神经网络学习
感知和学习
Rosenblatt Perceptron计算流程:
-
初始化:随机初始化权重 \(\mathbf{W}\) 和偏置 b 。
-
循环训练:
- 从训练集中随机选择一个样本$ (\mathbf{X}_i, y_i)$ 。
- 检查分类结果是否正确:如果 $y_i \cdot (\mathbf{W} \cdot \mathbf{X}_i + b) \leq 0 \((分类错误),则更新权重和偏置:\)\mathbf{W} \leftarrow \mathbf{W} + \eta \cdot y_i \cdot \mathbf{X}_i\(;\)b \leftarrow b + \eta \cdot y_i$
- 其中 \eta 是学习率。
-
停止条件:重复第 2 步,直到所有样本都被正确分类,或者达到最大迭代次数。
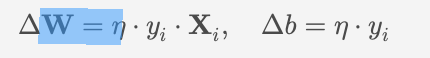
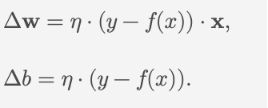
逻辑回归的损失函数:\(\text{Loss}(w, b) = -\frac{1}{N} \sum_{i=1}^{N} \left[ y_i \log \left( \sigma(w \cdot X_i + b) \right) + (1 - y_i) \log \left( 1 - \sigma(w \cdot X_i + b) \right) \right]\)
梯度下降优化:

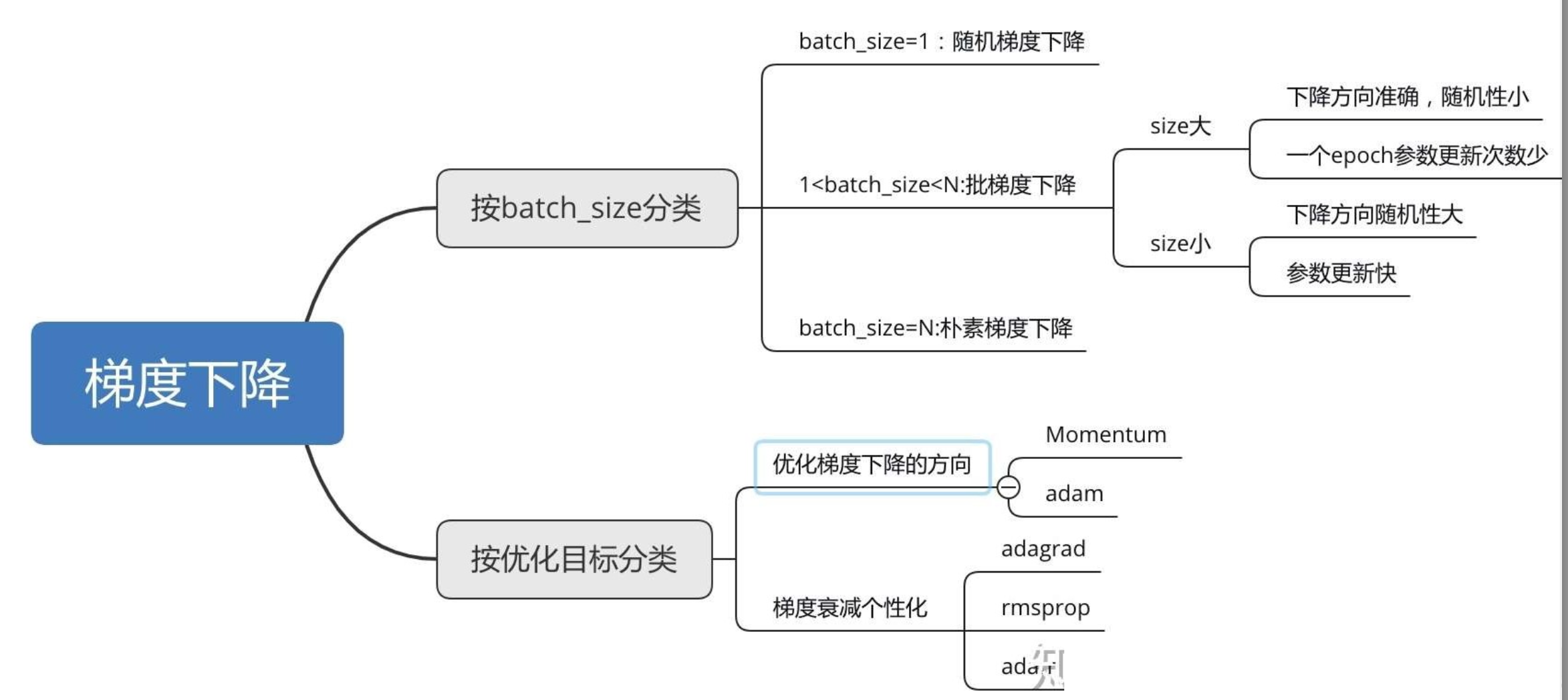
批量梯度下降BGD:
\(\theta \leftarrow \theta - \eta \cdot \frac{1}{N} \sum_{i=1}^N \nabla f_i(\theta)\)
随机梯度下降SGD:
\(\theta \leftarrow \theta - \eta \cdot \nabla f_i(\theta)\)
小批量梯度下降:
\(\theta \leftarrow \theta - \eta \cdot \frac{1}{m} \sum_{i=1}^m \nabla f_i(\theta)\)
动量优化MGD:累积历史梯度,减少振荡,加速收敛
AdaGrad:动态调整每个参数的学习率
RMSprop:动态调整每个参数的学习率

Adam(Adaptive Moment Estimation):动量+动态调整每个参数的学习率
基本思路:
-
Trail Feedforward: \(y_p=f(wx+b)\)
