cmu15545笔记-WAL和数据库恢复
总览
该笔记包含了原课程中关于数据库恢复的两节课的内容:
- 数据库日志(Database Logging)
- 数据库恢复(Database Recovery)
数据库的事务并发控制保障了数据库在正常运行时的原子性,隔离性和一致性,但是当数据库在执行事务过程中宕机了,导致事务无法正常执行时,该怎么办呢?
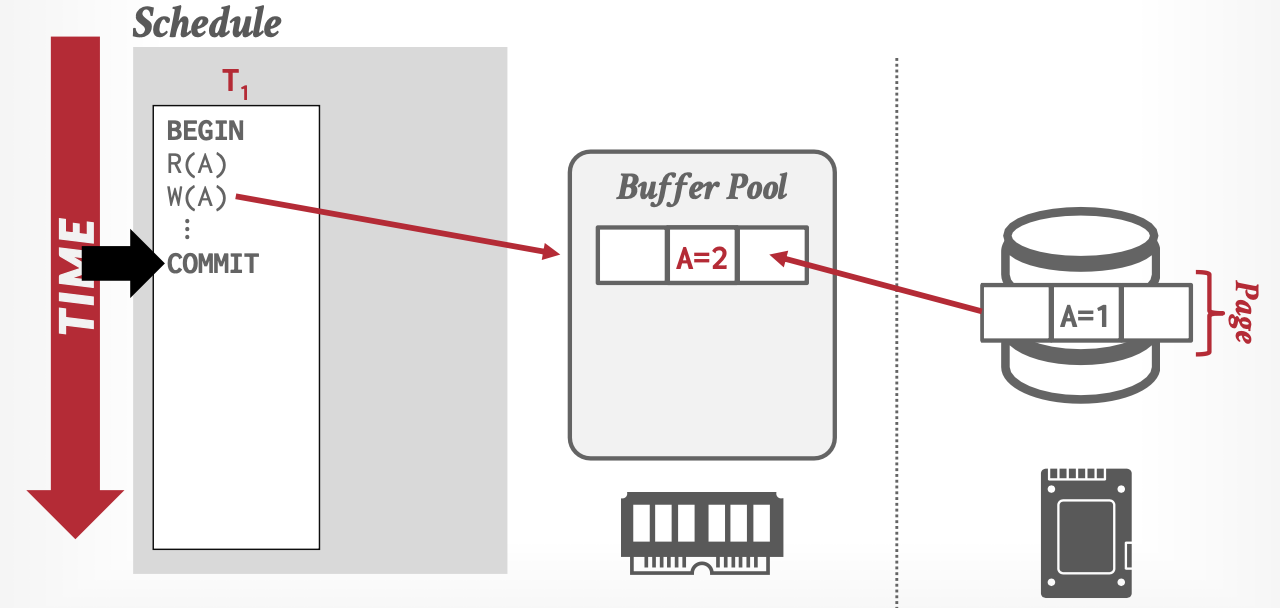
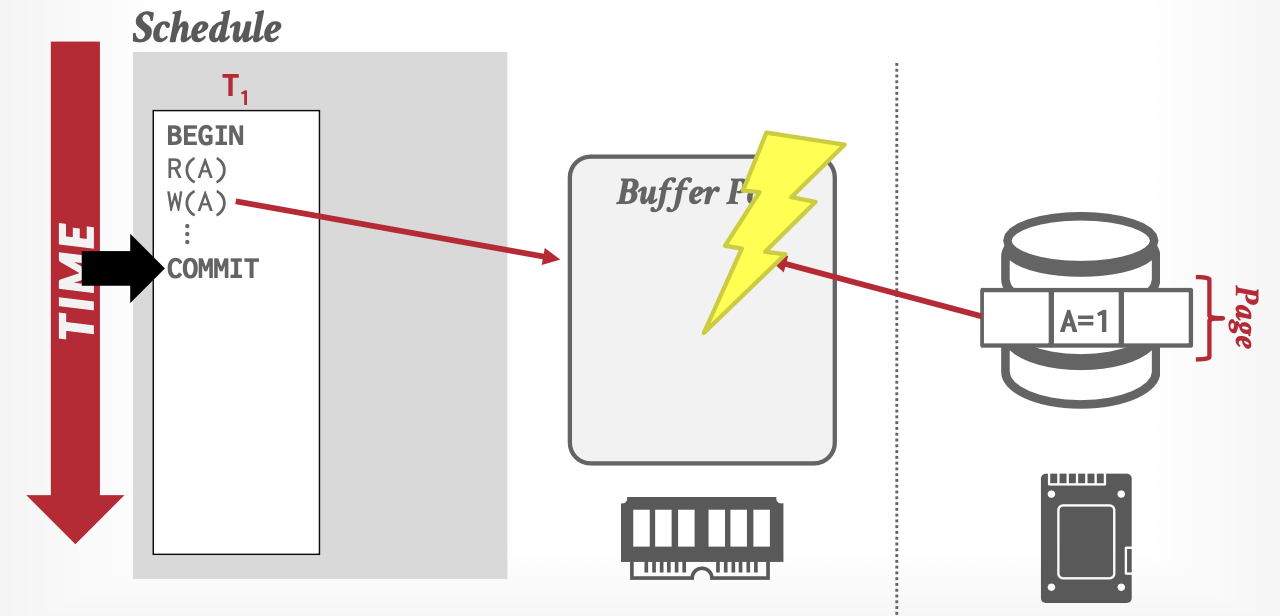
此时就需要数据库的恢复机制,来保障异常时,事务的原子性和持久化,而恢复机制的核心思想就是日志(Logging)。
日志包括Redo日志和Undo日志,分别用来重做数据库宕机前已经提交的日志,和撤销未提交的日志。
恢复机制分为两个部分:
- 事务执行过程中,如何记录日志,确保可以从宕机中恢复。
- 宕机后,怎么利用日志恢复到满足一致性的状态,主要采用ARIES算法。
缓存策略(Buffer Pool Policies)
会有数据库恢复问题,根本原因是为了利用内存更新快的特性,数据库的缓冲区和磁盘数据没有立刻同步,导致数据不一致。
