cmu15545笔记-数据存储(Database Storage)
蓝图
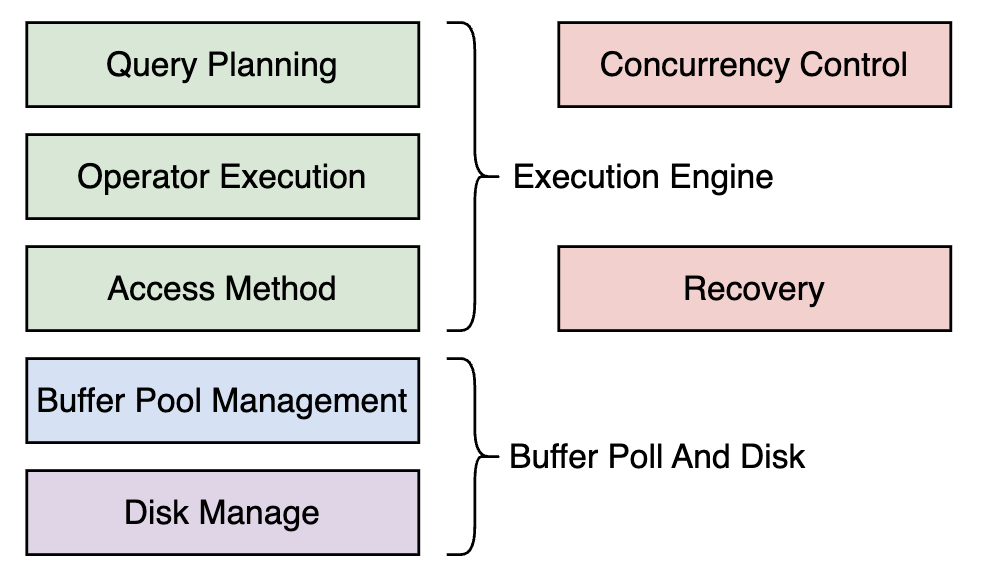
数据库自己管理磁盘数据和缓冲区,而不是通过操作系统管理(Os is not your friend.)。
数据存储
三层视图
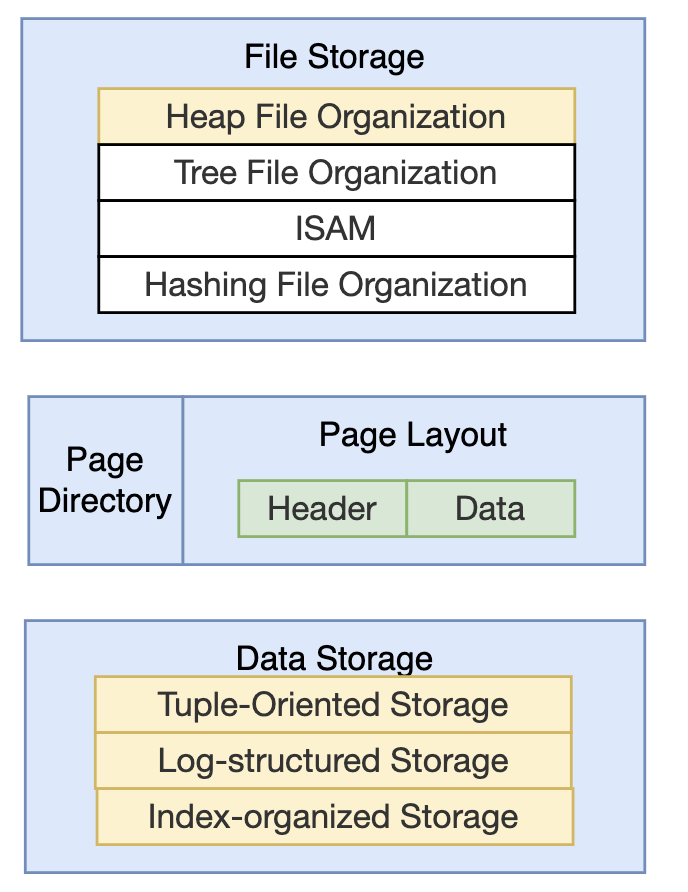
数据库以页(page)为存储数据的基本单位,文件(file)是一系列页的集合,页中存储页数据(data),形成文件-页-数据三层架构。
文件有不同的组织形式,页包含页头和页数据,页数据可以采用不同方式组织:元组,日志,索引。
黄色部分为课程会提及的内容。
采用Heapfile进行文件存储时的执行图:
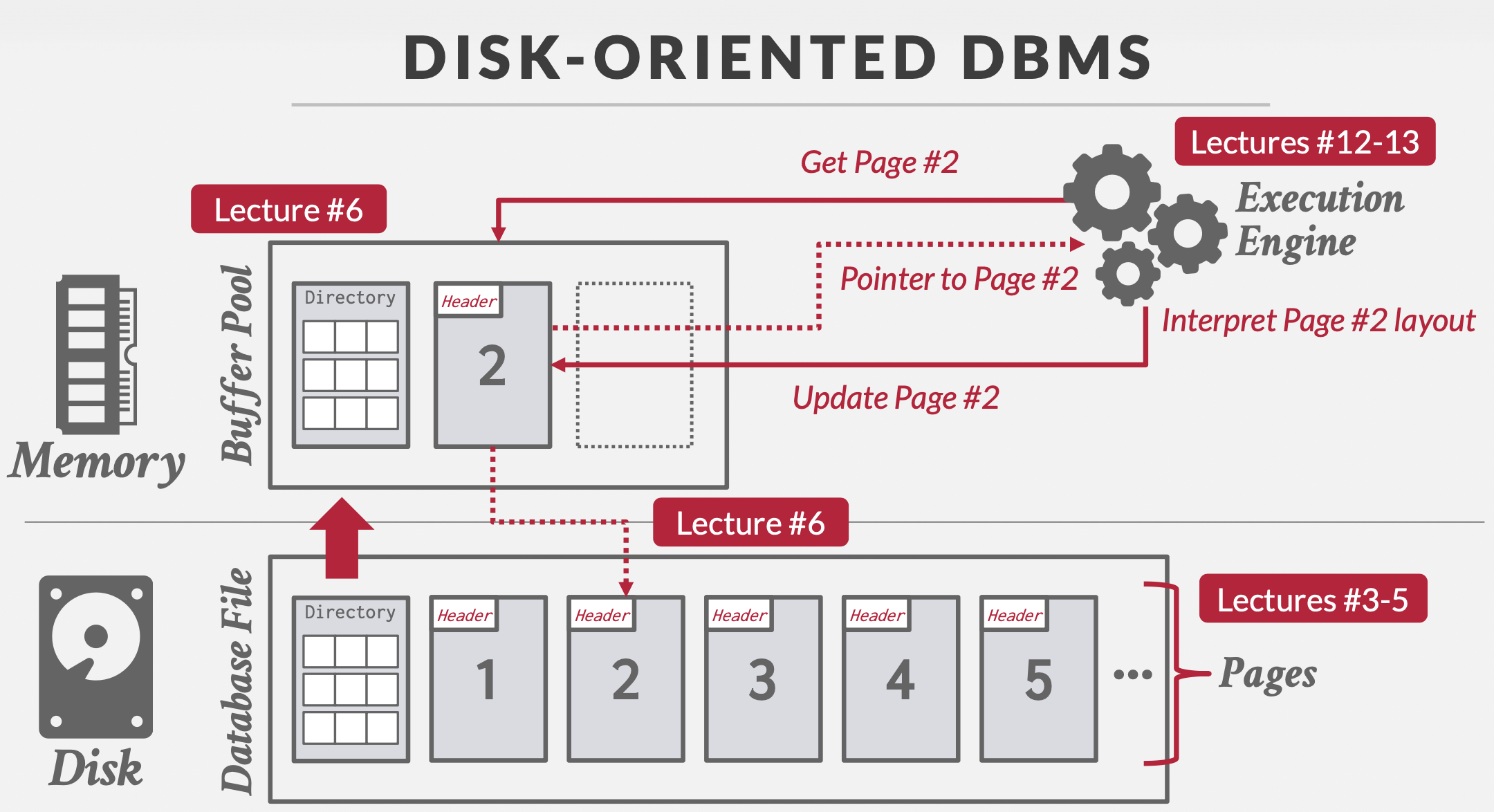
- 页目录:存储管理的页的元信息(空闲页,空页)
- 页头:存储页的元信息(页大小,校验和,数据库版本,事务可见性,压缩元数据)
面向元组的数据存储
