剖析虚幻渲染体系(14)- 延展篇:现代渲染引擎演变史Part 4(结果期)
14.5 结果期(2016~2022)
时间晃荡一下来到了2016年之后,这时期的游戏引擎朝着影视级、更加物理、更高效的方向发展。且看后面分析。
14.5.1 图形API
14.5.1.1 DirectX
DirectX在2016年之后主要发力于DirectX 12及相关子本版的更新,包含ID3D12Device、Shading Model 6.x、光线追踪、VRS、根签名、资源、同步、调试、PSO、命令列表、HLSL等方面的新增或改进。具体可参见:DirectX - Wikipedia和What's new in Direct3D 12。
14.5.1.2 OpenGL
OpenGL在2016年之后发布了4.6版本,新增或改进了SPIR-V、Multi-draw indirect、顶点着色器获取数据、统计和转换反馈溢出查询、各向异性过滤、夹紧多边形偏移、创建不报错的OpenGL上下文、原子计数器的更多操作、避免不必要的发散着色器调用等特性。
而OpenGL ES在此期间几乎纹丝不动。
14.5.1.3 Vulkan
在2016年及之后,Vulkan发布的版本、时间和特性如下表:
| 版本 | 时间 | 特性 |
|---|---|---|
| Vulkan 1.3 | 2022-01 | 查询给定物理设备可用的扩展、Vulkan Profiles工具解决方案、改进多线程应用程序的验证层性能、新的扩展。 |
| Vulkan 1.2 | 2020-01 | 时间轴信号量、形式化内存模型、线程同步和内存操作语义、描述符索引、多个着色器重用描述符布局、HLSL着色器的深入支持。 |
| Vulkan 1.1 | 2018-03 | subgroup、渲染和显示无法访问或复制的资源、多视图渲染、多GPU、16位内存访问、HLSL内存布局、YCbCr颜色格式、SPIR-V 1.3。 |
14.5.1.4 Metal
Metal作为Apple的自家图形API,2017年6月5日,苹果在WWDC上发布了第二个版本的Metal,由macOS High Sierra、iOS 11和tvOS 11支持。Metal 2不是Metal的单独API,由相同的硬件支持。Metal 2能够在Xcode中实现更高效的评测和调试,加速机器学习,降低CPU工作负载,支持macOS上的虚拟现实,尤其是Apple A11 GPU的特性。
在2020年WWDC上,苹果宣布将Mac迁移到Apple Silicon。使用Apple Silicon的Mac将采用Apple GPU,其功能集结合了之前在macOS和iOS上可用的功能,并将能够利用针对Apple GPU基于分块的延迟渲染(TBDR)架构定制的功能。
Metal旨在提供对GPU的低开销访问,命令预先编码,然后提交给GPU进行异步执行。应用程序控制何时等待执行完成,从而允许应用程序开发人员在GPU上执行命令时通过编码其它命令来增加吞吐量,或者通过显式等待GPU执行完成来节省电源。此外,命令编码与CPU无关,因此应用程序可以独立地对每个CPU线程的命令进行编码。渲染状态是预计算的,允许GPU驱动程序在执行命令之前提前知道如何配置和优化渲染管线。
Metal为应用程序开发人员提供了创建资源(缓冲区、纹理)的灵活性。可以在CPU、GPU或两者上分配资源,并提供更新和同步已分配资源的功能。Metal还可以在命令编码器的生命周期内强制执行资源的状态。在macOS上,Metal可以让应用程序开发人员自行决定要执行哪个GPU,可以选择CPU的低功耗集成GPU、分离式GPU(在某些MacBook和Mac上)或通过Thunderbolt连接的外部GPU。应用程序开发人员还可以优先选择在哪个GPU上执行GPU命令,并提供某个命令在哪个GPU上执行效率最高的建议。
14.5.2 硬件架构
在2016年之后,Nvidia先后发布了Pascal、Volta、Turing等架构的GPU,其中Turing架构配备了名为RT Core的专用光线追踪处理器,能够以高达每秒10 Giga Rays的速度对光线和声音在3D环境中的传播进行加速计算。Turing架构将实时光线追踪运算加速至上一代Pascal 架构的25倍,并可以以高出CPU30多倍的速度进行电影效果的最终帧渲染。

Turing架构的SM结构图。包含了用于光线追踪的RT Core和用于AI的Tensor Core。
Multi Adapter Integrated + Discrete GPUs由Intel呈现,阐述了2020年适用于集成和分离GPU的多适配器技术,包含集成+分离的机会、D3D12多适配器背景、实用非对称多GPU等。
集成图形的机会:许多游戏PC既有集成的GPU,也有离散的GPU,集成电路通常是空闲的,集成图形需要大量计算!而且Intel有一个扩展,可以帮助提高性能。然而,D3D12多适配器有许多缺陷,对于一类算法,有一种方法可以利用集成的GPU,通过适度的工程努力获得更高的性能。
D3D12多适配器支持,D3D支持多GPU的两种方式:
- 链接显示适配器(LDA, Linked Display Adapter)。显示为带有多个节点的一个适配器(D3D设备),跨节点/在节点之间透明地复制或使用资源,通常是对称的,即同一个的GPU。
- 显式多适配器。跨适配器共享资源有很多限制,可能是不对称的,这正是Intel正在做的。
多适配器方法:
- 共享渲染:分割帧、交替帧、棋盘格,非对称GPU只有很低的投资回报率。
- 后处理:CMAA、SSAO、相机效果…需要跨PCI总线两次。
- 遮挡剔除、物理、人工智能。生产者-消费者,从渲染运行异步时效果更好。
集成图形存储器是系统存储器,iGPU可以使用跨适配器共享资源,几乎不受损害:

D3D12跨适配器的资源:资源由绑定到适配器的D3D设备分配,如何在适配器之间传输数据?共享的、跨适配器的资源,必须放置在跨适配器共享堆中。堆创建的步骤:调整数据大小,在任意设备上创建共享堆,创建句柄。
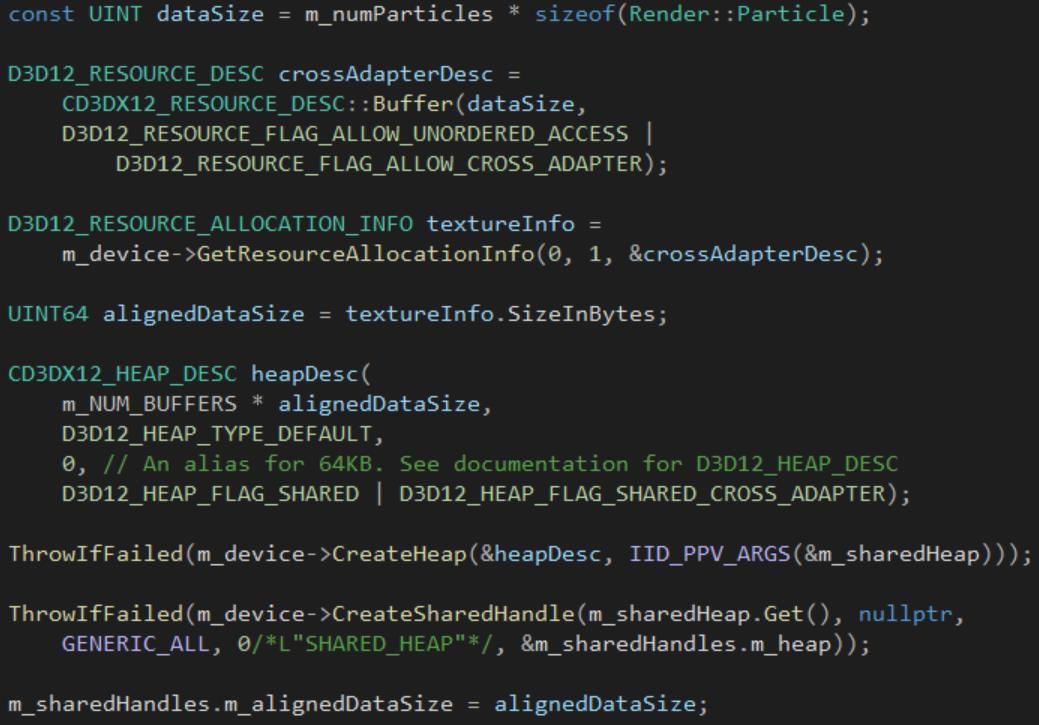
跨适配器资源创建:打开第二台设备上的句柄,对两个适配器都在跨适配器堆中创建放置的资源,使用相同的对齐方式和大小。
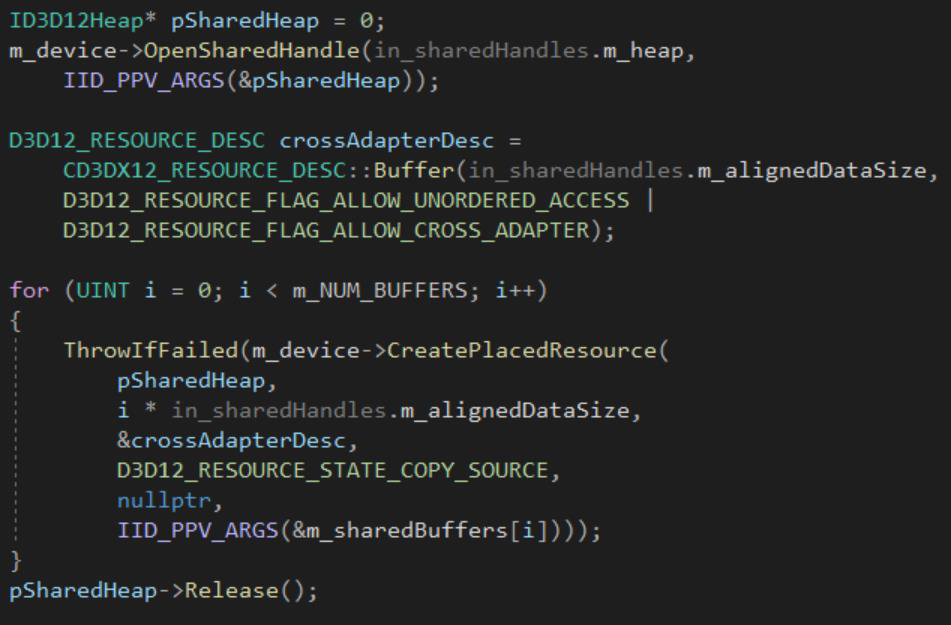
粒子案例中的异步计算:乒乓缓冲区保存源状态和目标状态,读取初始状态,计算下一个状态,呈现结果,通过在计算下一个状态时呈现前一个状态来并行化状态(异步计算),缓冲区计数与交换链长度匹配。
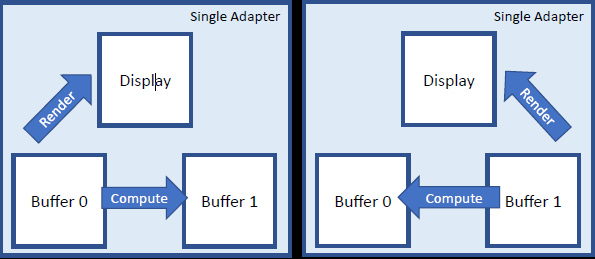
多适配器的添加复制阶段:想法是每个适配器都是乒乓缓冲区,形成并行管线:2个状态n的读取者,计算状态n+1,渲染状态n-1。
多适配器的Pong:每帧交换缓冲区。
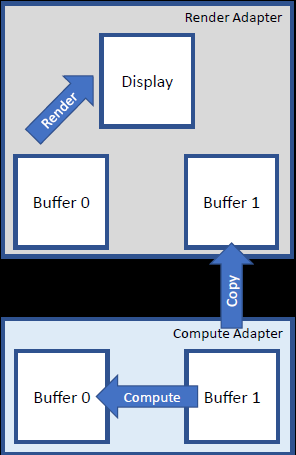
资源分配:渲染缓冲区使用局部适配器堆(Default、Committed),适配器离散存储器,适配器首选布局。计算缓冲区使用跨适配器堆、放置的交叉适配器,CPU存储器、线性布局。
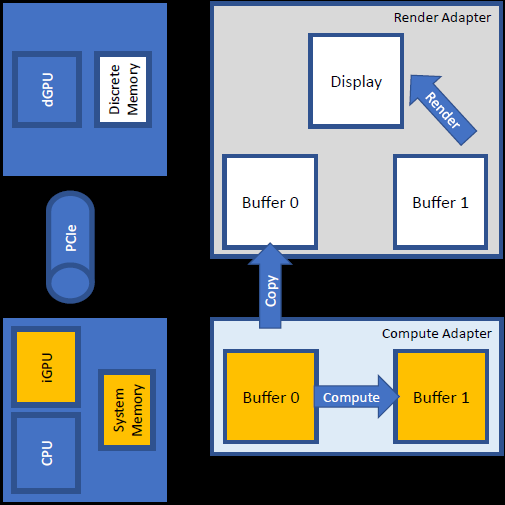
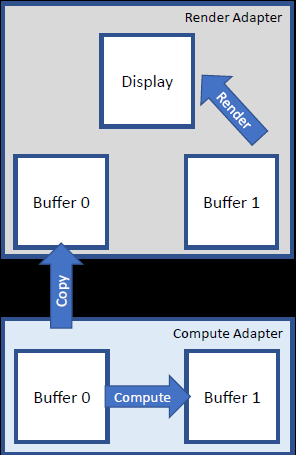
复制队列:关键想法是分离适配器上的复制队列,从系统内存复制到分离内存,集成内存是系统内存,所以这是一种逻辑安排,显式复制阶段松散的时序。
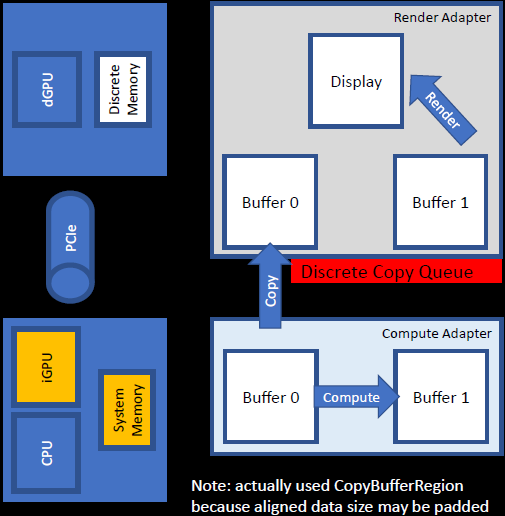
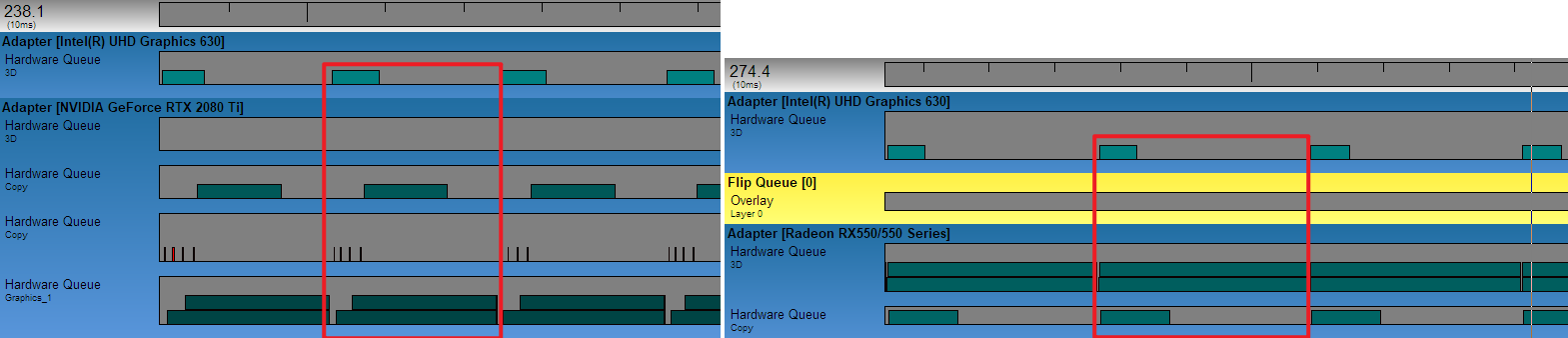
利用这种耦合+分离的多GPU架构,可以更加高效地处理资源创建、跨适配器同步、命令队列等操作。获得的结果在GpuView显示并行运行的阶段,两个例子,全屏应用,当3D占主导地位时,就有时间进行计算和复制,在某些情况下,复制可能占主导地位(帧时间>渲染+计算):
在以下情况下,此技术最适用:渲染GPU已饱和,纯生产者-消费者(数据只通过总线一次),任务可以完全卸载(无需协作),渲染不等待(管线有呼吸空间),最好是允许计算>1帧,许多异步计算任务都符合这种模式。请注意PCIe带宽:Gen3 x16是16GB/s,400万个粒子,每个粒子float4:64MB,16GB/64MB=256Hz最大帧速率,一些GPU/Config是x8:半带宽,尽可能降低数据传输大小!按使用情况拆分数据缓冲区具有性能优势。这个方案不仅适用于粒子,还可以是物理、网格变形、人工智能、阴影,许多异步计算任务都符合这种模式,检查英特尔集成图形!
14.5.3 引擎演变
14.5.3.1 综合演变
2016年,Towards Cinematic Quality, Anti-aliasing in Quantum Break谈及了影视级的质量和抗锯齿技术,比如间接照明、参与介质、几何体锯齿和镜面锯齿。
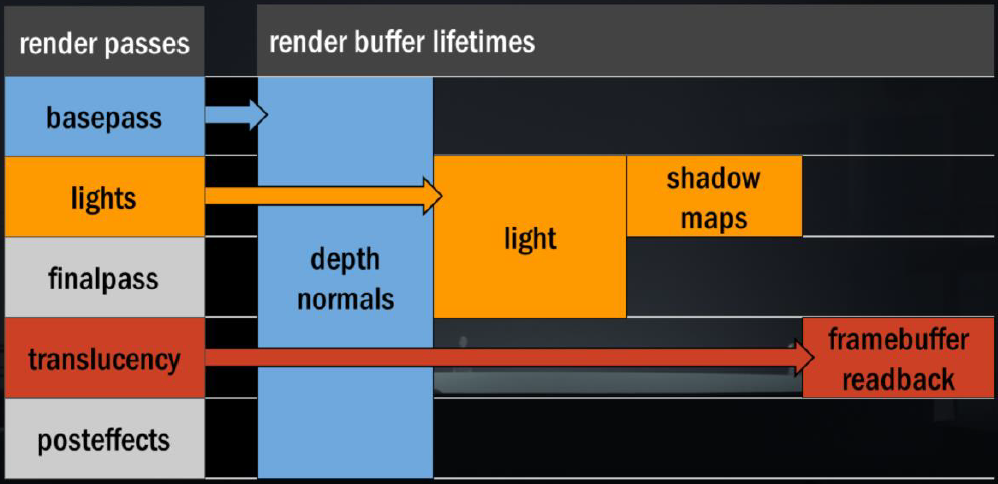
Light pre-pass就像完全延迟一样,想法是将照明与几何体分离,但与完全延迟不同的是,几何图形绘制两次。第1个Pass写入照明所需的一切数据,第2个Pass读取光源,并添加其它材质。

Light pre-pass的优势是用于照明的几何缓冲区占用少,易于在第2个几何通道上添加材质变化,通常在第2个几何通道中与MSAA结合。第2个几何通道决定使用什么样的照明采样,常用的方法是将当前几何图形与以前的几何图形进行比较,绘制几何缓冲区并选择最接*的匹配。当有匹配时,效果非常好,当没有好的样本可供选择时,就会出现问题。在头发和树叶着色器中,可以使用在alpha测试输出中使用棋盘格模式,但alpha测试输出上的棋盘格图案难以控制,要么在半分辨率照明下运行,要么开始丢失样本。多层的alpha测试让问题变得更加困难。
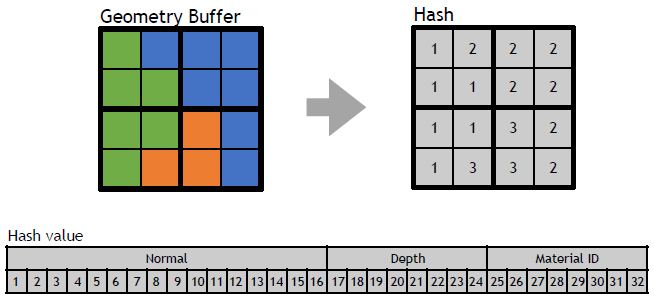
保存相关样本是需要解决的关键问题,希望可以使用4xMSAA几何缓冲区,但直接照明开销太大。文中给出的MSAA解决方案是使用几何分簇(Geometry Clustering),将几何缓冲区渲染到4xMSAA目标,将样本从4xMSAA减少到非MSAA(从4个样本减少到1个样本),在减少的样本上运行昂贵的着色,接着重建为4x MSAA,更多的几何样本(成本相对较小),更少的光照样本(计算繁重)。具体过程如下:
-
构造亚像素偏移。
- 计算16个样本的哈希值。32位值,其中16位法线值、8位深度、8位材质ID。
![]()
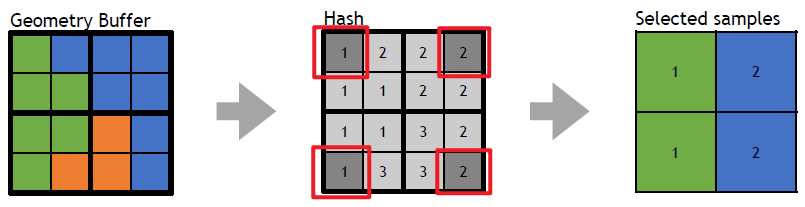
- 选择初始的4个样本。首先在角落里选择四个样本,通过选择角落,最大限度地增加独特样本的数量。
![]()
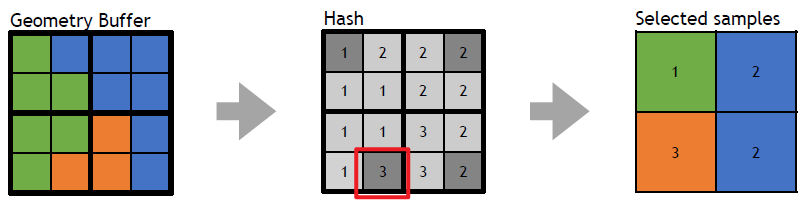
- 重新分配样本。对于每个选定的样本,测试是否存在重复,如果存在,用未选择的值替换重复项,确保避免不必要的重组,与屏幕保持一致是有道理的。
![]()
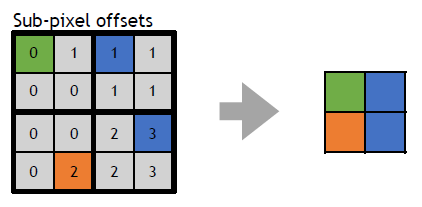
- 保存亚像素偏移。每2x2像素区域有32位,每个MSAA样本有2位,提供最终2x2输出上的采样位置,像素着色器输出一半大小的360p图像。
![]()
-
下采样。
- 读取亚像素偏移。每个2x2的tile共享单个32位亚像素偏移,在普通像素着色器中运行全屏通道。输出是最终的几何缓冲区,将用于AO、SSR、GI和照明。
- 先写入或*均值。输出第一个匹配项,*均值给出的结果稍好一些。
![]()

几何分簇和非MSAA的效果对比:

在处理第2个几何通道时,亚像素偏移提供每个MSAA采样使用哪个光照样本,读取基于2位偏移的光照样本。无需计算当前样本的几何特性,以便与几何缓冲区进行比较。在像素着色器中使用样本覆盖率(HLSL中的SV_Coverage),使用覆盖样本的*均值可以提高质量,但成本要高得多,文中使用firstbitlow和采样一次。
几何分簇、非MSAA和TAA的效果对比:

文中还涉及了时间抗锯齿和上采样。具有亚像素相机偏移的4帧,使用旋转的网格偏移。每帧将前三帧变换为当前投影,以尽可能减小帧间的增量,在单个计算着色器通道中共享夹紧的数据。对于TAA的夹紧,在当前帧计算相邻像素的最小/最大值,扩大了速度小的范围,以抑制亚像素偏移相机引起的闪烁。夹紧xyY并只扩展亮度,以便均衡锯齿和鬼影。对于TAA的上采样,组合4帧的结果,之前的帧已被重投影和夹紧,由于帧之间的采样是交错的,因此是上采样的良好位置,线性采样的效果出人意料地好。

另外,还大量使用了周期性噪点,因为TAA是4个连续帧的*均值。噪点过大可能会导致邻域夹紧出现问题,使用累积缓冲器降低噪点,在序列噪点中效果良好。
总之,具有4x MSAA的几何缓冲区,为720p图像提供了370万个分布良好的几何体样本。在使用较少样本计算照明时,需要进行高质量的下采样,以保留相关数据,下采样产生的亚像素偏移可用于其它效果。MSAA仍然与几何体锯齿相关,拥有更多更好的分布样本非常有意义。存储和重投影N个历史帧,为TAA和高端提供了一个良好的框架,输入过多变化的TAA会破坏系统,每帧都需要足够稳定。TAA将锯齿转换为鬼影,更紧的夹紧边界可能会导致闪烁。
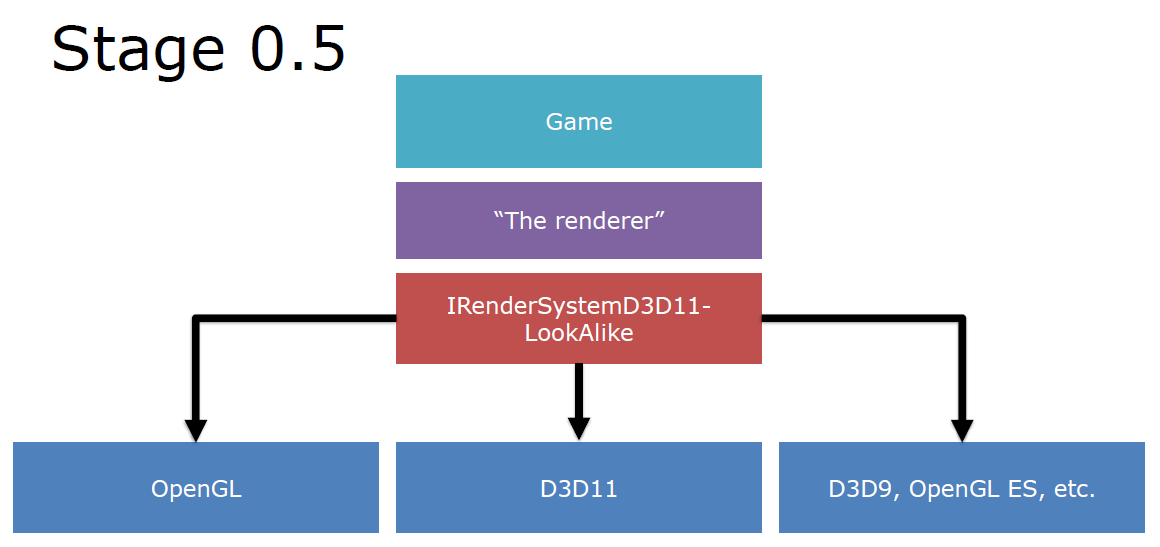
D3D12 & Vulkan: Lessons Learned在DX12和Vulkan发布的一年后呈现的演讲,阐述了基于新生代图形API的引擎架构演变以及带来的影响。D3D11驱动程序经过了很好的优化,利用掌握的知识可以超越D3D11驱动程序,发明D3D12并不是为了在上面编写遗留API驱动程序。若将游戏引擎比作火箭,则DirectX 12和Vulkan可视作助推器:

在没有DX12和Vulkan的图形API之前的游戏引擎可视作是0~0.5阶段,没有加速器:
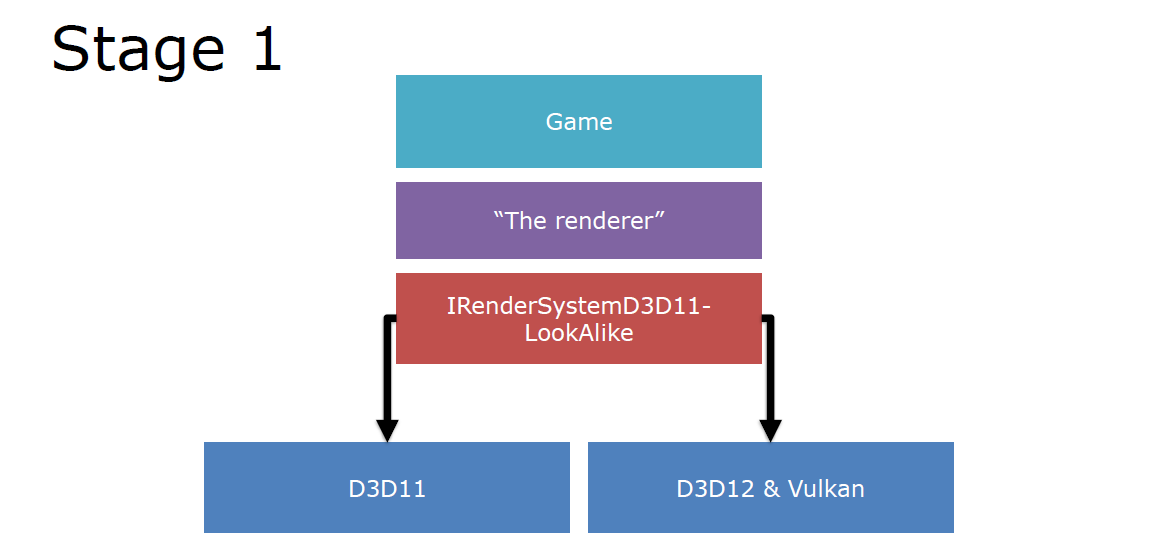
若融入DX12和Vulkan之后,有了一定的加速器,此时升级到了1.0阶段:
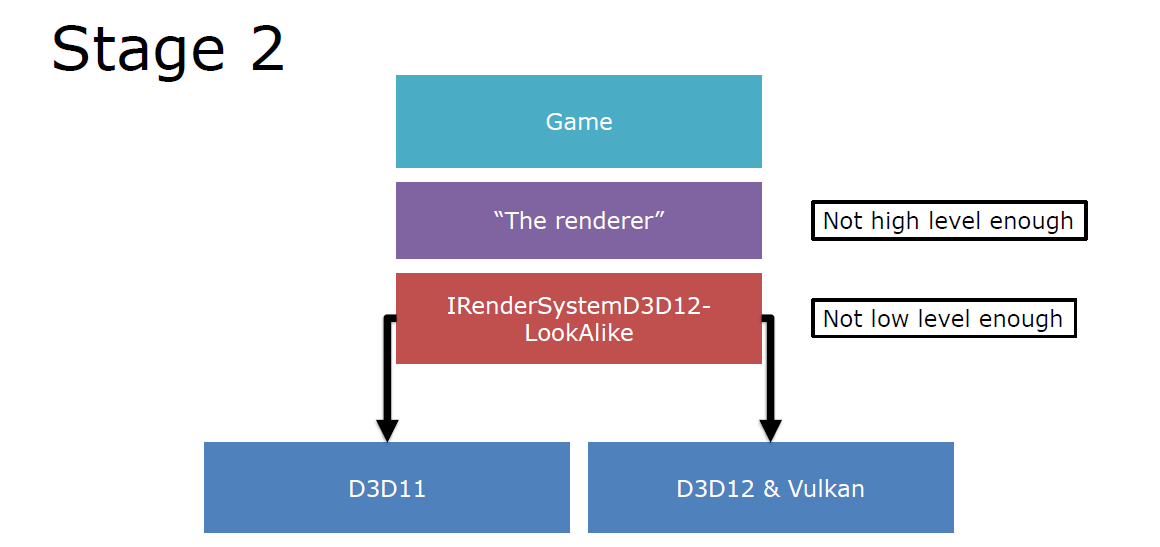
但此时的渲染器和图形API之间耦合过多,不够高级别或低级别,只能看作是有限加速的2.0:
将图形API下移,抽离出更底层的图形抽象层之后,则可以升级到3.0,获得了更大的助力器:
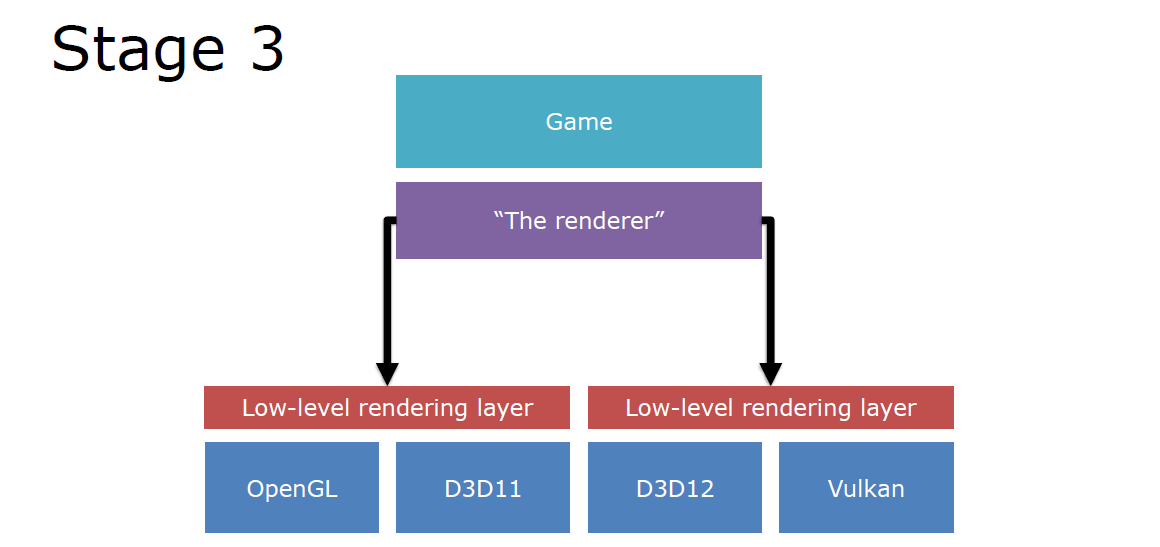
当时的游戏引擎正在过渡以支持Vulkana和D3D12,仍然需要D3D11支持,大多数引擎处于第1阶段和第2阶段之间。要充分利用所有API,需要进行大量思考,多队列支持需要额外的工作,需要兼容到D3D11,建议以D3D12/Vulkana为目标,并在D3D11上运行。
面向未来的设计,本文将指出常见的设计问题,把引擎准备好,将知识转化为更好的表现。
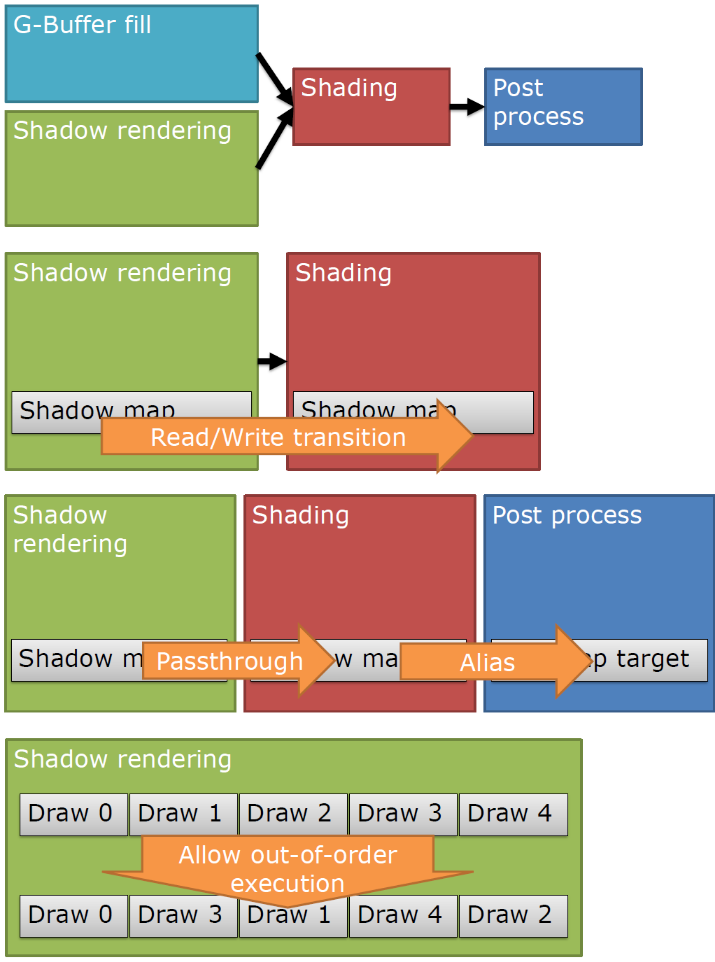
屏障控制:屏障是D3D12/Vulkan中的一个新概念,悲哀的事实是每个人理解错了。两个失败案例:太多或太宽导致性能差,缺失的屏障导致损坏(Corruption)。D3D11驱动在引擎下完成了屏障的这项工作——而且做得很好。到底什么是屏障?
- 将目标渲染转换为纹理。可能需要解压(和缓存刷新),供应商和GPU次代之间会发生什么变化?可能是无操作,可能是等待空闲,可能是完全缓存刷新。
- 将UAV转换成资源。如果做得不好,则需要产生刷新或等待空闲,如果操作正确,这些转换可以是免费的。
缺失的屏障:格式问题——GPU/特定于驱动程序的损坏,同步问题——依赖时间的损坏。
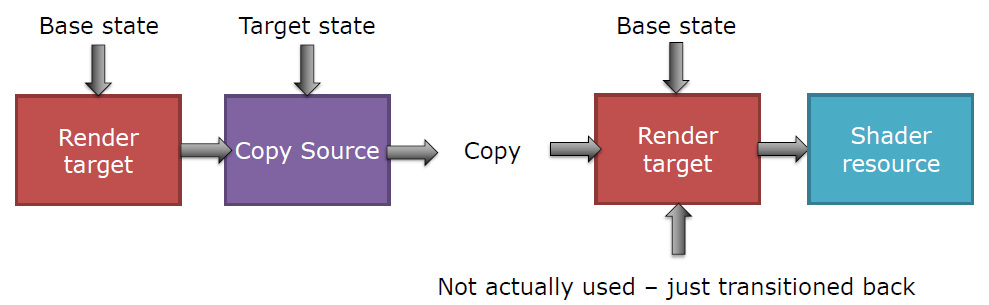
子资源(Subresource)需要单独跟踪,如下采样、阴影图集。如果转换所有的子资源,应该使用D3D12_RESOURCE_BARRIER_ALL_SUBRESOURCES,而不是逐个转换。对于放置资源和初始状态,使用前必须清除作为放置资源等创建的渲染目标,直接进入清除状态,不要从一些随机状态和转换开始。下图存在“基本状态”或冗余转换,即转换到目标状态然后恢复回基本状态(没有实际使用,只是转换回来了):
有意思的屏障:
- ResourceBarrier(0, nullptr),即没什么变化,表明状态追踪做了错误的事情。
- 前一状态等于下一状态。发生的事情比你想象的要多——说不就行了。
- 永远记住——驱动假设你做的是最佳的事情,而不是通过驱动自身的任何启发式!
不必追踪所有资源状态,99%的资源是不可变的——只读,找到过渡点——通道的结束时间,在此处批处理屏障,只转换必需的屏障。
屏障调试技巧:
- 有一个写/读位。
- 记录所有转换,Grep和spreadsheet是你的朋友,检查转换的数量和类型等。
- 转换的数量应按可写资源的数量排序,再说一遍,grep和log是你的朋友,如果屏障数量超过9000,就有些可疑了!
- 存在每件事都有一个屏障(barrier-everything)的模式,与前面描述的“最坏情况”模式相同,但仅供调试使用。
- 确保资源每帧至少处于已知状态一次,例如在帧结束/开始处,将所有事物转换为已知状态,从而解决TAA或阴影图集破坏等问题。
更好的是,给驱动一定时间处理转换,用D3D12中的“Split barrier”,Vulkan的vkCmdSetEvent+vkCmdWaitEvents。
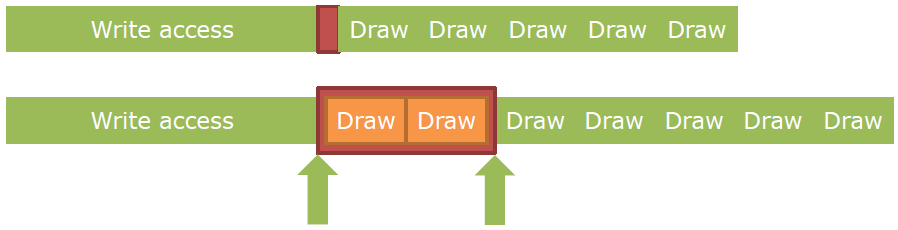
屏障总结:确保转换所有需要的资源(但不是更多),进入能进入的最具体的状态,可以把不同的状态联合起来。
运行控制,如何为GPU喂食(feed,即发送任务),首先提交命令列表,每帧资源更新和跟踪时间。不要通过手动分配内核来限制并行性
,使用任务/作业系统,自动使用所有内核,需要特别注意高效的工作提交和资源同步。

上图发生了什么?疯狂的线程池,CPU任务在最后提交工作,任务边界成为CPU/GPU同步点,任务完成后控制命令列表。

上图:每个栅栏基本上都是在GPU上等待IDL(或多或少)。更好的做法:保护每帧资源,无论如何,都不太可能在命令列表的“中间帧”开启工作,,用一个栅栏保护多个资源。确保作业系统能做到这一点,尽可能多地批量提交,提前提交,使GPU始终处于繁忙状态。理想的提交如下:
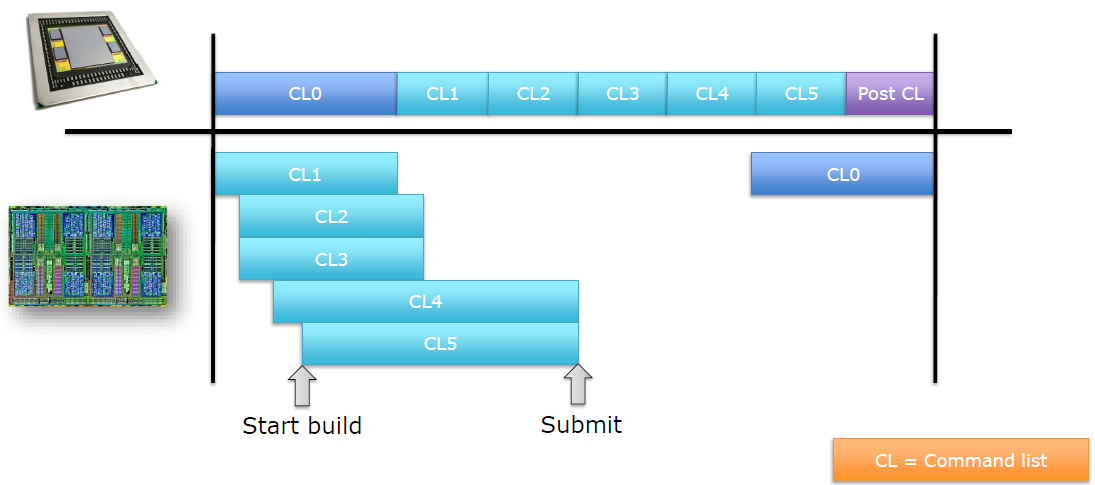
使用多线程设计,恰当地了解工作量和调度:
渲染通道:为帧建立一个高层次的图,通过Vulkan的渲染通道和子渲染通道告诉渲染器,允许驱动选择最佳的调度。允许你很好地表达“don’t care”。
调试提示:可以选择在一次提交中提交所有命令列表,有助于解决时序问题,如果不可能,则需要帧内GPU/CPU的同步。可以选择等待任何命令列表,有助于上传/资源同步,有些资源被破坏了?更新前刷新GPU。
提交总结:以每帧粒度追踪资源,理解帧结构,线程化对于获得良好的CPU利用率至关重要。
Practical DirectX 12 - Programming Model and Hardware Capabilities主要阐述了DX12的最佳实践、硬件特性等内容。
DX12旨在实现最大的GPU和CPU性能,能够投入工程时间!引擎注意事项,需要IHV特定路径,如果做不到这一点,请使用DX11,应用程序替换部分驱动程序和运行时,不能指望同样的代码在计算机上运行良好,所有的控制台、PC都是一样的,考虑特定于架构的路径,注意英伟达和AMD的细节。
工作提交方式有多线程、命令列表、命令束(bundle)、命令队列等。
多线程处理在DX11驱动程序:渲染线程(生产者)、驱动程序线程(消费者),在DX12驱动程序:不会启动工作线程,通过CommandList接口直接构建命令缓冲区。确保引擎在所有的核心上都有扩展,任务图体系结构效果最好,一个提交命令列表的渲染线程,多个并行构建命令列表的工作线程。
命令列表可以在提交其它命令列表时构建命令列表,提交或呈现时不要闲着,允许重复使用命令列表,但应用程序负责停止并发使用。不要把工作分成太多的命令列表,目标是每帧15-30个命令列表、5-10个ExecuteCommandLists调用。每个ExecuteCommandLists都有固定的CPU开销,每个ExecuteCommandLists调用会触发一个刷新,所以,把命令列表批处理起来,尝试在每个ExecuteCommandList中放置至少200μs的GPU工作,最好是500μs,提交足够的工作以隐藏操作系统调度延迟,对ExecuteCommandLists的小调用完成得比OS调度器提交新调用的速度更快。例如下图:

高亮显示的ECL执行时间约20μs,操作系统需要约60μs来调度即将到来的工作,等于有40μs的空闲时间。
命令束(bundle)是在帧中尽早提交工作的好方法,GPU上的束本身没有更快的速度,需要明智地使用它们!从调用命令列表继承状态–充分利用优势,但协调继承状态可能会有CPU或GPU成本。可以获得很好的CPU提升的是NVIDIA:重复同样的5+draw/dispatche用一个bundle,AMD:只有在CPU方面遇到困难时才使用bundle。
硬件状态包含管线状态对象(PSO)和根签名表(RST)。PSO对未使用的字段使用合理且一致的默认值,不允许驱动程序执行PSO编译,使用工作线程生成PSO,编译可能需要几百毫秒。在同一线程上编译类似的PSO,如具有不同混合状态的相同VS/PS,如果状态不影响着色器,将重用着色器编译,同时编译相同着色器的工作线程将等待第一次编译的结果。RST需要尽量保持小,按频率排列。
内存管理方面,需要谨慎和合理使用命令分配器、资源、驻留等操作。另外,还需要谨慎处理栅栏、屏障内同步操作。
GDC2017: D3D12 & Vulkan: Lessons learned是GDC2017上分享的DX12和Vulkan的学习课程。文中提到了引擎使用任务图的变革图例:
在屏障方面,手动操作不再有效,需要更高层次的抽象图,从第一天开始在Vulkan提供原生支持。着色器方面,着色器排列越来越少,Doom只有几百个,更多的游戏正在改变创作流程,以便更早地删减着色器变体,更多的高级工作(围绕编译器)正在进行。
引擎向更高级别的渲染发展,API的改进使其更易于使用,游戏受益!开放游戏/可伸缩性,可伸缩性还没有解决,游戏支持所有设置的新旧API,移动*台越来越重要,新的API似乎只是前进的道路。图形API的一种新方法需要ISV、IHV和标准机构之间的紧密合作,API随着游戏引擎的发展而发展,自发布以来,大量的变化让开发人员更轻松!
DirectX 12 Case Studies由NVidia呈现,讲述了DirectX12的相关技术和应用案例,文中涉及DX12的技术包含异步队列、内存管理、管线状态对象、着色器模型5.1资源绑定、多线程及其它。
对于异步队列,计算队列可以很好的跨供应商加速,*均5%的提升,异步工作负载主要与分辨率无关(针对1080p进行了调整),随着分辨率的增加,收益递减。

引擎使用3个复制队列,多个复制队列简化了引擎线程同步:

SM 5.1和/all_resources_bound着色器编译器标志将性能提高约1.0到1.5%,无需更改着色器代码,为纹理访问启用不太保守的代码生成。

Ubisoft的Anvil Next引擎:重新设计以充分利用DX12,最大限度地减少和批处理资源屏障,充分利用并行CMD列表录制,使用预编译渲染状态以最小化运行时工作,最小化内存占用,利用几个GPU队列。
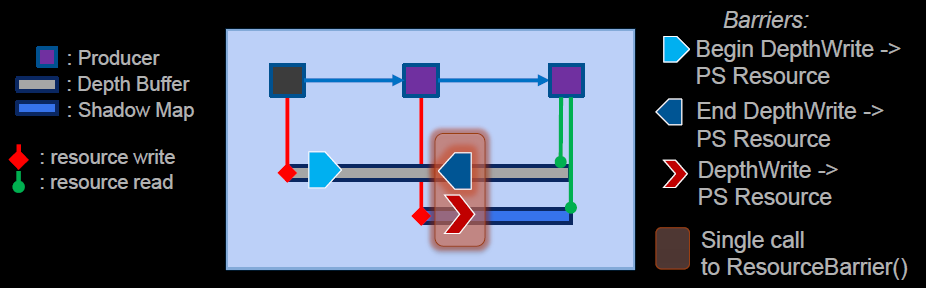
Anvil Next引擎分组屏障图例。
Hitman渲染器处理完全动态的场景,例外情况是在水*负载期间产生反射和环境探针。使用分块延迟照明,前向光源使用单独的通道,用于剔除照明的门/室(入口/单元)系统。阴影用4个VSM级联,第4个是静态的,4~8个额外的阴影贴图。
对于CPU性能,代码可以像引擎代码一样进行分析和修复,设置了太多多余的描述符,确保只设置实际使用的描述符。次优的合批:最终批量处理资源转换和命令列表提交,最终通过多线程与最快的驱动程序相匹配。
当时的DX12内存管理也存在问题,DX12视频内存消耗过高(与DX11相比),DX11驱动程序非常擅长在视频内存之间移动内存。最终实现了一个分页(逐出)资源的系统,使用非常简单的LRU模型,很多工作都是出乎意料的,仍然不理想,因为有MakeResident的卡顿,在DX12上的性能更差,尤其是在低显存的GPU卡上。已实现的渲染目标内存重用系统(放置的资源),引入静态资源的子分配,为所有内容创建提交的资源将占用大量内存,PC上的内存节省不如控制台上的高,资源层(Resource tier)防止所有内存被用于各种资源。

DX12资源分配和围栏:需要一个超级快速的分配器来实现帧资源的无锁分配,在一个帧中有大量动态资源分配,如描述符、上传堆等。栅栏开销也很大,尝试将它们用于资源的细粒度重用,最终使用一个信号栅栏来同步所有的资源重用。
DX12状态管理:使用像素着色器对象存储PSO和其它状态,绝大多数像素着色器只有少量排列,可通过哈希访问的排列,已从状态管理中删除采样器状态对象,决定使用16个固定采样器状态。
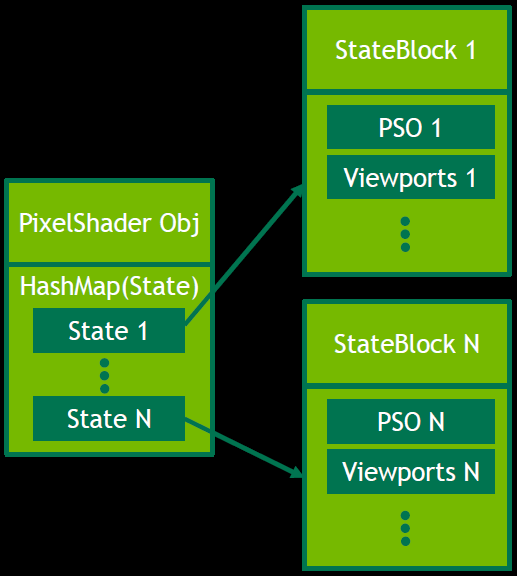
为每个状态创建唯一的状态哈希,将所有状态块放入具有唯一ID的池中,状态块包括光栅化器状态、着色器等,使用块ID作为位来构造状态哈希。

DX12资源转换:实现了简化的资源转换系统,假定读取/SRV为默认状态,仅支持转换到RTV、UAV、DSV和转回,仅UAV屏障需要额外的转换。主渲染线程提交所有转换,主渲染线程还可以记录命令列表,并执行所有多线程同步,大大简化了代码。

3A游戏”的DX12内存管理:显式内存管理是实现出色且一致性能的关键,LRU资源管理战略有很长的路要走,在上次使用资源后,将其保存在内存中一段时间,只有当它被驱逐时才带进回收堆里。支持资源绑定tier 2,不使用时,表中的CB描述符必须解除绑定(设置为0),Nvidia驱动程序现在支持未清除的描述符,将CBV移动到根签名中以跳过解除绑定,当用作根CBV时,CBV只是一个GPU地址,无需调用CreateConstantBufferView()。确保对所有RST条目使用最佳着色器可见性标志,尽可能避免Avoid SHADER_VISIBILITY_ALL标记,在CPU内存中缓存RST状态以跳过冗余绑定,从而提高CPU性能。结果证明,应最小化RST的变化,使用整个帧的两种布局。对于屏障,最初的DX12路径有冗余屏障,屏障隐藏在抽象层中(自动触发),大部分时间都有效,对于特殊情况,引擎将切换到显式屏障管理,延迟屏障用于跳过进一步的冗余和合批屏障,将屏障添加到待处理列表中,等到最后一刻刷新列表,过滤掉冗余。
调试GPU:根据API(CPU)的错误代码检测到崩溃,在最后N帧命令中发生了崩溃…CPU调用堆栈很可能是个麻烦。


NVIDIA AFTERMATH可以提高GPU崩溃位置的准确性,使用命令流内联用户定义的标记,一旦到达每个标记,GPU就会发出信号,最后到达的标记表示GPU崩溃位置。
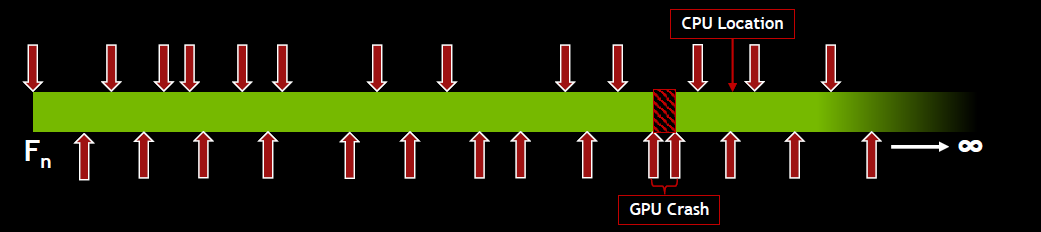
NVIDIA AFTERMATH帮助诊断GPU崩溃的新工具(标头+DLL),非常灵活/简单的API,当前与兼容DX11和DX12 UWP和/或Windows。它的局限性是需要NVIDIA GeForce驱动程序版本378.xx及以上,与D3D调试层不兼容。
Advanced Graphics Tech: Moving to DirectX 12: Lessons Learned也详细地阐述了育碧的Anvil Next引擎移植到DirectX12的具体过程、优化、技术、策略、经验教训等内容,诸如生产者消费者系统、调度图系统、屏障转换和优化、资源管理、资源依赖、内存重叠、资源同步、着色器、PSO等等内容。
总之,利用高级渲染过程知识优化API使用,高级生成系统节省了大量渲染工程师调试时间,粒度更小、基于blob的渲染接口,最大化CPU性能增益,避免重复工作,架构工作将使其它*台/API受益。利用DX12可获得约5%的GPU提升,15%~30%的CPU提升。
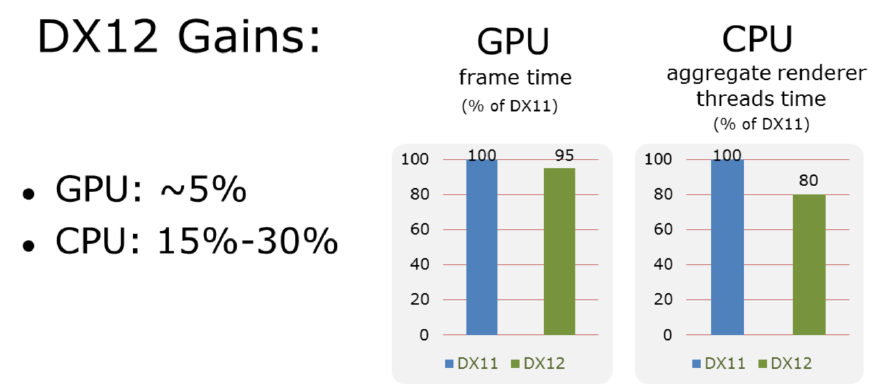
实现与DX11性能的对等是一项艰苦的工作,不要将性能视为最终目标,将努力视为通往:解锁异步计算、mGPU、SM6等功能,比以往任何时候都更接*与控制台的功能对等,改善引擎架构的机会,之后移植到其它等效的API要容易得多。
更多关于DX12和Vulkan的知识可参阅:剖析虚幻渲染体系(13)- RHI补充篇:现代图形API之奥义与指南。
Developing The Northlight Engine: Lessons Learned说明了Northlight引擎开发的DX12移植的过程和经验教训。Northlight引擎的渲染管线:
- G缓冲、速度、阴影通道(多线程)。
- 全屏阴影。
- 全屏照明。
- 主要、透明通道(多线程)。
- 后处理。
DX12特性清单包含描述符表、动态资源、管线状态对象、命令列表/分配器、资源转换、暂存资源、小型资源、mipmap生成、空资源、计数/追加缓冲区、查询等。下面对它们进行阐述。
- 描述符表:是一个表包含任何着色器阶段可能使用的所有资源的描述符,每个draw调用都需要一个表,一旦在GPU上完成draw,就可以重复使用。
- 动态资源:DX12中没有这种东西,需要自己管理版本控制/重命名/轮换,写一次(CPU),读一次(GPU)使用上传堆环缓冲区。
- PSO:创建是有问题的部分,理想情况下,在出口管线中输出,在游戏开始时加载,在第一次接触它们时就创建了它们,CS PSO可以在CS加载下生成,约500个单独的图形PSO需要约200毫秒才能生成。包含根签名(资源布局)、着色器代码、顶点着色器输入布局(不是顶点/索引缓冲区)、基本类型、混合、光栅状态、MSAA模式、渲染目标和深度模板格式等。
- 命令列表/分配器:DX11中的即时/延迟上下文,分配器拥有内存。
- 资源转换:驱动不再跟踪使用情况,使用前必须手动转换至正确状态:着色器资源、渲染/深度目标、复制源/目的地、UAV、呈现等。
- 暂存资源/更新子资源:没有动态资源,更频繁地使用暂存资源,按需从环形缓冲区或持久缓冲区,无更新子资源,不能依赖模拟的d3dx12.h的版本,无过渡纹理,通过过渡缓冲区进行模拟。
- 小型资源:CreateCommittedResource以64kB的页面进行分配,不会为少量资源而运行,理想情况下,在碎片整理堆中对所有资源进行子分配,或特殊情况下的小型资源。
- GenerateMips:DX12中没有这种东西,为其编写一个计算着色器,发现手动实现的性能优于DX11,但需要处理许多不同的情况(2D/3D/数组/颜色空间)。
- 空资源:不能再绑定nullptr了,需要1D/2D/3D纹理、缓冲区、UAV纹理/缓冲区、CBV、采样器的空资源,可能需要将空绑定提升到抽象中更高的位置才能了解类型。
- 计数/追加缓冲区:DX12中没有这种东西,有一个单独的计数缓冲区,可以原子增加。
- 查询:另一个需要注意的容易忘记的方面,管理/轮询查询堆,合并解析(即合批在一起,避免多个调用),在完整的堆中回读。
从DX11移植至DX12,你现在是驱动了(成为真正的老司机),注意内存使用和性能,将优化重点放在瓶颈上,在单独的CPU和GPU时间线中思考。Northlight在移植过程中,对不同的对象操作如下:
-
资源屏障。在主线程中自动执行资源转换:绑定RT时、在描述符表中设置资源、复制,其它异步渲染线程不允许转换,在执行命令列表之前,手动确保资源(主要是RT)处于正确的状态。不必要地滥用它们可能会扼杀GPU性能,但取决于硬件,仅在必要时使用UAV屏障,它们会迫使GPU在调度之间闲置(DX11样式)。
-
绘制。遍历绘制,捕捉DX11样式集的调用,跟踪之前的值,如果PSO发生了变化,请将其标记为脏,如果已脏,在绘图时进行哈希,从映射表中获取PSO。仅在更改时设置索引/顶点缓冲区、RT/DS和描述符堆,集合在CPU上很便宜,但会导致硬件上下文滚动。PSO是只读、绑定和遗忘的,每次draw调用时旋转到空闲(GPU)描述符表中,在GPU上执行命令列表后重用描述符表。
-
线程。没有区分即使/延迟上下文,在任何线程上记录命令列表,从一个线程提交。
- 在池中保存描述符表管理器(处理表的旋转)、描述符表管理器GPU栅栏(让你知道何时可以重用表)、 命令列表(在GPU完成执行后可以重用)、命令分配器(可用于多个命令列表)
![]()
- 初始化线程时获取描述符管理器、描述符管理器栅栏、命令分配器、命令列表。
- 结束线程时释放CPU可重复使用的描述符管理器、命令分配器。
- 执行命令列表之后释放GPU可重用的描述符管理器栅栏、命令列表。
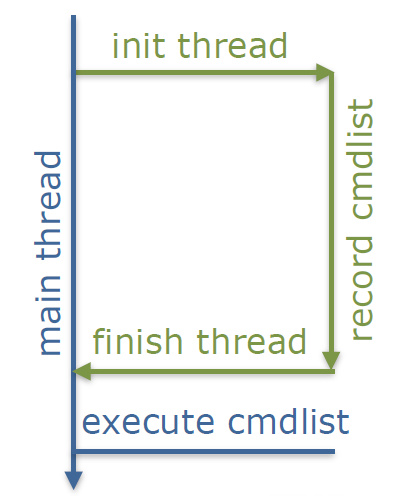
总之,GPU性能:做正确的事情,匹配DX11,在所有架构上都很重要,搞砸GPU内存管理可能代价高昂。CPU性能:轻松超越DX11,但是,真的受到API开销的限制吗?实例化、LOD、良好的剔除使得驱动程序不会被绘制调用淹没。
Rendering 'Rainbow Six | Siege'是游戏《彩虹六号|围城》基于当前新一代渲染引擎的首次迭代,文献将重点介绍利用当前一代硬件才可能实现的计算的架构优化,以及新的棋盘渲染技术,该技术可以在不造成质量损失的情况下将渲染速度提高50%。
Siege的GPU帧的层次视图:几何体渲染*均花费5毫秒,大量使用剔除,缓存阴影,*均5毫秒用于照明(包括SSR),棋盘渲染相助,SSAO和SSR射线追踪以异步方式完成,后处理/其它全屏处理*均花费4ms。

CPU关键路径的层次视图:关键路径*均10毫秒,所有通道和任务都能够分叉和连接,以最小化关键路径,缓存阴影,不透明通道的最大线性长度为4ms,基于材质的绘制调用系统!

不透明物体的渲染管线如下:

阴影渲染:所有阴影都是基于缓存的,使用缓存的Hi Z进行剔除。太阳阴影以全分辨率完成,分离通道以释放VGPR压力,使用缓存阴影贴图的Hi Z表示法来减少每像素的工作量。局部光源以四分之一的分辨率进行解析,解析的结果存储在纹理数组中,光照积累时VGPR使用率较低,双边上采样。对于太阳、月亮的阴影,包含加载时生成的所有静态对象的阴影贴图。
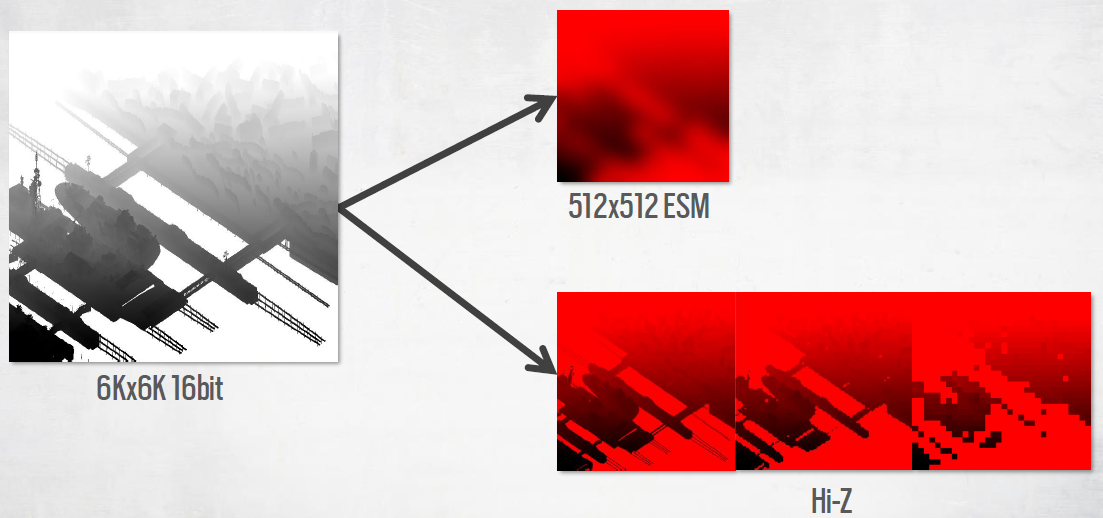
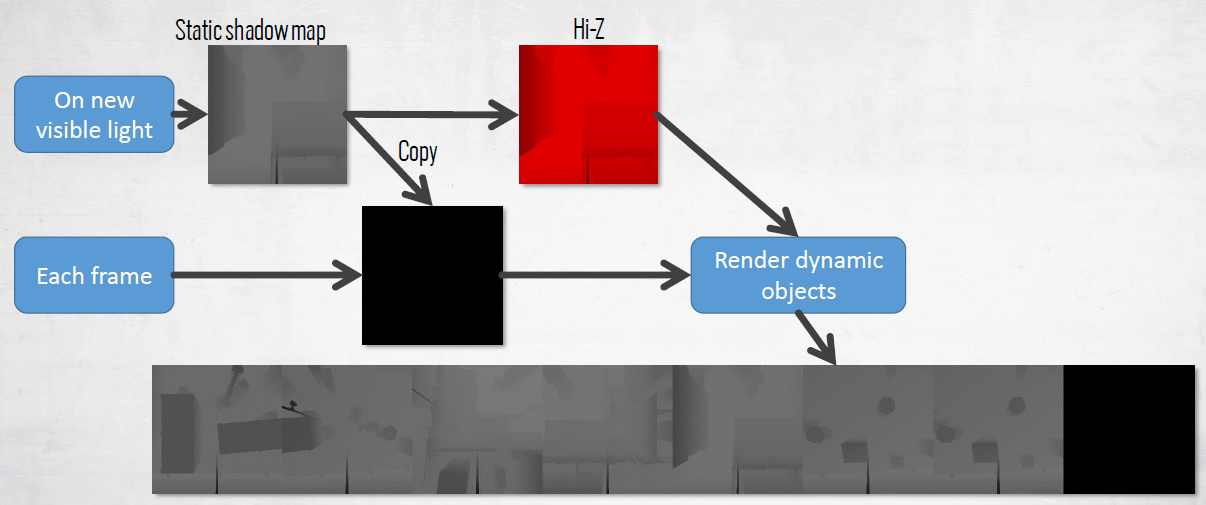
通过混合级联和静态贴图来缩放阴影成本的能力,静态Hi Z阴影贴图始终用于动态对象剔除。在Xbox One上:第一级级联是完全动态的(6K分辨率不够),第二级和第三级级联仅渲染动态对象,并与静态阴影贴图混合,第四级由静态阴影贴图替代。

对于局部光源投影,最多处理8个可见阴影局部光源,流程如下:
在光照方面,在frustum上使用分簇结构:基于32x32像素的分块,Z指数分布,分层剔除光源体积以填充结构,被视为光源的局部立方体图,阴影、立方体图和遮挡板(gobo)位于纹理阵列中,延迟使用预先解析的阴影纹理数组,前向使用阴影深度缓冲区数组。
统一缓冲区(UNIFIED BUFFER):彩虹六号中的许多资源都位于某种统一缓冲区中,如统一顶点缓冲区、统一索引缓冲区、统一常数缓冲区、...。结构化缓冲区构建在自动生成代码的原始缓冲区之上:使用C++数据描述符处理GPU统一数据,传递给指定访问模式的元数据。统一常数缓冲区示例代码:
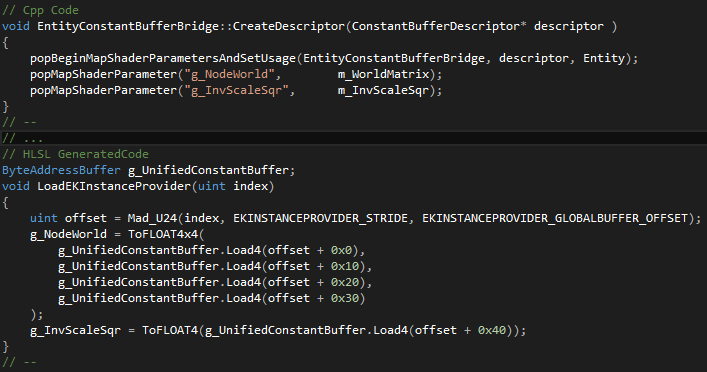
统一缓冲区的好处:完全控制数据布局,可以很容易地尝试不同的数据类型访问(AOS、SOA、u32数组的结构、…),自定义打包和对新数据类型的支持,高级API支持广播值,代码自动生成允许我们轻松地迁移到新的访问模式。
基于材质的绘制调用:几何和常数是统一的,然后绘制调用由以下内容定义:着色器、非统一资源(纹理等)、渲染状态(采样器状态、光栅状态),共享上述内容的元素被批处理在一起,不使用资源和状态子集的通道将进一步批处理在一起。
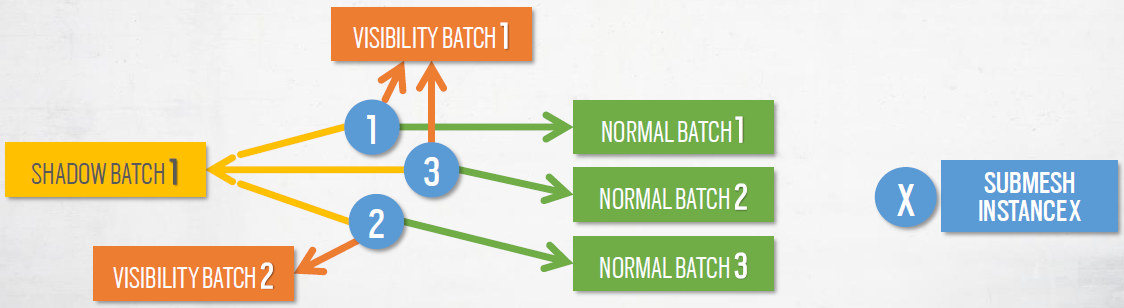
收集绘制调用:初始化时,每个子网格实例映射到3个批次:普通、阴影和可见性,批处理类型用于屏蔽非必要的数据,每个批次将对应一个MultiDrawIndexedIndirect命令。
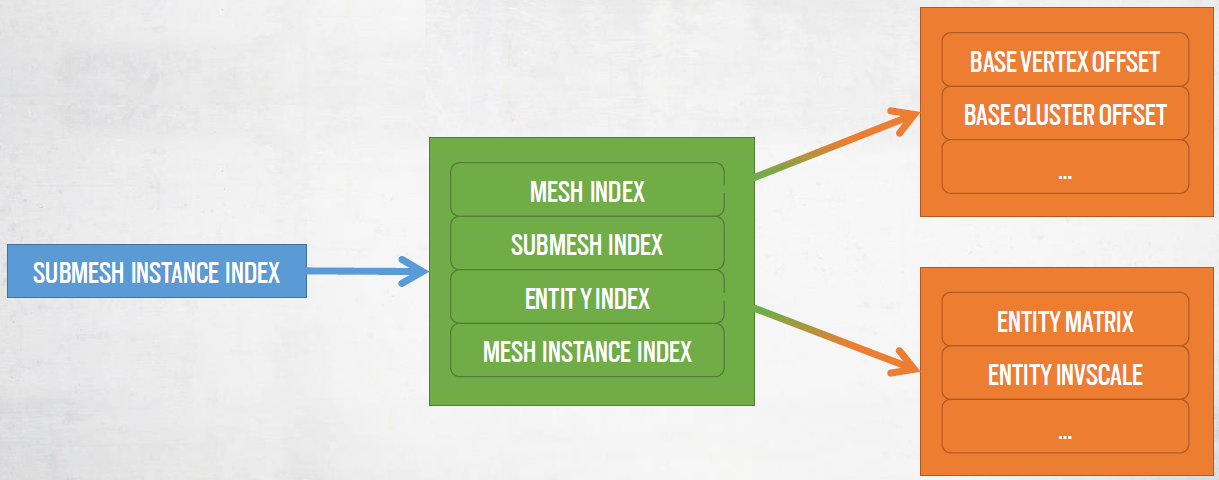
每个子网格实例都有一个全局唯一的索引:用于获取所有数据的索引,需要多个间接寻址。
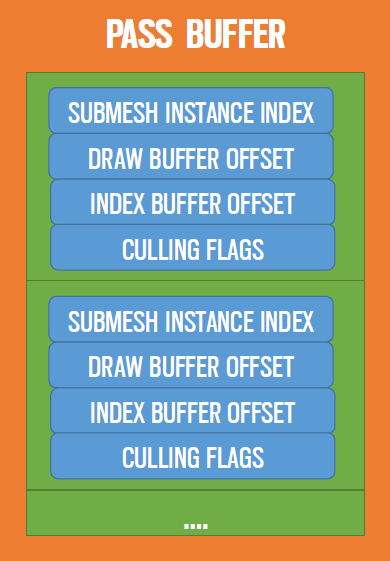
对于每个通道收集子网格实例索引到动态缓冲区:每个通道只映射到一个批次类型,多线程作业中的缓冲区填充(1.5ms线性)。添加了执行剔除的额外数据:MultiDrawIndexedIndirect条目、新索引缓冲区偏移量、附加剔除标志。
使用了性能剔除,定义了多种类型的剔除:级别1——子网格实例剔除,级别2:子网格块(chunck)剔除,级别3:子网格三角形剔除。
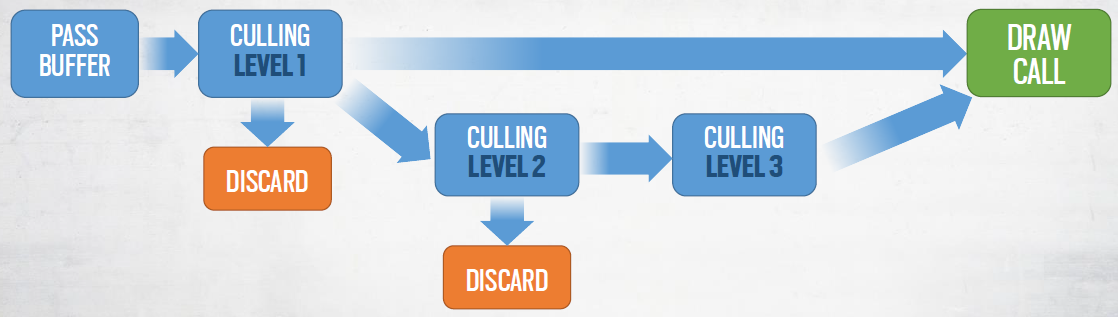
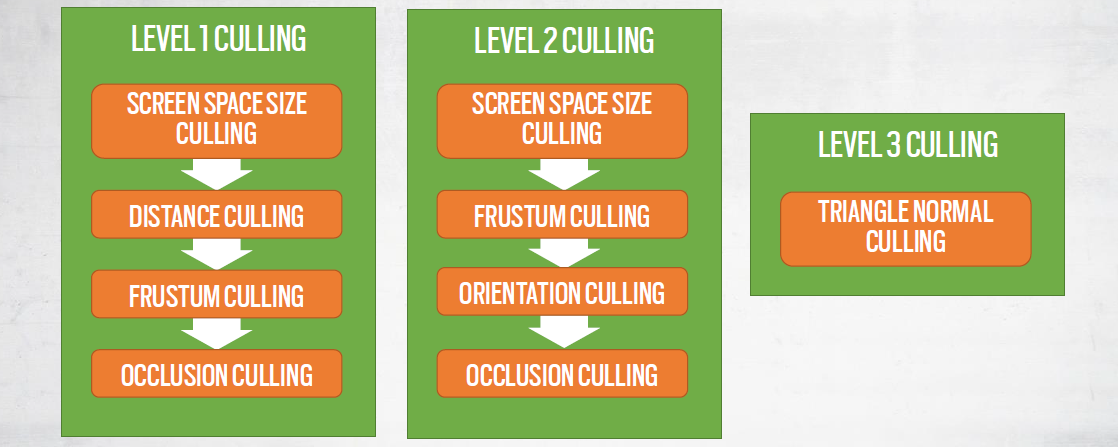
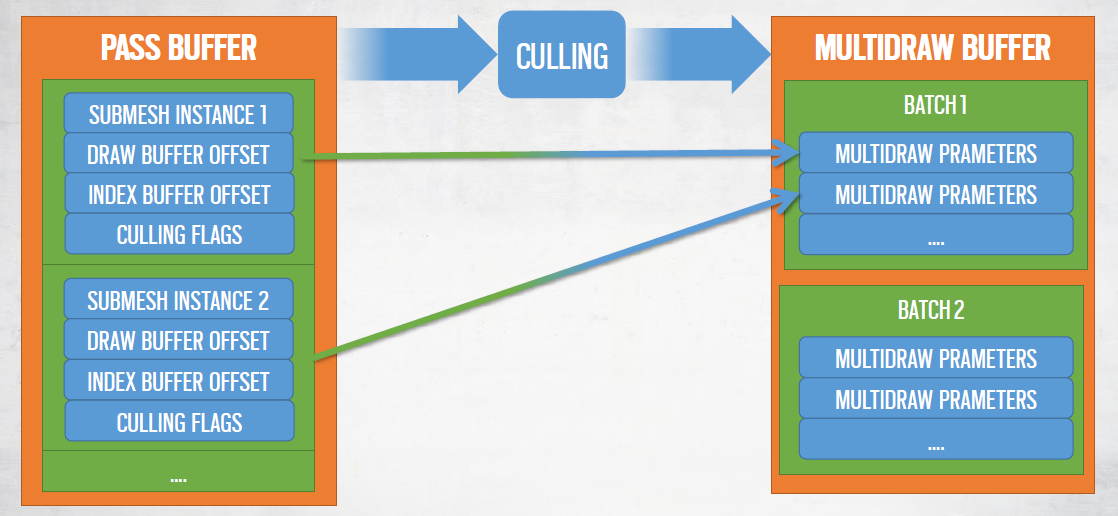
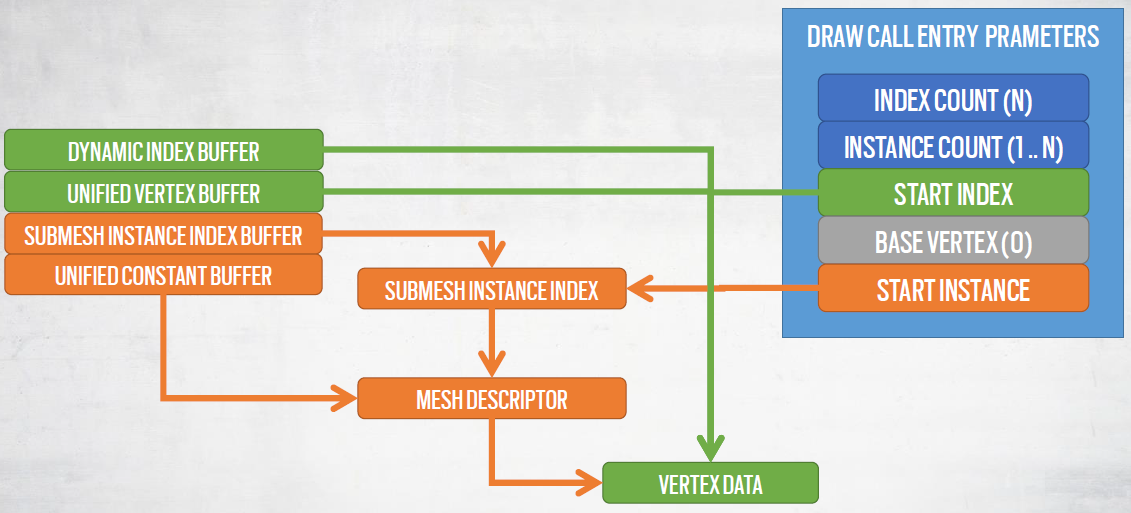
结果:
| 非核批的DC数量(共总) | 合批的DC数量(VIS + GBUFFER + DECALS) | 合批的DC数量(阴影) | 裁剪效率 |
|---|---|---|---|
| 10537 | 412 | 64 | 73% |
接下来聊棋盘渲染。
棋盘渲染的基本思想解决了锯齿问题,在一系列图像上进行实验,首先测试质量,对于大多数图像,使用棋盘模式时PSNR更好:视觉效果也更令人愉悦,从一开始,使用MSAA 2X的想法就开始流行起来。

上排是线性邻域插值,下排是棋盘邻域插值。
棋盘渲染实现:
- 渲染到1/4大小(1/2宽 x 1/2高)分辨率,使用MSAA 2X,最终得到全分辨率图像的一半样本。
- D3D MSAA 2x标准模式:2个颜色和Z样本。
- 采样修饰符或SV_SampleIndex输入以强制渲染所有样本。
- 每个样本都落在全屏渲染目标的精确像素中心。
棋盘渲染额外的好处:粒子效果可以很容易地按像素而不是按样本进行评估,可以在ESRAM中获得更多的东西!无需在着色器中修正渐变。
通过在每一帧中再次偏移投影矩阵可以改变模式,并不总是可以在PC上更改样本的位置。
填补空白处:为了重建下图未知像素P和Q的颜色,采样当前帧直接邻域线性Z、当前帧直接相邻颜色、历史颜色与Z。
历史颜色/Z:选择一个邻居作为运动速度:离相机最*的一个,以保持轮廓,使用运动速度,对之前解析的颜色进行采样。这样可以使用过滤,但会引入累积误差!用B、E、F为Q夹紧重投影的颜色,使用之前从运动计算的深度,计算一个信赖的值,用于向未夹紧的值混合。解析颜色:已有历史颜色、直接邻域的插值颜色,使用两个附加的权重计算最终的颜色:A、B、E、F与Q之间的最小差值和速度的大小。
完整的流程图如下,解决相当复杂的问题,内容有很多调整!消耗1.4ms,减少了8到10ms。

TAA可以和棋盘渲染集成,可以在同一个resolve着色器上运行,在子样本级别上完成,MSAA 4X风格在棋盘格图案顶部抖动,重投影颜色权重使用类似的逻辑,额外的信息(Unteething)可用于删除不良的棋盘模式。
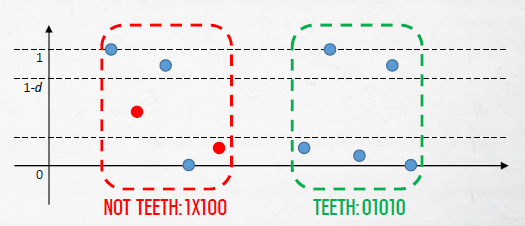
分辨率会在图像中引入明显的锯齿图案,应用过滤来消除它们,该过滤可在5个水*或垂直相邻的像素上工作,将阈值d和二进制像素分别设置为0或1,如果它们在[0, d]或[1-d, 1]范围内,我们检测到01010或10101模式。
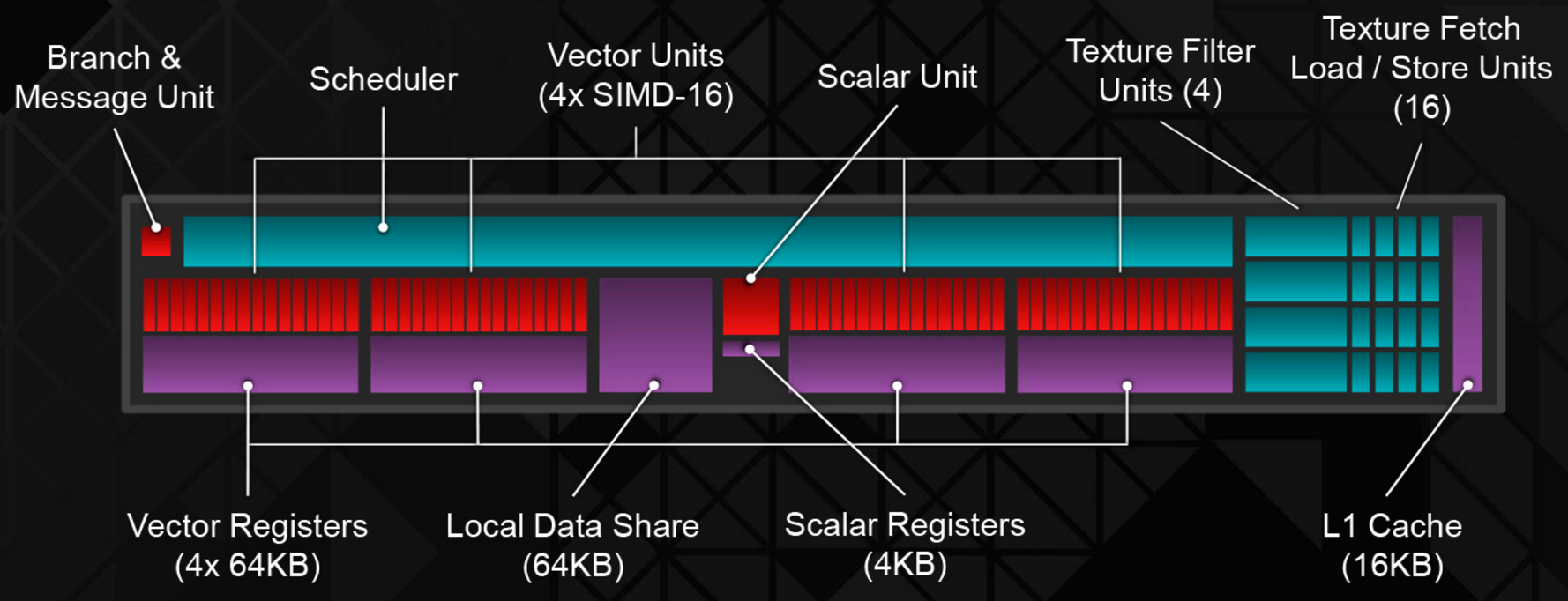
Optimizing the Graphics Pipeline With Compute由DICE的Frostbite引擎团队成员呈现,使用计算着色器优化图形管线,更具体地说,如何通过不渲染那么多三角形来快速渲染三角形。文中涉及的各种概念如下表:
| 概念 | 全称 | 翻译 |
|---|---|---|
| VGT | Vertex Grouper \ Tessellator | 顶点分组器、曲面细分器 |
| PA | Primitive Assembly | 图元装配 |
| CP | Command Processor | 命令处理器 |
| IA | Input Assembly | 输入装配 |
| SE | Shader Engine | 着色器引擎 |
| CU | Compute Unit | 计算单元 |
| LDS | Local Data Share | 局部数据共享 |
| HTILE | Hi-Z Depth Compression | 层级深度压缩 |
| GCN | Graphics Core Next | AMD的图形核心称号 |
| SGPR | Scalar General-Purpose Register | 标量通用寄存器 |
| VGPR | Vector General-Purpose Register | 向量通用寄存器 |
| ALU | Arithmetic Logic Unit | 算术逻辑单元 |
| SPI | Shader Processor Interpolator | 着色处理插值器 |
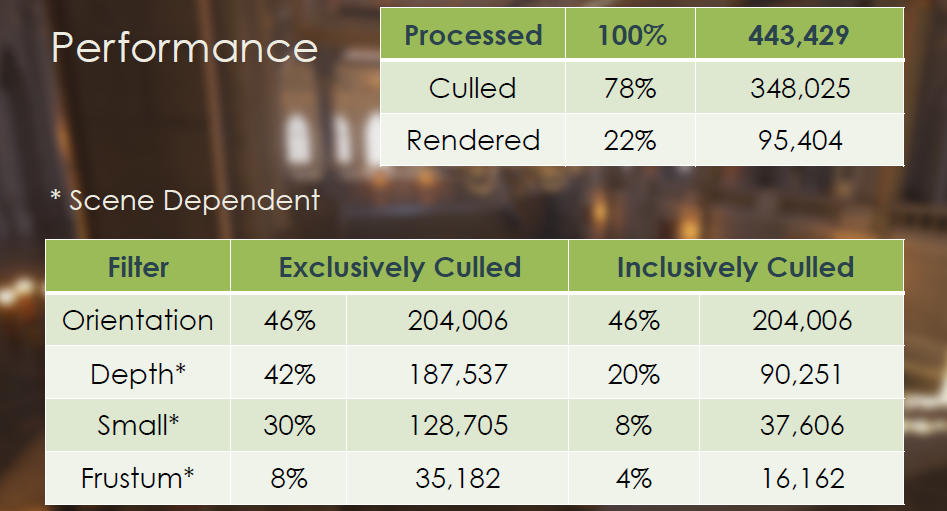
当时的Frostbite引擎面临绘制调用过多(1000+)、图元填充率过高等问题。解决的机会有:
-
在CPU上粗糙剔除,在GPU上精细剔除。
-
CPU和GPU之间的延迟会阻止优化。
-
GPU提交!
- 深度感知剔除。缩小阴影边界\样本分布阴影贴图,剔除没有贡献的阴影投射者,从颜色通道中剔除隐藏物体。
- VR的late-latch剔除。CPU提交保守的视锥体,GPU细化。
- 三角形与分簇剔除。
-
直接映射到图形管线。卸载外壳着色器工作,卸载整个细分管线!程序顶点动画(风、布料等),在多个过程和帧之间重用结果。
-
间接映射到图形管线。边界体积生成,预处理蒙皮,顶点动画(Blend Shape),从GPU生成GPU工作,场景和能见度测定。
-
将绘制当做数据!预构建,缓存和重用,在GPU上生成。
裁剪概览图:

左上:如图所示的场景,包含网格集合、特定视图、摄像机、灯等。右上:场景中的可配置网格子集,共享着色器和三角形带(顶点/索引)的批次内的网格,与DirectX 12 PSO的比例接*1:1(管线状态对象)。左下:代表一个索引的绘制调用(三角列表),有自己的顶点缓冲区、索引缓冲区、图元数量等。右下:波前处理的最佳三角形数,AMD GCN每个波前有64个线程,每个剔除线程处理1个三角形,工作项处理256个三角形。
剔除概览如下:

大致的过程和技术点包含将网格ID映射到多绘制ID、使用非交错顶点缓冲区、分簇剔除、绘制压缩、三角形剔除、朝向剔除、小图元剔除、视锥体剔除、深度剔除(深度分块、深度金字塔、HTILE、软光栅Z等)。
最终的剔除性能和效果如下:

The Rendering of INSIDE: Low Complexity, High Fidelity分享了当年爆火的一款解密探索类游戏Inside的渲染技术,包含用于实现大气外观的各种效果,例如局部阴影体积测量和强大的水渲染系统。通过对每个像素进行微调,将照明设计为完全独立的漫反射、镜面反射和反弹光实体,同时关注艺术家可接*的工具,意味着利用分析基于图元的环境光遮挡和屏幕空间反射。此外,还详细阐述如何通过适当使用抖动来消除分散注意力的瑕疵,避免艺术品的细微细节淹没在色带中。
Inside是一款暗黑解谜类游戏,可运行于安卓、ios等移动*台,是当年令笔者沉迷的一款游戏。笔者曾对它给予了很高的评价,有图为证:
该文涉及的内容比较多,包含雾与体积度量、HDR泛光、色带和抖动、投影贴花(定制照明、解析环境遮挡、屏幕空间反射)、水渲染、效果分解(吸引眼球)等。其中Inside使用了Light Prepass渲染,一帧概览如下:
雾原来是Inside艺术风格的核心,游戏中的许多初始场景实际上只是雾+剪影。以下是雾的组合效果:

从上到下:没有雾、线性雾、线性雾+发光。
作为大气散射的发光是非常宽的光晕,半个屏幕,向下采样,然后是多个模糊,因为只需要大范围的模糊。HDR发光是第二个发光通道,只对明亮发光的物体,遮罩对象的窄辉光仅发射材质(写入alpha通道)遮罩值将RGB重新映射为非线性强度,中间HDR值用\(x/(x+1)\)编码为[0:1]的定点数。

采样模式使用了发光过滤器[JIMENEZI4],下采样时13个样本模糊,上采样时9个样本模糊。后处理设置步骤和流程如下:

接下来聊体积光照。
体积照明用raymarch的相机光线,阴影贴图投影空间中背景深度的步长,每一步计算光照贡献:采样阴影图、cookie、衰减等。
使用了逐像素3个抖动的样本,蓝色噪声提供了良好的采样,而在采样不足的区域,回到噪声中寻找失真可以获得更少的样本。

半分辨率用于低频效果,是上采样时的深度感知模糊。步骤如下:
- 清理前深度缓冲为零。
- 通道1,半分辨率。正面深度。
- 通道2,半分辨率。射线步进体积雾,输出光源强度(8位)+最大深度(24位)。
- 通道3,全分辨率。对半透明对象排序,深度感知解析、上采样和模糊。
通道3的具体过程如下:

另外,使用方差尺寸模糊、4样本、深度感知样本等影响TAA、下采样,让TAA随着时间的推移进行集成。以下是几种不同抖动方法的对比:


在基础颜色通道,存在非常明显的颜色条带(色阶)的瑕疵:

为了解决上述问题,分别对光照进行抖动、最终通道引入完全均匀的噪点、半透明未引入噪点但使用特殊的混合模式,解决方案在每个通道后都会抖动,手动将所有中间渲染目标转换为srgb(pow2,没什么特别的),在较低的分辨率下抖动(用于模糊)会导致大于1像素的噪声,但幸好结果却不可见。

抖动和噪点不仅仅可用于颜色,还可用于法线!!
在定制光照方面,新增了反弹光照、AO贴花、阴影贴花等效果。反弹光被用于全局照明,几乎只是一个普通的兰伯特点光源,除了没有使用香草点积,而是使用滑块使其褪色,它被称为lambert扭曲(lambert wrap)或半lambert(half lambert),提供方向性更小、更*滑的结果。
 de14.png)
de14.png)
不同强度的反弹光。
因为它们不是静态的,所以经常用它们来打开窗户和移动手电筒。Inside没有使用常规方法(制作一系列点来覆盖走廊或一个数组来填充房间),而是使用完整的变换矩阵,以获得非均匀的形状,更适合使用拉伸的药片和压扁按钮的盒子,而且更低开销,因为过绘制和重叠更少。

文中还涉及了AO贴花和阴影贴图。
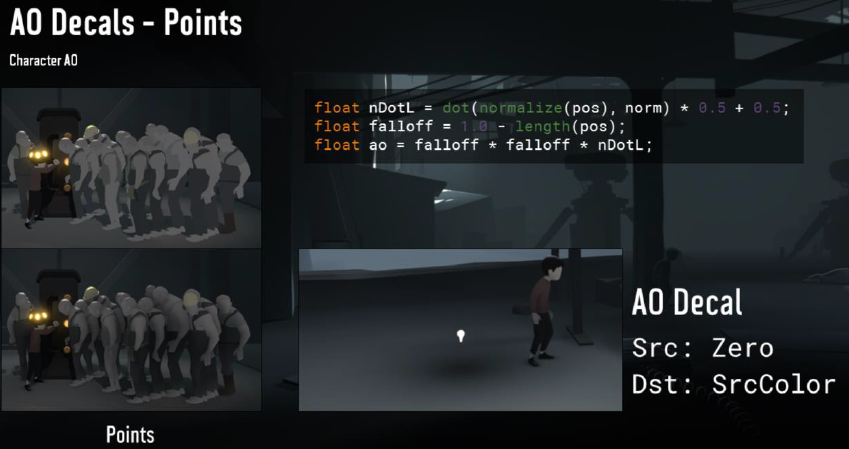


从上到下:点AO、球体AO、盒子AO效果及实现方法。

从上到下:无阴影贴花、有阴影贴花、阴影贴花可视化。
对于SSR,采用了特殊的屏幕空间追踪方式:

从左到右:屏幕空间向上发射射线、让射线移动到包围盒最*的水*出口、继续向上追踪。
// SSR方向计算(常规版)
// GPU的片元着色器
sDirProj = mul(projection, vec4(vDir + vPos, 1.0));
SDir = normalize(sDirProj.xyz / sDirProj.w - sPos);
// SSR方向计算(改进版)
// CPU计算投影空间的方向,并设置成uniform变量
_DirProject = vec(viewportSize, nearClip / (nearClip - fraClip));
// GPU的片元着色器
sDir = vec3(vDir.xy - vRay.xy * vDir.z, vDir.z * rcpDepth) * _DirProject;
为了避免阶梯式瑕疵,使用了随机采样(蓝色噪点 + TRAA)。

水体(水面和水下)使用了分层渲染,包含体积雾、半透明、折射、反射等效果:

水面的分层组合后的效果。
水下也和水面一样,具有相同的分层渲染,还增加位移边缘、外部或正面面、内部或背面面等层:

Inside的特效方也非常讲究,使用了很多技术和优化技巧。

在世界空间中将粒子纹理投射到粒子上,每个粒子上都有一个随机偏移,并向一个方向滚动。图中示例是向下的,因为是从盒子里出来的方向。

镜头眩光的采样方式。

各种水面效果的模拟。
Temporal Reprojection Anti-Aliasing in INSIDE也涉及了Inside,但专注点在TAA的应用和优化。

首先是一些基本的直觉,表面片元的局部区域可以在多个帧中保持可见,若观察者和被摄体之间的关系每一帧都发生变化,那个么光栅化也会发生变化,如果在时间上后退一步,那么可以使用这种变化来优化当前帧。
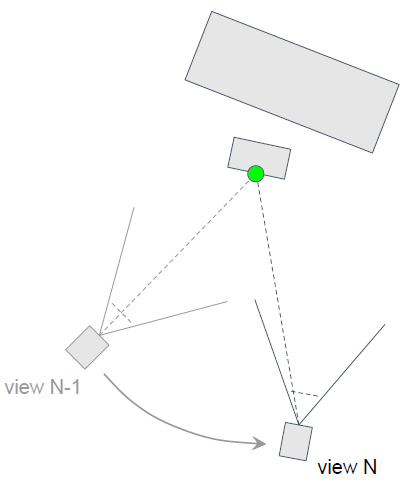
要将当前帧片段与前一帧的片元关联起来,可以在空间上进行,并进行重投影,依赖深度缓冲区信息,仅限于最接*的表面片元,但不总是可行,有时候数据根本就不存在。片元在任何时候都可能被遮挡或不被遮挡,因此很难准确后退,如果观看者和被摄者之间的关系从未改变,那么退一步就不会获得额外的信息…

第一步:抖动视锥。已经确定如果摄像机是静态的,然后就失去了信息,因此,渲染前的每一帧:从样本分布中获取texel偏移量,使用“偏移”计算投影偏移,使用“投影偏移”剪切*截头体。
第二步:对于每一个片元执行以下步骤:
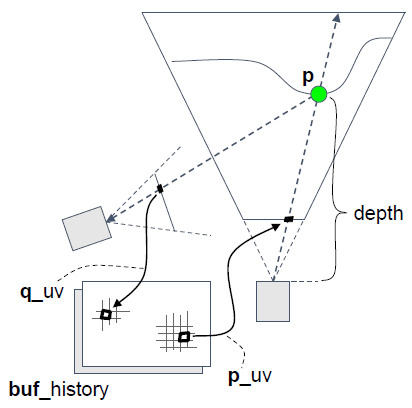
静态场景的重投影:
- 从当前片段p_uv开始。
- 使用当前帧的深度和*截体参数重建世界空间p,lerp角射线,按线性深度缩放。
- 将p重新投射到前一帧中:
q_cs = mul(VP_prev’, p),q_uv = 0.5 * ( q_cs.xy / q_cs.w ) + 0.5。 - 采样历史:
c_hist = sample( buf_history, q_uv。
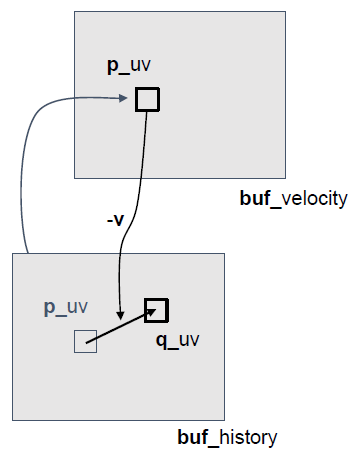
动态场景的重投影:
- 对于动态场景,需要一个速度缓冲区
- 在处理TAA之前需要专门的pass。
- 使用静态重投影初始化摄像机运动:
v = p_uv - q_uv。 - 在顶部渲染动态对象:
v = compute_ssvel(p, q, VP, VP_prev’)。
- 重投影步骤变为读取和减法:
v = sample(buf_velocity, p_uv),q_uv = p_uv - v。
在TAA过程还需要处理重投影与边缘运动、约束历史样本、邻域夹紧等细节,最终融合,用约束的历史加权。
Inside的TAA 2.0将运动模糊添加到混合中:
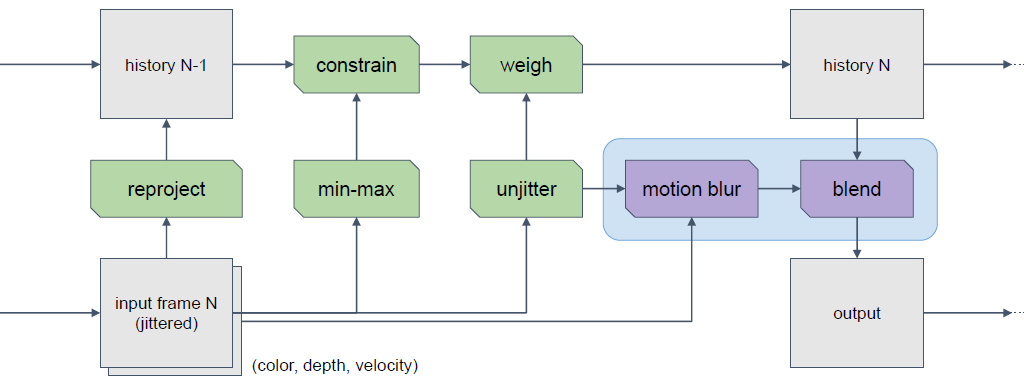
带运动模糊回退的最终混合步骤:
- 像以前一样更新历史缓冲区:rt _history = c _feedback。
- 对于输出目标,与运动模糊输入混合。
- c _motion = sample_motion ( buf _color , unjitter( p _uv ), v)
- rt _output = lerp( c _motion , c _feedback , k_trust)
- k_trust = invlerp( 15, 2, |v| )
- 强制过渡到运动模糊(无历史记录!)寻找快速移动的片元。

关于选择一个好的样本分布,大量的尝试和错误,采取了实用的方法,头部靠*屏幕,放大高对比度区域,希望在收敛的质量和速度之间找到良好的*衡,启发式:侧滚游戏。

测试的一些序列:
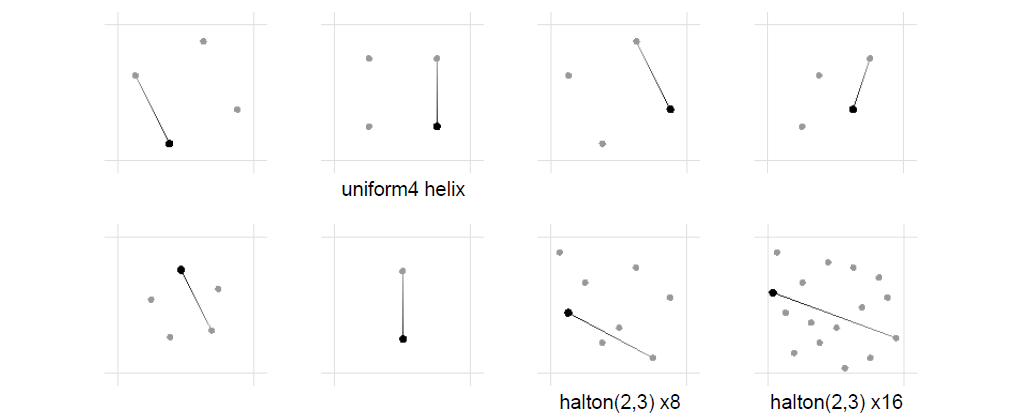
实现总结:用halton(2, 3)的前16个样本抖动视锥,生成速度缓冲,摄像头运动+动态(手动标记),基于最*的(深度)片元的速度重投影,使用中心剪辑到RGB最小最大圆形3x3区域的邻域夹紧,运动模糊回退,当||v||大于2时生效,15时完全生效,但不适用于历史。
Temporal Antialiasing In Uncharted 4也分享了神秘海域4的时间抗锯齿。本文的焦点在于提供更详细的实现细节。
对于静态图片,设置输入和输出,运行全屏幕着色器,在历史和当前渲染纹理之间插值:
float3 currColor = currBuffer.Load(pos);
float3 historyColor = historyBuffer.Load(pos);
return lerp(historyColor, currColor, 0.05f);
对于运动图像,不能在同一位置采样历史缓冲区,找出上一帧中当前帧像素的位置(如果有),需要处理屏幕外的像素和被遮挡的像素。需要先在GBuffer通道中生成全屏运动向量缓冲区(fp rg16):
// GBuffer VS
posProj = posObj * matWvp;
posLastProj = posLastObj * matLastWvp;
// GBuffer PS
posNdc -= g_projOffset;
posLastNdc -= g_projOffsetLast;
float2 motionVector = (posLastNdc - posNdc) * float2(0.5f, -0.5f);
对于程序化的动画对象(植物、毛发、水顶点运动等),需要对当前帧和最后帧执行两次,需要确定性,输入最后一帧的时间,产生完全相同的顶点位置,在纹理上滚动uv,即在表面uv空间(deltaU,deltaV)中滚动会导致屏幕空间(deltaX,deltaY)发生多少变化:
deltaU = ddx(U) * deltaX + ddy(U) * deltaY;
deltaV = ddx(V) * deltaX + ddy(V) * deltaY;
已解析的deltaX和deltaY以屏幕像素为单位,将它们转换为运动向量单位。对于反射,无法使用镜像的运动矢量,因为镜像像素在上一帧中通常反射不相同的东西。这个问题不难,但涉及很多步骤,仅适应于*面反射。一切都应该有运动矢量,但还有一些不受支持的:复杂纹理动画,如粒子烟、水流、云运动等;透明对象,如艺术家控制运动矢量不透明度。为什么不在TAA之后绘制呢?绘图顺序并不总是允许,任何跳过TAA的东西都会抖动,删除抖动还不够,因为使用了抖动深度缓冲进行测试。在TAA之后摆脱了问题:雨滴,弹痕,火花…除此之外,没有其它东西摆脱,一旦使用了TAA,就得一路走下去。将运动矢量缓冲区作为输入添加到TAA,使用运动矢量采样历史缓冲区:
float2 uvLast = uv + motionVectorBuffer.Sample(point, uv);
float3 historyColor = historyBuffer.Sample(linear, uvLast);
使用线性采样器的重要事项:点采样可能会落在不相关的像素上,线性采样不会完全丢失,但会导致模糊(稍后讨论)。
历史和当前颜色可能不匹配,由于遮挡/屏幕外而不存在、灯光变化、在边缘的不同侧面(投影抖动)等。需要夹紧历史颜色,使用Dust 514的夹紧方法,以当前帧像素为中心采样3x3邻域,计算每个rgb通道的最小/最大邻域:
float3 neighborMin, neighborMax;
// calculate neighborMin, neighborMax by
// iterating through 9 pixels in neighborhood
historyColor = clamp(historyColor, neighborMin, neighborMax);
对于不存在和灯光变化的情况,夹紧掉太不相同的历史颜色,3x3邻域确保夹紧不会影响边缘AA,对于边缘像素,边缘另一侧的历史不会被夹紧。是时候再次混合历史和当前颜色,这一次支持运动图像:
return lerp(historyColor, currColor, blendFactor /*0.05f*/);
需要动态的blendFactor来*衡模糊和抖动。基于UE4方法:局部对比度较低时增加,当像素运动达到亚像素时减少,当历史接*夹紧时减少,结果还是有点模糊。为了解决模糊,需要一个全屏幕通道使用以下的邻域权重进行处理:
return saturate(center + 4*center - up - down - left - right);
TAA仍然存在一个问题:鬼影,夹紧应该可以防止它,但在某些领域似乎不起作用。鬼影发生的原因是包含高频和高强度的颜色变化,如多棱茂密的草、黑暗中被强光照亮的凹凸不*的表面。邻域最小/最大值变得巨大,使夹紧失效:
historyColor = clamp(historyColor, neighborMin, neighborMax);
// 将上面的原有代码改成以下代码
uint currStencil = stencilBuffer.Sample(point, uv);
uint lastStencil = lastStencilBuffer.Sample(point, uvLast);
blendFactor = (lastStencil & 0x18) == (currStencil & 0x18) ? blendFactor : 1.f;
鬼影消失了,但新显示的像素看起来格外锐利和锯齿:

当blendFactor为1时返回高斯模糊颜色:
blendFactor = (lastStencil & 0x18) == (currStencil & 0x18) ? blendFactor : 1.0f;
float3 blurredCurrColor;
// Gaussian blur currColor with 3x3 neighborhood
if (blendFactor == 1.0f)
return blurredCurrColor;
其中高斯权重如下:
在模板修复后,仍然有1像素厚的鬼影:

颜色历史是线性采样的,而模板历史是点采样的,边缘不匹配,解决方案是使模板缓冲区中的对象轮廓扩大1个像素。使用当前帧深度和模板缓冲作为输入创建全屏着色器,每个像素(p)将其深度与4个邻域像素(左上、右上、左下、右下)进行比较,忽视其它邻域像素。输出最接*深度的像素模板,将扩大的模板缓冲区添加到TAA输入,上一帧的模板应来自扩大版本,使用扩大版本进行模板测试,边缘检测使用未扩大版本。修复了模板标记对象边缘周围的轻微抖动,避免给草之类的东西标记,手动标记的一个原因,运动模糊也会隐藏鬼影。
对于屏幕外的像素,像素历史记录可能在上一帧离开屏幕,在着色器中检测并将blendFactor设置为1,与新发现的情况一致:没有历史,使用高斯模糊的当前颜色。
在1080p的PS4 GPU上,主着色器低于0.8ms,许多其它相关成本:运动矢量计算、锐化着色器(0.15毫秒)、扩大模板着色器(0.4ms)。TAA的其它收益:每像素采集多个样本的图形功能,将计算扩展到多个帧,使用TAA进行合并,将显示一个样本,但在多个样本中使用。
该文还谈及了将TAA用于RSM(Reflective Shadow Map,反射阴影图)的思想。将场景从手电筒透视渲染到256x256缓冲区,每个像素都被视为一个VPL(虚拟点光源),运行全屏着色器,其中每个像素由所有(65536)VPL照亮,但算法复杂度是O(n*m),成本太高了!神秘海域4将VPL缓冲区下采样至16x16,1/4宽x 1/4高的全屏着色器,但由此产生的结果过于模糊和模糊,VPL(256)不足导致失真。需要一个不那么暴力的解决方案,渲染分辨率无法承担,每像素随机采样16个VPL,相邻像素采样不同的16个VPL,每个64x64屏幕空间tile可以覆盖所有64k的VPL。使用PBR手册中描述的低差异序列,确保64x64的tile中没有两个像素使用相同的VPL,在64k中采样16次具有巨大的差异,导致严重的噪点。因此可引入时间采样,每个像素每帧采样不同的16个VPL,实际上有超过16个VPL,TAA将帧收敛到稳定图像,最佳部分–无需更改TAA着色器。
TAA还可用于屏幕空间反射、阴影模糊、屏幕空间环境遮挡、*相机透明度、LOD转换、一些头发透明。未解决的问题:不受支持的运动矢量,一些颗粒/水在没有TAA的情况下看起来更好;下采样和模糊不友好,无法让SSR在半分辨率内工作;TAA在较高的帧速率下工作得更好,收敛速度更快,瑕疵不那么明显。
Mixed Resolution Rendering in 'Skylanders: SuperChargers'讲述了游戏Skylanders: SuperChargers所使用的混合分辨率渲染的技术。首次尝试使用了单通道的混合分辨率,场景深度被下采样,然后根据低分辨率缓冲区进行光栅化,使用双边上采样对低分辨率渲染进行上采样,然后最终合成到场景缓冲区。

双边上采样的代码:
float4 vBilinearWeights = GetBilinearweights(vTexcoord);
float4 vSampleDepths = GetLowResolutionDepths(vrexcoord);
float vPixelDepth = GetHighResolutionDepth(vTexcoord);
float4 vDepthWeights = GetDepthsimilarity( vPixelDepth, vSampleDepths);
return vDepthWeights * vBilinearWeights;
深度下采样时把最小值和最大值结合起来,因为它们处理的像素几乎是互斥的。事实证明,简单的事情有时也能奏效,只需在棋盘模式中交替使用最小值和最大值,这将为整个4x4像素块提供良好的深度表示。
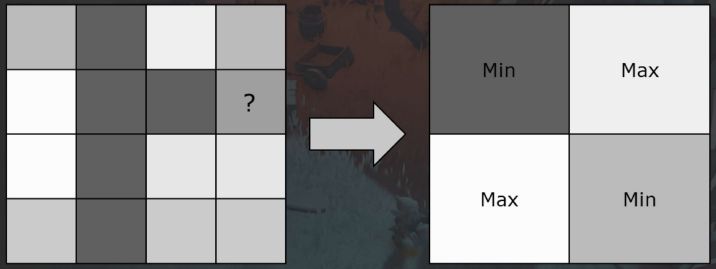
Texture2D SourceDepthTexture;
SamplerState PointSampler;
float main(float2 vTexcoord : TEXCOORD0, float2 vWindowPos : SV_Position) : SV_Target
{
// Gather the 4 depth taps from the high resolution texture that cover this texel SourceDepthTexture.
float4 fDepthTaps = GatherRed(PointSampler, vTexcoord, 0);
// Identify the min and max depth out of the 4 taps
// NOTE: It doesn't matter if your depth is negative or positive here
float fMaxDepth = max4( fDepthTaps.x, fDepthTaps.y, fDepthTaps.z, fDepthTaps.w);
float fMinDepth = min4( fDepthTaps.x, fDepthTaps.y, fDepthTaps.z, fDepthTaps.w);
// Classify the low resolution texel as either a max texel or min texel based on the window pos
return checkerboard( vWindowPos) > 0.5f ? fMaxDepth : fMinDepth;
}
由此产生的深度缓冲将高频深度不连续转化为棋盘格图案,正如从下图的拱门下的草叶中看到的那样。因此,需要一种评估它们的方法。

几种不同的深度下采样方法的像素误差值如下,可知min/max 方法误差最小:
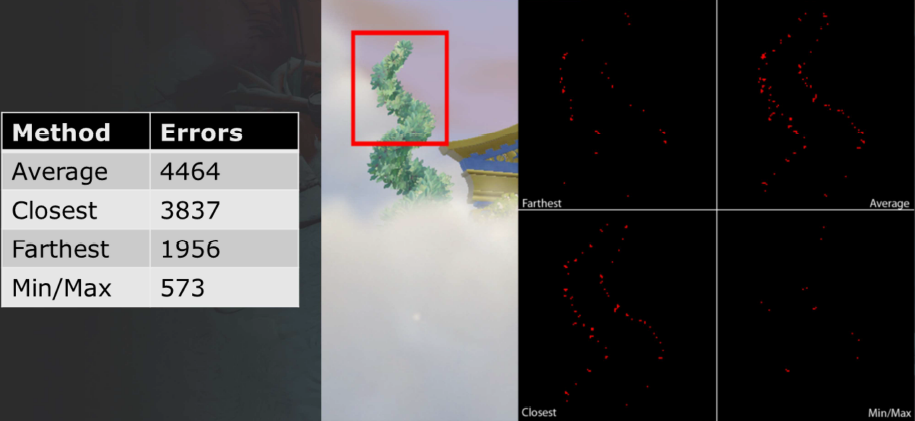
原始参考和min/max的渲染对比:

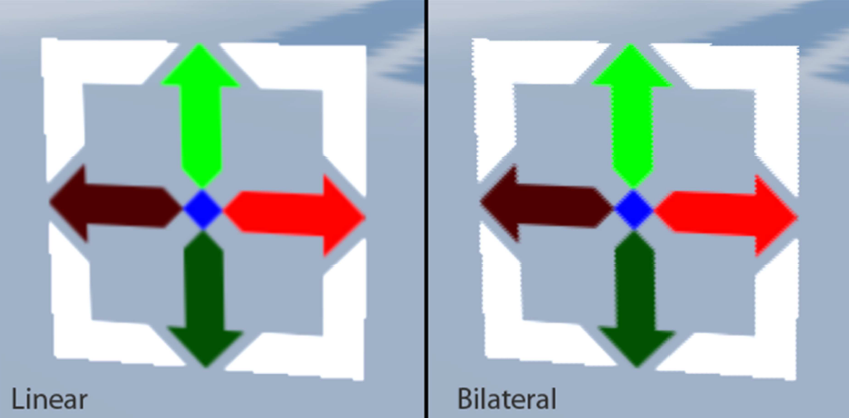
双边上采样的模式如下:
然而第二次尝试有时结果看起来比决心更糟糕,样本是否有问题?是否使用点采样更佳?事实证明,在某些情况下,当将结果与一个简单的线性滤波进行比较时,如果没有深度权重,结果会出现一些奇怪的伪影,就可以判断出发生了什么。那么为什么会发生下图这种情况(双边过滤明显的锯齿)呢?这与双边上采样以及如何计算深度相似性有关。
深度相似度一般由下面的代码计算:
float4 GetDepthSimilarity( float fCenterDepth, float4 vSampleDepths)
{
// fThreshold控制着深度相似度的强度
loat fScale = 1.0f / fThreshold;
float4 vDepthDifferences = abs(vSampleDepths - fCenterDepth);
return min(1.0f / (fScale * vDepthDifferences + fEpsilon) , 1.0f);
}
通常,通过确定高分辨率和低分辨率像素的深度差来计算深度相似性。该数字与阈值(fThreshold)一起用于确定深度是否相似。所以,如果选择一个小的阈值,最终会检测到假边缘(下图左)。类似地,如果阈值太大,则会丢失靠*的边(下图右)。

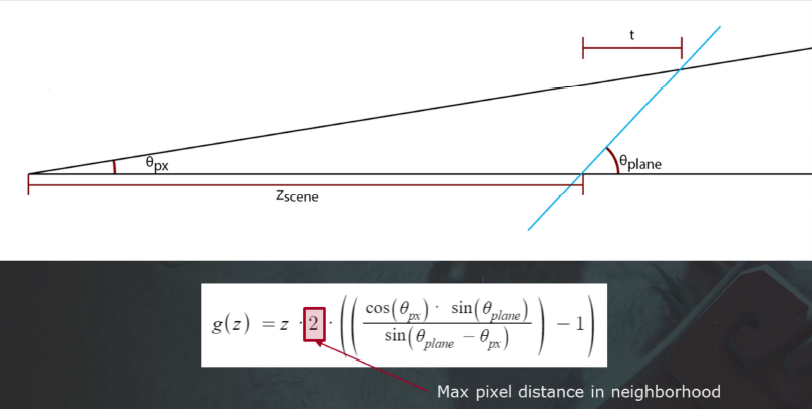
这是因为对双边加权使用了固定的深度偏差值。问题在于,随着表面逐渐退到屏幕中,单个像素步所代表的单位数增加了。因此,应该根据深度设置阈值。

文中改成使用*面被推回进场景的模型作为确定阈值的基础。给出单个像素的角度差和*面的斜率作为输入,以确保在前面保持线性混合。从而变成了一个简单的三角问题,可以得到结果,此外,还缩放该值以补偿这样一个事实——下采样时深度值可能来自2个像素之外。
改进后的阈值的效果和采样结果如下两图:

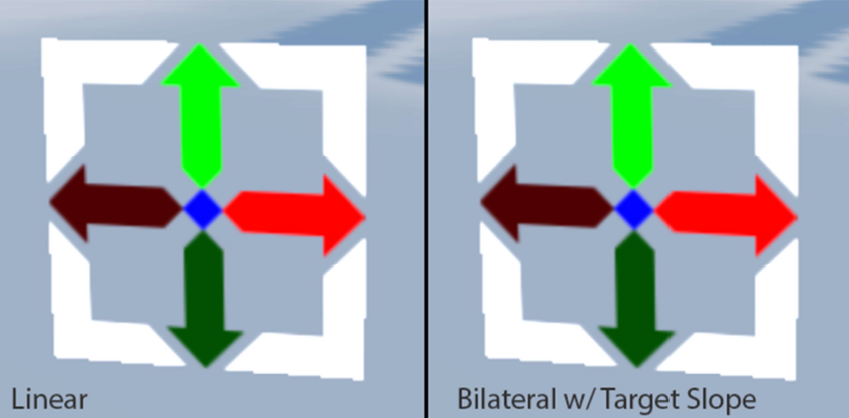
但是,下面是使用目标坡度阈值前后另一个问题的示例,图左所示得到的是水*过滤,而不是垂直过滤。

因此,第三次尝试有些影响看起来仍然很糟糕,有很多锯齿,透明模型更糟糕。为了减少边缘锯齿,采用了双通道方法方法:

对深度和颜色的边缘的检测采样了以下方法:

部分上采样步骤:
-
第1个Pass:
- 裁减边缘。
- 在通道中设置模板位。
-
第2个Pass:
- 配置高分辨率模板(hi-stencil)。
- 绘制全屏矩形以重新加载高分辨率模板。
第四次尝试得到的效果达到了发布水*,在360上运行的性能如下:

由于在游戏中使用了抖动衰减,在下图可以看到最小/最大缓冲区清楚地保持了正在淡出的树的抖动特性。

优势是有助于游戏的内容,屏幕外的渲染目标非常有用,性能可扩展。劣势是预乘的渲染目标,有限的混合模式,依赖高分辨率模板,最坏情况下的成本更高,高开销。
How we rethought driver abstraction谈及了如何更好地抽象和封装图形API。文中的抽象最初是基于DX9的轻量层,更新后与DX10匹配,抽象方法/调用,不是渲染过程本身。旧的渲染管线如下:
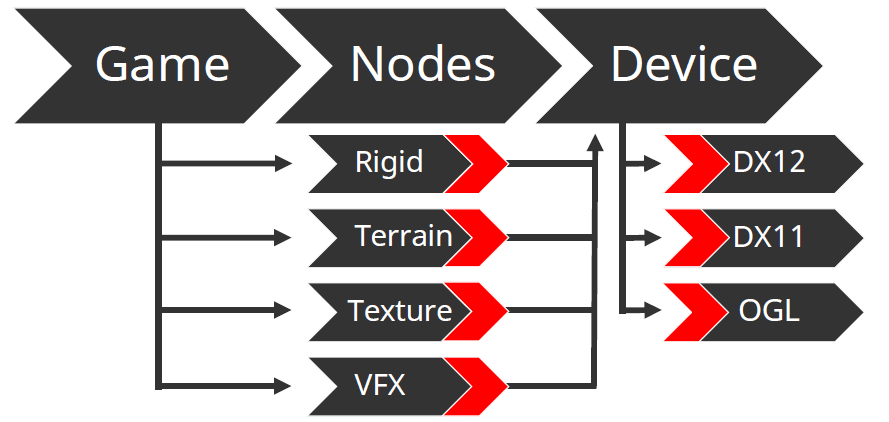
工作项(work item)是描述单个渲染工作所需的最少数据,如输入、输出、程序等,尽可能通用,不一定是GPU工作,完全独立。
资源可以是任何东西,是客户端代码的黑盒,可以在不同*台甚至不同运行有不同的实现,可能有实例,生命周期长,不一定存在于整个生命周期的内存中,资源的典型代表是纹理、着色器、模型等。实例是一种资源,是临时的,在客户端代码是黑盒,由与资源相同的代码处理,例如在当前帧中渲染的模型实例。句柄有设置(colour_handle, colour::red)、获取(colour_handle)等接口,在内部句柄是实例内存的偏移量,客户端访问资源和实例的唯一方法,如果给定实例或资源没有请求的参数,则为NOP,调试中有类型检测。
新的管线如下,增加了资源管理器,隔离开高级和低级渲染层,从而达到更好的解耦,并获得优化的机会:
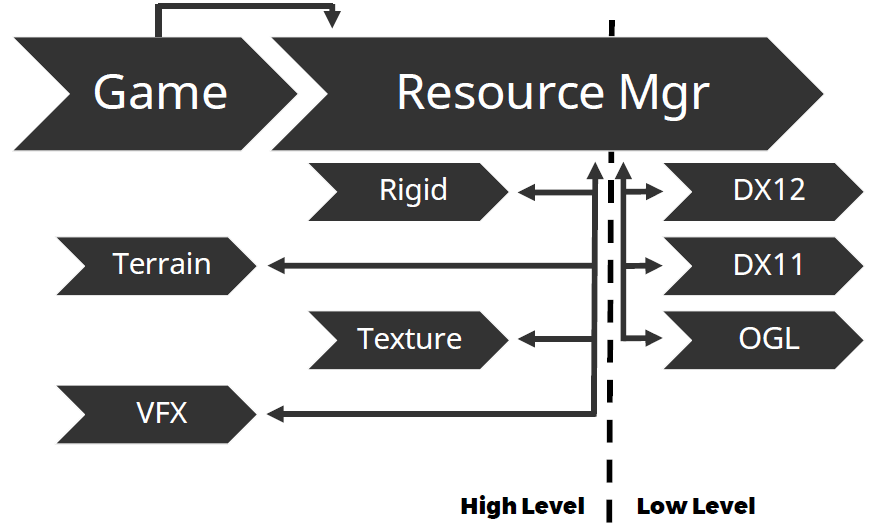
总之,尽可能多地为底层代码提供上下文,不要在高层做出任何假设,保留所有选项,在不影响性能的情况下,不要害怕概括和抽象事物,API上的轻量级封装不再是最佳选择。
From Pixels to Reality – Thoughts on Next Game Engine谈及了2016年的游戏引擎的现状以及未来的趋势。2016年,主流游戏引擎的特点是多线程、多*台、现代图形API、延迟渲染、PBR、全局照明、动态环境及60FPS@1080P,当时不够好的点有锯齿、阴影、透明度、动画、加载时间、性能、内容制作等,新兴的技术包含基于社区的游戏、用户创建内容、移动端、VR/AR、电子竞技、广播等。电影和游戏的区别见下表:
| 电影 | 游戏 |
|---|---|
| Reyes/Ray Tracing | Direct 3D / OpenGL |
| 物体空间着色 | 屏幕空间着色 |
| 大量可见性样本 | 少量可见性样本 |
| 照片级质量 | 吞吐量 |
在当时,REYES/Ray Tracing用于游戏的时机还不够成熟,因为基于GPU的REYES面临小三角形、场景复杂度、不够快等问题,而实时光追面临分辨率、多显示器、不够快等问题。更好的方法是借鉴和结合的思想。对象空间中的阴影=固有稳定,将可见性采样与着色分离=多速率,可见性缓冲区=减少内存和带宽。可能的渲染管线如下:

多速率可进一步地扩展到可见性样本、着色样本、照明样品、物理、人工智能、输入、光源传输更新等。在锯齿方面,镜面锯齿可用Lean Mapping[OlanoBaker 2010],阴影锯齿可用Frustum Traced Raster Shadows[WymanHoeltzleinLefohn15],半透明可用OIT。加载时间可用比zlib好2倍的压缩技术、程序化合成的Substance、Wang Tiles [Wang61] [Stam97] [Liyi04]。
云可支持巨大的世界、成千上万的玩家、微型客户端、内容制作、盒子里的工作室。亚马逊的云渲染GameLift架构图如下:
2018年的游戏引擎几乎没有锯齿、正确的空间、正确的频率、正确的位置、感知引导的“重要性”、程序化内容、云连接等。研究热点有程序化合成、压缩、三维扫描、感知科学、多速率渲染、动画、分布式的物理/人工智能/渲染等。
Building a Low-Fragmentation Memory System for 64-bit Games分享了游戏内的低碎片化的内存管理系统。旧的内存系统从PS3中移植而来,具有固定大小的内存池,模拟VRAM。存在的问题是浪费了很多内存,每个内存池都能应付最坏的情况,小型分配的开销,碎片化,无法支持纹理流。内存碎片是在小的非连续块中碎片化的堆,即使内存足够,分配也可能失败,由混合分配生命周期引起。

设计目标是低碎片、高利用率、简单配置、支持PlayStation®4操作系统和PC、支持高效的纹理流、全面的调试支持。
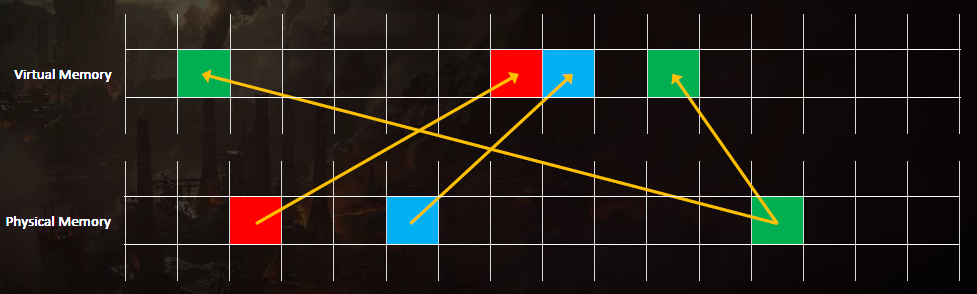
虚拟内存是在进程使用虚拟地址,是映射到物理地址的虚拟地址,CPU查找物理地址,需要操作系统和硬件支持。
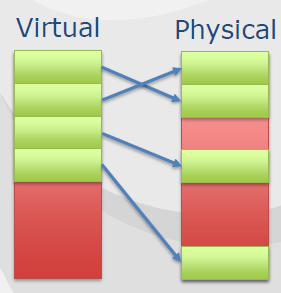
虚拟内存可以减少内存碎片,碎片就是地址碎片,使用虚拟地址,虚拟地址空间大于物理地址空间,连续的虚拟内存在物理内存中不连续。内存页(Memory Page)在页面中映射,x64支持4kB和2MB页面,PlayStation4操作系统使用16kB(4x4kB)和2MB,GPU有更多的尺寸。2MB页面最快,16kB页面占用的内存更少,文中使用64kB(4x16kB页面),64kB是PlayStation 4 GPU的最小最佳尺寸,特殊情况也使用16kB。
洋葱总线(Onion Bus)和大蒜总线(Garlic Bus)都可以倍CPU和GPU访问,但它们的带宽不同,洋葱=快速CPU访问,大蒜=快速GPU访问。
文中的内存系统分割整个虚拟地址空间,按需映射物理内存,分配器模块管理自己的空间,每个模块都是专门的,分配器对象是系统的接口。
class Allocator
{
public:
virtual void* Allocate(size_t size, size_t align) = 0;
virtual void Deallocate(void* pMemory) = 0;
virtual size_t GetSize(void* pMemory) { return 0; }
const char* GetName(void) const;
};
// 示例
void* GeneralAllocator::Allocate(size_t size, size_t align)
{
if (SmallAllocator::Belongs(size, align))
return SmallAllocator::Allocate(size, align);
else if (m_mediumAllocator.Belongs(size, align))
return m_mediumAllocator.Allocate(size, align);
else if (LargeAllocator::Belongs(size, align))
return LargeAllocator::Allocate(size, m_mappingFlags);
else if (GiantAllocator::Belongs(size, align))
return GiantAllocator::Allocate(size, m_mappingFlags);
return nullptr;
}
虚拟地址空间:

小型分配模块:大多数分配小于等于64字节,约25万个分配,约25M。打包以防止碎片,大小相同的16kB页面,没有头信息。
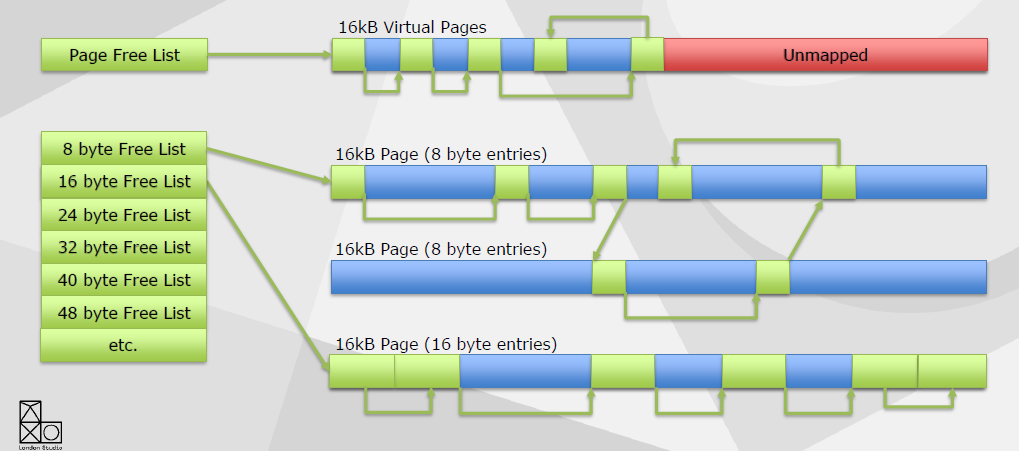
小型分配模块的利弊,+轻量实现,+非常低的浪费,+利用灵活的内存,+快速,-难以检测的内存瓶颈。
大型分配模块保留巨大的虚拟地址空间(160GB),每个表被分成大小相等的插槽,按需映射和取消映射64kB页面,保证连续内存。
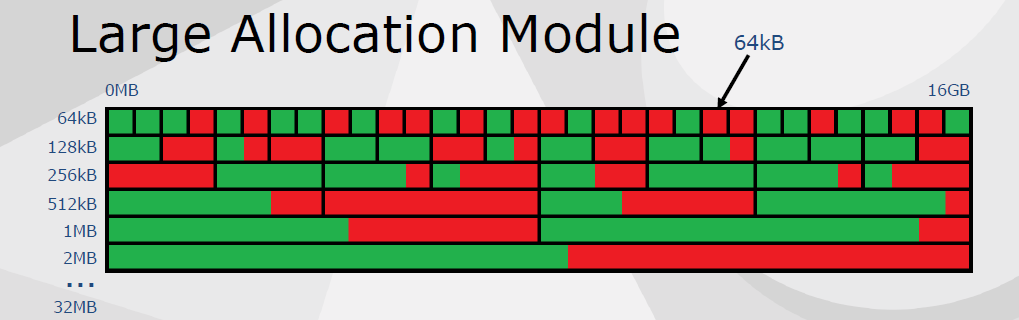
纹理流预留大的分配槽,四舍五入到最*的2的N次方,加载最小mip和64kB的最大值,按需映射和取消映射页面,无需复制或整理碎片。大型分配模块的利弊,+没有头信息,+简单的实现(大约200行代码),+没有碎片,-大小四舍五入到页面大小,-映射和取消映射内核调用相对较慢。
中型分配模块应对中等尺寸的分配,无头信息,除了大型和小型之外其它尺寸都在这里分配,非连续虚拟页,增长和收缩,传统的带头信息的双链表,不适合大蒜(GPU)的内存(与数据一起存储的头),Pow2自由列表。

无头分配模块(Headerless Allocation Module)用于GPU分配,中小型分配,哈希表查找。
分配器类型包含GeneralAllocator、VramAllocator、MappedAllocator、GpuScratchAllocator、FrameAllocator等。GPU暂存分配器(GpuScratchAllocator)是渲染器用于每帧分配,双缓冲,不需要释放分配,受原子保护。GpuScratchAllocator的优缺点:+没有头或账单,+没有碎片,+快速,-固定尺寸,-最糟糕的情况是对齐浪费空间。帧分配器(FrameAllocator),帧被推入和弹出,不需要释放内存,每个线程都是唯一的,适用于临时工作缓冲区。
#include <ls_common/memory/ScratchMem.h>
struct Elem
{
…
};
void ProcessElements(size_t numElements)
{
ls::ScratchMem frame;
Elem* pElements = (Elem*)MM_ALLOC_P(&frame, sizeof(Elem) * numElements);
}
FrameAllocator的优缺点:+没有头或账单,+没有碎片,+没有同步,+快速,-小心指针传递!
线程安全:最低级别的互斥体,分配器实例不受保护,帧分配器没有锁,又好又简单。
性能不是重点,但仍然很重要,映射/取消映射速度慢,没有明显的区别,游戏期间不要太多分配,文件加载是一个瓶颈。内存的清理值有以下几种(memset的字节值,保持可读可记):
0xFA: Flexible memory allocated
0xFF: Flexible memory free
0xDA: Direct memory allocated
0xDF: Direction memoryfree
0xA1: Memory allocated
0xDE: Memory deallocated
统计信息,追踪一切可能的事情,实时图表可用,通过自动测试记录。内存头保护,中型分配头中的空闲字节,检测内存瓶颈,但往往为时已晚。内存块哨兵,绕过正常分配器,每个分配都在自己的页面中,前后未映射的页面,写得太多/太少时崩溃。
总结:现代控制台具有丰富的虚拟内存支持,虚拟内存提供了许多选项,围绕分配模式设计内存系统,分析很重要,小型分配是一个良好的开端,模块化分配器使定制变得容易!调试功能非常重要!
The devil is in the details: idTech 666讲述了idTech引擎的渲染管线的渲染技术和性能优化。当时的idTech的渲染管线流程和性能数据如下:
其分簇光照系统衍生自“Clustered Deferred and Forward Shading” [Olson12]和“Practical Clustered Shading” [Person13],可工作于透明表面,不需要额外的通道或工作,独立于深度缓冲区,深度不连续处无误报。分簇光照步骤如下:
-
体素化/光栅化处理。在CPU上完成,每个深度片1个作业。
-
对数深度分布。扩大**面和远*面:\(\text{ZSlice}=\text{Near}_z\times \Big(\cfrac{\text{Far}_z}{\text{Near}_z}\Big)^\frac{\text{slice}}{\text{numSlices}}\)。
-
对每个项目进行体素化,项目可以是灯光、环境探针或贴花,项目形状是OBB或*截体(投影者),由屏幕空间\(\min_{xy}\)、\(\max_{xy}\)和深度边界的光栅化来界定。
-
在剪辑空间中进行细化。剪辑空间中的单元格是AABB,N个*面和单元格AABB,OBB是6个*面,*截体是5个*面,所有体积的代码都相同,使用SIMD。
//Pseudo-code - 1 job per depth slice ( if any item ) for (y=MinY; y<MaxY; ++y) { for (x =MinX; x<MaxX; ++x) { intersects = N planes vs cell AABB if (intersects) { Register item } } }
细节化世界的技术:虚拟纹理更新;反照率、镜面反射、*滑度、法线、HDR光照贴图,硬件sRGB支持,将Toksvig烘焙成*滑度,用于镜面抗锯齿;直接将UAV输出回读至最终分辨率;异步计算转码,成本几乎无关紧要;设计缺陷依然存在,例如反应性纹理流=纹理弹出;嵌入几何栅格化的贴花;实时替换到Mega纹理的压印(Stamping),更快的工作流程/更少的磁盘存储;法线贴图混合、所有通道的线性正确混合、mipmap/各向异性、透明度、排序、0个绘制调用、使用BC7的8k x 8k贴花图集;还有盒子投影、索引到贴花图集,由艺术家手工放置,包括混合设置,“混合层”的推广;每个视锥视图限制为4k,通常1k或更少可见;LOD化,艺术设置最大视距,玩家质量设置也会影响观看距离;研究动态不可变形几何体,将对象变换应用于贴花。
在光照方面,使用单一/统一照明代码路径,对于不透明通道、延迟、透明和解耦粒子照明,没有着色器排列,现在静态/连贯分支非常好——尽情使用它!对所有静态几何体使用相同的着色器,减少上下文切换。光照组件包含:漫反射间接照明——用于静态几何体的光照贴图,用于动态的辐照度体积,镜面间接照明——反射(环境探针、SSR、镜面遮挡),用于动态的灯光和阴影。
// Pseudocode
ComputeLighting( inputs, outputs )
{
Read & Pack base textures
for each decal in cell
{
early out fragment check
Read textures
Blend results
}
for each light in cell
{
early out fragment check
Compute BRDF / Apply Shadows
Accumulate lighting
}
}
阴影被缓存/打包到图集中,PC用32位的8k x 8k的图集(高规格),控制台用16位的8k x 4k,基于距离的可变分辨率,时间切片也基于距离,静态几何优化网格。如果光源不移动,缓存静态几何体阴影贴图,如果frustum内部没有更新则跳过,如果没有更新,用缓存结果组合动态几何体,仍然可以使用动画(例如闪烁),艺术设置/质量设置会影响以上所有内容。索引到阴影截锥投影矩阵,所有灯光类型的PCF查找代码相同,减少VGPR压力,包括*行光级联,级联之间使用抖动,单级级联查找,尝试VSM及其导数,有一些瑕疵,从概念上讲,对前向渲染有很好的发展潜力,例如将过滤频率与光栅化分离。
光照时,注意VGPR压力,打包寿命长的数据,例如float4表示HDR颜色 <--> RGBE编码的uint,最小化寄存器生命周期,最小化嵌套循环/最坏情况路径,最小化分支,控制台上56个VGRS(PS4),由于编译器效率低下,在PC上更高(@AMD编译器团队,漂亮的plz修复程序-抛出性能)。未来使用半精度支持将有所帮助,Nvidia:使用UBOs/常量缓冲区(所需的分区缓冲区=更多/丑陋的代码),AMD:优先SSBO/UAV。
粗糙玻璃*似:最高mip为半分辨率,总共4个mip,高斯核(*似GGX瓣),基于表面*滑度的混合mips,折射传输限制为每帧2次,以提高性能,通过贴花实现表面参数化/变化。

对于后处理,通过以下方法优化了数据读取:非分歧运算的GCN标量单位,非常适合加速数据获取,节省VGRP,一致性分支,指令更少(SMEM:64字节,VMEM:16字节)。分簇着色用例,每个像素从其所属单元获取灯光/贴花,本质上是不同的,但值得分析。
大多数wavefront只能进入一个cell,附*的cell共享大部分内容,线程主要获取相同的数据。每线程单元数据获取不是最优的,不利用这种数据融合。合并单元格内容上可能的标量迭代,不要让所有线程独立地获取完全相同的数据。
利用访问模式:对于数据,每个单元格的项目(灯光/贴花)ID排序数组,同样的结构适用于灯光和贴花处理,每个线程可能访问不同的节点,每个线程在这些数组上独立迭代。标量加载用序列化迭代,计算所有线程中的最小项目ID值,ds_swizzle_b32/小型位置不一致,与所选索引匹配的线程的进程项,统一索引->标量指令,匹配的线程移动到下一个索引。

特殊路径:如果只接触一个单元格,则为快速路径,避免计算最小的物品ID,在GCN1和2上不便宜,一些额外的(次要的)标量获取和操作,序列化假定线程之间存在局部性,如果接触过多的单元格,速度会明显减慢,禁用粒子照明图集生成。
动态分辨率缩放:基于GPU负载的自适应分辨率,PS4上的比例大多为100%,Xbox上的比例更大,在同一目标中渲染,调整视口大小
侵入式:需要额外的着色器代码,OpenGL上的唯一选项。未来:重叠多个渲染目标,可能在控制台和Vulkan上,TAA可以收集不同分辨率的样本,异步计算中的上采样。
异步后处理:阴影和深度过程几乎不使用计算单位,固定的图形管线繁重。不透明通道也不是100%忙,可以与后处理重叠,在特效队列上的预乘Alpha的缓冲区中渲染GUI,计算队列上处理后处理/AA/upsample/compose UI,与第N+1帧的阴影/深度/不透明重叠,从计算队列中显示(如果可用),潜在更低的延迟。
此外,文中还涉及了GCN架构上的特定优化。未来的工作是解构频率的消耗以获得收益,改进纹理质量、全局照明、整体细节、工作流程等。

[Top five technologies to watch: 2017 to 2021](https://www.bizcommunity.com/Article/196/706/154305.html#:~:text= Top five technologies to watch%3A 2017 to,commonplace%2C while VR will remains niche. More)阐述了2017到2021的技术趋势和新兴的技术。五项技术将帮助我们获得洞察力:
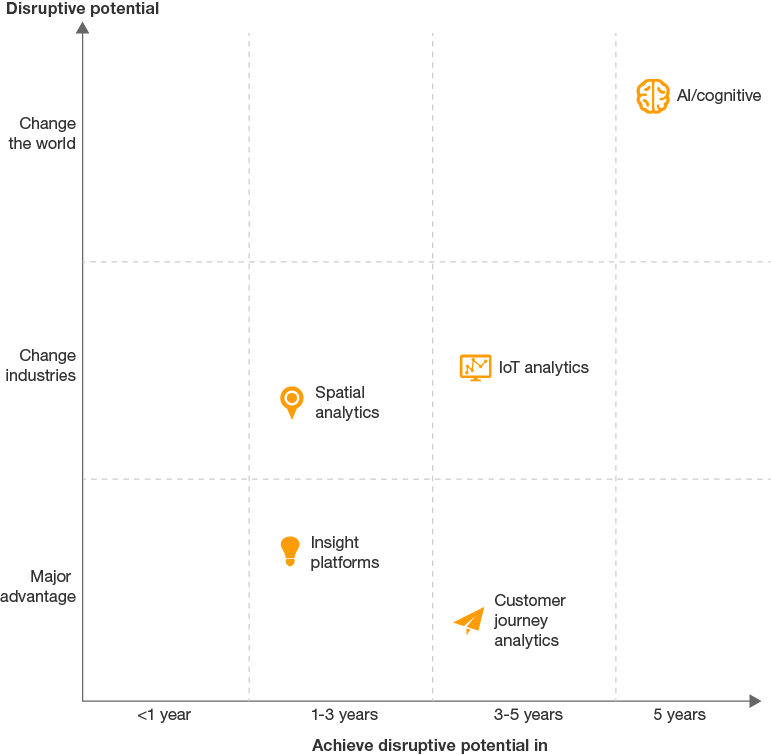
最重要的是人工智能与认知技术。以下五大技术支持快速互联:
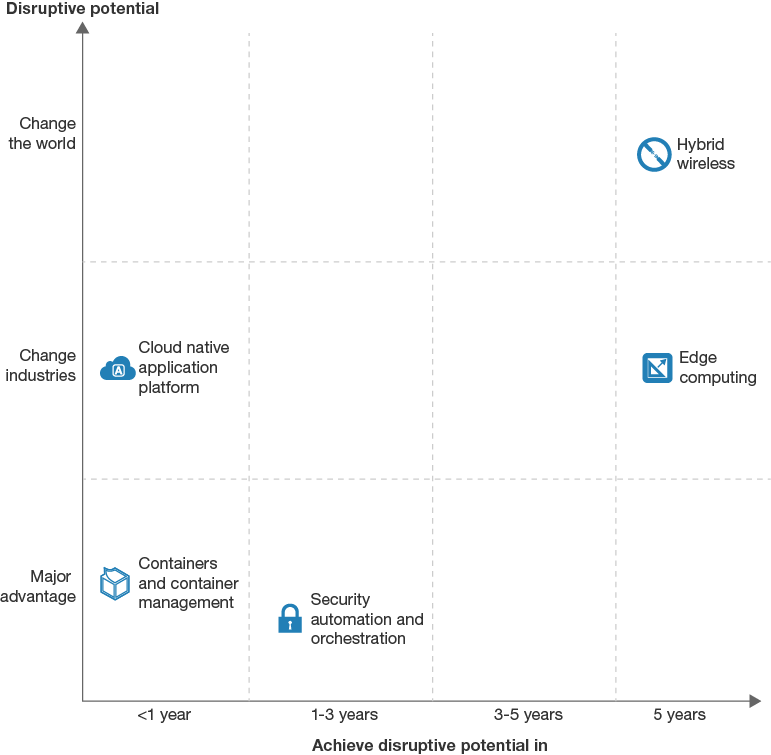
包含移动边缘计算、cloudlets、fog计算、工业互联网、SDN和OpenNFV。Edge computing将全面帮助人们,但需要更高层次的技术。
The Latest Graphics Technology in Remedy's Northlight Engine讨论了Remedy的Northlight引擎中渲染技术的引擎内实现和一些最新进展的结果,包含DirectX光线追踪、区域阴影、环境遮挡、反射、间接漫反射等。
实时光线追踪中的基于可见性的算法图例如下:
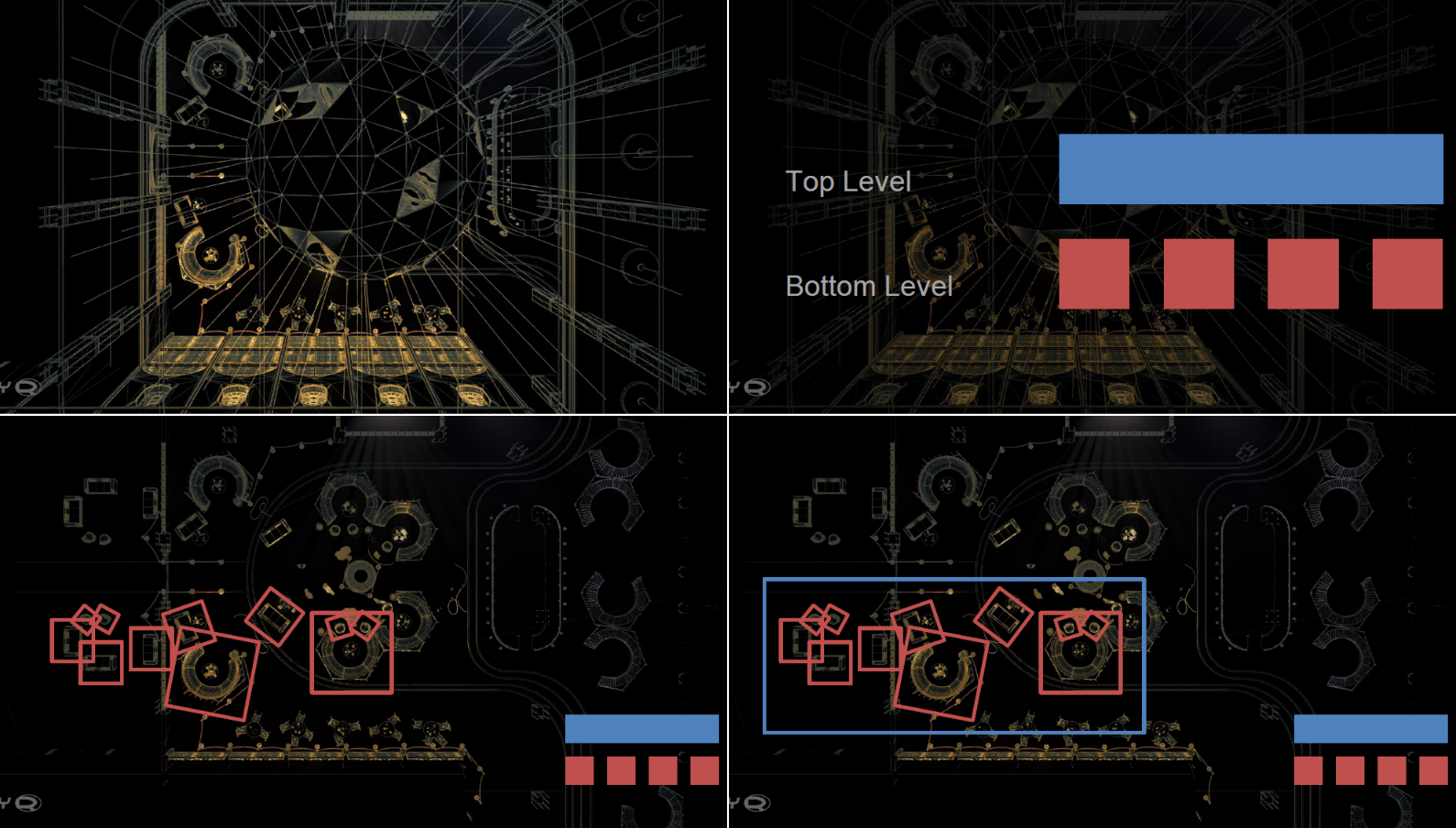
在AO上,SSAO和光追AO的对比如下:

而光追AO在不同的rpp上,效果也有所不同:

反射上,SSR和光追反射也有明显的区别:

对于间接漫反射,与AO类似,许多非相干光线,GI存储在稀疏网格体积中。基于静态几何图形和静态灯光集计算的辐照度,动态几何体可以接收光,但不影响计算的辐照度,动态几何没有贡献,三线性采样创建阶梯样式,薄几何体会导致光照泄漏,通过采样余弦分布上的辐射来收集照明,考虑丢失的几何图形。
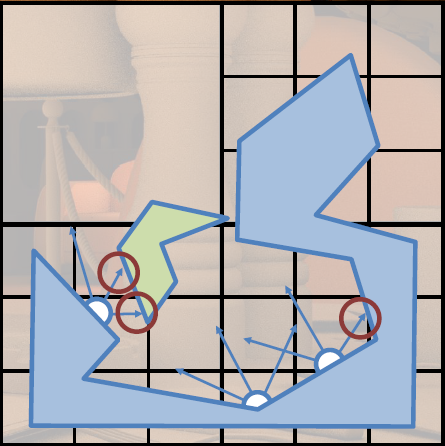
我们还可以在几何体交点上采样照明,最终的光追各分量和组合效果如下:


总之,通过DXR轻松访问最先进的GPU光线跟踪,性能正在达到目标,易于不适合光栅化的原型化算法,可与现有低频结构相结合。

Advanced Graphics Techniques Tutorial: GPU-Based Clay Simulation and Ray-Tracing Tech in 'Claybook'阐述了Second Order公司的第一款游戏《Claybook》包含了大量创新技术,包括基于GPU的粘土和流体模拟器、完全可变形的世界和角色、有向距离场建模和光线跟踪视觉效果。并讨论这项技术的产生、优化和技巧才能在当前一代游戏机上用游戏的光线跟踪视觉效果和模拟达到60 fps,以及他们的非标准渲染器和模拟技术是如何集成在虚幻引擎4之上的。
有向距离场(SDF):SDF(P)=到P处最*表面的有符号距离,有解析距离函数和体积纹理两种形式。解析距离函数在场景demo中流行,巨大的着色器,很多数学知识,没有数据。体积纹理存储距离函数,三线性滤波器,Claybook将体积纹理与mip贴图结合使用。Claybook的世界SDF的分辨率=1024x1024x512,格式=8位有符号,大小=586 MB(5 mip级别),[-4,+4]体素的距离,256个值/8个体素,1/32体素精度,每mip级别最大步进(世界空间)翻倍。
在GPU上生成世界SDF的步骤:
-
生成SDF笔刷网格。64x64x32的dispatch,4x4x4的线程组。
- 在分块中心T处采样刷子体积。如果SDF>光栅分块边界+4个体素,则剔除。如果接受,原子添加+存储到GSM。
- 通过GSM中的笔刷循环。细胞中心C处的样本[i],如果接受,存储到网格(线性),局部+全局原子压缩。
![]()
-
生成调度坐标。64x64x32的调度,4x4x4的线程组。
- 读取刷子网格单元。
- 如果不是空的:原子加法(L+G)得到写索引,将单元格坐标写入缓冲区。
![]()
-
生成Mip掩码。4x调度(mips),4x4x4的线程组。
- 分组:加载1个更宽的体素网格L-1邻域,下采样1=0掩码并存储到GSM。
- 将掩码放大1个体素(3x3x3)。
- 掩码=0则写入网格单元坐标。
-
在8x8x8的tile中生成0级(稀疏)。间接调度,8x8的线程组。
- 分组:读取网格单元坐标(SV_GroupId)。
- 从网格读取笔刷并存储到GSM。
- 通过GSM中的笔刷循环,采样[i],执行exp*滑最小/最大操作。
- 将体素写入WorldSDF的级别0。
-
生成mips(稀疏)。4倍间接调度(mips),8x8的线程组。
- 分组:加载更宽的L-1邻域的4个体素。2x2x2下采样(*均值)并在GSM中存储为\(12^3\),+-4体素带变成+-2体素阶(band)。
- 分组:在GSM中运行3步eikonal方程(下图),扩展阶:2个体素变成4个体素。
- 存储8x8x8邻域的中心。
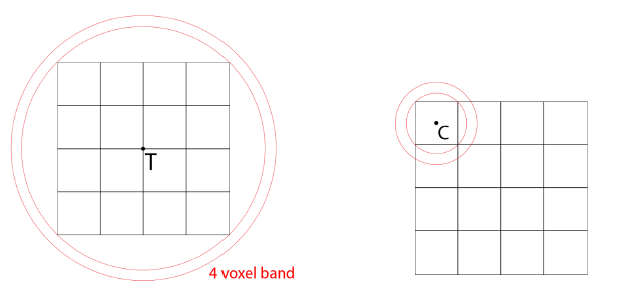

球体追踪算法:
- D = SDF(P)。
- P += ray * D。
- if (D < epsilon) break。
多层体纹理跟踪:
Loop
D = volume.SampleLevel(origin + ray*t, mip)
t += worldDistance(D, mip)
IF D == 1.0 -> mip += 2
IF D <= 0.25 -> mip -= 2; D -= halfVoxel
IF D < pixelConeWidth * t -> BREAK
// 如果曲面位于像素内边界圆锥体内,则中断,获得完美的LOD!
最后一步:球体追踪需要无限步才能收敛,假设我们碰到一个*面,三线性过滤=分段线性曲面,几何级数,使用最后两个样本,\(Step = D/(1-(D-D_{-1}))\)。
锥体追踪解析解:
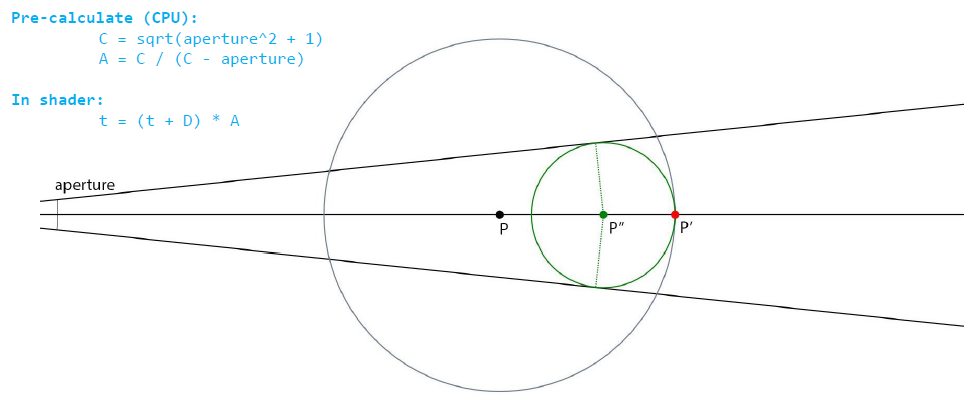
粗糙锥体追踪Prepass:
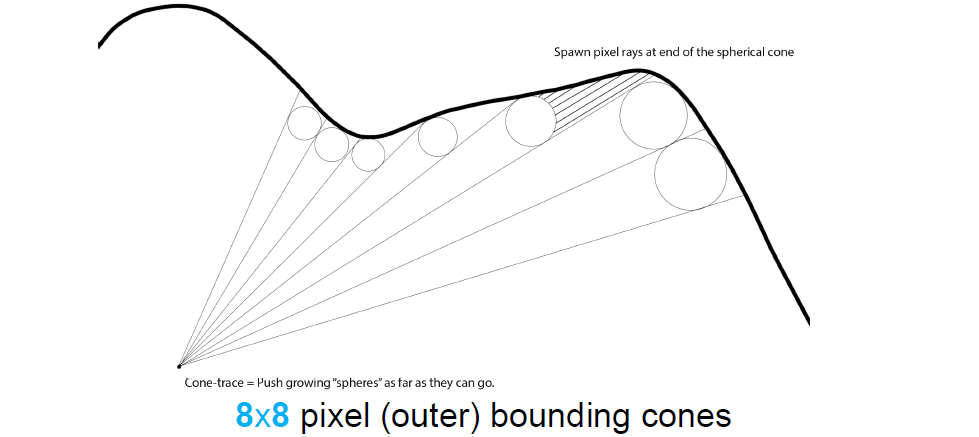
光线追踪结果:锥形追踪跳过大面积的空白空间,大幅缩短步长,体积采样更多缓存局部性。Mip映射改善缓存的局部性,Log8数据缩放:100%、12.5%、1.6%、0.2%、...测量(1080p渲染),访问8MB数据(512MB),99.85%的缓存命中率。存在的问题有:过步进(Overstepping)、加载*衡等,它们有各自的缓解方案。
对于AO,在表面法线方向构造圆锥体,加上随机变化+时间累积,AO射线使用低SDF mip,更好的GPU缓存位置和更少的带宽,软远程AO。Claybook也使用UE4 SSAO,小规模(*)的环境遮挡。

上:SSAO;下:SSAO + RTAO。
软阴影球体跟踪:柔和的半影扩大阴影,沿光线步进SDF*似最大圆锥体覆盖率,Demoscene圆锥体覆盖*似:
c = min(c, light_size * SDF(P) / time);
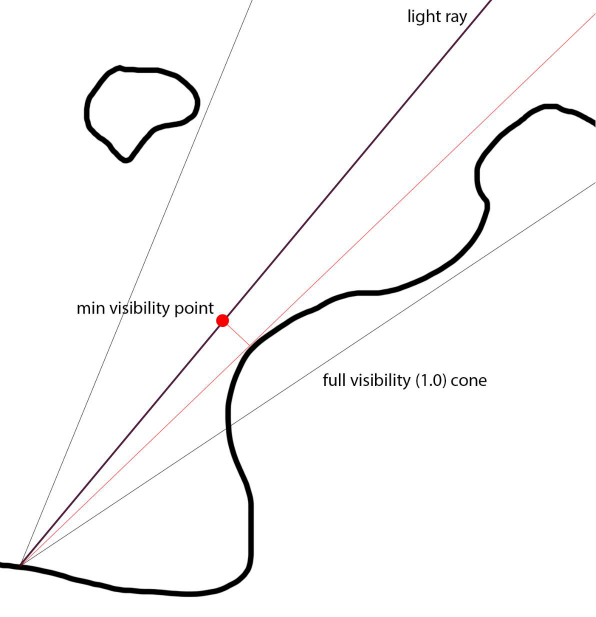
Claybook对软阴影的改进:三角测量最*距离,Demoscene=单个样本(最小),三角测量cur和prev样本,更少条带。抖动阴影光线,UE4时间累积,隐藏剩余的带状瑕疵,较宽的内半影。
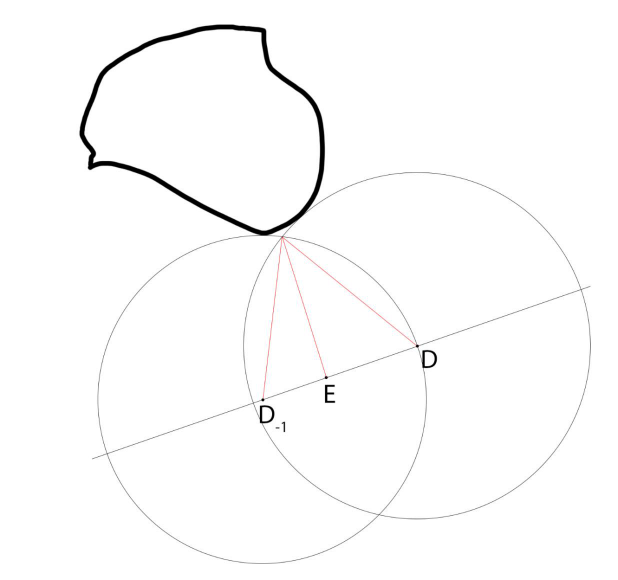
改进前后对比:

光追的各项时间消耗:

SDF到网格的转换:双通道*似,多个三角形指向同一个粒子,首先需要生成粒子。输出用于PBD模拟器的线性粒子数组(表面)和三角形渲染的索引缓冲区。使用单个间接绘制调用绘制的所有网格。转成粒子使用64x64x64的dispatch、4x4x4的线程组,过程如下:
- 分组:将\(6^3\)个SDF邻域加载到GSM。
- 读取\(2^3\) GSM的邻域,如果在边缘内/外找到:
- 将P移动到表面(梯度下降)。
- 分配粒子id(L+G原子)。
- 将P写入数组[id]。
- 将粒子id写入\(64^3\)网格。
转成三角形使用64x64x64的dispatch、4x4x4的线程组,过程如下:
- 分组:将\(6^3\)个SDF邻域加载到GSM。
- 读取\(2^3\) GSM的邻域,如果找到XYZ边缘:
- 每个XYZ边分配2倍三角形(L+G原子)。
- 从\(64^3\)的id网格读取3倍的粒子id。
- 将三角形写入索引缓冲区(3倍的粒子id)。
异步计算:
- 将帧拆分为3个异步段。
- 重叠UE4的GBuffer和阴影级联。
- 重叠UE4的速度渲染和深度解压缩。
- 重叠UE4的照明和后处理。
- 工作立即提交。
- 计算队列等待栅栏启动(x3)。
- 主队列等待栅栏继续(x3)。
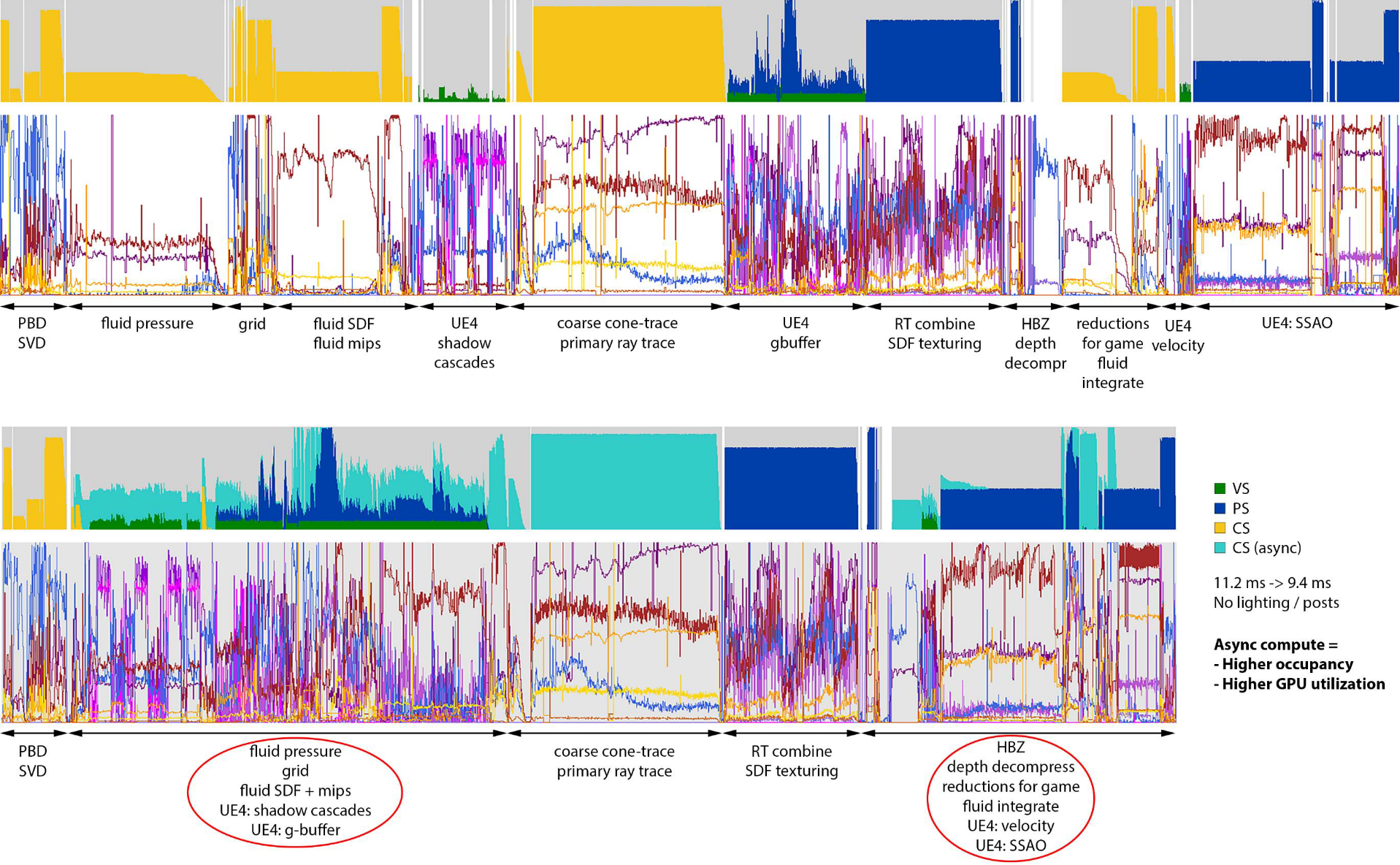
异步计算可以让fps提升19%+。
集成到UE4渲染器:
- GBuffer组合。
- 全屏PS组合光线追踪数据。
- 采样材质贴图(自定义gather4过滤)。
- 写入UE4的GBuffer+深度缓冲区(SV_Depth)。
- 阴影遮蔽(shadow mask)组合。
- 全屏PS到球体追踪阴影。
- 写入UE4阴影遮罩缓冲区(使用alpha混合)。
UE4 RHI定制:
- 在不进行隐式同步的情况下设置渲染目标。
- 可以对重叠深度/颜色进行解压缩。
- 可以将绘制重叠到多个RT(下图)。
- 清除RT/buffer而不进行隐式同步。
- 缺少异步计算功能。
- 缓冲区/纹理复制并清除。
- 计算着色器索引缓冲区写入。

UE4 RHI定制(额外):GPU->CPU缓冲区回读,UE4仅支持2d纹理回读而不停顿,其它readback API会让整个GPU陷入停顿,缓冲区可以有原始视图和类型化视图,宽原始写入=高效填充窄类型缓冲区。
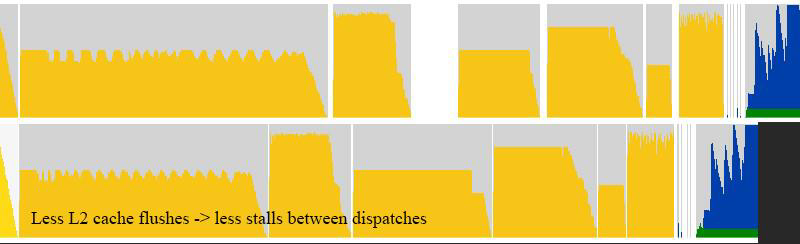
UE4优化:允许间接分派/提取的重叠,允许清除和复制操作重叠,允许不同RT的绘制重叠,减少GPU缓存刷新和停顿(下图),优化的暂存缓冲区,快速清晰的改进。优化屏障和栅栏,优化纹理数组子资源屏障,更好的3d纹理GPU分块模式,改进的部分2d/3d纹理更新,5倍更快的直方图+眼睛适应着色器,4倍更快的离线CPU SDF生成器(烘焙)。
实现说明:物理数据存储在一个大的原始缓冲区中,宽加载4/Store4指令(16字节),位压缩:粒子位置:16位范数、粒子速度:fp16、粒子标志(活动、碰撞等)的位字段,基准工具:https://github.com/sebbbi/perftest。Groupshared内存是一个巨大的性能利器,SDF生成、网格生成、物理,重复加载相同数据时使用。标量加载是AMD在性能上的一大胜利,用例:常量索引原始缓冲区加载,用例:基于SV_GroupID的原始缓冲区加载,存储到SGPR的负载获得更好的占用率。
Entity-Component Systems & Data Oriented Design In Unity分享了Unity的ECS和面向数据设计的技术,包含面向对象设计、面向数据的设计、实体组件系统、实践案例等。OO的典型实现:类层次结构,虚拟函数,封装经常被违反,因为东西需要知道,“一次只做一件事”的方法,迟来的决定。简单OO组件系统:
// Component base class. Knows about the parent game object, and has some virtual methods.
class Component
{
public:
Component() : m_GameObject(nullptr) {}
virtual ~Component() {}
virtual void Start() {}
virtual void Update(double time, float deltaTime) {}
const GameObject& GetGameObject() const { return *m_GameObject; }
GameObject& GetGameObject() { return *m_GameObject; }
void SetGameObject(GameObject& go) { m_GameObject = &go; }
private:
GameObject* m_GameObject;
};
class GameObject
{
public:
GameObject(const std::string&& name) : m_Name(name) { }
~GameObject()
{
for (auto c : m_Components)
delete c;
}
// get a component of type T, or null if it does not exist on this game object
template<typename T> T* GetComponent()
{
for (auto i : m_Components)
{
T* c = dynamic_cast<T*>(i);
if (c != nullptr)
return c;
}
return nullptr;
}
// add a new component to this game object
void AddComponent(Component* c)
{
c->SetGameObject(*this);
m_Components.emplace_back(c);
}
void Start()
{
for (auto c : m_Components)
c->Start();
}
void Update(double time, float deltaTime)
{
for (auto c : m_Components)
c->Update(time, deltaTime);
}
private:
std::string m_Name;
ComponentVector m_Components;
};
// Utilities
// Finds all components of given type in the whole scene
template<typename T>
static ComponentVector FindAllComponentsOfType()
{
ComponentVector res;
for (auto go : s_Objects)
{
T* c = go->GetComponent<T>();
if (c != nullptr) res.emplace_back(c);
}
return res;
}
// Find one component of given type in the scene (returns first found one)
template<typename T>
static T* FindOfType()
{
for (auto go : s_Objects)
{
T* c = go->GetComponent<T>();
if (c != nullptr) return c;
}
return nullptr;
}
// various components
// 2D position: just x,y coordinates
struct PositionComponent : public Component
{
float x, y;
};
// Sprite: color, sprite index (in the sprite atlas), and scale for rendering it
struct SpriteComponent : public Component
{
float colorR, colorG, colorB;
int spriteIndex;
float scale;
};
// Move around with constant velocity. When reached world bounds, reflect back from them.
struct MoveComponent : public Component
{
float velx, vely;
WorldBoundsComponent* bounds;
MoveComponent(float minSpeed, float maxSpeed)
{
/* … */
}
virtual void Start() override
{
bounds = FindOfType<WorldBoundsComponent>();
}
virtual void Update(double time, float deltaTime) override
{
/* … */
}
};
// components logic
virtual void Update(double time, float deltaTime) override
{
// get Position component on our game object
PositionComponent* pos = GetGameObject().GetComponent<PositionComponent>();
// update position based on movement velocity & delta time
pos->x += velx * deltaTime;
pos->y += vely * deltaTime;
// check against world bounds; put back onto bounds and mirror
// the velocity component to "bounce" back
if (pos->x < bounds->xMin) { velx = -velx; pos->x = bounds->xMin; }
if (pos->x > bounds->xMax) { velx = -velx; pos->x = bounds->xMax; }
if (pos->y < bounds->yMin) { vely = -vely; pos->y = bounds->yMin; }
if (pos->y > bounds->yMax) { vely = -vely; pos->y = bounds->yMax; }
}
// game update loop
void GameUpdate(sprite_data_t* data, double time, float deltaTime)
{
// go through all objects
for (auto go : s_Objects)
{
// Update all their components
go->Update(time, deltaTime);
// For objects that have a Position & Sprite on them: write out
// their data into destination buffer that will be rendered later on.
PositionComponent* pos = go->GetComponent<PositionComponent>();
SpriteComponent* sprite = go->GetComponent<SpriteComponent>();
if (pos != nullptr && sprite != nullptr)
{
/* … emit data for sprite rendering … */
}
}
}
OO设计的问题:将代码放在哪里?游戏中的许多系统不属于“一个对象”,例如碰撞、损坏、AI:在2+个物体上工作。游戏中的“精灵避免泡泡”:把回避逻辑放在回避某事的事情上?把回避逻辑放在应该避免的事情上?其它地方?许多语言都是“单一分派”,有一些对象和方法可以使用它们,但我们需要的是“多次派遣”,回避系统对两组物体起作用。
OO设计的问题:很难知道什么是什么。有没有开过Unity项目并试图弄清楚它是如何工作的? “游戏逻辑”分散在数百万个组件中,没有概述。
OO设计的问题:“凌乱的基类”问题:
EntityType entityType() const override;
void init(World* world, EntityId entityId, EntityMode mode) override;
void uninit() override;
Vec2F position() const override;
Vec2F velocity() const override;
Vec2F mouthPosition() const override;
Vec2F mouthOffset() const;
Vec2F feetOffset() const;
Vec2F headArmorOffset() const;
Vec2F chestArmorOffset() const;
Vec2F legsArmorOffset() const;
Vec2F backArmorOffset() const;
// relative to current position
RectF metaBoundBox() const override;
// relative to current position
RectF collisionArea() const override;
void hitOther(EntityId targetEntityId, DamageRequest const& damageRequest) override;
void damagedOther(DamageNotification const& damage) override;
List<DamageSource> damageSources() const override;
bool shouldDestroy() const override;
void destroy(RenderCallback* renderCallback) override;
Maybe<EntityAnchorState> loungingIn() const override;
bool lounge(EntityId loungeableEntityId, size_t anchorIndex);
void stopLounging();
float health() const override;
float maxHealth() const override;
DamageBarType damageBar() const override;
float healthPercentage() const;
float energy() const override;
float maxEnergy() const;
float energyPercentage() const;
float energyRegenBlockPercent() const;
bool energyLocked() const override;
bool fullEnergy() const override;
bool consumeEnergy(float energy) override;
float foodPercentage() const;
float breath() const;
float maxBreath() const;
void playEmote(HumanoidEmote emote) override;
bool canUseTool() const;
void beginPrimaryFire();
void beginAltFire();
void endPrimaryFire();
void endAltFire();
void beginTrigger();
void endTrigger();
ItemPtr primaryHandItem() const;
ItemPtr altHandItem() const;
// … etc.
OO设计的问题:性能。100万个精灵,20个泡泡:330ms游戏更新,470ms启动时间,分散在内存中的数据,虚拟函数调用。
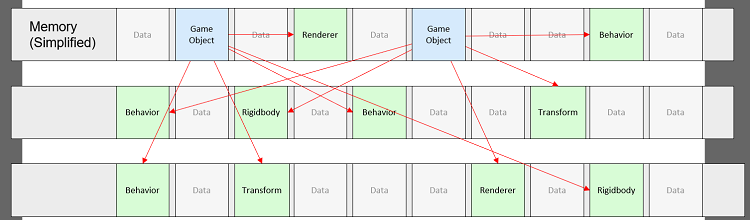
OO设计的问题:内存使用。100万个精灵,20个泡泡:310MB内存使用率,每个组件都有指向游戏对象的指针,但很少有人需要它,每个组件都有一个指向虚拟函数表的指针,每个游戏对象/组件都是单独分配的。典型内存视图:
OO设计的问题:可优化。如何多线程化?如何跑在GPU?在很多OO设计中非常难,没有清晰的谁读取什么数据和写入什么数据。
OO设计的问题:可测试性。将如何为此编写测试?OO设计通常需要大量的设置/模拟/伪造来进行测试,创建对象层次结构、管理器、适配器、单例…
CPU性能趋势:
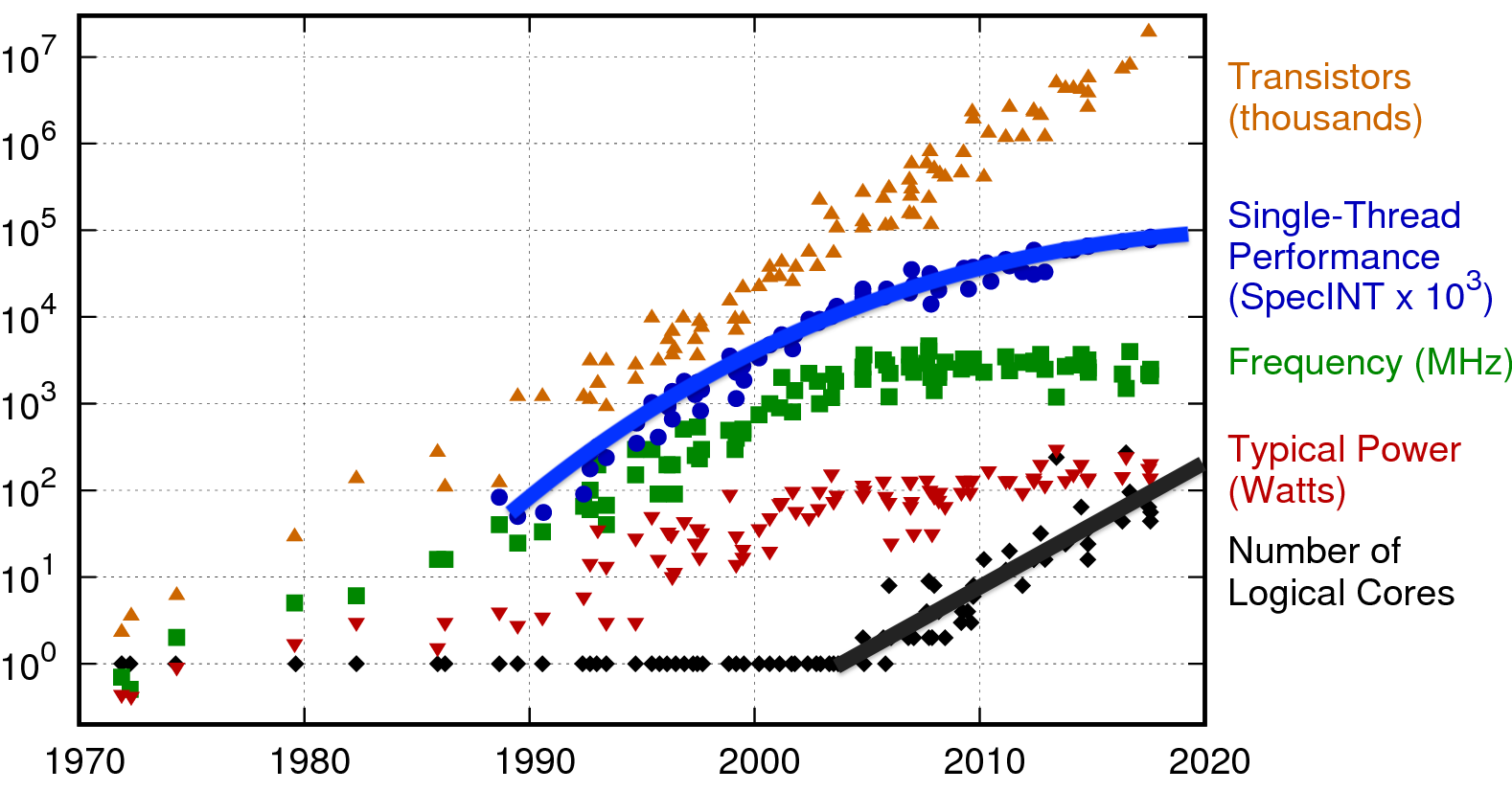
CPU-内存性能差距:
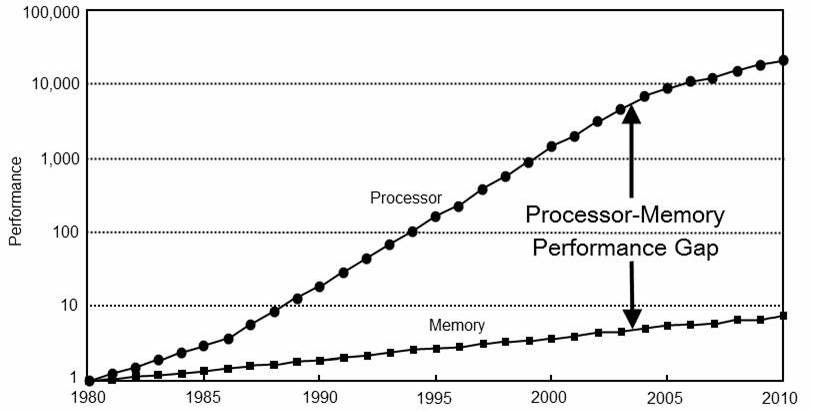
计算机中的延迟数据:
- 从CPU一级缓存读取:0.5ns。
- 分支预测失败:5ns。
- 从CPU二级缓存读取:7ns。
- 从RAM读取:100ns。
- 从SSD读取:150000ns。
- 从RAM读取1MB:250000ns。
- 发送网络数据包CA->NL->CA:150000000ns。
代码和数据需要结合在一起吗?典型的OO将代码和数据放在一个类中,为什么呢?回忆“代码放在哪里”的问题:
// this?
class ThingThatAvoids
{
void AvoidOtherThing(ThingToAvoid* thing);
};
// or this?
class ThingToAvoid
{
void MakeAvoidMe(ThingThatAvoids* who);
};
// why not this instead? does not even need to be in a class
void DoAvoidStuff(ThingThatAvoids* who, ThingToAvoid* whom);
数据优先:“所有程序及其所有部分的目的都是将数据从一种形式转换为另一种形式”,“如果你不了解数据,你就不了解问题所在”——迈克·阿克顿。这是尼克劳斯·沃思1976年的一本经典著作。有人可能会说,“数据结构”也许应该是第一位的,请注意,它根本不谈论“对象”!
有一个,就有很多。你多久吃一次某样东西?在游戏中,最常见的情况是:有几件事,任何代码都可以在这里使用,事情太多了,必须小心性能。
virtual void Update(double time, float deltaTime) override
{
/* move one thing */
}
// 将上面的改成下面
void UpdateAllMoves(size_t n, GameObject* objects, double time, float deltaTime)
{
/* move all of them */
}
面向数据的设计(DOD):理解数据解决这个问题所需的理想数据是什么?它是怎么布置的?谁读什么,谁写什么?数据中的模式是什么?常见情况下的设计,很少有“一”的东西,为什么你的代码一次只处理一件事?DOD相关资源:
- Data-Oriented Design (Or Why You Might Be Shooting Yourself in The Foot With OOP) blog post, Noel Llopis
- Practical Examples in Data Oriented Design slides, Niklas Gray
- Data-Oriented Design and C++ video, Mike Acton
- Typical C++ Bullshit slide gallery, Mike Acton
- Data-Oriented Design blog post & links, Adam Sawicki
传统的Unity GO/组件设置是ECS吗?传统的Unity设置使用组件,但不使用ECS。组件解决了“来自地狱的基类”问题的一部分,但不能解决其它问题:逻辑、数据和代码流难以推理,一次只对一件事执行逻辑(更新等),在一个类型/类中(“代码放在哪里”问题),内存/数据局部性不是很好,一堆虚调用和指针。
实体组件系统(ECS):实体只是一个标识符,有点像数据库中的“主键”?是的。组件就是数据。系统是在具有特定组件集的实体上工作的代码。
ECS/DOD样例:回忆一下简单的“游戏”:400行代码,100万个精灵,20个泡泡:330毫秒更新时间,470ms启动时间,310MB内存占用。

第1步:纠正愚蠢。GetComponent在GO each和每一次中搜索组件,我们可以找到一次并保存它!330毫秒→ 309ms。
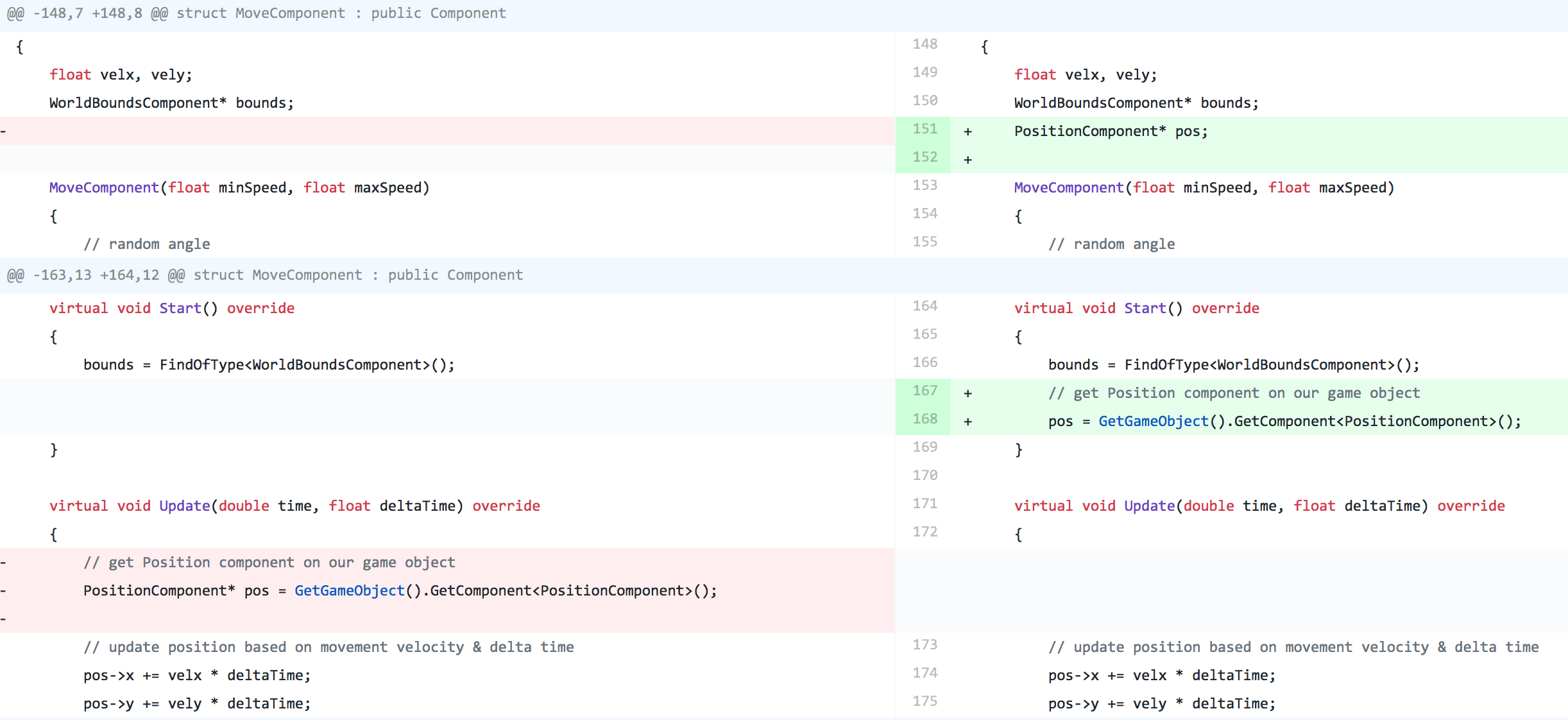
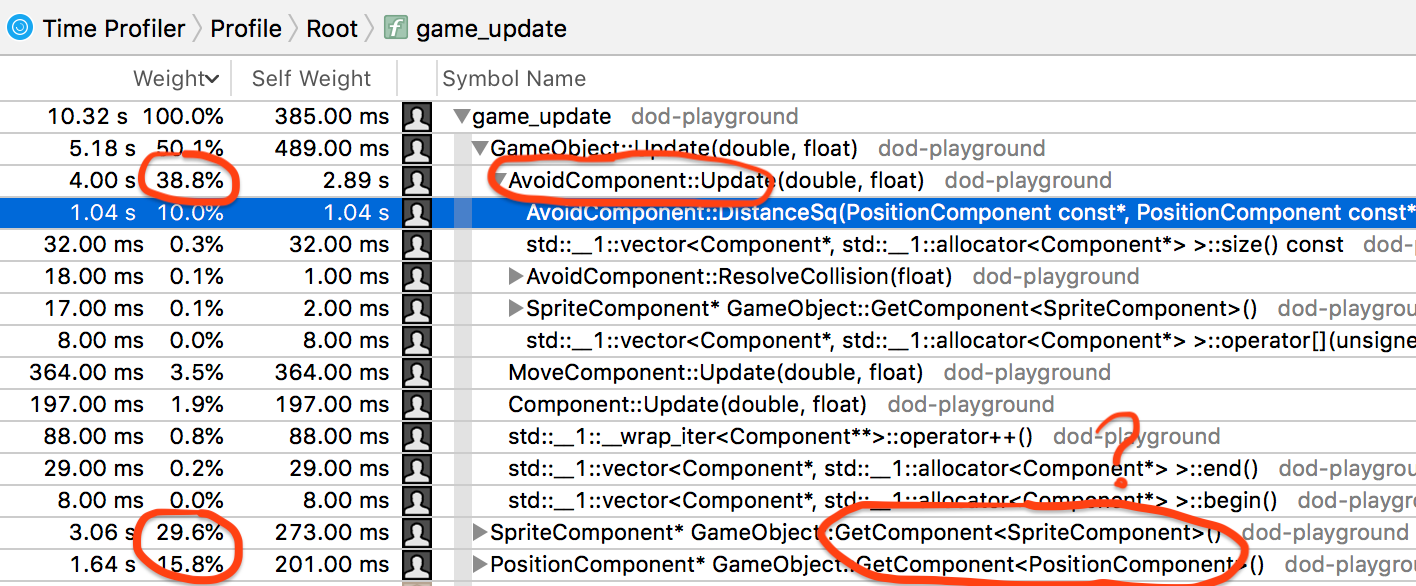
GetComponent在Avoid组件的内部循环中,也缓存它。309ms → 78ms。
现在时间花在哪里?使用探查器(Mac上是Xcode Instruments):
让我们做一些系统:AvoidanceSystem,避免和避免现在这些组件几乎只是数据,系统知道它将操作的所有东西。
struct AvoidThisComponent : public Component
{
float distance;
};
// Objects with this component "avoid" objects with AvoidThis component.
struct AvoidComponent : public Component
{
virtual void Start() override;
};
// "Avoidance system" works out interactions between objects that have AvoidThis and Avoid
// components. Objects with Avoid component:
// - when they get closer to AvoidThis than AvoidThis::distance, they bounce back,
// - also they take sprite color from the object they just bumped into
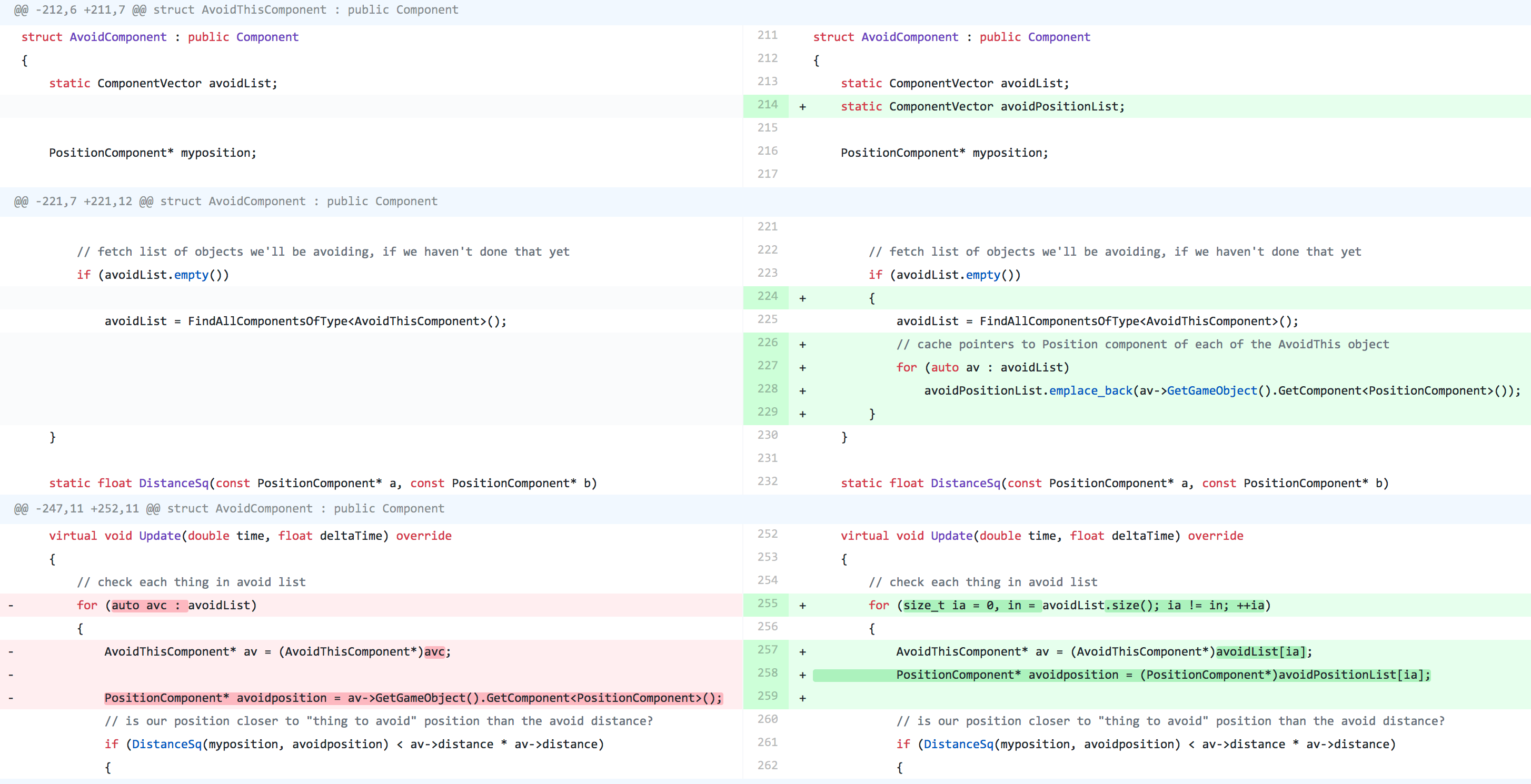
struct AvoidanceSystem
{
// things to be avoided: distances to them, and their position components
std::vector<float> avoidDistanceList;
std::vector<PositionComponent*> avoidPositionList;
// objects that avoid: their position components
std::vector<PositionComponent*> objectList;
void UpdateSystem(double time, float deltaTime)
{
// go through all the objects
for (size_t io = 0, no = objectList.size(); io != no; ++io)
{
PositionComponent* myposition = objectList[io];
// check each thing in avoid list
for (size_t ia = 0, na = avoidPositionList.size(); ia != na; ++ia)
{
float avDistance = avoidDistanceList[ia];
PositionComponent* avoidposition = avoidPositionList[ia];
// is our position closer to "thing to avoid" position than the avoid distance?
if (DistanceSq(myposition, avoidposition) < avDistance * avDistance)
{
/* … */
}
}
}
}
};
以上是系统的逻辑代码。78ms → 69ms。类似的,让我们做一个移动系统:MoveSystem。
// Move around with constant velocity. When reached world bounds, reflect back from them.
struct MoveComponent : public Component
{
float velx, vely;
};
struct MoveSystem
{
WorldBoundsComponent* bounds;
std::vector<PositionComponent*> positionList;
std::vector<MoveComponent*> moveList;
void UpdateSystem(double time, float deltaTime)
{
// go through all the objects
for (size_t io = 0, no = positionList.size(); io != no; ++io)
{
PositionComponent* pos = positionList[io];
MoveComponent* move = moveList[io];
// update position based on movement velocity & delta time
pos->x += move->velx * deltaTime;
pos->y += move->vely * deltaTime;
// check against world bounds; put back onto bounds and mirror the velocity component to "bounce" back
if (pos->x < bounds->xMin) { move->velx = -move->velx; pos->x = bounds->xMin; }
if (pos->x > bounds->xMax) { move->velx = -move->velx; pos->x = bounds->xMax; }
if (pos->y < bounds->yMin) { move->vely = -move->vely; pos->y = bounds->yMin; }
if (pos->y > bounds->yMax) { move->vely = -move->vely; pos->y = bounds->yMax; }
}
};
以上是移动系统的逻辑,69ms→ 83ms, 什么!!!???再次分析之:
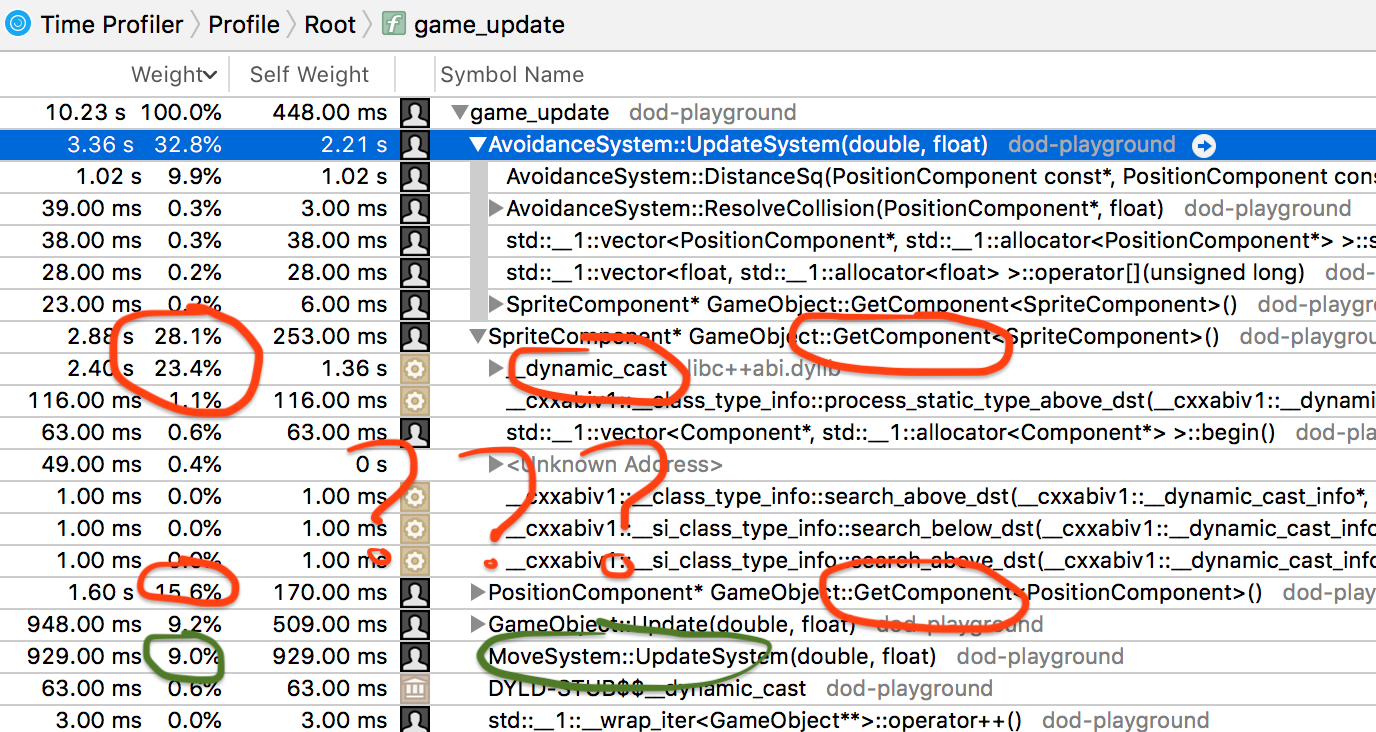
迄今为止的经验教训:由于意想不到的原因,优化一个地方可能会让事情变得更慢,乱序的CPU、缓存、预取等等。C++RTTI(dynamic_cast)可以非常慢,我们在GameObject::GetComponent中使用它。
// get a component of type T, or null if it does not exist on this game object
template<typename T> T* GetComponent()
{
for (auto i : m_Components)
{
T* c = dynamic_cast<T*>(i);
if (c != nullptr)
return c;
}
return nullptr;
}
那就停止使用C++RTTI吧。如果有一个“类型”枚举,并且每个组件都存储了类型…83毫秒→ 54毫秒!!
enum ComponentType
{
kCompPosition,
kCompSprite,
kCompWorldBounds,
kCompMove,
kCompAvoid,
kCompAvoidThis,
};
// ...
ComponentType m_Type;
// was: T* c = dynamic_cast<T*>(i); if (c != nullptr) return c;
if (c->GetType() == T::kTypeId) return (T*)c;
到目前为止,更新性能:提高6倍(330毫秒)→54毫秒)!内存使用:增加310MB→363MB,组件指针缓存,在每个组件中键入ID…代码行:400多行→500,让我们试着移除一些东西!
Avoid和AvoidThis组件,谁需要它们?没错,没有人,直接用AvoidanceSystem注册对象即可。54毫秒→ 46ms,363MB→325MB,500→455行。
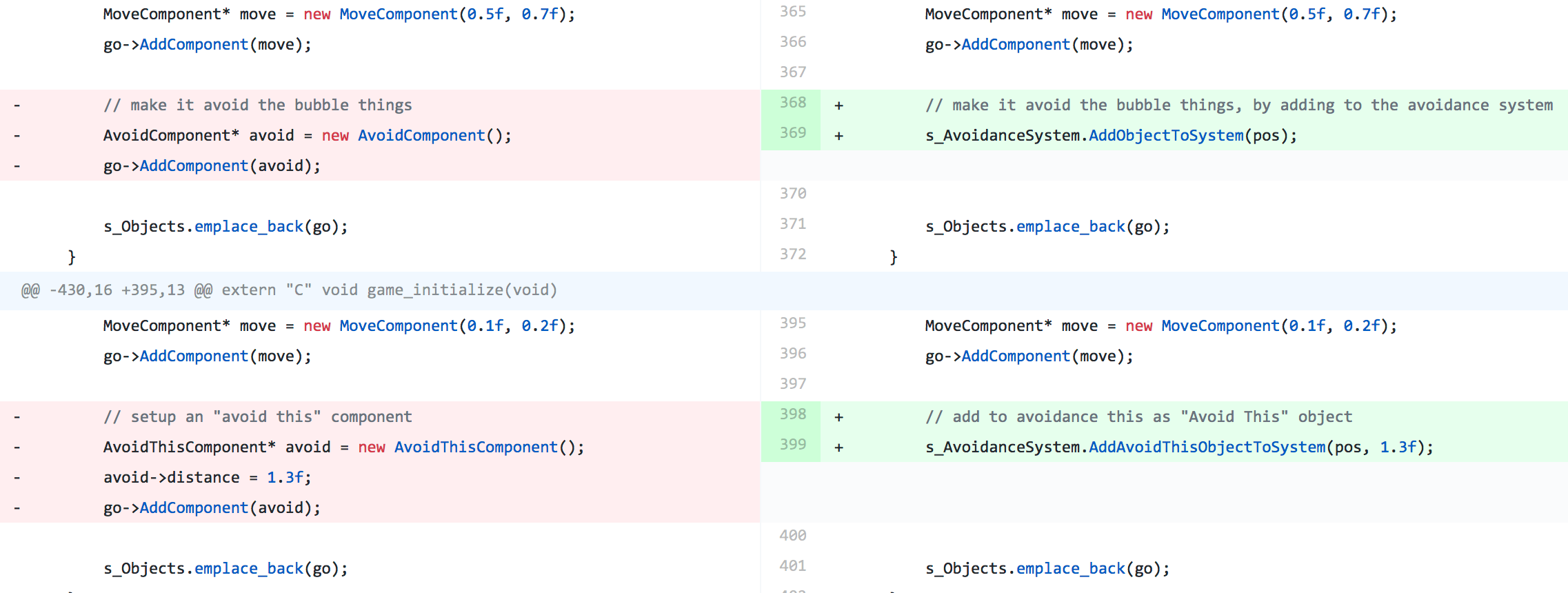
实际上,谁需要组件层次结构?只需在GameObject中包含组件字段。46毫秒→43ms更新,398→112ms启动时间,325MB→218MB,455→350行。
// each object has data for all possible components,
// as well as flags indicating which ones are actually present.
struct GameObject
{
GameObject(const std::string&& name)
: m_Name(name), m_HasPosition(0), m_HasSprite(0), m_HasWorldBounds(0), m_HasMove(0) { }
~GameObject() {}
std::string m_Name;
// data for all components
PositionComponent m_Position;
SpriteComponent m_Sprite;
WorldBoundsComponent m_WorldBounds;
MoveComponent m_Move;
// flags for every component, indicating whether this object "has it"
int m_HasPosition : 1;
int m_HasSprite : 1;
int m_HasWorldBounds : 1;
int m_HasMove : 1;
};
停止分配单个游戏对象,vector<GameObject*> → vector<GameObject>,43ms更新,112→99ms启动,218MB→203MB。
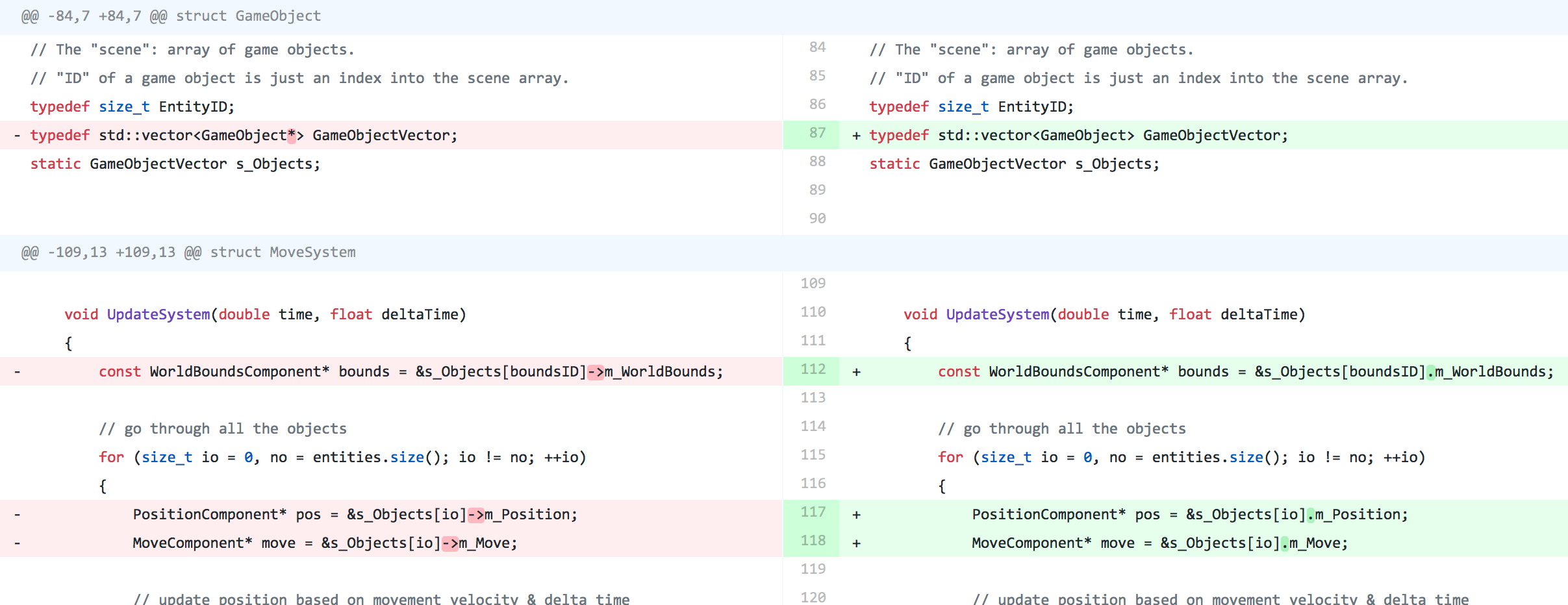
典型布局是结构数组(AoS):一些对象,以及它们的数组。易于理解和管理,太好了…如果我们需要每个物体的所有数据。
// structure
struct Object
{
string name;
Vector3 position;
Quaternion rotation;
float speed;
float health;
};
// array of structures
vector<Object> allObjects;
数据在内存中是什么样子的?
struct Object // 60 bytes:
{
string name; // 24 bytes
Vector3 position; // 12 bytes
Quaternion rotation; // 16 bytes
float speed; // 4 bytes
float health; // 4 bytes
};
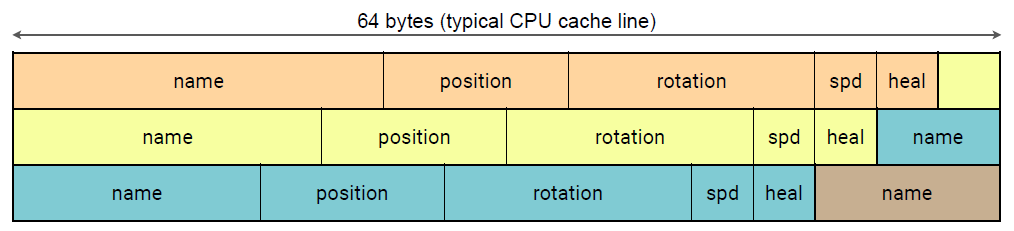
如果我们不需要所有数据呢?如果我们的系统只需要物体的位置和速度…嘿,CPU,读第一个物体的位置(下图上)!当然,就在这里…让我帮你从内存中读取整个缓存行(下图下)!
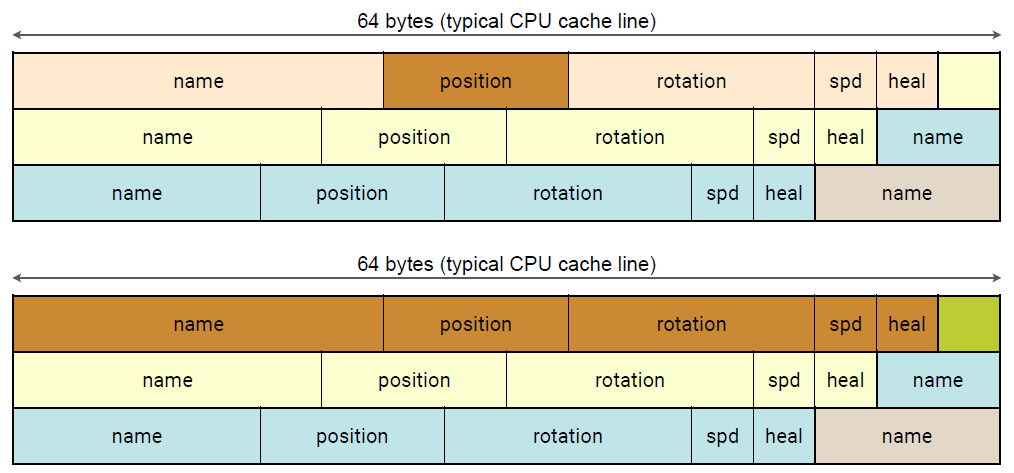
如果系统只需要物体的位置和速度…却最终从内存中读取了一切,但每个对象只需要60个字节中的16个字节,多达74%的内存流量浪费!
翻转:数组结构(SoA)。每个数据成员都有单独的数组,数组需要保持同步, “对象”不再存在;通过索引访问的数据。
// structure of arrays
struct Objects
{
vector<string> names; // 24 bytes each
vector<Vector3> positions; // 12 bytes each
vector<Quaternion> rotations; // 16 bytes each
vector<float> speeds; // 4 bytes each
vector<float> healths; // 4 bytes each
};
数据在内存中是什么样子的?
struct Objects
{
vector<string> names; // 24 bytes each
vector<Vector3> positions; // 12 bytes each
vector<Quaternion> rotations; // 16 bytes each
vector<float> speeds; // 4 bytes each
vector<float> healths; // 4 bytes each
};
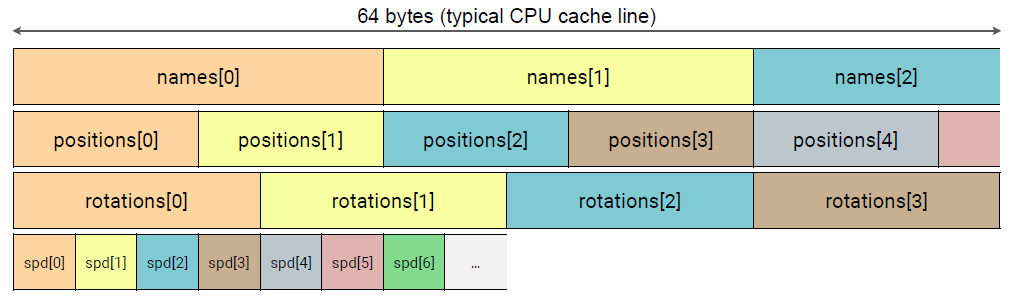
在SoA中读取部分数据:如果我们的系统只需要物体的位置和速度…嘿,CPU,读读第一个物体的位置!(下图上)。当然,就在这里…让我帮你从内存中读取整个缓存行!(旁白)所以接下来4个对象的位置也被读入了CPU缓存(下图下)。
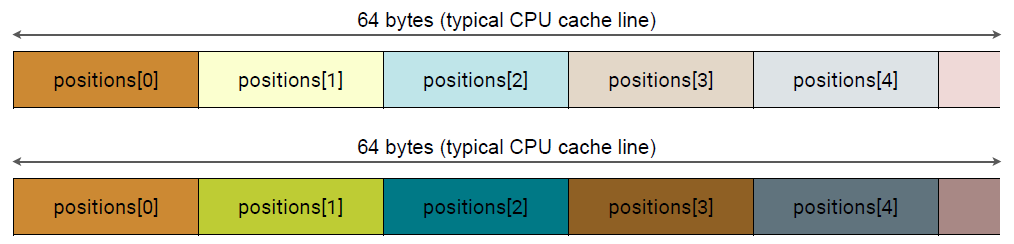
SoA数据布局转换:相当普遍, 不过要小心,不要做得过火!在某些情况下,单个数组的数量可能会适得其反,结构数组的结构(SoAo等)。
回到组件数据的SoA布局。不再是一个游戏对象类,只是一个EntityID。43毫秒→31ms更新,99→94ms启动,350→375行。
// "ID" of a game object is just an index into the scene array.
typedef size_t EntityID;
// /* … */
// names of each object
vector<string> m_Names;
// data for all components
vector<PositionComponent> m_Positions;
vector<SpriteComponent> m_Sprites;
vector<WorldBoundsComponent> m_WorldBounds;
vector<MoveComponent> m_Moves;
// bit flags for every component, indicating whether this object "has it"
vector<int> m_Flags;
结果:100万个精灵,20个泡泡:330ms→ 31ms的更新时间,快10倍!470ms→ 94ms的启动时间,快5倍!310MB→ 203MB内存使用率,节省了100MB!400→ 375行代码,代码甚至变得更小了!甚至都还没有开始线程化、SIMD…
Rendering Technology in 'Agents of Mayhem'分享了游戏Agents of Mayhem所采用的渲染技术,包含话题OIT、照明计算、全局照明等。
在OIT上,之前的半透明渲染是从后向前在CPU排序alpha,大量排序的alpha意味着CPU渲染效率低下,按“对象”排序,而不是按像素排序,排序跳变,低分辨率alpha不与高分辨率排序。解决方案:OIT?但许多OIT技术在GPU上效率低下。可以尝试加权混合OIT(Weighted Blended OIT,WBOIT):

加权混合OIT的好处是反向的CPU成本,现在可以按渲染状态(即材质/着色器)而不是深度对alpha进行排序,在GPU上高效,alpha着色器中添加了一些数学,简单的全屏合成步骤,低分辨率和高分辨率alpha无缝地排序,永远没有跳变,排序问题*滑过渡,不太复杂。缺点是到处都是神奇的数字,非常不透明的alpha表现不好,总是“错”的。加权混合OIT用加权*均代替有序混合:
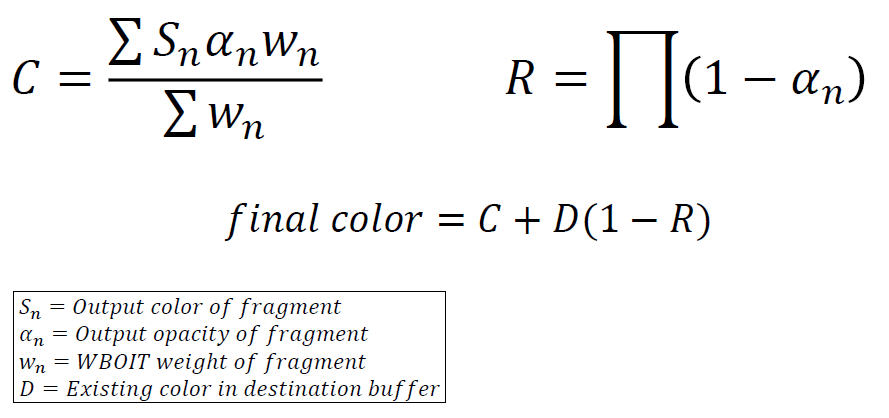
加权函数(McGuire)的权重是“魔法”数据,权重高,覆盖率高,权重更接*物体本身。
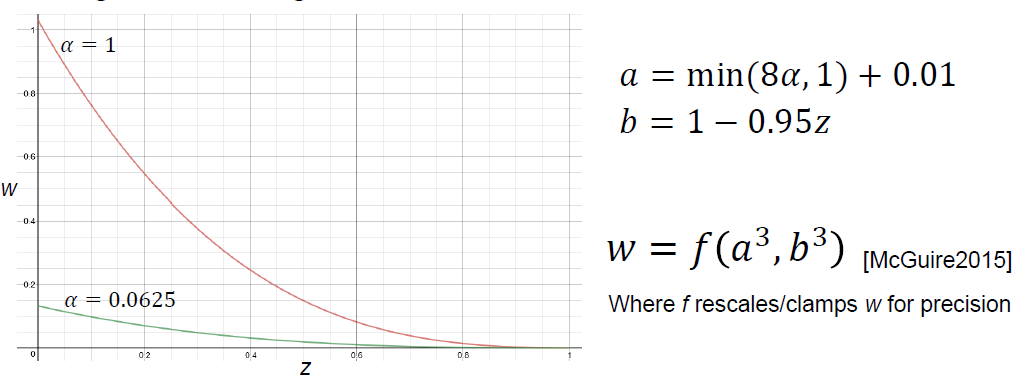
自发光的Alpha是主要问题,可以考虑具有相同自发光Alpha值E的n层:
主要思路:积累更多信息,“相加性”≈ 添加层的数量,通过相加性放大加权*均值。新WBOIT的视觉摘要:

其中WBOIT的公式和可相加性描述如下:

新的组合方式:
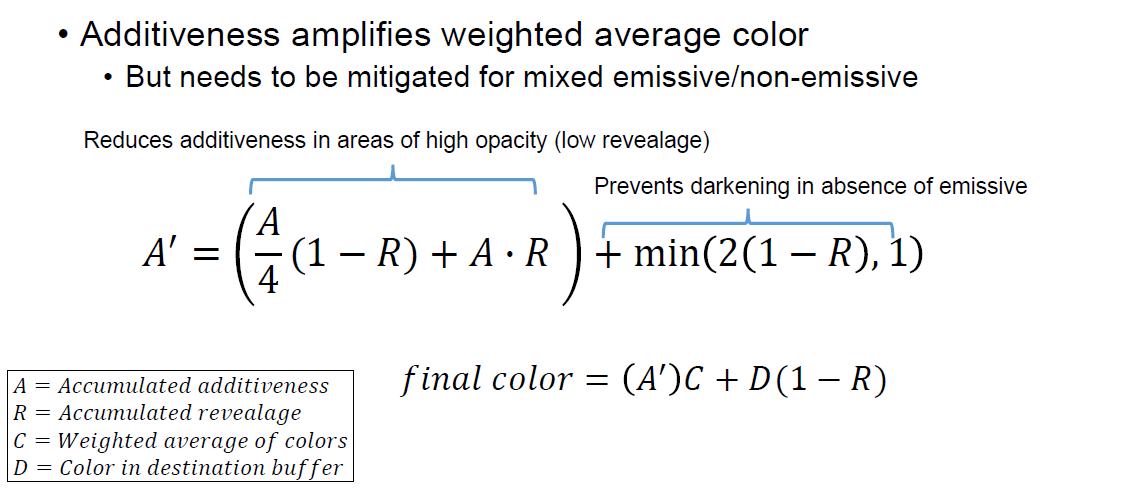
加权函数与自发光:纯自发光Alpha的不透明度为零,在计算重量时必须包括自发光,必须允许权重为零。
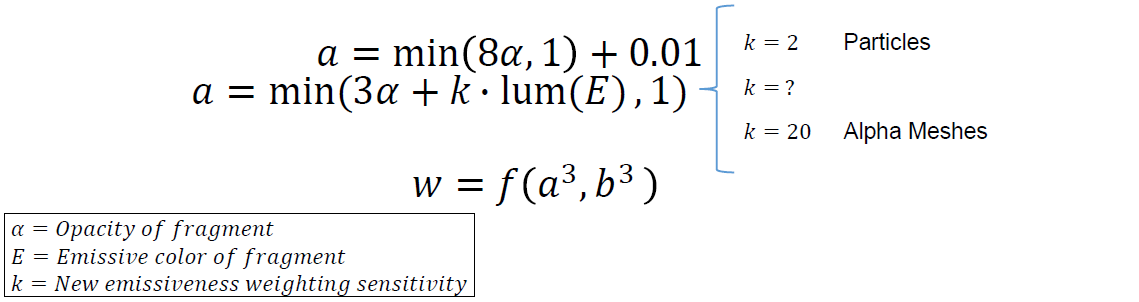
实现:简单的2个RT的MRT设置。第2个MRT将*均值存储在R通道,可加性存储为Alpha通道,对alpha通道使用单独的混合控制。
在光照方面,大量(昂贵的)照明功能已实现,如多个照明模型(所有PBR)、PCF阴影、可变半影阴影(PCSS)、投影纹理、纹理发射器区域灯光、泛光灯、“逼真”的管状灯、方形或圆形聚光灯、黑色(负光)、光源裁减*面、光源遮挡和门户。光照泄露是熟悉的问题,标准的解决方案:
采用光照遮挡体,使用有限光剪裁*面:


工作原理是在遮挡体“阴影”视锥体体上剔除tile(下图左),列出需要对每个灯光进行逐像素检查的遮罩(下图右):

实现的流程图概览:
在GI方面,使用了LPV,改进了光照遮挡效果,在室内使用了固定的局部体积,质量更高,无需每帧注入和传播。以往的LPV光照遮挡存在粗糙离散化的光照溢出和几何缺失等问题:

不管怎样,艺术家们放置遮挡体也可以用于GI!

传播过程中的遮挡体:光照遮挡体注入体积时,存储为“轴向”遮挡(沿每个轴的遮挡量),在传播过程中遮挡光线,生成GI“阴影”(下图左)。针对4x4x4宏观单元格剔除的光照遮挡体,减少每个LPV单元格中考虑的一组遮挡体,应用过程中遮挡三线性采样的光照,消除来自粗糙网格的漏光(下图右):
Rebuilding Your Engine During Development: Lessons from 'Mafia III'分享了重构游戏Mafia III所用的引擎的过程、技术和经验教训。该引擎重构的目标是更容易使用的工具,能够处理大量数据,数据驱动,主要变化在于新世界编辑、新对象系统、构建系统、局部迭代、可视化脚本、中间件集成、物理、动画、导航、用户界面、音频等。
新的世界编辑器使用C#/WPF和DevExpress中的新工具,在新编辑器中集成旧编辑器插件,使用C++/CLI进行引擎通信,尽早让用户参与。
新对象系统包含资产和文件管理、继承和分组、赋予内容创作者权力等。资产和文件管理的目标是轻松跟踪依赖关系,支持二进制和文本格式,省力,按ID标识对象,前后兼容。使用C++反射进行序列化,对于工程师来说,公开数据非常简单,基于宏的内部框架,合理的前后兼容性,不需要版本控制系统,强大的代码数据依赖性。每个对象都有一个唯一的标识符,资产的自由移动,服务读取TOC和跟踪ID,易于查询依赖项。继承系统提高资产的可重用性,易于工程师们和内容创作者使用,超越一切的能力,在序列化代码中处理,基于反射和唯一ID,对可以修改的内容没有限制。结果很好,但是…在保存上与父节点相比,子节点是碎片化的。

重新保存依赖,但不知道如何在生产中修复,引入了一项“功能”来重新保存依赖,很难理解何时使用它。赋予内容创作者权力。合成对象的能力,将对象分组在一起,使用可视化语言编写对象级脚本。每个对象都有唯一的ID很好,基于比较的泛型继承系统,有子节点的父节点很棘手,赋予用户的权力超出了我们的预期,技术允许的一切都将被使用。
总之,升级到现代引擎,为新用户提供更快的学习曲线,编辑器的一致控制,在生产过程中部署并不有趣。
在过去的20年里,GPU厂商和游戏开发者都在努力追求“更好的帧速率”的圣杯。然而,人们对*滑度的问题知之甚少。The Elusive Frame Timing: A Case Study for Smoothness Over Speed探讨了一个非常奇特、不为人所知但相当重要的原因,即可怕的“微结巴”,即使在单个GPU的情况下也经常发生,也将讨论潜在问题、问题的历史以及解决问题的原型方法。在应用程序中,口吃(stuttering)的情况比完美情况“更快”?是的,详见下图:

Stutter的发生是因为游戏不知道它的显示速度有多快!为什么游戏“认为”它运行得比较慢?上世纪80/90年代,8位/16位纪元,是固定硬件,总是相同的时间没有问题,还记得不同的NTSC/PAL版本吗?到了90/00年代,软件渲染/图形加速器,开始计时和插值,但没有管线也没问题。那么,当今怎么了?
理论:“APl的/驱动的错“。真正的GPU负载对游戏是“隐藏”的,该“功能”可能是在21世纪初的“驱动基准测试大战”中引入的,由当时的Flush()和Finish()行为的改变,组合器也帮不上忙。试图弥补这一点的内部机制?这就是为什么很难找到它!无论如何,使用流水线硬件来发挥其潜力是不可避免的,“缓冲空闲时间”是可以有的,但我们需要知道!
错误时机的两面,首先是错误的时间反馈,心跳口吃的主要原因(但有时也有其它原因)。其次是错误的帧调度,是导致从“缓慢”恢复到“完美”时口吃的主要原因。建议,必须知道过去的画面持续了多久,异步统计,需要使用启发式,必须承认它并不完美,理想情况下,知道下一帧将持续多长时间,但这是不可能的。必须能够安排下一帧的显示时间,更快并不总是更好!一定知道还有多少时间剩余,实际上是最有问题的部分。老的逻辑算法通常是以下的模样:
frame_step = 16.67 ms // (assuming 60fps as initial baseline)
current_time = 0
while(running)
Simulate(frame_step) // calculate inputs/physics/animation... using this delta
RenderFrame()
current_time += frame_step
PresentFrame() // scheduled by the driver/OS
frame_step = LengthOfThisFrame() // calculated by the game
新的逻辑算法改成以下代码:
frame_step = 16.67 ms // (assuming 60fps as initial baseline)
current_time = 0
pending_frames_queue = {} // (empty)
frame_timing_history = {}
while(running)
Simulate(frame_step) // calculate inputs/physics/animation... using this delta
RenderFrame()
current_time += frame_step
// current_time是新增的时间戳
current_frame_id = PresentFrame(current_time)
AddToList(pending_frames_queue, current_frame_id)
// 查询帧信息
QueryFrameInfos(pending_frames_queue,frame_timing_history)
// 帧时序启发式
frame_step = FrameTimingHeuristics(pending_frames_queue, frame_timing_history)
上面的FrameTimingHeuristics()的内部结构:
- 轮询所有在
pending_frames_queue队列中已经可用的帧,将它们各自的计时记录到frame_timing_history中。 - 如果看到任何一个未完成其时间表的帧,返回其长度以用于frame_step(这就是我们降低帧率的方式)。
- 如果看到recovery_count_threshold连续帧都是早且它们的margin < recovery_margin_threshold,返回用于frame_step的长度(这就是我们提高帧率的方式)。
OpenGL+VDPAU原型:2015年8月在塔洛斯原则(The Talos Principle)中实现,作为概念证明。使用NV_present_video的OpenGL扩展,最初用于视频播放,因此具有计时功能。差不多了:合理安排未来的帧,获取过去帧的计时信息,但没有边缘信息,很难恢复。仅适用于Linux下OpenGL*台的某些NVIDIA板,应用不是很广,但证明了这一点。
Vulkan和VK_GOOGLE_display_timing:在塔洛斯原则和Serious Sam Fusion中实现,什么信息都有:安排未来的帧、过去帧的计时信息、有边缘信息(模棱两可?)。仅可用于安卓,Metal、DX12尚没有。
考虑因素:何时决定从缓慢恢复到完美?如何(以及是否?)当下降到慢速时,如何校正计时?我们能预测速度并做出完美的下降吗?如果可能的话,这将是“神圣的*滑”,可能会做得更好!VRR显示器呢?如果Vsync关闭了怎么办?这两个都是可行的,但还没有实现!
主观性:最终是一个感知的问题,也许有些人有不同的看法,不同的开发者会有不同的方法,向用户公开不同的选项?
Performance and Memory Post Mortem for Middle earth: Shadow分享了Monolith在《中土世界:战争的阴影》中实现30fps和内存的工程策略,主要分为性能优化和内存优化。
线程的同步原语:不再使用内核原语,转而使用轻量级原子自旋锁来保护原子数据访问,当需要上下文切换时,仍然使用内核原语,上下文切换的真正成本是缓存逐出。引入了一个轻量级的多读单写的原语,从多个线程读取物理模拟的状态就是一个例子。微软*台有一个超轻读写(SRW)锁原语,索尼也有类似的原语。可以使用两个原子自旋锁实例和一个原子计数器来跟踪读取数量,第一个原子自旋锁用作读取锁,第二个原子自旋锁用作写入锁。
线程的CPU集群:在控制台上的两个CPU集群之间分离工作负载,以利用共享的L2$。第一个CPU集群执行游戏逻辑,第二个CPU集群执行渲染逻辑。由于Shadow of War的复杂性增加,性能提高了10%,要求群集不同时接触相同的缓存行,黑魔法。
线程的整体方法:保持大量工作,尽可能多地保持单线程代码,降低初级工程师的上手门槛,降低并发带来的bug数量,需要更少的整体同步,通常会更好地使用CPU缓存。将整个系统移到后台线程,为大系统设置硬亲缘关系。用优先级较低的线程来填补CPU空闲,类似于异步计算的概念,但适用于CPU核心,例如文件I/O、流式传输和异步光线投射。
线程的管线:通过使用循环命令缓冲区,操作以管线的方式进行,管线将操作推向一个方向,然后这些命令缓冲区中的每一个都在一个运行在专用内核上的专用线程上执行,允许每个管线阶段获得每帧33.3ms的完整数据。

线程的动态帧调整:当管线化线程时,保证管线中的下一阶段不超过1帧(33.3ms)。理想情况下,所有管线阶段都是并行运行的,每个阶段之间有几毫秒的偏移。如果整个管线都被管线中的第一个阶段所约束也是真实的。如果整个系统受到最后一个阶段的约束,那么我们最终会显示几帧前模拟的帧,是由管线的伸缩性造成的,我们总是被v-sync的最后阶段所束缚。
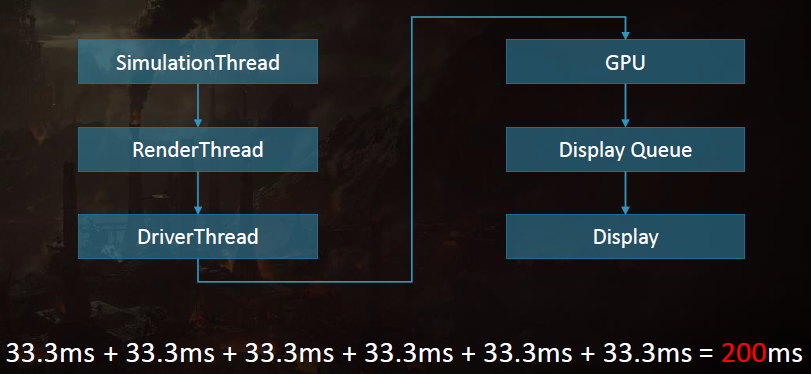
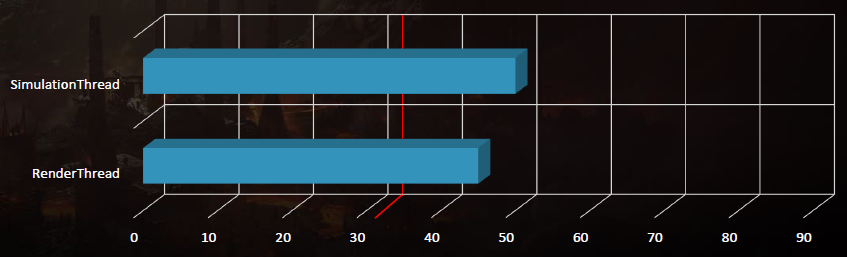
输入延迟成为一个问题,因为输入是在模拟线程上评估的,比屏幕上显示的帧早200毫秒。解决方案是动态帧调整系统,该系统监控GPU上的显示队列,如果队列已满,那么将受GPU限制,当受GPU限制时,人为地暂停第一阶段,即SimulationThread,这样它所花费的时间比分配的时间稍多,例如Sleep(33.3 TimeOfSimulationThread + 1),会导致望远镜收缩。
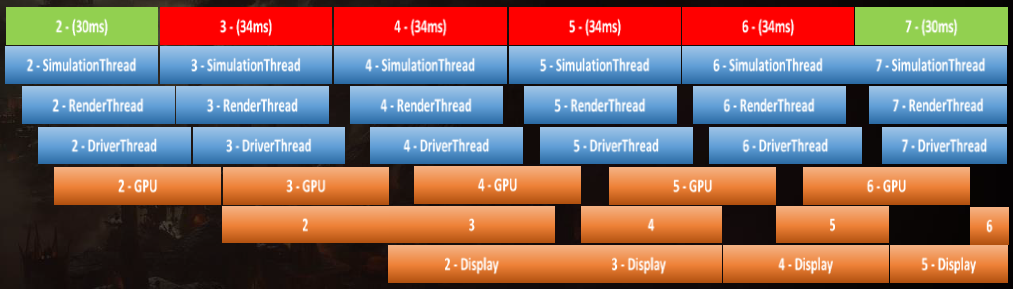
在已知的最坏情况下,模拟线程现在下降到50毫秒:
渲染器的常量缓冲区:游戏到引擎抽象层之间的复制太多,每个常数被单独设置,然后组装成一个常数缓冲区,每次drawcall都会重新生成常量缓冲区。根据更新频率打破了常量缓冲区,访问渲染器中的常量会返回指向实际常量缓冲区的指针,通过访问器将常量缓冲区直接暴露给游戏。跟踪脏状态和帧代码,一旦发送到GPU,就会生成一个新副本,并清除脏状态,在GPU清除帧代码之前,内存不会被重用。绑定命名常量缓冲区只是设置指针,材质常量缓冲区在构建阶段烘焙到资产中。
以骨骼变换为例:

每个常量缓冲常数都是通过获取关于常量使用频率的启发式方法手动排序的,很少使用的常量和通常设置为0的常量被排序到常量缓冲区的底部。分配的常量缓冲区仅足以容纳已使用的常量和不为0的常量,大大降低了访问的内存量。在GPU上读取超过缓冲区末尾的数据只返回0,导致图形API错误信息,但可以抑制。缓存的常量缓冲区带有渲染节点,如果它们没有改变,可以在不同阶段重用,例如G-Buffer阶段和CSM阶段的骨骼。
渲染器的常规优化:切换到更快的第1方图形API,如具有快速语义/LCUE的D3D11.X。已删除的所有帧到帧的参考计数器,仅使用帧代码管理生命周期。缓存整个图形API状态,删除对第1方图形API的冗余状态更改。通过在缓存行边界上分配动态GPU内存并填充到缓存行的末尾,然后使用帧代码跟踪该内存以进行CPU访问,减少了CPU和GPU缓存刷新。动态CPU负载缩放,根据CPU负载推出LOD以降低网格数,暂停高mip流以降低CPU使用率、内存压力和物理页面映射的成本。在已知的最坏情况下,渲染线程现在降至45毫秒:
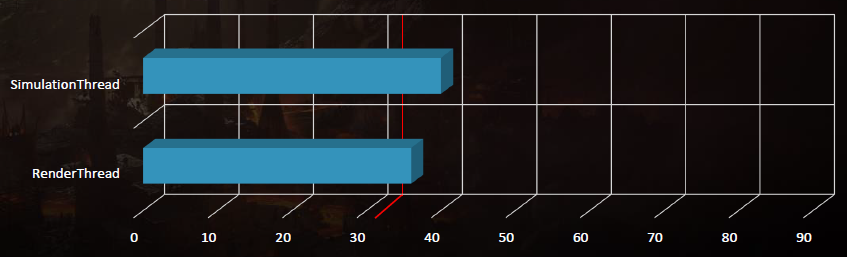
在内存方面,Shadow of War的一个巨大性能胜利是将所有分配切换到大型2MB页面,超过64KB的页面,性能提升20%。大页面减少了代价高昂的翻译查找缓冲区(TLB)丢失,在创建流程时预先分配所有大页面。虽然PC几乎总是受限于GPU,但它也在PC上实现了这一点。
在已知的最坏情况下,模拟线程现在下降到40毫秒,渲染线程现在下降到36毫秒:
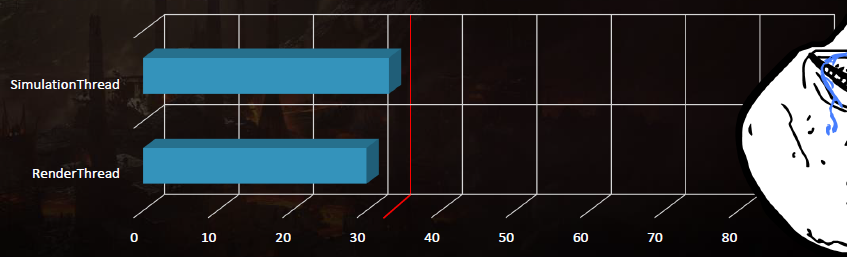
开发构建:DLL用于改进工程迭代,所有项目都启用了增量链接,调试:一些工程师可以使用FastLink,可执行文件是加载和运行这些DLL的一个小存根。零散构建:DLL现在编译为LIBs,增量链接已禁用,可执行文件仍然是一个小存根,现在链接到LIBs中,将运行时性能提高约10%。LTCG在所有*台和所有项目上都是启用的,包括所有中间件,微软*台上的LTCG给了另外10%的改进,而PS4上的LTCG则提高了大约5%。PGO在所有*台上都已启用,PGO在所有*台上的性能都提高了约5%,确保在Microsoft*台上禁用COMDAT折叠,将抵消PGO带来的收益。在已知的最坏情况下,模拟线程现在下降到33毫秒,渲染线程现在下降到30毫秒:
GPU虚拟内存:现代GPU和CPU一样使用虚拟内存,物理内存不必是连续的,物理内存可以按页面粒度进行映射和取消映射,一个物理内存页可以映射到多个虚拟内存地址。
64K页:使用64KB页面的优点是它们比较大的页面小,并允许更大的共享和重用。使用64KB页面的缺点是,由于TLB未命中率增加,访问速度较慢。
Mipmap流:Shadow of Mordor不断地流加载mipmap,但从未卸下,主要是为了缩短加载时间。如果使用了纹理,其高mip会被流化。Shadow of War为了节省内存,需要流入和流出高级别的mipmap,使用了一个固定的mipmap内存池,高mip是纹理2D内存的66%。在构建时间,分析每个网格,并确定具有最大纹理密度的最大三角形,把它保存下来。在运行时,渲染网格时,使用CPU将该三角形投影到屏幕空间,并计算*似的mipmap值。

CPU系统由多个网格/材质控制,这些网格/材质可以每帧(64)进行分析,每个网格由一个帧代码控制,并由一个阻尼器控制,以避免颠簸。每秒测试1920个网格,mipmap分析的CPU成本固定为每帧0.1ms。高mips使用64KB页面池。这个页面池是在进程创建时预先分配的,高MIP被加载,直到池耗尽,所有支持高mip流的纹理都是在没有物理内存支持的情况下创建的。
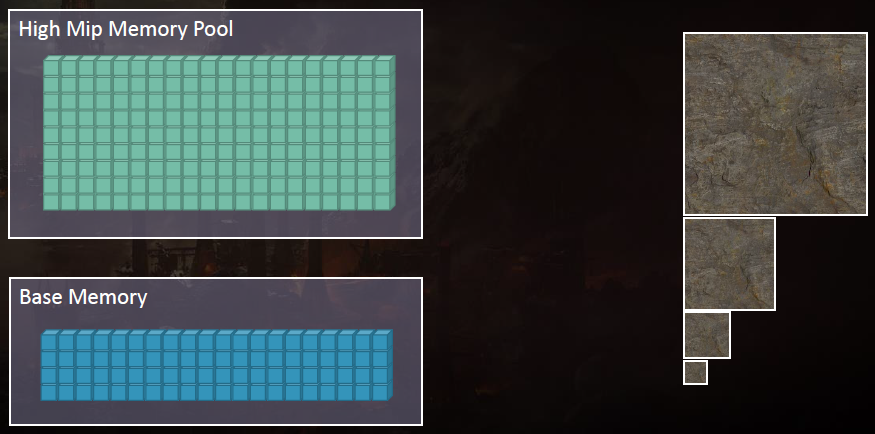
以上做法为高mips使用内存池可节省约1.0 GiB的内存。
《战争阴影》使用了大量的纹理数组,如地形、角色模型、大多数结构、FX序列帧等。好处是Texture2Darray中的切片都在同一级别进行采样,这对于混合非常有用。与采样多个2D纹理时相比,通常更容易避免着色器中的分支来采样Texture2Darray。但存在的问题是填充(padding)、复制。为了避开填充,手动将64KB页面绑定到GPU实际读取的纹理部分,不支持使用物理内存进行布局填充。压缩MIP是小于64KB页面并共享64KB页面的MIP,它们总是由物理内存页支持。

通过在切片之间共享64KB物理内存页来解决复制问题,Texture2DArray仅包含对Texture2D切片的引用,在运行时,切片的物理页面被映射到Texture2Darray上,每个切片都是引用计数的,切片的物理内存在所有引用消失之前不会被释放。压缩的MIP比单个64KB页面小,并且保持重复。该解决方案还允许我们将切片用作常规纹理2D,并将其与内存中的Texture2DArray共享,构建时间也减少了,因为我们一次只需要做一个切片。
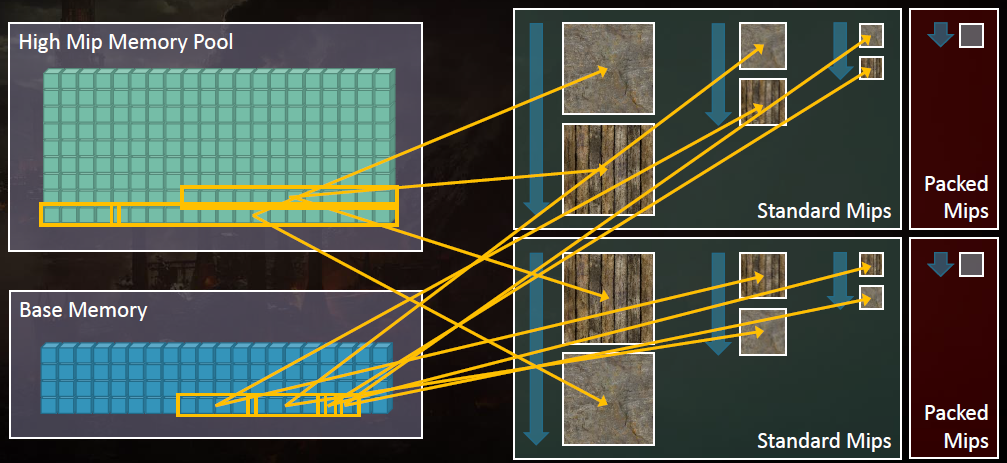
结论:避免重复*均节省了大约300M,视场景而定,避免填充允许艺术家创建非2的N次方的数组。
The Challenges of Rendering an Open World in Far Cry 5阐述了Far Cry 5开发世界的渲染技术。
对于水体渲染,深度多分辨率处理使用水的深度,好处是艺术家更喜欢水上的SSAO和SSS(屏幕空间阴影),由于阴影、大气散射和雾在水面上延迟,因此有优化。缺点是延迟的阴影出现在水面上,分块的灯光剔除不能正确剔除水下的灯光,但QC没有报告任何错误,所以这是一个很好的折衷方案。如果我们想看到水下的透明物体呢?最终FC5将透明通道一分为二:
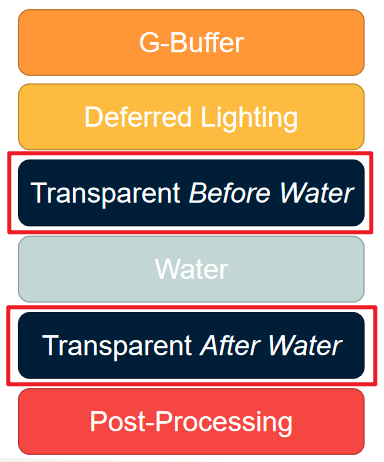
for each transparent object
find water plane at XY location
if above water plane
render after water
else if below water plane
render before water
else // if intersecting water plane
render before and after water
end
end
对于剔除,After water使用深度测试来裁剪水,Before water在顶点着色器中对水裁剪*面进行剔除。
在一天的时间周期方面,挑一个你喜欢的日子!太阳或月亮总是存在的,不断循环。计算今天和昨天太阳和月亮的位置,随着时间的推移,从今天的位置过渡到昨天的位置,所以明天12:00和今天12:00是一样的。
CalculateSunPosition( timeToday, latitude, longitude, &azimuthToday, &zenithToday );
CalculateSunPosition( timeYesterday, latitude, longitude, &azimuthYesterday, &zenithYesterday );
float dayBlendFactor = secondsFromMidnight / (24.0f * 60.0f * 60.0f); // seconds in a day
float azimuth = LerpAnglesOnCircle(azimuthToday, azimuthYesterday, dayBlendFactor);
float zenith = LerpAnglesOnCircle(zenithToday, zenithYesterday, dayBlendFactor);
像计算满月一样计算月光,可见的月相仍在发生,将月亮光的方向改为来自月亮的发光部分,以防止类似这样的bug:

但存在的问题还有不少,无法支持夜间物理照明值的对比度范围,夹紧光照半径只会增加对比度范围,灯光艺术家将灯光调暗以支持夜晚,在一天中的其它时间导致不正确的行为。借鉴了电影使用照明设备来模拟月球照明的方法,解决方案:增加月亮的亮度,把月亮光源改成浅蓝色,用于模拟填充灯光并降低对比度的最小环境条件。明亮的月亮会冲淡黎明/黄昏,因为它与衰落的太阳竞争。

FC5还采用了局部色调映射,色调以不同的方式映射图像的不同区域,减少明亮区域,使其进入更小的动态范围。尝试了后处理局部色调映射,但存在光晕等瑕疵。新想法:主要问题是黑暗的内部和明亮的外部,手动标记屏幕上需要调整曝光的区域,如窗户、门等,我们称之为曝光门户。双面几何体,乘法混合使后面的颜色变暗或变亮,靠*相机时淡出。

曝光门户的局部色调映射。
还有一种是基于GI的局部色调映射。双边模糊用于局部曝光,区分屏幕上的以下区域:2D空间的闭合区域、3D空间的远距离区域,提供照明值的局部*均值,如果已经有了3D空间中照明值的局部*均值呢?事实上,有这些信息!这是全局照明系统,它存储来自局部灯光和太阳的间接照明、天空遮挡。算法:从当前场景曝光创建一个参考中灰色,计算当前像素处的*均照明亮度:天空照明加上间接照明并忽略所有直接光(包括太阳光),比较值并相应地调整像素照明(发生在所有照明着色器中)。

The Road toward Unified Rendering with Unity’s High Definition Render Pipeline分享了Unity的HDRP管线的实现过程和涉及的技术。
高清晰度渲染管线(HDRP)的设计目标是跨*台,如PC(DX11、DX12、Vulkan)XBox One、PS4、Mac,始终基于物理的渲染;统一照明,同样的照明功能可用于不透明、透明和体积;一致性照明,所有灯光类型都适用于所有材质和全局照明,尽可能避免双重照明/双重遮挡。在光照架构方面,延迟、前向、混合的对比如下:
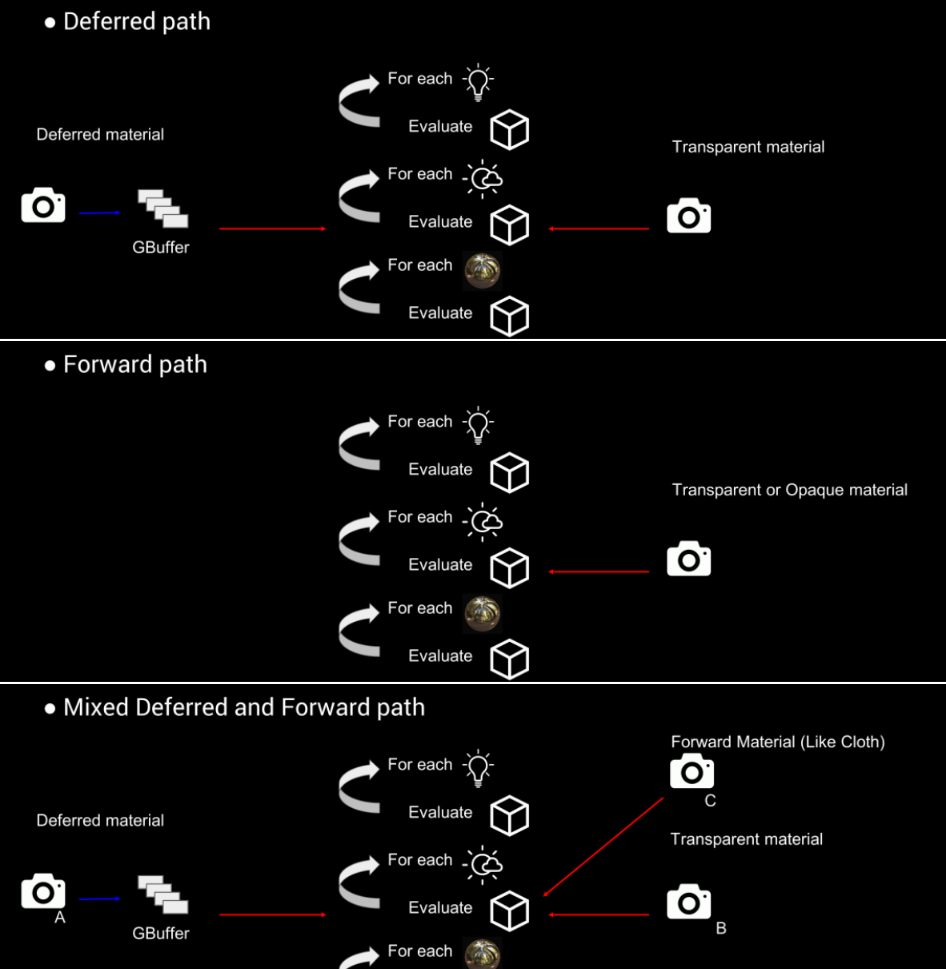
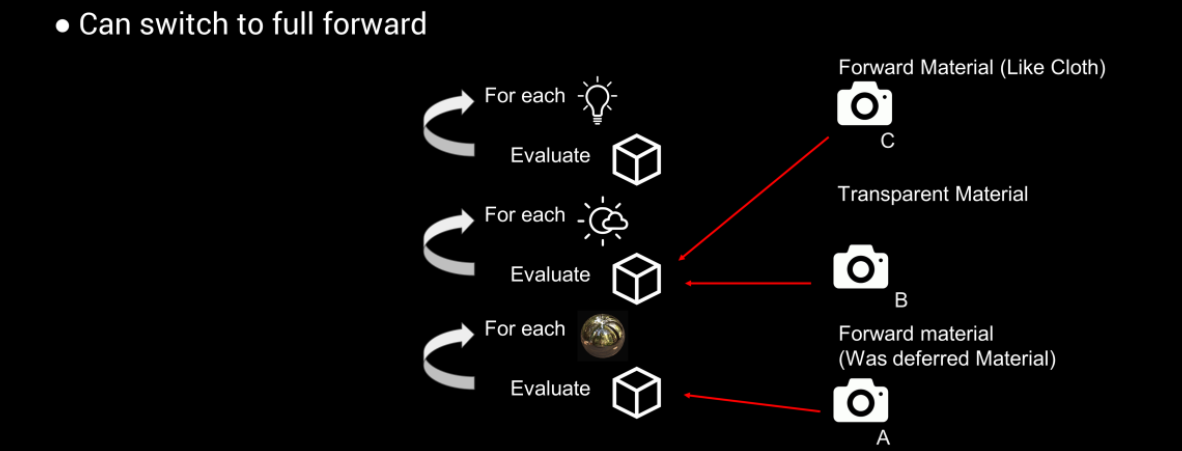
也可以切换到所有都用前向渲染:
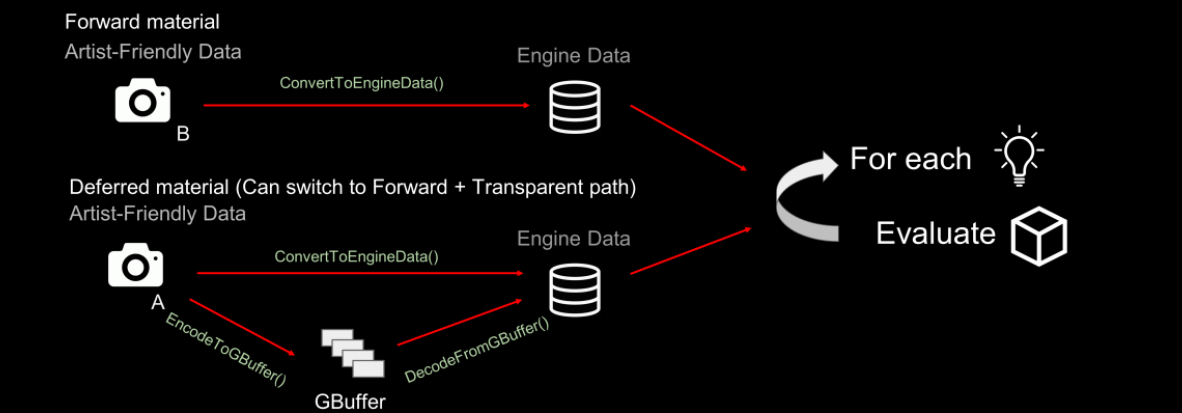
材质架构如下:
贴花的渲染架构如下:

HDRP的BRDF如下:
- 光照着色器。HDRP中的材质ID:材质特征的位掩码,例如标准+半透明、标准+清漆+各向异性、标准+彩虹+次表面散射。
- GBuffer约束。存储空间带来的独特的材质特性,如虹彩、各向异性和次表面散射/半透明。
标准着色器的GBuffer布局如下:

另外,HDRP支持各向异性、清漆、GGX多散射、彩虹(Iridescence)、次表面散射等效果:

在光照方面,支持LPV的全局光照:

硬件和支持实时光线跟踪的API的最新进展为新的图形功能让路,这些功能可以大幅提高最终帧的质量。Leveraging Real-Time Ray Tracing to build a Hybrid Game Engine将重点讨论在将实时光线跟踪功能(与现有图形API)集成到生产游戏引擎中时应考虑的问题,深入研究实时光线跟踪功能的实现细节,并提供开发过程中的经验教训。然后,还概述几种在现代渲染管线中利用实时光线跟踪的算法,例如反射和随机区域光阴影,切深入了解在生产引擎中实现商品消费类硬件快速性能所需的重要优化。
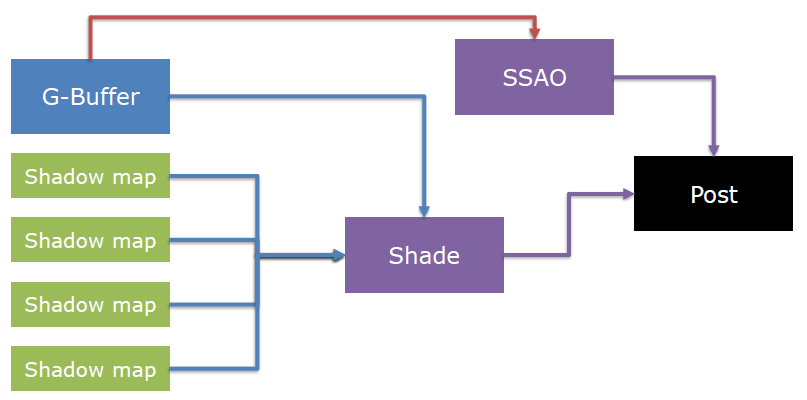
传统的渲染管线如下图上所示,其中蓝色部分和间接光无关,可以忽略。下图下的红色是和间接光相关的阶段。
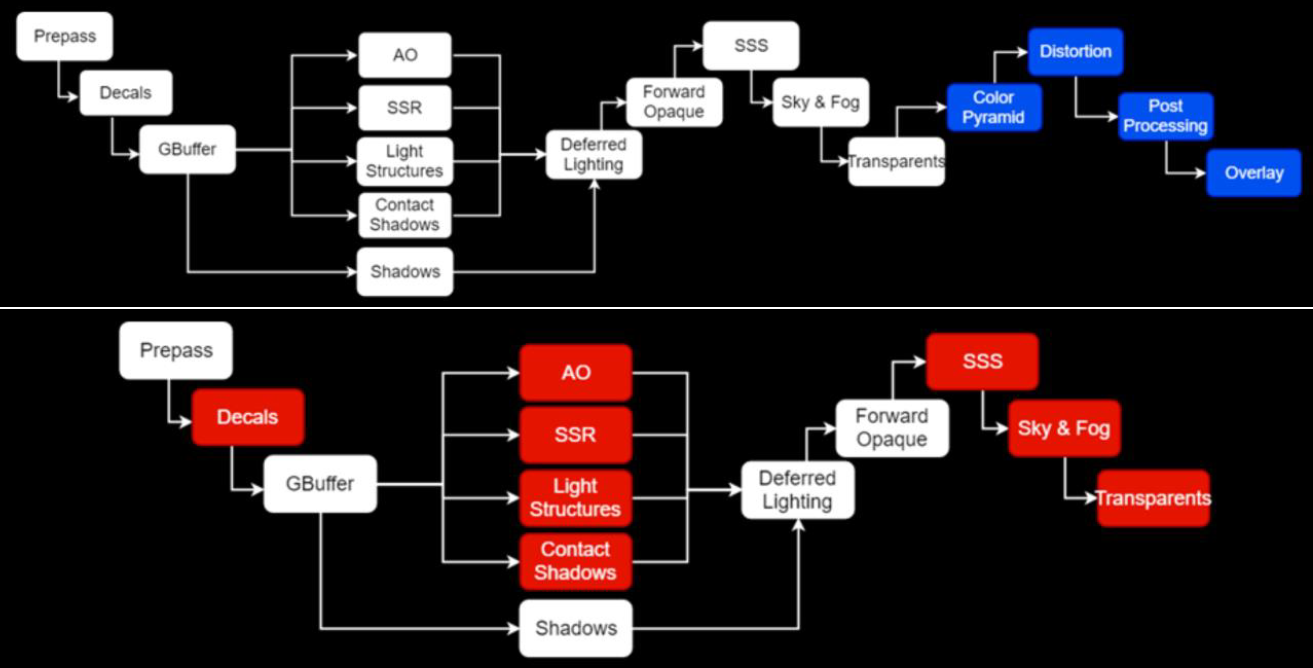
对于下图的黄色步骤,解决方案是多次反弹或*似。接下来要看的是透明度,它似乎是光线追踪的一个很好的候选者,对吗?
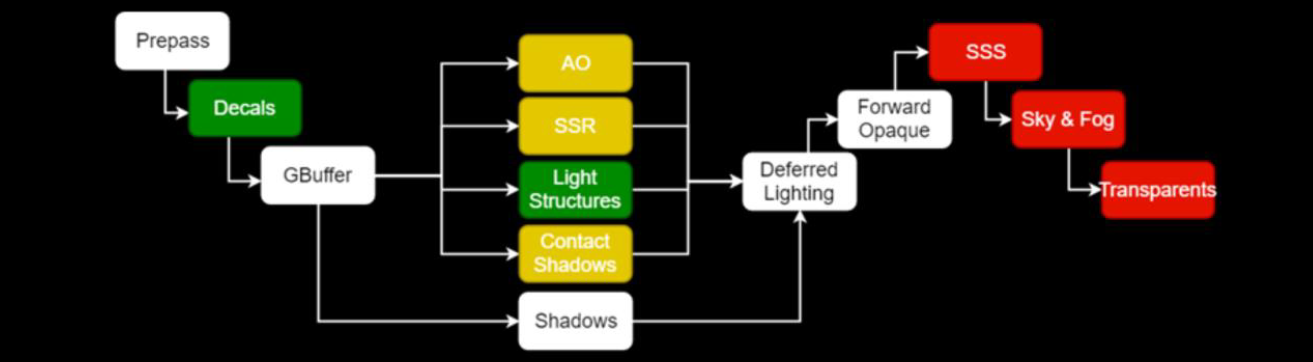
事实证明,屏幕空间照明问题同样适用于透明材质(多维性、性能、过滤)。当前已经在探索SSS的体积解决方案,但没有正确的SSS体积解决方案。混合渲染管线的流程如下:
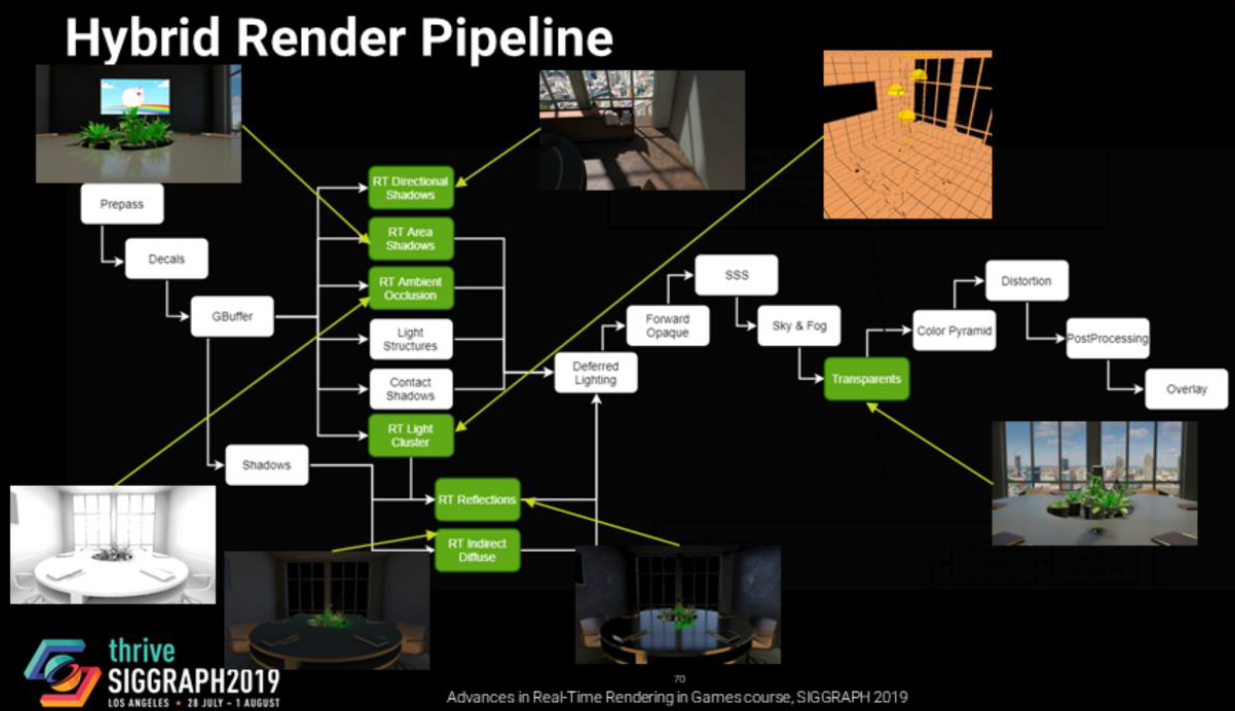
对于非直接光照,分裂和*似Karis 2013有助于减少方差,蓝色是预先计算的,使用光栅化或光线跟踪进行评估。

在RTX的渲染流程如下:
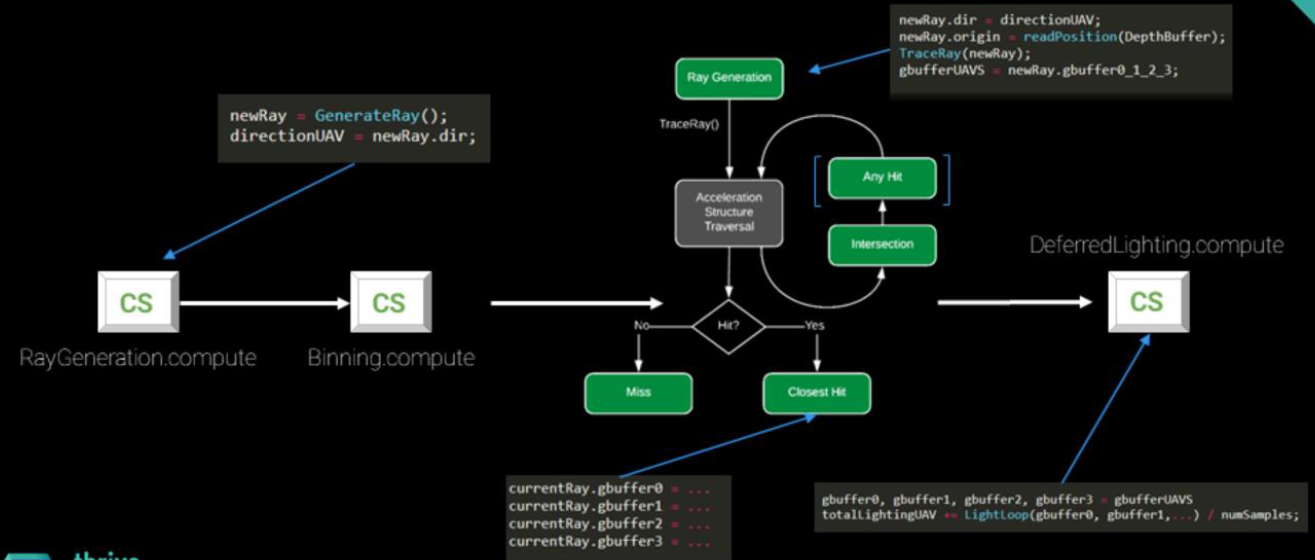
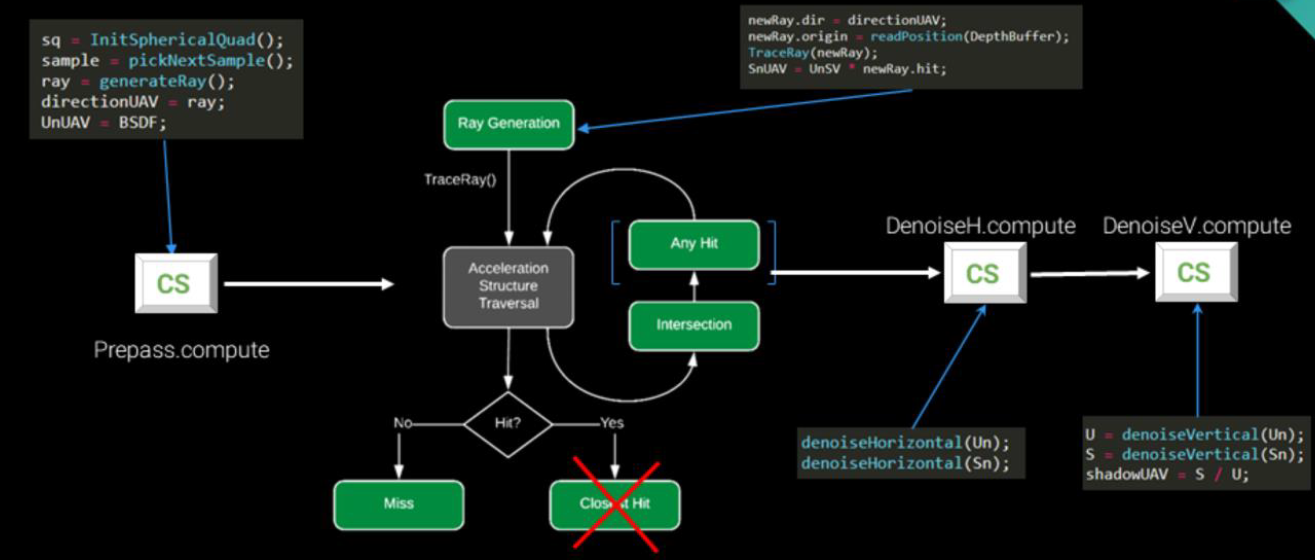
随机化的区域光渲染流程如下:
数据驱动架构是视频游戏中非常常见的概念,因为团队中的非编程部分需要轻松添加新功能。这种模式在每一个流行的游戏引擎中都得到了实现,它是增强内容创作者能力和释放他们创造力的关键技术。Content Fueled Gameplay Programming in 'Frostpunk'介绍了11 bit studios内部技术的数据驱动的游戏玩法架构,它如何影响Frostpunk的游戏玩法代码以及游戏的整体制作过程。
数据驱动架构:基于实体组件系统(ECS),灵活、易于扩展的配置,由设计和艺术团队创建的内容,程序员只提供工具,架构可以进行多次迭代和实验。没有数据驱动的体系结构,创建独特的社区建设者是不可能的。
RTTI类是运行时类型标识,可序列化为XML节点或二进制的C++类,编辑器中使用XML,游戏中使用二进制格式。模板是RTTI类定义游戏中对象的文件,由GUID识别,编辑器支持。

模板示例:实体模板-定义游戏中的对象类型、组件模板-定义组件、网格模板-定义网格并导入数据、UI样式-UI元素/UI屏幕定义。ECS实现示例如下:
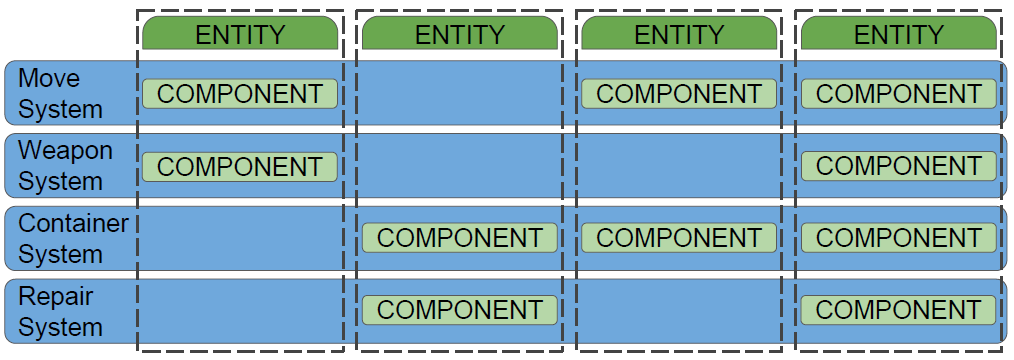
在组件中保存的状态/数据,在系统中实现的逻辑,系统可以保持全球状态,ECS之外的一些功能(UI、输入…)。组件和组件模板是RTTI类,实体模板有一个组件模板列表,组件保留对其模板对象的引用,模板对象中保存的常量数据,组件对象中保存的可变数据。每个实体一个类型的组件,清晰的配置,更少的配置错误。每个组件类型一个系统,单一责任原则,简化架构。没有系统/组件类继承,每个组件类型规则一个系统的后果,可能的位掩码ID(下图),通过添加新组件类型扩展功能。

支持组件依赖和初始化顺序:RequireComponent<Type>、AddAfterComponent<Type>。组件集:设计师定义的组件批次,包含定义最常用实体类型的组件,例如建筑物、公民、资源堆,可以嵌套,如果重复,则使用最高级别的组件定义。
class GeneratorComponent : public ComponentImpl<GeneratorComponent, GeneratorComponentTemplate>
{
DECLARE_PROPERTIES(GeneratorComponent, ComponentBase)
{
DECLARE_ATTRIBUTES(Attr::RequireComponent<BuildingComponent>());
DECLARE_ATTRIBUTES(Attr::AddAfterComponent<HeaterComponent>());
DECLARE_PROPERTY(SteamGenerationUpkeep, 0);
DECLARE_PROPERTY(SteamPower, 0);
...
}
...
Map<EntryLink<ResourceEntry>, int> SteamGenerationUpkeep;
float SteamPower = 0.0f;
friend class GeneratorSystem;
};
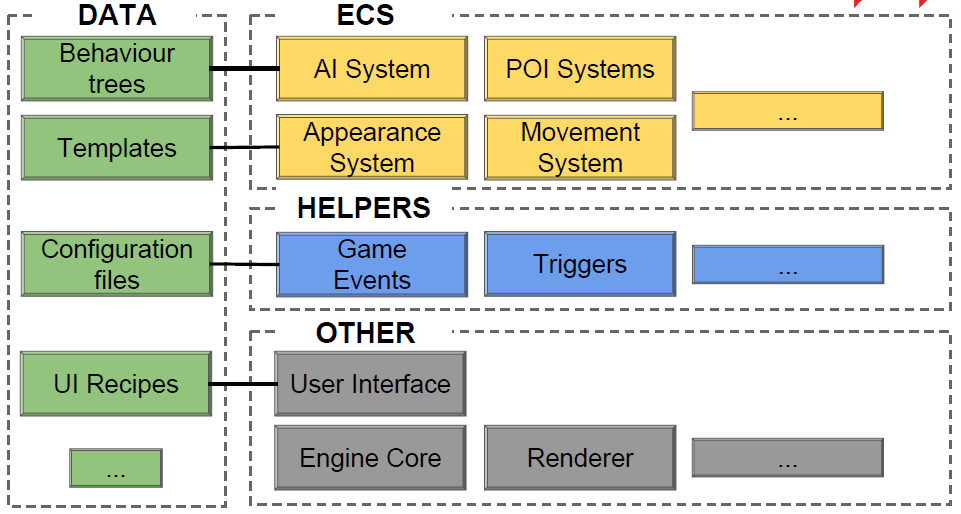
架构预览:
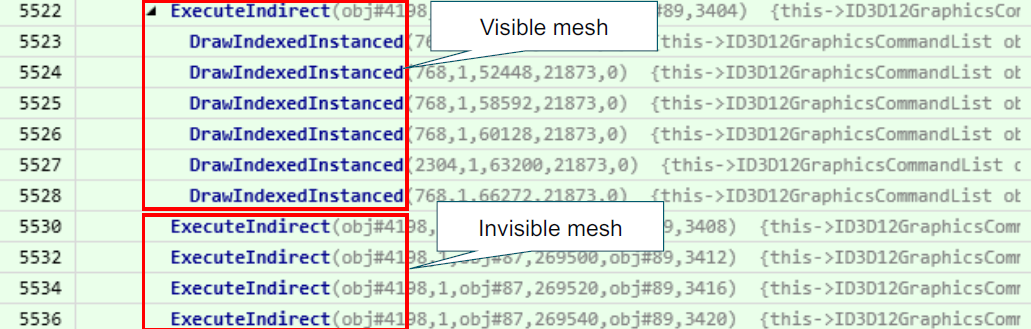
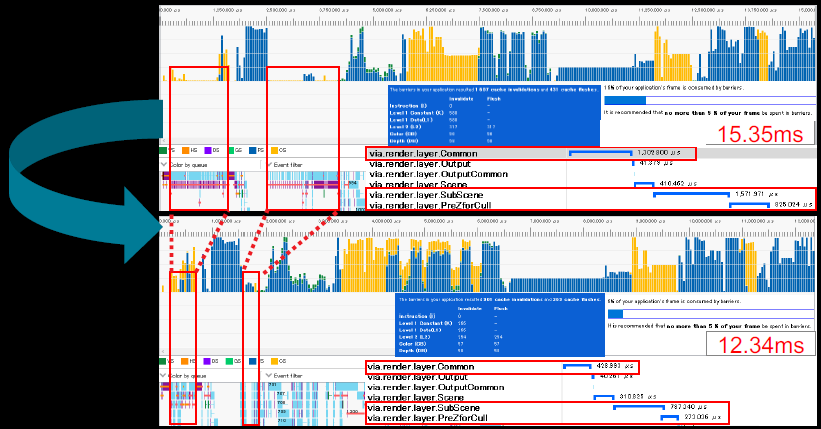
《DirectX 12 Optimization Techniques in Capcom’s RE ENGINE》讲述了Capcom公司的RE引擎使用及优化DX12的技术。用到的工具包含RGP、RGA等。
RE Engine使用“中间绘图命令”,独立于*台的命令,允许程序员在没有*台知识的情况下编写绘图命令,对多*台开发有用,能够在多个线程上创建绘图命令,这些“中间绘图命令”在创建后进行排序,然后转换为API命令,使用优先级变量(uint 64位值)控制绘图顺序,允许用户自行决定批处理,用于控制UAVOverlap和异步调度的同步定时。
控制台优化适应PC的措施有使用MultiDraw进行遮挡剔除、UAVOverlap、Wave指令、深度界限测试,针对DirectX 12的优化有减少资源屏障、缓冲区更新、根签名、内存管理等。ExecuteIndirect总体而言,没有想象的那么多改善,但对于基于GPU的遮挡剔除的实现非常有用。基于GPU的遮挡剔除的实现可以用ExecuteIndirect和预测指令(Predication command)两种实现方式。ExecuteIndirect是4字节对齐,使用CountBuffer控制间接参数执行的次数,预测命令是8字节对齐,与控制台不兼容。使用“VisibleBuffer”管理可见性,实际上,它是RE引擎中的缓冲区,字节地址缓冲区,元素数等于场景中的最大网格数,每个元素包含每个网格的可见性,0xffff表示可见,0x0000表示不可见。可见性测试时,用EarlyZ绘制([earlydepthstencil]属性),将0xffff存储到VisibleBuffer中,尽量减少以波为单位的同一地址的写入[dorobot16]:
[earlydepthstencil]
void PS_Culltest(OccludeeOutput I)
{
// 减少以波为单位的同一地址的写入.
uint hash = WaveCompactValue(I.outputAddress);
[branch]
if (hash == 0)
{
RWCountBuffer.Store(I.outputAddress, 0xffff);
}
}
然后应用可见性测试结果:按网格应用绘图,使用MaxCommandCount指定绘图数量,VisibleBuffer作为CountBuffer,CountBuffer 0xffff:启用绘图(计数为MaxCommandCount),计数缓冲区0:禁用绘制。
void ExecuteIndirect(
ID3D12CommandSignature *pCommandSignature,
UINT MaxCommandCount,
ID3D12Resource *pArgumentBuffer,
UINT64 ArgumentBufferOffset,
ID3D12Resource *pCountBuffer,
UINT64 CountBufferOffset);
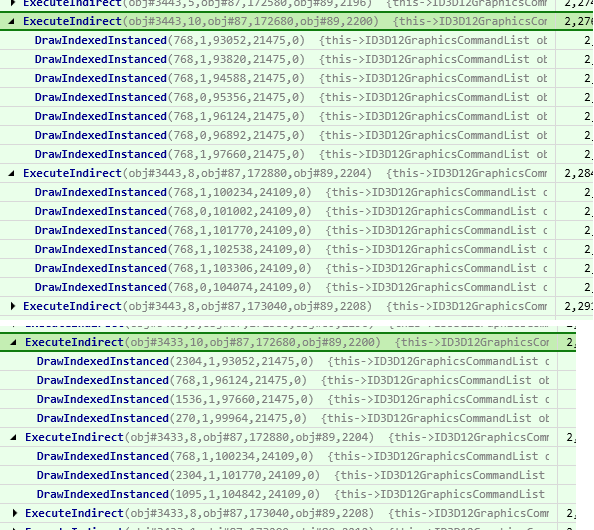
还有另外一些改进的余地:有效针对道具和角色网格,剔除方法对较小的AABB单元有效,但对大网格无效,大网格始终可见,需要精细分割网格以获得更好的效果。可以自动细分大的网格,剪取256个三角形作为一批,每批由连续的间接参数组成,每批创建AABB。然而这种方法也存在一些问题:几乎所有绘制都低于768个索引,大量批次导致性能不佳(取决于硬件),如果相邻间接参数连续,则合并命令。
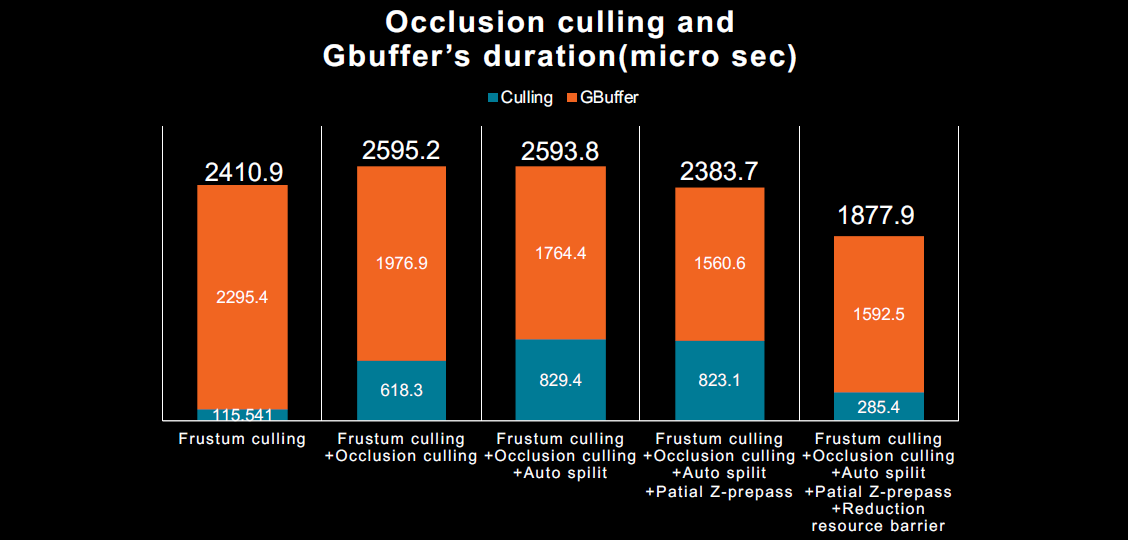
分区z-prepass(Partial Z-prepass):运行尽可能少的片段着色器,每个网格的Z-prepass都很昂贵,成本可以超过收益,将Z-prepass限制为相机附*的网格,重用自动划分模型。不同裁剪方法的性能对比:
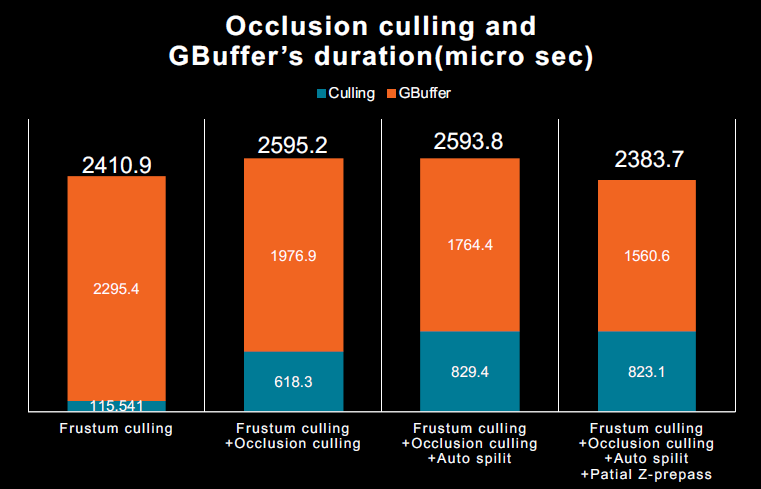
但发现基于GPU的遮挡剔除无法获得明显的性能提升:
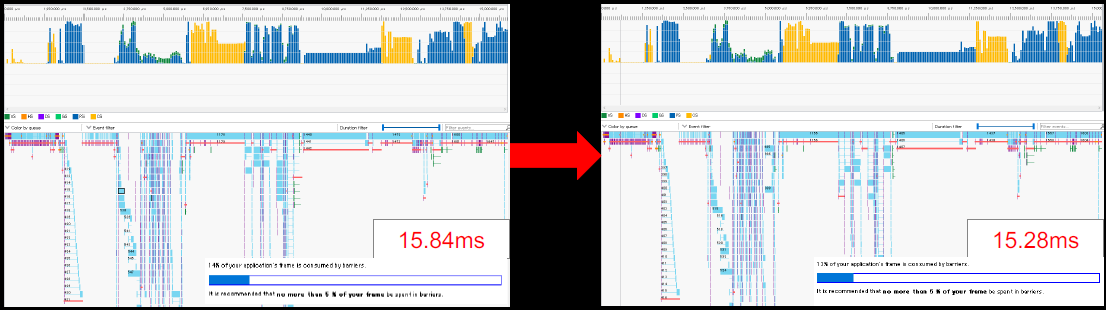
UAVOverlap:DirectX12无依赖的着色器可以并行执行,UAV屏障的依赖性不明确,不清楚是读还是写,如果每个批写入单独的位置,则可以并行地执行,如果WAW(write-after-write)危险是可以避免的。用于每次计算着色器dispatch的可控的UAV同步,通过禁用UAV的同步,使并行执行成为可能,在DirectX 11中,可以使用AGS和NVAPI引入等效函数。
// uavResourceSyncDisable就是禁用UAV的同步。
void dispatch(u32 threadGroupX, u32 threadGroupY, u32 threadGroupZ, bool uavResourceSyncDisable = false);
void dispatchIndirect(Buffer& buffer, u32 alignedOffsetForArgs, bool uavResourceSyncDisable = false);
启用UAVOverlap有略微的提升:
wave指令:着色器标量化可以提高线程并行工作的速度,用于照明、基于GPU的遮挡剔除、SSR…Wave Intrinsic通过消除不必要的同步来提高标量化的效率。在DirectX 11和DirectX 12中受支持,使用AGS内置着色器模型5.1,也可与Shader Model 6.0一起使用。
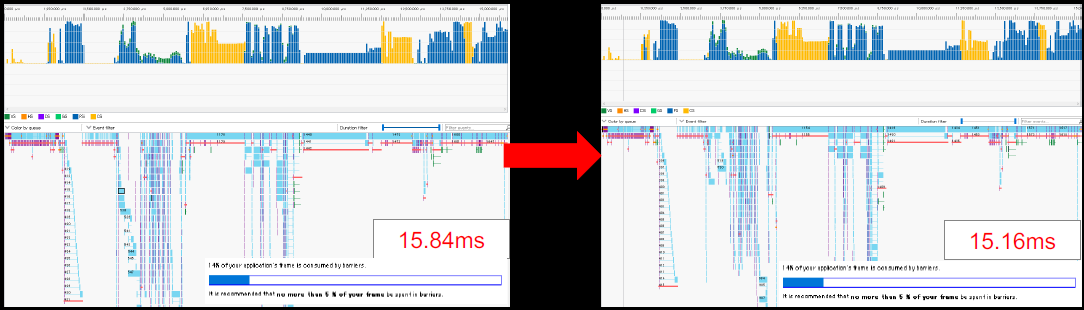
深度边界测试:夹紧深度达到特定深度范围,主要用于消除无关的像素着色器,可与DirectX 12(创作者更新)和DirectX 11.3一起使用,带有AGS和NVAPI的DirectX 11,在RE ENGINE中,它用于贴花和光束。处理贴花时,在深度测试失败的像素上运行,完全遮挡时,最好跳过处理,使用深度边界测试解决。
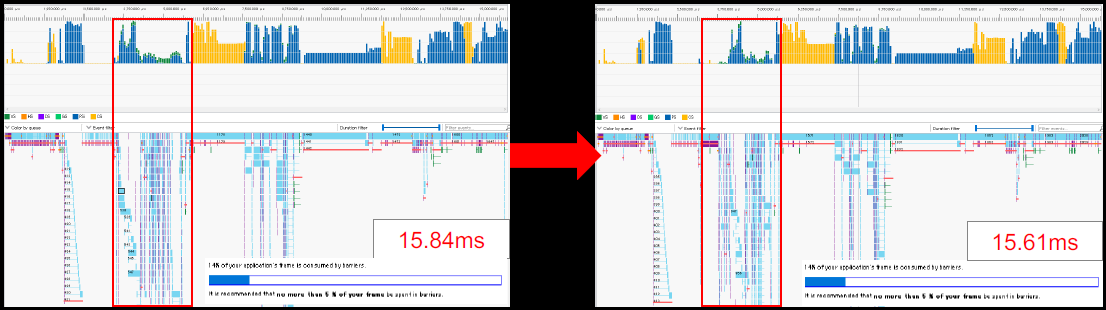
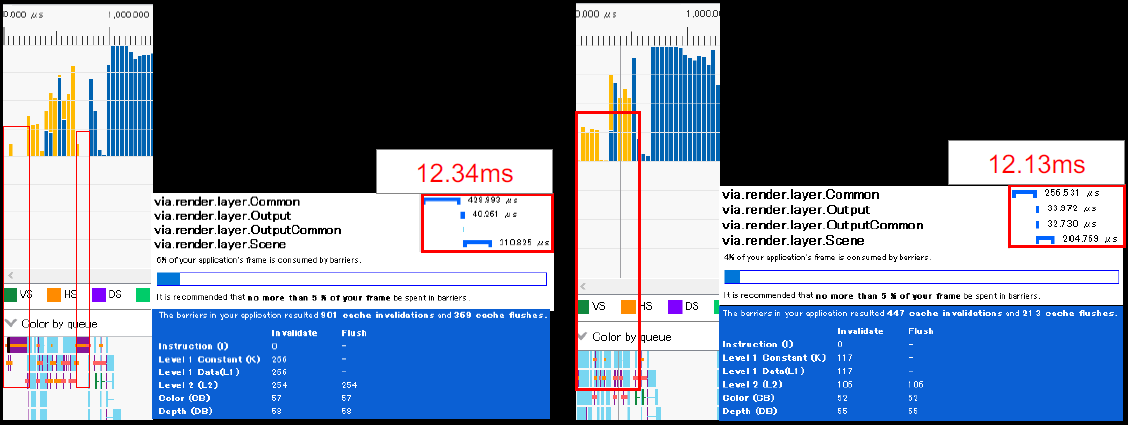
在没有对资源屏障进行优化的原始构建中,批量插入了资源屏障,在执行绘图命令之前,立即转换当前批次所需的资源屏障:

导致大量资源屏障,是基于GPU的遮挡剔除并没有显著提高性能的原因之一:
资源屏障较多的阶段运行效率不高:
减少资源屏障:通过考虑每个资源的子资源进行优化,很难通过所有中间绘图命令手动创建最佳资源屏障,困难表现在获得最大的GPU性能和保持无Bug。为命令分析添加pre-pass,自动计算资源屏障的位置,分析中间绘图命令,中间绘图命令按优先级排序,可以按时间顺序跟踪每个资源的绘图命令使用情况,通过改变优先级顺序,分析具有依赖性的批次可以轻松提高GPU的效率。压缩打包资源屏障的过程如下:
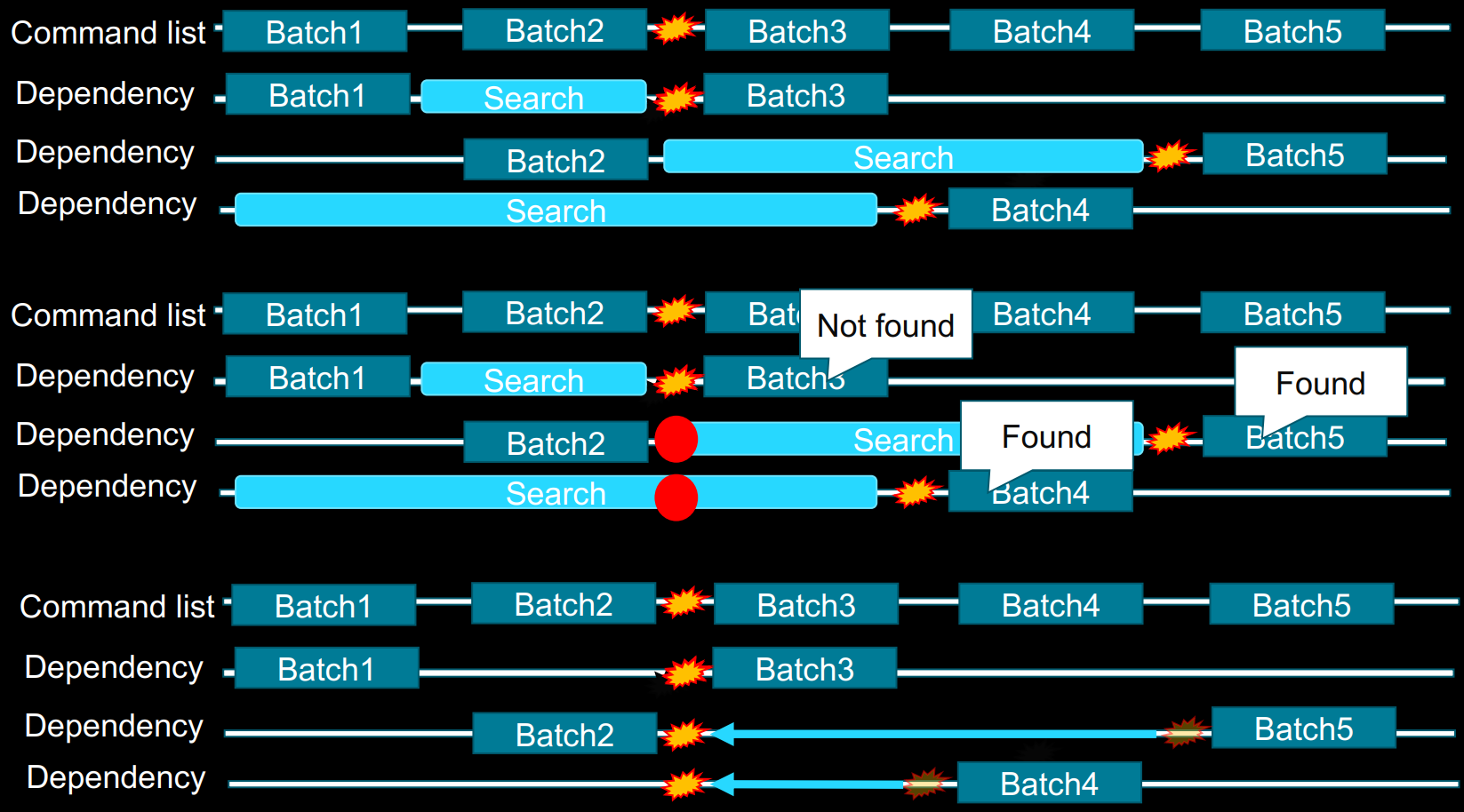
上:对不同时间点的Barrier向前搜寻前面资源的Barrier;中:找到这些Barrier的共同时间点;下:迁移后面Barrier到同一时间点,执行合批。
优势是不必对内部实现和缓存如此敏感,减少不必要的资源屏障。劣势是需要命令解析时间,但PC超级速!
在更新缓冲区时仍然存在效率低下的部分如下图:
DMA传输中驱动程序造成的大量资源屏障:

发生了什么事?图形队列上的缓冲区更新,复制缓冲区,如GPU粒子缓冲区更新和更新蒙皮矩阵,CopyBufferRegion作为DMA传输执行。在执行DMA传输时,强缓存刷新正在运行,一级缓存、二级缓存、K级缓存,批处理资源屏障没有任何影响!可能的解决方案是如果每帧只有一次更新,则使用CopyQueue进行更新,使用计算着色器进行更新,前提是使用了计算着色器。
StructuredBuffer<uint> fastCopySource;
RWStructuredBuffer<uint> fastCopyTarget;
[numthreads(256,1,1)]
void CS_FastCopy( uint groupID : SV_GroupID, uint threadID : SV_GroupThreadID )
{
fastCopyTarget[(groupID.x * 2 + 0)*256 + threadID.x] = fastCopySource[(groupID.x * 2 + 0)*256 + threadID.x];
fastCopyTarget[(groupID.x * 2 + 1)*256 + threadID.x] = fastCopySource[(groupID.x * 2 + 1)*256 + threadID.x];
}
固定缓冲区更新的优化:通过上传堆更新所有常量缓冲区,更新同一固定缓冲区需要资源屏障和CopyBufferRegion(DMA传输),将新值存储到上传堆中,并获取上传堆偏移地址,使用ConstantBuffer的着色器只需要参考偏移地址,不再需要资源屏障和复制缓冲区。复制缓冲区缩减比较,成功消除了低效率:
根签名:DirectX12使用与DX11和控制台类似的RootSignature,在运行时确定,而不是在着色器构建时确定,为每个IHV提供定制优化,对于AMD,使用RootParameter作为表格,对于NVIDIA,使用RootParameter优化ConstantBuffer访问。
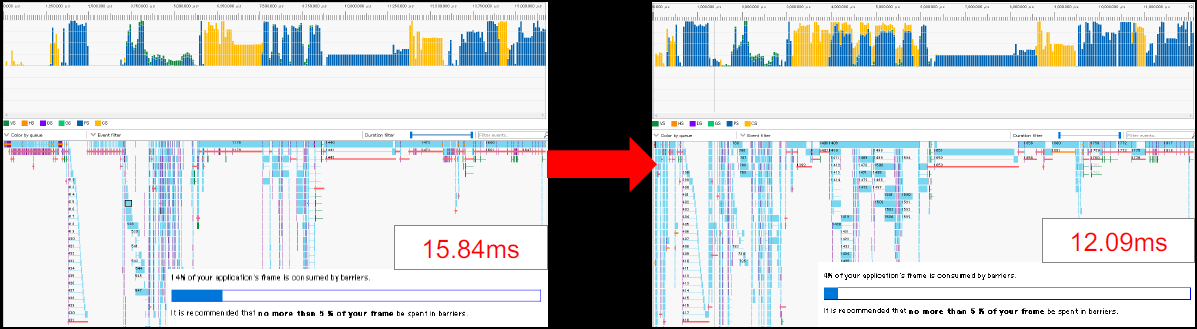
内存管理:在第一个实现中,内存回收从大约50%的内存使用率开始,相当保守,游戏过程中出现了许多尖峰。在《生化危机2》中,每次角色移动时,控制每个房间的装载和处理都会导致尖峰,甚至在加载暂停菜单的UI时发生。在内存耗尽之前不要逐出,防止微型逐出,当内存使用率超过90%时,未引用的内存将被逐出。
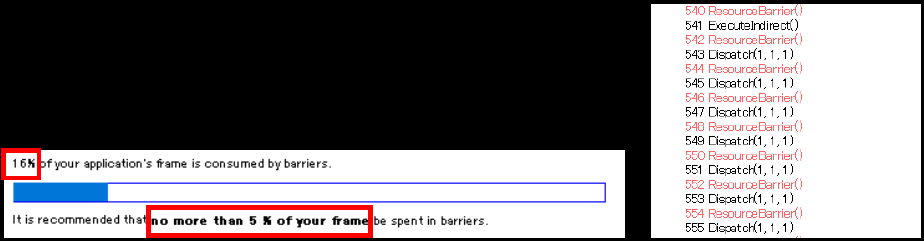
经过以上所有优化之后,性能得到了24%的提升(优化实属不易啊!!):
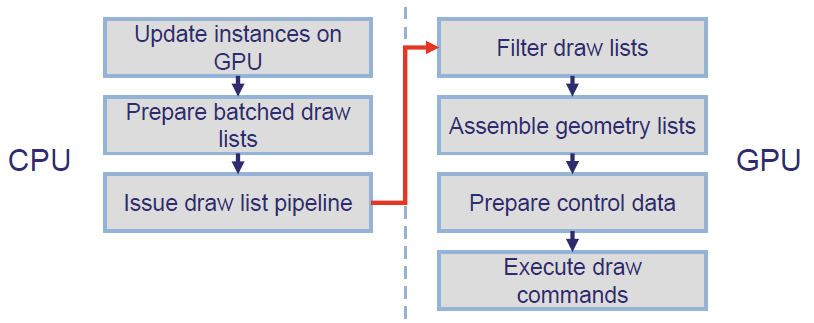
GPU Driven Rendering and Virtual Texturing in 'Trials Rising'介绍了Trials Rising团队在所有目标*台(PS4、Xbox One、Switch、PC)上实现60 FPS恒定性能的过程,这些*台的世界复杂性大大增加,包含GPU驱动的渲染实现及其与虚拟纹理的集成、主要创新、优化和性能结果的详细信息,致力于介绍任天堂交换机*台上GPU驱动的渲染可扩展性和技术效率的改进。
GPU驱动的渲染将可见性测试转移到GPU,直接在GPU上使用测试结果,GPU上的批处理实例,将不同网格的实例合并在一起,GPU能够感知场景状态,而不仅仅是通过frustrum测试的部分,GPU为自己提供渲染功能。
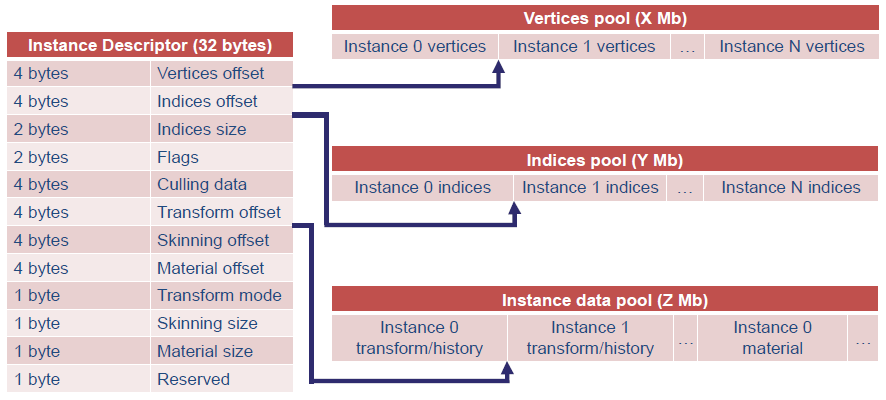
GPU数据结构:两个GPU缓冲区用于存储几何体(即顶点和索引池),一个大型GPU缓冲区,用于保存实例参数(即实例数据池),实例描述符表示的实例,一个GPU缓冲区,用于存储场景中所有描述符的数组,CPU和GPU主要使用此列表中的索引进行操作。实例描述符包含内部和外部数据,几乎是一个指针表,可以表示场景中的任何实例,和描述集非常接*:
CPU和GPU实例状态同步:CPU负责实例状态模拟并上传到GPU,GPU等待信号读取实例数据,直接的状态再生每一帧都不起作用,根据第一次实施结果,数据流量相当高,并且在未来有增加的趋势。数据传输改进:实例更新率不是恒定的,状态参数*均更新率不同,通常是稳定的,“固定”参数适用于特定实例类别,大量“闲置”组件,同步状态的最小值。
微型合批:写一个包含缓冲区偏移量和要写入的数据的简单列表,合批程序的顺序很重要:
GPU实例表合批:
池合批:
微型合批结果:延迟同步,所有GPU结构只有一个显式同步点,不与GPU争用以访问/修改缓冲区,合批数据收集显著提高了CPU性能,合批池数据散射影响GPU性能,在“脏”状态下的实例要少得多。
可变同步速率:使用可变动画速率的想法,基于“重要性”因素同步实例状态,保持确定性(用于回放、调试等),尽可能自动计算“重要性”,整体同步问题看起来与网络同步非常相似。
文中还使用异步计算来并行处理物理模拟:
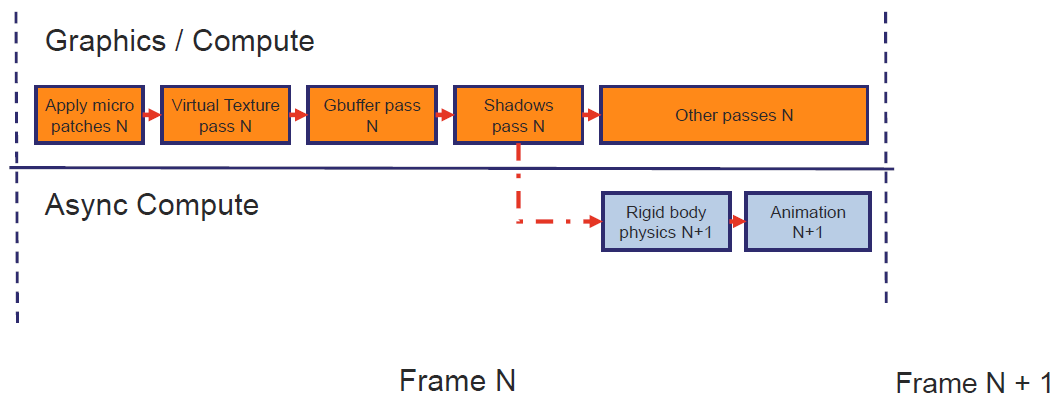
虚拟纹理:一次访问所有纹理数据,通常比普通纹理流技术的内存使用和数据传输压力更低,极大地提高了GPU驱动渲染的“批处理”效率,替换某些*台/API可用的无绑定纹理。
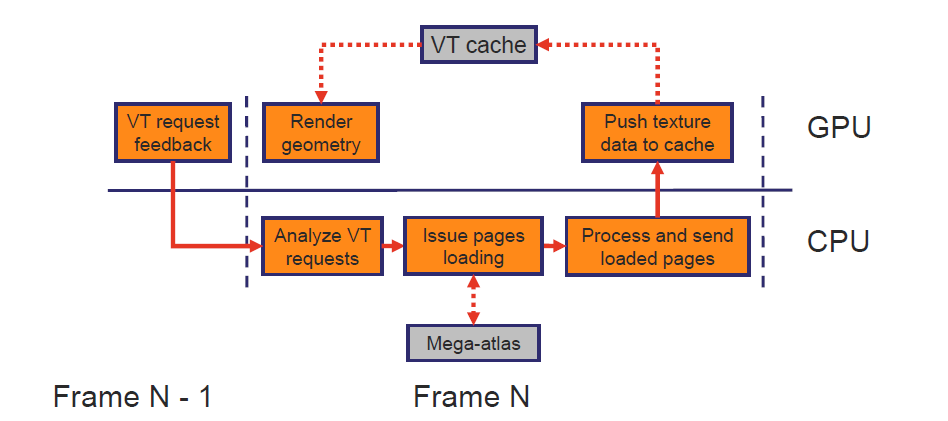
VT使用了专用通道:使用专用摄像头查看VT页面请求通道,流预测、纹理预加载等,需要额外的视口剔除。光栅化几何体两次以生成页面请求RT,较小的渲染目标(1/4分辨率+抖动),存储页面请求(x坐标、y坐标、mip),分析CPU并生成加载请求。In place PR:用两个UAV缓冲区(Bloom过滤缓冲区、页面请求缓冲区)替换渲染目标,将PR过滤、排序等移动到GPU,并将其委托给GBuffer中的每个像素,允许从CPU上节省一些时间,对透明通道、alpha混合通道等的页面请求。Trials Rising“In最终使用了“In place PR”,这一变化使得每一个奇数帧(Xbox One计时)的CPU时间减少了约35毫秒,可能会导致额外的纹理加载延迟,必须加以考虑。半透明可以放置在Mega纹理中,很棒的着色器代码简化。虚拟纹理可伸缩性:每帧的页面请求决定了系统的“性能”,高度依赖于渲染分辨率和VT页面缓存大小,这两个参数都可以在“在线”和“离线”设置中控制。
GPU驱动的渲染可伸缩性:GPU管线的计算部分速度非常快,剔除和几何组合可根据GPU时钟和内存带宽/延迟进行缩放,光栅化基于分辨率和比例,GPU管线需要CPU/GPU的特定数据路径,实例同步对内存带宽的影响,具有少量实例开销的批处理比实际工作量要高。对低端*台的远距离对象使用更激进的消隐设置,根据CPU/GPU负载调整运行时的详细级别。
Snowdrop是一款AAA级游戏引擎,由育碧开发,为The Division及其续集提供动力。Efficient Rendering in 'The Division 2'阐述了The Division 2中使用的一些技巧,以在PC和控制台上实现最佳性能,如构造帧、异步计算、多线程、内部函数、命令列表提交等。
Snowdrop使用了异步计算和图形管线相结合的计算,管线总览如下(上半部分是图形管线,下半部分是异步计算):
整体管线使用CPU/渲染/GPU工作交错,尽早提交,频繁提交,没有渲染图或帧布局的先决信息,自动资源过渡跟踪,但可以选择不自动追踪。每帧50到60次提交,200次过渡/100次屏障,3到6k个绘制调用,3到6百万个图元,(一些供应商)提交的时间比构建即时命令列表的时间要多。渲染核心处理非命令列表操作,包含渲染状态/PSO和资源创建:缓冲区、像素存储、纹理、RT。。。管理渲染上下文,图形/计算/延迟/DMA。
更新缓冲区时,所有瞬态数据复制到上传缓冲区,然后复制到GPU局部缓冲区,着色器仅从GPU本地缓冲区读取!没有更快,而是可以获得更稳定的帧率。命令列表链接(Command list chaining)在一些控制台上可用,允许在记录命令列表时执行命令列表,将CPU和GPU停顿的风险降至最低,但在DirectX®12中不可用…解决方案:模仿!!!进入队列管理器,处理命令列表操作,如ExecuteCommandLists、关闭、重置,隐藏这些操作的CPU成本,有自己的工作线程和任务队列,实际上是一个自定义驱动程序线程。
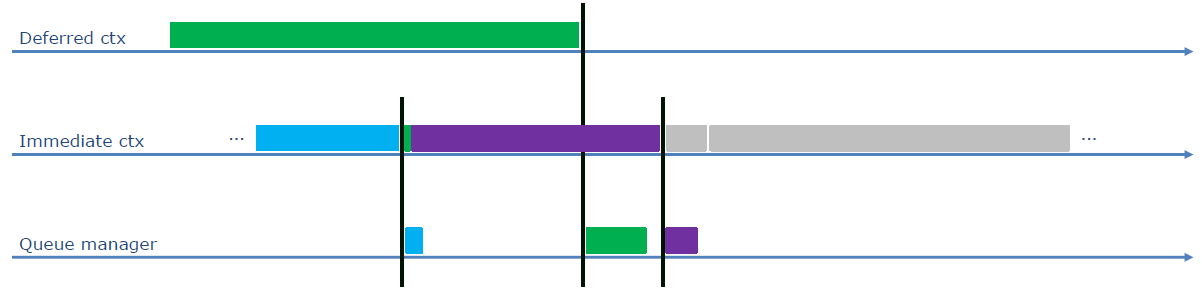
队列管理器提交它可以提交的内容,原子追踪命令列表状态,如录制、打开,每个上下文一个队列,按优先顺序的俄罗斯转盘(Round robins)方式执行计算机、图形、DMA等。队列管理器细节:
原生和队列管理器对比:
队列管理器可以消除大多数CPU停顿,预测性地准备命令列表,避免命令列表创建/重置的停顿,消除多余的信号/等待。
异步计算的提交也由队列管理器处理,2种类型的计算工作负载:依赖于gfx状态、独立的,用于不需要很快完成的工作负载。异步计算示例:深度下采样和光源剔除、雾与体积计算、雨和雪的GPU粒子、天空/覆盖采样、草地/植被更新、阴影(可变半影预计算)、GI重新照明等。异步计算可能会让gfx管线停顿,可能会导致GPU使用不足,控制台上:限制异步计算占用,在PC上不支持D3D12_COMMAND_QUEUE_PRIORITY。
High Zombie Throughput in Modern Graphics讲述了Saber引擎的渲染管线(高级GPU工作流、着色概述、Vulkan优化)和僵尸渲染(特写和中档角色、远距飞机群、贴花)等内容。Saber引擎渲染管线的特点是GPU驱动的可见性系统、完整的深度prepass、前向+PBR着色、烘焙GI:RNM+主导方向、2帧延迟、多线程命令缓冲区记录。GPU工作流如下:
GPU可见性系统:基于“游戏的实用、动态可视性”[Hill11],简单高效,无需PVS/门户等,主摄像机:HZB遮挡剔除与手工遮挡器,PSSM拆分:仅是追究剔除,0.7ms(XBox One)的GPU预算,用于100k+对象的场景,CPU回读需要1帧延迟。

D3D11和Vulkan的渲染管线对比:
Vulkan vs D3D11:GPU时间最多减少10%,wave指令(GL_KHR_shader_subgroup),前向+照明/反射循环在着色过程中进行标量化,异步计算,半精度数学。无辅助驱动程序线程:渲染CPU总负载减少40%,由于MT命令缓冲区,CPU关键路径减少20%。渲染目标内存重叠使得内存减少30%,并支持动态分辨率。
僵尸渲染:每帧超过5k个可见僵尸,大多数都是非互动背景,300多个前景“真实”游戏内的实体/角色,只有50个僵尸大脑发育完全,实例被用来降低绘制调用压力,灵活的每实例可视化定制系统。自定义网格:3种基本原型/骨架(男/女/“大”男),每具骨骼约50根骨头,每个模型4个网格区域(腿/躯干/头/头发),每个区域2-5k个三角形,每个区域4-8个网格变体,总共70多种独特的网格组合,再加上10个独特的僵尸模型(化学制品、尖叫器等)。

定制颜色和染色口罩:每个网格区域(衬衫/牛仔裤/鞋子/头发):颜色掩蔽纹理(ARGB8纹理,低分辨率)、污渍掩蔽纹理(ARGB8纹理,低分辨率);共享污渍纹理集(血迹/雪/灰尘):反照率/法线/粗糙度纹理,所有纹理都是tile的,存储为纹理数组;每实例常数,如颜色:通道遮罩+纯色,着色:通道掩码+纹理数组索引。

僵尸渲染的实例化:从可见性系统中获取单个僵尸,将相同的网格收集到实例化桶中,一个区域中变化相同的网格进入一个桶,不同的LOD模型将分离存储桶。将累积的存储桶处理到渲染队列中,按可见性遮罩对桶进行排序(每个活动摄像头都有自己的位), 将具有相同可见性遮罩的网格分批次收集(最多30个网格),对于每个批次,使用每个实例数据填充连续常量缓冲区,为每个过程/摄像头(Z、SM、着色)每批生成1个绘图调用。
僵尸渲染的背景群体:超过5000个僵尸,非交互式:本质上只是一个GPU驱动的动画,共8种预焙变体:2种网格类型 x 4种独特外观,每个网格约400个三角形,灵感来源于The Technical Art of Uncharted 4” [Maximov16]。利用现有的草地渲染解决方案,添加纹理烘焙顶点动画,沿着预先建模的轨道移动。
Halcyon Architecture - "Director's Cut"分享了迷你游戏PICA PICA的渲染架构和相关技术。Halcyon的渲染概览如下:
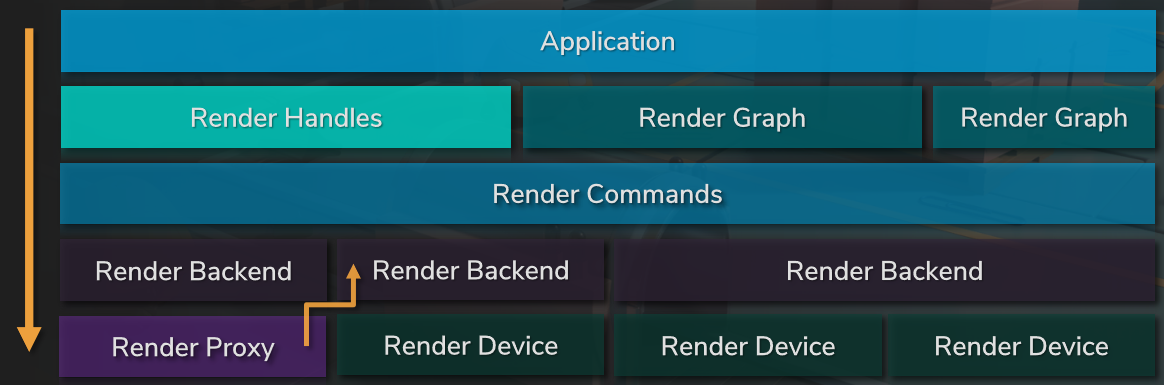
渲染句柄:由句柄关联的资源,轻量级(64位),恒定时间查找,类型安全(即缓冲区与纹理),可以序列化或传输,次代之间安全,如双重删除、删除后使用。可以在同一过程中混合搭配后端,使得调试VK实现变得更加容易,DX12位于屏幕左半部分,VK位于屏幕右半部分。
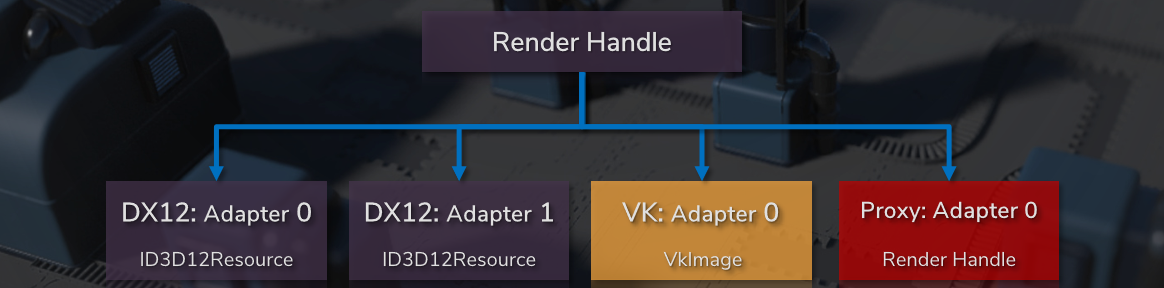
渲染命令:指定的队列类型,规格验证,允许运行?例如利用计算,自动调度,它能跑哪?异步计算。
渲染图:帧图 -> 渲染图:没有“帧”的概念,全自动转换和分割屏障,单个实现,不考虑后端,从高级渲染命令流转换,渲染图中隐藏的API差异。对多GPU的支持,大多是隐式且自动的,可以指定计划策略。多个图在不同频率下的组合,相同的GPU:异步计算,mGPU:每个GPU的图形,核心外:服务器集群、远程流。

渲染图有两个阶段:图形构造(指定输入和输出,串行操作)和图形评估(高度并行化,记录高级渲染命令,自动屏障和过渡)。它还支持多GPU的渲染调度:
另外,Halcyon使用了虚拟多GPU的技术。大多数开发者只有一个GPU,不适用于2台GPU机器,对于3+GPU来说很少见,适用于展厅,最高可达11个,不适合常规开发。
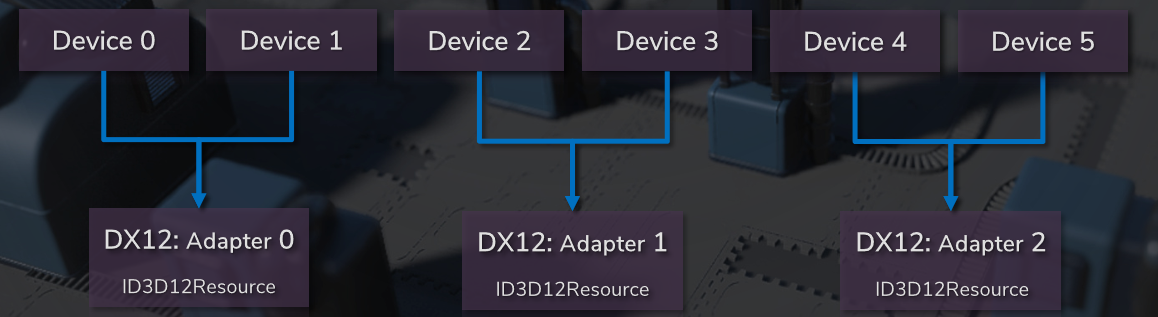
Halcyon的着色器跨*台方案如下:
Not-So-Little Light: Bringing 'Destiny 2' to HDR Displays介绍了为支持《命运2》的HDR显示而采取的方法,探讨了如何改变“命运”渲染管线以支持这项新技术,包括将SDR创建的内容引入HDR世界所面临的挑战。还将介绍在《命运2》中实现高质量HDR输出所使用的技术,以保持命运的独特外观,并反思从工作中吸取的经验教训。

Destiny 2的渲染管线如下:
色调映射效果对比:

颜色分级使用的LUT是SDR,使用数学映射:我们总是想要线性输入,先是色调映射,然后转换。忽略变换,则是可逆的。
SDR Color = TonemapForSDR (Input Color);
LUT Color = LutLookup (SDR Color);
...
Transform = Input Color / max (SDR Color , 0.001);
...
LUT Color *= Transform;
当InputColor为0时,LutColor也为0。其中UI的渲染流程如下:
新的渲染管线如下:
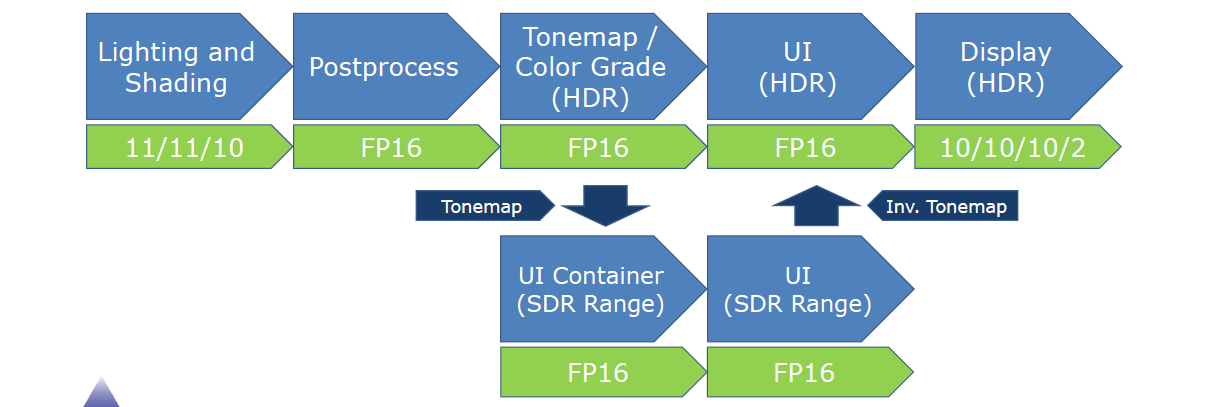
EOTF是电-光的传输函数,从电压到光强度。OETF是光-电的传输函数,从光强度到电压。sRGB的EOTF如下:
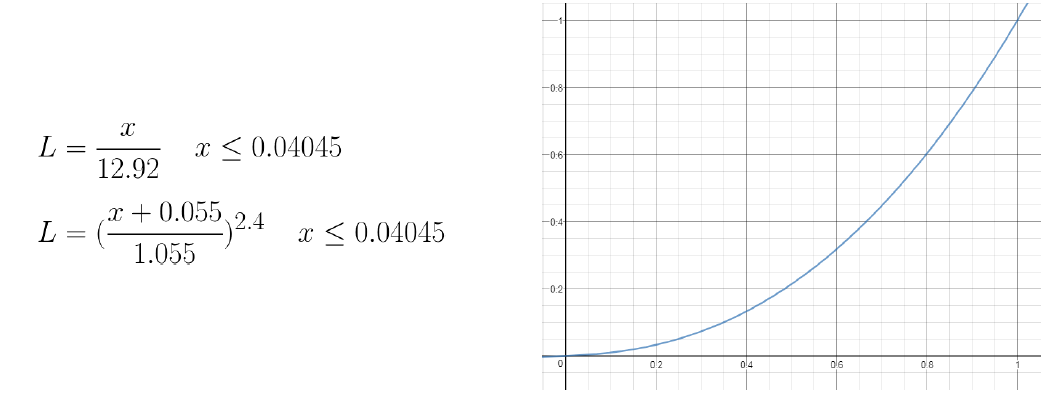
BT.709 OETF:
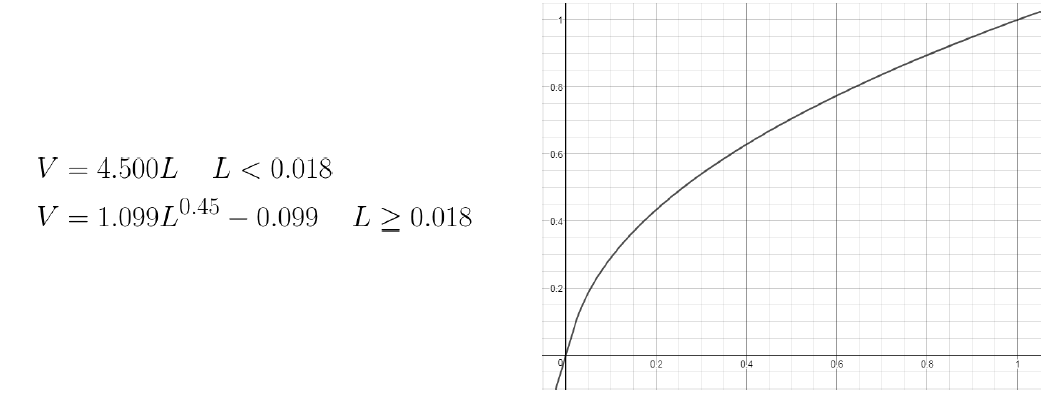
技术陷阱:增强型HDMI,在着色器中小心使用饱和,fp16缓冲区表示负数,SDR空间中的AA,更深的黑色会加重屏幕噪音。文中采用了HDR的LUT,在用户界面中使用色度/亮度,利用ICtCp或其它,最后一步是色调映射。离线的HDR管线如下:

经验教训:内容验证,做好改变SDR管线的准备,尽可能长时间地维护HDR缓冲区,探索RGB的替代方案,使用光度单位,做一个比较工具。
6 Years of Optimizing World of Tanks: Making the Game a Great Experience on All Systems from Laptops to High End PCs分享了坦克世界的多年优化经验,包含并行渲染、并发渲染、坦克履带、Havok/AVX2、光线追踪阴影等。
优化Ultrabook - 阴影:使用共享视频内存正确检测英特尔硬件,静态对象的自适应阴影贴图(ASM),动态对象的级联阴影贴图(CSM)。
优化Ultrabook - 性能优化:动态分辨率根据性能的不同,场景以动态分辨率渲染,且不缩放,UI始终以完全分辨率渲染,PC游戏的首批实现之一,在游戏中允许稳定的30 fps帧速率。硬件特定优化(2015年),用于在英特尔GPU上进行植被渲染的两次模具写入,以获得最佳模板+clip()的性能。
2018年,引入了TBB,让引擎为现代多核CPU做好准备,第一个问题是选择一个好的作业系统。如何选择一个好的作业系统?WoT工程团队标准:易于使用,两种类型的并行:功能/任务和数据,功能丰富且强大,很好的支持。线程构建模块(TBB)是并行算法和数据结构、线程和同步,可扩展内存分配和任务调度,是一种仅限于库的解决方案,不依赖于特殊的编译器支持,支持C++、Windows、Linux、OS X、Android和其它操作系统。
WoT 1.0多线程渲染架构如下:
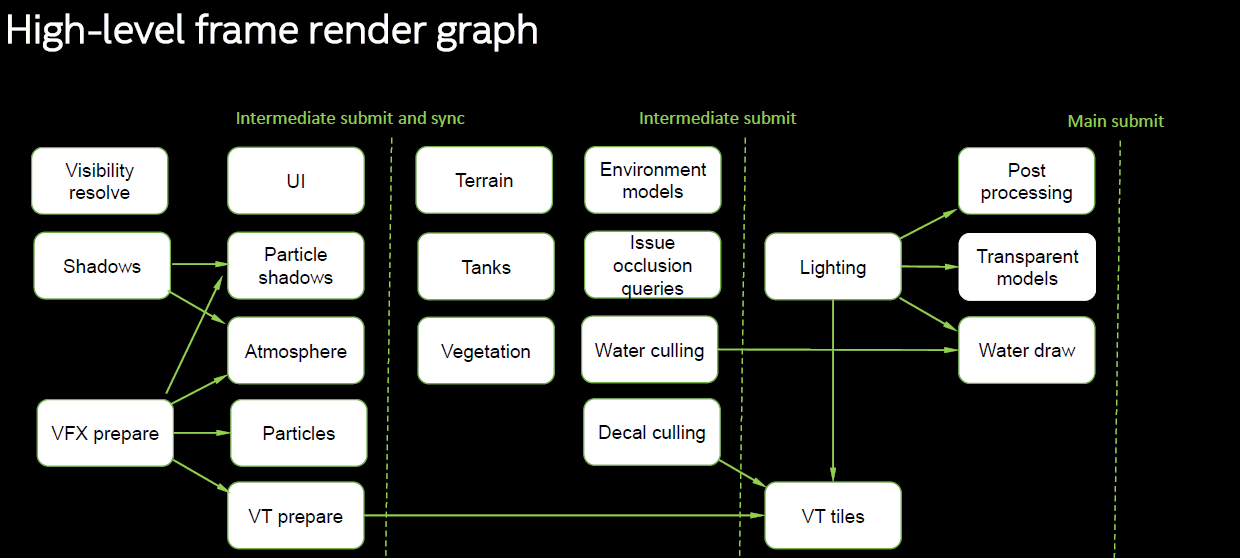

到了2018年,WoT使用了SIMD(AVX2、ISPC)等技术进一步加速并行,并且使用TBB来加速Havok的破坏系统。

到了2019年,WoT使用光线追踪来改进阴影的质量。

RT阴影的实现细节:
-
CPU端:两级加速结构。
- BLAS BVH。适用于所有坦克网格,在网格加载期间构建一次,并上传至GPU,网格中的硬蒙皮部分拆分为多个静态BVH,跳过软蒙皮部分。
- TLAS BVH。多线程,使用英特尔Embree和英特尔TBB,重建每一帧并上传到GPU。
-
GPU端:像素着色器或计算着色器。
- 基于均匀锥分布的时间射线抖动。
- BVH遍历和射线三角形交点。
- 时间积累。
- 降噪器(基于SVGF)。
- 时间抗锯齿。
![]()

CPU BVH性能:CPU帧时间占2.5%,TBB线程,SSE 4.2(比原始WoT内部BVH builder快5.5倍),每帧更新多达5mb的GPU数据,高达72mb的静态GPU数据。相关优化:RT阴影只能由坦克投射,不支持alpha测试的几何体,BLAS的LOD,每像素1射线,如果出现以下情况便停止追踪光线像素:NdotL<=0、如果像素已被阴影贴图遮挡、距离摄像机超过300米。
Software-based Variable Rate Shading in Call of Duty: Modern Warfare涵盖了《使命召唤:现代战争》(2020)中使用的一种新型渲染管线。它可以实现高度可定制的基于软件的可变速率着色;以与图像频率匹配的分辨率渲染部分渲染目标的方法。与仅限于可用设备子集的基于硬件的解决方案不同,其基于软件的实现使得在广泛的消费类硬件上实现更高的质量和性能成为可能。文中介绍了设计过程、最终实现,以及对管线每个阶段的深入检查,包括预过程渲染、可变速率估计器、用于计算着色器内核的新颖且独特的像素打包方案,以及forward+渲染器中的最终帧渲染,还讨论了其它渲染器类型和作业类型中的潜在实现及前瞻性扩展,以更好地满足质量和性能范围内的许多不同用例。

2020年的不少硬件已经支持硬件可变速率着色(Variable Rate Shading,VRS),支持硬件中的可变速率着色,如DX12 Ultimate[DX19] [DX20],包含AMD-RDNA2 GPU、英特尔-11代APU、英伟达-图灵GPU等。

在不同的Tier支持不同的特性:
- Tier 1:设置每次绘制的着色速率。
- Tier 2:设置每个屏幕tile的着色率(和其它频率),最小为8x8像素的tile大小。
可以选择适合图像频率的着色速率[LEI19]。

由此催生了多分辨率渲染管线 [DRO17]:
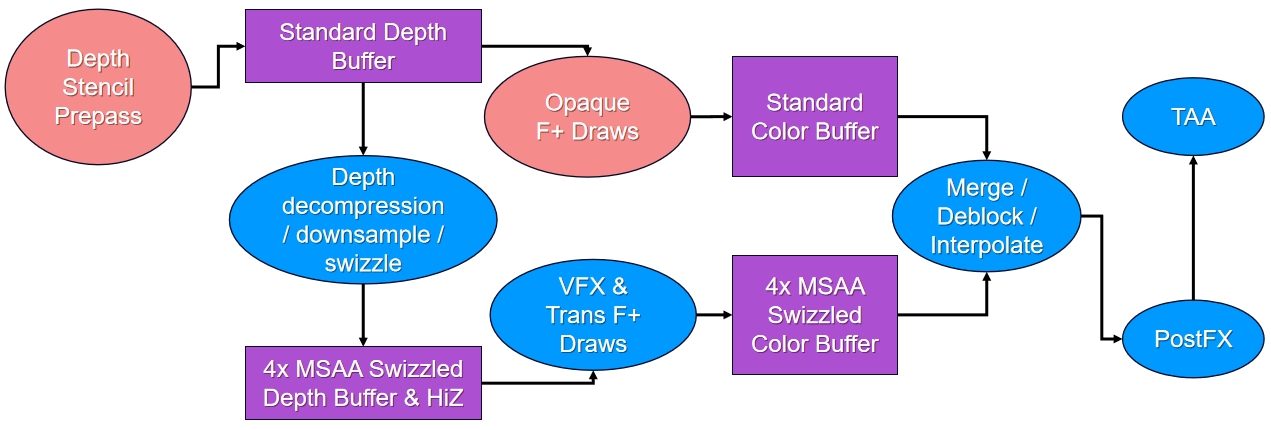
在标记为低分辨率的材质上进行3x–3.8x性能伸缩,方差取决于渲染目标微分块的命中量、屏幕上全分辨率和低分辨率粒子之间的重叠。0.3ms–0.4ms的组合:向上采样/解析/重建过程,方差来自需要所有子样本的微分块的数量。可能因GPU MSAA效率而异,对某些高三角形透明图形上的quad占用的担忧。
COD团队以4xMSAA(½分辨率以匹配原始分辨率目标)渲染prepass,在4xMSAA中渲染不透明,每次绘图允许1s、2s、4s模式,发现对prepass渲染的巨大加速,与DX12 VRS Tier 1.0相匹配的灵活性。然而本次的实验结果是失败的:未达到IQ目标(性能模式下),未达到性能目标(最坏情况下无变化)。

原因是有132k幸存的三角形,886k幸存的像素,*均每个三角形有6.7个像素。
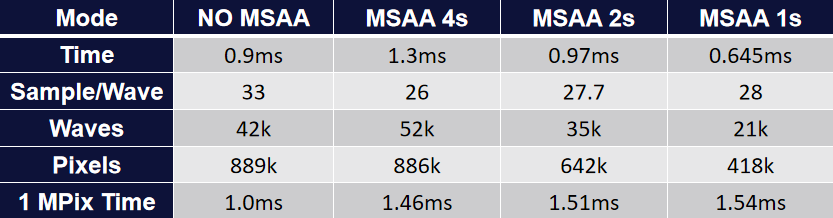
令人耳目一新的概念:光栅化和quad占用、MSAA与quad占用的交互、MSAA与内存的交互(交错渲染)、与MSAA和quad占用的模板交互。
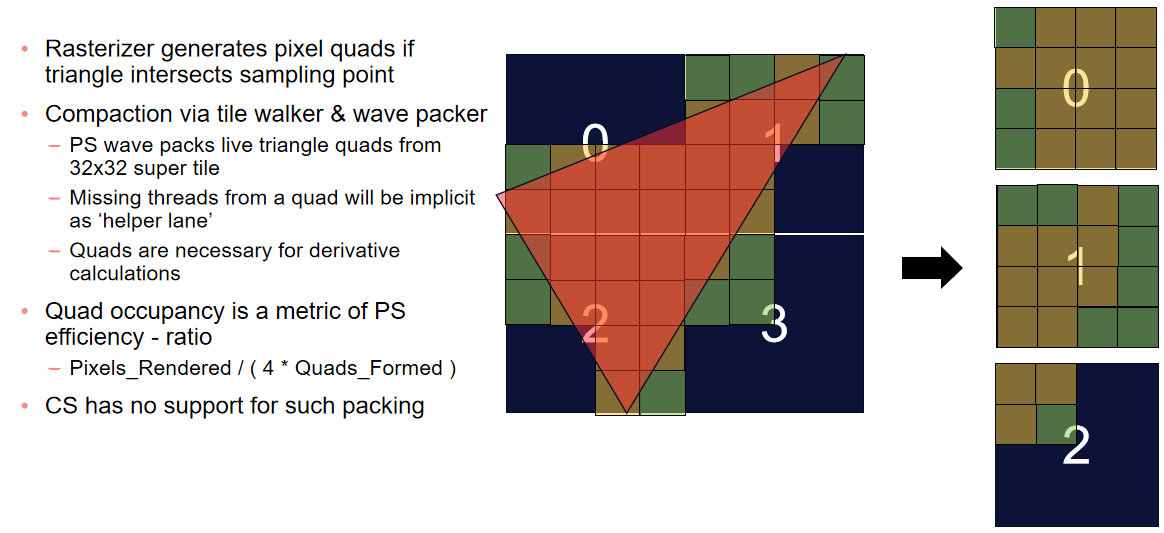
光栅化和quad占用的关系。
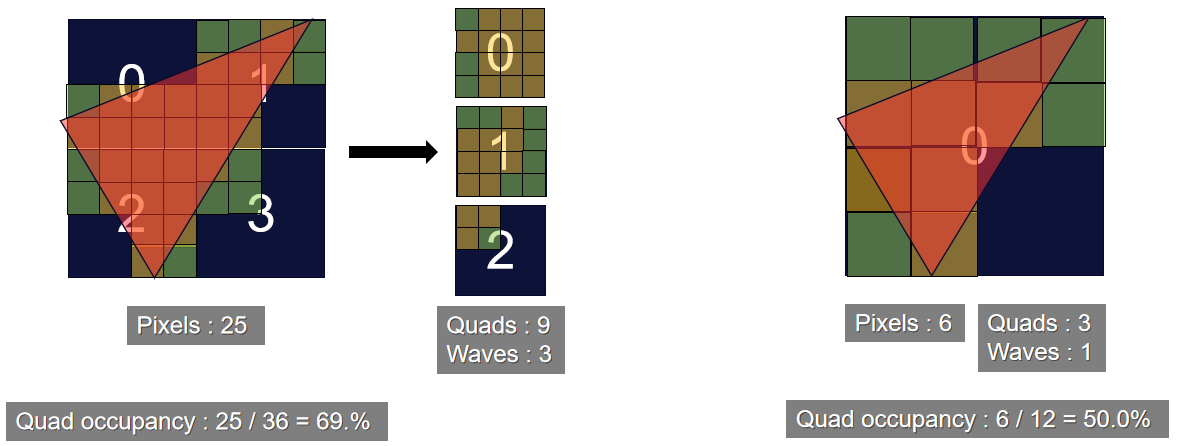
quad占用和分辨率的关系。
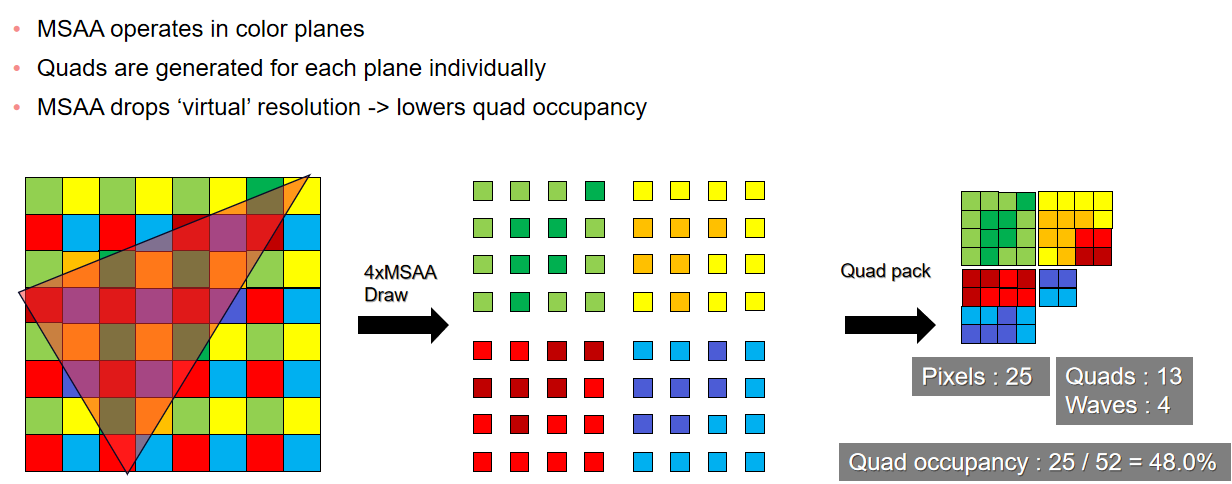
quad占用和MSAA的关系。

quad占用和MSAA、模板的关系。
MSAA重组和交错渲染的关系。
COD团队的计划是把所有东西都设成白色,使用模板进行VRS遮蔽。早期研究表明,在最坏的情况下,负面的性能损失可以最小化,如聚合采样率、交错渲染、利用VRS遮蔽优化的CS/PostFX作业。与硬件VRS相比,软件VRS的主要优势是可在所有*台上使用,由于tile较小,因此可能具有更高的性能,由于较小的tile和隐含的重建方法,图像质量可能更高。软件VRS的管线如下:
常规设置:帧渲染时对绘制和CS作业考虑了4xMSA重组/反交错,VRS以像素quad粒度(2x2)运行,与在MSAA的tile大小(16x16)上工作的硬件实现不同。Swizzle图案是带旋转的方形,从VRS着色速率贴图手动创建模板遮罩。

VRS图像遮罩:逐quad粒度,仅基于非图像数据的2位掩码,用于图像着色速率估计和VRS渲染遮罩的生成。4种模式:单一样本、Delta H、Delta V、所有样本,在所有样本模式下都保留激发像素。

梯度检测:
// Image Base Gradient Codes
#define VRS_IB_0 ( 0x0 ) // No grad
#define VRS_IB_DH ( 0x1 ) // Dir Hor
#define VRS_IB_DV ( 0x2 ) // Dir Ver
#define VRS_IB_ALL ( 0x3 ) // All dirs
#define VRS_IB_MASK( VRS_IB_ALL )
// Local Weber-Fechner JND k calculation
float tileLuma = min3( colorM, colorNW,
min3(colorSW, colorSE,
min3(colorNE, colorW,
min3( colorE, colorN, colorS ) ) ) );
float visiblityThreshold = vrsQualityThreshold * max(tileLuma, deviceBlack);
// Horizontal
float dh = max( abs( colorW - colorM ), abs( colorE - colorM ) );
float ddh= max( abs( colorNW - colorNE ), abs( colorSW - colorSE ) );
dh = max( dh, ddh );
// Repeat for Vertical
// VH direction and delta
result.vrsRate = VRS_IB_0;
result.vrsRate |= dh < visiblityThreshold ? 0 : VRS_IB_DH;
result.vrsRate |= dv < visiblityThreshold ? 0 : VRS_IB_DV;
// Merge quads – promoting through individual directions to all directions
result.vrsRate |= ddx( result.vrsRate );
result.vrsRate |= ddy( result.vrsRate );
梯度历史滚动(FIFO队列):保留4个重投影的帧。
// VRS history roll during gradient detection at quad resolution
// Reprojection happens in main VRS tile shader.
if(((dispatchThreadID.x | dispatchThreadID.y) & 0x1) == 0)
{
uint vrsHistoryRate = vrsRateRWTex[dispatchThreadID >> 1];
vrsRateRWTex[dispatchThreadID >> 1] = (freshResults.vrsRate & 0x3) | ((vrsHistoryRate<<2) & 0xFC);
}
VRS渲染遮罩生成:
-
CS作业消费者:速度缓冲器,4帧VRS图像遮罩历史,带重投影和不一致拒绝[JIM17],来自prepass的FMask–生成VRS几何遮罩。
-
CS作业生产者:
- 重新投影4帧VRS图像遮罩历史,8位–4 x 2位图像遮罩一次性重投影,稍后在梯度检测过程中旋转。
- VRS渲染遮罩(逐quad),在最后4帧中,8位重新排序的FMask或2位图像掩码,如果VRS图像掩码3个样本且FMask3,则首选FMask,优化重几何体的不连续渲染,如alpha测试的草,FMask是按样本顺序重新排序的,以避免在采样时进行间接排序,仅用于解块(de-blocking)和重建。
- 4XMSA模板更新到点画渲染模式。源于VRS渲染模板,直接写入重叠的texture2D的模板目标。
- VRS波前缓冲区(每像素)。
此外,软件VRS的绘制过程涉及了prepass、Forward+等过程,而后续的图像重建涉及解块、解析等过程,文中还对CS作业进行了优化,包含*面迭代、wave压缩、太阳可见性作业。经过这些复杂的操作之后,在森林如此复杂的情况下,可以获得超过1ms的提升:

而在室内这种辐照度稍低的场景,收益更明显:

挑选软件VRS管线的部分:

For the Alliance! World of Warcraft and Intel Discuss an Optimized Azeroth分享了2020年的魔兽世界的渲染优化。
WOW对Direct X 12(和Metal)所做的工作包含多线程命令列表生成、异步管线创建、异步纹理上传,帧率从50提升到了80。此外还使用了硬件的VRS,减少像素着色器工作的硬件功能,其工作原理是对像素组而不是每像素进行像素着色器调用,可以认为是MSAA的扩展,类似于着色速率下的LOD。控制VRS的方法有:按绘制调用、通过屏幕空间遮罩、从顶点/几何体着色器。

屏幕空间的大三角形是VRS的最大受益者:

VRS的过渡可能相当不明显,2x1利用假定的16:9屏幕比例,实现更*滑的过渡:

使用VRS的最佳位置:查找重像素着色器和较低,视觉质量可能在感知上不明显,如地形、运动模糊、DOF、远处的物体等。VRS的优点是保留边缘/轮廓,与基于边缘的AA(如CMAA)配合良好,控制哪些系统应用了VRS,尤其适用于基于深度的文本效果,不需要放大通道。渲染比例优点是可以降低顶点和带宽成本,*滑的强度范围,如1920到3840之间的所有值。VRS的限制是如果相对屏幕空间的三角形密度较高,则效益最小,在粒子系统上使用VRS可能看起来有点笨重。
Elwynn Forrest场景的性能,1x1时为61FPS,2x2时是68FPS,4x4时是76FPS,在*衡视觉质量时,通常有5%到10%的提升。总之,按绘制调用的VRS非常容易集成(在DX12引擎中),可以无缝地动态打开,可以降低像素着色器的成本,同时将质量降低到最低。
随着新的强大GPU IP的发布,Imagination Technologies一直在与Roblox密切合作,研究低水*的性能改进,为玩家提供最佳的游戏体验。Rendering Roblox Vulkan Optimisations on PowerVR探索了Roblox游戏内的体素照明系统、EVSM阴影贴图实现、着色器优化,以及为PowerVR优化的Roblox渲染器的其它最新功能,还将阐述在移动设备上进行分析和优化的过程,并研究如何使用异步计算来提高PowerVR的性能。
Roblox的光照系统的目标是不要烘焙,每个物体都可以在任何时间点移动,不能完全禁用照明——对视觉和游戏性的影响很大,想要从内容中获得最小的“性能”影响,想要在低端笔记本电脑/手机上运行(D3D9/GL2/GLES2类),想要在高端笔记本电脑/手机上获得好看的照明效果。
照明系统的高级概述,已有的特征包含光源(太阳/月亮、天空、局部灯光),几何体和光源是动态的,所有光源都可以投射阴影,粗糙体素照明无处不在,产生高效柔和的照明,阴影贴图支持从中端到高端和高质量的太阳阴影。将来会引入前向+:高端、高品质的局部光源,更好的体素照明:更好的天空光。
照明系统的相位0是体素:大部分工作都是在CPU上完成的,体素化动态几何,计算每个体素的灯光影响,如阳光、天空光、累积局部光RGB,将信息上传到GPU(RGB:灯光 + 天空光 x 天空颜色,A:阳光),片元着色器中最终照明。管理CPU性能:体素网格被分割成块,只有少数块会每帧更新,固定质量,但更新可能“过时”,更新内核使用手工优化的SSE2/NEON。管理GPU性能:使用双线性过滤的单个3D纹理查找,GLES2使用2个2D纹理图谱查找模拟3D纹理查找,完全解耦的几何体与光源复杂度。
照明系统的相位1是更好的体素:保持系统的整体设计,HDR光源颜色使用RGBM编码以节省空间,单独存放天空光,更好地将sky集成到BRDF中,各向异性占用率,体素化器为每个体素保留3个轴向值,对内容兼容性至关重要,结果更接*阴影贴图/前向+。GLSL的优化如下:
// 分组标量算法
vec_1 = (float_1 * vec_2) * float_2; --> vec_1 = (float_1 * float_2) * vec_2;
// inversesqrt比sqrt开销更低
vec_1 = sqrt(vec_2); --> vec_1 = vec_2 * inversesqrt(vec_2);
// abs() neg() and clamp(…, 0.0, 1.0)可以免费
float_0 = max(float_1, 0.0); --> float_0 = clamp(float_1, 0.0, 1.0);
vec_0 = vec_1 *vec_2 +vec_3; --> vec_0 = clamp(vec_1 *vec_2 +vec_3, 0.0, 1.0);
使用的寄存器太多,导致单个cluster中处理的线程更少,导致利用率降低。允许PowerVR使用16位浮点,降低寄存器压力,增加占用率(高达100%)。对于PBR着色器,A系列的周期数减少9%,Rogue(Oppo Reno)的周期数减少12%,利用率提高33%。对于PBR+IBL着色器,A系列的周期数减少9%,Rogue(Oppo Reno)的周期数减少20%,利用率提高36%,使用PVRShaderEditorto分析周期数和汇编。
在PowerVR上分析Roblox。
照明系统的第2阶段是阴影图:体素阴影太粗糙,阴影图来救援!优良的品质,挑战是“柔和”阴影、重新渲染成本高、许多阴影投射光源,仅释放太阳阴影以简化。渲染阴影图:级联分块影贴图,1-4个级联,取决于质量水*,远级联被分割成块,以便能够阻止阴影更新;使用了CSM滚动,是级联阴影贴图渲染的加速技术;当需要更新级联时,只需在一个通道完成,如果多个tile被标记为脏,将在这些tile中重新渲染几何体,CPU进行逐块的视锥体剔除。灯光方向更改会使缓存无效,还没有找到解决这个问题的好办法。阴影柔和度:想要大范围的阴影贴图“柔和”,宽PCF内核在高分辨率下成本昂贵,由于透明的几何结构和*铺机性能,屏幕空间过滤不切实际,Roblox使用EVSM,将阴影渲染与采样完全解耦,但存在漏光…缩小Z范围!将阴影*截头体紧密贴合到接收几何体,渲染投射者几何体时的“*移(Pancaking)”(VkPipelineRasterizationStateCreateInfo::depthClampEnable),采样EVSM时过度变暗,接着使用标准的两通道模糊(水*和垂直)来模糊阴影图。移动高斯模糊进行计算?
可分离核高斯模糊使用两个1D过程执行2D高斯模糊,数学等效(秩1矩阵),2n的纹理获取,而不是\(n^2\)的纹理获取。
计算高斯模糊收集算法:PowerVR上的最佳工作组大小为32,处理8x8区域的8x4工作组大小,多次尝试循环着色器(此处为每线程2个纹素):
将包括周围区域在内的深度值读取到共享内存中,减少纹理获取的次数。
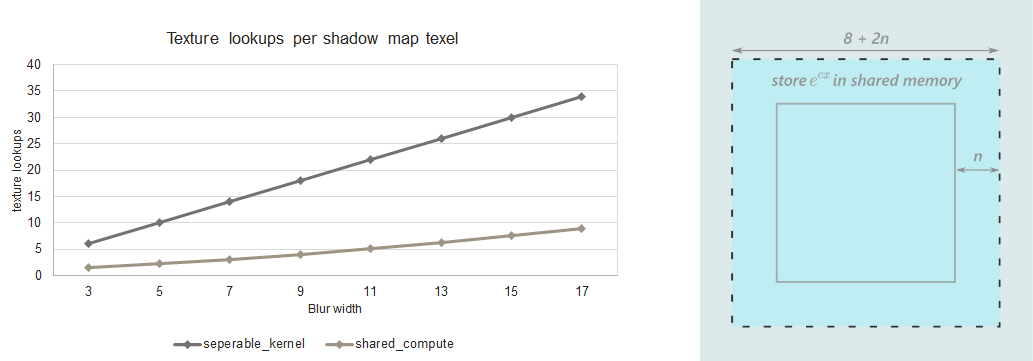
Morton顺序:使用VK_IMAGE_TILING_OPTIMAL创建的图像使用Morton排序进行寻址优化,通过加载对齐的texel区域(512位缓存行)提高缓存效率。
任务打包:在每个帧的两个队列之间交替提交命令,允许独立于帧的调度并增加任务打包!可能需要在两组资源之间交替使用。更多开发者推荐Imagination Tech Doc。

使用计算的改进:5x5模糊的帧速率提高40%!(MeizuPro 7 Plus PowerVR 7XTP)
idTech 7: Rendering the Hellscape of Doom Eternal分享了idTech 7的渲染技术。idTech 7完全使用前向渲染,uber着色器仍然很少,更大的关卡和更复杂的环境,更多流加载,所有*台上的低级API,在相同分辨率的控制台上仍保持60 fps。
在Doom中使用了混合装箱(Hybrid Binning)[Olson12],面临的挑战是Doom中更大的场景,远处的小光源和贴花最终形成一个大簇,敌人有轻型装备,在战斗中,弹丸和冲击贴纸的动态体积更大,艺术家们想要放置更多的灯光和贴花,想要转移到GPU剔除以减少CPU负载,分簇与分块的新混合。
混合装箱(Hybrid Binning)的灵感来源于“改进的拼贴和集群渲染挑选”[Drobot2017],问题是某些场景中有数千个灯光或贴花,由于状态更改,硬件光栅tile装箱效率低下,预算非常紧张(<500us)。
计算着色器光栅化:为了简单起见,只装箱六面体,低分辨率,需要保守光栅化,许多边缘案例,艺术家们会找到它们,反向浮点深度以实现精度。Binned光栅化[Abrash2009]:设置和剔除、粗糙光栅、精细光栅,将位域解析为列表,这些过程都涉及很多细节,由于已经有不少章节阐述过此技术,故此处略过。
几何体细节:艺术家想要几何定义的小贴花,创作网格的一部分。挑战是几乎没有额外的帧预算,前向渲染器:无法在G缓冲区上混合,G缓冲混合太慢,即使切换到延迟。

来自网格UV的投影矩阵,世界空间->纹理空间,每个投影使用2x4的矩阵(8个浮点数=32字节),在磁盘上存储对象->纹理的空间,与模型矩阵相乘得到世界->纹理空间矩阵,每个实例的几何贴花都需要内存。将索引渲染到R8缓冲区:后深度通道,大于等于的深度比较,深度偏移以避免z-fighting,贴花需要共面,此通道要耗费50us。片元着色器中每个子网格投影列表的遍历:绑定到实例描述符集的列表,任意混合,因为没有G缓冲区传递。

限制:每个子网格最多254个投影,一个贴花可能需要多个投影,不能很好地做曲线几何,每个实例需要投影存储,目前每个关卡最多1000个贴花,装箱贴花始终位于顶部,每帧计算的动画几何体投影。
几何缓存:基于[Gneiting2014],从Alembic缓存编译,改进的压缩,预测帧,分层B帧,前向和后向运动预测,用于比特流压缩的Oodle Kraken,如果缓存相同,实例可以共享流数据块,可带动画的颜色和UV。
自动蒙皮:位置流的大数据速率降低[Kavan2010],骨骼矩阵像其它流一样被量化和压缩,仅适用于某些网格,仍然支持顶点动画。
3字节切线坐标系:为每个帧计算切线坐标系并流式传输,储存两个用于法线和切线的向量非常昂贵。想法:仅存储切线的法线+旋转,用叉积重构副切线,2字节用于八面体标准编码(对于顶点法线已足够好),1字节用于旋转。解码:需要确定的正交向量来旋转切线,法线与向量(如\((1,0,0)^T\))的粗糙叉积会导致奇点,而罗德里格斯的旋转公式[Euler1770]可计算出切线:
因为向量是正交的,所以上一项被抵消。
此外,idTech 7还支持材质混合、GPU三角形剔除、GPU几何合并。其中几何合并的实现细节如下:
- 所有资源都是全局可索引的。在单个全局池中分配的所有顶点缓冲区,与几何流一致,所有纹理和缓冲区描述符的全局数组。
- 在几何体集中使用相同的PSO将最多256个可见网格分组。
- 剔除着色器为每个几何体集生成自定义间接索引缓冲区。在每个32位索引中打包顶点ID和实例ID,每个几何体集一次绘制调用,在一次紧凑的绘制调用中渲染256个网格。
- VS:使用实例ID+几何图形集ID检索实例数据。几何图形集ID作为内联常量发送,实例ID从索引值中提取,顶点缓冲区获取、实例描述符集等的偏移量。
- 着色器编译器生成“可合并的”着色器变体。不同纹理/缓冲区获取的序列化,实例数据的附加间接寻址,SSBO获取顶点数据,而不是顶点属性。
- 异步计算上的计算剔除/合并与阴影渲染并行。

从左到右:场景样例、网格、几何体集。
结果:通过三角形剔除+合并,在密集场景中节省高达5毫秒的GPU,在VS中几乎没有浪费,基本上摆脱了固定的功能瓶颈。类似的CPU节省:对深度和不透明通道重复使用相同的间接索引缓冲区,在CPU可见性通道期间完成的设置,已经令人尴尬地并行。对于已经在执行标量优化的代码非常有用,在排列数较低的情况下效果最好,无论如何,都尽可能地降低着色器计数。理论上的权衡:实例数据获取现在是不同的,通常发生在VS内部,最终难以察觉。
文中还涉及水体渲染、半透明表面等技术。

随着硬件的最新发展,在GPU上追踪光线的功能比以往任何时候都更容易实现,游戏引擎已经利用了这一点,将光线追踪效果(如反射、软阴影、环境遮挡或全局照明)集成到实时管线中,在可能的情况下替换屏幕空间中更*似的光线追踪效果。大多数(如果不是所有的话)效应都依赖于二维蒙特卡罗积分。沿着这条路,我们可以想象冒险进入更高的维度,添加更多间接反弹,或更多分布式效果(自由度、运动模糊),更接*完整的路径追踪。需要调整采样方案,以确保最佳利用通常有限的实时/交互式预算。From Ray to Path Tracing: Navigating through Dimensions便阐述了如何逼*上述的效果。
光线追踪从离线到实时的几个重要方面:
- 明智地选择光线。采用蒙地卡罗积分法、方差、重要性采样、多重重要性采样。
- 仔细选择你的(非)随机数。域扭曲、准随机序列、低差异、分层。
- 把你的射线预算花在最有用的地方。自适应采样。
- 理解并防止错误。强度夹紧、路径正则化。
蒙特卡罗快速回顾:

准蒙特卡罗(QMC):确定性、低差异序列/集合(Halton、Hammersley、Larcher-Pillichshammer)比随机的收敛速度更好,例如Sobol或(0-2)序列不需要知道样本数量,奇妙的分层特性。
见下图,我们有一个大面积的光在倾斜,漫反射地面上。相机正前方是一片薄玻璃片,折射率为1(因此完全透射)。这将是一个相当常见的场景的调试版本,其中场景的大部分(如果不是全部的话)都在一个窗口后面。
因为我们对光线有一个固定的分裂因子,索引也很容易跟踪:对于每个光采样计算,我们使用样本i到i+3。诚然,如果每个照明位置都与对应位置非常不同,就像康奈尔盒子的情况一样,它不会有太大的区别(但考虑到属性或我们的顺序,至少会同样好)。然而,如果位置更相似(或者甚至与我们当前场景中的位置完全相同)。。。
在地面上使用64个相机直接可见的光源样本。
下图是一个稍微不同的场景,使我们的采样预算更容易测试。场景中的薄玻璃片更粗糙,为了更好地欣赏这种粗糙的效果,对地面进行纹理处理。
若使用之前一样的采样方式,由粗糙玻璃产生的BSDF射线的相干度当然不如以前,由此获得了下图那样更加毛躁的图像:

我们遇到了一个像素之间相关性很差的情况,4D序列中的一些维度在一个像素内的相关性很差。为此,我们想查看4D点的不同2D投影,遵循Jarosz等人(在正交阵列论文中使用的可视化约定:可以在轴上看到对应于每个维度的索引,在数组的每个单元格中,将显示相应的2D切片,是尺寸(0,1)和(2,3)的2D切片,是在采样例程中使用的切片,它们其实是一样的。
现在让我们看看下图的“诊断”切片,(0,3)和(1,2)也是相同的。剩下的(0,2)和(1,3)相当于(0,0)和(1,1)。。。
实际上,需要使用高纬度的Sobol序列。有许多可能的Sobol序列,[Grünschloß]和[Joe 2008]的Sobol序列优化了低维2D投影的分层特性,用于低样本数量:
虽然样本数量少,但任何维度配对都会产生非常好的结果!在我们之前的各种填充尝试中,我们注意到的问题已经消失了。
如果我们在维度上上升,我们确实可以找到质量明显最差的2D切片(==>确保对被积函数的最重要部分使用最低维度):
额外的改进包括将Owen指令应用于所有维度,如前所述,它有助于打破序列特征的对齐模式,并提高收敛速度。由于这不是一个快速的过程(特别是对于实时),它可以预计算并存储大量样本==>这是HDRP中的操作,256D中有256个点。
锦上添花:屏幕空间中的蓝色噪点:
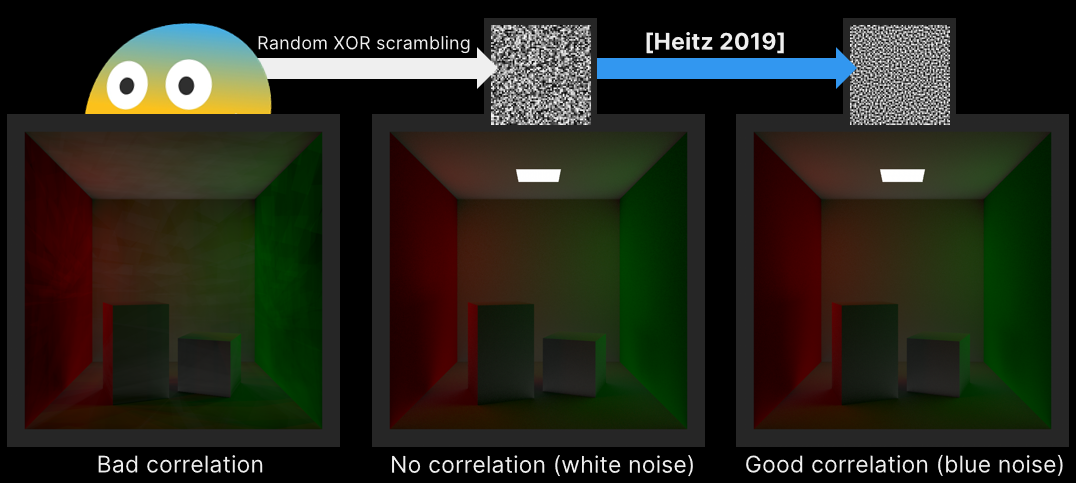
白噪点和蓝噪点的对比:

最终维度:当进入高维时,同时考虑所有维度,避免考虑递归的低维积分(即使这样开始更自然)。实时(预计算)选择序列:一种低差异采样器,将蒙特卡罗方差作为蓝色噪声分布在屏幕空间[Heitz 2019],渐进式多抖动样本序列[Christensen 2018]。*期在高维集合方面值得注意的工作:蒙特卡罗渲染的正交数组采样[Jarosz 2019]。实时路径跟追踪的未来?实时重构光照传输[Wyman 2020]。
Real-Time Samurai Cinema: Lighting, Atmosphere, and Tonemapping in Ghost of Tsushima阐述了游戏Ghost of Tsushima中所使用的光照、天空大气、色调映射等渲染技术。

光照:艺术方向呼唤“程式化现实主义”,光照模型是基于物理的,用物理上合理的值编写的材质,一些摄影测量,从动态天空和局部光照传输数据计算运行时的间接照明,基于物理的天空模型,用于天空、云、薄雾和雾粒子,使用自定义技术以HDR和色调图渲染,照明可能会偏离物理正确性,艺术家可以在全局范围内进行调整,以获得理想的外观。间接照明包含漫反射和镜面反射,大气体积照明包含天空与云彩、薄雾、粒子等,色调映射包含局部色调映射算子、自定义色调映射颜色空间和白*衡、Purkinje shift(微光视觉模拟)。
间接光的漫反射:Tsushima的大小、动态时间和天气需要一种新的方法:二次SH探针的规则网格,每个200m方形tile使用16x16x3,总共20x80个tile。四面体网格用于更复杂的情况,如城镇、村庄、农庄、城堡等。通过位置流入,覆盖常规网格,在交界处混合。

运行时重新照明:需要在运行时更新辐照度探针,离线阶段捕获天空可见度,编码为2度SH(单通道),不捕获辐照度。在运行时将天空投射到SH,将天空SH乘以天空可见度,与兰伯特余弦瓣卷积。
反弹的天空光:是可行的,但只提供直接的天空照明,无反射光。完全转移矩阵?内存太多(9倍),捕获时间太长。假设整个半球的天光是大致恒定的,用统一的白色天空照亮世界,捕捉“反弹天空可见度”。乘以*均天空颜色(从第0阶的SH开始)。

添加太阳/月亮反弹:在假想的地面和墙壁上反射光线,投影\(-\hat{r}_g\)和\(-\hat{r}_w\)到SH;窗口化以避免负波瓣,按RGB灯光强度缩放(由动态云阴影调制),乘以反弹的天空SH,并将其添加到之前的结果中。
方向性增强:2级SH的频率相对较低,间接照明在很多地方看起来都很*淡,沿线性SH最大值方向向三角形的Lerp,计算便宜,直接部分和反弹部分分别计算,在所有天气状态下有着25%的增强。
去振铃(deringing):不能保证最终辐照度在任何地方都是正的,对天空能见度应用固定的去振铃会降低方向性和保真度,相反,在运行时计算天空亮度和最终辐照度,一个牛顿迭代找到最小值,使用在CPU上计算的深度为3的二叉搜索树。
去振铃关闭(左)和开启(右)对比:

漏光解决方案:将四面体网格探针分为内部探针和外部探针,为表面指定一个0-1的内部遮罩\(w_{interior}\),几何体属性或着色器参数,顶点绘制,延迟贴花。按正常情况计算重心,然后乘以重量:\(w_{interior}\)用于内部探头内部,\(1-w_{interior}\)用于外部探头。重新规范化重心(如果全部为0,则使用原始重心)。

间接光的镜面反射:Seattle in Infamous使用了230个静态反射探头,已经在突破内存限制了。而Tsushima使用了235个,重新照明所需的额外数据,随需应变,每生物群落默认探针,实例化内部探针,增加了对嵌套探针的支持,一次最多128个重照明探针。
离线捕获的数据:反照率立方体图(BC1格式),法线+深度立方体贴图(BC6H格式),RG:八面体法线编码,深度(双曲线),所有立方体贴图256x256x6。
反射探针新照明:在异步计算中执行循环(每帧一个),用远距阴影图集着色阴影,每tile的阴影图,每个tile有128x128个纹素。间接照明用单SH样本,也用作反射探针亮度的标准化,使用过滤的重要性采样(filtered importance sampling)进行预过滤,使用GPURealTimeBC6H压缩至BC6H,减少内存占用并提高采样性能。
立方体图阴影追踪:远阴影图不足以对内部进行阴影处理,低阴影分辨率和LOD的组合。观察:深度立方体贴图有很多遮挡信息,重新照亮每个立方体贴图纹理时:求*行光线的交点,使用立方体贴图体积,交叉点处的采样深度,天空深度⇒ 未遮挡,使用4x4 PCF。相当粗糙,但又便宜又有效。
水*遮挡:解释由于法线贴图法线\(\hat{n}_m\)相对于顶点法线\(\hat{n}_v\)的倾斜而导致反射锥上基础几何体的遮挡,快速、*似、合理的结果,对于GGX粗糙度,包含能量分数的锥半角如下所示:

天空大气光使用了预计算的3D LUT,对Mie辐照度应用阴影,对瑞利辐照度应用环境遮挡,Haze使用AO的*均天空可见度,云渲染为抛物面纹理(paraboloid texture),每帧将当前太阳和月亮角度的3D LUT重采样为2D,使用立方滤波进行上采样,以避免日出和日落时出现锯齿,使以后的查找更便宜。此外,还自定义了瑞利颜色空间:
云体渲染为768x768抛物面纹理,用云密度来抗锯齿,对Mie散射使用Henyey-Greenstein相位函数,实现了体积雾度(局部光、抗锯齿)。此外,还阐述了粒子光照。
色调映射方面,在Infamous的游戏中,努力维持物理上合理的漫反射反照率值,创建了漫反射颜色参考图:

切换到主要基于照度的曝光系统,仅当高光亮度超过阈值时才使用亮度。处理动态范围时,的室内照明比较暗,天空驱动了大部分照明。人类视觉系统能够感知非常大的动态范围,双边过滤器可用于保持图像细节,同时降低整体对比度。
色调映射对颜色空间也进行了处理。渲染颜色中的每通道色调映射,空间裁剪饱和颜色为青色、品红色和黄色只应用每通道的“Reinhard”操作符:

尝试了部分颜色空间:ACES2065-1 (AP0)、ACEScg (AP1)、Rec.2020、DCI-P3,ACEScg是其中最好的,但仍然让红色过于偏向黄色,调整后的红色主x坐标(0.713⇒ 0.75)。

效果对比:

此外,色调映射还处理了白*衡、Purkinje Shift等效果。

Experimenting with Concurrent Binary Trees for Large Scale Terrain Rendering分享了Unity中使用并发二叉树进行大规模地形渲染的新技术的结果,包含并发二叉树的基础和在计算大规模地形几何体的自适应细分方面的好处,深入探讨将原始技术集成到Unity游戏引擎中的最新努力。下图的绿色节点是二叉树表示的叶节点,对应于想要为细分方案显示的三角形:
这是一个和归约树,存储在并发二叉树的所有其它级别。它逐步将位字段中设置为一个(或叶节点)的位的数量相加,直到根节点,提供了由位字段编码的二叉树中叶节点的总数。然后,通过遍历这个和归约树,提供了一种在忽略零的情况下循环设置为1的位的方法,或者换句话说,在叶节点上循环。回到实际例子中,编码的二叉树代表最长的边二等分,使用它为细分中的每个活动三角形分配一个线程。
初始化曲面细分:选择最大细分深度,CBT编码完全可能的二叉树,直到一个设定的深度。如果改变,重新编码CBT,初始化CBT缓冲区,无符号整数数组,和归约树,位字段打包为uint。
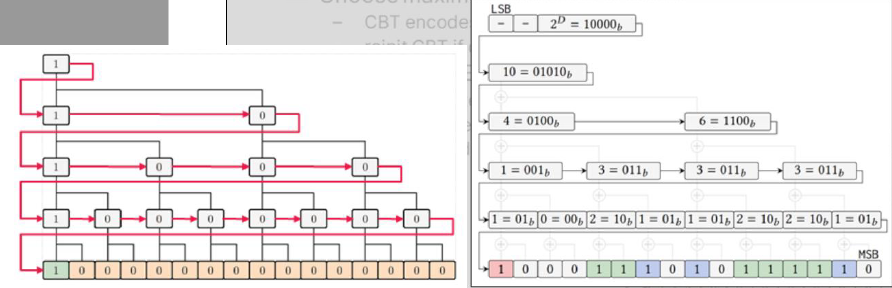
更新曲面细分:
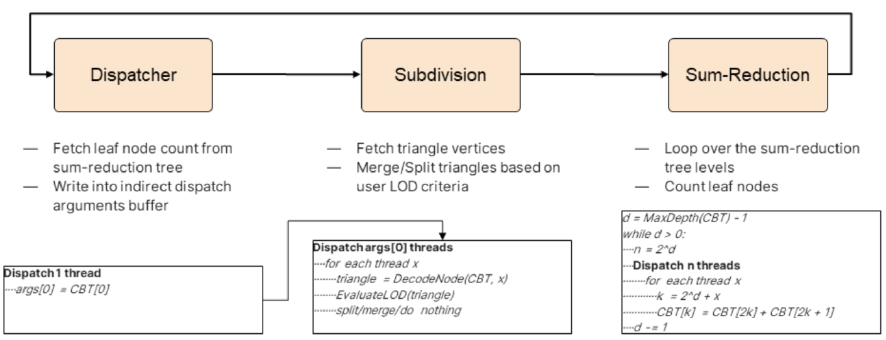
渲染曲面细分:
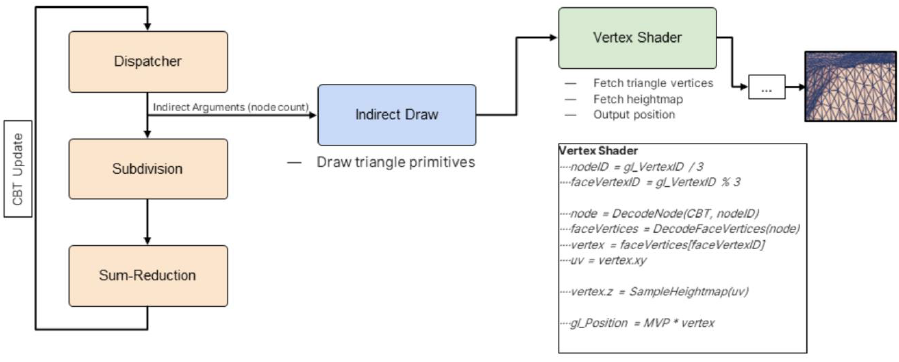
同步更新渲染:
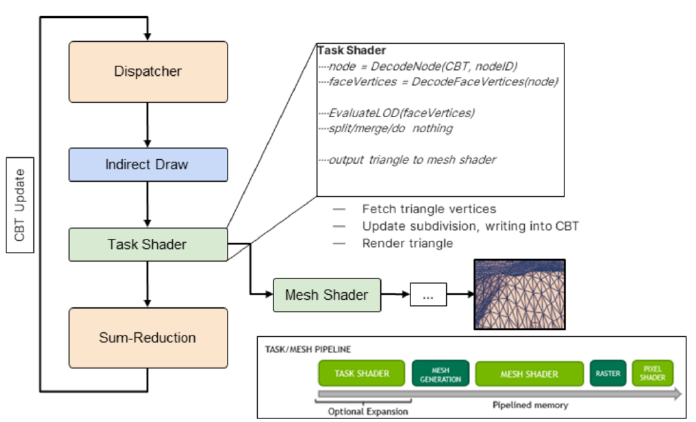
结论:CBT是一种具有低存储成本和良好性能的大规模地形几何绘制方法,高度可定制的LOD标准。
14.5.3.2 光影技术
Deferred Lighting in Uncharted 4分享了神秘海域4的延迟光照。
目标和动机是许多需要读取/修改材质数据的屏幕空间效果(粒子、贴花),以及更重要的SSR、立方体图、间接阴影等,无法避免保存材质数据。紧凑型GBuffer的在高密度几何物体下开销大,前向着色器中照明的复杂性增加了难以置信的寄存器压力,进一步拖累了几何通道的速度。
神秘海域4最终采用了完整的延迟(fully deferred)。GBuffer必须支持游戏中的所有材质,不过当时的硬件有很多内存和带宽。GBuffer是每像素16位无符号缓冲区,在生产过程中不断地在特性之间移动位,大量的视觉测试来确定各种特性需要多少位,大量使用GCN参数封装内部函数。

第三个可选GBuffer用于更复杂的材质,根据材质的类型对其进行不同的表达,使用可选GBuffer的材质包括布料、头发、皮肤和丝绸。GBuffer的表达是相互排斥的(即不能将布料和皮肤放在同一个像素中),此约束在材质编写管线中强制执行。如果材质不需要,则可选GBuffer既不写入也不读取。
问题是延迟着色器很快就会变得非常臃肿,因为必须支持皮肤、布料、植物、金属、头发等等,更不用说所有的光源类型。可以通过材质分类(classification)来改进:保存材质“ID”纹理,不是真正的材质ID,只是使用的着色器功能的位掩码,12位压缩为8位(通过考虑特征互斥性)。对于每个16x16的tile,使用整个tile的材质遮罩将其索引到查找表中,查找表是预计算的,拥有最简单的着色器,支持tile中的所有特性。
uint materialMask = DecompressMaterialMask(materialMaskBuffer.Load(int3(screenCoord, 0)));
uint orReducedMaskBits;
ReduceMaterialMask(materialMask, groupIndex, orReducedMaskBits);
short shaderIndex = shaderTable[orReducedMaskBits];
原子地将tile坐标加入到该着色器将计算光照的tile列表,原子整数也是dispatchIndirect参数缓冲区的dispatch数量。
if (groupIndex == 0)
{
uint tileIndex = AtomicIncrement(shaderGdsOffsets[permutationIndex]);
tileBuffers[shaderIndex][tileIndex] = groupId.x | (groupId.y << 16);
}
分类使得性能已经有了巨大的进步,以前也有文献曾使用过类似的技术。

还可以进一步优化。以布料着色器为例,对于所有像素都是布料的tile(即将布料材质掩码位设置为1),该分支所做的只是增加开销,因为它应该始终评估为真。创建另一个预计算表,当tile中的所有像素具有相同的材质遮罩时使用该表——“无分支”排列表。在分类过程中检查该情况,并使用适当的表,不仅删除了分支,还为全局编译器优化提供了机会。
// 之前
short shaderIndex = shaderTable[orReducedMaskBits];
// 之后
bool constantTileValue = IsTileConstantValue( … );
short shaderIndex = constantTileValue ? branchlessShaderTable[orReducedMaskBits] : shaderTable[orReducedMaskBits];

改进前(左)后(右)的对比。
在最坏情况下的性能改善昂贵的场景:4.0ms——无任何优化(“uber着色器”),3.4ms(-15%)——通过选择最佳着色器,2.7ms(-20%,整体-30%)——使用无分支着色器。*均而言,无分支着色器可以提供额外的10-20%的改进,而且成本很低,而选择最佳着色器*均可以提高20-30%。使得我们可以在不影响基本性能的情况下实现材质的复杂性和多样性,为一个着色器(例如丝绸着色器)添加复杂性不会影响游戏的其余部分。经过几次迭代之后接口实现依然干净透明,额外的好处是分类计算着色器在异步计算上运行——几乎不影响运行时。
还可以更进一步改进,根据光源类型分配不同的计算着色器,少数光源类型增加了大多数复杂性和成本。迭代很难,真正了解一位(bit)的价值,最终达到了一个良好的系统。越简单越好,可能会牺牲某些特性来获得轻微的性能提升。
接着聊镜面遮挡。立方体图不考虑局部遮挡,解决方案是有时在遮挡体内/周围添加更多立方体图,由于几何体的排列方式,不总是可行的,更不别说性能/内存成本了。在采样位置只能使用AO值,例如Frostbite的镜面遮挡,效果很好,但方向性呢?
为了获得更精确的遮挡,Uncharted 4将以某种方式用某种编码来遮挡镜面反射波瓣,该编码对采样点的遮挡方式和方向进行编码。

左:反射波瓣;右:最小遮挡圆锥——弯曲圆锥。
在离线处理过程中,用Bent Normals and Cones in Screen-Space中描述的方法生成弯曲圆锥,最小遮挡的方向定义为:

其中如果光线的长度小于一定距离,则\(d(\overrightarrow{v})\)为1,而角度:
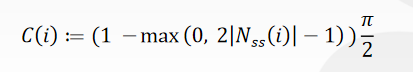
对于反射圆锥,使用一个类似Drobot的匹配Phong/GGX lobe的想法,找到适合90%波瓣能量的圆锥。对于GGX,发现了一个简单匹配:
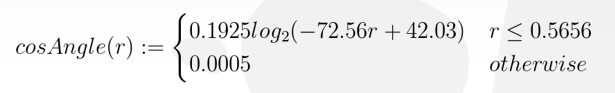
两个圆锥体相交,求出交点的立体角。
可以使用以下公式计算两个相交圆锥体的立体角,给定两个锥角\(\theta_1\)和\(\theta_2\)及它们之间的角\(\alpha\),交点的立体角在右边。
稍微改变变量,将\(\cos/ \sin \theta\)作为查找纹理的输入,将交点的立体角除以BRDF圆锥体的立体角\(\cfrac{1-\cos \theta_1}{2\pi}\),以获得遮挡的百分比。
float IntersectionSolidAngle(float cosTheta1, float cosTheta2, float cosAlpha)
{
float sinAlpha = sqrt(clamp(1.f - cosAlpha*cosAlpha, 0.0001f, 1.f));
float tanGamma1 = (cosTheta2 - cosAlpha*cosTheta1) / (sinAlpha*cosTheta1);
float tanGamma2 = (cosTheta1 - cosAlpha*cosTheta2) / (sinAlpha*cosTheta2);
float sinGamma1 = tanGamma1 / sqrt(1 + tanGamma1*tanGamma1);
float sinGamma2 = tanGamma2 / sqrt(1 + tanGamma2*tanGamma2);
// Now we compute the solid angle of the first cone (This is divided by 2*kPi. That factor is taken into account in the texture)
float solidAngle1 = 1 - cosTheta1;
return (SegmentSolidAngleLookup(cosTheta1, sinGamma1) + SegmentSolidAngleLookup(cosTheta2, sinGamma2)) / solidAngle1;
}

当样本被严重遮挡时,返回到方向光照图的描述,保留能量,但反射细节丢失,大多数时候看起来都不错!这种方法相对昂贵,如果一个参数是固定的,函数就会简化。也许可以确定粗糙度参数,然后根据粗糙度调整最终结果。由于性能原因,它在某些级别上被禁用。不适用于动态对象(例如角色),可以使用前面提到的更简单的遮挡方法。不是基于物理的,但它解决了很多遮挡问题。可以向前推进,使用其它表示法进行更精确的遮挡,走向完全不同的方向。
Rendering Antialiased Shadows with Moment Shadow Mapping阐述了利用MSM(矩阴影图)来实现阴影抗锯齿的技术。
阴影图是实时渲染的基础技术,但由于分辨率有限,会带来严重的锯齿。以往的解决方案有PCF(百分比渐进过滤)、VSM(方差阴影图)等。PCF对每个像素执行样本过滤区域、阈值、过滤,消耗大。
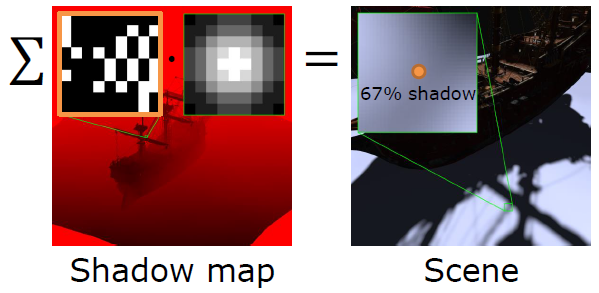
对于深度分布,阴影是深度的函数,一步一个纹素,通常是单调的函数。
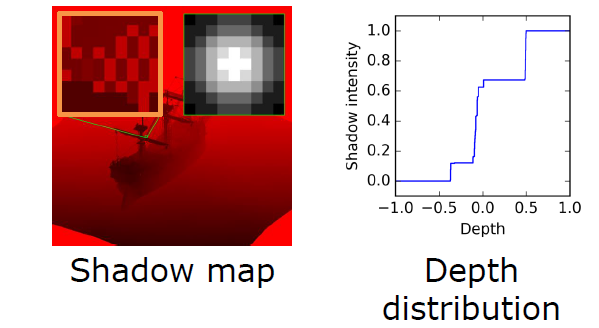
VSM存储\(z\)和\(z^2\),存在冗余数据,直到过滤,有2个矩,用下边界重建。

此外,还有存储傅里叶系数的CSM(Convolution shadow map,卷积阴影图),存储\(\exp(𝑐\cdot 𝑧)\)的ESM(Exponential shadow map,指数阴影图),存储\(\exp(𝑐_+ \cdot 𝑧),\ \exp(𝑐_+ \cdot 𝑧)^2,\ \exp(−𝑐_− \cdot 𝑧),\ \exp(−𝑐_− \cdot 𝑧)^2\)的EVSM(Exponential variance shadow map,指数方差阴影图)。而文中提出的方法是MSM(Moment shadow mapping,矩阴影图),有4个通道、4个矩、每个纹素64位,少量光照泄露。

从矩到阴影,许多分布共享相同的4个矩,以避免表面的阴影粉刺。

需要一种有效的方法来计算界限,基本思想是利用一个有用的数学定理,该数学定理指出,边界总是通过非常特定的深度分布来实现,只使用三个不同的深度值来匹配四个给定的矩,其中之一是正在最小化的深度。因此,只需要计算另外两个深度值和三个台阶的高度,正是矩阴影映射算法所做的。
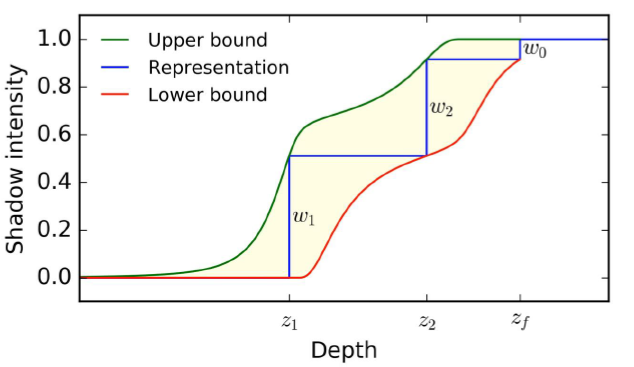
上一个示例中的边界不够清晰,而下图所示的边界非常窄,因此重建非常精确。过滤区域中的两个表面,完美重建,涵盖大多数情况。

但有一个问题,负担不起每纹素超过64位来过滤硬阴影,但若只存储深度的幂,舍入误差就太大了。基本上,阴影贴图的四个通道将存储底部显示的四个基函数。
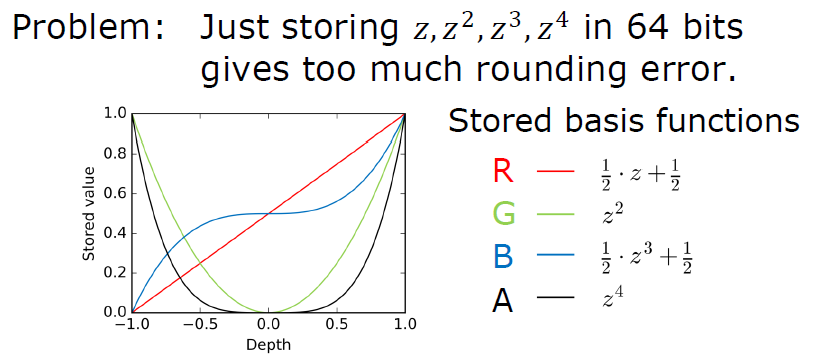
可用的价值范围利用率很低:
解决方案:使用优化的多项式基,现在64位就足够了。
利用范围的体积最大化:
MSM的使用过程如下:
-
生成矩阴影图。
- 渲染到多采样的深度缓冲区。
![]()
- 解析时计算矩。
![]()
- 过滤,例如2通道的高斯+mipmap。
![]()
-
恢复矩。
- 给片元着色,
- 对过滤的矩阴影图进行采样(使用mipmapping、各向异性等)。
- 逆向量化变换:
![]()
-
偏倚矩。示例:两个矩存储在2⋅3位。
- 舍入误差使矩无效。
- 用插值恢复它们:\(𝛼 = 0.15\),\(𝑏′ ≔ (1 − 𝛼) ⋅ 𝑏 + 𝛼 ⋅ (0,\ 0.63,\ 0,\ 0.63)^T\)。
- 如果在4⋅16位,\(𝛼 = 6 ⋅ 10^{−5}\)。
- 漏光稍微多一些。

MSM和EVSM、PCF的对比:

MSM还支持半透明遮挡体的阴影、矩软阴影和预过滤单次散射。


结论:矩阴影图优于其它可过滤阴影贴图,内存需求远低于卷积阴影图,与方差阴影图、指数阴影图和指数方差阴影图相比,漏光更少。在以下情况下,矩阴影图比普通阴影图更快:小的阴影图分辨率(由于抗锯齿而可行),大的输出分辨率(即4k和VR),较大的过滤区域(适用于柔和阴影),表面粉刺几乎不是问题。
Real-Time Area Lighting: a Journey from Research to Production阐述了区域光源的研究到产品应用的整个链路技术。文中提到想要所有频率(即不同粗糙度)的区域光源的正确响应:
想要各向异性,可由线性变换余弦作为入口:

利用LTC可以实现余弦、粗糙度、各向异性、斜切、随机等光照效果:
预先应用要给矩阵之后可以获得线性变换的余弦,若将粗糙度和视角等因素预先计算,可以得到约80kb的查找表数据:
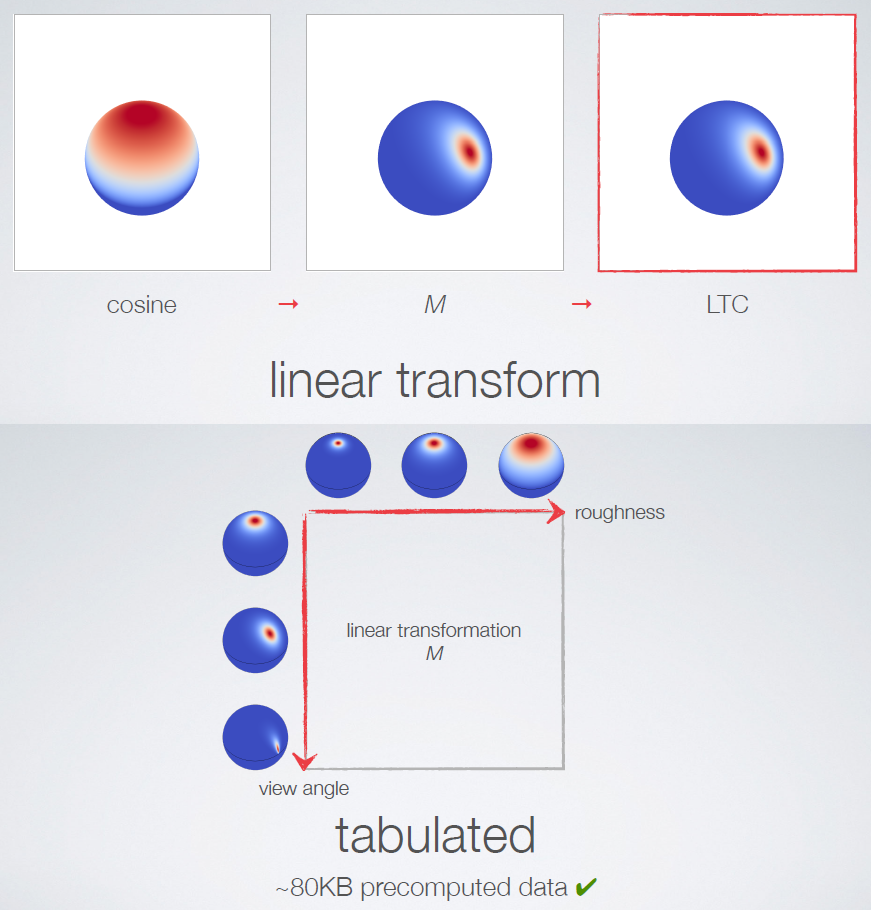
通过LTC的逆向变换,可以恢复原来的余弦项:
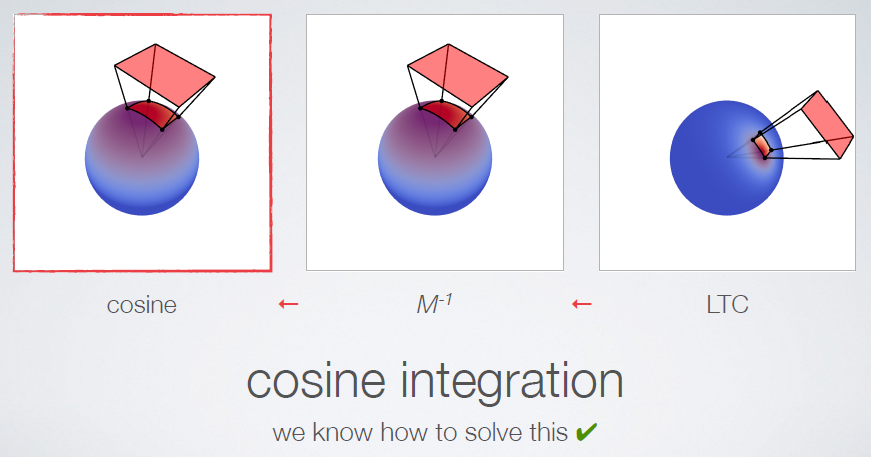
区域积分实际上可以转换成边缘积分:

相关的代码:
float EdgeIntegral( float v1, float v2, float n)
{
float theta = acos(dot(v1, v2));
float3 u = normalize(cross(v1, v2));
return theta * dot(u, n);
}
float PolyIntegral(float3 v[4], float3 n)
{
float sum;
sum += EdgeIntegraL(v[0], v[1]);
sum += EdgeIntegral(v[1], v[2]);
sum += EdgeIntegral(v[2], v[3]);
sum += EdgeIntegral(v[3], v[0]);
return sum/(2.0 * pi);
}
实现过程:
-
根据粗糙度和视角查找\(M^{-1}\)。当粗糙度较大,会产生过胖的照明区域:
![]()
需要标准化矩阵的4项:
![]()
![]()
渲染效果变得稳定且正确:
![]()
查找LUT时有更简单的方式:
![]()
-
用\(M^{-1}\)变换多边形。
-
将多边形裁剪到上半球。可以去掉乘以法线,用向量形状因子代替:
![]()
而多边形可用代理球体*似:
![]()
效果对比:
![]()
-
计算边积分。如果用以下代码计算,会出现亮处的条带瑕疵:
float EdgeIntegral( float v1, float v2, float n) { float theta = acos(dot(v1, v2)); float3 u = normalize(cross(v1, v2)); return theta * dot(u, n); }![]()
修改成以下代码:
float EdgeIntegral( float v1, float v2, float n) { float theta = acos(dot(v1, v2)); // 改了此行 float3 u = cross(v1, v2) / sin(theta); // 原来:float3 u = normalize(cross(v1, v2)); return theta * dot(u, n); }![]()
看起来好一些,但
acos将邪恶潜伏其中!需要修改acos的实现,利用合理的拟合:float EdgeIntegral( float v1, float v2, float n) { float x = dot(v1, v2); float y = abs(x); float a = 5.42031 + (3.12829 + 0.0902326*y)*y; float b = 3.45068 + (4.18814 + y)*y; float theta_sintheta = a / b; if(x < 0.0) theta_sintheta = pi*rsgrt(1.0 - x*x) - theta_sintheta; float3 u = cross(v1, v2); return theta_sintheta*dot(u, n); }新旧曲线的对比:
![]()
最终效果终于好了:
![]()
然而还有更低成本的拟合:
float EdgeIntegral( float v1, float v2, float n) { (...) // float a = 5.42031 + (3.12829 + 0.0902326*y)*y; // float b = 3.45068 + (4.18814 + y)*y; // float theta_sintheta = a / b; float theta_sintheta = 1.5708 + (-0.879406 + 0.368609*y)*y; (...) }





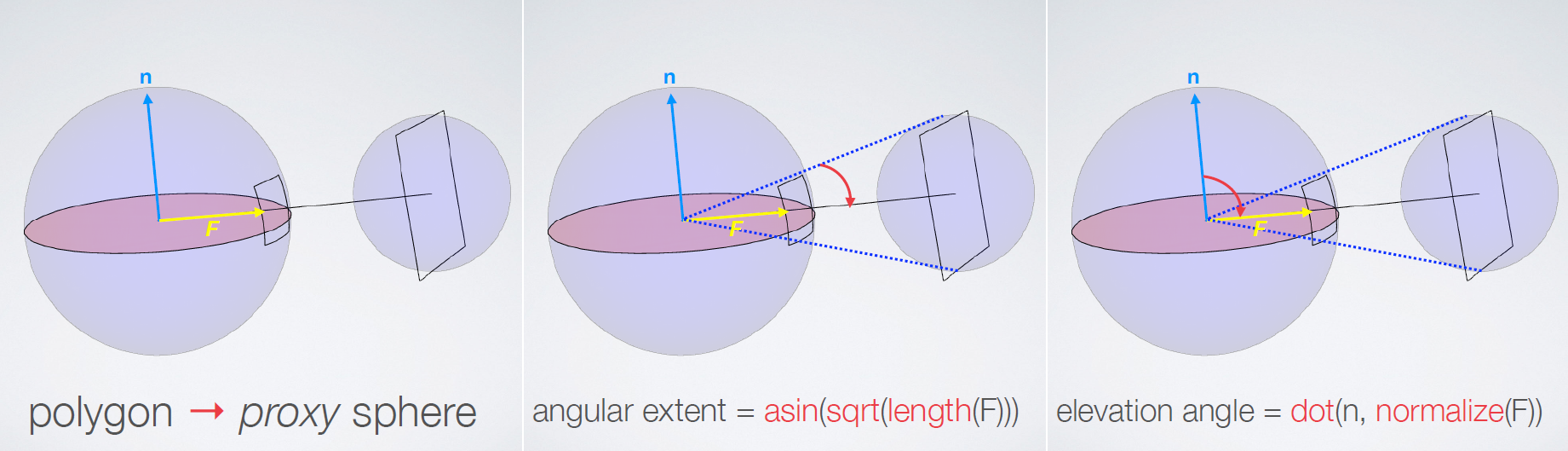




此外,这种LTC的方式还支持纹理区域光源:

总结:数值问题被解决,在PS4@1080p的漫反射+镜面反射的性能:0.9ms。
Volumetric Global Illumination At Treyarch是暴雪呈现的关于体积全局光照的技术,包含体纹理中的GI、Lean纹理数据、由探针烘焙的IBL、凸混合形状。传统的反射探针、辐照度体积都存在可见性的问题,即没有考虑每个探针的可见性项。
如果按体素渲染反射探头,需要的时间将是巨大的数字:

从反射探针收集颜色,重投影立方体图,组合起来填充孔洞。

实际上,每个体素4096条射线,考虑15个邻域样本,漏掉的光线被涂上了颜色。

另外,从已存在的探针重投影:
重投影时,基于距离排序的邻居候选对象,角度和到曲面的距离定义了立方体贴图中的立体角,根据深度金字塔验证样本区域,如果可见,则进行适当的mip采样。
distFromUnitCube = sqrt( 1 + u^2 + v^2 ); // Compensation for cube-map shape.
angleOfVoxel = 4 * PI / numSamples; // Solid angle from voxel.
inSqrt = 1 + distFromVoxel^2 * angleOfVoxel * ( angleOfVoxel – 4*PI ) / ( 4 * PI^2 * distFromProbe^2 );
angleOfProbe = 2*PI * ( 1 – sqrt(inSqrt) ); // Solid angle from reflection probe.
cubeRes = 1.0f / sqrt( angleOfProbe * distFromUnitCube^3 ); // Resolution needed for sample.
mipLevel = clamp( mipCount – log2( cubeRes ), 0, mipCount ); // Mip level to use.
return mipLevel;
最大的收益是硬件渲染、重新渲染以获得反弹、只需光线跟踪和重新投影一次。纹理编码使用BC6H压缩的环境立方体,好处是只有3个样本,硬件三线性滤波:
color = xVolume.SampleLevel( coord ) * normal.x * normal.x +
yVolume.SampleLevel( coord ) * normal.y * normal.y +
zVolume.SampleLevel( coord ) * normal.z * normal.z;
// 评估
color[n] = normal^2 * float3(Xsample[n], Ysample[n], Zsample[n]);
另外,光照漏光是个很大的问题,传统的解决方案是根据正常值调整三线性[Silvennoine15]。文中尝试了更多的体素数据的方案:*面、SDF,但存在不良的瑕疵——墙壁黑点。于是使用了衰减体积,让艺术家放置长方体,这些长方体定义了GI体积的剪辑形状,长方体的每一面都有一个衰减GI的羽状距离。对于复杂的房间,使用凸面体衰减形状。运行时实现:
- 对体积AABB进行剔除,以建立体积列表。
- 每像素计算可见体积上的衰减,凸壳CSG,由六个*面组成的一组,可以是扩展的、合并的或减去的。
- 根据法线采样三个环境立方体值。
- 在所有体积之间混合结果。
需要解决的问题有体素内的几何体、光照裂缝等问题。另外,反射使用了反射*面。
Tiled shading: light culling – reaching the speed of light介绍了一种新的分块和剔除分块灯光的技术,该技术利用光栅化器进行免费的粗糙剔除,并进行早期深度测试以快速剔除工作。此外,还介绍了利用显式多GPU编程功能的技术。
分块着色的优点是照明阶段一次性使用所有可见光,缺点是使用tile粒度进行不太精确的剔除,*截头体原始测试要么太粗糙,要么太慢。为什么要关心剔除?因为剔除本身可能是一项成本高昂的动作,精确的剔除可以加快照明速度,引入“误报”会显著降低照明性能!剔除挑战是尽量减少在剔除阶段获得的“误报”的灯光数量,提高分块着色渲染中的灯光着色性能。
球体和截锥体*面:永远不要用!最常用的测试,事实上,是截锥体和包围盒测试,对于大球体来说非常不准确。
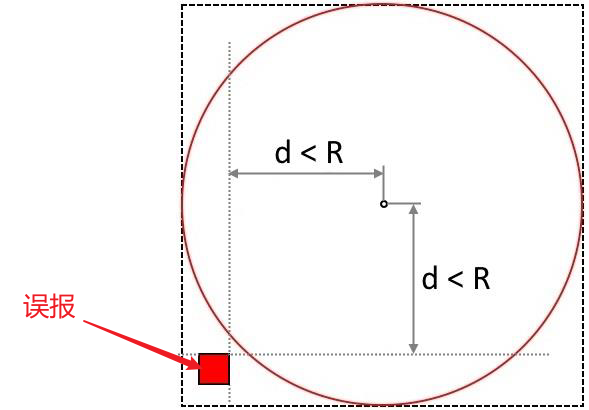
如何提高剔除精度?将tile的最小最大z与所有交点中的最小最大z进行比较,4条射线效果更好。
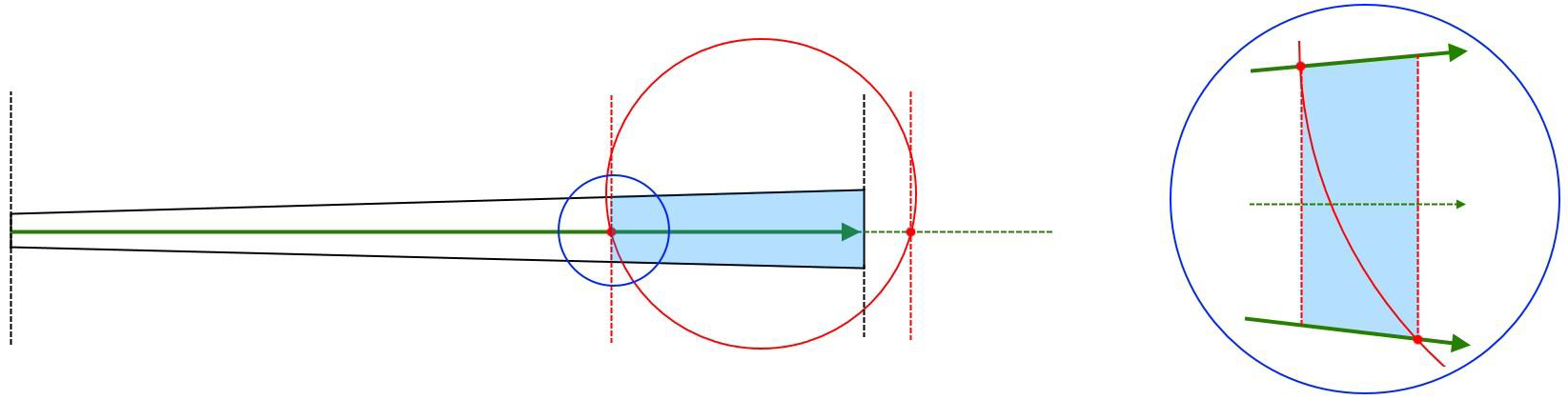
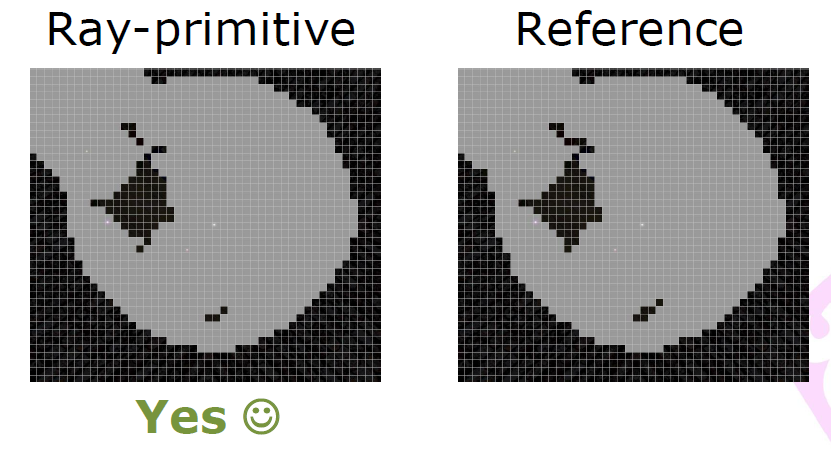
但对计算着色器的剔除很糟糕,这是一个简单的枚举:总操作数 = X * Y * N,其中X–分块网格宽度、Y–分块网格高度、N–光源数量。如何提高剔除性能?减少枚举的顺序,将屏幕细分为4-8个子屏幕,根据子屏幕截锥体粗略剔除灯光,在剔除阶段选择相应的子屏幕,少量光源时最多可提升2倍,但需要更多!我们受到计算能力的限制,试着将一些工作从着色器转移到特殊的硬件单元!让我们从计算切换到图形管线!就像过去的好时光一样!
使用图形进行灯光剔除:使用光栅化器生成灯光片元,空的tile将被原生地跳过,使用深度测试来遮挡,遮挡分块的无用工作将被跳过,在PS中使用图元-光线相交进行精细剔除和灯光列表更新。想法概览:剔除阶段分块→ 1像素,光源体积→ 代理几何体,粗XY剔除→ 光栅化,粗Z剔除→ 深度测试,精细剔除→ 像素着色器。
如何集成?不要使用uber着色器,始终将分块着色分为3个阶段:减少、剔除(用新方法)、照明。新剔除方法的概览:相机截锥剔除、深度缓冲区创建、光栅化与分类,它们的说明如下:
-
步骤1:相机截锥剔除。根据相机截锥剔除灯光,将可见光源分为“外部”和“内部”。
![]()
-
第2步:创建深度缓冲区。对于每个tile:查找并复制“外部”灯光的最大深度,查找并复制“内部”灯光的最小深度,深度测试是高性能的关键!在着色器中使用[earlydepthstencil]。
-
步骤3:光栅化和分类。使用深度测试渲染灯光几何体,“外部”——最大深度缓冲区,正面直接深度测试,“内部”——最小深度缓冲区,反向深度测试的背面,使用PS进行精确剔除和逐tile灯光列表创建。
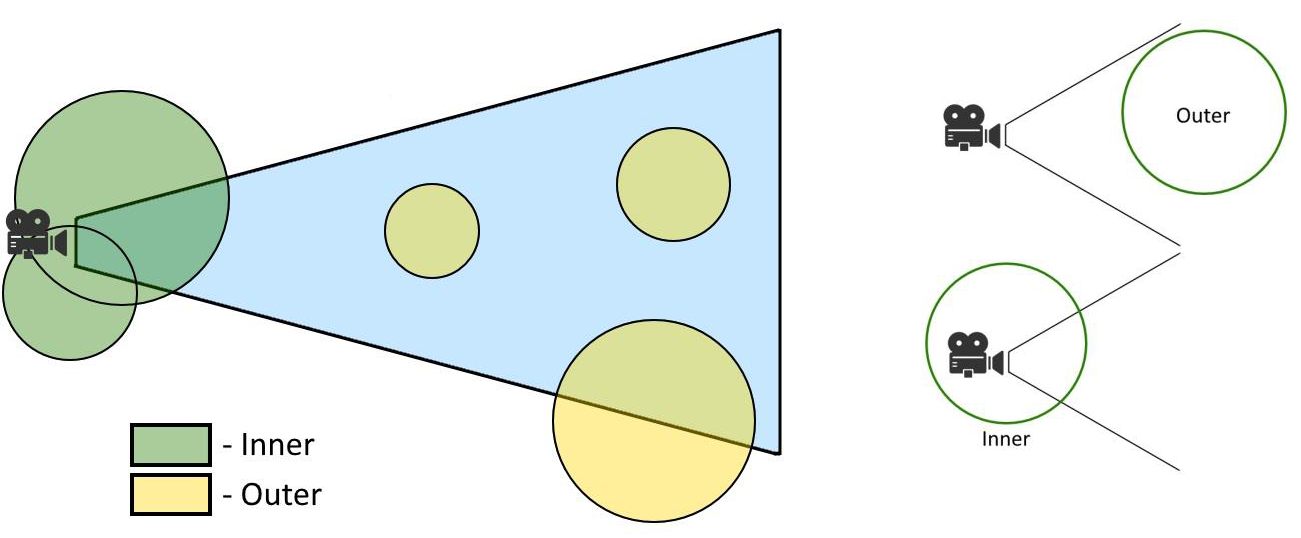
常见灯光类型:点光源(全向)、*行光(聚光灯),灯光几何体可以替换为代理几何体。
点光源的代理几何体用几何球体(2个细分,基于八进制,下图左),离球体足够*,低多边形在低分辨率下工作良好,等边三角形可以减少光栅化器的时间。聚光灯的代理几何体(下图右)易于参数化,从探照灯到半球,*面部分可用于处理区域光。
光栅化的光源剔除的优势:不适用于无光源的tile和被遮挡的光源,粗糙剔除几乎是免费的!对小尺寸的光源性能提升惊人,可以使用复杂的代理模型!从数学上讲,这是一个分支定界过程!性能对比如下,普遍有数倍的提升:

光栅化剔除的结论:比同样的CS版本快3-20倍,以较小的成本产生较少的“误报”,具有更好的分辨率缩放,光栅允许我们使用复杂的光源体积。
Decima Engine: Advances in Lighting and AA分享了Decima Engine的光照和抗锯齿技术。其中Decima引擎最初是为Killzone系列开发的,现在为Horizon:Zero Dawn和Death Stranding提供动力。该文将介绍的渲染技术包括通过弯曲单点光源的光矢量来*似球形区域光源的改进方法、高度雾的实际大气散射、针对1080p的两帧时间消除锯齿解决方案,以及在PS4 Pro上使用的优化的2160p棋盘渲染和“七巧板”解决策略。
在区域光方面,在形状上积分GGX是很困难的,不同的*似方法,均衡性能与质量,特定形状(例如[Hill16]用于多边形灯光),对于球形灯光:廉价的“扭曲”点光源技巧[Karis13],可能会导致失真,但可以改进。

如何使用每像素1个点光源来*似区域光?通过将点光源移向像素的反射向量[Karis13](下图左),非常适合Phong模型[Picott92],但对于微*面模型来说不是很好:峰值响应仍然可能被“忽略”。想法:将点光源移动到周边,以最大限度地提高其响应,主导因素:N·H(下图右)。
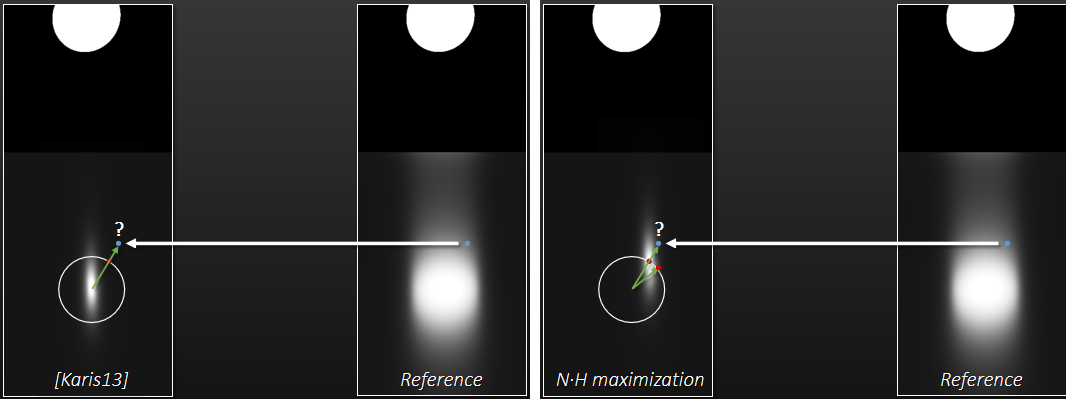
[Karis13]的方法是向反射向量方向弯曲L,相反,弯曲L最大化N∙H:

求解使N最大的φ∙H很难,可以解决等效问题:

然后使用牛顿迭代法求解:

效果对比如下:

文中涉及了高度雾的实现,其主要步骤和算法如下:



高度雾的效果:

对于Decima引擎而言,拥有复杂的自然场景来,光靠形态学是不够的,例如弯曲或亚像素宽度、所有植被都是Alpha测试的、半透明。开销可能很贵,例如,SMAA[Jimenez12]对植被可能较慢,用TAA补充FXAA。下表是不同的AA在不同场景下的消耗:

TAA需要之前的帧数据,但Horizon没有,很多很薄的几何体,AA应用于所有其它方面之后,低质量运动向量。没有回馈循环的累积历史,仅将当前和上一个原始渲染作为输入。TAA的两帧内每像素4倍边缘采样,具有自适应1D锐化:
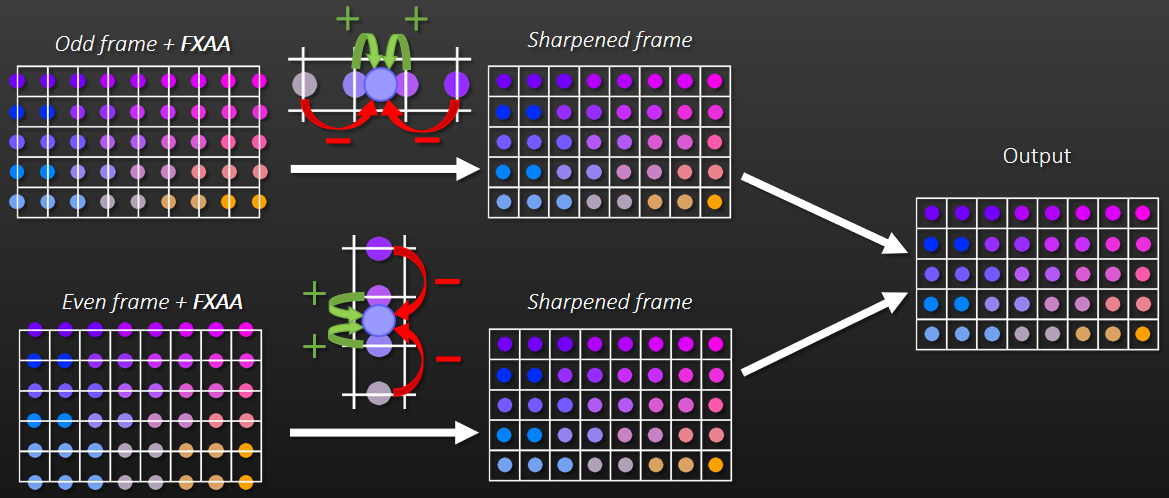
采样模式类似于FLIPQUAD[Akenine02],但是比较锐利,没有额外的mipmap逻辑,无需MSAA/EQAA硬件,在去除线条和网格上的锯齿方面较差(由FXAA解决)。
棋盘渲染和其它AA在效果、性能方面的对比如下:

PS4 Pro上的2160p棋盘渲染:
-
典型棋盘渲染。
- 每帧渲染50%的像素。
- 每帧交替采样位置。
- 渲染原生分辨率提示以“智能地”填补空白:深度缓冲区、三角形索引缓冲区、阿尔法测试覆盖率。
- 在2160p@30Hz的频率下,原生分辨率对地*线来说太大开销,只有UI和最终backbuffer是原生分辨率,一切都在2160p棋盘上运行,没有原生分辨率提示,打破标准决心…
-
每帧渲染50%的所有像素角点(下图左),以及*均可用的角落,所有像素的处理都是一样的。不需要原生分辨率提示,没有形态的技巧,没有抖动模式(下图中)。两帧中每个原生像素的4个样本,AA稳定性与1080p的TAA相似(下图右)。

*均两个最*的像素角点本质上没有锯齿:

单帧对角线仍然存在问题,FXAA沿对角线方向施加:
棋盘渲染总结:以棋盘分辨率进行渲染和后期处理(1920x2160),转换为(YCoCg)的七巧板(2160x2160),其中YCoCg用于下一个通道:单个gatherRed()的4个亮度样本。应用常规的FXAA,由于七巧板的缘故,消除了对角线上的锯齿。混合当前七巧板和重投影的历史七巧板,输出到2160p。

PBR Diffuse Lighting for GGX+Smith Microsurfaces讲述了基于微*面的BRDF、GGX+Smith微面模型的漫反射模拟、与其它漫反射BRDF的比较等内容。
漫反射微表面:数值求解积分,希望找到好的*似值,与Oren Nayar论文的方法相同,多达一半的光照不见了!不能忽略多次反弹。。。(完整的Oren Nayar还包括第二次反弹)。

文中对G项进行了校正(下图左未校正,右已做校正):

改进后的Smith*似方法在成本和效果上都有提升:

效果对比(Lambert、Disney、新模型):

Improved Culling for Tiled and Clustered Rendering分享了暴雪的COD使用的分块和分簇光照算法的改进。

以往的光照算法在数据结构分支的性能问题:
- 分块:在前向,三角形可以穿过多个分块;在延迟,波前可以匹配分块大小。
- 分簇:在前向,三角形可以跨越多个簇,在延迟,波前可以穿过多个Z切片。
- 体素树:波前可以跨越多个体素
- 三角形/纹素:波前可以跨越多个三角形/纹理。
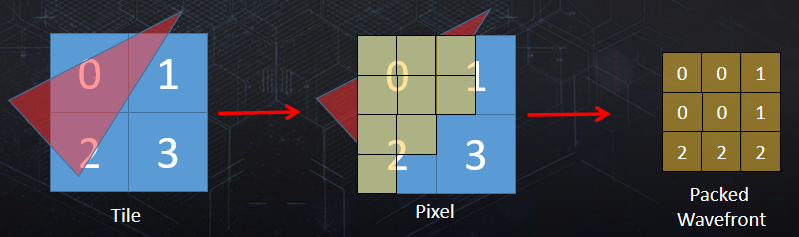
分支的性能问题:VMEM和VALU成本高,超过分支(即tile内)的所有计算均按向量进行,所有的内存加载,即使是一致的,也会发生在每个向量上,从而大量占用TCC单元,内存运算将按向量进行,增加了ALU消耗。高VGPR消耗,因为所有操作都是基于向量的,所以所有常量数据(如实体描述符)都必须加载到VGRS中。
标量化:一次仅在一个分支项上执行波前,通过波前对所有采样项进行循环,遮罩所有波前线程以仅对选定项起作用,转到下一个。可用于前向和延迟。

数据容器:层级。指向叶子簇的指针,叶子簇存储指向每个条目中可见实体的所有指针,不受entity编号的约束,间接寻址导致的昂贵遍历,可变内存存储成本。
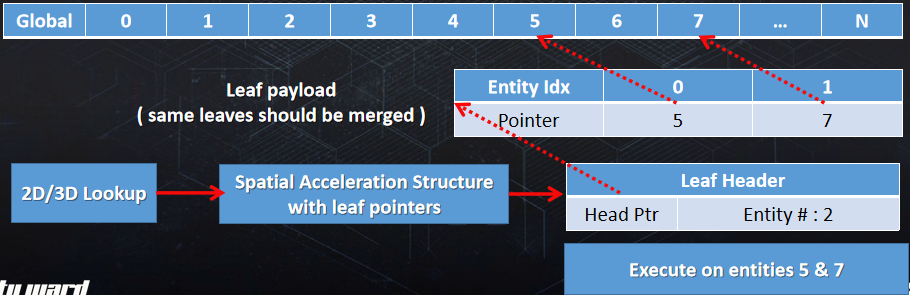
标量化的层次容器:着色器是完全标量化的,更好的VMEM/SMEM和VALU/SALU*衡,VGPR使用率低(类似于前向恒定加载)。性能高度可变,如果相同的实体在不同的容器中,波前可以多次处理实体,根据数据一致性/冗余性,可能会导致速度减慢。理想情况下,在实体级别进行标量化,这需要有序的容器——扁*位数组。
数据容器:扁*。扁*位数组是位的集合–表示全局列表中第n个实体可见性的第n位,简单遍历——遍历位,内存/实体绑定–主要用于每个视锥体上下文。
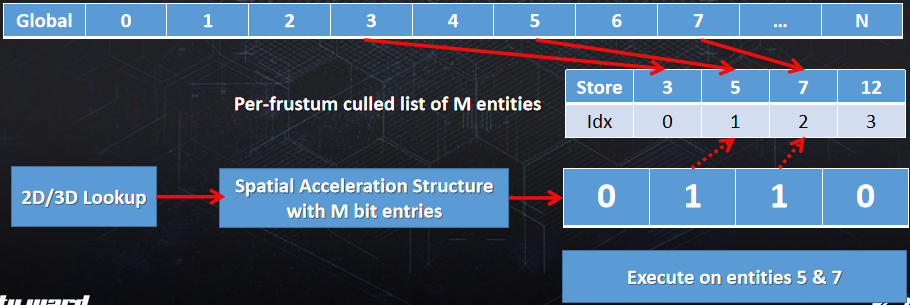
位掩码标量化:着色器完全标量化,每个实体执行一次,VGPR使用率低,显著高于基线,可以说是更优雅的代码。合成测试着色器的标量化结果(应用于密集照明环境中灯光查找的标量化):

分层数据容器可以在容器级别上进行标量化,如分块、分簇、体素地址,扁*数据容器可以在存储实体级别上进行标量化,如光源/探头/贴花索引。
此外,在深度箱化(Z-Binning)的过程做了改进:

前向+渲染器的Z-binning算法步骤:
- CPU:
- 按Z排序灯光。
- 在可能的总深度范围内设置均匀分布的箱。
- 在每个箱子边界内生成带有最小/最大灯光ID的2 x 16位的LUT。
- GPU(PS/CS):
- 向量加载Z-BIN。
- 波均匀光源的最小/最大ID。
- 波均匀加载来自最小/最大范围内的光源位。
- 从灯光最小/最大ID创建向量位掩码。
- 用向量Z-Bin遮罩来遮罩均匀的光源。
// Flat Bit Array iterator scalarized on entity with Z-Bin masked words
wordMin = 0;
wordMax = max(MAX_WORDS - 1, 0);
address = containerAddressFromScreenPosition(screenCoords.xy);
zbinAddr = ContainerZBinScreenPosition(screenCoords.z);
zbinData = maskZBin.TypedLoad(zbinAddr, TYPEMASK_NUM_DATA(FORMAT_NUMERICAL_UINT, FORMAT_DATA_16_16));
minIdx = zbinData.x;
maxIdx = zbinData.y;
mergedMin = WaveReadFirstLane(WaveAllMin(minIdx)); // mergedMin scalar from this point
mergedMax = WaveReadFirstLane(WaveAllMax(maxIdx)); // mergedMax scalar from this point
wordMin = max(mergedLightMin / 32, wordMin);
wordMax = min(mergedLightMax / 32, wordMax);
// Read range of words of visibility bits
for (uint wordIndex=wordMin; wordIndex<=wordMax; wordIndex++)
{
// … //
}
// Read range of words of visibility bits
for (uint wordIndex=wordMin; wordIndex<=wordMax; wordIndex++)
{
// Load bit mask data per lane
mask = entityMasksTile[address + wordIndex];
// Mask by ZBin mask
uint localMin = clamp((int)minIdx - (int)(wordIndex*32), 0, 31);
uint maskWidth = clamp((int)maxIdx - (int)minIdx+1, 0, 32);
// BitFieldMask op needs manual 32 size wrap support
uint zbinMask = maskWidth == 32 ? (uint)(0xFFFFFFFF) : BitFieldMask(maskWidth, localMin);
mask &= zbinMask;
// Compact word bitmask over all lanes in wavefront
mergedMask = WaveReadFirstLane(WaveAllBitOr(mask));
while (mergedMask != 0) // processed scalar over merged bitmask
{
bitIndex = firstbitlow(mergedMask);
entityIndex = 32*wordIndex + bitIndex;
mergedMask ^= (1 << bitIndex);
ProcessEntity(entityIndex);
}
}
前向+渲染器的内存性能:

前向+渲染器的Z-Bin性能:

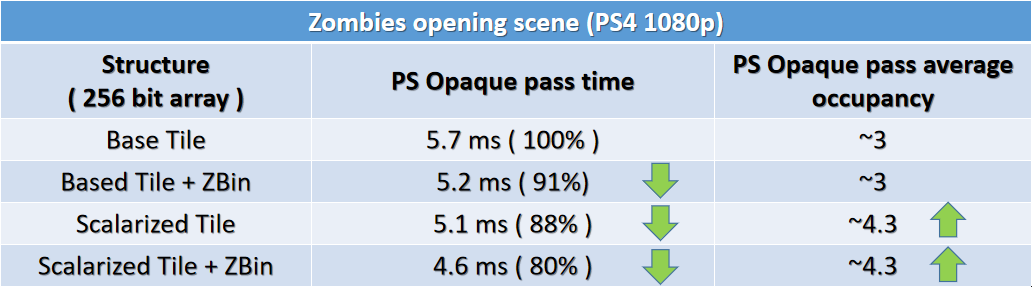
文中还使用了保守光栅化剔除、解决原子争用、光源代理等方法来优化光照的效果和性能。其中光源代理将代理扩展到更多渲染实体,改进光栅化批处理。
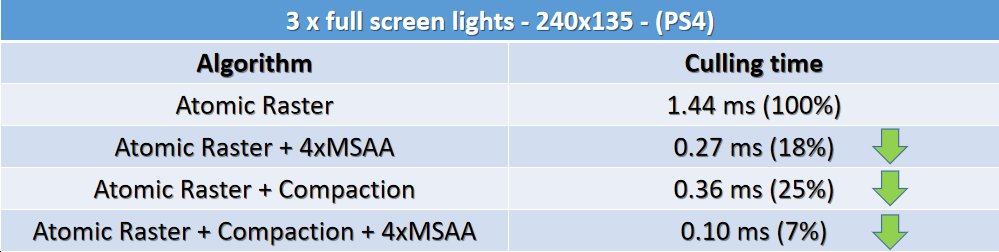
分块光栅化的不同方法的性能。
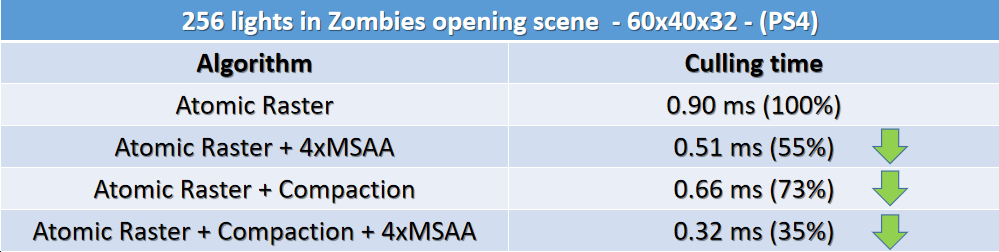
分簇光栅化的不同方法的性能。

光源代理的效果对比。

光源代理的性能对比。
Precomputed lighting in Call Of Duty: Infinite Warfare阐述了COD的预计算光照涉及的各项技术,其在预计算光照过程中涉及的技术有光照图、探测照明、光照贴图–大型结构几何(代表、投影)、光探针——其它一切(将可见性与照明分离、可见度的表示、插值照明、用于存储和访问的轻型网格结构:生成、烘焙、可见性表示)等。
结构化几何体:光照图用ADH(Ambient Highlight Direction)编码获得最大的性能提升,在切线空间中,半八面体编码,BC6H的颜色,选项以禁用每个贴图的压缩。

左:传统的光照图效果;右:COD预期的光照图效果。
仅具有遮挡的远距离照明下漫反射曲面的渲染方程:
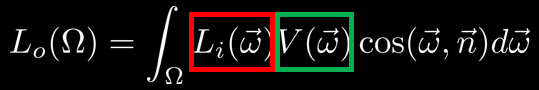
两个特征截然不同的项:入射光(*滑且表现良好)和可见性(快速变化,高频定向组件),需要把两者分离!COD在顶点处存储的可见性,灯光存储在对象上的一些点上。对于可见性,将可视性存储为圆锥体:轴、锥角和比例(0到1),可见性在实例之间共享,只需烘焙一次(在转化过程中)。
烘焙可见性时,生成四阶SH,表面均匀取样,验证样本,非线性迭代*滑器,将线性SH的范数插值为额外通道,重新缩放。圆锥体的最小二乘拟合:最佳线性轴,非线性拟合角度,但仅1d,比例只是圆锥体上积分的可见性与圆锥体自身积分的比率。
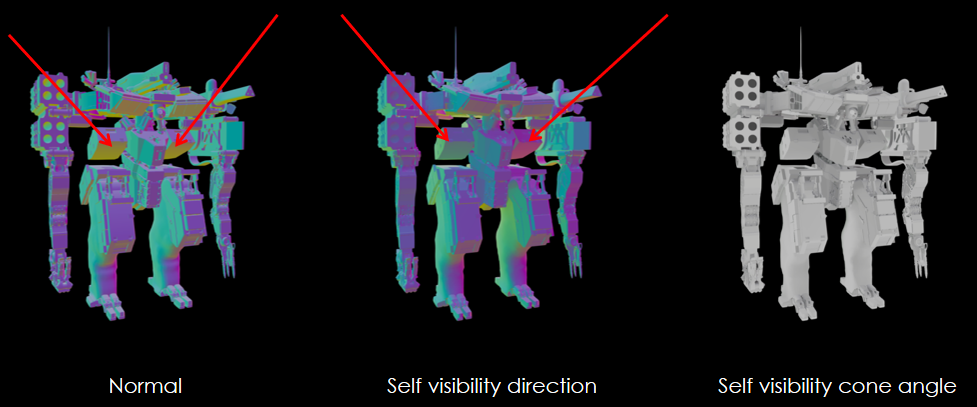
光照:单一的照明环境不够,大型对象的照明可能会发生剧烈变化,可以转换为梯度[Annen2004],但质量/成本不满意,生成多个采样点,散落在物体周围,数量取决于对象大小,将入射光存储在这些点上,并对整个对象进行插值。确定采样位置:算出N——探头的目标数量——基于对象大小,均匀地、相当密集地采样对象几何体,执行k-means分簇,将样本分配给N个分簇,松散后的最终分簇中心成为采样位置。

插值照明:计算采样位置集的协方差矩阵,特征值的相对大小决定插值模式,特征向量定义了插值的局部空间。不同维度的插值方式如下:
效果对比:
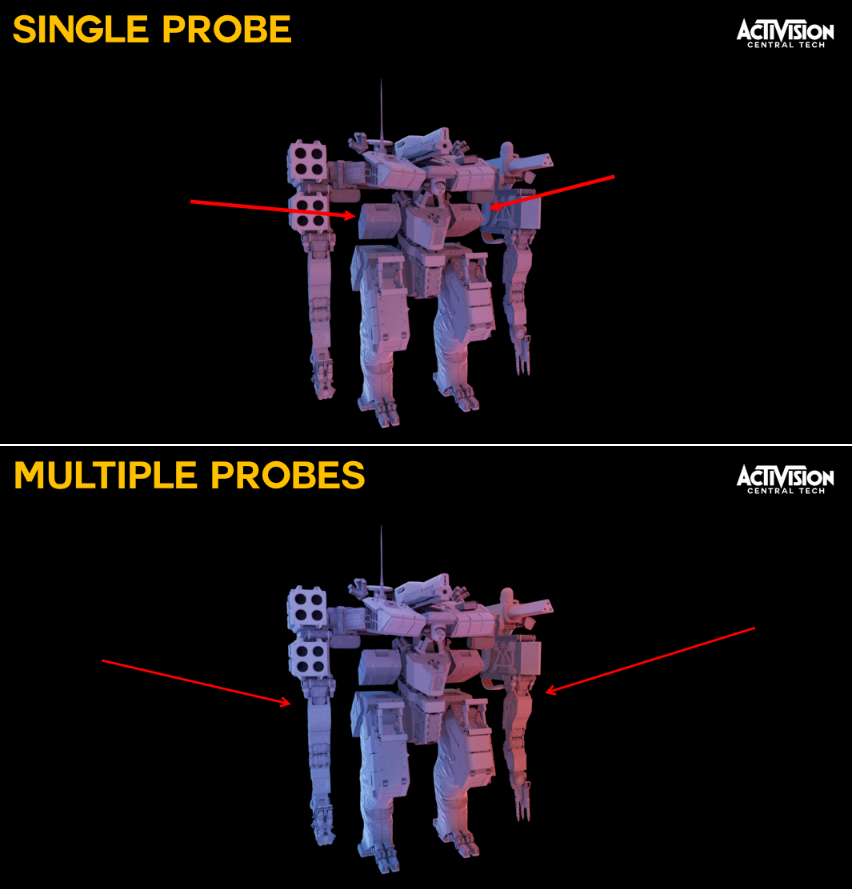
对于光照探针网格,使用了非均匀网格。首先对level的体积进行非常粗略的体素化,四面体化体素化,仅输入长方体=漂亮且常规的TET。细分四面体(来自[Schaeffer04]的方案),确保相邻区域之间最多相隔1个细分级别,细分*几何体、navmesh和手动放置的感兴趣的区域。

计算层次底部点的粗略照明,对于层次中的每个细分,计算误差,给定级别和更低级别的插值照明之间的*方差,分析单元格体积上的积分。从层次结构的顶部开始再次优化,基于误差、接*感兴趣区域等的优化优先级。最后一组点是规则的,与几何图形和信号对齐,然而,TET单元格不仅仅是重建网格的单元格。

左:四面体网格(Tetrahedral Mesh);右:光照网格。
光照网格可见性:灯光穿透墙壁,即使从查找位置看不到探头,也要使用探头。使用一些可见性信息来增强探针,以限制其影响,对于每个探头,它接触的每个tet存储一个三角形深度图,第一个交点的重心:0-1范围。
不同预计算方法的效果对比:

ADH投影过程:
总之,分别考虑渲染方程的不同组件,随着照明变得更加详细,表示变得更加复杂——重新采样到更简单的结构以降低成本,最小二乘法是你的朋友,但别忘了规则化。
The Lighting Technology of 'Detroit: Become Human'阐述了底特律-变人的光照技术,包含PBR、直接照明(解析光、阴影、体积光照)、间接照明等。
光度单位(Photometric Units)是照明一致性是主要目标,更容易与现实生活中的参考资料进行比较,艺术家可以使用现实生活中的输入值,防止它们将照明信息烘焙为反照率,允许更好的场景对比度/范围。
光度单位有以下几种:
- 发光功率(Luminous power ,lm):发出的总光量。*行光之外的其它光源以lm为单位。
- 发光强度(Luminous Intensity,cd):每立体角方向lm。
- 照度(Illuminance,lux):落在表面上的光量。*行光以lux为单位。
- 亮度(Luminance ,cd/m²):特定方向上每单位面积的cd。
强制二次衰减,照度非常高,接*正点光(punctual light)。

发光表面:所有材质上的发射强度参数(+颜色),以曝光值(EV)表示,cd/m²是一个线性刻度,但人眼无法感知,cd/m²在感知上是线性的,+1 EV是感知光强度的两倍。
场景曝光:需要在关卡编辑器中正确曝光场景,不建议自动曝光,使用典型照明条件下的测量曝光量,关卡分为场景区(Scene Zone,SZ),摄影总监为每个“SZ”提供曝光,是没有过渡的固定值,当相机进入SZ时应用曝光。曝光以EV100表示,表示相机快门速度和光圈数的组合,EV100是ISO100传感器灵敏度的曝光值,为我们提供了一个框架,以确保一致的照明范围,场景曝光对于预曝光(pre-expose)积累缓冲区来说非常好,游戏中曝光需要更多控制。
相机曝光:场景曝光的曝光补偿,提供动态更改曝光的控制,艺术家可以选择4种相机曝光类型,自动曝光=游戏阶段(主要)、手动曝光=剪切场景(主要)。相机曝光类型:手动(EV100中的曝光值可由动画曲线控制)、相机(根据物理相机的设置来计算,如f光圈、ISO、快门时间)、自动*均(根据场景的对数*均亮度计算)、自动区域(根据手动放置在场景中的“场景区域”+EV“贴花”中提供的曝光值计算)。
光度单位(调试):
- 虚拟光点计(Virtual Spot Meter)提供像素绝对亮度,以cd/m²和EV100为单位,RGB和sRGB值,真的很有用,可以调整发射表面,调试镜面反射的高值。

-
错误颜色调试菜单用于检查场景是否曝光良好。绿色是中灰色(18%),粉红色是肤色,紫色是死黑,红色是死白:
![]()

材质校准:现在我们有了一个很好的照明框架,现实生活中的参考资料和相干值,材质需要同样的处理,无法扫描我们所有的材质。捕获一些对象和材质样本,设置一个环境受控的房间,建立一个有三个白炽灯泡的暗房,易于在引擎中复制,捕获的材质有助于验证照明环境。围绕这一点,建立了一个“冻结工具”,提供一些经过校准的照明环境,包含暗房和在各种照明环境下捕获的其它全方位IBL[LAG16],材质属性可视化,与对象/材质参考的比较,所有道具都可以通过该工具进行验证。

高亮显示材质属性超出范围的值。红色:基础色不对,电介质材质必须在[30 240]的sRGB内,金属材质必须在[186 255]的sRGB内;蓝色:错误的玻璃着色器反射率,菲涅耳反射率必须在[52 114]的sRGB范围内;黄色:金属参数错误,金属值应接*0或1,介于两者之间的值通常是错误的。

在直接光方面,所有的光源都是准时的:定向光、点光源、聚光灯、投影灯(“定向的”光,被限制在具有衰减的盒子中)。
在阴影方面,阴影图具有8个样本的PCF+时间超级采样,使用蓝色噪点以抖动,3倍默认模糊半径,最高可达15倍。根据几何体法线计算的自动阴影偏移(定制的[HOL11])。尝试过PCSS,由于寄存器压力过大,不实用,仅用于牙齿着色器。
阴影图集的阴影以16位精度存储在8192x8192x的图集上,拆分为256x256块,艺术家可以在3种不同尺寸之间选择分辨率:256、512、1024,根据相机距离调整阴影大小,分辨率最多可以减半,在4步中降低分辨率以防止像素条纹,当达到256px的倍数时,重新打包在图集中。仅当有东西在光的视锥中移动时更新,可以单独排除点光源阴影面,裁减*面附*的可调整阴影,有助于数字精度和光线定位,可以与裁减*面附*的灯光解相关(无旋转)。
方向级联阴影映射具有时间超级采样的PCF(8个样本),使用抖动和TAA,每个高达1440px的4次分割和16位精度,大多数场景使用2或3个分割,自动分割分配。
静态阴影根据相机距离切换到静态阴影,只有1个样本具有双线性比较,静态阴影图集,图集尺寸:2048x2048,每个阴影64x64,最多1024个阴影。定向静态阴影是一个带有关卡所有静态几何图形的大纹理,尺寸:8192x8192。
特写阴影(Close-up Shadow)增加接触和自阴影的精确度,以1536²像素的速度增加最多两个阴影,艺术家在场景中选择相关对象,例如角色,只有这些对象接收特写阴影。对象选择:半径10米以内的所有可见标记对象,从蒙皮点云计算蒙皮对象边界体积。*/远*面适合*距离接收器选择的边界体积,截锥体外部的对象投影在*阴影*面上。
特写阴影类似于UE的逐物体阴影。特写阴影开启(下图左)和关闭(下图右)对比:

体积照明使用统一体积照明([WRO14] [HIL15]),匹配在灯组深度上,使用棋盘渲染,蓝色噪音抖动的TAA,由直射光和漫反射探针光栅照亮,雾对GI烘焙的影响,伪多次散射。体积光可能会透过表面泄漏(下图上),修复泄漏步骤(下图下):逐tile存储的最小/最大深度,使用“最大深度”在灯光评估时夹紧体素厚度,对体积纹理采样应用Z偏移(TileDepthVariance > threshold)。

在间接照明方面,使用了HL2环境多维数据集,静态几何的顶点烘焙,用于动态几何的光源探针,伪间接镜面照明,需要静态和动态的统一解决方案。基于探针的解决方案非常适合基于镜面反射图像的照明(IBL),捕捉场景立方体贴图,烘焙GGX NDF[WAL07] [KARIS14],过滤重要采样以防止萤火虫,艺术家控制影响盒和视差盒。另外,还使用了辐照度稀疏八叉树,一个八叉树单元格有8个探针,每个角一个,空间点始终由8个探针包围,不丢弃任何探针,实际上是偏移探针。其中八叉树级不连续,下图的橙色点是计算的探针,浅蓝色点是插值的探针:
下图上在每个叶子节点存储2x2x2的数据,有很多冗余;下图下以3x3x3的父节点存储数据,更少冗余数据。
球谐函数使用二阶SH,4系数,使用Geomerics重建[Geomer15],3个RGBA16F体积纹理(R、G、B),24055个探针→ (105x105x3)x 3纹理约3MB。
GI显示时永不丢弃探针允许采样体积纹理,只需使用硬件(3D)双线性滤波,从3d文字中找到八叉树单元哈希键(Morton键,O(1),限制为32位),对纹理坐标缓冲区使用预计算的哈希:X坐标在前15位编码、Y坐标按以下15位编码、Z坐标在最后2位编码。这样做的好处是使用计算着色器混合多个GI集非常简单,支持GI开关(内部光源开关、闪电等)和GI转换(一天中的时间、限制/关闭等)。
GI过渡:避免场景区域之间的硬GI过渡,如内部↔ 外部,设置入口周围的距离,通过GI的动态对象,基于到入口的距离和法线方向。
GI过渡关闭和开启的对比图:

大多数静态对象都位于唯一的场景区域中,如内墙与外墙,那么门、窗、窗框呢?指定给场景区域,但从其它区域也可见,未指定给场景区域。
Cluster Forward Rendering and Anti-Aliasing in 'Detroit: Become Human'介绍了Quantic引擎从Playstation 3到Playstation 4的演变,从延迟照明到集群前向照明的转换、好处以及如何解决遇到的问题,还介绍了TAA及TAA的应用,例如SSR、SSAO、PCF阴影、皮肤次表面散射和体积照明。


分簇前向渲染使用GPU更加灵活高效,新的照明算法:分块渲染、前向+渲染、分簇前向渲染,它们的对比如下:

分簇前向渲染有3个通道,它们的过程如下:
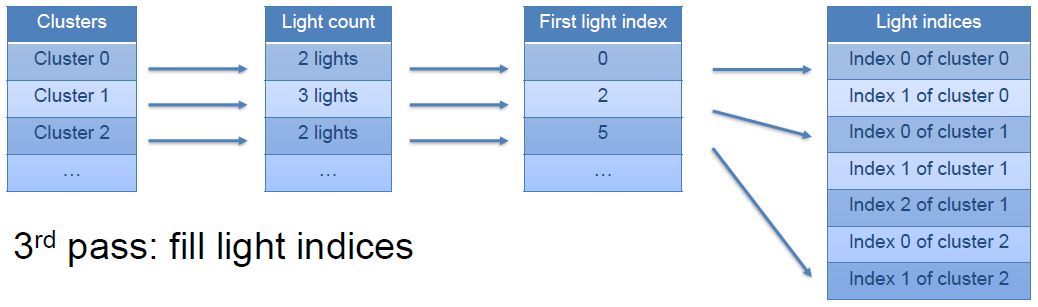
分簇前向渲染的优化:强制灯光循环使用标量寄存器而不是矢量寄存器,并对灯光进行排序,确保所有东西尽可能使用相同的空间(视图空间)。对TAA使用较少的阴影纹理样本(仅8个),强制编译器使用带有2x4纹理阴影样本的循环,在一定距离内只使用一个纹理阴影样本的烘焙阴影纹理。深度通道是必要的,分簇可用于逐像素照明和逐顶点照明!如果可能,将基于图像的照明转移到延迟通道。
光照循环优化:有4种灯(点光源、聚光灯、定向灯和投影仪),阴影和投影纹理,第一个版本使用4个循环(每种灯类型一个),后面改成到1个循环处理所有类型的灯光:
For each light:
ComputeLightAttenuation(...);
ComputeShadow(...); // → Higher register usage for sun shadow
ComputeProjectedTexture(...);
ComputeFinalLightingColorWithMaterialBRDF(...);
// 优化太阳阴影,增加各种可见性测试
ComputeSunShadow(...); // → Lower register usage
For each light:
VisibilityTestBitField(...); // → Early exit
ComputeLightAttenuation(...); // → Early exit
TestNDotL(...); // → Early exit
ComputeShadow(...); // → Early exit
ComputeProjectedTexture(...);
ComputeFinalLightingColorWithMaterialBRDF(...);
经过以上步骤的优化之后,光源的数量随之减少:

半透明优化:透明度可能是性能杀手,玻璃仅基于图像的照明,粒子:每质心、球谐函数、半分辨率。
底特律游戏实现了TAA的着色抗锯齿,可以使用GPU导数进行多次着色,效果不错,但代价高昂。可以使用法线分布函数 (NDF) 过滤(Filtering Distributions of Normals for Shading Antialiasing及优化版本[Error Reduction and Simplification for Shading Anti-Aliasing](https://yusuketokuyoshi.com/papers/2017/Error Reduction and Simplification for Shading Anti-Aliasing.pdf)),与TAA配合得很好,雨水细节更为明显。

从上到下:TAA关闭、TAA开启、TAA+NDF过滤。
TAA还可用于阴影、HBAO、SSR、皮肤的屏幕空间次表面散射、体积光照。和TAA常搭档的有Blue Noise(蓝色噪点),具有最小低频成分且无能量集中峰值的噪音。

左边是白噪点,右边是蓝噪点,下排是*铺(tiling)模式。
对于带时间采样的SSR,拥有TAA通道,使用棋盘夹紧邻域:
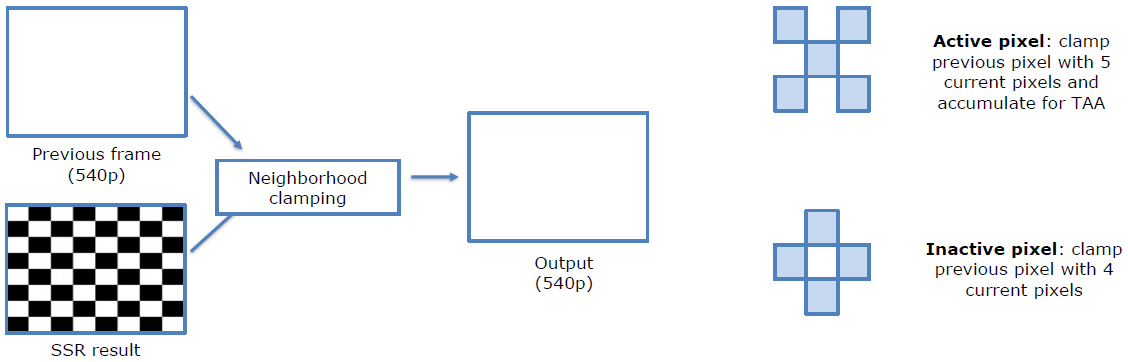
Precomputed Global Illumination in Frostbite讲描述了Frostbite为“FIFA”、“Madden”、“前线”和未来游戏开发的静态GI技术,包含路径跟踪、球面谐波光照贴图和高效的光照贴图打包算法。
Flux是Frostbite的路径追踪器,具有下一事件估计的单向路径跟踪(蛮力),烘焙的CPU实现(Intel Embree、IncrediBuild XGE),实时艺术家工作流程的GPU实现。

Frostbite中路径追踪的SH光照图包含漫射照明、高效编码、*似镜面照明等方面的技术。烘焙的GI是一个数据库/缓存,由位置𝑥产生键值,存储渲染方程的部分解:

其中眼睛向量𝜔𝑜未知(烘焙期间没有摄像头),着色法线𝑛烘烤时可能不知道,运行时可以使用法线贴图或几何体LOD,光通量(Flux)烘焙光照图和探针中的球面辐照度函数,假设基本漫反射BRDF(如\(𝑓_𝑟=\cfrac{𝑘}{\pi}\))和\(𝑛_{𝑠ℎ𝑎𝑑𝑖𝑛𝑔}=𝑛_{𝑓𝑎𝑐𝑒}\),在运行时使用每像素曲面法线进行评估𝑛和底色𝑘,使用球谐函数。
使用球谐函数的原因:不需要切线坐标系,与RNM或ℋ-Basis不同,色度分离的RGB方向照明,不同于环境光+高光方向(AHD),高对比度漫反射照明,*似间接镜面照明,RGB L1的SH的良好压缩选项。烘焙球谐函数过程:

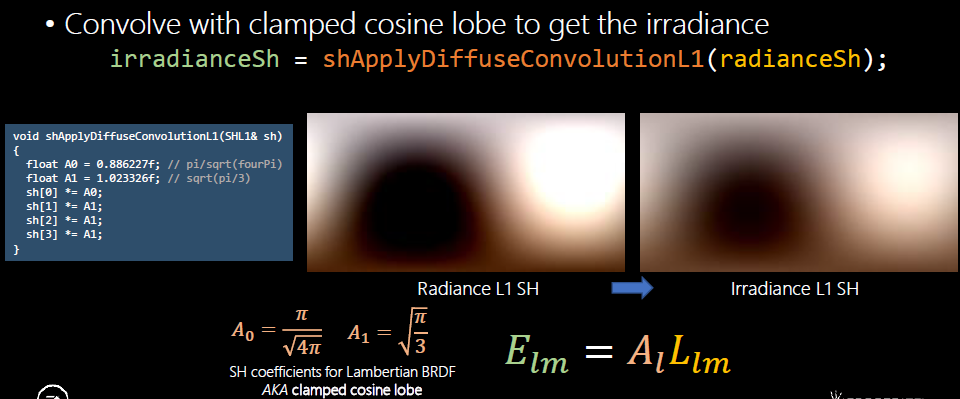
为了简化辐照度的SH,需要对辐射率等公式进行推导:
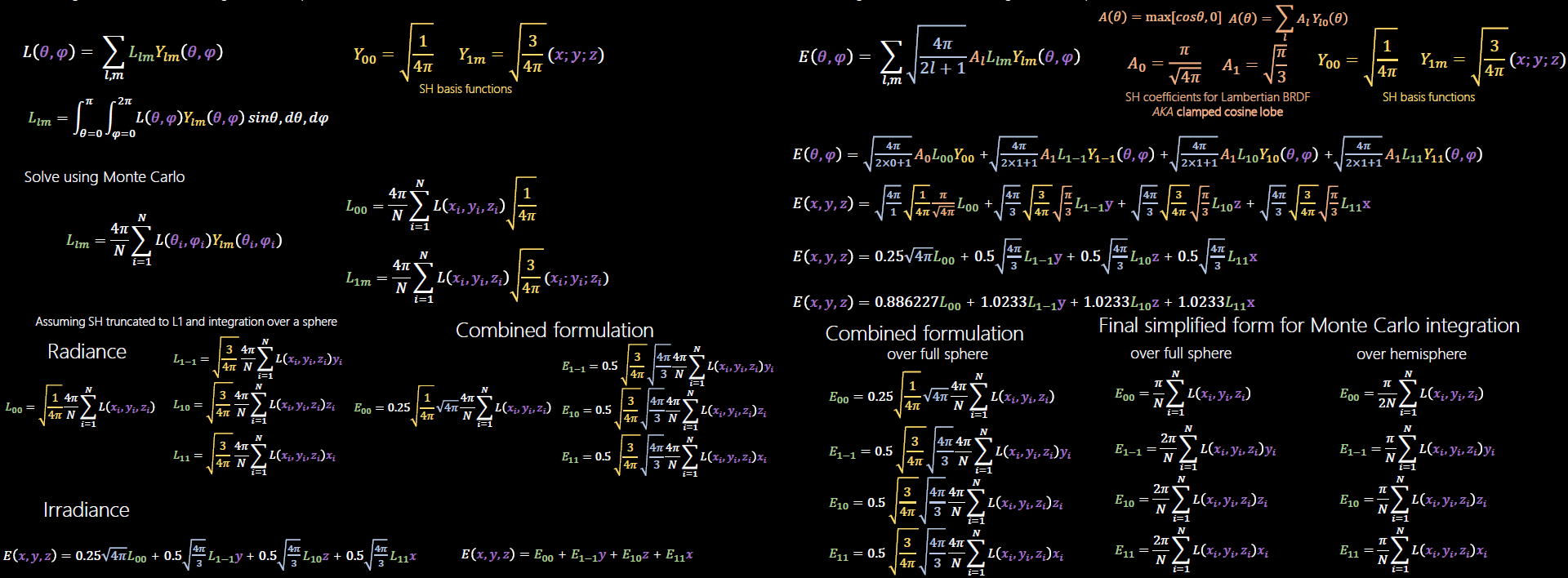
辐照度SH光照图编码:使用4个RGB纹理存储12个SH系数,L0 HDR中的系数(BC6H纹理),L1 LDR中的系数(3倍BC7或BC1纹理),RGB SH光照贴图的总占用:高质量模式32位(4字节)/texel,用于BC6+BC7;低质量模式20位(2.5字节)/texel,用于BC6+BC1。例子:4096 x 4096光照图,32位/texel时为64MB,20位/texel时为40MB。
在镜面光照上,*似镜面反射的一般思想是在光照贴图中使用L1球面谐波数据,从SH推导出主光源方向(仅规范化L1数据),根据L1波段的长度估计“传播”或“聚焦”:
float focus = lightmap.L1 ); // [0..1]
使用估计的参数创建一个假想光源,将这些数字插入标准GGX镜面反射公式。*似镜面反射光照贴图着色器:使用L1幅度来估计灯光的聚焦程度,与非线性漫反射SH照明类似的原理,接*0.0意味着光线来自多个方向,接*1.0意味着光主要来自一个方向。将表面粗糙度调整为快速区域光*似值,当启发式建议全方位照明时,使高光更柔和,纯粹基于视觉上令人愉悦且可信的结果的任意经验*似:
// Approximate an area light by adjusting smoothness/roughness
float lightmapDirectionLength = length(lightmapDirection); // value in range [0..1]
float3 L = lightmapDirection / lightmapDirectionLength;
float adjustedSmoothness = linearSmoothness * sqrt(lightmapDirectionLength);
// Proceed with standard GGX specular maths

文中还涉及了很多技巧,诸如半球和纹素采样、渲染收敛检测、处理重叠几何体、确保正确的双线性插值、高效的光照图集打包等。有兴趣的童鞋可以阅读原文。
HDR Image Based Lighting: From Acquisition to Render阐述了HDR下的IBL从需求到实现的过程和涉及的技术、优化。基于图像的照明(IBL)具有真实照片、物理正确、光度单位、环境匹配照明等特点,下面分别是HDR和LDR的IBL效果对比图:


为什么HDR和LDR有如此显著的差异呢?IBL作为点光源的总和:
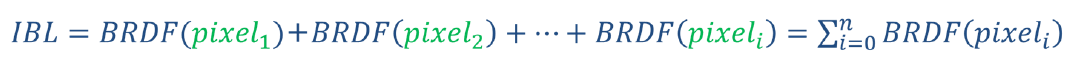
和的函数不等于函数的和:
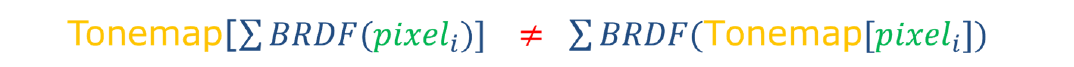
IBL获得正确照明的关键是亮度,色调映射的输出,而不是资产,色调映射是任何真正的HDR渲染的基本部分。作为辐射的环境贴图:全亮度范围,没有后期处理,没有白*衡,线性的。真实世界的亮度值,99%的可能物体位于10000nit的前方,但剩余物体会对照明产生很大影响:
靠数码相机捕捉的环境图仍然比太阳暗约350倍,数码图像质量又取决于分辨率、镜头光斑、噪点等因素。辐射贴图的组装:原始预处理,PTGui/HDR存储,逆转的响应曲线,光度校正。

其中PTGui是全景拼接和HDR组装软件,使用真正的HDR选项,使用预定义的反向响应曲线。
存储时,以绝对值存储,如果不能使用浮点格式,则可以进行更精确的打包,每个环境的照明设置基本相同。对于太阳亮度,用照度计测量照度,如果没有硬件,在颜色检查器上拍摄白色目标以恢复颜色或亮度,执行一些数学运算。太阳亮度的照度计测量传感器何时正常朝向太阳,使用“*面”传感器。
太阳的亮度计算过程:让目标暴露在阳光下拍摄,在阳光被小物体遮挡的情况下拍摄,以获得天光,从第一个减去第二个,除以反照率,获取照度:
利用HDR、摄影学校正、IBL光照渲染之后,以下是渲染器(Maxwell Render)和数码相片的对比:

Material Advances in Call of Duty: WWII阐述了COD: WWII的高级材质特性,例如法线和光泽映射(有理函数拟合、结合细节光泽)、材质表面遮挡、多散射漫反射BRDF(能量守恒扩散)等。
法线和光泽度(NDF)表示不同比例的几何信息,当法线后退到一定距离时,像素足迹下的法线变化应该用光泽度(NDF)表示。

MIPMAPPING的处理过程(将缩短的法线长度转换为光泽):

法线变化用MIPs编码,较低的MIP编码较高的正常变异,颜色较深。

法线图生成高度图,再从高度图生成遮挡图:

在处理AO时,被遮挡的方向具有相同的漫反射反照率,并且被遮挡的方式相似:

原始AO和改进AO的对比:

另外,将遮挡转换为等效锥角:
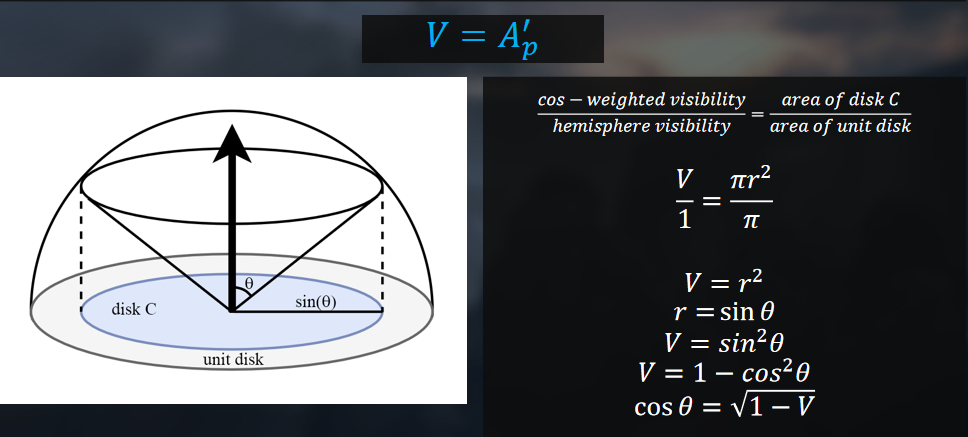
不同的遮挡方式的效果对比:

间接镜面遮挡采用了基于锥体的方法,环境BRDF扩展到三维:锥角θ,32x32x8纹理查找表,最左边的切片与二维查找表相同:完全未包含的圆锥体,最右边的切片是scale=0、bias=0:完全闭塞的圆锥体。
为了让漫反射达到能量守恒,使用了ENVBRDF查找表。EnvBRDF查找表表示聚集并反射到眼睛的镜面反射光能量的分数,同一个查找表还表示准时光源表面散射的光能的分数。

普通兰伯特和能量守恒兰伯特的对比:

另外,加强了掠射角的反光效应:
兰伯特和完全多散射漫反射BRDF的对比:
使用了BRDF切片的2D有理函数拟合:

完全多散射漫反射与拟合多散射漫反射的对比:
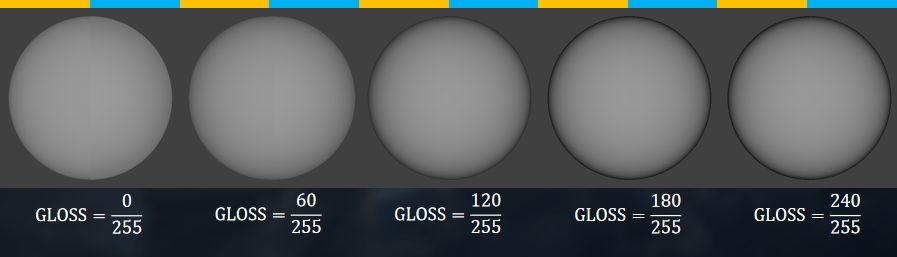
随着实时着色技术的最新进展,已经可以用复杂的区域光源照亮基于物理的存在。一个关键的挑战仍然存在:精确的区域光阴影。DXR的出现为通过光线追踪解决这个问题打开了大门,但正确的公式并不明显,而且存在几个潜在的陷阱。例如,最流行的策略包括追踪光线到光源上随机分布的点,并*均可见性,但这是不正确的,并且会产生视觉失真。相反,Real-Time Ray Tracing of Correct* Soft Shadows提出了一个软阴影的定义,可以计算正确的结果,以及一个与现有分析区域照明解决方案一起工作的高效实现。
之前的LTC并不能处理遮挡的光照,但更真实的光影应该具备:

之前有文献提出了仅光追的软阴影,做法是*均可见性:

但如果使用BRDF获得直接光,再乘以光追的*均可见性的软阴影,将得到错误的结果:
正确的做法应该如下图右边所示:
也可以采用随机化的方式,但必须强制BRDF的所有项都是随机化的:

随机化的结果是过多噪点和过于模糊:

所以仅光追的软阴影和完全随机化的两种方案都将获得错误或不良的结果。正确的软阴影算法应该如下所示:
从数学上讲,我们可以看到事情显然是正确的:\(a·b/a=b\):
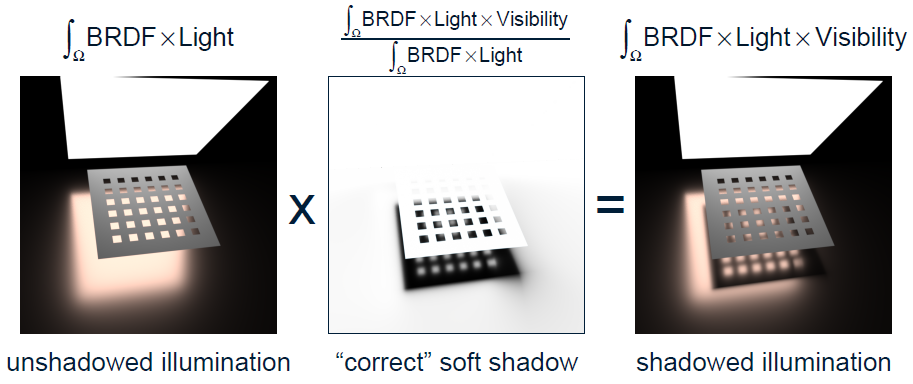
对应的正确随机化公式:
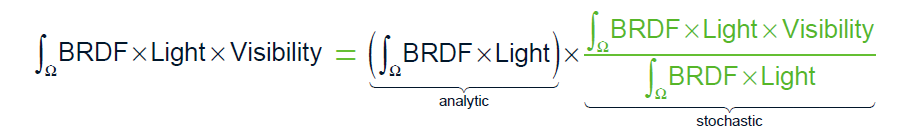
文中提出的方法如下:
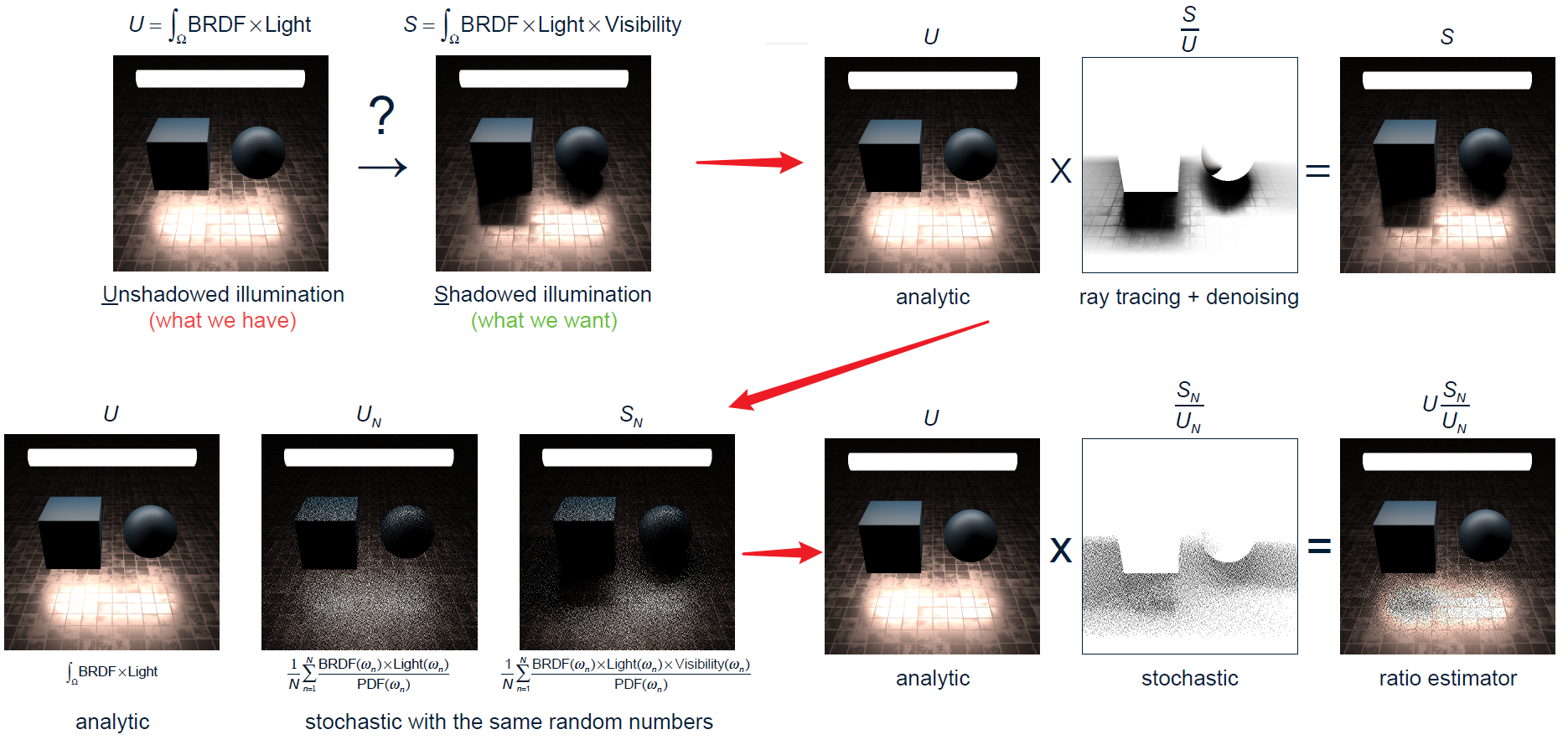
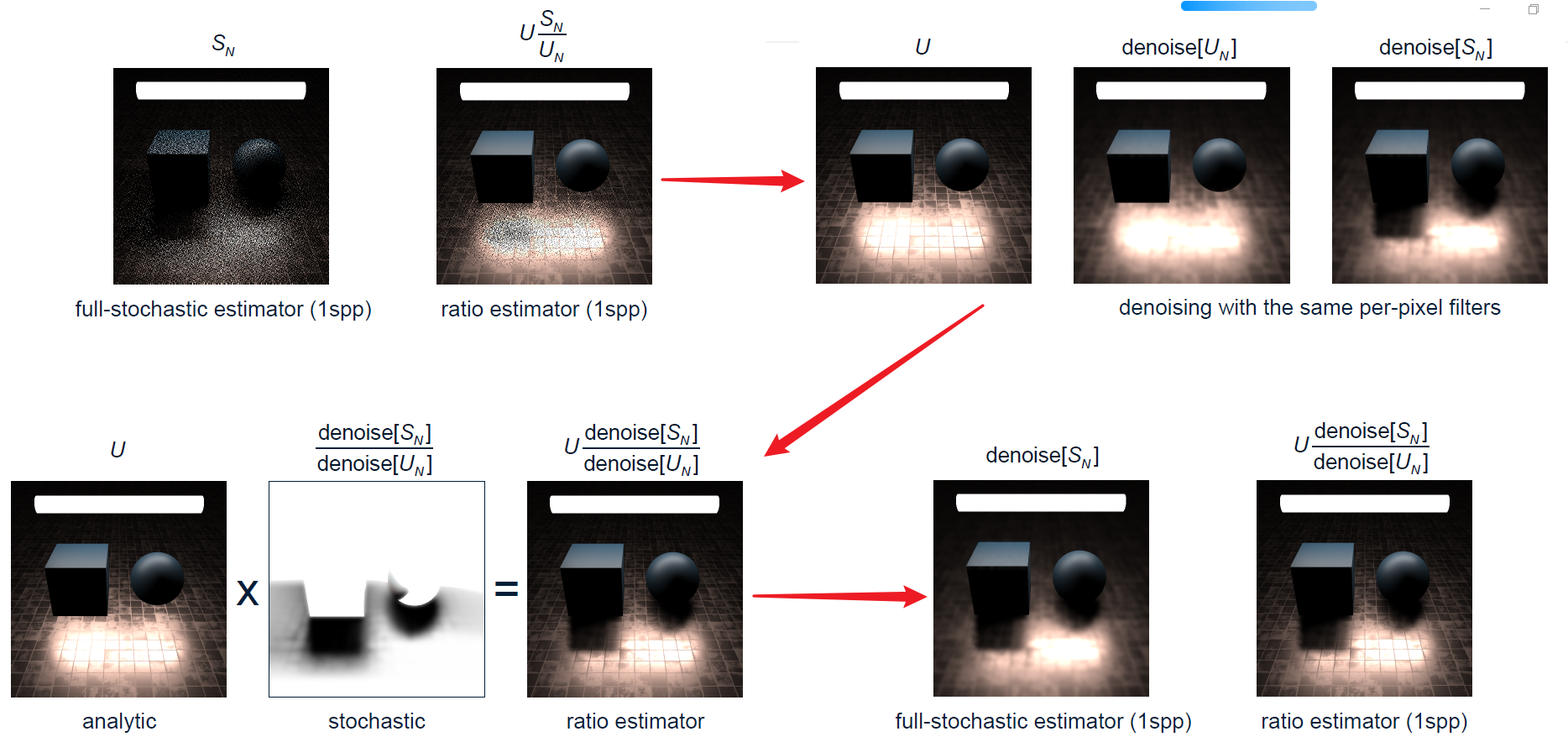
正确降噪的各个频率的函数如下:
降噪图例:

在采样方面,使用了多重要性采样:
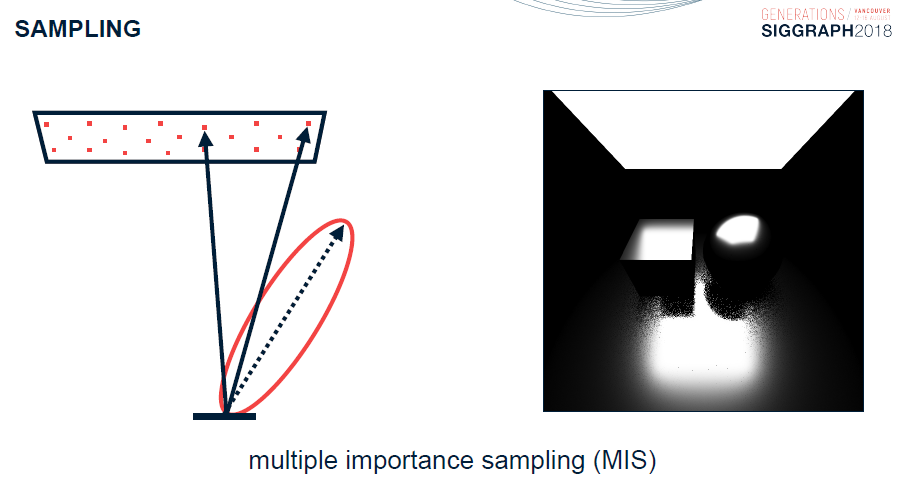
对于电介质(非金属),使用了电解质多重要性采样:
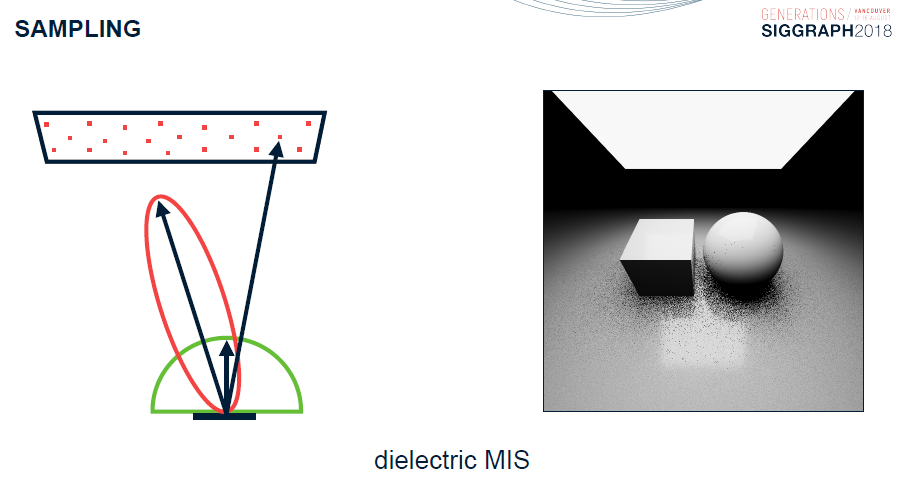
最终效果对比:

渲染通道和流程如下:
总之,比率估计器:无噪声有偏分析+无偏噪声随机,作为稳健噪声估计的总变化(非方差),由分析着色驱动的阴影多重要性采样,实时光线追踪GPU的注意事项:活动状态、延迟和占用率、多重要性采样的分支、波前与内联,混合的光线+光栅图形示例。
光线跟踪最终进入了实时图形管线,与光栅化、着色和计算紧密结合。跟踪光线的能力提供了最终能够在实时图形中准确模拟全局光散射的希望。正如*年来基于物理的材质彻底改变了实时图形一样,基于物理的全球照明也有机会对图像质量以及开发者和艺术家的生产力产生类似的影响。然而,要做到这一点并不容易:目前,在每个像素上只能追踪到少量光线,需要图形程序员非常谨慎和创造性。10年前广泛采用光线跟踪的离线渲染有一些经验教训,Adopting lessons from offline ray tracing to real-time ray tracing for practical pipelines讨论了离线管线使用该技术的经验,并强调在该领域开发的各种关键创新,这些创新对于采用实时光线追踪的开发人员来说是值得了解的。
离线渲染的经验:大约10年前,多通道光栅化达到了临界点,对于艺术家来说,迭代时间长,工作流程笨拙,从可视性角度渲染工件
*似值,预烘焙和缓存照明通常有效…直到它不起作用(╯°□°),无法按预期准确模拟光照传输。采用路径追踪:处理一切的统一光照传输算法,图元包含曲面、头发、体积测量…反射:所有类型的BSDF、BSSRDF…灯光:点光源、区域光源、环境图光源…
文中涉及四个主题:明智地选择光线(以及为什么必须选择),仔细地生成(非)随机数,把射线预算花在最有用的地方,理解并防止误差。首先了解一下方差的概念和公式:
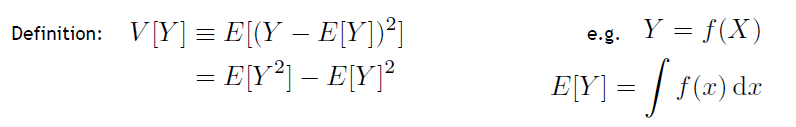
所有采样技术都基于将随机数从单位*方扭曲到其它域,再到半球、球体、球体周围的圆锥体,再到圆盘。还可以根据BSDF的散射分布生成采样,或选择IBL光源的方向。有许许多多的采样方式,但它们都是从0到1之间的值开始的,其中有一个很好的正交性:有“你开始的那些值是什么”,然后有“你如何将它们扭曲到你想要采样的东西的分布,以使用第二个蒙特卡罗估计”。
对应采样方式,常用的有均匀、低差异序列、分层采样、元素区间、蓝噪点抖动等方式。低差异类似广义分层,蓝色噪点类似不同样本之间的距离有多*。过程化模式可以使用任意数量的前缀,并且(某些)前缀分布均匀。

方差驱动的采样:根据迄今为止采集的样本,周期地估计每个像素的方差,在差异较大的地方多采样,更好的做法是在方差/估计值较高的地方进行更多采样,在色调映射等之后执行此操作。离线(质量驱动):一旦像素的方差足够低,就停止处理它。实时(帧率驱动):在方差最大的地方采集更多样本。计算样本方差(重要提示:样本方差是对真实方差的估计):
float SampleVariance(float samples[], int n)
{
float sum = 0, sum_sq = 0;
for (int i=0; i<n; ++i)
{
sum += samples[i];
sum_sq += samples[i] * samples[i];
}
return sum_sq/(n*(n-1))) - sum*sum/((n-1)*n*n);
}
样本方差只是一个估计值,大量的工作都是为了降噪,MC渲染自适应采样和重建的最新进展。总体思路:在附*像素处加入样本方差,可能根据辅助特征(位置、法线等)的接*程度进行加权。
高方差是个诅咒,一旦引入了一个高方差样本,你就有大麻烦了,例如考虑对数据进行均匀采样:
6个样本:(1, 1, 1, 1, 1, 100 ) ≈ 17.5,再取6个样本:(1, 1, 1, 1, 1, 100, 1, 1, 1, 1, 1, 1 ) ≈ 9.25,回想一下,方差随样本数呈线性下降…面对这种高方差样本,最hack但也最有效的方式是clamp,如下图所示:

更复杂的选择:基于密度的异常值剔除[Decoro 2010],保存所有样本,分析并过滤异常值;[Zirr 2018]:根据亮度将样本分成几个单独的图像,然后根据统计分析重新加权。

Real-Time Reflections in 'Mafia III' and Beyond阐述了游戏Mafia III实现实时反射的方案,包含现有解决方案、GPU上的光线投射
反射渲染、粗糙表面上的反射、结果等。
当时已经存在的解决方案有SSR、预过滤立方体图查找、SSR+预过滤立方体图查找、SSR+视差校正立方体贴图(预过滤)、锥体追踪等。现有的解决方案均未满足所有要求:相机运动的稳定性、良好的性能和内存成本、在所有环境(室内、城市、景观)中无缝工作、合理的内容创作成本、实时更新(场景更改)等。
GPU上的光线投射:网格/BVH有分支、非相干存储器存取、如何计算着色等问题,体素有内存繁重、重要实现等问题,深度纹理对GPU友好,普通的实现,不是完美的空间覆盖等。
文中采用的立方体图设置:8个活动几何体CM、1个天空CM,每个512像素的分辨率,带完整的MIP链,无法离线预渲染CM,因为要支持动态时间和天气,如果可以预渲染,则不需要单独的天空CM。立方体图离线预计算最大视距(每一侧):
用于所有侧面的CHull场景查询,使用几何体着色器输出到受影响的边,有限的特性集。在更新上,天空CM每隔几帧更新一次(云、ToD),几何CMs定期更新动态照明(循环),缓存G缓冲区和静态照明,找到更好的CM后渲染新的。
活动立方体贴图选择:每个项目可能会有所不同,使用8个离玩家最*的,但有2个特殊情况:至少一个室外CM,在垂直轴上分开楼层的不利影响。可能的改进是使用边界框(内/外、距离),使用遮挡查询,预计算体积的最佳CM集。
反射的渲染步骤:
-
下采样G-Buffer,应用NDF。检测深度不连续性,如果检测到边缘,丢弃“小样本”,选择随机样本(利用时间过滤器),抖动法线(应用NDF),输出(均为半分辨率)RT0(深度)、RT1(抖动的法线和粗糙度)、RT2(原始法线和粗糙度)。
-
追踪屏幕,输出距离。追踪屏幕空间深度,输出行进的距离、“完成”标志,“完成”标志的模板遮罩。
![]()
-
追踪立方体图,输出距离和索引。基于粗糙度(HQ/LQ)的2次通道,从SSR终点开始,使用最佳CM,如果追踪失败,切换到链中的下一个CM并继续,如果所有CM都失败,使用回退,输出行进的距离和CM索引(发现命中的位置)。
-
解析颜色。半分辨率通道:解析SSR颜色,解析CM颜色。全分辨率通道:放大半分辨率的解析缓冲区,生成低粗糙度的模板掩模,在低粗糙度像素上解析SSR,在低粗糙度像素上解析CM。
-
放大。输入半分辨率的颜色、半分辨率的无抖动法线、半分辨率的深度、全分辨率的法线、全分辨率的深度,输出:全分辨率的颜色(高粗糙度像素)、模板掩模,从半分辨率颜色中选择一个最匹配全分辨率的法线和深度的样本。

对于粗糙表面的反射,当前的解决方案是混合所有3+一些技巧:50%重要性采样、50%使用预过滤MIP(SSR和CM)、5样本的BRDF加权屏幕空间模糊、修正的样本分布、时间过滤,数学基于Blinn Phong(尚未转换为GGX)。

在实现反射的过程中,重用了邻域样本。4个邻域的采样深度和法线,与像素分类相同的模式,使用未抖动的法线,计算加权*均数:中心样本:1、深度/粗糙度不连续性:0,否则评估BRDF。

A Journey Through Implementing Multiscattering BRDFs and Area Lights阐述了多散射的光照模型和区域光的技术。
在多散射的镜面反射上,非金属不明显,但金属有着较明显的区别:

目标是对Lambertian漫反射的改进,考虑多散射,漫反射会对表面粗糙度产生反应,漫反射取决于法线的分布,漫反射和镜面反射都是能量守恒的。以往的光照模型如下:
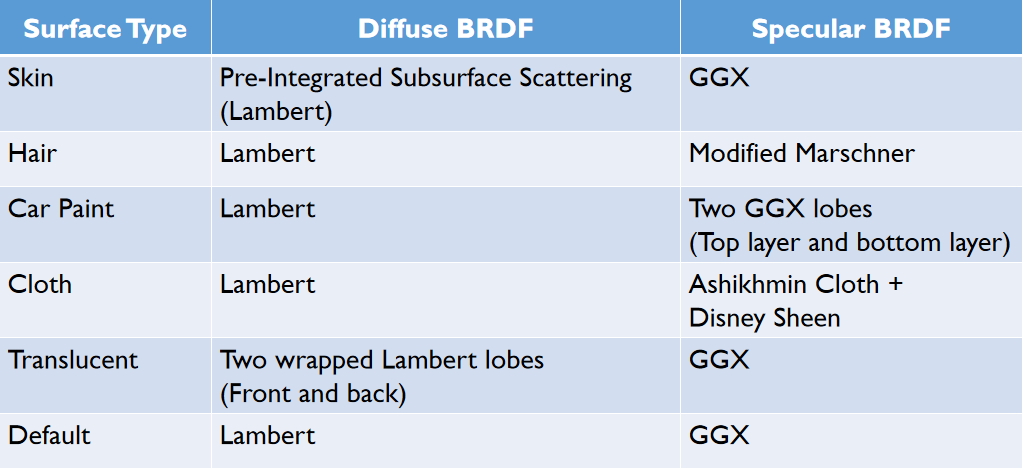
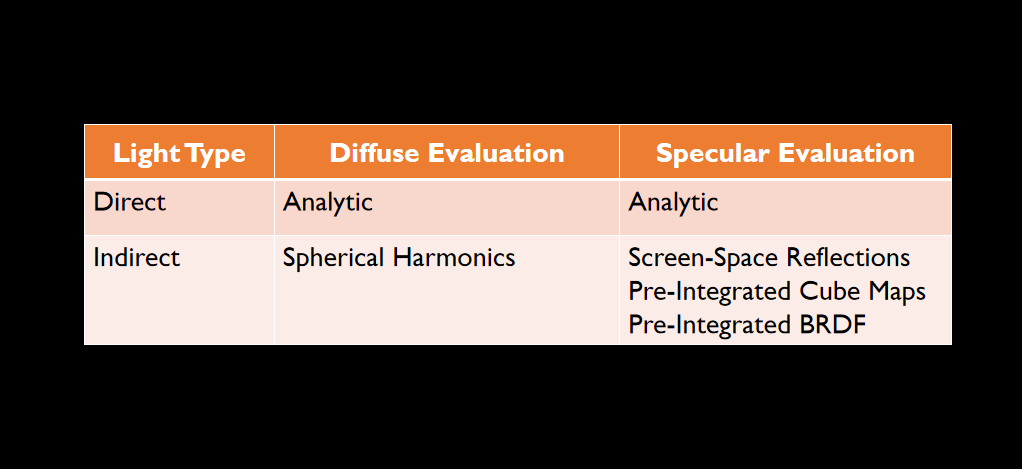
存在的问题是无多散射间接镜面反射,头发上没有多散射镜面反射,无多散射间接漫反射,皮肤上无多散射,无多散射。在镜面多散射上面,公式的推导、*似过程如下:
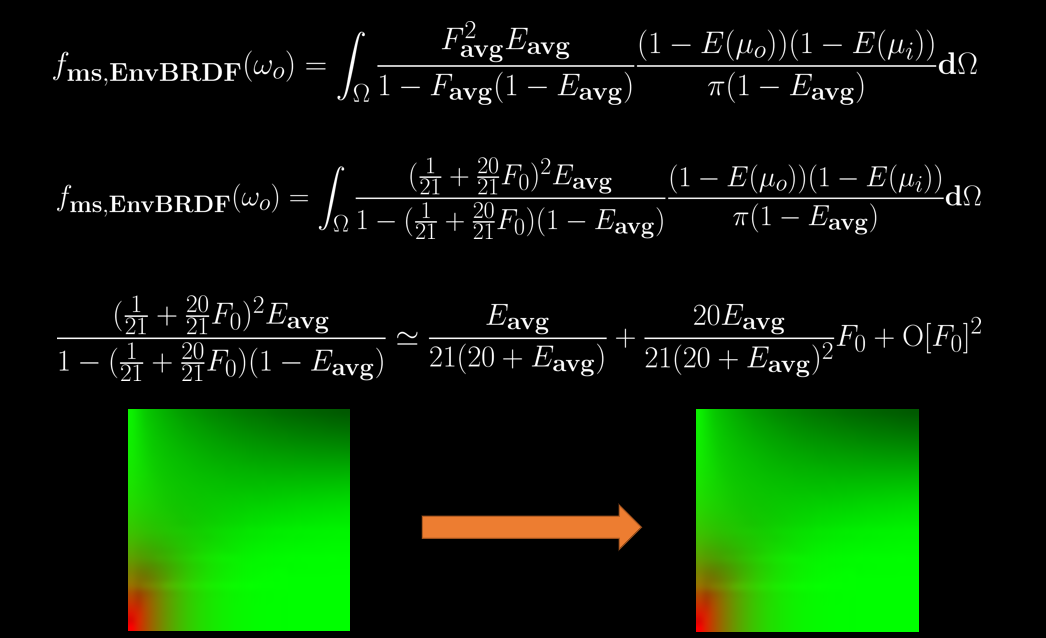
单次散射的能量实际上是环境BRDF中红色和绿色通道的总和:
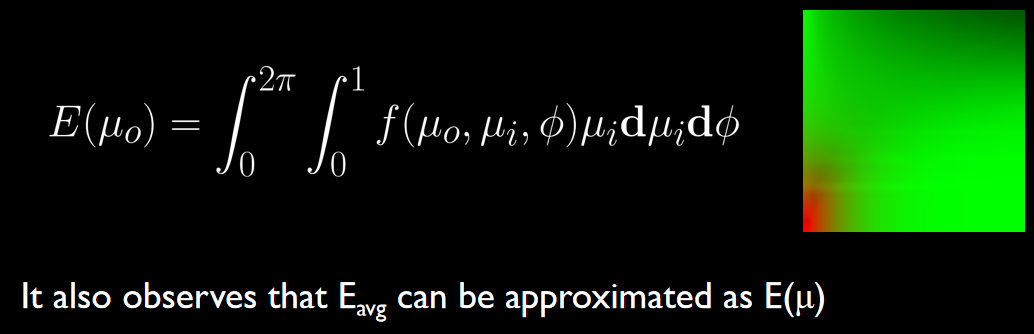
考虑到\(F_{avg}\)可以解析计算,且多重散射光是漫反射的,我们得到以下公式:
float2 FssEss = envBRDF.x + F0 * envBRDF.y;
float Ess = envBRDF.x + envBRDF.y;
float Ems = 1.0f - Ess;
float Favg = F0 + (1.0f / 21.0f) * (1.0f - F0);
float Fms = FssEss * Favg / (1.0f - Favg * (1.0f - Ess));
float Lss = FssEss * radiance;
// irradiance改成了radiance。
float Lms = Fms * Ems * radiance;
return Lss + Lms;
效果对比:

至此,可以更新不同材质使用的光照模型:
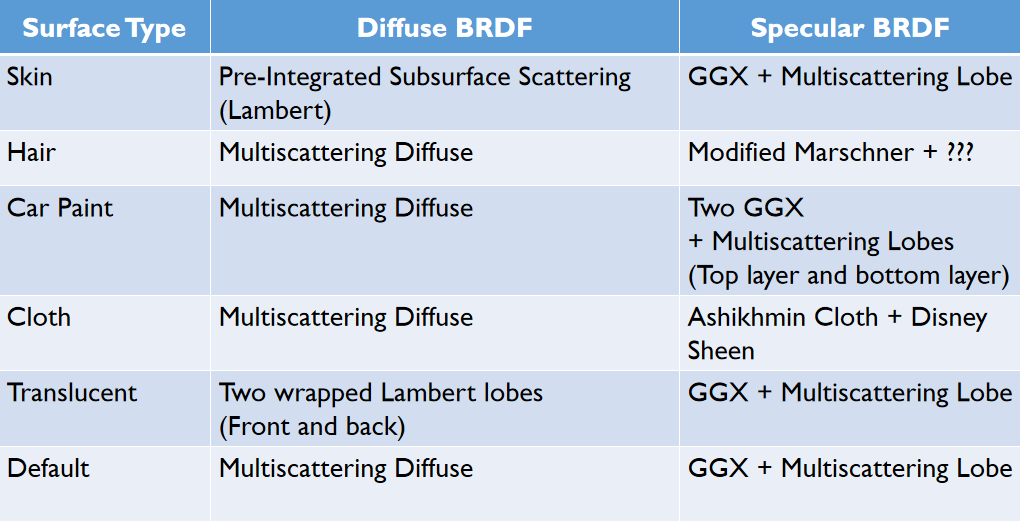
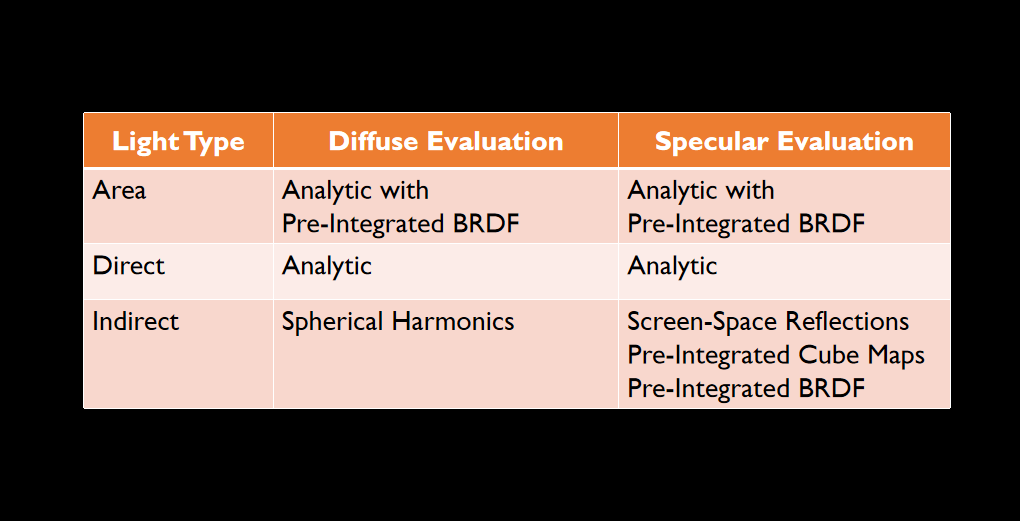
对于多散射镜面反射,LTC幅度和菲涅耳依赖于F0的线性依赖关系(下图上),但该文的多散射BRDF具有非线性依赖性(下图下):
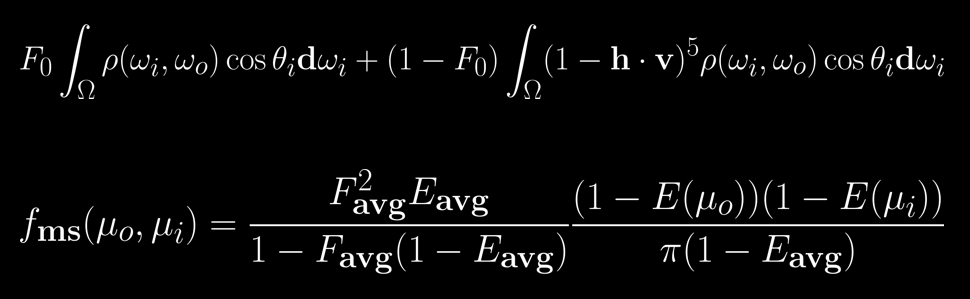
有一个多散射BRDF的公式,E(μ)是在幅度和菲涅耳LUT中的红色通道:

效果对比:

文中还涉及了组合扭曲漫反射和LTC、组合预计算SSS和LTC等方法。
It Just Works: Ray-Traced Reflections in "Battlefield V"阐述了游戏Battlefield V的光线追踪相关的技术,包含GPU光线追踪管线、DXR的引擎集成、GPU性能等。

(简单)光线跟踪管线:
生成管线阶段,读取GBuffer的纹理,使用随机光栅化来生成光线:
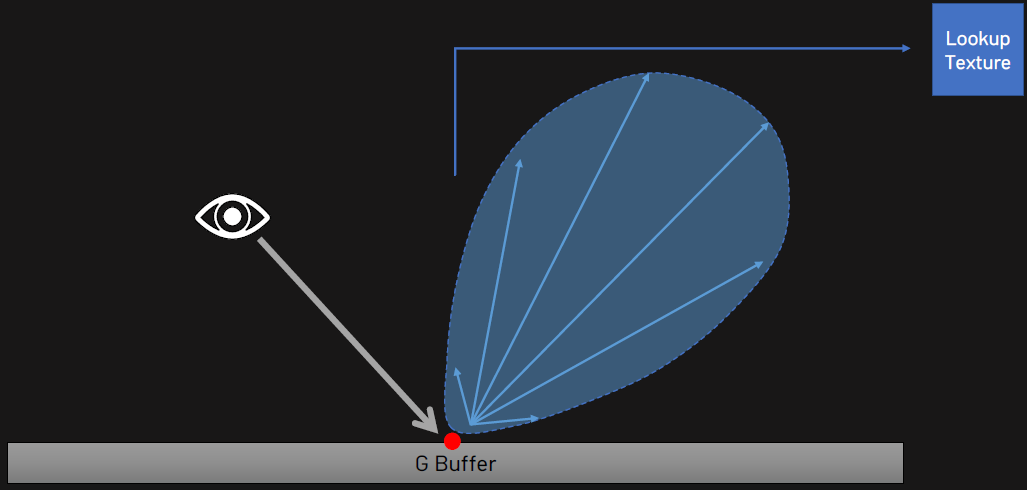
float4 light(MaterialData surfaceInfo , float3 rayDir)
{
foreach (light : pointLights)
radiance += calcPoint(surfaceInfo, rayDir, light);
foreach (light : spotLights)
radiance += calcSpot(surfaceInfo, rayDir, light);
foreach (light : reflectionVolumes)
radiance += calcReflVol(surfaceInfo, rayDir, light);
…
}
然而这种简单的光追管线渲染出来的画质存在噪点、低效、光线贡献较少等问题:

现在改进管线,在生成射线时加入可变速率追踪:

可变速率追踪的过程如下:
可变速率追踪使得水上、掠射角有更多光线。但依然存在问题:

可以加入Ray Binning(光线箱化),将屏幕偏移和角度作为bin的索引。

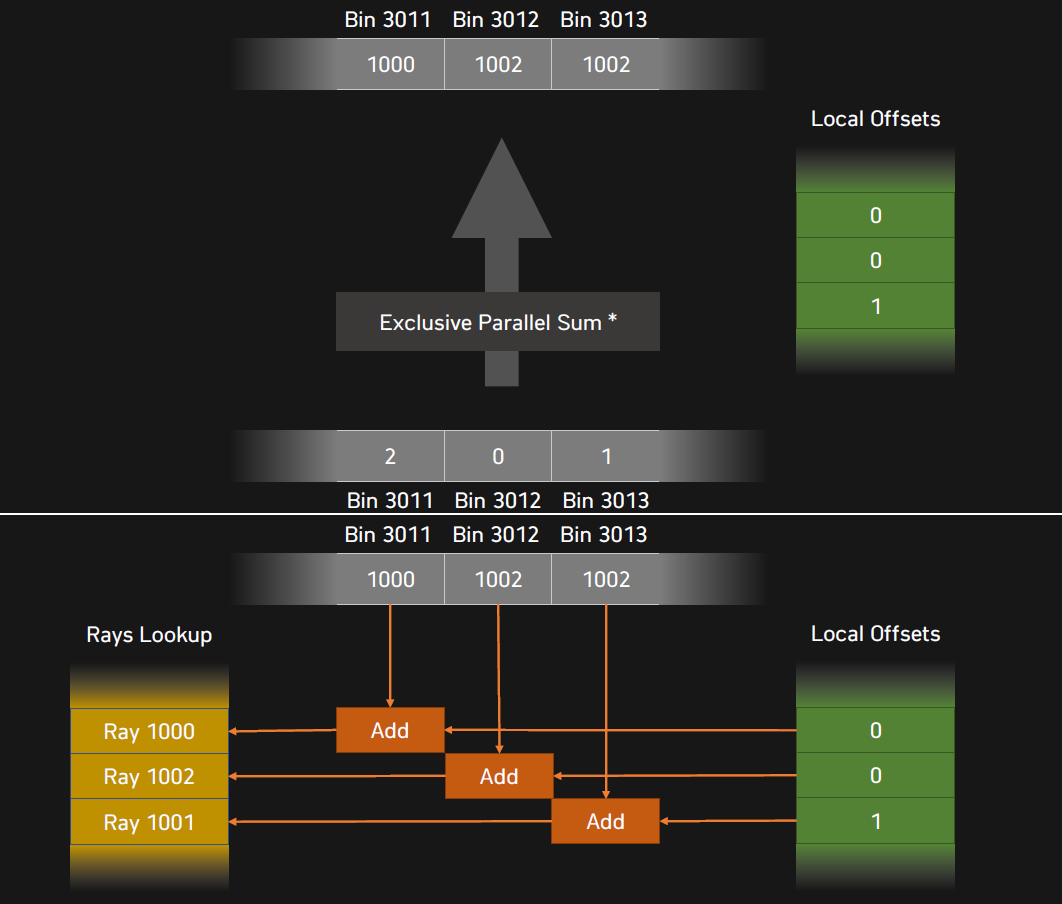
依次可以加入SSR混合(SSR Hybridization)、碎片整理(Defrag)、逐单元格光源列表光照、降噪(BRDF降噪、时间降噪)等优化。

SSR Hybridization的过程和结果。
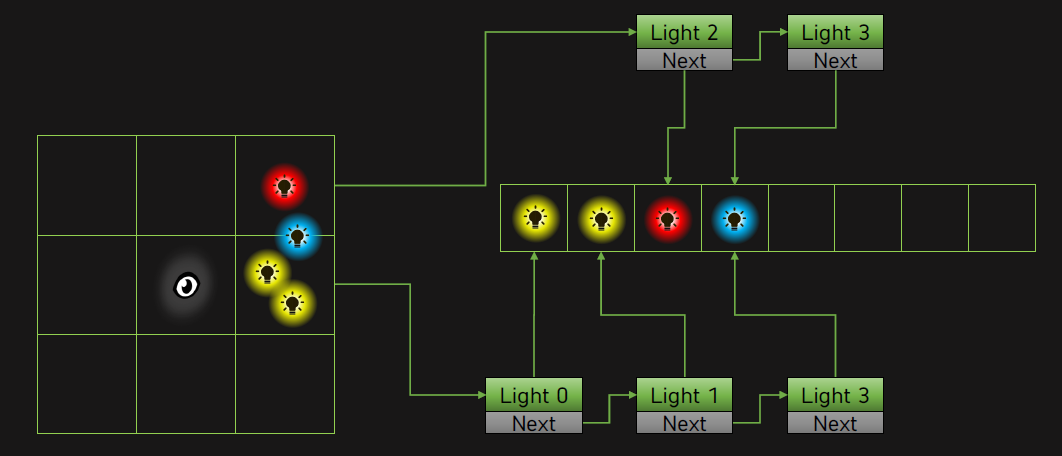
逐单元格光源列表光照。
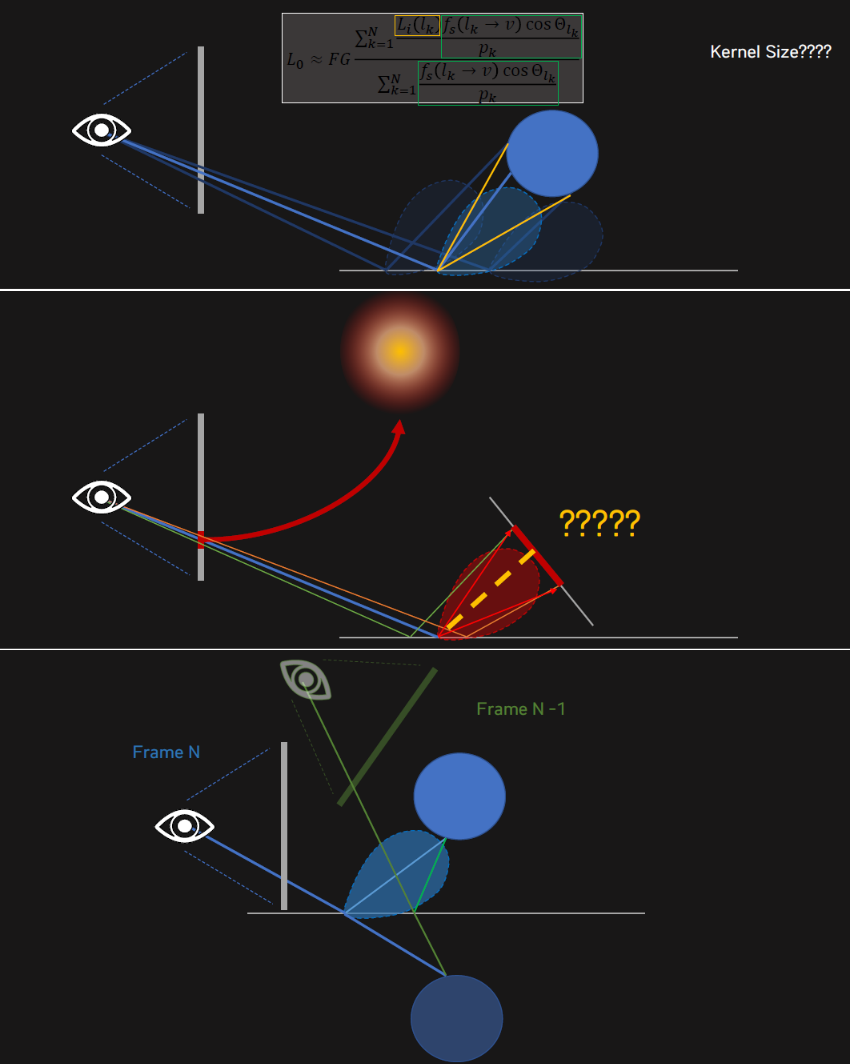
BRDF降噪过程。
最终形成的新管线和时间消耗如下:

渲染效果:

DXR基础:
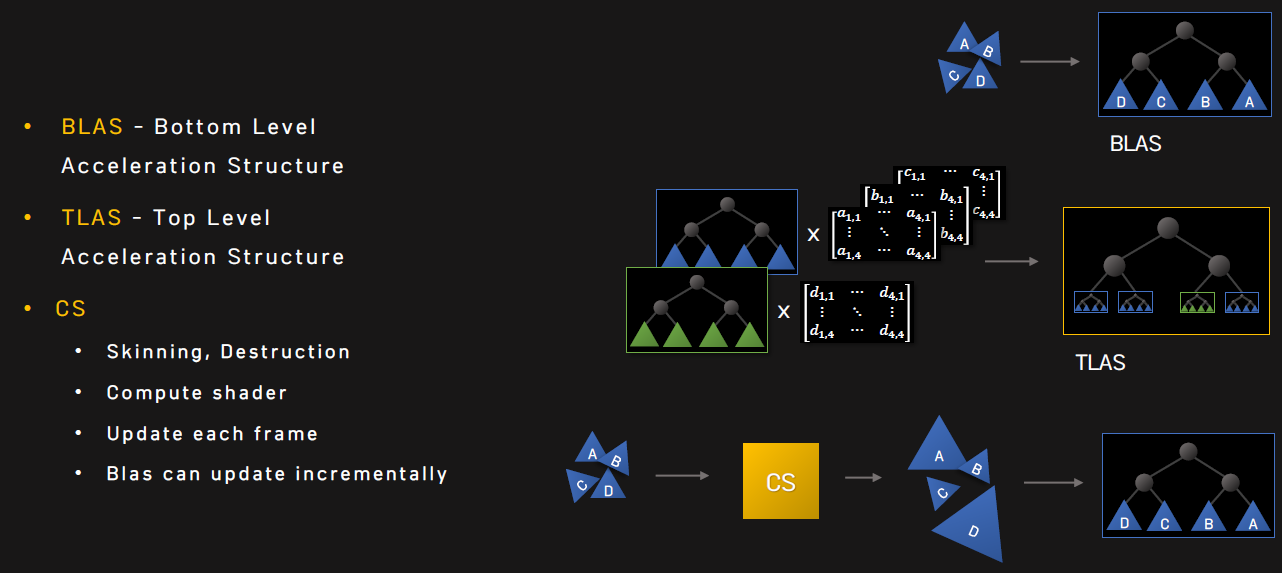
DXR的性能优化包含减少实例数、使用剔除启发法、接受(一些)小瑕疵。剔除启发法假设远处的物体并不重要,除了桥梁、建筑等大型物体物,需要一些测量。投影球体包围盒,如果\(\theta\)小于某个阈值,则剔除:
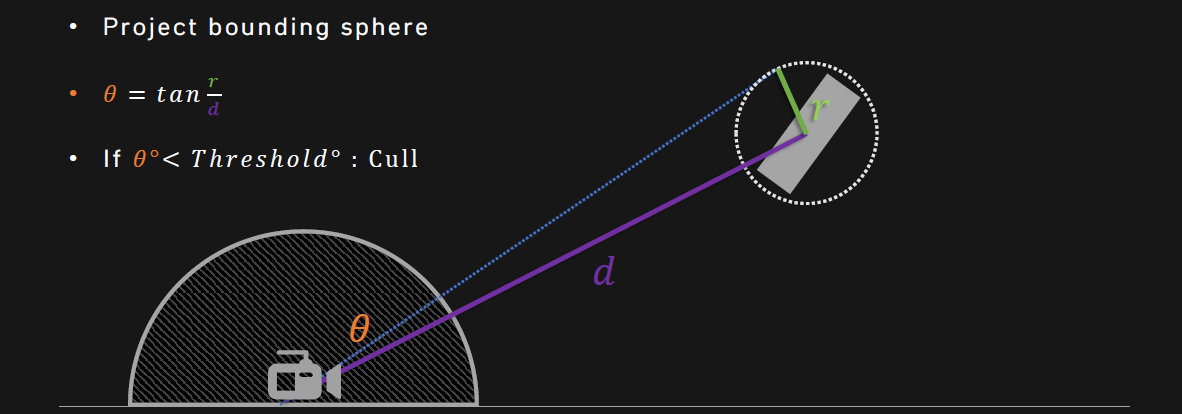
不同阈值的效果:

剔除结果:使用4度剔除,5000-->400 BLAS重建每帧,20000-->2800个TLAS实例,TLAS+BLAS构建(GPU):64毫秒-->14.5毫秒,但引入了偶尔跳变及物体丢失等瑕疵。
BLAS更新优化:BLAS更新依旧开销大,可以采用以下方法优化:
- 错开完整和增量BLAS重建。在完全重建之前N帧增量。
- 使用D3D12_RAYTRACING_ACCELERATION_STRUCTURE_BUILD_FLAG_PREFER_FAST_BUILD。
- 避免重复重建。检查CS输入(骨骼矩阵),400 --> 50,将BLAS更新与GFX重叠,如Gbuffer、阴影图。
结果TLAS+BLAS构建(GPU):14.5毫秒-->1.15毫秒,RayGen(GPU):0.71毫秒-->0.81毫秒(交错重建+标志)。
不透明总结:总是使用ClosestHit着色器,仅对Alpha tested物体使用Any Hit着色器,对蒙皮、破坏使用计算着色器。
射线有效载荷(RAY PAYLOAD)在ray交点出返回,与Gbuffer RTV的格式相同,包含材质数据、法线、基础色、*滑度等。
struct GbufferPayloadPacked
{
uint data0; // R10G10B10A2_UNORM
uint data1; // R8G8B8A8_SRGB
uint data2; // R8G8B8A8_UNORM
uint data3; // R11G11B10_FLOAT
float hitT; // Ray length
};
验证正确性:光栅化输出,向场景中发射主要光线,将有效载荷与Gbuffer进行比较,非零输出?有bug!修正错误。

The Indirect Lighting Pipeline of 'God of War'阐述了God of War的间接光渲染,包含整个管线的概述、动机和权衡、推动决策的背景/情况、技术概述等。
Gl体积针对低频静态间接照明,每个体素1米以上的粒度,松散地放在Maya中,额外烘焙。编码用4种3D纹理:2阶球谐函数、RGB反弹和天空可见性+单色反弹,用Float16格式。分割天空和反弹可以提高方向性,天空不可知,单独表示,在运行时与Gl合并:

大的体素产生自遮挡和漏光,通过体素法线偏移Gl的采样位置,兼容硬件过滤。

对于移动物体,使用法线偏移移动对象可以获得闪亮的外观,不要在动态对象上用法线偏移,因为它们不在烘焙中。间接镜面反射可选屏幕空间反射,立方贴图(mip链中的光泽卷积),盒子视差校正,手动放置(包括盒子碰撞),从cubemap深度缓冲区中查找最佳拟合框碰撞的实用程序,盒子对有机环境不是很好的选择。
立方映射标准化:目标是在漫反射和镜面反射环境照明之间保持自然*衡,将立方体贴图用于角度细节和空间细节。在构建过程中从cubemap生成球谐函数,使用球面谐波消除低频细节,替换为GI的低频细节:

立方体标准化关闭(上)和开启(下)的对比:

环境遮挡:SSAO、AO图、角色AO胶囊类似于Last of Us的固定项 + 方向项,战神用了布娃娃胶囊,在生产后期几乎超过了极限。

光照注入:最初的技术在光照图中积累了中间结果,这是在持久的surfel集合中完成的,创建surfel时,照明保持发光状态。针对每种光线(添加到emissive)的每一个表面评估直射光,使用与主渲染相同的照明计算/模型。
射线处理:N条射线:将surfel投影到链接列表中,对列表进行排序,遍历列表,在surfel之间传输光线,解析到GI体积。构建列表:对于每个光线方向,将表面投影到链接列表的纹理中,每个texel存储当前列表头指针,原子交换将新的surfel附加为新的头(下图左)。排序列表:对于每个光线方向,排序并压*,每个线程可以是高度不同的、唯一的链表,处理过程中最慢的部分,使用冒泡排序(下图右)。

光照传输:对于每个光线方向,遍历排序的列表,将邻域的照明贡献累积到surfel中,使用渲染器的共享照明代码,以同样的方式积累天空,但首个surfel将天空视为光源(下图左)。解析体积:随着处理的进展,立即积累SH编码,对于每个光线方向,对于每个体素中心,投射到头部纹理中,遍历直到在两个surfel之间,编码surfel贡献(下图右)。

文中还涉及体积雾、半透明、可变分辨率等技术进行了分享。
Scalable Real time Global Illumination for Large Scenes讲述了用于大规模场景的可扩展的实时GI解决方案。其解决方案是场景的体素表示(如体素圆锥体跟踪),相机周围的初始体素化照明场景尽可能好,尽可能快,如碰撞几何、实体的较低LOD、高度图数据,来自屏幕GBuffer的反馈体素化灯光场景,可见光辐照度volmap(体积图)部分地在每一帧重新计算,使用真实的强力光线投射(无光)。
辐照度图:将辐照度存储在相机周围的嵌套体积贴图中(3d clipmap),每个级联为约64x32x64,单元格大小为\(0.45m \cdot 3^i\)(或在低端设备上为\(0.9m \cdot 3^i\),i是级联索引),选择了HL2环境立方体基,正交基,但GPU对样本非常友好,可以很容易地更改为其它基。
基本场景参数化:将场景存储在相机周围的嵌套体积贴图(3d clipmap)中,每个级联为128x64x128,单元大小为\(0.25m \cdot 3^i\)(或在低端设备上为\(0.5m \cdot 3^i\),i是级联索引),要么存储完全照明的结果,要么存储两个体积纹理中的照明+反照率。
Sponza场景参数化:

初始场景填充:当相机移动时,“以环形方式”填充新的体素(类似于纹理包裹),用高度贴图数据和碰撞几何体(顶点着色)或实体的低级LOD填充新的体素,然后立即用太阳光、间接光辐照度和该区域最重要的光照亮这个新的体素。
场景反馈循环:在中等设置下,场景不断更新,随机选择32k GBuffer像素,对于每个随机选择的GBuffer像素,使用它的反照率、法线和位置以及直接光和间接辐照度贴图来照亮它,使用移动*均更新这个新的发光颜色的体素化场景表示。这提供了反馈循环,因为使用重照明GBuffer像素更新场景体素,使用当前辐照度体积图更新它们,并用当前场景体素更新辐照度体积图。它不仅提供多次反弹,还解决了体素化问题(墙比2个体素薄,精度高),此外,环境探针(在渲染时)提供了“主”摄像头无法捕捉到的更多数据。
辐照度贴图初始化:当摄像机移动时,我们填充新的纹理(探针),对于更精细的级联,从更粗糙的级联复制数据,对于“场景相交”和最粗糙的级联贴图,跟踪64条光线以获得更好的初始*似,用magic(“不是真正计算的”)值来标记它们的时间收敛权重,所以一旦它们变得可见,它们就会被重新激活。
辐照度图-计算循环:在辐照度体积图中随机选择几百个可见的“探针”(位置),选择的概率取决于“探测”的可见性和探测的收敛因子(上次变化的程度),对于选定的“探针”,在场景中投射1024到2048条光线(取决于设置),用移动*均法累积结果。
辐照度图-计算队列:为了快速收敛,在辐照度图中为不同的“探针”设置不同的队列非常重要,第一次看到,从未计算过要尽快计算,即使质量较低。使用256条射线,但队列中有4096个探针,不相交的场景探针不参与光照传输,但仍然需要为动态对象、体积测量和粒子计算它们。使用1024条射线,队列大小只有64到128个探针。
初始化光照-鸡和蛋问题:当摄像机传送时,它周围的所有级联都是无效的,所以不能用辐照度(第二次反弹)来照亮初始场景,也不能计算没有初始场景的初始辐照度。分两次完成:体素化场景,仅使用直射光照亮,计算天光和第二次反弹的辐照度,然后重新缩放场景,很少发生(剪影)。
使用辐照度贴图进行渲染:选择最好的级联,根据法线符号,从六个辐照度体积贴图纹理中抽取三个进行采样(请参见HL2 Ambient Cube)。在边界上,将其与下一个级联混合,延迟通道和向前通道(以及体积光照)也一样。
另外,使用凸面偏移过滤来解决光照泄漏:

对于室内的过暗问题,添加“孔/窗”体积(永远不会用体素填充)来解决:

GI结论:具有多个光反弹的一致间接照明,可调质量,从低端PC到超高端硬件支持,但不影响游戏性,可扩展的细节大小,以及光线跟踪质量。动态的(在某种程度上),炸毁一堵墙,摧毁一栋建筑,光照可以照进,建造围墙产生反射和间接阴影,快速迭代。
Precomputed Lighting Advances in Call of Duty: Modern Warfare分享了2020年的COD的预计算光照技术,包常规烘焙改进、球谐编码(关注关于球谐函数的见解)、一种新的线性SH重建算法、动态光集实现细节。
常规烘焙改进包含射线导向、回溯太阳、大地图(天窗、流)、光照一致性(缝合模型、合并模型、薄模型)、光照图编码等。
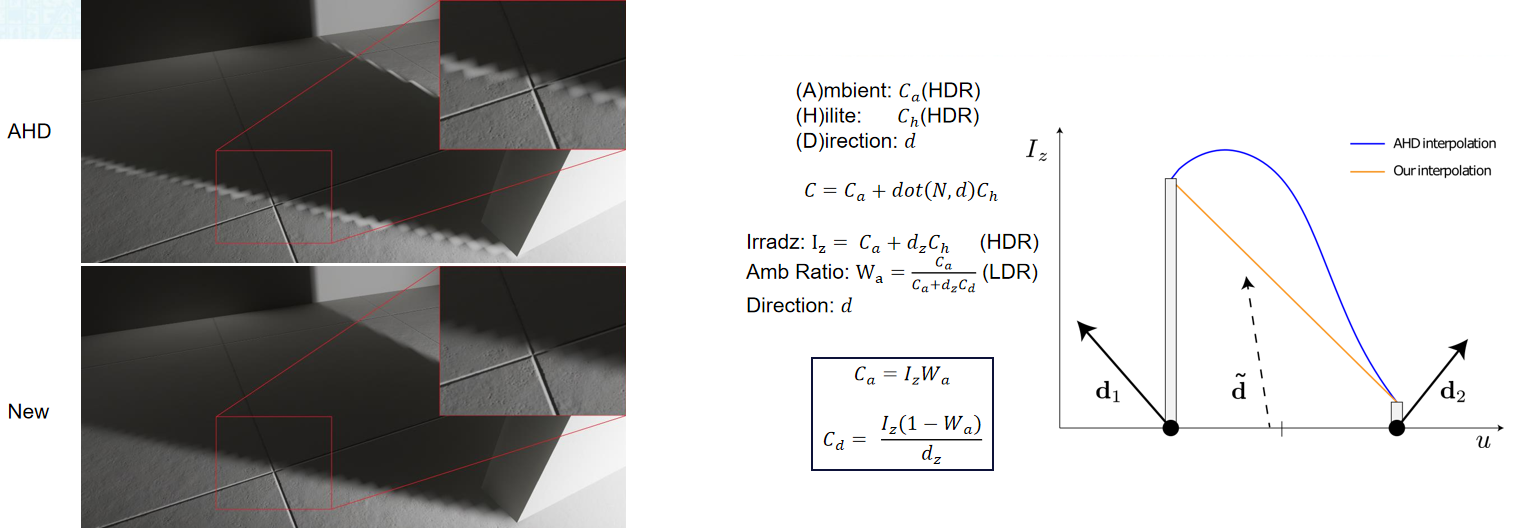
新的光照图编码对比及公式。
文中采用了SH差异函数来编码:

SH重建*行光时,使用线性的SH的效果并不怎么好:
可以将SH转换成ZH基:
ZH计算:
效果对比如下:

编码数据:LG和LGV都很简单,SH编码最初仅用于此目的,LM更具挑战性,读修改写资源问题,大部分数据。新的LM格式最初仅适用于DLS,Texel尺寸为当时LM的一半。
VRS Tier 1 with DirectX 12 From Theory To Practice介绍了DX12 Tier 1的可变速率着色、虚拟现实引擎4中的VRS及骑士精神II实践中的VRS。
VRS边缘保持解释:以2x2渲染的16x16三角形,28个2x2粗像素+8个1x1像素=120像素,边缘像素在粗像素的中心进行采样,覆盖区域外的像素没有着色,边缘保持是分辨率缩放的一个优势。
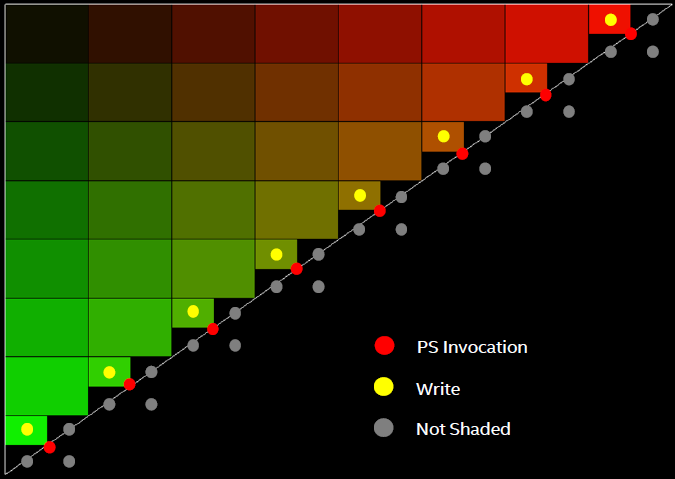
VRS Tier 1的限制:如果SV_Coverage被声明为VRS Tier 1的着色器输入或输出,则着色速率将降低到1x1。SampleMask必须是完整的遮罩,如果将SampleMask配置为其它类型,则着色速率将降低到1x1。EvaluateAttributeAt[ Centroid|Sample|Snapped ]与tier 1 VRS不兼容,如果使用这些内置函数,着色率将降低到1x1。着色器中引用的HLSL的sample关键字将使着色速率降低到1x1。
虚幻引擎4集成延迟和前向着色,在DirectX 12 RHI集成,RHICheckVRSSupport确定硬件支持,并在初始化时调用,RHISetVRSValues采用控制结构,使用D3D12CommandList5将着色速率值传递到命令列表中,控制台变量的实现用于网格通道的着色速率,针对每种材质着色速率的编辑器集成。
VRS网格通道控制GBuffer放置期间的着色速率。由EMeshPass枚举定义的多个网格过程用于GBuffer放置,如BasePass、TranslucencyStandard、TranslucencyAfterDOF、TranslucencyAll,为像素限制的工作负载提供性能提升,BasePass和半透明通道是最无失真的通道,用其它通道进行的试验没有达到可接受的质量。由于边缘保留,网格通道的视觉质量高于等效渲染比例,但性能将取决于内容。
VRS网格通道:分辨率缩放不也有类似的好处吗?分辨率缩放是在低功耗图形部件上*滑帧率的常用技术,分辨率缩放会在多个管线阶段影响整帧的质量。通过控制网格通过着色速率,可以更好地控制以质量换取性能的位置。分辨率缩放可以提供更高的性能,但网格通道着色速率可以保留三角形边,而分辨率缩放则不能,网格通道着色速率可用于DRR的性能提升。
SSR+VRS实验:将VRS应用于SSR会导致视觉伪影,但是我们能提高视觉质量吗?启用TAA时,右上角的对角线瑕疵会闪烁,设置r.SSR.Temporal为1,并通过着色速率X/着色速率Y缩小r.TemporalAAFilterSize可以减少闪烁,也会增加清晰度。在ScreenSpaceReflections.usf通过着色速率缩放ScreenSpacerReflectionsPS中的StepOffset值可以减轻视觉损坏,但边缘瑕疵仍然存在。


该文作者不建议将其用于最终产品,但它指出了SSR+VRS可能可行的未来。
VRS材质:子通道材质系统。新的材质属性——着色率,具有实例覆盖的材质实例支持,“材质”视口中的实时更新,将着色速率应用于共享材质的多个资源,创建实例以智能地控制网格子集的着色速率,使用最高的着色率1x1保存高质量资产。对于不太重要的资产,使用较低的着色速率,如2x2或4x4。混合和匹配材质着色速率,以选择性地保持单个网格的质量。
混合和匹配材质着色速率:使用两种材质在每个模型的基础上有选择地改变着色速率(下图左)。在某些情况下,使用2x2或4x4可能会导致视觉质量差(下图中)。通过混合着色速率,可以保留高保真的内容(下图右)。
VRS的LOD:为每个LOD级别创建VRS材质,定义*(1x1)、中(1x2)、远(2x2)。在“材质编辑器”中,将LOD材质插入材质槽。使用材质窗将VRS材质应用于自定义LOD。
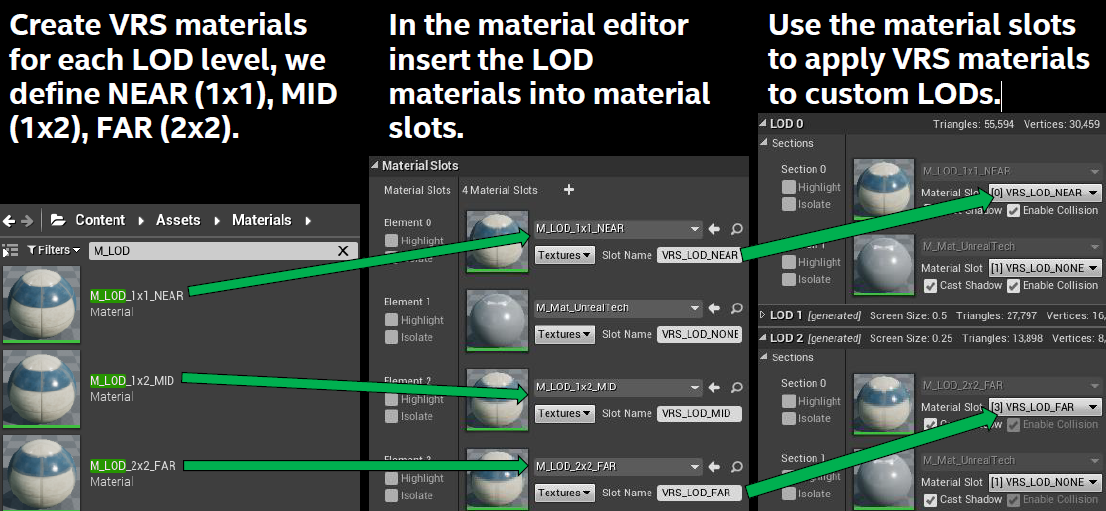
VRS速度和摄像机旋转:

VRS体积和粒子:

材质限制:一切都要适度…过度使用VRS材质可能会导致性能不佳。尽量减少着色率的变化,以避免API性能损失和Ice Lake架构上的部分管线Flush。驱动程序中的重复着色速率被删减,但切换速率仍有开销。可以在渲染器中静态缓存着色速率,以减少开销,但太多的材质排列可能会导致性能不佳。带有不透明遮罩的材质(即Masked材质)不会在透明区域保留边缘,请考虑半透明。
游戏Chivalry II的Base Pass对比:

VRS和渲染缩放对比:

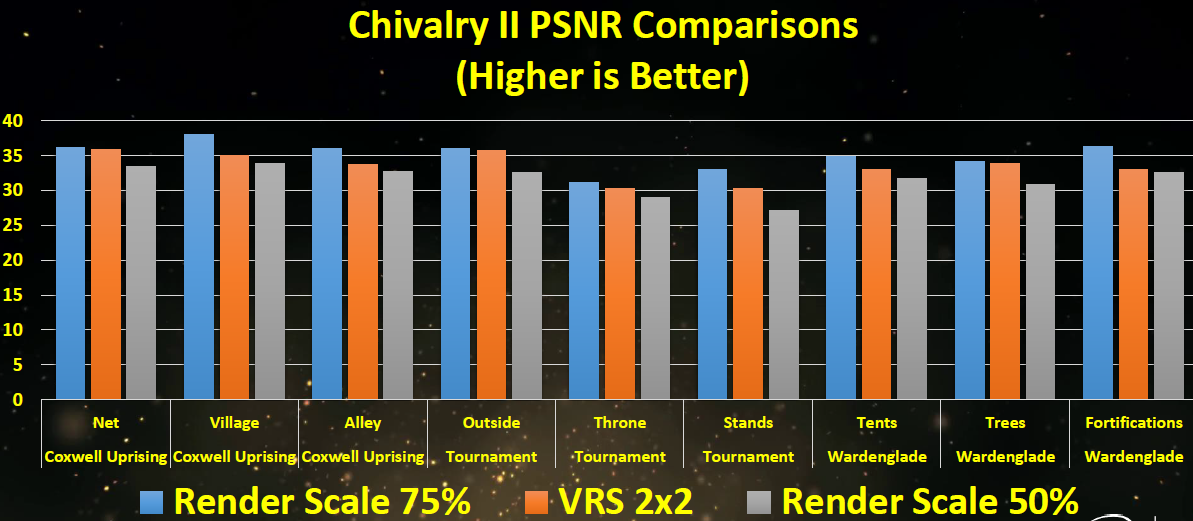
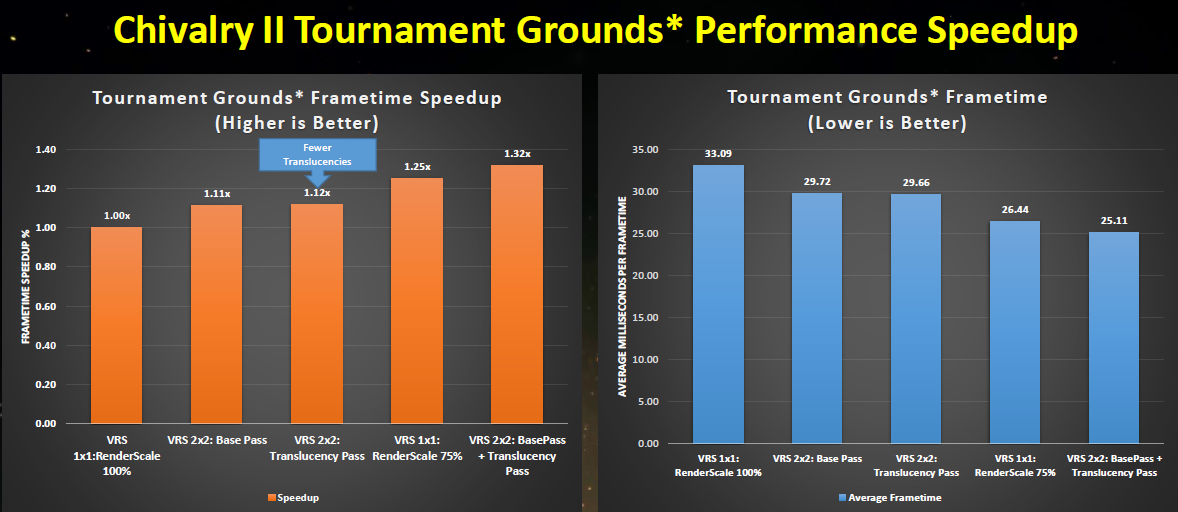
Large-Scale Global Illumination in Call of Duty阐述了COD的大规模GI,包含通过Activision的预计算照明管线、扭曲辐照度体积、采样体积照明、球谐函数的约束投影、照明数据的压缩、预计算光传输的移动基分解等内容。
扭曲辐照度体积:从上方和下方拍摄光线,以获得高度包络(下图左)。 自适应无块边界问题,如果已经有高度图可用,则可能是“免费的”(下图右)。
采样体积照明:光照泄漏是体积光表示的一个基本问题,大体素和小几何特征之间的不匹配。解决方案:将室内和室外划分为不同的体量[Hill15,Hooker16],使用几何感知重建过滤[ST15]。对大体素和薄几何体,每一条光线都构成了hat内核的三线性足迹,基于可见性的样本验证,生成空间样本,发射可见度光线并使低可见度样本无效。
效果对比:

约束球谐函数:在SH域中,关于逐点约束的推理并不容易,示例:非负性在线性SH中很简单,但推广到更高阶需要搜索窗口的系数[Sloan17],空间域与频率域:空间域是关于逐点约束推理的自然选择。同样的方法也适用于一般的凸约束,选择球体上的一个点集,例如64-128个斐波那契点,根据空间域编写投影操作符,示例:半球形域约束。无需导出自定义半球形底座,无需应用基础运算符的更改,最终结果是SH基础,适用于任意域,例如球形帽等。

接下来聊压缩。使用移动基分解(Moving Basis decomposition,MBD)的效果更*滑,尺寸更小:


直接光传输对比:
间接光传输对比:
总体效果预览:

结论:基于可见性的样本验证,概率视角,最大限度地减少超出预期视角位置的误差,处理约束SH投影的RKHS框架,颜色约束、可见性约束、域约束等。移动基分解高效无缝地压缩高维数据。
14.5.3.3 移动*台
Architecting Archean: Simultaneously Building for Room-Scale and Mobile VR, AR, and All Input Devices涵盖了在支持Archean广泛的VR和AR设备方面所学到的经验和技术,包括Rift、Vive、GearVR、Cardboard、Tango以及大量第三方物理、光学和传统输入。重点讨论代码库体系结构,旨在通过创建抽象层将硬件支持与游戏功能分离,开发人员可以添加更多*台,也可以添加更多游戏功能,同时既不为其它*台添加任何额外工作,也不为编辑器扩展和SDK管理器自动处理特定于*台的场景和项目设置,允许在各种各样的*台上立即构建。文中提出的VR分层架构如下:
-
特定于SDK的输入类:每个硬件/SDK一个类,没有特定于项目的逻辑!监听设备输入,调用抽象处理程序,调用工具的down/hold/up,调用常规输入的down/hold/up。
-
输入组件:SDK特定组件类包含对硬件功能的特定引用:
public class ViveControllerComponents : WandComponents { public SteamVR_Controller.Device viveController; }特定于类别的组件类包含硬件类型的公共属性:
public class WandComponents : InputComponents { public Transform handTrans; public override Vector3 Position { get { return handTrans.position; } } public override Vector3 Forward { get { return handTrans.forward; } } public override Quaternion Rotation {get{ return handTrans.rotation; }} }InputComponents基类包含大多数抽象数据:
public class InputComponents { public virtual bool Valid { get { return true; } } public virtual Vector3 Position { get { return Vector3.zero; } } public virtual Vector3 Forward { get { return Vector3.forward; } } public virtual Quaternion Rotation { get { return Quaternion.identity; } } } -
工具基类。
// 每个SDK的向下/保持/向上挂钩 public virtual void DoToolDown_Sixense(SixenseComponents sxComponents) { DoToolDown_Wand(sxComponents); } public virtual void DoToolDown_Leap(LeapComponents leapComponents) { DoToolDown_Optical(leapComponents); } public virtual void DoToolDown_Tango(TangoComponents tangoComponents) { DoToolDown_PointCloud(tangoComponents); } // 每个类别的向下/保持/向上挂钩 public virtual void DoToolDown_Wand(WandComponents wandComponents) { DoToolDown_Core(wandComponents); } public virtual void DoToolDown_Optical(OpticalComponents opticalComps) { DoToolDown_Core(opticalComps); } public virtual void DoToolDown_PointCloud(PCComponents pcComponents) { DoToolDown_Core(pcComponents); } // 工具基础函数 DoToolDown_Core DoToolDownAndHit* DoToolHeld_Core DoToolUp_Core DoToolDisplay_Core public virtual void DoToolDown_Core(InputComponents comp) { if (Physics.Raycast(comp.Position, comp.Forward, out hit, dist, layers)) { DoToolDownAndHit(comp); } } -
特定工具类型。
// 可以覆盖DoToolDown_Core等,实现完全*台无关逻辑 public class MoveTool : Tool { protected override void DoToolHeldAndHit(InputComps comps) { selectedTrans.position = hit.point; } } // 可以覆盖任何类别或特定于SDK的挂钩,以实现更定制的行为 public class MoveTool : Tool { // ... protected override void DoToolHeld_Optical(OpticalComps comps) { // Move mechanic that’s more appropriate for optical control } } -
硬件输入基类。非工具抽象输入,适用于一般游戏功能和一次性交互,三种处理方法:
// 比如Unity的原生输入类 bool HardwareInput.ButtonADown/Held/Up // 当想要那个观察者的时 event HardwareInput.OnButtonADown // 集中输入/游戏逻辑 void HardwareInput.HandleButtonADown() -
游戏性/一般输入类...。
// 一次性输入 public class GameplayController : MonoBehaviour { void Update() { if(HardwareInput.TriggerDown) { WorldConsole.Log("Fire ze missiles!"); } } void Awake() { HardwareInput.OnButtonADown += HandleButtonA; } void HandleButtonA() { WorldConsole.Log("Boom!"); // Btw: use a “world console”! } } // 组件的一般输入, 更新的三种方法: // 添加硬件输入/位置/向前等 HardwareInput.ButtonADown/Held/Up // 传递包含组件的事件参数 HardwareInput.OnButtonADown(args) HandleButtonADown(components)
所有SDK都以Libs/dir的形式存在于项目中:
SDK太多了!SDK之间的AndroidManifest和插件冲突,在某些情况下,可以通过合并清单来解决(例如Cardboard+Nod),在许多情况下,只需要将冲突的SDK移入或移出Asset文件夹,可以连接到构建管线中。对于多SDK场景设置,将场景设置为支持所有SDK,Player对象包含用于ViveInput、GamepadInput、CardboardInput、NodeInput、LeapInput、TangoInput的组件...好处是场景之间没有重复的工作,所有设备都可以同时启用(例如Vive+Leap)。好处是让多种设备类型交互意味着新的设计挑战,更多*台==更复杂的场景,可以将播放器拆分为更易于管理的预置体,并在运行时或使用编辑器脚本组装这些预置。对于SDK管理器编辑器脚本,在编辑器中或在构建时启用/禁用每个*台的组件和对象。
public void SetupForCardboard()
{
Setup(
// Build settings
bundleIdentifier: "io.archean.cardboard",
vrSupported: false,
// GameObjects
cameraMasterActive: true,
sixenseContainerActive: false,
// MonoBehaviours
cardboardInputEnabled: true
);
}
此外,可以自定义输入模块将允许向uGUI添加新的硬件支持。块状和点击用户界面(Block-and-pointer UI),点击或按下时,<设备>将光线投射输入用户界面(例如Vive),或简单的碰撞(如Leap)。自定义按钮组件:
ButtonHandler类中有一个巨大的switch语句来映射所有动作:
switch(button.action)
{
case ButtonStrings.Action_TogglePalette: TogglePalette(button, state); break;
case ButtonStrings.Action_ChangePage: ChangePage(button, state); break;
case ButtonStrings.Action_ChangePagination:ChangePagination(button); break;
case ButtonStrings.Action_SelectProp: SelectProp(button, state); break;
case ButtonStrings.Action_SelectTool: Tool.HandleSelectToolButton(button); break;
…
还有一个文件,里面有用于操作的常量字符串:
public const string Action_TogglePalette = "togglePalette";
public const string Action_ChangePage = "changePage";
public const string Action_ChangePagination = "changePagination";
public const string Action_SelectProp = "propSelect";
public const string Action_SelectTool = "toolSelect";
....
通过参数字段可以获得更高级和可重用的功能,用户界面代码集中,按钮可以传递任何数据类型,非常方便。所以你想做一个多*台的虚拟现实应用…你确定吗?SteamVR&Cardboard加入Unity的原生VR支持,从一开始就计划多*台。
Advanced VR Rendering Performance阐述了2016年的VR渲染优化技巧,包含多GPU、注视点渲染和径向密度遮罩、重投影、自适应质量等。
单GPU情况下,单个GPU完成所有工作,立体渲染可以通过多种方式完成(本例使用顺序渲染),阴影缓冲区由两只眼睛共享。多GPU亲和API,AMD和NVIDIA有多个GPU亲和API,使用关联掩码跨GPU广播绘制调用,为每个GPU设置不同的着色器常量缓冲区,跨GPU传输渲染目标的子矩形,使用传输栅栏在目标GPU仍在渲染时异步传输。2个GPU时,每个GPU渲染一只眼睛,两个GPU都渲染阴影缓冲区,“向左提交”和“应用程序窗口”在传输气泡中执行,性能提高30-35%。4个GPU时,每个GPU渲染一只眼睛的一半,所有GPU渲染阴影缓冲区,PS成本成线性比例,VS成本则不是,驱动程序的CPU成本可能很高。
从上到下:1个、2个、4个GPU渲染示意图。
投影矩阵与VR光学:投影矩阵的像素密度分布与我们想要的相反,投影矩阵在边缘每度像素密度增加,VR光学在中心像素密度增加,我们最终在边缘过度渲染像素。使用NVIDIA的“多分辨率着色”,可以在更少的CPU开销下获得额外约5-10%的GPU性能。

径向密度遮蔽(Radial Density Masking):跳过渲染2x2像素方块的棋盘格图案,以匹配当前的GPU架构。

重建滤波器的过程如下:
径向密度遮蔽的步骤:
- 渲染时Clip掉2x2的像素方块,或使用2x2的棋盘格图案填充模板或深度,然后进行渲染。
- 重建滤波器。
在Aperture Robot Repair中节省5-15%的性能,使用不同的内容和不同的着色器可以获得更高的增益,如果重建和跳过像素的开销没有超过跳过像素四元体的像素着色器节省,那么就是一次wash。在低端GPU上几乎总是能节省很多工作。
处理漏帧,如果引擎未达到帧速率,VR系统可以重用最后一帧的渲染图像并重新投影:仅旋转重投影、位置和旋转重投影,用重投影来填充缺失的帧应该被视为最后的安全网。请不要依赖重投影来维持帧率,除非目标用户使用的GPU低于应用程序的最低规格。
仅旋转重投影:抖动是由摄影机*移、动画和被跟踪控制器移动的对象引起的,抖动表现为两个不同的图像*均在一起。

旋转重投影是以眼睛为中心,而不是以头部为中心,所以从错误的位置重投影,ICD(摄像机间距离)根据旋转量在重投影过程中人为缩小。
好的一面:几十年来,人们对算法有了很好的理解,并且可能会随着现代研究而改进,即使有已知的副作用,它也能很好地处理单个漏帧。所以…有一个非常重要的折衷方案,它已足够好,可以作为错过帧的最后安全网,总比丢帧好。
位置重投影:仍然是一个非常感兴趣的尚未解决的问题,在传统渲染器中只能获得一个深度,因此表示半透明是一个挑战(粒子系统),深度可能存储在已解析颜色的MSAA深度缓冲区中,可能会导致颜色溢出。对于未表示的像素,孔洞填充算法可能会导致视网膜竞争,即使有许多帧的有效立体画面对,如果用户通过蹲下或站起来垂直移动,也有需要填补空白。
异步重投影:理想的安全网,要求抢占粒度等于或优于当前一代GPU,根据GPU的不同,当前GPU通常可以在draw调用边界处抢占
,目前还不能保证vsync能够及时重新发布。应用程序需要了解抢占粒度。
交错重投射提示:旧的GPU不能支持异步重投影,所以需要一个替代方案,OpenVR API有一个交错重投影提示,如果底层系统不支持始终开启的异步重投影,应用程序可以每隔一次请求仅限帧旋转的重投影。应用程序获得约18毫秒/帧的渲染。当应用程序低于目标帧率时,底层VR系统还可以使用交错重投影作为自动启用的安全网,每隔一帧重新投影是一个很好的折衷。
维持帧率很难,虚拟现实比传统游戏更具挑战性,因为用户可以很好地控制摄像机,许多交互模型允许用户重新配置世界,可以放弃将渲染和内容调整到90fps,因为用户可以轻松地重新配置内容,通过调整最差的20%体验,让Aperture Robot Repair达到了帧率。
自适应质量:它通过动态更改渲染设置以保持帧率,同时最大限度地提高GPU利用率。目标是减少掉帧和重投影的机会和在有空闲的GPU周期时提高质量。例如,Aperture Robot Repair VR演示使用两种不同的方法在NVIDIA 680上以目标帧率运行。利益是适用于应用程序的最低GPU规格,增加了艺术资产限制——艺术家现在可以在保真度稍低的渲染与更高的多边形资产或更复杂的材质之间进行权衡,不需要依靠重投影来维持帧率,意想不到的好处:应用程序在所有硬件上都看起来更好。
在VR中,无法调整的:无法切换镜面反射等视觉功能,无法切换阴影。可以调整的内容:渲染分辨率/视口(也称为动态分辨率)、MSAA级别或抗锯齿算法、注视点渲染、径向密度遮蔽等。自适应质量示例(黑体是默认配置):
测量GPU工作负载:GPU工作负载并不总是稳定的,可能有气泡,VR系统GPU的工作量是可变的:镜头畸变、色差、伴侣边界、覆盖等。从VR系统而不是应用程序获取计时,例如,OpenVR提供了一个总的GPU计时器用于计算所有GPU工作。
GPU定时器-延迟,GPU查询已经有1帧了,队列中还有1到2个无法修改的帧。

实现细节——3条规则,目标是保持70%-90%的GPU利用率。
- 高GPU利用率=帧的90%(10.0ms),大幅度降低:如果最后一帧在GPU帧的90%阈值之后完成渲染,则降低2级,等待2帧。
- 低GPU利用率=帧的70%(7.8毫秒),保守地增加:如果最后3帧完成时低于GPU帧的70%阈值,则增加1级,等待2帧。
- 预测=帧的85%(9.4ms),使用最后两帧的线性外推来预测快速增长,如果最后一帧高于85%阈值,线性外推的下一帧高于高阈值(90%),则降低2个级别,等待2帧。
10%空闲的规则:90%的高阈值几乎每帧都会让10%的GPU空闲用于其它处理,是件好事。需要与其它处理共享GPU,即使Windows桌面每隔几帧就需要一块GPU。对GPU预算的心理模型从去年的每帧11.11ms变为现在的每帧10.0ms,所以你几乎永远不会饿死GPU周期的其它处理。
解耦CPU和GPU性能,使渲染线程自治,如果CPU没有准备好新的帧,不要重投影!相反,渲染线程使用更新的HMD姿势和动态分辨率的最低自适应质量支持重新提交最后一帧的GPU工作负载。要解决动画抖动问题,请为渲染线程提供两个动画帧,可以在它们之间进行插值以保持动画更新,但是,非普通的动画预测是一个难题。然后,可以计划以1/2或1/3 GPU帧速率运行CPU,以进行更复杂的模拟或在低端CPU上运行。
总之,所有虚拟现实引擎都应支持多GPU(至少2个GPU),注视点渲染和径向密度遮蔽是有助于抵消光学与投影矩阵之争的解决方案,Adaptive Quality可上下缩放保真度,同时将10%的GPU用于其它进程,不要依靠重投影来达到最小规格的帧率!考虑引擎如何通过在渲染线程上重新提交来分离CPU和GPU性能。
Higher Res Without Sacrificing Quality, plus Other Lessons from 'PlayStation VR Worlds'讲述了PS的VR渲染技术,包含纹理流、无绑定、SRT、绘制校验、分辨率渐变、源码级别的着色器调试、自适应分辨率等。
由于不再使用像素坐标来进行查找,也就是说,在视图空间中进行有效的分块,只需使用组合*截头体对两只眼睛进行一次即可,已用于贴花分块:
混合的分块前向、延迟的缺点:失去了前向的优势,对MSAA采用延迟方法也很重要,虚拟现实世界中没有MSAA。但结果很好,为重新照明模型提供了灵活性。性能良好,将灯光分块分辨率与图像分辨率分离是一个巨大的胜利。
部分驻留纹理,硬件提供了一个内着色器机制,通知使用者读取了未映射的内存,然后可以用这些信息做些事情,例如,可以把这个失败信息记录下来,然后在后面里把那页带进来。
虚拟内存系统:充分利用Aaron MacDougall提出的系统,纹理按两个字节大小的幂进行分组,每两种大小的幂都有自己的插槽分配器,每个插槽分配器都有4GB的虚拟内存,总共使用36GB。然后,游戏会提供一大袋物理页面供用户使用,可以根据需要在运行时改变页面数量。
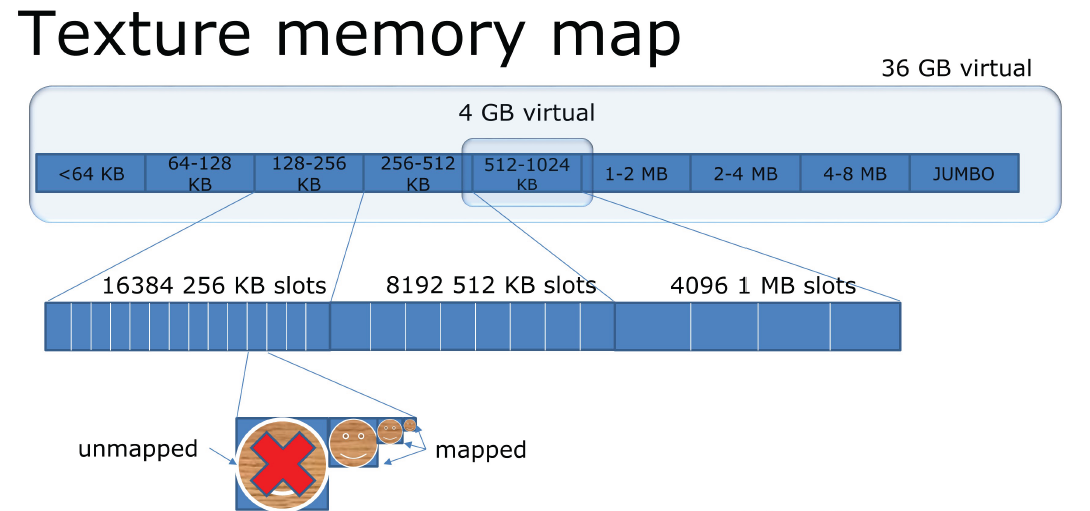
随着纹理质量的提高,然后映射到64KB的页面中,纹理的最小/最大mip字段立即更改,新的波前将在这一帧中看到这种变化。随着纹理质量的降低,最小/最大mip字段会立即更改,但下一帧页面将被取消映射。由于页面映射不变,因此没有明显的卡顿。无需复制或碎片整理,我们不关心虚拟内存碎片,物理碎片并不重要,纹理映射的绘制调用验证很容易。总之,虚拟内存使纹理流更容易!并带来许多其它好处,在着色器中,PRT是一场噩梦,但基于mip的PRT非常容易管理,另外,别忘了PRT也适用于CS和VS。
绘制调用校验:当事情不可避免地出错时,将投入了大量的时间来制作东西来帮助解决问题,这就就是绘制调用校验。在发送绘制之前,尝试捕捉明显的错误,GPU崩溃和超时很难调试,此外,并不是所有的错误都会导致如此明显、直接的错误。当GPU崩溃时,将会花相当多的时间进行调试,当时的工具让这变得非常困难,哪个绘制失败了?为什么?可能花了一周的时间来追踪,几分钟来修复:
GPU Protection fault. Access Read: Unmapped page access: Addr(VA)0x000000000433e000
大多数故障都很微妙(不是崩溃),不可见的物体、损坏的材质、空白纹理,如果没有看到这个物体,就会错过问题,或者可能会认为是艺术家有意设计的。但它仍然在崩溃:GPU Protection fault. Access Read: Unmapped page access: Addr(VA)0x000000000433e000,没有程序计数器,没有着色器ID,没有绘图ID。启动命令缓冲区后,状态可能已损坏,内存可能无法映射,锋利的东西可能会被扔掉,代码仍然可能被破坏。如果可以在指令发生时捕捉崩溃,那么就不需要那么多猜测了。可以检查激活的状态,看看出了什么问题,就像使用普通的调试器一样,需要在着色器中进行验证。
打包着色器代码:向量加载示例,用跳转到新代码片段替换向量加载。
新代码片段:从V#计算基址和缓冲区大小,检查范围是否已映射,检查每个页面的权限,如果满意,运行原始指令并返回,否则,将PC写入主存储器,并向CPU和用户发送信号。
总之,验证是值得做,很容易做到,而且会节省时间!捕捉异步页面错误很棘手,但在关键时期之前开发一个基础设施是值得的。
接下来聊分辨率渐变(Resolution Gradient)。VR画面变形的流程和预期分辨率的关系如下:

更高的内部分辨率:对于PlayStation VR,建议瞄准\(1.4^2\)的面板分辨率,相当于是原来2倍的像素数量!需要60fps。
因此,需要找到一种方法,以可变分辨率渲染中心的多个像素,外围区域较少,没有硬件支持。一种方法是使用两个通道:以高分辨率渲染中心部分,以低分辨率渲染其余部分,组合和混合它们(下图)。但是要求我们在每个视图中使用额外的几何通道,只有两个级别:高或低,形状不是很灵活。

构造抖动模板遮罩以应用于图像,更多控制,没有额外的几何通道(因为需要高分辨率插入方法)。在中间照常着色,然后,随着离中心越来越远,逐渐遮蔽了更多的像素。在图像的外部,仅以1/4个像素进行渲染(下图右)。


你可能已经注意到,屏蔽了2x2的像素网格,为了阻止quad overdraw让整个事情变得毫无意义。Quad粒度的遮蔽:如果在Quad中遮罩一些像素,同样适用。因此,为了获得任何好处,需要以Quad(2x2的像素块)的粒度遮蔽,而不是像素。然后,用一个放大通道来填充孔洞,只需在最*的着色像素上进行复制(下图)。
在许多情况下,填充“按需”调整着色器中的采样位置以选择最*的有效像素会更快,不再需要单独的扩张通道,多通道中的额外ALU通常比额外的读/写便宜,需要修改所有着色器代码!
Prepass之后遮蔽:根据场景的几何和深度复杂性,有时不在预处理过程中遮罩会更快。这会使预处理稍微慢一点,但可能不会太多,因为预处理着色是轻量的,并且避免了扩大深度的需要,可以节省成本。
时间魔法:改变抖动模式每帧TAA累积贡献,确保所有像素以较低的时间频率做出贡献,以时间分辨率换取空间分辨率,对现有TAA的改动很少。
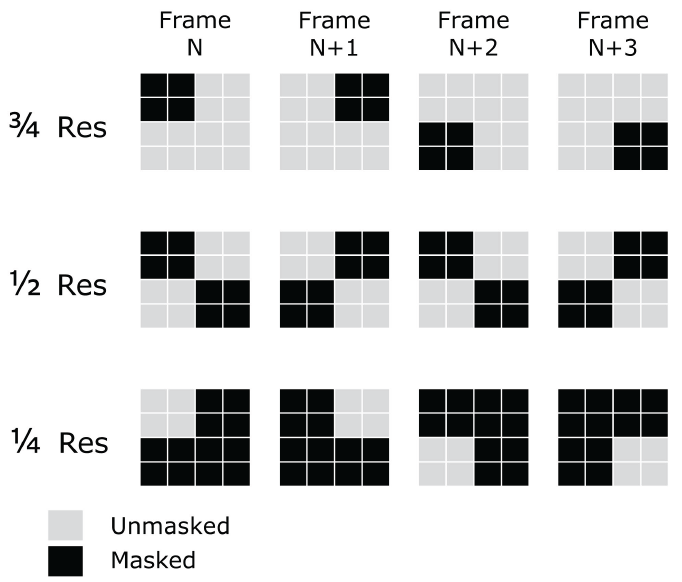
结果出人意料的好,即使在1/4分辨率的区域!即使以Quad粒度遮蔽!在16.6ms的帧上节省约4ms!


MSAA滥用:Quad粒度遮蔽确实会加剧高频区域的不稳定性,在运动中更引人注目,但找到了一种在像素粒度上屏蔽的方法!没有过绘制问题,多亏了Mark Cerny的insight。以4XMSAA的采样频率渲染(调整MSAA样本位置)和1/4分辨率(1/2 x 1/2),仍然有相同数量的样本,但是,组成quad的样本现在在分辨率图像中相距更远。像
素粒度的遮蔽过程。A:2x2的像素网格,每个右4个样本。B:使用每个像素中的相应样本构建的像素Quad,第一个quad由2x2像素网格中每个像素的第一个样本组成。C:其它像素类似。D:像以前一样遮蔽掉绿色和黄色标记的quad,就得到了像素粒度遮蔽!


MSAA技巧难题:处理它的代码开始渗入所有着色器和运行时代码,尤其是按需扩展,图形调试工具更难使用,图像分为4个样本,需要下定决心把它正确地可视化。
高分辨率和低延迟图形是为VR用户提供真正沉浸式体验的关键。High quality mobile VR with Unreal Engine and Oculus分享了UE4上移动虚拟现实的技巧、最佳实践、UE4的最新渲染技术,以及图形管线如何从移动外形因素中获得最大收益,还讨论移动虚拟现实技术是如何发展的以在未来可以期待什么。
VR最佳实践:与PC和控制台相比,移动设备有更多的限制,最易访问的开发环境,最具挑战性的*台。电池续航和散热是主要问题,快速峰值性能,但不能无限期地运行,优化比PC和控制台更复杂,仅仅保持帧速率不够,安卓N持续性能模式,保证以较低的性能水*无限期运行。
资产预算和建议:整个场景的*均三角形数为50-60k,最多10万,每只眼睛50次DC,合并材质和网格,使用实例,多视图改进了这一点!聚合性LOD,考虑对内存的影响。新的自动LOD生成示例输出,维护顶点数据,以便共享材质和光照贴图(下图)。材质应不超过125个指令,没有动态灯光或阴影,烘焙和伪造,使用没有后期处理的LDR,创建具有代表性内容的测试关卡,在打算发布的设备上配置文件,以验证预算,测试预算会话时间的持续时间。

内容建议:删除用户看不到的三角形,删除背面,细分大尺寸的模型,将远处的环境烘焙到skybox,使用最佳采样的Oculus立方体环境图层,Monoscopic可用于中间地带。完全粗糙的存在,假的环境反射。不要渲染被遮挡的对象,浪费DC和图元剔除时间,设计场景以最小化绘制距离,使用预计算的可见性体积,利用场景信息主动手动隐藏不在视野中的对象。最小化透明过绘制,仍然绘制100%透明的对象。设置可见性标志!使用MSAA,至少2倍,如果可能,至少4倍。避免后期处理消除锯齿,使用ASTC进行纹理压缩,尽量最大化块大小,生成MIP映射,避免复杂的过滤选项。跟踪tick对象数量,如果不需要就不要tick,创建对象极其昂贵,放到加载时创建,在多个帧上摊销。考虑构建一个管理器来共享对象,尝试蓝图原生化以减少脚本VM开销。
立体层:未在引擎中渲染,在组合器(compositor)中进行光线跟踪,只有一次采样!支持四边形、圆柱体和立方体贴图,有头部锁定、跟踪器锁定或世界锁定等锁定模式,立体层组件,与UMG一起协作!
当时的UE新增了单视远场(Monoscopic Far Field)渲染和移动端多视图渲染。
Monoscopic渲染:渲染两只眼睛,位置差造成双眼视差,投影差异造成双眼视差,深度一样。存在性能问题,将CPU使用率提高一倍,将顶点/片元的使用增加一倍。
随着距离的增加,位置差异不那么显著。添加第三个摄像头,两个立体摄像机有一个30英尺远的*面,单镜相机在飞机附*有一个30英尺的摄像头,像素的严格排序,新的渲染管线。

新管线的问题:单镜相机渲染未使用的像素,立体相机绘制视锥剔除的远距离目标,合成瑕疵(主要是透明度),运行第三个摄像头的性能卡顿。结果:性能非常依赖于环境,在某些情况下增加20%以上,CPU和GPU的影响,也会导致性能下降,动态系统,包括开/关和视距,vr.FarFieldRenderingMode 0/1/2/3/4。
移动端多视图(Multiview)渲染:图元粒度上视图之间的最小差异,以下是常规与多视图模式的CPU-GPU时间线:

消耗项:用于PC的实例化立体渲染,PS4实例立体的多视图扩展,Nvidia的单通道的立体渲染,来自AMD的DirectX 11多视图扩展,OpenGL ES的多视图扩展。
UE4的实现:PC/PS4实例立体和PS4多视图,基于管线的标准图形,实例化绘制调用、变换、剔除、剪裁顶点着色器,PS4的小扩展,以减少顶点着色器工作。移动多视图:绘制调用实例和顶点工作完全由驱动程序完成,利用实例立体的视图统一系统。多视图的CPU性能:
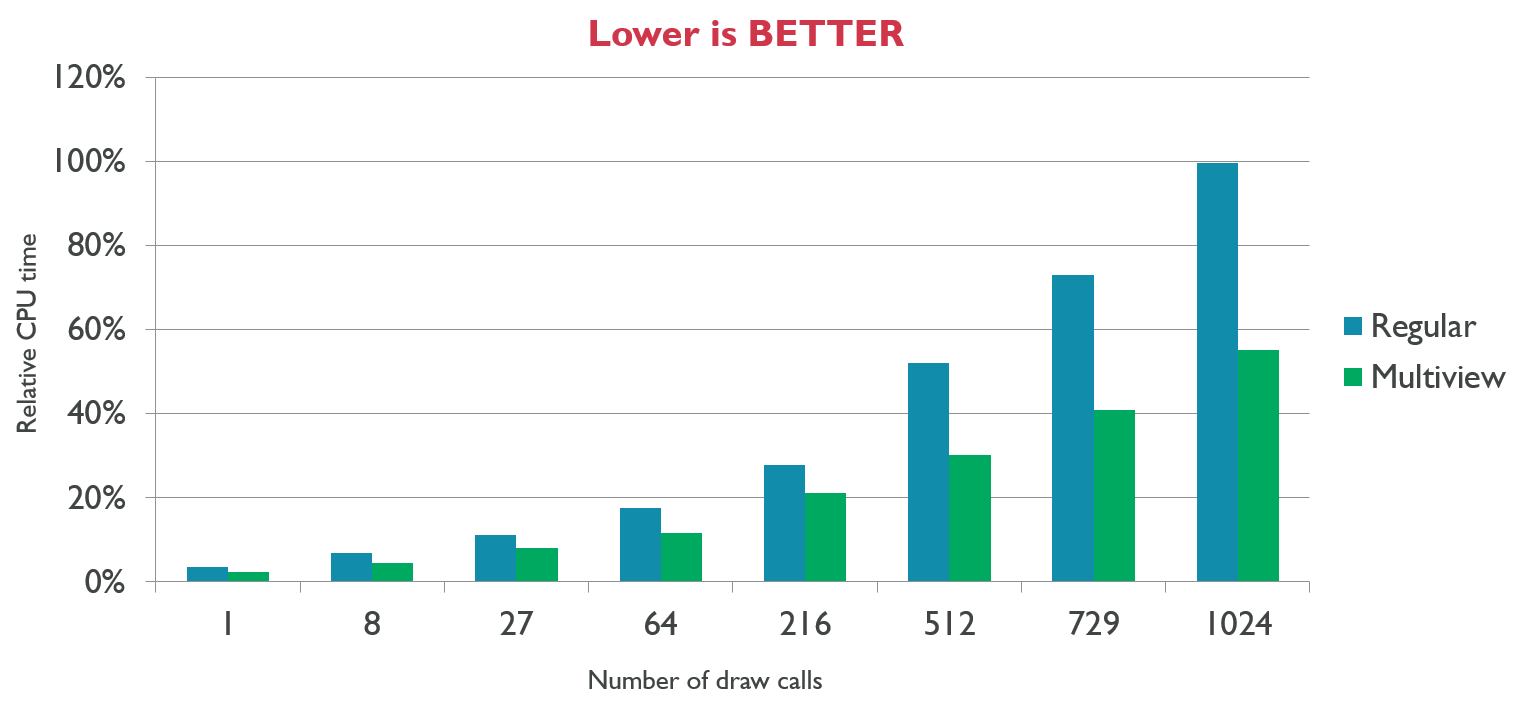
OpenGL ES相关的扩展:
- GL_OVR_multiview:将gl_ViewID_OVR的使用限制为计算gl_position。
- GL_OVR_multiview2:没有限制使用gl_ViewID_OVR,gl_ViewID_OVR可以在片元和顶点着色器阶段使用。
- OVR_multiview_multisampled_render_to_texture:EXT多采样渲染到纹理的多视图版本。
支持多视图的顶点着色器:
在应用程序中使用多视图:


UE4的材质编译和渲染流程如下:
驱动程序支持环境:多个GPU供应商,所有供应商的初始实现中都存在许多驱动程序错误,驱动程序更新和最终用户设备上的可用性之间的长时间延迟,如果已知设备存在问题,会在应用程序初始化期间从着色器中删除多视图代码,以确保驱动程序错误不会破坏应用程序。例如Samsung Galaxy S6、Samsung Galaxy S7 Mali (Android M and N)、S7 Adreno (Android N)。
当前的开发工作流程:
注视点渲染是4视图的多视图:

使用4视图的多视图进行注视点渲染比2视图的可以减少65%的工作量:
结果对比:
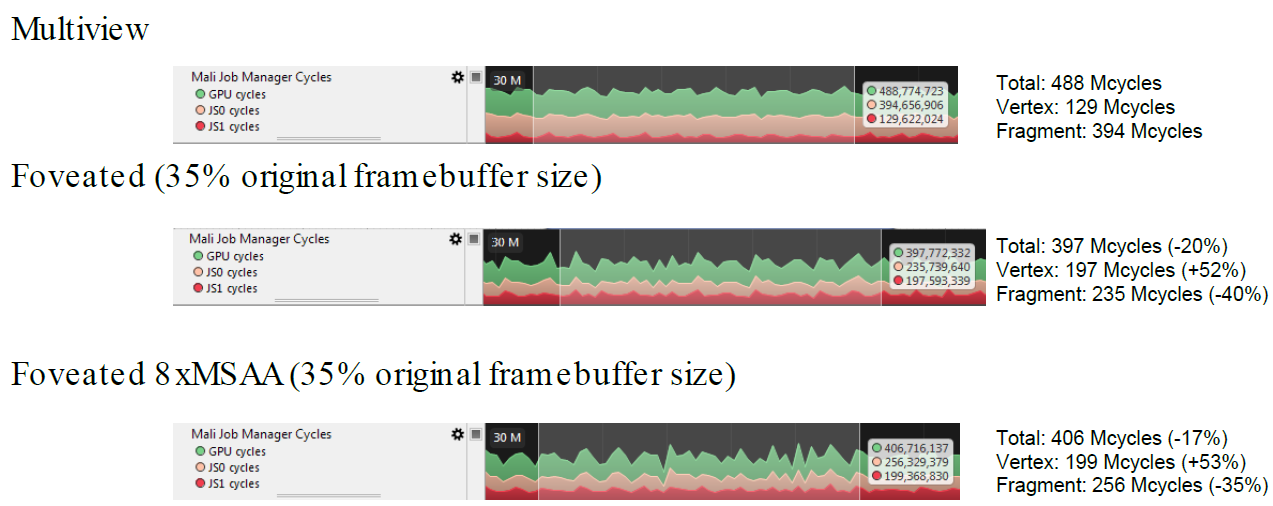
可以使用Mali Graphics Debugger (MGD)进行详细深入的多视图和VR渲染调试:
Shading of 'Spellsouls': Achieving AAA Quality on Mobile分享了如何在移动端实现3A级的渲染品质,包含PBR、特效、蒙皮、优化等方面的内容。PBR具有逼真的外观,不同的照明条件,标准的GGX方法很昂贵,标准化的Blinn-Phong。其中标准化的Blinn-Phong计算如下:

线性颜色空间是PBR的必要条件,但在2018年只有50%的移动设备支持它。在光照上,假设支持4个点光源,用逐光源计算还是Forward+?Forward+已由Spotty用计算着色器支持,但受限于GPU。如何优化?去掉深度的prepass,使用CPU剔除光源,用64x64像素tile,以球体*似光源面积:

包围圆在透视不强时可以使用,投影假设摄像头是正交的,并增加安全半径。如果投射很强,投影到AABB中。
在阴影方面,移动对象用动态阴影,环境用静态阴影。动态阴影用动态的阴影图,硬件4样本PCF,静态阴影直接用烘焙的光照图。在渲染地形时进行组合,为每个像素评估光照图颜色和动态阴影颜色。
color = albedo.rgb * lightmap.rgb;
color = color * lerp(lightColor, shadowColor, lightmap.a * min(NdotL, dynamicShadow);

特效方面,去掉后处理,粒子系统很昂贵,使用精灵图集!精灵图集可以使用运动向量来优化:
- 从相同的UV坐标读取当前帧像素和运动矢量值。
- 使用运动矢量确定要从下一帧读取的UV坐标。
- 在当前像素和下一帧像素之间插值。
左:精灵图集的颜色;右:精灵图集的运动向量。

精灵图集的运动向量的数据:R、G通道存储了下一个像素的UV,B通道存储了UV的缩放因子。
对于蒙皮,CPU蒙皮占用了2个完整的核心,每帧向GPU上传网格都会影响性能。可以尝试GPU蒙皮,无GPU网格上传、支持实例化、快速。也可以使用基于纹理的矩阵调色板(Texture Based Matrix-palette,TRS)GPU蒙皮:定期采集骨骼TRS样本,将骨骼TRS烘焙成纹理,3x4个浮点需要3个纹理,每个实例数据1个浮点、U坐标。
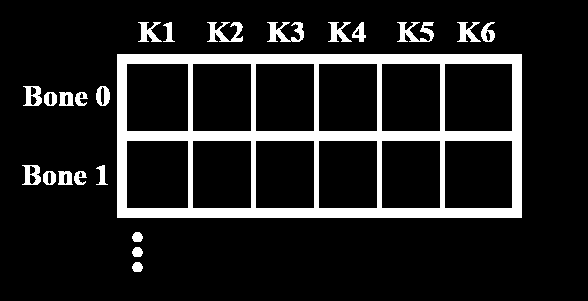
TRS的GPU蒙皮的插值过程:读取两个关键帧,重建矩阵,插值。其中每个骨骼影响6个纹理读取!
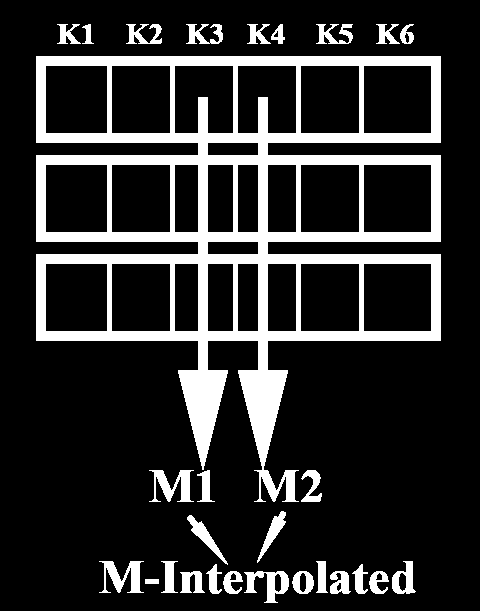
需要解决的问题:6个纹理读取、3个纹理、插值数学。可以使用基于纹理的双四元数GPU蒙皮(Texture Based Dual Quaternion GPU Skinning)进行优化,其使用双四元数,2个纹理(第3个缩放纹理可选),双线性过滤,在低采样率(15FPS)下看起来不错。但如果要实现混合动画,需要双倍的纹理读取。
针对帧率、热量、电量续航等方面进行了优化。其中对于着色器指令,不使用固定精度,在精度之间进行转换时要小心谨慎,小心指令数量(No-ops)。
// 250条指令
float4x4 sum = (boneMatrices[index0] * weight0) + (boneMatrices[index1] * weight1);
// 180条指令,减少了28%。
float4x4 matrix0 = boneMatrices[index0];
float4x4 matrix1 = boneMatrices[index1];
float4x4 sum = (matrix0 * weight0) + (matrix1 * weight1);
热量保护(Thermal throttling):
- 等待设备进入稳定状态(25FPS)。
- 确定目标帧率——在这种情况下为30FPS。
- 设置图形质量,使FPS比目标高30%——40FPS。
- 限制帧率至目标–30FPS。
热量保护的好处:我们没有使用设备的所有计算资源,摊销帧时间峰值,根据GPU确定的质量设置。
性能跟踪:分析跟踪*均FPS、电池耗电,电池耗电与热量有关。
MOBILE GAME DEVELOPMENT阐述了移动游戏开发的部分技术,如开发移动游戏的原因、方法、阶段、引擎等。2020年的移动端市场份额,达到770亿美元,在新冠的阴霾下依然逆势同比增长13.3%:
游戏开发过程的多学科性质结合了音频、视觉艺术、动画、控制系统、人工智能(AI)和人为因素,使得软件游戏开发实践不同于传统的软件开发。用于游戏开发和设计的许多方法,敏捷方法是目前管理数字游戏开发最流行和最常用的软件工程框架,这种开发方法基于迭代和增量方法。生产阶段分为几个小的迭代,主要关注最关键的特性,前期制作、制作和后期制作是手机游戏开发的主要阶段。
适合移动游戏开发的引擎包含Unreal Engine、Unity、Monogame、Solar2D、Titanium、Amazon Lumberyard、Cocos2d-x、Haxe、Gideros、Godot、CRYENGINE、Phaser、Defold、Starling等。
Optimizing Roblox: Vulkan Best Practices forMobile Developers阐述了用Vulkan优化游戏Roblox的技术,加载/存储操作、subpass、管线屏障、MSAA、Roblox CPU优化、命令缓冲区管理、渲染通道、管线状态、描述符管理等。下面是立即模式和分块模式的GPU架构对比图:
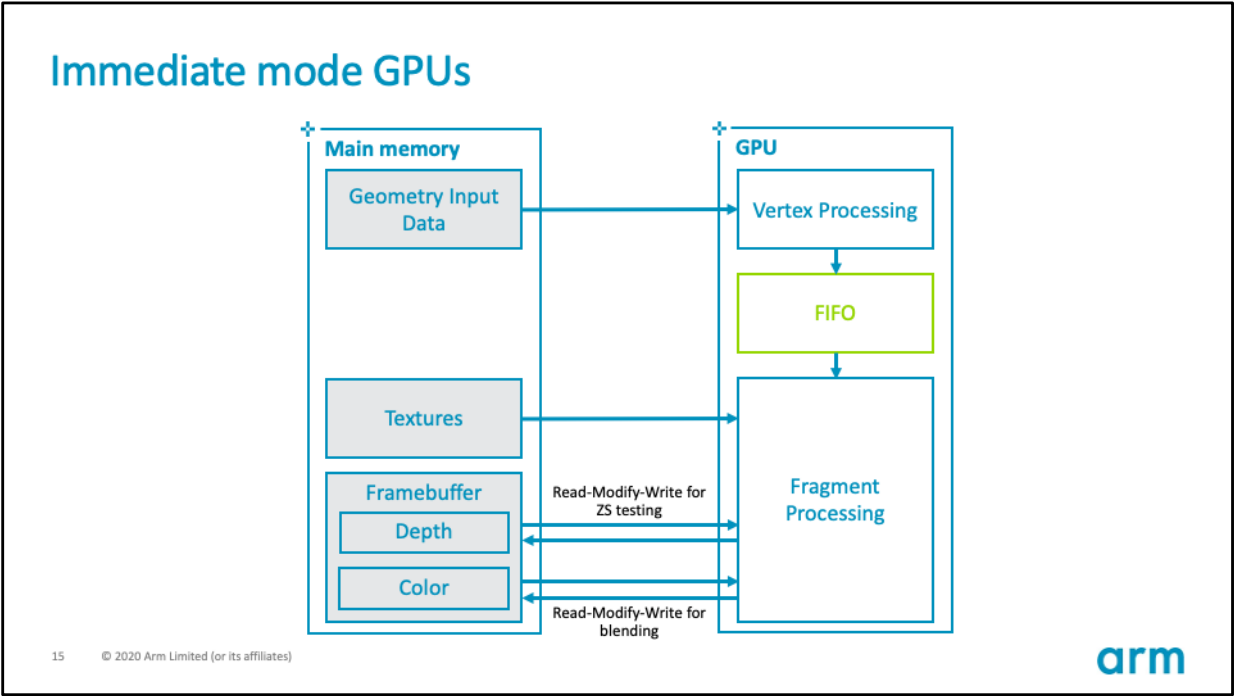
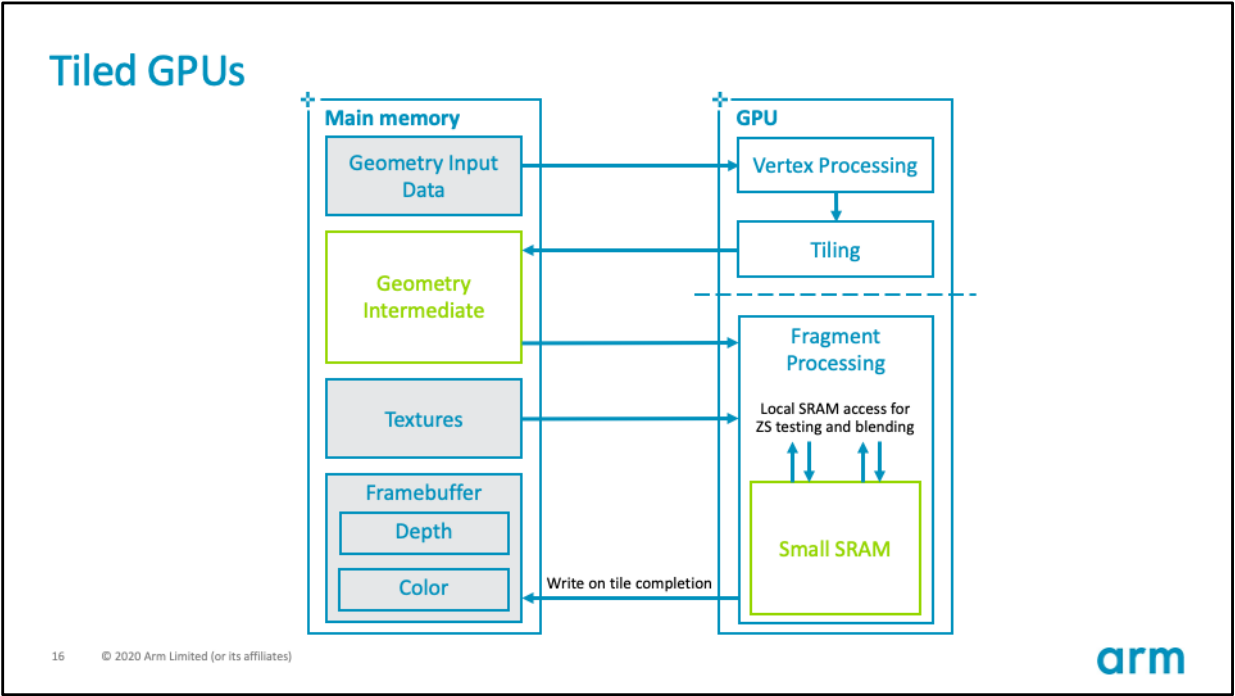
Vulkan的RenderPass和Subpass的关系如下:
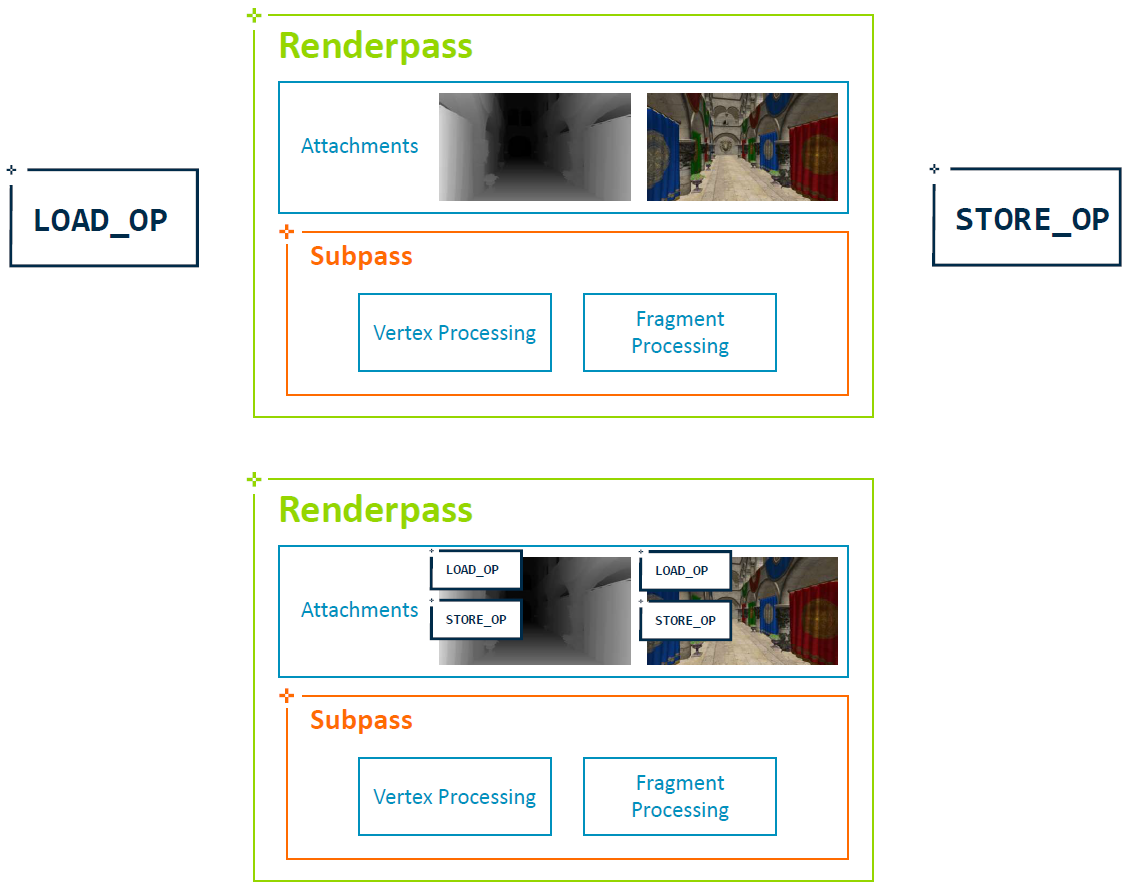
使用Vulkan实现多pass的延迟渲染图例如下:
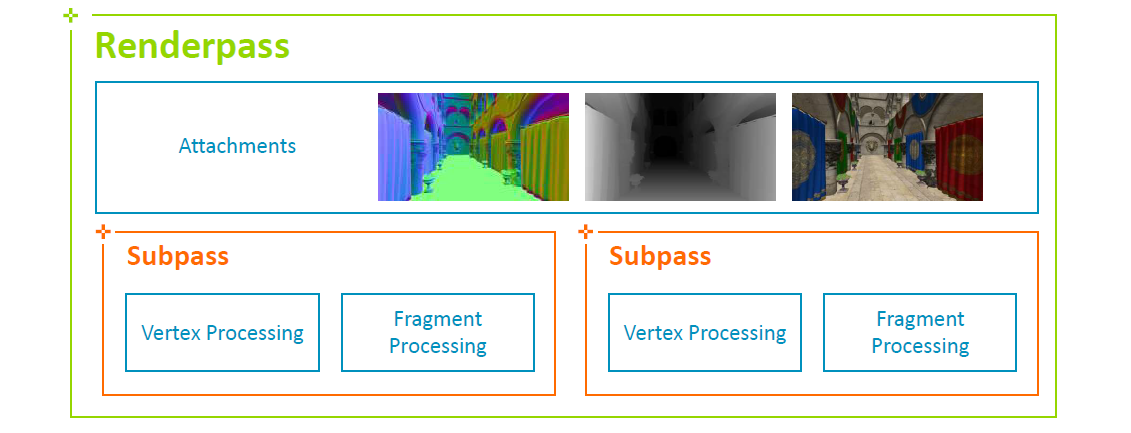
利用Subpass可以显著减少额外的内存读取和写入:

利用屏障依赖标记,可以提升各个着色器阶段的重叠度,从而减少延迟:
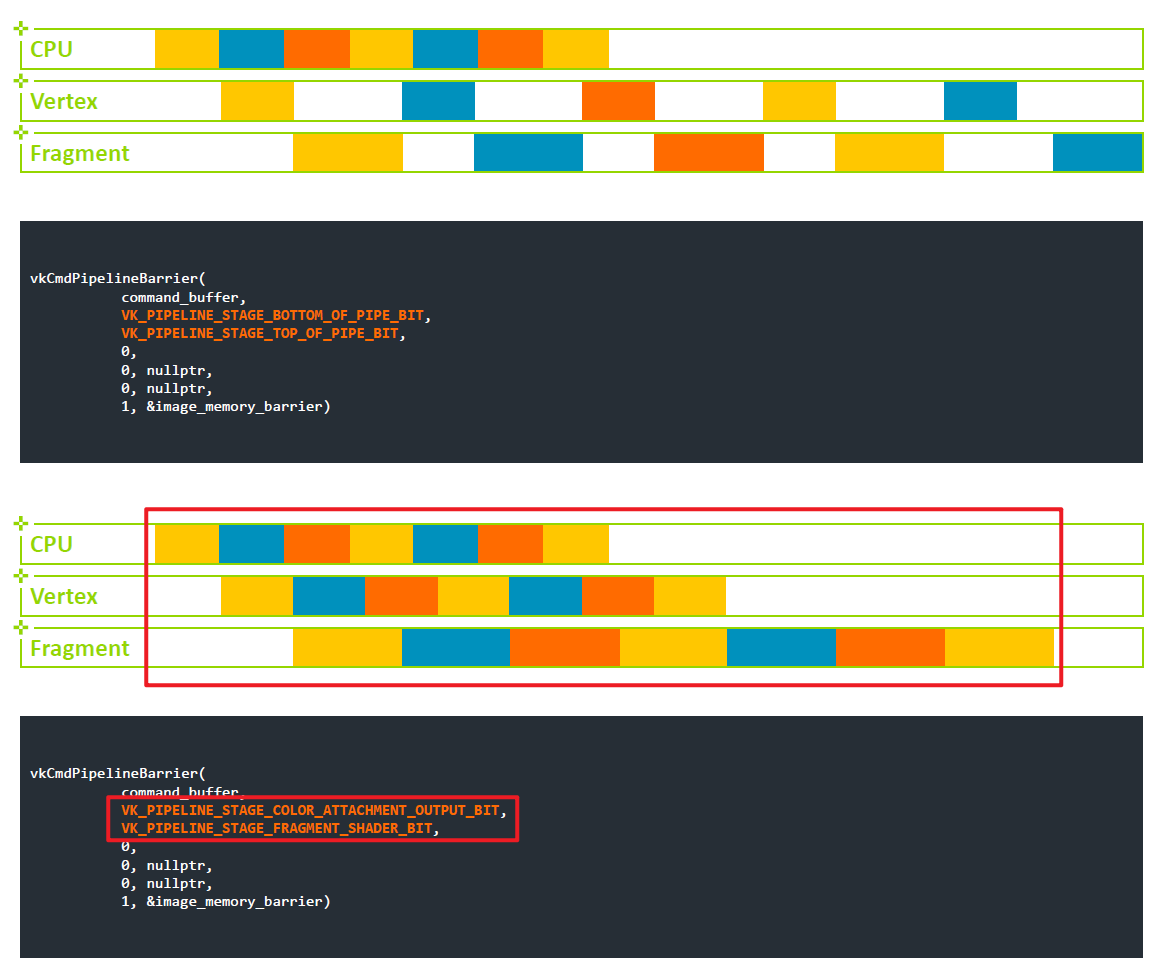
使得帧时间可以减少56%:

利用tile内解析MSAA数据(下图左),可以显著降低内存的读取和写入(分别降低261%、440%!!)。
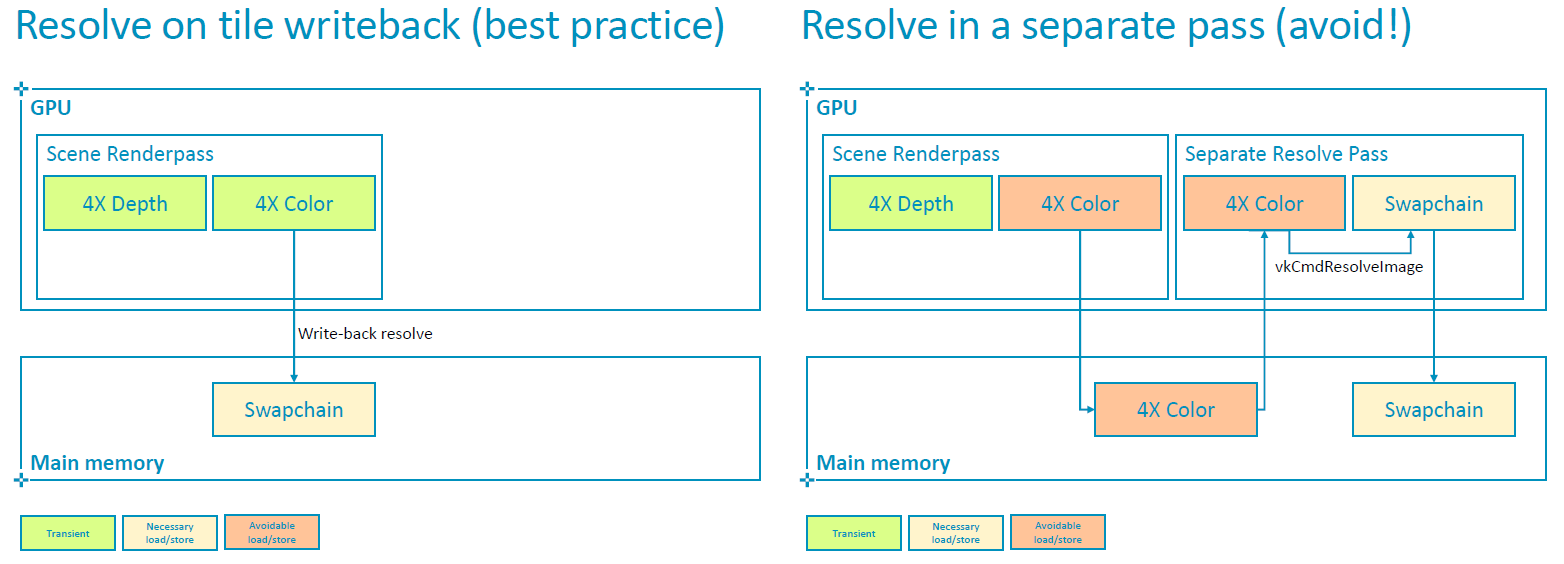
优化绘制调用:Vulkan在公共渲染界面上实现,我们如何通过合理的努力获得最大的性能?关注稳定状态的性能,缓存所有易于缓存的内容。采用常规帧结构,最大限度地减少绘制调用,在易用性和性能之间找到折衷方案,尽可能优化实现、线程友好的实现,允许每个线程单独录制绘制调用。
// 1. Command buffer management
DeviceContext* ctx = device->createCommandBuffer();
PassClear passClear;
passClear.mask = Framebuffer::Mask_Color0;
// 2. Render passes
ctx‐>beginPass(fb, 0, Framebuffer::Mask_Color0, &passClear);
// 3. Pipeline state
ctx‐>bindProgram(program.get());
// 4. Descriptor management
ctx‐>bindBuffer(0, globalDataBuffer.get());
ctx‐>bindBufferData(1, ¶ms, sizeof(params));
ctx‐>bindTexture(0, lightMap, SamplerState::Filter_Linear);
// 5. General optimizations
ctx‐>draw(geometry, Geometry::Primitive_Triangles, 0, count);
ctx‐>endPass();
device->commitCommandBuffer(ctx);
命令缓冲区管理:看似简单…createCommandBuffer() => vkAllocateCommandBuffers,commitCommandBuffer() => vkQueueSubmit…但实际上很复杂。每个线程都需要一个单独的VkCommandPool进行分配,如果从VkCommandPool分配的命令缓冲区正在运行,则不能使用VkCommandPool,vkAllocateCommandBuffers不是免费的,vkFreeCommandBuffers并不总是回收命令内存,vkQueueSubmit可能很昂贵。命令池:createCommandBuffer()在关键部分下窃取(或创建)VkCommandPool,我们从不释放命令缓冲区,并重用分配的命令缓冲区,批量命令缓冲区提交,commitCommandBuffer()将命令缓冲区添加到帧列表并返回池,一个vkQueueSubmit,位于submitCount=1的帧末尾。命令池回收:录制帧后,从全局池中删除所有具有挂起命令缓冲区的池,帧完成后,将所有池放回全局池,别忘了运行vkResetCommandPool,它会自动重置所有分配的命令缓冲区,并将其置于就绪状态。
常规优化:驱动比典型的GL驱动轻量得多,暴露了以前微不足道/不可察觉的事情!除非需要,否则不要调用vk*函数,缓存所有易于缓存的内容,过滤冗余状态绑定。积极消除缓存未命中,减少抽象中的分配和间接操作,例如,使用的GeometryVulkan类似于OpenGL VAO–struct的所有几何体状态。通过vkGetDeviceProcAddr获得的指针调用大多数函数,volk loader为我们做这件事,可获得些许性能的提升。
结果:与GLE相比,所有供应商的CPU性能提高了2-3倍,端到端渲染帧,真实内容。移动测试关卡,840次绘制调用、单核、在2.4 GHz Cortex-A73、Mali-G72,GLES花费38毫秒,Vulkan单核:13毫秒,良好的多核扩展功能!小心big vs LITTLE core。
14.5.3.4 并行技术
计算机硬件越来越并行,需要理解并发性才能利用并行性,需要了解硬件和内核才能理解并发编程!Parallelism and Concurrent Programming详尽地介绍了现代并行计算硬件、并发编程技术,以及如何将其应用于构建高性能游戏引擎。
并发可以定义为共享数据文件的转换,由多个控制流共享进程、线程、纤程等,有多个共享数据的读取和/或写入。数据“文件”可以是任何东西,线程之间共享的全局布尔变量、共享队列,数据文件可以存放在任何地方,如多线程进程中的虚拟内存空间、多个进程在一台计算机内共享虚拟内存页、GPU和CPU共享物理RAM、两个进程之间的管线、存在于多台计算机可访问的网络驱动器上的文件。如果数据没有被共享,那就不是并发性,它只是“同时”计算:
并发意味着在共享数据上运行的多个控制流,并行性是指多个硬件组件同时运行,即使在单核CPU上,并发也是可能的,例如先发制人的多任务处理。同样,并行硬件甚至可以提高单线程代码的性能,隐式并行(流水线或超标量CPU架构)。
并行分为隐式并行和显式并行,当前的硬件架构基本都是显式并行。显式并行将并行计算硬件的存在暴露给:程序员和/或编译程序,自2002年起用于消费电子产品,包含多处理器计算机、多核CPU、x86(SSE)中的SIMD矢量处理单元、多核GPU(SIMT),显式并行支持并发。
指令集架构(Instruction Set Architecture,ISA):每个CPU都提供不同的ISA,ISA定义:CPU识别的一组操作码、寄存器的数目及名称、CPU支持的寻址模式、公开了硬件的一些细节:CPU是否包含FPU?VPU?I/O是如何完成的?内存映射?基于寄存器?它能在每个时钟上发出多条指令吗?(VLIW)是否支持特权模式?有多少个保护环?其中CPU的执行上下文如下图:
内存缓存层次架构通过利用时间和空间的局部性减少了*均内存访问延迟。时间局部性:数据往往在短时间内被重复访问,如果一个程序访问地址x,它很有可能在不久的将来再次访问地址x。空间局部性:数据往往是按顺序或按块访问的,如果程序访问地址x,它很有可能也会访问地址x+n(对于较小的|n |)。
缓存的工作原理是将主内存分成几行,典型的缓存行是64字节或128字节。主RAM的行可以读入缓存,一旦进入缓存,CPU就可以更快地访问数据。
一旦缓存中有一行,我们如何知道它来自哪个内存行?可根据行索引(64字节缓存:地址 & 0x3F,128字节缓存:地址 & 0x7F)和标签(64字节缓存:地址 >> 6,128字节缓存:地址 >> 7),将标签与每个缓存行一起存储,以跟踪其在内存中的原始位置(下图)。
当CPU读取数据项(单字节或更大)时:转换为行索引的地址,内存控制器检查一级缓存:缓存是否已经包含该行?如果命中(Hit),则从该行获取数据,如果未命中,请从下一级缓存(L2)中提取……刷新并重复,直到达到主存储器。在多核系统上,读请求也可以由同一级别的其它核来完成。
当CPU写入数据项(单字节或更大)时:转换为行索引的地址,内存控制器检查一级缓存:缓存是否已经包含该行?如果命中,将项目写入行中,标记行已修改(在多核机器中,这会变得更复杂…)。如果未命中,则从L2、L3……主存储器中提取行,写入并标记已修改,写入缓存行不一定立即写回主RAM。下次读取缓存线或使缓存线失效时触发写回,直写操作可以绕过缓存。
上面描述的是直接映射缓存,内存中的每一行都映射到缓存中的一行可能存在冲突(例如地址0x80、0x100和0x180)。全关联缓存是内存中的任何行都可以放在缓存中的任何位置,需要对标记进行线性搜索才能在缓存中找到行。n路集关联缓存是内存中的每一行映射到缓存中的n行,两全其美:将线路冲突减少n倍,有限搜索(只搜索路径,不搜索整个缓存)。例如2路集合关联缓存,内存中的每一行映射到缓存中的两行:
当缓存满了会发生什么?必须删除以前的数据才能腾出空间,缓存行替换策略:先进先出(直接映射缓存中的唯一选项),NMRU(不是最*使用的):每组1位,LRU(最*最少使用):n>2时成本较高,LFU(使用频率最低),伪随机。
那么我们为什么要关心缓存呢?了解缓存是一种优化工具,构造数据以避免过度缓存未命中,将数据打包到非稀疏数组中,避免在内存中跳转。
该文还详细介绍了内核、进程、线程、虚拟内存等概念。其中虚拟内存是每个进程都有的私有内存“视图”,用户空间程序根据虚拟地址执行所有内存访问,CPU和内核协同工作,以便在运行时将虚拟地址映射到物理地址。
线程和进程的关系:
线程调度的几个状态:
线程上下文切换:
进程上下文切换:
早期的CPU是串行(serially)执行的,一次一条指令,CPU内部的组件没有很好地分开,执行指令时,许多组件处于空闲状态。现代CPU是流水线的(pipelined),每个指令都经过明确定义的阶段,每个阶段对应于CPU内核中的一个组件,组件之间的清晰分隔,通过允许多条指令同时“运行”,可以让所有组件保持忙碌,每个都在核心中使用不同的组件。
不同的CPU对其阶段的定义不同,从四到五个阶段,在深度流水线CPU中多达30多个阶段。基本阶段:
- Fetch:从内存中提取指令字(F)。
- Decode:将指令解码为操作码和操作数(D)。
- Register:寄存器访问(R),假设D和R是组合的(D/R)。
- Execute:在ALU上执行指令(E)。
- Memory:内存读/写(M)。
- Register writeback:寄存器写回,例如将结果存储在寄存器中(W)。
为了让每个阶段保持忙碌,每个时钟发出一条新指令:
流水线是指令级并行(ILP)的一种形式,衡量性能的指标有吞吐量(每单位时间失效的指令数)和延迟(使一条指令失效所需的时间长度)。
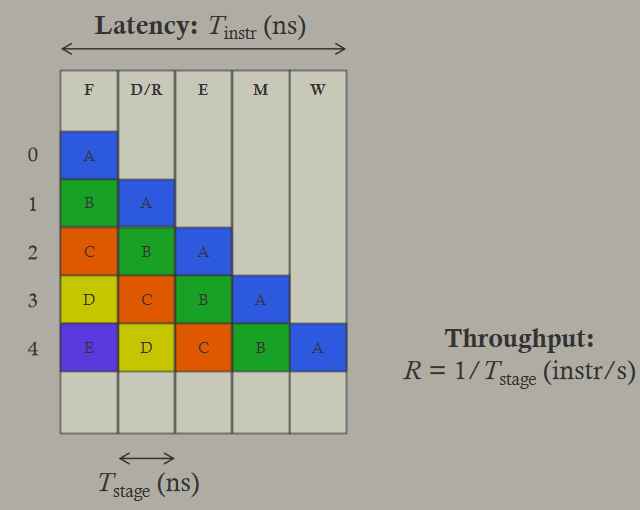
停顿(stall)被定义为并非所有阶段都保持忙碌的情况,换句话说,由于某种依赖关系,无法发出下一条指令。CPU管线中有三种依赖关系:
- 数据相关性:一条指令中使用的寄存器在下一条指令中再次使用。
- 分支依赖性:指令的操作取决于前一条指令的结果(例如BZ)。
- 资源依赖性:某些类型的指令只能在某些硬件上执行(例如整数ALU)。
依赖是指令流的属性,依赖关系可能导致危害——对CPU管线的影响(停顿):
- 数据依赖导致数据危害:发出本指令需要之前指令的结果。
- 分支依赖导致控制危害:需要在条件表达式的结果已知之前预测分支。
- 资源依赖导致结构危害:想发出(例如整数加法),但ALU正忙。
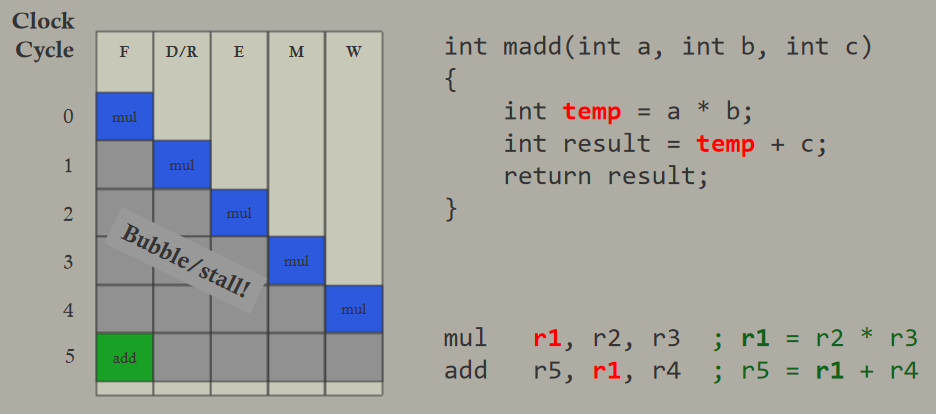
数据危害示例。
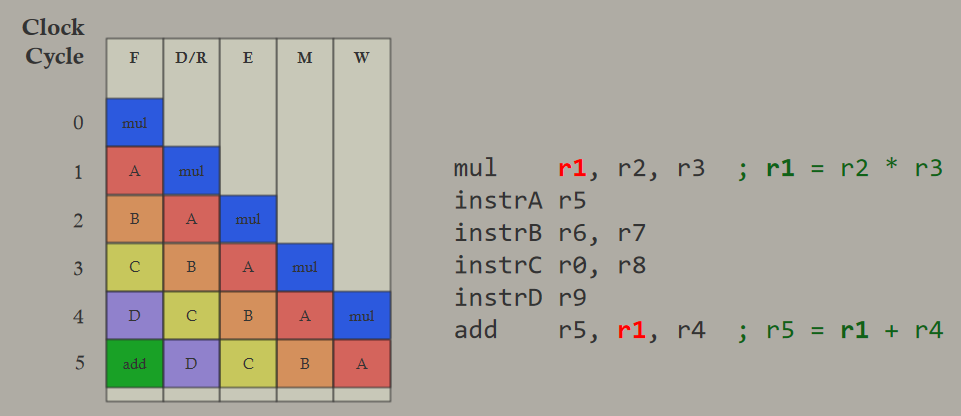
OOO执行允许CPU对指令A、B、C和D(取自add之前)进行重新排序,以便它们位于add和mul指令之间。
内存延迟隐藏:请注意,由于内存延迟,也可能发生停顿,mov r3, [r1+8]可能需要4、40或400个周期!(L1、L2、主RAM)。OOO执行还有助于隐藏内存延迟,在等待内存控制器响应时,在延迟槽中执行其它独立指令。多线程是另一种隐藏内存延迟的方法,当一个线程正在等待内存时,可以安排其它线程使用CPU内核。
当遇到条件分支指令时,CPU应该做什么?问题发生时尚不清楚的情况的结果,管线深度可达10+级,因此,条件分支引入了10+周期停顿,这被称为分支损害(branch penalty),控制危害,这是原始数据危害的特例。
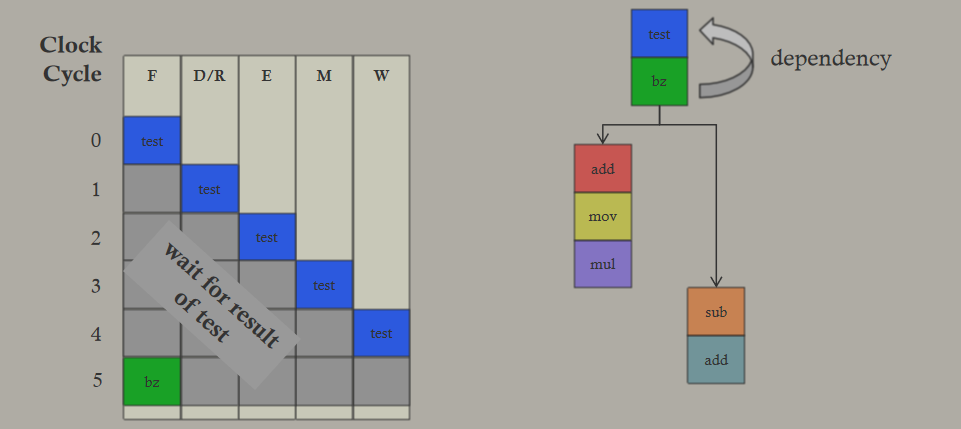
分支损害问题的解决方案:
- 软件:
- 循环展开以增加运行长度(如果测试较少)。
- 重新排列代码以最小化“分支”。
- 硬件:
- 延迟槽(Delay Slot)。选择stall期间要运行的指令(OOO执行)。
- 从两个分支中选择一个,然后进行预测性地执行。如果预测是正确的,就不会延迟。如果预测是错误的,则刷新管线,返回中间结果,然后在正确的分支上重新开始。
CPU应该如何猜测?简单的想法:假设向后的分支总是被执行,向前的分支永远不会被执行。for循环中非常常见的模式:
for (i = 0; i < count; ++i)
{
// do work...
if (special_case)
break;
// forward branch (rare)
} // backward branch (common)
另一个想法是依靠人工标记if语句:
for (i = 0; i < count; ++i)
{
// do work...
if (UNLIKELY(special_case))
break;
}
// gcc definitions:
#define LIKELY(x) __builtin_expect((x), 1)
#define UNLIKELY(x) __builtin_expect((x), 0)
另一个想法是:在CPU芯片上包含分支预测逻辑,记录哪些分支被取走的历史。逻辑可能会变得相当复杂,一些CPU可以检测像Y,N,Y,N,Y,N等模式…显著增加晶体管数量和电路复杂性,预测执行需要将计算结果临时存储。
还有一个想法:根本不要分支!相反,始终执行分支的两侧,但在每条指令上标记与其关联的条件(预测),当条件(预测)为真时,CPU才实际提交谓词指令的结果,这种方法称为预测(predication)。更简单的形式:部分预测(Partial Predication),条件移动,条件选择指令。
条件选择,例如PowerPC的fsel和isel指令:isel RR, RA, RB, predicate_code,如果预测位为1,则移动RA -> RR,如果预测位为0,则移动RB -> RR。

完整的预测如下:
超标量(Superscalar):
管线化和超标量的CPU对比如下:
弗林分类法(Flynn’s Taxonomy)在1966年由斯坦福大学的迈克尔·J·弗林提出,将并行性分为指令级并行(ILP)和数据级并行(DLP):
- 单指令单数据(SISD)。
- 多指令多数据(MIMD)。
- 单指令多数据(SIMD)。
- 多指令单数据(MISD)。
- 单指令多线程(SIMT),用于GPU。
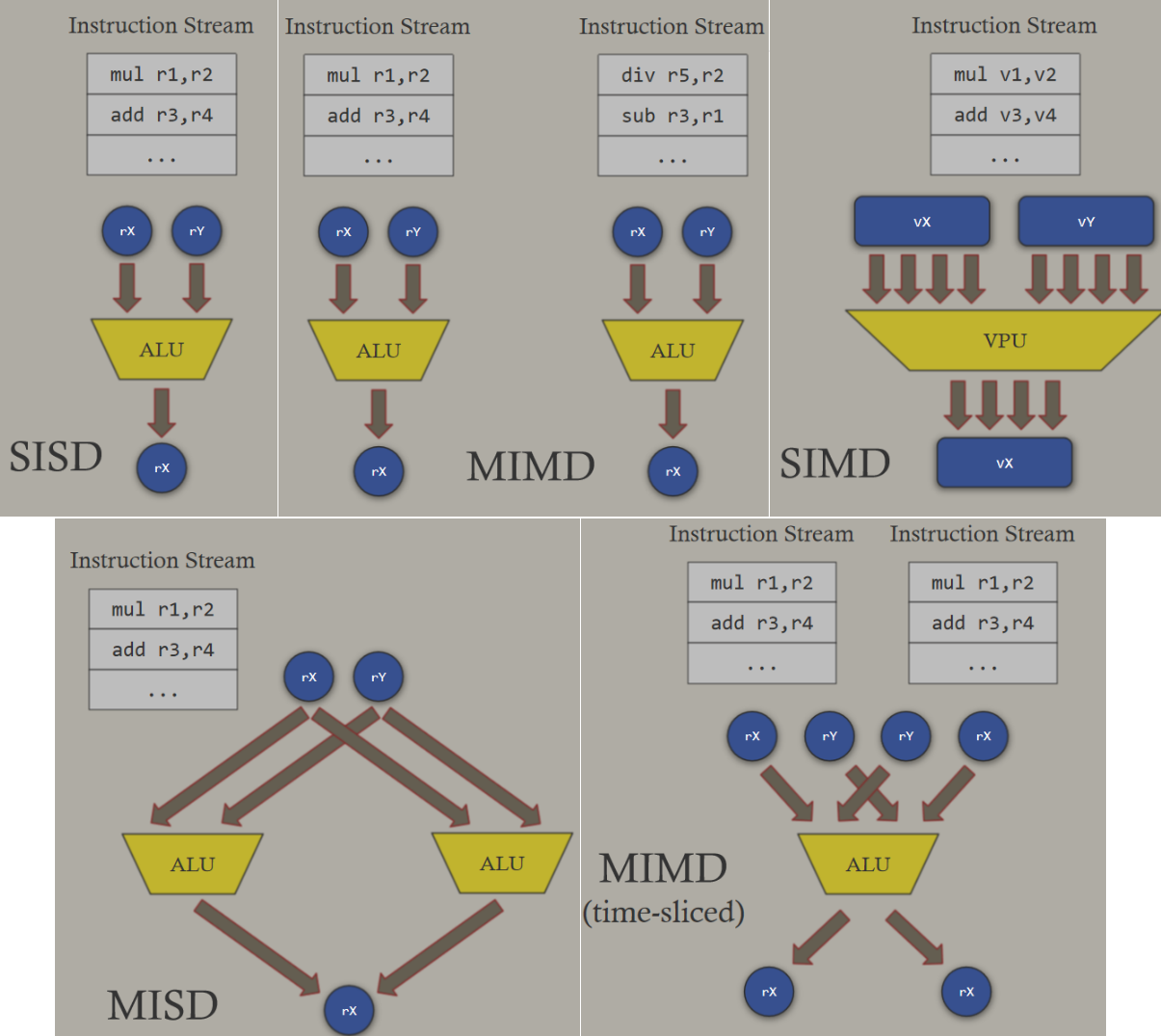
串行、超线程、多核CPU的架构对比如下:
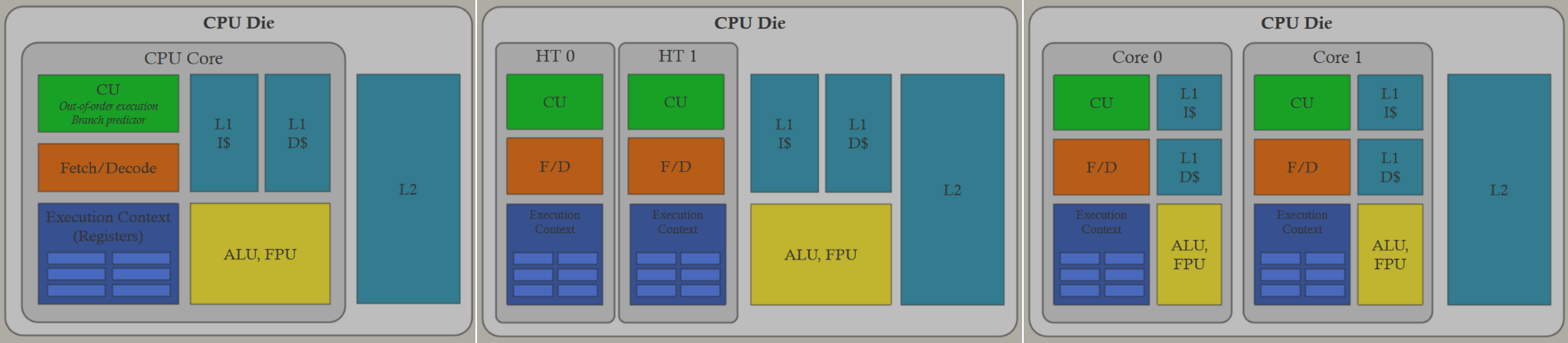
GPU架构是SIMD和MIMD的混合体,SIMD内核将单个指令流(线程)并行应用于多个数据“通道”,为了隐藏延迟,许多线程通过时间切片共享一个SIMD内核,Nvidia调用此单指令多线程(SIMT)。
此外,计算机集群:多台同质计算机,机架安装在附*,通过快速本地网络连接。网格计算:松散耦合的异构计算机(例如SETI@home)。云计算:按需计算和存储,软件即服务(SaaS),灵活、可扩展、经济高效,只使用你需要的,随用随付。
并发编程比顺序编程困难得多,在顺序程序中运行良好的许多假设、技术和数据结构在并发情况下会崩溃,新种类的bug:新问题、新的限制。需要以数据为导向的思维方式,需要了解目标硬件,同时数据访问是并发问题,解决这个问题需要新技术!
竞争条件是软件(或硬件)系统的行为取决于事件的顺序或时间的情况。并非所有的比赛条件都有不利影响,例如在单帧中,武器射线投射的处理顺序无关紧要,一个关键的竞争条件(critical race condition)是导致不正确的行为。数据竞争是一种特定的竞争条件:在共享数据上运行的两个或多个指令流(线程),根据具体的时间,读取或写入共享数据的结果会变得不一致,数据竞争是并发问题!
细粒度的数据竞争:增量竞争可以在多核机器上以真正的并行性发生,但原因稍有不同。现在,同一条指令可能会在两个或多个线程中同时执行,指令需要多个时钟周期才能运行,所以指令之间的重叠可能是完整的,也可能是部分的。
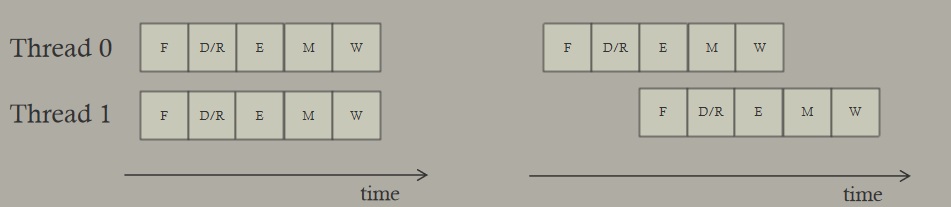
粗粒度的数据竞争:读取/写入共享磁盘文件的多个进程之间也可能发生数据竞争:1个读1个写、1个写多个读、多个写,例如,两个进程将一个32kib的块写入一个共享文件,进程A打开文件,写入其第一个4kb块,进程B然后打开文件,写入它的第一个4kb块,与此同时,A继续写入导致数据损坏!
增加共享计数器的问题的关键是什么?增量操作可能会中途中断,为了避免数据竞争,我们需要一种使某些关键操作原子化(不可中断)的方法。使用这些原语称为基于锁的编程,可靠但也昂贵(互斥体涉及内核调用),也可以编写无锁算法,要想做对要困难得多,可以比基于锁的方法执行得更好,更容错。
文中还涉及了原子(atomic)、互斥量(mutex)、临界区(critical section)、信号量(Semaphore)、范围锁(Scoped Lock)、条件变量(condition variable)、线程安全的函数等技术。其中线程安全函数是一种在内部锁定互斥体的函数,以提供原子操作的假象。虽然方便,但是可能会导致程序员倾向于长时间持有锁。这样的函数是不可重入的:a()调用b()调用c()…调用a()会导致死锁,因为a()已经持有锁!缓解线程安全函数问题的想法:保持锁的时间最短,目标是尽可能接*“无锁”。
// 不良的代码
void NotGreat(args)
{
g_mutex.lock();
// do huge amount of work...
g_mutex.unlock();
}
// 良好的代码
void Better(args)
{
g_mutex.lock();
WorkItem workItem(args);
g_workQueue.enqueue(workItem);
g_mutex.unlock();
}
void ProcessWorkItems()
{
for (workItem : g_workQueue)
// do huge amount of work...
}
如果操作需要以原子方式完成,请编写一个不安全版本,然后从安全版本调用它,这支持可重入调用或使用可重入锁:
// 无锁的函数(不安全)
void DoWorkNoLock()
{
if (conditionA)
return;
for (auto x : collection)
{
if (!IsValid(x))
return;
DoStuff(x);
}
}
// 有锁的函数(安全)
void DoWork()
{
g_mutex.lock();
// 调用无锁的函数
DoWorkNoLock();
g_mutex.unlock();
}
此外,文中还涉及加载链接/存储条件、LL/SC和缓存行、屏障、内存屏障、原子变量、内存顺序、自旋锁(Spin Lock)、读写锁(Reader/Writer Lock)、可重入锁(Reentrant Lock)等技术。
基于锁的并发是在共享内存系统中同步线程的最简单、最可靠的方法。但是,它很容易出现单线程程序中不会出现的问题(使用无锁或无等待算法也可以避免):死锁(Deadlock)、活锁(Livelock)、饥饿(Starvation)、优先级反转(Priority inversion)等。
还有餐饮哲学家问题(Dining Philosophers Problem):五位哲学家围坐在餐桌旁,桌子上有五把叉子,每个哲学家之间各有一把,每个哲学家可以处于两种状态之一:思考或吃。为了进入进食状态,哲学家必须获得两只叉子,一只手一把,一有食物,就可以抓住任何一个叉子,离开进食状态时,他放下两个叉子,哲学家们从不互相交谈。问题陈述:设计一种行为模式(并行算法),让所有哲学家在不饿的情况下无限地思考和进食。天真的解决方案:总是先抓住左叉子,然后抓住右叉子,如果每个哲学家都同时抓住左叉子…那么他们谁也抓不到正确的叉子!导致一种被称为死锁的情况。

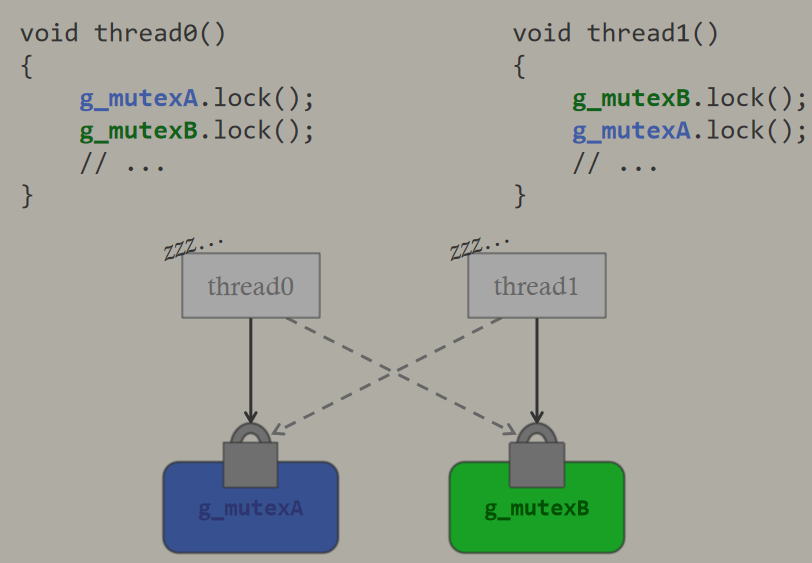
我们可以通过绘制连通图来解释死锁,节点代表线程(\(T_i\))和资源(\(R_j\)),有向边表示锁,T -> R:线程T正在等待资源R,R -> T:线程T持有/锁定的资源R。资源图包括\(T_s\)和\(R_s\),等待图仅包括\(T_s\),等待图中的循环=死锁。
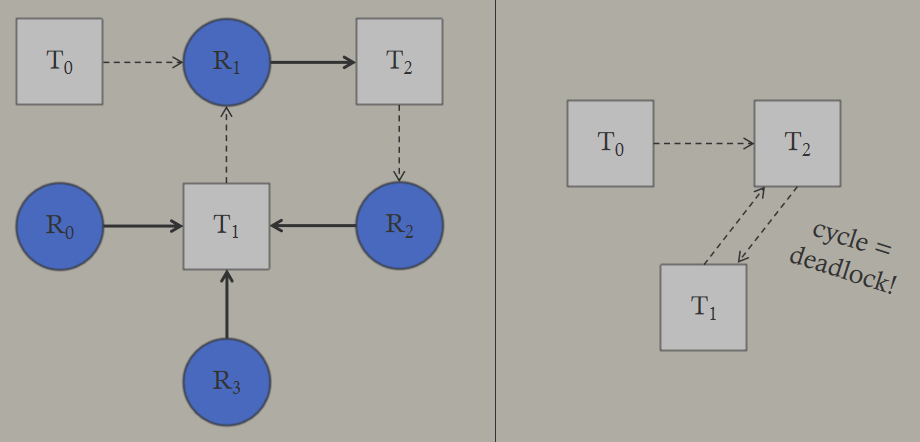
资源图和等待图。
活锁(livelock)是一种线程可以取得局部处理,但无法取得全局处理的情况。在多线程程序中,当线程试图通过后退和重试来避免死锁时发生,例如,它们都会退出,然后在相同的时间后重试。换句话说,系统的状态可以提高,但没有线程可以做任何真正的工作,线程将所有时间都花在后退和重试锁定资源上。
活锁示例。
死锁问题的解决方案总是需要消除四个必要和充分条件中的一个或多个:
- 消除互斥。例如,为每个线程提供自己的资源。
- 取消等待。例如,一次不要持有超过一把锁,例如,无锁算法。
- 允许抢占锁。例如,内核或主管线程可以检测死锁,并通过抢占锁来“修复故障”,迫使线程重新尝试。
- 移除循环等待。例如,设定全球排序/资源优先级。
优先级反转:如果低优先级线程L获得了资源a的锁,但在等待资源B时进入睡眠状态,会发生什么?高优先级线程H将无法获得资源A上的锁,因此,线程L的优先级似乎高于线程H的优先级,它们的优先次序被颠倒了。如果中等优先级线程M在持有资源a的锁时抢占了线程L,也可能发生优先级反转,线程L锁定资源A,线程M抢先线程L,使L进入睡眠状态,线程H再次无法获得资源a上的锁。
优先级反转的可能后果:
- 没有。如果线程L快速释放资源,线程H将能够运行,而反转可能不会被注意到。
- 感知到的系统放缓。如果线程H长时间缺乏对资源的访问,系统可能会显得迟钝(例如,如果线程H响应用户输入)。
- 系统故障。线程H可能会因无法访问资源而导致系统故障(例如,错过实时截止日期)。
游戏引擎中的并发从初级到高级有以下几种形式:

节点图可以有依赖,每个依赖项都会创建一个同步点,同步点是一个时间点,在这个时间点上,多个并行任务必须同步,以便进行排序。第一个要完成的任务必须等到最后一个任务完成,每个同步点都可能导致系统资源使用效率低下(硬件空闲时间)。
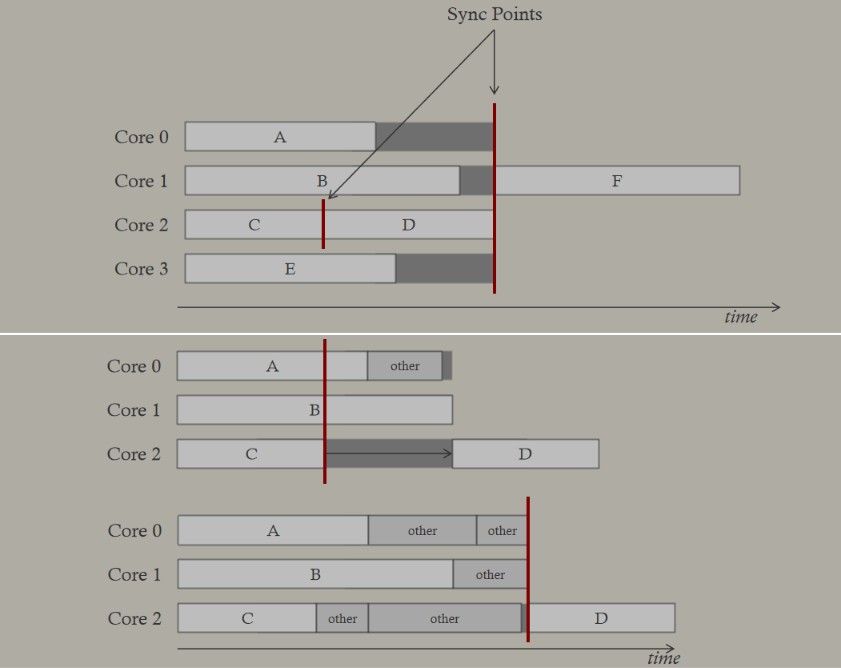
并发地更新游戏对象:让我们将这些想法应用到游戏对象更新中,我们如何同时更新游戏对象?大多数游戏引擎根本解决不了这个问题,因为它是以单线程方式编写的遗留代码,因为这很难!游戏对象通常相互依赖:
处理游戏对象依赖关系的一种方法:水体化(Bucketed)更新。
enum Bucket
{
kBucketVehiclesPlatforms,
kBucketCharacters,
kBucketAttachedobjects,
kBucketCount
};
void UpdateBucket( Bucket bucket)
{
// ...
for (each gameObject in bucket)
gameObject.PreAnimUpdate(dt);
g_animationEngine.CalculateIntermediatePoses(bucket, dt);
for (each gameObject in bucket)
gameObJect.PostAnimUpdate(dt);
g_ragdollSystem.ApplyskeletonsToRagDolls(bucket);
g_physicsEngine.Simulate(bucket, dt) // ragdolls etc.
g_collisionEngine.DetectAndResolveCollisions(bucket, dt);
g_ragdollSystem.ApplyRagDollsToSkeletons(bucket);
g_animationEngine.PinalizePoseAndMatrixPalette(bucket);
for (each gameObject in bucket)
gameObject.FinalUpdate(dt);
// ...
}
void RunGameLoop()
{
while (true)
{
// ...
UpdateBucket(kBucketVehiclesAndPlatforms);
UpdateBucket(kBucketCharacters);
UpdateBucket(kBucketAttachedobiects);
// ...
g_renderingEngine.RenderSceneAndswapBuffers();
}
}
并发操作总是涉及延迟,同时思考需要我们将每个操作分解为调用和响应(完成)。
系统的吞吐量要求是什么?通常可以用延迟换取吞吐量,延迟增加 -> 增加吞吐量,如果客户端可以等待结果(更高的延迟),那么:锁的争用减少了,少等待,更少的同步点,更高的吞吐量。
文中还涉及作业系统并行、无锁队列、非阻塞保证、原子快照对象、SIMD与GPU编程等等技术,可谓是并发编程的大而全。其中GPU编程模型:编写几何体、顶点、像素着色器(用于图形)或编写计算着色器(GPGPU),对大量数据执行单个相对简单操作的循环适用于GPU,考虑一个循环,它迭代并处理N个数据项。典型工作流程:编写CPU循环,测试,让它工作;将循环体转换为GPU内核;GPU将在一个或多个CU内的SIMD单元上并行运行循环体N次。程序员编写“单线程”内核,启动它在GPU上执行,单线程内核由编译器/GPU矢量化,因此它可以在CU中的SIMD上并行运行,每个“lane”都被称为一条线程,在SIMD上运行的一组线程称为波前(wavefront)。
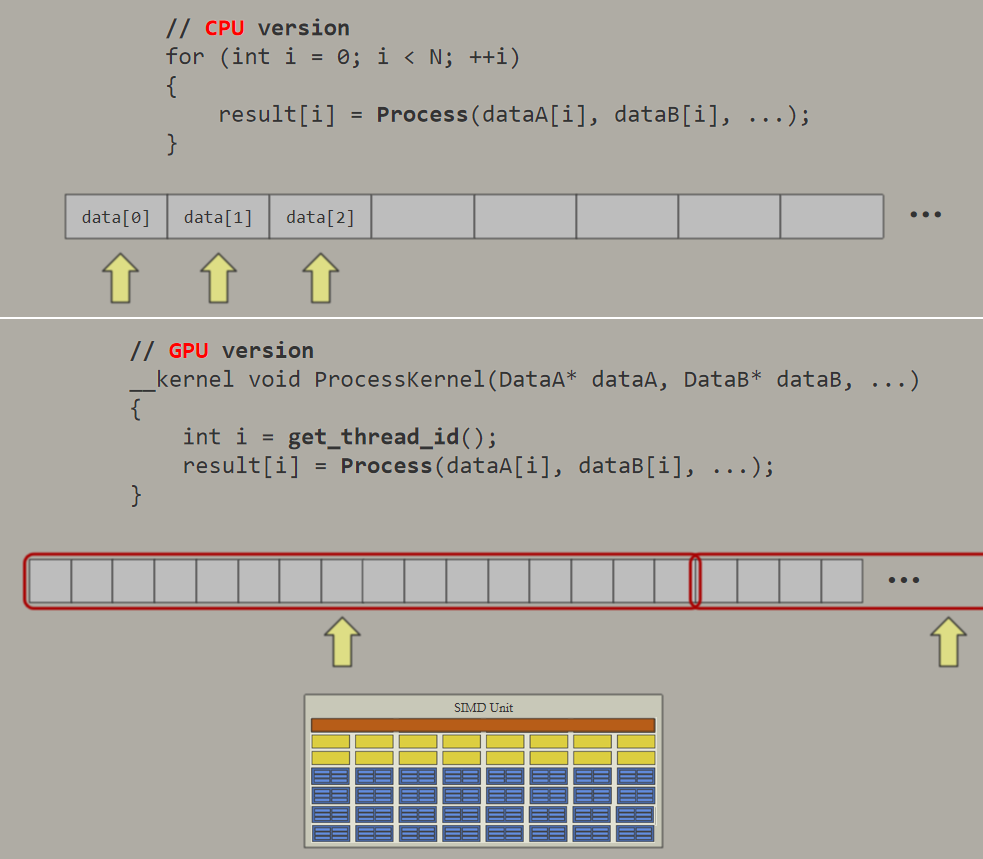
CPU和GPU编程模型对比。
GCN Wavefront:Radeon GCN的波前有64线程(lane)宽,但我们知道每个SIMD实际上只有16线程宽,这是怎么回事?答案:循环指令处理!一个16 lane的SIMD在4个时钟周期内执行由64 lane组成的波前,通过运行4组16个线程,每个时钟周期一个。
总结:SIMD单元在数据的 4、8或16 lane上并行执行单个指令流,可以循环处理更多通道(例如,通过循环处理4组16个线程,每个SIMD 64个线程)。计算单元(CU)有多个SIMD,每个CU时间在多个线程之间切片以隐藏停顿,使用预测处理分支,循环是可能的,但整个wavefront / warp必须循环。GPU有多个CU。
传统上,CPU上的SIMD矢量化是使用特定于*台的内部函数完成的。有了英特尔ISPC,这已经成为过去。基于行业标准LLVM编译器,英特尔ISPC是一种易于编写矢量代码的语言。它为许多不同的指令集生成高性能矢量代码——SSE、AVX、AVX-512甚至ARM NEON。它使用简单,易于与现有的代码库集成,外观和行为非常像C。
Intel® ISPC in Unreal Engine 4: A Peek Behind the Curtain阐述了英特尔ISPC现在在虚幻引擎4中的实现,可以用了解英特尔如何与Epic Games的合作,优化物理和动画系统,以及任何虚幻开发者如何使用它让游戏变得更好。
利用并行性对于在Chaos和动画中获得最佳性能至关重要,即使在现代高端系统上也是如此,任务并行性包含多线程、多核,SIMD并行性有SIMD向量指令,自动向量化很难控制,如果每个人都在学习如何编写向量内部函数,就没有时间去创建任何东西,让你不用成为一个忍者程序员就可以轻松获得所有的失败。这些难题可以使用英特尔的SPMD程序编译器(ISPC)来解决!Ice Lake U(第10代)四核CPU,黄色圆圈代表神奇发生的CPU执行单元!

