
cmu15545笔记-查询优化(Query Optimization)
概述#
数据库系统的执行流程:
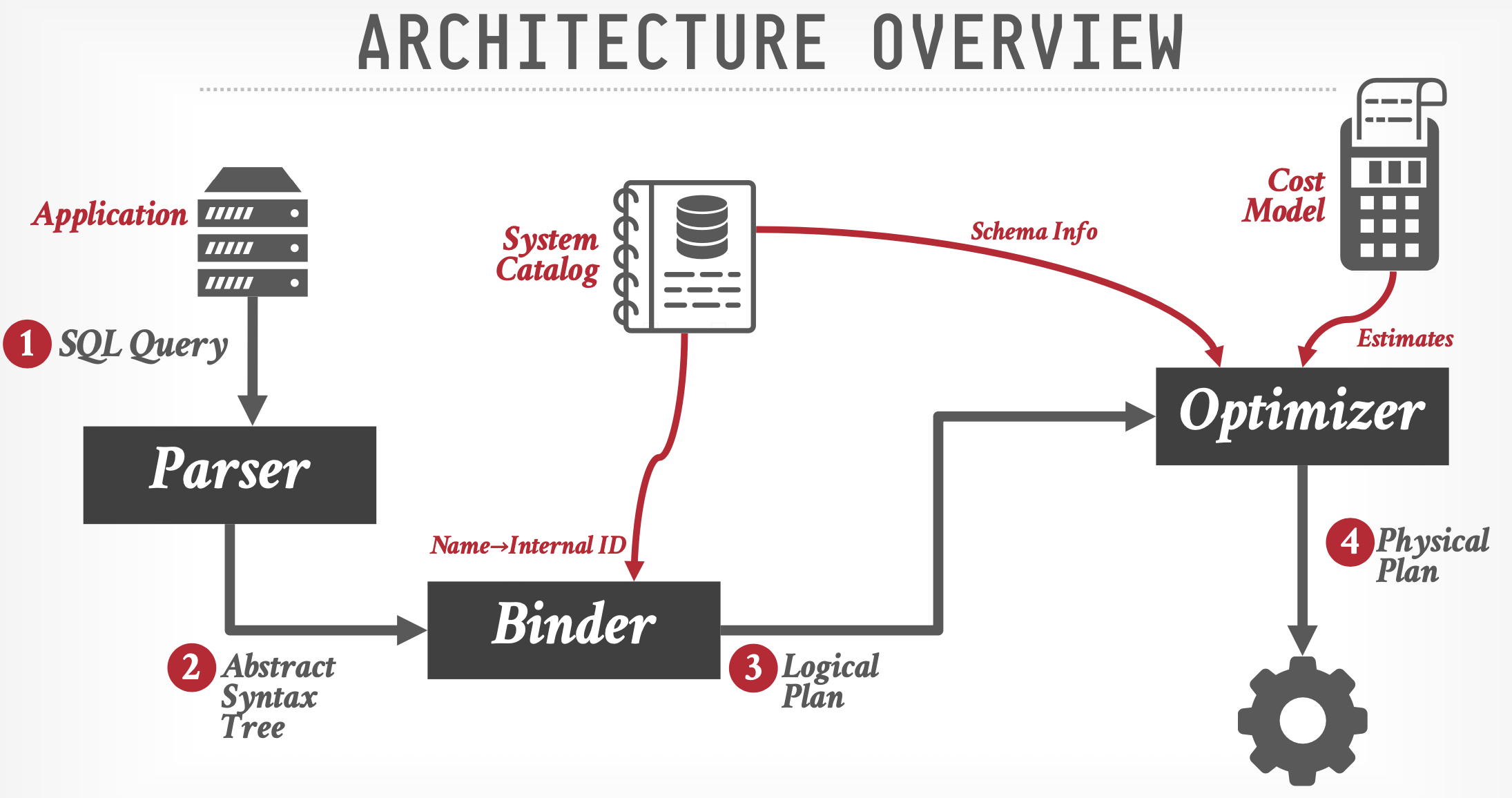
从优化器到磁盘所设计的步骤:

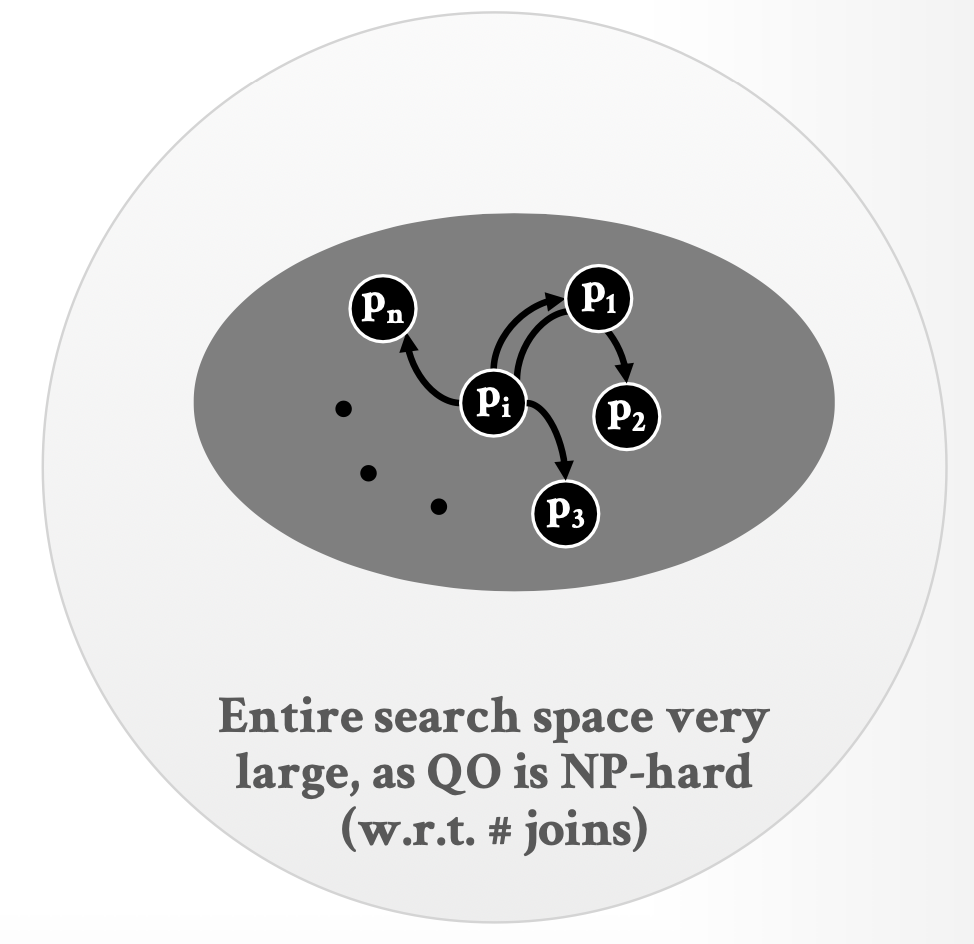
查询优化分为两类:
- Heuristics / Rules:启发式的,基于规则的
- Cost-based Search:基于代价模型。选择代价最小的路径
- Single relation:单表
- Multiple relation:多表。Bottom-Up或Top-Down
- Nested sub-queries:嵌套子查询。重写,分解。
Heuristics / Rules#
