剖析虚幻渲染体系(14)- 延展篇:现代渲染引擎演变史Part 2(成长期)
14.3 成长期(2000~2009)
14.3.1 图形API
14.3.1.1 DirectX
在2000时代,DirectX发布了8、9、10、11四个大版本,每个大版本又包含数个小版本。
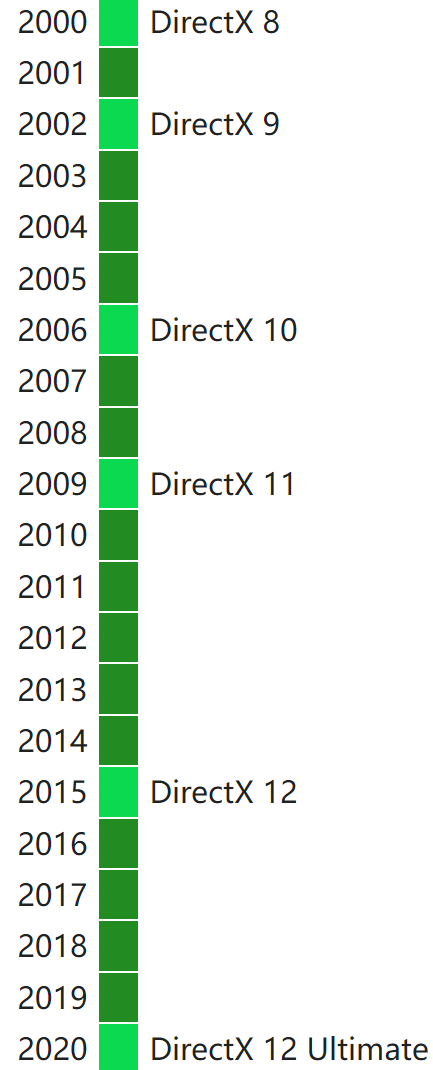
它们的具体描述如下表:
| 版本 | 时间 | 着色模型 | 特性 |
|---|---|---|---|
| DirectX 8 | 2000 | Shader Model 1.0 -1.4 | 可编程着色器、曲面细分 |
| DirectX 9 | 2002 | Shader Model 2.0 - 3.0 | 4K纹理、3D纹理、事件查询、BC1-3、遮挡查询、浮点格式(无混合)、扩展功能、MRT(4个)、浮点混合(有限)等。 |
| DirectX 10 | 2006 | Shader Model 4.0 - 4.1 | 统一着色器模型、几何着色器、流输出、alpha-to-coverage、8K纹理、MSAA纹理、双面模板、通用渲染目标视图、纹理数组、BC4/BC5、全浮点格式支持、立方体贴图数组,扩展的MSAA |
| DirectX 11 | 2009 | Shader Model 5.0 | hull&domain着色器、DirectCompute (CS 5.0)、16K纹理、BC6H/BC7、扩展的像素格式、逻辑混合操作、独立于目标的光栅化、每个管道阶段的UAV增加槽数、UAV仅渲染强制样本计数、恒定缓冲区偏移和部分更新 |
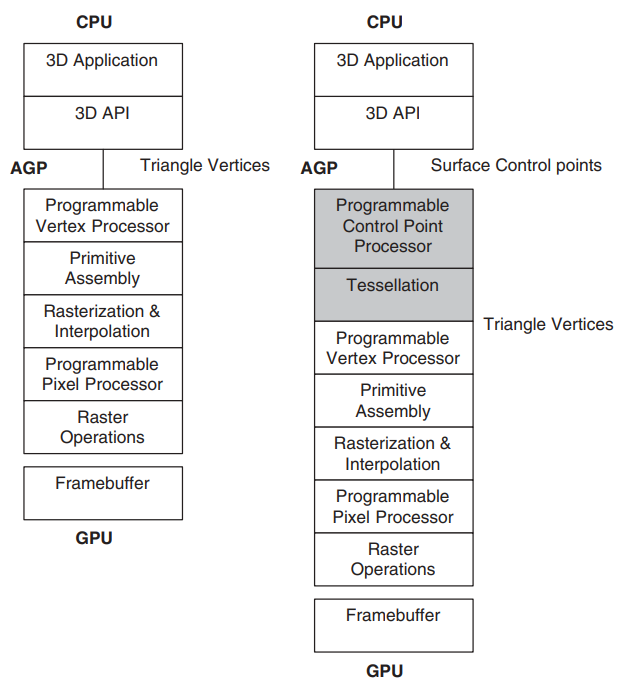
传统可编程架构(左),新的曲面细分架构(右)。新架构为GPU流水线增加了两个阶段,以灰色显示。
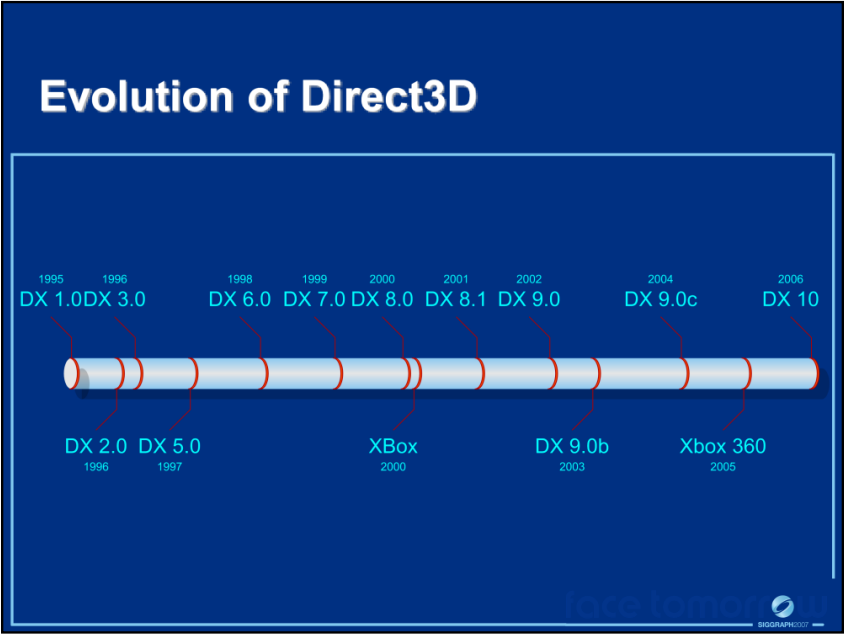
DX1.0到10.0的演变图。
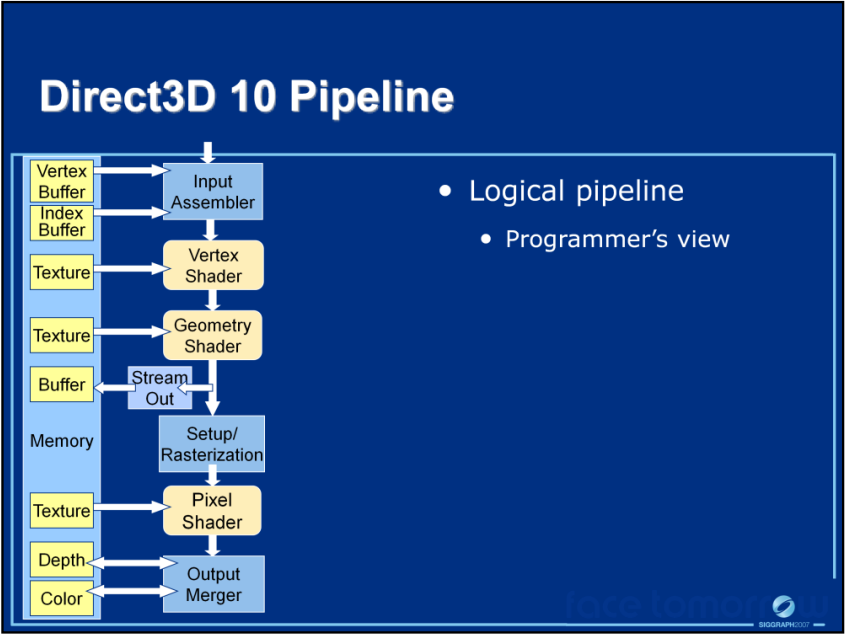
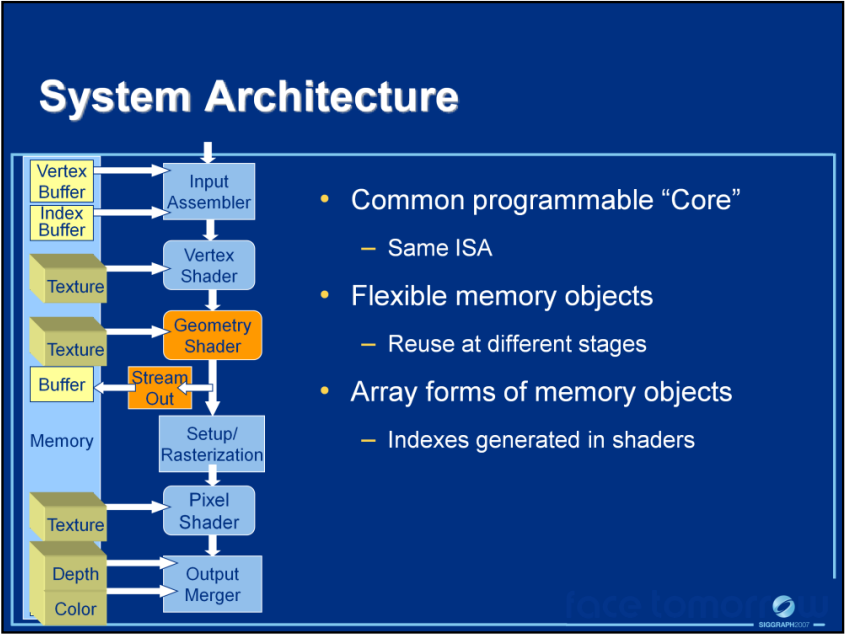
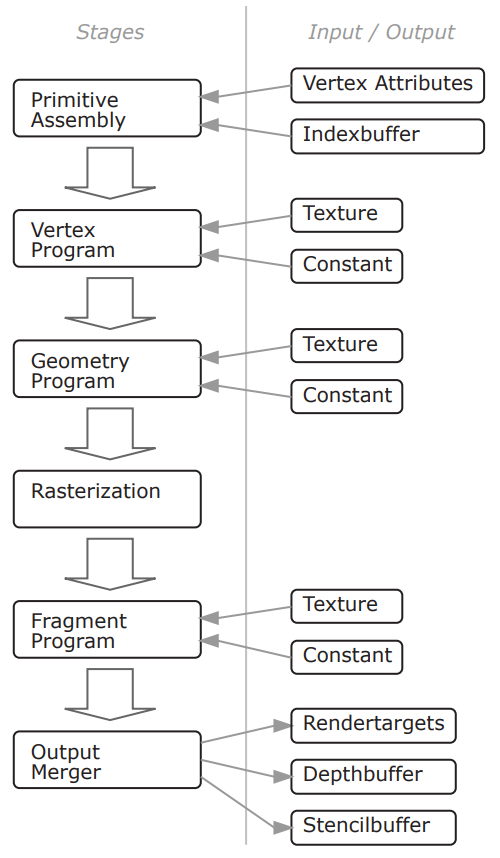
DirectX10的程序员视角(上)、系统架构(中)和可配置管线(下)。
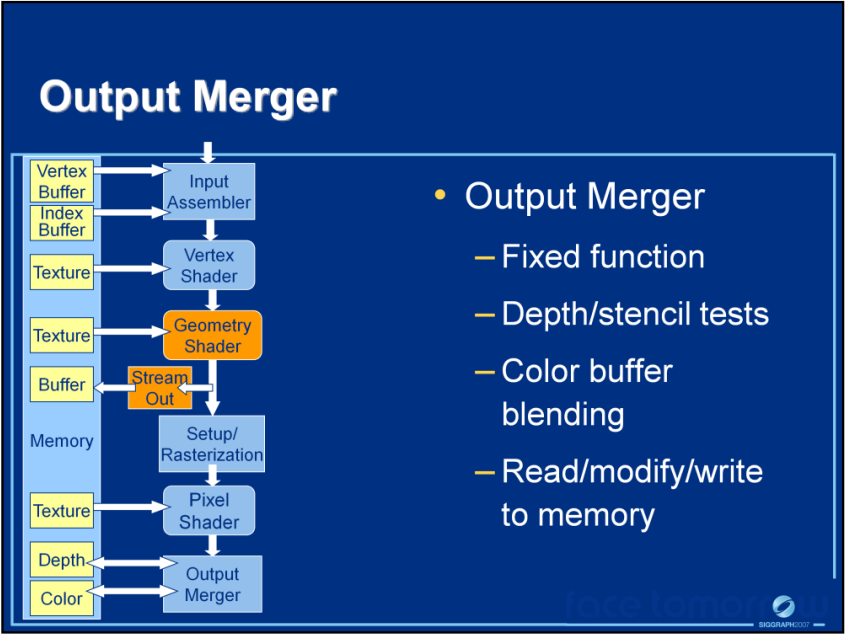
DirectX10的输出合并阶段。