因此,在介绍数据库日志之前,有必要先了解不同的缓存策略,会给数据库恢复问题早餐哪些影响。
- Steal和No-Steal:是否刷脏
- Force和No-Force:事务结束后是否先写回磁盘再提交成功
Shadow Paging(No-Steal + Force)
不需要恢复策略。
- Master Pointer:指向当前使用的缓冲区
- 开启时:复制一个缓冲区,缓冲区指向元数据
- 更新数据时:磁盘上复制元数据,然后对应缓冲区指向新数据
- 提交时:将Master Pointer指向新缓冲区
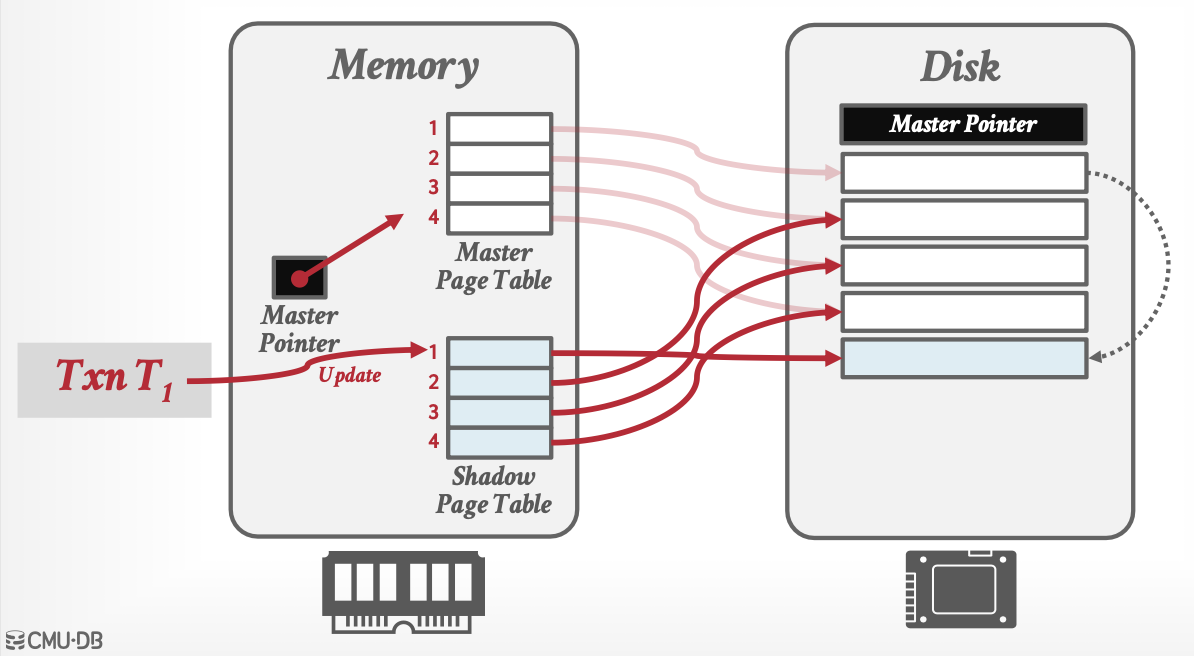
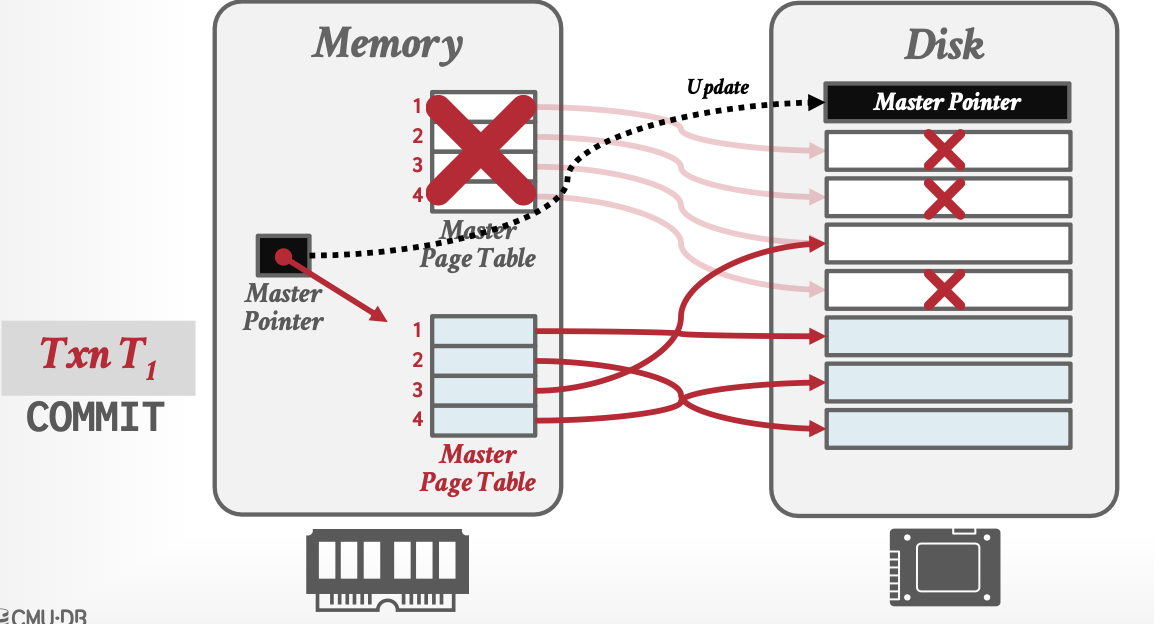
Redo:不需要,因为Force保证只要提交成功,就已经刷盘。
Undo:不需要,No-Steal保证没有提交的事务不会写入磁盘,所以把内存中的无用缓冲区清理掉即可。
SQLite Rollback Mode(Steal + Force)
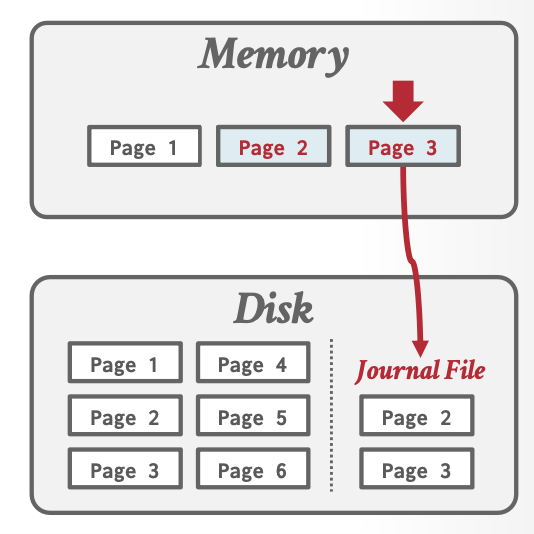
