11-3 关联容器操作
11.3.0 关联容器中额外的类型别名


11.3.1 关联容器迭代器
map的关键字是const的
解引用时得到的是value_type(即元素类型)的值的引用
map类型的元素是pair,map的vaule_type是pair<const first, second>
即不能通过迭代器改变map的键,只能改变值
//获得指向word_count的元素的迭代器
auto map_it = word_count.bengin();
//*map_it是一个指向pair<const string, int>对象的引用
cout<<map_it->first; //打印元素关键字
cout<<" "<<map_it->second; //打印元素的值
map_it->first = "new key"; //错误:关键字是const的
++map_it->second; //正确:可以改变元素的值
set的关键字是const的
set<int> iset = {0,1,2,3,4,5};
set<int>::iterator set_it = iset.begin();
if(set_it != iset.end()){
*set_it = 42; //错误:set中的关键字是const的
cout<<*set_it<<endl; //正确:可以读取关键字
}
遍历关联容器
和顺序容器一样,可以用迭代器遍历关联容器
//获得一个指向首元素的迭代器
auto map_it = word_count.begin();
//比较当前迭代器和尾后迭代器
while(map_it != word_count.end()){
//解引用迭代器,打印关键字-值对
cout<<map_it->first<<" "
<<map_it->second<<endl;
++map_it; //递增迭代器,移动到下一个元素
}
关联容器与泛型算法
我们通常不对关联容器使用泛型算法
- 关键字是 const这一特性意味着不能将关联容器传递给修改或重排容器元素的算法,因为这类算法需要向元素写入值,而set类型中的元素是const的,map中的元素是pair,其第一个成员是const的。
- 关联容器可用于只读取元素的算法。但是,很多这类算法都要搜索序列。由于关联容器中的元素不能通过它们的关键字进行(快速)查找,因此对其使用泛型搜索算法几乎总是个坏主意。例如,我们将在11.3.5节(第388页)中看到,关联容器定义了一个名为find 的成员,它通过一个给定的关键字直接获取元素。我们可以用泛型find算法来查找一个元素,但此算法会进行顺序搜索。使用关联容器定义的专用的find成员会比调用泛型find快得多。
在实际编程中,如果我们真要对一个关联容器使用算法,要么是将它当作一个源序列,要么当作一个目的位置。
例如,可以用泛型copy算法将元素从一个关联容器拷贝到另一个序列。类似的,可以调用inserter将一个插入器绑定(参见10.4.1节,第358页)到一个关联容器。通过使用inserter,我们可以将关联容器当作一个目的位置来调用另一个算法。
11.3.2 添加元素
insert()成员:
- 添加元素
- 添加元素范围
vector<int> ivec = {2,4,6,8};
set<int> set2;
set2.insert(ivec.begin(), ivec.end()); //接受一对迭代器
set2.insert({1,2,3,4}); //接受一个初始化器列表
向map添加元素
时刻记住:map的元素是pair
如果没有现成的pair,就在insert中构造pair
//向word_count中添加word的四种方法
//构造pair的四种方法
word_count.insert({word,1}); //花括号初始化
word_count.insert(make_pair(word,1)); //make_pair
word_count.insert(pair<string,int>(word,1)); //直接构造
word_count.insert(map<string, int>::value_type(word,1)); //同上

检测insert的返回值
统计单词在输入中的出现次数在之前已经用map作为关联数组的性质实现过
map<string, int> word_count;
string word;
while(cin>>word){
++word_count[word];
cout<<word<<" "<<word_count[word]<<endl;
}
现在用insert及其返回值再实现一次
map<string, int> word_count;
string word;
while(cin>>word){
//插入一个元素pair,关键字为word,值为1
//如果word已在word_count中,insert什么也不做
//返回的pair.second==0,此时要加word的计数器
//word不在word_count中,则插入{word,1}
auto ret = word_count.insert({word,1});
if(!ret.second)
++ret.first->second;
cout<<word<<" "<<word_count[word]<<endl;
}
- ret:一个pair
- ret.first:一个map迭代器,指向map中的元素,该元素是一个pair
- ret.first->:解引用得到map的元素pair
- ret.first->second:map中元素的值的部分
- ++ret.first->second:递增此值
向multiset或multimap添加元素
对允许重复关键字的容器,接受单个元素的insert操作返回一个指向新元素的迭代器.这里无须返回一个bool值,因为insert总是向这类容器中加入一个新元素。
11.3.3 删除元素
关联容器有三个版本的erase
- 迭代器:返回void
- 迭代器对:返回void
- 关键字:返回删除的元素的数量,如果不是multi则只为0或1

