

版权声明:本文为博主原创文章,未经博主允许不得转载。
决心开始研究OpenCV。闲言少叙,sourceforge网站最近的版本是2011年8月的OpenCV2.3.1,下载安装,我这里使用的开发环境是vs2008,网上搜了一下配置的教程,与之前的几个OpenCV版本的配置过程大体相同:(教程网上很多,知之为知之,不知百度之,我这里粗略再讲一下)
1. 配置电脑的环境变量(Path变量)这里我的是D:\Program Files\OpenCV2.3.1\build\x86\vc9\bin(需要注销才能生效),这里需要注意网上的教程又让增加一个OPENCV变量,值为D:\Program Files\OpenCV2.3.1\build(你安装的路径中的build目录)
2. 添加包含文件和库文件,这个和前几个版本方法类似,都是去工具->选项->VC目录添加build目录下的include目录及其子目录和你电脑对应版本的lib目录(选择x86 or x64,vc9 or vc10)
下面是第一个实例:
新建一个空项目,添加源文件如下:
- #include <opencv2/core/core.hpp>
- #include <opencv2/highgui/highgui.hpp>
- #include <iostream>
- using namespace cv;
- using namespace std;
- int main( int argc, char** argv )
- {
- if( argc != 2)
- {
- cout <<" Usage: display_image ImageToLoadAndDisplay" << endl;
- return -1;
- }
- Mat image;
- image = imread(argv[1], CV_LOAD_IMAGE_COLOR); // Read the file
- if(! image.data ) // Check for invalid input
- {
- cout << "Could not open or find the image" << std::endl ;
- return -1;
- }
- namedWindow( "Display window", CV_WINDOW_AUTOSIZE );// Create a window for display.
- imshow( "Display window", image ); // Show our image inside it.
- waitKey(0); // Wait for a keystroke in the window
- return 0;
- }
这段程序可以在你安装目录下的samples\cpp\tutorial_code\introduction\display_image找到,编译后,将图片test.jpg放到opencvtest.exe相同的目录中去,利用cmd命令行进入的可执行文件所在的目录,
运行opencvtest test.jpg
则会显示一个图片,第一个程序成功。如图