在修改数据之前,要先把原数据写入磁盘中(SQLite 称为 Journal File)。
- 开启时:创建空Journal File
- 更新数据时:先把元数据写入Journal File,再更新缓冲区数据
- 提交时:删除Journal File,数据落盘
Redo:不需要。
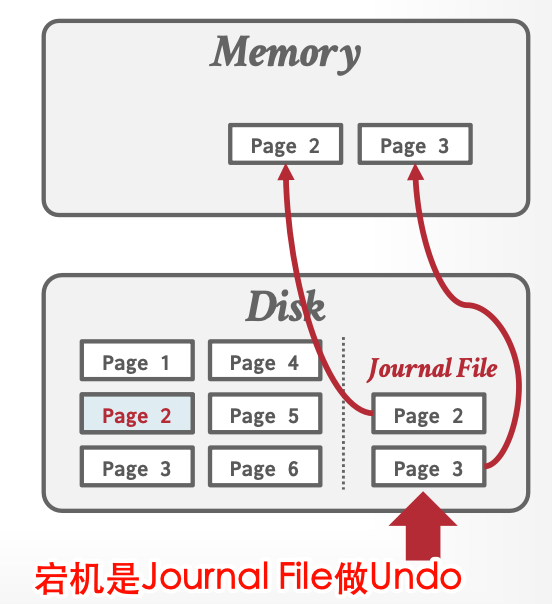
Undo:检查是否有Journal File,有则重新写入磁盘即可。
总结
Steal需要做Undo,No-Force需要做Redo。
No-Steal+Force不需要额外恢复措施,但是性能弱。
Steal+No-Force需要Redo+Undo恢复手段,但是性能高。
大多数数据库都是 Steal+No-Force。

WAL(Write-Head Log)
基本思想
更新数据的时候同步添加数据修改日志,事务返回成功前保证日志已经落盘。
日志结构:
<BEGIN>:事务开始<LSN, preLSN, TxnId, Type, ObjectId, Before Value, End Value, UndoNextLSN>- TxnId和ObjectId记录事务和对象信息