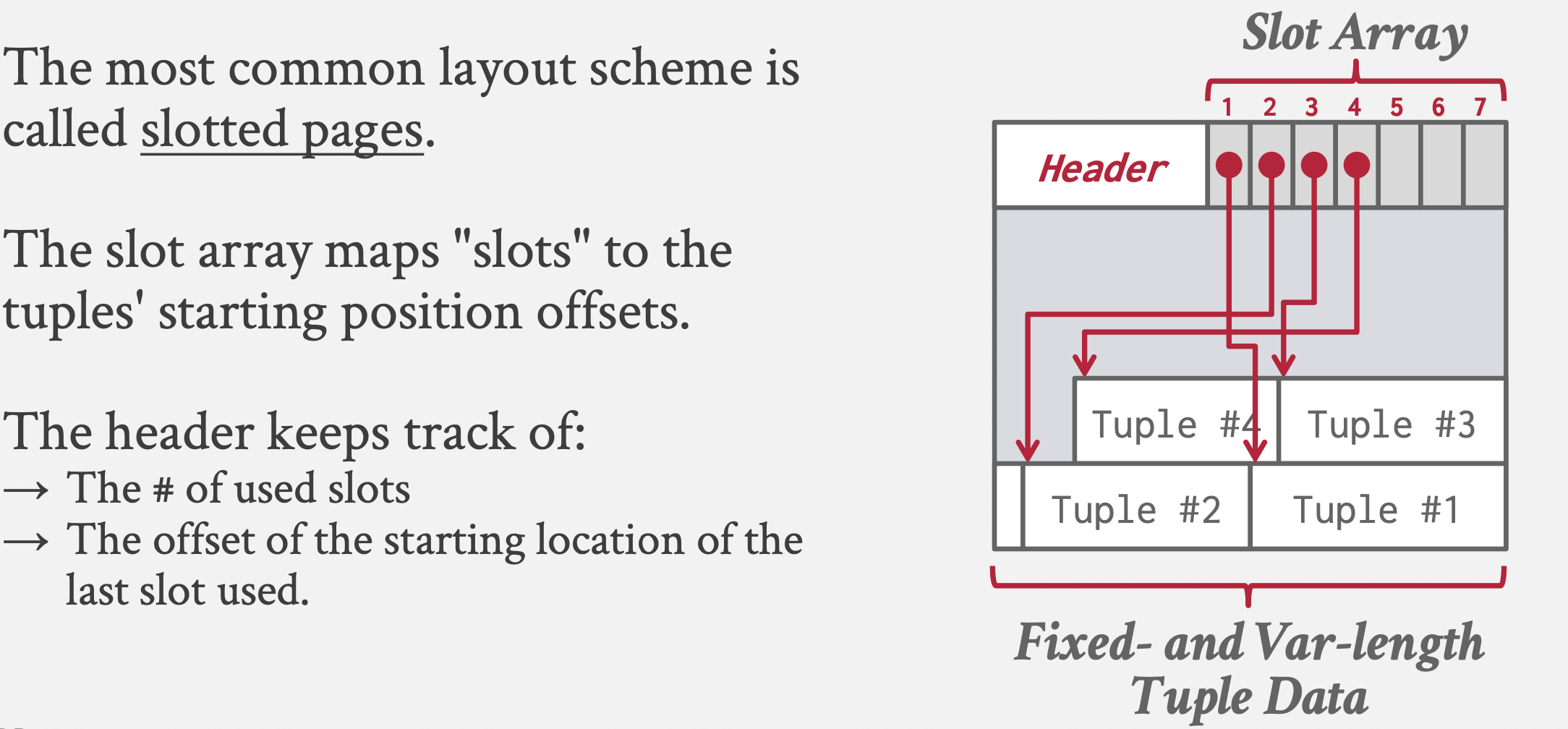
-
通过<FileId, PageId, Slot>定位到一个指向tuple的指针(磁盘地址),然后找到tuple。
-
slot指针的灵活性:内部元组位置变化时,外部无感知;指针可以指向其他页,可以存储大数据(文件,大文本);支持变长记录。
-
数据库会为每个元组分配一个数据记录的唯一标识(record identifier),来表示元组的物理位置。SQLite和Oracle中为ROWID,Pg中是CTID,<PageId, Slot>。但是他们对于应用程序是无用的。

-
Header包含:可见性信息;NULL Bit Map。
-
Data包含:行数据。
Tuple只是一个字符串(char[]),本身不存储类型信息,类型信息存在数据库的System Catalogs中。(为了保证数据紧凑;非自解释的)
存数据时会遇到的问题:
- 数据对齐:填充,重排序
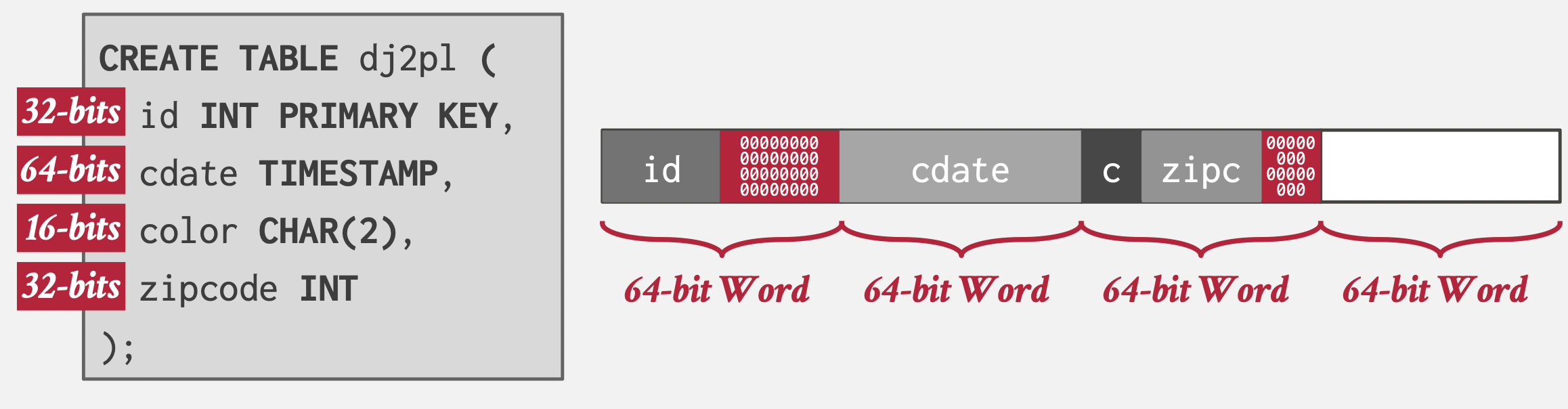