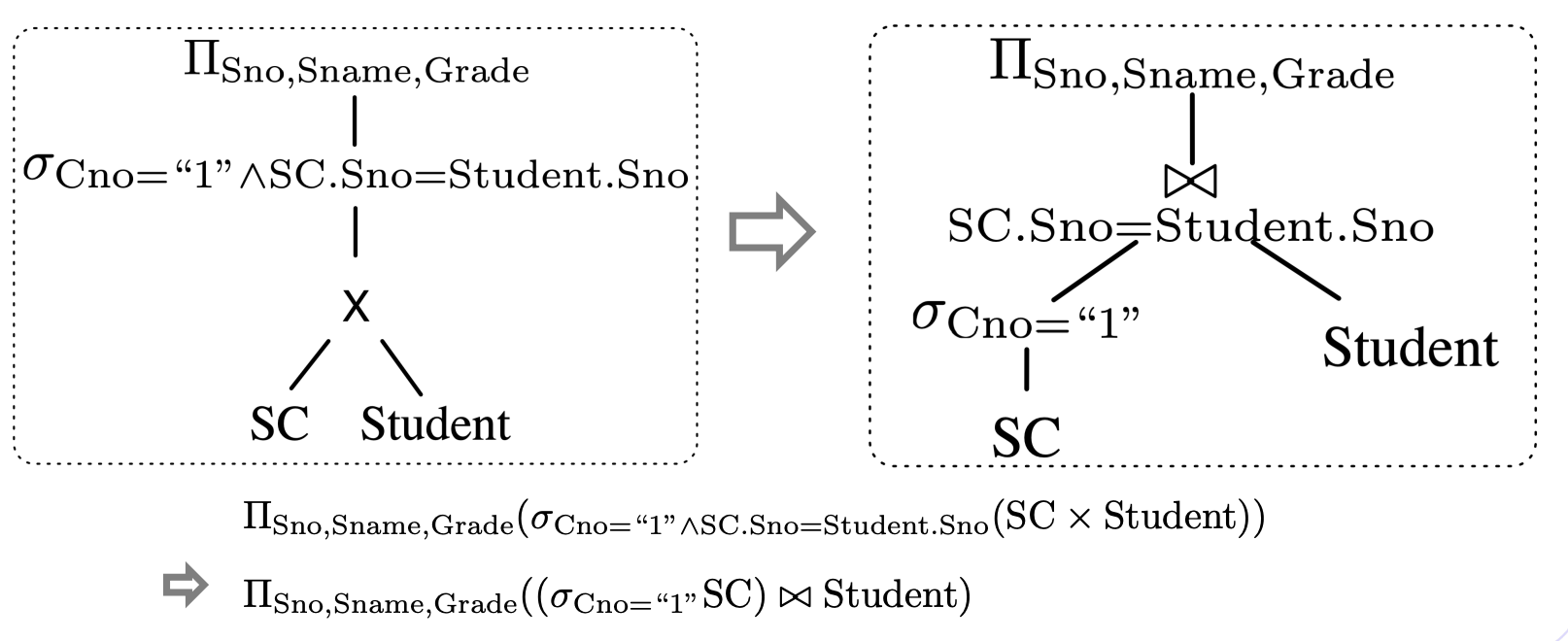
基本思想:关系代数的等价变换。
谓词下推,投影替代笛卡尔积,投影下推(下图没体现)。
Cost-based Search#
查询优化是NP难问题,因此我们无法穷尽所有查询计划,只能选取部分子集,同时无法准确计算代价,只能进行估计:
-
逻辑代价:谓词选择性,操作符或算法的逻辑复杂度,中间结果大小
-
物理代价:IO代价,CPU代价,内存使用,数据分布和存储结构
-
代价的计算来自于统计数据:直方图,快照,采样
-
搜索方式:Bottom-Top和Top-Down
统计数据 -> 逻辑代价 -> 物理代价 -> 搜索物理代价最小的计划。
结束条件:找到当前所有查询计划中代价最小的一个 或 到达限定时间。
Single relation#