- Before Value用于Undo,After Value用于Redo。
- LSN见后文描述
<Commit>:事务提交
如果使用Append-Only型MVCC可以不需要Before Value。
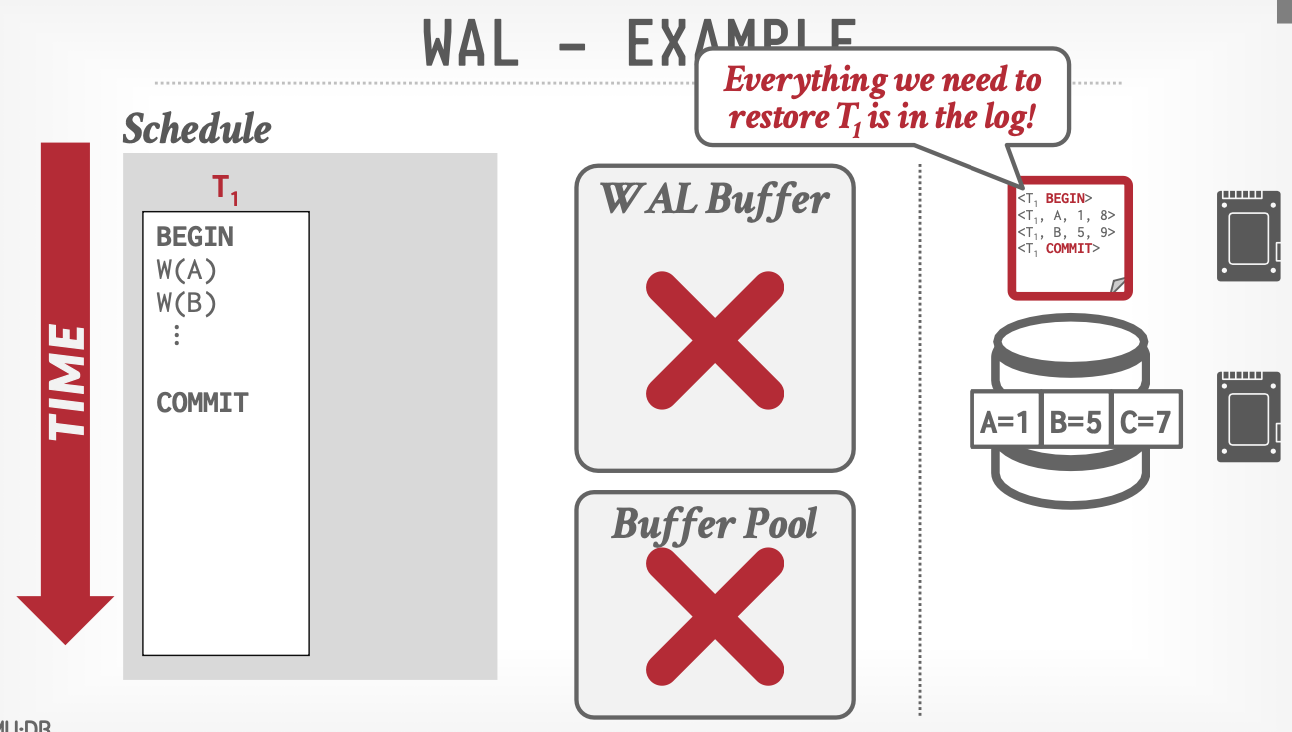
怎么区分要做Redo还是Undo:事务是否提交。未提交做Undo,提交了做Redo。
从哪里开始做Redo和Undo:检查点Check Point。保存点之前到日志都已经刷盘,恢复时只需要对保存点之后到日志做Redo和Undo。
Group Commit优化:日志缓冲区满了或者到一定时限(e.g. 5ms),将日志缓冲区落盘,而不是每次事务提交都落盘,以此减少IO次数。
日志格式 (Log Schemes)
| 形式 | 优点 | 缺点 | |
|---|---|---|---|
| 物理日志(Physical Log) | 字节变动记录日志 | 恢复快 | 日志大 |