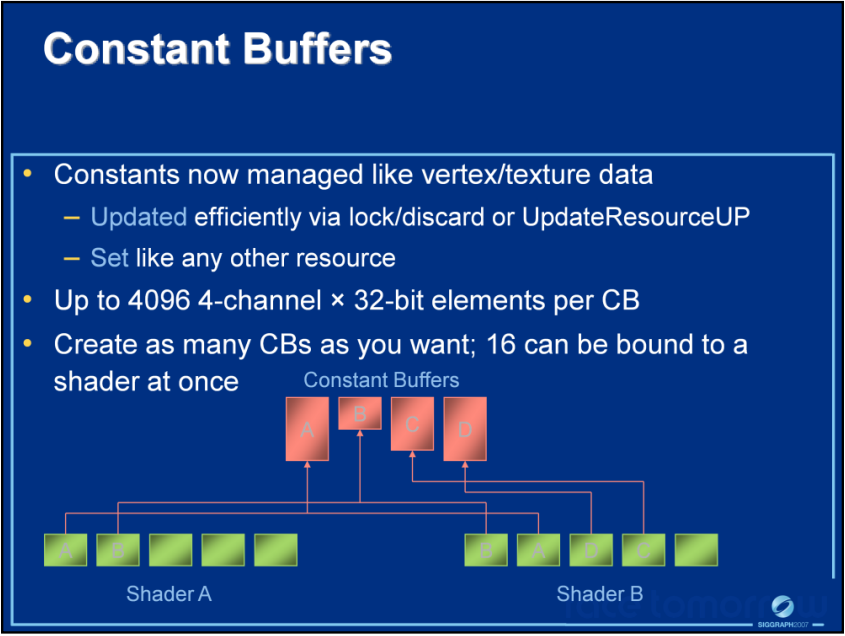
DirectX10的固定缓冲区说明及建议,建议按更新频率拆分参数到不同的缓冲区,并启用缓存(上)。固定缓冲区被不同的Shader共享并访问(下)。
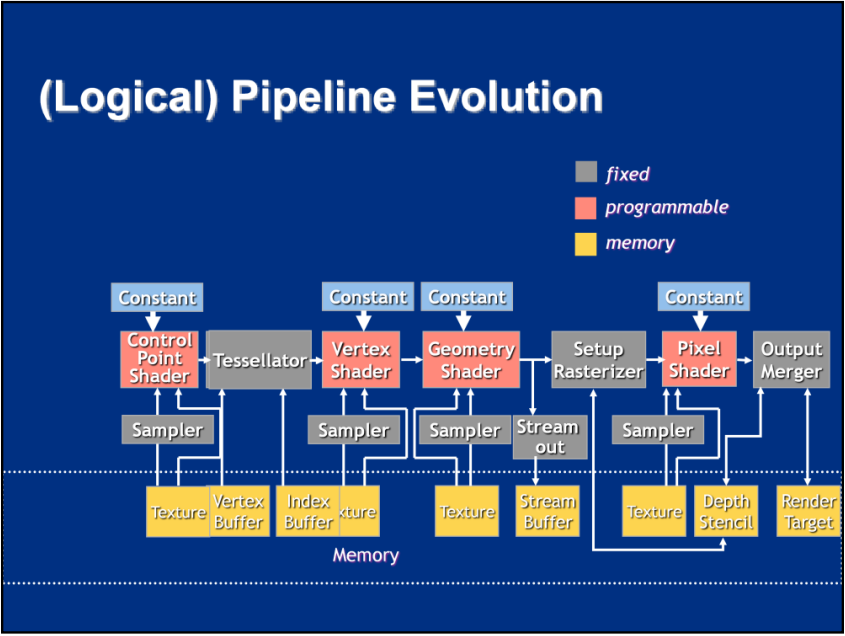
DirectX10的逻辑管线演变。


DirectX10新的跨阶段的联动方式。放弃了“按名称绑定”模型,转而采用可归类为“按位置绑定”的方案。该模型将其视为每个阶段之间的一组寄存器,每个阶段按一定顺序输出数据,下一个阶段按该顺序使用它。并且在寄存器库中按位置绑定 - 链接由物理位置标识,意味着不是在绘制时进行映射,而是由应用程序在着色器创作时维护顺序。换句话说,已经将这项工作推到了外循环,这些链接通过叫签名的构造被维护并绑定到着色器(上图)。签名的使用案例(下图)。

DX9和DX10的画面对比。
2009年发布的DirectX 11专注于提高可伸缩性、改善开发经验,扩展GPU覆盖面,提高性能。Direct3D 11是D3D 10和10.1的严格超集,添加对新特性的支持。DirectX 11的新增的特性有曲面细分、计算着色器、多线程、动态着色器链接、改进的纹理压缩及其它。
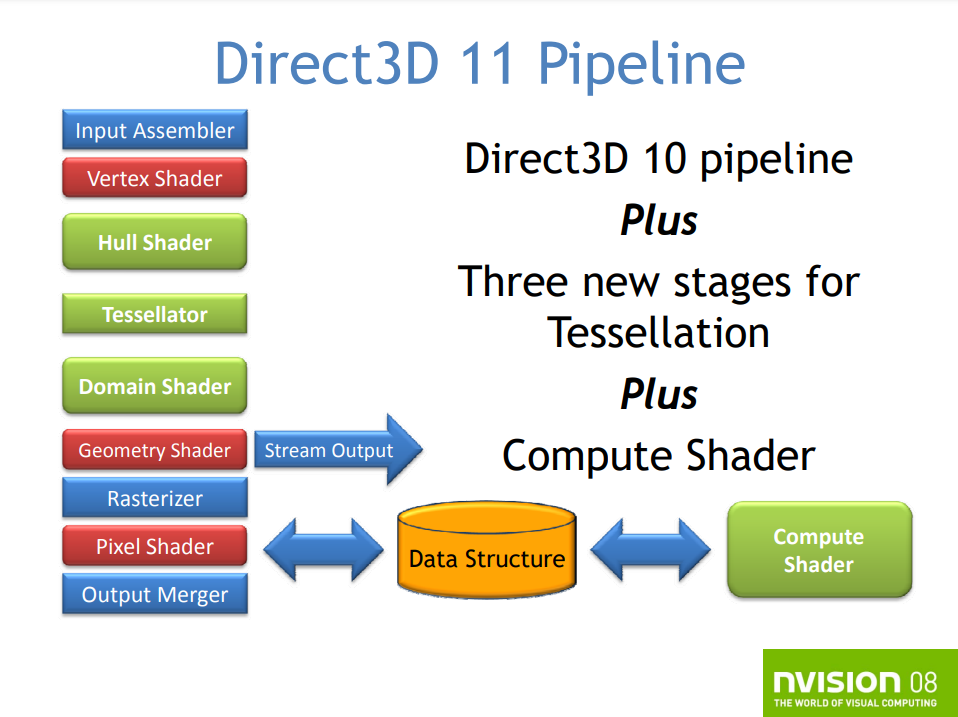
DX11的渲染管线,新增了曲面细分、计算着色器。
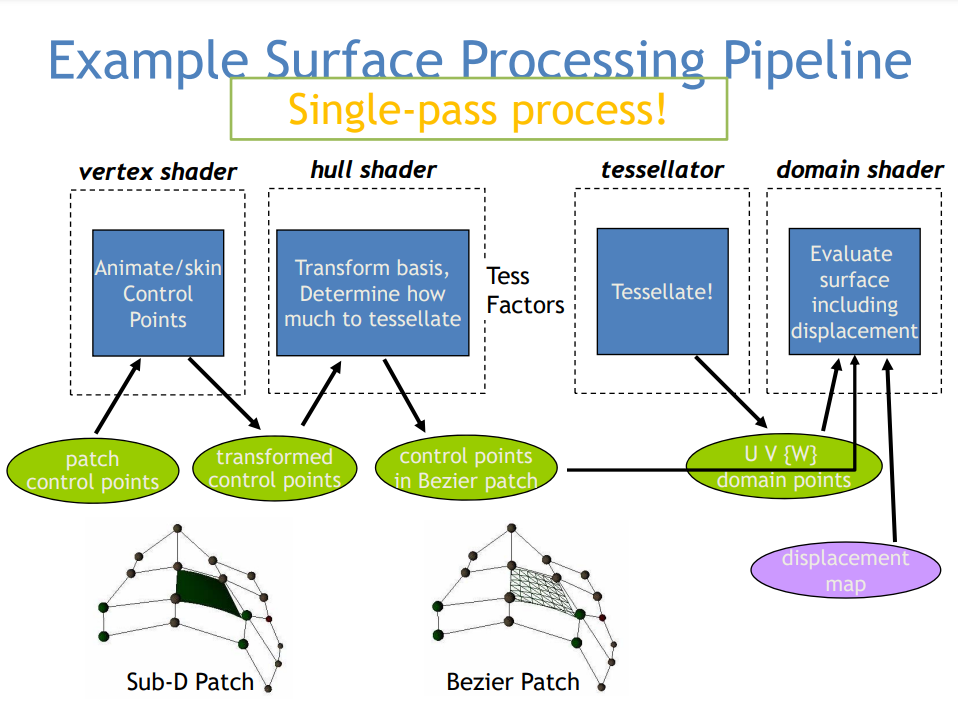
DX11的曲面细分运行示意图。