对于单表操作来说,简单的启发式优化(Heuristics)+对谓词合理排序往往已经足够了,只需要考虑选择哪种数据库访问方式。
- 全表扫描
- 二分查找(聚簇索引)
- 索引扫描
SELECT *
FROM Employees
WHERE age > 40 AND department = 'IT';
该SQL中,age > 40的选择性为0.1,department = 'IT'为0.9。
- 两个都有索引:分别进行索引扫描过滤,结果取交集。
- 一个有索引(如
age):对age进行索引扫描,得到age>40的数据,再用department = 'IT'对结果进行过滤。 - 都没有索引:全表扫描,用两个条件过滤得到最终结果。
Mutiple relation#
Genertive / Bottom-Up#
基本思想:通过从最小的数据子集(如单个表或中间结果)开始,逐步合并这些子集,并使用动态规划技术找到整个查询的最优执行计划。
数据库:IBM System R,,DB2,MySQL,Postgres,most open-source DBMSs
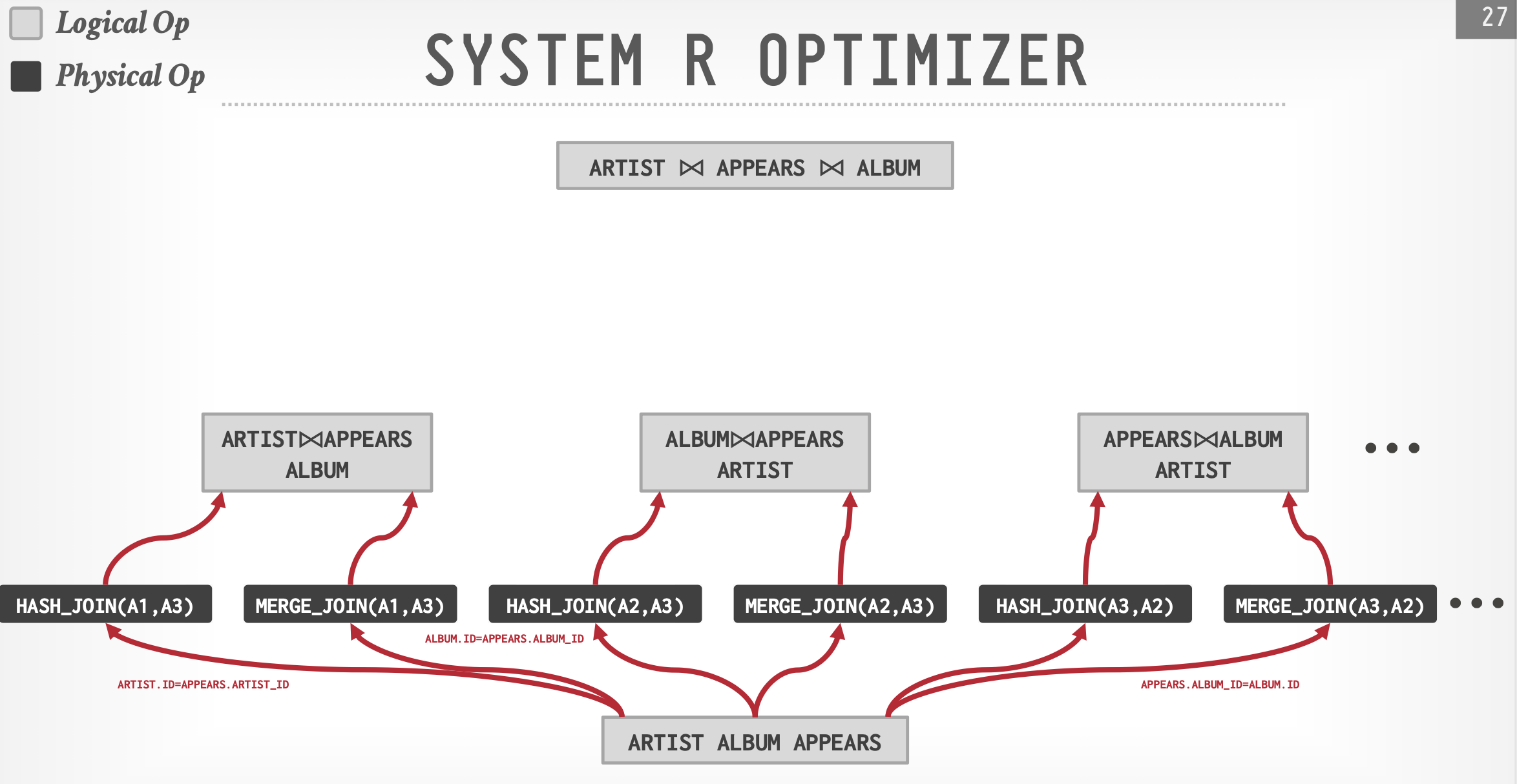
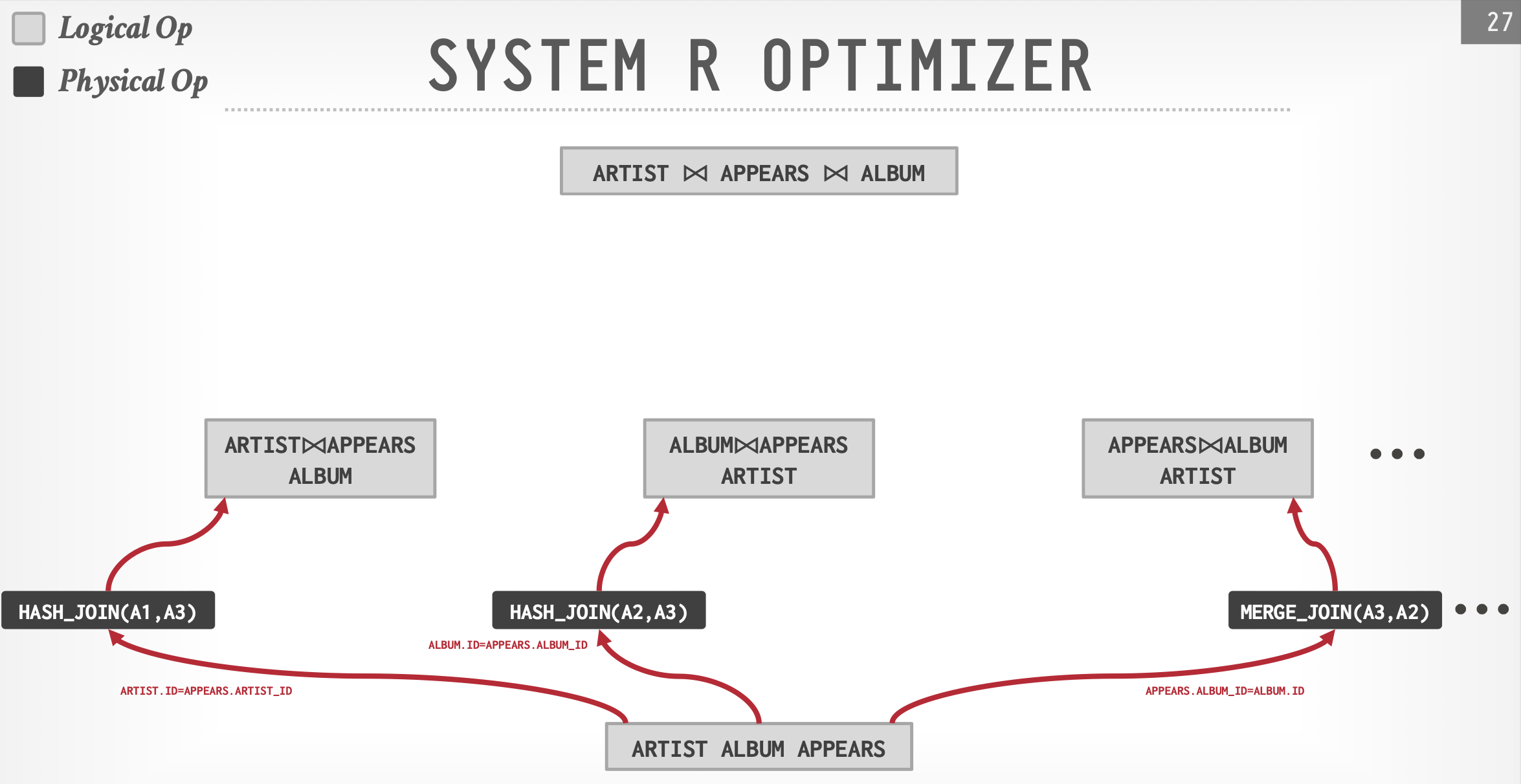
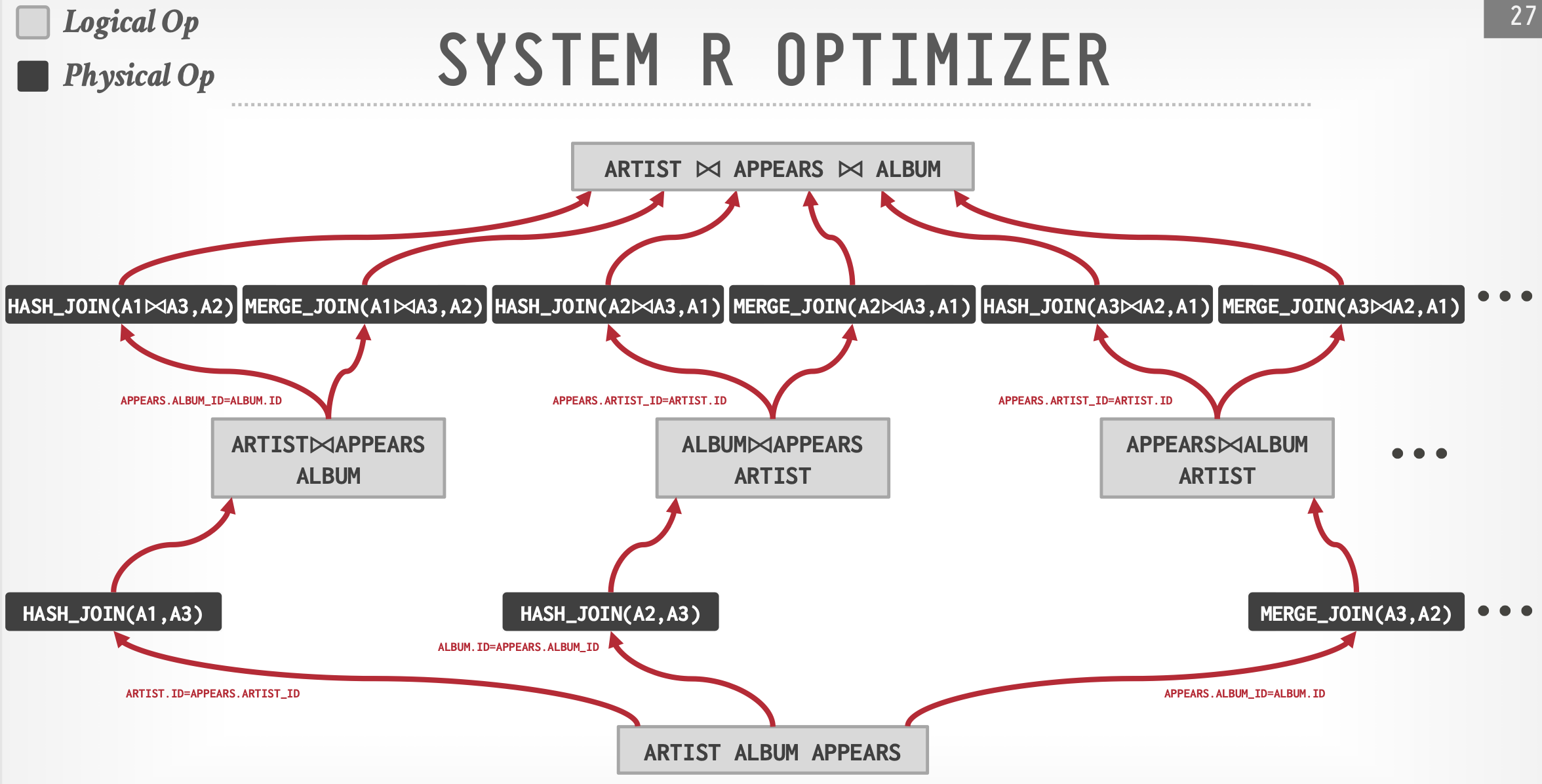
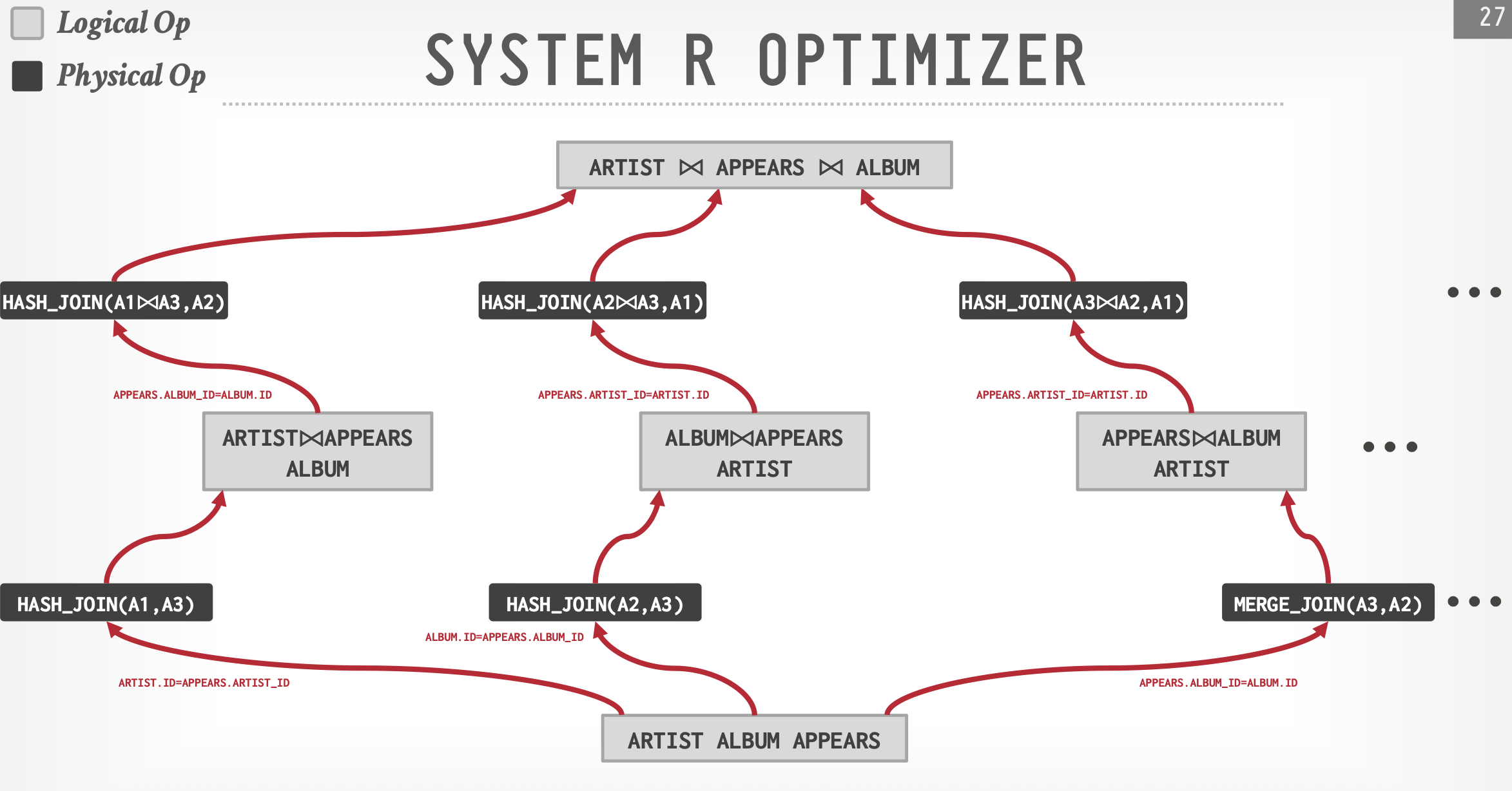
例子:IBM System R
- 确定表数据访问方式,列出可能的连接方式

- 搜索最小代价:动态规划+剪枝

Transformation / Top-Down#