| 逻辑日志(Logical Log) | 一般是SQL语句 | 日志小 | 每次执行结果不一定一致(如时间和随机数函数,并发访问性问题) |
| 物理逻辑日志(Phylogical Log) | PageId + Slot Number "Physical-to-a-page, logical-within-a-page" |
- | - |
Phylogical Log是一种折中,现在大多数数据库都采用这种形式。

检查点(Check Point)
减少数据恢复时的数据写回量,将全量恢复变成增量恢复,加快恢复速度。
步骤如下:
- 停滞所有查询
- 将WAL记录刷盘
- 将脏页刷盘
- 将
<CheckPoint>写入WAL并刷盘 - 恢复查询
将CheckPoint作为恢复时日志分析的起点:CheckPoint后提交的事务做Redo,未提交的做Undo。

ARIES算法
基本思想:WAL;Undo时记录撤销日志。

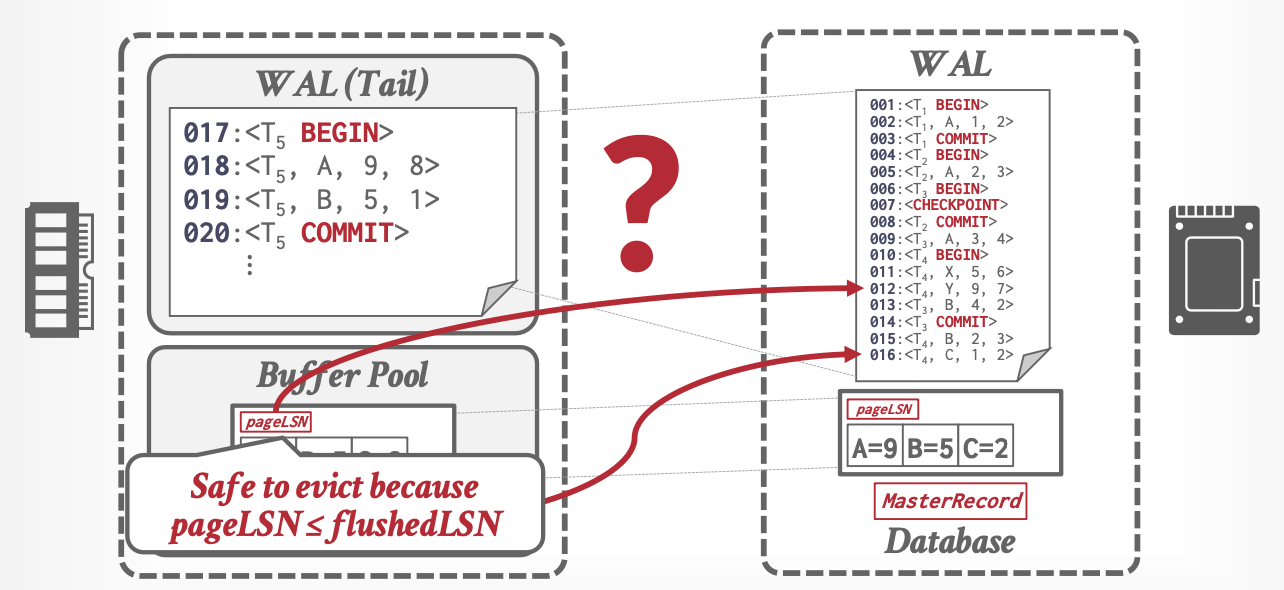
日志序列号
日志序列号(Log Sequence Number),作为日志Id标识日志。
| 名称 | 位置 | 定义 |
|---|---|---|