如果遇到找不到tbb_debug.dll文件的问题,参考这里http://www.opencv.org.cn/forum/viewtopic.php?p=52223,只是我的环境是vs2008,大同小异。祝你成功!(PS:后来我发现这不是最好的处理办法,最好的处理办法是在Path路径里添加环境变量D:\Program Files\OpenCV2.3.1\build\common\tbb\ia32\vc9)
接下来我觉得应该好好研究一下OpenCV里的doc文件夹下的教程和使用手册,我个人觉得《学习OpenCV》这本书已经远远跟不上OpenCV发展的速度了
版权声明:本文为博主原创文章,未经博主允许不得转载。
还是老话题,2.2版本对OpenCV可是进行了大刀阔斧的改革,用c++重新了大部分结构,而不是1.X版本中的c结构。这些模块包括:
core——定义了基本数据结构,包括最重要的Mat和一些其他的模块
imgproc——该模块包括了线性和非线性的图像滤波,图像的几何变换,颜色空间转换,直方图处理等等
video——该模块包括运动估计,背景分离,对象跟踪
calib3d——基本的多视角几何算法,单个立体摄像头标定,物体姿态估计,立体相似性算法,3D信息的重建
features2d——显著特征检测,描述,特征匹配
objdetect——物体检测和预定义好的分类器实例(比如人脸,眼睛,面部,人,车辆等等)
highgui——视频捕捉、图像和视频的编码解码、图形交互界面的接口
gpu——利用GPU对OpenCV模块进行加速算法
ml——机器学习模块(SVM,决策树,Boosting等等)
flann——Fast Library for Approximate Nearest Neighbors(FLANN)算法库
legacy——一些已经废弃的代码库,保留下来作为向下兼容
版权声明:本文为博主原创文章,未经博主允许不得转载。
自从版本2.0,OpenCV采用了新的数据结构,用Mat类结构取代了之前用extended C写的cvMat和lplImage,更加好用啦,最大的好处就是更加方便的进行内存管理,对写更大的程序是很好的消息。
需要注意的几点:1. Mat的拷贝只是复制了Mat的信息头,数据的指针也指向了被拷贝的数据地址,而没有真正新建一块内存来存放新的矩阵内容。这样带来的一个问题就是对其中一个Mat的数据操作就会对其他指向同一块数据的Mat产生灾难性的影响。
2.建立多维数组的格式是这样的- int sz[3] = {2, 2, 2};
- Mat L(3, sz, CV_8UC(1), Scalar::all(0));
3.传统的lplImage格式也可直接转换为Mat格式
- IplImage* img = cvLoadImage("greatwave.png", 1);
- Mat mtx(img); // convert IplImage* -> Mat
如果想将新版本的Mat格式转换为老版本,则需要如下调用:
- Mat I;
- IplImage* pI = &I.operator IplImage();
- CvMat* mI = &I.operator CvMat();
不过更安全的调用格式为:
- Ptr<IplImage> piI = &I.operator IplImage();
4.Mat结构更加友好,很多操作更接近matlab的风格
5.也有Point2f,Point3f,vector等数据结构可以使用
6.RNG类可以产生随机数
7.实现颜色通道的分离使用函数split
版权声明:本文为博主原创文章,未经博主允许不得转载。
2.0新版本对数据结构进行了大幅修改:
定义了DataType类
定义了Point_模板类,取代了之前版本的CvPoint、CvPoint2D32f
定义了Point3_模板类,取代了之前版本的CvPoint2D32f
定义了Size_模板类,取代了之前版本的CvSize和CvSize2D32f
定义了Rect_模板类,取代了之前版本的CvRect
RotatedRect模板类,
TermCriteria模板类,取代了之前的CvTermCriteria,这个类是作为迭代算法的终止条件的,这个类在参考手册里介绍的很简单,我查了些资料,这里介绍一下。该类变量需要3个参数,一个是类型,第二个参数为迭代的最大次数,最后一个是特定的阈值。类型有CV_TERMCRIT_ITER、CV_TERMCRIT_EPS、CV_TERMCRIT_ITER+CV_TERMCRIT_EPS,分别代表着迭代终止条件为达到最大迭代次数终止,迭代到阈值终止,或者两者都作为迭代终止条件。以上的宏对应的c++的版本分别为TermCriteria::COUNT、TermCriteria::EPS,这里的COUNT也可以写成MAX_ITER。
Matx模板类。Matx模板类是对Mat类的一个拓展,从Matx类有派生出Vec类,又Vec类又派生出Scalar_类,取代了CvScalar
定义了Range类指定了一个序列的一个连续的子序列
定义了Ptr类用来对老版本的数据结构进行指针操作,更安全有效,可以防止内存的不正常使用。
最最重要的定义了Mat类来表示矩阵,取代了之前的CvMat和lplImage。Mat结构支持的操作有:
构造析构函数Mat和~Mat
对=、MatExpr、( )、CvMat、IplImage进行了运算符重载
row、col函数
rowRange、colRange
类似matlab的运算操作diag、t、inv、mul、cross、dot、zeros、one、eye
复制转换变形clone、copyTo、convertTo、assignTo、setTo、reshape、create、addref
其中copyTo函数有个妙用,不但可以复制Mat,还可以通过mask提取出感兴趣的部分
数据的操作release、resize、reserve、push_back、pop_back、locateROI、adjustROI
Mat的信息total、isContinuous、elemSize、elemSize1、type、depth、channes、step1、size、empty
其中step1函数返回Mat结构每一行的字节数=列数*通道数,更方便用指针定位特定元素
定位ptr、at、begin、end
还做了几个扩展类Mat_、NAryMatlterator、SparseMat、SparseMat_取代了之前的CvSparseMat。这些类的操作运算与Mat大同小异,类声明参考core的具体头文件
当然,新版本对老版本的数据结构和函数依然支持。
新版本还在这些结构里支持dft、dct变换,我这里讲一下我的新发现PCA类、SVD类
PCA类有构造函数PCA,运算符重载(),project,backProject。SVD类有构造函数SVD,运算符重载(),compute,solveZ,backSubst
这里介绍几个我使用过的实用函数:
inRange函数可以检查Matsrc的内容是否在Matlower、Matupper之间,输出结果是一个uchar型矩阵,1表示在两者之间,否则为0,值得注意的是,Matlower,Matupper也可以用Scalar的格式
bitwise_xxx函数对两个矩阵进行位运算,结果保存在第三个矩阵当中
mixChannels函数可以实现矩阵的指定通道复制到新矩阵的指定通道
总之,新版本支持更多的数学运算,还支持一些画图操作
版权声明:本文为博主原创文章,未经博主允许不得转载。
首先来看一下2.0版本对之前版本的进行了哪些修改
1.采用了新的数据结构Mat作为图像的容器,取代了之前的CvMat和lplImage,这个改动不是太复杂,只需适应一下新东西,而且可以自由转换
- Mat I;
- IplImage pI = I;
- CvMat mI = I;
对于指针的操作要相对复杂一些,而且还要注意内存的释放,我这里不推荐用老版本的数据结构,例如:
- Mat I;
- IplImage* pI = &I.operator IplImage();
- CvMat* mI = &I.operator CvMat();
2.对library进行了重组,将原来的一个大库根据功能结构分成具体小库,这样包含头文件的时候只需要加入你需要的库,只是原来库的子集
3.使用了cv 这个namespace来防止和其他的library 结构冲突。所以在使用的时候也要预先加上cv::关键字,这也是新版本的函数,数据都省略了cv前缀的原因,一般放在include之后,格式为:
- using namespace cv; // The new C++ interface API is inside this namespace. Import it.
 OpenCV知识库
OpenCV知识库版权声明:本文为博主原创文章,未经博主允许不得转载。
1. XML、YAML文件的打开和关闭
XML\YAML文件在OpenCV中的数据结构为FileStorage,打开操作例如:
- string filename = "I.xml";
- FileStorage fs(filename, FileStorage::WRITE);
- \\...
- fs.open(filename, FileStorage::READ);
文件关闭操作会在FileStorage结构销毁时自动进行,但也可调用如下函数实现
- fs.release();
2.文本和数字的输入和输出
写入文件使用 << 运算符,例如:
- fs << "iterationNr" << 100;
读取文件,使用 >> 运算符,例如
- int itNr;
- fs["iterationNr"] >> itNr;
- itNr = (int) fs["iterationNr"];
3. OpenCV数据结构的输入和输出,和基本的C++形式相同
- Mat R = Mat_<uchar >::eye (3, 3),
- T = Mat_<double>::zeros(3, 1);
- fs << "R" << R; // Write cv::Mat
- fs << "T" << T;
- fs["R"] >> R; // Read cv::Mat
- fs["T"] >> T;
4. vector(arrays) 和 maps的输入和输出
vector要注意在第一个元素前加上“[”,在最后一个元素前加上"]"。例如:
- fs << "strings" << "["; // text - string sequence
- fs << "image1.jpg" << "Awesomeness" << "baboon.jpg";
- fs << "]"; // close sequence
对于map结构的操作使用的符号是"{"和"}",例如:
- fs << "Mapping"; // text - mapping
- fs << "{" << "One" << 1;
- fs << "Two" << 2 << "}";
读取这些结构的时候,会用到FileNode和FileNodeIterator数据结构。对FileStorage类的[]操作符会返回FileNode数据类型,对于一连串的node,可以使用FileNodeIterator结构,例如:
- FileNode n = fs["strings"]; // Read string sequence - Get node
- if (n.type() != FileNode::SEQ)
- {
- cerr << "strings is not a sequence! FAIL" << endl;
- return 1;
- }
- FileNodeIterator it = n.begin(), it_end = n.end(); // Go through the node
- for (; it != it_end; ++it)
- cout << (string)*it << endl;
5. 读写自己的数据结构
这部分比较复杂,参考最后的实例中的MyData结构自己领悟吧
最后,我这里上一个实例,供大家参考。
源文件里填入如下代码:
- #include <opencv2/core/core.hpp>
- #include <iostream>
- #include <string>
- using namespace cv;
- using namespace std;
- void help(char** av)
- {
- cout << endl
- << av[0] << " shows the usage of the OpenCV serialization functionality." << endl
- << "usage: " << endl
- << av[0] << " outputfile.yml.gz" << endl
- << "The output file may be either XML (xml) or YAML (yml/yaml). You can even compress it by "
- << "specifying this in its extension like xml.gz yaml.gz etc... " << endl
- << "With FileStorage you can serialize objects in OpenCV by using the << and >> operators" << endl
- << "For example: - create a class and have it serialized" << endl
- << " - use it to read and write matrices." << endl;
- }
- class MyData
- {
- public:
- MyData() : A(0), X(0), id()
- {}
- explicit MyData(int) : A(97), X(CV_PI), id("mydata1234") // explicit to avoid implicit conversion
- {}
- void write(FileStorage& fs) const //Write serialization for this class
- {
- fs << "{" << "A" << A << "X" << X << "id" << id << "}";
- }
- void read(const FileNode& node) //Read serialization for this class
- {
- A = (int)node["A"];
- X = (double)node["X"];
- id = (string)node["id"];
- }
- public: // Data Members
- int A;
- double X;
- string id;
- };
- //These write and read functions must be defined for the serialization in FileStorage to work
- void write(FileStorage& fs, const std::string&, const MyData& x)
- {
- x.write(fs);
- }
- void read(const FileNode& node, MyData& x, const MyData& default_value = MyData()){
- if(node.empty())
- x = default_value;
- else
- x.read(node);
- }
- // This function will print our custom class to the console
- ostream& operator<<(ostream& out, const MyData& m)
- {
- out << "{ id = " << m.id << ", ";
- out << "X = " << m.X << ", ";
- out << "A = " << m.A << "}";
- return out;
- }
- int main(int ac, char** av)
- {
- if (ac != 2)
- {
- help(av);
- return 1;
- }
- string filename = av[1];
- { //write
- Mat R = Mat_<uchar>::eye(3, 3),
- T = Mat_<double>::zeros(3, 1);
- MyData m(1);
- FileStorage fs(filename, FileStorage::WRITE);
- fs << "iterationNr" << 100;
- fs << "strings" << "["; // text - string sequence
- fs << "image1.jpg" << "Awesomeness" << "baboon.jpg";
- fs << "]"; // close sequence
- fs << "Mapping"; // text - mapping
- fs << "{" << "One" << 1;
- fs << "Two" << 2 << "}";
- fs << "R" << R; // cv::Mat
- fs << "T" << T;
- fs << "MyData" << m; // your own data structures
- fs.release(); // explicit close
- cout << "Write Done." << endl;
- }
- {//read
- cout << endl << "Reading: " << endl;
- FileStorage fs;
- fs.open(filename, FileStorage::READ);
- int itNr;
- //fs["iterationNr"] >> itNr;
- itNr = (int) fs["iterationNr"];
- cout << itNr;
- if (!fs.isOpened())
- {
- cerr << "Failed to open " << filename << endl;
- help(av);
- return 1;
- }
- FileNode n = fs["strings"]; // Read string sequence - Get node
- if (n.type() != FileNode::SEQ)
- {
- cerr << "strings is not a sequence! FAIL" << endl;
- return 1;
- }
- FileNodeIterator it = n.begin(), it_end = n.end(); // Go through the node
- for (; it != it_end; ++it)
- cout << (string)*it << endl;
- n = fs["Mapping"]; // Read mappings from a sequence
- cout << "Two " << (int)(n["Two"]) << "; ";
- cout << "One " << (int)(n["One"]) << endl << endl;
- MyData m;
- Mat R, T;
- fs["R"] >> R; // Read cv::Mat
- fs["T"] >> T;
- fs["MyData"] >> m; // Read your own structure_
- cout << endl
- << "R = " << R << endl;
- cout << "T = " << T << endl << endl;
- cout << "MyData = " << endl << m << endl << endl;
- //Show default behavior for non existing nodes
- cout << "Attempt to read NonExisting (should initialize the data structure with its default).";
- fs["NonExisting"] >> m;
- cout << endl << "NonExisting = " << endl << m << endl;
- }
- cout << endl
- << "Tip: Open up " << filename << " with a text editor to see the serialized data." << endl;
- return 0;
- }
编译后,在命令行进入到文件目录,执行test test.xml,运行结果如下,生成一个test . xml文件,内容如下:
- <?xml version="1.0" ?>
- - <opencv_storage>
- <iterationNr>100</iterationNr>
- <strings>image1.jpg Awesomeness baboon.jpg</strings>
- - <Mapping>
- <One>1</One>
- <Two>2</Two>
- </Mapping>
- - <R type_id="opencv-matrix">
- <rows>3</rows>
- <cols>3</cols>
- <dt>u</dt>
- <data>1 0 0 0 1 0 0 0 1</data>
- </R>
- - <T type_id="opencv-matrix">
- <rows>3</rows>
- <cols>1</cols>
- <dt>d</dt>
- <data>0. 0. 0.</data>
- </T>
- - <MyData>
- <A>97</A>
- <X>3.1415926535897931e+000</X>
- <id>mydata1234</id>
- </MyData>
- </opencv_storage>
版权声明:本文为博主原创文章,未经博主允许不得转载。
先介绍几个最基本的核滤波器相关的类
2D图像滤波器基础类BaseFilter:dst(x,y) = F(src(x,y), src(x+1,y)... src(x+wdith-1,y), src(y+1,x)... src(x+width-1, y+height-1) ); 相关的调用函数为getLinearFilter、getMorphologyFilter
单行核滤波器基础类BaseRowFilter:dst(x,y) = F(src(x,y), src(x+1,y),...src(x+width-1,y));相关的调用函数为getLinearRowFilter、getMorphologyRowFilter
单列核滤波器基础类BaseColumnFilter:dst(x,y) = F(src(x,y), src(x,y+1),...src(x,y+width-1));相关的调用函数为getColumnSumFilter、getLinearColumnFilter、getMorphologyColumnFilter
类FilterEngine:该类可以应用在对图像的任意滤波操作当中,在OpenCV滤波器函数中扮演着很重要的角色,相关的函数有createBoxFitler、createDerivFitlter、createGaussianFilter、createLinearFilter、createMorphologyFilter、createSeparableLinearFilter
基于这些类有一些基本的滤波器bilateralFilter、blur、boxFilter
还有一些形态学操作如:dilate、erode、morphologyEx
还有基于核和图像卷积的滤波器filter2D
还有一些典型的滤波器如GaussianBlur、medianBlur、Laplacian、pyrMeanShiftFiltering、sepFilter2D
还有Sobel、Scharr运算符
其他一些函数有borderInterpolate、buildPyramid、copyMakeBorder、createBoxFilter、createDirivFilter、createGaussianFliter、createLinearFilter、createMorphologyFilter、createSeparableLinearFilter、getDerivKernels、getGaussianKernel、getKernelType、getStructuringElement、pyrDown、pyrUp
还老版本的滤波器cvSmooth
这里介绍一下我使用Laplacian滤波的心得,这个函数的第三个参数为输出的图像的深度,注意经过拉普拉斯算子处理后得到的值是有正有负的,所以输出图像的深度最好为输入图像深度的2倍,才能有效防止数据溢出,如必须要使用8位的数据,可以再使用函数convertScaleAbs处理。而且要注意使用的拉普拉斯算子掩膜的中心系数为负。
版权声明:本文为博主原创文章,未经博主允许不得转载。
直方图histograms也是图像处理中经常用到的一种手段。新版本对直方图不再使用之前的histogram的形式,而是用统一的Mat或者MatND的格式来存储直方图,可见新版本Mat数据结构的优势。先介绍下其相关的函数
calcHist、calcBackProject、compareHist、EMD、equalizeHist。除了这几个常用的函数以为,还有一些c函数写的直方图类CvHistogram的相关操作,如下:cvCalcBackProjectPatch、cvCalcProbDensity、cvClearHist、cvCopyHist、cvCreateHist、cvGetHistValue_XD、cvGetMinMaxHistValue、cvMakeHistHeaderForArray、cvNormalizeHist、QueryHistValue_XD、cvReleaseHist、cvSetHistBinRanges、cvThreshHist、cvCalcPGH
calcHist函数为计算图像的直方图,使用方法如下:
- // C++:
- void calcHist(const Mat* arrays, int narrays, const int* channels, InputArray mask, OutputArray hist, int dims, const int* histSize, const float** ranges, bool uniform=true, bool accumulate=false )
- // C++:
- void calcHist(const Mat* arrays, int narrays, const int* channels, InputArray mask, SparseMat& hist, int dims, const int* histSize, const float** ranges, bool uniform=true, bool accumulate=false )
arrays为输入图像指针,narrays为输入图像的个数,channels为用来计算直方图的通道列表,mask为掩膜矩阵,不为空的时候,只计算arrays中的掩膜区域的直方图,hist为输出的直方图矩阵,dims为直方图矩阵的维度,histSize为每一维直方图矩阵的大小,ranges为每一维直方图元素的取值范围,是一个2维数组的地址,uniform为直方图是否为统一模式,统一模式下会拉伸为range的大小,accumulate为累计标志,方便直方图的更新,不需要重新计算
举几个实例方便大家理解:
对于图像为灰度图,调用方式如下:
- int histSize = 255;
- float ranges[] = {0, 255};
- const float* histRange = {ranges};
- calcHist(&img, 1, 0, Mat(), hist, 1, &histSize, &histRange);
直方图的归一化已经不再适合cvNormalizeHist这个函数了,只需要用对矩阵的归一化函数normalize就可以实现了。
直方图均衡化函数为equalizeHist,这个函数比较简单,这里就不详细介绍了
直方图的比较函数为compareHist,函数返回值为两矩阵的相似程度,相似度衡量的办法目前支持4种
计算反向投影图函数为calcBackProject。所谓反向投影图就是一个概率密度图。calcBackProject的输入为图像及其直方图,输出与待跟踪图像大小相同,每一个像素点表示该点为目标区域的概率。这个点越亮,该点属于物体的概率越大。关于反向直方图,可以参考一下这篇文章http://blog.163.com/thomaskjh@126/blog/static/370829982010112810358501/,这个函数使我们利用特征直方图寻找图片中的特征区域变得更加方便容易。这里举一个比较常用的例子:如果已经有一个肤色的特征直方图,则可以在待检测图像中利用直方图方向投影图找出图片中的肤色区域。– CV_COMP_CORREL Correlation相关系数,相同为1,相似度范围为[ 1, 0 )
– CV_COMP_CHISQR Chi-Square卡方,相同为0,相似度范围为[ 0, +inf )
– CV_COMP_INTERSECT Intersection直方图交,数越大越相似,,相似度范围为[ 0, +inf )
– CV_COMP_BHATTACHARYYA Bhattacharyya distance做常态分别比对的Bhattacharyya 距离,相同为0,,相似度范围为[ 0, +inf )
版权声明:本文为博主原创文章,未经博主允许不得转载。
基于特征点的图像匹配是图像处理中经常会遇到的问题,手动选取特征点太麻烦了。比较经典常用的特征点自动提取的办法有Harris特征、SIFT特征、SURF特征。
先介绍利用SURF特征的特征描述办法,其操作封装在类SurfFeatureDetector中,利用类内的detect函数可以检测出SURF特征的关键点,保存在vector容器中。第二部利用SurfDescriptorExtractor类进行特征向量的相关计算。将之前的vector变量变成向量矩阵形式保存在Mat中。最后强行匹配两幅图像的特征向量,利用了类BruteForceMatcher中的函数match。代码如下:
- /**
- * @file SURF_descriptor
- * @brief SURF detector + descritpor + BruteForce Matcher + drawing matches with OpenCV functions
- * @author A. Huaman
- */
- #include <stdio.h>
- #include <iostream>
- #include "opencv2/core/core.hpp"
- #include "opencv2/features2d/features2d.hpp"
- #include "opencv2/highgui/highgui.hpp"
- using namespace cv;
- void readme();
- /**
- * @function main
- * @brief Main function
- */
- int main( int argc, char** argv )
- {
- if( argc != 3 )
- { return -1; }
- Mat img_1 = imread( argv[1], CV_LOAD_IMAGE_GRAYSCALE );
- Mat img_2 = imread( argv[2], CV_LOAD_IMAGE_GRAYSCALE );
- if( !img_1.data || !img_2.data )
- { return -1; }
- //-- Step 1: Detect the keypoints using SURF Detector
- int minHessian = 400;
- SurfFeatureDetector detector( minHessian );
- std::vector<KeyPoint> keypoints_1, keypoints_2;
- detector.detect( img_1, keypoints_1 );
- detector.detect( img_2, keypoints_2 );
- //-- Step 2: Calculate descriptors (feature vectors)
- SurfDescriptorExtractor extractor;
- Mat descriptors_1, descriptors_2;
- extractor.compute( img_1, keypoints_1, descriptors_1 );
- extractor.compute( img_2, keypoints_2, descriptors_2 );
- //-- Step 3: Matching descriptor vectors with a brute force matcher
- BruteForceMatcher< L2<float> > matcher;
- std::vector< DMatch > matches;
- matcher.match( descriptors_1, descriptors_2, matches );
- //-- Draw matches
- Mat img_matches;
- drawMatches( img_1, keypoints_1, img_2, keypoints_2, matches, img_matches );
- //-- Show detected matches
- imshow("Matches", img_matches );
- waitKey(0);
- return 0;
- }
- /**
- * @function readme
- */
- void readme()
- { std::cout << " Usage: ./SURF_descriptor <img1> <img2>" << std::endl; }
当然,进行强匹配的效果不够理想,这里再介绍一种FLANN特征匹配算法。前两步与上述代码相同,第三步利用FlannBasedMatcher类进行特征匹配,并只保留好的特征匹配点,代码如下:
- //-- Step 3: Matching descriptor vectors using FLANN matcher
- FlannBasedMatcher matcher;
- std::vector< DMatch > matches;
- matcher.match( descriptors_1, descriptors_2, matches );
- double max_dist = 0; double min_dist = 100;
- //-- Quick calculation of max and min distances between keypoints
- for( int i = 0; i < descriptors_1.rows; i++ )
- { double dist = matches[i].distance;
- if( dist < min_dist ) min_dist = dist;