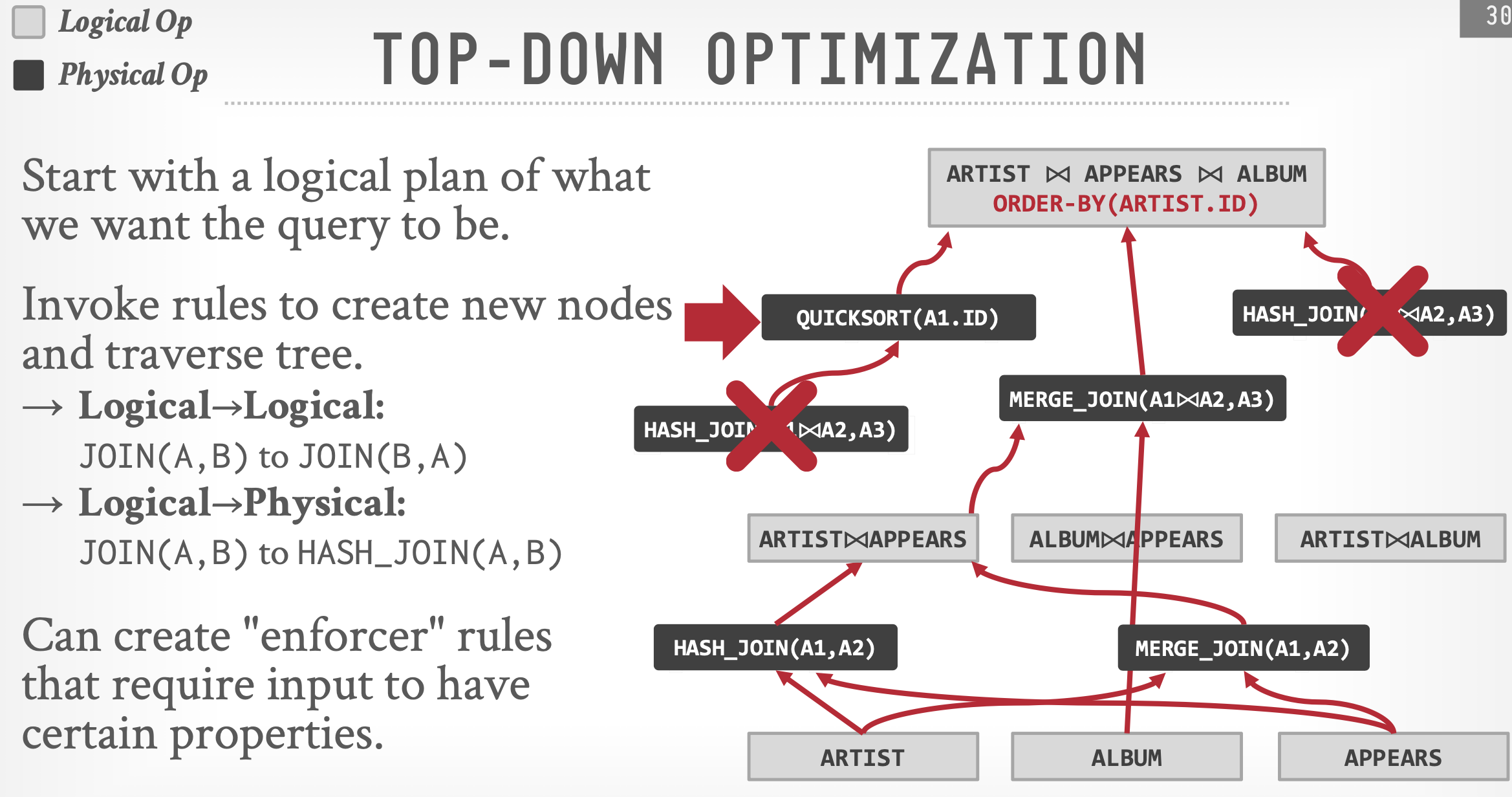
基本思想:从逻辑查询计划出发,利用分支界限法,逐步转换为物理查询计划,在搜索空间中保留最优方案,同时在规划过程中直接考虑数据的物理属性。
数据库:MSSQL, Greenplum, CockroachDB
存在强制规则(enforer)进行约束,如果不满足就直接剪枝,强制规则可以是一个接受的成本底线,或者是禁用的操作,比如在需要有序结果时却采用Hash Join。
Nested sub-queries#
Decomposing Queries#
基本思想:嵌套的子查询如果与外部查询无关,分解成一个单独的查询。

Expression/Queries Rewriting#
基本思想:对查询或表达式进行同义替换。