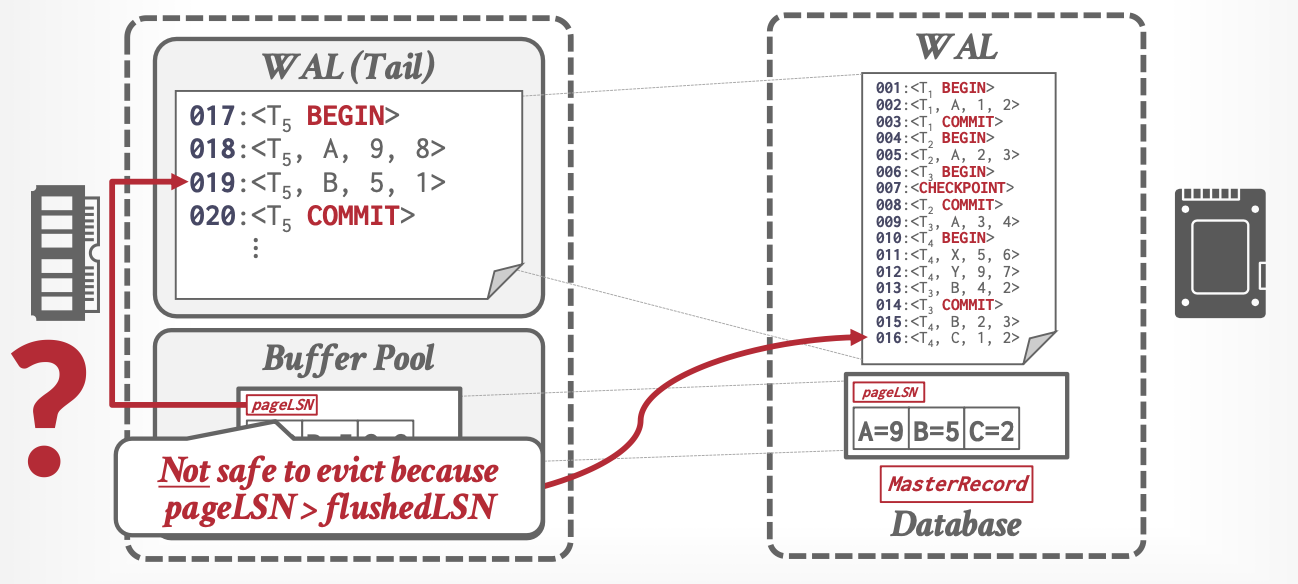
| flushedLSN | 内存 | 上次刷盘时的LSN |
| pageLSN | 缓存页 | 该页上最新更新的LSN |
| MasterRecord | 磁盘 | 检查点的LSN |
| recLSN | 脏页表 | 上次刷盘后的第一个LSN (第一个未刷盘的LSN) |
| lastLSN | 活动事务表 | 该事务的最新LSN |

流程:
-
事务更新一个页时,更新该页的pageLSN
-
日志刷盘时,更新flushedLSN
-
缓存页刷盘时判断:pageLSN <= flushedLSN允许数据落盘,否则不允许,因为日志还没落盘。
事务提交流程
新增下面两种日志类型:
TXN-END日志:表示事务生命期结束,后续日志不会再出现该事务。
添加TXN-END前必须保证当前事务的脏页都刷入磁盘。
CLR日志:事务Abort和Crash之后,未提交事务需要进行回滚,CLR日志(Compensation Log Record)记录回滚这一行为。
正常提交:走上文提到的流程。
Abort提交:
- 将