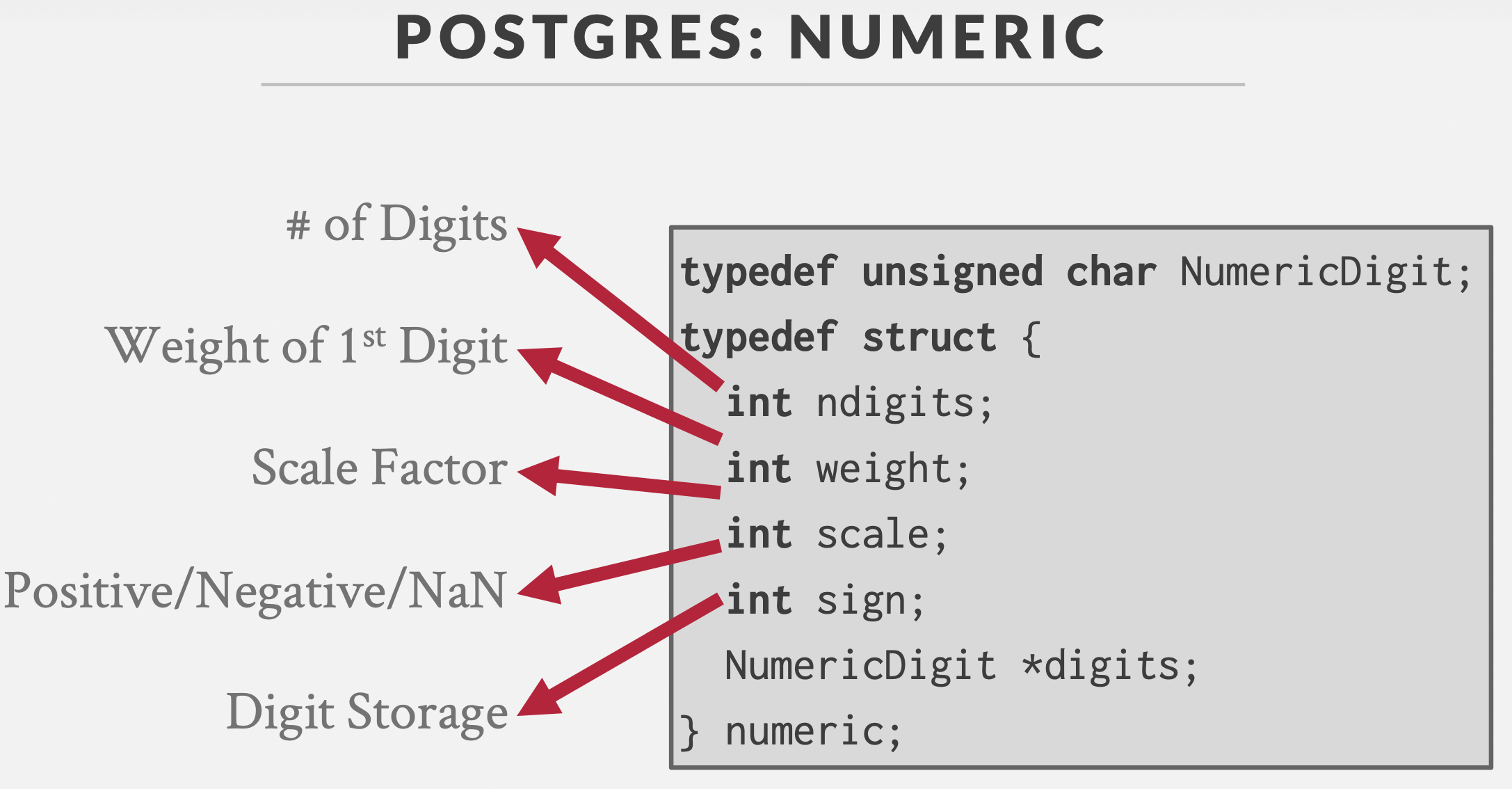
- 精确值问题:BIGDECIMAL(转为字符串存储)
-
空值:Bit Map;特殊值
-
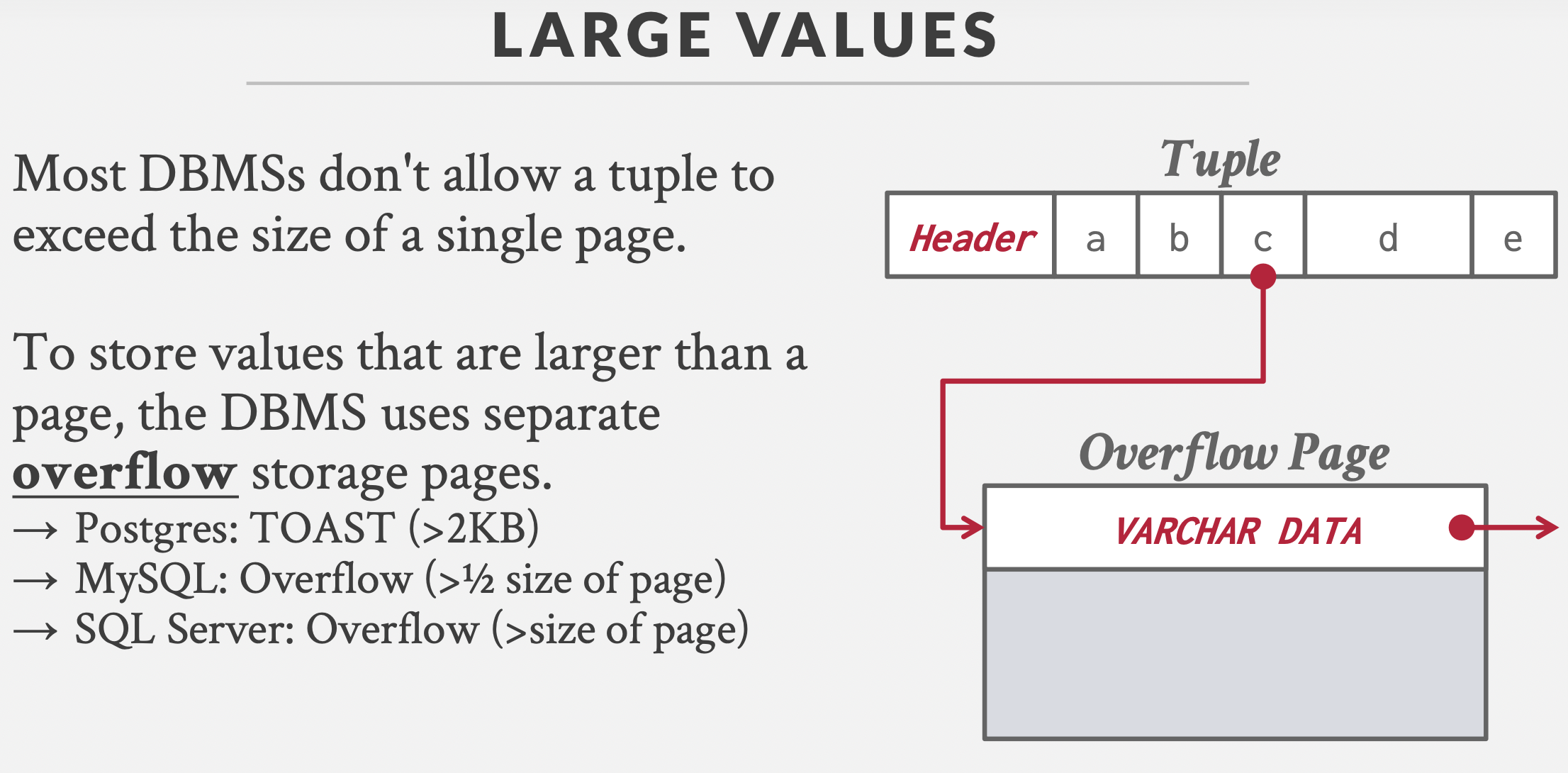
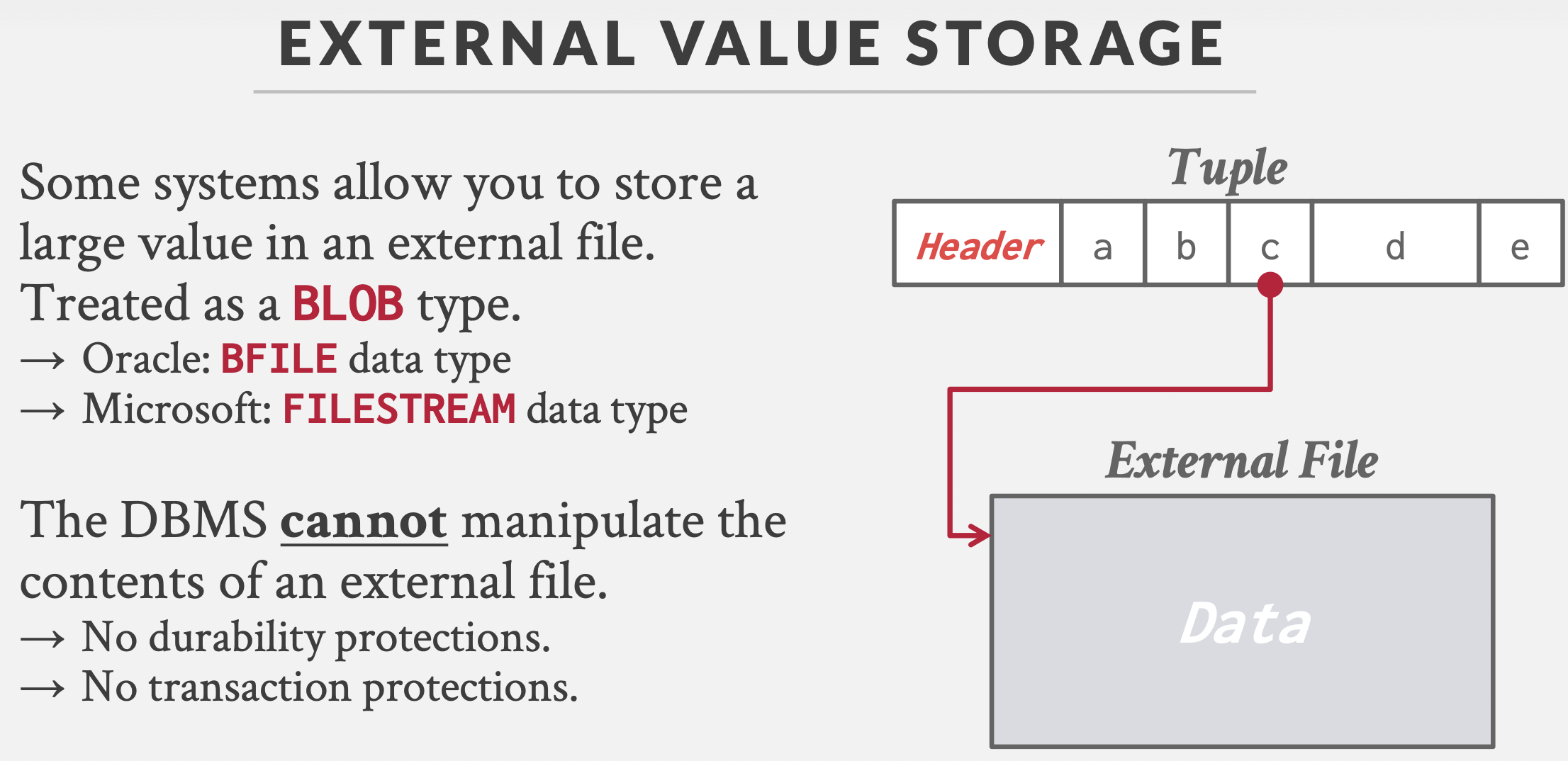
大值和文件:Overflow Page和External File。
大值采用溢出页;大文件可以采用溢出页,也可以用外部文件系统存储,然后存储一个指向文件路径的指针,而不是直接存储文件内容(Oracle:BFILE, Microsoft: FILESTREAM)。
日志结构存储
基本概念:
- 利写不利读,非原地更新:只有PUT和DELETE操作,顺序IO。查询时由最新到最老时查询日志。
- 加速查询:索引。
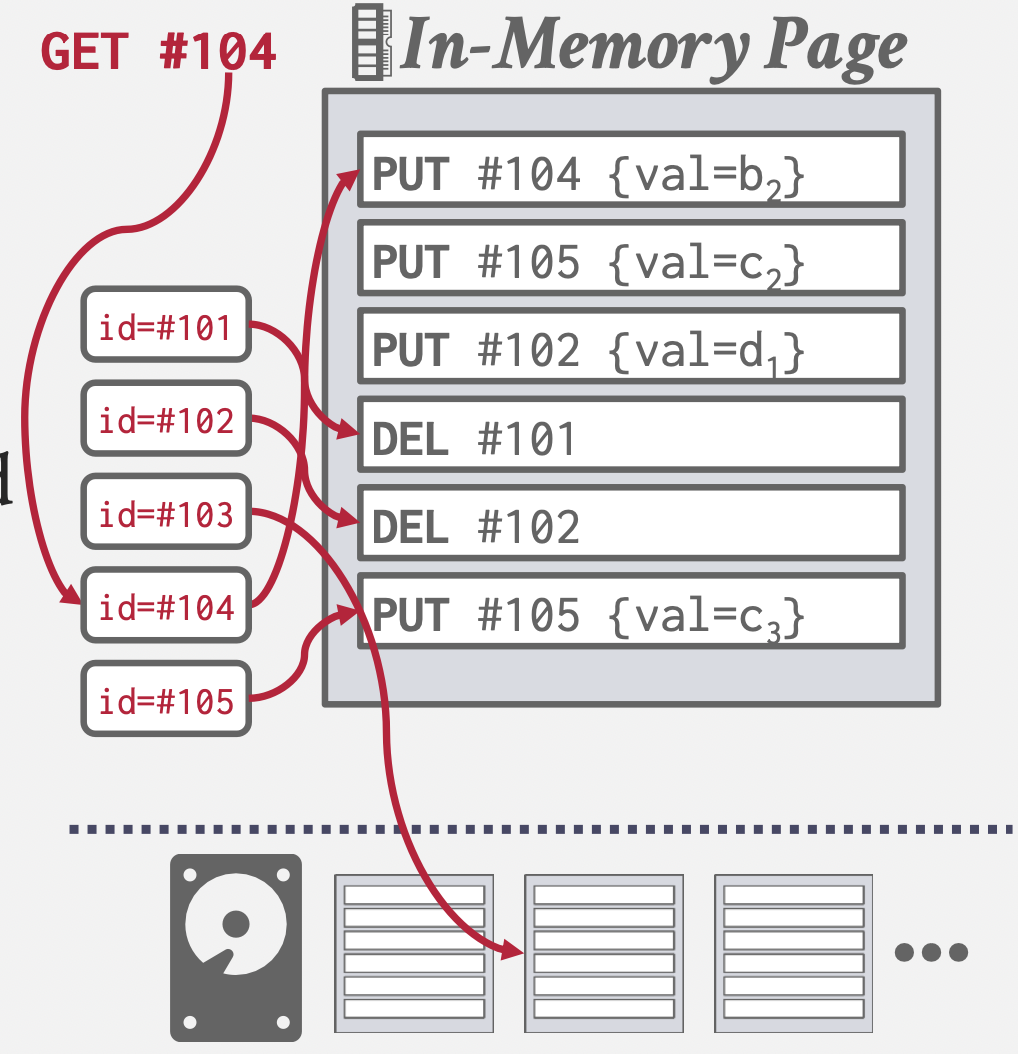
- 加速查询:日志压缩,且压缩时会排序日志。
- 压缩方式:层级压缩,统一压缩