SELECT * FROM A WHERE 1 = 0; -> false
SELECT * FROM A WHERE NOW() IS NULL; -> false
SELECT * FROM A WHERE false; -> 不做查询
SELECT * FROM A
WHERE val BETWEEN 1 AND 100
OR val BETWEEN 50 AND 150; -> Where val BETWEEN 1 AND 150
SELECT name FROM sailors AS S
WHERE EXISTS (
SELECT * FROM reserves AS R
WHERE S.sid = R.sid
AND R.day = '2022-10-25'
); ->
SELECT name FROM sailors AS S, reserves AS R
WHERE S.sid = R.sid
AND R.day = '2022-10-25'
Statistics#
数据库会在内部的数据目录(Data Catalog)中存储关于表,属性,索引的统计信息(Statistics),不同的系统会在不同的时间更新。
手动调用:
- Postgres/SQLite:ANALYZE
- Oracle/MySQL:ANALYZE TABLE
- SQL Server:UPDATE STATISTICS
- DB2:RUNSTATS
直方图(histogram):等宽直方图;等深直方图
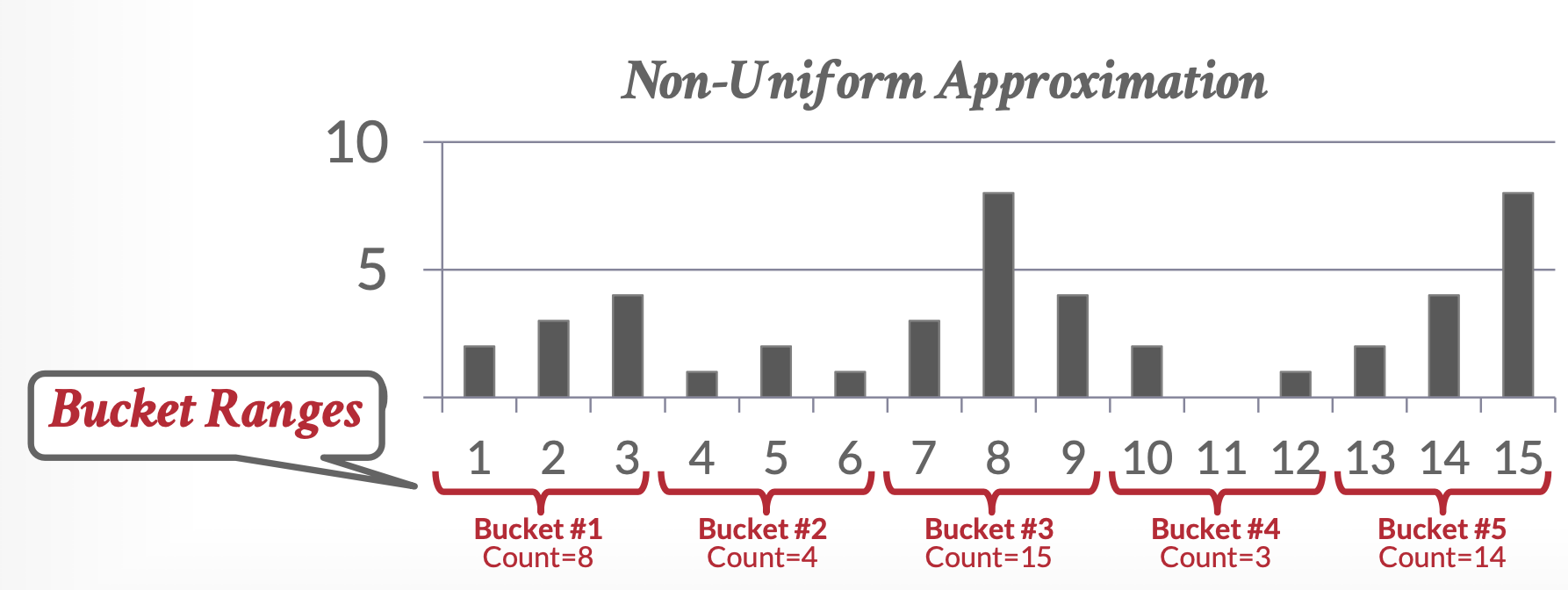
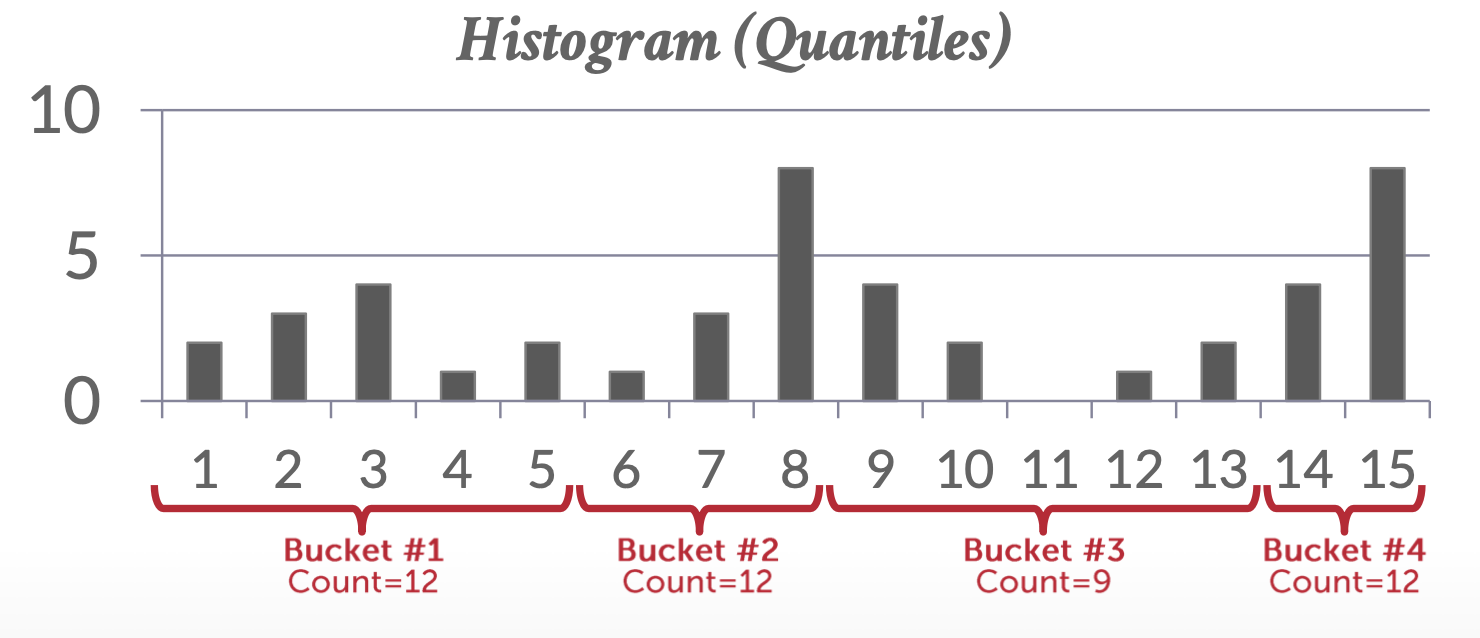