ABORT记录写进日志 - 利用日志中的preLSN不断回溯进行undo,对于每个更新记录
- 记录CLR Record
- 恢复数据
- 将
TXN-END写进日志
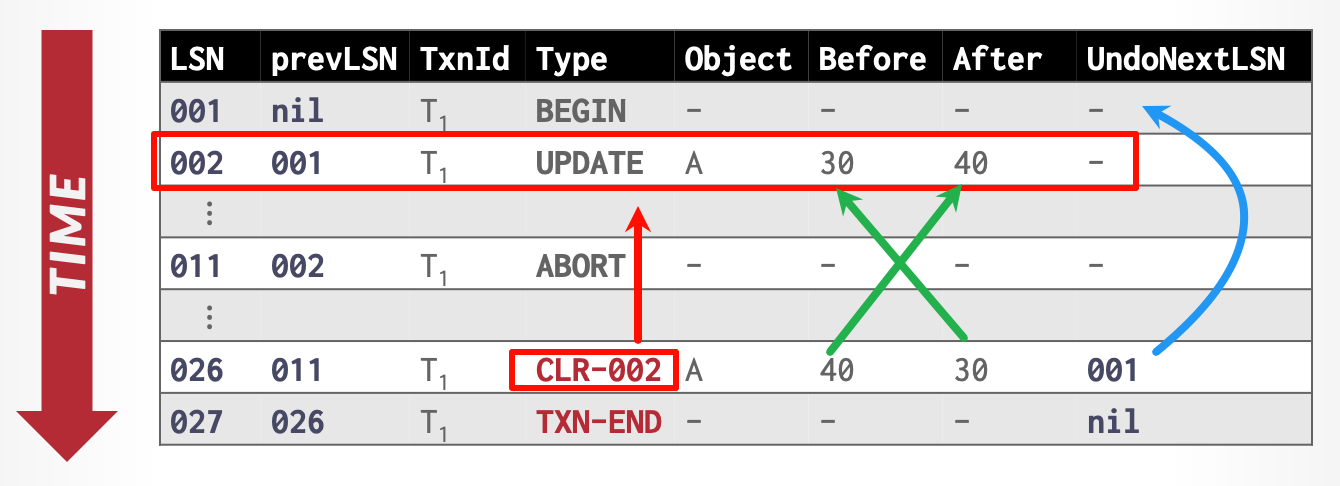
正常提交时,TXN-END接在COMMIT之后;Abort时,ABORT和TXN-END之间是CLR Records。
模糊检查点(Fuzzy CheckPointing)
原有检查点的问题:需要将所有脏页刷盘;停止所有事务,避免刷盘过程中产生新的脏页;不确定当前有哪些活动事务,导致需要重放所有日志确定哪些日志没有提交。
模糊检查点:将检查点由一个时间点变成时间段,并且记录活动事务(ATT)和脏页(DPT)。
CHECKPOINT-BEGIN:检查点开始CHECKPOINT-END:记录ATT+DPT

ARIES恢复算法
总过程
- 分析阶段:构建DPT和ATT
- Redo阶段:从DPT找到最小的recLSN(从此处开始未刷盘),开始Redo
- Undo阶段:从ATT找到每个活动事务的lastLSN(该事务的最新LSN),用preLSN逆推所有修改,开始Undo