ISPC是什么?英特尔SPMD程序编译器,SPMD==单程序、多数据编程模型,它是一个编译器和一种用于编写向量(SIMD)代码的语言。针对许多SIMD的基于LLVM的开源语言和编译器架构,为许多向量ISA生成高性能向量代码,如SSE/AVX/AVX2/AVX 512/NEON…(实验),这种语言看起来很像C语言,简单易用,易于与现有代码库集成,C函数调用。
为什么是ISPC?使用SIMD快速加速现有C++代码,内部函数是硬件加速的,并且是特定于指令集的,添加AVX意味着另一种排列。Unreal在*台抽象中使用SSE2本质,集成到引擎中有利于所有基于它构建的游戏,适用于虚幻的任何地方(Win、Mac、Linux、PS4、Xbox、ARM),通过其它引擎集成的成熟技术,如Embree Lightmass(静态照明)、ISPC纹理压缩器(BC6H/BC7/ASTC)。
ISPC编程模型:ISPC不是“自动矢量化”编译器,不会通过分析和转换标量循环来生成向量代码,更像是一个所见即所得的矢量化编译器。程序员告诉ISPC什么是向量、什么是标量,向量类型是显式的,SIMD向量和任务编程模型的清晰分离,适用于现有的C/C++内存分配、数据缓冲区。
ISPC看起来很像C,所以很容易阅读和理解,代码看起来是顺序的,但并行执行,轻松混合标量计算和向量计算,使用两个新的ISPC语言关键字uniform和varying进行显式矢量化,同样,ISPC不是一个自动矢量化编译器。
export void rgb2grey(uniform int N, uniform float R[], uniform float G[], uniform float B[], uniform float grey[])
{
foreach(i=0 ... N)
{
grey[i] = 0.3f*R[i] + 0.59f*G[i] + 0.11f*B[i];
}
}
uniform用于标量数据,结果在标量寄存器中(eax、ebx、ecx等),所有SIMD线程共享相同的值。Varying用于向量数据,结果在SIMD向量寄存器中(XMM、YMM、ZMM等),默认是Varying,每个SIMD线程都有一个唯一的值,宽度取决于目标。

ISPC包含内部变量、控制流、数组、结构体等概念和关键字。在内存与性能方面,ISPC在生成的代码非常棒,但它不能重新排列代码,不能加速内存访问,所以数据布局很重要,数据需要在缓存中,并且需要在正确的布局中。收集/分散指令可能很痛苦,首选SoA或AoSoA内存布局,它们将生成向量装载/储存,Mike Acton,面向数据的设计和C语言++。
ISPC提供了丰富的操作标准:逻辑运算符、位操作、数学、夹紧与饱和算法、超越运算、RNG(不是最快的!)、遮罩/跨线程操作、减少,还不止这些!ISPC提供了此处未涉及的其它功能:指针和内存分配、AoS到SoA辅助函数、类似C++的引用、结构(+、--、*、/、<<,>>)的二进制运算符重载、内置任务系统、多个数学库(标准、快速、SVML、系统)语言功能。
虚幻的ISPC集成:ISPC在4.23版的《虚幻》中提供,在4.25中增加了控制台支持,用于Chaos物理和动画系统,支持自定义使用。在build.cs中包括ISPC模块,将ispc文件添加到项目中,include生成的C++头,虚幻构建工具处理其余的问题。
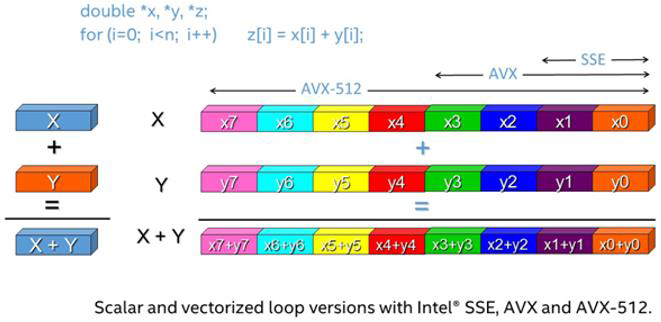
什么时候在虚幻中使用ISPC?适用于密集的计算负载,沉重的数学负担,比如物理交叉测试、布料或CPU顶点变换。最好使用连续内存加载、操作、存储,如虚幻的TArray。最好操作之间没有数据依赖关系,与并行和批处理结合使用时特别有用。
ISPC对Chaos的好处:ISPC提供了一个类似于着色器语言的简单界面,用于使用SIMD进行性能优化,跨*台工作,无需特定于*台的内在代码,在Fortnite和Destruction中都被Chaos所积极使用。
刚体蒙皮:使用输入顶点缓冲区生成变换顶点,并根据骨骼阵列进行变换。骨骼经常重复,使用foreach_unique减少变换操作所需的数量,短向量数组被压缩,使用aos_to_soa消除聚集。
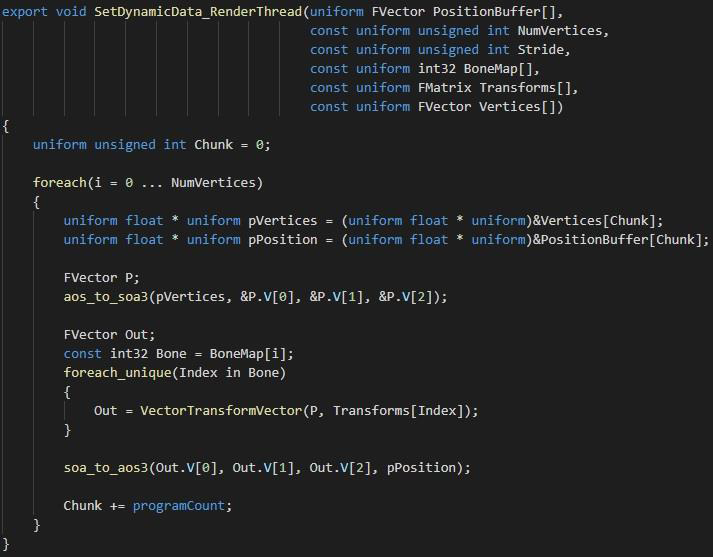
包围盒:定制减少,问题是,对于要求和的大型包围盒数组,有时求和会是负数,做reduce_min和reduce_max似乎是正确的,如果一个盒子无效呢?然后将钳制为零(默认初始化),而不是希望Foreach_active的值,运算符+序列化并处理这种情况。
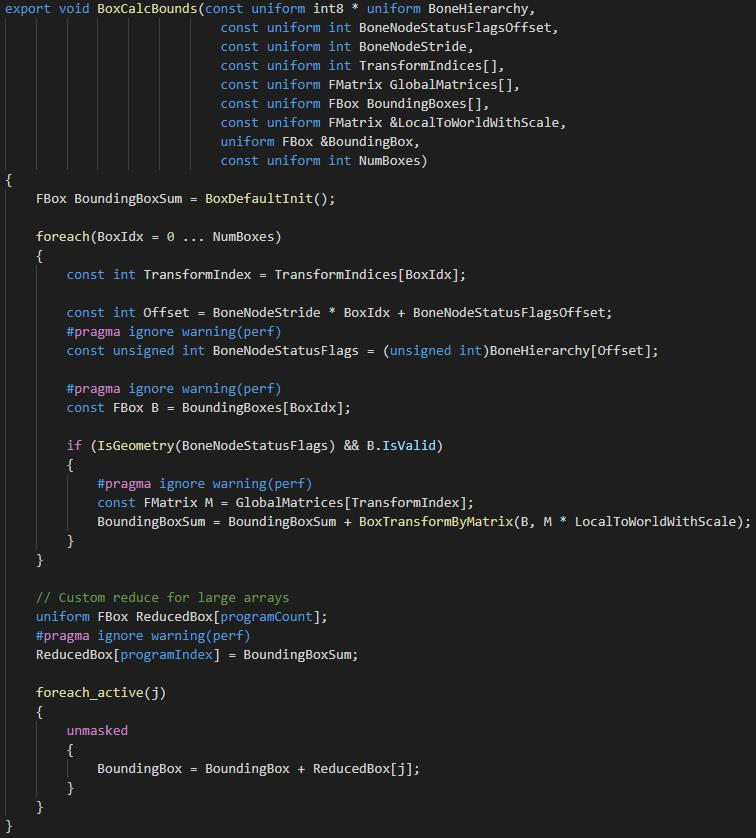
场景查询:同时处理列表中的多个元素,可以直接从ispc调用cpp代码,根据列表的大小,性能可能会有所不同。伸缩性很好,但确实有开销,所以更多的元素做得更好。
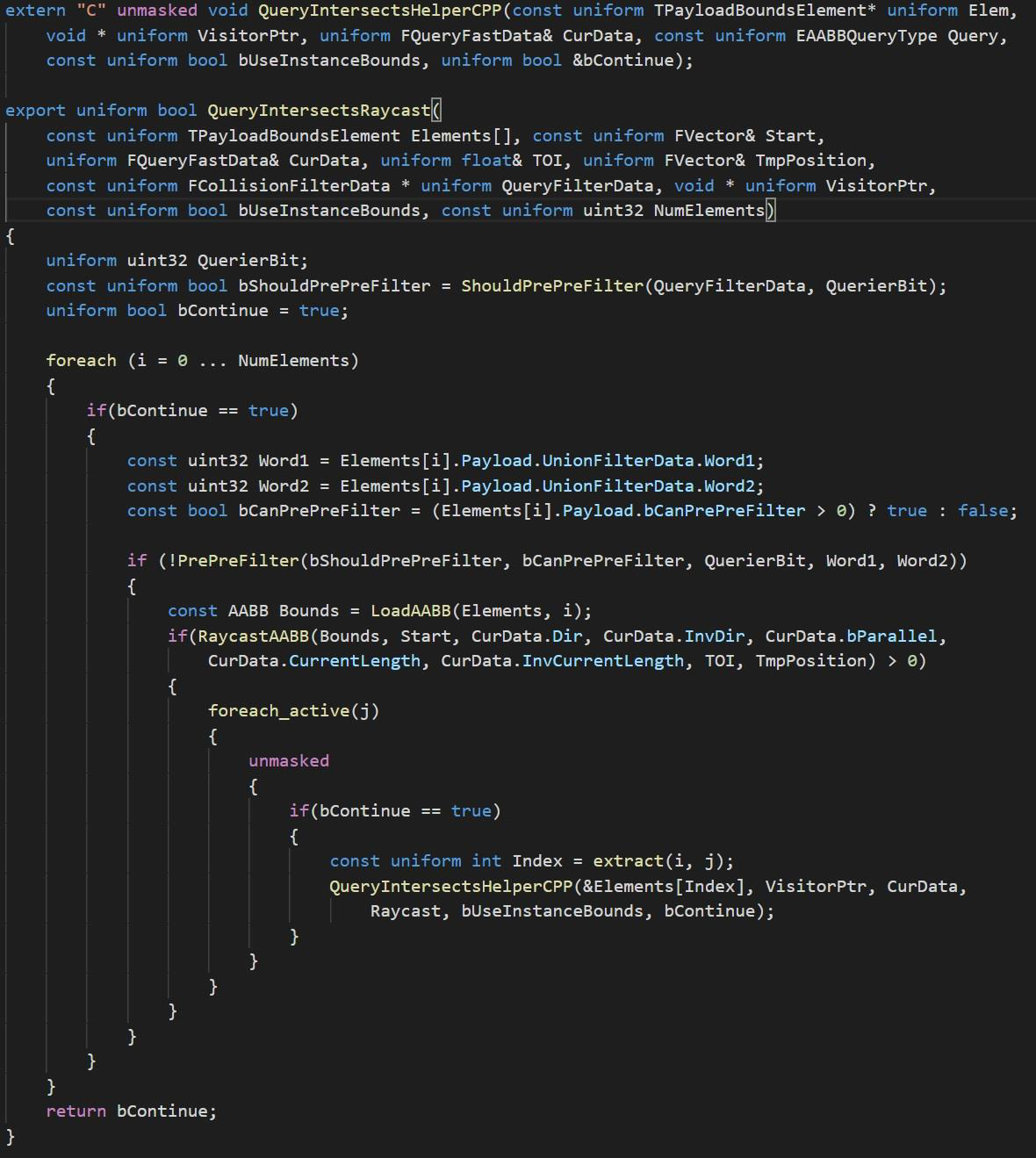
Rigid Chains:简单的数学和繁重的计算,将所有数据转换为uniform,以便获得最佳的性能,与原生指令相比没有成本,总计提高15到20%的角色蒙皮速度。
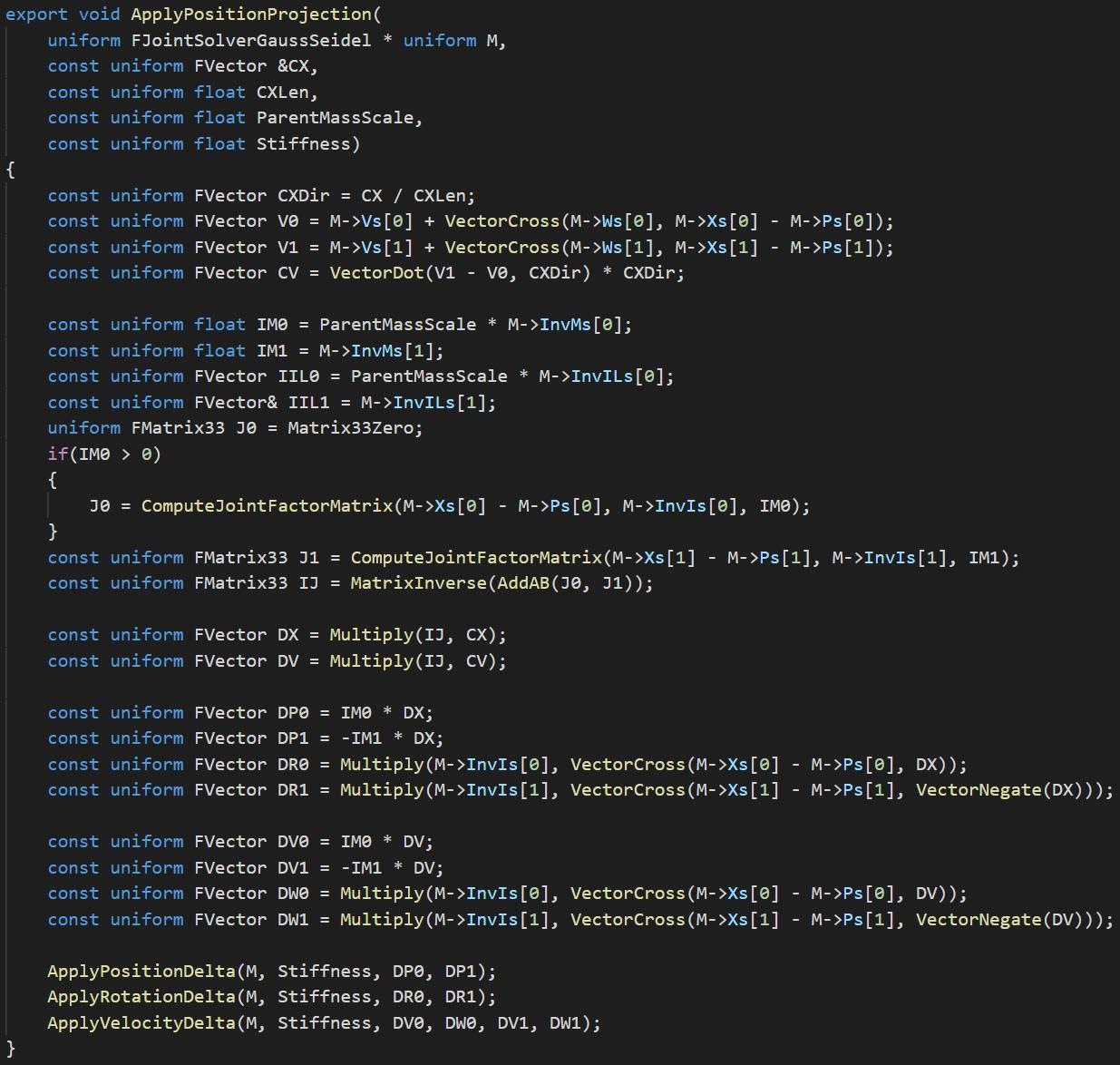
UE4中的动画:Unreal Engine目前支持8个*台,其中10个带有下一代控制台,在所有目标中维护SIMD代码是一项巨大的任务,动画团队历来没有时间去完成,性能改进的重点是高级算法更改或多线程处理,以前,动画中唯一的矢量化来自UE4中的通用库代码。
Fortnite中的动画:Fortnite正在推动整个引擎的角色性能改进,大量角色(BR中有100个),LTM(如Team Rumble/50v50 tend)倾向于接*的大团队玩家,妨碍正常性能的“技巧”。随着新游戏玩法(如NPC)的推出,对动画的性能要求不断提高。如果可以运行2倍的角色,那会解锁什么新游戏。
ISPC:性能对于动画来说总是至关重要的(更复杂的角色,屏幕上同时出现更多的角色等等),能够一次编写代码并达到所有目标*台是一个巨大的胜利。让团队专注于构建动画技术,而不是维护相同逻辑的N个版本。
在UE4动画中使用ISPC,首先关注运行时热点:姿势混合、附加姿势转换、规范化旋转、解压动画数据、构建组件空间变换、为渲染器准备骨骼变换。姿势混合是ISPC的理想场景,给定两个骨骼变换数组和一个权重,创建第三个变换数组,之前的优化工作意味着已经在运行连续的转换数组,在测试中,可以看到ISPC的性能提高了*两倍。
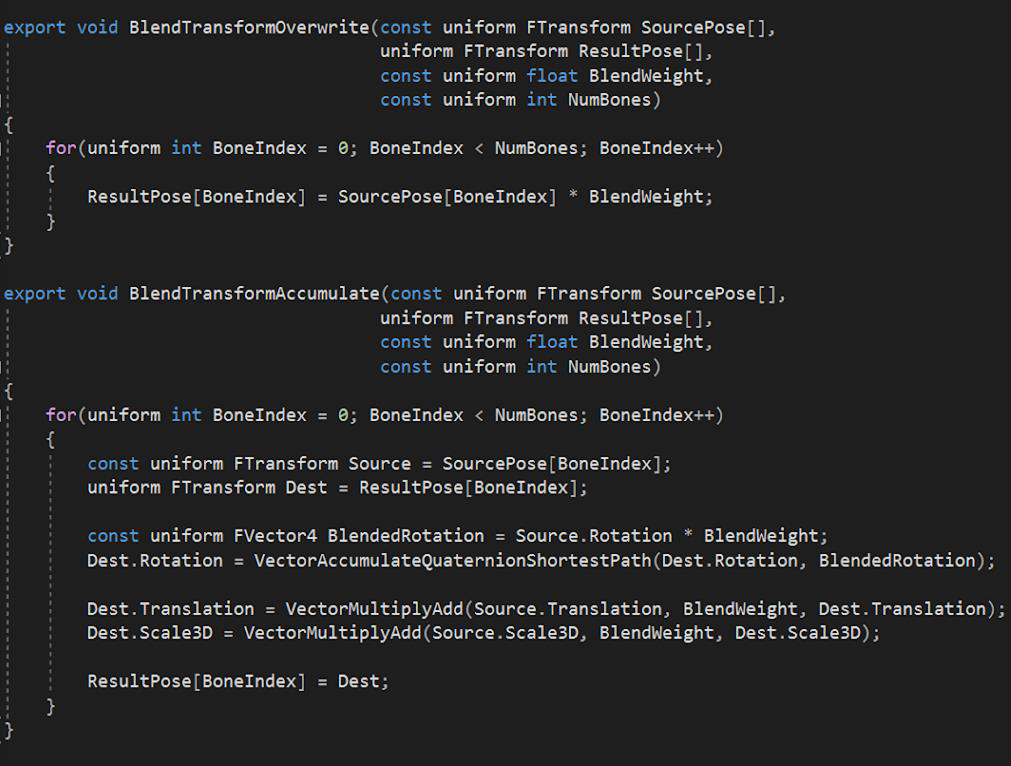
解压缩:在UE4中,解压是动画性能成本的很大一部分,引擎中支持的每种压缩格式都有为其编写的ISPC代码。在测试中观察到,根据使用的压缩类型,性能提高了1.5倍到2倍。
14.5.3.5 特殊技术
Math for Game Programmers: Voxel Surfing详细地介绍了体积表达、体素的知识、应用及优化。
对于任意连续的函数\(f(x, y, z)\),隐式地将体积定义为\(f(x, y, z) > 0\),表面是\(f(x, y, z) = 0\)的水*集。
只需要一个连续的函数,任意的代数函数、有向距离场(CSG树,在网格三线性采样)、密度函数(在网格三线性采样)。

使用密度(Density)要容易得多(局部更改),但在距离场上的一些有用操作(如放大、缩小体积、更高质量的渐变计算)上会失败,可以将密度视为距离场,夹紧距离约为一个采样单元格。
将隐式曲面或参数化网格体素化的过程:1、在网格上采样。2、*似每个单元格中的表面。3、确保表面与单元边界对齐。体素化的理想特征是:易于实现、局部独立、*滑、自适应/适合LOD、最小化三角形条形、保留锐利和薄的特征。
对于简单的立方体,在每个网格单元的中心采样\(f(x, y, z)\),在具有不同符号的单元格之间绘制一个面。
这种表达方式在体素化的理想特征的优劣如下表:
| 易于实现 | 局部独立 | *滑 | 自适应LOD | 最小化三角形 | 锐利 | 薄 |
|---|---|---|---|---|---|---|
| ++ | + | - | - | + | - | - |
步进立方体(Maring Cube):在每个单元格的角落采样\(f(x, y, z)\),在三角形拓扑中使用角的符号,沿着边缘在插值的0点处定位顶点。
这种表达方式在体素化的理想特征的优劣如下表:
| 易于实现 | 局部独立 | *滑 | 自适应LOD | 最小化三角形 | 锐利 | 薄 |
|---|---|---|---|---|---|---|
| + | + | + | - | - | - | - |
超体素(transvoxel)算法:在每个单元格的角落采样\(f(x, y, z)\),允许细分一次单元格的边(以缝合相邻的LOD级别),为三角形拓扑使用采样点的符号,沿边在插值的0点处定位顶点。

Transvoxel是一种允许行进立方体跨越不同LOD级别的方法。总共71种拓扑方式,用于处理任意边组合的细分。
这种表达方式在体素化的理想特征的优劣如下表:
| 易于实现 | 局部独立 | *滑 | 自适应LOD | 最小化三角形 | 锐利 | 薄 |
|---|---|---|---|---|---|---|
| + | + | + | + | - | - | - |
双重轮廓(Dual Contour):在每个单元格的角落采样\(f(x, y, z)\),在每个边交叉点位置采样\(f'(x, y, z)\),在轮廓上的每个单元格内找到一个理想点,连接相邻单元格的两点(支持多个LOD分辨率)。
这种表达方式在体素化的理想特征的优劣如下表:
| 易于实现 | 局部独立 | *滑 | 自适应LOD | 最小化三角形 | 锐利 | 薄 |
|---|---|---|---|---|---|---|
| - | - | + | + | + | + | ~ |
双重行进立方体(Dual Marching Cube):在精细网格上采样\(f(x, y, z)\),找出误差最小的点(QEF),如果误差 > $\varepsilon $,则在该点细分八叉树。重复前面的步骤,直到索引的误差 < \(\varepsilon\)。构造此八叉树的拓扑对偶(topological dual),当成双重轮廓曲面细分之。

这种表达方式在体素化的理想特征的优劣如下表:
| 易于实现 | 局部独立 | *滑 | 自适应LOD | 最小化三角形 | 锐利 | 薄 |
|---|---|---|---|---|---|---|
| - | - | + | + | + | + | + |
立方体行进正方体(Cubical Marching Square):构建一个带有误差细分的八叉树(类似于DMC),对于任何体素(在任何八叉树级别):展开体素,分别观察每一侧;使用行进立方体创建曲线,如果出现误差,则进行细分;将两边折叠在一起,形成三角形。

| 易于实现 | 局部独立 | *滑 | 自适应LOD | 最小化三角形 | 锐利 | 薄 |
|---|---|---|---|---|---|---|
| - | + | + | + | + | + | + |
Windborne的体素化概览:\(F(x, y, z)\) = 合成的、轴对齐的密度网格,每个块(chunk)都有重叠的特征列表,在计算时,使用布尔运算累积到块。

组合时,每个特征都是一个层,每一层要么减去,要么叠加,Alpha混合密度:\(\alpha_a + \alpha_b (1-\alpha_a)\)。
除了组合,还有减去、叠加、并集、轮廓指示器、网格密度(可用于动态光照,如光流、AO)、暴露参数、利用特征等等操作或应用。具体可参阅原文。
Aggregate G-Buffer Anti-Aliasing in Unreal Engine 4由Nvidia呈现,讲述了在UE4实现的用聚合GBuffer来达成抗锯齿的特殊技术。

从左到右:4xTAA、4xSSAA、4xAGAA。其中AGAA快了1.7倍。
TAA大幅提升质量[Karis 2014],然而存在鬼影、闪烁、过度*滑视觉特征(如镜面反射高光),需要与SSAA结合以获得最佳质量。
AGAA(Aggregate G-Buffer Anti-Aliasing,聚合几何缓冲抗锯齿)将着色率与G-Buffer采样数量分离,使用动态预过滤,以4x或8x MSAA/SSAA进行光栅化,光照最大为2倍/像素。

预过滤、超采样、后过滤的目标是捕捉或再现亚像素细节的外观,用于过滤各种几何比例的各种工具。其流程如下:
AGAA管线的高级别视图:
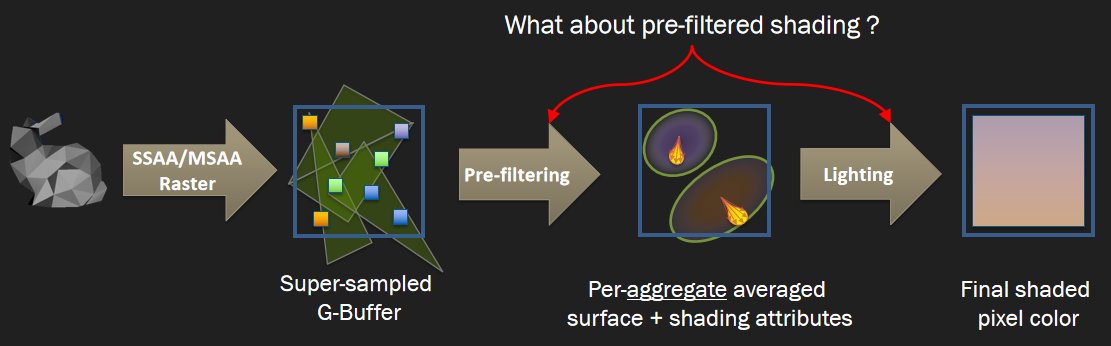
光照预过滤聚合:目标是聚合足迹上的*似*均反射率,为每个聚合独立预过滤着色函数的输入,灵感来自纹理空间和体素空间预过滤方案,属性去相关(decorrelation)假设,远距离场(far field)假设。逐聚合统计信息:*均多数着色参数、建立法线分布函数(NDF)、阴影的*均衰减。
远距离场假设。
聚合创建:分簇(cluster)。目标是将相关属性导致的着色误差降至最低,距离度量有光照模型、法线、深度/位置。其中分簇样本可以跨图元 + 离散的表面。
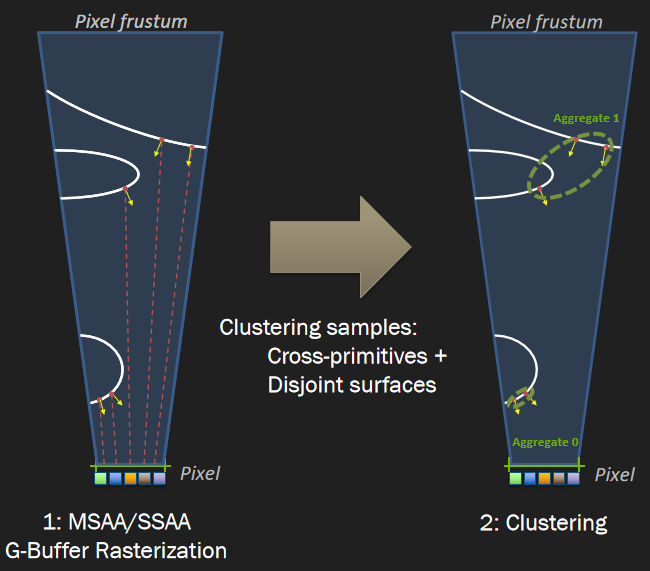
接着是聚合。一旦有了样本到聚合映射,剩下的步骤就是使用超采样G缓冲区中的数据,执行每个聚合的着色属性过滤。总而言之,对大多数着色属性进行*均,并将每个样本的法线和粗糙度信息转换为与BRDF模型相关联的法线分布表示,使得可以线性组合它们,并*似它们在聚合足迹上的方差。
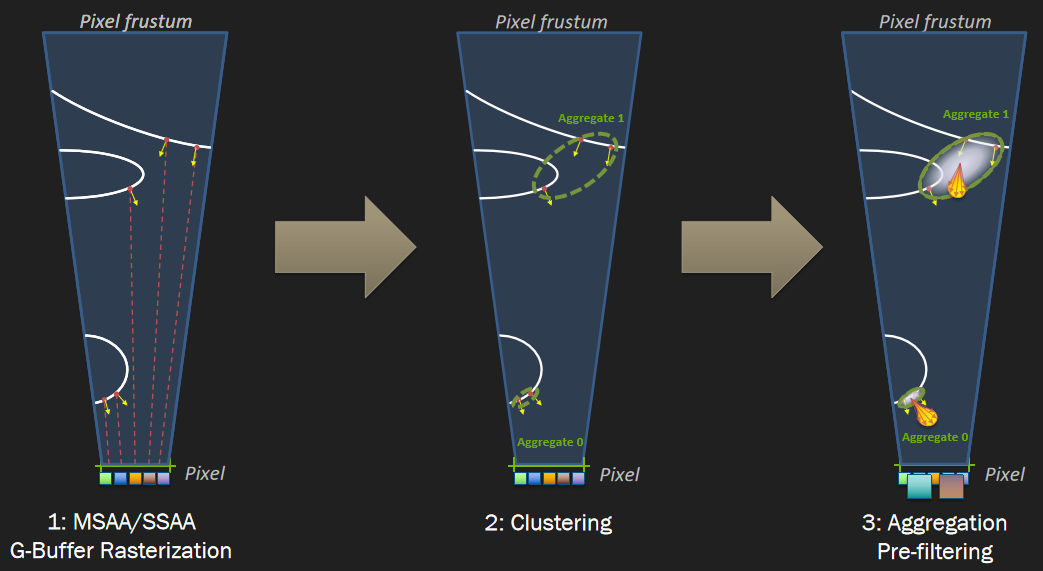
在UE4中,有多个可能的渲染路径来执行着色,其中之一是分块延迟着色。文中将引擎配置为尽可能使用分块延迟路径,并在分块延迟着色计算着色器中实现AGAA聚合和照明。为了获得最佳性能,在该计算着色器的着色阶段开始时实现了G-Buffer聚合步骤,以便重用当前分块的所有已处理光源的聚合属性。
分簇通道获取每个像素的所有ShadingModel ID、深度和法线,并计算从样本ID到聚合ID的映射。因为每个像素只有2个聚合,所以每个样本聚合ID可以存储为每个样本一位。接下来,对于每个GBuffer样本,基于GBuffer数据重建着色参数(以用于聚合着色的格式),在每个聚合中的所有样本中*均这些着色参数。但有一个例外:对于世界空间位置,首先计算每个聚集的*均视图空间深度,然后通过假设该位置的屏幕空间XY坐标位于像素中心来重建世界空间位置,速度要快得多。这种*似不会在测试中引入任何可见的瑕疵。
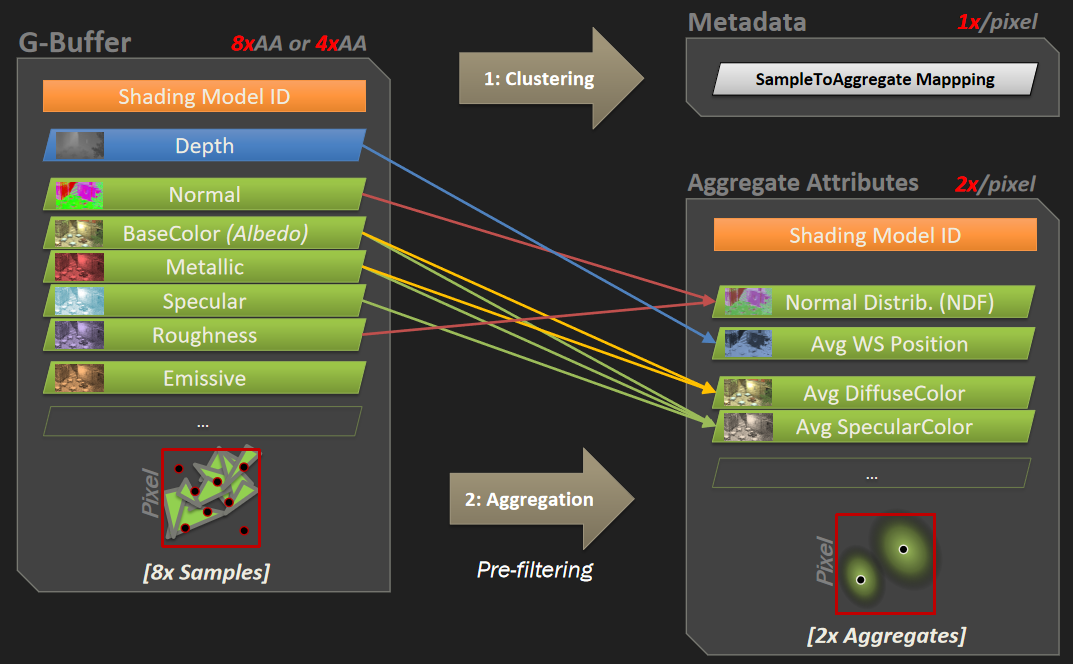
预过滤G-Buffer样本用到了法线贴图预过滤(Toksvig 2005)和几何曲率过滤(Kaplanyan 2016)。
float3 GetAgaaAverageQuadNormal(FMaterialPixelParameters MaterialParameters, float3 N)
{
int2 PixelPos = MaterialParameters.SVPosition.xy;
N -= ddx_fine(N) * (float(PixelPos.x & 1) - 0.5);
N -= ddy_fine(N) * (float(PixelPos.y & 1) - 0.5);
return N;
}
// 几何曲率过滤(Kaplanyan 2016)
float2 GetAgaaKaplanyanFilteringRect(FMaterialPixelParameters MaterialParameters)
{
// Shading frame
float3 T = MaterialParameters.TangentToWorld[0];
float3 ShFrameN = normalize(MaterialParameters.TangentToWorld[2]);
float3 ShFrameS = normalize(T - ShFrameN * dot(ShFrameN, T));
float3 ShFrameT = cross(ShFrameN, ShFrameS);
// Use average quad normal as a half vector
float3 hppW = GetAgaaAverageQuadNormal(MaterialParameters, ShFrameN);
// Compute half vector in parallel plane
hppW /= dot(ShFrameN, hppW);
float2 hpp = float2(dot(hppW, ShFrameS), dot(hppW, ShFrameT));
// Compute filtering region
float2 rectFp = (abs(ddx_fine(hpp)) + abs(ddy_fine(hpp))) * 0.5f;
// For grazing angles where the first-order footprint goes to very high values
rectFp = min(View.AgaaKaplanyanRoughnessMaxFootprint, rectFp);
return rectFp;
}
float GetAgaaKaplanyanRoughness(FMaterialPixelParameters MaterialParameters, float InRoughness)
{
float2 rectFp = GetAgaaKaplanyanFilteringRect(MaterialParameters);
// Covariance matrix of pixel filter's Gaussian (remapped in roughness units)
// Need to x2 because roughness = sqrt(2) * pixel_sigma_hpp
float2 covMx = rectFp * rectFp * 2.f * View.AgaaKaplanyanRoughnessBoost;
// Since we have an isotropic roughness to output, we conservatively take the largest edge of the filtering rectangle
float maxIsoFp = max(covMx.x, covMx.y);
return sqrt(InRoughness * InRoughness + maxIsoFp); // Beckmann proxy convolution for GGX
}

GBuffer NDF预过滤关闭(左)和开启(右)的对比。
4xAGAA的显存消耗如下:
| AGAA Pass | Render Target | Video Memory Bytes |
|---|---|---|
| AGAA Clustering | AGAA MetaData | WxHx1 R16_UINT |
| AGAA Lighting & Reflections | Per-Aggregate Lit Colors | WxHx2 R11G11B10F |
| Merge Emissive | Per-Pixel Lit Color + Emissive | WxHx4 R11G11B10F |
| Total VRAM overhead: 26 bytes / pixel |
对于解析,自发光保持逐样本解析,始终解析色调映射颜色[Karis2014]。
4xAGAA的性能(GPU时间,单位是ms)如下:
| 阶段 | 4xSSAA | 4xAGAA | 4xAGAA / 4xSSAA |
|---|---|---|---|
| Z PrePass | 0.13 | 0.13 | 1.0x |
| GBuffer Fill | 1.26 | 1.26 | 1.0x |
| Lighting | 4.71 | 2.85 | 1.65x |
| PostProcessing | 0.55 | 0.55 | 1.0x |
| Frame | 6.65 | 4.79 | 1.39x |
另外,使用可能很复杂的材质图来控制材质定义(下图),可以实现4xMSAA。这些图形可以包含许多非线性操作,例如丢弃调用、幂函数、夹紧、遮罩、条件,以及这些操作的各种组合,会破坏纹理空间的预过滤。
使MSAA更可行。在GBuffer填充中使用MSAA可以产生比超级采样更好的性能提升(约2倍),但是,如果像素着色器使用丢弃或非线性数学,则逐片元着色可能会引入瑕疵。提议的解决方案:1、鼓励艺术家避免非线性材质节点(pow、clamp等);2、对具有非线性的GBuffer属性进行选择性超级采样。
AGAA的限制是只加快了光照通道的速度,尚未测试UE的非标准着色模型,也未测试每个像素超过2个着色模型的情况。总之,AGAA加速了超采样光照,4x AGAA照明比4x SSAA快1.7倍,8x AGAA照明比8x SSAA快2.6倍,可与TAA结合使用或单独使用。
自2015年发布DirectX 12和Vulkan等现代图形API之后,游戏引擎、游戏应用等开始支持和兼容它们。Explicit Multi GPU Programming with DirectX 12旧阐述了在DirectX 12下如何实现多GPU的显式编程。
以往的多GPU是隐式编程,理想的状态是驱动施展了魔法,很管用,开发者不必在意驱动的细节。然而事实是,驱动需要很多提示,如清除、丢弃,特定于供应商的API,开发人员需要了解驱动程序试图做了什么,它仍然不总是能让性能起飞。。。
显式多GPU可以控制跨GPU传输,没有意外的隐性传输,控制每个GPU上完成的工作,不仅仅是交替帧渲染(AFR)。基于DirectX 12的显式多GPU不再有驱动魔法,AFR没有驱动程序级别的支持,现在应用层开发任意可以自己做得更好,甚至好得多,并且不需要特定于供应商的API。DX12有链接节点适配器(下图上)和多适配器(下图下)两种模式:
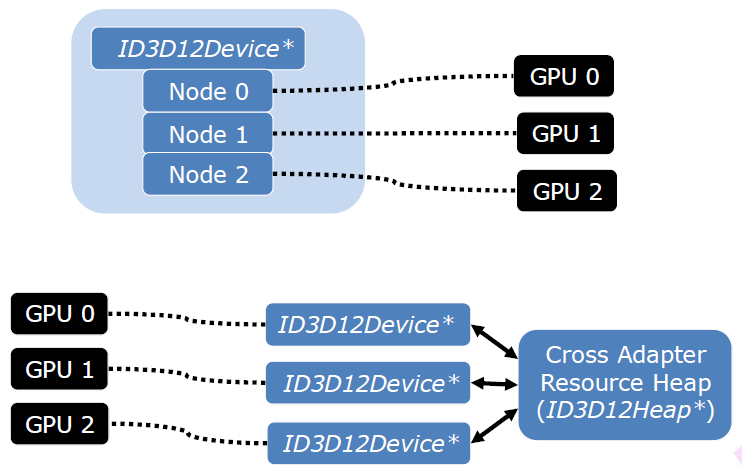
两种模式下的命令队列、资源管理、同步和应用方式等都有所不同。
对于交叉帧渲染,老的管线可能存在依赖。新的帧流水线在一个GPU上开始帧,将工作转移到下一个GPU以完成渲染和呈现,GPU和复制引擎形成一条管线:

允许使用时间技术而不损害性能:

总之,不再有驱动魔法,可以尽情地控制着AFR,尝试使用时间技术进行管线化,充分利用复制引擎,可以用额外的GPU做任何想做的事情!
Real-time BC6H Compression on GPU讲述了在GPU中实时用BC6H进行压缩的技术。BC6H是为FP16 HDR纹理设计的基于块的有损压缩,自DX11和当前次代的控制台以来支持的硬件,4x4固定尺寸的纹素块,没有Alpha,6:1压缩比(每个纹素8比特),很好地替代了像RGBE、RGBM、RGBK这样的黑代码。。。
有一些关于纹理的技巧:有符号或无符号半浮点数,三种算法的混合:端点和指数、增量压缩、分区,每个块选择不同的压缩模式。
BC6H端点和指数:每个块存储两个端点和16个索引,端点在RGB空间中定义线段,索引定义块中每个纹素在该段上的位置(下图左)。BC6H增量压缩:第一个端点以更高的精度存储,存储端点之间的有符号偏移量,而不是第二个端点,提高具有相似值的块的质量(下图右)。

BC6H分区:每个块允许两条单独的线段,提高包含较大颜色变化的块的质量,使用32个预定义分区中的一个将当前纹理指定给两条线段中的一条(下图上)。BC6H带增量压缩的分区:一个基本端点直接存储,其它3个存储为自基准端点的有符号偏移,有助于有限的端点精度下图下)。
BC6H有14种不同的模式:1种不使用分区或增量压缩的模式,3种仅使用增量压缩的模式,1种仅使用分区的模式,9种使用分区和增量压缩的模式。模式在端点精度和偏移精度之间选择不同的折衷。最佳压缩是困难的,有10种分区模式,每个分区都需要找到4个端点和16个最优指标(有32个分区),巨大的搜索空间。
GPU上实时压缩的典型案例:动态环境图、运行时从其它格式转录的HDR纹理、用户生成的内容,基于GPU的压缩避免了CPU-GPU同步以及CPU和GPU之间的数据传输。文中的用例包含动态光照条件、程序化世界几何、在相机移动期间生成附*的地图、实时将生成的环境图压缩到BC6H、启用密集环境贴图放置。
实时压缩需要权衡性能和质量。性能至关重要,质量不一定是一流的,质量很重要,压缩可能需要几毫秒。“快速”预设用哪种模式?分区模式太慢,仅使用增量压缩的模式速度很快,但仅在少数特定情况下有所改善。模式11只有终点和指数,量化为10位浮点的两个端点,16个索引(每个索引4位)。端点计算块的纹理的RGB边界框[Waveren06],将其最小值和最大值用作端点。
RGB BBox插图,小比例插入RGB BBOX,以提高精度(下图上)。HDR数据会导致非常大的偏移量(下图下)。
RGB BBox细化,使用第二小和第二大的R、G和B重建bbox:
需要在端点之间的线段上选择16种插值颜色之一,在段上投影并选择最*的索引(下图左),不像插值权重分布不均匀那么简单(下图右)。

简单的*似方法是拟合最小误差的方程:
修正索引:第一个索引的MSB隐式假定为零,并且未存储,需要通过交换端点来确保这个属性。
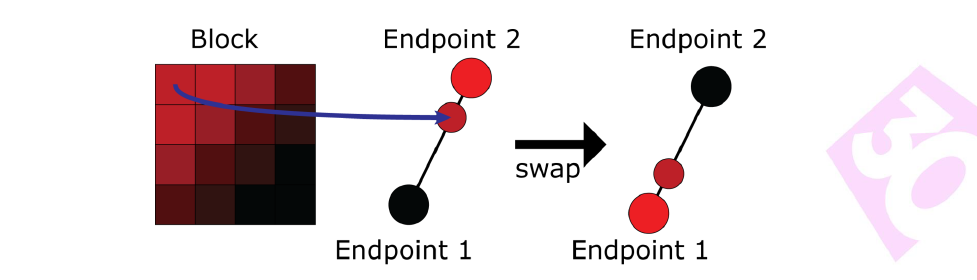
快速和质量预设的效果对比:

DX11的实现:渲染到比R32G32A32A32小16倍的临时目标,运行像素着色器并将压缩块作为像素输出,将结果复制到BC6H纹理(CopyResource),使用现代API:跳过复制步骤,实现为异步计算。着色器优化:使用“聚集”获取源纹理,将16位整数数学替换为浮点数学,将查找表紧密位打包为无符号整数。
Rendering Rapids in Uncharted 4讲述了神秘海域4的激流的渲染技术。在水体模拟方面,使用了FFT、波粒子、流向图等技术,水体网格使用了CDLOD(Continuous Distance-Dependent Level of Detail for Rendering Heightmaps,渲染高度图的连续距离相关细节级别):
从河流几何体中的一组固定四边形开始,按范围确定四边形LOD级别,使用高度贴图范围bbox进行相机过渡,根据相机的xz位置细分每个基础四边形,使用高度贴图+波浪向上置换顶点。对于物体变形,例如水体上的船只,对每个相交的四边形顶点使用对象边界框和过滤,基于遮罩偏移四边形中的顶点。

粒子的变形相对更复杂,其管线如下:
Crest: Novel ocean rendering techniques in an open source framework阐述了Crest——一个在Unity3D中实现的开源海洋渲染器,展示了网格生成、形状表示和表面着色方面的许多新技术。为了生成几何图形,使用连续的细节级别扩展clipmapping,并将一条踢脚线几何图形扩展到地*线,该表面由支持视锥体剔除的非重叠分块组成。为了保持屏幕空间的网格密度,展示了如何在相机改变高度时水*缩放网格,而不会出现明显的跳变。还实现了一个简单的启发式算法,用于将细节中心放置在查看器前面,这对所有视图位置和方向都是鲁棒的。在GPU上将海洋形状渲染为置换纹理,以匹配几何体LOD的密度和位置。如果每个形状纹理的波长太短,会限制添加的Gerstner波列的数量,以避免锯齿和不必要的工作,还使用乒乓渲染目标来模拟波动方程,以添加动态运动层。对于着色,法线贴图UV可以使用几何体LOD环进行缩放,以实现接*观察者的细节,同时防止在中到远距离出现细节不足的玻璃般*坦外观,并消除可见重复。对于泡沫,在形状纹理旁边添加了额外的渲染目标,并使用反馈渲染过程来模拟耗散。最后,还展示应用深度剥离来实现通过多个表面的非*凡光传输路径的结果。
裁剪图的运动可视化。
CD裁减图的运动可视化。
水*缩放可视化。
对比CDLOD:用于驱动细节的欧几里德距离,四叉树以放置几何体分块,*滑几何过渡,神秘海域4:Gonzalez-Ochoa。
| CDLOD | CDClipmap |
|---|---|
| 欧几里得距离 | 出租车(Taxicab )距离 |
| 四叉树 | 最小化CPU |
| 裙子几何? | 裙子几何 |
| 无形状连接 | 形状连接 |

左:CDLOD的欧几里得距离;右:CDClipmap的出租车(Taxicab )距离。
在形状方面,GPU管线如下:
可以渲染任何其它可以进行数学建模的内容:

另外,还支持泡沫、深度剥离(Depth Peeling):

深度剥离过程:获取最前面水层的深度,渲染后续层,累积散射/吸收,渲染最前面的层,典型的折射着色器,但具有正确的散射,可以应用于水下后处理。
渲染层后,有最后面的表面深度,与场景颜色相结合,计算从最后面的深度和水内的吸收和散射,只能应用水下后期处理效果,例如焦散。


最终效果:

Data Binding Architectures for Rapid UI Creation in Unity阐述了在Unity中实现数据绑定来创建UI的架构和技术。旧的UI制作方法是艺术家在Photoshop中工作、UI开发者应用魔法、QA发现了漏洞之间循环:
这种方式存在诸多问题:”不是我的问题“的态度,开发者扮演UI艺术家,未经测试的意大利面条(混乱的)代码,开发周期长。Lost Survivor中的架构:艺术家直接在Unity中工作,开发/艺术资源解耦,开发/艺术并行工作。相关的技术有MVC模型:
Object更易于重用,其接口也更易于定义。原生iOS SDK支持,关注点分离,XCode中的可视化设计器。还有MVVC模型:
ViewModel为视图提供服务,每个模型视图一个视图,基于数据绑定。Lost Survivor的架构如下:
类图:
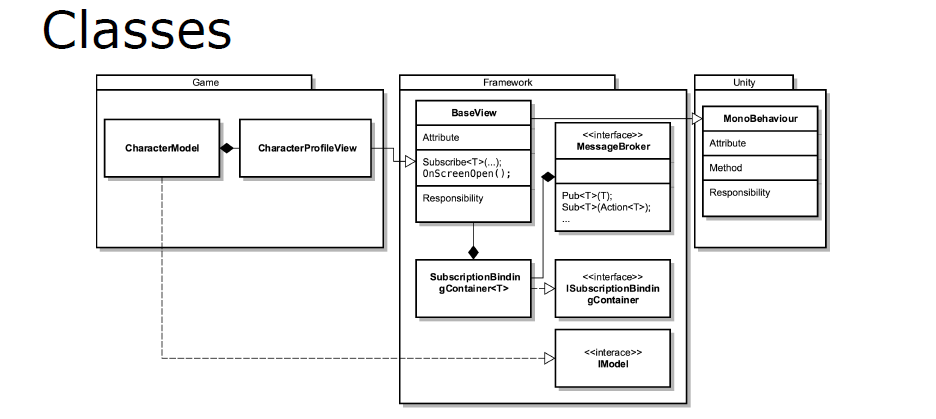
数据绑定示例:
// bind toggles to method calls
Subscribe<SettingsConfigurationModel>()
.BindToggle(MusicToggle, _audioService.MuteMusic, true)
.BindToggle(SfxToggle, _audioService.MuteSfx, true)
.BindToggle(PushNotificationToggle, SetPushEnabled)
还可以自定义数据绑定:
Subscribe<CharacterModel>()
.BindModelChangeAction(UpdateBuffObjects)
.BindButton(HealButton, CurrentBuffSubview, (model, script) => ...)
...
.Finish();
...
private void UpdateBuffObjects(CharacterModel model)
{
for (int i = 0, count = model.ActiveStageBuffs.Count; i < count; i++)
{
InstantiateNewBuffGameObject(CurrentBuffSubview, model.ActiveStageBuffs[i]);
}
...
}
性能影响:基于反射,仅限初始阶段,无垃圾回收压力。可以实现分离测试,快速迭代,少依赖,一切都可以模拟。总之,可以实现开发/艺术可以各自专注、模拟对象、团结协作、单元测试、用户界面测试等。
The Destiny Particle Architecture阐述了Destiny引擎粒子特效的架构,包含表达能力和灵活性、亚秒级迭代和性能。

Destiny的粒子采用了脚本化、可视化的架构:
component c_emitter_shape:ring
{
c_initial_velocity_type:* initial_velocity_type;
float radius;
#hlsl
float3 calculate_initial_position()
{
float2 circle_point= random_point_on_unit_circle();
return float3(0, circle_point * radius);
}
#end
}
其数据层次结构如下:
粒子的内存布局如下:
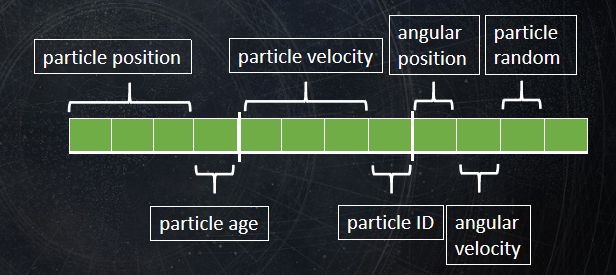
表达式和字节码转换过程及亚秒级迭代如下:
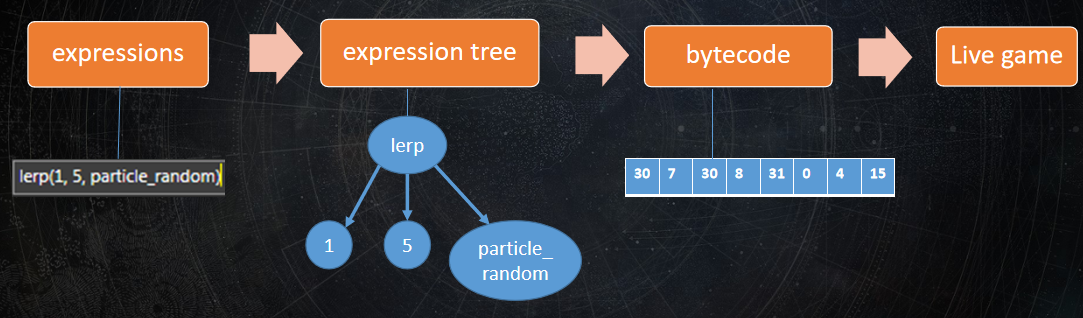
那么执行速度够快吗?对于CPU粒子(其最大值通常在3k左右),足以用于开发目的:

此外,还尝试了GPU字节码和烘焙的HLSL的方案,它们在速度和迭代的关系如下图:
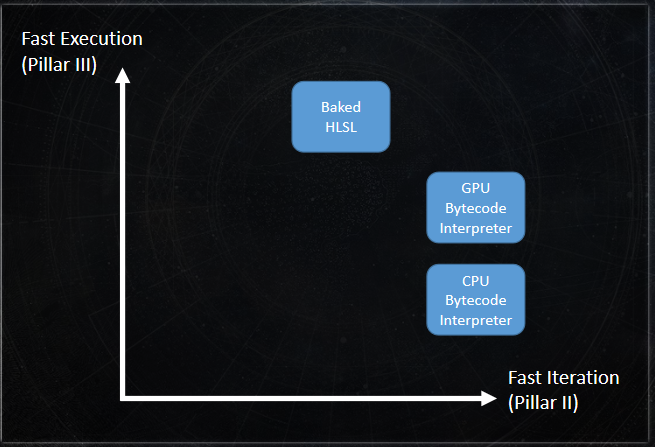
《Evolution of Programmable Models for Graphics Engines》讲述了Unity引擎的架构演变史。一个(糟糕的)方法是在每个资产、每个*台的基础上编写代码,显然无法扩展,因此不是真正要做的方式:
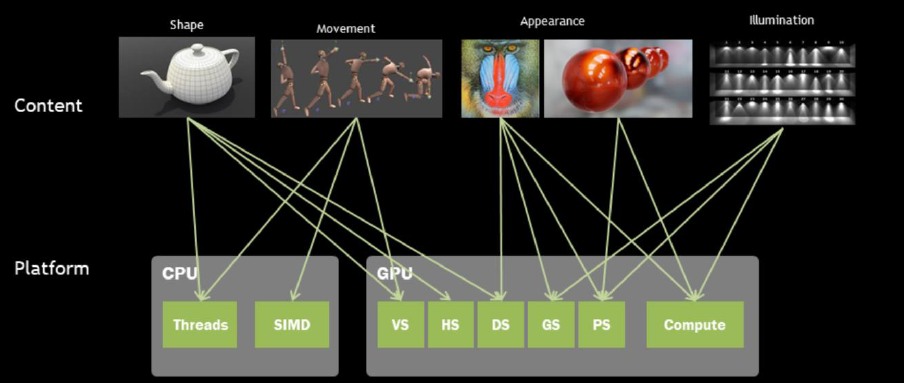
可以使用应用层的特定接口的映射来解耦:
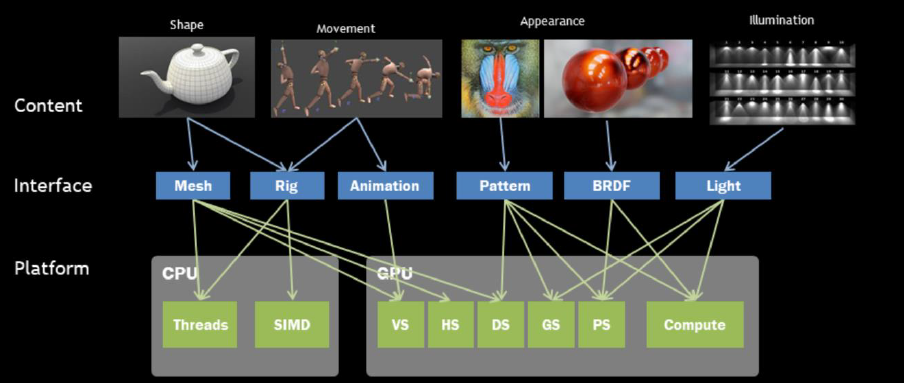
有助于创新的原则:易于共享可复制的执行行为,广泛的基础设施支持服务,游戏引擎很容易做到这一点,框架应该具有灵活性,沉重的基础设施层不应阻碍创新。当时的引擎普遍分为低级别API层、引擎抽象层、渲染通道抽象层:
渲染管线的复杂性已经上升了几个数量级,基于逻辑的渲染控制包含游戏逻辑、内容控制的渲染选择:
对于图形开发的迭代,希望在低级别API和引擎抽象层尽量不修改,而将修改放在渲染通道和游戏逻辑层。图形引擎编程的范式转换,每个特性有一个小的C++内核,暴露APl给C#层,在C#语言中实现细节。Unity希望渲染框架的预期是:前瞻性:最小表面积、易于测试、松散的耦合;以用户为中心:放置在用户的项目空间,易于快速调试,易于扩展和修改;最优的:性能非常快,针对特定*台应用程序类型的优化允许用户仅执行必要的操作以实现其预期目标;明确的:它完全按照你说的做,没有更多,没有更少,没有魔法,清晰的API。为此,Unity提出了新的SRP(脚本化渲染管线):
SRP高级概念:从脚本中调用已过滤的绘制调用,可以为特定的渲染管线设计着色器,与可见对象列表、灯光等结合使用,大大简化了渲染管线的高级代码。其原则是:深度配置、没有隐式假设、可发现性、灵活、快速开发迭代、高性能。其中C++层负责性能关键区域:剔除、对对象集进行排序/批处理/渲染、GPU命令缓冲区的生成、内部图形*台抽象、低级别资源管理。C#负责高层指令:摄像机设置、照明/阴影设置、帧渲染通道设置/逻辑、后处理逻辑。着色器负责GPU的工作:材质定义、光线和应用、阴影生成、全屏过程、计算着色器。
应该是数据(图形/配置文件)还是代码(C#/Lua)?有些决定取决于分支和游戏状态,Unity更喜欢C#,已经是Unity的核心设计原则,代码是图形程序员的舒适区,脚本热加载的快速迭代非常好。
SRP优势:新算法的超快速迭代,Unity引擎框架的所有好处,关注算法本身而不是搭建架构,低级别的精益执行的所有性能优势,脚本中热重新加载的所有好处。命令缓冲区调度,一切都入队排着,Submit会倍自动调用,按添加操作的顺序执行,每个命令都是一个作业。SRP非常适合于延迟/前向//前向+(例如G缓冲区布局/包装的变化)、照明架构的变化、阴影算法、灯光类型研究(区域灯光等)、材质模型、对后处理的更改、分簇的变化。
可编写脚本的渲染管线的好处是建立在伟大的引擎框架之上,图形技术开发的快速迭代,内置的性能分析,高效的多*台执行,轻松分享技术,开发新管线的伟大起点。对用户的限制是需要触及底层*台APL或引擎层抽象的更改需要C++源代码,这些改变并非不可能,但需要对核心引擎进行改变。
4K Checkerboard in Battlefield 1 and Mass Effect Andromeda阐述了Battlefield 1的4K级别的棋盘渲染。
EQAA(AMD)是MSAA的超集,可以存储比深度片元更少的颜色片元,颜色<=ID<=深度。4K棋盘利用了这种配置:1x颜色片元、2x ID片元、2倍深度片元。着色分块有两种:2x颜色4x深度、1x颜色2x深度:
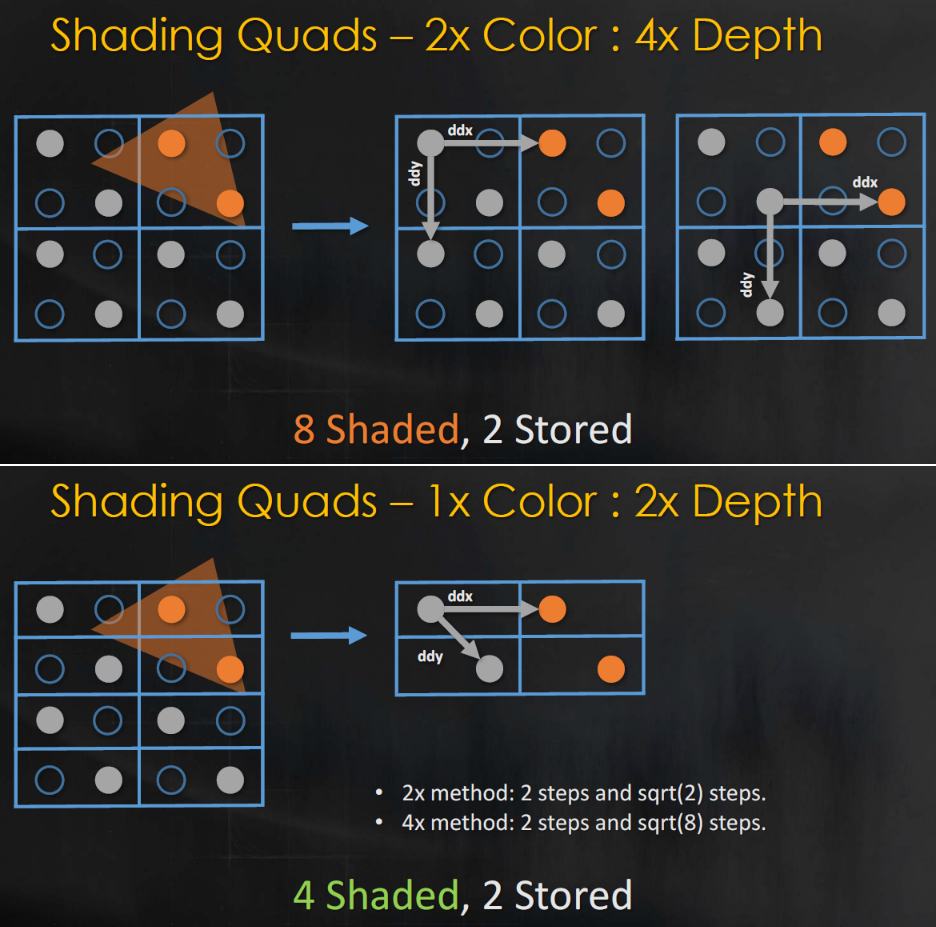
EQAA的棋盘布局如下:
另外,COD使用了物体和图元ID缓冲区、梯度调整、重心评估、Alpha展开等技术。在优化上,使用PS调用、FP16、EQAA深度解析等。在后处理上,使用了棋盘解析、空间组件、颜色包围盒、不同的混合操作、物体和图元ID、时间组件、基于速度的重投影、锐化过滤等技术。
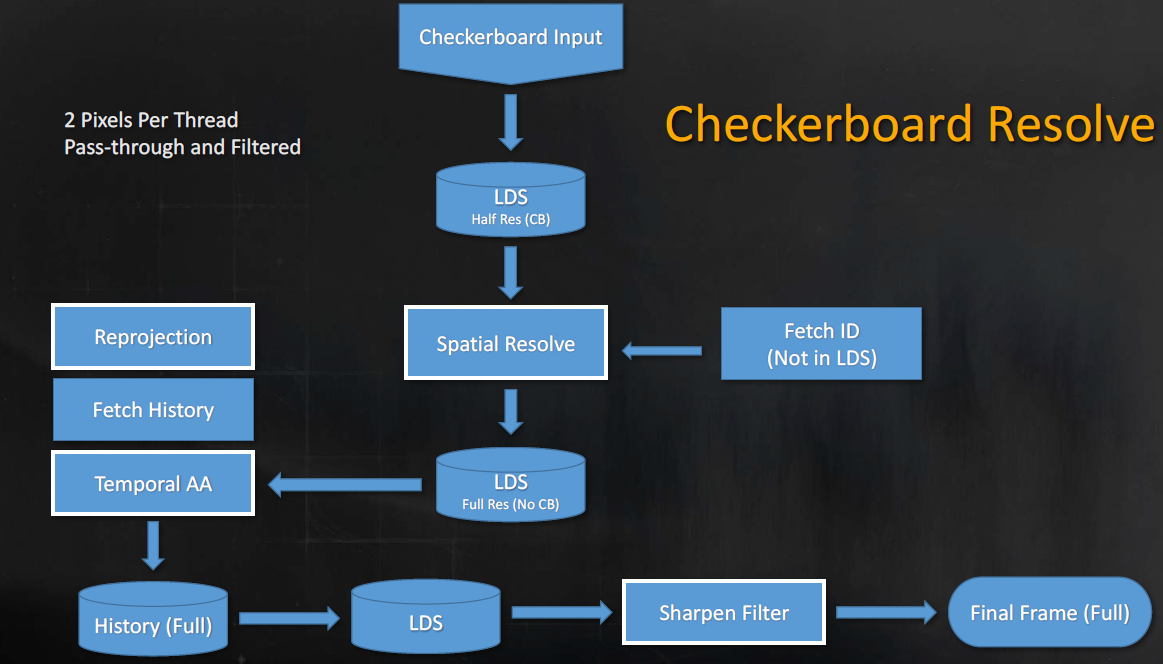
棋盘解析过程。
此外,文中还涉及渲染目标重叠、动态分辨率缩放及性能等内容。
A Life of a Bokeh分享了UE的Bokeh景深效果的实现、步骤和相关优化,具体地说包含分散即收集、混合散射、孔洞填充、轻微失焦、膜片模拟、性能结果和可扩展性。UE的景深目标是高端品质、硬件可扩展性、实时渲染。UE的DOF处理流程如下:
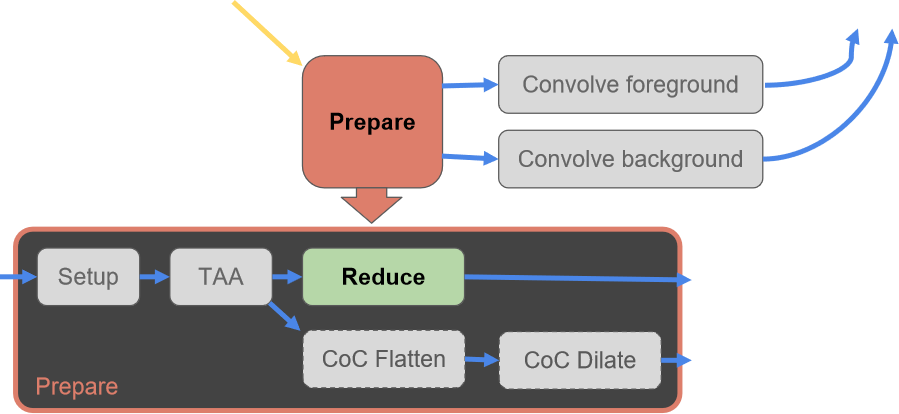
在采样模式上,均匀的模式过于分散。尝试小样本CoC,使用更大的内核,因为附*的大屏幕无法聚焦,只有一些像素会与之相交,取决于随机内核偏移量,mip级别越低,显示越多。

收集采样密度改变,让密度变化发生在环之间,无每个样本权重改成完全修改之前的桶状权重:

扩大BGD-MIN-COC和扩大BGD MIN INTERSECTABLE COC的对比:

间接散射通道:用于前景和背景,分散独立精灵,在受支持的*台上使用矩形列表拓扑进行优化,要分散的精灵数量各不相同,间接绘制调用[Kawase15.3]:
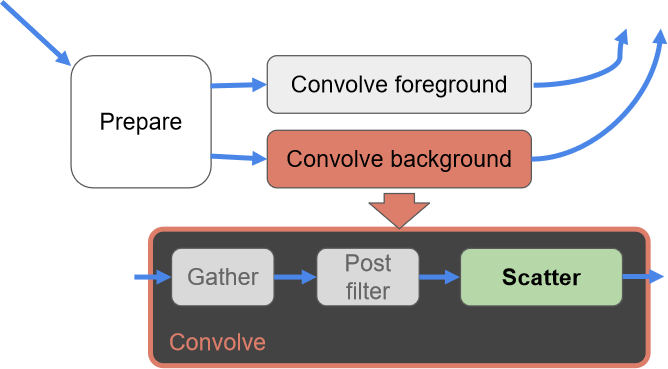
邻域对比:在Reduce pass中将颜色与邻域进行比较,使用四分之一分辨率缓冲区,聚集分散像素的颜色为黑色,RGB加法渲染目标混合。
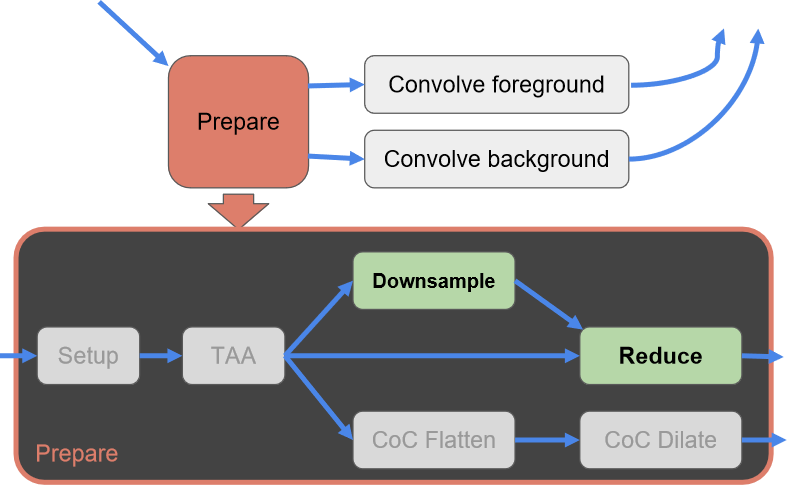
重组通道的流程如下:
用于前景的镜像孔填充:反映每个样本的贡献[Jimenez14],仅限前景收集通道,在2个相反的环形样本的CoC中取小值,在相交之前执行。
专用于填孔的收集通道:仅适用于前景不透明度不等于0且不等于1,发现距离较*前景的不透明度,使用背景*滑过渡,输出RGBA,允许在重组过程中进行不透明度修改。
半分辨率焦点收集:收集所有输入样本,3个半分辨率像素的半径,颜色和不透明度,已知从扩张通道收集什么分块。
重组:RGBA夹紧全分辨率聚集,使用最接*的2x2半分辨率暴力收集输出,RGB用于稳定闪烁的高光,不透明度可在头发等抖动材质上保持稳定。随机收集重组中的全部资源,基于Sobol的随机发生器[OlanoXX],将正方形分布映射到磁盘[Reynolds17],对于交叉点模型,必须达到亚像素精度。使用主TAA通道作为后过滤器。最终的效果和性能对比如下:

Efficient Screen-Space Subsurface Scattering Using Burley’s Normalized Diffusion in Real-Time阐述了利用Burley的标准化扩散来实现高效高质量的屏幕空间次表面散射的效果。
以往的可分离次表面散射用可分离的高斯卷积,速度很快,仅在*面上过滤时可分离,双边滤波使卷积“伪可分离”,结果在视觉上是可信的。但是,高斯混合公式显然是不可分离的,除非每个高斯函数执行2次卷积通道,可能让SSSSSS导致必须在内容端修复的瑕疵,在实践中,用2个高斯进行4次通道代价太高。高斯混合不适合艺术家,高斯只是一个数学概念,艺术家被迫使用测量数据或“眼球”的数值拟合,太多自由度,大多数组合都无意义。
Burley标准化扩散模型(又叫迪士尼SSS)由Brent Burley和Per Christensen开发【Burley 2015年】,参考了MC数据的曲线拟合(1995年),参与介质中的单次和多次散射。
扩散剖面是标准化的,可以用作PDF格式:
实现次表面散射:漫反射BRDF是SSS的远场*似,使用迪士尼漫反射BRDF公式定义漫反射传输行为[Burley 2015],物理上不合理,但比假设兰伯特分布更好。
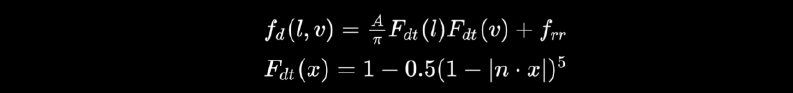
不支持无镜面反射传输(仅单次和多次散射)。漫反射BRDF是SSS的远场*似值,使用表面反照率作为体积反照率,提供2种纹理选项
:后处理散射纹理(出射位置的反照率)、预处理和后处理散射纹理。
它们的效果对比:
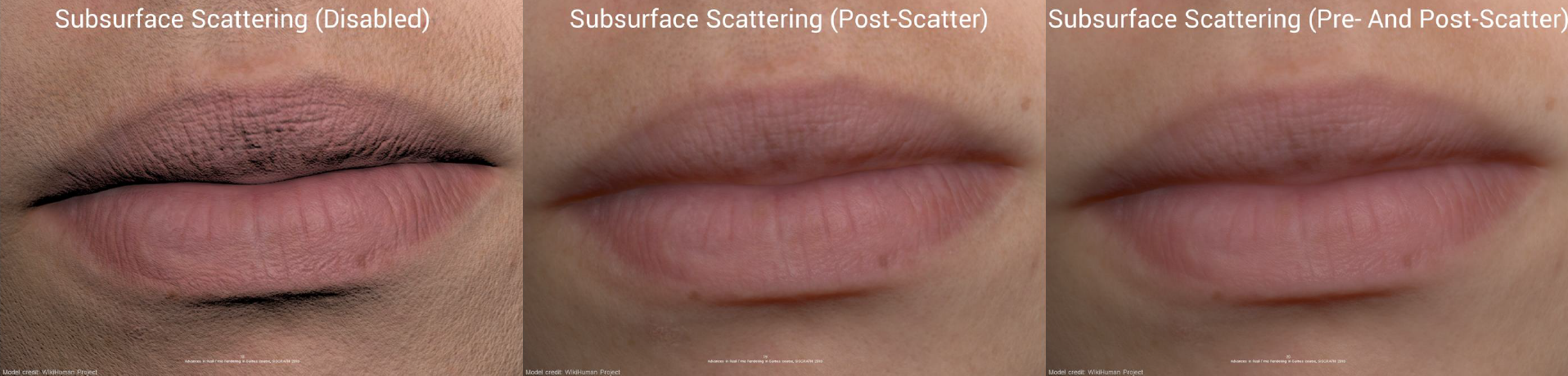
扩散剖面被归一化,实际上是沿几何表面的能量守恒模糊,在屏幕空间中使用双边过滤器进行*似计算。
采样扩散剖面:根据扩散曲线进行圆盘采样,使用斐波那契序列Hannay均匀采样角度,通常比分布在球体和磁盘上的其它低差异序列表现更好。然后,与扩散曲线的卷积就是样本值和权重的点积:
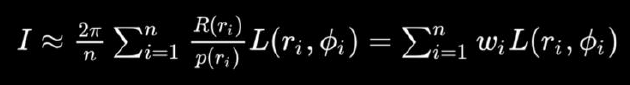
双边滤波允许跨非*面曲面进行过滤:
修改PDF并不是那么简单,因为样本位置已经根据旧的“*面”PDF分布,相反,只需执行能量守恒(使权重标准化以满足单位分割):
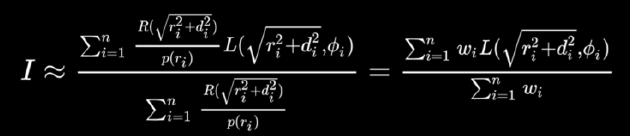
另外,还支持薄及厚的半透明物体的模拟:

优化:SSS实现为通过R11G11B10缓冲区的全屏CS通道,SSS pass CS针对GCN的高占用率进行了大量优化,如32 VGRS、38 SGPR、用于16x16线程组大小6656字节LDS。将LDS用作20x20邻域的L0缓存,以减少VRAM传输,在SoA中存储辐射度和线性深度,以减少bank冲突,沿Z顺序曲线排列线程[Morton 1966],以匹配GCN渲染目标的内存布局。G-Buffer通道用材质类型标记模板,提取HTile信息,以便尽早剔除,照明通道使用材质分类[Garawany 2016],SSS材质使用扩展的标准照明着色器,标记SSS缓冲区,以避免在SSS通道期间读取模板,在照明通道中,同时应用入射点和出射点传输,虽然概念上是错误的,但视觉上的差异很小。实现一个内部着色器离散LOD系统,最大半径在1像素足迹内的圆盘——无卷积,最大半径在4x4像素范围内的圆盘——使用较少的样本,最大半径超过4x4像素足迹的圆盘——使用更多样本,始终如一的视觉效果,没有LOD跳变。带有随机核旋转的欠采样[Jimenez 2014]的对比(左边是Jimenez,右边是Burley):

性能方面,在1080p的基础PS4上进行测试,每像素21个样本,CS执行卷积和组合,使用镜面反射照明的结果,GPU时间为1.16毫秒。局限性:采样不足会导致视觉噪点(下图),将散射距离设置为较大的值可能会降低性能,对于较大的厚度值,厚对象半透明不是很精确。

你的精灵会让你的内存爆掉吗?使用精灵动画的游戏面临的一个常见问题是每帧使用的纹理内存量,这对移动设备来说是一个特别严重的限制。为了解决这个问题,可以使用sprite打包和图集来更有效地利用内存,但这些解决方案可能会导致图集中的空间浪费,无法完全填满。Grabthar's Hammer是秘密实验室团队为“森林之夜”的移动端口编写的工具,通过使用sprite dicing以最小的浪费最大限度地利用atlas,以更高效的方式解决了这个问题。By Grabthar's Hammer, What a Savings: Making the Most of Texture Memory with Sprite Dicing介绍了这项技术,讨论《森林之夜》是如何被改编来使用它的,以及如何通过使用视频压缩技术来进一步利用精灵切分技术,从而从内存预算中获得最大数量的精灵。
对精灵纹理的常规优化包含:
- 纹理压缩。对不同纹理格式的不同支持,如PVRTC、ASTC。
- 向量追踪。非常紧凑,无法很好地保存小细节,通常需要手动调整以获得最佳效果。
- 纹理图集。非常适合PVRTC压缩,打包不完整时浪费空间。
文中使用了特殊的方法,即精灵切分(Sprite Dicing),步骤如下:
- 把精灵切成小块。
- 丢弃任何透明小块。
- 把这些小块打包成图集。
精灵切分有更好的图集覆盖率,透明区域移除,并非所有小块都被保存。具体的过程图例如下:

结合上图,按从左到右、从上到下依次编排序号,它们的说明如下:
1、如果精灵是凹面的,它包含许多简单修剪无法移除的透明像素。
2、这里的绿色区域是我们可以通过简单的修剪去除的;红色区域是透明的,但无法触及,因为它位于装饰框内。
3、这里所有标记为绿色的东西都是我们可以丢弃的。请注意,这里有一些不必要的透明区域,可以丢弃——这是因为这些部分是32x32。
4、没有理由让每一块都是16x16,所以也把它们修剪成最小的单个矩形。
5、这是一张720x720的图片,所有透明的部分都被移除,每个部分都被单独修剪,并打包成一张图集——它可以放进一个512x512,还有很多剩余的部分。它必须是512x512,因为PVRTC需要两个纹理的幂。
6、缺点是网格密度增加了一点——每个顶点大约有18个字节。然而,额外的网格成本远低于存储更少像素的纹理数据所节省的成本。
这种方式的优势是更好的图集覆盖率,图集纹理可压缩,更低的着色器复杂性。缺点是预处理通道,图集大小限制,更高的多边形数,需要填充,在Unity中没有内置的支持。
另外,可以进一步优化,那就是查找并删除冗余。冗余的类型包含空间冗余(同一图像中的多个副本)和时间冗余(一系列图像的多个副本)。查找空间冗余的过程如下:
1、我们利用了这样一个事实,即两个完全相同的片段相距甚远的可能性很小。所以,我们只对靠得很*的成对小块进行测试。
2、它们是一样的吗?
3、只检查唯一对。
查找时间冗余的过程如下:

我们将检查两幅图像中相同位置的块;对所有区块位置和所有图像对重复上述操作(或者,如果我们想加快速度,在序列中相互跟随的图像对之间重复)。
接下来是寻找分簇(cluster)。

1、现在有一个区块图…
2、…及其连接-这些连接可以是同一图像上的块之间的连接,也可以是多个图像上的块之间的连接。如果相似性分数足够高,认为一个区块与另一个区块“相连”。然后可以找到块的“强连通集”;在每一组中,所有的块都会非常相似,所以选择其中任何一个,让其余的块使用该块的纹理数据,使用Tarjan算法来寻找强连通集。
Altas纹理问题:最大纹理大小为8192x8192像素,图集必须是方形的,无法始终将所有区块放入一个图集,浪费空间。
结果是23个720x720的RGBA精灵,PVRTC 4bpp压缩,16x16小块尺寸,原来的裁剪版2.68mb,切块版1.5mb(原版的55%)。若是106个1024x512的精灵,原来的裁剪版9.76mb,切块版1.5mb(原版的15%)。
Bungie's Asset Pipeline: 'Destiny 2' and Beyond分享了命运引擎的资产管线、变化、迭代改进等。命运引擎的资产管线流程如下:
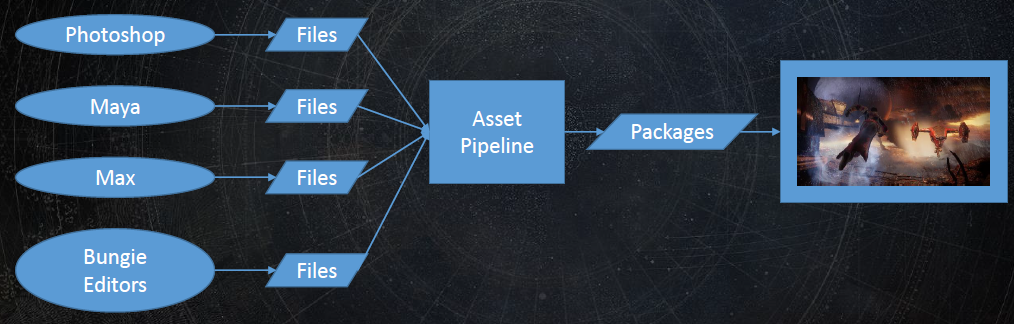
使用的依赖图如下:
原始的资产管线流:
存在的核心问题是大量任务和数据统计,Destiny 1全球有910万个任务、1930万个数据元素,跟踪结构非常庞大,难以检查/理解,粒度强调缓存机制。
到了命运2,工作流程的目标是制作更多内容,速度更快。现在是时候做出更大改变的机会,但是,仍然需要源内容的向后兼容性,最小化生产成本。命运2的资产管线的重大修改是将图表拆分为许多较小的逐资产图表,随着任务数量的减少,上下文工作的范围会更快,并行运行资产图操作,更容易检查和理解较小的单一资产图,更合理的缓存粒度,更难在资产之间引入数据依赖关系,更容易理解工作流的影响,允许在加载时修复资产引用。DESTINY 2的资产管线流:
DESTINY 2的资产管线的并行:
限制:向后兼容性/最低生产成本:
总之,单个大规模依赖关系图的扩展问题,引入了资产级粒度,引入了带有加载时间修正的资产引用。这些新工具能够构建高效的工作流,继续完成并升级/优化现有工作流,删除/减少代价高昂的数据依赖关系,定义新资产,调整资产边界。可以结合每资产和基于依赖关系图的数据管线的主要优点,在添加数据依赖项之前了解影响至关重要。
Terrain Rendering in 'Far Cry 5'阐述了Far Cry 5的地形渲染,包含高场渲染(基本原理、GPU管线)、着色、悬崖着色、超越高度场、屏幕空间着色、基于地形的效果。

高度场的基础和过程如下:

地形四叉树:分区(Sector)64m x 64m,世界160 x 160个分区、共10km x 10km,地形分辨率0.5m x 0.5m。

四叉树的节点存储在图集上:
地形的渲染过程如下:
流传输四叉树节点图例如下:
遍历和剔除节点的过程如下:
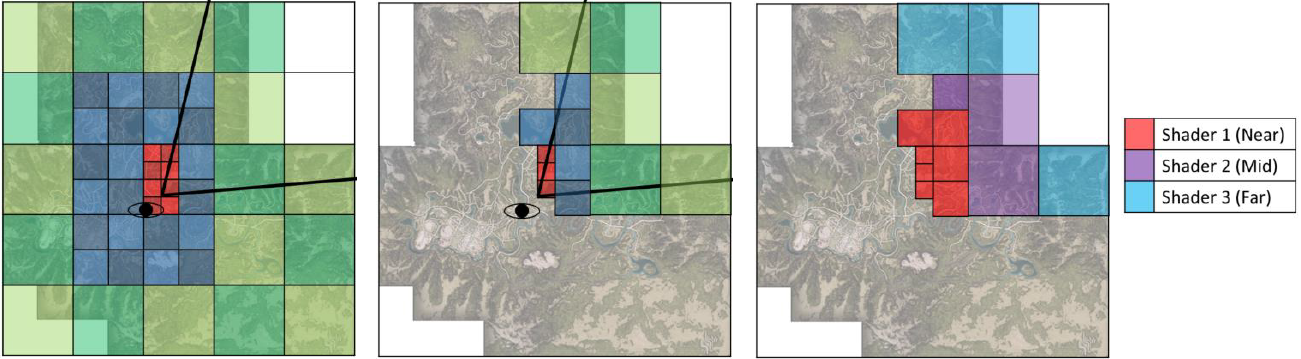
上图的3个步骤都在GPU中执行,动机是数据仅由GPU使用,消除CPU成本,降低GPU成本!实现最大顶点剔除,使地形数据可用于其它GPU系统树木、岩石、草地等。GPU中的数据结构包含:
- 地形四叉树。加载/卸载节点时的持久更新。
- 地形节点列表。四叉树遍历生成的节点列表,每帧构建一次。
- 地形LOD图。世界上每个分区使用的几何体LOD,从地形节点列表中每帧重建一次。
- 可见渲染批次列表。要渲染的最终剔除节点列表,每个渲染视图生成一次。


对于地形着色,使用了溅射图:
前景着色步骤如下:
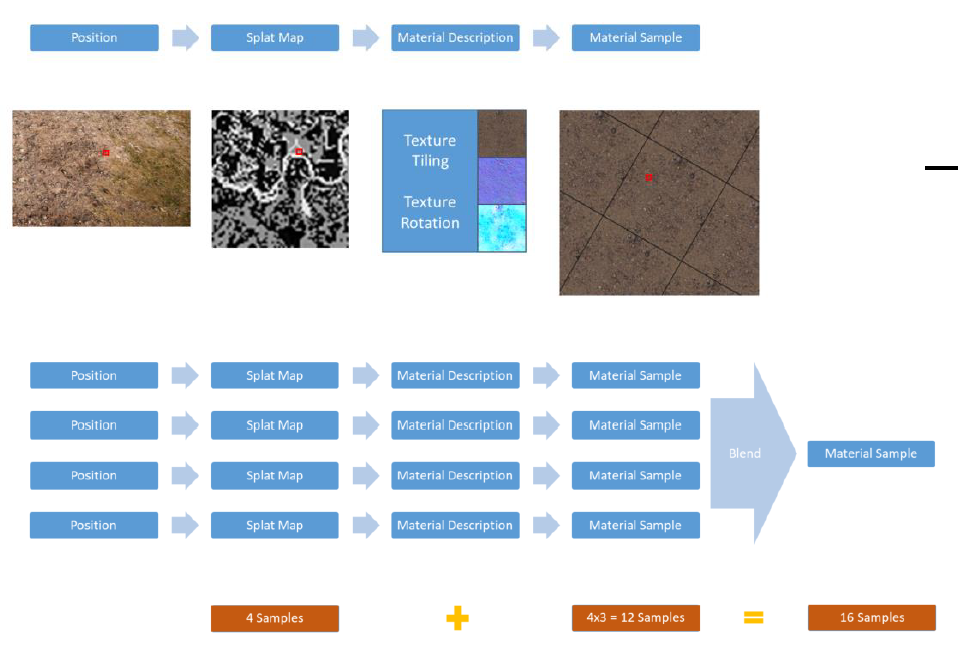
虚拟纹理的处理过程如下:

对于悬崖着色,使用了随机化采样和着色:
屏幕空间的地形着色是根据视距采用不同成本的着色方案:

屏幕空间的地形着色的通道如下:
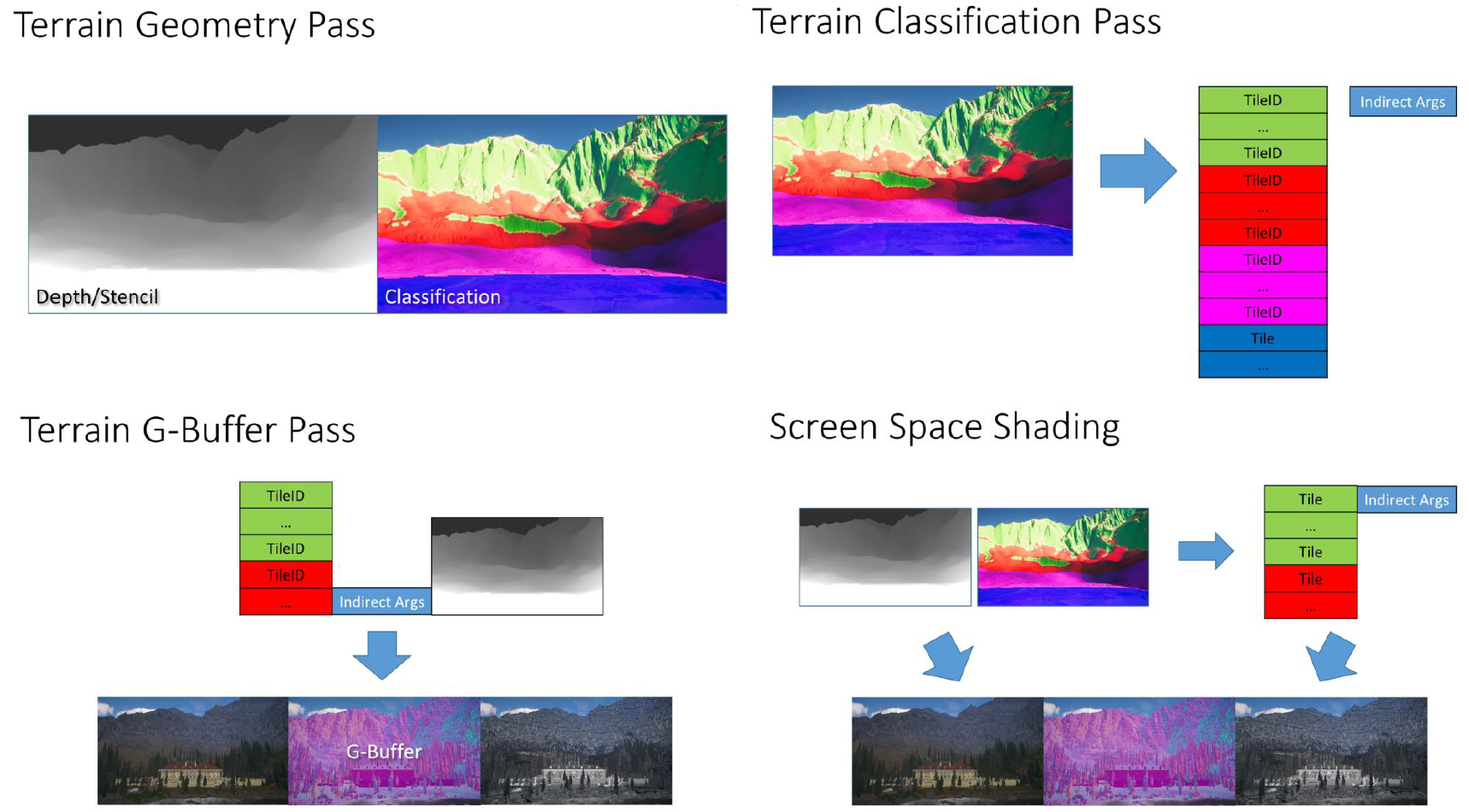
Interactive Wind and Vegetation in 'God of War'阐述了God of War的关于风的逼真模拟,包含风流模拟、风力触发器、风力接收器、网格数据和计算细节、创作和最佳实践等内容。
风力场体积。
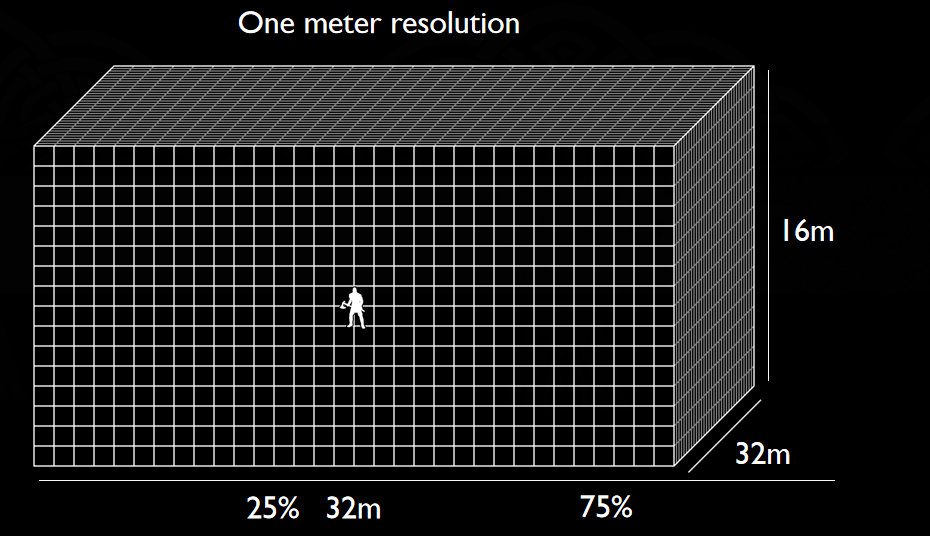
风力场体积分辨率。
风还支持和音频、布料、粒子、网格等物体的交互。

风接收器由下图的5个部分组成。逐顶点数据定义模型的哪些部分移动,哪些部分不移动,模型参数描述了运动部件的行为。
风的网格参数包含:密度、运动缩放、弯曲、伸展、僵硬、摇摆弹簧、摇摆阻尼、树模式、树弯曲、树运动缩放、树叶滞后等。

风的网格伸展参数对比。
风采用了分形噪声函数:

文中还涉及了树的简化技术,测试已知坐标系中的所有卡片*面,展**的面,好处在于最大最小扭曲面=最大总*面面积,为最好的卡片获取面,重复之(下图左)。6D到2D:卡片的方向到卡片的距离,将卡片空间离散化,测量半球方向的距离,批量并行卡片处理,卡片必须与模型边界相交下图中)。渲染到纹理:来自正交相机的材质通道,将摄像头匹配到卡边界,剪裁*面匹靠*度,Python图像库+Maya UV自动布局,最后卡片重新获取面(下图右)。
UE版本的实现源码在"Interactive Wind and Vegetation in 'God of War'" in Unreal Engine 4。
Strand-based Hair Rendering in Frostbite分享了基于线条的头发渲染和模拟。
人类头发是蛋白质丝,*似圆柱形,覆盖着称为角质层的鳞片,头发纤维非常薄,约17-181µm,主要由白色/透明的角蛋白制成,深色头发是头发中黑色素浓度的影响,人类头上有大约10万根头发。以往的游戏通常使用头发卡片或壳状物,存在昂贵的创作、有限的发型、真实感模拟差、着色简单等缺点。基于线条的头发模拟可以避免以上问题,实现更复杂、逼真的头发模拟:

基于线条的头发概览如下:
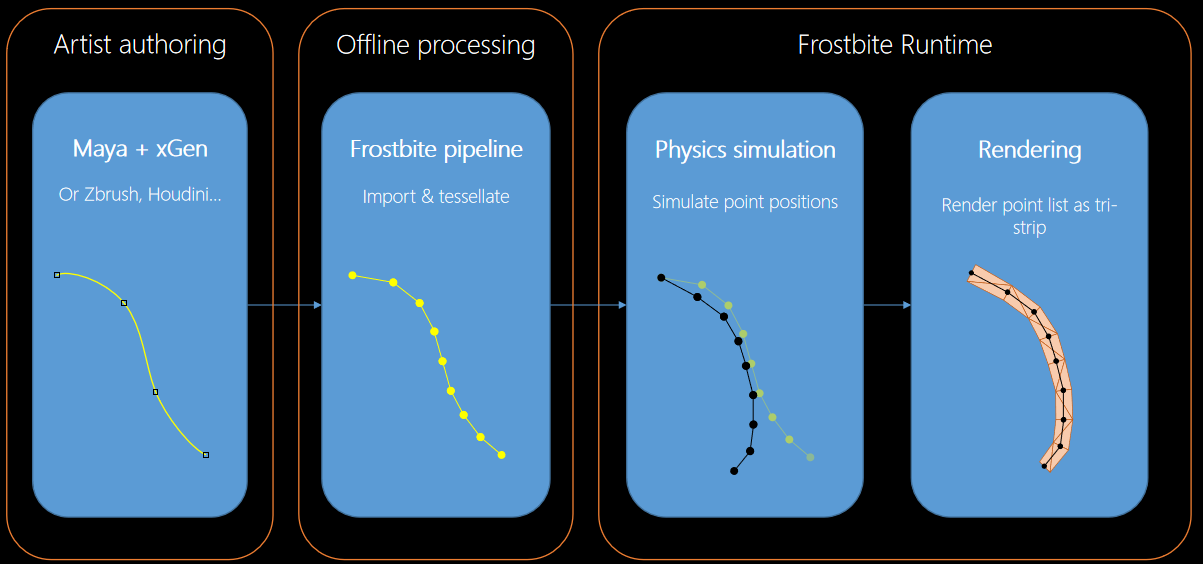
头发模拟:线条被模拟为一系列带有约束的点,欧拉和拉格朗日模拟的结合,使用网格计算的链-链相互作用,摩擦、体积保持、空气动力学,在每个点上分别进行积分,然后通过迭代约束和碰撞器来求解点。渲染概览如下:
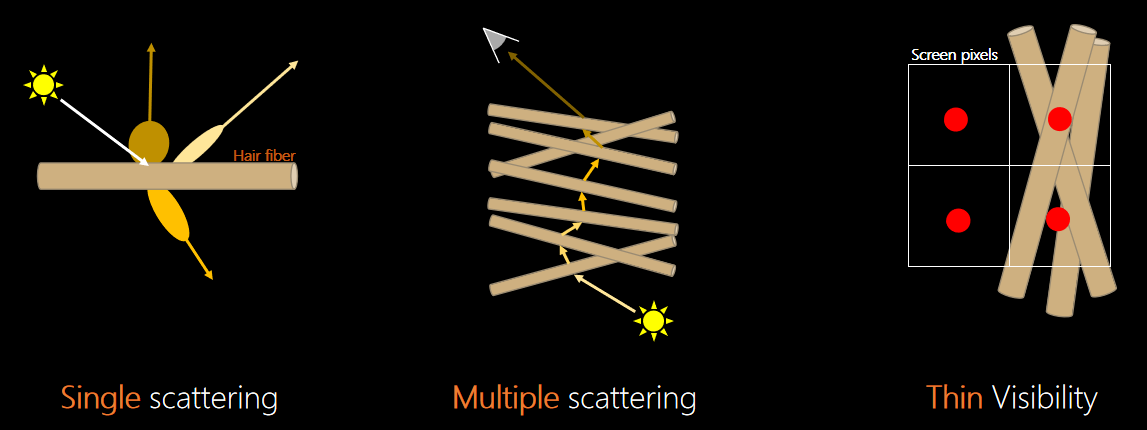
单次吸收使用Marschner03的着色模型,考虑R、TRT、TT等组成部分:

可以实现头发的吸收、*滑等特征:

期间还会考虑纵向散射\(M_p\)和方位散射\(N_p\):
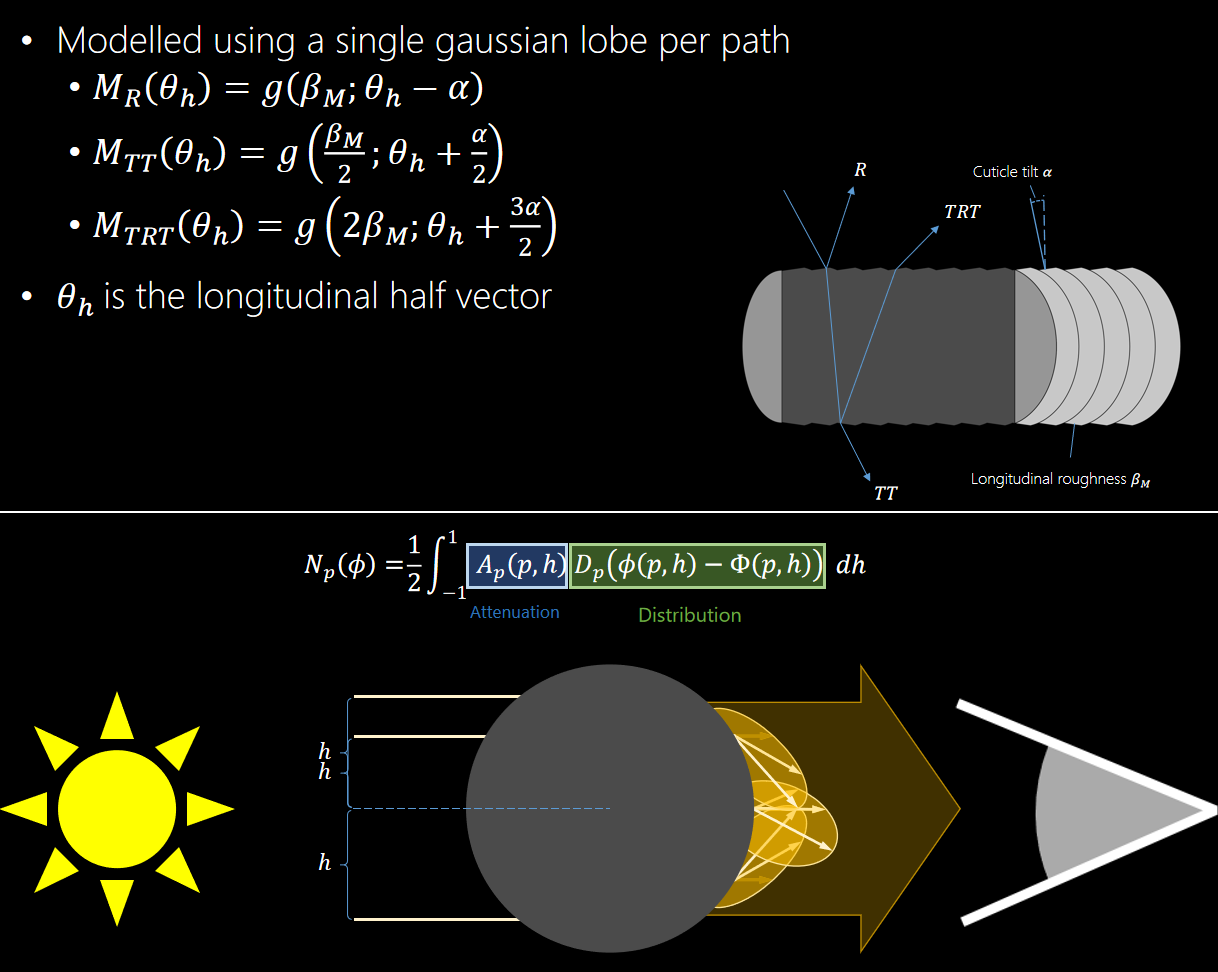
透视通过一个3D的LUT来*似:
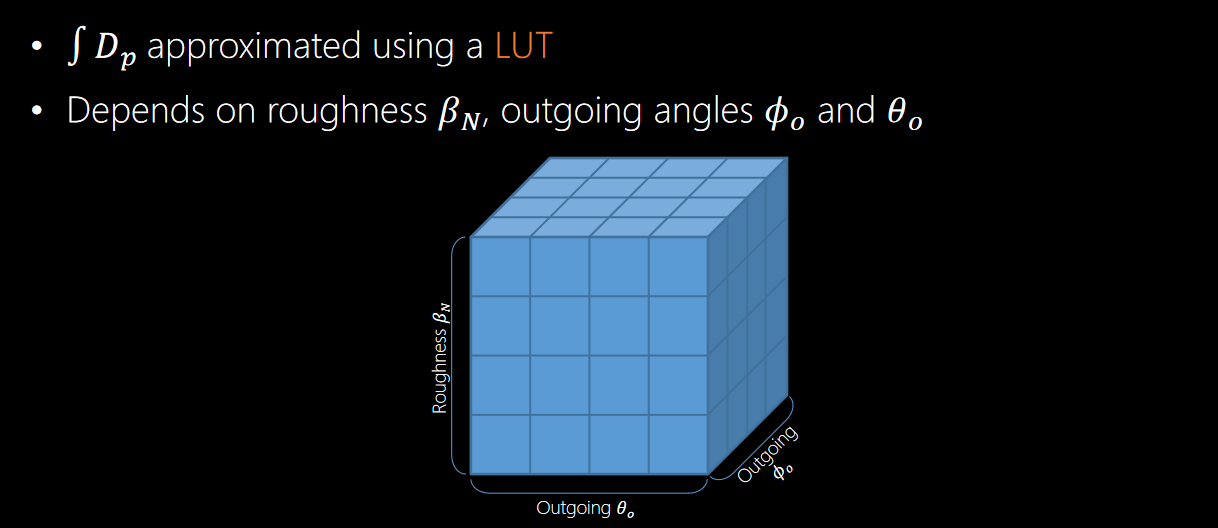
多重散射对真实感很重要,考虑从灯光到摄像机的所有可能路径,不可能实时完成,使用双散射*似[Zinke08],局部散射解释了靠*着色点的散射,全局散射解释了光在头发体积中的传播。
深度不透明度贴图[Yuksel08]用于估计全局散射光路径上的头发数,它们也用于阴影。
渲染时,头发被曲面细分成三角形条纹,宽度通常小于像素大小,细分必须考虑像素大小。
仅仅启用MSAA并没有真正的帮助,需要Visibility buffer + MSAA:
着色时,对相似样本只进行一次着色,约2倍的性能提升:

渲染总览如下:
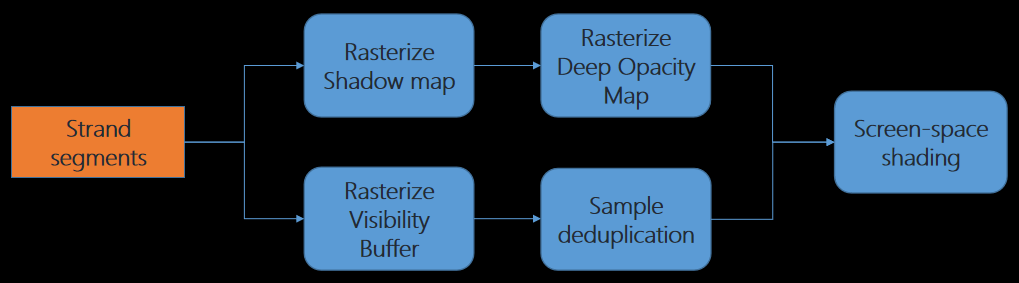
通过“Forza Horizon 4”,游乐场游戏公司开发了一种基于分光光度法的新型物理校准(PBC)管线,以前所未有的精度匹配*900种真实世界汽车涂料的游戏外观。Physically-Based Calibration: Accurate Material Production in 'Forza Horizon 4'的新方法克服了计算机图形学中的一个重大挑战,其灵感来自汽车行业的颜色管理技术,可以轻松地应用于各种渲染系统中的各种材质表示。基于之前在分光光度法和比色法方面的研究,新的校准方法科学地消除了材质复制中的大多数系统误差,并能可靠地找到准确复制真实世界“真实”材质外观的最佳着色模型输入。新的基于物理的校准技术被认为是一项重大突破,对未来在虚拟环境中精确复制材质具有重要意义。
汽车漆是“看不见的”:

文中由基于感知的方式转变程物理基础的方式:
现实中和游戏内的测量对比:
都有关反射分布,匹配反射率分布,你就能匹配材质。苹果对苹果的对比——定量颜色分析:

使用“Digital Masters”XML来*似SPD:

ASTM E 308标准:从光谱功率分布(SPD)到颜色信息,SPD --> XYZ:
从SPD到XYZ颜色:
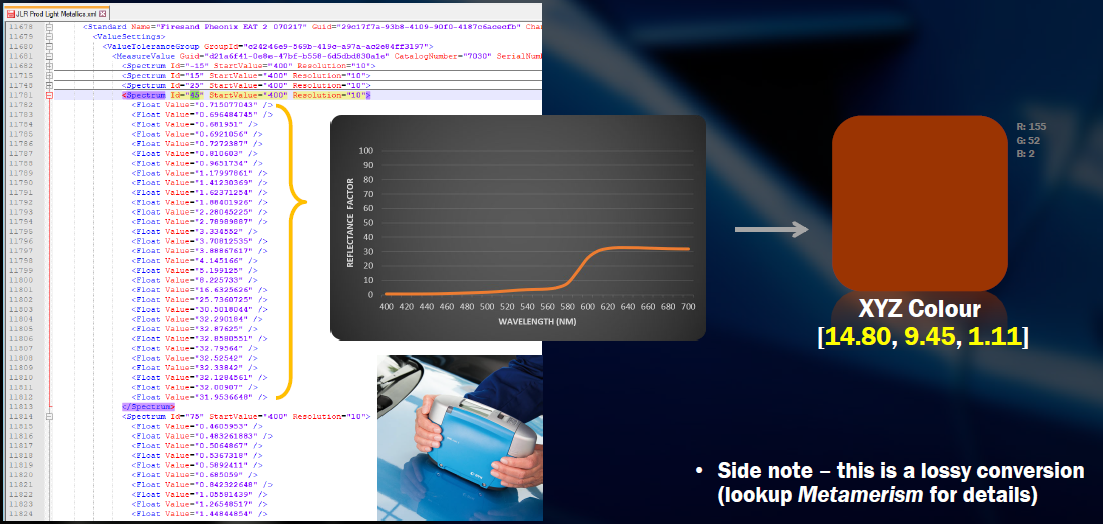
同色异谱:
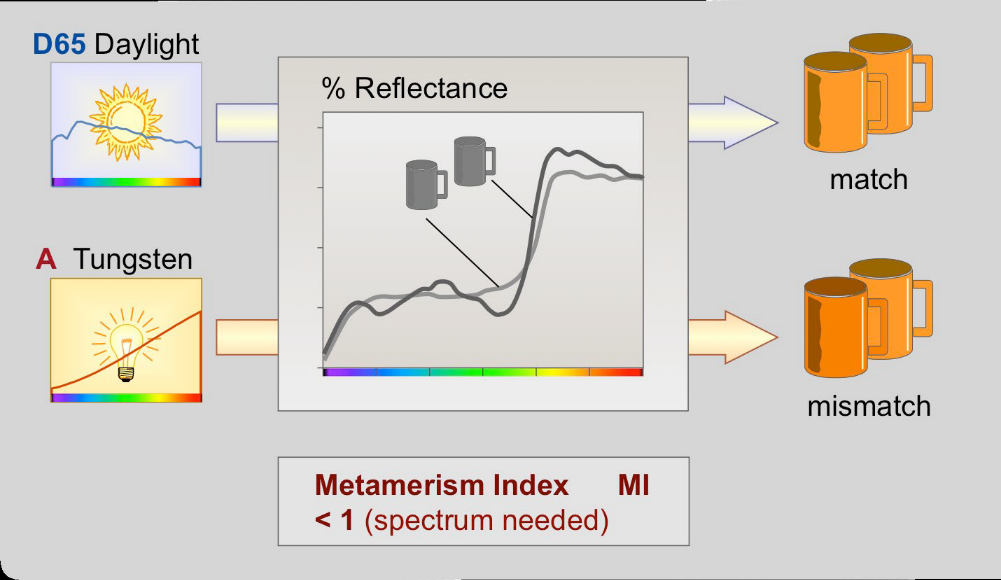
从XTZ到Lab:

Lab和sRGB颜色空间的对比:
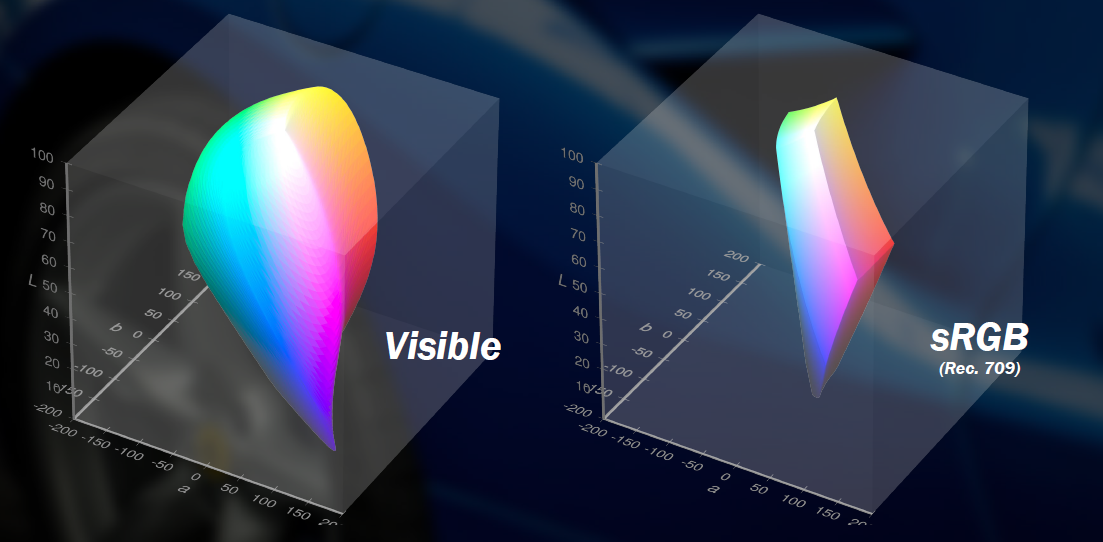
从游戏测量到实验室:
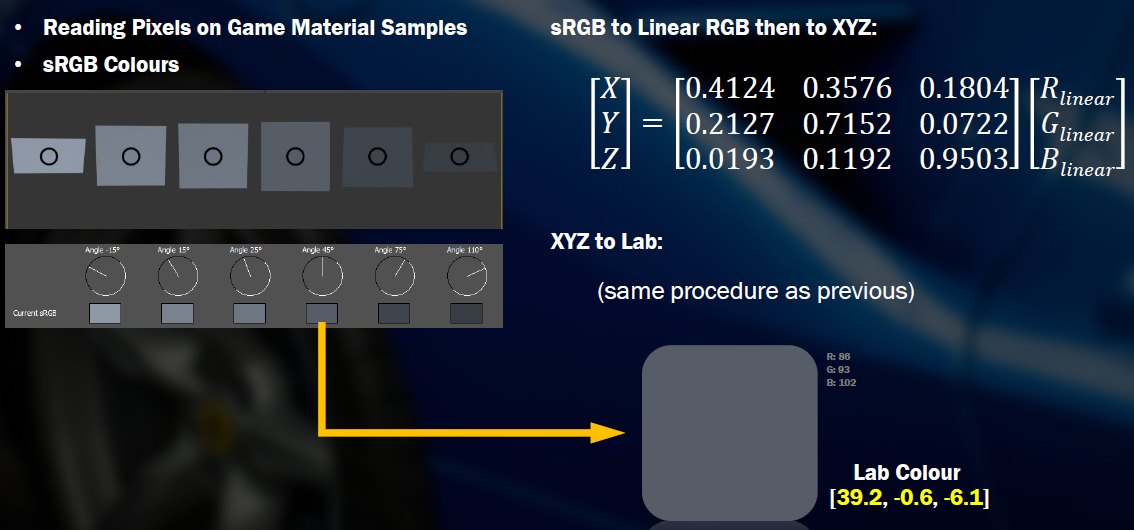
校准管线:
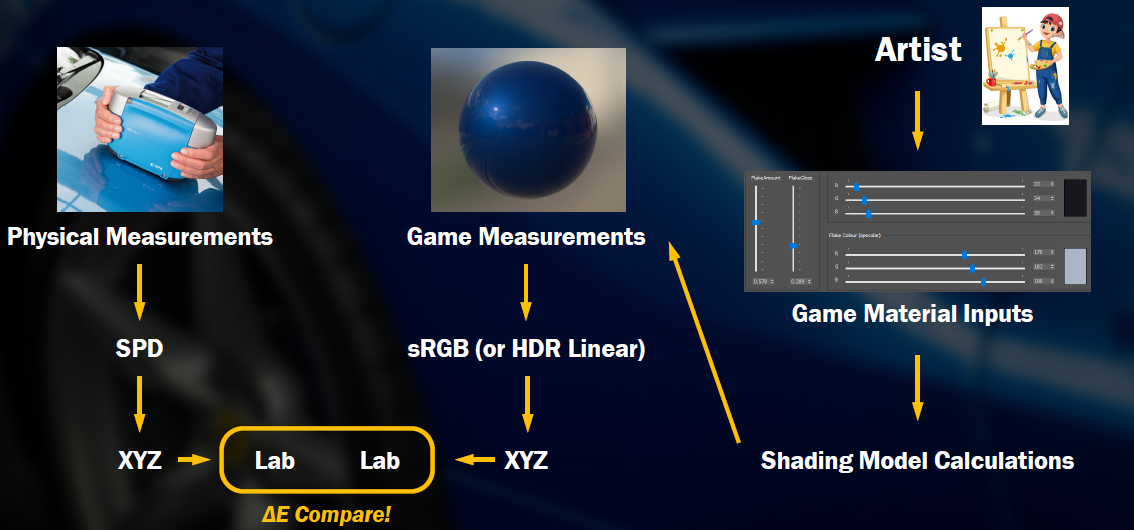
新旧对比:


新的渲染:

Procedurally Crafting Manhattan for Marvel’s Spider-Man讲述了游戏蜘蛛侠的过程化打造曼哈顿场景的技术。
蜘蛛侠的场景有6公里×3公里,9个区,544条路,1202条小巷,8300栋建筑,3250栋大楼预制件,350个店面,3000个罪犯,3000个插曲,包含故事、任务、英雄人物、恶棍等。程序系统计划:定义道路和小巷、地面修改、分块及ID、地面、地面细节、建筑物等。

场景中还包含大量的物体、特效和技术:

程序化系统管线集成:
按程序生成大部分内容:
传统手工处理:
效果一览:

Creating the Atmospheric World of Red Dead Redemption 2: A Complete and Integrated Solution介绍了Rockstar的Red Dead Redemption 2(荒野大镖客2)游戏中的天空渲染技术,包括云/雾渲染、体积效果以及由此产生的表示天空间接照明的环境照明模型。这套技术共同体现了团队如何在Red Dead Redemption 2的开放世界中创造一种自然氛围。这些技术的构思和设计既符合光传输的物理特性和规律,但重要的是,也提供了强大的直接性手段,允许艺术家精心设计我们的自然环境,以创造一种强烈的氛围,始终支持和增强游戏的故事、任务和情绪。

在地形处理中使用了雾体积、环境光、彩虹渲染、局部光、闪电等,下面是光照散射的总览:
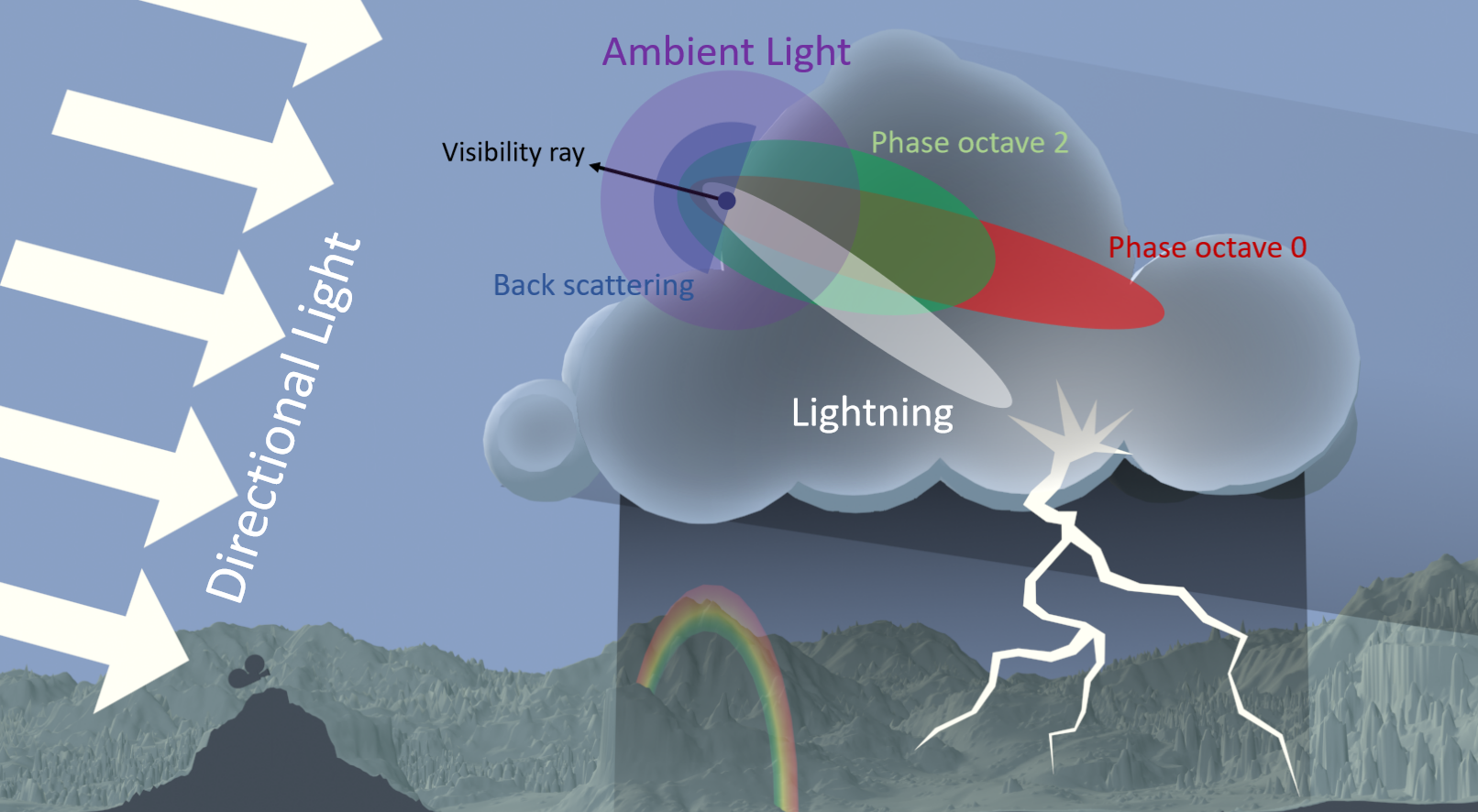
散射过程中使用了视锥体素网格、阴影体积、材质体积、散射光体积、视锥体积、光线行进等技术。

材质体积。
游戏回放在电子竞技、学习和社交分享中变得越来越重要,因为它推动玩家参与核心游戏循环之外的活动。Bringing Replays to World of Tanks: Mercenaries概述实现服务器端游戏记录和回放所需的基础设施,包括当现有游戏引擎关于时间和空间流动的假设不再成立时,客户端问题的架构解决方案。WoT将帧更新拆分成以下部分和路径:
并且对物体移动采用了插值:
文中还对实现过程中的不少问题提出了可靠有效的解决方案,对回放系统感兴趣的童鞋不妨点击原文详细阅读。
2014年初,Frostbite团队开始为基于quad的Bioware角色模型开发内部LOD技术。如今,这项技术为工作室在电子艺术领域使用的工具提供了动力,从战场到植物与僵尸。基于四边形的模型在行业中被广泛使用,艺术家们非常关注它们的拓扑结构和边缘流。然而,四边形网格的简化在文献中研究较少——流行的LOD工具对网格进行三角化,忽略拓扑。虽然LOD有时被认为是一次性的,但保持良好的拓扑结构有利于后续的手动编辑、照明和动画。出于这个原因,Bioware在历史上花了数天的时间来制作每个模型的角色LOD。这项工作的目的是在程序上生成LOD,大多数情况下看起来像艺术家创作的模型,为每个游戏节省数十万美元。Quad mesh simplification in Frostbite将阐述如何实现以上目标。
使用Garland和Heckbert二次误差度量的边折叠算子的前后对比:

仅有复合弦折叠的LOD结果:

使用笔刷可以改变顶点的优先级,下图是优先级的可视化和对应的LOD对比效果:

使用子复合弦折叠的LOD结果:

优先级绘制可以覆盖对称性:

使用对称的子复合弦折叠的LOD结果:

Lima Oscar Delta!: Scaling Content in 'Call of Duty: Modern Warfare'分享了COD的离线LOD处理、模型打包、运行时LOD处理、世界代理LOD等技术。LOD离线处理的第一部分:找出一个通用几何缩减的解决方案(又名“简单部分”),第二部分是其它的一切。

需要多少LOD级别?支持最多5倍的额外离散条目,为所有模型使用所有插槽就是浪费。

减少的目标是顶点、三角形、法线方差、轮廓保持、流重要性权重等。什么时候需要切换LOD?模型将如何在游戏中使用?英雄人物、简单道具、边缘、视图模型、结构体等等。碰撞体需要匹配渲染LOD或其它内容。尽可能优化LOD计数、缩减目标、开关距离、游戏上下文、碰撞等。第一次尝试:自动化一切!1、减少网格,直到其几何偏差超过某个阈值。

2、计算阈值消耗特定数量像素的开关距离。

3、跳过生成的切换距离与前一个切换距离“太*”的LOD。
4、重复此操作,直到在生成的开关距离处LOD“太小”。
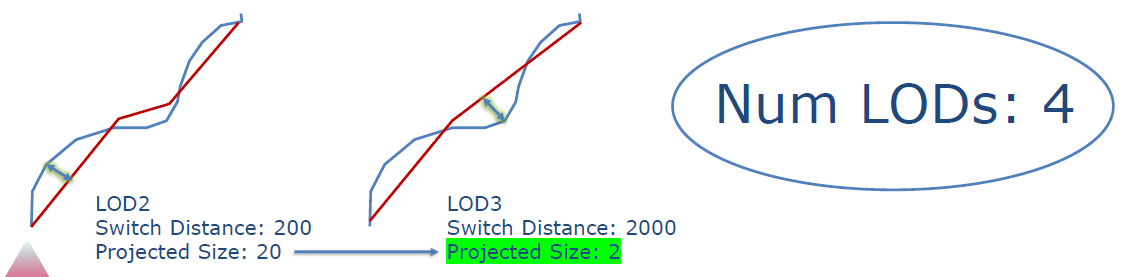
以上的初次实现(对程序员)有意义,确定性性能和视觉效果,对艺术家完全不敏感…
第二次尝试:混合解决方案。保持LOD设置的自动生成,但仅为方便起见。如果需要,允许艺术家覆盖几乎所有内容。1、从DCC工具导出一些模型几何图形。2.在资产管理工具中创建新的模型资产。3、启动后台流程,生成“技术上理想”的LOD数量、切换距离等。4、使用这些值在资产管理工具中植入GUI表单。5、如果艺术家喜欢他们看到的东西,就不需要再做什么了。否则,他们可以根据需要进行微调。
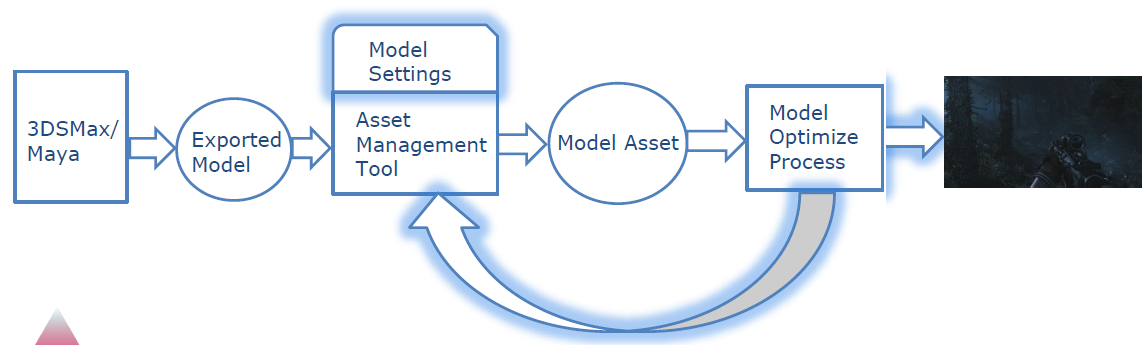
第二次尝试的混合解决方案提供直观的视觉反馈,帮助评估给定的运行效率。

LOD包装:将LOD拆分为单独的可流化块:
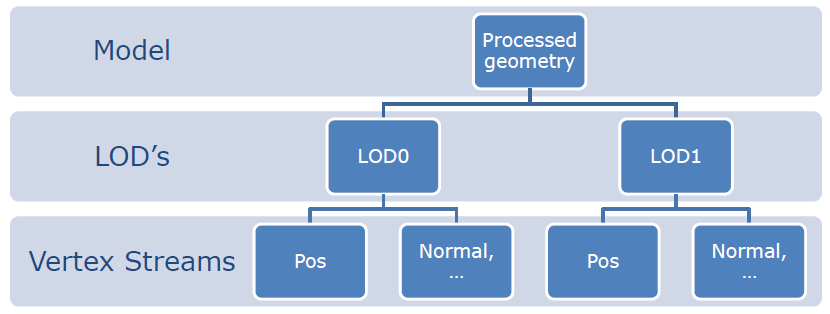
物体空间位置量化:

将刚体动画的表面升级为软蒙皮,并且聚合合并几何体和材质:

在LOD运行时,LOD选择标准:创作的开关距离,示意图如下:
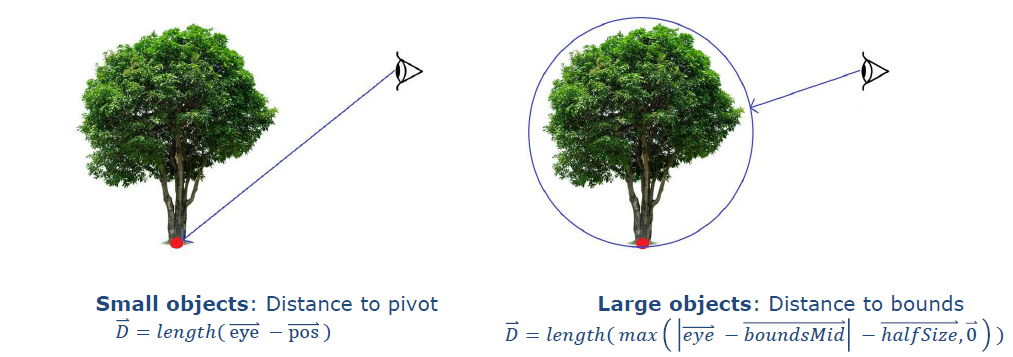
LOD选择标准:FOV变化。无论显示纵横比(4:3、16:9、16:10,…)如何,使用垂直视场确保相同的结果。

LOD选择标准:场景分辨率缩放。运行时计算一次,defaultFOV=65.0,defaultScreenHeight=1080.0。


最终,LOD选择标准有创作的开关距离、FOV、场景分辨率、顶点处理效率、通用GPU性能、基于预算的偏移等因素,计算公式如下:
此外,还可以考虑拒绝小物件、程序运动、静态模型尽量保持公*、流加载等因素。
代理LOD的“战区”概述:200名玩家,地面和空中机甲、120倍于大多数10v10地图的面积,但密度相同,长视线。代理LOD表示世界网格单元的单个模型,是对该单元中所有静态几何体组成部分的重新划分。使用自动化FTW:
输入:1000个独特的模型、其它世界几何图形和创作,千万个三角形!输出:一对模型,每个模型有一种材质,它们代表了世界cell的中远距离版本。代理LOD's的困难:匹配材质模型、处理建筑内部、透明表面、树、大型物体、小物件、构成大对象的小对象、缓存、新硬件(+规格)。
总之,一套强大的工具对于创建几何内容至关重要,它可以在运行时视觉和性能目标之间取得适当的*衡。这些工具的核心行为需要尽早解决,这不仅是为了提高效率,也是为了让艺术家们相信,他们不是在与移动的目标合作。这些工具应该用可操作的反馈来指导艺术家,而不是强迫他们。最佳运行时几何LOD选择应基于多个动态标准,而不仅仅是距离相机的距离。大型世界LOD有一套不同的要求需要*衡。由于世界LODing的所有输入都经过了微调,因此这一过程(几乎)完全自动化是可取的。
创造合作的角色行为是非常具有挑战性的,而且对所有规模的工作室来说都是昂贵的。深度强化学习是一种很好的方法,因为开发人员可以清楚地表达期望的目标,让机器学习最佳行为,可能会影响游戏开发的经济性。然而,大多数DRL算法旨在解决单个角色的任务(因此角色之间没有协作)。然而,协作DRL工具有了新的进展,例如集中评估,可以用来在游戏中创建协作角色行为。Creating Cooperative Character Behaviors using Deep Reinforcement LearningVincent将回顾这些主题,并举例说明一个工作室使用深度强化学习在游戏中创建合作角色的真实示例。
角色的合作行为一直是一个难题,行为的复杂性增加了,有多少个角色,角色之间的合作程度。
传统的AI和深度学习的AI对比:
深度强化学习:
集中学习:集中学习允许角色为队友的状态和行为赋予价值,而不仅仅是他们自己。
同步决策和异步决策:
代理j的优势计算:
Blowing from the West: Simulating Wind in 'Ghost of Tsushima'分享了游戏Ghost of Tsushima中使用的风模拟。风模拟的模型包含了向量 + 噪点 + 漩涡 + 位移,其中漩涡模拟过程如下:
风可对粒子、树叶、草、布料等物体进行交互。草的模拟流程如下:
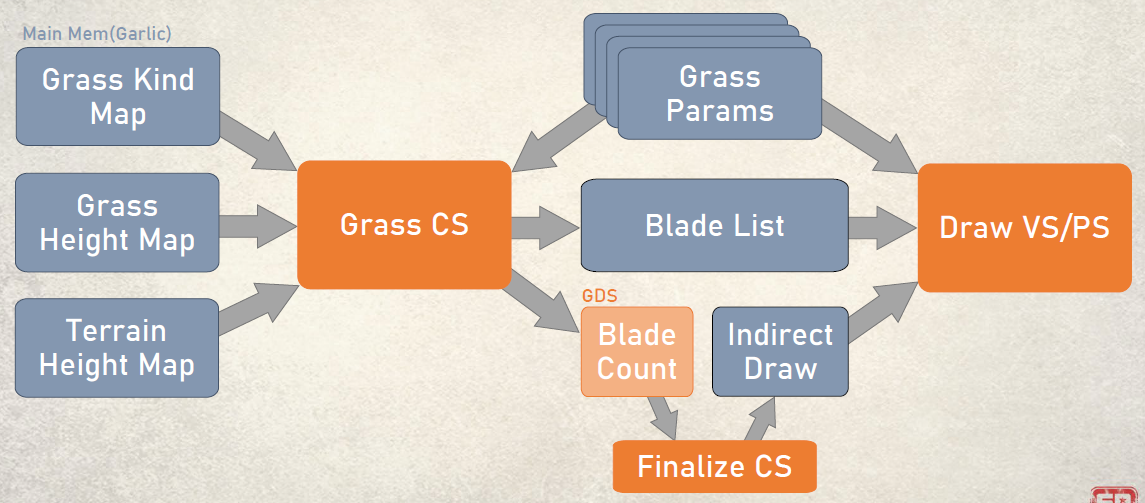
风和布料的交互过程如下:
FidelityFX Super Resolution (FSR)阐述了AMD的高保真超分辨率的技术。
边缘自适应空间上采样(EASU)是FSR 1.0中的上采样算法。EASU的目的是提供比CAS+硬件扩展更好的扩展,质量改进,由于着色器中的缩放,成本更高,扫描输出上的硬件缩放在视觉上与水*和垂直Lanczos匹配,EASU是一种局部自适应的类Lanczos椭圆滤波器。由于方向适应性,EASU要求输入具有良好的抗锯齿能力。EASU算法:使用固定的12-tap内核窗口,12-tap=良好上限,单通道算法(径向/椭圆滤波),12 taps * 3 channels = 36 VGPRs (FP32),64 VGPR (good upper limit) - 36 = 28 VGPRs for logic,算法需要全部12-tap进行分析,然后进行过滤。对luma(r+2g+b)中内部2x2 quad的每个“+”图案进行分析。
分析是双线性插值,并用于形成最终的滤波器核。
EASU采样:Vega/Navi/Xbox系列S |X/PS4Pro/PS5/etc硬件支持压缩16位操作,将gather4用于FP32和压缩FP16路径,12-tap通过4个位置完成。
EASU分析:根据中心差估计边缘方向,特征长度是通过对梯度反转量进行评分来估计的。
EASU与色彩空间:大多数游戏机最终都会在边缘上产生感知上均匀的梯度,因此,方向分析在游戏的感知空间中效果更好,因为从线性到感知的转换非常昂贵,而且需要12 tab,强烈建议在感知空间运行EASU。
EASU内核成形:插值后的分析产生{direction,length},X在{轴与对角线对齐}方向上从{1.0到sqrt(2.0)}缩放,在{small to Large feature length}上,Y从{1.0到2.0}缩放。
EASU内核:对lanczos使用多项式*似,使用基础*窗口的优化*似:
EASU去振铃:本地2x2 texel quad{min,max}用于钳制EASU输出,删除所有振铃,还删除了12-tap限制窗口的一些瑕疵,或者内核自适应的一些瑕疵。Unity的HDRP后处理管线如下:
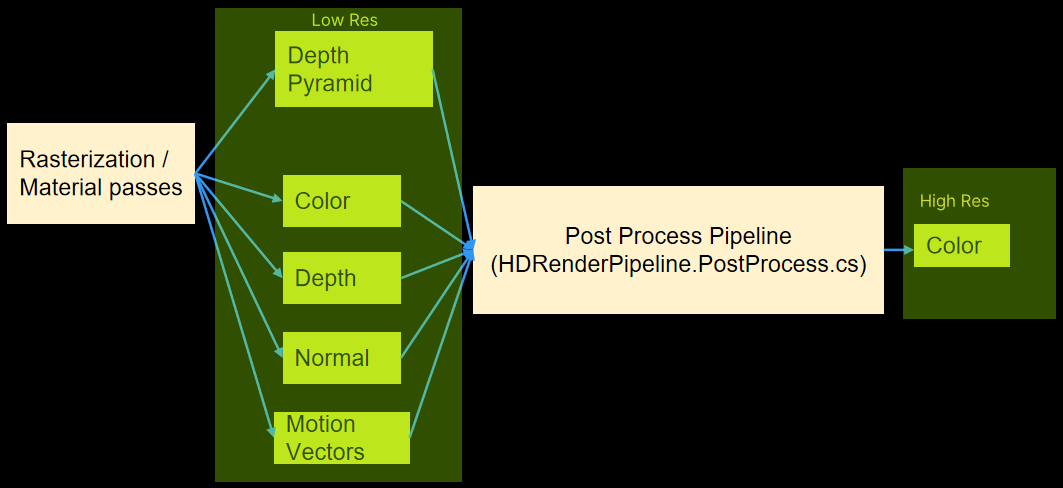
EASU在集成进Unity时,在光栅化过程中输出颜色、深度、运动矢量和法线之后,立即应用缩放。
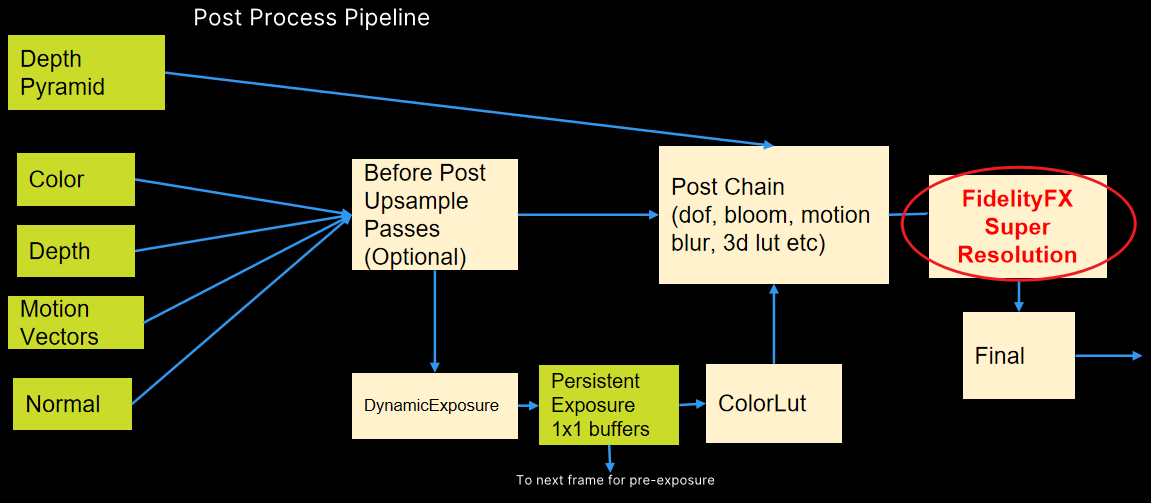
在unity中,有两种处理锯齿的方法,即查看一段内存的方法,这样就可以以不同的分辨率对其进行光栅化。第一种是基于软件的,适用于dx11、dx12、Vulkan、Metal和GNM等渲染*台,基本上是HDRP支持的所有功能。第二个是基于硬件,处理渲染API的子集,这些API包含更高级的功能,如直接访问资源描述符,以及纹理/资源重叠。
对于基于软件的应用程序,该技术非常简单,所做的就是在采样期间在x轴和y轴上应用缩放,只缩放从中采样的任何纹理的UV,会处理好边界。对于光栅化,在软件中所做的是设置一个视口,它是最终目标大小的子集。在unity中,在渲染图中有这样的设置,在渲染图(render graph)中,通常保留一个渲染目标,该目标是使用软件缩放创建虚拟或软件视图的渲染目标中所有相机的最大分辨率。

在使用纹理采样器对软件DRS中的某个部分进行采样时,请确保夹紧UV:
float2 borderUv(float2 uv, float2 texelSize, float2 scale)
{
// texelSize = 1.0/resolution.xy
float2 maxCoord = 1.0f - 0.5f * texelSize.xy;
return min(uv, maxCoord) * scale;
}
float2 borderUvOptimized(float2 uv)
{
//innerFactor => 1.0f / (1.0f - 0.5f*texelSize.xy)
//outerFactor=> scale * (1.0f - 0.5f*texelSize.xy)
return saturate(uv * innerFactor) * outerFactor;
}
对于基于硬件的锯齿,所做的有点不同,在unity的C++端有一个非常大的堆,在那里基本上分配一个放置的资源。开始按需将这些资源放在堆上,取决于目前需要的解决方案,就是产生重叠的地方。这种方法唯一棘手的一点是,它比基于软件的方法快得多,因为不必使用乘法器或视口,实际上是在硬件级别上处理这种原生分辨率。但问题是,正在为遇到的每个解决方案创建描述符,必须非常小心CPU的实现,以确保回收这些描述符,并且不会膨胀内存并导致CPU性能成本。
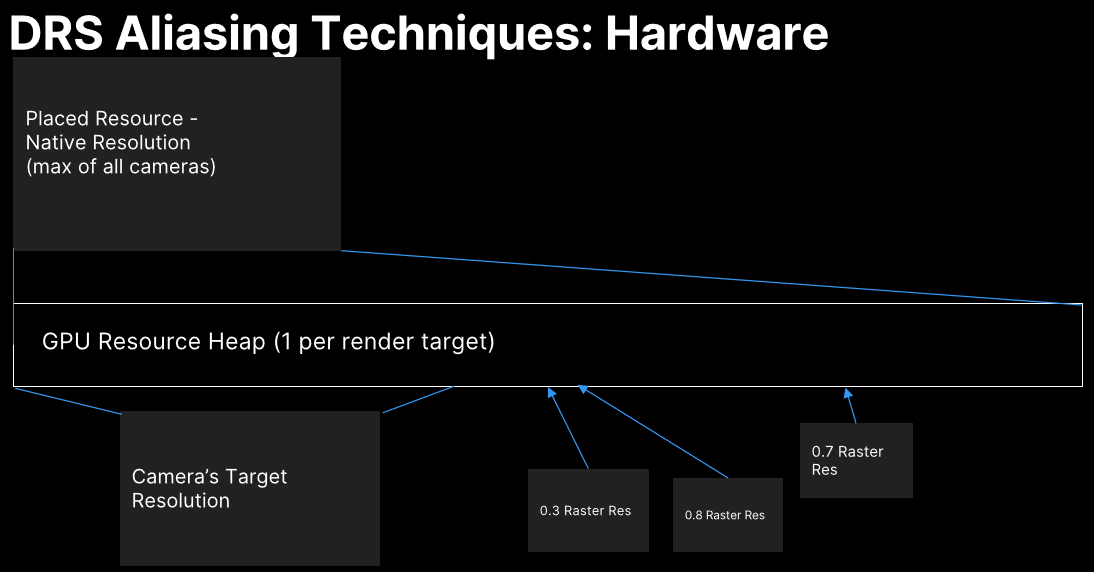
对于效果链,要做的是启动uber post流程,这是bloom之后输出的所有内容,在色调映射之后。对渲染目标执行*方根,所以在*方根空间输出,可称之为空间感知色彩空间,这就进入了EASU算法,该算法消耗色彩空间并应用上采样器。在上采样器中输出后,确保返回线性空间,然后应用RCAS算法,RCAS算法改进了边缘和之前可能丢失的所有细节。

效果对比:

EASU运行时消耗:PS4 Pro上4k输出分辨率的Unity Spaceship演示,为EASU和RCAS使用FP32路径(可移植到PS4),EASU隔离计时0.43毫秒,隔离计时的RCAS为0.16毫秒。
14.5.4 渲染技术
14.5.4.1 Visibility Buffer
4K Rendering Breakthrough: The Filtered and Culled Visibility Buffer介绍了一种新的渲染系统:过滤和剔除的可见性缓冲区,其性能将比具有更高分辨率的传统系统好得多,至少与具有最常见分辨率的传统渲染系统一样好。它将三角形数据存储在可见性缓冲区中,而不是将数据存储在G缓冲区中,G缓冲区随着屏幕分辨率的大幅增加而增加。为了优化该缓冲区中存储的三角形的数量和质量,在预处理步骤中应用了三角形过滤和剔除。此外,三角形和消隐预处理步骤还准备了所有其它读取视图,如阴影图渲染。
前向渲染按三角形提交顺序对所有片段进行着色,浪费对最终图像没有贡献的像素的渲染能力,延迟着色通过两个步骤解决此问题:首先,表面属性存储在屏幕缓冲区->G缓冲区中,其次,仅对可见片段计算着色。但是,延迟着色会增加内存带宽消耗,例如屏幕缓冲区:法线、深度、反照率、材质ID,…G缓冲区大小在高分辨率下变得很有挑战性。以下多图是不同年代的延迟着色和可见性缓冲区的对比图:
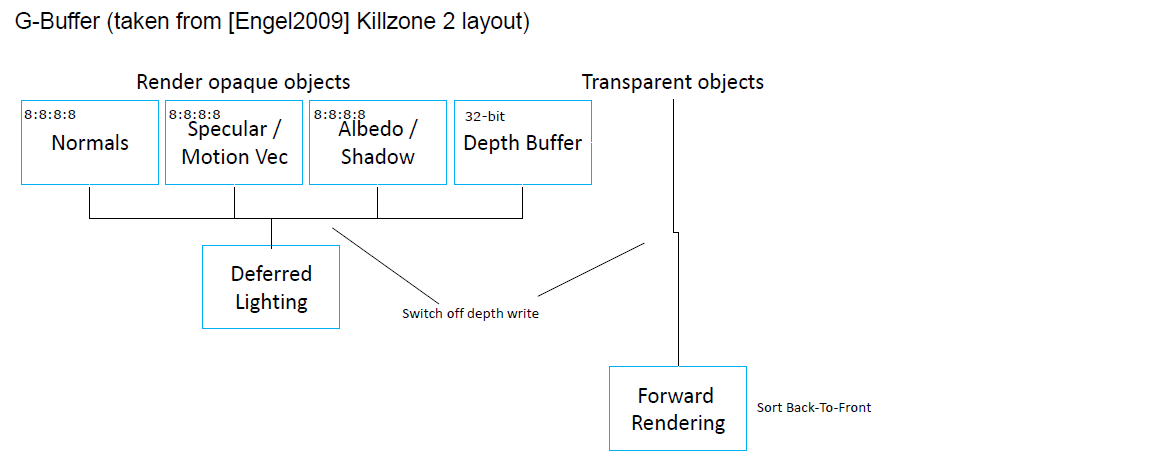
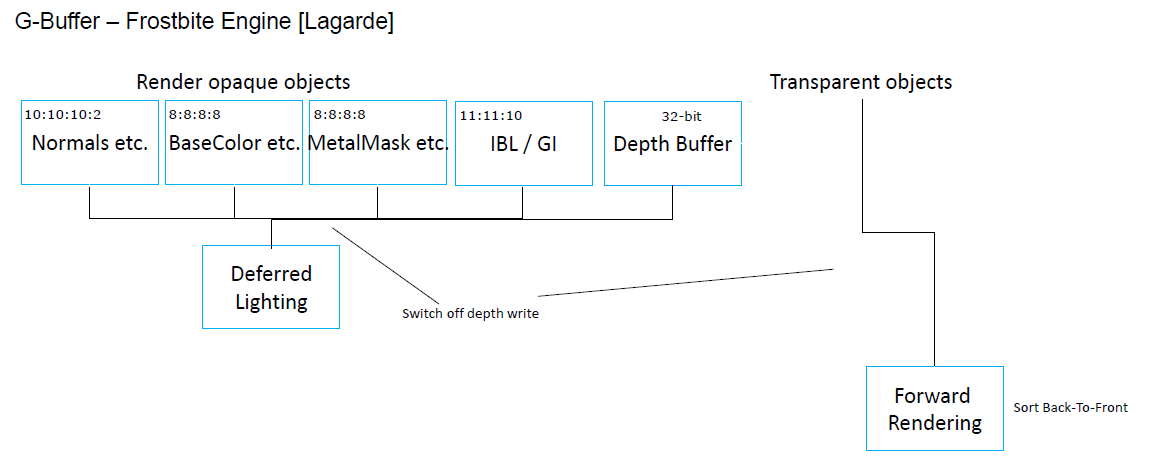
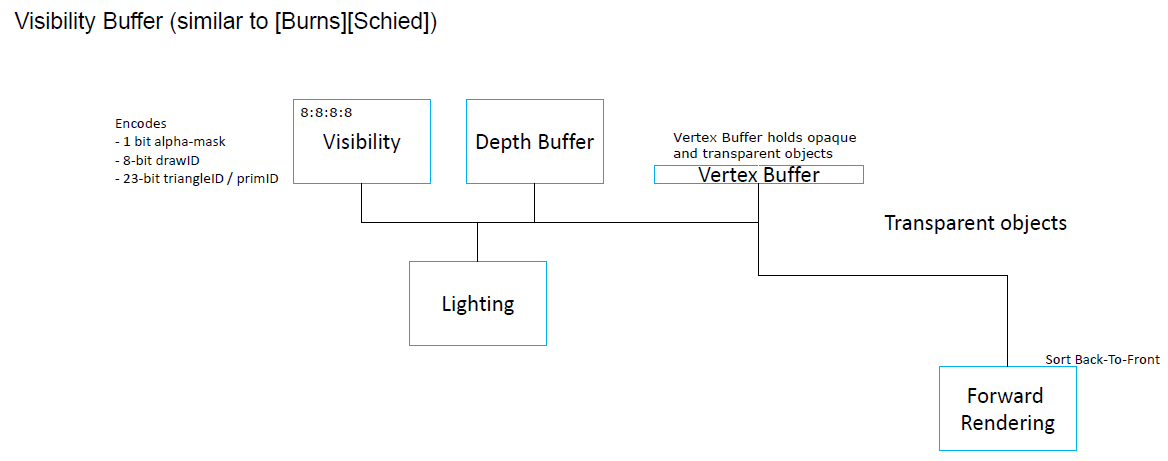
以下是可见性缓冲区和GBuffer的显存消耗对比:




VisibilityBuffer的填充步骤:
- 可见性缓冲区生成步骤。
- 对于屏幕中的每个像素:
- 将(alpha屏蔽位、drawID、primitiveID)打包到1个32位UINT中。
- 将其写入屏幕大小的缓冲区。
- 元组(alpha掩码位、drawID、primitiveID)将允许着色器在着色步骤中访问三角形数据。
VisibilityBuffer的着色步骤:
- 对于屏幕空间中的每个像素,执行以下操作:
- 获取drawID/triangleID像素位置。
- 从VB加载3个顶点的数据。
- 计算三角形梯度。
- 使用渐变在像素点处插值顶点属性(可以进行三角形/对象空间照明)。
- 属性使用w从位置计算透视正确插值。
- MVP矩阵被应用于位置。
- 已经准备好所有数据:着色和计算最终颜色。
VisibilityBuffer的优势:更好地从着色中分离可见性,计算导数可以与着色阶段分开进行(将其包括在当前阶段),可以用不同的频率或质量来着色。提高内存效率,提高缓存利用率,内存访问是高度一致的(高速缓存命中率高),G缓冲区需要存储每个屏幕空间像素的数据,与顶点/索引缓冲区相比,其中一些数据是冗余的,可以看到纹理、顶点和索引缓冲区的可见性缓冲区的99%二级缓存命中率。与g缓冲区相比,为复杂照明模型(如PBR)存储的数据更少,可见性缓冲区的PBR数据是由顶点结构中的材质id索引的结构常量内存,该结构将索引保存到各种PBR纹理的纹理数组中,它还包含驱动BRDF所需的材质说明,每像素变化的任何数据都存储在结构引用的纹理中。将缓冲区足印与屏幕分辨率解耦,在高分辨率下提高性能:2K、4K、MSAA…在带宽有限的*台上提高性能。
怎么执行照明?可以选择最喜欢的照明结构:延迟分块、向前分块等。向前分块或Forward++似乎是一种自然的搭配,因为它将受益于通过剔除、过滤和可见性检查减少的顶点数,并为不透明和透明对象提供一致的照明。三角形或物体空间的照明也是可能的。
游戏的多边形复杂性每年都在增加,有效剔除三角形非常重要。2个剔除阶段:1、分簇剔除:在将三角形组发送到GPU之前剔除它们;2、三角形过滤:在发送到GPU后剔除单个三角形。
分簇剔除:将三角形分组为256个具有相似朝向的三角形的小块,块有一个相关的模型矩阵(它们可以移动),每个块在发送到GPU之前必须通过快速可见性测试:圆锥测试。

快速分簇剔除的圆锥测试,如果眼睛在安全区域,我们就看不到任何三角形,因为它们是背向的:
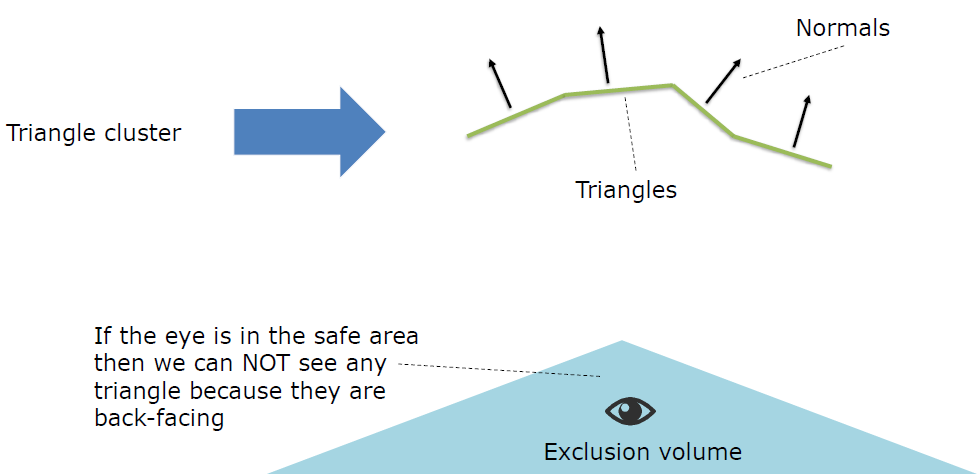
具体的过程和解析如下:
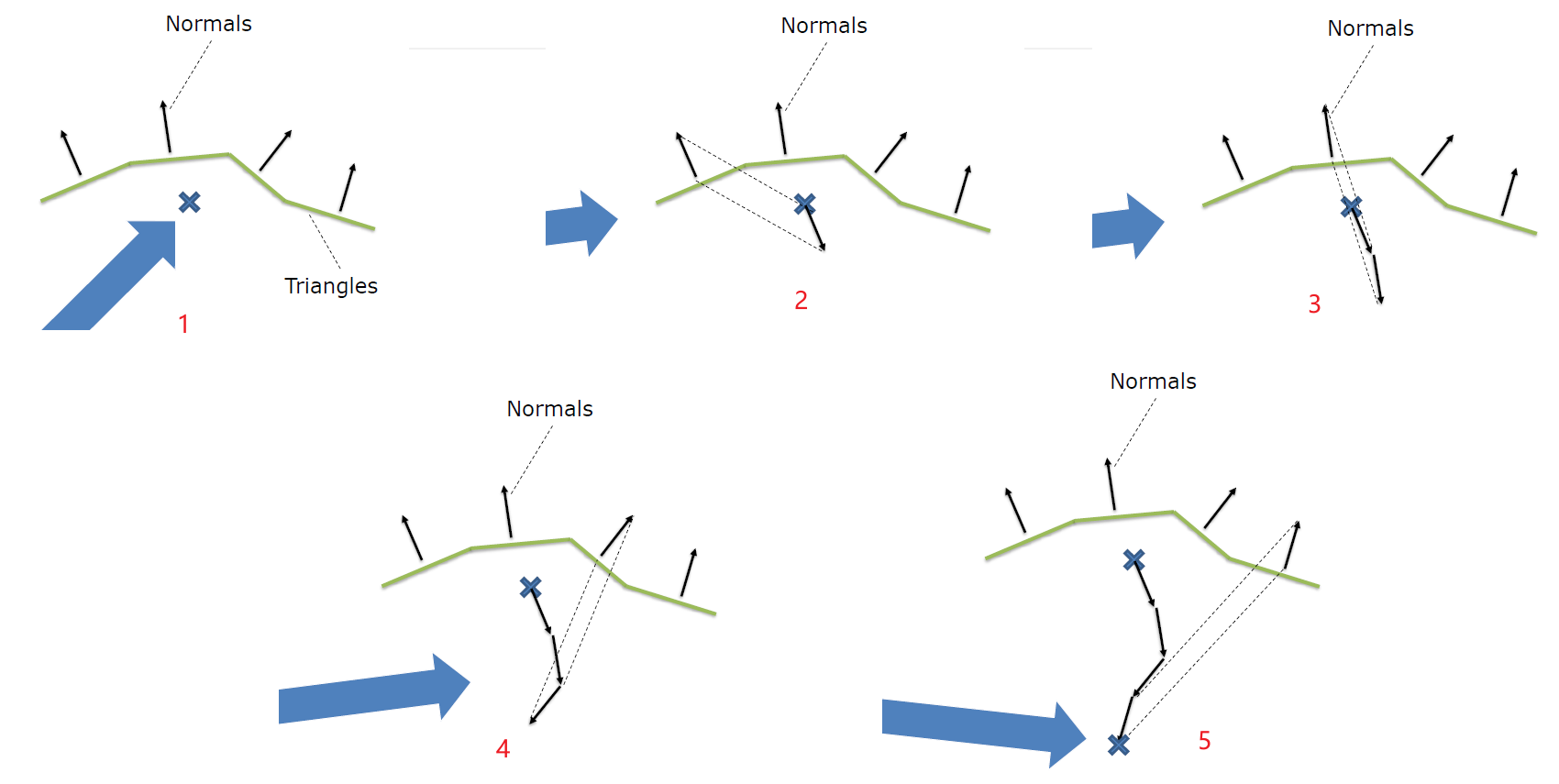
1:找到分簇的中心。
2:从分簇中心开始负向累加法线值。
3:负向累加第一个法线值之后的第二个法线值。
4:累加下一个。
5:在累加最后一个之后,得到了排除体积的起点和方向。
接着,结合下图,分别是用于计算圆锥体张角的最严格的三角形*面、计算出的排除体积:
分簇剔除效率:有效性取决于在簇中的面的朝向,方向越相似,排除/剔除体积越大。根据三角形,无法计算排除体积,用于分簇剔除的分簇无效,只需要略过。
基于计算的三角形过滤:动机是在三角形进入图形管线之前剔除它们,使用异步计算在图形管线执行期间使用未使用的计算单元。基于计算的过滤,每个线程一个三角形,过滤的三角形包含退化三角形剔除、背面剔除、视锥剔除、小图元剔除、深度剔除(需要粗糙的深度缓冲),通过这些测试的三角形索引将附加到索引缓冲区。基于计算的三角形过滤:
-
退化三角形剔除。允许剔除不可见的零面积三角形。成本:快速测试(如果至少两个三角形索引相等,则放弃),效果:低。
cull = (indices[0] == indices[1] || indices[1] == indices[2] || indices[0] == indices[2] ); -
背面剔除。允许剔除远离观察者的三角形,如果使用细分,则必须考虑最大面片高度。成本:计算3x3矩阵的行列式,效果:高(可能会剔除50%的几何体)。
-
视锥剔除。允许剔除投影在剪裁立方体外部的三角形,考虑**面和远*面。成本:检查所有顶点是否位于剪辑空间立方体的负侧,效果:中高(取决于场景大小和眼睛位置)。
-
小图元剔除。允许剔除太小而看不见的三角形,投影后不接触任何采样点的三角形,不接触任何样本的细长三角形也会被剔除,更高效地利用硬件资源。成本:三角形接触任何亚像素样本,效果:中(取决于三角形的大小和屏幕分辨率)。
![]()
-
深度剔除。允许剔除被场景遮挡的三角形,该测试需要一个粗糙的深度缓冲区。成本:从地图加载深度值并检查三角形/BB交点,效果:中高(取决于场景复杂度和三角形的大小)。
![]()


基于计算的三角形过滤的概览如下:
三角形过滤在256个三角形(一批)-> 空绘制的组上执行,绘制批次压缩来援救,可以在计算着色器中并行运行,从多间接绘图缓冲区中删除空绘图。
添加三角形/分簇过滤的帧步骤:
- [CPU] 使用分簇剔除提前丢弃不可见的几何。
- [CS] 使用三角形过滤(每个线程一个三角形)生成未被剔除的索引和多绘制间接缓冲区。
- 像之前一样执行。
添加三角形/分簇过滤的数据管理:对于这个静态场景,一个大的顶点缓冲区和一个由三角形剔除和过滤生成的索引缓冲区。绘制批次,每个批次为一种材质保存一块几何体,只有两种“材质”不透明和alpha遮罩的透明对象和其它材质将进入同一缓冲区。对于动态对象,将为每个对象使用专用的VB/IB对;是可选的。
基于计算的三角形过滤的好处:允许在将三角形发送到图形管线之前剔除它们,避免在图形管线(光栅化器)中占据压倒性的部分,图形管线可以更好地利用可见三角形(光栅化效率、命令处理器等),可以利用异步计算与图形管线重叠。
可以对多个视图/渲染过程重用三角形过滤结果。将算法推广到不同的N视图上进行测试,加载索引/顶点一次,变换每个视图的顶点。

添加三角形过滤数据的重用的步骤:
- [CPU]使用分簇剔除提前丢弃从任何视图中都看不到的几何体。
- [CS]对N个视图使用三角形过滤测试生成N个索引和N个多绘制间接缓冲区(每个线程一个三角形)。
- 对于每个视图i使用(第i个索引缓冲区和第i个MDI缓冲区):
- [Gfx]清除可视性和深度缓冲区。
- [VS, PS]可视性缓冲区通道,[PS]输出三角形/实例ID。
- [PS]从梯度和着色像素插值属性。
结果:

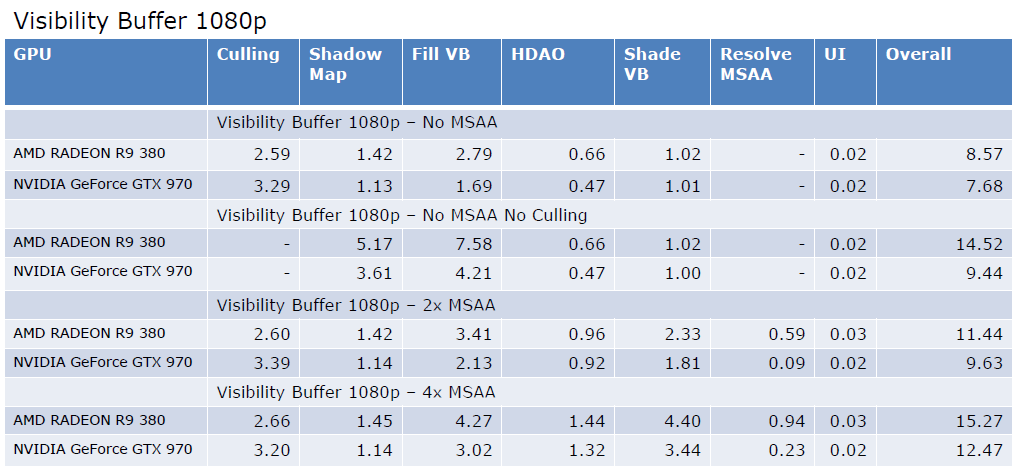
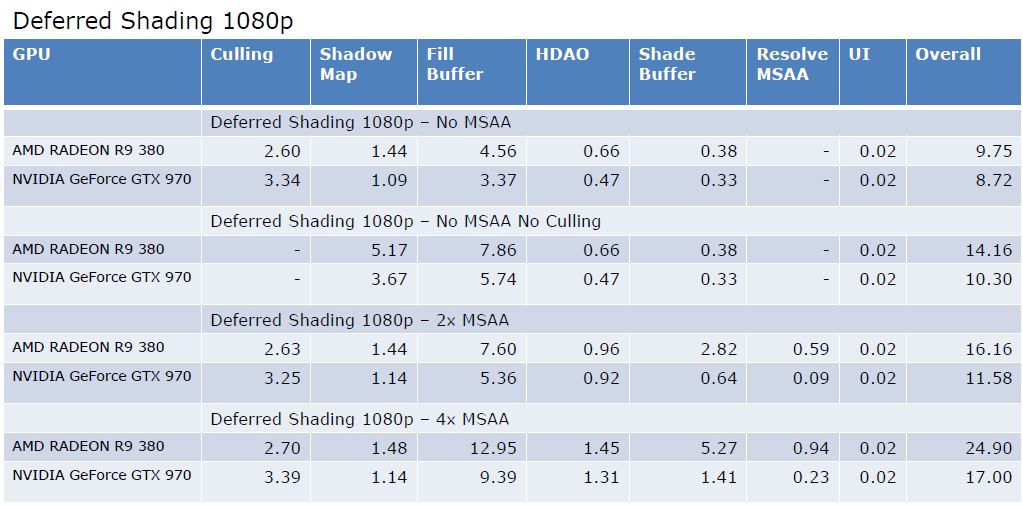
总结:
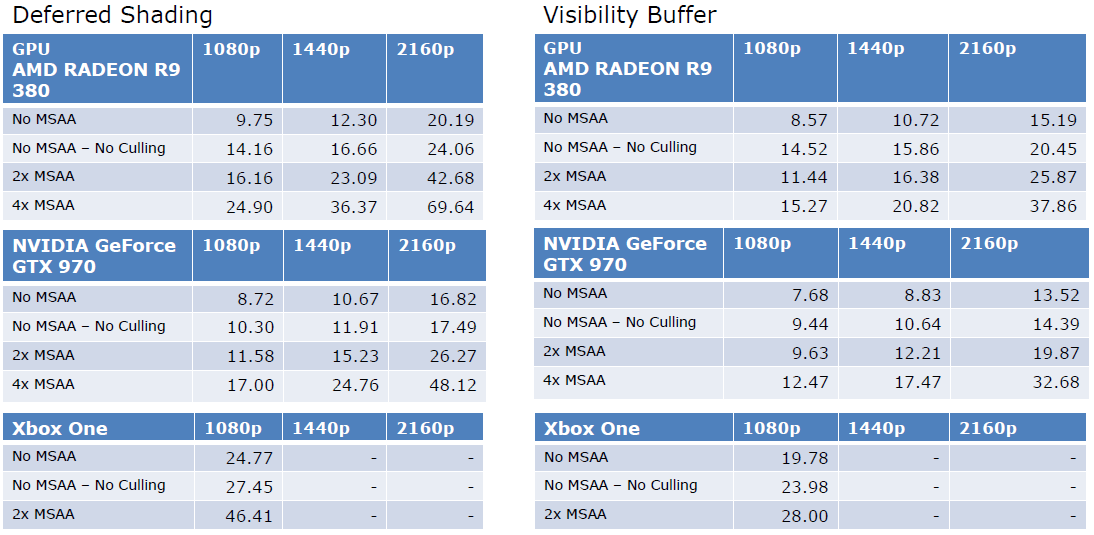
虚拟现实呢?正在处理饥饿问题,它能以非常高的分辨率显示大视场,可见性缓冲区将大大提高性能,可以一次完成所有视图和阴影贴图视图的数据筛选和准备,提供forward+,因此不必处理透明度问题。
总之,建立的渲染系统为不同视图(如主视图、阴影视图、反射视图、GI视图等)分簇剔除和过滤三角形,优化后的三角形用于填充屏幕空间可见性缓冲区或更多视图的更多可见性缓冲区。然后,使用基于可见性的优化几何体渲染灯光、阴影和反弹灯光,可以区分几何体的可见性和着色频率,可以在每个三角形或所谓的物体空间中计算照明。
14.5.4.2 Filmic SMAA
Filmic SMAA: Sharp Morphological and Temporal Antialiasing由任职于暴雪的抗锯齿的鼻祖Jorge Jimenez呈现,讲述了电影级的SMAA的最新成果。
SMAA的目标是锐利、鲁棒性、高性能。形态抗锯齿(SMAA 1x),增加了时间超采样(SMAA T2x)、空间多采样(SMAA S2x)和组合(SMAA 4x)不适用于暴雪的游戏。Filmic SMAA是Filmic过滤(Filmic变体):Filmic SMAA 1x、Filmic SMAA T2x–用于PS4和XB1,时间过滤 ≠ 时间超采样。
先重温以下形态抗锯齿基础。结合下图,先搜索线的左右两端,然后获得线两侧的交叉边,有了距离和交叉边,有足够的信息来计算重建线下的面积。
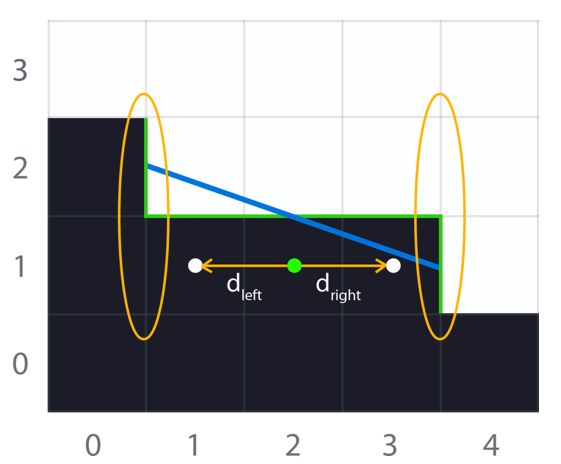
形态抗锯齿改进包含质量(形态学边缘抑制、轮廓线检测、U形*滑)和性能(延迟队列、使用LDS、双面混合)。文中谈及的质量方面的知识点包含局部对比度边缘抑制、形态边缘抑制、轮廓线检测、U型*滑,性能方面的知识点包含形态多通道法、使用Compute简化为一个通道、像素着色器效率低下、模板剔除效率低下、延迟队列、重复模式搜索、SMAA用CS解决问题的方法、使用LDS、双线性获取和解码等。

局部边缘抑制图例。对于给定的边,如右图中红色标记的边,检查附*的边缘,如果发现另一个边缘在对比度上占主导地位,就会抑制它。
通过(左)和不通过(右)当前边缘的图案的对比。其中右边的方法会检查哪一个得分更高(强度)如果不通过当前边缘的图案获胜,则抑制边缘。
三种基本的U型模式。小U型图案在时间上是不稳定,想要软化或摆脱它们,使用LUT,可以根据感知调整。

SMAA形态多通道方法。
延迟队列图例。上:检测到的边被附加到附加/消耗缓冲区,执行间接分派以使用该缓冲区,允许所有线程执行实际工作。下:避免读取全屏模板缓冲区,在某些情况下,由于边缘分布分散,层次模板并不总是最佳的。文中调整了SMAA以使用类似的方法,显著提高了性能,也适用于时间。
文中也涉及了TAA的基础,诸如抖动、采样模式、重投影、速度等,还涉及了不一致(Disocclusion)和速度加权。不一致是指新帧中的像素在前一帧中不存在,解决方案是如果速度相差太大,不要混合,不适用于没有速度的像素(alpha混合)。

颜色信息也可用于不一致,加上速度加权,无法比较当前帧和上一帧,但由于不同的抖动,即使在静态图像上也会经常被拒绝。解决方案是比较N帧和N-2帧,在没有速度的情况下减轻对象上的重影(alpha混合)。
指数历史/指数移动*均:SMAA T2x和类似使用两个帧的技术:\(c_{aa}=0.5c_i+0.5c_i−1\)。

可以利用指数累积缓冲区:
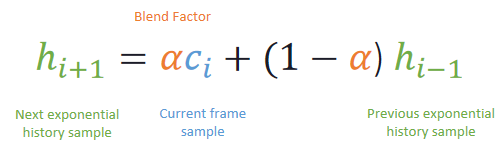
类似于多帧移动*均[Karis2004],增加有效子样本数,反馈循环。
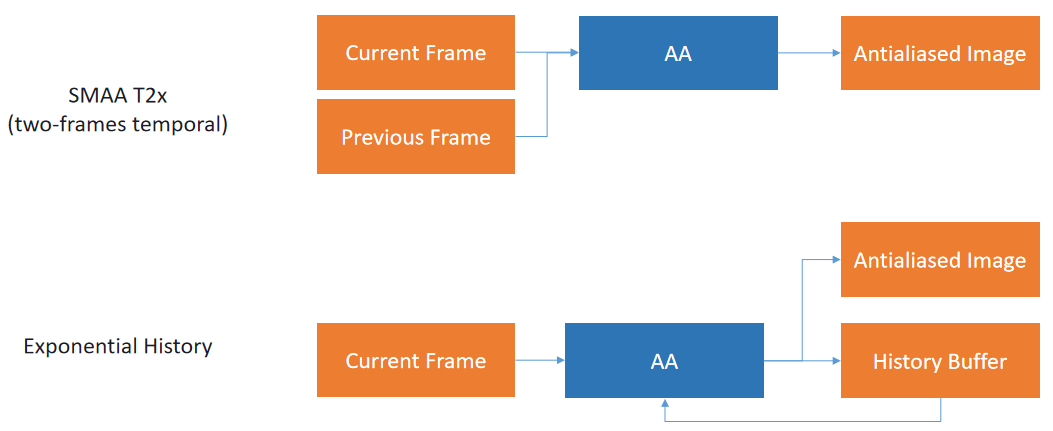
指数累加缓冲技术通常使用邻域夹紧来消除混淆[Lottes2011],其基本形式:
\(n_{min}\)和\(n_{max}\)是3x3虚线邻域中的最小和最大颜色。
当使用这种夹紧与时间抖动一起使用时,可能会导致闪烁。
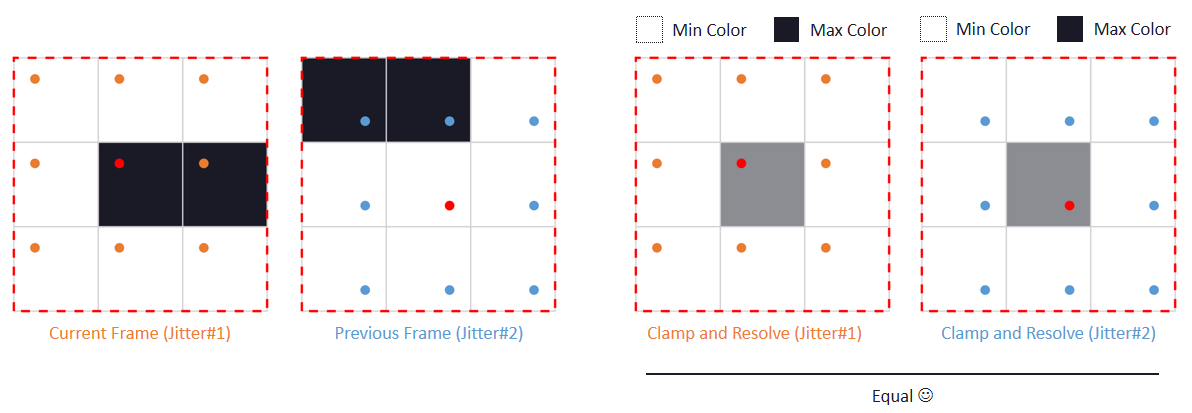
在这种情况下,考虑到几何体非常小,它在第二帧中消失了,在帧之间,颜色的邻域范围也发生了变化。使得输出不一样,从而在静态图像上产生闪烁的伪影。
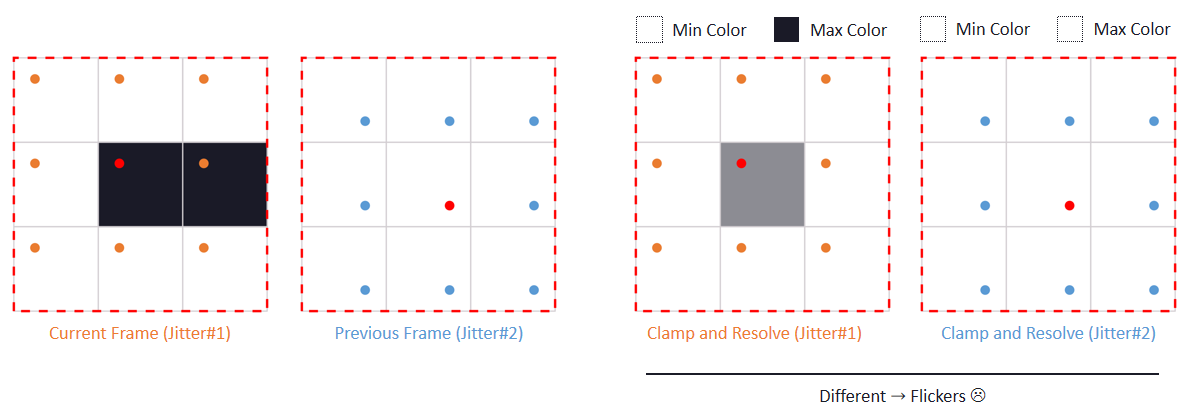
最*的速度:指数历史*滑且抗锯齿,新的帧速度是带锯齿的(在重投影时引入锯齿),解决方案是湖区最前面的邻域速度[Karis2014]。

有关TAA的知识点还有形状邻域的YCoCg裁剪[Karis2014]、软邻域夹紧[Drobot2014]、高阶重采样[Drobot2014]、方差剪裁[Salvi2016]...
之前已有不少相关的研究,如SMAA 1TX [Sousa2013]、Unreal Engine 4 TAA [Karis2014]、HRAA [Drobot2014]。文中给出的关键要点是时间滤波与AA解耦。使用指数历史是一个可以与亚像素抖动的超采样分离的过程,从现在起将被称为临时过滤,它可以在时间上过滤(或模糊)图像。可以认为,作为一种副产品,它可以模糊或*均时间亚像素抖动,即使在不抖动的情况下,运动中的对象也会在每帧中自然地落在不同的子采样位置,即使不使用抖动,运动中的对象也会有AA。Filmic SMAA T2x和SMAA T2x的对比如下:
| Filmic SMAA T2x | SMAA T2x |
|---|---|
| 子样本:2x(可选对比度感知的Quincunx约4x) 边缘:形态学 时间过滤:是 |
子样本:2x 边缘:形态学 时间过滤:否 |
| 减少鬼影 少量的性能预算 锐利 在静态图像中稳定 |
在没有速度的物体上鬼影 在静态图像中稳定 |
文中涉及的时间抗锯齿改进:
- 分离时间超采样和时间滤波。
- 时间过滤锐利。
时空对比度跟踪。基于FPS的时域过滤。- 用深度测试扩展邻域夹紧。
- 改进的时间超采样重采样。
- 改进的时间Quincunx。
- 超采样导数。
- 改进的颜色权重。
- 低轮廓的速度缓冲区。
- 更快的最*速度。
- 时间上采样。
Drobot2014的单通道和Filmic的双通道对比:
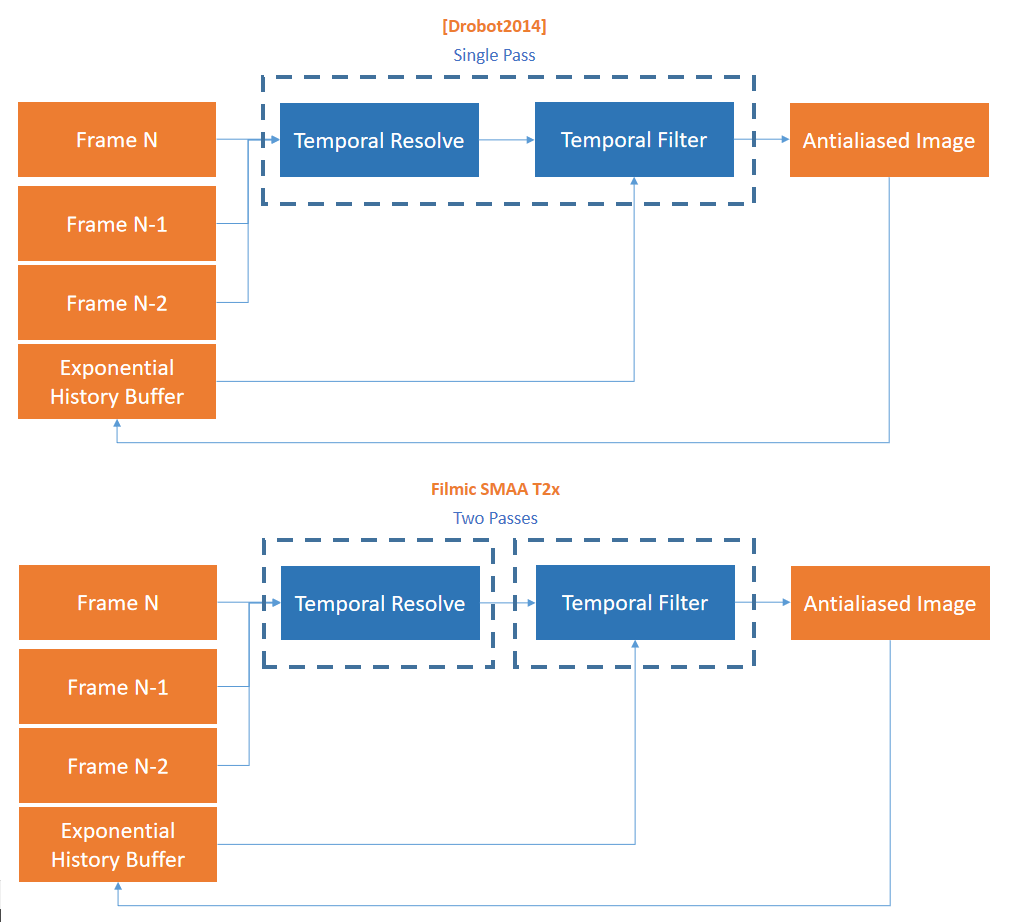
它们的方法和效果对比:
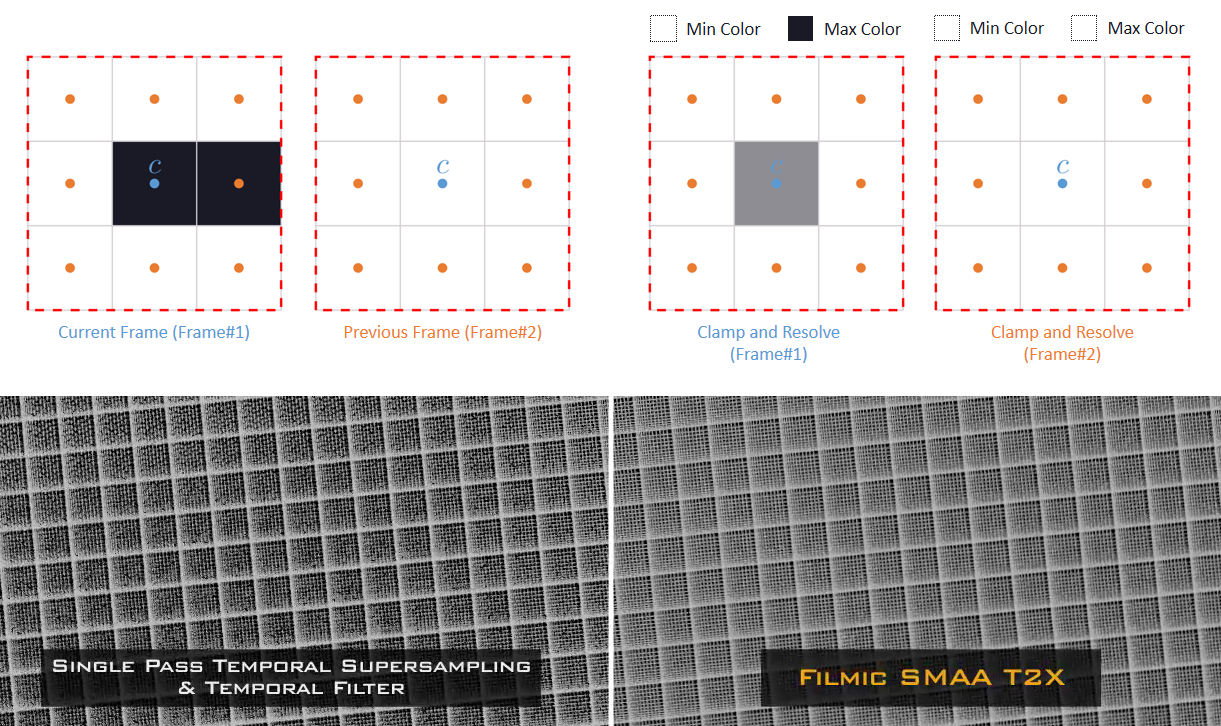
对于时间锐利度,使用了双三次重采样(Bicubic Resampling),优化的Catmull Rom使用9个双线性样本处理4x4区域。最终的方案是忽略4个角会产生非常相似的结果,从9个样本减少到5个。小数值误差,可能可以应用在其它领域。
左:原始的Bicubic;右:减少到5个样本的*似方法。
两种方法的误差。
// 5样本的采样方法shader代码
float3 SMAAFilterHistory(SMAATexture2D colorTex, float2 texcoord, float4 rtMetrics)
{
float2 position = rtMetrics.zw * texcoord;
float2 centerPosition = floor(position - 0.5) + 0.5;
float2 f = position - centerPosition;
float2 f2 = f * f;
float2 f3 = f * f2;
float c = SMAA_FILMIC_REPROJECTION_SHARPNESS / 100.0;
float2 w0 = -c * f3 + 2.0 * c * f2 - c * f;
float2 w1 = (2.0 - c) * f3 - (3.0 - c) * f2 + 1.0;
float2 w2 = -(2.0 - c) * f3 + (3.0 - 2.0 * c) * f2 + c * f;
float2 w3 = c * f3 - c * f2;
float2 w12 = w1 + w2;
float2 tc12 = rtMetrics.xy * (centerPosition + w2 / w12);
float3 centerColor = SMAASample(colorTex, float2(tc12.x, tc12.y)).rgb;
float2 tc0 = rtMetrics.xy * (centerPosition - 1.0);
float2 tc3 = rtMetrics.xy * (centerPosition + 2.0);
float4 color = float4(SMAASample(colorTex, float2(tc12.x, tc0.y )).rgb, 1.0) * (w12.x * w0.y ) +
float4(SMAASample(colorTex, float2(tc0.x, tc12.y)).rgb, 1.0) * (w0.x * w12.y) +
float4(centerColor, 1.0) * (w12.x * w12.y) +
float4(SMAASample(colorTex, float2(tc3.x, tc12.y)).rgb, 1.0) * (w3.x * w12.y) +
float4(SMAASample(colorTex, float2(tc12.x, tc3.y )).rgb, 1.0) * (w12.x * w3.y );
return color.rgb * rcp(color.a);
}
改进的时间超采样重采样:
尝试了不同的*滑曲线,选择了下图上排右边的曲线,因为它具有最强的S形。接着要做的是用立方**滑来*似它,使用了夹紧和重缩放,也就是下排右边的图:
效果如下:

文中改进了Quincunx采样。结合下图,Quincunx的定义是:\(0.5 \times 蓝色样本 + 0.5 \times 橙色样本\)。
其中橙色是单一样本,可以用双线性来获取全部蓝色样本,Quincunx变成纹理坐标移量,与2x相同的性能。对比度感知的Quincunx的想法:根据局部对比度来调整纹理坐标的偏移量,低对比度(纹理细节)用2x,高对比度(边缘)用Quincunx,使用Quincunx子样本确定对比度,如果对比度低,则使用2x偏移重新获取,开销低:约0.02毫秒PS4@1080。

文中还涉及了很多技术改进细节和对比,有兴趣的童鞋可以点击原文阅读。总之,Filmic SMAA T2x的亮点是良好的锐利、高健壮性及高性能。
14.5.4.3 High Dynamic Range Imaging
高动态范围(HDR)图像和视频包含像素,这些像素可以代表比现有标准动态范围图像更大的颜色和亮度范围。这种“更好的像素”极大地提高了视觉内容的整体质量,使其看起来更真实,对观众更有吸引力。HDR是未来成像管线的关键技术之一,它将改变数字视觉内容的表示和操作方式。
High Dynamic Range Imaging对HDR方法和技术进行了广泛的回顾,并介绍了HDR图像感知背后的基本概念,也回顾了HDR成像技术的现状。它涵盖了与用相机捕捉HDR内容以及用计算机图形学方法生成内容相关的主题;HDR图像和视频的编码和压缩;用于在标准动态范围显示器上显示HDR内容的色调映射;反向色调映射,用于放大传统内容,以便在HDR显示器上显示;提供HDR范围的显示技术;最后是适合HDR内容的图像和视频质量指标。
图左:透明实体代表人眼可见的整个色域。在较低的亮度水*下,随着颜色感知的降低,固体逐渐向底部倾斜。为了便于比较,内部的红色固体代表标准sRGB(Rec. 709)色域,由高质量显示器产生。图右:与CRT和LDR监视器上显示的亮度范围相比的真实亮度值。大多数数字内容的存储格式最多能保留典型显示器的动态范围。
从应用角度来看,HDR图像的质量往往要高于LDR,下图是HDR和LDR视觉内容之间的潜在差异,而下表给出的数字只是一个例子,并不意味着是一个精确的参考。
使用标准的高位深度编解码器(如JPEG2000、JPEG XR或选定的H.264配置文件)对HDR图像或视频内容进行编码。HDR像素需要编码到一个亮度通道和两个色度通道中,以确保颜色通道的良好去相关性和编码值的感知一致性。标准压缩可以选择性地扩展,以便为鲜明对比的边缘提供更好的编码。

下图是向后兼容HDR压缩的典型编码方案,深棕色框表示视频编解码器的标准(通常为8位)图像,如H.264或JPEG。
基于仅向前的视觉模型的色调映射的典型处理管线如下图。原始图像使用视觉模型转换为抽象表示,然后直接发送到显示器。

基于正向和逆向视觉模型的色调映射的典型处理管线见下图。使用正向视觉模型将原始图像转换为抽象表示,可以选择编辑,然后通过反向显示模型转换回物理图像域。
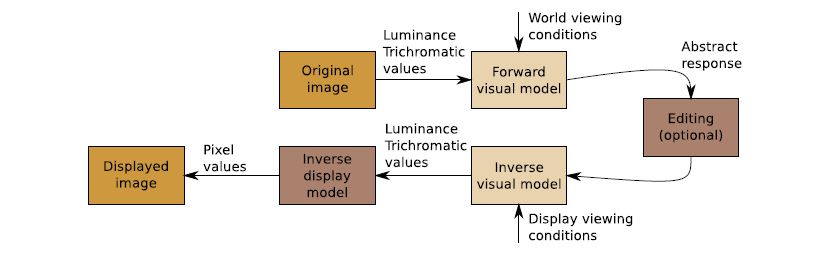
色调映射的典型处理管线解决了一个约束映射问题,使用默认参数对图像进行色调映射,然后使用视觉度量将显示的图像与原始HDR图像进行比较。然后,在迭代优化循环中使用度量中的标量误差值,以找到最佳色调映射参数。请注意,在实践中,解决方案往往被简化,并制定为二次规划,甚至有一个封闭形式的解决方案。
驱动HDR显示器中的低分辨率背光调制器和高分辨率前LCD面板所需的图像处理流程:
HDR-VDP-2度量的处理阶段,测试图像和参考图像经过相似的视觉建模阶段,然后在单个空间和方向选择带(BT和BR)水*上进行比较。该差异用于预测可见度(检测概率)或质量(感知的失真程度)。
为色调映射的图片(底部)预测动态范围无关度量(顶部),绿色表示可见对比度的损失,蓝色表示不可见对比度的放大,红色表示对比度反转。

14.5.4.4 Texture Streaming
Efficient Texture Streaming in 'Titanfall 2'分享了Titanfall 2的高效纹理流技术。纹理流动态加载以提高图像质量,概念上是一种压缩形式,常见方法有手动分割、边界几何测试、GPU反馈。工作流程要求尽量减少设计和艺术方面的手工工作,艺术家可以自由映射纹理(无固定密度),可以在不损害其它纹理的情况下添加MIPs,预处理应该是稳定的,一些好的手动暗示,与“资产面包房”合作,包括热插拔。
算法概述:任何低于64k的MIP都是永久性的,可以逐个添加/删除MIP,使用预先计算的信息建立重要/不重要内容的列表,每一帧都对着这个列表工作。
什么是“直方图”?想要根据mip在屏幕上覆盖的像素数(覆盖率)来区分mip的优先级,而不仅仅是“是/否”,‘“直方图”是每种材质每个MIP的覆盖率,16个标量“箱”(通常为浮点数)——每个MIP一个。假设屏幕分辨率为256 x 256的4k x 4k纹理,变换和缩放分辨率和移动模型,使用低密度纹理贴图适当地加权小的、被遮挡的或背面的三角形。
算法-预计算:计算每种材质的直方图,对于静态物体,使用GPU渲染世界的每列,放入文件。对于动态物体,每个模型在加载时:计算每个三角形的纹理梯度,将三角形区域添加到MIP的直方图区域,计划从不同的角度进行项目,但不值得,手动调整比例因子以匹配静态数据。
每帧会发生什么?从磁盘播放播放器的“列”,添加模型覆盖率,将覆盖率除以纹素数量,得到一个“指标”,生成最重要和最不重要的MIP列表,更精细的MIPs级联(更粗糙的始终>=更精细)。加载最重要的MIP,删除最不重要的MIP,捕捉运行数量上限和每帧丢弃的字节数,除非你正在加载更重要的东西,否则不要丢掉东西!
如何选择探针?运行“rstream.exe
如何渲染探针?将静态几何信息上传到GPU一次,渲染N个探针的UAV:
float2 dx = ddx( interpolants.vTexCoord ) * STBSP_NOMINAL_TEX_RES; // STBSP_NOMINAL_TEX_RES is 4096.0
float2 dy = ddy( interpolants.vTexCoord ) * STBSP_NOMINAL_TEX_RES;
float d = max( dot( dx, dx ), dot( dy, dy ) );
// miplevel is log2 of sqrt of unclamped_d. (MATERIAL_HISTOGRAM_BIN_COUNT is 16.)
float mipLevel = floor( clamp( 0.5f * log2(d), 0.0f, (float)(MATERIAL_HISTOGRAM_BIN_COUNT - 1) ) );
InterlockedAdd( outHistogram[interpolants.vMaterialId * MATERIAL_HISTOGRAM_BIN_COUNT + (uint)mipLevel], 1 );
每个立方体面做一次(累积结果),不透明通过写入深度,透明仅测试,没有帧缓冲区!
编译探针数据:现在,有每种材质每个MIP在探针上的覆盖率,在每列内以max方式组合探针,记录材质ID、MIP数量、覆盖范围(4字节),每列存储512条最重要的记录,将4x4列分组为约32k的可流化页面,索引到稳定的全局材质ID和位置,每个关卡一个‘.stbsp’文件。
管理纹理资源:每个压缩(和旋转)纹理文件可能有一个“可流化”的片段,在为一个关卡构建快速加载的“rpak”文件时,会聚集到第二个“starpak”文件中。对于发布版本,在所有级别使用共享starpak,磁盘上仅复制了<64k的MIP,Starpak包含对齐的、准备加载的数据。
// Crediting World Textures
Compute column (x,y integer), Ensure active page is resident (cache 4 MRU), or request it.
totalBinBias = Log2(NOMINAL_SCREEN_RES * halfFovX / (NOMINAL_TEX_RES * viewWidthInPixels) )
For each material represented in column,
For each texture in that material
For each record (<material,bin,coverage>) in column (up to 16)
If texture->lastFrame != thisFrame,
texture->accum[0..15] = 0, and texture->lastFrame = thisFrame
mipForBinF = totalBinBias + record->bin + Log2(textureWidthInPixels)
mipForBint = floor( max( 0.0, mipForBucketF ) ), clamped to (16-1).
texture->accum[mipForBin] += record->coverage * renormFactorForStbspPage;
// Crediting Models
float distInUnits = sqrtf( Max( VectorDistSqr( pos, *pViewOrigin ), 1.0f ) );
if ( distInUnits >= CUTOFF ) continue;
float textureUnitsPerRepeat = STREAMINGTEXTUREMESHINFO_HISTOGRAM_BIN_0_CAP; // 0.5f
float unitsPerScreen = tanOfHalfFov * distInUnits;
float perspectiveScaleFactor = 1.0f / unitsPerScreen;
// This is the rate of pixels per texel that maps to the cap on bin 0 of the mesh info.
// ( Exponentiate by STREAMINGTEXTUREMESHINFO_HISTOGRAM_BIN_CAP_EXPBASE for other slots )
float pixelsPerTextureRepeatBin0 = viewWidthPixels * textureUnitsPerRepeat * perspectiveScaleFactor;
Float perspectiveScaleAreaFactor = perspectiveScaleFactor * perspectiveScaleFactor;
pixelsPerTextureRepeatBinTerm0 = (int32)floorf(-Log2( pixelsPerTextureRepeatBin0 ); // Mip level for bin 0 if texture were 1x1.
For each texture t:
if first use this frame, clear accum.
if high priority, t->accum[clampedMipLevel] += HIGH_PRIORITY_CONSTANT (100000000.0f)
For dim 0 and 1 (texture u,v):
const int mipLevelForBinBase = (i32)FloorLog2( (u32)textureAsset->textureSize[dim] ) + pixelsPerTextureRepeatBinTerm0 ;
For each bin
// Log2 decreases by one per bin due to divide by two. (Each slot we double pixelsPerTextureRepeatBin0, which is in the denominator.)
const int32 clampedMipLevel = clamp(mipLevelForBinBase - (i32)binIter, 0..15 )
t->accum[clampedMipLevel] += modelMeshHistogram[binIter][dim] * perspectiveScaleAreaFactor;
If accum exceeded a small ‘significance threshold’, update t’s last-used frame.
// Prioritization
For each texture mip,
metric = accumulator * 65536.0f / (texelCount >> (2 * mipIndex));
If used this frame:
non-resident mips are added to ‘add list’, with metric.
resident mips are added to ‘drop list’ with same metric.
If not used this frame:
all mips added to ‘drop list’ with metric of ( -metric + -frames_unused.)
(also, clamped to finer mips’ metric + 0.01f, so coarser is always better)
Then partial_sort the add and drop lists by metric to get best & worst 16.
// Add/Drop
shift s_usedMemory queue
for ( ; ( (shouldDropAllUnused && tDrop->metric < 0.0f) || s_usedMemory[0] > s_memoryTarget) && droppedSoFar <16MiB && tDrop != taskList.dropEnd; ++tDrop ) { drop tDrop, increase droppedSoFar; }
for ( TextureStreamMgr_Task_t* t = taskList.loadBegin; t != tLoadEnd; ++t ) { // t points into to add list
if ( we have 8 textures queued || t->metric <= bestMetricDropped ) break;
if ( s_usedMemory[STREAMING_TEXTURES_MEMORY_LATENCY_FRAME_COUNT - 1] + memoryNeeded <= s_memoryTarget ) {
for ( u32 memIter = 0; memIter != STREAMING_TEXTURES_MEMORY_LATENCY_FRAME_COUNT; ++memIter ) {
s_usedMemory[memIter] += memoryNeeded; }
if ( !begin loading t ) { s_usedMemory[0] -= memoryNeeded; } // failure eventually gets the memory back
} else for ( ;; ) { // Look for ‘drop items’ to get rid of until we'll have enough room.
if ( planToLoadLater + memoryNeeded + s_usedMemory[0] <= s_memoryTarget ) {
planToLoadLater += memoryNeeded; break; }
if ( droppedSoFar >= 16MiB || tDrop >= taskList.dropEnd || t->metric <= tDrop->metric ) { break; }
bestMetricDropped = Max( bestMetricDropped, tDrop->metric );
drop tDrop, increase droppedSoFar;
++tDrop; } }
如何调整纹理大小?在Windows/DirectX下,最初的CPU可写纹理、贴图、读取新MIPs,创建GPU纹理,GPU复制新的和旧的MIPs,现在只需加载到堆中并传递到CreateTexture。控制台下,直接读取新的MIP进来,放入排队3帧,以刷新管线。
异步I/O:异步线程,运行中的2个请求,多优先级队列,纹理优先级低,音频优先级很高,为了提高可中断性,读取以64kb的数据块进行。
14.5.4.5 Frame Graph
FrameGraph: Extensible Rendering Architecture in Frostbite阐述了2017年的Frostbite的演变历史,最终采用了帧图的方式。
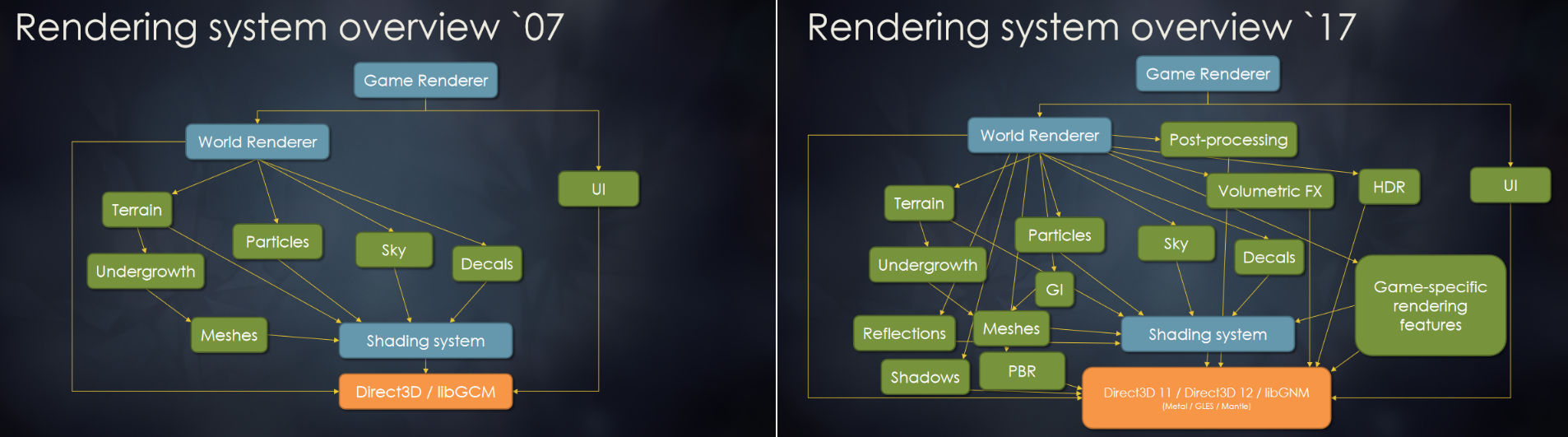
Frostbite引擎在07年(左)和17年(右)的渲染系统对比。
渲染体系的简化图如下:
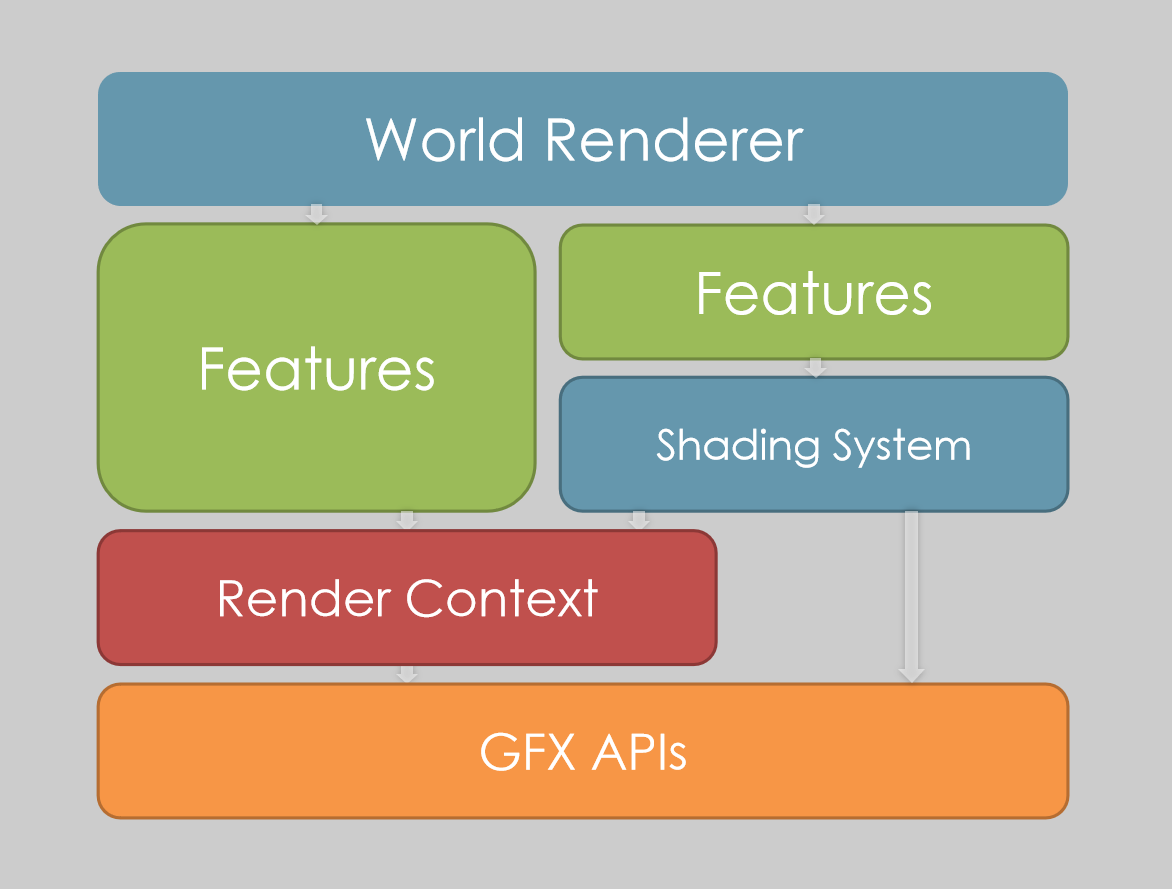
其中WorldRenderer协调所有渲染,采用代码驱动的架构,是主要的世界几何(通过着色系统),照明、后处理(通过渲染上下文),掌管所有视图和渲染通道,在系统之间管理设置和资源,分配资源(渲染目标、缓冲区)。
WorldRenderer面临诸多挑战,例如显式立即模式渲染,显性资源管理,定制、手工制作的ESRAM管理,不同游戏团队的多种实现,渲染系统之间的紧密耦合。有限的可扩展性,游戏团队必须fork / diverge才能定制,从4k增长到15k SLOC,具有超过2k SLOC的单个功能,维护、扩展和合并/集成成本高昂。
WorldRenderer模块化的目标是高层次知识框架,改进的可扩展性,解耦和可组合的代码模块,自动资源管理,更好的可视化和诊断。新的架构组件如下:
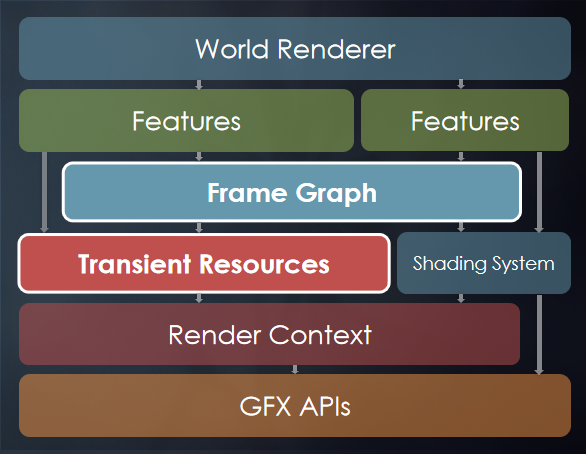 h3.png)
h3.png)
其中帧图(Frame Graph)是渲染通道和资源的高级表示,完全掌控整帧;临时资源系统(Transient Resource System)负责资源分配、内存重叠。它的目标是建立整帧的高层次信息,简化资源管理,简化渲染管线配置,简化异步计算和资源屏障,允许独立且高效的渲染模块,可视化和调试复杂的渲染管线。

引擎资源的生命周期视图,引用十分复杂。
帧图的设计是远离立即模式渲染,将代码拆分为通道的渲染,多阶段保留模式渲染API:设置阶段、编译阶段、执行阶段,每一帧都是从零开始建造的,代码驱动的架构。
设置阶段定义渲染/计算通道,定义每个通道的输入和输出资源,代码流类似于立即模式渲染。
// 资源示例
RenderPass::RenderPass(FrameGraphBuilder& builder)
{
// Declare new transient resource
FrameGraphTextureDesc desc;
desc.width = 1280;
desc.height = 720;
desc.format = RenderFormat_D32_FLOAT;
desc.initialSate = FrameGraphTextureDesc::Clear;
m_renderTarget = builder.createTexture(desc);
}
// 设置示例
RenderPass::RenderPass(FrameGraphBuilder& builder, FrameGraphResource input, FrameGraphMutableResource renderTarget)
{
// Declare resource dependencies
m_input = builder.read(input, readFlags);
m_renderTarget = builder.write(renderTarget, writeFlags);
}
高级的帧图操作:延迟创建资源,尽早声明资源,在第一次实际使用时分配,基于使用情况的自动资源绑定标志。派生资源参数,根据输入大小/格式创建渲染通道输出,根据使用情况派生绑定标志。移动子资源,将一种资源转发给另一种资源,自动创建子资源视图/重叠,允许“时间旅行”。

移动子资源示例。
编译阶段剔除未引用的资源和通道,在声明阶段可能会有点粗糙,旨在降低配置的复杂性,简化条件传递、调试渲染等。计算资源生命周期。根据使用情况分配具体的GPU资源,简单贪婪分配算法,首次使用前获得,最后一次使用后释放,延长异步计算的生命周期,根据使用情况派生资源绑定标志。
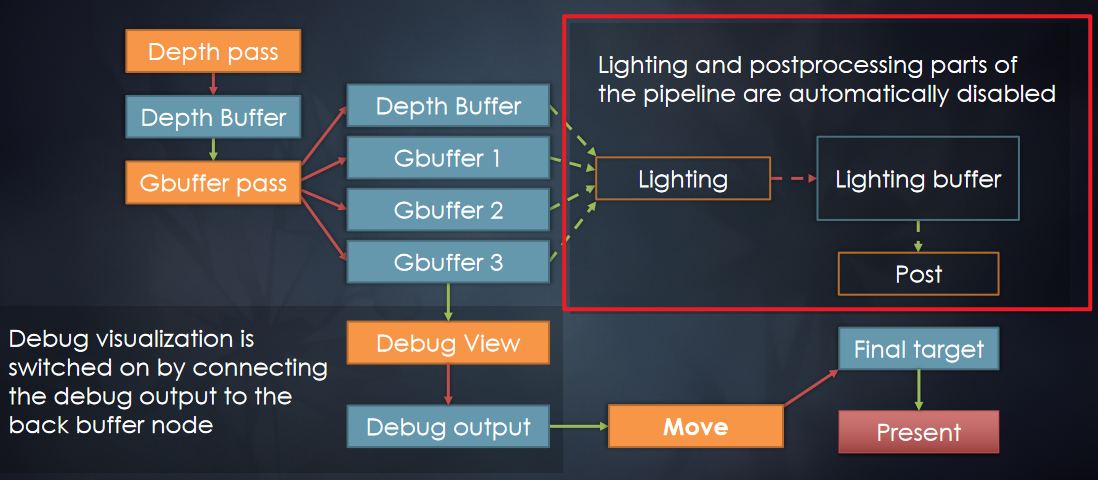
上图处于调试的特殊渲染模式,因此会剔除掉红框内的通道和资源。
执行阶段为每个渲染通道执行回调函数,立即模式的渲染代码,使用熟悉的RenderContext API,设置状态、资源、着色器、绘制调用、派发,从设置阶段生成的句柄中获取真正的GPU资源。
异步计算:可以自动从依赖关系图派生,需要手动控制,节省性能的潜力很大,但是内存增加,如果使用不当,可能会影响性能。每次渲染通道选择性加入,在主时间线上开始,第一次使用另一个队列上的输出资源时的同步点,资源生命周期自动延长到同步点。
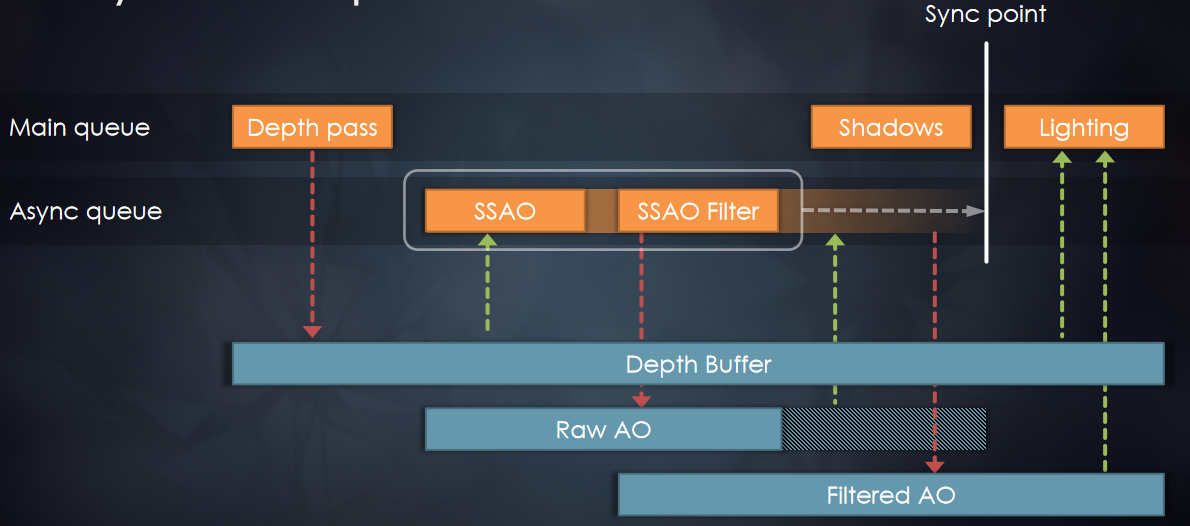
Async compute的同步点示意图。
// 异步设置示例
AmbientOcclusionPass::AmbientOcclusionPass(FrameGraphBuilder& builder)
{
// The only change required to make this pass
// and all its child passes run on async queue
builder.asyncComputeEnable(true);
// Rest of the setup code is unaffected
// …
}
渲染模块:
-
有两种类型的渲染模块:
-
独立无状态函数。输入和输出是帧图资源句柄,可以创建嵌套的渲染通道,Frostbite中最常见的模块类型。
-
持久化渲染模块。可能有一些持久性资源(LUT、历史缓冲区等)。
-
-
WorldRenderer仍在协调高级渲染。不分配任何GPU资源,只需在高级启动渲染模块,更容易扩展,代码大小从15K减少到5K SLOC。
模块之间的通讯:模块可以通过黑板进行通信,组件哈希表,通过组件类型ID访问,允许受控耦合。
void BlurModule::renderBlurPyramid(FrameGraph& frameGraph, FrameGraphBlackboard& blackboard)
{
// Produce blur pyramid in the blur module
auto& blurData = blackboard.add<BlurPyramidData>();
addBlurPyramidPass(frameGraph, blurData);
}
#include ”BlurModule.h”
void TonemapModule::createBlurPyramid(FrameGraph& frameGraph, const FrameGraphBlackboard& blackboard)
{
// Consume blur pyramid in a different module
const auto& blurData = blackboard.get<BlurPyramidData>();
addTonemapPass(frameGraph, blurData);
}
UE的RDG没有blackboard的概念,所有信息都放到FRDGBuilder(类似于FrameGraph)中。
临时资源系统(Transient resource system):Transient是活动时间不超过一帧的资源,如缓冲区、深度和颜色目标、UAV等。在1帧内尽量减少资源使用时间,在使用资源的地方分配资源,直接在叶子节点渲染系统中,尽快释放分配,使编写独立功能变得更容易。是帧图的关键组件。
临时资源系统的实现取决于*台功能,物理内存中的重叠(XB1)、虚拟内存中的重叠(DX12、PS4)、对象池(DX11)。用于缓冲区的原子线性分配器没有重叠,只用于快速传输内存,主要用于向GPU发送数据。纹理的内存池。

以下是不同*台的临时资源分配机制图:



内存重叠注意事项:一定要非常小心,确保有效的资源元数据状态(FMASK、CMASK、DCC等),执行快速清除或放弃/重写资源或禁用元数据,确保资源生命周期是正确的,比听起来更难,考虑计算和图形流水线,考虑异步计算,确保在重新使用之前将物理页写入内存。
资源的丢弃和清除:必须是新分配资源上的第一个操作,要求资源处于渲染目标或深度写入状态,初始化资源元数据(HTILE、CMASK、FMASK、DCC等),类似于执行快速清除,资源内容未定义(未实际清除),如果可能的话,宁愿放弃资源也不要清除。
重叠屏障(Aliasing barriers):在GPU上的工作之间添加同步,添加必要的缓存刷新,使用精确的屏障将性能成本降至最低,可以在困难的情况下使用通配符屏障(但预期IHV分裂),在DirectX 12中批量处理所有其它资源屏障!
重叠屏障示例。上:管线化CS和PS工作导致的潜在重叠危险,CS和PS使用不同的D3D资源,所以过渡屏障是不够的,必须在PS之前刷新CS或延长CS资源生命周期。下:串行计算工作确保了内存重叠时的正确性,在某些情况下可能会影响性能,当重叠对性能至关重要时,使用显式异步计算。
720p下使用重叠内存前(上)后(下)的对比。其中下图是DX12的内存重叠布局,可以节省*50%的内存占用,4k分辨率下可以节省超过50%。
总之,整帧的信息有很多好处,通过资源重叠节省大量内存,半自动异步计算,简化渲染管线配置,很好的可视化和诊断工具,图形是渲染管线的一种有吸引力的表示形式,直观而熟悉的概念,类似于CPU作业图或着色器图,现代C++功能减轻了保留模式API的痛苦。更多可参阅:
14.5.4.6 Display Latency
Controller to Display Latency in 'Call of Duty'详细且深入地讨论了控制器的显示延迟:玩家按下按钮和在屏幕上看到按下结果之间的最短持续时间,还介绍Call of Duty游戏中添加的动态调节功能,以控制影响输入延迟的权衡,最终目标是减少控制器到显示器的延迟。最先讨论如何测量延迟,然后将深入研究引擎的特定方面,这些方面必须考虑到节流阀(throttle)。玩家按下控制键按钮到看到画面的流程实际上包含了以下方面的步骤或阶段:
上面的Controller/OS sample、Game engine query、Game logic and rendering、Video scan-out是在游戏引擎涉及的阶段。
首先要明白,延迟不等于性能,延迟只是对性能变化的适应性,延迟在整个渲染管线中的流向图和简化图如下:
COD将采用的减少延迟的策略是在输入样本之前引入一个节流阀(throttle)。通过在此处添加延迟,输入样本将被压缩到更接*帧末尾的位置。
为了更容易地考虑这个限制,可以将延迟持续时间分为两类。首先是工作,工作是为这个特定的帧积极处理某些东西所花费的时间:例如游戏逻辑或渲染,就是下图的彩色框中表示的时间。
除了工作的其它一切,可称之为“slop”:
Slop不一定是空闲时间:它通常是一条时间线在前一帧上工作的片段,或者一条时间线在等待另一条时间线释放共享资源的片段。如果你看一个通用的生产者-消费者系统,生产者执行一个工作单元,将结果传递给消费者,然后开始生产下一个工作单元。如果消费者始终比生产者慢,系统将变为“消费者受限”。消费者的时间线保持完整,试图跟上生产者,但生产者可以尽可能领先。这就是slop存在的原因:生产者领先于消费者,所以生产者何时完成与消费者何时开始之间存在差距。生产者的领先程度取决于生产者和消费者之间允许的缓冲量,以及它们获取和释放对缓冲数据的访问的确切时间。
另一方面,当我们被生产者限制时,slop通常会消失。消费者的时间线被释放了,所以一旦生产者完成了一个画面,消费者就可以立即开始,我们不会得到一个空隙。
延迟输入采样时,slop会从第一段开始挤出,直到消失,然后移动到第二段,依此类推。另一方面,工作会在时间上向前移动,而整个帧的总工作持续时间理想情况下保持不变。
延迟 = 工作+Slop,更高的slop ⟷ 更高的延迟,更低的slop ⟷ 更低的延迟。
让我们先看看延迟持续时间结束时会发生什么。游戏将最终的图像渲染到一个名为帧缓冲区的内存中。然后,视频扫描硬件从上到下逐行读取帧缓冲区,并通过电缆将像素数据传输到显示器。扫描输出以与显示器刷新率相匹配的速率连续传输。如今,传统显示器的刷新率为60Hz,因此帧缓冲区通常也会以60Hz的频率扫描,或者每16.6ms扫描一次。16.6ms的大部分时间用于主动传输可见像素数据,但在传输的数据与可见像素不对应的情况下,会有短暂的暂停。首先,在每一行的末尾有一个暂停,称为水*空白(HBLANK),在最后一行之后有一个暂停,称为垂直空白(VBLANK)。这些暂停在旧的CRT监视器上是物理上必要的,但由于遗留原因和传输元数据,它们今天仍然存在。
如果我们把它放在一个时间轴上,我们得到扫描接着是vblank,扫描接着是vblank等等,所有这些都以固定的60Hz频率发生。
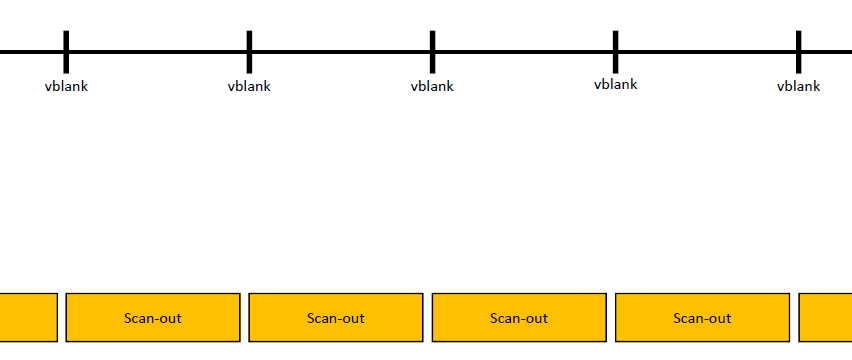
现在我们知道延迟时间的结束是固定的:每16.6毫秒发生一次,意味着我们可以提前准确地预测这一帧的扫描何时开始。我们现在的目标是找出与固定扫描相关的其它时间线的位置。向上移动,GPU将图像渲染到帧缓冲区。
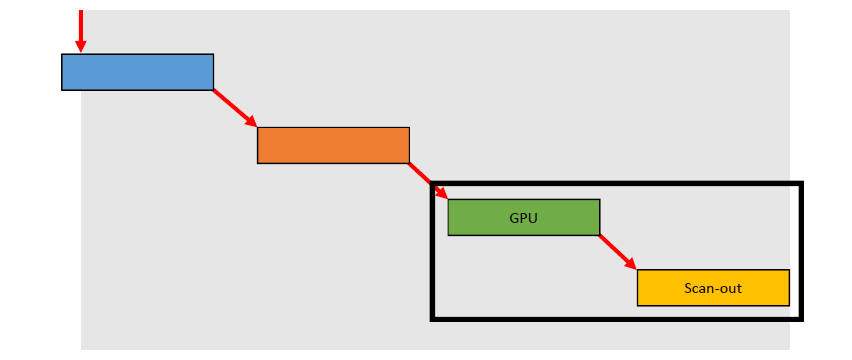
扫描输出是不断从帧缓冲区读取数据并将数据发送到显示器,意味着我们同时在同一个内存中读写:一种竞争条件。传统的解决方案是双缓冲:分配两个帧缓冲区,并在每一帧渲染到备用缓冲区,在渲染到帧缓冲区A时,帧缓冲区B会被扫描出来,然后我们渲染到帧缓冲区B,然后从帧缓冲区A扫描出来。
在GPU使用帧后立即翻转是不够的,比方说渲染完成,接着立即翻转,A开始向外扫描,而B开始渲染。B在A的扫描结束之前完成渲染。如果翻转现在发生,B完成渲染之后会发生什么?然后,扫描输出将在从A读取到从B读取的中间切换,而无需重置扫描线位置。屏幕上生成的图像将从缓冲区A扫描上半部分,而屏幕的下半部分将从缓冲区B扫描。这种伪影被称为撕裂,当A和B之间有较大的水*移动时,最为明显,比如游戏相机在旋转。解决这个问题需要另一条规则:只在扫描完成后翻转,换言之,仅在VBLANK期间翻转,此规则称为垂直空白同步(VSyync)。
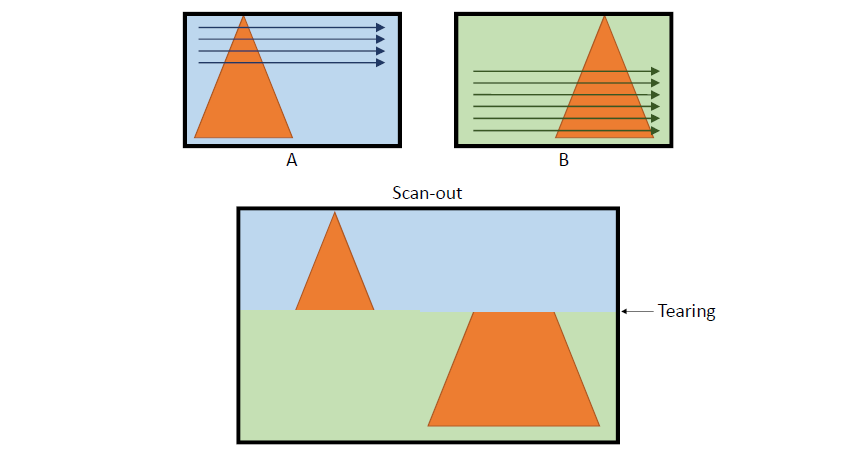
简而言之,中扫描渲(Mid-scan)染用双缓冲修正,撕裂用等待vblank翻转修正。使用60Hz和vsync的双缓冲,在vblank期间每次扫描出后,帧缓冲区A和B之间会发生翻转。
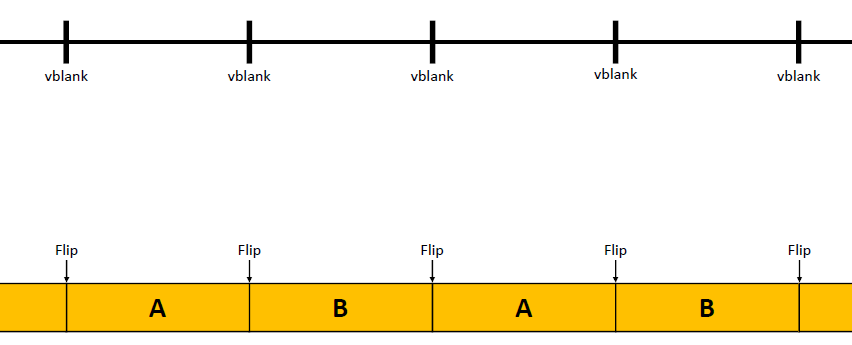
结合下图,假设GPU正在渲染到帧缓冲区A中,GPU不允许触摸A的时间段是蓝色大矩形中的区域。在第一个阶段,GPU必须空闲等待帧缓冲区A可用,对A的扫描完成后,可以开始渲染到A。一旦GPU完成渲染,不能立即翻转,因为会导致撕裂。相反,GPU“将翻转排队”:它表示A已准备好在下一次vblank中翻转。这是slop(斜坡)的第一个来源:介于翻转队列和实际翻转之间。
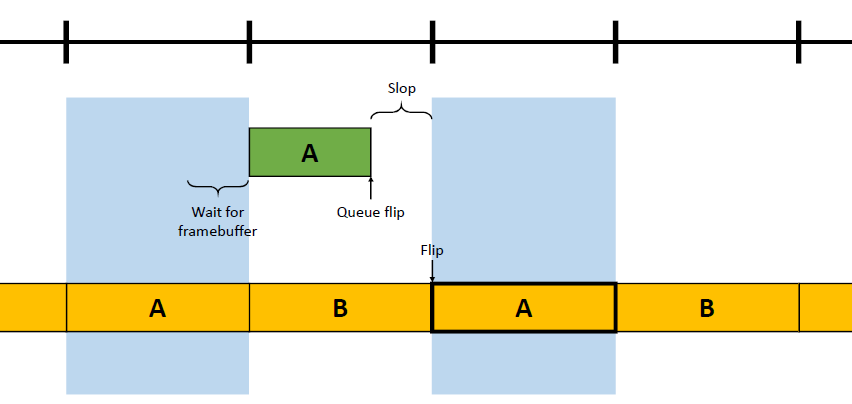
如果计算slop持续时间,它是约16.6ms减去GPU的总工作时间。但请记住,我们希望尽可能多地使用可用硬件,GPU周期是一种特别有价值的资源,如果GPU的工作负载一直很低,就相当于浪费。如果我们工作做得好,可以以更高的分辨率绘制更多的图形。如果在更重的GPU负载下,slop会发生什么?
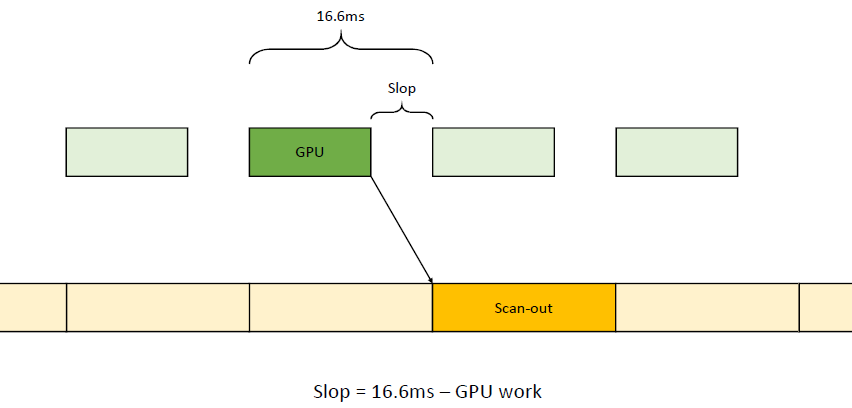
当GPU工作负载满时,接*16.6ms,slop消失。但请记住,节流阀应该将slop挤出延迟持续时间。如果这里没有斜坡,那么首先查看GPU进行扫描有什么意义?
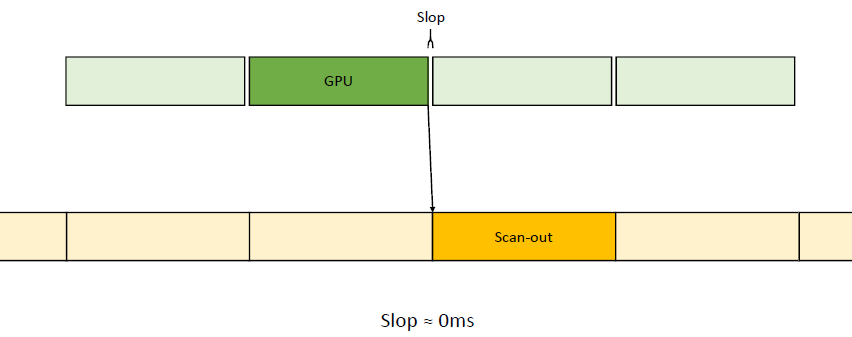
事实上,事情要复杂一点,实际上有一个巨大的slop源,即使GPU负载很重。原因是,帧的大多数绘制都是在其它地方渲染的,而不是在帧缓冲区中。几乎所有的GPU时间都花在了渲染屏幕外缓冲区上,大部分3D绘图都渲染到了第三个屏幕外缓冲区,称为“场景缓冲区”。场景缓冲区的分辨率可以低于最终显示分辨率,并且可以使用不同的颜色编码。场景渲染完成后,场景缓冲区将上采样到帧缓冲区中,通常在上采样期间应用时间抗锯齿。在上采样之后,UI元素以显示分辨率呈现到帧缓冲区中,然后是排队等待翻转的帧缓冲区。这里最重要的一点是,大部分GPU帧时间都花在渲染3D场景上,帧缓冲区直到帧后期的上采样才被触及。这并不完全是三重缓冲,因为场景缓冲永远不会扫描到显示器上。但是计时的结果类似于三重缓冲,所以我们称之为“伪三重缓冲”。

在最初的双缓冲设置中,GPU需要在帧的最开始处等待帧缓冲,将GPU时间线与扫描输出时间线同步。现在有了伪三重缓冲,GPU只需要在帧的后期,即上采样之前等待帧缓冲。
对于严格的双缓冲,只允许在蓝色矩形之间的时间段内渲染帧缓冲区A。
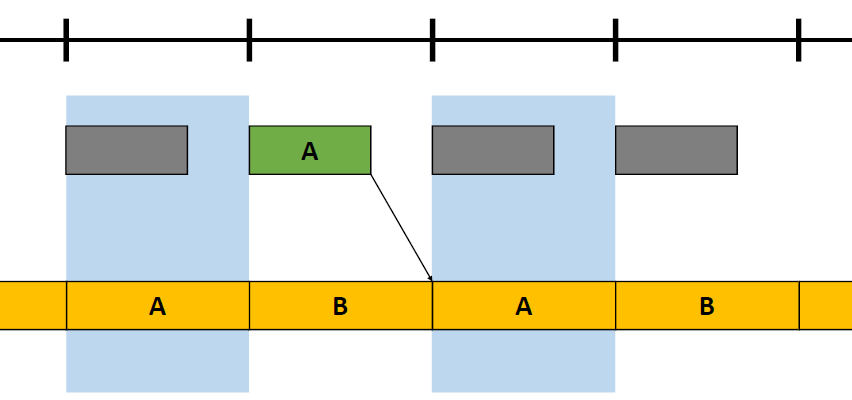
现在,GPU工作负载分为两部分:场景渲染(不使用帧缓冲区)和帧缓冲区渲染(使用帧缓冲区)。帧缓冲区渲染部分仍然必须位于两个蓝色矩形之间,以避免中间扫描渲染,但场景渲染部分可以随时启动。
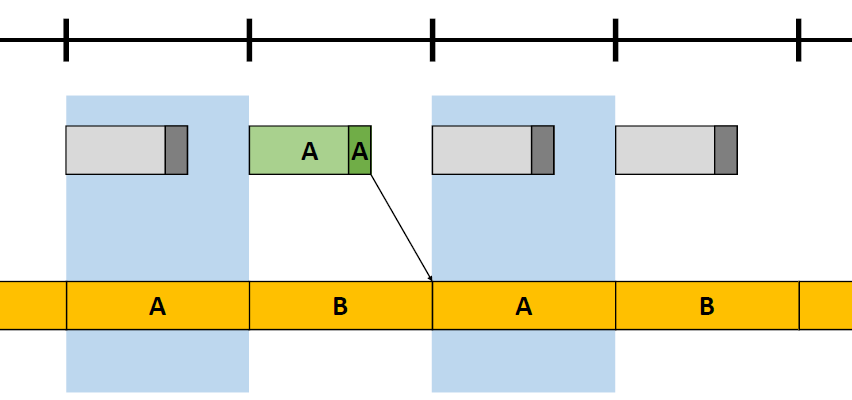
一切都被允许在时间上向后移动,GPU在完成最后一帧后立即开始场景渲染,帧缓冲区渲染仍然必须与扫描输出同步,但它会被移回场景渲染留下的空间。
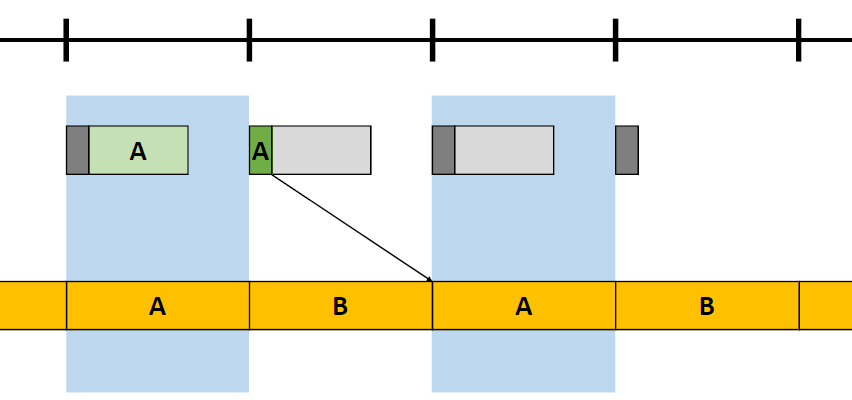
在严格的双缓冲中,slop仅为~16.6ms减去GPU的总工作时间,随着GPU工作负载的增加,slop消失了。
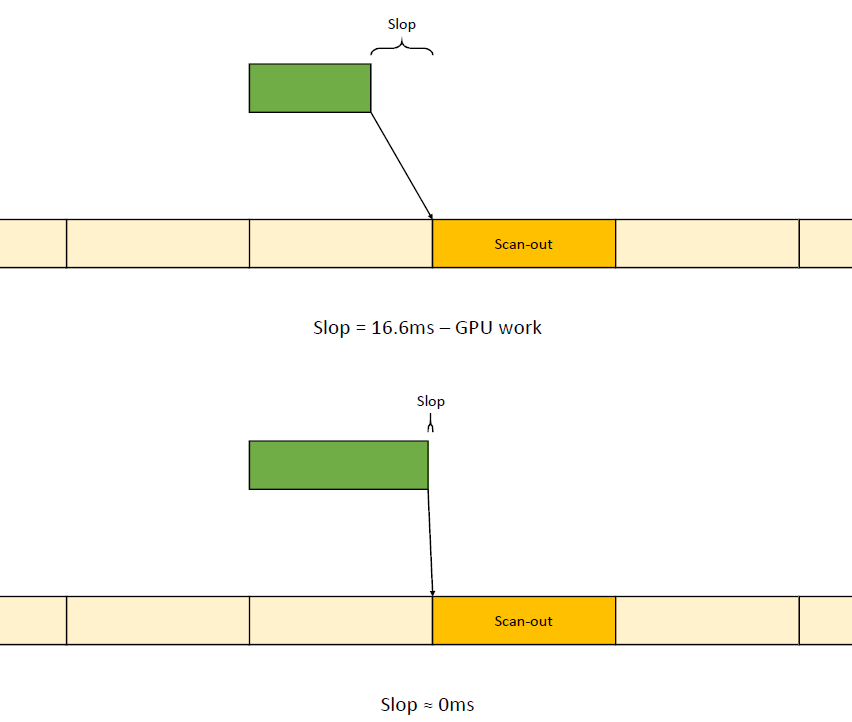
现在使用伪三重缓冲,slop被分成两部分。第一个slop持续时间是帧缓冲区等待:介于场景渲染结束和帧缓冲区渲染开始之间,等于16.6ms减去GPU的总工作量,第二个slop持续时间介于翻转队列和实际翻转之间,大约16.6ms减去帧缓冲区渲染工作负载。
一个完整的GPU工作负载通常意味着更多的场景渲染:更多的3D对象和更高的场景分辨率,帧缓冲区渲染通常很短。因此,当GPU工作负载满时,第一个slop仍然会消失,而第二个slop可以保持很长时间。
即使充分利用,也可能有很多slop。
但伪三重缓冲还有另一个后果。到目前为止,我们一直假设GPU的工作负载总是快于16.6ms。但是,如果你想让GPU尽可能地忙碌,很容易不小心会有一点过度,使得帧变慢。假设在严格的双缓冲情况下,帧B的渲染速度低于16.6ms。在即将到来的vblank间隔之前,帧尚未准备好扫描,因此它“错过了vblank”。没有帧缓冲区排队等待翻转,因此在下一次vblank期间不会发生翻转。取而代之的是,scan out保持指向帧缓冲区A,A再次被扫描出来,B的扫描必须等到下一个vblank开始。现在,由于A正在被第二次扫描,GPU必须一直等到下一次翻转开始渲染A。如果渲染帧A也很慢,它会错过另一个vblank,以此类推。
如果GPU渲染时间始终低于刷新速度,即使是微秒,也会错过每一个vblank,帧速率将固定在30Hz而不是60Hz。这是一个非常灾难性的后果,尤其是如果我们试图让GPU的工作负载尽可能满。
现在在伪三重缓冲的情况下,假设第一个vblank仍然丢失:帧缓冲区A仍然需要扫描两次。但现在允许立即开始A的场景渲染,即使A仍在被扫描,因为GPU可以渲染到屏幕外缓冲区的时间没有限制。这与双缓冲区的情况有很大不同,在双缓冲区的情况下,GPU必须一直闲置到下一个vblank。即使GPU的工作负载仍然大于16.6ms,A也不会错过下一个vblank。
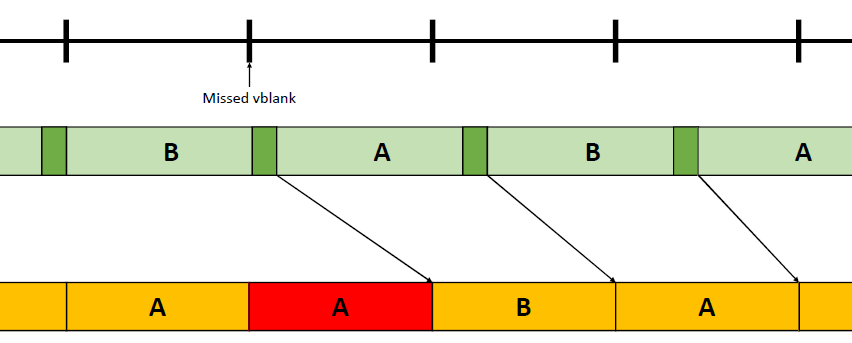
缩小并查看多个帧上的行为(假设固定的、低于16.6ms的GPU工作负载)。第一帧未命中vblank,A被扫描两次,但是下一帧,下一帧,下一帧都会生成它们的Vblank。最终,一个vblank确实会再次被忽略,但在六个缓慢的帧通过之前,不会错过它们的vblank。
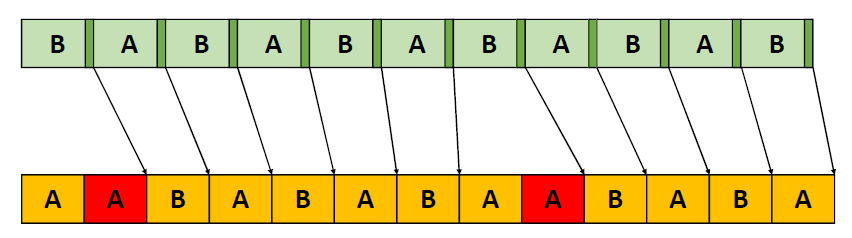
使用伪三重缓冲时,*均帧率不会达到30Hz。取而代之的是,*均帧速率从60Hz慢慢下降到50Hz。
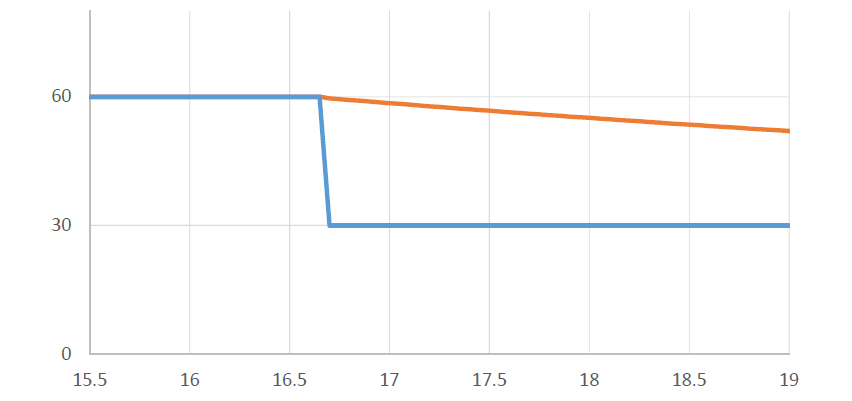
看看底部的大括号:这些是测量翻转队列和每个帧的实际翻转之间的slop。请注意,在第一次错过vblank之后,slop是高的。当慢速帧通过时,斜率逐渐减小。每一个慢帧都会消耗可用的slop,直到slop最终降到零以下,vblank就会丢失。这说明了slop的一个重要方面:slop充当缓冲空间,让慢速帧在不丢失vblank的情况下通过。
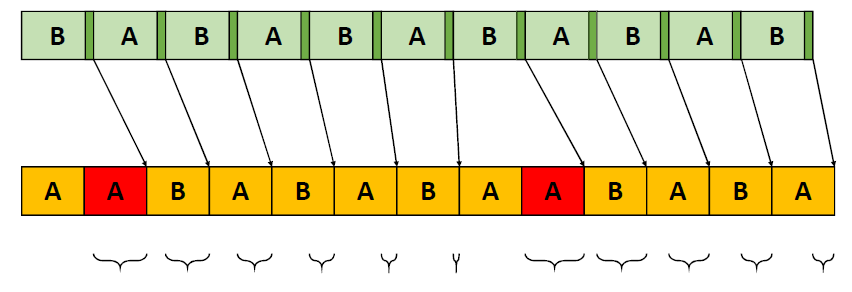
能够保持在50Hz比降到30Hz要好,但它仍然会产生一种令人不快的效果,即每隔几帧就会错过一帧。我们更愿意保持在一个稳定的60,这就是动态分辨率的来源——当游戏注意到GPU时间低于阈值时,引擎就会启动。
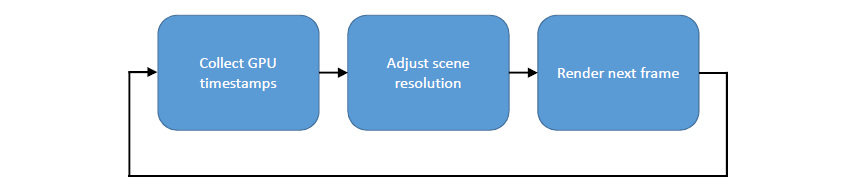
但现在有了动态分辨率,让我们再次看看伪三重缓冲的时间线。几帧缓慢的画面经过,一帧也没有漏掉。Slop变得非常低,但最终分辨率下降。现在,GPU的帧时间快于16.6ms。请注意,随着快速帧的流逝,slop会累积回安全水*。其想法是,慢帧会吞食slop,而快帧会将其重建。使用伪三重缓冲带来的额外slop,慢帧阈值可以提高到接*16.6ms,并且有可能在该阈值以上的峰值中存活。这种特性对于动态分辨率成为一种可行的技术至关重要。
低slop意味着低延迟,但在慢帧上更容易错过Vblank。高slop意味着更高的延迟,有缓冲空间,以容忍几个慢帧。
1、在一般情况下要最大化slop。在缓冲方面权衡额外的内存,给定缓冲范围,考虑最大化slop。
下面是一个非常简单的例子,从最*的一个任务召唤游戏中,可以在实践中最大化slop。添加HDR支持后,场景缓冲区-帧缓冲区分割发生了变化。第一个场景渲染通常对场景缓冲区执行,场景缓冲区被上采样到显示分辨率,但这次以显示分辨率进入另一个屏幕外缓冲区,UI以屏幕外缓冲区的显示分辨率呈现,最后,在帧的最后,该缓冲区被转码到其最终颜色空间中的实际帧缓冲区。请注意,第一次接触真正的帧缓冲区是在转码之前。帧缓冲区仅用于帧时间的一小部分,即1080p时约170微秒。
在一个*台上,帧缓冲区最初是在帧的最开始处获取的,完全抵消了伪三重缓冲的好处,使其行为与严格的双缓冲相同。任何慢帧都会导致vblank丢失,从而降低动态分辨率的效率。
在另一个*台上情况有所好转:等待帧缓冲区是在场景渲染后插入的,但当添加HDR支持时,此等待未被移动。此设置的性能优于前一种情况,但仍会导致帧缓冲区部分的长度超出必要的长度。即使允许帧比严格的双缓冲更早开始,slop也没有最大化,导致丢失Vblank的几率高于最佳值。
获取帧缓冲区的正确位置就在转码之前,这将最大限度地提高slop,并最小化丢掉VBlank的机会。
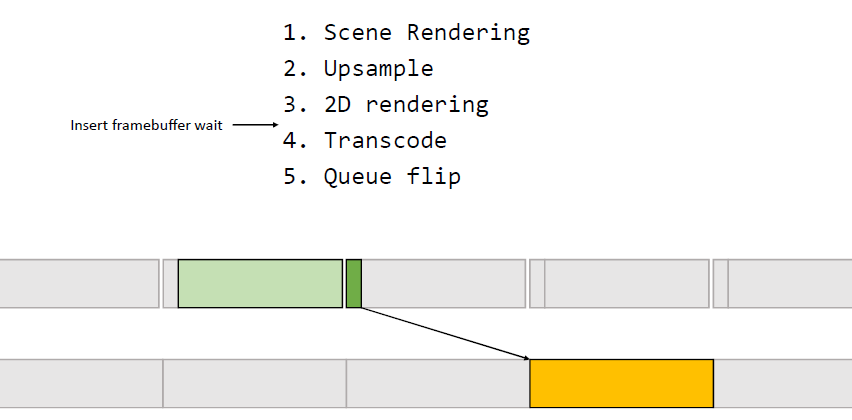
建议检查代码,确保等待帧缓冲区的时间尽可能晚。它通常是一个单一的函数,但当帧的结构发生变化时,很容易忘记移动它,因为当vsync关闭时,它对性能或计时没有影响。对于DX12,在帧缓冲区资源上执行从当前状态到渲染目标(或其它写入)状态的转换屏障时,会发生等待。
D3D12_RESOURCE_STATE_PRESENT → D3D12_RESOURCE_STATE_RENDER_TARGET
其它*台上也有类似的功能。还建议对这些等待进行计时,可以在这些调用周围卡住GPU时间戳,并将测量结果纳入GPU计时系统。启用vsync时,必须从GPU总时间中减去这些值,才能获得动态分辨率的精确帧定时。
CPU的很大一部分工作负载被用来告诉GPU该做什么,意味着记录状态更改、绘制和分派到命令缓冲区中供GPU使用,以及生成相关的渲染数据,如动态顶点和索引缓冲区。CPU写入的缓冲区和GPU读取的缓冲区通常是双缓冲区或从环中分配的,在CPU建立了命令缓冲区之后,它会告诉GPU通过“kick”开始处理它:这个kick事件类似于GPU和扫描输出之间的帧缓冲区翻转。就像GPU进行扫描一样,slop可以在CPU的启动和GPU实际启动这一帧之间累积。
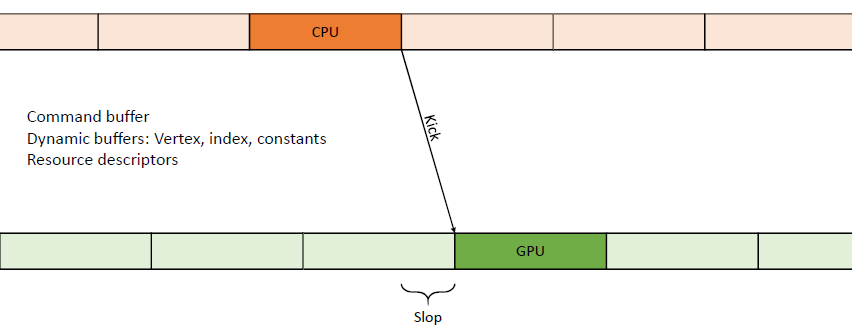
不过,与GPU扫描系统不同的是,CPU记录命令的顺序与GPU使用命令的顺序大致相同。例如,CPU上的一个帧可能由录制prepass命令、阴影命令、不透明命令等组成。在kick之后,GPU也会按这个顺序绘制。
我们利用这个事实在CPU和GPU之间以比一帧更细的粒度分割缓冲区。CPU不需要预先生成整个帧的所有数据,并一次性启动整个帧,而是可以在每个帧上进行多个较小的启动。例如,CPU可以在记录prepass前半部分的数据后立即启动。GPU开始处理prepass,而CPU同时记录prepass后半部分的数据,依此类推。这允许CPU和GPU帧之间有明显的重叠。为了正确解释这种重叠情况下延迟的工作方式,需要修改slop和work的定义。
在不重叠的情况下,slop是从CPU帧的末尾到GPU帧的开头的段。回顾slop和work的定义:当节流阀时,工作是延迟持续时间的一部分,它会随着时间向前移动,但不会收缩;Slop是延迟持续时间缩短的部分。
现在有了重叠的情况,GPU可以在CPU第一次启动后立即开始工作,Slop需要定义为CPU的第一次启动和GPU启动帧之间的范围。工作就是其它一切:CPU帧开始到第一次启动之间的持续时间,加上整个GPU帧时间。请注意,仅通过允许重叠,测量的工作就显著减少了。
这并不是说CPU和GPU被迫重叠。CPU帧的结束和GPU帧的开始之间可能仍有延迟。因为GPU可以更早地启动,所以slop的测量值会高得多。通过允许重叠,所做的就是允许throttle比在非重叠情况下挤压得更远。
让我们来谈谈性能。GPU周期通常是最宝贵的硬件资源:在《使命召唤》中,更有可能在GPU上工作繁重,而不是CPU上。在理想情况下,CPU记录命令的速度始终比GPU消耗命令的速度快,这样GPU就永远不会空闲和闲置。
但如果其中一个CPU段被kick得太晚,GPU可能会闲置:这被称为GPU气泡。当GPU和CPU明显重叠,并且GPU只稍微落后于CPU时,气泡的风险会更高,尤其是在帧的早期。气泡是低效的,意味着空闲的GPU周期,但它也会使用于动态分辨率的GPU帧时间测量发生偏差,导致不必要的分辨率下降。
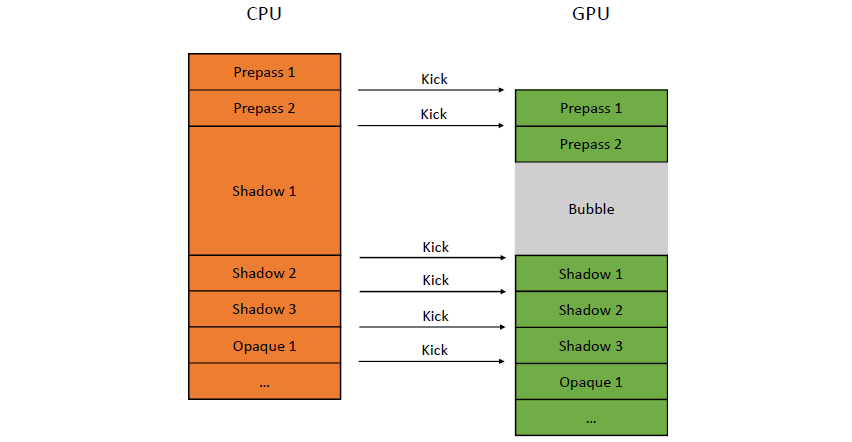
但是,如果GPU和CPU之间有一些slop,那么这个slop可以作为缓冲空间,以最小化CPU峰值,产生一个较小的气泡或一起避免气泡。
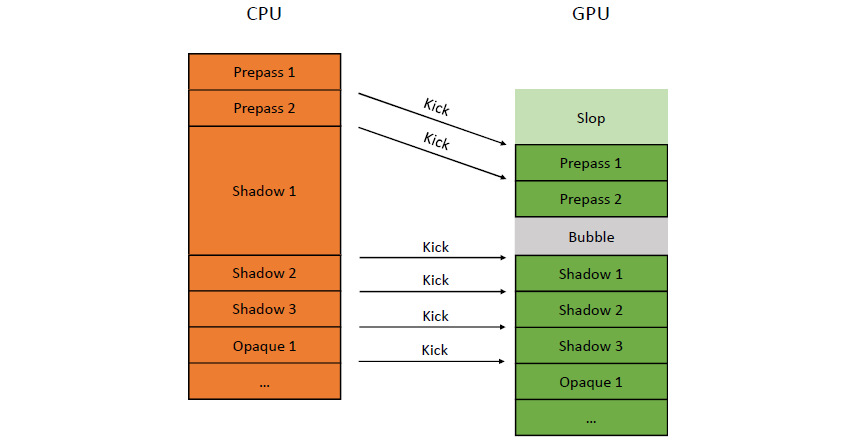
低slop——重叠越多,延迟越低,易受泡沫影响。高slop——重叠越少,延迟越高,有足够的空间吸收尖峰,避免起泡。避免气泡:并行命令缓冲区生成,调整绘制列表拆分,仔细安排工作,避免争用。减少绘制调用次数,启用CPU剔除、实例化、多重绘制。减少绘制调用开销,如材质排序、bindless。
现在我们有了超快速的命令缓冲区生成,它可以在多个内核上广泛运行。一个线程提取完成的命令缓冲区,然后将它们kick到GPU,在理想情况下,GPU的运行速度比CPU慢,因此它保持稳定,并为整个帧提供数据。
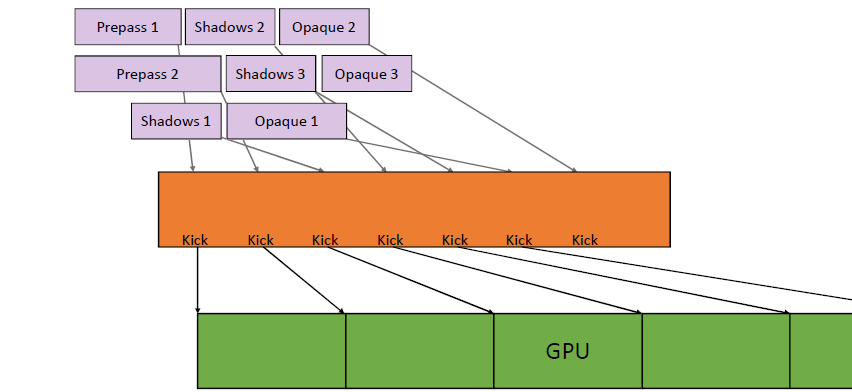
不幸的是,理想的情况并不总是发生。也许其中一个绘图作业开始晚了,或者它被系统线程踢出了一个内核,或者它只是有太多的工作要做。提交线程必须等待作业完成后才能启动命令缓冲区,如果等待时间太长,GPU就会闲置并产生气泡。
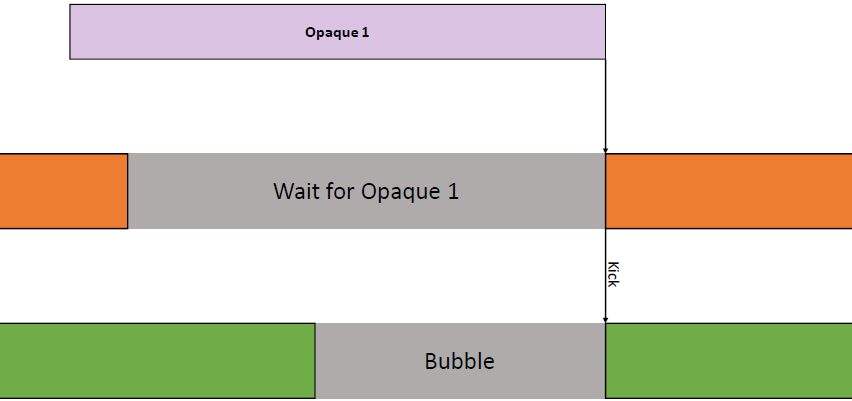
但是在一个代码库中有一件很酷的事情可以避免出现气泡。提交线程对绘制作业的等待有一个超时,如果作业没有及时完成,就会发出中止信号,通知作业停止。作业会定期检查信号,如果检测到中止,它会停止迭代并关闭命令缓冲区。然后提交线程接管作业并执行作业本应完成的所有工作。但这一次它不止一次,而是在工作的最后一次。通过更频繁地kick,GPU比提交线程等待作业完成的时间要早一点获得填鸭式的工作。这是以更频繁的kick带来的额外CPU和CP开销为代价的,但它可能会减少气泡的影响或完全避免气泡。
单帧CPU工作涉及许多系统的交互,下面是有一个非常简单的总结:首先,从服务器获取权威的游戏状态,以更新客户端游戏状态;然后,对输入进行采样,并将输入因素纳入客户端游戏模拟;最后,完成了渲染游戏模拟结果所需的所有工作。让我们关注渲染部分。
渲染分为许多小任务,包括遍历场景图、剔除、为模型拾取LOD等等,所有这些作业的最终输出都是一组可见表面列表。然后将作业分配给迭代每个单独的列表,这些作业生成命令缓冲区和相关的渲染数据。最后,一个作业收集所有已完成的命令段,并将它们kick到GPU。此作业还记录表面列表中未包含的命令:解压缩表面、后处理和二维图形。
从概念上讲,所有这些工作可以分为三组:场景准备、绘图和GPU提交。

一帧上的所有工作都是多线程的,并尽可能广泛地运行。然而,*均而言,场景准备和绘图是从广泛运行中受益最多的部分。与可用的内核相比,帧的开头和结尾实现了更低的利用率,留下了更多空闲的CPU周期。
为了使CPU内核更加一致地饱和,绘图和提交工作被分开。然后在这一帧的场景准备之后,下一帧就可以立即开始了。这样一来,下一帧的开头与该帧的绘图和提交重叠,可以产生相当大的加速。
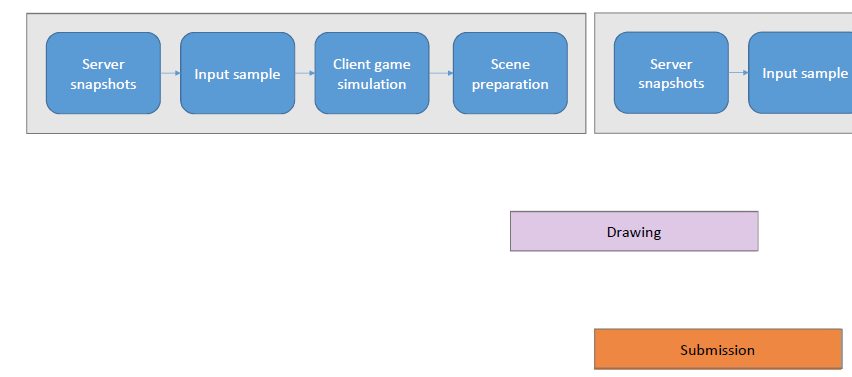
从概念上讲,整个场景准备过程中的一切都可以称为“客户端帧”,有一个专门的客户端线程来协调所有相关的作业。第二个渲染线程执行所有命令缓冲区提交、PostFX、2D绘图等,并包含第二个并行“渲染帧”。在这两条时间线之间是生成命令缓冲区的所有绘图作业,客户端启动这些作业,渲染线程等待它们并启动它们的结果。