DX11下新的资产创作管线。
DX11的计算着色器可用于图形处理、后处理、A-Buffer、OIT、光线追踪、辐射度量、物理、AI等等。
DX11还允许多线程处理,异步资源加载(上传资源、创建着色器,创建状态对象),并行并发地渲染,多线程绘制和状态提交,在许多线程中展开渲染工作,对每个对象显示列表的有限支持。
D3D设备的功能拆分成3个:设备(Device)、立即上下文(Immediate Context)、延迟上下文(Deferred Context)。设备有空闲的线程资源创建,即时上下文是状态、绘制和查询的单一主设备,延迟上下文是状态和绘制的逐线程设备。
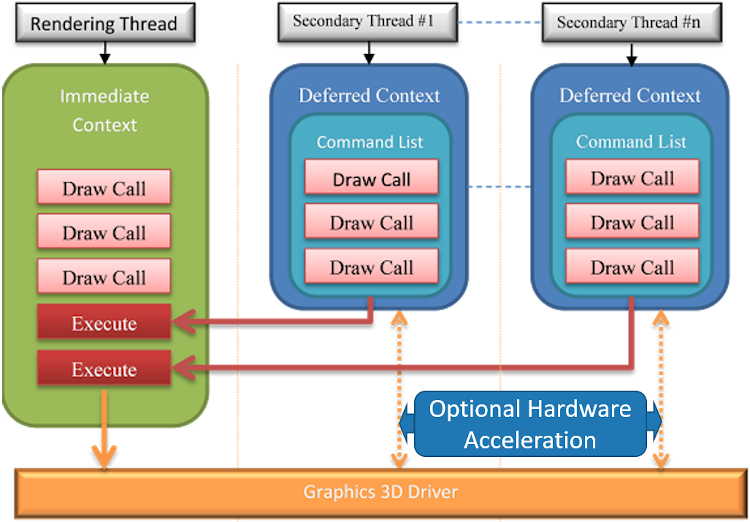
DirectX11的多线程模型。
对于异步资源,使用Device的接口创建资源,所有接口都是线程无关的,使用良好的粒度同步图元。资源的上传和着色器编译可以同时发生。对状态和绘制提交,存在两个优先级,高优先级的是多线程的提交,专用的显示列表(display list),低优先级的是逐物体的显示列表,可多次重复使用。此外,DX11的显示列表是不可更改的。
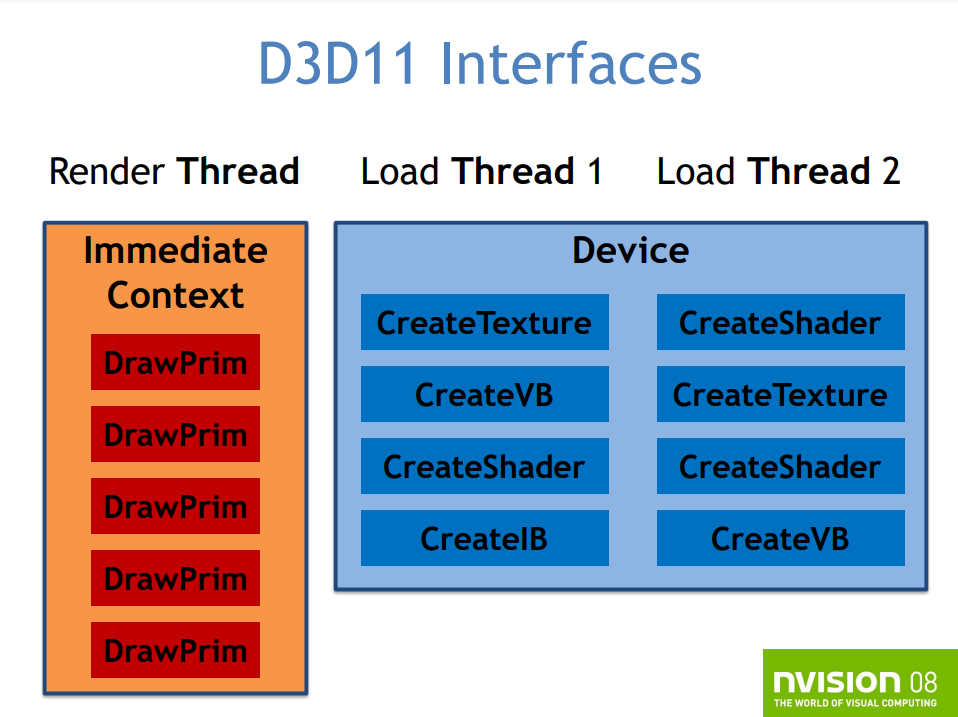

DirectX11的多线程资源创建和图元绘制。
DX11可以创建多个延迟上下文,每个都可绑定到一个线程(线程不安全的),延迟上下文上传显示列表,显示列表被立即上下文或延迟上下文使用。延迟上下文不可从GPU下载或回读数据(如查询、资源锁定),也不支持带DISCARD的锁定方式。
DX11时代的着色器已经变得越来越大且复杂,需要兼容宽泛的硬件平台,需要优化不同着色器配置驱动的特例化(Specialization)。解决的方案有两种:
-
全能着色器(Uber Shader)。所有组合情况的逻辑都在同一个着色器中。
foo(...) { if(m == 1) { // do material 1 } else if (m == 2) { // do material 2 } (...) if(l == 1) { // do light model 1 } else if (l == 2) { // do light model 2 } (...) }- 优点:
- 一个着色器控制了所有的着色代码。
- 所有函数在一个文件。
- 减少运行时的状态改变。
- 只要一个编译步骤。
- 更流行的编码方式。
- 缺点:
- 复杂。
- 缺乏组织。
- 寄存器使用总是在最坏情况的路径上。
- 优点:
-
特例化(Specialization)。每个组合情况生成一个专门的shader。
-
优点:
- 总是最好的寄存器使用情况。
- 更易针对性地优化。
-
缺点:
- 海量的生成着色器,导致爆炸式的组合。(下图)
![]()
- 运行时管理是个痛点。
-

解决方案是动态着色器链接和面向对象编程(OOP)。选择你想要的特定类实例,运行时将内联类的方法,等效注册使用到一个专门的着色器,内联是在本机程序集快速操作中完成的,适用于所有后续的Draw()调用。
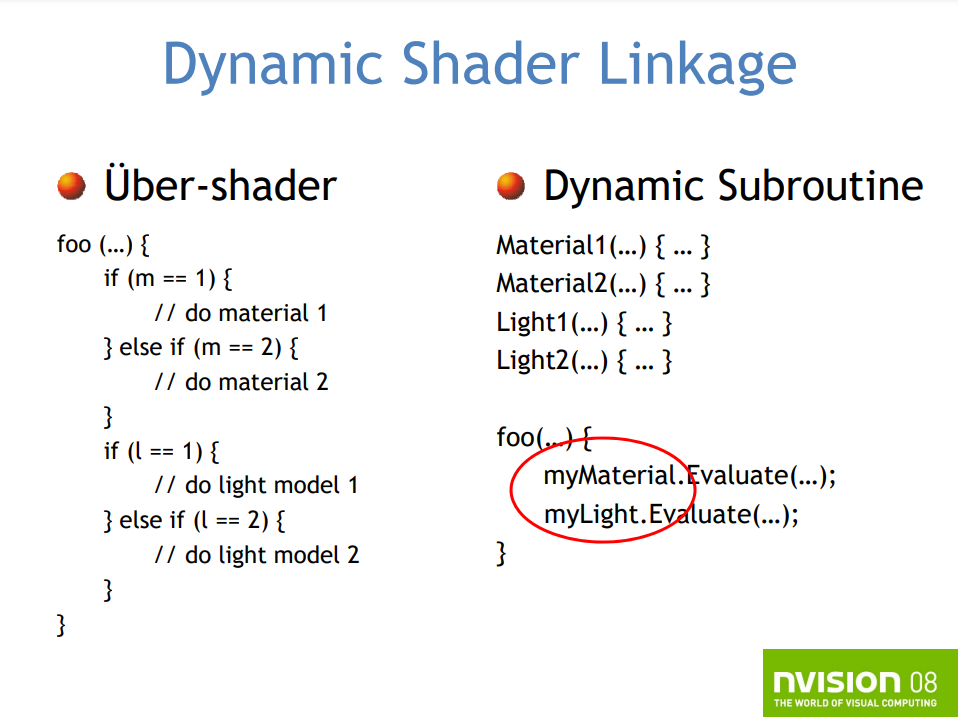
全能着色器和动态链接的对比。
在纹理压缩方面,由于之前的块状调色板插值过于简单,导致过于明显的块状瑕疵,不支持HDR,于是DX11新增了BC6和BC7。BC6支持HDR,达到1/6的压缩比(16 bpc RGB),针对高质量(非无损)的视觉效果。BC7支持Alpha的LDR,1/3的压缩比,高的视觉效果。新的格式依旧采用块状压缩,每个块是独立的,具有固定的压缩比,但新增了多种块类型,为不同类型的内容量身定制,如平滑的梯度和带噪点的法线贴图、变化的Alpha和不变的Alpha等。
BC纹理格式的块状分区表图例。

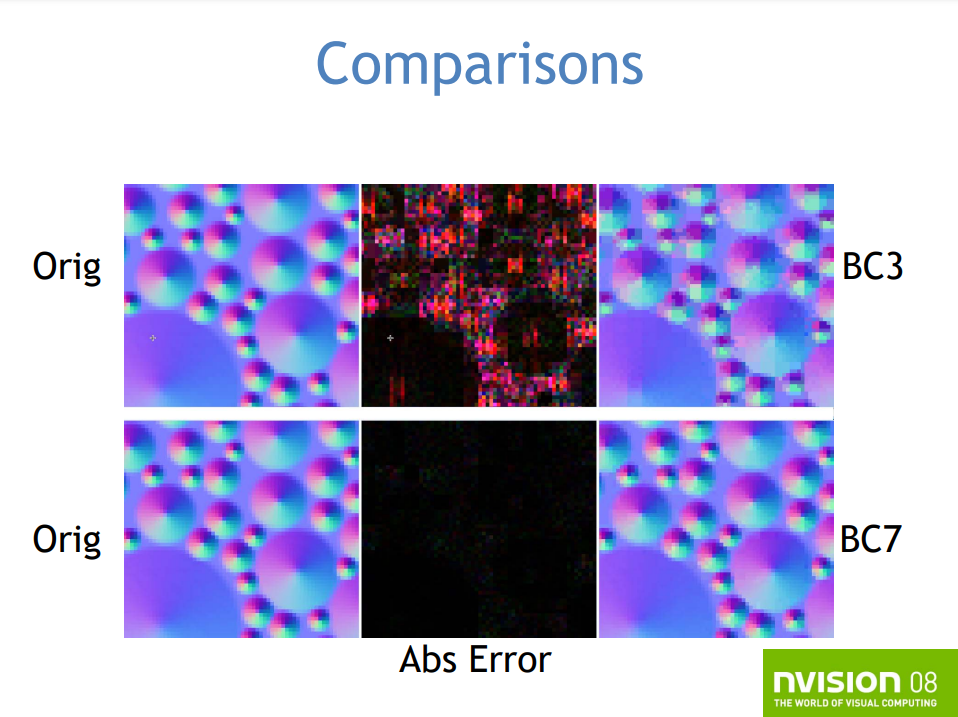
BC纹理格式的新旧对比。
DX11还支持以下特性:
- Addressable Stream Out
- Draw Indirect
- Pull-mode attribute eval
- Improved Gather4
- Min LOD Texture clamps
- 16K texture limits
- Required 8-bits subtexel, submip filtering precision
- Conservative oDepth
- 2 GB Resources
- Geometry shader instance programming model
- Optional double support
- Read-Only depth or stencil views
14.3.1.2 OpenGL
OpenGL在2000时代发布了以下几个版本:
| 版本 | 时间 | 特性 |
|---|---|---|
| OpenGL 1.3 | 2001年8月 | 多重纹理、多重采样、纹理压缩 |
| OpenGL 1.4 | 2002年7月 | 深度纹理、GLSlang |
| OpenGL 1.5 | 2003年7月 | 顶点缓冲区对象 (VBO)、遮挡查询 |
| OpenGL 2.0 | 2004年9月 | GLSL 1.1、MRT、NPOT纹理、点精灵、双面模板 |
| OpenGL 2.1 | 2006年7月 | GLSL 1.2、像素缓冲对象 (PBO)、sRGB纹理 |
| OpenGL 3.0 | 2008年8月 | GLSL 1.3、纹理阵列、条件渲染、帧缓冲对象 (FBO) |
| OpenGL 3.1 | 2009年3月 | GLSL 1.4、实例化、纹理缓冲区对象、统一缓冲区对象、图元重启 |
| OpenGL 3.2 | 2009年8月 | GLSL 1.5、几何着色器、多采样纹理 |
OpenGL在GPU上运行的图形管道的扩展版本,部分固定功能流水线已被可编程级取代。
同时,作为嵌入式和移动设备的轻量级图形API Open ES也在发展。OpenGL和OpenGL ES之间的显著区别是OpenGL ES不再需要用glBegin和glEnd括起OpenGL库调用,原始渲染函数的调用语义被更改为有利于顶点数组,并且为顶点坐标引入了定点数据类型,以及添加了属性以更好地支持嵌入式处理器的计算能力,这些处理器通常缺少浮点单元 (FPU)。下表是OpenES在2000时代发布的版本及说明:
| 版本 | 时间 | 特性 |
|---|---|---|
| OpenGL ES 1.0 | 2003年7月 | 四边形和多边形渲染基元,texgen、线条和多边形网格,删除部分技术性更强的绘图模式、显示列表和反馈、状态属性的推送和弹出操作、部分材料参数(如背面参数和用户定义的剪切平面) |
| OpenGL ES 1.1 | 未知 | 多纹理(包括组合器和点积纹理操作)、自动mipmap生成、顶点缓冲区对象、状态查询、用户裁剪平面、更好控制的点渲染。 |
| OpenGL ES 2.0 | 2007年3月 | 可编程管线、着色器控制流 |
14.3.2 硬件架构
在新世纪的初期,索尼发布了风靡一时的PS2游戏主机。


