10.693862 0 -2.168791 0.143632 1 1.388610 9.341997 0 0.317029 14.739025 0
比较我们预测得到的h(a)和标准答案y,如果按照0.5为分界线的话,我们利用前90个样本训练出来的分类器对后面10个样本的类型预测全部正确。
附件:
github上的代码更新到python3.6, 2019-1-6
完整代码:https://github.com/OnlyBelter/MachineLearning_examples/tree/master/de_novo/regression
训练数据:https://github.com/OnlyBelter/MachineLearning_examples/blob/master/de_novo/data/Logistic_Regression-trainingSample.txt
测试数据:https://github.com/OnlyBelter/MachineLearning_examples/blob/master/de_novo/data/Logistic_Regression-testingSample.txt
参考:
http://baike.baidu.com/item/logistic%E5%9B%9E%E5%BD%92
https://en.wikipedia.org/wiki/Sigmoid_function
《机器学习实战》,哈林顿著,李锐等译,人民邮电出版社,2013年6月第一版
逻辑回归
在生成模型中讲到了,可以利用手头的数据,假设数据是满足高斯分布,且是不同的均值,但是同一个协方差矩阵,基于贝叶斯的判别式,可以得到
p(c1|x)>0.5 是第一类 p(c1|x)可以转化为sigmod(z)=w*x +b




 浙公网安备 33010602011771号
浙公网安备 33010602011771号