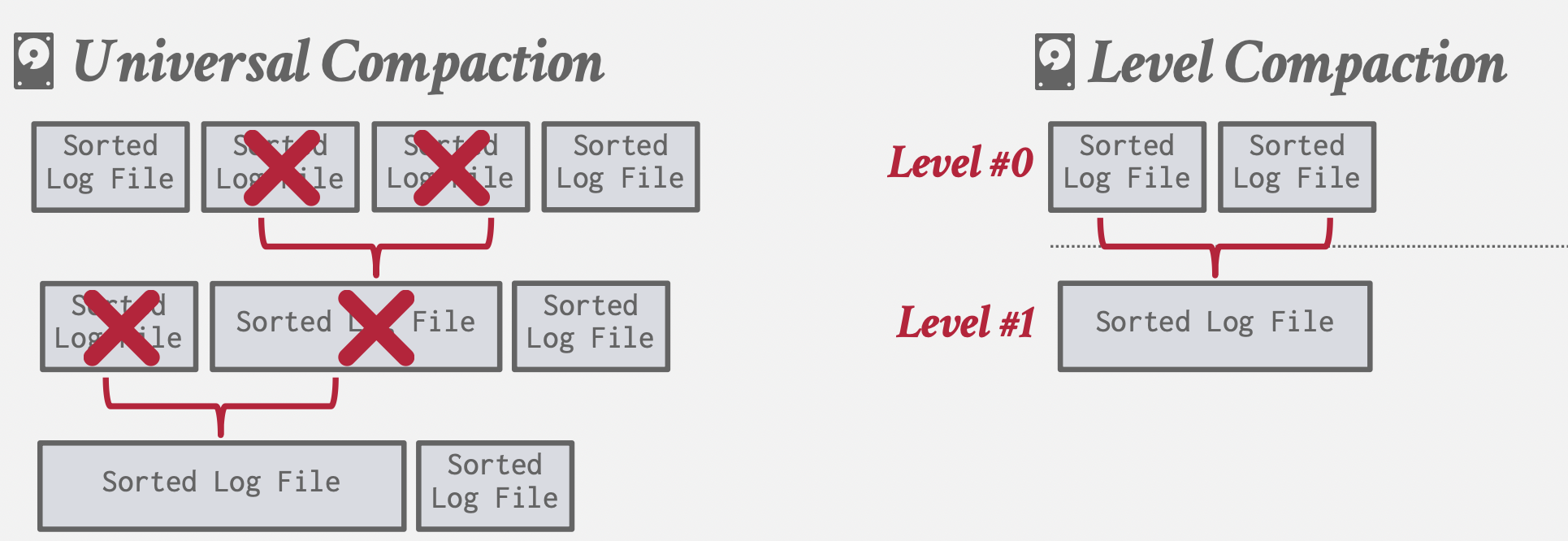
| 特点 | Level Compaction | Universal Compaction |
|---|---|---|
| 层级结构 | 有多层级,L0、L1、L2 等 | 无层级结构,所有文件在同一级别 |
| 文件组织方式 | 每个层级内文件不重叠,跨层逐渐下推 | 基于文件大小和数量合并,文件可能有重叠 |
| 合并策略 | 层级压缩,按顺序下推合并 | 文件数量和大小超过阈值时触发合并 |
| 写放大 | 较高,因为需要不断下推文件至更低层级 | 较低,因为减少频繁合并 |
| 读放大 | 较低,因为相同键在每层只存在一次 | 较高,因为没有严格层级,需检查多个文件 |
| 适用场景 | 读多写少的场景 | 写多读少、实时数据的高写入场景 |
索引组织存储
直接用索引组织数据,数据挂在叶子结点上,Page内部的tuple有序。
SQLite和MySQL默认用这种方式组织数据,Oracle和SQL Server可选。