- if( dist > max_dist ) max_dist = dist;
- }
- printf("-- Max dist : %f \n", max_dist );
- printf("-- Min dist : %f \n", min_dist );
- //-- Draw only "good" matches (i.e. whose distance is less than 2*min_dist )
- //-- PS.- radiusMatch can also be used here.
- std::vector< DMatch > good_matches;
- for( int i = 0; i < descriptors_1.rows; i++ )
- { if( matches[i].distance < 2*min_dist )
- { good_matches.push_back( matches[i]); }
- }
- //-- Draw only "good" matches
- Mat img_matches;
- drawMatches( img_1, keypoints_1, img_2, keypoints_2,
- good_matches, img_matches, Scalar::all(-1), Scalar::all(-1),
- vector<char>(), DrawMatchesFlags::NOT_DRAW_SINGLE_POINTS );
- //-- Show detected matches
- imshow( "Good Matches", img_matches );
在FLANN特征匹配的基础上,还可以进一步利用Homography映射找出已知物体。具体来说就是利用findHomography函数利用匹配的关键点找出相应的变换,再利用perspectiveTransform函数映射点群。具体代码如下:
- //-- Localize the object from img_1 in img_2
- std::vector<Point2f> obj;
- std::vector<Point2f> scene;
- for( int i = 0; i < good_matches.size(); i++ )
- {
- //-- Get the keypoints from the good matches
- obj.push_back( keypoints_1[ good_matches[i].queryIdx ].pt );
- scene.push_back( keypoints_2[ good_matches[i].trainIdx ].pt );
- }
- Mat H = findHomography( obj, scene, CV_RANSAC );
- //-- Get the corners from the image_1 ( the object to be "detected" )
- Point2f obj_corners[4] = { cvPoint(0,0), cvPoint( img_1.cols, 0 ), cvPoint( img_1.cols, img_1.rows ), cvPoint( 0, img_1.rows ) };
- Point scene_corners[4];
- //-- Map these corners in the scene ( image_2)
- for( int i = 0; i < 4; i++ )
- {
- double x = obj_corners[i].x;
- double y = obj_corners[i].y;
- double Z = 1./( H.at<double>(2,0)*x + H.at<double>(2,1)*y + H.at<double>(2,2) );
- double X = ( H.at<double>(0,0)*x + H.at<double>(0,1)*y + H.at<double>(0,2) )*Z;
- double Y = ( H.at<double>(1,0)*x + H.at<double>(1,1)*y + H.at<double>(1,2) )*Z;
- scene_corners[i] = cvPoint( cvRound(X) + img_1.cols, cvRound(Y) );
- }
- //-- Draw lines between the corners (the mapped object in the scene - image_2 )
- line( img_matches, scene_corners[0], scene_corners[1], Scalar(0, 255, 0), 2 );
- line( img_matches, scene_corners[1], scene_corners[2], Scalar( 0, 255, 0), 2 );
- line( img_matches, scene_corners[2], scene_corners[3], Scalar( 0, 255, 0), 2 );
- line( img_matches, scene_corners[3], scene_corners[0], Scalar( 0, 255, 0), 2 );
- //-- Show detected matches
- imshow( "Good Matches & Object detection", img_matches );
然后再看一下Harris特征检测,在计算机视觉中,通常需要找出两帧图像的匹配点,如果能找到两幅图像如何相关,就能提取出两幅图像的信息。我们说的特征的最大特点就是它具有唯一可识别这一特点,图像特征的类型通常指边界、角点(兴趣点)、斑点(兴趣区域)。角点就是图像的一个局部特征,应用广泛。harris角点检测是一种直接基于灰度图像的角点提取算法,稳定性高,尤其对L型角点检测精度高,但由于采用了高斯滤波,运算速度相对较慢,角点信息有丢失和位置偏移的现象,而且角点提取有聚簇现象。具体实现就是使用函数cornerHarris实现。
除了利用Harris进行角点检测,还可以利用Shi-Tomasi方法进行角点检测。使用函数goodFeaturesToTrack对角点进行检测,效果也不错。也可以自己制作角点检测的函数,需要用到cornerMinEigenVal函数和minMaxLoc函数,最后的特征点选取,判断条件要根据自己的情况编辑。如果对特征点,角点的精度要求更高,可以用cornerSubPix函数将角点定位到子像素。
版权声明:本文为博主原创文章,未经博主允许不得转载。
OpenCV提供一个功能强大的UI接口,可以在MFC、Qt、WinForms、Cocoa等平台下使用,甚至不需要其他的平台。新版本的HighGUI接口包括:
创建并控制窗口,该窗口可以显示图片并记录其内容
为窗口添加了trackbars控件,可以方便利用鼠标进行控制而不是之前版本的只能利用键盘
读写硬盘和内存的图片
读取摄像头的视频、读写视频文件
先来介绍UI,包括函数createTrackbar、getTrackbarPos、setTrackbarPos、imshow、namedWindow、destroyWindow、destroyAllWindows、MoveWindow、ResizeWindow、SetMouseCallback、waitKey。这些函数保证了图像的基本处理、tarckbar的控制和鼠标键盘的响应
介绍一下读写图像视频的函数:图像相关的函数有imdecode、imencode、imread、imwrite。读取视频相关为VideoCapture类,负责捕捉文件和摄像头的视频,该类内有成员函数VideoCapture、open、isOpened、release、grab、retrieve、read、get、set,写视频的类为VideoWriter,类内有成员函数VideoWriter、open、isOpened、write
新版本还为Qt做了新函数,这里就不介绍了,有兴趣的朋友可以自己看一下参考手册的第四章第三节。
这里介绍几个常用的新功能,首先介绍一下添加滑杆控件Trackbar。调用函数为:
- createTrackbar( TrackbarName, "Linear Blend", &alpha_slider, alpha_slider_max, on_trackbar );
第一个参数为字符串作为标签,第二个参数为所在窗口的名字,第三个参数为存储滑杆位置的值地址,其范围为0~alpha_slider_max(第四个参数),最后一个参数为移动滑杆时调用的回调函数名。
OpenCV2.0版本加强了对视频处理的支持,不再需要对一组连续的图片进行处理,可以进行实时的图像采集和记录以及存储。视频的操作基本都被封装在VideoCapture类中。打开视频可以可以通过如下代码实现:
- VideoCapture captRefrnc(sourceReference);
- // or
- VideoCapture captUndTst;
- captUndTst.open(sourceCompareWith);
其中sourceReference和sourceCompareWith为string型,为文件名。还可以通过isOpened函数检测视频是否成功打开。也可以调用release函数提前关闭视频。还可以讲VideoCapture放到Mat结构中,因为视频流是一连串的,可以通过read函数或>>操作符逐帧的读取,例如:
- Mat frameReference, frameUnderTest;
- captRefrnc >> frameReference;
- captUndTst.open(frameUnderTest);
read函数只能逐帧的抓取,如果要抓取某一帧,可以成对的调用grab函数和retrieve函数。get函数可以获取视频相关信息。set函数可以控制视频的一些值,比如是指视频的当前位置或帧数。
可以使用VideoWriter类创建新视频,其open,isOpened函数调用方法类似,write函数或<<运算符向视频写入内容,可以使用split函数和merge函数单独调整RGB通道的值
今日,被一个网友指出,说OpenCV以前提供的读写功能采用VFW,效率低下且有些格式支持不好。而 OpenCV 2.0 内置了videoInput Library,可以自动在VFW和DirectShow间切换。videoInput是老外写的功能强大的开源视频处理库。是一个第三方库,2.0~2.2的版本专门有一个3rdparty对该库进行支持,而在最新的2.3版本中,已经讲videoInput库集成到highgui中了,想使用它的话,只需要在cmake中设置宏WITH_VIDEOiNPUT=OFF/ON即可。
以后有新学到的东西都会陆续补充进来。
版权声明:本文为博主原创文章,未经博主允许不得转载。
Templates是c++的一个很强大的特征,可以是数据结构更加安全高效。但也会增加编译时间和代码的长度,当函数被频繁调用的时候便步那么高效,所以在目前的OpenCV版本不推荐过多的使用templates。矩阵元素可以是如下类型中的一种:
• 8-bit unsigned integer (uchar)
• 8-bit signed integer (schar)
• 16-bit unsigned integer (ushort)
• 16-bit signed integer (short)
• 32-bit signed integer (int)
• 32-bit floating-point number (float)
• 64-bit floating-point number (double)
对于这些数据类型又定义了如下的枚举变量:
- enum { CV_8U=0, CV_8S=1, CV_16U=2, CV_16S=3, CV_32S=4, CV_32F=5, CV_64F=6 };
- CV_32FC1 == CV_32F;
- CV_32FC2 == CV_32FC(2) == CV_MAKETYPE(CV_32F, 2);
- CV_MAKETYPE(depth, n) == ((x&7)<<3) + (n-1);
版权声明:本文为博主原创文章,未经博主允许不得转载。
用OpenCV做算法的朋友们肯定为随机数烦恼过,新版本一直支持随机数产生器啦,而且还继续支持之前版本的c格式的函数,不过与时俱进,我这里介绍C++的RNG类。它可以压缩一个64位的i整数并可以得到scalar和array的随机数。目前的版本支持均匀分布随机数和Gaussian分布随机数。随机数的产生采用的是Multiply-With-Carry算法和Ziggurat算法。
其构造函数的初始化可以传入一个64位的整型参数作为随机数产生器的初值。next可以取出下一个随机数,uniform函数可以返回指定范围的随机数,gaussian函数返回一个高斯随机数,fill则用随机数填充矩阵。
这里介绍一个uniform的使用事项,就是比如利用它产生0~1的随机数的问题,具体代码如下:
- RNG rng;
- // always produces 0
- double a = rng.uniform(0, 1);
- // produces double from [0, 1)
- double a1 = rng.uniform((double)0, (double)1);
- // produces float from [0, 1)
- double b = rng.uniform(0.f, 1.f);
- // produces double from [0, 1)
- double c = rng.uniform(0., 1.);
- // may cause compiler error because of ambiguity:
- // RNG::uniform(0, (int)0.999999)? or RNG::uniform((double)0, 0.99999)?
- double d = rng.uniform(0, 0.999999);
就是不能写成rng.uniform( 0 , 1),因为输入为int型参数,会调用uniform(int,int),只能产生0。请大家注意使用^_^
还有一些随机数相关的函数,比如randu可以产生一个均匀分布的随机数或者矩阵,randn可以产生一个正态分布的随机数,randShuffle可以随机打乱矩阵元素
再简单介绍一下c版本的随机数产生器的相关函数,有cvRNG、cvRandArr、cvRandInt、cvRandReal
版权声明:本文为博主原创文章,未经博主允许不得转载。
寻找一幅图像的匹配的模板,可以在一段视频里寻找出我们感兴趣的东西,比如条形码的识别就可能需要这样类似的一个工作提取出条形码区域(当然这样的方法并不鲁棒)。而OpenCV已经为我们集成好了相关的功能。函数为matchTemplate。
所谓模板匹配就是在一幅图像中寻找和模板图像(patch)最相似的区域。该函数的功能为,在输入源图像Source image(I)中滑动框,寻找各个位置与模板图像Template image(T)的相似度,并将结果保存在结果矩阵result matrix(R)中。该矩阵的每一个点的亮度表示与模板T的匹配程度。然后可以通过函数minMaxLoc定位矩阵R中的最大值(该函数也可以确定最小值)。
匹配的方法有:
CV_TM_SQDIFF 平方差匹配法,最好的匹配为0,值越大匹配越差
CV_TM_SQDIFF_NORMED 归一化平方差匹配法
CV_TM_CCORR 相关匹配法,采用乘法操作,数值越大表明匹配越好
CV_TM_CCORR_NORMED 归一化相关匹配法
CV_TM_CCOEFF 相关系数匹配法,最好的匹配为1,-1表示最差的匹配
CV_TM_CCOEFF_NORMED 归一化相关系数匹配法
前面两种方法为越小的值表示越匹配,后四种方法值越大越匹配。
其实模板匹配的使用和直方图反向投影calcBackProject函数很像,只是直方图反向投影对比的是直方图,而模板匹配对比的是图像的像素值,相比较而言,直方图反向投影的匹配鲁棒性更好。
总结这个函数,感觉功能不是很强大,应用不是很广,因为只能在图像中搜索出指定的模板,如果模板是从待搜索目标中截取出来的,效果会很好,如果模板不是待搜素图像的一部分,效果就差的多了,所以该函数的使用还是有很大的局限性。
版权声明:本文为博主原创文章,未经博主允许不得转载。
OpenCV支持大量的轮廓、边缘、边界的相关函数,相应的函数有moments、HuMoments、findContours、drawContours、approxPolyDP、arcLength、boundingRect、contourArea、convexHull、fitEllipse、fitLine、isContourConvex、minAreaRect、minEnclosingCircle、mathcShapes、pointPolygonTest。还有一些c版本的针对老版本的数据结构的函数比如cvApproxChains、cvConvexityDefects。这里先介绍一些我用过的函数,以后用到再陆续补充。
OpenCV里支持很多边缘提取的办法,可是如何在一幅图像里得到轮廓区域的参数呢,这就需要用到findContours函数,这个函数的原型为:
- //C++:
- void findContours(InputOutputArray image, OutputArrayOfArrays contours, OutputArray hierarchy, int mode, int method, Point offset=Point())
- void findContours(InputOutputArray image, OutputArrayOfArrays contours, int mode, int method, Point offset=Point())
这里介绍下该函数的各个参数:
输入图像image必须为一个2值单通道图像
contours参数为检测的轮廓数组,每一个轮廓用一个point类型的vector表示
hiararchy参数和轮廓个数相同,每个轮廓contours[ i ]对应4个hierarchy元素hierarchy[ i ][ 0 ] ~hierarchy[ i ][ 3 ],分别表示后一个轮廓、前一个轮廓、父轮廓、内嵌轮廓的索引编号,如果没有对应项,该值设置为负数。
mode表示轮廓的检索模式
CV_RETR_EXTERNAL表示只检测外轮廓
CV_RETR_LIST检测的轮廓不建立等级关系
CV_RETR_CCOMP建立两个等级的轮廓,上面的一层为外边界,里面的一层为内孔的边界信息。如果内孔内还有一个连通物体,这个物体的边界也在顶层。
CV_RETR_TREE建立一个等级树结构的轮廓。具体参考contours.c这个demo
method为轮廓的近似办法
CV_CHAIN_APPROX_NONE存储所有的轮廓点,相邻的两个点的像素位置差不超过1,即max(abs(x1-x2),abs(y2-y1))==1
CV_CHAIN_APPROX_SIMPLE压缩水平方向,垂直方向,对角线方向的元素,只保留该方向的终点坐标,例如一个矩形轮廓只需4个点来保存轮廓信息
CV_CHAIN_APPROX_TC89_L1,CV_CHAIN_APPROX_TC89_KCOS使用teh-Chinl chain 近似算法
offset表示代表轮廓点的偏移量,可以设置为任意值。对ROI图像中找出的轮廓,并要在整个图像中进行分析时,这个参数还是很有用的。
具体应用参考sample文件夹下面的squares.cpp这个demo
findContours后会对输入的2值图像改变,所以如果不想改变该2值图像,需创建新mat来存放,findContours后的轮廓信息contours可能过于复杂不平滑,可以用approxPolyDP函数对该多边形曲线做适当近似
contourArea函数可以得到当前轮廓包含区域的大小,方便轮廓的筛选
findContours经常与drawContours配合使用,用来将轮廓绘制出来。其中第一个参数image表示目标图像,第二个参数contours表示输入的轮廓组,每一组轮廓由点vector构成,第三个参数contourIdx指明画第几个轮廓,如果该参数为负值,则画全部轮廓,第四个参数color为轮廓的颜色,第五个参数thickness为轮廓的线宽,如果为负值或CV_FILLED表示填充轮廓内部,第六个参数lineType为线型,第七个参数为轮廓结构信息,第八个参数为maxLevel
得到了复杂轮廓往往不适合特征的检测,这里再介绍一个点集凸包络的提取函数convexHull,输入参数就可以是contours组中的一个轮廓,返回外凸包络的点集
还可以得到轮廓的外包络矩形,使用函数boundingRect,如果想得到旋转的外包络矩形,使用函数minAreaRect,返回值为RotatedRect;也可以得到轮廓的外包络圆,对应的函数为minEnclosingCircle;想得到轮廓的外包络椭圆,对应的函数为fitEllipse,返回值也是RotatedRect,可以用ellipse函数画出对应的椭圆
如果想根据多边形的轮廓信息得到多边形的多阶矩,可以使用类moments,这个类可以得到多边形和光栅形状的3阶以内的所有矩,类内有变量m00,m10,m01,m20,m11,m02,m30,m21,m12,m03,比如多边形的质心为 x = m10 / m00,y = m01 / m00。
如果想获得一点与多边形封闭轮廓的信息,可以调用pointPolygonTest函数,这个函数返回值为该点距离轮廓最近边界的距离,为正值为在轮廓内部,负值为在轮廓外部,0表示在边界上。
版权声明:本文为博主原创文章,未经博主允许不得转载。
先简单回顾一下计算机视觉的知识。这里研究生的摄像机模型都是zhenkong摄像机,摄像机的标定问题是CV领域的一个入门级的问题,初学摄像机标定时会被各种坐标系弄晕,这里再介绍一下,常提到的坐标系有四个:世界坐标系(Ow,以空间一点为原点)、摄像机坐标系(Oc以小孔即光心为原点)、图像物理坐标系(O1以像平面中心为原点)、图像像素坐标系(O以像平面左下角为原点)。这样再看相关资料的时候就不会混了吧,这里再介绍一篇张正友的摄像机定标办法的相关资料http://beidou841026.blog.163.com/blog/static/4629535201021731344572/
其参数分为内参数和外参数:内参数是摄像机坐标系和理想坐标系之间的关系(5个内参数,分别为α、β、u0、v0、θ);外参数表示摄像机在世界坐标系里的位置和方向(6个外参数,3个表示旋转R的角度,3个表示平移t)。
利用calibrateCamera函数可以得到这些内外参数,而calibrationMatrixValues可以得到摄像机投影透视方程的投影矩阵,composeRT可以合并两个旋转平移变换,computeCorrespondEpilines计算其他图像的相应epilines,convertPointsToHomogeneous把点从欧式空间转换到齐次空间,convertPointsFromHomogeneous把点从齐次空间变换到欧式空间,而函数convertPointsHomogeneous把上述两个函数功能综合到一起了,decomposeProjectionMatrix可以将矩阵分解,drawChessboardCorners获得检测棋盘的角,findChessboardCorners获得棋盘的内角点位置,findCirclesGrid得到圆圈光栅的中心,solvePnP实现物体位置的3维坐标和2维坐标之间的转换,solvePnPRansac利用RANSAC实现上述功能,findFundamentalMat计算两幅图像关联点的基础矩阵,findHomography找出两个平面的透视变换,estimateAffine3D计算两个3维点集的理想仿射变换,filterSpeckles可以过滤不同块的小斑点,getOptimalNewCameraMatrix得到自由比例参数的新摄像机矩阵,initCameraMatrix2D得到3D到2D的初始化的摄像机矩阵,matMulDeriv计算矩阵的偏导数,projectPoints将3D坐标投影到图像平面上,reprojectImageTo3D根据一组差异图像重建3D空间,RQDecomp3x3计算3x3矩阵的RQ分解,Rodrigues实现旋转矩阵和旋转向量之间的转换,steroCalibrate校准立体摄像机,steroRectify是对校准过的摄像机计算修正变换,stereoRectifyUncalibrated是对未校准过的摄像机计算修正变换
还包括了BM块匹配算法类StereoBM、SGBM块匹配算法类StereoSGBM类
版权声明:本文为博主原创文章,未经博主允许不得转载。
CamShitf算法,即Continuously Apative Mean-Shift算法,基本思想就是对视频图像的多帧进行MeanShift运算,将上一帧结果作为下一帧的初始值,迭代下去。基本步骤为:
1.选取关键区域
2.计算该区域的颜色概率分布--反向投影图
3.用MeanShift算法找到下一帧的特征区域
4.标记并重复上述步骤
该算法的关键就是可以在目标大小发生改变的时候,可以自适应的调整目标区域继续跟踪
在进行CamShitf和MeanShift算法的时候,需要输入反向投影图,这就要求有个很重要的预处理过程是计算反向投影图。对应的函数为calcBackProject。所谓反向投影图就是一个概率密度图。calcBackProject的输入通常为目标区域的直方图和待跟踪图像的直方图,输出与待跟踪图像大小相同,每一个像素点表示该点为目标区域的概率。这个点越亮,该点属于物体的概率越大。这样的输入参数太适合做MeanS算法了。关于反向直方图,可以参考一下这篇文章http://blog.163.com/thomaskjh@126/blog/static/370829982010112810358501/
具体代码如下:
- calcHist(&roi, 1, 0, maskroi, hist, 1, &hsize, &phranges);
- calcBackProject(&hue, 1, 0, hist, backproj, &phranges);
- backproj &= mask;
- RotatedRect trackBox = CamShift(backproj, trackWindow,
- TermCriteria( CV_TERMCRIT_EPS | CV_TERMCRIT_ITER, 10, 1 ));
版权声明:本文为博主原创文章,未经博主允许不得转载。
这个库中相关的函数有calcOpticalFlowPyrLK、calcOpticalFlowFarneback、estimateRigidTransform、updateMotionHistory、calcMotionGradient、calcGlobalOrientation、segmentMotion、CamShift、meanShift;还有卡尔曼滤波器类KalmanFilter,类内成员函数有构造函数、init、predict、correct。背景单元类BackgroundSubtractor,包括运算符重载,getBackgroundImage,其派生类BackgroundSubtractorMOG和BackgroundSubtractorMOG2,以及只支持Python版本的函数CalcOpticalFlowBM、CalcOpticalFlowHS,c版本的函数cvCalcOpticalFlowLK
这些函数每一个背后几乎都是一篇论文,很多都是经典的方法,我才疏识浅,只能边学边总结,先介绍一些我用过的函数,待日后陆续补充
calcOpticalPlowPyrLK是利用Lucas-Kanade方法计算图像的光流场
版权声明:本文为博主原创文章,未经博主允许不得转载。
imgproc是OpenCV一个比较复杂的lib,我是分开介绍的,之前介绍过了滤波器、直方图、结构分析和形状描述三节,这次介绍一下图像的变换,OpenCV对于图像的变换又可分为几何变换和其他的变换,我这节先介绍一下其他的变换。
这部分的函数包括adaptiveThreshold,对图像进行自适应的阈值操作。
相应的也有更一般常用的阈值操作函数threshold。
这里还是详细介绍一下cvtColor,这个函数是用来进行颜色空间的转换,随着OpenCV版本的升级,对于颜色空间种类的支持也是越来越多。这里汇总一下,把我知道的全部空间列举出来,也许还不完整,希望大家补充。需要先告诉大家的是OpenCV默认的图片通道是BGR。
RGB <--> BGR:CV_BGR2BGRA、CV_RGB2BGRA、CV_BGRA2RGBA、CV_BGR2BGRA、CV_BGRA2BGR
RGB <--> 5X5:CV_BGR5652RGBA、CV_BGR2RGB555、(以此类推,不一一列举)
RGB <---> Gray:CV_RGB2GRAY、CV_GRAY2RGB、CV_RGBA2GRAY、CV_GRAY2RGBA
RGB <--> CIE XYZ:CV_BGR2XYZ、CV_RGB2XYZ、CV_XYZ2BGR、CV_XYZ2RGB
RGB <--> YCrCb(YUV) JPEG:CV_RGB2YCrCb、CV_RGB2YCrCb、CV_YCrCb2BGR、CV_YCrCb2RGB、CV_RGB2YUV(将YCrCb用YUV替代都可以)
RGB <--> HSV:CV_BGR2HSV、CV_RGB2HSV、CV_HSV2BGR、CV_HSV2RGB
RGB <--> HLS:CV_BGR2HLS、CV_RGB2HLS、CV_HLS2BGR、CV_HLS2RGB
RGB <--> CIE L*a*b*:CV_BGR2Lab、CV_RGB2Lab、CV_Lab2BGR、CV_Lab2RGB
RGB <--> CIE L*u*v:CV_BGR2Luv、CV_RGB2Luv、CV_Luv2BGR、CV_Luv2RGB
RGB <--> Bayer:CV_BayerBG2BGR、CV_BayerGB2BGR、CV_BayerRG2BGR、CV_BayerGR2BGR、CV_BayerBG2RGB、CV_BayerGB2RGB、 CV_BayerRG2RGB、CV_BayerGR2RGB(在CCD和CMOS上常用的Bayer模式)
YUV420 <--> RGB:CV_YUV420sp2BGR、CV_YUV420sp2RGB、CV_YUV420i2BGR、CV_YUV420i2RGB
还有函数distanceTransform,是用来计算各像素距离最近的零像素距离的。
floodFill函数用来用指定颜色填充一个连通部件。
inpaint函数用来用附近区域信息重建选中区域,可以对图像里由于传输噪声丢失的块进行重建。
integral函数用来获得图像的积分值。
寻找边界使用分水岭分割办法的函数watershed。
对图像进行GrabCut算法的grabCut函数(有待研究,不熟悉)。
总之,这些变换千奇百怪,不是很系统,常用的还是我先介绍的几个,比如threshold、cvtColor。就这样吧,以后有收获再陆续补充。
版权声明:本文为博主原创文章,未经博主允许不得转载。
contrib为最新贡献但不是很成熟的函数库。作为最新的东西,就更有价值进行庖丁解牛了,我来也。
首先介绍一个CvAdaptiveSkinDetector类。该类的功能是自适应的皮肤检测。分析了一下代码,其构造函数的输入参数有两个,samplingDivider样本分类,morphingMethod为变形方法。该类的关键函数为process函数,该函数先将输入图像由RGB转换为HSV空间,Hue的范围是3~33,Intensity(V)的范围为15~250。然后进行必要的腐蚀膨胀,去除噪声,使轮廓更加清晰平滑。具体的使用代码参考sample文件夹中的adaptiveskindetector.cpp
版权声明:本文为博主原创文章,未经博主允许不得转载。
最近也在玩手势识别,资料找了很多,基本可以分为静态手势识别和动态手势识别,先弄个简单的静态手势识别给大家看看。
基本流程如下:
先滤波去噪-->转换到HSV空间-->根据皮肤在HSV空间的分布做出阈值判断,这里用到了inRange函数,然后进行一下形态学的操作,去除噪声干扰,是手的边界更加清晰平滑-->得到的2值图像后用findContours找出手的轮廓,去除伪轮廓后,再用convexHull函数得到凸包络。
结果如下:
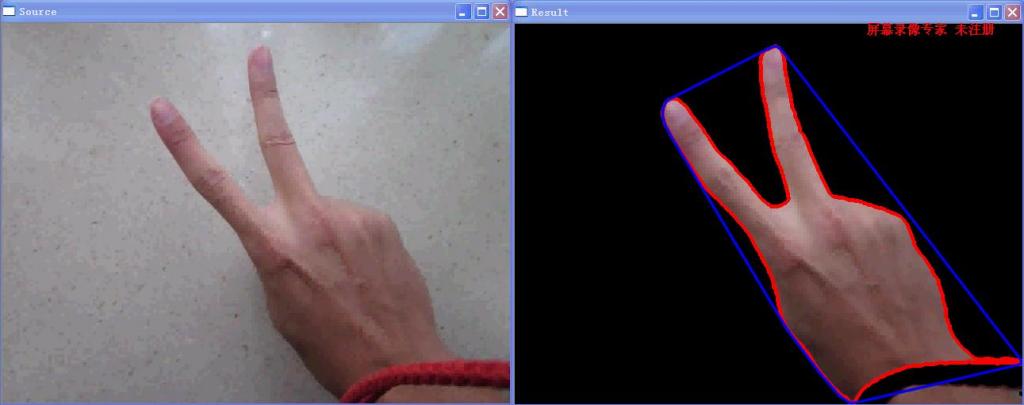
源代码下载位置:http://download.csdn.net/detail/yang_xian521/3746669,有点贵哦,当时随便设了个值,呵呵
版权声明:本文为博主原创文章,未经博主允许不得转载。
在图像中,我们经常想要在图像中做一些标识记号,这就需要绘图函数。OpenCV虽然没有太优秀的GUI,但在绘图方面还是做得很完整的。这里就介绍一下相关的函数。
在绘图函数中都会用到颜色,这里用Scalar结构表示颜色参数。
作图相关的函数有circle、clipLine、ellipse、ellipse2Poly、line、rectangle、polylines、类LineIterator。
填充相关的函数有fillConvexPoly、fillPoly。
显示文字相关的函数有getTextSize、cvInitFont、putText。
以上这些函数使用都非常简单方便,我就不过多介绍了。
版权声明:本文为博主原创文章,未经博主允许不得转载。
粒子滤波法是指通过寻找一组在状态空间传播的随机样本对概率密度函数进行近似,以样本均值代替积分运算,从而获得状态最小方差分布的过程。
对于粒子滤波跟踪方法,这里有一篇很浅显易懂的博客,我分享给大家http://www.cnblogs.com/yangyangcv/archive/2010/05/23/1742263.html。他的工作也是参考Rob Hess的程序做的,感谢老外的开源精神,我看了他的程序,我也提出了我的几点改进,作者本身的设想是想做多目标的运动跟踪,但函数接口写的还是有些混乱,以至于最后不能实现(估计是我才疏识浅,没能领会作者的精神),而且用到了gsl数学库,这个库我是不熟悉的,开了一下程序,主要也就只用了里面的随机数的功能,这功能在新版本的OpenCV里已经集成啦,作者用的数据结构还是老版本的结构,好多函数还是作者自己写的,我这里用新版本的数据结构重新写了一遍这个算法,简化跟踪目标为一个。下面介绍一下我的设计流程
首先还是将视频转换到HSV颜色空间,我发现很多图像处理的办法都是在该空间下完成的,Rob Hess对HSV颜色空间的特征提取还是很有意思的,他知道色度和饱和度提供的信息和亮度提供的信息分开考虑,做出了他自己的特征直方图。我这里用了新版本的calcHist做的特征直方图,偷了个懒,效果感觉还可以。
初始化阶段就是对鼠标选中的目标区域的特征直方图提取,进入搜索阶段,通俗的讲,就是在待搜索区域里放入大量的粒子particle,放入粒子的规则有很多,这里使用的是让粒子的分布为高斯分布,计算每个粒子所在区域的特征直方图,与目标区域特征进行比较,特征接近的粒子的权重大一些,反之权重小一些。通过调整各粒子的权重大小和样本位置来近似实际的概率分布,以样本期望作为系统估计值。然后进行重采样,重新分布粒子的位置。(对于重采样的目的,是为了解决序列重要性采样(SIS)存在的退化现象,即几步迭代之后,许多粒子的权重变得很小,大量的计算浪费在小权值的粒子上。解决退化问题的一般办法就是重采样原理,基本思想就是对后验概率密度再采样,保留复制权重大的粒子,剔除权重小的粒子。程序里感觉只是据粒子的权重的后验概率分布进行一次重新采样,感觉并不是yangyangcv说的那个类似ransac的意思,因为我对代码分析并没有循环放粒子的过程,欢迎大家拍砖)
具体的算法流程为