-
Evaluate Loss Function: \(E = \frac{1}{2}(Y_A - Y_P)^2\), minimize GD
-
Analist Back-Progagation: new - old
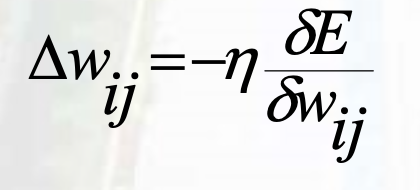
卷积神经网络
基本概念
特点:
- Image Processing
- Feed-Forward & Back-Propagation
- recongnize visual patten(the ordering and patterns)
- Filter/Kernel:权重矩阵
- End-To-End
拓扑结构:
-
C(Convolution Layer) : feature extraction
- Kernel:Flatten:Local Connectivity Parameter Sharing
-
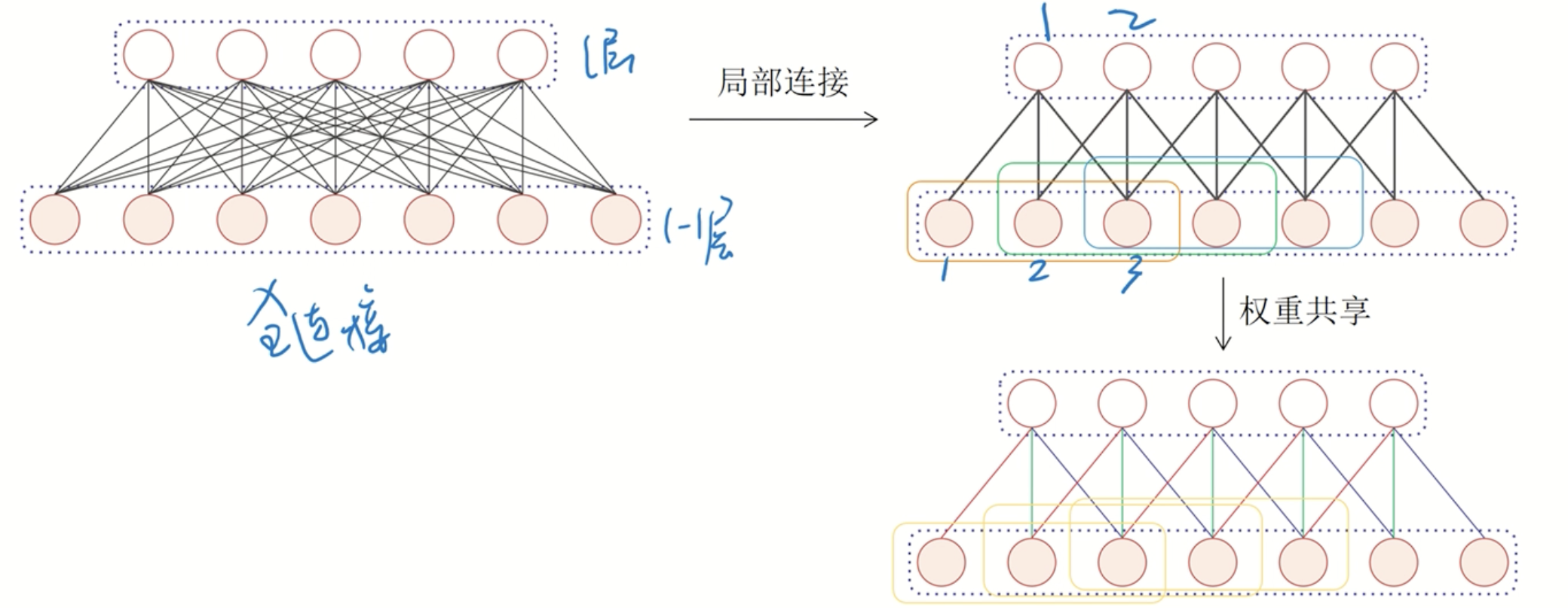
P(Pooling Layer): Subsampling 进一步减少结点大小
- Max Pooling
- Average Pooling
- Normal Pooling