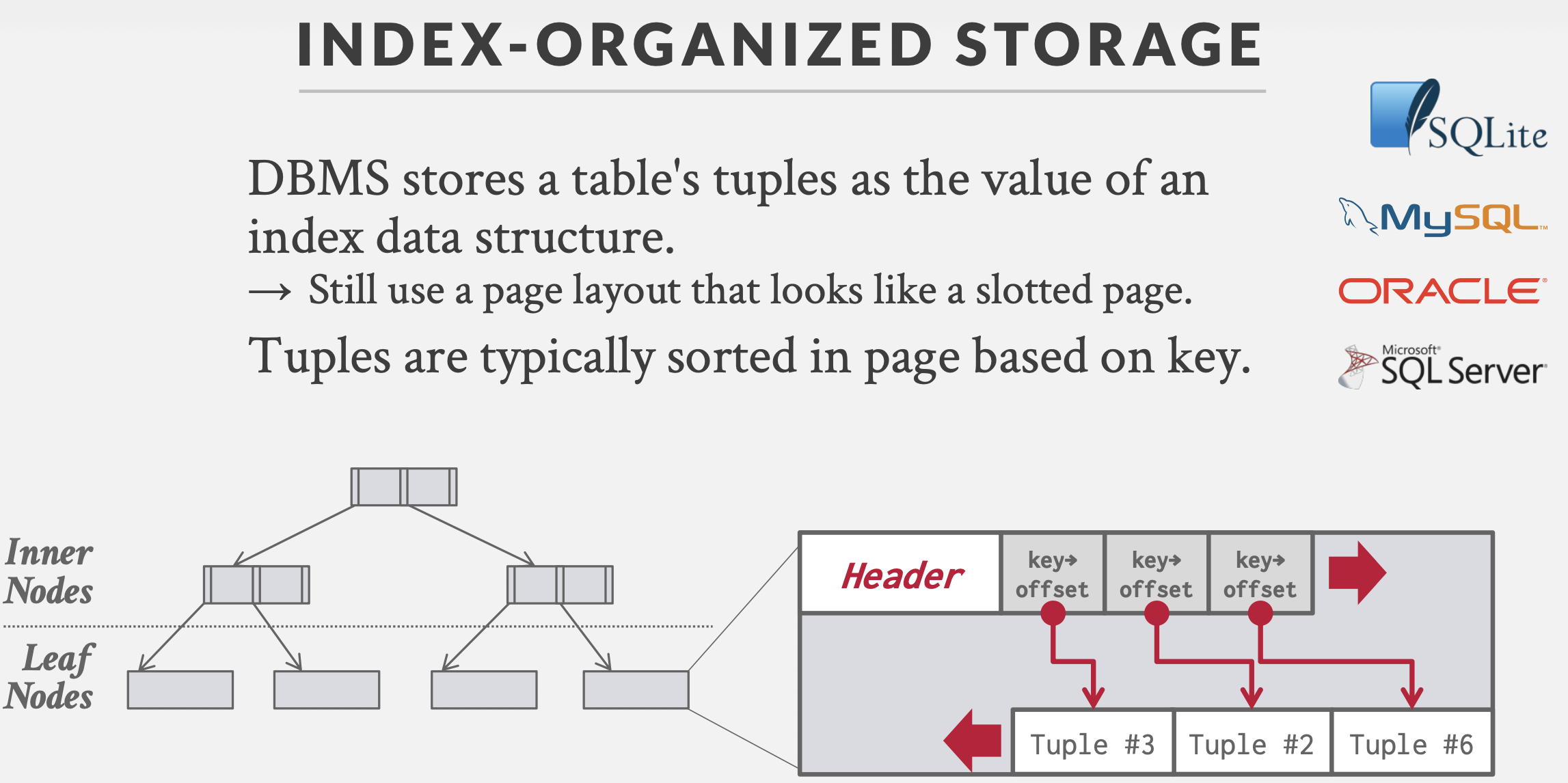
和基于元组的存储对比:
| 特性 | Index-Organized Storage | Tuple-Oriented Storage |
|---|---|---|
| 数据与索引存储 | 数据存储在主键索引结构中 | 数据和索引独立存储 |
| 数据排序 | 数据按照主键顺序排序 | 数据无序存储 |
| 主键查询性能 | 高效,因数据已按主键排序 | 依赖主键索引,但数据本身无序 |
| 插入和更新性能 | 插入和更新时可能需要索引重排,较慢 | 插入和更新较快,无需主键排序 |
| 适用场景 | 主键查询频繁,数据顺序性强的场景 | 多种查询模式,插入和更新频繁的场景 |
数据模型
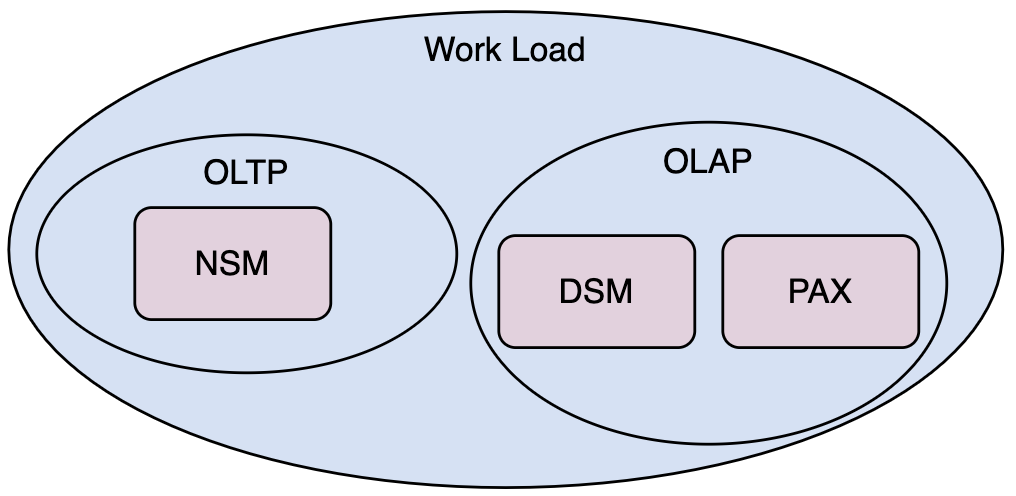
- N-ary Storage Model (NSM)
- Decomposition Storage Model (DSM)
- Hybrid Storage Model (PAX)
NSM