我的实际编程步骤大概可以分为如下几步:
// step 1: 提取目标区域特征
// step 2: 初始化particle(粒子的个数很影响跟踪的速度)
// step 3: 求particle的transition(这一步的参数会很影响粒子的变化区域,需要对不同的跟踪对象进行调整参数)
// step 4: 求particle区域的特征直方图(特征选取的不合适也很影响结果)
// step 5: 特征的比对,更新particle权重(特征比较的方法也是影响结果的因素)
// step 6: 归一化粒子权重
// step 7: resample根据粒子的权重的后验概率分布重新采样
// step 8: 计算粒子的期望,作为跟踪结果
再写一下我试验后的心得,我用的是最基本的粒子滤波算法,考虑因素较少,受参数影响很大,而且参数众多,不方便自动调整。对不同的视频跟踪效果差别很大,而且会出现目标丢失的情况。这都是可以改进的。
试验代码下载地址为:http://download.csdn.net/detail/yang_xian521/3756240
版权声明:本文为博主原创文章,未经博主允许不得转载。
版权声明:本文为博主原创文章,未经博主允许不得转载。
这部分内容应该是OpenCV高深精髓的一部分。给OpenCV插上了翅膀,可以使它实现更强大的功能,而不是简单的做一些基本的图像处理。文采太差,就不描绘machine learning的强大了。直接剖析之。
大部分的分类器和识别的算法都封装在了c++的类中。有些类有一些共同的基础,都被定义在CvStatModel类中了。
那就先介绍这个统计模型类CvStatModel,它是机器学习统计模型的基础类,其包括了构造函数和析构函数,清除内存重置模型状态的clear函数(功能类似析构函数,但可以重用,在析构函数里也调用该函数),模型保存 / 加载XML文件的save / load函数,读写文件和模型的函数write / read,训练模型的函数train,预测样本结果predict函数。
普通的贝叶斯分类器CvNormalBayesClassifier,有train和predict函数
k近邻算法CvKNearest,有train、find_nearest、get_max_k、get_var_count、get_sample_count、is_regression函数
支持向量机SVM相关的有类CvParamGrid用来表示统计参数范围的对数格子,类CvSVMParams、类CvSVM
决策树类CvDTreeSplit、CvDTreeNode、CvDTreeParams、CvDTreeTrainData、CvDTree
Boosting算法相关类CvBoostParams、CvBoostTree、CvBoost
Gradient Boosted Trees(GBT)算法相关类CvGBTreesParams、CvGBTrees
随机森林相关算法类CvRTparams、CvRTrees
随机树算法的扩展类CvERTrees
期望最大EM算法相关类CvEMParams、CvEM
神经网络算法相关类CvANN_MLP_TrainParams、CvANN_MLP
OpenCV果然够强大,几乎囊括了目前比较流行的全部机器学习方面的经典算法。以上这些牛叉的算法我都好膜拜啊,得下苦功专研了。
记得哪位牛人说过algorithm is king,data is queen。有了算法还需要对应的数据类CvMLData、CvTrainTestSplit
这部分内容真是博大精深啊,作为初学者,我一直不太敢写这方面的博客,很多算法只知道个皮毛,没有实现过,更不知道其中的奥妙,这里只能先做个介绍,待我日后慢慢丰富内容
版权声明:本文为博主原创文章,未经博主允许不得转载。
一直对MFC对OpenCV的支持不好而耿耿于怀,了解了Qt对OpenCV支持很好,但网上这方面的资料很少。大部分的图形交互的设计都是基于OpenCV2.0之前的数据结构lpImage进行的。最近得到了一本好书《OpenCV 2 Computer Vision Application Programming Cookbook》,下载的链接为http://ishare.iask.sina.com.cn/f/20485520.html?retcode=0,2011年5月出版,全书都是基于OpenCV2.2版本的实现,采用了新的数据结构。我这里强烈建议利用C++开发的朋友们不要再使用老版本的数据结构了,实在影响开发效率。至于大家最熟悉的参考书《learning OpenCV》和《OpenCV教程——基础篇》这两本广为流传的书,我的看法是已经远远不能满足OpenCV新版本的学习了。真的希望这本新书的中文版尽快出炉。
参考这本书的利用Qt创建GUI,不过书中的办法是在Qt Creator下实现的,我这里通过VS2008+Qt实现。下面结合一个例程介绍一下如何在Qt的GUI环境下开发OpenCV。
先新建工程Qt Project --> Qt Application,点击finish完成工程的创建。然后在项目属性里的连接器的附加依赖项里面添加opencv的lib文件。工程创建好之后,一个后缀名为.ui的文件就是关于界面设计的。首先创建两个按钮,拖拽两个Push Buttons到Form中去,修改其属性,一个名字为Open Image,一个为Process。右键按钮选择connect signal为其添加响应函数,选择clicked()。对应的cpp文件多出了on_OpenImage_clicked函数,代码如下:
- #include "qttest1.h"
- qttest1::qttest1(QWidget *parent, Qt::WFlags flags)
- : QMainWindow(parent, flags)
- {
- ui.setupUi(this);
- }
- qttest1::~qttest1()
- {
- }
- void qttest1::on_OpenImage_clicked()
- {
- }
接下来要在对应的头文件中添加显示图片的必要代码,添加QFileDialog类的声明,OpenCV必要的include头文件包含,在类中声明一个cv :: Mat成员变量。代码如下:
- #ifndef QTTEST1_H
- #define QTTEST1_H
- #include <QtGui/QMainWindow>
- #include <QFileDialog>
- #include "ui_qttest1.h"
- #include <opencv2/core/core.hpp>
- #include <opencv2/highgui/highgui.hpp>
- class qttest1 : public QMainWindow
- {
- Q_OBJECT
- public:
- qttest1(QWidget *parent = 0, Qt::WFlags flags = 0);
- ~qttest1();
- private:
- Ui::qttest1Class ui;
- cv::Mat image; // cv图片
- private slots:
- void on_OpenImage_clicked();
- };
- #endif // QTTEST1_H
接下来添加on_OpenImage_clicked的函数内容。代码如下:
- void qttest1::on_OpenImage_clicked()
- {
- QString fileName = QFileDialog::getOpenFileName(this, tr("Open Image"), ".", tr("Image Files (*.png *.jpg *.jpeg *.bmp)"));
- image = cv::imread(fileName.toAscii().data());
- cv::namedWindow("Original Image");
- cv::imshow("Original Image", image);
- }
类似的办法添加Process按钮的相应代码:
- void qttest1::on_Process_clicked()
- {
- cv::flip(image, image, 1);
- cv::namedWindow("Output Image");
- cv::imshow("Output Image", image);
- }
这样就可以实现一个普通的按钮响应。但我们的目的是将图片显示在对话框form中,这还需要进一步深入学习。与MFC中显示图片需要CvvImage类似,要想在Qt的Form中显示图片,图片的格式也必须为QImage,需要将cv::Mat的BGR通道顺序变换为RGBA,QImage的格式为Format_RGB32,调用cvtColor实现(这里例程里调用的为BGR2RGB,然后QImage的格式为Format_RGB888,但我试验显示结果是有问题的,故自己调整了一下)。(后经实验,BGR2RGB,Format_RGB888这组参数对于webcam视频是正确的,对于我当时的实验照片是不正确的,格式的问题真是混乱!!!)实现代码如下:
- cv::cvtColor(image, image, CV_BGR2RGBA);
- QImage img = QImage((const unsigned char*)(image.data), image.cols, image.rows, QImage::Format_RGB32);
- QLabel *label = new QLabel(this);
- label->move(200, 50);
- label->setPixmap(QPixmap::fromImage(img));
- label->resize(label->pixmap()->size());
- label->show();
注意打开图片的路径不要有中文,最后的显示结果为