- Log propability Pooling
-
上面两层可以不断重复
-
Flatten:拉平,送进全连接神经网络
-
F(Fully-Connected Layer): classifier
Local Connectivity & Parameter Sharing
局部连接:一个卷积核在图像上Move Around
权重共享:卷积核同位置参数一致
- Convulation Operation(Stride, Padding)
- Kernel
- Feature Map:\(FeatureMap_{size} = \left\lfloor \frac{Image_{size} + 2Padding - Kernel_{size}}{S} \right\rfloor + 1\)
Pooling
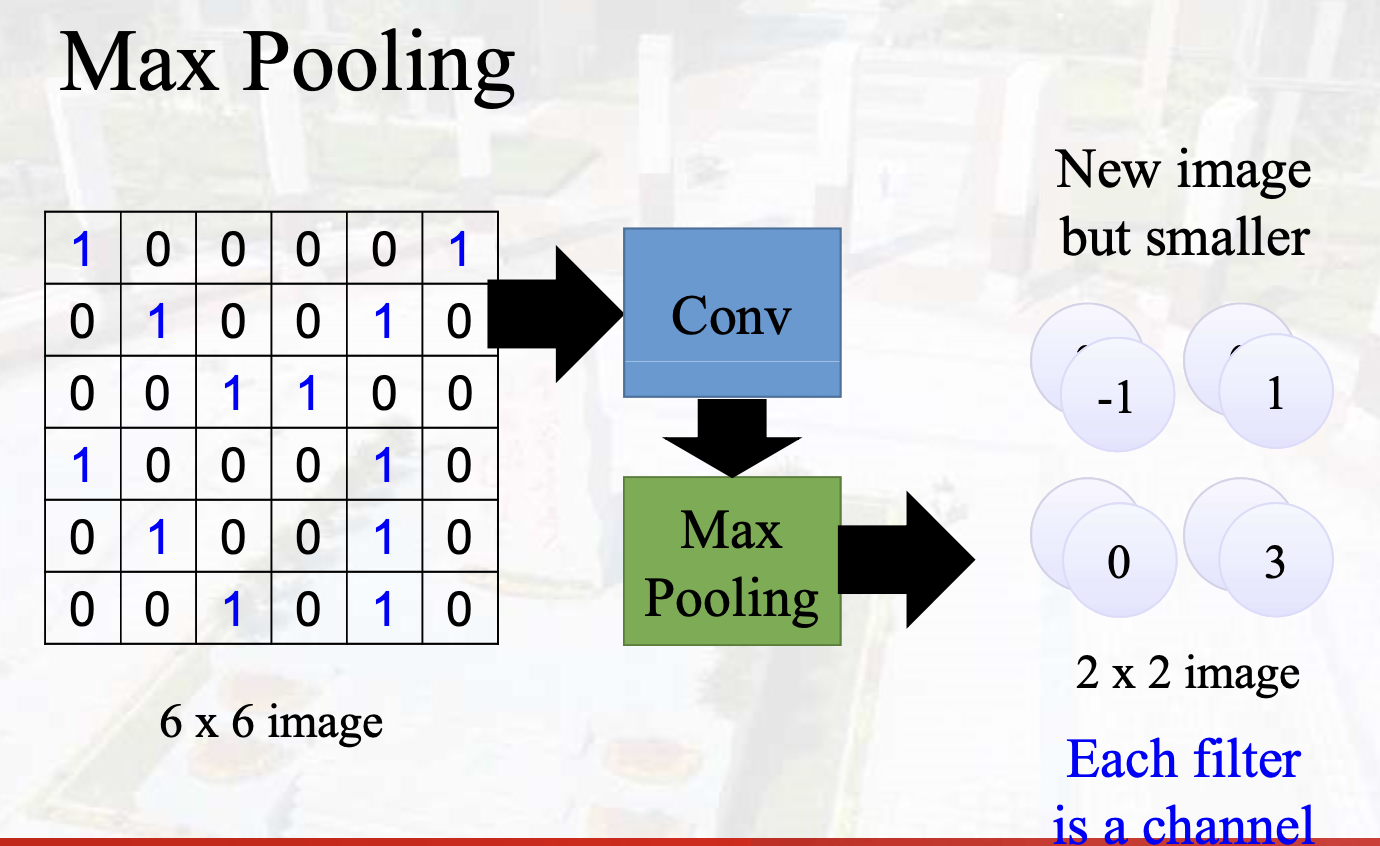
The number of channels is the number of filters
Feature Map:计算方法同卷积特征图计算方法
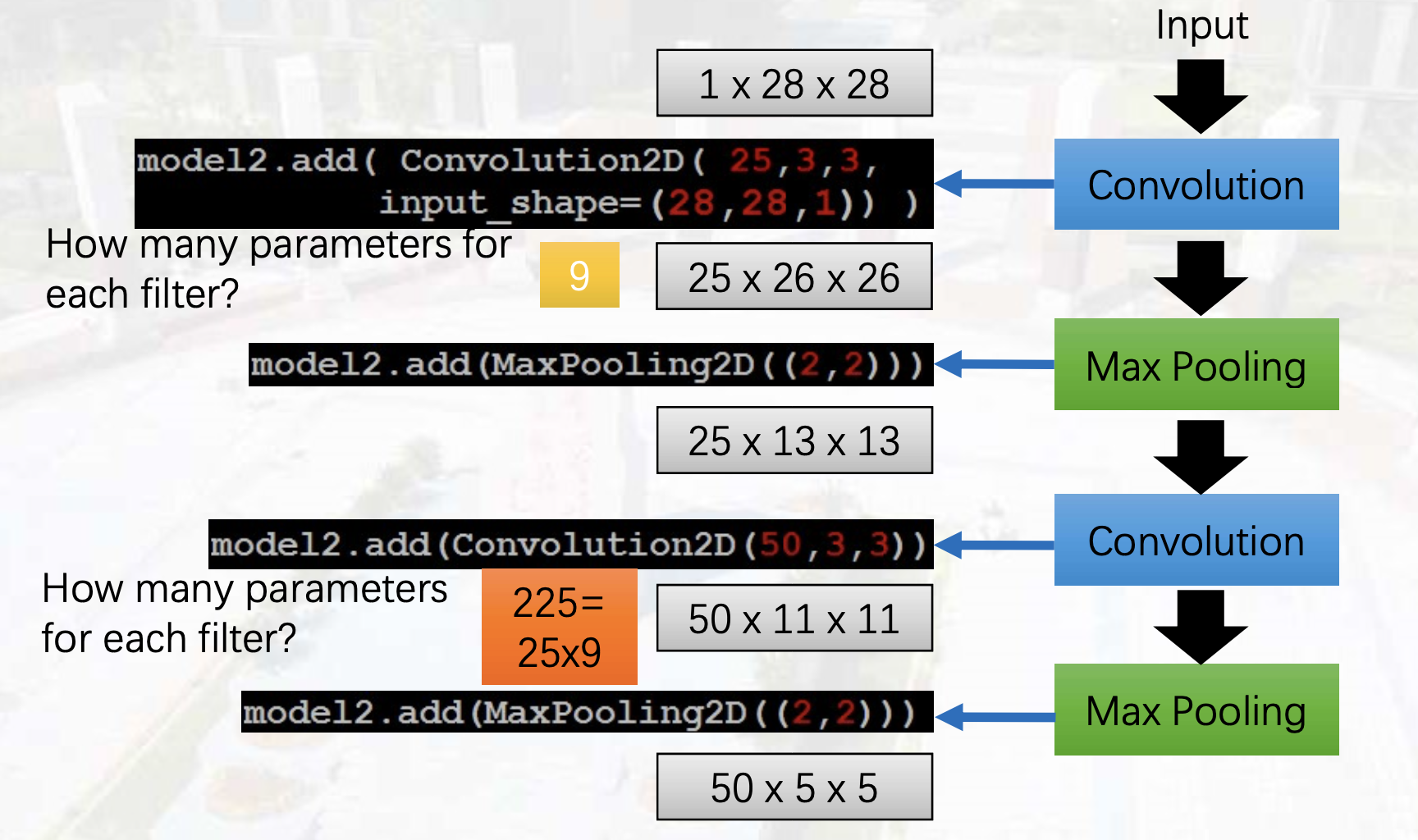
计算:特征图大小,参数量
(图中池化阶段得到的特征图大小不准确,应该和卷积层阶段的计算方法一样)