优点:操作一条完整记录时快速。
缺点:操作一批记录的某一个特定列的时候,非顺序读取,会有无效IO,且数据不好做压缩。
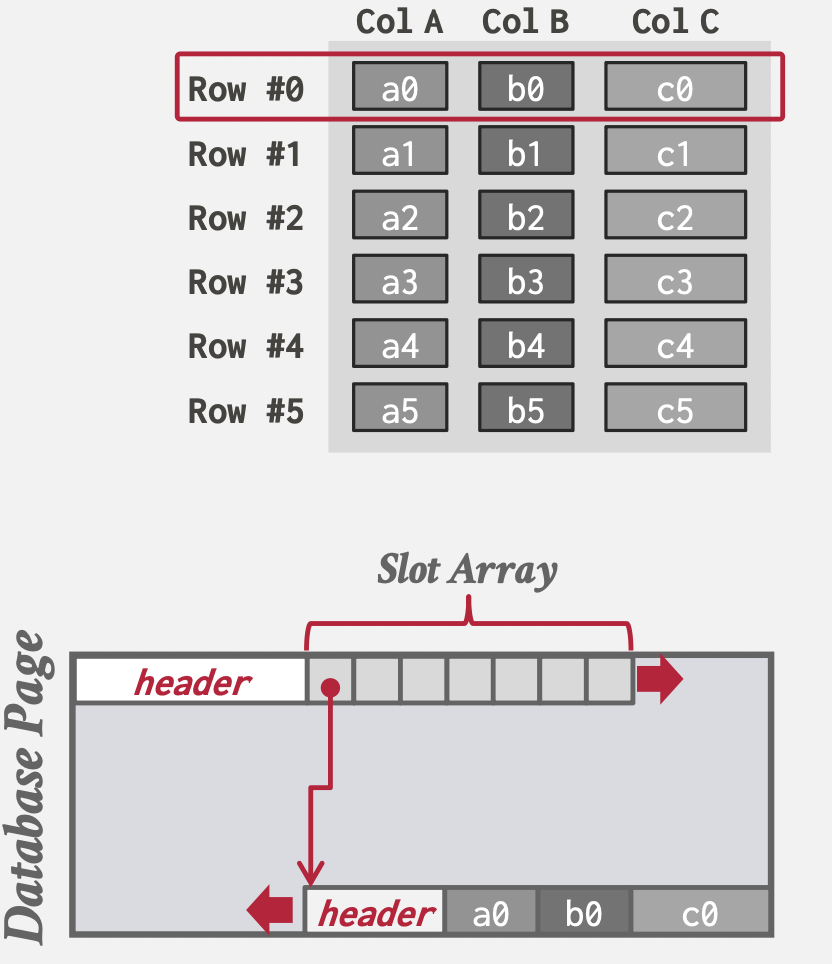
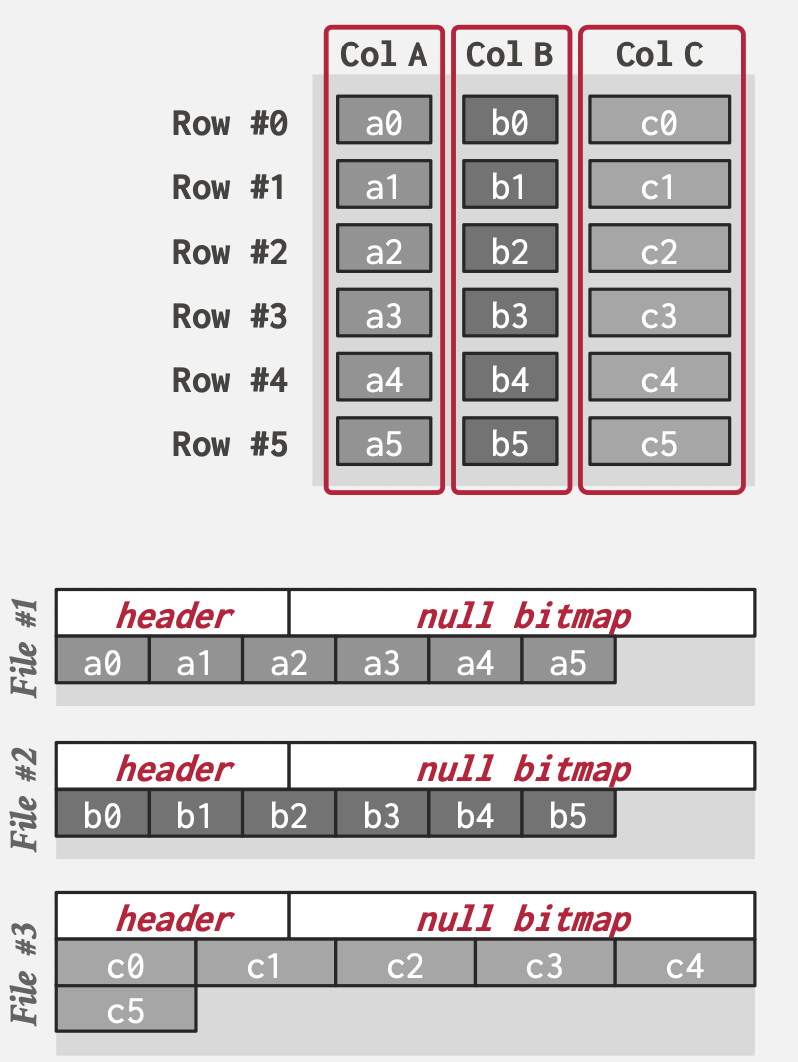
DSM
优点:可以取到一批特定列;可以做数据压缩。
缺点:在操作完整记录的时候,需要分解查询,得到结果后还需要再进行合并。
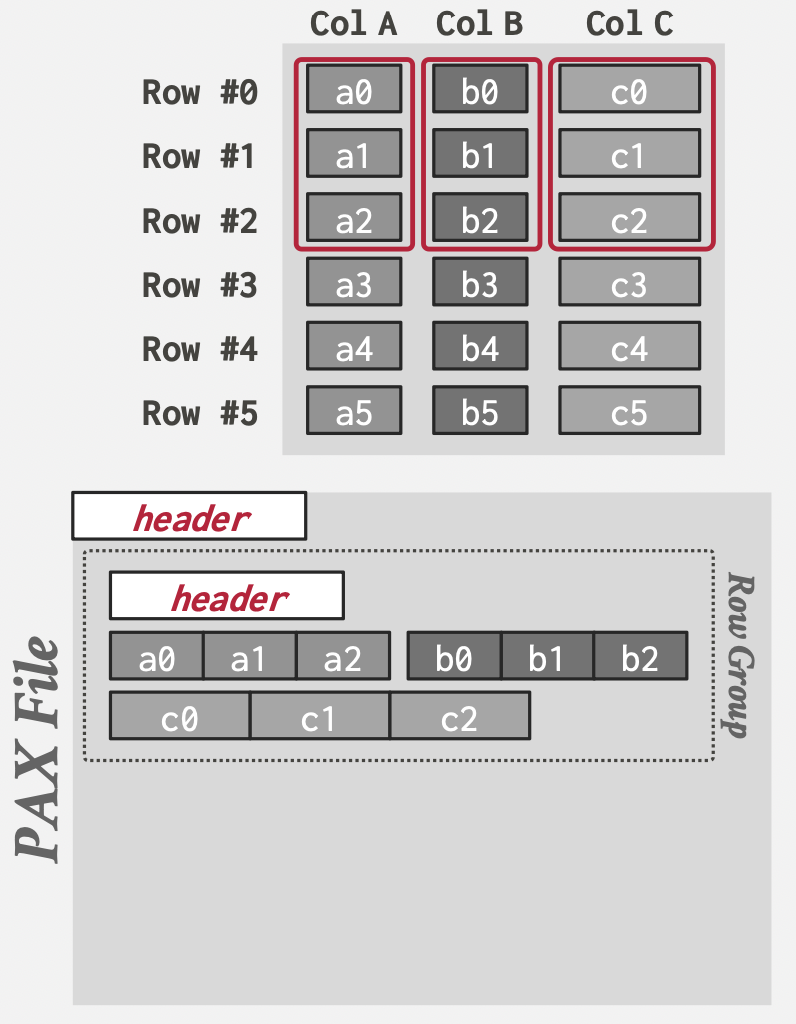
PAX
结合了NSM和DSM,既能一次处理一个完整记录,也能在读取一系列特定的属性时顺序读取并避免过多的无用IO。
数据压缩方式
目标:
-
压缩结果为定长值(存储定长数据)。
-
仅在需要时解压缩,否则都采用压缩形式处理数据。
-
必须是无损的。
常用的压缩方式:字典压缩。
维护字典映射,数据表中存储映射值。结果定长,且可以支持范围查询。
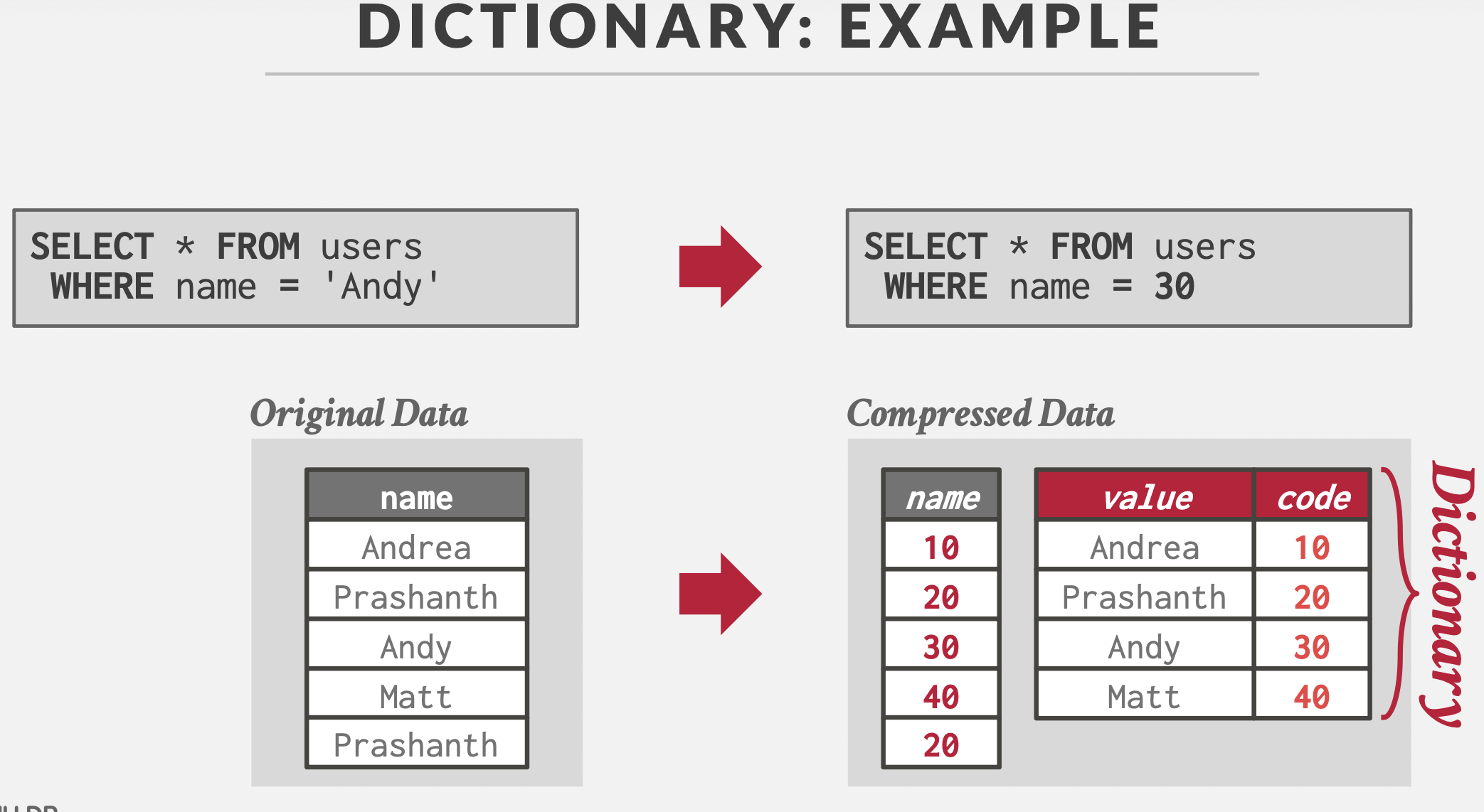