相关代码的下载地址为http://download.csdn.net/detail/yang_xian521/3793960
版权声明:本文为博主原创文章,未经博主允许不得转载。
总感觉自己停留在码农的初级阶段,要想更上一层,就得静下心来,好好研究一下算法的东西。OpenCV作为一个计算机视觉的开源库,肯定不会只停留在数字图像处理的初级阶段,我也得加油,深入研究它的算法库。就从ml入手吧,最近做东西遇到随机森林,被搞的头大,深深感觉自己肚子里货太少,关键时刻调不出东西来。切勿浮躁,一点点研究吧。
这次就先介绍一下机器学习中的一个常用算法SVM算法,即支持向量机Support Vector Machine(SVM),是一种有监督学习方法,更多介绍请见维基百科http://zh.wikipedia.org/wiki/SVM。
OpenCV开发SVM算法是基于LibSVM软件包开发的,LibSVM是台湾大学林智仁(Lin Chih-Jen)等开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归的软件包。用OpenCV使用SVM算法的大概流程是
1)设置训练样本集
需要两组数据,一组是数据的类别,一组是数据的向量信息。
2)设置SVM参数
利用CvSVMParams类实现类内的成员变量svm_type表示SVM类型:
CvSVM::C_SVC C-SVC
CvSVM::NU_SVC v-SVC
CvSVM::ONE_CLASS 一类SVM
CvSVM::EPS_SVR e-SVR
CvSVM::NU_SVR v-SVR
成员变量kernel_type表示核函数的类型:
CvSVM::LINEAR 线性:u‘v
CvSVM::POLY 多项式:(r*u'v + coef0)^degree
CvSVM::RBF RBF函数:exp(-r|u-v|^2)
CvSVM::SIGMOID sigmoid函数:tanh(r*u'v + coef0)
成员变量degree针对多项式核函数degree的设置,gamma针对多项式/rbf/sigmoid核函数的设置,coef0针对多项式/sigmoid核函数的设置,Cvalue为损失函数,在C-SVC、e-SVR、v-SVR中有效,nu设置v-SVC、一类SVM和v-SVR参数,p为设置e-SVR中损失函数的值,class_weightsC_SVC的权重,term_crit为SVM训练过程的终止条件。其中默认值degree = 0,gamma = 1,coef0 = 0,Cvalue = 1,nu = 0,p = 0,class_weights = 0
3)训练SVM
调用CvSVM::train函数建立SVM模型,第一个参数为训练数据,第二个参数为分类结果,最后一个参数即CvSVMParams
4)用这个SVM进行分类
调用函数CvSVM::predict实现分类
5)获得支持向量
除了分类,也可以得到SVM的支持向量,调用函数CvSVM::get_support_vector_count获得支持向量的个数,CvSVM::get_support_vector获得对应的索引编号的支持向量。
实现代码如下:
- // step 1:
- float labels[4] = {1.0, -1.0, -1.0, -1.0};
- Mat labelsMat(3, 1, CV_32FC1, labels);
- float trainingData[4][2] = { {501, 10}, {255, 10}, {501, 255}, {10, 501} };
- Mat trainingDataMat(3, 2, CV_32FC1, trainingData);
- // step 2:
- CvSVMParams params;
- params.svm_type = CvSVM::C_SVC;
- params.kernel_type = CvSVM::LINEAR;
- params.term_crit = cvTermCriteria(CV_TERMCRIT_ITER, 100, 1e-6);
- // step 3:
- CvSVM SVM;
- SVM.train(trainingDataMat, labelsMat, Mat(), Mat(), params);
- // step 4:
- Vec3b green(0, 255, 0), blue(255, 0, 0);
- for (int i=0; i<image.rows; i++)
- {
- for (int j=0; j<image.cols; j++)
- {
- Mat sampleMat = (Mat_<float>(1,2) << i,j);
- float response = SVM.predict(sampleMat);
- if (fabs(response-1.0) < 0.0001)
- {
- image.at<Vec3b>(j, i) = green;
- }
- else if (fabs(response+1.0) < 0.001)
- {
- image.at<Vec3b>(j, i) = blue;
- }
- }
- }
- // step 5:
- int c = SVM.get_support_vector_count();
- for (int i=0; i<c; i++)
- {
- const float* v = SVM.get_support_vector(i);
- }
版权声明:本文为博主原创文章,未经博主允许不得转载。
OpenCV支持的目标检测的方法是利用样本的Haar特征进行的分类器训练,得到的级联boosted分类器(Cascade Classification)。注意,新版本的C++接口除了Haar特征以外也可以使用LBP特征。
先介绍一下相关的结构,级联分类器的计算特征值的基础类FeatureEvaluator,功能包括读操作read、复制clone、获得特征类型getFeatureType,分配图片分配窗口的操作setImage、setWindow,计算有序特征calcOrd,计算绝对特征calcCat,创建分类器特征的结构create函数。级联分类器类CascadeClassifier。目标级联矩形的分组函数groupRectangles。
接下来,我尝试使用CascadeClassifier这个级联分类器类检测视频流中的目标(haar支持的目标有人脸、人眼、嘴、鼻、身体。这里尝试比较成熟的人脸和眼镜)。用load函数加载XML分类器文件(目前提供的分类器包括Haar分类器和LBP分类器(LBP分类器数据较少))具体步骤如下:
这里再补充一点:后来我又进行了一些实验,对正面人脸分类器进行了实验,总共有4个,alt、alt2、alt_tree、default。对比下来发现alt和alt2的效果比较好,alt_tree耗时较长,default是一个轻量级的,经常出现误检测。所以还是推荐大家使用haarcascade_frontalface_atl.xml和haarcascade_frontalface_atl2.xml。
1)加载级联分类器
调用CascadeClassifier类成员函数load实现,代码为:
- CascadeClassifier face_cascade;
- face_cascade.load("haarcascade_frontalface_alt.xml");
2)读取视频流
这部分比较基础啦~~从文件中读取图像序列,读取视频文件,读取摄像头视频流看过我之前的文章,这3种方法应该了然于心。
3)对每一帧使用该分类器
这里先将图像变成灰度图,对它应用直方图均衡化,做一些预处理的工作。接下来检测人脸,调用detectMultiScale函数,该函数在输入图像的不同尺度中检测物体,参数image为输入的灰度图像,objects为得到被检测物体的矩形框向量组,scaleFactor为每一个图像尺度中的尺度参数,默认值为1.1,minNeighbors参数为每一个级联矩形应该保留的邻近个数(没能理解这个参数,-_-|||),默认为3,flags对于新的分类器没有用(但目前的haar分类器都是旧版的,CV_HAAR_DO_CANNY_PRUNING利用Canny边缘检测器来排除一些边缘很少或者很多的图像区域,CV_HAAR_SCALE_IMAGE就是按比例正常检测,CV_HAAR_FIND_BIGGEST_OBJECT只检测最大的物体,CV_HAAR_DO_ROUGH_SEARCH只做初略检测),默认为0.minSize和maxSize用来限制得到的目标区域的范围。这里调用的代码如下:
- face_cascade.detectMultiScale( frame_gray, faces, 1.1, 2, 0|CV_HAAR_SCALE_IMAGE, Size(30, 30) );
4)显示目标
这个也比较简单,调用ellips函数将刚才得到的faces矩形框都显示出来
更进一步,也可以在得到的每一幅人脸中得到人眼的位置,调用的分类器文件为haarcascade_eye_tree_eyeglasses.xml,先将脸部区域选为兴趣区域ROI,重复上诉步骤即可,这里就不详细介绍了。当然,感兴趣的朋友也可以试试其他的xml文件作为分类器玩一下啊,感觉LBP特征虽然xml文件的大小很小,但效果还可以,不过我没有做过多的测试。光说不练假把式,最后贴上效果图和源代码的下载地址
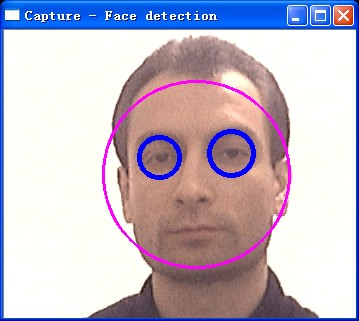
版权声明:本文为博主原创文章,未经博主允许不得转载。
OpenCV配套的教程Tutorials对于Video的部分,没有实例进行说明,我只能摸石头过河啦,之前试过一个camShift做目标检测,这次试一试光流法做运动估计。这里使用的光流法是比较常用的 Lucas-Kanade方法。对于光流法的原理,我就不过多介绍了,主要讲使用OpenCV如何实现。
首先利用goodFeaturesToTrack函数得到图像中的强边界作为跟踪的特征点,接下来要调用calcOpticalFlowPyrLK函数,输入两幅连续的图像,并在第一幅图像里选择一组特征点,输出为这组点在下一幅图像中的位置。再把得到的跟踪结果过滤一下,去掉不好的特征点。再把特征点的跟踪路径标示出来。说着好简单哦~~
程序的效果和代码下载http://download.csdn.net/detail/yang_xian521/3811478
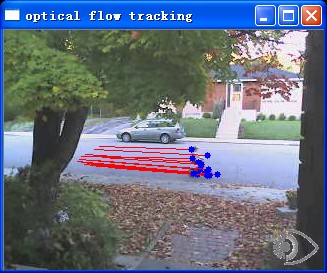
版权声明:本文为博主原创文章,未经博主允许不得转载。
视频捕捉的对象中,背景通常保持不变。一般分析中关注移动的前景物体,威力提取出前景物体,需要建立背景的模型,将模型和当前帧进行比对检测前景物体。前景提取应用非常广泛,特别是在智能监控领域中。
如果有不含前景物体的背景图片,提取前景的工作相对容易,只需要比对当前帧和背景图片的不同,调用函数absdiff实现。但是大多数情况,获得背景图片是不可能的,比如在复杂的场景下,或者有光线条件的变化。因此,就需要动态的变换背景。一种简单的办法是对所观察到的图片取平均,但这样做也有很多弊端,首先,这种办法在计算背景图片的前需要输入大量的图片,其次我们进行取平均的过程中不能有前景物体进入。所以一种相对好的办法是动态建立背景图片并实时更新。
具体的实现过程主要分为两部分:一部分是调用absdiff函数找出当前图片和背景图片的区别,这之中使用了threshold函数去除为前景,当前图片像素与背景图片像素变化超过一定阈值的时候才认定其为前景;另一个工作是更新背景图片,调用函数accumulateWeighted,根据权重参数可以调整背景更新的速度,将当前图片更新到背景中,这里巧妙利用得到的前景提取结果作为mask,在更新背景图片的过程中避免了前景的干扰。
程序效果如图,代码下载地址为http://download.csdn.net/detail/yang_xian521/3814878

虽然可以调整阈值参数和权重更新速度调节前景提取的结果,但从测试视频可以发现,树叶的运动对结果的干扰还是不小的,特别对于第一帧出现前景的情况,由于后续更新背景都是对前景mask后对背景进行更新的,所以第一帧的前景部分对背景的影响因子很难被更新掉。这里提出一种改进的办法——混合高斯模型。可以使一个像素具有更多的信息,这样可以有效的减少类似树叶的不停飘动,水波的不停荡漾这种对前景的干扰。这个精密的算法比之前我所介绍的简单方法要复杂很多,不易实现。还好,OpenCV已经为我们做好了相关工作,将其封装在类BackgroundSubtractorMOG,使用起来非常方便。实现代码如下:
- Mat frame;
- Mat foreground; // 前景图片
- namedWindow("Extracted Foreground");
- // 混合高斯物体
- BackgroundSubtractorMOG mog;
- bool stop(false);
- while (!stop)
- {
- if (!capture.read(frame))
- {
- break;
- }
- // 更新背景图片并且输出前景
- mog(frame, foreground, 0.01);
- // 输出的前景图片并不是2值图片,要处理一下显示
- threshold(foreground, foreground, 128, 255, THRESH_BINARY_INV);
新程序的效果图如下,下载地址为http://download.csdn.net/detail/yang_xian521/3815366
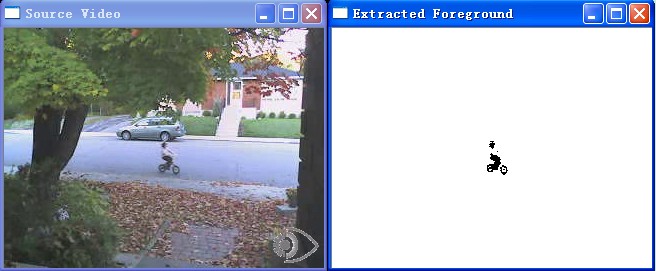
版权声明:本文为博主原创文章,未经博主允许不得转载。
最近做一个东西,摄像头使用的高清摄像头,采集出来的视频是D1格式(720*480)。使用VideoCapture发现速度很忙,网上的朋友说VideoCapture提供的读写功能采用VFW,效率低下且有些格式支持不好。而 OpenCV 2.0 内置了videoInput Library,可以自动在VFW和DirectShow间切换。videoInput是老外写的功能强大的开源视频处理库。是一个第三方库,2.0~2.2的版本专门有一个3rdparty对该库进行支持,而在最新的2.3版本中,已经讲videoInput库集成到highgui中了,想使用它的话,只需要在cmake中设置宏WITH_VIDEOiNPUT=OFF/ON即可。好像我使用的2.3.1自带的那个build文件夹下面的库就是在ON条件下编译得到的,所以就不用cmake重新编译了。2.3中使用手册和教程对VideoInput类只字未提,我只好自己摸索了。还好有源代码可以看,开源伟大。
网上见过其他朋友写过2.2实现VideoInput的使用,我实验发现2.3中的使用方法基本没有变化。后面再把配套例程奉上,先把VideoInput类内的公有成员函数一一介绍一下,该类还有个相关的类是VideoDevice。包括控制是否在控制台输出信息开关setVerbose函数,打印出可用视频设备信息的函数listDevices,之后可以得到设备名函数getDeviceName,视频捕捉的回调函数设置函数setUseCallback,调整捕捉帧率的函数setIdealFramerate(默认30fps,可修改,但不能被保证准确,directshow会尝试一个邻近的帧率),防止设备休眠重新连接的函数setAutoReconnectOnFreeze,开启设备函数setupDevice,在setpuDevice之前可以设置视频制式,调用函数为setFormat,检测是否有新的帧函数isFrameNew,检测视频是否开启isDeviceSetup,获得数据的函数getPixels(注意这里获得的数据时uchar型的指针),显示视频设置窗口函数showSettingsWindow,控制视频设置的相关函数有setVideoSettingFilter、setVideoSettingFilterPct、getVideoSettingFilter、setVideoSettingCamera、setVideoSettingCameraPct、getVideoSettingCamera,获得视频宽高信息的函数有getWidth、getHeight、getSize,停止设备函数stopDevice,重启设备函数restartDevice。
讲了这么多函数,还是直接上代码说话吧,我这是找的VideoInput注释中的一个例程。
- //create a videoInput object
- videoInput VI;
- //Prints out a list of available devices and returns num of devices found
- int numDevices = VI.listDevices();
- int device1 = 0; //this could be any deviceID that shows up in listDevices
- int device2 = 1; //this could be any deviceID that shows up in listDevices
- //if you want to capture at a different frame rate (default is 30)
- //specify it here, you are not guaranteed to get this fps though.
- //VI.setIdealFramerate(dev, 60);
- //setup the first device - there are a number of options:
- VI.setupDevice(device1); //setup the first device with the default settings
- //VI.setupDevice(device1, VI_COMPOSITE); //or setup device with specific connection type
- //VI.setupDevice(device1, 320, 240); //or setup device with specified video size
- //VI.setupDevice(device1, 320, 240, VI_COMPOSITE); //or setup device with video size and connection type
- //VI.setFormat(device1, VI_NTSC_M); //if your card doesn't remember what format it should be
- //call this with the appropriate format listed above
- //NOTE: must be called after setupDevice!
- //optionally setup a second (or third, fourth ...) device - same options as above
- VI.setupDevice(device2);
- //As requested width and height can not always be accomodated
- //make sure to check the size once the device is setup
- int width = VI.getWidth(device1);
- int height = VI.getHeight(device1);
- int size = VI.getSize(device1);
- unsigned char * yourBuffer1 = new unsigned char[size];
- unsigned char * yourBuffer2 = new unsigned char[size];
- //to get the data from the device first check if the data is new
- if(VI.isFrameNew(device1)){
- VI.getPixels(device1, yourBuffer1, false, false); //fills pixels as a BGR (for openCV) unsigned char array - no flipping
- VI.getPixels(device1, yourBuffer2, true, true); //fills pixels as a RGB (for openGL) unsigned char array - flipping!
- }
- //same applies to device2 etc
- //to get a settings dialog for the device
- VI.showSettingsWindow(device1);
- //Shut down devices properly
- VI.stopDevice(device1);
- VI.stopDevice(device2);
版权声明:本文为博主原创文章,未经博主允许不得转载。
这一节的内容感觉比较土鳖。这从来就是一个老生常谈的问题。学MFC的时候就知道这个事情了,那时候记得老师强调多次,如果写的demo想在人家那里演示一下,一定要选择静态库使用mfc,而不是选择动态链接库,否则在人家电脑里没有对应的dll文件,是无法运行起来的。可见老师在这方面吃过亏啊。昨天用OpenCV写了个东西,发过去让人家测试,可人家告诉我:“你这土鳖程序在我这无法运行“,好囧啊。这里把我的解决过程记录一下。希望能对大家遇到类似的问题有所帮助。
首先,介绍一下我的开发环境32bits+winXP+VS2008+OpenCV,他的电脑32bits+Win7+none(他电脑其他开发环境基本没装,是个裸机)。
我程序里用到的库文件包括core、highgui、imgproc、video,用的是debug版本,写的是个控制台程序。所以把相应的dll文件copy过去,分别是opencv_core231d.dll、opencv_highgui231d.dll、opencv_imgproc231d.dll、opencv_video231d.dll(如果是release版本,要copy相应的没有d结尾的动态链接库,下面相应的dll都存在类似的问题)。本以为这样就ok了,第一次传给他,他告诉我运行不了,没有任何提示,用命令行运行,提示应用程序缺少相应的并行配置,百度出来的答案千奇百怪,感觉都没有切中要害。
于是又找了一台装的xp的电脑试验,这次弹出错误是缺少tbb_debug.dll,我忽然想起来我第一次运行程序的时候也是弹出过这个错误。于是根据电脑的配置是32位机,开发环境是vs9,找到对应目录下的tbb_debug.dll文件,copy过去,再试。
这次弹出的错误比较离奇,提示缺少msvcp100d.dll,可是大哥,我用的开发环境是vs2008,对应的文件应该是msvcp90d.dll才对吧(这个问题目前没想出合理解释),不管了,死马当活马医,又去别人电脑copy过来msvcp100d.dll和msvcr100d.dll,再试。
这次弹出缺少msvcp90d.dll了,呵呵,该来的还是会来。这是由于他的电脑没有vs平台运行时的对应dll造成的,网上搜了下解决办法。去C:\Program Files\Microsoft Visual Studio 9.0\VC\redist\x86\Microsoft.VC90.CRT目录把Microsoft.VC90.CRT.manifest、msvcm90.dll、msvcp90.dll、msvcr90.dll四个文件都copy过来,又去C:\Program Files\Microsoft Visual Studio 9.0\VC\redist\x86\Microsoft.VC90.OPENMP目录下把Microsoft.VC90.OpenMP.manifest、vcomp90.dll两个文件copy过去。
这次总算离胜利比较近了,不报错了,但是视频文件无法打开,感觉还是OpenCV相关的动态链接库没有copy过去,又copy了几个dll,比如opencv_ffmpeg.dll。这次总算可以运行了。oh yeah~~
问题是解决了,不过对于dll文件的理解还是不够深刻,网上还有说是因为运行时库的问题,需要在相关项目设置里把MDD设置为MTD,但我试过,发现不是这个问题。要是能有办法,像MFC那样把相应的dll进行静态编译,都做到exe里面就好了。不知道是我知之甚少,还是OpenCV的程序不行。期待高手指点一二。
感谢大家指导,我把心得又写了一篇http://blog.csdn.net/yang_xian521/article/details/7027190
版权声明:本文为博主原创文章,未经博主允许不得转载。
感谢大家对我博客的支持,昨天写的那个土鳖的bloghttp://blog.csdn.net/yang_xian521/article/details/7022701,为了让自己的程序在别人那里运行起来,竟然加了十余个dll,才搞定,太不方便了。对于我这土鳖的办法,有好心的网友看不下去了,告诉我OpenCV是可以制作静态链接库。我顿时来了兴致,百度之,发现确实有办法,但很多都是老版本的数据结构,还是对cv.lib等等的处理。我这里用2.3版实现了一下,把我的心得分享给大家。
首先用cmake重新生成vs2008的解决方案,之前我都用的编译好的OpenCV,现在用的多了,才知道cmake的妙处。因为是要生成opencv的静态库, 去掉一些无关的选项. 去掉BUILD_NEW_PYTHON_SUPPORT,BUILD_SHARED_LIBS, BUILD_TESTS, 勾选OPENCV_BUILD_3RDPARTY_LIBS, WITH_TBB,WITH_JASPER, WITH_JPEG, WITH_PNG, WITH_TIFF选项,然后点击configure. 提示TBB_INCLUDE_DIR找不到,忽略即可,直接点击configure,配置完成,点击generate,完成后关闭cmake得到解决方案后,打开OpenCV.sln,哇,要不要这么多工程...一个一个来吧。根据OpenCV编译好的动态链接的lib,有calib3d、contrib、core、features2d、flann、gpu、haartraining_engine(这个是静态链接的,不需要重新编译)、highgui、imgproc、legacy、ml、objdetect、ts、video,以上这些工程需要重新编译为静态链接库。打开对应工程的属性,找到下图中的对应项,
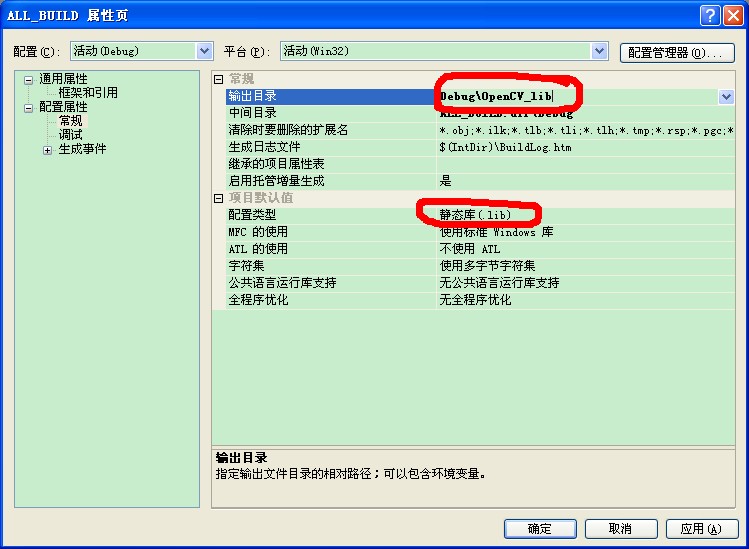
把输出目录改为自己设定的目录,把配置类型由动态库(.dll)改为静态库(.lib),把运行时库改为静态。重新生成(ctrl+F7)。得到了我心爱的lib文件,不过也吓了我一跳,每个lib比动态链接的lib要大出几十倍,都10M左右,推荐大家写程序,如果不是做成demo,给别人展示,还是不要用静态链接的好,否则做出来的exe好大啊...
我这里把生成的lib库整理了一下,debug版本的在后缀加了231ds,(s表示静态库),release后缀加上了231s。(由于发现OpenCV有做好的静态lib,我就不上传了)
做好了库之后,准备把lib文件copy到我OpenCV的安装目录下准备使用,才悲催的发现原来这个工作OpenCV早已给我做好,都放在build文件夹下面的对应的staticlib目录中了,但和我自己做出来的lib文件大小不一样(估计是cmake时候的选项选择的不同)。还有一个问题就是悲催的发现OpenCV自带的静态lib文件和动态lib文件命名是相同的,这可如何在附加依赖项中选择填写啊,还是用我自己写的后缀名不同的库做测试吧(后来发现只有在配置的vc++目录里的库文件目录中添加staticlib路径,然后把该路径的顺序调整到lib路径前,就可以优先调用staticlib了)。我在我原来的程序里测试了一下,还是不能编译通过,很让我恼火,求助了高人发现是附加依赖库并没有添加完全,找到对应的3rdparty\lib文件夹下面的zlibd.lib、libjasperd.lib、libjpegd.lib、libpngd.lib、libtiffd.lib。把这几个文件copy到安装目录下,并在vs2008中配置好,这次有些可以编译通过了,但涉及到video的highgui.lib还是不能通过。查了一下,是没有调用系统库文件vfw32.lib和videoInput.lib(这个lib可以在cmake时选择是否使用),新的gui还调用了滑杆控件,还需要添加comctl32.lib这个lib,把这两个库链接时添上即可。总结一下,就是需要多添加comctl32.lib vfw32.lib zlibd.lib libjasperd.lib libjpegd.lib libpngd.lib libtiffd.lib opencv_core231d.lib opencv_objdetect231d.lib opencv_highgui231d.lib opencv_imgproc231d.lib,对应的release版本就把带d后缀的去掉即可。
最后再补充一下上一讲没说清楚的运行时库的问题,我的程序想在朋友电脑(没有vs开发环境)上运行,就需要运行时库的支持。除了我上一讲比较土鳖的办法(把运行时库的dll全部copy过去),还有一种办法就是在工程的属性设置里把c++ -->代码生成 --> 运行时库的对应项选好。这里介绍一下运行库(Runtime Library)。运行库是最基本的库,配合C++的语法及操作系统实现了一些基本的功能,如内存操作(new/delete等)等。可以说运行库是任何 程序,库的基础。在VC(2005以上)中有四种运行库:Multi-threaded、Multi-threaded-Debug、Multi- threaded-dll、Multi-threaded-debug-dll:前两个为一组,是静态类型库,提供的函数会被链接到最后的程序中,其中两 者的区别就在于一个带些调试用的信息及检查代码;后两个为一组,是动态库,最后会以动态链接库的形式(如在VC2008中为MSVCR90.dll或 MSVCR90D.dll),提供函数给程序调用。这里把MDD改为MTD(不然好像编译也无法通过)。就不需要copy过去多余的dll文件啦。
至此,只需要copy过去一个tbb_debug.dll,我的程序就能正常运行啦,我想通过cmake重新得到不嵌入tbb的opencv的lib,应该就能解决,但对于tbb是个啥东西还不懂,还是学精了再拿出来分享吧。路漫漫啊,感谢大家的阅读和支持。
版权声明:本文为博主原创文章,未经博主允许不得转载。
之前介绍过一篇利用级联分类器对目标进行检测的文章http://blog.csdn.net/yang_xian521/article/details/6973667,用的就是haar特征。发现OpenCV自带的库里的haar特征只有人脸、人脸的器官和人的身体,最近又想玩一个人手的检测,之前用颜色特征做的,感觉很不靠谱,这次用haar特征再试一次。这就需要用haartraining这个工具训练自己的手。先介绍一些预备知识,推荐个网址http://www.opencv.org.cn/index.php/%E7%89%B9%E5%BE%81%E6%A3%80%E6%B5%8B%E4%B8%93%E9%A2%98,读完相信对haar特征来龙去脉有个认识了,具体怎么使用,推荐看看这个http://note.sonots.com/SciSoftware/haartraining/document.html,再推荐这个网址http://note.sonots.com/SciSoftware/haartraining.html,都是英文哦,我就是按照这个英文介绍的教程训练自己的手分类器的。后来发现有人已经做了这个教程的翻译http://blog.csdn.net/onlyyouandme/article/details/4722160和http://blog.csdn.net/onlyyouandme/article/details/4722202(还是看英文原文比较详细),我也参考了这个http://hi.baidu.com/andyzcj/blog/item/3b9575fc63c3201f09244d9a.html,都贴上来以备以后再训练时学习需要。训练过程相当痛苦漫长,累死我心爱的PC了。由于训练数据不是我的个人财富,所以不便上传,这里把我download的一个老外训练的拳头的手势分类器(拳头在英文手语里表示字母A)作为实验来源。
资料还是得看啊,又读了经典文献《Robust Real-Time Face Detection》,不愿意读原文的朋友可以看看http://blog.csdn.net/hqw7286/article/details/5556767,作者把文中的要点基本也都总结出来了。OpenCV的实现过程也是在这篇文章的基础上,后来又不断完善的。
自己跟踪了一下代码,发现OpenCV的级联分类器的分为老版本和新版本,所有的haar级联分类器都是老版本的,只有一个lbp分类器是新版本的,而老版本的级联分类器的训练检测还是用老版本的数据结构来写的(让我很不爽,真想变得强大起来,用新数据结构写一下),为了这个新版本的级联分类器,多添加了大量的代码,可是用haartraining训练出来的分类器也是老版本的,该如何添加新版本的级联分类器啊,期待下一版本的OpenCV能够用新版本的haar级联分类器替代老版本。从这段代码中,我也深深体会到版本兼容的辛酸了。再这里也默默祝OpenCV越来越好,更规整,更强大。
最后上传一下效果图,再上传一段录制的视频(上镜了,很挫)http://v.youku.com/v_show/id_XMzI4NTQ1OTQ4.html和代码下载地址http://download.csdn.net/detail/yang_xian521/3873942