(参数了计算不准确:9*25和25*9*50)
卷积神经网络模型
LeNet
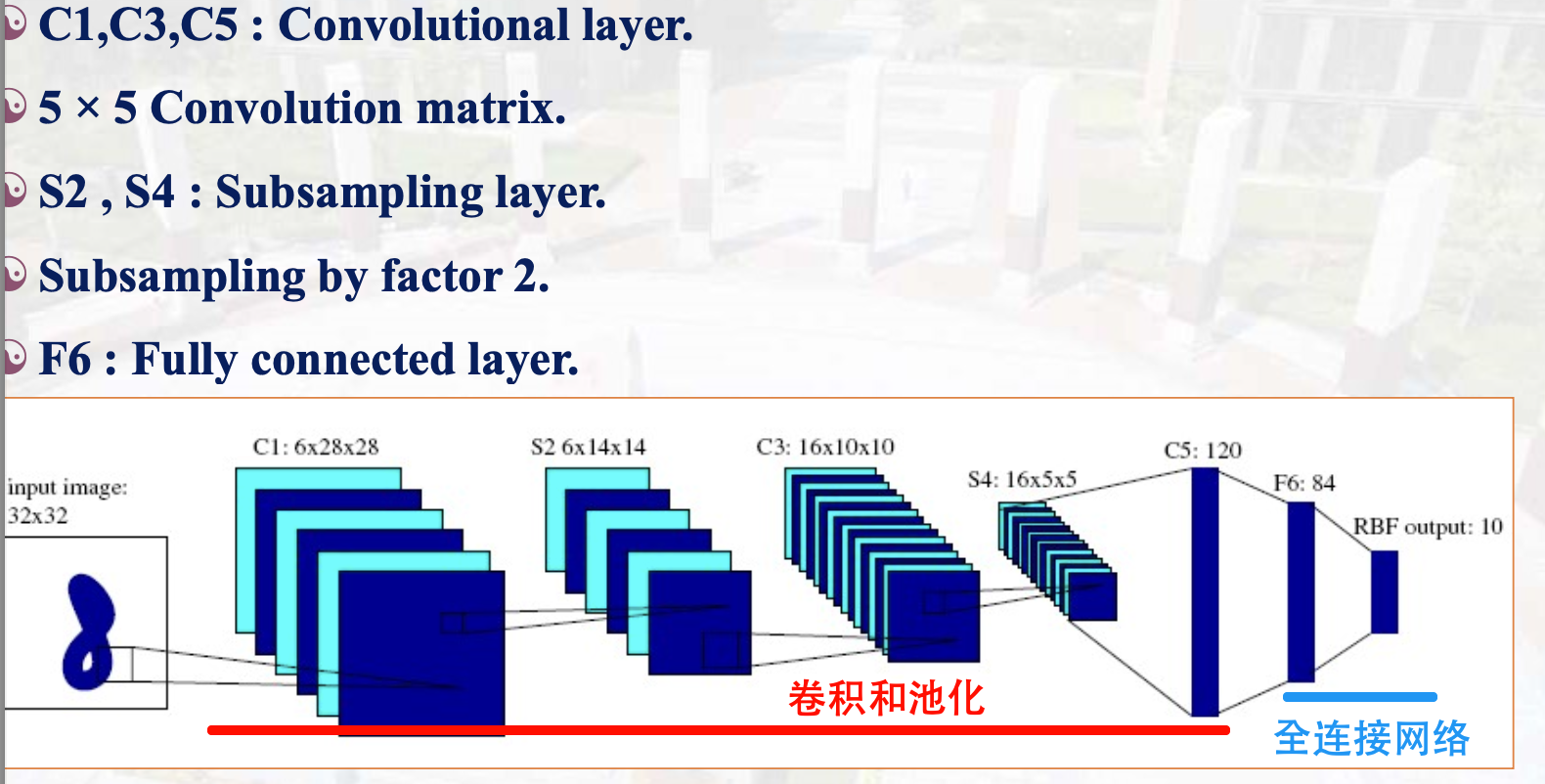
AlexNet
背景:大数据,超算
创新点:
- Dropout:过拟合
- Norm(归一化):LRN
- ReLu激活函数:梯度消失


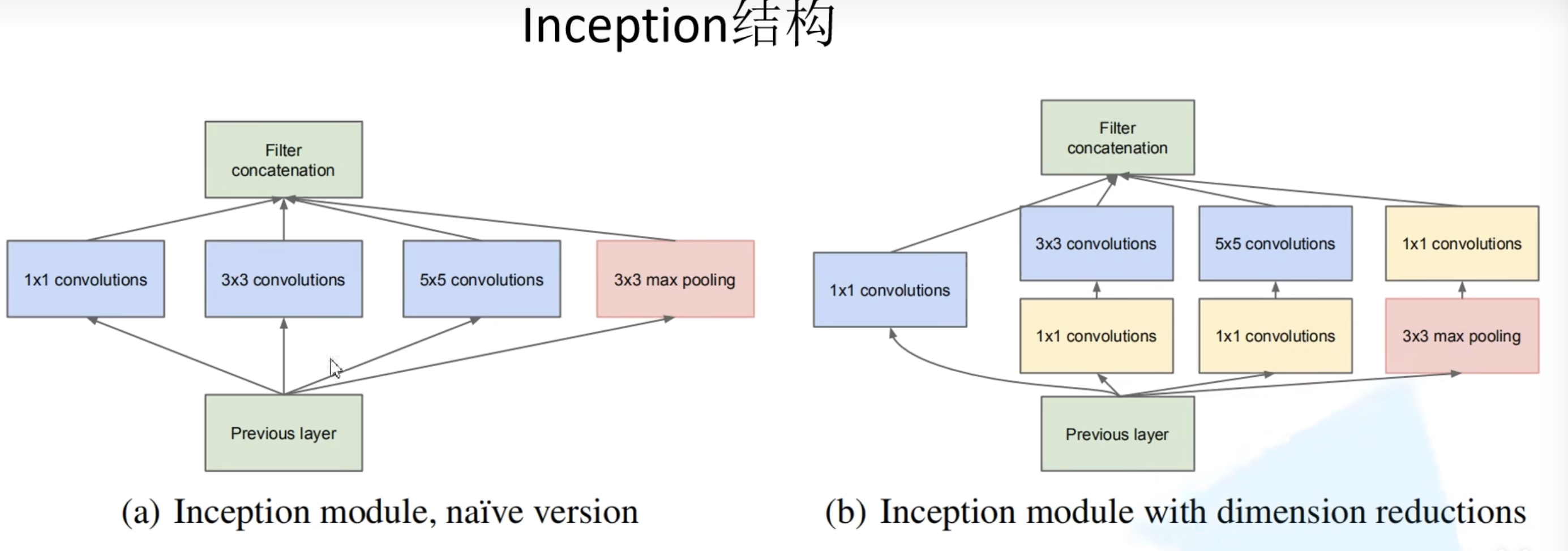
GoogleNet
创新点:
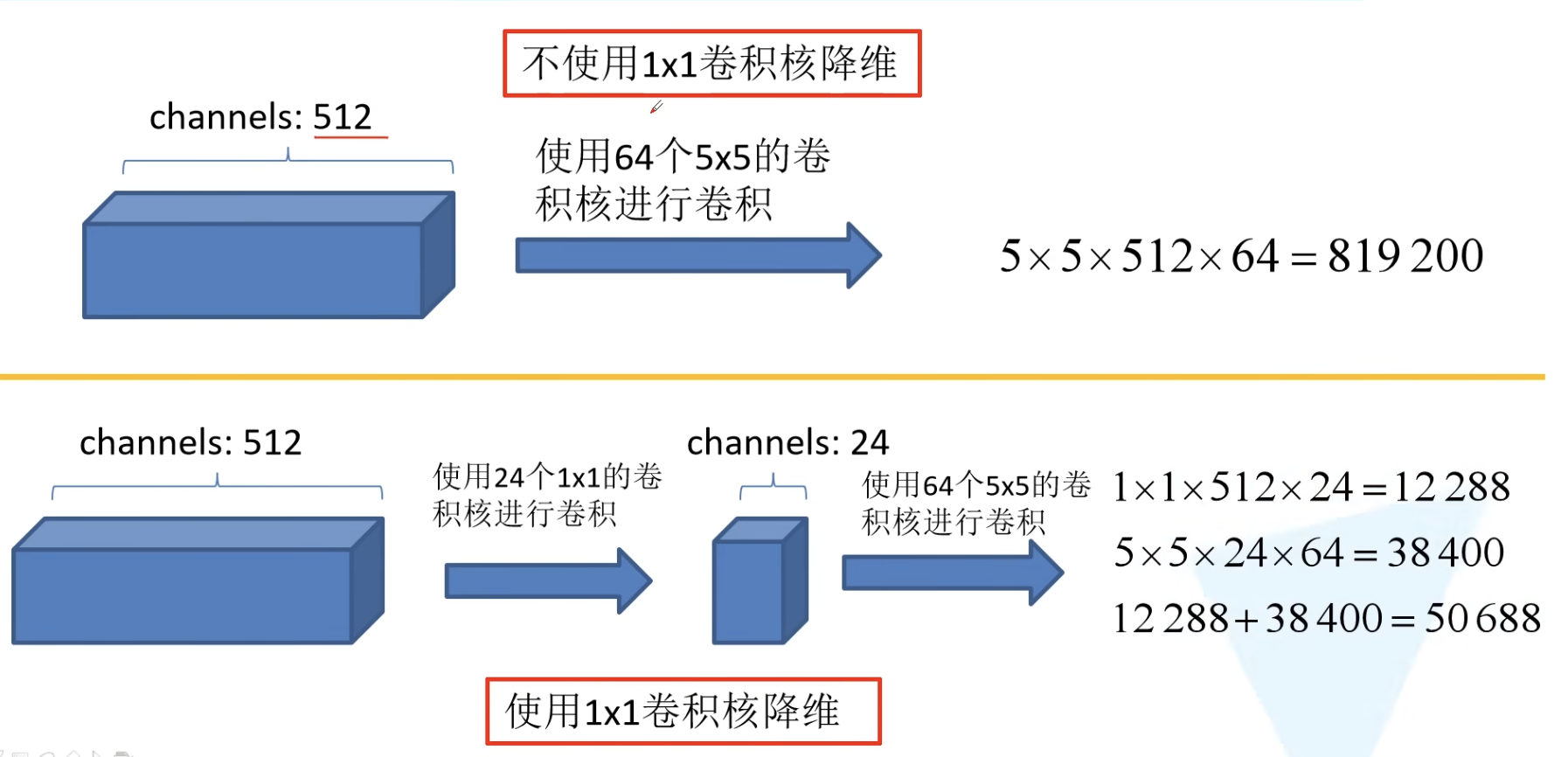
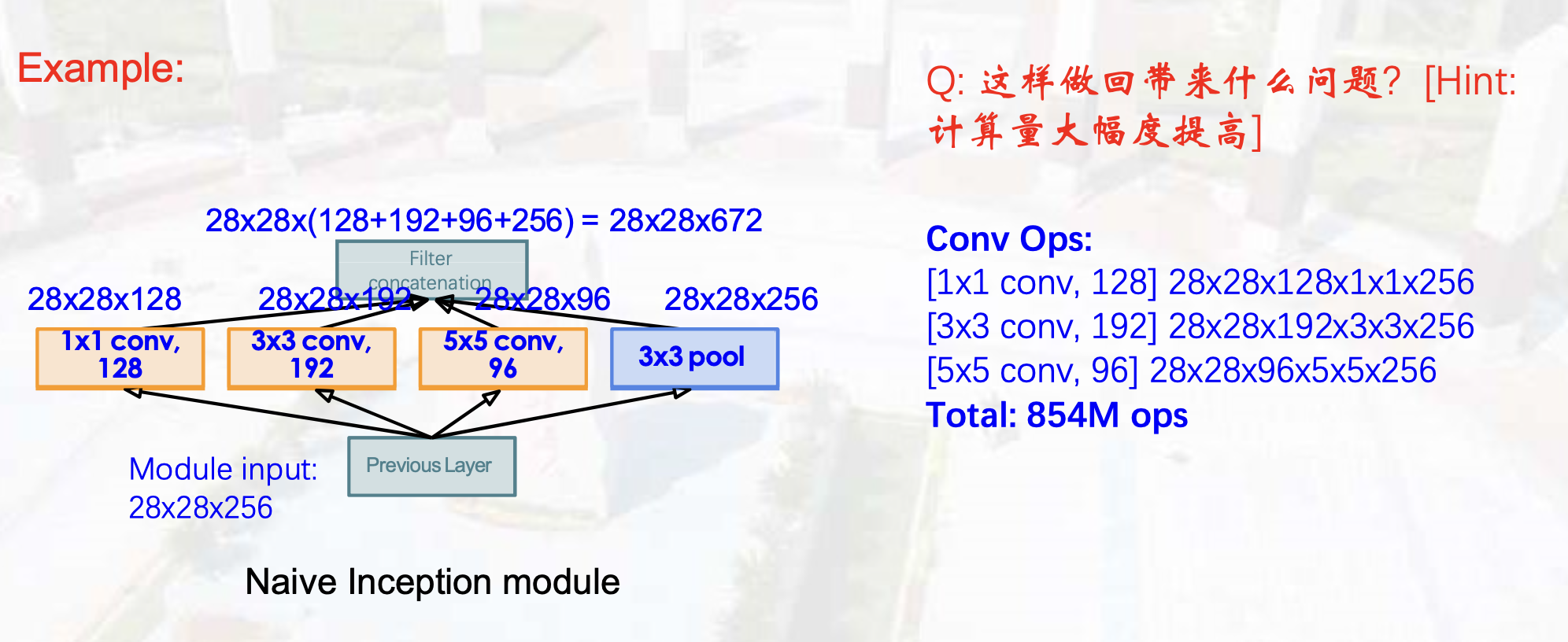
- Inception结构:并行;1*1卷积核降维
- 最左:保留初始信息
- 中间两列:不同尺度的特征提取
- 最右:池化提取
- 合并:特征图层叠拼接
- 辅助分类器
- 及时反向传播
- 决策融合
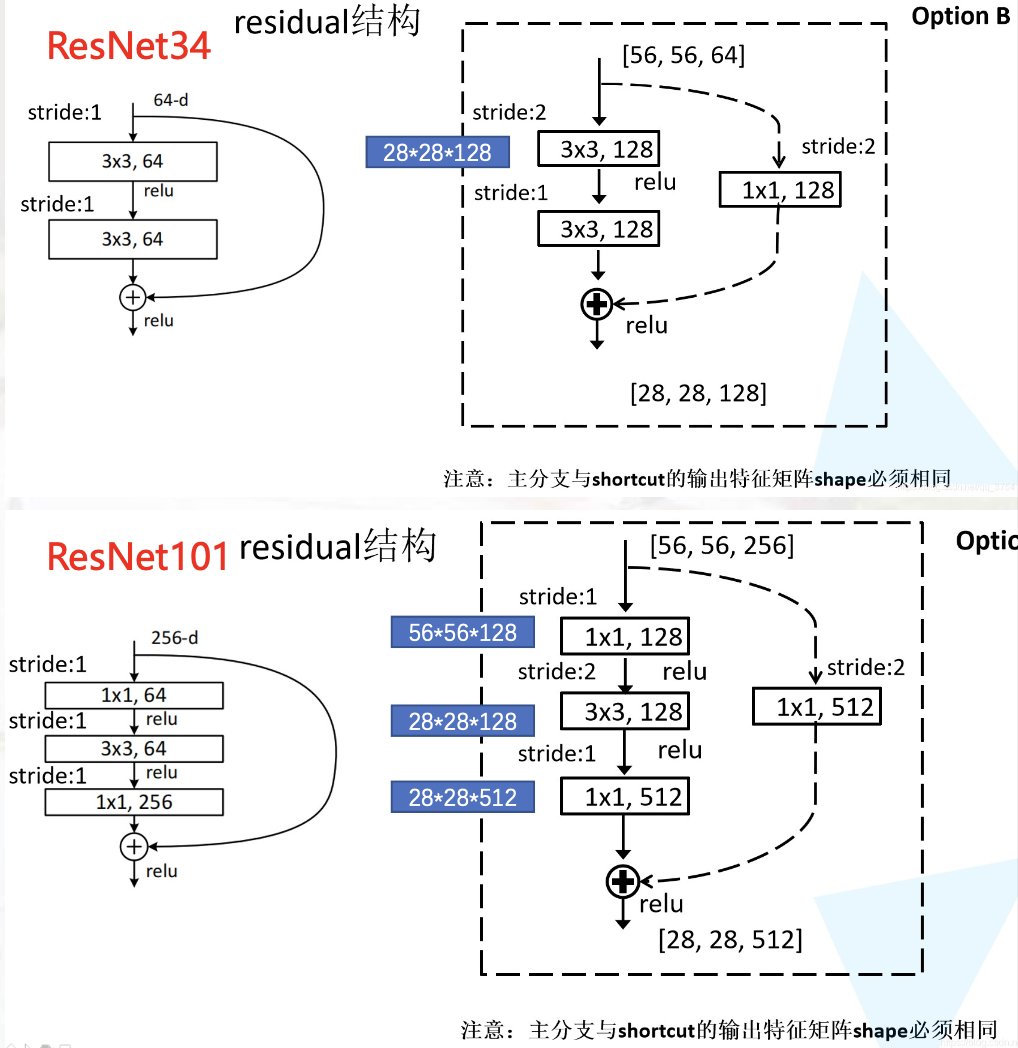
ResNet
残差(短路):保留原始特征,解决退化问题
BN(批量归一化):解决梯度消失/爆炸 (过拟合)【减均值 除方差】
DenseNet
-
DenseBlock:内部结构BottleNeck