分析阶段:从CHCKPOINT-BEGIN开始
- 每遇到一个事务,添加到ATT,状态为U
- 每遇到一个脏页,添加到DPT
- 每遇到一个
COMMIT,修改事务状态为C;TXN-END,将事务移除ATT - 过程中,维护DPT表的lastLSN和ATT表的recLSN

Redo阶段:
- 找到DPT中最小的reclSN
- 对于每个update log record和CLR,进行重做,除非:
- 不在DPT内
- 在DPT内,但是LSN < 最小的recLSN
- LSN <= pageLSN
- 对于所有状态为C的事务,添加
TXN-END,然后从ATT中删除。
Undo阶段:对于每个状态为U的事务,用recLSN逆推所有更新,添加CLR
例子如下,没有体现Redo过程:
Crash前:
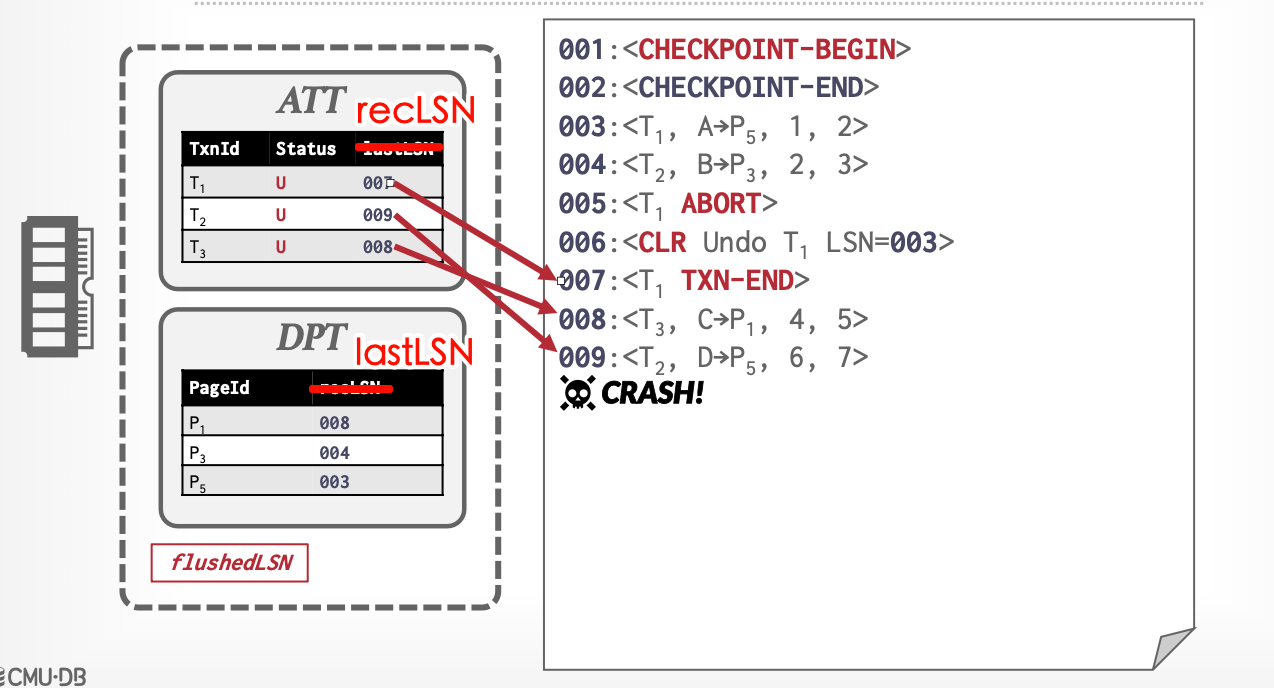
两次Crash后,\(T_2\)和\(T_3\)已经提交TXN-END,从ATT表删除。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号