版权声明:本文为博主原创文章,未经博主允许不得转载。
之前做了haartraining的东西,感觉到OpenCV里面实现的东西还不是很好,这个老版本的haartraining的东西在新版本仍然是用老版本的函数来实现的,让我很不爽。于是好期待下一版本的到来,索性研究一下OpenCV路在何方,由于才接触OpenCV不久,就研究它的路在何方有些自不量力,但还是搜集了不少的资料,把我搜集的东西和大家分享一下,有说的不对的,欢迎大家都指点出来~~
首先说说OpenCV接下来的动作,然后再分析分析OpenCV如今还欠缺的东东
一、 Coming Soon
1.听说OpenCV要成为Khronos Group的成员啦,这真是一个振奋的消息,这个组织致力于发展开放标准的应用程序接口 API,大名鼎鼎的OpenGL也是这个组织的成员。成为该组织的成员,我想更有利于OpenCV做出标准的APIs,也更好的实现对其的硬件加速。
2.现在OpenCV已经实现了对Android的支持,随着移动设备的应用的越来越广泛,下一步OpenCV也要实现对iPhone的支持
3.增强对GPU的支持,GPU现在发展速度很快,OpenCV也要跟上脚步哈
4.也准备对FPGA进行一些支持,以后搞硬件开发的也许也能用到OpenCV,也许几年后,你用到的视觉芯片里面就有OpenCV的东西呢
5.ecto flow 图形交互也要加强。这点我理解的不是很好,目前OpenCV的图形交互确实做的不够好,对科研人员常用的MFC(虽然古老,但长青啊)支持越来越少,现在对Qt的支持倒是还可以,但我找了半天,也没明白这个ecto flow 图形交互是个什么东西,期待OpenCV的交互越做越好~~只能默默期待了。
6.OpenCV终于要做新网站了,不要再寄生在source forge和wiki上了,很期待它的新主页
7.更多的文档和更多的教程永远是我们这些学习人员心中的痛,捧着《learning OpenCV》总让我感觉吃不饱啊,期待新的reference manual和tutorials赶快出炉,之前读到一些感兴趣的地方就发现写着TBD(to be discuss),真让人心里不好受,看看人家微软的MSDN,难道开源的东西维护文档就不能做的那么好么,这是我们所有使用OpenCV人肩上的重担啊。
8.可能也会做更多的训练好的分类器,将来data\文件夹下面将有更多的xml可以利用,值得期待
9.接下来的一些加强应该是现在比较火的一些东西,对人体的2D和3D的跟踪,基于纹理的物体检测,Winner take all engine(不理解啊。。。),linemod(同样不理解-_-|||),三维模型的捕获,2维条形码,3维的训练和评估,相信以后用OpenCV做开发会越来越方便~~
二、 Missing Now
1.intrinsic image是透视图么?难道以后用OpenCV能看到人的透视图,我邪恶了。。。
2.对光线的检测一直是图像处理方面的一个难题,目前解决的还不好
3.颜色的不变性也是个问题
4.SFM(交叉矩阵),是不是又对Mat这个数据结构不满意了,以后可能有更好的数据结构出现,真是精益求精
5.vSLAM也没有支持,看来OpenCV对机器人的支持也有个想法,未来机器人定位的开发也许会用到更多的OpenCV
6.AR的支持也不好,这对做增强现实的朋友也许是个痛,希望有更多的API可以给开发者调用
7.还有就是对硬件的支持还不够完美,要是能对ARM平台也有类似IPP、TBB的优化就好了;要是能对GPU加速能实现自动化就好了;要是。。。。好啦,不做梦啦
就说这些吧,很多都是搜集的东西,自己的水平距离全部理解这些还远着呢,先随便说说,有说错的,请大家见谅,欢迎留言,看了觉得我胡说八道,颠倒是非的,您大可提出来。您的关注是我进步的动力,您的指导是我前进的方向!
版权声明:本文为博主原创文章,未经博主允许不得转载。
之前介绍了Qt+OpenCV的图形界面设计http://blog.csdn.net/yang_xian521/article/details/6968012,那篇里面只是读取了图片,这次再略进一步,再实现一个摄像头视频的读取。
再介绍一下我的开发环境Qt4.7.4+OpenCV2.3.1+VS2008,其实很简单,先在自己的QMainWindow子类里面声明如下变量:
- public:
- camCapture(QWidget *parent = 0, Qt::WFlags flags = 0);
- ~camCapture();
- protected:
- void paintEvent(QPaintEvent * e);
- private:
- Ui::camCaptureClass ui;
- cv::Mat frame;
- cv::VideoCapture capture;
- QImage *image;
- QTimer *timer;
- private slots:
- void nextFrame();
paintEvent函数是重载的,目的是为了更新绘图,在其定义中添加:
- void camCapture::paintEvent(QPaintEvent * e)
- {
- // 更新图像
- QPainter painter(this);
- painter.drawImage(QPoint(0, 12), *image);
- }
camCapture的构造函数里面添加如下初始化代码:
- // 初始化处理,建立QImage和frame的关联,开启定时器
- capture.open(-1);
- if (capture.isOpened())
- {
- capture >> frame;
- if (!frame.empty())
- {
- cv::cvtColor(frame, frame, CV_BGR2RGB);
- cv::flip(frame, frame, 1);
- image = new QImage((const unsigned char*)(frame.data), frame.cols, frame.rows, QImage::Format_RGB888);
- timer = new QTimer(this);
- timer->setInterval(30);
- connect(timer, SIGNAL(timeout()), this, SLOT(nextFrame()));
- timer->start();
- }
- }
析构函数里释放timer和image变量。
nextFrame函数实现数据的更新:
- // 更新数据
- capture >> frame;
- if (!frame.empty())
- {
- cv::cvtColor(frame, frame, CV_BGR2RGB);
- cv::flip(frame, frame, 1);
- this->update();
- }
这里我又想起来了我当时做图片读取的时候把参数CV_BGR2RGB、Format_RGB888改为了CV_BGR2RGBA、Format_RGB32,但这次试验发现那组参数可能只对我试验的图片有效,对视频还是CV_BGR2RGB、Format_RGB888这组参数是能用的。
还有一点很不爽,就是添加函数nextFrame和重载paintEvent函数都找不到向导,都是我自己敲进去的,可能是我的开发环境VS对Qt工程的支持不够霸气,以后可能要果断使用QtCreator了。我是Qt方面的真菜鸟,要是有经验的朋友可以给我说说怎么在VS环境里找到添加Qt事件的向导。万分感谢。
版权声明:本文为博主原创文章,未经博主允许不得转载。
kalman滤波大家都很熟悉,其基本思想就是先不考虑输入信号和观测噪声的影响,得到状态变量和输出信号的估计值,再用输出信号的估计误差加权后校正状态变量的估计值,使状态变量估计误差的均方差最小。具体它的原理和实现,我想也不用我在这里费口舌,但这个理论基础必须的有,必须得知道想用kalman滤波做跟踪,必须得先建立运动模型和观察模型,不是想用就能用的。如果不能建立运动模型,也就意味着你所要面对的问题不能用kalman滤波解决。
我结合一下OpenCV自带的kalman.cpp这个例程来介绍一下如何在OpenCV中使用kalman滤波吧,OpenCV已经把Kalman滤波封装到一个类KalmanFilter中了。使用起来非常方便,但那繁多的各种矩阵还是容易让人摸不着头脑。这里要知道的一点是,想要用kalman滤波,要知道前一时刻的状态估计值x,当前的观测值y,还得建立状态方程和量测方程。有了这些就可以运用kalman滤波了。
OpenCV自带了例程里面是对一个1维点的运动跟踪,虽然这个点是在2维平面中运动,但由于它是在一个圆弧上运动,只有一个自由度,角度,所以还是1维的。还是一个匀速运动,建立匀速运动模型,设定状态变量x = [ x1, x2 ] = [ 角度,角速度 ],则运动模型为
x1(k+1) = x1(k)+x2(k)*T
x2(k+1)= x2(k)
则状态转移方程为
x* = Ax + w
这里设计的噪声是高斯随机噪声,则量测方程为:
z = Cx + v
看了代码,对应上以上各项:
状态估计值x --> state
当前观测值z --> measurement
KalmanFilter类内成员变量transitionMatrix就是状态转移方程中的矩阵A
KalmanFilter类内成员变量measurementMatrix就是量测方程中矩阵C
- Mat statePre; //!< predicted state (x'(k)): x(k)=A*x(k-1)+B*u(k)
- Mat statePost; //!< corrected state (x(k)): x(k)=x'(k)+K(k)*(z(k)-H*x'(k))
- Mat transitionMatrix; //!< state transition matrix (A)
- Mat controlMatrix; //!< control matrix (B) (not used if there is no control)
- Mat measurementMatrix; //!< measurement matrix (H)
- Mat processNoiseCov; //!< process noise covariance matrix (Q)
- Mat measurementNoiseCov;//!< measurement noise covariance matrix (R)
- Mat errorCovPre; //!< priori error estimate covariance matrix (P'(k)): P'(k)=A*P(k-1)*At + Q)*/
- Mat gain; //!< Kalman gain matrix (K(k)): K(k)=P'(k)*Ht*inv(H*P'(k)*Ht+R)
- Mat errorCovPost; //!< posteriori error estimate covariance matrix (P(k)): P(k)=(I-K(k)*H)*P'(k)
我想就不用我再翻译了吧。相信有了以上的注释,大家都能找到它们的对应项。
使用的时候,除了初始化我刚刚初始化过的transitionMatrix和measurementMatrix外,还需要初始化processNoiseCov,measurementNoiseCov和errorCovPost。
把它们初始化好之后,接下来的动作就很简单了,分两步走,第一步调用成员函数predict得到当前状态变量的估计值,第二步调用成员函数correct用观测值校正状态变量。再更新状态变量做下一次估计。听着好简单啊,代码就不上传坑爹了,在opencv2.3.1\samples\cpp\kalman.cpp中其义自见。
版权声明:本文为博主原创文章,未经博主允许不得转载。
如果你想在OpenCV的基础上自己开发一些算法,我觉得core这部分内容不得不精啊,能熟练使用OpenCV的数据结构是开发的基础,又是重中之重。最近就又拌在这上头了,所以再重温一下。这次分析一下Utility and System Functions and Macros这部分,就是实用函数、系统函数和宏。
OpenCV在这部分里包含一些类似标准c++、c里面的一些东西。
系统函数有很多。有些是内存方面的操作,类似new delete之类的操作,很多都是为了防止内存溢出的函数有alignPtr、alignSize、allocate、deallocate、fastMalloc、fastFree。格式输出的函数啦format(是不是太熟悉了)。还有一些和系统相关的东西checkHardwareSupport、getNumThreads、getThreadNum、getTickCount、getTickFrequency、getCPUTickCount、setNumThreads。还有一些比较有意思的东西,比如功能类似#ifdef #endf这样的开关,也有函数setUseOptimized实现 ,相关的还有useOptimized函数。还有一个不懂的函数saturate_cast(求指点)等待各位补充。
实用函数很接近<math.h>里的一些函数,很有意思,可以方便大家开发,有计算向量角度的函数fastAtan2、计算立方根的函数cubeRoot、向上取整函数cvCeil、向下取整函数cvFloor、四舍五入函数cvRound。注意cvCeil、cvFloor、cvRound和大家常用的ceil、floor、round函数略有不同,标准库函数返回值并不是int型的变量,必要时需强制转换,而OpenCV里面的取整函数返回值为int型。还有一些类似matlab里面的函数,比如cvIsInf判断自变量是否无穷大,cvIsNaN判断自变量是否Not a Number。
宏也很多,这些宏在标准c++、c里也有出现,CV_Assert是个断言,不知道和assert()有什么区别。error也是一种异常,还有Exception类这个异常类。
有了这些东西,开发起来有没有更顺手一些呢~~随着使用的深入,我会再补充一些上诉东西的使用心得
版权声明:本文为博主原创文章,未经博主允许不得转载。
最近做一个东西,需要实时显示,于是想在屏幕显示FPS。FPS是Frame Per Second的缩写,中文意思是每秒帧数,即帧速。FPS是测量用于保存、显示动态视频的信息数量。通俗来讲就是指动画或视频的画面数。
这就需要我在系统函数一讲里提到的getTickCount、getTickFrequency这两个函数了。前一个函数返回tick次数,后一个函数返回每秒tick次数,它们的比就是时间咯。
如果想得到一段程序的运行时间,可以套用下面的例子:
- double t = (double)getTickCount();
- // do something ...
- t = ((double)getTickCount() - t)/getTickFrequency();
以上这段程序在测试算法的时间消耗在哪里是很好的测试程序。我这里只需要稍微改写一下这个例子,得到每帧之间的时间,再用我之前在绘图函数那节讲过的putText把FPS显示到屏幕上咯。
不过有个问题还是让我感觉不舒服,就是用它做的定时不是很准,感觉时间比实际的快一些。测试较少,也不敢乱讲,欢迎大家测试并发表意见
简单的很,源程序下载地址:http://download.csdn.net/detail/yang_xian521/3957523
版权声明:本文为博主原创文章,未经博主允许不得转载。
还是一个实时性要求的程序最近把我弄得有些上火。为了提高代码运行的速度,我也是又新啃东西学了。由于我代码里使用了vector,网上搜来搜去有人说vector慢,又有人说STL里的sort排序速度是我等常人不能企及的,有人说要少resize,这个重新分配内存非常耗时,又有人说要用swap来彻底删除不要的内存空间。带着这么多疑问,我实在不知道我程序慢的原因。于是乎阅读了《Effective STL》,这书挺深的,粗浅读读,先把自己急着弄清楚的以上各问题弄懂。再看程序,做了些优化,速度还是提高不多,头开始大了
我的解决办法是用我上一讲提到的getTickCount、getTickFrequency函数分析我代码的运行时间,遇到的问题是下面这句非常耗时
- vector<vector<int>>test = vector<vector<int>>(10000, vector<int>(10, 0));
10000*10只是我要开辟的空间,不知道怎么用reserve函数开辟,这句运行了大概100ms。今天再看这段代码,发现我太傻了,何必要用vector<vector<int>>呢,完全可以用OpenCV自带的Mat来解决啊,于是把上面这句改写如下
- Mat test1 = Mat_<int>::zeros(10000, 10);
结果只需要0.2ms!!!同志们,STL在Mat面前都显得如此无力啊,有木有啊!我决定花费几天的时间再好好读读reference的core的部分,来吃透OpenCV的数据结构。而且感觉Mat跟STL的兼容性很好,也有push_back,pop_back这样的操作,所以啊,同志们,千万别把Mat只当做是显示图片用的,它是很强大的数据结构,用了它,可以事半功倍,谁用谁知道!~~
版权声明:本文为博主原创文章,未经博主允许不得转载。
我记得开始接触OpenCV就是因为一个算法里面需要2维动态数组,那时候看core这部分也算是走马观花吧,随着使用的增多,对Mat这个结构越来越喜爱,也觉得有必要温故而知新,于是这次再看看Mat。
Mat最大的优势跟STL很相似,都是对内存进行动态的管理,不需要之前用户手动的管理内存,对于一些大型的开发,有时候投入的lpImage内存管理的时间甚至比关注算法实现的时间还要多,这显然是不合适的。除了有些嵌入式场合必须使用C语言,我任何时候都强烈像大家推荐Mat。
Mat这个类有两部分数据。一个是matrix header,这部分的大小是固定的,包含矩阵的大小,存储的方式,矩阵存储的地址等等。另一个部分是一个指向矩阵包含像素值的指针。
- Mat A, C; // creates just the header parts
- A = imread(argv[1], CV_LOAD_IMAGE_COLOR); // here we’ll know the method used (allocate matrix)
- Mat B(A); // Use the copy constructor
- C = A; // Assignment operator
需要注意的是,copy这样的操作只是copy了矩阵的matrix header和那个指针,而不是矩阵的本身,也就意味着两个矩阵的数据指针指向的是同一个地址,需要开发者格外注意。比如上面这段程序,A、B、C指向的是同一块数据,他们的header不同,但对于A的操作同样也影响着B、C的结果。刚刚提高了内存自动释放的问题,那么当我不再使用A的时候就把内存释放了,那时候再操作B和C岂不是很危险。不用担心,OpenCV的大神为我们已经考虑了这个问题,是在最后一个Mat不再使用的时候才会释放内存,咱们就放心用就行了。
如果想建立互不影响的Mat,是真正的复制操作,需要使用函数clone()或者copyTo()。
说到数据的存储,这一直就是一个值得关注的问题,Mat_<uchar>对应的是CV_8U,Mat_<uchar>对应的是CV_8U,Mat_<char>对应的是CV_8S,Mat_<int>对应的是CV_32S,Mat_<float>对应的是CV_32F,Mat_<double>对应的是CV_64F,对应的数据深度如下:
• CV_8U - 8-bit unsigned integers ( 0..255 )
• CV_8S - 8-bit signed integers ( -128..127 )
• CV_16U - 16-bit unsigned integers ( 0..65535 )
• CV_16S - 16-bit signed integers ( -32768..32767 )
• CV_32S - 32-bit signed integers ( -2147483648..2147483647 )
• CV_32F - 32-bit floating-point numbers ( -FLT_MAX..FLT_MAX, INF, NAN )
• CV_64F - 64-bit floating-point numbers ( -DBL_MAX..DBL_MAX, INF, NAN )
这里还需要注意一个问题,很多OpenCV的函数支持的数据深度只有8位和32位的,所以要少使用CV_64F,但是vs的编译器又会把float数据自动变成double型,有些不太爽。
还有个需要注意的问题,就是流操作符<<对于Mat的操作,仅限于Mat是2维的情况。
还有必要说一下Mat的存储是逐行的存储的。
再说说Mat的创建,方式有两种,罗列一下:1.调用create(行,列,类型)2.Mat(行,列,类型(值))。例如:
- // make a 7x7 complex matrix filled with 1+3j.
- Mat M(7,7,CV_32FC2,Scalar(1,3));
- // and now turn M to a 100x60 15-channel 8-bit matrix.
- // The old content will be deallocated
- M.create(100,60,CV_8UC(15));
要是想创建更高维的矩阵,要写成下面的方式
- // create a 100x100x100 8-bit array
- int sz[] = {100, 100, 100};
- Mat bigCube(3, sz, CV_8U, Scalar::all(0));
对于矩阵的行操作或者列操作,方式如下:(注意对列操作时要新建一个Mat,我想应该跟列地址不连续有关)
- // add the 5-th row, multiplied by 3 to the 3rd row
- M.row(3) = M.row(3) + M.row(5)*3;
- // now copy the 7-th column to the 1-st column
- // M.col(1) = M.col(7); // this will not work
- Mat M1 = M.col(1);
- M.col(7).copyTo(M1);
下面的东西就比较狂暴了,对于外来的数据,比如你从别的地方接受了一幅图片,但可以不是Mat结构的,而只有一个数据的指针,看看接下来的代码是如何应付的,重点哦,亲
- void process_video_frame(const unsigned char* pixels,
- int width, int height, int step)
- {
- Mat img(height, width, CV_8UC3, pixels, step);
- GaussianBlur(img, img, Size(7,7), 1.5, 1.5);
- }
亲,有木有很简单!!!
还有一种快速初始化数据的办法,如下:
- double m[3][3] = {{a, b, c}, {d, e, f}, {g, h, i}};
- Mat M = Mat(3, 3, CV_64F, m).inv();
也可以把原来的IplImage格式的图片直接用Mat(IplImage)的方式转成Mat结构,也可以像Matlab一样调用zeros()、ones()、eye()这样的函数进行初始化。
如果你需要提前释放数据的指针和内存,可以调用release()。
对于数据的获取,当然还是调用at<float>(3, 3)这样的格式为最佳。其他的方法我甚少尝试,就不敢介绍了。
最后要提的一点是关于Mat的表达式,这个也非常多,加减乘除,转置求逆,我怎么记得我以前介绍过呢。那就不多说啦~
版权声明:本文为博主原创文章,未经博主允许不得转载。
记得我在OpenCV学习笔记(四)——新版本的数据结构core里面讲过新版本的数据结构了,可是我再看这部分的时候,我发现我当时实在是看得太马虎了。对于新版本的数据结构,我再说说。
Point_类不用多言,里面两个成员变量x,y。Point_<int>就是Point2i,也是Point,Point_<float>就是Point2f,Point_<double>就是Point2d。
Point3_类不太常用,跟Point_类差不太多,成员变量x,y,z。
Size_类成员变量width、height。Size_<int>就是Size2i,也是Size,Size_<float>就是Size2f,大家就要不臆断出来个Size2d啥的让编译器发懵了。
Rect_类有些意思,成员变量x、y、width、height,分别为左上角点的坐标和矩形的宽和高。常用的成员函数有Size()返回值为一个Size,area()返回矩形的面积,contains(Point)用来判断点是否在矩形内,inside(Rect)函数判断矩形是否在该矩形内,tl()返回左上角点坐标,br()返回右下角点坐标。值得注意的是,如果想求两个矩形的交集,并集,可以用如下格式
- Rect rect = rect1 & rect2;
- Rect rect = rect1 | rect2;
- Rect rectShift = rect + point;
- Rect rectScale = rect + size;
Matx其实是个轻量级的Mat,必须在使用前规定好大小,比如一个2*3的float型的可以声明为Matx23f。我想很容易理解的。
Vec是Matx的一个派生类,就是一个1维的Matx,跟vector很相似。比如想声明一个10个数据的float数组,可以写成Vec2f。
这样就很容易引出一个大家经常使用的数据结构了,Scalar_类,这个类其实就是一个Vec4x的一个变种,大家常用的Scalar其实就是Scalar_<double>。这样一说,大家是不是就很容易理解了,为啥很多函数的参数输入可以是Mat,也可以是Scalar了。其实OpenCV定义的InputMat,outputMat参数格式,以上的这几种数据结构都可以作为参数的。
接下来介绍一个有意思的类Range,大家可能用的不多,对它不熟悉,其实它就是为了使OpenCV的使用更像Matlab而产生的。比如Range::all()其实就是Matlab里的符号:或者...。而Range(a, b)其实就是Matlab中的a:b。有趣吧,注意a,b都需要是int型的哦,亲。
Ptr类我就不太敢介绍了,是智能指针,我也没有用过,文档里说是很类似大名鼎鼎的Boost库里的shared_ptr。希望以后有机会用一下再拿出来分享心得。
最后出场的还是最重量级的Mat,介绍几个比较重要的成员变量flag(就是我之前说过的header里的结构信息,深度信息,通道数),dims是Mat的维数,要求大于等于2,rows和cols参数代表2维矩阵的行数列数(对于更高维的矩阵,这两个参数都是-1),还有个比较常用的参数应该uchar* data,是Mat的数据指针(比较暴力的同学可以直接调用它好了,不推荐),还有个参数refconst,我理解应该就是我上一讲提到的释放内存的时候要判断这个矩阵是否是最后一个被使用的,这个参数应该就是控制跟当前矩阵结构相关的个数的。
版权声明:本文为博主原创文章,未经博主允许不得转载。
首先还是要感谢箫鸣朋友在我《OpenCV学习笔记(四十)——再谈OpenCV数据结构Mat详解》的留言,告诉我M.at<float>(3, 3)在Debug模式下运行缓慢,推荐我使用M.ptr<float>(i)此类方法。这不禁勾起了我测试一下的冲动。下面就为大家奉上我的测试结果。
我这里测试了三种操作Mat数据的办法,套用流行词,普通青年,文艺青年,为啥第三种我不叫2b青年,大家慢慢往后看咯。
普通青年的操作的办法通常是M.at<float>(i, j)
文艺青年一般会走路线M.ptr<float>( i )[ j ]
暴力青年通常直接强制使用我第40讲提到的M.data这个指针
实验代码如下:
- t = (double)getTickCount();
- Mat img1(1000, 1000, CV_32F);
- for (int i=0; i<1000; i++)
- {
- for (int j=0; j<1000; j++)
- {
- img1.at<float>(i,j) = 3.2f;
- }
- }
- t = (double)getTickCount() - t;
- printf("in %gms\n", t*1000/getTickFrequency());
- //***************************************************************
- t = (double)getTickCount();
- Mat img2(1000, 1000, CV_32F);
- for (int i=0; i<1000; i++)
- {
- for (int j=0; j<1000; j++)
- {
- img2.ptr<float>(i)[j] = 3.2f;
- }
- }
- t = (double)getTickCount() - t;
- printf("in %gms\n", t*1000/getTickFrequency());
- //***************************************************************
- t = (double)getTickCount();
- Mat img3(1000, 1000, CV_32F);
- float* pData = (float*)img3.data;
- for (int i=0; i<1000; i++)
- {
- for (int j=0; j<1000; j++)
- {
- *(pData) = 3.2f;
- pData++;
- }
- }
- t = (double)getTickCount() - t;
- printf("in %gms\n", t*1000/getTickFrequency());
- //***************************************************************
- t = (double)getTickCount();
- Mat img4(1000, 1000, CV_32F);
- for (int i=0; i<1000; i++)
- {
- for (int j=0; j<1000; j++)
- {
- ((float*)img3.data)[i*1000+j] = 3.2f;
- }
- }
- t = (double)getTickCount() - t;
- printf("in %gms\n", t*1000/getTickFrequency());
最后两招可以都看成是暴力青年的方法,因为反正都是指针的操作,局限了各暴力青年手段就不显得暴力了。
在Debug、Release模式下的测试结果分别为:
| Debug | Release | |
| 普通青年 | 139.06ms | 2.51ms |
| 文艺青年 | 66.28ms | 2.50ms |
| 暴力青年1 | 4.95ms | 2.28ms |
| 暴力青年2 | 5.11ms | 1.37ms |
根据测试结果,我觉得箫铭说的是很可信的,普通青年的操作在Debug模式下果然缓慢,他推荐的文艺青年的路线确实有提高。值得注意的是本来后两种办法确实是一种比较2b青年的做法,因为at操作符或者ptr操作符,其实都是有内存检查的,防止操作越界的,而直接使用data这个指针确实很危险。不过从速度上确实让人眼前一亮,所以我不敢称这样的青年为2b,尊称为暴力青年吧。
不过在Release版本下,几种办法的速度差别就不明显啦,都是很普通的青年。所以如果大家最后发行程序的时候,可以不在意这几种操作办法的,推荐前两种哦,都是很好的写法,操作指针的事还是留给大神们用吧。就到这里吧~~
补充:箫铭又推荐了两种文艺青年的处理方案,我也随便测试了一下,先贴代码,再贴测试结果:
- /*********加强版********/
- t = (double)getTickCount();
- Mat img5(1000, 1000, CV_32F);
- float *pData1;
- for (int i=0; i<1000; i++)
- {
- pData1=img5.ptr<float>(i);
- for (int j=0; j<1000; j++)
- {
- pData1[j] = 3.2f;
- }
- }
- t = (double)getTickCount() - t;
- printf("in %gms\n", t*1000/getTickFrequency());
- /*******终极版*****/
- t = (double)getTickCount();
- Mat img6(1000, 1000, CV_32F);
- float *pData2;
- Size size=img6.size();
- if(img2.isContinuous())
- {
- size.width = size.width*size.height;
- size.height = 1;
- }
- size.width*=img2.channels();
- for(int i=0; i<size.height; i++)
- {
- pData2 = img6.ptr<float>(i);
- for(int j=0; j<size.width; j++)
- {
- pData2[j] = saturate_cast<float>(3.2f);
- }
- }
- t = (double)getTickCount() - t;
- printf("in %gms\n", t*1000/getTickFrequency());
测试结果:
| Debug | Release | |
| 加强版文艺青年 | 5.74ms | 2.43ms |
| 终极版文艺青年 | 40.12ms | 2.34ms |
版权声明:本文为博主原创文章,未经博主允许不得转载。
在上一讲OpenCV学习笔记(四十二)——Mat数据操作之普通青年、文艺青年、暴力青年里,对Mat内数据的各种读写操作进行了速度的比较,都是我自己想到的方法,感觉不够系统,这次整理了下思路,参考了文献,把能想到的方法进行了汇总,希望能对大家有所帮助。
1.存取单个像素值
最通常的方法就是
- img.at<uchar>(i,j) = 255;
- img.at<Vec3b>(i,j)[0] = 255;
如果你觉得at操作显得太笨重了,不想用Mat这个类,也可以考虑使用轻量级的Mat_类,使用重载操作符()实现取元素的操作。
- cv::Mat_<uchar> im2= img; // im2 refers to image
- im2(50,100)= 0; // access to row 50 and column 100
2.用指针扫描一幅图像
对于一幅图像的扫描,用at就显得不太好了,还是是用指针的操作方法更加推荐。先介绍一种上一讲提到过的
- for (int j=0; j<nl; j++)
- {
- uchar* data= image.ptr<uchar>(j);
- for (int i=0; i<nc; i++)
- {
- data[i] = 255;
- }
- }
更高效的扫描连续图像的做法可能是把W*H的衣服图像看成是一个1*(w*h)的一个一维数组,这个想法是不是有点奇葩,这里要利用isContinuous这个函数判断图像内的像素是否填充满,使用方法如下:
- if (img.isContinuous())
- {
- nc = img.rows*img.cols*img.channels();
- }
- uchar* data = img.ptr<uchar>(0);
- for (int i=0; i<nc; i++)
- {
- data[i] = 255;
- }
更低级的指针操作就是使用Mat里的data指针,之前我称之为暴力青年,使用方法如下:
- uchar* data = img.data;
- // img.at(i, j)
- data = img.data + i * img.step + j * img.elemSize();
3.用迭代器iterator扫描图像
和C++STL里的迭代器类似,Mat的迭代器与之是兼容的。是MatIterator_。声明方法如下:
- cv::MatIterator_<Vec3b> it;
或者是:
- cv::Mat_<Vec3b>::iterator it;
扫描图像的方法如下:
- Mat_<Vec3b>::iterator it = img.begin<Vec3b>();
- Mat_<Vec3b>::iterator itend = img.end<Vec3b>();
- for (; it!=itend; it++)
- {
- (*it)[0] = 255;
- }
4.高效的scan image方案总结
还是用我们之前使用过的getTickCount、getTickFrequency函数测试速度。这里我就不一一列举我测试的结果了,直接上结论。测试发现,好的编写风格可以提高50%的速度!要想减少程序运行的时间,必要的优化包括如下几个方面:
(1)内存分配是个耗时的工作,优化之;
(2)在循环中重复计算已经得到的值,是个费时的工作,优化之;举例:
- int nc = img.cols * img.channels();
- for (int i=0; i<nc; i++)
- {.......}
- //**************************
- for (int i=0; i<img.cols * img.channels(); i++)
- {......}
后者的速度比前者要慢上好多。
(3)使用迭代器也会是速度变慢,但迭代器的使用可以减少程序错误的发生几率,考虑这个因素,可以酌情优化
(4)at操作要比指针的操作慢很多,所以对于不连续数据或者单个点处理,可以考虑at操作,对于连续的大量数据,不要使用它
(5)扫描连续图像的做法可能是把W*H的衣服图像看成是一个1*(w*h)的一个一维数组这种办法也可以提高速度。短的循环比长循环更高效,即使他们的操作数是相同的
以上的这些优化可能对于大家的程序运行速度提高并不明显,但它们毕竟是个得到速度提升的好的编程策略,希望大家能多采纳。
还有就是利用多线程也可以高效提高运行速度。OpenMP和TBB是两种流行的APT,不过对于多线程的东西,我是有些迷糊的,呵呵
5.整行整列像素值的赋值
对于整行或者整列的数据,可以考虑这种方式处理
- img.row(i).setTo(Scalar(255));
- img.col(j).setTo(Scalar(255));
版权声明:本文为博主原创文章,未经博主允许不得转载。
好久没有更新啦,感觉最近没有什么特别的收获值得和大家分享,还是有些懒,TLD结束了也没有写个blog做总结。还是和大家分享一下OpenCV的一个大家很少接触的模块吧——GPU。这个部分我接触的也是很少,只是根据教程和大家简单交流一下,如果有高手有使用心得,欢迎多多批评。
OpenCV的GPU模块只支持NVIDIA的显卡,原因是该部分是基于NVIDIA的CUDA和NVIDIA的NPP模块实现的。而该模块的好处在于使用GPU模块无需安装CUDA工具,也无需学习GPU编程,因为不需要编写GPU相关的代码。但如果你想重新编译OpenCV的GPU模块的话,还是需要CUDA的toolkit。
由于GPU模块的发展,使大部分函数使用起来和之前在CPU下开发非常类似。首先,就是把GPU模块链接到你的工程中,并包含必要的头文件gpu.hpp。其次,就是GPU模块下的数据结构,原本在cv名字空间中的现在都在gpu名字空间中,使用时可以gpu::和cv::来防止混淆。
需要再说明的是,在GPU模块中,矩阵的名字为GpuMat,而不是之前的Mat,其他的函数名字和CPU模块中相同,不同的是,现在的参数输入不再是Mat,而是GpuMat。
还有一个问题就是,对于2.0的GPU模块,多通道的函数支持的并不好,推荐使用GPU模块处理灰度的图像。有些情况下,使用GPU模块的运行速度还不及CPU模块下的性能,所以可以认为,GPU模块相对而言还不够成熟,需要进一步优化。很重要的一个原因就是内存管理部分和数据转换部分对于GPU模块而言消耗了大量的时间。
需要注意的是,在所有使用GPU模块的函数之前,最好需要调用函数gpu::getCudaEnabledDeviceCount,如果你在使用的OpenCV模块编译时不支持GPU,这个函数返回值为0;否则返回值为已安装的CUDA设备的数量。
还有一点就是使用GPU模块,需要在用CMake编译OpenCV时使其中的WITH_CUDA和WITH_TBB的宏生效,为ON。
由于我对GPU部分的熟悉程度还不行,先拿来一段sample自带的一段求矩阵转置的程序来做例子,代码如下:
- #include <iostream>
- #include "cvconfig.h"
- #include "opencv2/core/core.hpp"
- #include "opencv2/gpu/gpu.hpp"
- #include "opencv2/core/internal.hpp" // For TBB wrappers
- using namespace std;
- using namespace cv;
- using namespace cv::gpu;
- struct Worker { void operator()(int device_id) const; };
- int main()
- {
- int num_devices = getCudaEnabledDeviceCount();
- if (num_devices < 2)
- {
- std::cout << "Two or more GPUs are required\n";
- return -1;
- }
- for (int i = 0; i < num_devices; ++i)
- {
- DeviceInfo dev_info(i);
- if (!dev_info.isCompatible())
- {
- std::cout << "GPU module isn't built for GPU #" << i << " ("
- << dev_info.name() << ", CC " << dev_info.majorVersion()
- << dev_info.minorVersion() << "\n";
- return -1;
- }
- }
- // Execute calculation in two threads using two GPUs
- int devices[] = {0, 1};
- parallel_do(devices, devices + 2, Worker());
- return 0;
- }
- void Worker::operator()(int device_id) const
- {
- setDevice(device_id);
- Mat src(1000, 1000, CV_32F);
- Mat dst;
- RNG rng(0);
- rng.fill(src, RNG::UNIFORM, 0, 1);
- // CPU works
- transpose(src, dst);
- // GPU works
- GpuMat d_src(src);
- GpuMat d_dst;
- transpose(d_src, d_dst);
- // Check results
- bool passed = norm(dst - Mat(d_dst), NORM_INF) < 1e-3;
- std::cout << "GPU #" << device_id << " (" << DeviceInfo().name() << "): "
- << (passed ? "passed" : "FAILED") << endl;
- // Deallocate data here, otherwise deallocation will be performed
- // after context is extracted from the stack
- d_src.release();
- d_dst.release();
- }
以上介绍的内容不但肤浅,而且显得比较凌乱。希望高手看完后多多指正,跟我一样不太明白的朋友仅供参考。
版权声明:本文为博主原创文章,未经博主允许不得转载。
对于随机森林算法,原理我想大家都会去看论文,推荐两个老外的网址http://www.stat.berkeley.edu/users/breiman/RandomForests/和https://cwiki.apache.org/MAHOUT/random-forests.html,第一个网址是提出随机森林方法大牛写的,很全面具体,第二个是我自己找的一个,算是一个简化版的介绍吧。说白了,随机森林分类的过程就是对于每个随机产生的决策树分类器,输入特征向量,森林中每棵树对样本进行分类,根据每个树的权重得到最后的分类结果。所有的树训练都是使用同样的参数,但是训练集是不同的,分类器的错误估计采用的是oob(out of bag)的办法。如果大家看懂了,接下来就简单咯
还是先介绍一下对应OpenCV的类和函数吧,之前有笼统介绍过机器学习的类,对于随机森林相关算法类有CvRTParams、CvRTrees。具体再讲解一下:
CvRTParams类包涵了随机森林训练过程中需要设置的全部参数,继承自CvDTParams。其中
max_depth表示单棵树的最大深度
min_sample_count阈值,当节点的样本数比阈值小的时候,节点就不在进行分裂
regression_accuracy回逆树时候的阈值
use_surrogates是否使用代理?(这是神马功能。。。)
max_categories最大分类的阈值
priors先验分类可能性
calc_var_importance变量重要性是否计算标志
nactive_vars每棵树选取特征子集的大小
max_num_of_trees_in_the_forest森林内树的数目上限
forest_accuracy森林训练OOB error的精度
termcrit_type森林训练阈值选取的类型
以上参数的赋值都通过CvRTParams的构造函数实现。
CvRTrees就是随机森林的主体了。包涵了train训练函数、predict预测函数、predict_prob返回预测分类标签、getVarImportance返回变量权重矩阵、get_proximity返回两训练样本之间的相似度、calc_error返回随机森林的预测误差、get_train_error返回训练误差、get_rng返回使用随机数的当前值、get_tree_count返回构造随机森林的树的数目、get_tree返回构造随机森林的其中一棵树。
接下来,结合sample自带的letter_recog.cpp讲解一下如何应用随机森林算法做字母的识别,这里选择的训练样本库是http://archive.ics.uci.edu/ml/下的一个训练集,这个网站还有很多其他的资源提供,非常好的机器学习的data库。这个训练文件letter-recognition.data有20000个训练字母,每一字母用16维的特征表示。本程序使用前16000个进行训练,后4000个进行测试。唯一让我很不爽的是这个程序是用老版本的数据结构写的,所以我决定用新结构再写一下,我对原程序进行了简化,删除了很多不相关和不是必须的部分。
其实随机森林使用起来非常简单,两个最重要的步骤无非就是train()和predict()函数,其他的函数都是用来得到测试结果。
这里把我简化并用新结构改写之后的代码下载链接奉上http://download.csdn.net/detail/yang_xian521/4134557
版权声明:本文为博主原创文章,未经博主允许不得转载。
特征点检测和匹配是计算机视觉中一个很有用的技术。在物体检测,视觉跟踪,三维常年关键等领域都有很广泛的应用。这一次先介绍特征点检测的一种方法——FAST(features from accelerated segment test)。很多传统的算法都很耗时,而且特征点检测算法只是很多复杂图像处理里中的第一步,得不偿失。FAST特征点检测是公认的比较快速的特征点检测方法,只利用周围像素比较的信息就可以得到特征点,简单,有效。
FAST特征检测算法来源于corner的定义,这个定义基于特征点周围的图像灰度值,检测候选特征点周围一圈的像素值,如果候选点周围领域内有足够多的像素点与该候选点的灰度值差别够大,则认为该候选点为一个特征点。
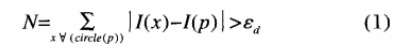
其中I(x)为圆周上任意一点的灰度,I(p)为圆心的灰度,Ed为灰度值差得阈值,如果N大于给定阈值,一般为周围圆圈点的四分之三,则认为p是一个特征点。
为了获得更快的结果,还采用了额外的加速办法。如果测试了候选点周围每隔90度角的4个点,应该至少有3个和候选点的灰度值差足够大,否则则不用再计算其他点,直接认为该候选点不是特征点。候选点周围的圆的选取半径是一个很重要的参数,这里我为了简单高效,采用半径为3,共有16个周边像素需要比较。为了提高比较的效率,通常只使用N个周边像素来比较,也就是大家经常说的FAST-N。我看很多文献推荐FAST-9,作者的主页上有FAST-9、FAST-10、FAST-11、FAST-12,大家使用比较多的是FAST-9和FAST-12。上个图说明的更形象一些