PS2主机外观(上)和内部硬件部件图(下)。
PS2主机的硬件架构交互和关系图如下,其硬件架构和内部结构包含了EE Core、VIF0、VIF1、GIF、DMAC和路径1、2 和 3,每条数据总线都标有其宽度和速度,实际上这个架构经历了多次修改:
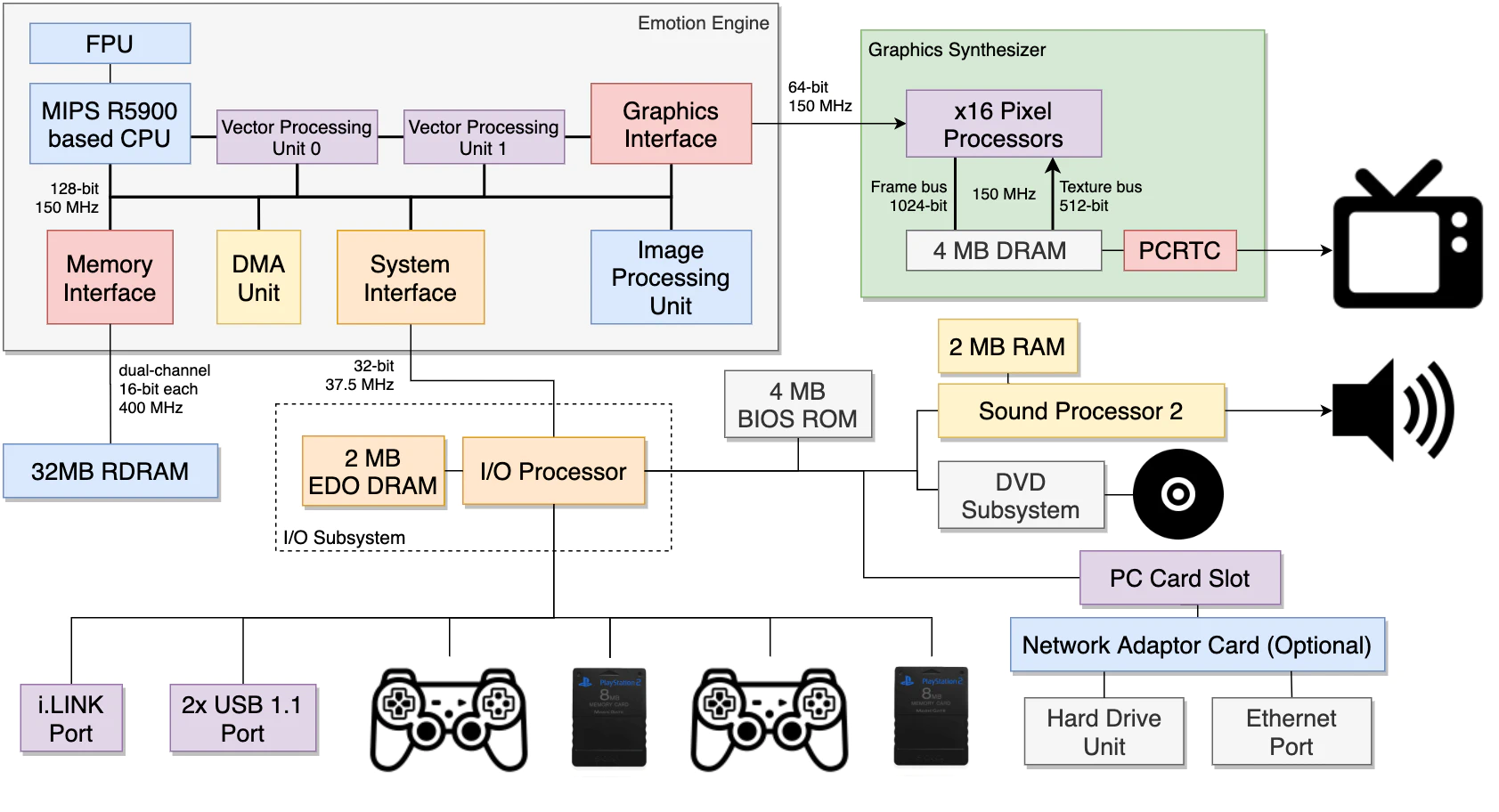
PS2硬件架构简化图例。包含Emotion引擎、图形合成器、RAM、IO处理器、音频处理器等等部件。每个部件之间的带宽已在线条中标明。
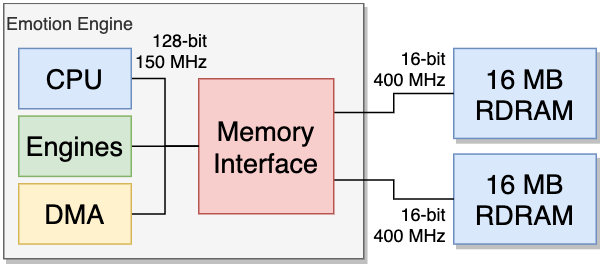
上图的Emotion引擎包含了CPU、DMA、内存接口和两条16M的内存:
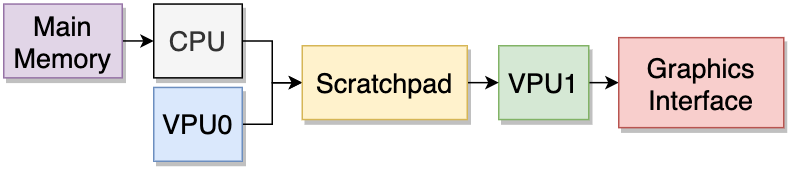
Emotion引擎使用了两个向量处理单元(VPU),被成为VPU0和VPU1,它们的硬件结构和交互有所差异。在VPU0和VPU1的支持下,PS2有了少许的并行处理能力。下面是串联和并行对比图:
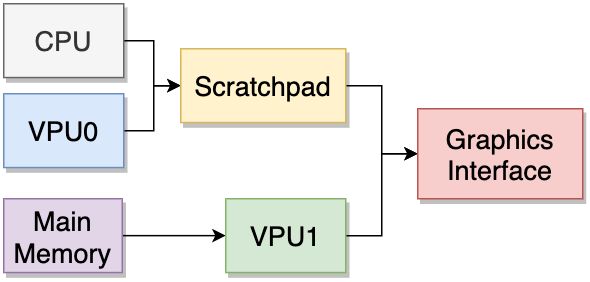
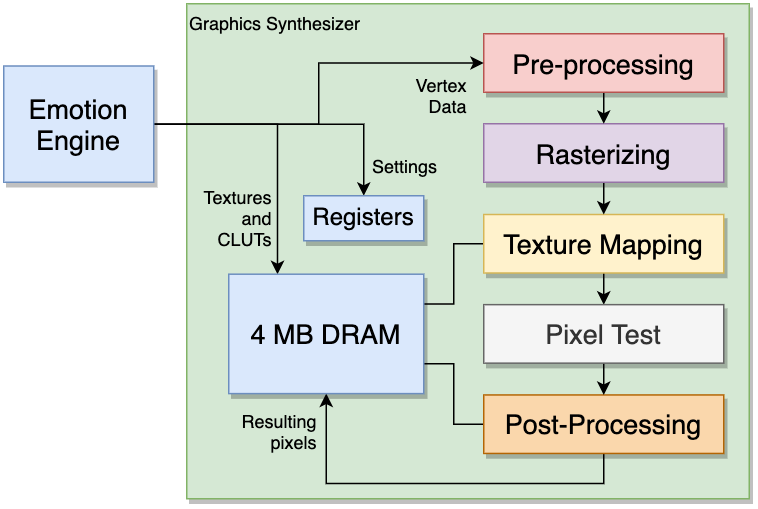
PS2的图像合成器拥有较完整的渲染管线(预处理、光栅化、纹理映射、像素测试、后处理)、寄存器和4M的显存,它们的交互和流程图如下:
PS2架构还支持多缓冲机制(双缓冲、三缓冲、四缓冲),使用每个实例的不同变换矩阵渲染单个图元的多个实例——并显示出显著的加速,降低延时:

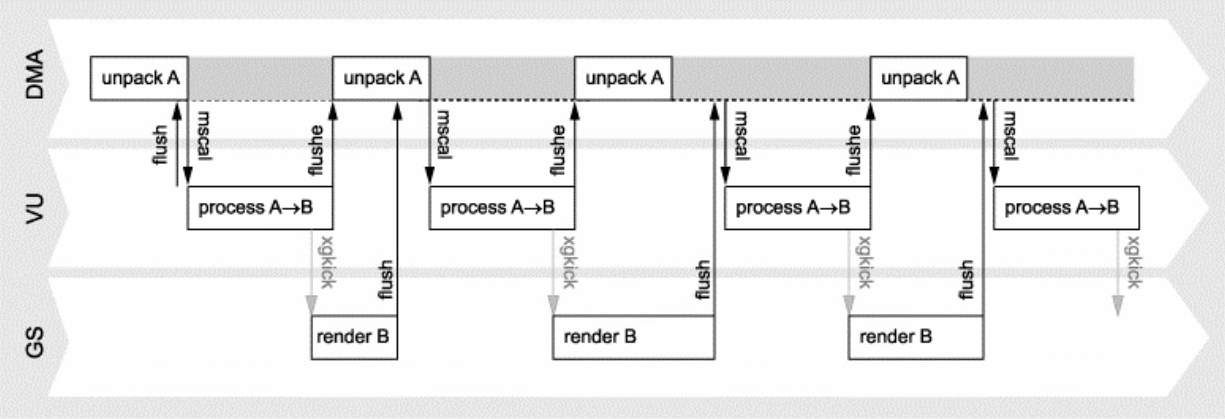
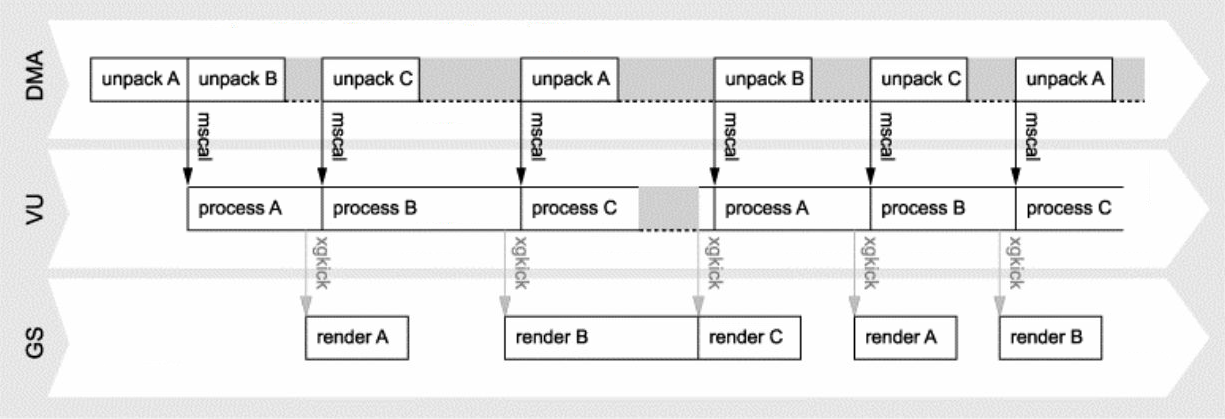
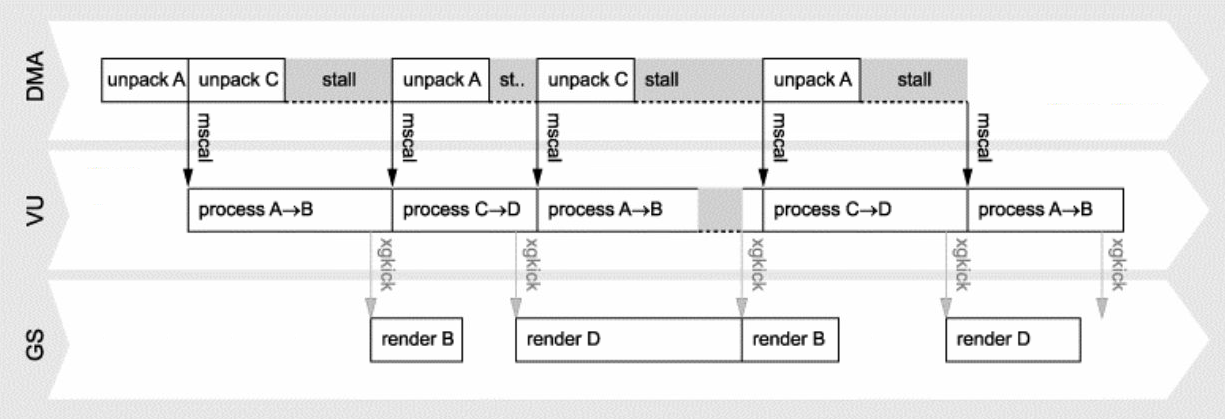
从上到下:PS2的单缓冲、双缓冲、三缓冲、四缓冲的交互和时序图。
结合多缓存机制和两个VPU等部件,可以实现GS、DMA、VU的并行处理,下面是它们的数据流和时序图:
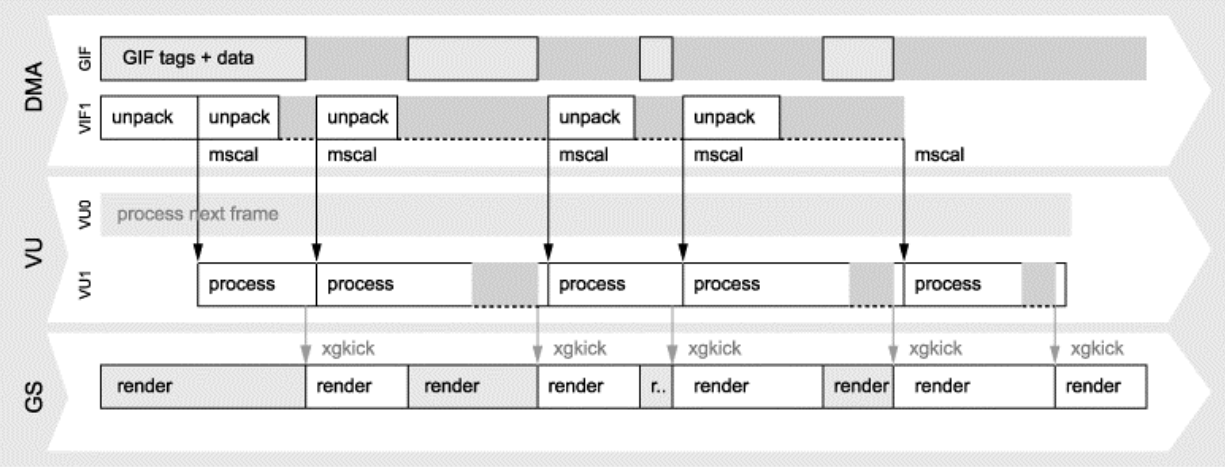
有了全新的图像合成器、并行计算架构以及多缓冲技术的支撑,PS2平台上游戏的画质也有了较大提升。下面分别是2001年发行的Crash Bandicoot: The Wrath of Cortex和Final Fantasy X的游戏截图:

2000年,Nvidia收购了研制出Voodoo芯片的3dfx,从而开启了GPU发展的迅猛纪年。GPU包含大量算术逻辑单元(ALU),具有数量级计算速度更快的能力,但每个处理单元都应该运行相同的命令,只是数据不同(即数据并行)。GPU和CPU之间存在物理和交互上的距离,它们通过系统总线连接,这会导致将数据从主存传输到GPU内存消耗大量的时间,是渲染瓶颈的主要诱因之一。
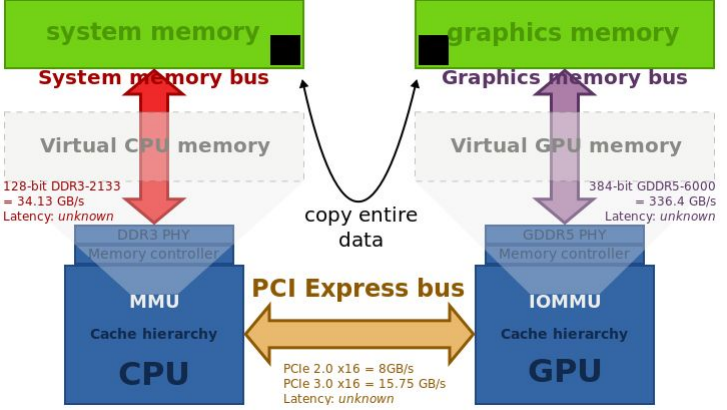
CPU和GPU通过PCI-E总线连接,是引发渲染瓶颈的主因之一。
早期开发了多种总线类型(原标准:ISA、MCA、VLB、PCI,1997年的AGP(加速图形端口)标准制定),当时主要的解决方案是PCI Express标准,提供高速串行计算机扩展总线标准。下表是不同PCI Express版本的速度表:
| PCIe 1.0 | PCIe 2.0 | PCIe 3.0 | PCIe 4.0 | PCIe 5.0 | PCIe 6.0 |
|---|---|---|---|---|---|
| 2.5 GT/s | 5.0 GT/s | 8.0 GT/s | 16.0 GT/s | 32.0 GT/s | 64.0 GT/s |
更详细的PCIe的属性和描述见下表:
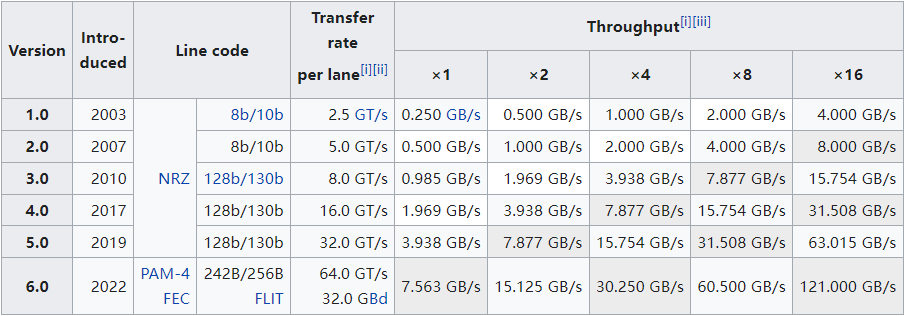
PCIe的发展,为渲染性能提升了不少,另外,GPU硬件架构也在飞速发展。以ATI Radeon HD 3800 GPU为例,拥有320个流处理器、6亿多个晶体管、计算速度超过1 terraFLOPS。
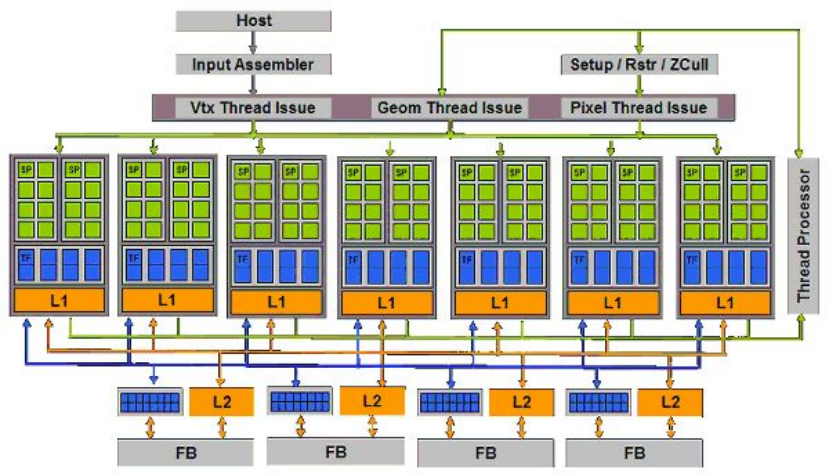
Geforce 8800硬件架构图。
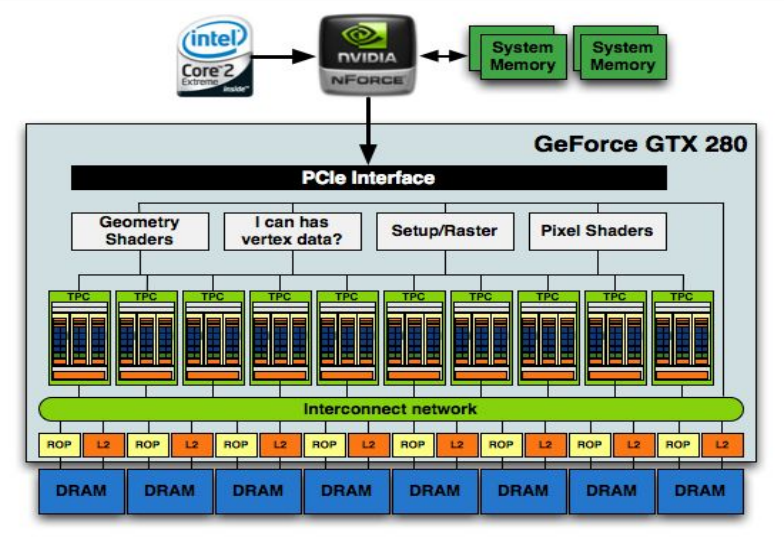
Geforce GTX 280硬件架构图。
GPU硬件的改进,使得计算速度以大于摩尔定律的曲线发展:

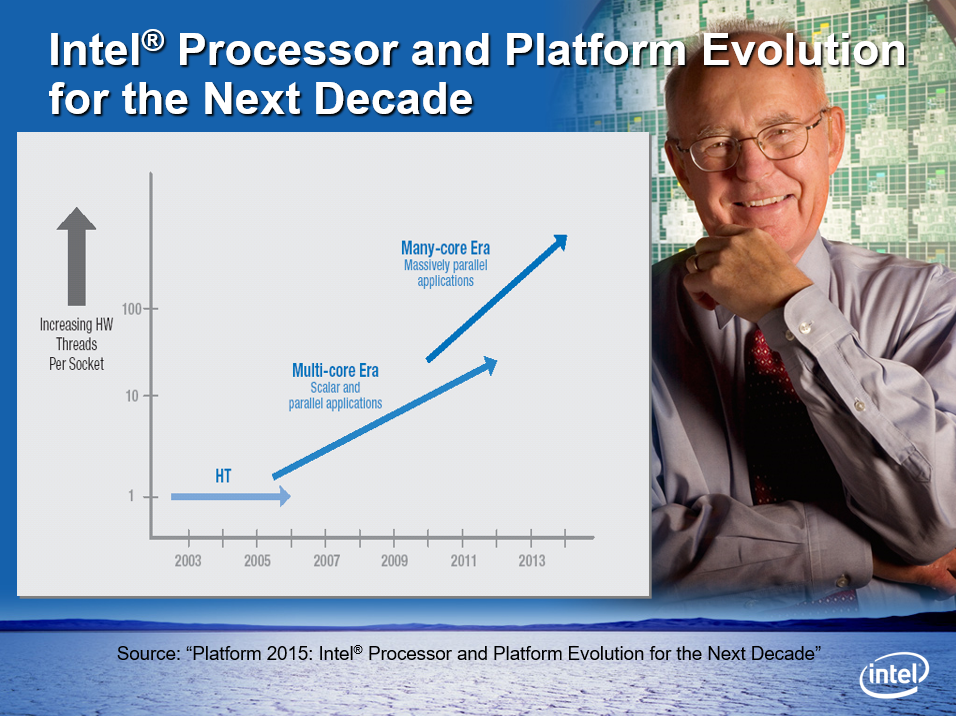
Intel CPU从2003到2013的发展趋势图。
2006年的单元处理器模型如下图:
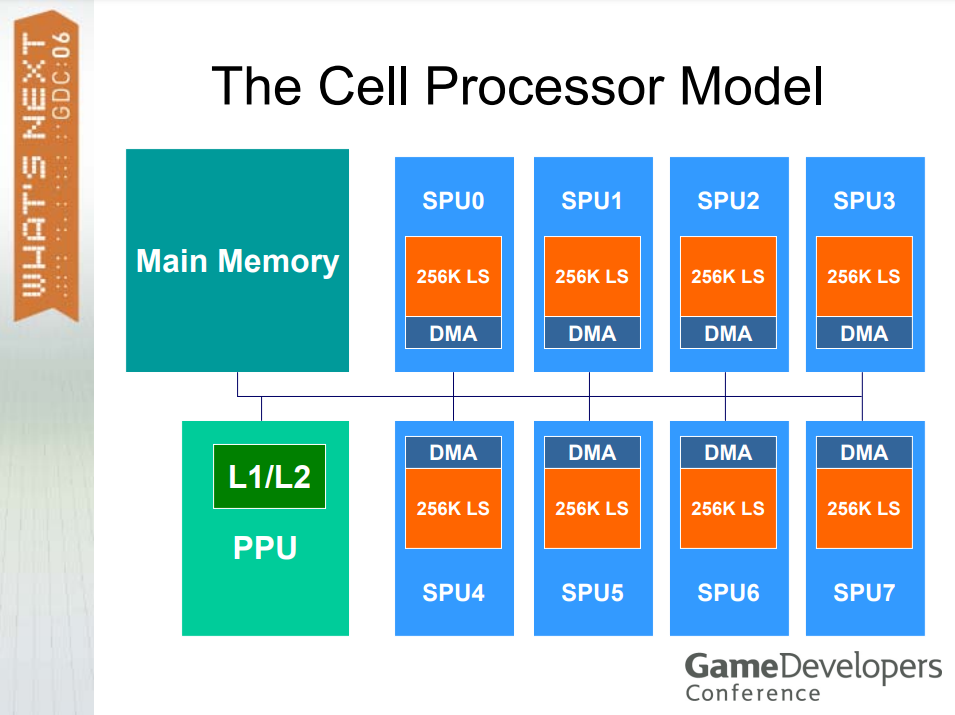
GPU芯片设计重点和CPU不同,主要区别在于GPU使用多线程来容忍延迟,每次等待读取时,只需启动另一个线程,如果有很多线程,就可以保持核心的工作负载(详见下表)。
| CPU | GPU |
|---|---|
| 指令多,数据少 乱序执行 分支预测 |
指令少,数据多 SIMD 硬件线程 |
| 重用和局部性 | 很少重复使用 |
| 任务并行 | 数据并行 |
| 需要操作系统 | 无操作系统 |
| 复杂同步 | 简单同步 |
| 延迟机器 | 吞吐量机器 |
| 指令保持不变 | 指令不断变化 |
GPU的指令架构集(ISA)的指令变化很快的原因有:
- 一个新的游戏变得流行。
- API设计师 (Ms) 添加新功能,让游戏编写更简单。
- 硬件厂商关注游戏,并添加新硬件以加快游戏运行速度。
- 新的硬件。
- 游戏开发者着眼于新硬件并通过超越任何人认为指令可以做的事情来思考有趣的新效果(更逼真)。
对类似的代码,CPU和GPU的性能的区别是怎么样的?举个具体的例子,假设CPU和GPU都要在线程中执行以下代码:
// load
r1 = load (index)
// series of adds
r1 = r1 + r1
r1 = r1 + r1
......
// Run lots of threads
典型的CPU操作是单个CPU单元一次迭代,无法达到100%核心利用率。难以预取数据,多核无济于事,集群没有帮助,未完成的提取数量有限:

GPU线程在于吞吐量(较低的时钟,不同的规模),ALU单元达到100%利用率,最终输出的硬件同步,海量线程,Fetch单元 + ALU单元,快速线程切换,有序完成:
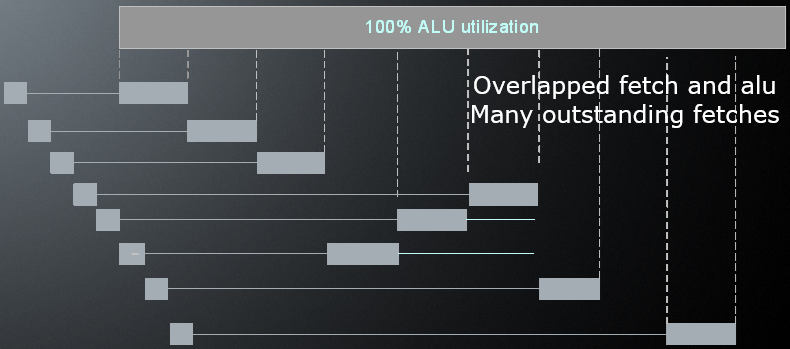
注意上图的Fetch和ALU是可重叠的,存在许多未完成的抓取。顶部的大条显示ALU何时运行,如果有足够的线程,它是100%处于活动状态。
Wavefront是64个线程的单元,它们也被称Warp,所有资源都是在启动时分配的,因此不会出现死锁。

运行队列中的线程数量计算如下:
-
每个SIMD有256个寄存器集。
-
每个寄存器集有64个寄存器(每个寄存器128位)。
- 256 * 64 * 10 个128位寄存器 = 163840个128位寄存器。
- 256 * 64 * 10 * 4 个32位寄存器 = 665360个32位寄存器。
-
如果每个线程需要5个128位寄存器,那么:
- 有256 / 5 = 51个Wavefront可以进入运行队列。
- 51个Wavefront = 每个SIMD有3264个线程或32640个运行或等待线程。
因此,CPU的负载决定性能,编译器尽量最小化ALU代码,减少内存开销,尝试使用预取和其它技巧来减少等待内存的时间。而GPU的线程决定性能,编译器尽量最小化ALU代码,最大化线程,尝试重新排序指令以减少同步和其它技巧以减少等待线程的时间。
2008年主流的GPU编程模型如下:
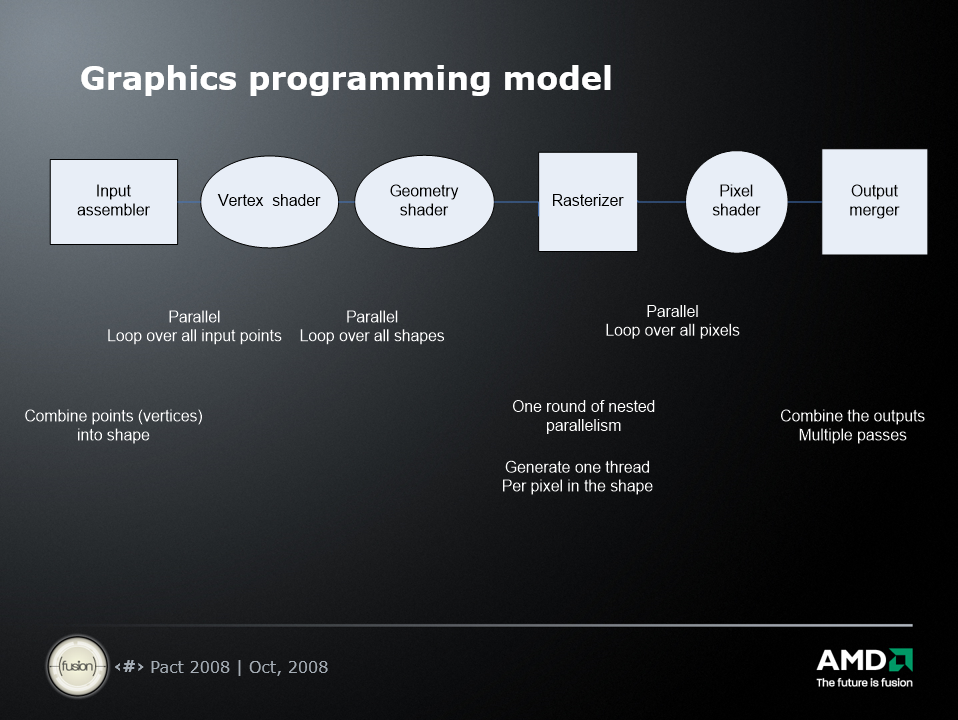
圆框是可编程,方框是固定功能,所有其它东西都在库中浮动。
上图中的所有并行操作都通过特定领域的API调用隐藏,开发人员编写顺序代码 + 内核,内核对一个顶点或像素进行操作,开发人员从不直接处理并行性,不需要自动并行编译器。这样的机制下,开发者只需写一小部分程序,其余代码来自库,一般是200-300个小内核,每个少于100行代码,可以没有竞争条件和没有错误报告,可以将程序视为串行(每个顶点/形状/像素)。没有开发人员知道处理器的数量(不像 pthreads)。这样的结果非常成功,编程足够简单。
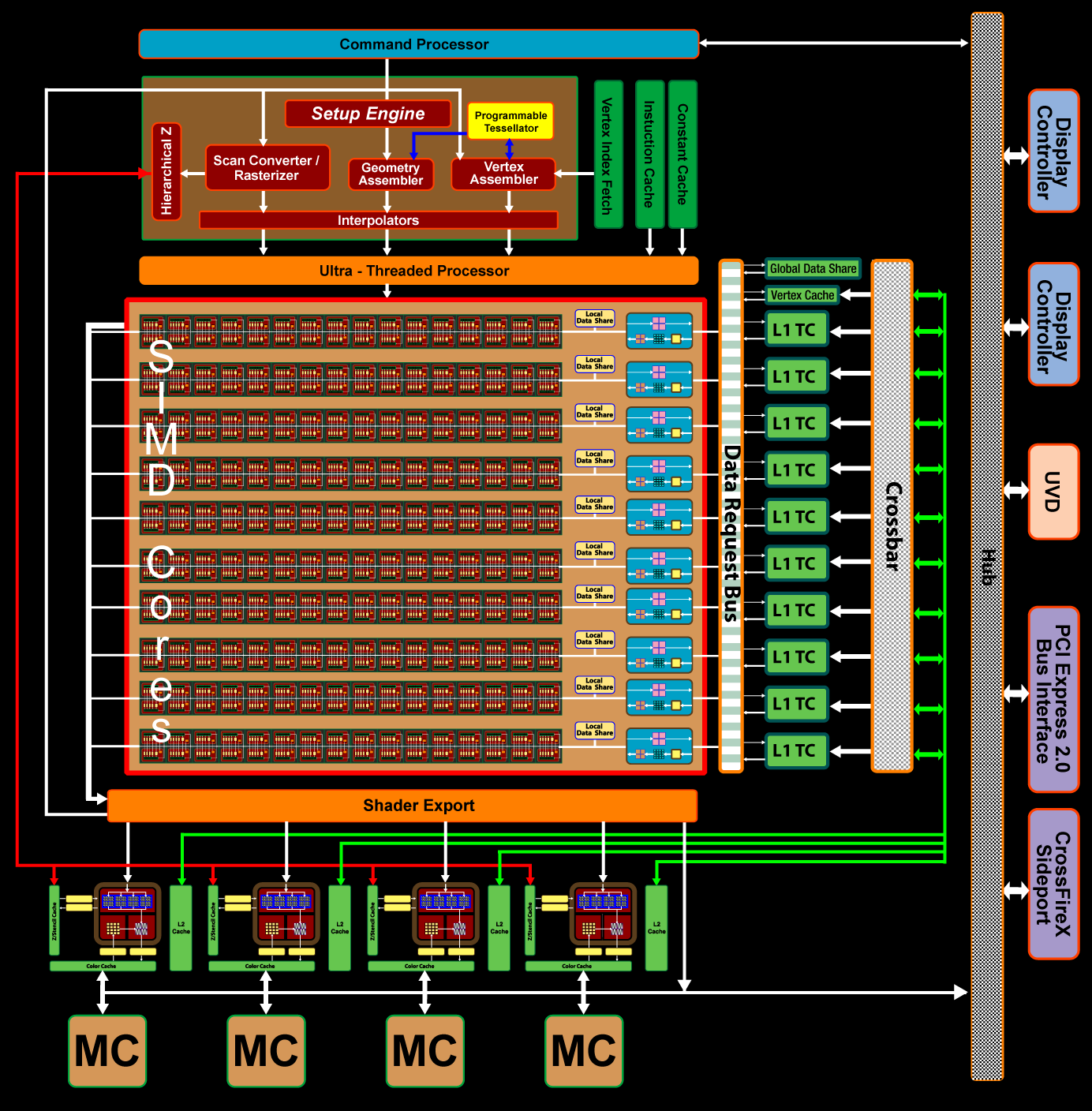