BN + ReLU+1*1 Conv + BN + ReLU + 3*3 Conv
1*1卷积降维,先激活后卷积
-
Transation:池化,降低参数量
BN + ReLU + 1*1 Conv + 2*2 AvgPooling
-
优势:解决退化问题,进一步减少梯度消失/爆炸

\(Channel\_Size = Origin\_size + Group\_rate * Bottleneck\_num\)
循环神经网络
基本概念
解决的问题:序列数据
核心点:数据处理依赖历史数据,需要临时记忆Memory
体现:当前隐藏层的输出取决于输入和上层隐藏层输出 \(h_n = f(W_1x+W_2h_{n-1})\)
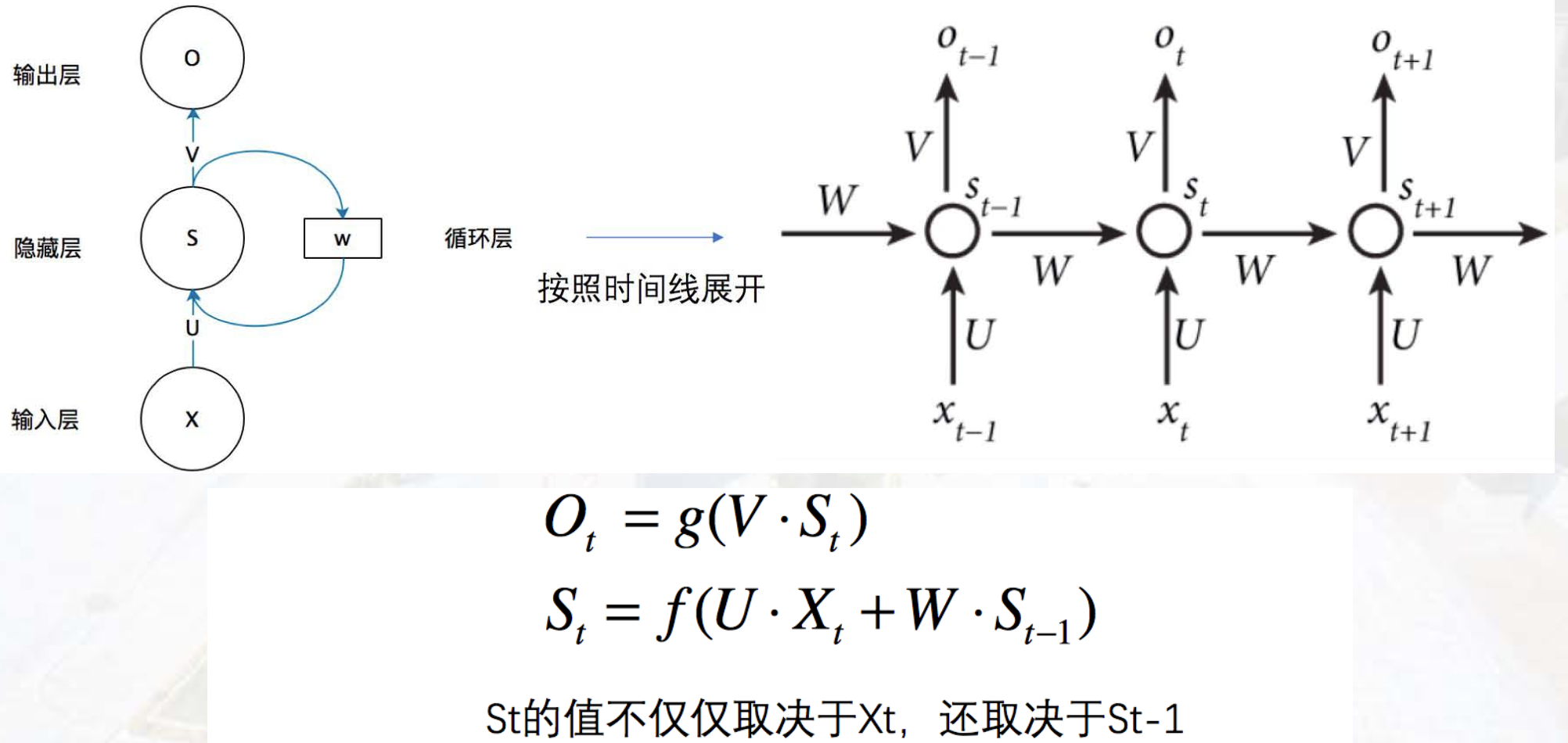
分类:
- one 2 many: Image Caption
- many 2 one: Sentiment classification
- many 2 many: machine translation
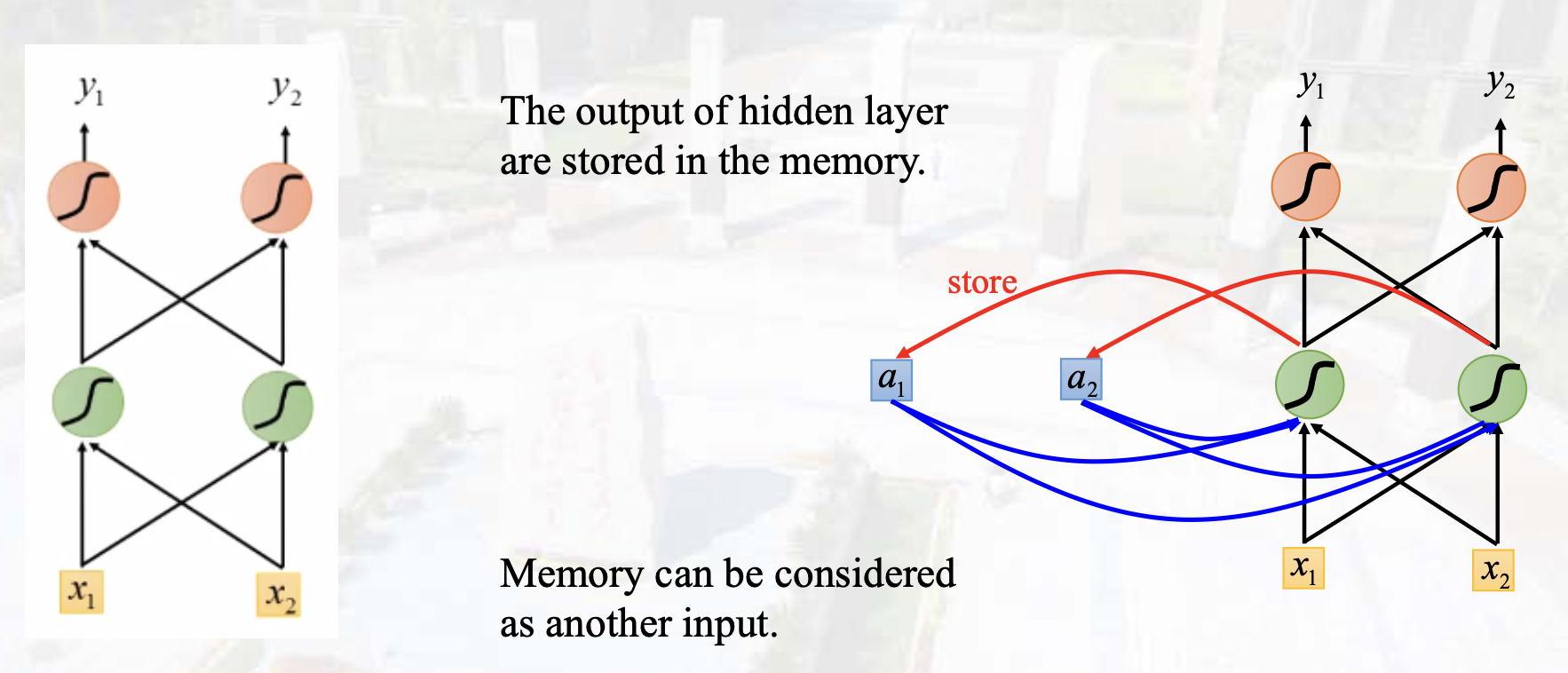
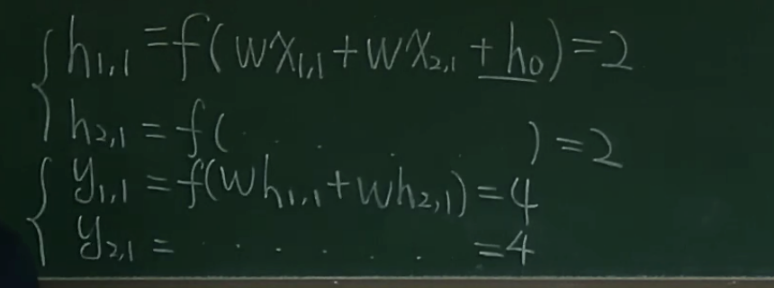
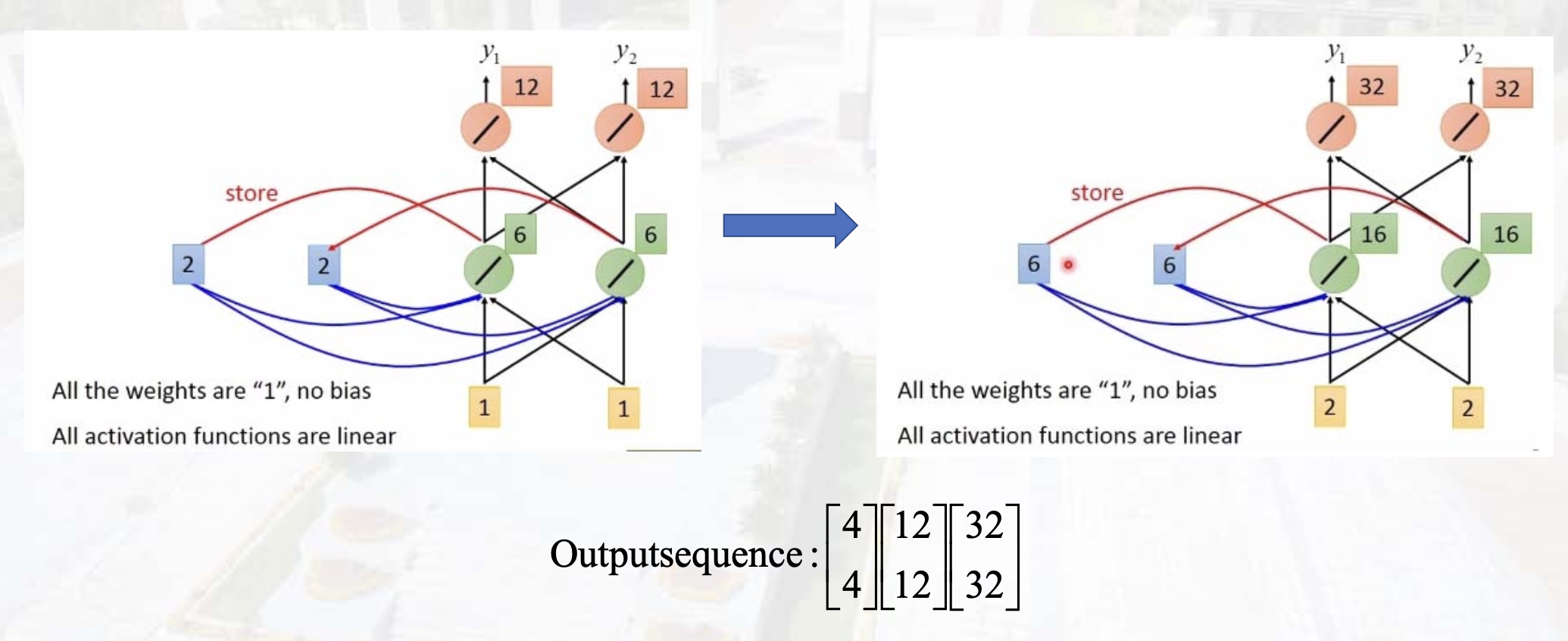