与其它生产者-消费者对一样,slop可以在客户端和渲染帧之间累积。
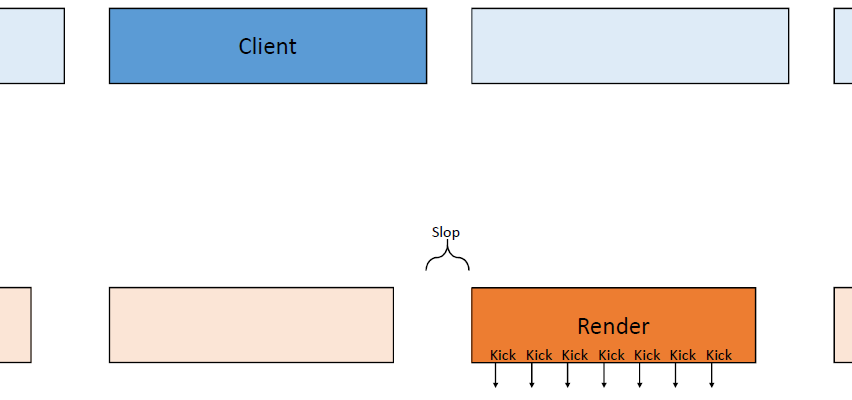
但让我们关注一下这两条时间线之间的同步,以及它如何影响slop。首先,客户端必须与GPU同步,因为它会写入与场景渲染共享的缓冲区。这些资源是双缓冲的,因此在客户端可以启动其帧之前,它必须等待两帧前的GPU场景完成。客户端和渲染线程也共享此数据。最初,渲染线程在下一个客户端帧开始之前不允许启动帧。
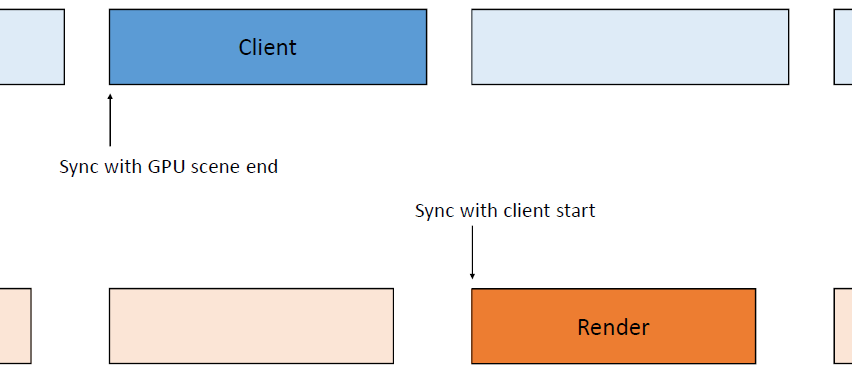
缩小之后,底部是GPU时间线。客户端帧的开始与两帧前GPU场景渲染的结束同步。然后,渲染帧的开始与下一个客户端帧的开始同步,会在客户端帧的结束和渲染帧的开始之间创建一些slop。如果管线没有绑定到渲染帧上,为什么会存在这种slop?
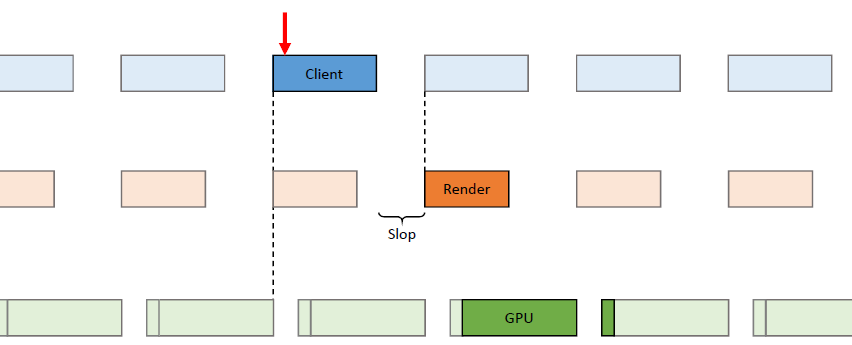
渲染帧不能从这里开始,没有正确的理由:就在当前客户端帧的末尾。进行此更改对总延迟没有影响:整个帧的总slop保持不变,只是从渲染帧的左侧移动到右侧。
2、稍后在帧中移动slop。
记住,slop可以防止尖峰,但并不是所有的slop都能*等地防止所有可能的尖峰。
例如,如果客户端帧出现尖峰,帧中稍后的所有slop源都可用于吸收尖峰并避免丢失帧。
但是如果GPU出现尖峰,只有GPU帧后的slop可以吸收尖峰。
需要尽快开始所有工作。
同步已更改为允许渲染帧在客户端帧完成后立即开始。现在请记住为什么渲染帧和客户端帧不允许同时运行:因为客户端写入渲染线程读取的缓冲区。
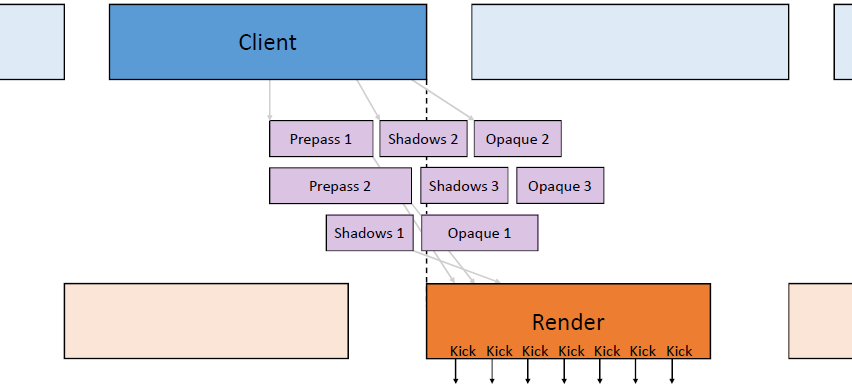
事实上,渲染帧可以更早开始,从而允许它在客户端帧结束之前开始工作。这种重叠在一个代码分支中实现,它不会像CPU-GPU重叠那样显著减少延迟,但它仍然可以收回几毫秒。这种重叠是通过在客户端和渲染器之间分割共享数据并最小化分割之间的依赖关系来实现的,重叠的程度取决于数据拆分可以在客户端帧依赖关系中执行的距离。
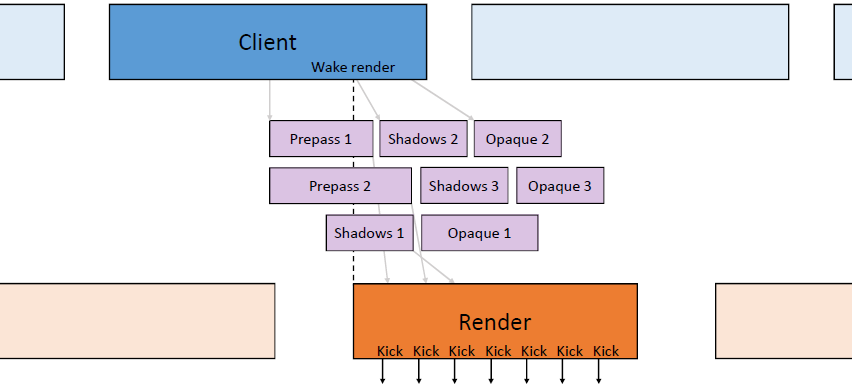
需要修改客户端和渲染帧之间的slop定义,以考虑这种重叠:现在是在客户端中较早唤醒渲染线程和渲染帧实际启动之间的延迟。
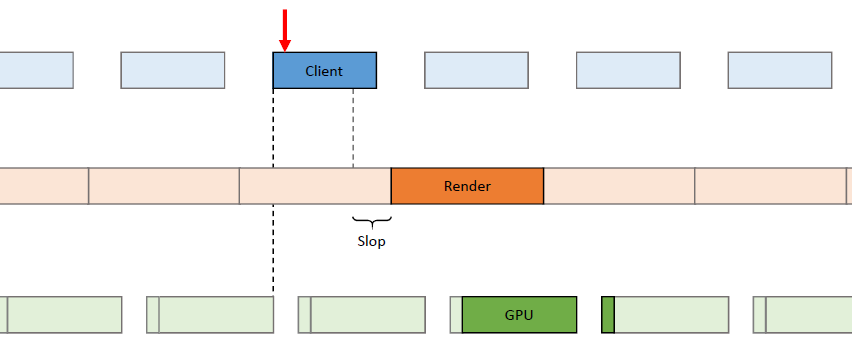
关于同步还有最后一件事。请记住,只有GPU在两帧前完成场景,客户端才能启动,可以保护对CPU和GPU之间共享的双缓冲数据的访问。但是,这些缓冲区仅在渲染相关操作(场景准备、绘制和提交)期间由CPU写入。在帧的前半部分,所有的客户端模拟工作都不会触及GPU可见缓冲区(下图上)。这意味着等待可以在稍后的帧中移动,就在写入任何共享缓冲区之前。(下图下)
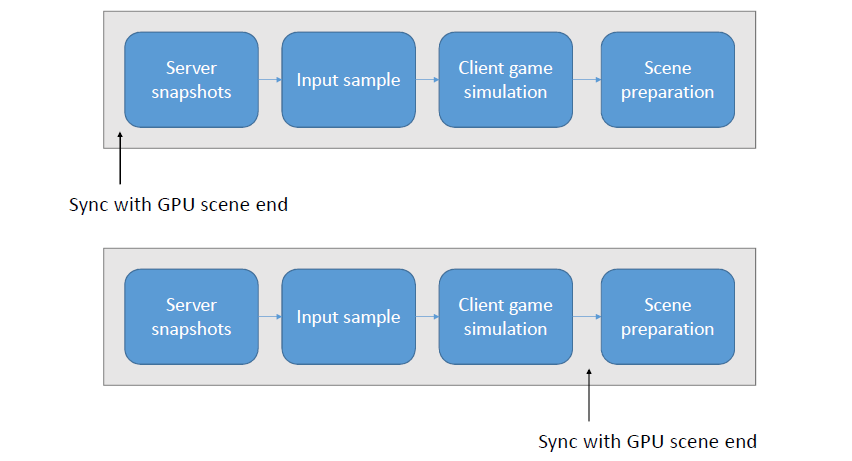
通过此更改,客户端帧被分为两部分:一部分在与GPU同步之前,另一部分在与GPU同步之后。GPU现在等待在输入样本之后,因此在延迟路径中引入了一个新的slop。
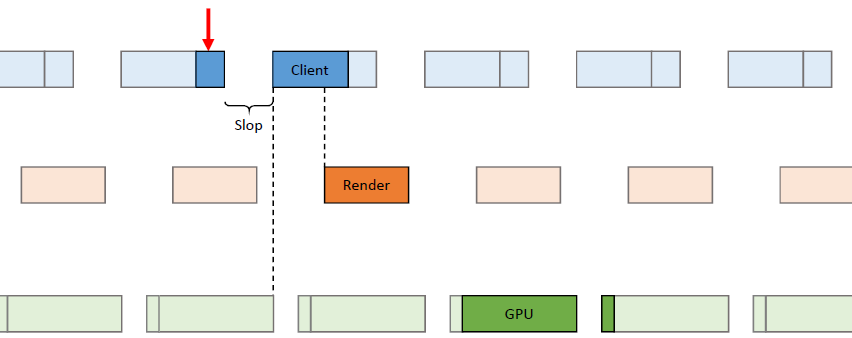
现在我们已经查看了引擎中的所有主要时间线,并确定了延迟路径中的所有工作和slop部分。
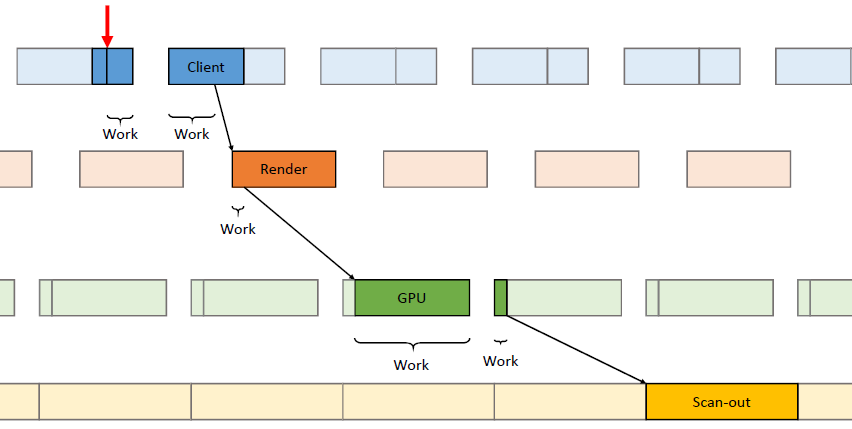
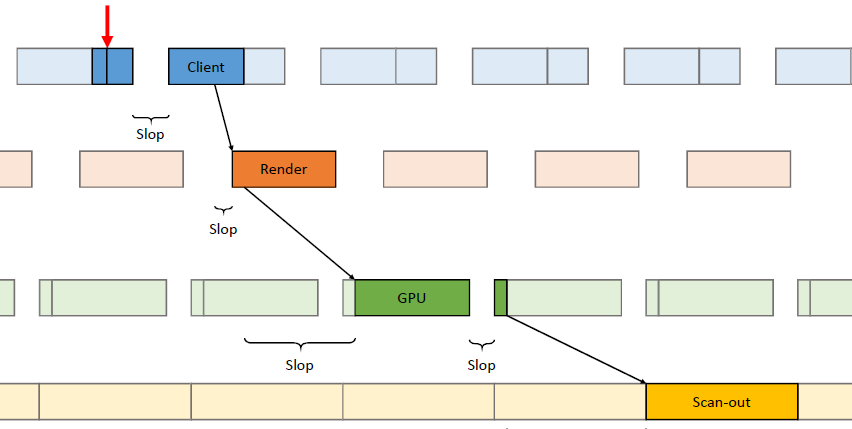
现在,让我们将所有这些整合到throttle实现中。我们在输入样本之前引入throttle,这样样本和后续工作就会延迟并向右移动。
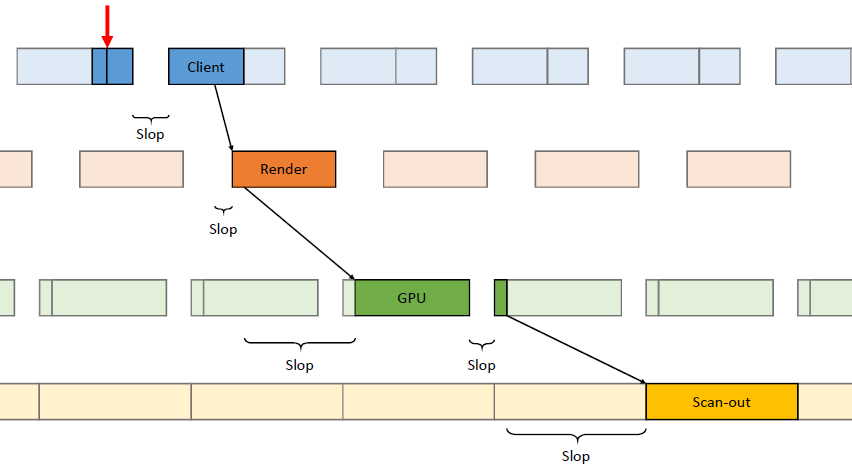
注意slop是如何从左边开始被挤出的,但总的工作保持不变。
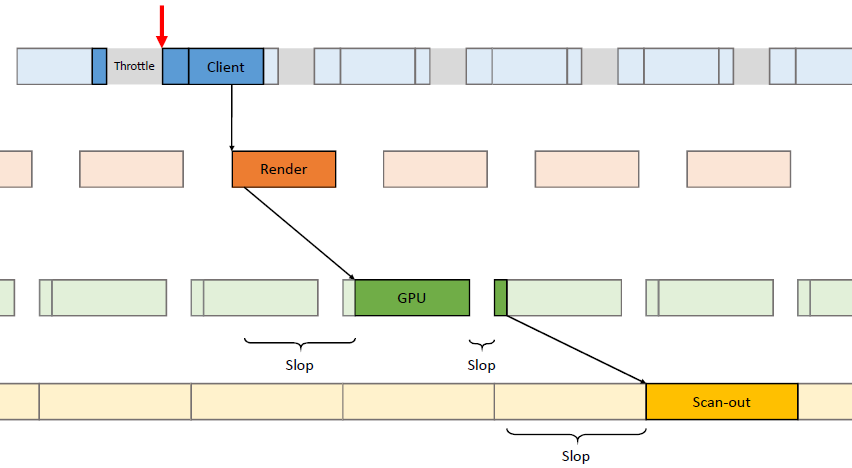
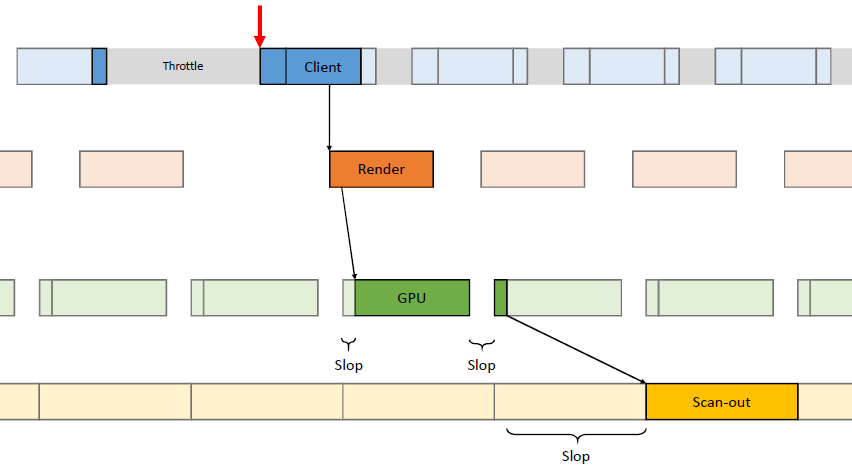
现在,客户端、渲染器和GPU之间不再有任何slop,throttle已经足够长了。唯一剩下的slop在GPU和扫描输出之间。
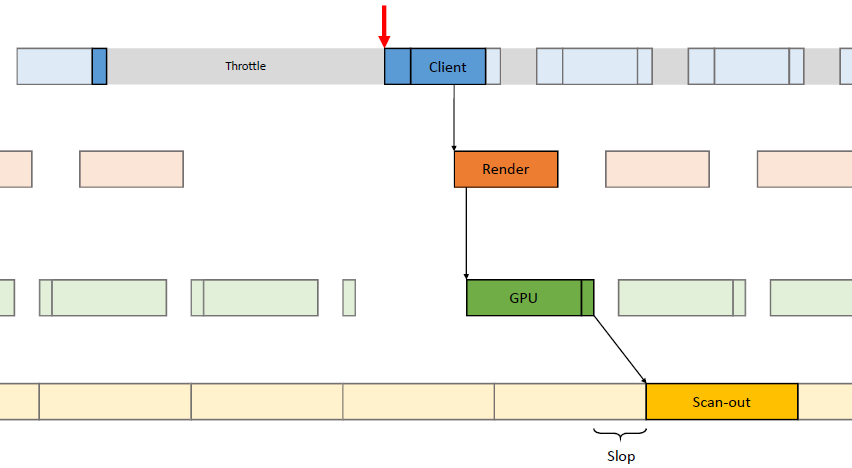
如果我们再延迟一点,GPU工作的结束就会被推过vblank并错过一帧。
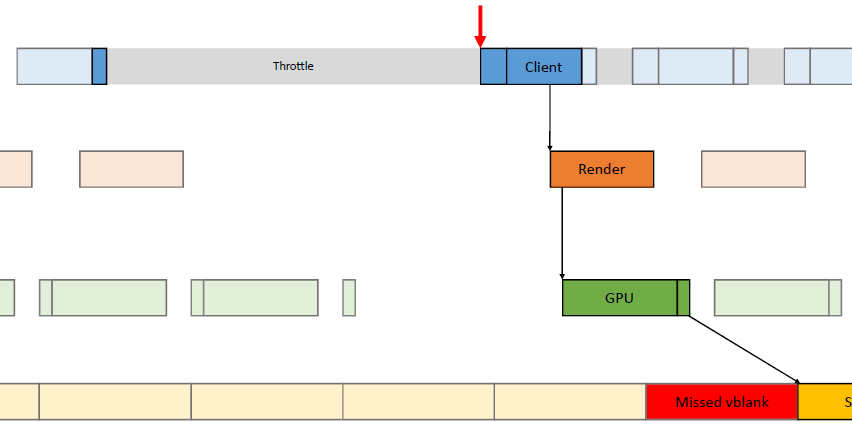
所以问题是:throttle应该等多久?throttle位于客户端帧的中间,就在输入示例之前。延迟持续时间的结束是在未来的vblank期间,此时该帧将被翻转。从现在到预期翻转之间的时间是我们正在解决的throttle加上帧剩余部分的工作和slop。求解throttle,我们得到从现在到vblank的持续时间减去总工作和slop。但请记住,throttle接*帧的开始,在它运行之前,我们不知道会有多少工作和slop。
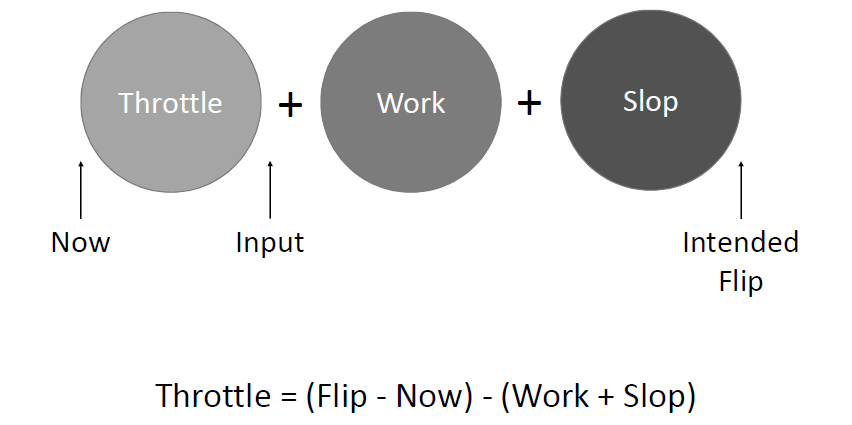
取而代之的是,我们必须根据之前的帧数据来估计此帧将有多少工作,而且必须事先决定要达到此帧的目标slop值。问题就变成了:给定一个目标量的slop,throttle应该休眠多长时间?
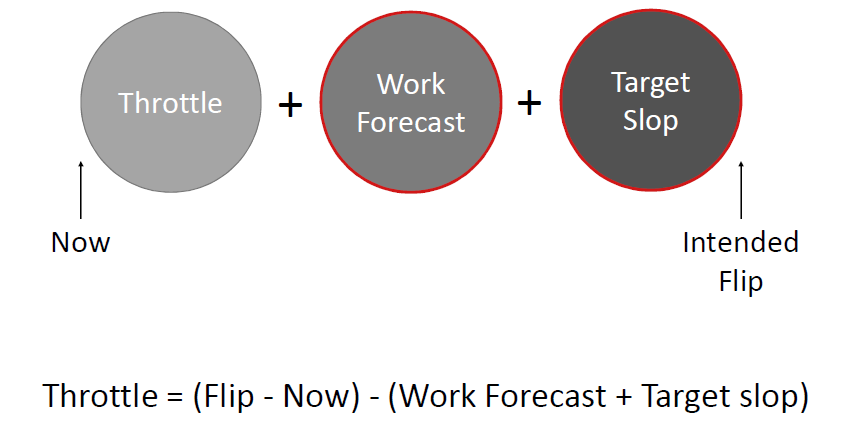
让我们先看看如何找到预期翻转的时间,需要计算当打算翻转时的vblank的绝对时间。因为每16.6ms出现一次vblank,所以未来帧的vblank可以根据之前的帧计时进行推断。
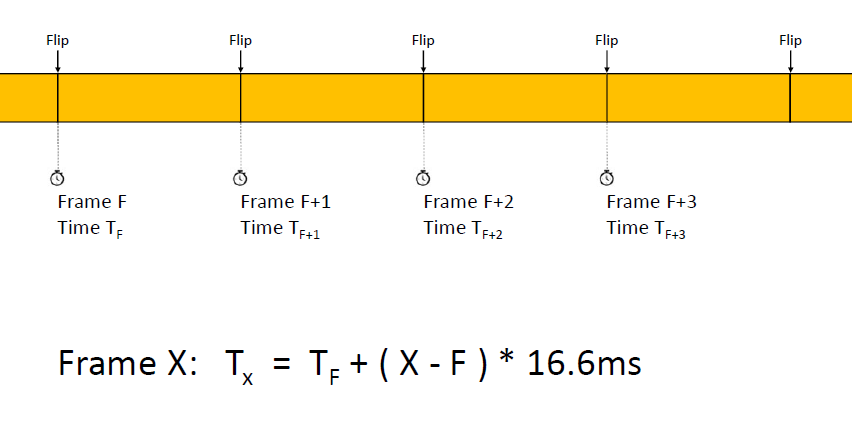
翻转时间:专用的高优先级线程,等待GPU中断事件,自己使用API提供的时间戳或时间戳。Xbox One的翻转时间过程:1、在当前状态下传递引擎的帧索引:
DXGIX_PRESENTARRAY_PARAMETERS params
params.Cookie = [internal frame index]
...
DXGIXPresentArray( ..., ¶ms )
2、查询帧统计信息以获取时间:
DXGIX_FRAME_STATISTICS stats[4]
DXGIXGetFrameStatistics( 4, stats )
然后获取首个有效的stats[i].Cookie和stats[i].CPUTimeFlip。
为了预测这一帧的工作量,需要从之前帧中收集工作段的时间戳。在throttle打开之前,需要收集并汇总最新的测量结果,以从前一帧中获得总的工作估计。因为throttle在客户机时间线中,所以客户机工作测量不需要双缓冲,而是可以直接从最后一帧读取,因为它们保证是完整的。但是,由于客户端帧与渲染和GPU帧同时运行,所以在收集时间戳时,工作持续时间可能会处于运行状态,从而导致开始时间戳位于结束时间戳之后。相反,非客户端时间线上的时间戳可以进行双缓冲。每对时间戳中至少应有一个完整:通过比较两对的开始和结束时间,可以确定最*的有效时间戳对。
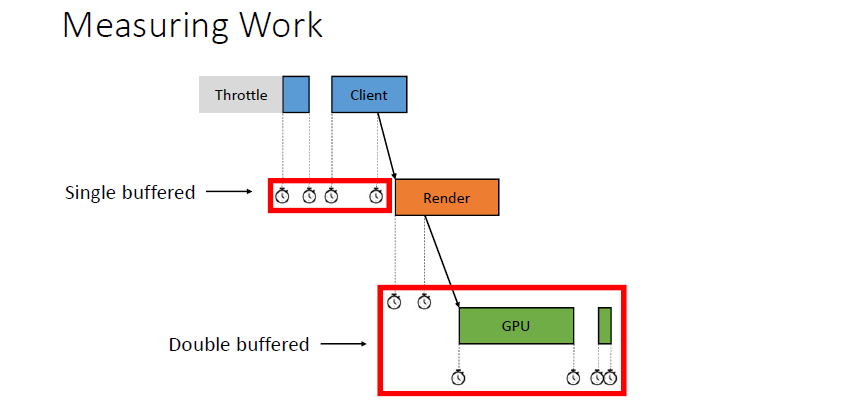
newEstimate = estimate * smooth + work * (1 - smooth)
目标slop:减少延迟与漏帧风险?值判断;工作有多紧张?从工作值的历史中估算方差;可调整的slop,根据方差进行调整,如果slop低于阈值,则设置为无限(unthrottled))。
减少方差:持续的问题,需要定期重新审视,引擎内测量,通常由计划不周的工作引起:重新安排依赖关系,限制关键作业可以在哪些核心上运行,拆分/合并作业。
我们现在已经讨论了计算throttle所需的每一项:下一帧应该翻转的时间可以从之前的翻转推断出来,通过*滑前一帧的测量值,可以预测该帧的总工作,在这个帧中允许的slop可以通过基于观察到的方差的启发式方法来决定。使用这些项,我们可以计算客户端帧在采样输入之前需要睡眠多长时间。
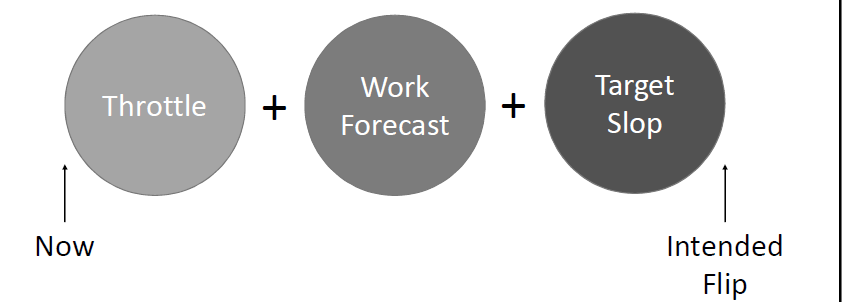
退一步,让我们回顾一下为什么我们必须通过识别引擎中每一个工作源和slop的过程。
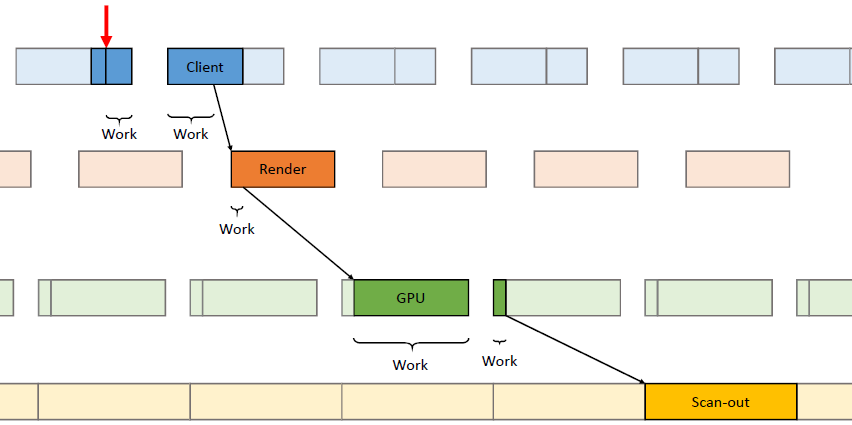
有了工作和slop的正确定义,throttle对这些值的影响变得非常可预测。使得在给定目标slop的情况下,计算合适的throttle变得容易。然后,测量的slop在一帧内迅速收敛到目标附*。
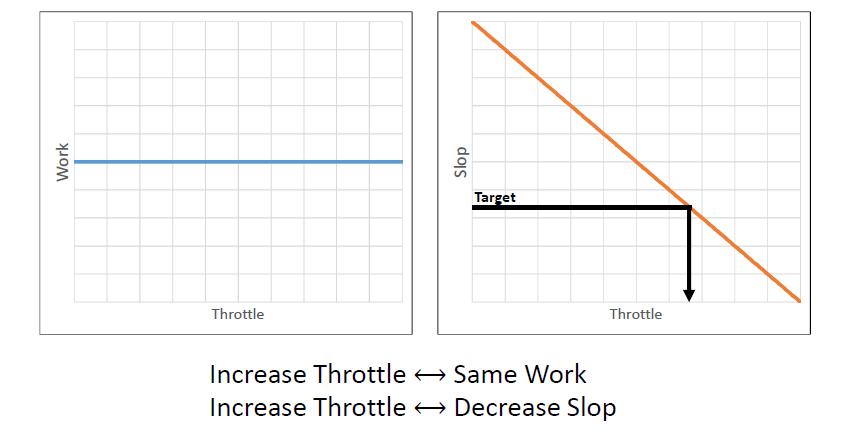
当该文献作者第一次研究延迟时,将引擎视为一个大黑匣子,把大黑匣子里的一切都称为工作,唯一的问题是从队列翻转到翻转的持续时间,忽略了发动机内部所有额外的slop源,但它使功测量变得容易得多。
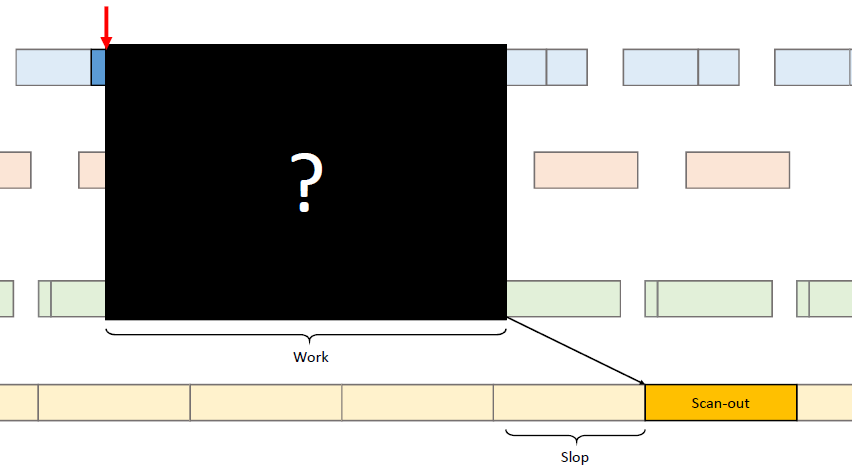
问题是throttle不再是可预测的,一些最初的throttle挤压是有效的,但不会影响slop。
不再是线性的,需要搜索多个帧。
结果:经审核的数据流和同步提高CPU密集型场景的帧率,修复错误,增加了throttle的测量。*台1下,带throttle:∼*均帧可节省5毫秒延迟,提前移动帧缓冲区等待:避免重场景中的vblank未命中。*台2下,带throttle:约*均每帧减少22毫秒延迟,帧缓冲区等待已在帧中延迟。未来的工作:关注内容和解决方案的工作预测,可变刷新率支持,延迟输入样本重投影。建议:默认情况下打开Vsync的配置文件,使用引擎内定时器可视化延迟,映射从输入样本到扫描输出的数据路径,确保同步尽可能紧密,寻找重叠的机会,测量并减少方差。
14.5.4.7 Mesh Shading
Mesh Shading: Towards Greater Efficiency of Geometry Processing分享了Mesh着色器的技术,包含简史、背景和动力、网格着色编程模型、新兴应用和未来方向。图形管线vs计算着色器是GPU的人格分裂:
如果将计算管线化进光栅呢?
基本网格着色模型:
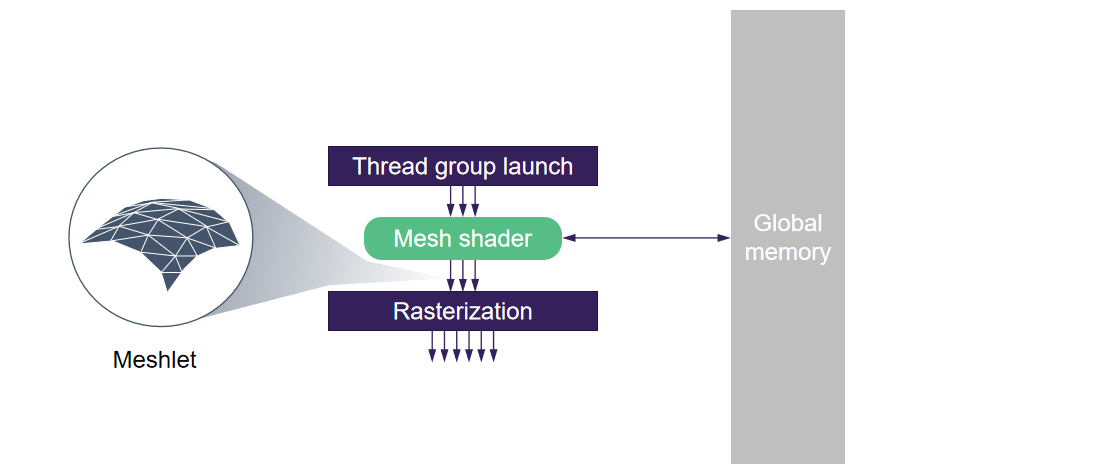
Meshlet是屏幕空间的标准化接口:
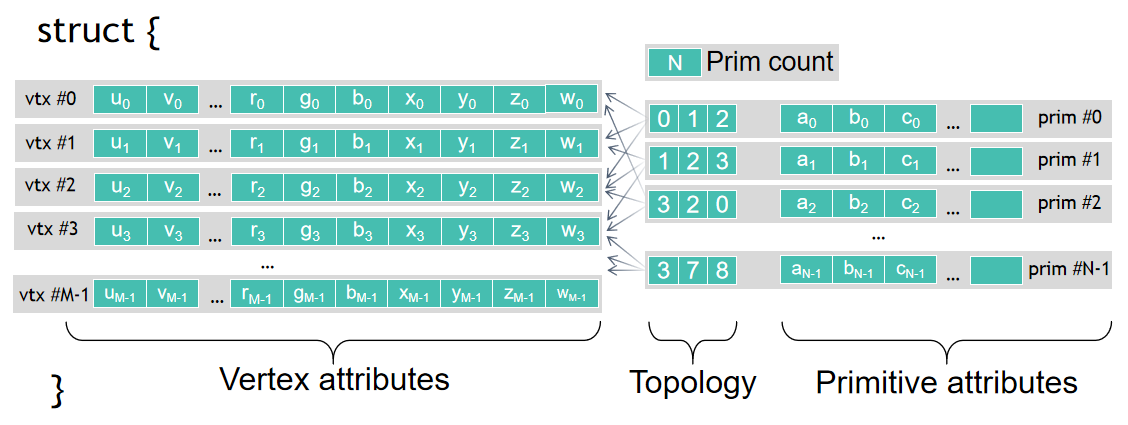
网格着色器编程模型:应用程序定义的线程角色,比如计算、协同生成输出网格,结合顶点和几何体着色,假设面与顶点的比率是固定的,有限动态扩展。
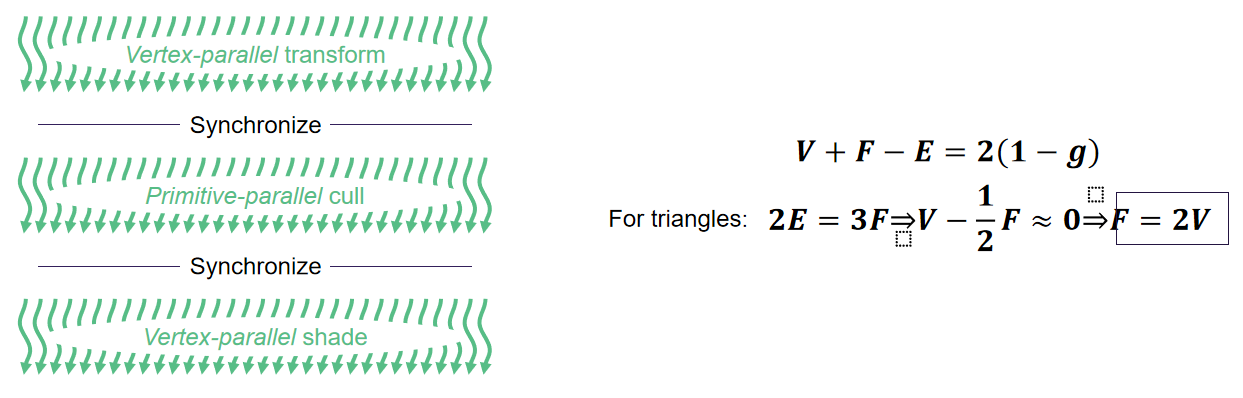
输入表示是应用程序定义的,自定义压缩、非B-rep方案…可使用网格着色器id直接寻址。管线顶部的固定功能消失了…无索引重复数据消除,无顶点属性提取。避免序列化点—可扩展性,负责利用顶点重用的应用程序,可以预计算优化的图元分簇,运行时没有重复工作-节省功率。
动态扩展:几何合成需要支持放大,推广了细分扩展模型,删除固定功能拓扑生成。
带有任务和网格着色器的几何体管线:
任务和网格包含旧着色器阶段:
网格着色器剔除:任务着色器剔除图元分簇,*截头体、背面、亚像素,逐图元的FF剔除。利用预计算,局部化图元分簇,预计算法线分布等。更紧凑,内存比索引缓冲区少25-50%!
动态加载*衡:英伟达的“小行星”演示,每帧5000万以上三角形,使用任务着色器的动态LOD,从一组预计算的LOD中进行选择,生成要渲染的网格着色器,没有CPU干预!
自适应曲面细分:动态三角形细分格式,使用二进制密钥进行高效编码,多帧上的增量细化,网格着色器支持单通道管线,任务着色器更新隐式细分,网格着色器从二进制键解码。
还可以模拟dx11细分。总之,网格着色–几何体的新编程模型,结合了计算的灵活性和流水线调度的效率,通过消除串行瓶颈优化管线,在几何图形处理中实现更高的效率和控制,支持网格着色的新应用程序的机会,如LOD管理、数据结构遍历、几何合成、程序化。
14.5.4.8 Nanite
A Deep Dive into Nanite Virtualized Geometry由Epic Games的Brian Karis等人在siggraph2021峰会上呈现,讲述了UE5 Nanite的实现细节。
行业的研发人员一直有个梦想,就是将几何体虚拟化,就像使用纹理一样,但无需更多的预算,直接使用电影质量源艺术,无需手动优化,没有质量损失。但实现起来比虚拟纹理更难,不仅仅是内存管理,还有几何细节直接的影响。Nanite团队对比了体素、曲面细分、位移映射、点云、三角形等表达方式,最终发现比三角形更高质量或更快的解决方案,使用三角形是Nanite的核心(但其它表达方式也可用于其它方面的实现)。
GPU驱动的流水线:渲染器仍处于保留模式,GPU场景表示在多帧之间保持不变,在事情发生变化的地方很少更新,单个大型资源中的所有顶点/索引数据。逐视图进行GPU实例剔除、三角光栅化,如果仅绘制深度,则整个场景可以使用1个DrawIndirect绘制。三角形分簇剔除的方式先将三角形分成簇,为每个簇构建边界数据,基于边界剔除分簇,如视锥剔除、遮挡剔除等。
其中遮挡剔除是基于层次Z缓冲区(HZB)的遮挡剔除,从边界计算屏幕矩形,在屏幕矩形小于等于4x4像素的情况下,测试最低mip。怎么建立HZB?本帧还没有渲染任何内容,将Z缓冲区从上一帧重新投影到当前帧?需要填洞才能有用,不保守。最终使用2通道的裁剪剔除,最后一帧的可见对象可能在此帧中仍然可见,至少是遮挡体的好选择。2通道解决方案:绘制上一帧中可见的内容,构造HZB,绘制现在可见但不在最后一帧中的内容,几乎完美的遮挡剔除!保守的,只有在可见性发生极端变化时才会出现视觉瑕疵。
将可见性与材质分离,以消除在光栅化过程中切换着色器、材质计算过绘制、深度prepass避免过绘制、密集网格导致的像素quad效率低下,可选的方案有REYES、纹理空间着色、延迟材质。
可见性缓冲区:将几何数据写入屏幕(深度、实例ID、三角形ID),每像素材质着色器:加载缓冲区,加载实例转换,加载3个顶点索引,加载3个位置,将位置转换为屏幕,导出像素的重心坐标,加载和插值属性。听起来很疯狂?不像看上去那么慢,因为有大量缓存命中,没有过绘制或像素quad的效率低下。材质通道写入GBuffer,与其它延迟着色渲染器集成。现在可以用1个绘制调用绘制出所有不透明的几何体,完全由GPU驱动,不仅仅是深度prepass,每个视图栅格化一次三角形。
次线性缩放:可见性缓冲区比以前快得多,但仍然与实例数和三角形数成线性比例。实例中的线性缩放是可以的,至少在通常希望加载的关卡的缩放范围内。这里可以轻松处理一百万个实例,三角形中的线性缩放不合适,如果线性扩展,就无法实现“不管你怎么努力都能成功”的目标。光线追踪是LogN,很好但还不够。即使渲染速度足够快,也无法将这些场景的所有数据存储在内存中。虚拟几何部分与内存有关。但是光线追踪对于Nanite的目标来说速度不够快,即使它适合内存,需要比logN更好的。
换一种说法,屏幕上只有这么多像素。为什么要画更多的三角形而不是像素?对于簇,希望在每一帧中绘制相同数量的簇,而不管有多少对象或它们的密度。一般来说,渲染几何体的成本应该随着屏幕分辨率而定,而不是场景复杂度。就场景复杂度而言,意味着恒定的时间,而恒定的时间意味着LOD。
LOD的解决方案是分簇层次结构(Cluster hierarchy),以簇为基础确定LOD,建立层次结构的LOD,最简单的是簇树,父节点是子节点的简化版(下图左)。LOD运行时找到所需LOD树的切割,基于知觉差异的视点依赖(下图中)。使用流,整棵树不需要同时存储在内存中,可以把树上的任何一块都标记为叶子,然后把剩下的扔出去,渲染期间按需请求数据,类似虚拟纹理(下图右)。
如果每个簇独立于相邻簇决定LOD,则会出现裂缝!粗略的解决方案:在简化过程中锁定共享边界边,独立的簇总是在边界上匹配。锁定的边界:收集密集的杂乱部分(dense cruft),尤其是在深层的子树之间。
可以在构建过程中检测到这些情况,分组簇:强迫它们做出同样的LOD决策,现在可以自由解锁共享边并折叠它们。
不同LOD的切换过程示意图如下:

LOD裂纹的选项:
- 直接索引相邻顶点。
- *行视图相关的详细程度控制。
- *行视图相关的核心外渐进网格。
- 无依赖并行渐进网格。
- 需要能够索引任何状态下的边界顶点,由于精度原因,不可能出现裂缝,在计算和内存方面复杂且昂贵,三角形的粒度太细了。
- 裙子(skirt)。
- 与邻居的软关系。
- 体素没有裂缝,为什么没有?实体体积数据,而非边界表示,将网格视为实体体积,分簇必须闭合,至少在移动范围内。
- 分块LOD。
- 只有当边界是笔直的空间分割时。
- 隐式依赖。空间意味着节点之间的依赖关系。
- 渐进式缓冲区。当所需数据不存在时会发生什么?
- 自适应四字谜(Adaptive TetraPuzzles)。
- 将级别X的节点强制为特定大小或形状。
- 显式依赖。节点之间的依赖关系在构建和存储期间确定。
合批多重三角剖分是一个很好的理论框架,但Brian Karis发现这篇论文非常难以理解,因为它过于抽象和理论化。直到几年后,在部分实现了QuickVDR之后,Brian Karis才再次尝试重新阅读它,发现它作为一个由多个方案组成的超级集合是多么有洞察力。构建步骤的分解与接下来将介绍的基本步骤相同,并进行一些调整。之前的工作会对三角形本身进行分组,从而使每组的三角形数量可变。但需要128个三角形的倍数,这样它们就可以被分成正好128个的簇,将簇分组(而不是三角形分组)可以实现这一点。
构建操作:分簇原始三角形,当NumClusters>1时:将簇分组以清理其共享边界,将组中的三角形合并到共享列表中,将三角形数量简化为50%,将简化的三角形列表拆分为簇(128个三角形)。
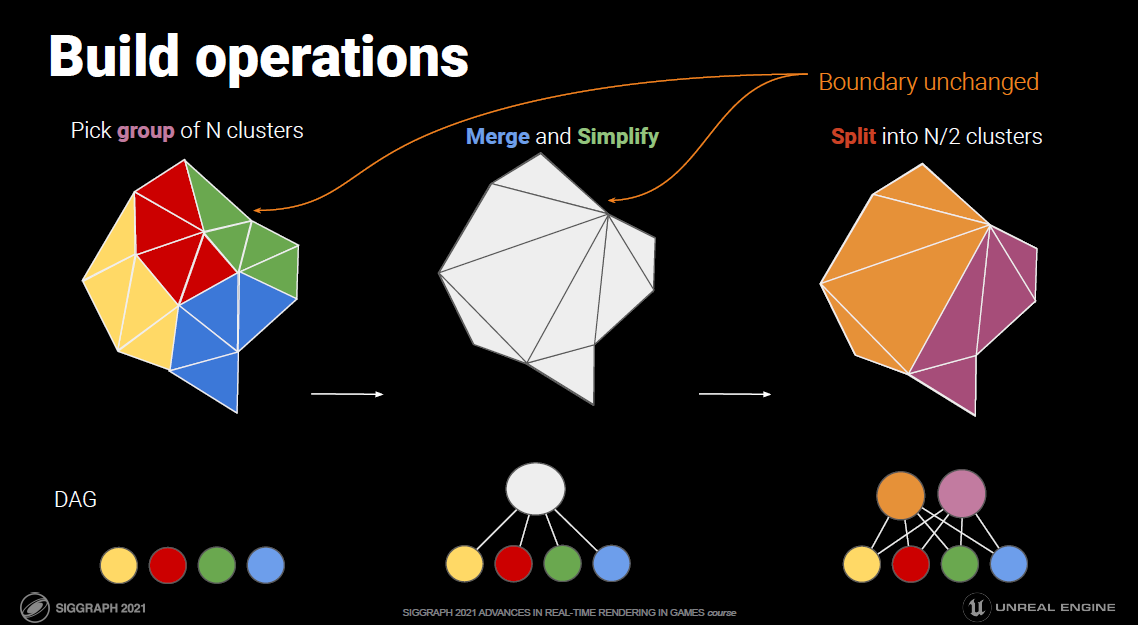
合并和拆分使其成为DAG而不是树:
DAG:哪些簇需要分组?将那些具有最多共享边界边的对象分组,更少的边界边更少的锁定边,这个问题称为图分区。最小化边切割代价图的划分优化,图节点=簇,图边=用直接连接的三角形连接簇,图边权重=共享三角形边的数量,用于在空间上闭合簇的附加图边,为孤岛情况添加空间信息、最小图边切割最小锁定边,使用METIS库来解决。
图划分:挑两个,希望剩下的都能解决,簇边界边的数量,每簇的三角形数量<=最大值。与簇分组问题完全相同,图是网格的对偶。需要严格的分区大小上限,图分区算法不能保证这一点,设法用小缺口(small slack)和fallback来强制它。
网格简化:边缘折叠,首先选择最小误差边,使用二次误差度量(QEM)计算的误差,优化新顶点的位置,使误差最小,高度细化,返回引入的错误估计,稍后投影到屏幕上的像素数出现错误,也是最难的部分。
误差度量:基本二次曲面是面积上距离^2误差的积分,具有属性的二次曲面将所有错误与权重混合在一起,完全启发式hack。能做得更好吗?Hausdorff网格距离?渲染结果并使用基于图像的感知?没有比率失真优化的概念。导入和构建时间也很重要,Nanite builder的所有代码都经过了高度优化,希望折叠以优化与返回的像素错误相同的度量。缩放独立性,需要知道屏幕上的尺寸才能知道权重,鸡和蛋的问题,假设大多数集群以恒定的屏幕大小绘制,表面积归一化,边长度限制,大量的调整,非常注意浮点精度,二次曲面中的许多地方都具有固有的灾难性相消。
下面阐述运行时视图相关的LOD。首先是LOD的选择。具有相同边界但LOD不同的两个子图,根据屏幕空间误差在它们之间进行选择,由投影到屏幕的simplifier计算的误差,修正了球体边界中最坏情况点的距离和角度失真,组中的所有簇必须做出相同的LOD决策,相同的输入=>相同的输出。
LOD并行选择:LOD选择对应于剪切DAG,如何并行计算?不想在运行时遍历DAG。定义切割的是父子节点之间的差异。在以下情况下绘制簇:父节点误差太高且当前节点的误差很小,可以并行评估(下图左)!只有当有一个独特的切割,强制误差是单调的(monotonic),父视图误差>=子视图误差,仔细执行以确保运行时更正也是单调的(下图右)。
无缝LOD:二元选择父或子,这不会产生明显的跳变吗?需要*稳过渡吗?涉及几何过渡(Geomorphing)和跨簇过渡。如果误差小于1像素,则它们会有细微差别,TAA将任何差异视为锯齿。
基于表面角度的LOD:简化产生的簇误差是对象空间的标量,未知方向,位置误差可能是方向性的,属性错误的混合使得这很困难。投影到屏幕不考虑表面角度,类似于如果mipmap仅仅是距离的函数,也适用于细分因子计算。表示在细分上扫掠角度曲面,求解需要各向异性LOD,不可能通过簇选择,簇选择必须是各向同性的,就像mip选择一样。其它方案也会产生扫视角成本,如基于点的过绘制、SDF和SVO中的表面读取。
层次LOD选择:可见的簇可能是*的(全部来自单个实例)或远的(来自不同实例的所有根簇)。需要分层,但是DAG遍历是复杂的!记住:LOD决策完全是局部的,可以使用任何想要加速的数据结构!
层次剔除:什么时候可以LOD剔除一个簇?

ParentError<=阈值,基于ParentError的树,而不是ClusterError!BVH8:子节点的最大ParentError,内部节点:8个子节点,叶节点:组中的簇列表。
持久线程:理想的情况是父节点一结束就开始子节点,直接从compute生成子线程。而持久线程模型相反,无法生成新线程,重新使用它们!管理自己的作业队列,单次调度,有足够的工作线程来填充GPU,使用简单的多生产者多消费者(MPMC)作业队列在线程之间进行通信。层次剔除:当工作队列不是空的,将节点提取出队列,测试,让通过测试的子节点入队。单次dispatch,没有递归深度或展开(fanout)限制,无需反复排空(drain)GPU,节省10-60%(通常约25%),具体取决于场景复杂度。依赖于调度行为,要求一旦一个组开始执行,它就不会无限期地挨饿,D3D或HLSL未定义调度行为,在控制台和测试过的所有相关GPU上工作,仅是优化要求,而非Nanite的要求。分簇剔除:叶子是有着共同父亲的簇,作为节点进行类似的剔除检查,输出可见簇。在同一个持久着色器中进行簇剔除,一次可能没有足够的活动BVH节点来填充GPU,执行时间最终可能由最深遍历的深度决定,尽早开始簇剔除工作,并使用它来填补孔洞。两个队列,等待节点出现在节点队列中时,从簇队列处理,合并成64的批。
2通道的遮挡剔除:显式跟踪以前可见的状态变得复杂,LOD选择可能不同,上一帧中可见的簇可能已经不在内存中了!测试当前选定的簇在最后一帧是否可见,使用以前的变换测试以前的HZB。
剔除总览:
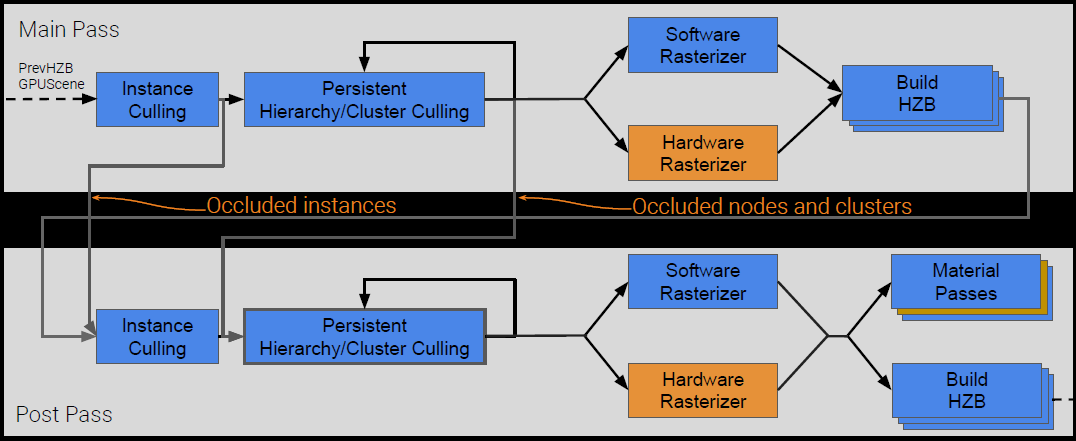
接下来聊光栅化。
像素级细节:能用大于1个像素的三角形达到像素级细节吗?取决于如何*滑,一般来说没有。需要绘制像素大小的三角形。对于小三角形,如果用典型的光栅化器来说太可怕了。典型光栅化器:大型tile用binning,微型tile用4x4,输出2x2像素quad,像素高度并行而非三角形。现代GPU设置最大4个三角形/clock,输出SV_PrimitiveID会让情况变得更糟,能用软件光栅打败硬件光栅吗?实际上,软件光栅是硬件光栅的3倍速度!!!

对于小三角形,将三角形binning和只写最后的像素一样困难,即使是单个向量戳也会对小三角形进行浪费的测试,基本边界框更快。在tile级别进行序列化,以处理深度和ROP,输出2x2像素四边形,通用的VS+PS调度、输出格式、排序、混合、clip...针对覆盖多个像素的较大三角形进行了优化,在像素上广泛运行,想要很多像素的三角形,在三角形三运行。
微型软件光栅化器:128三角形簇=>线程组大小128,每个顶点1个线程,变换位置,存储在groupshared中,如果超过128个顶点循环(最多2个)。每个三角形1个线程,获取索引、变换的位置,计算边缘方程和深度梯度,计算屏幕边界矩形,对于rect中的所有像素,如果在所有边内,则写入像素。
for( uint y = MinPixel.y; y < MaxPixel.y; y++ )
{
float CX0 = CY0;
float CX1 = CY1;
float CX2 = CY2;
float ZX = ZY;
for( uint x = MinPixel.x; x < MaxPixel.x; x++ )
{
if( min3( CX0, CX1, CX2 ) >= 0 )
{
WritePixel( PixelValue, uint2(x,y), ZX );
}
CX0 -= Edge01.y;
CX1 -= Edge12.y;
CX2 -= Edge20.y;
ZX += GradZ.x;
}
CY0 += Edge01.x;
CY1 += Edge12.x;
CY2 += Edge20.x;
ZY += GradZ.y;
}
硬件光栅化:大三角形使用硬件光栅化器,逐簇选择软件或硬件光栅化,还用于64b原子写入UAV。
扫描线软件光栅化器:多大才算太大?比预期的要大得多,边缘小于32像素的簇被软件光栅化,在rect上迭代测试大量像素,最好的情况包括一半,最糟糕的情况是没有一个(下图左)。扫描线可以更快吗?传统的梯形比较复杂,很多设置和边缘遍历(下图右)。
for( uint y = MinPixel.y; y < MaxPixel.y; y++ )
{
float CX0 = CY0;
float CX1 = CY1;
float CX2 = CY2;
float ZX = ZY;
for( uint x = MinPixel.x; x < MaxPixel.x; x++ )
{
// 难道不能知道经过的x区间是多少吗?
if( min3( CX0, CX1, CX2 ) >= 0 )
{
WritePixel( PixelValue, uint2(x,y), ZX );
}
CX0 -= Edge01.y;
CX1 -= Edge12.y;
CX2 -= Edge20.y;
ZX += GradZ.x;
}
CY0 += Edge01.x;
CY1 += Edge12.x;
CY2 += Edge20.x;
ZY += GradZ.y;
}
// 改进版本
float3 Edge012 = { Edge01.y, Edge12.y, Edge20.y };
bool3 bOpenEdge = Edge012 < 0;
float3 InvEdge012 = Edge012 == 0 ? 1e8 : rcp( Edge012 );
for( uint y = MinPixel.y; y < MaxPixel.y; y++ )
{
// 这不再是固定点,也就是说它不完全相同。
float3 CrossX = float3( CY0, CY1, CY2 ) * InvEdge012;
float3 MinX = bOpenEdge ? CrossX : 0;
float3 MaxX = bOpenEdge ? MaxPixel.x - MinPixel.x : CrossX;
// 求解经过的x间隔
float x0 = ceil( max3( MinX.x, MinX.y, MinX.z ) );
float x1 = min3( MaxX.x, MaxX.y, MaxX.z );
float ZX = ZY + GradZ.x * x0;
x0 += MinPixel.x;
x1 += MinPixel.x;
// 现在只迭代填充像素
for( float x = x0; x <= x1; x++ )
{
WritePixel( PixelValue, uint2(x,y), ZX );
ZX += GradZ.x;
}
...
}
光栅化过绘制:没有逐三角形的剔除,没有硬件HiZ剔除像素,软件HZB来自上一帧,剔除簇而不是像素,基于簇屏幕大小的分辨率。过绘制来自大型簇、重叠簇、聚合体、快速运动,过绘制成本:小三角——顶点变换和三角形设置边界,中等三角形——像素覆盖测试边界,大三角形——原子约束。
小实例:当整个网格只覆盖几个像素时会发生什么?DAG以1个根簇结束,128个三角形,停止分辨率缩放。太小的时候剔除?如果结构化成块则不能。显然需要在某个时候合并,即使渲染按次线性扩展,内存也不会。实例内存积累得很快,10M * float4X3 = 457MB,未来所需的分层实例化,实例的实例的实例。Nanite没有合并的特殊解决方案,合并的唯一代理必须在极端距离处替换实例,关键的改进是将这段距离推远。
可见性缓冲区替代物(imposter):atlas中12 x 12的视图方向,XY图集位置八面体映射到视图方向,抖动方向量化。每个方向12 x 12个像素,正交投影,适用于网格AABB的最小范围,8:8的深度和三角形ID,每个网格40.5K始终驻留。光线行进以调整方向之间的视差,由于视差小,只需几步,直接从实例剔除通道中绘制,绕过可见实例列表,想换个更好的方法。

接下来聊延迟材质评估。
材质ID:这个像素是什么材质的?VisBuffer解码:
- VisibleCluster => InstanceID、ClusterID。
- ClusterID+TriangleID => MaterialSlotID。
- InstanceID+MaterialSlotID=>MaterialID。

材质着色:每种独特材质的全屏四边形,跳过与此材质ID不匹配的像素,CPU不知道某些材质是否没有可见像素,无论如何都会发出材质绘制调用,GPU驱动的不幸副作用。如何有效地做?不要测试每个像素是否匹配每个材质通道的材质ID。
材质剔除:模板测试?不想为每种材质重置。可以利用深度测试硬件,材质ID->深度值。构建材质深度缓冲区,CS还为两个深度缓冲区输出标准深度和HTILE,对于所有材质:绘制全屏四边形,quad的Z=材质深度,深度测试设置为等于。

UV导数:仍然是一个连贯的像素着色器,所以有有限差分导数。像素quad跨度(三角形),好!也跨越深度间断、UV接缝、不同的物体(不好!)。解析导数:计算解析导数,三角形上的属性梯度,利用链式规则在材质节点图中传播,如果导数不能用解析的方法计算,回到有限差分,用于使用SampleGrad对纹理进行采样。额外成本微乎其微,<2%的材质通道成本,仅影响纹理采样的计算,虚拟纹理代码已经完成了SampleGrad。

管线数字:
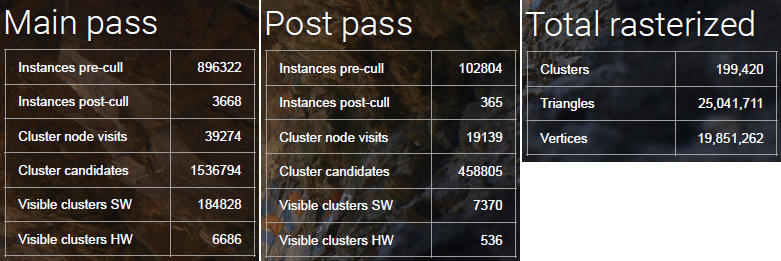
性能:上采样到4k*均约2496x1404,当时使用TAAU,现在使用TSR。约2.5ms以绘制整个VisBuffer,查看+GPU场景=>完成VisBuffer,几乎零CPU时间。约2ms的延迟材质通道,VisBuffer=>GBuffer,CPU成本低,每种材质1次绘制。
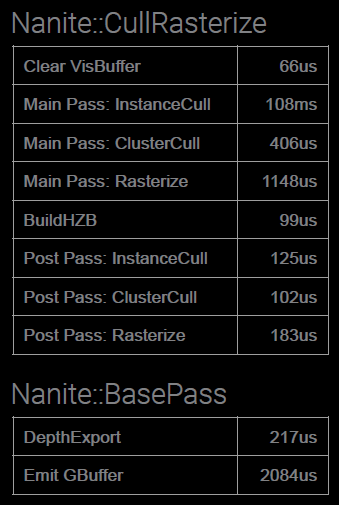
接下来聊Nanite的阴影。Nanite的阴影用光线追踪?DXR不够灵活,复杂的LOD逻辑,自定义三角形编码,没有部分BVH更新。想要光栅解决方案,利用所有的其它工作,大多数灯都不移动,应该尽可能多地缓存。
虚拟阴影图:Nanite使新技术成为可能,16k x 16k阴影贴图无处不在,聚光灯用1x投影,点光源用6倍立方体,*行光用Nx clipmap。选择mip级别,其中1纹素=1像素,仅渲染可见的阴影图像素,按LOD需求的Nanite剔除和LOD。

页面大小=128 x 128,页表=128 x 128,带mip。标记需要的页面,屏幕像素投影到阴影空间,选择mip级别,其中1 texel=1像素,标记那一页。为所有需要的页面分配物理页面,如果缓存页面已经存在,请使用该页面,如果没有缓存则无效,从需要的页面掩码中删除。

多视图渲染:具有显著同步开销的深层管线,NumShadowViews = NumLights x NumShadowMaps x NumMips,可以同时剔除和光栅化不同的视图,以分摊成本,使用视图id标记元素。
剔除和寻址页面:如果不重叠所需页面,则进行剔除,与HZB试验类似。软件光栅逐重叠页面发出簇,硬件光栅在原子写入前逐像素的页表间接寻址。

Nanite阴影LOD:使用1 texel=1像素渲染页面,与屏幕像素成比例的NumPages,LOD匹配<1个像素的误差,与阴影像素成比例的numtriangle。阴影成本与分辨率成正比!而不是场景的复杂性,和每像素的光源数量成正比。
接下来聊流(streaming)。虚拟几何,固定内存预算下的无限几何体。概念上类似于虚拟纹理,GPU请求所需的数据,CPU完成了填充, 独特的挑战。在运行时将DAG剪切为仅加载的几何图形,必须始终是完整DAG的有效切割,类似于LOD切割,没有裂缝!
流单元:簇可以与任何父簇重叠,Rendering cluster=>所有父级都不应渲染,父节点没有被渲染=>所有兄弟姐妹(或其后代)都需要渲染以填充孔洞,需要完整的组才能渲染组中的簇。应该在组粒度上进行流,几何体的大小是可变的,使用固定大小的页面以避免内存碎片 => 每页可变的几何体数量。
分页:用组填充固定大小的页面,基于空间局部性以最小化运行时所需的页面。根页面的第一页包含DAG的顶层,总是常驻,所以总是有东西要渲染。页面内容:索引数据、顶点数据、元数据(边界、LOD信息、材质表等),驻留页面存储在一个大的GPU页面缓冲区中。
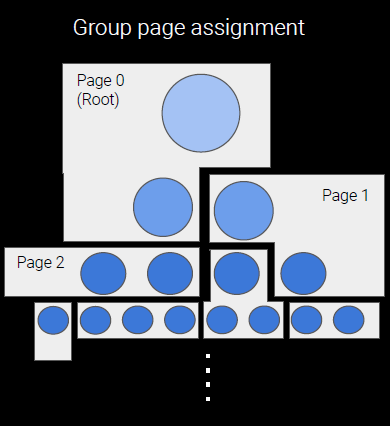
对于分组部件,松散的:簇很小(约2KB),组可以很大(8-32个集群),如果分配整个组,则会出现明显的松弛。拆分组:组可以跨越多个连续页面,根据内存使用情况在簇粒度上进行拆分,在装载所有部件之前,未激活组,页面现在以簇粒度(约2KB)填充,约*均每页1KB的空闲时间!(128KB页面约有1%的空闲时间)
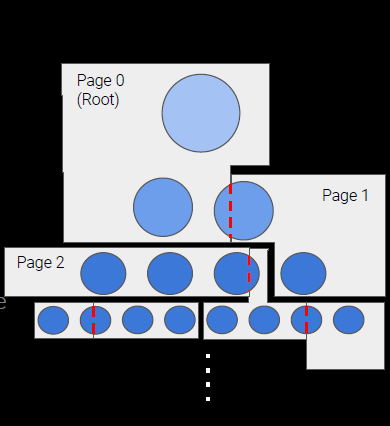
决定流的内容:对于虚拟纹理而言容易,直接由UV和渐变/LOD级别给出。对于Nanite,需要层次遍历,找到本应绘制的簇,需要超越流式切割。完全剔除层次结构始终驻留,关于簇组的元数据(微小),遍历可以超出加载的级别,立即要求达到目标质量所需的所有级别。
流请求:持久着色器在剔除遍历期间输出页面请求,根据LOD误差请求具有优先级的页面范围,更新已加载页面的优先级。请求的异步CPU回读:添加任何缺少的DAG依赖项,对总优先级最高的页面发出IO页面请求,逐出低优先级页面。处理已完成的IO请求:在GPU上安装页面,修复GPU侧指针,修复指向新加载/卸载页面中的组的指针,修复指向已完成或不再完成的拆分组的指针,将簇标记/取消标记为叶子。
接下来聊压缩。有两种表示:内存表示和磁盘表示。内存表示:直接用于渲染,*即时解码时间,需要支持从可见性缓冲区进行随机访问,量化和位压缩,目标是节省内存和/或带宽。磁盘表示:当数据流入时,转码到内存表示,能够承受更高的解码成本,不需要随机访问,假设数据将由(硬件)基于字节的LZ压缩,目标是减少压缩磁盘大小。
顶点量化与编码:全局量化,艺术家控制和启发的结合,簇以局部坐标存储值,相对于最小值/最大值范围。每簇自定义顶点格式,使用每个组件的最小位数:ceil(log2(range)),顶点比特流需要解码顶点声明,只是一串位,甚至没有字节对齐。使用GPU位流读取器解码:不同格式=>每次读取时重新填充?读取指定读取大小的编译时界限,仅当累计编译时读取大小溢出时重新填充。
顶点位置:不一致的量化会导致裂缝!对于单个对象容易避免,如何避免物体之间的裂缝?用模块构建标高几何图形的常用方法。量化到对象空间网格:每物体2N次方的绝对指数(例如1/16cm),以对象原点为中心,不要标准化到边界。在以下情况下,顶点落在同一网格上:量化级别是相同的,对象之间的*移也是步长的倍数。只有叶子级别是完全对齐的,简化决策在对象之间不一致,运行时LOD决策不同步。
隐式切线空间:0位!切线/副切线是视图空间法线*面中的U/V方向,推导出它们!类似于屏幕导出的切线空间(Mikkelsen),直接在三角形坐标上计算,而不是使用屏幕ddx/ddy,重用已为材质通道中的重心和纹理LOD计算而计算的局部三角形uv/位置三角形。传统的显式切线坐标是通过邻域*均来计算的,对于高多边形网格不太重要。
材质表:每个簇存储材质表,指定材质指定的三角形范围,两个编码别名相同的32位,快速路径编码3个范围,慢路径指向内存,最多64种材质。
磁盘表示:硬件LZ解压,在游戏机里,在使用DirectStorage的PC上,速度惊人,用途广泛,字符串重复数据消除和熵编码。为了更好地压缩:特定于域的转换,假设数据将被LZ压缩,关注LZ尚未捕获的冗余,转换成更可压缩的格式。
GPU转码:在GPU上进行代码转换,并行转换的高吞吐量,只要是并行的,每个字节都有大量(异步)计算,目前运行速度约为50GB/s,PS5上的代码相当未优化,最终将数据直接传输到GPU内存。结合硬件LZ功能强大,LZ处理串行熵编码和字符串匹配工作,可能会成为这一代人的共同模式。Nanite:GPU有上下文,页面可以引用父页面中的数据,而无需CPU拷贝。
Lumen in the Land of Nanite的结果:4.33亿个输入三角形,8.82亿个Nanite三角形,原始数据:25.90GB,全浮点、字节索引、隐式切线,内存格式:7.67GB,压缩:6.77GB,压缩磁盘格式:4.61GB, 自EA版本以来改善了约20%,每个Nanite三角形5.6字节,每个输入三角形11.4字节,1百万个三角形=磁盘上约10.9MB。
关于Nanite的源码剖析,可参见:剖析虚幻渲染体系(06)- UE5特辑Part 1(特性和Nanite)。
14.5.4.9 Radiance Caching
Radiance Caching for real-time Global Illumination由Epic Games的Daniel Wright呈现,讲述了UE5 Lumen的实时全局光照实现技术——辐射率缓存(Radiance Caching)。Radiance Caching是Lumen中使用的最终收集技术,针对下一代游戏机上的游戏,在高端PC上提升为质量第一的企业。光线追踪很慢,存在二级BVH、非相干树遍历、实例重叠等问题:
每像素只能提供1/2光线,但高质量的GI需要数百个!

以往的实时研究有辐照度场(Irradiance Fields)、屏幕空间降噪器(Screen Space Denoiser)等方式。而Lumen使用了屏幕空间降噪器(Screen Space Radiance Caching)。
下采样入射辐射,入射光是相干的,而几何法线不是,以全分辨率积分BRDF上的输入照明:

在辐射缓存空间中过滤,而不是屏幕空间(下图左)。首先要进行更好的采样——重要的是对入射光进行采样(下图中)。稳定的远距离照明和世界空间辐射缓存(下图右)。
最终收集管线:
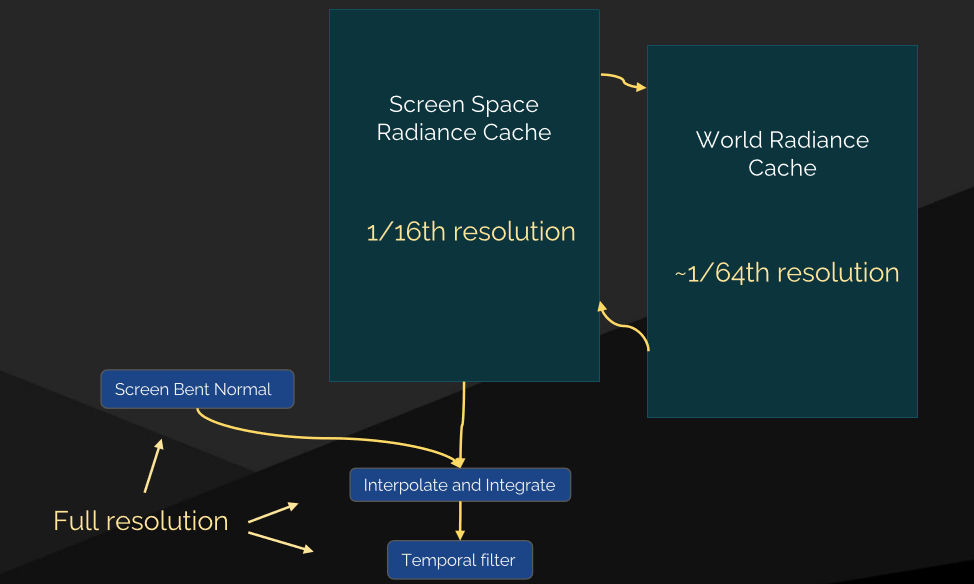
其中屏幕空间的辐照率缓存可以细分成以下阶段:
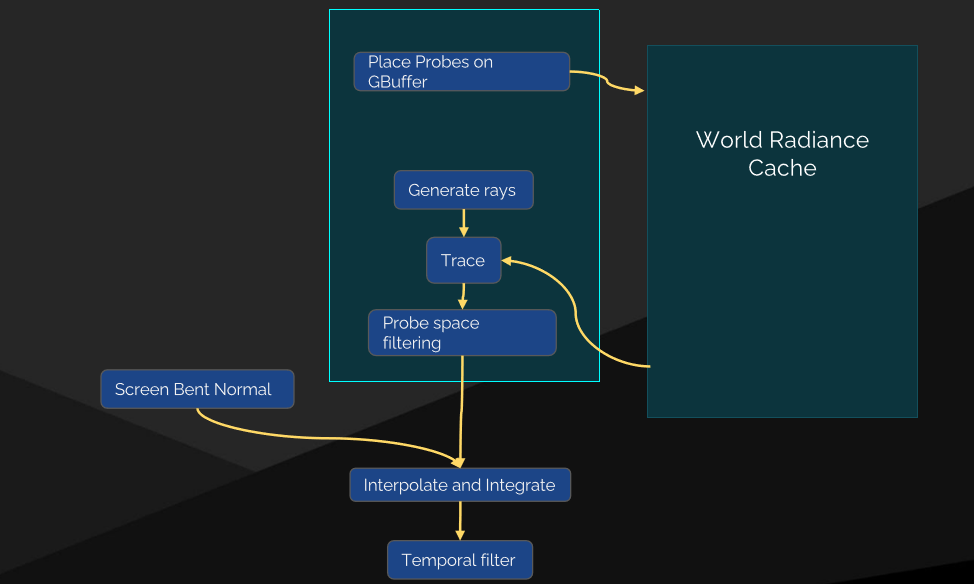
屏幕探针结构体:带边框的八面体图集,通常每个探针8x8个,均匀分布的世界空间方向,邻域有相同的方向,二维图集中的辐射率和交点距离。

屏幕探针放置:分层细化的自适应布局[Křivánek等人2007],迭代插值失败的地方,最终级别的地板填充(Flood fill)。

自适应采样:实时性需要上限,不希望在处理自适应探头时遇到额外障碍,将自适应探头放在图集底部。
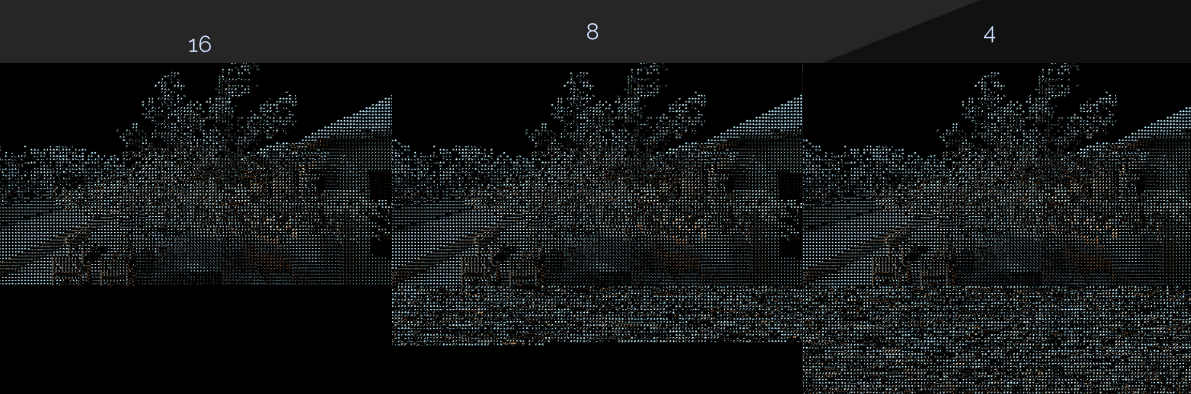
屏幕探针抖动:时间抖动放置网格和方向,直接放置在像素上,没有泄露,屏幕单元格内的遮挡差异必须通过时间过滤来隐藏。
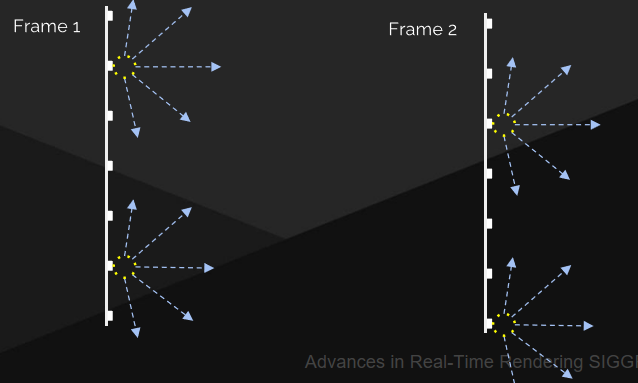
插值:*面距离加权,防止前台未命中泄漏到后台,插值中的抖动偏移,只要还在同一个*面上,在空间上分布探针之间的差异,通过扩展TAA 3x3的邻域达到时间稳定最终照明。
重要性采样:对于入射辐射率\(L_i(l)\),重投射最后一帧的屏幕探针的辐射率!不需要做昂贵的搜索,光线已按位置和方向索引,回退到世界空间探针上。对于BRDF,从将使用此屏幕探针的像素累积,更好的是,希望采样与入射辐射率\(L_i(l)\)和BRDF的乘积成比例。
结构重要性采样(Structured Importance Sampling):将少量样本分配给概率密度函数(PDF)的层次结构区域[Agarwal等人2003],实现良好的全局分层,样本放置需要离线算法。
完美地映射到八面体mip四叉树!

集成到管线中:向追踪线程添加间接路径,存储RayCoord、MipLevel,追踪后,将TraceRadiance组合进均匀的探头布局,以进行最终集成。

光线生成算法:计算每个八面体纹理的BRDF的PDF x 光照的PDF,从均匀分布的探针射线方向开始,需要固定的输出光线计数-保持追踪线程饱和。按PDF对光线进行排序,对于PDF低于剔除阈值的每3条光线,超级采样以匹配高PDF光线。

改进:不允许光照PDF来剔除光线,光照PDF为*似值,BRDF为精确值,借助空间过滤可以更积极地进行剔除,具有较高BRDF阈值的剔除,在空间过滤过程中减少剔除光线的权重,修复角落变暗的问题。

重要性采样回顾:使用最后一帧的光照和远距离光照引导此帧的光线,将射线捆绑到探针中可以提供更智能的采样。
接下来聊空间过滤的技术。
辐射缓存空间中的过滤:廉价的大空间滤波,探针空间为\(3^2\),屏幕空间为\(48^2\),可以忽略空间邻域之间的发现差异,仅深度加权。从邻域收集辐射率:从相邻探针中匹配的八面体单元收集,误差权重:重投影的相邻射线击中的角度误差,过滤远处的灯光,保留局部阴影。
对于*坦表面的效果是良好的,但对于几何接触的地方,存在漏光的问题:

保持接触阴影:角度误差偏向远光=泄漏,远距离光没有视差,永远不会被拒绝。解决方案:在重投影之前,将邻域的命中距离夹紧到自己的距离。

接下来聊世界空间的辐射缓存。
远距离光存在问题,微亮特征的噪点随着距离的增加而增加,长而不连贯的追踪是缓慢的,远处的灯光正在缓慢变化——缓存的机会,附*屏幕探针的冗余操作。解决方案:对远距离辐射进行单独采样。用于远距离照明的世界空间辐射缓存(The Tomorrow Children [McLaren 2015]的技术),自世界空间以来的稳定误差-易于隐藏,就像体积光照图一样。
管线集成:在屏幕探针周围放置,然后追踪计算辐射,插值以解决屏幕探测光线的远距离照明。
避免自光照:世界探针射线必须跳过插值足迹。
连结光线:屏幕探针光线必须覆盖插值足迹+跳过距离。
还存在漏光的问题。世界探针的辐射应该被遮挡,但不是因为视差不正确。
解决方案:简单的球面视差。重投影屏幕探针光线与世界探针球相交。
稀疏覆盖:以摄像头为中心的3d clipmap网格将探针索引存储到图集中,Clipmap分布保持有限的屏幕大小。

图集:八面体探针图谱存储辐射、追踪距离,通常每个探针为32x32的辐射率。

放置和缓存:标记将在后面的clipmap间接中插入的任何位置,对于每个标记的世界探针:重用上一帧的追踪,或分配新的探针索引,重新追踪缓存命中的子集以传播光照更改。
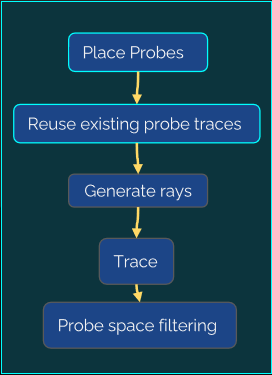
问题:高度可变的成本,快速的摄像机移动和不连续需要追踪许多未经缓存的探针。解决方案:全分辨率探针的固定预算,缓存未命中的其它探针追踪的分辨率较低,跳过照明更新的其它探针追踪。
重要性采样。BRDF的重要采样:从屏幕探针累积BRDF,切块(Dice )探针追踪分块,根据BRDF生成追踪分块分辨率。超采样*的相机,高达64x64的有效分辨率,4096条追踪!非常稳定的远距离照明。
探针之间的空间过滤:再次拒绝邻域交点,问题是不能假设相互可见性。理想情况下,通过探测深度重新追踪相邻射线路径,单次遮挡试验效果良好,几乎免费-重复使用探针深度。
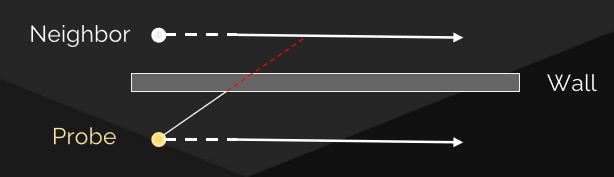

世界空间辐射缓存还用于引导屏幕探针重要性采样、头发、半透明、多反弹。
回到积分,现在已经在屏幕空间的辐射缓存中以较低的分辨率计算了入射辐射,需要以全分辨率进行积分,以获得所有的几何细节。

重要性采样BRDF会导致不一致的获取,8spp*4相邻探针方向查找,可以使用mips(过滤重要性采样),但会导致自光照[Colbert等人2007],尤其是在直接照明区域周围。将探针辐射转换为三阶球谐函数:SH是按屏幕探针计算的,全分辨率像素一致地加载SH,SH低成本高质量积分[Ramamoorthi 2001]。

粗糙镜面:高粗糙度下的光线追踪反射,在漫反射上聚集。重用屏幕探针:从GGX生成方向,采样探针辐射,自动利用已完成的探针采样和过滤!下采样追踪会丢失接触阴影。全分辨率弯曲法线:使用快速屏幕追踪进行计算,与屏幕探针之间的距离耦合的追踪距离:约16像素。与屏幕空间辐射缓存积分:将屏幕探针GI视为远场辐照度,全分辨率弯曲法线表示*场的数量,基于水*的间接照明[Mayaux 2018],多重反弹*似给出*场辐照度。
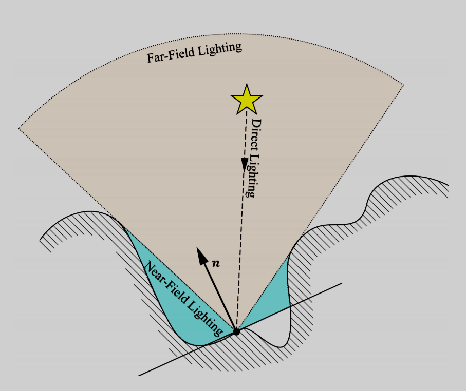

时间过滤:抖动探针位置需要可靠的时间过滤,使用深度剔除,结果稳定,但对光线变化的反应也很慢。追踪过程中追踪命中速度和命中深度,属于快速移动对象的投影面积。当追踪击中快速移动的对象时,切换到快速更新模式,降低时间过滤,提高空间过滤。

最终收集性能:
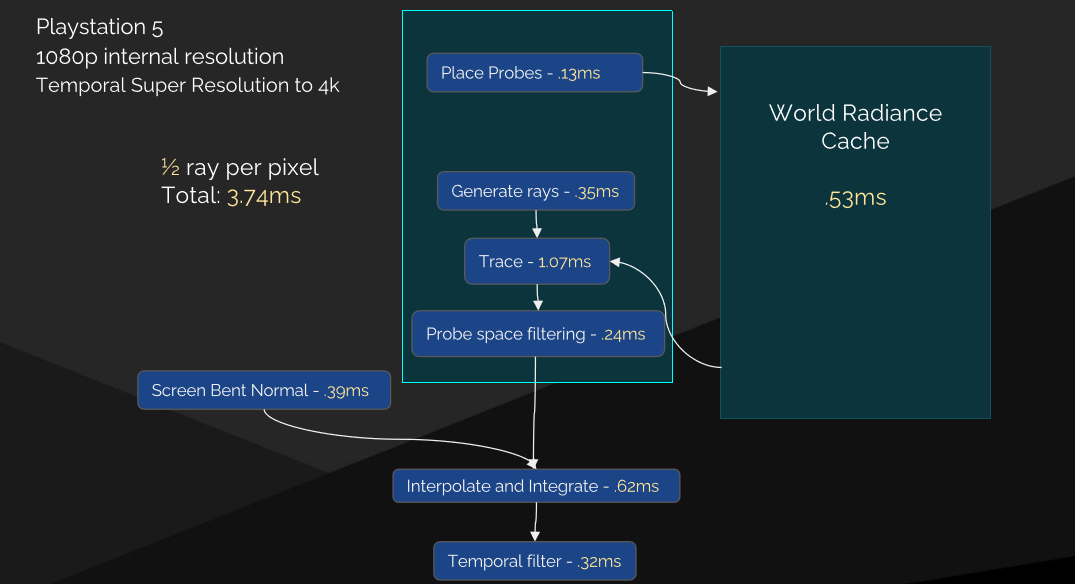
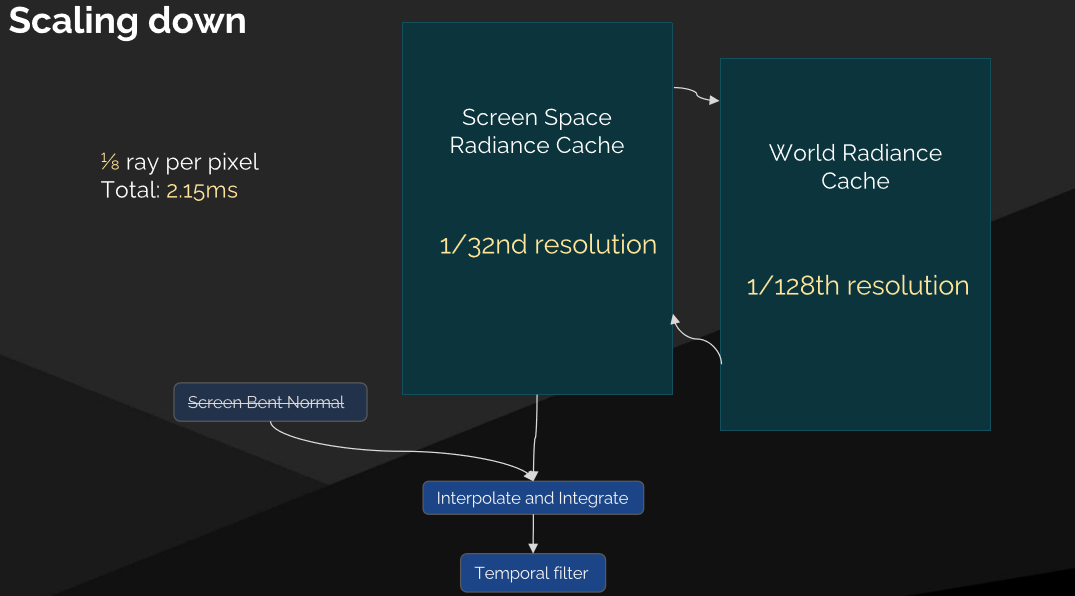

未来的工作是去遮挡质量、高动态场景中的时间稳定性、将屏幕空间辐射缓存应用于Lumen的表面缓存以实现多反弹GI。Radiance Cache只是Lumen的一小部分技术,Lumen还涉及表面缓存、软件射线追踪、硬件光线追踪、反射、透明GI等内容。关于Lumen的源码剖析可参见:剖析虚幻渲染体系(06)- UE5特辑Part 2(Lumen和其它)。
14.5.4.10 Surfels GI
Global Illumination Based on Surfels讲述了EA内部引擎使用面元来实现实时全局光照的技术。“基于曲面(GIB)的全局照明”是一种实时计算间接漫反射照明的解决方案。该解决方案将硬件光线跟踪与场景几何体的离散化相结合,以跨时间和空间缓存和分摊照明计算。它不需要预先计算,不需要特殊的网格,也不需要特殊的UV集。GIBS支持高保真照明,同时可容纳任意比例的内容。“

基于面元(surfel)全局光照的面元可视化。
该文演讲的内容包含Surfel离散化、非线性加速度结构、辐照度积分技术、颜色溢出缓解、多光源采样、透明度等。首先要弄清楚面元的概念,Surfel=表面元素(Surface Element),一个surfel由位置、半径和法线定义,并*似了给定位置附*表面的一个小邻域。
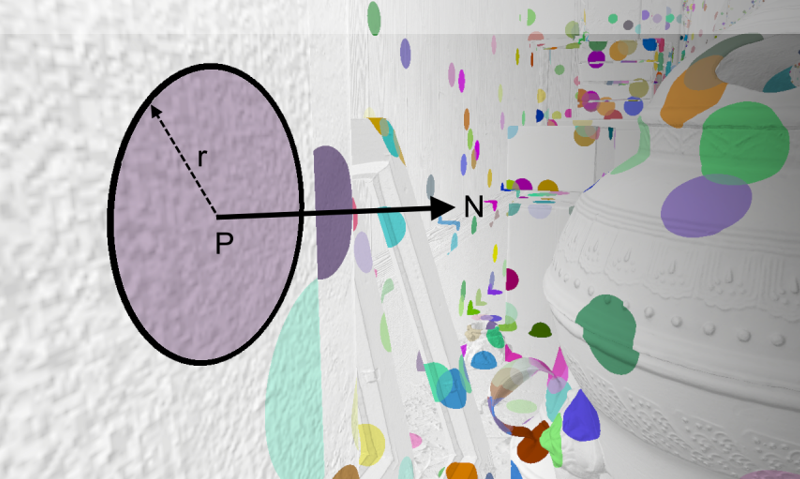
场景的面元化:从GBuffer中生成面元,当几何图形进入视图时填充屏幕,在世界空间中持久存在,累积和缓存辐照度。迭代屏幕空间填充,将屏幕拆分为16x16块,找到覆盖率最低的tile,应用面元覆盖率和追踪权重,如果tile超过随机阈值,则生成surfel。

除了支持刚体,还支持蒙皮骨骼的面元化。由于所有东西都假设是动态的,所以蒙皮几何体和移动几何体都与解决方案的其余部分交互,就像静态几何体一样。

面元根据屏幕空间投影进行缩放,生成算法确保覆盖范围在任何距离,由非线性加速度结构支撑。

面元管理:所有东西都有固定大小的缓冲区,可预测的预算,固定数量的面元,固定的加速度结构,回收未使用的面元。
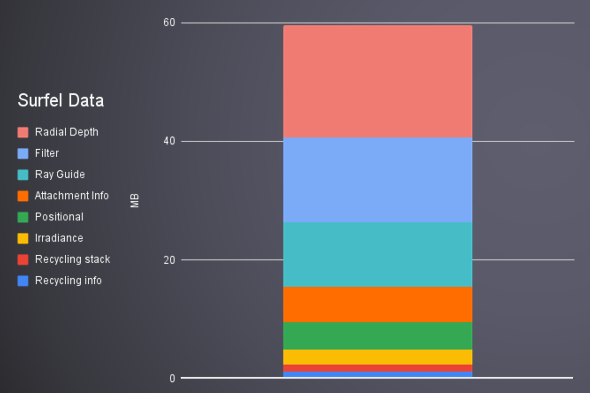
回收启发式:让相关的面元保持活跃,最后一次见到时追踪,如果在间隙检测期间看到,则重置,位置更新期间增加。启发式基于激活的面元总数、自从见过的时间、距离、覆盖率。下图是距离启发式:
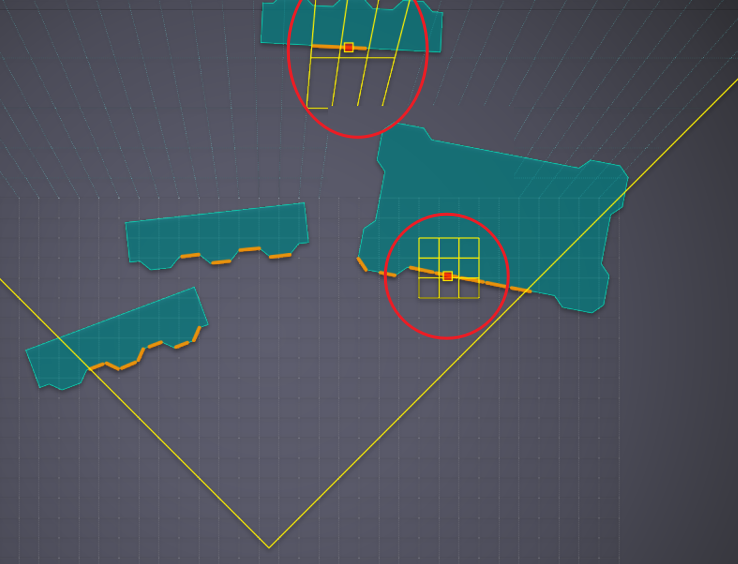
光照应用:对每个像素:查找表面网格单元,从单元格里取N个面元,累积表面辐照度,按距离和法线加权,如果辐照度权重<1,则添加加权的*均单元格的辐照度。存在光照溢出的问题,使用径向高斯深度来解决:

修复前后对比:

积分辐照度图示:
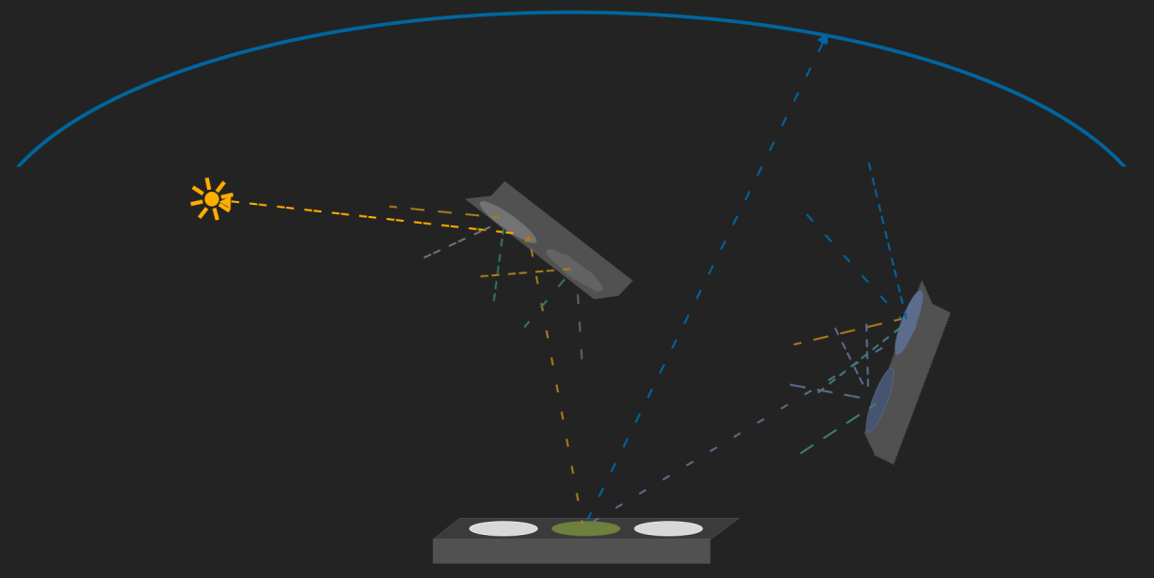
积分器:修正指数移动*均估值器[BarréBrisebois2019],跟踪短期均值和方差估计值,使用短期估计器调整混合因子,使我们能够快速响应变化,同时收敛到低噪点。基于短期方差的偏差光线计数,使用射线计数通知相对置信度的多尺度均值估计器,反馈回路对变化和变化做出快速反应,在稳定的情况下保持光线计数小。
BRDF的重要性采样:累积漫反射辐照度,假设是兰伯特BRDF,通过对余弦叶进行重要采样来生成光线。
射线引导:
每个surfel在其半球上生成一个移动*均6x6亮度图,存储在单个4K纹理中(可支持所有surfels的7x7),每个纹理8位+每个纹理单个16位缩放,规范化每帧函数。
有了重要性采样变量,函数的每个离散部分都将根据其值按比例选取,还有它的概率密度函数,这是函数在那个位置的值。
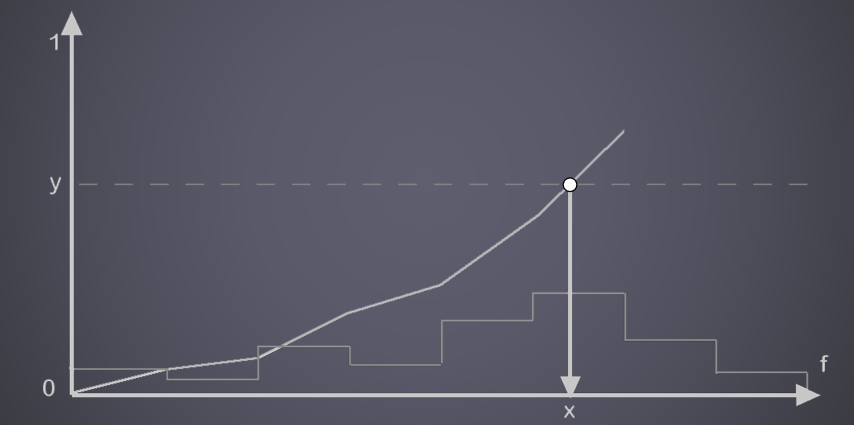
辐照度共享:利用附*的面元数据,允许surfels查找相邻surfels的辐射,结构加速,使用与surfel VPL相同的权重,Mahalanobis 距离、深度函数。
辐照度共享前后对比:

还可以使用BF5方法对光线进行排序,按位置和方向排列的箱射线,12位表示空间,4位表示方向,空间散列的单元定位,射线方向定向,计算箱子总计数和偏移量,根据光线索引和以前计算的面元偏移对光线重新排序。
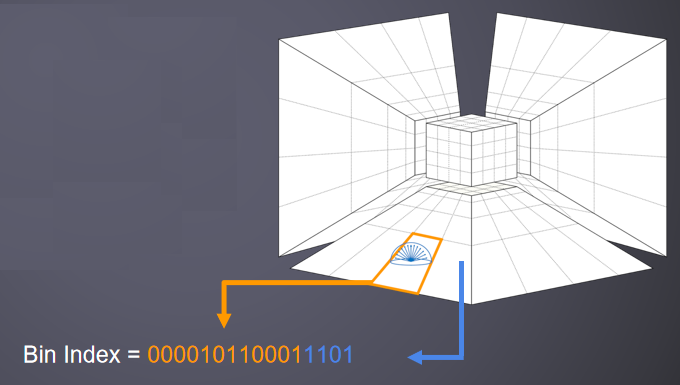
多光源采样使用了重要性采样(随机光源分割、储备采样)。随机光源切割是小样本快速收敛,需要预先构建的数据结构,采样可能开销很大。
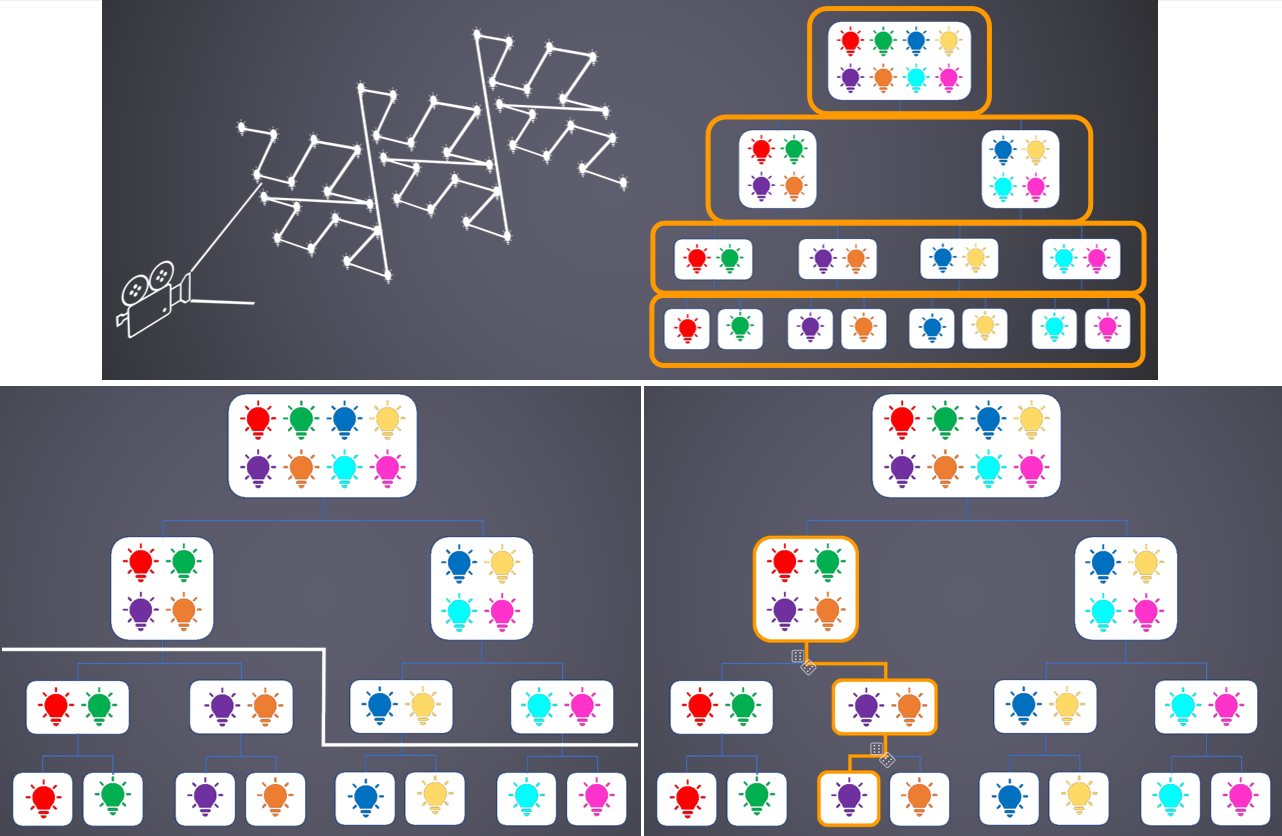
蓄水池采样(Reservoir Sampling)示意图:
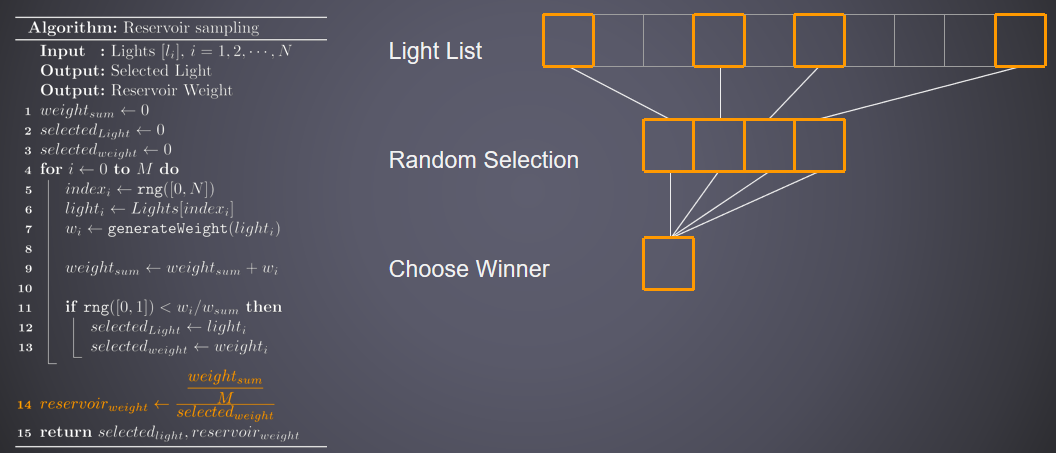
光线追踪探针示意图:
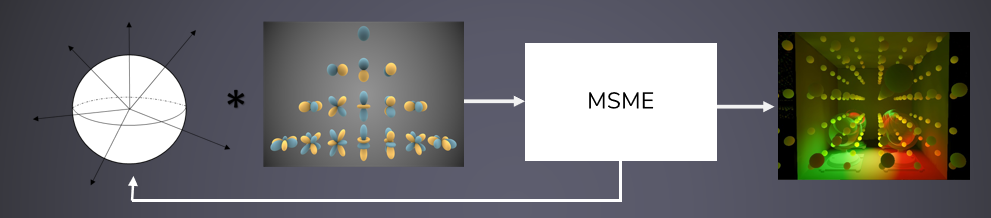
RT探针体积结构:透明对象需要大屏幕支持,例如不透明对象,Clipmap是满足需求的最佳选择:保持*距离的细节,支持大规模场景,具有低内存成本的稀疏探针放置,LOD的变速率更新。
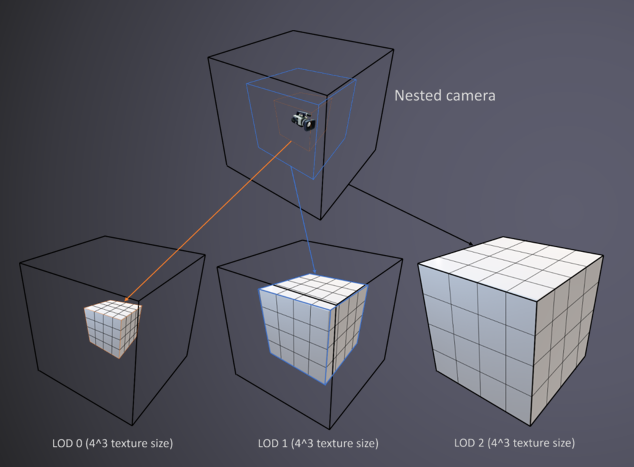
Clipmap更新算法:计算更新方向和距离,复制移位后有效的探针数据,用更高级别的探针初始化新创建的探针。
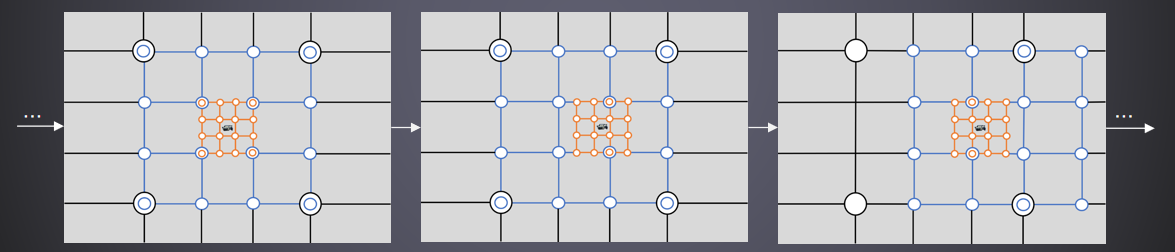
4级clipmap的放置示意图:

Clipmap采样过程如下:
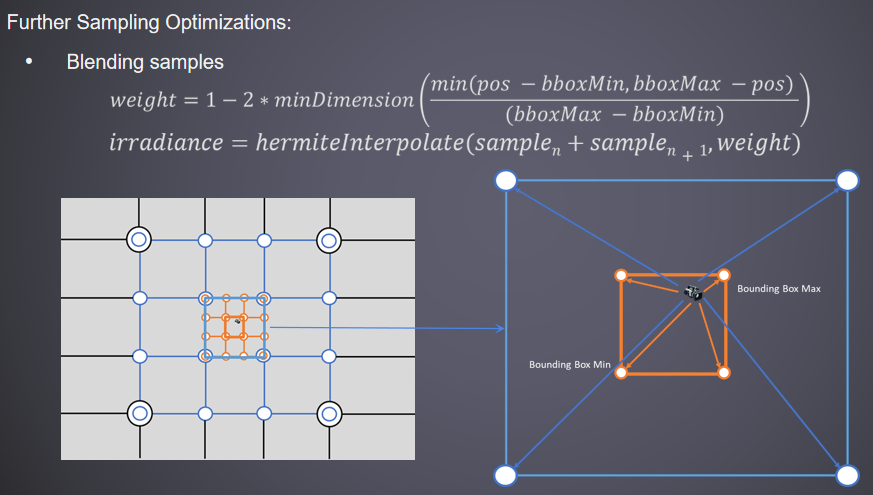
进一步的采样优化:蓝色噪声梯度抖动采样。

一帧概览:
- 持续的。位置更新,回收利用,网格分配,射线排序,光线追踪,Clipmap更新,探针追踪。
- 创建。几何法线重建,空隙填充,射线排序,光线追踪,写入持久存储,写入探针体积。
- 过滤。空间降噪,时间降噪。
- 应用。注入新的创建,应用照明(以四分之一区域分辨率运行),照明上采样,Clipmap采样。
14.5.5 结果期总结
CPU和GPU的总计算能力和并行度都有了显著的提升,各类省电、高性能的架构、部件和管线诞生,例如多核、TBDR、HSR、FPK、RT Core等等。
游戏引擎向着更加逼真、可信度、影视级效果发展,各类实时的全局光照计算层出不穷,最为突出的是基于硬件的光线追踪和UE5的Nanite和Lumen。现代图形API的诞生和发展,给游戏引擎带来了新的机会,使得游戏引擎有了更大的发挥空间,从而也催生了基于渲染图的中间层渲染计算,也使得渲染画质迈向新的高度。
各类渲染技术(如AA、地形、物理、景观模拟、特殊材质等)的出现,为游戏引擎和游戏开发团队提升了扎实的动力。
移动端、XR、云渲染、Web端等分支也得到了充分的发展,成为行业丰富生态的重要组成部分。
14.6 本篇总结
14.6.1 游戏引擎的未来
未来将实现和普及一个场景一次绘制调用。GPU管线命令序列几乎每帧不变,命令不会根据场景结构进行更改,绘制调用的数量可预测且合理较低,可管理的最大索引缓冲区大小,最糟糕的内存开销约为6%,在嵌套命令列表中记录所有可能损害的GPU管线命令。
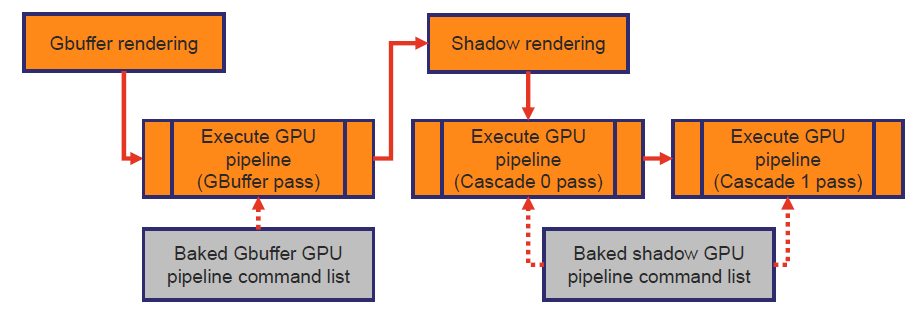
设备生成的命令。有条件地编写GPU管线命令的可能性,GPU上的PSO选择更具灵活性,基于运行时条件,通过编译时优化切换PSO的可能性,避免空牵引链的可能性,减少了保留内存大小。
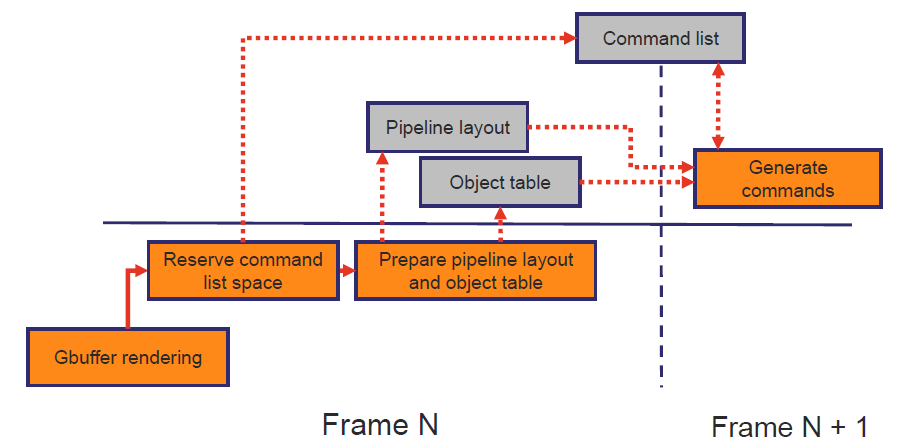
此外,硬件和引擎的架构更加完善、全面,工具链更加人性化、自动化、智能化,光线追踪逐渐普及,视觉效果更加逼真、绚丽。PBR更加彻底,并引入纳米级的光照模型,如干涉、色散、衍射、叠加、焦散等等。AI的融合更广泛、普遍,并行化、多GPU、多设备逐渐普及。GPU-Driven、离线技术实时化、其它分支充分发展,渲染调试工具更加完善、智能、可视化。
免责声明:以上纯凭经验预测,不具备权威性。
14.6.2 结语
本篇是笔者撰写的所有文章中,参考文献最多的一篇,达到540多篇。在整理参考文献之前,参阅了1000多篇各类文献,即便如此,笔者尚以为这只是图形渲染技术和游戏引擎技术的冰山一角。
很多技术深深刻着时代的烙印,但也很多技术突破时代的枷锁,即便过去数十年,依然历久弥新,流传于当今主流的引擎之中。如同历史一样,技术演进的轮回一直在上演着,从未间断。
本篇从规划到完成,耗费*半年,总字数达到43万多,参考文献达到540多,配图达到3400多,蕴含了*几十年来实时渲染领域的主要研究和应用成果,信息密度高,总量也大。所以,童鞋们学fei了吗O_O?发量可还健在?(反正博主先掉为敬,童鞋们随意~)
特别说明
- 感谢所有参考文献的作者,部分图片来自参考文献和网络,侵删。
- 本系列文章为笔者原创,只发表在博客园上,欢迎分享本文链接,但未经同意,不允许转载!
- 系列文章,未完待续,完整目录请戳内容纲目。
- 系列文章,未完待续,完整目录请戳内容纲目。
- 系列文章,未完待续,完整目录请戳内容纲目。
参考文献
- Unreal Engine Source
- Rendering and Graphics
- Materials
- Graphics Programming
- Unreal Engine 2 Documentation
- Unreal Engine 3 Documentation
- Game engine
- List of game engines
- Game Engine Architecture
- Game Engine Architecture Third Edition
- Game Engine Architecture Course
- Welcome to CS1950u!
- Game Engine Fundamentals
- Designing the Framework of a Parallel Game Engine
- 深入GPU硬件架构及运行机制
- 由浅入深学习PBR的原理和实现
- 剖析Unreal Engine超真实人类的渲染技术Part 1 - 概述和皮肤渲染
- 剖析Unreal Engine超真实人类的渲染技术Part 2 - 眼球渲染
- 剖析Unreal Engine超真实人类的渲染技术Part 3 - 毛发渲染及其它
- Playstation 2 Architecture
- Procedural Rendering on Playstation® 2
- Independent Game Development
- CryEngine Sandbox Far Cry Edition
- Information Visualisation utilising 3D Computer Game Engines
- Using Commonsense Reasoning in Video Games
- GeForce 6 series
- List of game engines
- 3D Game Engine Architecture
- 《黑神话:悟空》12分钟UE5实机测试集锦
- Unreal Engine
- 虚幻引擎
- FROM ABSTRACT DATA MAPPING TO 3D PHOTOREALISM: UNDERSTANDING EMERGING INTERSECTIONS IN VISUALISATION PRACTICES AND TECHNIQUES
- Game Developer - October 2005
- Torque Tutorial #2
- Game Engine Tutorials:Chapter 1 - Introduction
- Unreal Engine 3 Technology
- Using the Source Engine for Serious Games
- Designing a Modern Rendering Engine
- Finding Next Gen – CryEngine 2
- CryENGINE 3 Game Development Beginner's Guide
- GPU overview Graphics and Game Engines
- 3dfx Interactive
- RIVA TNT
- DirectX
- Direct3D feature levels
- Feature levels in Direct3D
- High-Level Shader Language
- DirectX 3.0
- Microsoft Ships DirectX Version 3.0
- Microsoft Ships DirectX 5.0
- DirectX 5.0
- Microsoft's Official DirectX 6.0
- Multitexturing in DirectX 6
- Microsoft® DirectX® 7: What's New for Graphics
- GLFW
- OpenGL Related toolkits and APIs
- Nurien Mstar Online - (4minute - Huh) Bubble Item Mode
- GDM_April_2008(Game Developer)
- How To Go From PC to Cross Platform Development Without Killing Your Studio
- “A bit more Deferred” - CryEngine 3
- CryEngine
- Far Cry®
- CryENGINE 2
- Crysis 1 XBOX/PS3
- CryENGINE 3
- CryEngine Features
- The Matrix Awakens: An Unreal Engine 5 Experience
- Hitting 60Hz with the Unreal Engine: Inside the Tech of Mortal Kombat vs DC Universe
- Parallel Graphics in Frostbite – Current & Future
- Frostbite (game engine)
- EA Tech Blog
- irrlicht
- Practical techniques for managing Code and Assets in multiple cross platform titles
- Next-Gen Asset Streaming Using Runtime Statistics
- Light Pre-Pass Deferred Lighting: Latest Development
- The Next Mainstream Programming Language: A Game Developer’s Perspective
- An explanation of Doom 3’s repository-style architecture
- TerraForm3D Plasma Works 3D Engine & USGS Terrain Modeler
- Entity component system
- Entity Component Systems in Unity
- Entity Component System VS Entity Component
- Entities, components and systems
- Redefining Game Engine Architecture through Concurrency
- Tim Sweeney on the first version of the Unreal Editor
- Integrating Architecture Soar Workshop
- Ray Tracing for Games
- Modern Graphics Engine Design
- Ogre Golf
- Selecting the Best Open Source 3D Games Engines
- Theory, Design, and Preparation
- The Benefits of Multiple CPU Cores in Mobile Devices
- GAME ENGINES
- Development of a 3D Game Engine - OpenCommons
- Physically Based Shading Models for Film and Game Production
- Physically Based Shading at Disney
- Real Shading in Unreal Engine 4
- The Game Engine Space for Virtual Cultural Training
- Game Engines
- Quake III Arena Game Structures
- iOS and Android development with Unity3D
- The use cases that drive XNAT development
- Exploiting Game Engines For Fun & Profit
- GAME ENGINES: A 0-DAY’S TALE
- Comparison and evaluation of 3D mobile game engines
- Barotrauma
- Microsoft XNA
- Game Engines
- Game Engines-The Overview
- Multithreading for Gamedev Students
- A History of the Unity Game Engine
- A brief insight into BRTECH1
- CRYENGINE 5.3 - Getting Started Guide
- The architecture and evolution of computer game engines
- Designing a Modern GPU Interface
- Game Engine Programming
- DX12 & Vulkan Dawn of a New Generation of Graphics APIs
- GPU-Driven Rendering Pipelines
- Limitation to Innovation in the North American Console Video Game Industry 2001-2013: A Critical Analysis
- The 4+1 View Model of Architecture
- Architectural Blueprints—The “4+1” View Model of Software Architecture
- Serious Games Architectures and Engines
- Game Engine Solutions
- Remote exploitation of the Valve Source game engine
- Game Engines - Computer Science
- High quality mobile VR with Unreal Engine and Oculus
- The Report by the written by Amanda Wong funded by the July 2017
- Entity Component Systems & Data Oriented Design
- A Taxonomy of Game Engines and the Tools that Drive the Industry
- Torque 3D Documentation
- Comparative Study on Game Engines
- MOBILE GAME DEVELOPMENT
- Evaluation of CPU and Memory performance between Object-oriented Design and Data-oriented Design in Mobile games
- Efficient generation and rendering of tube geometry in Unreal Engine
- Global Illumination Based on Surfels
- Radiance Caching for real-time Global Illumination
- BigWorld
- Ubisoft Anvil
- Destiny Game Engine: Tiger
- Multithreading the Entire Destiny Engine
- Lessons from the Core Engine Architecture of Destiny
- Destiny 2: Tiger Engine Changes
- Destiny
- Destiny 2
- RE Engine
- Rockstar Advanced Game Engine
- NVIDIA DLSS
- OpenGL
- OpenGL ES
- Tone Reproduction and Physically Based Spectral Rendering
- A Framework for an R to OpenGL Interface for Interactive 3D graphics
- Beyond Finite State Machines Managing Complex, Intermixing Behavior Hierarchies
- Game Mobility Requires Code Portability
- Challenges in programming multiprocessor platforms
- Adding Spherical Harmonic Lighting to the Sushi Engine
- Real World Multithreading in PC Games Case Studies
- Speed up the 3D Application Production Pipeline
- New 3D Graphics Rendering Engine Architecture for Direct Tessellation of Spline Surfaces
- A realtime immersive application with realistic lighting: The Parthenon
- The Parthenon Demo: Preprocessing and Rea-Time Rendering Techniques for Large Datasets
- Rendering Gooey Materials with Multiple Layers
- Practical Parallax Occlusion Mapping For Highly Detailed Surface Rendering
- Real-time Atmospheric Effects in Games
- Shading in Valve’s Source Engine slide
- Shading in Valve’s Source Engine
- Ambient Aperture Lighting
- Fast Approximations for lighting of Dynamic Scenes
- An Analysis of Game Loop Architectures
- Exploiting Scalable Multi-Core Performance in Large Systems
- Ritual™ Entertainment: Next-Gen Effects on Direct3D® 10
- Feeding the Monster: Advanced Data Packaging for Consoles
- Best Practices in Game Development
- High-Performance Physics Solver Design for Next Generation Consoles
- Collaborative Soft Object Manipulation for Game Engine-Based Virtual Reality Surgery Simulators
- Introduction to Direct3D 10 Course
- Practical Global Illumination with Irradiance Caching
- General-Purpose Computation on Graphics Hardware
- GPUBench
- The Mobile 3D Ecosystem
- Advanced Real-Time Rendering in 3D Graphics and Games
- Frostbite Rendering Architecture and Real-time Procedural Shading & Texturing Techniques
- Saints Row Scheduler
- PCI Express
- The Delta3D Gaming and Simulation Engine: An Open Source Approach to Serious Games
- Software Requirement Specification Common Infrastructure Team
- Dragged Kicking and Screaming: Source Multicore
- OpenGL ES 2.0 : Start Developing Now
- Interactive Relighting with Dynamic BRDFs
- Advances in Real-Time Rendering in 3D Graphics and Games (SIGGRAPH 2008 Course)
- Advanced Virtual Texture Topics
- March of the Froblins: Simulation and rendering massive crowds of intelligent and detailed creatures on GPU
- Using wavelets with current and future hardware
- StarCraft II: Effects & Techniques
- The Intersection of Game Engines & GPUs: Current & Future
- Software Instrumentation of Computer and Video Games
- John Carmack Archive - Interviews
- UnrealScript: A Domain-Specific Language
- GPU evolution: Will Graphics Morph Into Compute?
- Introduction to the Direct3D 11 Graphics Pipeline
- Lighting and Material of HALO 3
- Snakes! On a seamless living world
- Threading Successes of Popular PC Games and Engines
- THQ/Gas Powered Games Supreme Commander and Supreme Commander: Forged Alliance
- Emergent Game Technologies: Gamebryo Element Engine
- Namco Bandai, EA Partner For Hellgate: London
- Project “Smoke” N-core engine experiment
- New Dog, Old Tricks: Running Halo 3 Without a Hard Drive
- Creating believable crowds in ASSASSIN'S CREED
- id Tech 5 Challenges - From Texture Virtualization to Massive Parallelization
- Building a Dynamic Lighting Engine for Velvet Assassin
- Techniques for Improving Large World and Terrain Streaming
- A Novel Multithreaded Rendering System based on a Deferred Approach
- Regressions in RT Rendering: LittleBigPlanet Post Mortem
- Meshless Deformations Based on Shape Matching
- sphere ambient occlusion - 2006
- Insomniac Physics
- State-Based Scripting in Uncharted 2: Among Thieves
- Zen of Multicore Rendering
- Star Ocean 4 - Flexible Shader Managment and Post-processing
- Light Propagation Volumes in CryEngine 3
- [Lighting Research at Bungie](https://advances.realtimerendering.com/s2009/SIGGRAPH 2009 - Lighting Research at Bungie.pdf)
- Precomputed Atmospheric Scattering
- Theory and Practice of Game Object Component Architecture
- Rendering Technology at Black Rock Studio
- NVIDIA Developer Tools for Graphics and PhysX
- Animated Wrinkle Maps
- Terrain Rendering in Frostbite Using Procedural Shader Splatting
- Spherical Harmonic Lighting: The Gritty Details
- Precomputed Radiance Transfer for Real-Time Rendering in Dynamic, Low-Frequency Lighting Environments
- A Gentle Introduction to Precomputed Radiance Transfer
- Spherical harmonics
- Tetris packing [Levy 02]
- Multi-Chart Geometry Images
- Direct3D 11.1 Features
- Direct3D 11.2 Features
- Vulkan
- Metal (API)
- Mantle (API)
- ADVANCED GRAPHICS ENGINE BASED ON THE NEW OPENGL FEATURES
- A High Dynamic Range Rendering Pipeline
- A Real Time Radiosity Architecture for Video Games
- Advanced Screenspace Antialiasing
- The Benefits of Multiple CPU Cores in Mobile Devices
- Direct3D 11 In-Depth Tutorial: Tessellation
- Real-time Diffuse Global Illumination in CryENGINE 3
- Future graphics in games
- Physically-Based Shading Models in Film and Game Production
- Crafting Physically Motivated Shading Models for Game Development
- Pre-computing Lighting in Games
- Direct3D 11 Performance Tips & Tricks
- Oit And Indirect Illumination Using Dx11 Linked Lists
- [Uncharted 2: Character Lighting and Shading](http://advances.realtimerendering.com/s2010/Hable-Uncharted2(SIGGRAPH 2010 Advanced RealTime Rendering Course).pdf)
- UFO Invasion: DX11 and Multicore to the Rescue
- CryENGINE 3: reaching the speed of light
- 光线追踪小记:空间加速结构Regular Grid与3DDDA
- Destruction Masking in Frostbite 2 using Volume Distance Fields
- Sample Distribution Shadow Maps
- Shears - Squeeze the Juice Out of the CPUs: Post Mortem of a Data-Driven Scheduler
- Advanced Material Rendering
- Water and lightin underwater photography
- Toy Story 3: The Video Game Rendering Techniques
- [Adaptive Volumetric Shadow Maps](http://advances.realtimerendering.com/s2010/Salvi-AVSM(SIGGRAPH 2010 Advanced RealTime Rendering Course).pdf)
- DiRT2 DirectX 11 Technology
- What Is Ambient Occlusion? (SSAO, HBAO, HDAO And VXAO)
- HORIZON-BASED AMBIENT OCCLUSION PLUS (HBAO+)
- R-Trees -- Adapting out-of-core techniques to modern memory architectures
- Streaming Massive Environments from 0 to 200 MPH
- A Dynamic Component Architecture for High Performance Gameplay
- The Game Engine Space for Virtual Cultural Training: Requirements, Devices, Engines, Porting Strategies and a Future Outlook
- DirectCompute Performance on DX11 Hardware
- DirectCompute Optimizations and Best Practices
- Per-Pixel Linked Lists with Direct3D 11
- Texture Compression in Real-Time Using the GPU
- Reflection for Tools Development
- The Asset pipeline for Just Cause 2: Lessons learned
- Real-Time Order Independent Transparency and Indirect Illumination Using Direct3D 11
- Multi-Core Memory Management Technology in Mortal Kombat
- Mega Meshes - Modeling, Rendering and Lighting a World Made of 100 Billion Polygons
- Game Worlds from Polygon Soup: Visibility, Spatial Connectivity and Rendering
- Building a Multithreaded Web Based Game Engine Using HTML5, CSS3 and JavaScript
- Culling the Battlefield: Data Oriented Design in Practice
- Dynamic lighting in GOW3
- Firaxis LORE And other uses of D3D11
- DirectX 11 Rendering in Battlefield 3
- Secrets of CryENGINE 3 Graphics Technology
- Rendering in Cars 2
- [An Optimized Diffusion Depth Of Field Solver (DDOF)](http://www.klayge.org/material/4_2/DoF/An Optimized Diffusion Depth of Field Solver.pdf)
- DX11 Performance Gems
- Lighting the Apocalypse: Rendering Techniques for RED FACTION: ARMAGEDDON
- Five Rendering Ideas from Battlefield 3 & Need For Speed
- UE制作PBR材质攻略Part 1 - 色彩知识
- High Performance Post-Processing
- Separating Semantics from Rendering:A Scene Graph based Architecture for Graphics Applications
- Pre-Integrated Skin Shading
- Scaling the Pipeline
- Practical Occlusion Culling on PS3
- Putting the Plane Together Midair
- 《调教三国》产品研发及技术感悟
- Accelerating Rendering Pipelines Using Bidirectional Iterative Reprojection
- CSM Scrolling: An acceleration technique for the rendering of cascaded shadow maps
- Analytic Anti-Aliasing of Linear Functions on Polytopes
- iOS and Android Development with Unity3D
- [Deus Ex is in the Details](http://twvideo01.ubm-us.net/o1/vault/gdc2012/slides/Programming Track/DeSmedt_Matthijs_Deus Ex Is.pdf)
- Effects Techniques Used in Uncharted 3: Drake's Deception
- Cutting the Pipe: Achieving Sub-Second Iteration Times
- Mastering DirectX 11 with Unity
- Practical Physically Based Rendering in Real-time
- GPU Task-Parallelism: Primitives and Applications
- Beyond a simple physically based Blinn-Phong model in real-time
- Water Technology of Uncharted
- Geometry Clipmaps: Terrain Rendering Using Nested Regular Grids
- Graphics Gems for Games - Findings from Avalanche Studios
- New particle trimming tool
- Particle trimmer
- LEAN Mapping
- Forward Rendering Pipeline for Modern GPUs
- Using GPUView to Understand your DirectX 11
- Realtime global illumination and reflections in Dust 514
- Advanced Procedural Rendering with DirectX 11
- Survey of Physics Engines for Games
- [Rock-Solid Shading](http://advances.realtimerendering.com/s2012/Ubisoft/Rock-Solid Shading.pdf)
- Linear Efficient Anti-aliased Normal Mapping
- Sand Rendering in Journey
- Scalable High-Quality Motion Blur and Ambient Occlusion
- 剖析Unreal Engine超真实人类的渲染技术Part 1 - 概述和皮肤渲染
- 剖析Unreal Engine超真实人类的渲染技术Part 2 - 眼球渲染
- Bringing AAA Graphics to Mobile Platforms
- Deferred Radiance Transfer Volumes: Global Illumination in Far Cry 3
- The Technology Behind the “Unreal Engine 4 Elemental demo”
- Interactive Indirect Illumination Using Voxel-Based Cone Tracing
- Terrain in Battlefield 3: A Modern, Complete and Scalable System
- Practical Implementation of Light Scattering Effects Using Epipolar Sampling and 1D Min/Max Binary Trees
- Accelerate your Mobile Apps and Games for Android™ on ARM
- OpenGL ES 3.0 - Challenges and Opportunities
- An Architecture Approach for 3D Render Distribution using Mobile Devices in Real Time
- Destiny: From Mythic Science Fiction to Rendering in Real-Time
- Graphics Gems from CryENGINE 3
- Oceans on a Shoestring: Shape Representation, Meshing and Shading
- Practical Clustered Shading
- Clustered Deferred and Forward Shading
- Pixel Synchronization: Solving Old Graphics Problems with New Data Structures
- REDengine 3 Character Pipeline
- Virtual Reality Capabilities of Graphics Engines
- Efficient Usage of Compute Shaders on Xbox One and PS4
- Killzone Shadow Fall: Threading the Entity Update on PS4
- Developing Virtual Reality Experiences with the Oculus Rift
- Virtual Reality and Getting the Best from Your Next-Gen Engine
- Diving into VR World with Oculus
- Solving Visibility and Streaming in The Witcher 3: Wild Hunt with Umbra 3
- Volumetric Fog: Unified compute shader based solution to atmospheric scattering
- SCRIPTING PARTICLES
- Compute-Based GPU Particle Systems
- Multithreading for Gamedev Students
- Moving Frostbite to Physically Based Rendering 3.0
- 《天涯明月刀》引擎开发
- Landscape creation and rendering in REDengine 3
- Next-Gen Characters From Facial Scans to Facial Animation
- PCA
- Hybrid Reconstruction Anti Aliasing
- OpenGL ES 3.0 and Beyond: How To Deliver Desktop Graphics on Mobile Platforms
- Rendering in Codemasters’ GRID2 and beyond Achieving the ultimate graphics on both PC and tablet
- Real-time lighting via Light Linked List
- Authoring Tools Framework: Open Source from Sony's Worldwide Studios
- Introduction to PowerVR Ray Tracing
- Practical Techniques for Ray Tracing in Games
- Next Generation Post Processing in Call of Duty
- Concurrent Interactions in The Sims 4
- Crafting a Next-Gen Material Pipeline for The Order: 1886
- Reflection System in Thief
- Rendering Techniques in Ryse
- Tessellation in Call of Duty: Ghosts
- Achieving the Best Performance with Intel Graphics Tips, Tricks, and Clever Bits
- High Quality Temporal Supersampling
- Realistic Cloud Rendering Using Pixel Sync
- Calibrating Lighting and Materials in Far Cry 3
- Adaptive Clothing System in Kingdom Come: Deliverance
- Sound Propagation in Hitman
- Visual Effects in Star Citizen
- Adaptive Virtual Texture Rendering in Far Cry 4
- Rendering the World of Far Cry 4
- Assassin's Creed Identity: Create a Benchmark Mobile Game!
- D3D12 A new meaning for efficiency and performance
- PowerVR Graphics - Latest Developments and Future Plans
- Unified Telemetry, Building an Infrastructure for Big Data in Games Development
- Quick and Dirty: 2 Lightweight AI Architectures
- Dynamic Occlusion With Signed Distance Fields
- Fast Approximations for Global Illumination on Dynamic Scenes
- SIMD at Insomniac Games
- Frostbite on Mobile
- Destiny's Multi-threaded Renderer Architecture
- Lessons from the Core Engine Architecture of Destiny
- Parallelizing the Naughty Dog Engine Using Fibers
- Strategies for efficient authoring of content in Shadow of Mordor
- Multi-Scale Global Illumination in Quantum Break
- Physically-based & Unified Volumetric Rendering in Frostbite
- Piko: A Framework for Authoring Programmable Graphics Pipelines
- Rendering the Alternate History of The Order: 1886
- MSAA Resolve Filters
- Far Cry 4 and Assassin’s Creed Unity: Spicing Up PC Graphics with GameWorks
- The Real-Time Volumetric Cloudscapes of Horizon Zero Dawn
- Sampling Methods for Real-time Volume Rendering
- Stochastic Screen-Space Reflections
- Hybrid Ray-Traced Shadows
- Advancements in Tiled-Based Compute Rendering
- Advanced VR Rendering
- 如何打造一款秒级别的全局光烘培软件
- Authoring Realtime Volumetric Cloudscapes with the Decima Engine
- Towards Cinematic Quality, Anti-aliasing in Quantum Break
- Math for Game Programmers: Voxel Surfing
- The Transvoxel Algorithm
- Aggregate G-Buffer Anti-Aliasing in Unreal Engine 4
- D3D12 & Vulkan: Lessons Learned
- Deferred Lighting in Uncharted 4
- Bent Normals and Cones in Screen-Space
- Rendering 'Rainbow Six | Siege'
- 4K Rendering Breakthrough: The Filtered and Culled Visibility Buffer
- Filmic SMAA: Sharp Morphological and Temporal Antialiasing
- Architecting Archean: Simultaneously Building for Room-Scale and Mobile VR, AR, and All Input Devices
- Optimizing the Graphics Pipeline With Compute
- The Rendering of INSIDE: Low Complexity, High Fidelity
- Mixed Resolution Rendering in 'Skylanders: SuperChargers'
- High Dynamic Range Imaging
- How we rethought driver abstraction
- From Pixels to Reality – Thoughts on Next Game Engine
- Explicit Multi GPU Programming with DirectX 12
- Building a Low-Fragmentation Memory System for 64-bit Games
- Real-time BC6H Compression on GPU
- Temporal Reprojection Anti-Aliasing in INSIDE
- Rendering Antialiased Shadows with Moment Shadow Mapping
- Real-Time Area Lighting: a Journey from Research to Production
- Rendering Rapids in Uncharted 4
- Temporal Antialiasing In Uncharted 4
- The devil is in the details: idTech 666
- Practical DirectX 12 - Programming Model and Hardware Capabilities
- Developing The Northlight Engine: Lessons Learned
- Advanced VR Rendering Performance
- Volumetric Global Illumination At Treyarch
- Top five technologies to watch: 2017 to 2021
- Tiled shading: light culling – reaching the speed of light
- Efficient Texture Streaming in 'Titanfall 2'
- GDC2017: D3D12 & Vulkan: Lessons learned
- Crest: Novel ocean rendering techniques in an open source framework
- Decima Engine: Advances in Lighting and AA
- Data Binding Architectures for Rapid UI Creation in Unity
- DirectX 12 Case Studies
- FrameGraph: Extensible Rendering Architecture in Frostbite
- Parallelism and Concurrent Programming
- Advanced Graphics Tech: Moving to DirectX 12: Lessons Learned
- Higher Res Without Sacrificing Quality, plus Other Lessons from 'PlayStation VR Worlds'
- PBR Diffuse Lighting for GGX+Smith Microsurfaces
- High quality mobile VR with Unreal Engine and Oculus
- Evolution of Programmable Models for Graphics Engines
- Improved Culling for Tiled and Clustered Rendering
- Precomputed lighting in Call Of Duty: Infinite Warfare
- SIGGRAPH: The Destiny Particle Architecture
- 3D Repo 4 Unity Dynamic Loading of Version Controlled 3D Assets into the Unity Game Engine
- 4K Checkerboard in Battlefield 1 and Mass Effect Andromeda
- A Life of a Bokeh
- The Latest Graphics Technology in Remedy's Northlight Engine
- Advanced Graphics Techniques Tutorial: GPU-Based Clay Simulation and Ray-Tracing Tech in 'Claybook'
- Entity-Component Systems & Data Oriented Design In Unity
- Data-Oriented Design blog post & links
- Typical C++ Bullshit slide gallery
- Data-Oriented Design and C++ video
- Data-Oriented Design (Or Why You Might Be Shooting Yourself in The Foot With OOP) blog post
- Practical Examples in Data Oriented Design slides
- The Lighting Technology of 'Detroit: Become Human'
- Efficient Screen-Space Subsurface Scattering Using Burley’s Normalized Diffusion in Real-Time
- Precomputed Global Illumination in Frostbite
- Rendering Technology in 'Agents of Mayhem'
- Rebuilding Your Engine During Development: Lessons from 'Mafia III'
- HDR Image Based Lighting: From Acquisition to Render
- The Elusive Frame Timing: A Case Study for Smoothness Over Speed
- By Grabthar's Hammer, What a Savings: Making the Most of Texture Memory with Sprite Dicing
- Cluster Forward Rendering and Anti-Aliasing in 'Detroit: Become Human'
- Filtering Distributions of Normals for Shading Antialiasing
- [Error Reduction and Simplification for Shading Anti-Aliasing](https://yusuketokuyoshi.com/papers/2017/Error Reduction and Simplification for Shading Anti-Aliasing.pdf)
- Material Advances in Call of Duty: WWII
- Performance and Memory Post Mortem for Middle earth: Shadow
- Bungie's Asset Pipeline: 'Destiny 2' and Beyond
- Real-Time Ray Tracing of Correct* Soft Shadows
- Adopting lessons from offline ray tracing to real-time ray tracing for practical pipelines
- Real-Time Reflections in 'Mafia III' and Beyond
- Shading of 'Spellsouls': Achieving AAA Quality on Mobile
- Terrain Rendering in 'Far Cry 5'
- The Challenges of Rendering an Open World in Far Cry 5
- The Road toward Unified Rendering with Unity’s High Definition Render Pipeline
- A Journey Through Implementing Multiscattering BRDFs and Area Lights
- Leveraging Real-Time Ray Tracing to build a Hybrid Game Engine
- Content Fueled Gameplay Programming in 'Frostpunk'
- It Just Works: Ray-Traced Reflections in "Battlefield V"
- GPU Driven Rendering and Virtual Texturing in 'Trials Rising'
- Efficient Rendering in 'The Division 2'
- Interactive Wind and Vegetation in 'God of War'
- "Interactive Wind and Vegetation in 'God of War'" in Unreal Engine 4
- Strand-based Hair Rendering in Frostbite
- High Zombie Throughput in Modern Graphics
- The Indirect Lighting Pipeline of 'God of War'
- Controller to Display Latency in 'Call of Duty'
- Physically-Based Calibration: Accurate Material Production in 'Forza Horizon 4'
- Mesh Shading: Towards Greater Efficiency of Geometry Processing
- Procedurally Crafting Manhattan for Marvel’s Spider-Man
- Creating the Atmospheric World of Red Dead Redemption 2: A Complete and Integrated Solution
- Not-So-Little Light: Bringing 'Destiny 2' to HDR Displays
- Halcyon Architecture - "Director's Cut"
- Scalable Real time Global Illumination for Large Scenes
- 6 Years of Optimizing World of Tanks: Making the Game a Great Experience on All Systems from Laptops to High End PCs
- Bringing Replays to World of Tanks: Mercenaries
- Software-based Variable Rate Shading in Call of Duty: Modern Warfare
- For the Alliance! World of Warcraft and Intel Discuss an Optimized Azeroth
- Rendering Roblox Vulkan Optimisations on PowerVR
- Imagination Tech Doc
- Intel® ISPC in Unreal Engine 4: A Peek Behind the Curtain
- MOBILE GAME DEVELOPMENT
- Multi Adapter Integrated + Discrete GPUs
- Optimizing Roblox: Vulkan Best Practices forMobile Developers
- volk loader
- Quad mesh simplification in Frostbite
- Lima Oscar Delta!: Scaling Content in 'Call of Duty: Modern Warfare'
- idTech 7: Rendering the Hellscape of Doom Eternal
- Precomputed Lighting Advances in Call of Duty: Modern Warfare
- From Ray to Path Tracing: Navigating through Dimensions
- VRS Tier 1 with DirectX 12 From Theory To Practice
- CHOPIN: Scalable Graphics Rendering in Multi-GPU Systems via Parallel Image Composition
- Evaluation of CPU and Memory performance between Object-oriented Design and Data-oriented Design in Mobile games
- Creating Cooperative Character Behaviors using Deep Reinforcement LearningVincent
- Real-Time Samurai Cinema: Lighting, Atmosphere, and Tonemapping in Ghost of Tsushima
- A Deep Dive into Nanite Virtualized Geometry
- Adaptive TetraPuzzles
- Quick-VDR
- Batched Multi-Triangulation
- Radiance Caching for real-time Global Illumination
- Blowing from the West: Simulating Wind in 'Ghost of Tsushima'
- Global Illumination Based on Surfels
- Experimenting with Concurrent Binary Trees for Large Scale Terrain Rendering
- Large-Scale Global Illumination in Call of Duty
- FidelityFX Super Resolution (FSR)
- What's new in Direct3D 12
- History of OpenGL
- LunarG Releases New Vulkan 1.3.204.0 SDKs with Profiles Toolset and New Extensions
- Khronos Group Releases Vulkan 1.2
- Khronos Group Releases Vulkan 1.1
- Metal (API)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号