ATI Radeon HD 4870(上)和4800系列(下)的架构和参数。
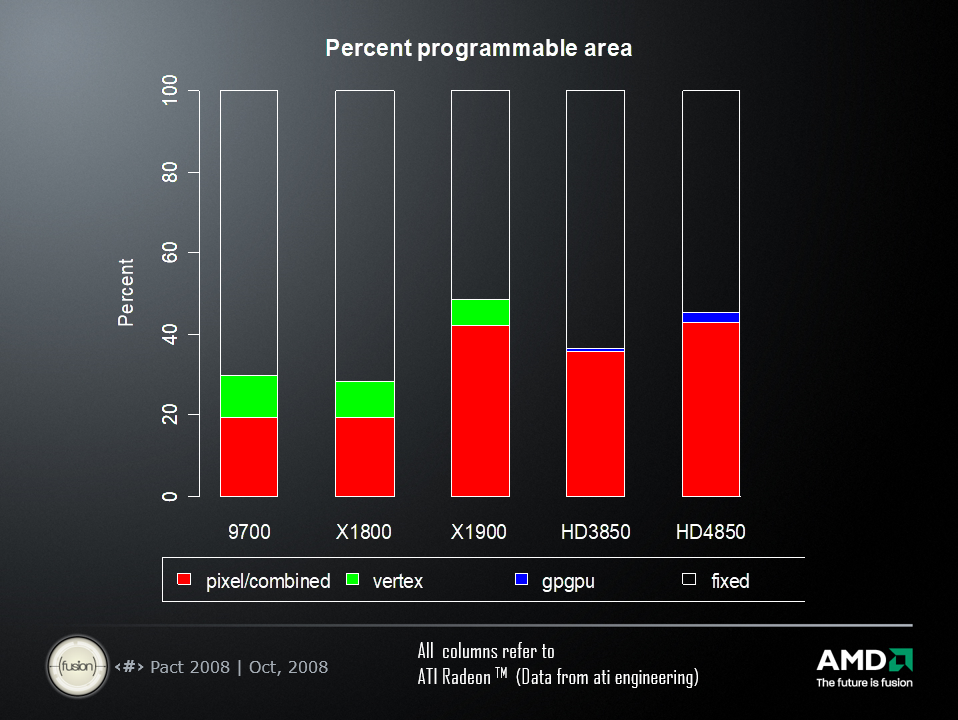
部分ATI GPU的可编程区域百分比对比。
2000年代GPU的渲染管线变化如下图所示:



2009年的Nvidia提供了完整的开发者套件,包含各类内容创建、软件开发SDK、性能调试和技术书籍等:

14.3.3 引擎演变
14.3.3.1 综合演变
2000时代,渲染技术的进步和硬件性能的提升,为游戏引擎提供了强力的支撑,使得游戏引擎能够提供更加强大的功能,使得游戏开发者可以研制出多种多样的游戏类型。



2000时代的多种游戏类。从上到下依次是实时策略、格斗、赛车、多人在线游戏。
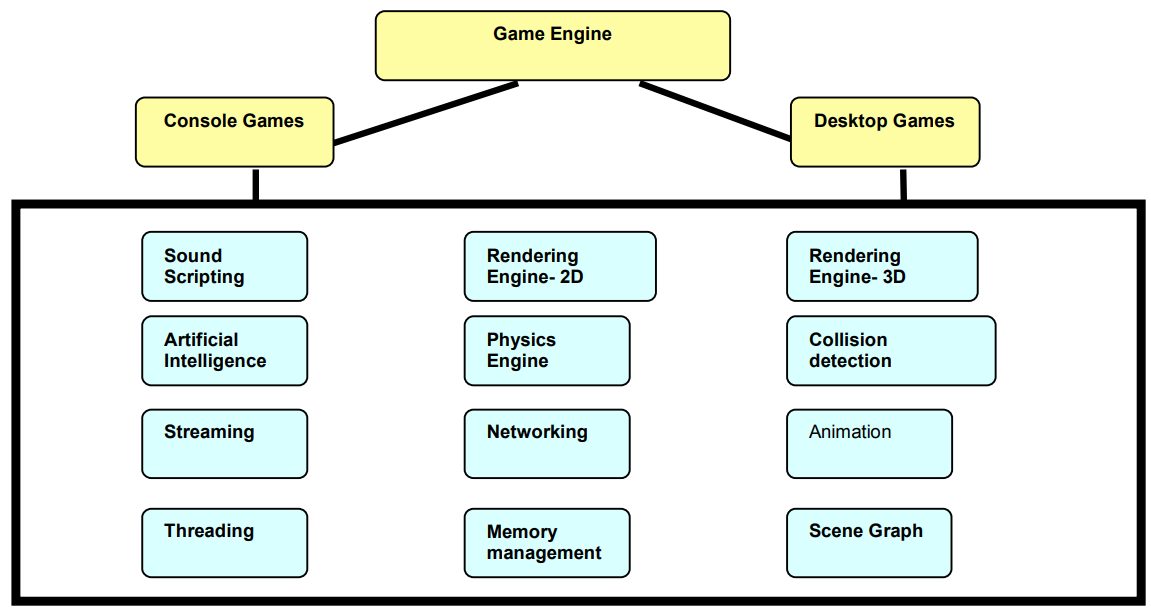
2000年早期,游戏引擎初具规模,核心模块引入了诸多通用功能,例如音频、AI、流、线程、物理、渲染、碰撞、动画网络等等,具体见下图:
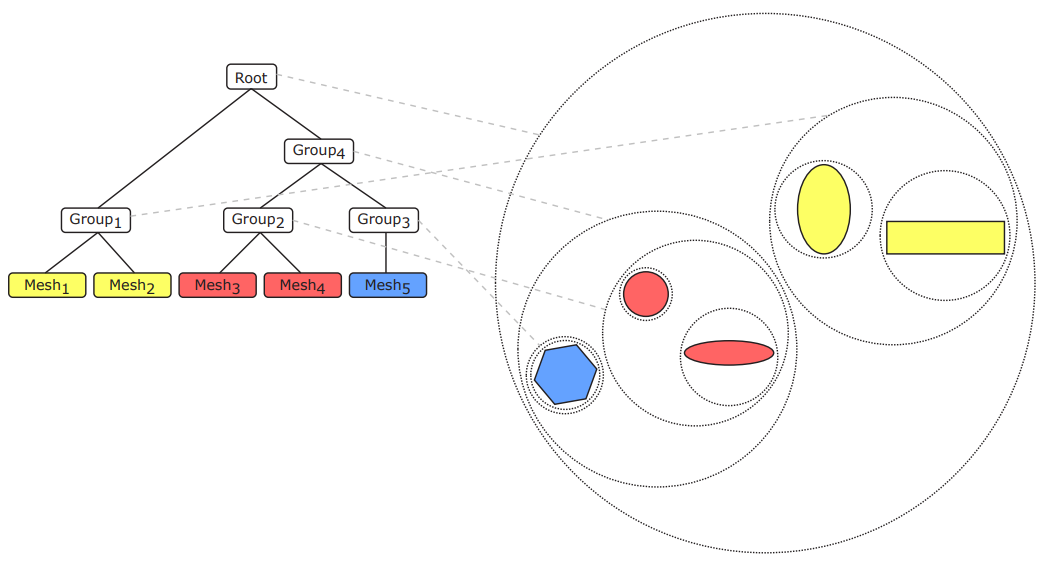
随着场景的复杂度越来越高,场景管理的技术也在发生改变,例如下面两图分别是BVH(层次包围盒)加速结构和共享数据的一种场景节点结构:
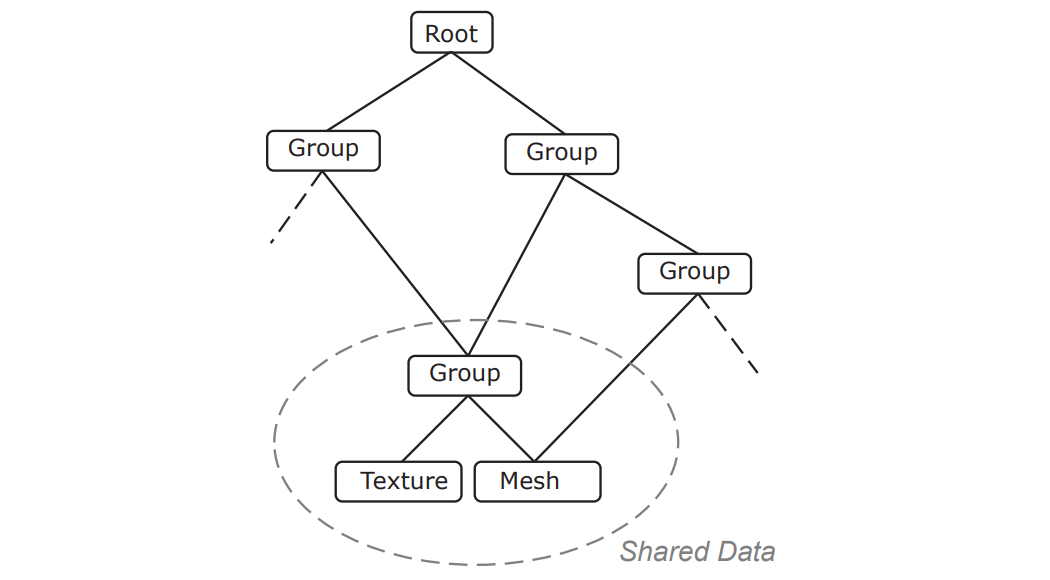
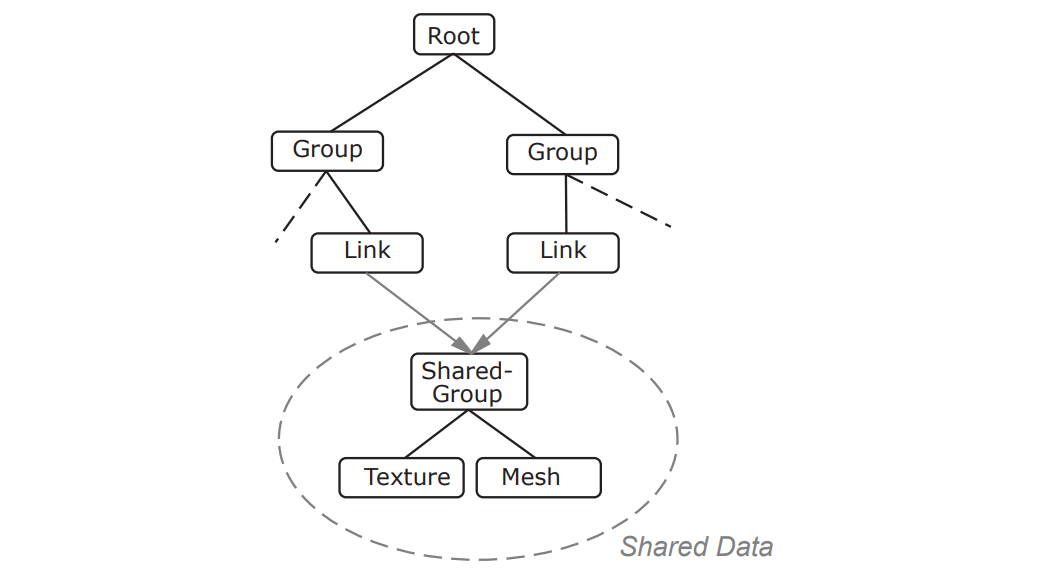
基于共享数据的结构还有其它变种,比如用链接节点解耦资源(下图上)和场景节点及基于组件的场景节点结构(下图下):
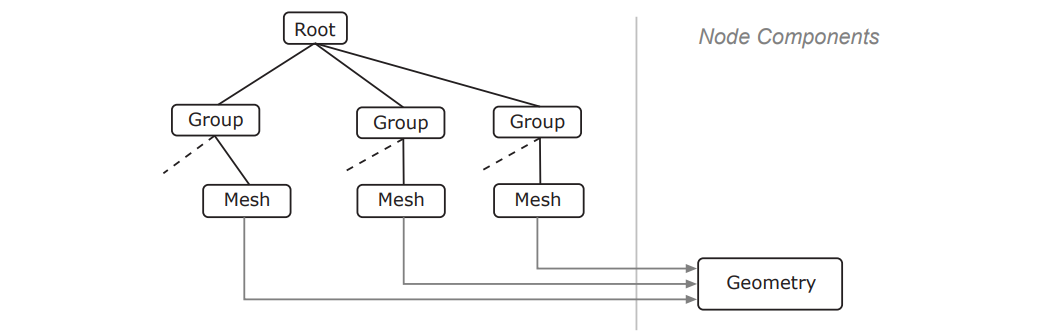
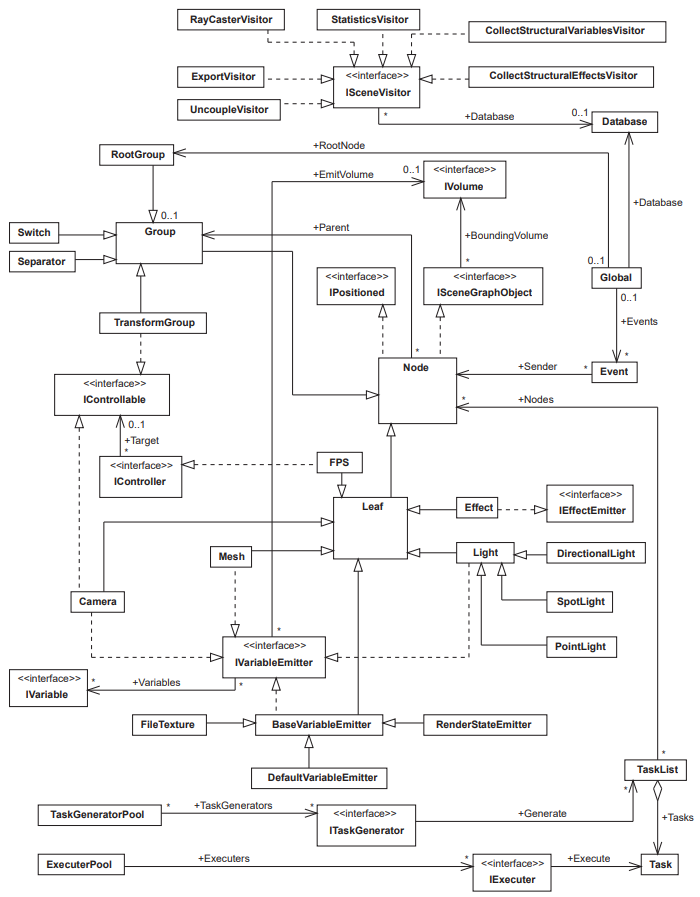
其场景图节点的UML图如下:
用于引擎的设计模式常用的有抽象工厂模式(Abstract Factory Pattern)、原型模式(Prototype Pattern)、单例模式(Singleton Pattern)、适配器模式(Adapter Pattern)、桥接模式(Bridge Pattern)、代理模式(Proxy Pattern)、命令模式(Command Pattern)、观察者模式(Observer Pattern)、模板方法模式(Template Method Pattern)、访问者模式(Visitor Pattern)等。
利用以上设计模式,可以很好地将引擎分层,解决循环依赖的问题。下面分别是Designing a Modern Rendering Engine中的YARE引擎的分层架构和图形、核心的子模块图:
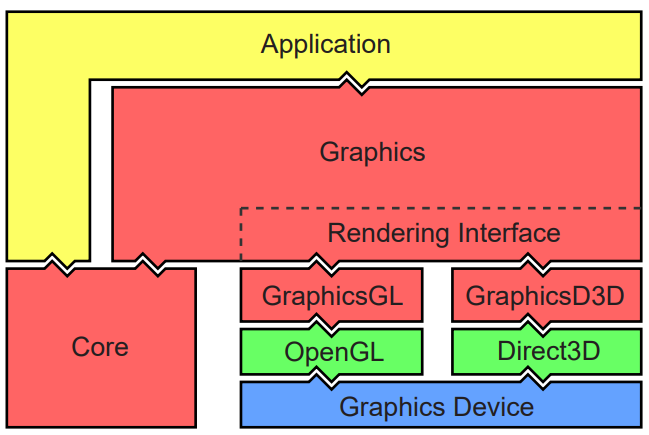