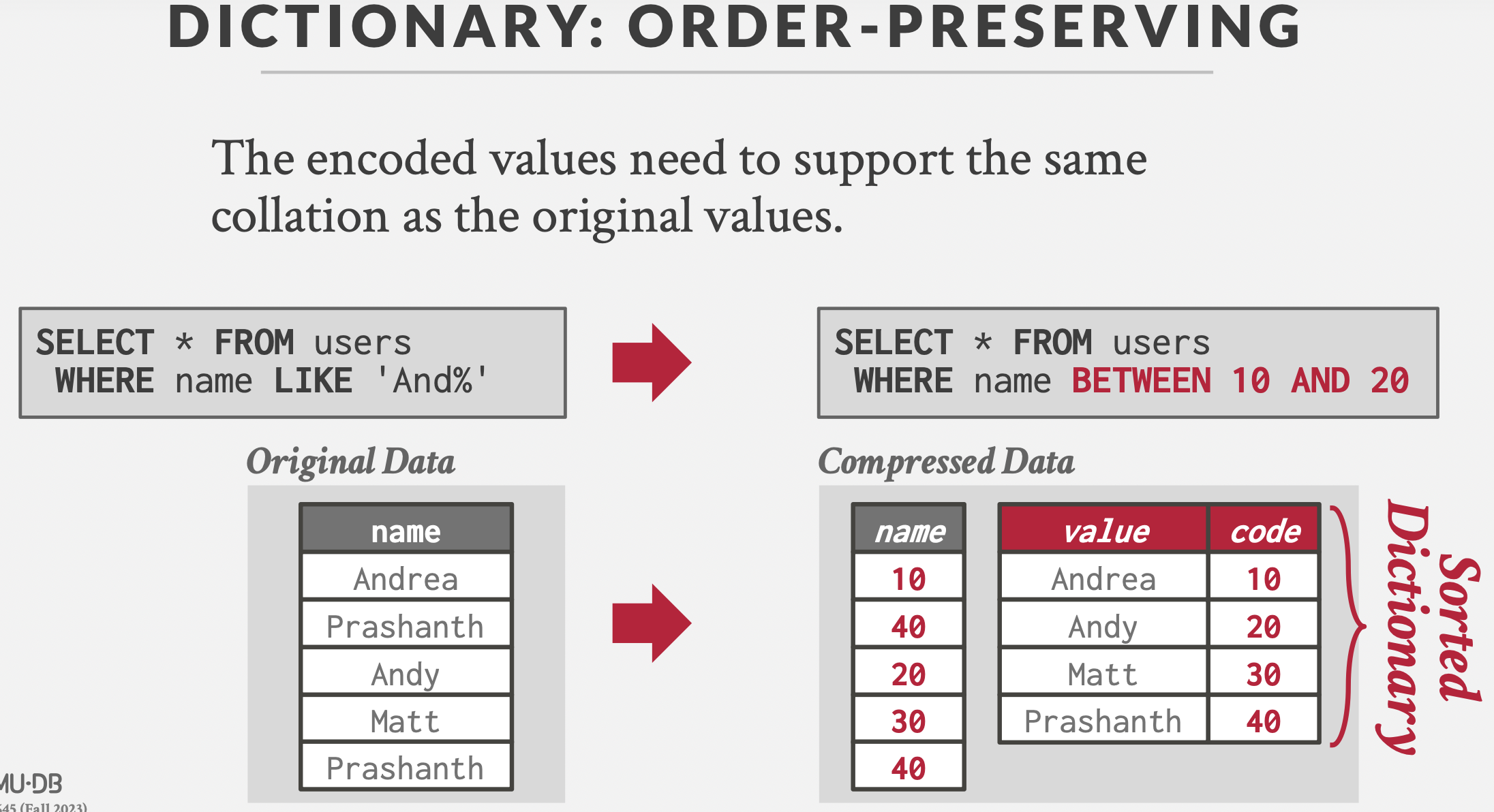
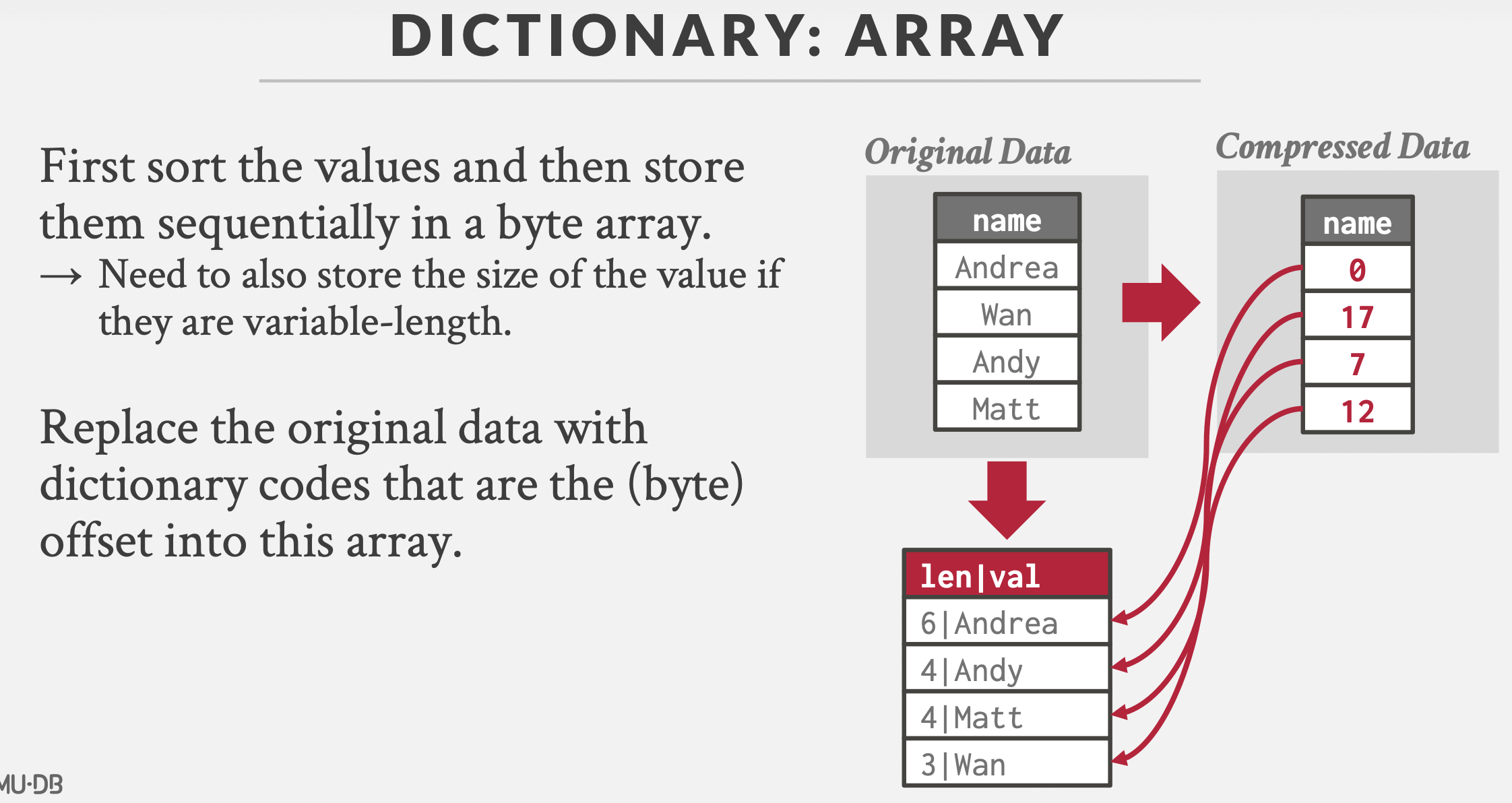
字典映射的实现方式:数组。【哈希表不支持范围查询,B+树内存消耗大】
内存缓冲区
基本介绍
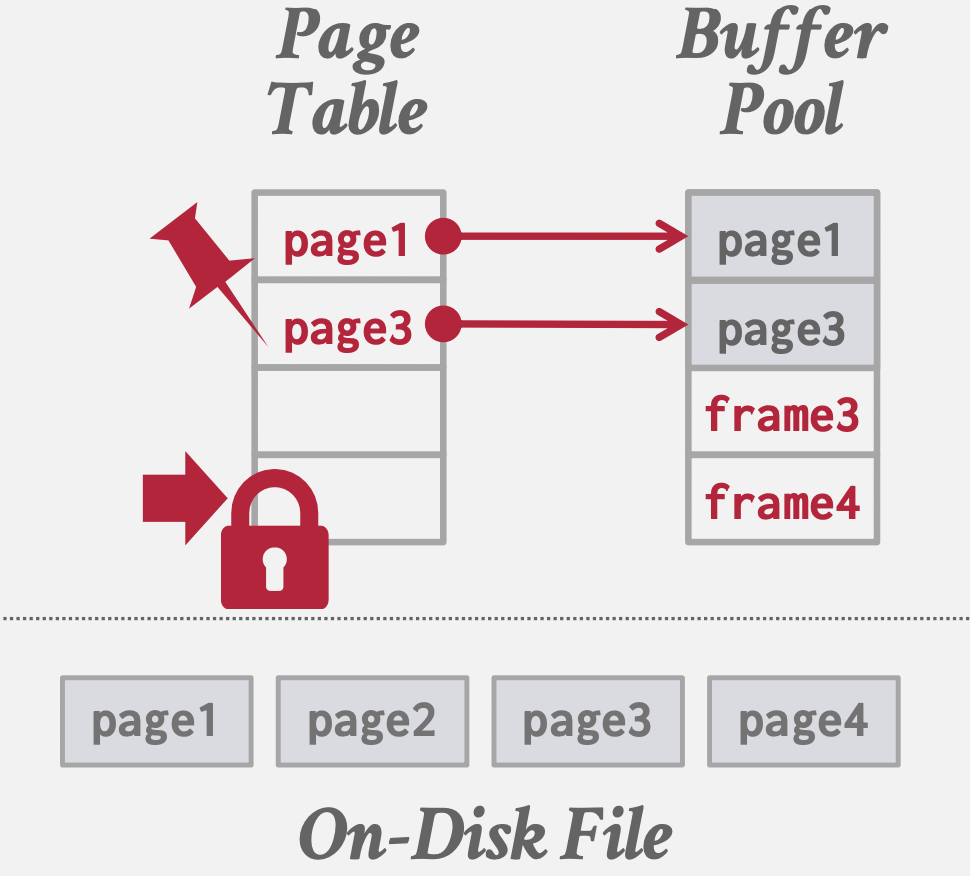
一般是一个固定大小的Hash table,同时附带一些元数据:
- 脏页标志位
- Pin/引用计数
- 访问控制信息
- Lock/Latch
DBMS的缓冲区不采用操作系统的页缓冲区,而是通过直接IO来读取硬盘,自己管理缓冲区,目的是:
- 避免重复的页拷贝
- 自定义替换策略
- 对IO更有掌控度
替换策略
目标:正确性,准确性,速度,元数据开销小
-
LRU
-
CLOCK:近似的LRU,开销小,一个Page只需要维护一个bit
-
LRU-K:记录最近K次的访问时间(解决顺序洪泛问题;可以再维护一个Hash表,记录驱逐时间,避免新热点页由于缺乏历史信息一直被驱逐)