OpenCV里对FAST的使用也非常简单,先声明一组特征点,构建FAST特征检测,接下来调用detect函数检测图像中的特征点,最后把特征点绘制到图片上。上代码说的清楚些
- #include <opencv2/core/core.hpp>
- #include <opencv2/features2d/features2d.hpp>
- #include <opencv2/highgui/highgui.hpp>
- #include <vector>
- using namespace cv;
- void main()
- {
- Mat image;
- image = imread("church01.jpg");
- // vector of keyPoints
- std::vector<KeyPoint> keyPoints;
- // construction of the fast feature detector object
- FastFeatureDetector fast(40); // 检测的阈值为40
- // feature point detection
- fast.detect(image,keyPoints);
- drawKeypoints(image, keyPoints, image, Scalar::all(255), DrawMatchesFlags::DRAW_OVER_OUTIMG);
- imshow("FAST feature", image);
- cvWaitKey(0);
- }
最后上一张效果图

版权声明:本文为博主原创文章,未经博主允许不得转载。
首先要先纠正个误区,我见有人用OpenCV做多媒体开发,真的是很搞笑,OpenCV这东西再强大,这方面也不行的,之所以把视频读取写入这部分做的强大一些,也是为了方便大家做视频处理的时候方便些,而且这部分也是基于vfw和ffmpeg二次开发的,功能还是很弱的。一定要记住一点,OpenCV是一个强大的计算机视觉库,而不是视频流编码器或者解码器。希望大家不要走入这个误区,可以把这部分简单单独看待。目前,OpenCV只支持avi的格式,而且生成的视频文件不能大于2GB,而且不能添加音频。如果你想突破这些限制,我建议你最好还是看看ffMpeg,而不是浪费时间在OpenCV上。不过也可以利用视频后期合成工具制作。闲言少叙,进入重点VideoWriter类。
这个类是highgui交互很重要的一个工具类,可以方便我们容易的将图片序列保存成视频文件。类内成员函数有构造函数,open,isOpened,write(也可以用<<),使用还是很简单的。
使用很简单,先调用构造函数确定文件的名称,格式,帧率,帧大小,是否彩色。其中格式作为第二个参数,OpenCV提供的格式是未经过压缩的,目前支持的格式如下:
CV_FOURCC('P', 'I', 'M', '1') = MPEG-1 codec
CV_FOURCC('M', 'J', 'P', 'G') = motion-jpeg codecCV_FOURCC('M', 'P', '4', '2') = MPEG-4.2 codec
CV_FOURCC('D', 'I', 'V', '3') = MPEG-4.3 codec
CV_FOURCC('D', 'I', 'V', 'X') = MPEG-4 codec
CV_FOURCC('U', '2', '6', '3') = H263 codec
CV_FOURCC('I', '2', '6', '3') = H263I codec
CV_FOURCC('F', 'L', 'V', '1') = FLV1 codec
然后就<<不停的把image传进去就行啦,太简单了,我都不好意思写了。上代码:
- #include <opencv2/core/core.hpp>
- #include <opencv2/highgui/highgui.hpp>
- using namespace cv;
- void main()
- {
- VideoCapture capture(0);
- VideoWriter writer("VideoTest.avi", CV_FOURCC('M', 'J', 'P', 'G'), 25.0, Size(640, 480));
- Mat frame;
- while (capture.isOpened())
- {
- capture >> frame;
- writer << frame;
- imshow("video", frame);
- if (cvWaitKey(20) == 27)
- {
- break;
- }
- }
- }
版权声明:本文为博主原创文章,未经博主允许不得转载。
PCA(principal component analysis,主成分分析),我想是大家用的最多的降维手段,对于PCA的理解,我想大神们都各有各的绝招,可以应用的场合也非常多。下面就介绍一下OpenCV中PCA这个类,因为常用,所以这个类相对OpenCV而言显得比较独立,放在了core这部分中。
PCA类的成员函数包括构造函数、运算符重载()、project、backProject这几个函数,还包括成员变量eigenvectors、eigenvalues、mean。使用也很方便。比如我要计算一组向量的PCA,我们只需要定义个PCA实例,获得主成分,调用project测试新样本,也可以再调用backProject重建原始向量,是project的一个逆运算。
在实际使用我我发现了一个bug,构造函数和运算符重载()函数的第三个参数只能使用0或者1(分别对应CV_PCA_DATA_AS_ROW和CV_PCA_DATA_AS_COL),但调用对应的宏却编译无法通过,不知道大家是否也是一样的情况
下面结合一个实例分析:
2001年全国各地区消费情况指数
北京 101.5 100.4 97.0 98.7 100.8 114.2 104.2
天津 100.8 93.5 95.9 100.7 106.7 104.3 106.4
河北 100.8 97.4 98.2 98.2 99.5 103.6 102.4
山西 99.4 96.0 98.2 97.8 99.1 98.3 104.3
内蒙古 101.8 97.7 99.0 98.1 98.4 102.0 103.7
辽宁 101.8 96.8 96.4 92.7 99.6 101.3 103.4
吉林 101.3 98.2 99.4 103.7 98.7 101.4 105.3
黑龙江 101.9 100.0 98.4 96.9 102.7 100.3 102.3
上海 100.3 98.9 97.2 97.4 98.1 102.1 102.3
江苏 99.3 97.7 97.6 101.1 96.8 110.1 100.4
浙江 98.7 98.4 97.0 99.6 95.6 107.2 99.8
安徽 99.7 97.7 98.0 99.3 97.3 104.1 102.7
福建 97.6 96.5 97.6 102.5 97.2 100.6 99.9
江西 98.0 98.4 97.1 100.5 101.4 103.0 99.9
山东 101.1 98.6 98.7 102.4 96.9 108.2 101.7
河南 100.4 98.6 98.0 100.7 99.4 102.4 103.3
湖北 99.3 96.9 94.0 98.1 99.7 109.7 99.2
湖南 98.6 97.4 96.4 99.8 97.4 102.1 100.0
广东 98.2 98.2 99.4 99.3 99.7 101.5 99.9
广西 98.5 96.3 97.0 97.7 98.7 112.6 100.4
海南 98.4 99.2 98.1 100.2 98.0 98.2 97.8
重庆 99.2 97.4 95.7 98.9 102.4 114.8 102.6
四川 101.3 97.9 99.2 98.8 105.4 111.9 99.9
贵州 98.5 97.8 94.6 102.4 107.0 115.0 99.5
云南 98.3 96.3 98.5 106.2 92.5 98.6 101.6
西藏 99.3 101.1 99.4 100.1 103.6 98.7 101.3
陕西 99.2 97.3 96.2 99.7 98.2 112.6 100.5
甘肃 100.0 99.9 98.2 98.3 103.6 123.2 102.8
青海 102.2 99.4 96.2 98.6 102.4 115.3 101.2
宁夏 100.1 98.7 97.4 99.8 100.6 112.4 102.5
新疆 104.3 98.7 100.2 116.1 105.2 101.6 102.6
我们用PCA来分析这些向量的对消费水平的贡献,代码实现如下:
- #include <opencv2/core/core.hpp>
- #include <iostream>
- #include <fstream>
- using namespace cv;
- using namespace std;
- void main(int argc, char** argv)
- {
- const int SAMPLE_NUM = 31;
- const int VECTOR_NUM = 7;
- fstream fp;
- string temp;
- char* filename = argv[1];
- Mat pcaSet(SAMPLE_NUM, VECTOR_NUM, CV_32F);
- // 读取数据,生成pcaSet
- fp.open(filename, ios::in);
- for (int i=0; i<SAMPLE_NUM; i++)
- {
- getline(fp, temp, ' ');
- for (int j=0; j<VECTOR_NUM; j++)
- {
- fp >> pcaSet.at<float>(i, j);
- }
- }
- fp.close();
- // cout << pcaSet << endl;
- PCA pca(pcaSet, Mat(), 0/*CV_PCA_DATA_AS_ROW*/);
- cout << pca.eigenvalues << endl;
- cout << endl;
- cout << pca.eigenvectors << endl;
- }
我这里只把前3维的结果显示如下:
eigenvalues:[43.18,14.60,9.21]、
eigenvectors:[0.013,0.034,-.0.100, -0.130, 0.207,0.963,-0.020;
0.157,0.038,0.121,0.893,0.395,0.046,0.060;
0.214,0.018,-0.001,-0.404,0.813,-0.228,0.277]
版权声明:本文为博主原创文章,未经博主允许不得转载。
最近一直很忙,没有及时回复网友的咨询和疑问,有些回复也是寥寥数语。其实我也没有办法,面对大量的问题,有大部分都是可以通过网络和图书获得答案,我实在没有精力每个问题都详细具体的回答,希望大家谅解,还是一位老师说的好:“知之为知之,不知百度知”。
前阵子有些朋友已经发现了OpenCV-2.4.0beta已经放出了,又有重大改动,很是让人兴奋,我前一篇blog——OpenCV学习笔记(三十四)——OpenCV路在何方中提到的OpenCV下一步的改进在这次版本中很多都得到了实现。最让我欣慰的是OpenCV有了自己的主页code.opencv.org,之前的http://opencv.willowgarage.com终将退出历史。其实这个beta版我也下载下来看过了,其中的文档并没有跟上,所以我一直在等。
五一节日,OpenCV也给大家送上了大礼,2.4.0release出炉。下载地址还是在Sourceforge上,之前听说OpenCV要把项目主页挪到ROS上,看来还没有实施。这次的压缩包竟然有201M啊,有木有啊!可见这次版本添加了很多内容啊,由于有重大改动,接下来还是详细给大家说说,其实新主页上都有,大家英文好可以去那里看,免得我给翻译错了~~。还有就是OpenCV许诺大家下一个版本2.4.1将在五个月后出炉,看来只能是活到老学到老了。。。
首先提到的还是网站的事,code.opencv.org现在是OpenCV开发首要的网站,相信日后的最新消息都会从这里放出。而opencv.org将作为官网(现在还没有投入使用,期待一下)。
还有一个重要的消息是一部分imgproc, video, calib3d, features2d, objdetect模块中的函数将废弃,扔到legacy中去了。兴奋的同时又让我很期待,新版本的整合是如何重整这些模块的呢,看来我又得好好重新学习了。版本的重大变化肯定也导致了CMake脚本的改变,这部分不是太精通,这里不班门弄斧。
一个新的模块cv::Algorithm出炉。这个模块包含了众多算法,也是接下来研究的重点,有新研究再和大家分享,文档我目前才开始看。
之前被大家诟病的视频部分这次又有所加强,大家经常抱怨OpenCV对视频支持的不好,不知道这次的改动会不会打一个翻身仗,还有待大家实践。
feature2d模块之前使用还是很不方便的,现在都被整合到Algorithm模块中了。SURF和SIFT被挪到了nonfree模块,这又是什么模块,看来新版本的惊喜还不少。。。还有一些函数的增添和改进,这里由于没有使用过,还是不乱讲,有兴趣自己去看一下咯。
一个新模块photo出炉,是为了计算摄影学而设计的,目前该模块只有从imgproc中移植出来的inpainting算法,还有一个模块是videostab是用来稳定视频的(这个模块还是beta版的)?这都是神马啊!具体咋用我也不知道啊。。。
之前我blog里提到的对GPU的支持力度要加强,OpenCV兑现了它的诺言,把光流法和特征点的提取检测算法都在GPU模块中实现了。之前我提过的Android模块也有所加强,但具体就不介绍了,我本身也不是搞移动开发的。新版本还特意提到了一个函数getBuildInformation,日后也要试试做啥的。
从今日起,我的学习笔记都将使用OpenCV-2.4.0开发,之前的blog都是用2.3.1写的,肯定有些东西,大家看看就乱了,给大家的学习带来了不便,还请大家包涵理解。
版权声明:本文为博主原创文章,未经博主允许不得转载。
刚开始学习新的2.4.0,大概看了一遍使用手册,还是有些失望的,很多章节还是2.3.1的内容,文档上的代码也是漏洞很多。这里就简单介绍一下Algorithm这个新的基类。本来以为这部分是一个新模块的,看了referenceManual后才知道它只是一个基类,集成了一些相对复杂的算法,比如BM算法等立体匹配算法,前景背景分离的算法,光流法等模块都集成在其中。类内成员函数主要有get、set、writhe、read、getList、create这些函数。前4个是用来从字符串和XML文件中读取算法的参数用的,使用get,set要注意参数的名字对应的类型要和数据的类型对应,后果大家肯定懂的。有了Algorithm::write,以后SITF::wirte啊SURF::write啊,神马的都可以再见了。getList可以得到Algorithm支持的算法类型。我测试了一下getList目前getList的算法有:BRIEF、Dense、FAST、CFIT、HARRIS、MSER、ORB、SIFT、STAR、SURF,日后应该都会实现,在手册上只有SURF和SIFT的介绍,至少目前,我看来只支持这两个算法。create就是创建算法的函数。使用呢,也相对简单。这里还是要说明一下,新版的features2d模块有较大改动,反正我看文档中该部分大多剩下的都是一些公共接口,比如特征描述子、描述子的提取、特征的匹配等。只有FAST、MSER、ORB还在文档中坚挺的出现(估计日后也要移植走),以前的Star、randomTree、rTreeClassifer神马该被遗弃的一起,该放ml的去ml,SIFT、SURF啥的也被弄到nonfree这个新模块里去了,不过这个新模块好弱啊,目前只有SIFT和SURF算法,估计以后还要把其他的算法整合进去。
接下来我就根据文档中的一个示例实践一下新版本的SIFT特征点检测算法,并且对比下之前版本的SITF的写法,大家从中感受新结构的不同吧。
- #include <opencv2/opencv.hpp>
- #include <opencv2/nonfree/nonfree.hpp>
- #include <opencv2/nonfree/features2d.hpp>
- using namespace cv;
- void main()
- {
- Mat image = imread("church01.jpg");
- Mat imageGray = imread("church01.jpg", 0);
- Mat descriptors;
- vector<KeyPoint> keypoints;
- // 新版本2.4.0方法
- initModule_nonfree();
- Ptr<Feature2D> sift1 = Algorithm::create<Feature2D>("Feature2D.SIFT");
- sift1->set("contrastThreshold", 0.01f);
- (*sift1)(imageGray, noArray(), keypoints, descriptors);
- // 2.3.1方法
- // SiftFeatureDetector sift2(0.06f, 10.0);
- // sift2.detect(imageGray, keypoints);
- drawKeypoints(image, keypoints, image, Scalar(255,0,0));
- imshow("test", image);
- waitKey();
- }
注意initModule_<modulename>()函数,这个函数要在create前使用,才可以动态的创建算法,不然那个create的指针很野哦。大家都懂的。如果要使用SURF、SIFT算法,就要调用inintModule_nonfree(),要使用EM算法,就要先调用initModule_ml()。
其实在我看来,这个Algorithm类更重要的是为开发者的算法提供一个公共的接口,以后开发者开发的算法,想要增加到OpenCV中去,就按照Algorithm的接口做就OK了,以免以后算法越来越多,我们的OpenCV也要变得臃肿了。
创建自己的算法类现在也很容易了,用Algorithm类做基类,算法的参数作为成员变量,用get函数调用,添加AlgorithmInfo* info() const到自己的算法类中去,添加构造函数,AlgorithmInfo变量,可以参考EM算法的初始化看如何操作,添加其他函数。做好后就用create调用你自己的函数就ok啦,这次先简单介绍,以后有机会自己做个函数了,体会深了再详细写出来跟大家分享。
版权声明:本文为博主原创文章,未经博主允许不得转载。
stitching是OpenCV2.4.0一个新模块,功能是实现图像拼接,所有的相关函数都被封装在Stitcher类当中。这个类当中我们可能用到的成员函数有createDefault、estimateTransform、composePanorama、stitch。其内部实现的过程是非常繁琐的,需要很多算法的支持,包括图像特征的寻找和匹配,摄像机的校准,图像的变形,曝光补偿和图像融合。但这些模块的接口、调用,强大的OpenCV都为我们搞定了,我们使用OpenCV做图像拼接,只需要调用createDefault函数生成默认的参数,再使用stitch函数进行拼接就ok了。就这么简单!estimateTransform和composePanorama函数都是比较高级的应用,如果各位对stitching的流程不是很清楚的话,还是慎用。
实例也非常简单,下载链接哦:http://download.csdn.net/detail/yang_xian521/4321158。
输入原图(为了显示,我都压缩过):




版权声明:本文为博主原创文章,未经博主允许不得转载。
距离2.4.0放出来才一个月。儿童节当天2.4.1就出炉了。。。。真心跟不上节奏啊,路漫漫其修远兮。。。。
这次主要的改变还是bug的修订,之前有朋友告诉我,说他的2.3.1版本说什么都不能成功配置CUDA,后来他用2.2版本就成功了,看来新出的版本bug还是很多的,也不能盲目求新。这次的2.4.1版本更新如下:
GPU模块支持了CUDA4.1、CUDA4.2版本,添加了一个文件字符串存储回读的API接口
完善了光流法的clacOpticalFlowPyrLK,支持了金字塔图像作为输入
完善了文档,使文档和版本更加对应
修正了SURF、MSER的Python包装
修正了其他45处bug
版权声明:本文为博主原创文章,未经博主允许不得转载。
OpenCV 2.4.2简介
OpenCV从未放慢自己前进的步法,就在7月4日,最新版的2.4.2又放出来了。与之同时放出的还有两个网站http://opencv.org/和http://answers.opencv.org,前者作为一个正式的全新的官方用户网站,简单浏览了一下,应该是一个对应之前维基百科上的那个网站,是一个介绍性的新闻网站,对开发者的意义可能不是太大;后面这个网站就厉害了,是一个类似google讨论组一样的交流区,大家可以在上面提问,留言,解答,我也刚刚注册了个用户,刚成立没几天已经有60多个问题了,应该还是很活跃的一个讨论区。
还是老样子,介绍一下新版本的更新以及改动:
现在支持iOS操作系统了!开发iphone的朋友们,你们也可以用OpenCV了,是不是内牛满面。
添加了一个新的特征点描述算法FREAK,这也是今年的CVPR的一个新算法,也是一个2值的特征,文章里说是根据人视网膜的原理,挺玄乎的,据说是效果比ORB和SURF都好,我要试试看。
对GPU的模块进一步优化,对个别算法的性能有较大提升。
还修正了2.4.1的50多个bug。
介绍就这么多,感觉亮点就是网站的建设和这个FREAK特征,其他的还得慢慢摸索啊
FREAK和ORB特征描述子效果对比
ORB就是BRIEF的改进,BRIEF太简单了,就不介绍了,有兴趣的朋友自己看paper吧。ORB的paper我读下来,感觉改进主要有以下几点:用FAST作为特征点提取的算法,更快了,添加了特征点的主方向,这样就具有了旋转不变性。最后一点其实我也想到了,当时看BRIEF的时候就想应该可以优化,就是ORB采用贪婪穷举的方法得到了相关性较低的随机点对,还有一个改进就是对于随机点对,受噪声的影响很大BRIEF的办法就是对原图像滤波,降低噪声的影响,ORB不在使用像素点的直接比较,而是选择该像素为中心的一个小patch作为比较对象,提高了抗噪能力。
FREAK我只是大致看了下,理解可能不到位,我的理解是这个算法是基于人眼视网膜细胞的分布,中间密集,四周稀疏,从而在图像中构建很多的区域,当然越靠近中心的区域采样更密集,四周区域采样稀疏,随机对比各区域的像素得到一组2值特征,这个算法也关注了尺度和方向的问题,都有对应的解决办法,还根据了人眼看事物时眼睛不停的转动,设计了一种级联的搜索器,总而言之,我感觉这个算法也是受ORB和BRISK这种2值特征的启发下的一种改进吧。
下面就利用OpenCV对其进行一下对比,值得说明的是,在2.4.2中,FREAK给出了pattern的训练代码。
对比实验效果如下:(上图为ORB,下图为FREAK)


经过筛选之后的特征点如下图:(上图为ORB,下图为FREAK)