11.3.4 map的下标操作
map和multimap提供下标操作和对应的at函数
与其他下标运算符不同的是:
如果关键字不在map中,会创建一个元素插入到map中,并对关联值进行值初始化
map <string, size_t> word_count;
//插入一个关键字为Anna的元素,关联值进行值初始化,并把1赋给它
word_count["Anna"] = 1;
上述代码执行如下操作:
- 在word_count中搜索天键字为Anna的兀系,未找到。
- 将一个新的关键字-值对插入到word_count中。关键字是一个const string,保存Anna。值进行值初始化,在本例中意味着值为0。
- 提取出新插入的元素,并将值1赋予它。

所以在单词计数循环中,如果不希望添加不在map中的单词,就不能使用下标运算,而要使用insert
11.3.5 访问成员
对于允许重复的关联容器来说,count会比find做更多的事情,不仅可以知道是否存在元素,还可以知道有几个元素
set<int> iset = {0,1,2,3,4,5};
iset.find(1); //返回一个迭代器,指向key==1的元素
iset.find(11); //返回一个迭代器,其值为iset.end()
iset.count(1); //返回1
iset.count(11); //返回0

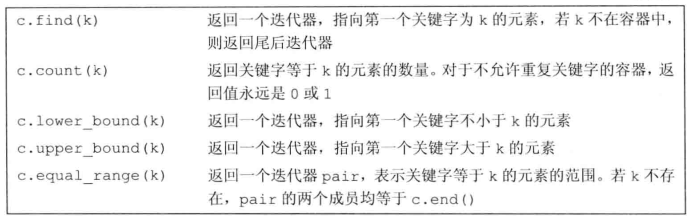
查找时用find代替下标
用下标时,没有的元素会插入;如果不希望这件事情发生,那么应该用find
//表示没找到,此时不会添加"Anna"关键字
if(word_count.find("Anna") == word.count.end());
在multimap中查找元素()
方法一:find + count
原理:相同关键字的pair在multimap中会相邻存储,multiset同理
//查找一个作者都写了哪些书
string search_item = "Anna"; //要查找的作者
auto entries = authors.count(search_item); //元素的数量
auto iter = authors.find(search_item); //此作者的第一本书
while(entries){
cout<<iter->first<<" "<<iter->second<<endl; //打印
++iter; //前进到此作者的下一本书
--entries; //循环控制:记录已经打印了多少本书
}
方法二: 迭代器方法
lower_bound和upper_bound
当元素在容器内时:
- lower_bound指向第一个具有该关键字的元素
- upper_bound指向最后一个具有该关键字的元素的后一个元素
当元素不在容器中时:
- lower_bound == upper_bound
- 都指向关键字的第一个安全插入点
//beg和end表示此作者的著作元素的范围
for(auto beg = authors.lower_bound(search_item),
end = authors.upper_bound(search_item);
beg != end; ++beg)
cout<<beg->first<<" "<<beg->second<<endl; //打印每个题目
equal_range函数
equal_range:
- 输入关键字
- 输出一个pair
- pair->first == beg
- pair->second == end
//pos是一个pair,保存迭代器对
for(auto pos = authors.equal_range(search_item);
pos.first != pos.second; ++first)
cout<<pos.first->first<<" "<<pos.first->second<<endl; //打印:”作者 著作名“

 浙公网安备 33010602011771号
浙公网安备 33010602011771号