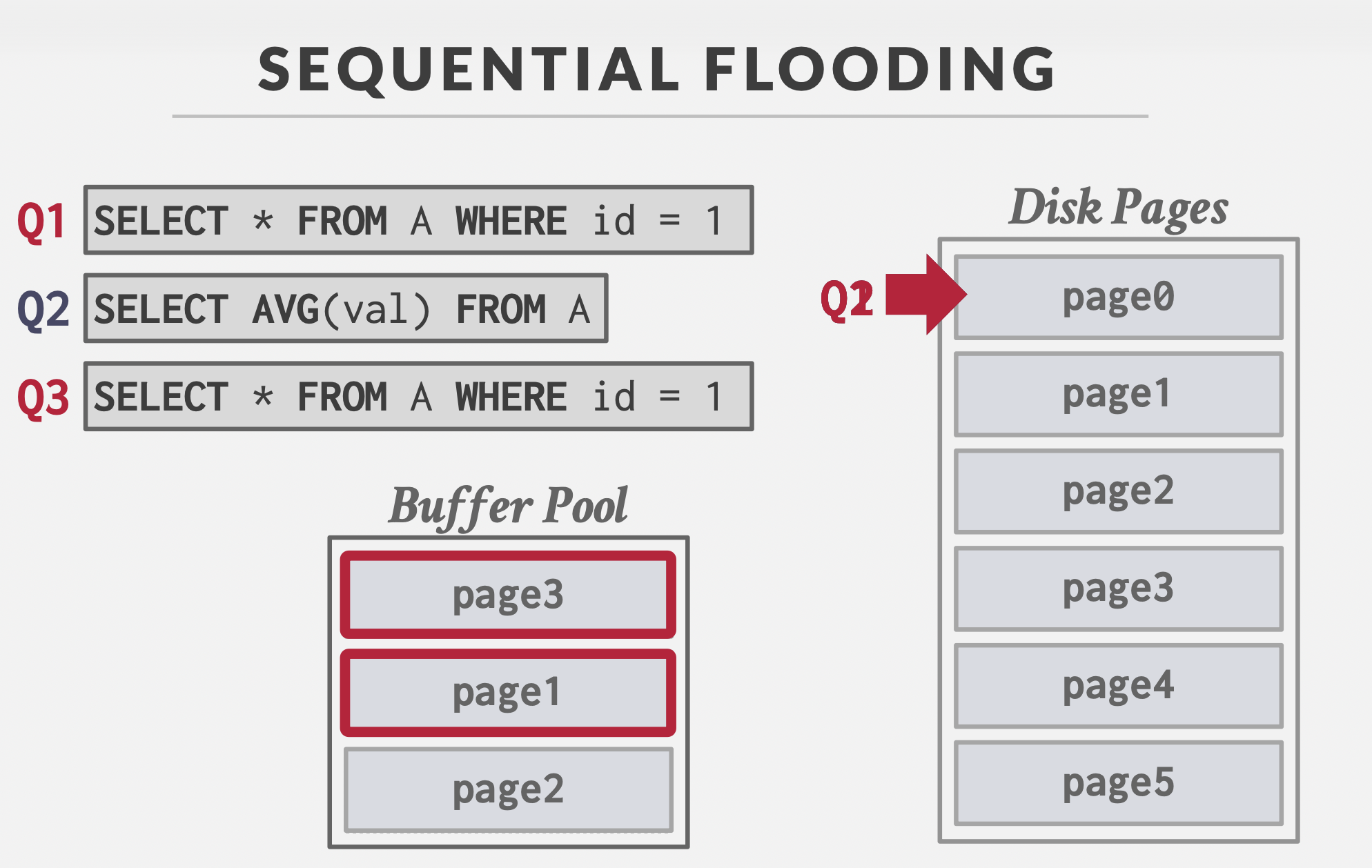
-
MySQL双列表:近似的LRU-K

脏页后台定期写回,无需考虑写会脏页的开销。
缓存优化
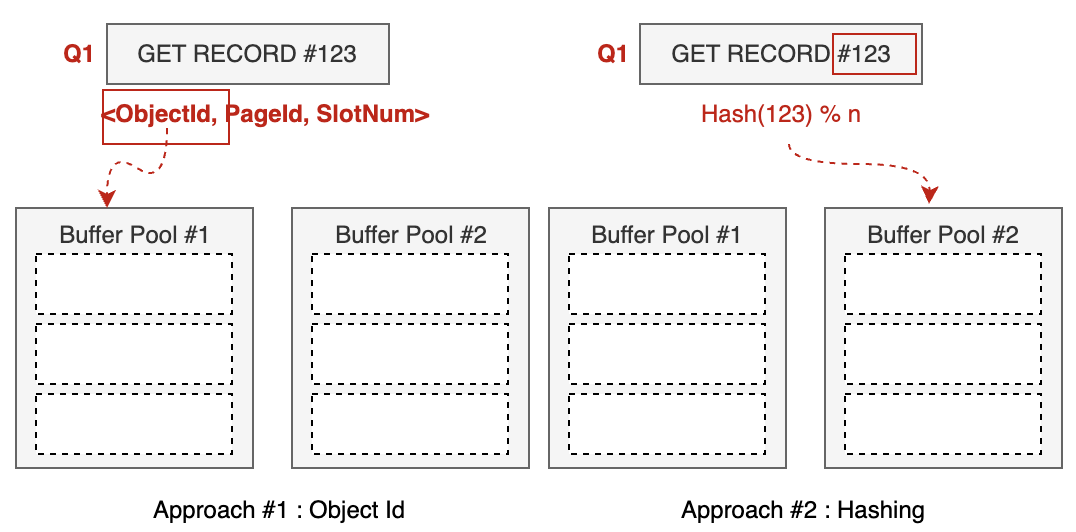
1. 多缓冲区:对象ID映射;哈希映射。
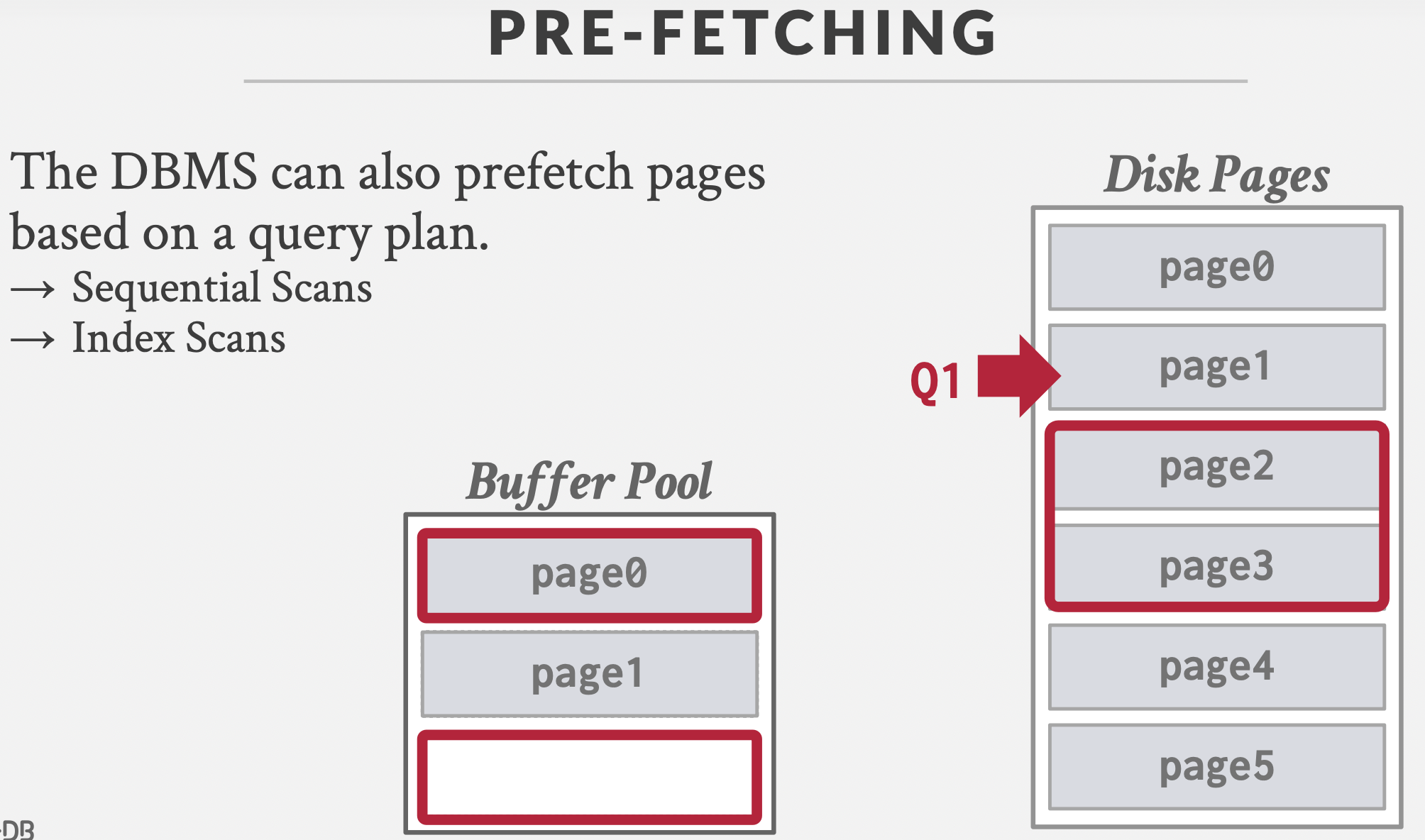
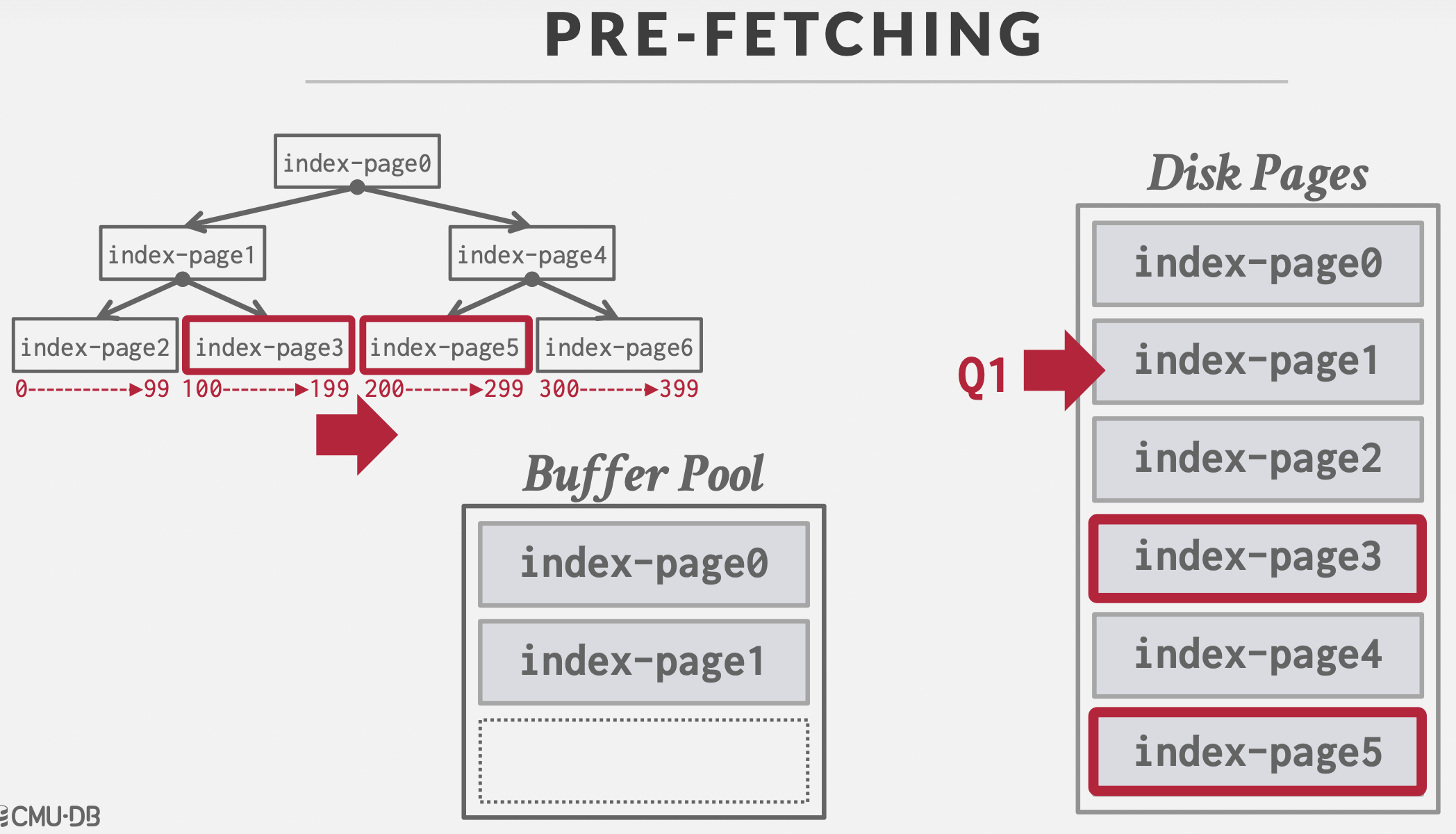
2. 预取:顺序扫描;索引扫描。
3. 扫描共享(同步扫描):减少扫描次数,避免缓存颠簸;如何使得结果一致是个挑战。

4. 旁路缓存:不缓存顺序扫描结果或是临时数据(join,sorting),也叫轻量扫描(Light Scans)。
总结:顺序扫描时,需要预取(pre-fetch)。
- 结果进缓存:LRK-K或近似的LRU-K
- 结果不进缓存:旁路缓存(放到一个临时缓冲区)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号