当然,我这里只是个简单的测试,其实并不能完全反应实际的性能,因为我这里FREAK的特征点位置的检测用的是SURF,而ORB用的是FAST。但从我这里的比较效果来看,ORB要好很多。下面让我来对比一下算法的运行时间:
| ORB | FREAK detection | FREAK extraction | |
| debug | 0.317s | 0.301s | 0.167s |
| release | 0.094s | 0.162s | 0.085s |
虽然两种算法不能直接比较,因为FREAK没有提供特征点位置检测的算法,个人感觉如果FREAK采用FAST来做detection,确实速度应该要逼ORB要快一些。
最后分享给大家我的工程链接:http://download.csdn.net/detail/yang_xian521/4421537
版权声明:本文为博主原创文章,未经博主允许不得转载。
在最新版的2.4.2中,文档的更新也是一大亮点,refrence manual扩充了200多页的内容,添加了contrib部分的文档。contrib就是指OpenCV中新添加的模块,但又不是很稳定,可以认为是一个雏形的部分。这次结合refman的阅读,介绍一下FaceRecognizer这个人脸识别类,这个类也是2.4.2更新日志里着重强调过的更新,配套的文档也是相当充实。这个类的基类也是Algorithm类,对于Algorithm类的简单介绍,请参看我之前的blogOpenCV学习笔记(五十)——Algorithm类介绍(core),这个类内的接口函数也是异常简单,人脸识别的任务也就是两大部分,训练和预测,分别对应着train函数和predict函数,还有对应的数据加载保存函数save和load。不过它当然还可以调用其基类Algorithm的函数。特别说明的是,人脸识别中预测的参数也是可以调节的,但这里只给出了train和predict函数,为啥没有setparameter的函数呢,那是因为各中人脸识别方法的参数并不相同,要通过Algorithm的get和set函数实时的调整~~v5啊!
先来说说训练的过程,train函数的两个参数也很简单,训练的图像组vector<Mat>和对应的标签组vector<int>,这个label标签只需保证同一个人的标签相同即可,不需要保证图像的按标签顺序输入,方便极了。对于预测,有两种调用,其中的参数有测试图像、返回的标签值和测试样本和标签样本的相似性。返回的标签值为-1,说明测试样本在训练集中无对应或距离较远。这里用个FisherFace作为示例说明一下如何训练和预测:
- vector<Mat> images;
- vector<int> labels;
- // images for first person
- images.push_back(imread("person0/0.jpg", CV_LOAD_IMAGE_GRAYSCALE));
- labels.push_back(0);
- images.push_back(imread("person0/1.jpg", CV_LOAD_IMAGE_GRAYSCALE));
- labels.push_back(0);
- // images for second person
- images.push_back(imread("person1/0.jpg", CV_LOAD_IMAGE_GRAYSCALE));
- labels.push_back(1);
- images.push_back(imread("person1/1.jpg", CV_LOAD_IMAGE_GRAYSCALE));
- labels.push_back(1);
- Ptr<FaceRecognizer> model = createFisherFaceRecognizer();
- model->train(images, labels);
- Mat img = imread("person1/2.jpg", CV_LOAD_IMAGE_GRAYSCALE);
- int predicted = model->predict(img);
当然我们也不需要每次使用都进行一次训练,可以把训练好的模型通过save函数保存成一个文件,下次使用的时候只需load即可。
目前支持的3种人脸识别的方案:特征脸EigenFace、Fisher脸FisherFace、LBP直方图LBPHFace。分别调用函数createEigenFaceRecognizer、createFisherFaceRecognizer、createLBPHFaceRecognizer建立模型。
对于EigenFace两个输入参数,分别为PCA主成分的维数num_components和预测时的阈值threshold,主成分这里没有一个选取的准则,要根据输入数据的大小而决定,通常认为80维主成分是足够的。除了这两个输入参数外,还有eigenvalues和eigenvectors分别代表特征值和特征向量,mean参数为训练样本的平均值,projections为训练数据的预测值,labels为预测时的阈值。
对于FisherFace,和EigenFace非常相似,也有num_components和threshold两个参数和其他5个参数,FisherFace的降维是LDA得到的。默认值为c-1,如果设置的初始值不在(0,c-1]的范围内,会自动设定为c-1。
特别需要强调的是,EigenFace和FisherFace的训练图像和测试图像都必须是灰度图,而且是经过归一化裁剪过的。
对于LBPHFace,我想不用过多介绍,LBP简单和效果是大家都很喜欢的,参数包括半径radius,邻域大小即采样点个数neighbors,x和y方向的单元格数目grid_x,grid_y,还有两个参数histograms为训练数据得到的直方图,labels为直方图对应的标签。这个方法也要求训练和测试的图像是灰度图
接下来应该结合文档进一步研究一下这个人脸识别类。我之前大量的人脸实验都是在matlab下进行的,有了这个利器,我感觉会有越来越多的学生做老师和老板布置的project会选择用OpenCV,而不是Matlab。希望我们都爱的OpenCV越来越好,越来越强大。欢迎交流
版权声明:本文为博主原创文章,未经博主允许不得转载。
人脸识别的故事说也说不完,调研的事还是交给大家吧。这里说的是用OpenCV做人脸识别。
因为是真正的人脸识别,不是搞笑娱乐的东西,所以数据库一定要强大的,推荐个网站http://www.face-rec.org/databases/。这里有最全的人脸库的概述,希望大家能找到自己需要的人脸库(PS:我现在特别需要一个3d的人脸库,不知道哪位大侠知道如何free获取,或者愿意共享给我那更是极好的了,先谢过咯)。这里简单介绍两个库,ORL和Yale,ORL是一个轻量级的库,Yale更为复杂,但并不是免费的。
数据的准备:在我们程序里需要读取图像和对应的标签,这里采用CSV文件,是一种简单的数据交互格式,在我们最常用的Excel里就支持这种格式。这种格式每条信息占一行。信息格式为:文件名;标签,例如C:/ORL/image.jpg;0。只要创建了一个CSV文件和对应的图像,你就可以对任何一个数据库进行训练了。当然,这个CSV文件并不一定要自己手动的创建,也可以Python脚本自己生成自己需要的CSV文件,对应的脚本为\modules\contrib\doc\facerec\src\create_csv.py,唉,谁让咱对这个脚本不熟悉,只能偷懒了,直接调\modules\contrib\doc\facerec\etc\at.txt或者\samples\cpp\facerec_at_t.txt。这个txt对应的是ORL的数据库,其中的路径就按照其改一下就好了。
至于人脸识别的具体实现,我已经在blogOpenCV学习笔记(五十四)——概述FaceRecognizer人脸识别类contrib提到了如何实现。\modules\contrib\doc\facerec\src很多很好的示例,我这里就不上传代码了。
最后再说一下人脸的标定。因为对Python也不是太熟悉,只给大家一个脚本文件吧,是\modules\contrib\doc\facerec\src\crop_face.py,通过这个脚本可以制作自己需要的人脸图片大小。
性别识别和视频中的识别在对应的demo里都有介绍,我这里就不详细说了,因为性别识别无非就是把训练样本的标签只有两类:男性和女性。需要说明的是,EigenFace是基于PCA的,是一种非监督的模型,不太适合性别识别的任务,这里的demo用的是FisherFace。对于视频的人脸识别,无非就是添加了个VideoCapture和一个人脸检测的CascadeClassifier。
关于训练的模型的保存和调用,就是用save和load函数,好简单的,就不介绍了吧。
最后说一下伪彩色图的这个函数applyColorMap,其中colorMap参数是用来选择伪彩色图的样式。因为人眼对颜色的敏感的程度要比对亮度的敏感程度要高,所以用伪彩色图 的对比效果要更好。这才医学图像处理中用的比较多,以前的B超现在都用彩超了,价格竟然要贵好多,其实就是一个伪彩色处理罢了,医院真黑啊!!
版权声明:本文为博主原创文章,未经博主允许不得转载。
看过OpenCV源代码的朋友,肯定都知道很多函数的接口都是InputArray或者OutputArray型的,这个接口类还是很强大的,今个就来说说它们的那些事。
InputArray这个接口类可以是Mat、Mat_<T>、Mat_<T, m, n>、vector<T>、vector<vector<T>>、vector<Mat>。也就意味着当你看refman或者源代码时,如果看见函数的参数类型是InputArray型时,把上诉几种类型作为参数都是可以的。
有时候InputArray输入的矩阵是个空参数,你只需要用cv::noArray()作为参数即可,或者很多代码里都用cv::Mat()作为空参。
这个类只能作为函数的形参参数使用,不要试图声明一个InputArray类型的变量
如果在你自己编写的函数中形参也想用InputArray,可以传递多类型的参数,在函数的内部可以使用_InputArray::getMat()函数将传入的参数转换为Mat的结构,方便你函数内的操作;必要的时候,可能还需要_InputArray::kind()用来区分Mat结构或者vector<>结构,但通常是不需要的。例如:
- void myAffineTransform(InputArray _src, OutputArray _dst, InputArray _m)
- {
- Mat src = _src.getMat(), m = _m.getMat();
- CV_Assert( src.type() == CV_32FC2 && m.type() == CV_32F && m.size() == Size(3, 2) );
- _dst.create(src.size(), src.type());
- Mat dst = _dst.getMat();
- for( int i = 0; i < src.rows; i++ )
- for( int j = 0; j < src.cols; j++ )
- {
- Point2f pt = src.at<Point2f>(i, j);
- dst.at<Point2f>(i, j) = Point2f(m.at<float>(0, 0) * pt.x + m.at<float>(0, 1) * pt.y + m.at<float>(0, 2);
- }
- }
至于有的源代码里使用InputArrayOfArrays作为形参,不用慌张,其实它和InputArray是一样一样一样的。
OutputArray是InputArray的派生类。使用时需要注意的问题和InputArray一样。和InputArray不同的是,需要注意在使用_OutputArray::getMat()之前一定要调用_OutputArray::create()为矩阵分配空间。可以用_OutputArray::needed()来检测输出的矩阵是否需要被计算。有时候传进去的参不是空就不需要计算
还有就是OutputArrayOfArrays、InputOutputArray、InputOutputArrayOfArrays都是OutputArray的别名而已
版权声明:本文为博主原创文章,未经博主允许不得转载。
好久没更新blog里,看到OpenCV官网做的越来越好,心里也是很高兴的,真有些冲动将来加入到这个组织里做些事。估计2.4.3要在国庆左右跟大家见面,让我们多期待一下吧。
闲话少说,今天不介绍复杂的算法了,来个简单的,大家写文章做图经常用Matlab,在Matlab里经常在一个窗口里打开多幅图片。遗憾的是OpenCV没有集成这样的功能,但这难不倒大家,让我试试用ROI来解决这个问题。
没啥好讲的,上代码好了:
- void imshowMany(const std::string& _winName, const vector<Mat>& _imgs)
- {
- int nImg = (int)_imgs.size();
- Mat dispImg;
- int size;
- int x, y;
- // w - Maximum number of images in a row
- // h - Maximum number of images in a column
- int w, h;
- // scale - How much we have to resize the image
- float scale;
- int max;
- if (nImg <= 0)
- {
- printf("Number of arguments too small....\n");
- return;
- }
- else if (nImg > 12)
- {
- printf("Number of arguments too large....\n");
- return;
- }
- else if (nImg == 1)
- {
- w = h = 1;
- size = 300;
- }
- else if (nImg == 2)
- {
- w = 2; h = 1;
- size = 300;
- }
- else if (nImg == 3 || nImg == 4)
- {
- w = 2; h = 2;
- size = 300;
- }
- else if (nImg == 5 || nImg == 6)
- {
- w = 3; h = 2;
- size = 200;
- }
- else if (nImg == 7 || nImg == 8)
- {
- w = 4; h = 2;
- size = 200;
- }
- else
- {
- w = 4; h = 3;
- size = 150;
- }
- dispImg.create(Size(100 + size*w, 60 + size*h), CV_8UC3);
- for (int i= 0, m=20, n=20; i<nImg; i++, m+=(20+size))
- {
- x = _imgs[i].cols;
- y = _imgs[i].rows;
- max = (x > y)? x: y;
- scale = (float) ( (float) max / size );
- if (i%w==0 && m!=20)
- {
- m = 20;
- n += 20+size;
- }
- Mat imgROI = dispImg(Rect(m, n, (int)(x/scale), (int)(y/scale)));
- resize(_imgs[i], imgROI, Size((int)(x/scale), (int)(y/scale)));
- }
- namedWindow(_winName);
- imshow(_winName, dispImg);
- }
附上效果图一张:
工程的下载链接为http://download.csdn.net/detail/yang_xian521/4531610
版权声明:本文为博主原创文章,未经博主允许不得转载。
好久没更新这个系列了。去年12月初的时候就知道出了一本OpenCV的新书《Master OpenCV with Practical Computer Vision Projects》,一直没来得及看,春节前也不想做什么任务,就把这书读一读吧。大概看了一下,和OpenCV的其他书对比了一下,感觉如下:
《Learning OpenCV》是一本经典的老书了,是一个入门教材,读完可以知道OpenCV能做些什么,但里面的具体代码个人觉得还是有点out,但好处就是中文资料很全,网上可以找到很多参考资料。
《OpenCV Cookbook》是我以前推荐过的一本书,是基于2.2版本写的。我的感觉是一本上手教材,书的目的是让大家知道应该如何去调用OpenCV的函数,如何用OpenCV的类去实现简单的视觉任务。需要一定的C++基础。
《Master OpenCV》感觉更像是一个上层建筑,是基于2.4版本写的。是教会大家如何用OpenCV去实现复杂的任务,去完成OpenCV自带函数没有提供的功能。(因为大家经常会因为“OpenCV里面有xxx的函数么?”的否定答案而苦恼,这本书就是告诉大家OpenCV只是个工具,如何去驾驭这个工具进行二次开发是要动脑的)
这本《Master OpenCV》书第一章没有很复杂的东西。
第一章就是介绍了一个边缘检测、肤色检测、一个填充算法,并把这个功能移植到Android平台,边缘检测和填充算法都是OpenCV自带的函数功能。这里随便说说读完第一章的几点收获:
1、具体任务要具体分析。这里因为要做到嵌入式平台中,算法的复杂度被放在了首位,所以双边滤波做了简化、填充算法也只是在原图的缩小1/2的图上进行的计算。肤色检测也没有先用经典的人脸检测算法,而是用了一种土鳖的方案,都是为了在嵌入式平台上能运行的高效。这种处理问题的方法值得借鉴学习
2、面向对象编程的思想。这章里也提到了显示FPS,只是人家是在一个类中实现,再对比自己之前写的OpenCV学习笔记(三十八)——显示当前FPS,高下自分。实在是自惭形愧啊~~。
3、貌似把自己的c++工程移植到android平台并不需要改写自己的代码,只要做个JNI function作为接口就可以调用c++的程序了,感觉有点像Matlab中的mex。android下的OpenCV开发基本不懂,这里就不乱讲了。
版权声明:本文为博主原创文章,未经博主允许不得转载。
第二章原本是讲如何将基于标定的增强现实在iOS平台实现,包括以下4个方面:
1、在ios平台建立OpenCV工程
2、Marker检测识别
3、摄像机标定及Marker姿态估计
4、在Marker基础上渲染一个3维虚拟物体
这里面第一部分是IOS平台的开发,我不是太关注,略去;第四部分是基于OpenGL的3维虚拟物体建立,也是基于IOS平台,因为第三章里还要用到OpenGL,这里留着第三章再解剖。所以这里主要分析第二部分和第三部分。这一篇介绍第二部分。感觉这个东西有点像二维码识别。不知道2维码是怎么做的哦
MarkerDetection类任务processFrame:图1

转为灰度图、2值化(固定阈值法threshold:受光照等影响明显;自适应阈值法adaptiveThreshold:更好)(我这里用OpenCV243里的adaptiveThreshold函数未能实现自适应滤波的效果,效果像边缘检测的算法,很困惑。。最后用threshold函数代替,这个问题未能解决,希望高手指点,ps:网上高手多啊,这个问题已经解决了),检测后的结果如图threshold(图1左上)
findMarkerContours函数进行轮廓检测findContours(用多边形的顶点最好,去掉小于阈值的点(对小的轮廓不感兴趣),把每个轮廓的点按照逆时针排序,并去掉距离太近的轮廓),结果如图contours(图1中上)
接下来findMarkerCandidates函数对轮廓进行筛选,先用approxPolyDP得到轮廓近似的多边形。进行筛选,为凸多边形且顶点为4的才有可能是marker,并检测这个4边形的边长,最小边长如果小于10pixel,也不认为是一个marker。然后把得到的可能的marker的轮廓点按照逆时针排序。并且检测是否检测到重复的marker,如果检测到重复的marker,去掉周长更短的那个。这步之后效果如下markerCandidate(图1左下)
detectMarkers函数有3个任务,去除投影变换的影响(getPerspectiveTransform得到投影矩阵,warpPerspective得到正面的视角的图像),得到marker正面的视图。
然后对这个marker的正面图进行解码,threshold对marker使用THRESH_OTSU进行2值化。效果图:

接下来对这个marker进行识别marker.decode。检测编码marker(对marker解码,marker编码为7*7的栅格,中心5*5为ID,周围一圈为黑色边界,检测的时候先检测周围一圈是否为黑色边界,然后再对中心5*5解码(注意,只有5*5具有旋转不变形才能得到唯一的码),是5bit*5word,每个word中的5bit,2位为id(2位4位),3位为校验码(用来保证旋转),所以5word一共有2^10=1024个不同id,而且第一位要置反,目的是要防止一个word全黑,不易检测。举例,我这里使用的marker的5个word的id分别为10、01、11、11、11。那么如何从刚刚得到的marker图提取出7*7的2值栅格呢,这里用个Mat(Rect)取marker中的小方块,用countNonZero来判断这个方块为0or1。因为marker有4个方向,哪个方向才是我对应的marker的id的,这里用id和我验证用的id的hamming距离来做依据,汉明距最小的即marker的方向。
确认为一个marker后再得到轮廓的细致的corner,使用cornerSubPix,这时才进行细化,是因为这个函数相对耗时,如果之前就对各corner细化,由于候选目标很多,会加重计算负担。)效果图marker(图1右下)。
最后我试了其他的marker编码,都能正确解码出id信息,效果图如下:第一幅图的id为0011010101,第二幅图为第一图的旋转,id相同,第三图id为0011000110,第四图不是一个marker,故没有检测出来。

代码的下载地址:http://download.csdn.net/detail/yang_xian521/5040634
在下一篇里,将介绍如何用这个marker的轮廓位置,和轮廓(红色)的方向(黄点)来在marker上建立一个3维的虚拟物体。
版权声明:本文为博主原创文章,未经博主允许不得转载。
从OpenCV2.4beta版本,OpenGL就可以有接口到highgui的模块中了。结合Master OpenCV第三章的阅读,这里说说如何在OpenCV的显示中嵌入OpenGL的虚拟物体。
要注意的一点:如果想使OpenCV支持OpenGL,不能使用预编译好的library,要用cmake rebuild工程,注意ENABLE_OPENGL = YES,(在2.4.2版本中,默认ENABLE_OPENGL = NO),标签的改变在CMake的高级版本都是图形界面的,只需把WITH_OPENGL的对号勾选即可。
这里实战过程中我还遇到了一个问题,用这个CMake得到的vs工程(添加了WITH_OPENGL)无法编译通过,郁闷了好久。因为opengl在vs中是支持的,不需要安装,最后找到了这个bug,需要把\modules\core\src\opengl_interop.cpp文件中使用<gl\gl.h>前面添加#include <windows.h>,(其实#include <gl.h>前都需要添加#include <windows.h>)这样才能编译通过,这里我只重新编译opencv_core243d.lib 和opencv_highgui243d.lib
已经得到了支持OpenGL的OpenCV lib,接下来就是如何用OpenCV建立OpenGL窗口,基本的调用方式很像OpenCV中鼠标的使用,都是通过回调函数实现,核心代码如下:
- // callback function
- void onDraw(void* param)
- {
- // Draw something using OpenGL here
- }
- int main(void)
- {
- string openGLWindowName = "OpenGL Test";
- namedWindow(openGLWindowName, WINDOW_OPENGL);
- resizeWindow(openGLWindowName, 640, 480);
- setOpenGlContext(openGLWindowName);
- setOpenGlDrawCallback(openGLWindowName, onDraw, NULL);
- updateWindow(openGLWindowName); // when needed
- return 0;
- }
以前我们调用namedWindow最后一个参数通常会用默认或者使用WINDOW_AUTOSIZE,这回用WINDOW_OPENGL,然后调用setOpenGLContext建立窗口关联,为了在这个窗口上画虚拟物体,需要使用回调函数,建立方法就是setOpenGLDrawCallback,注意这个函数第一个参数是窗口名称,第二个参数是回调函数名,第三个参数是回调函数的参数,因为我这里回调函数onDraw是无参函数,所以这里为NULL。跟MFC重绘需要调用Invalidate或者uadate类似,在需要重绘的时候还要调用updateWindow。
把我做的一个最基础的OpenGL演示上传:http://download.csdn.net/detail/yang_xian521/5023063(附上我rebulid的支持OpenGL的lib),效果图如下:

版权声明:本文为博主原创文章,未经博主允许不得转载。
现在Python火啊,每次OpenCV自带的ml模块都让我直呼坑爹,索性准备用python来做OpenCV后期的机器学习算法的处理。于是赶紧拿起这本书读读。
适合OpenCV和python都有一定基础的。。。。由于都比较熟悉这两个东西,我阅读之前比较关心的只有几个问题,具体的应用实例没有仔细看。
1.如何在python中安装opencv
2.OpenCV的Mat数据结构能否方便的转换成numpy的array结构
3.OpenCV的GUI模块在python里好用么
4.二者还能擦出什么我想不到的火花么。。。。
书中提到在windows系统中,python-32bit表现的比64bit要好,推荐安装32位的python
第一个问题在windows下很简单,OpenCV安装好之后,找到目录<build_folder>\lib\Release\cv2.pyd(from a Visual Studio build) 这个文件,然后copy到C:\Python2.7\Lib\site-packages。搞定了,就这么简单。毕竟脚本语言,简直无情,\sources\samples下有很多python的例子,跑几个试试就知道是否安装好了。import cv2这句就可以导入cv2模块了
第二个问题也不用担心了,因为python不用声明变量的类型,实验了一下,发现得到的矩阵的数据类型就是array,稳了,直接拿来用。
第三个问题也超简单,图像显示读写的模块、摄像头模块、鼠标键盘的响应模块都可以,跟c++的版本使用起来也差不多。
第四个问题我简单粗看了一遍书,没发现什么亮点,只是书中提到一个pygame可以用来做hgui效果还行,支持画画和编辑文本,不过好像对CV也没啥帮助,所以就没研究了。
补充几个我学习的时候遇见的问题:
opencv里的Rect数据结构在python里是没有对应类型的,这个要注意调用的时候需要注意。比如rectangle函数输入的就是矩形两个点的坐标,不是Rect。
还有就是opencv里的很多宏在python里需要加上cv2.cv前缀就可以生效了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号