长时依赖
长程依赖问题:梯度消失/爆炸
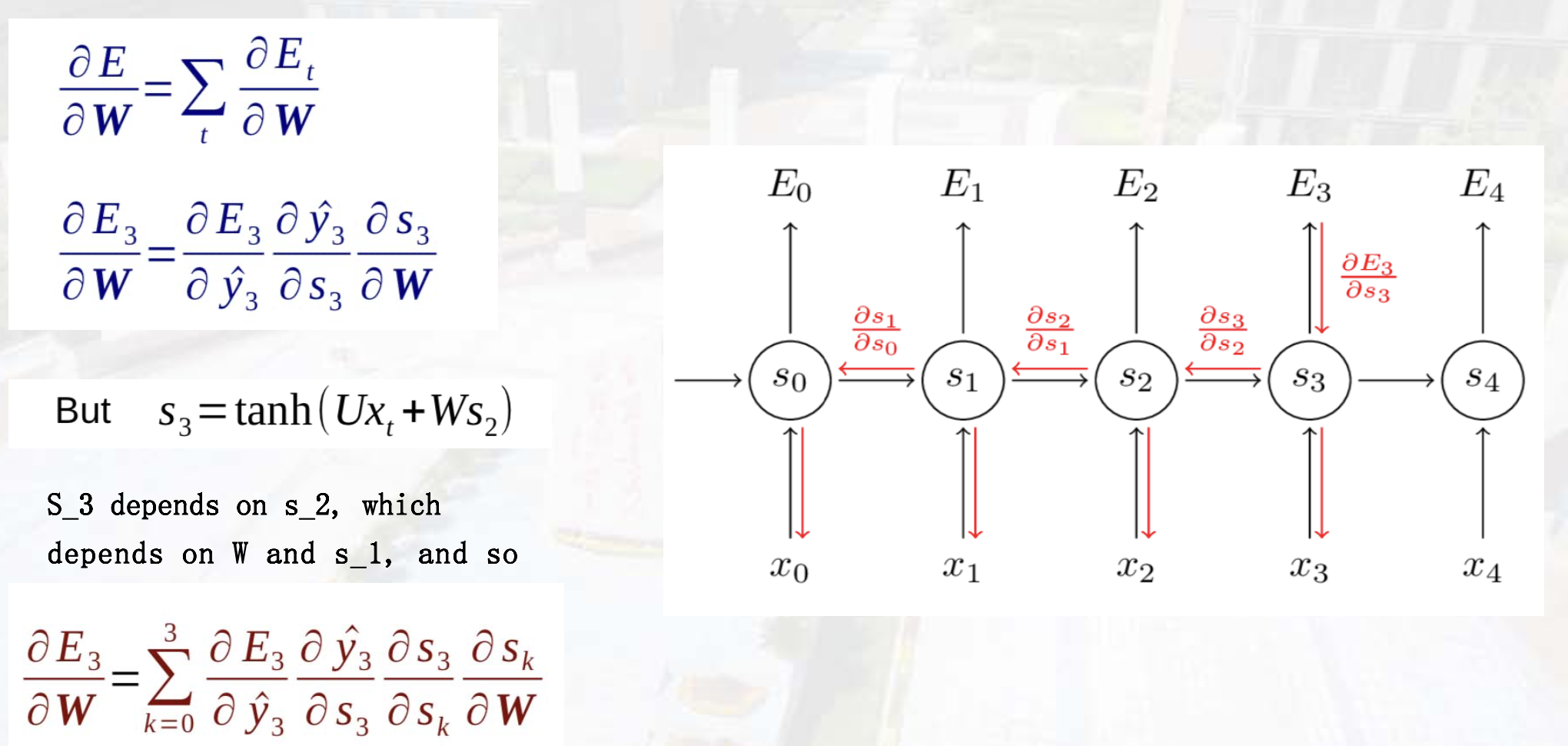
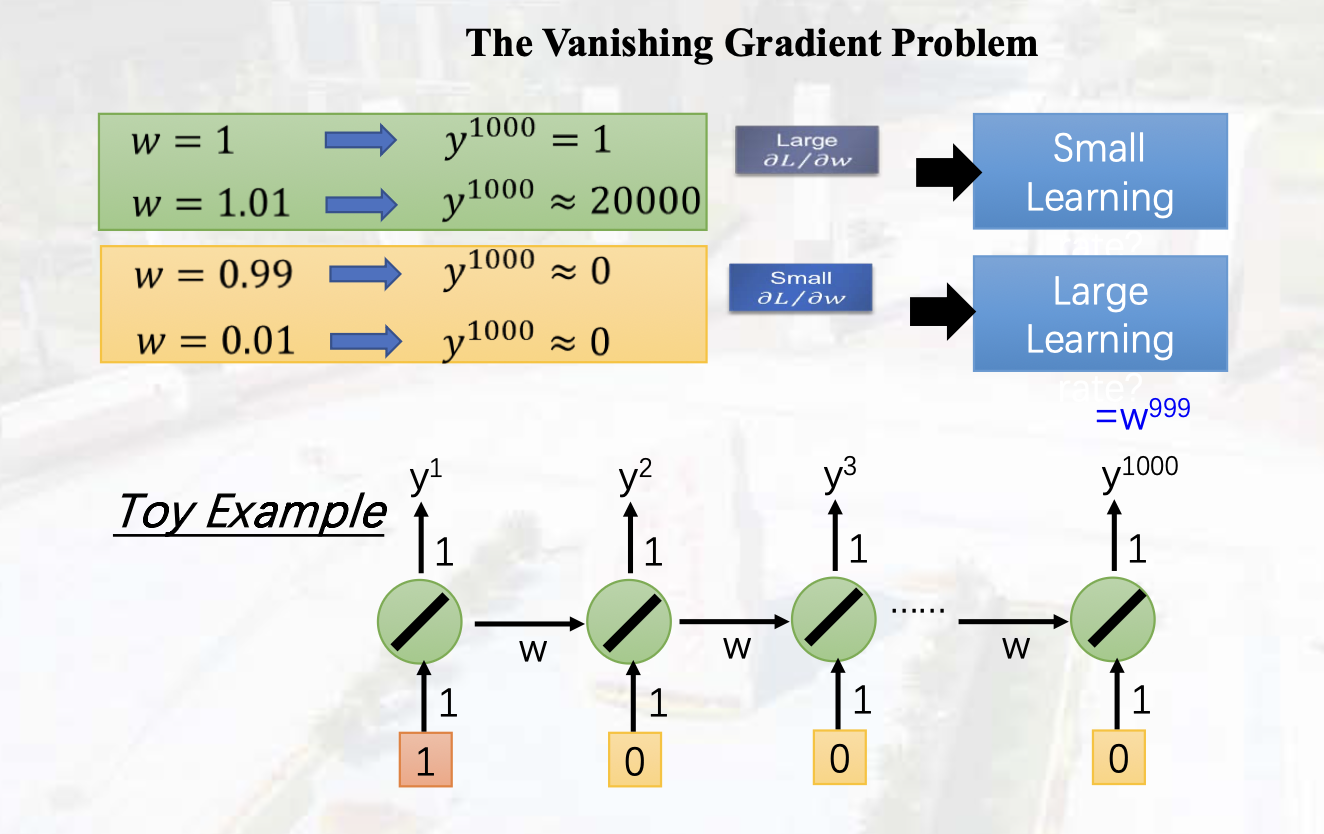
RNN模型
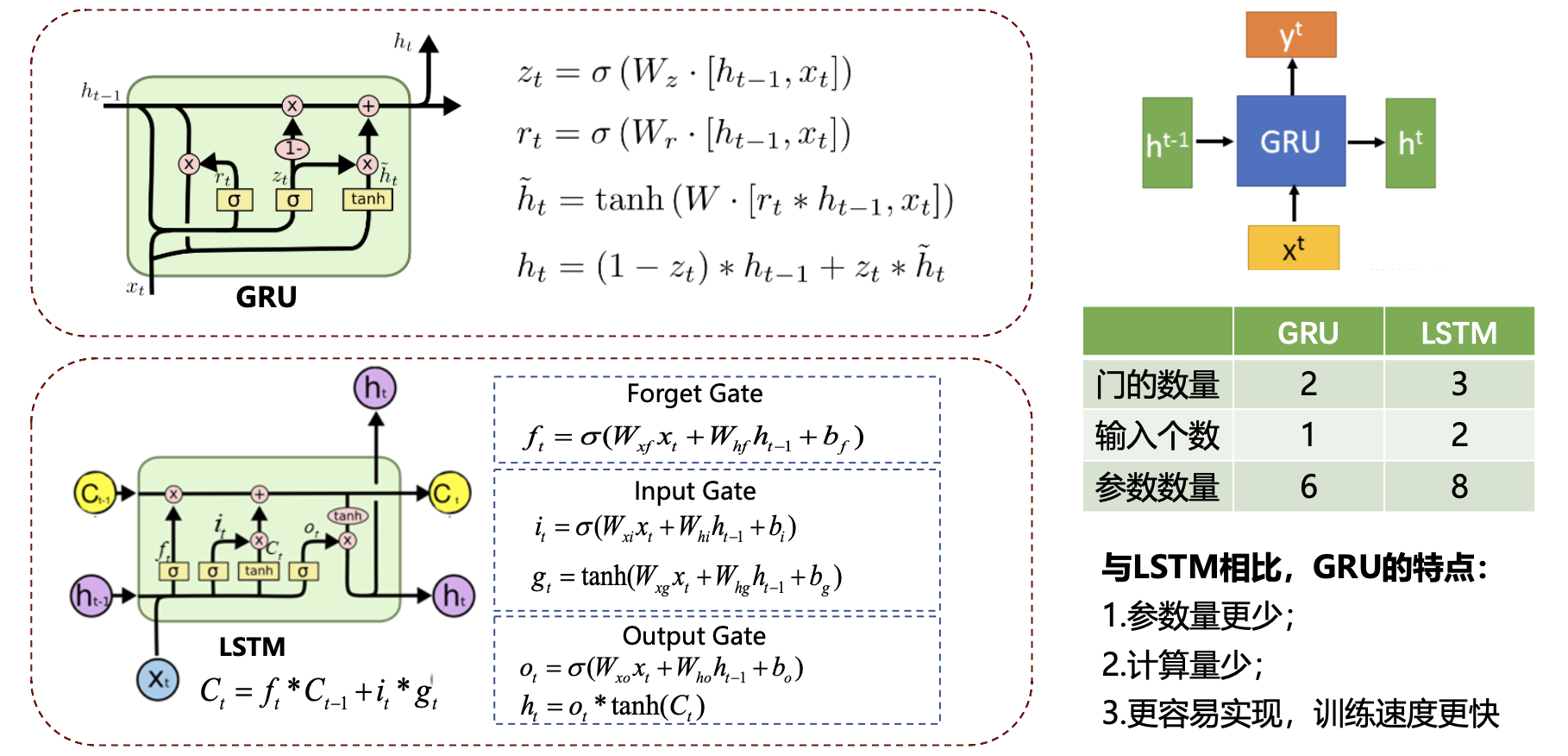
LSTM(Long Short Term Memory)
门控机制
-
Forget Gate
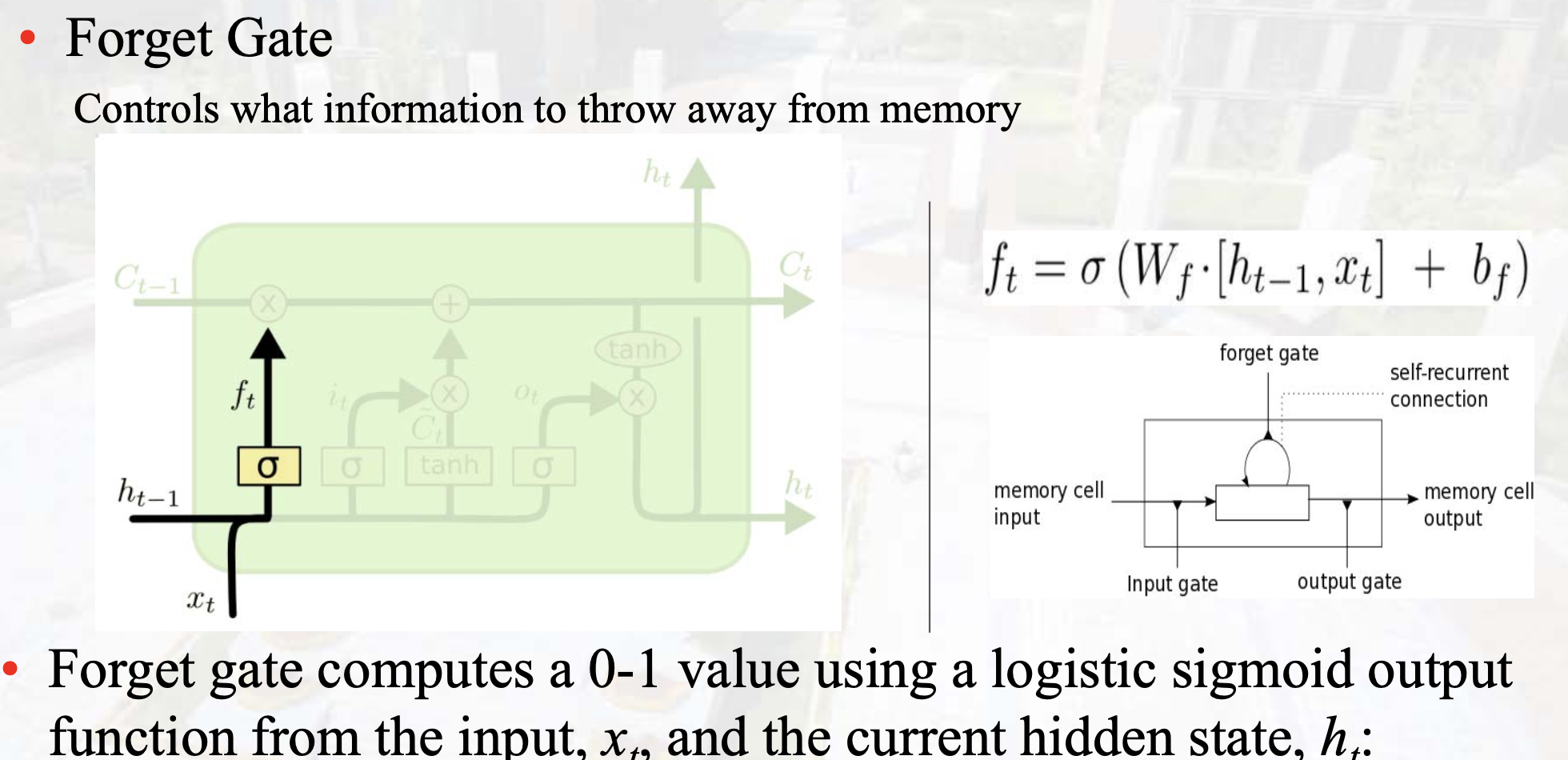
-
Inout Gate
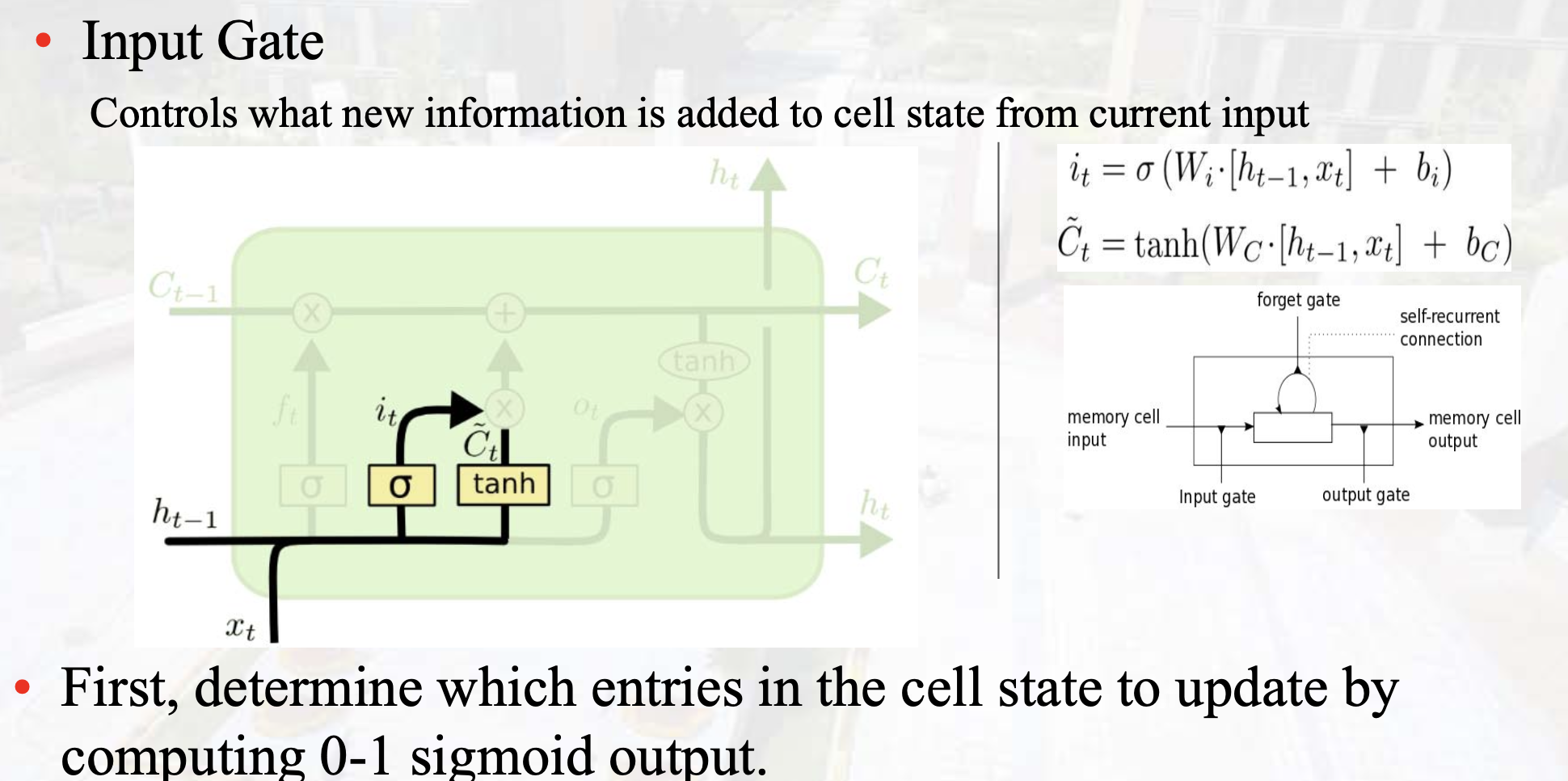
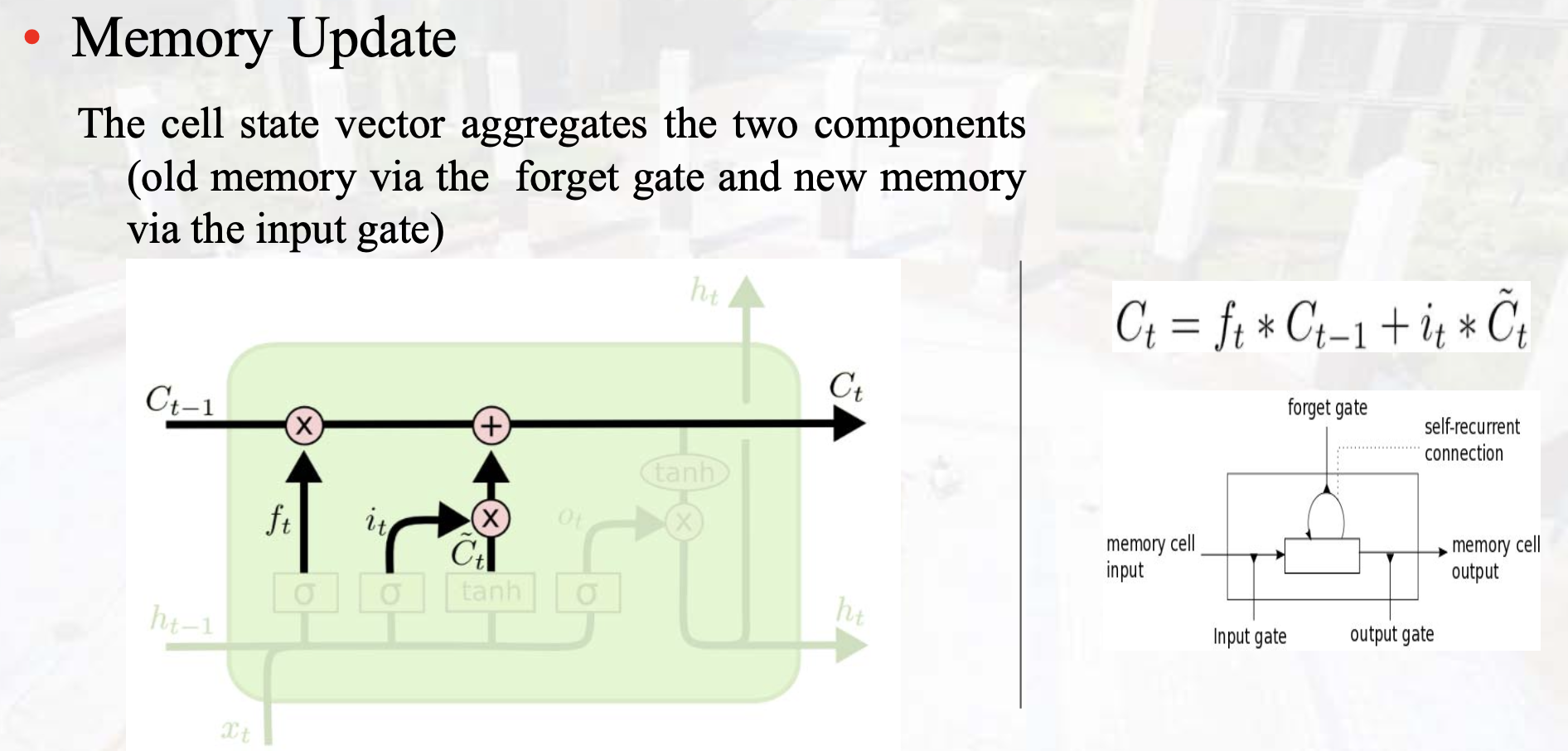
-
Output Gate
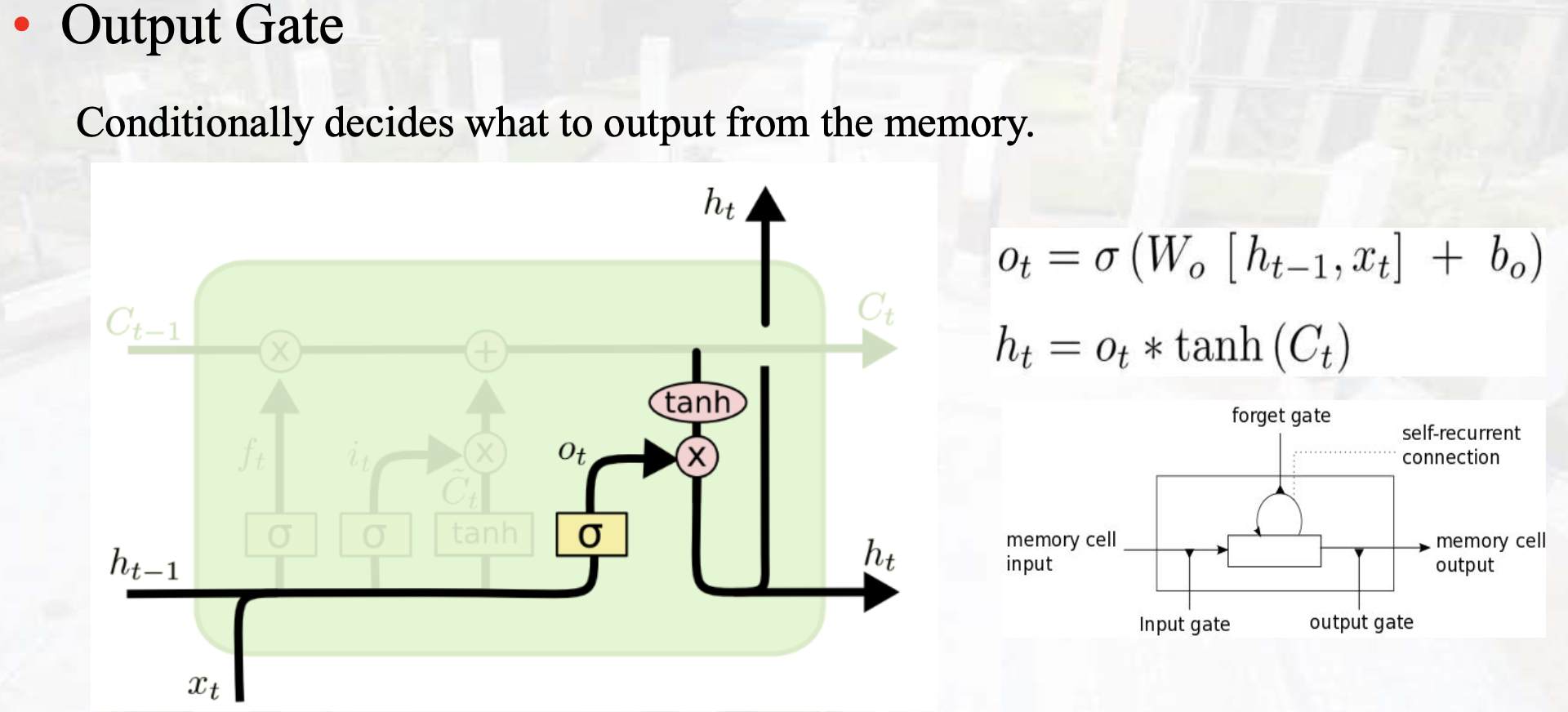
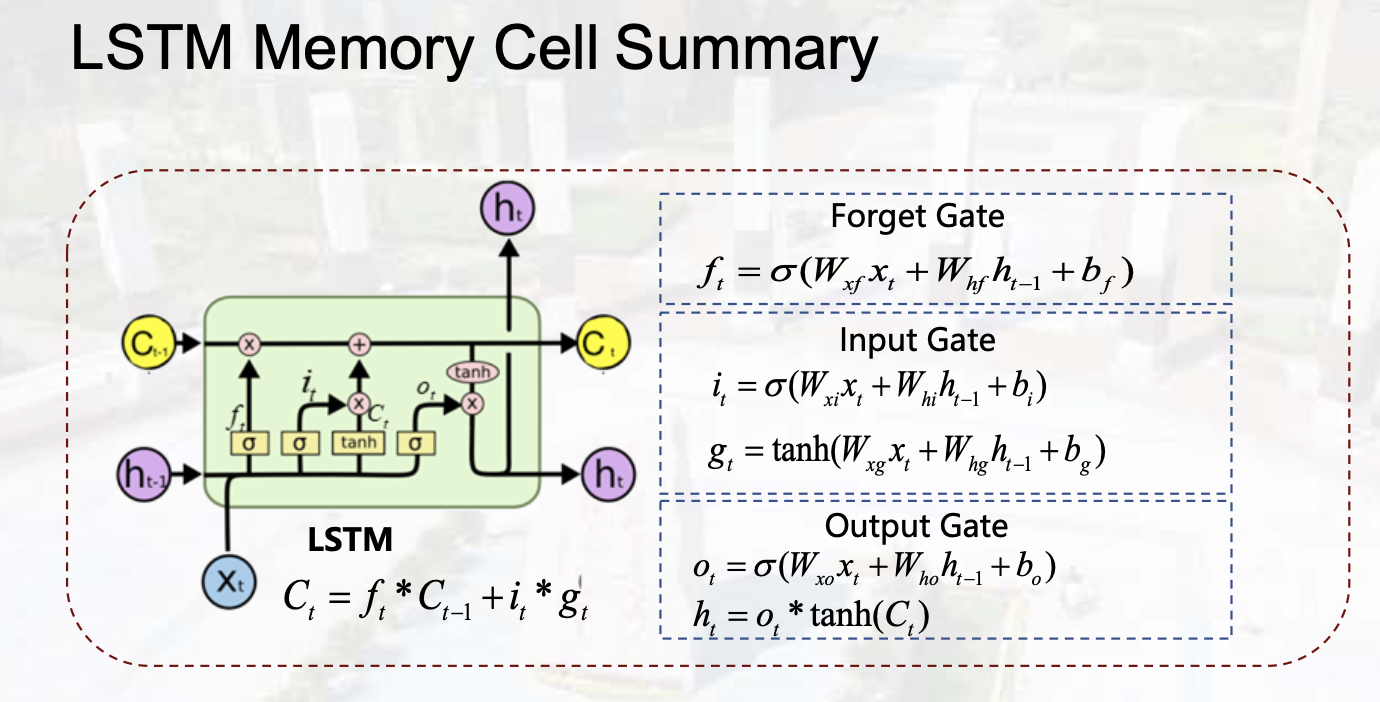
计算梯度时:部分连乘拆分成加法,减缓了梯度消失。
GRU(Gate Recurent Unit)
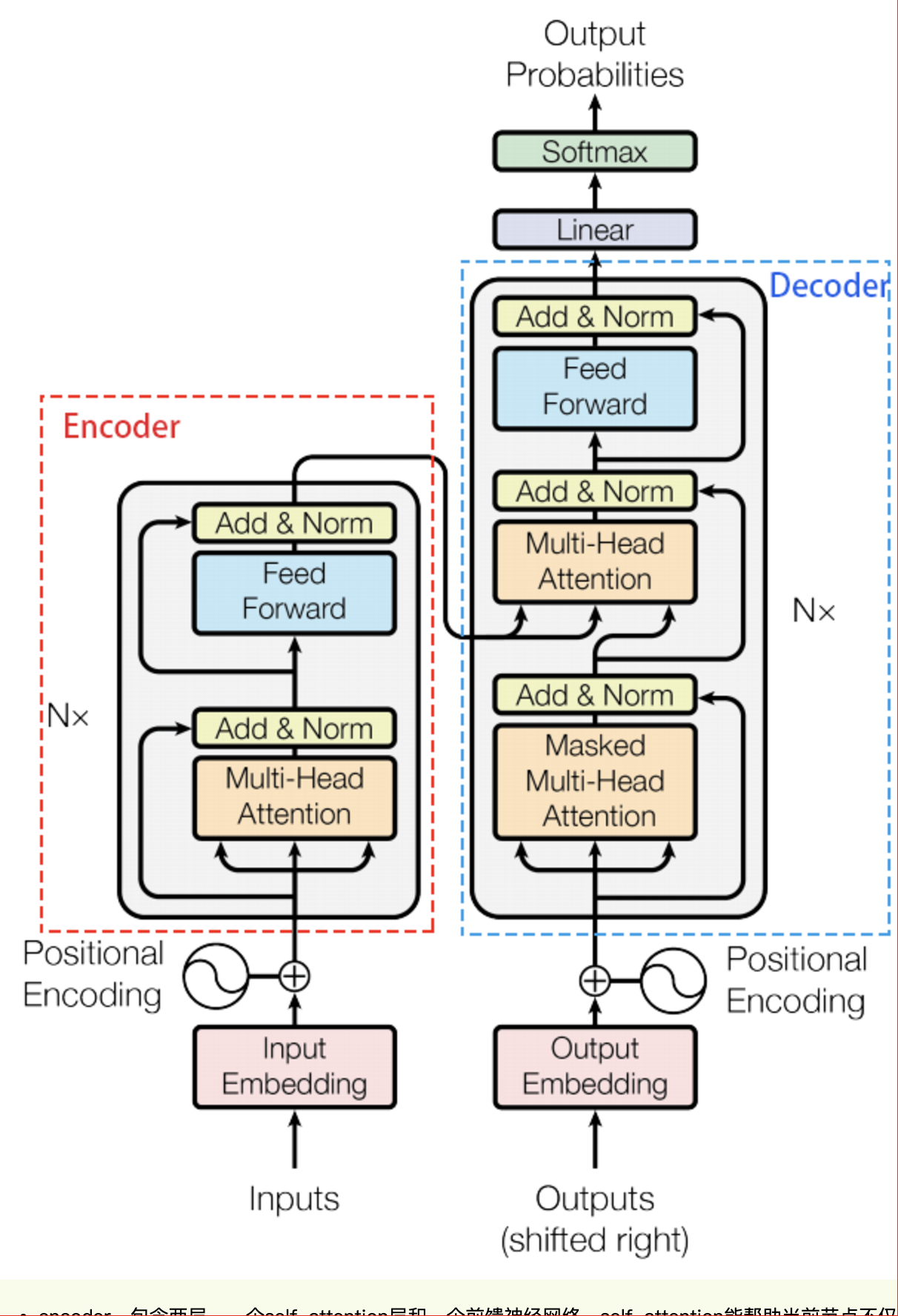
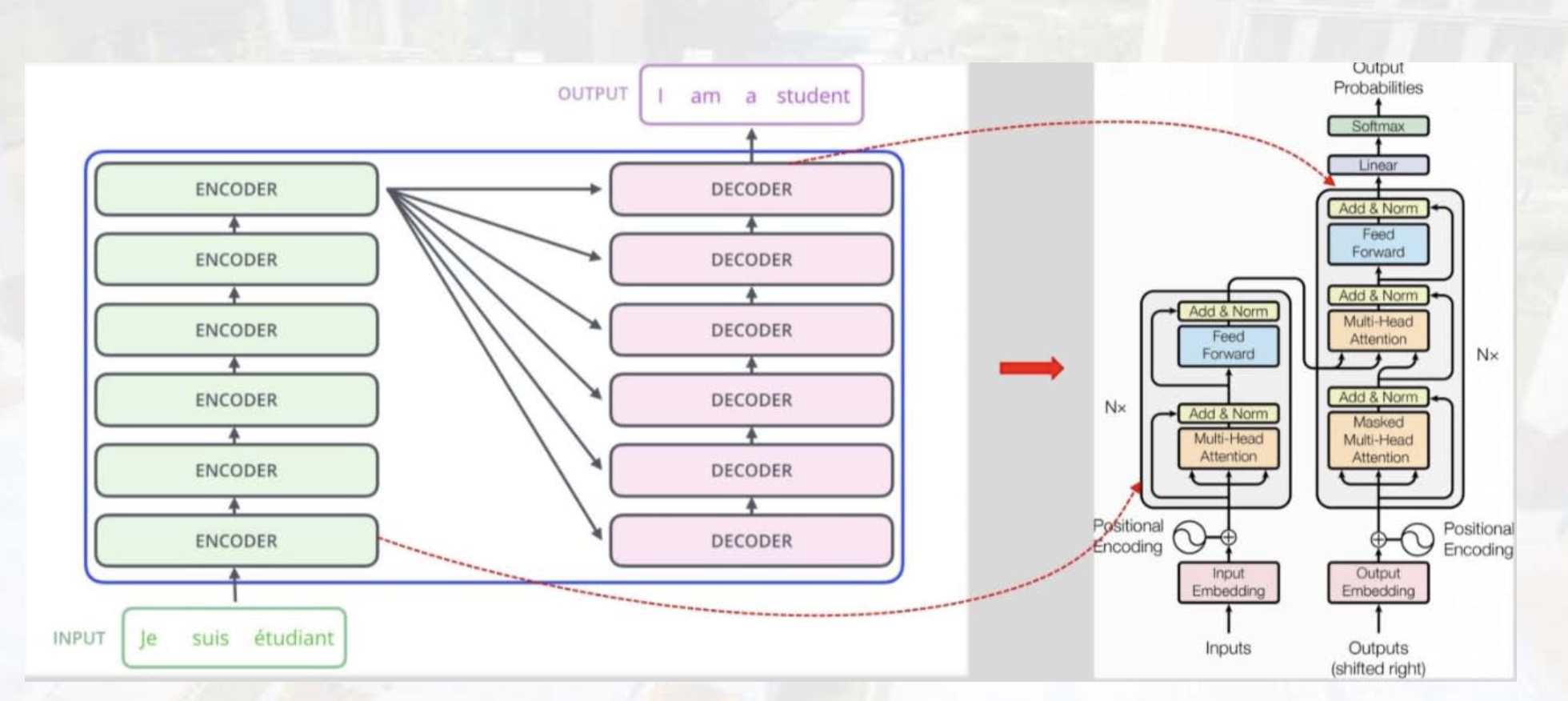