快照(sketch):是一种轻量级的近似统计工具,适合在大数据和实时流场景下使用。
- 相比直方图,能够动态适应数据变化,并显著降低存储和计算成本。
- 在选择性估计中,快照可以有效提高数据库优化的效率,特别是对于高维和动态数据。
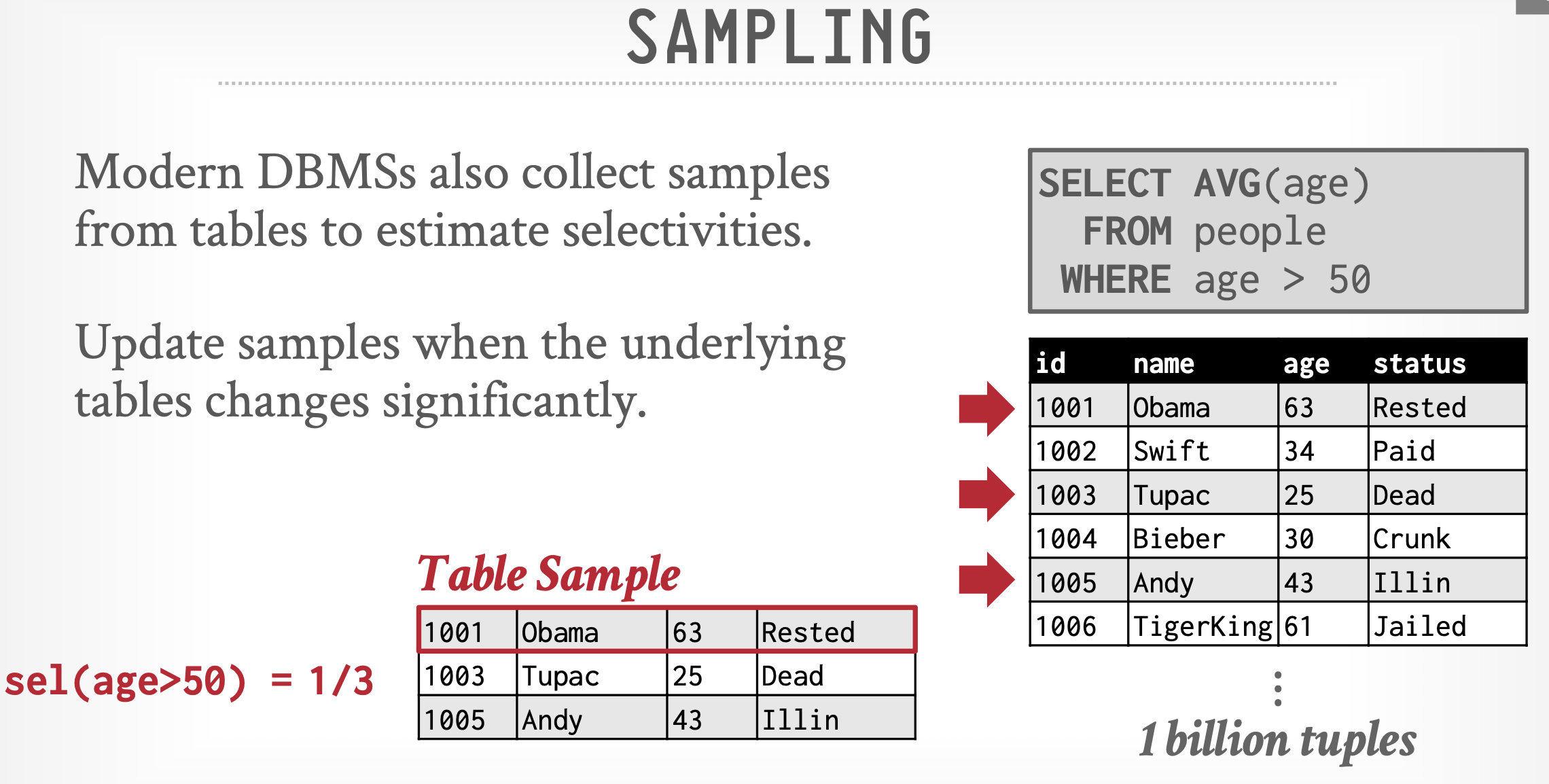
采样(sampling):数据规模大时,可以根据样本预估选择性。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 记一次.NET内存居高不下排查解决与启示
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· DeepSeek 开源周回顾「GitHub 热点速览」