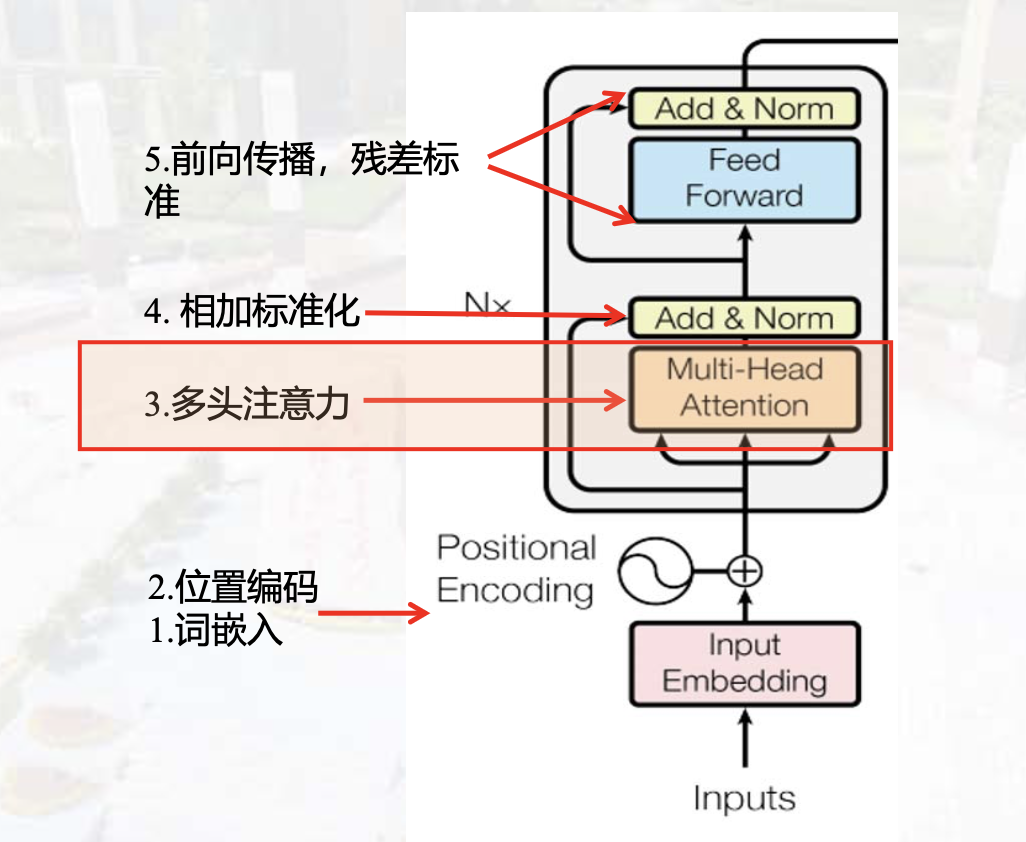
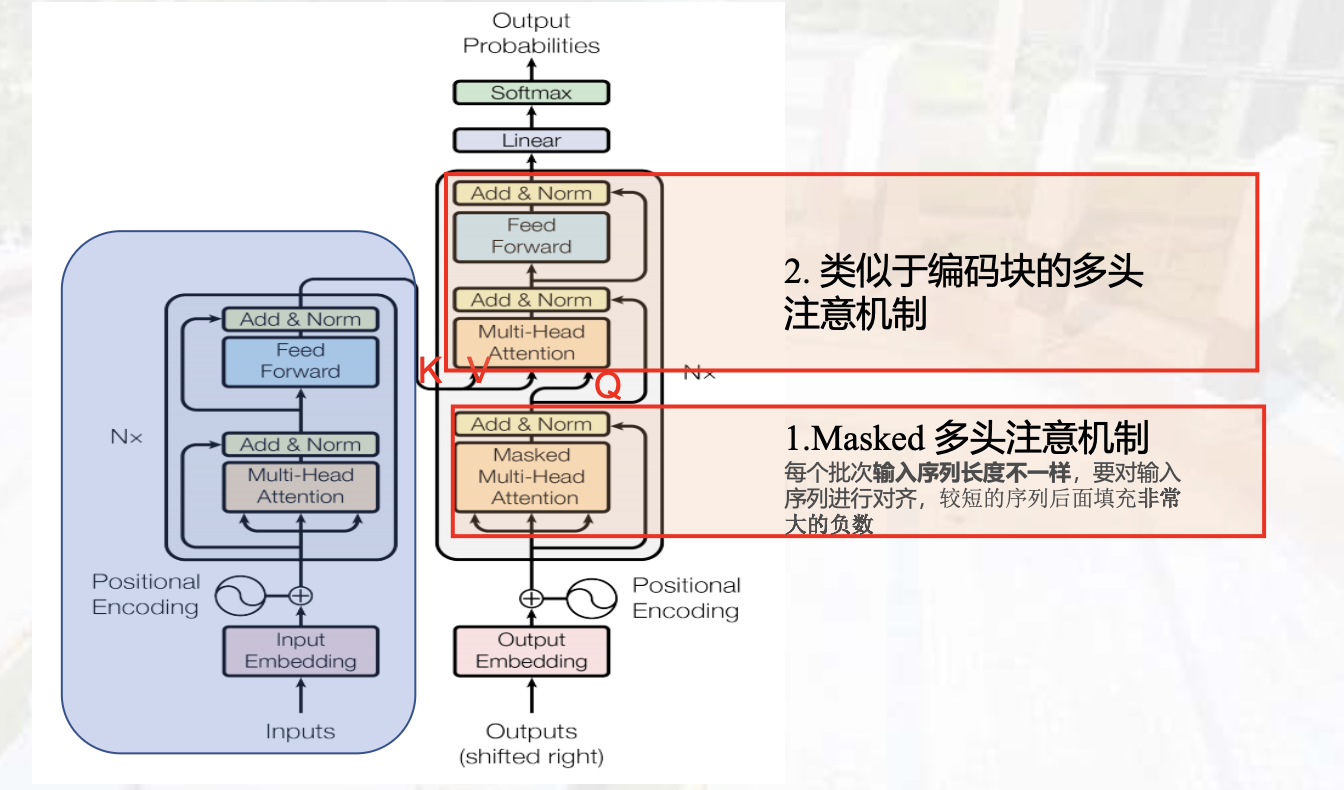
Transformer
- Encoder (Context) :Self-Attension
- Decoder
结构:
- 完全依赖注意力机制来刻画各个单词间的全局依赖关系
- 利用类似残差结构有效的防止梯度消失的问题
- 在自然语言处理中单词的输入是并行的,大大加快了计算效率
Attention:数学上即为权重
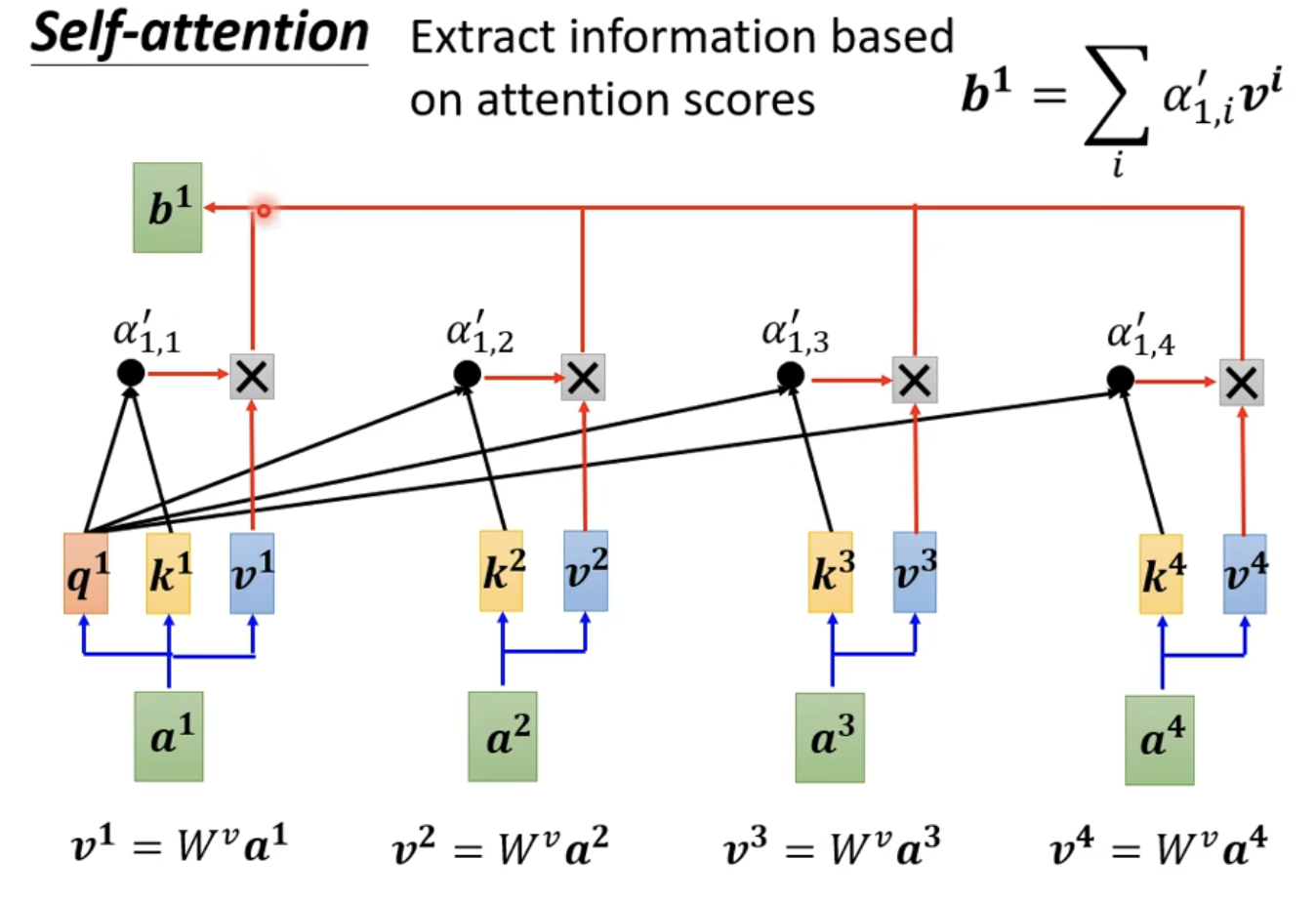
多头注意力:
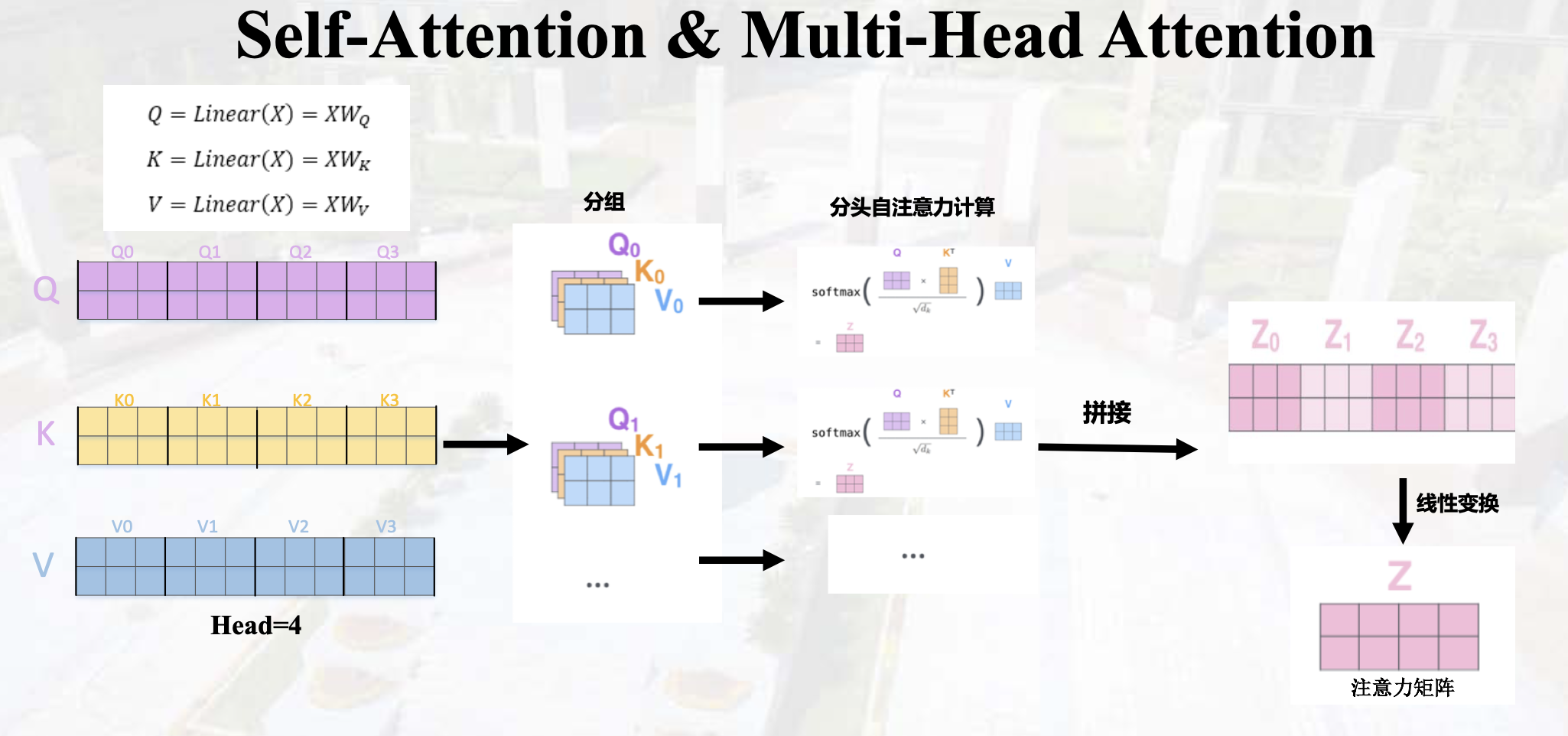
Bert
堆叠的Transformer Encoder,进行MLM和NSP任务。

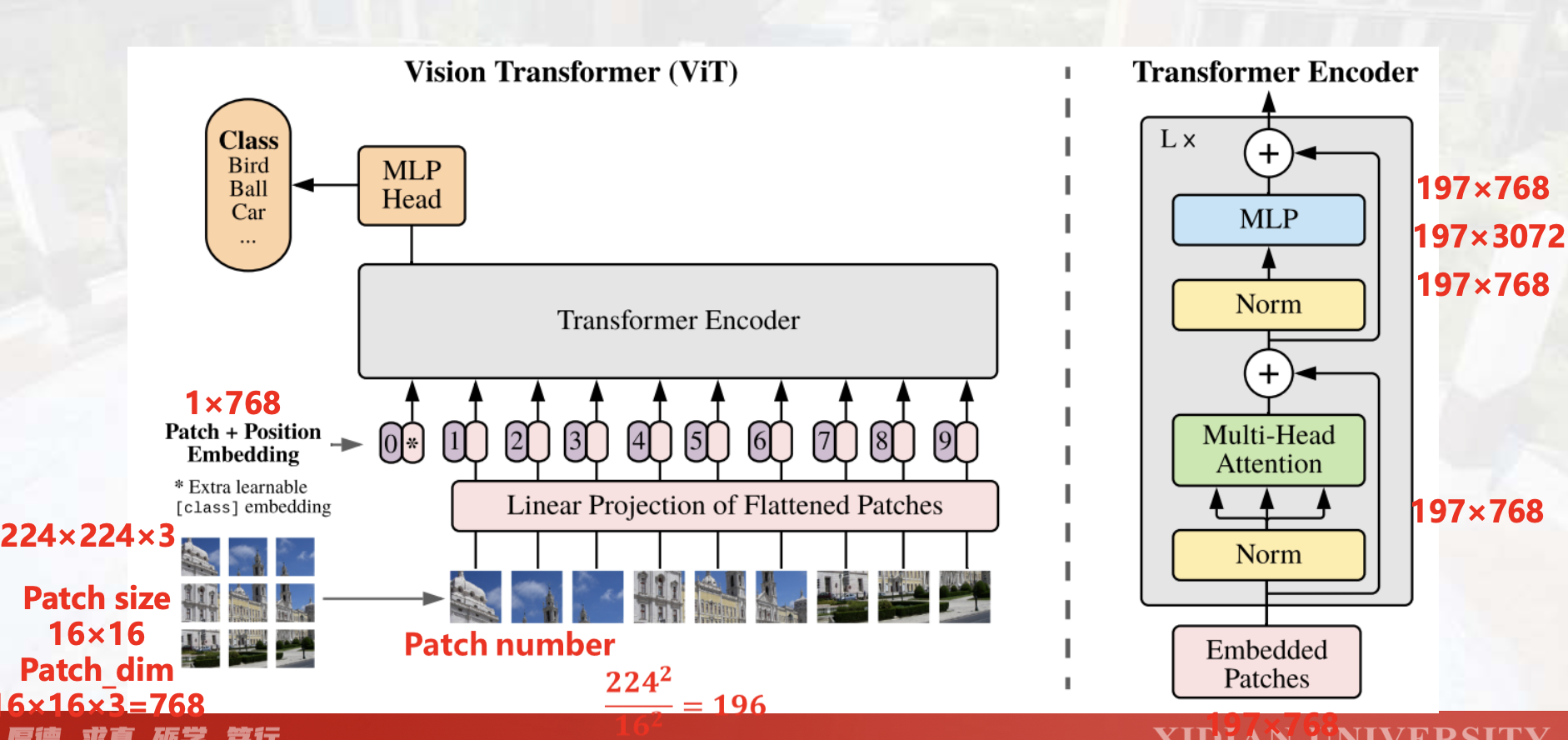
VIT
用Transformer处理图片:核心问题是怎么转为文字形式。
图像分块,Patch Embedding,位置编码 => token => encoder


 浙公网安备 33010602011771号
浙公网安备 33010602011771号