YARE引擎在应用层的渲染管线如下所示:
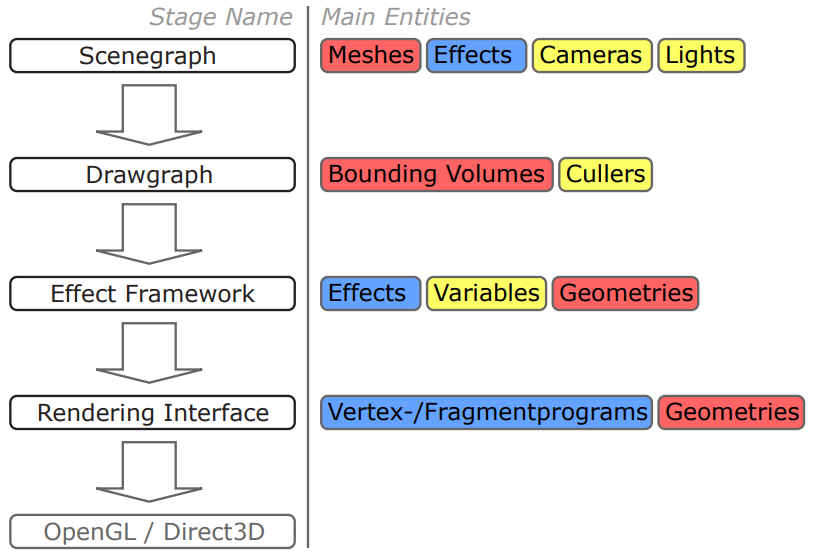
YARE引擎在Shader上,采取了当时比较流行的Effect、Technique框架 + CG着色器语言:
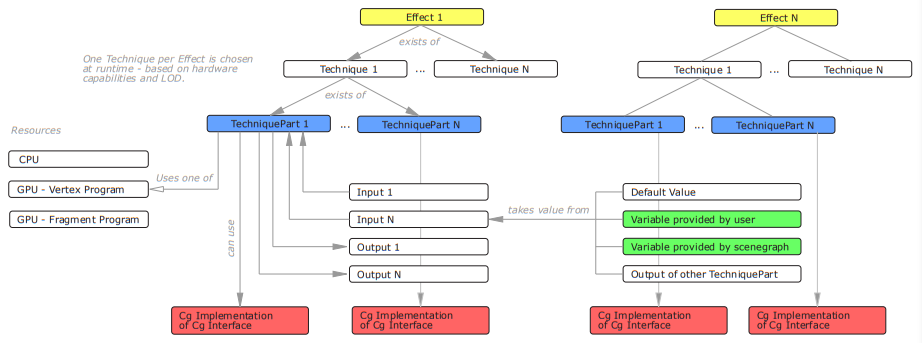
其Effect框架UML图如下:
 )
)
YARE在绘制管线上,会对场景节点执行如下处理:
- 首先,为网格对象中的每个几何图形创建一个Renderable类的实例。
- 其次,对每个Renderable的instance执行以下步骤:
- 可渲染对象获得分配的相应几何图形。
- 从网格对象中检索可渲染的包围体。
- 可渲染的结构上下文从场景数据库中检索(包括结构变量和效果)并分配给可渲染。
- 从场景数据库中获取所有全局变量和效果并分配给可渲染对象。
- 从场景数据库中获取与可渲染对象相交的所有体积变量和效果,并将其分配给可渲染对象。
- 如果在此更新过程中创建了可渲染实例,则将其添加到绘图中。
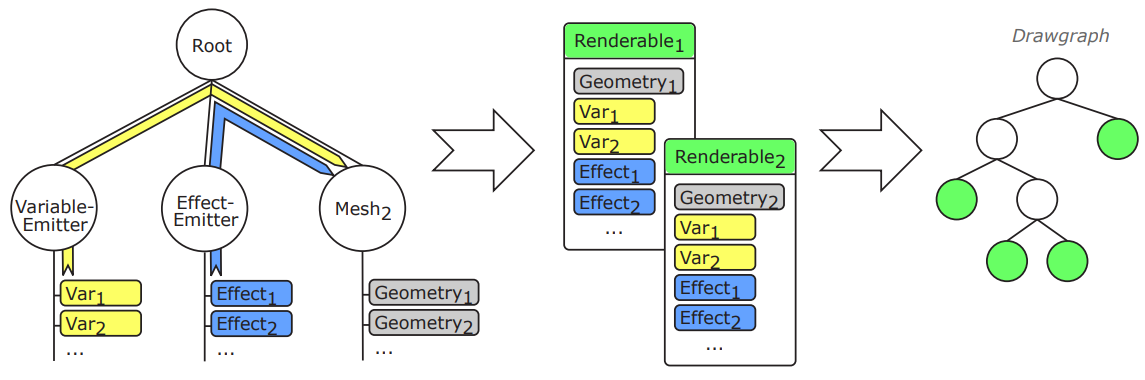
YARE引擎的可渲染对象由场景图的几何形状、变量和效果构成,并被插入到绘图中。

YARE引擎的渲染效果。
2003年,A Framework for an R to OpenGL Interface for Interactive 3D graphics描述了一个在R中提供交互式3D图形的框架。其中RGL1(简称R)是一个扩展库,使用了具有交互式视点导航的3D可视化设备系统。R使用OpenGL作为实时渲染后端,关键组件是R和OpenGL之间的接口,提供了一组命令,用于指定启用3D图形可视化的对象和操作。
设计中的一个重要目标是促进对不同操作系统的可移植性,使用面向对象的方法,通过在围绕相关空间的球体表面移动查看器,提供了一个简单直观的用户界面,用于使用指针设备进行3D导航,视图集中在球体的中心。
该框架实现的重点是操作3D “图元”,构成更复杂的3D对象。可以直接从R访问通过控制形状和外观的函数,以实现许多有吸引力的OpenGL功能,例如多重光照、雾、纹理映射、alpha混合和依赖于侧面的渲染,以及控制设备和场景管理、环境设置(设置灯光、边界框、视点)和导出(制作和导出快照)等。
为了能够无缝集成到R系统中,软件设计需要高度抽象,从而进一步实现跨平台可移植的总体设计目标。由于R缺少窗口系统和OpenGL的可移植接口,而该架构提供了这些功能。(下图)
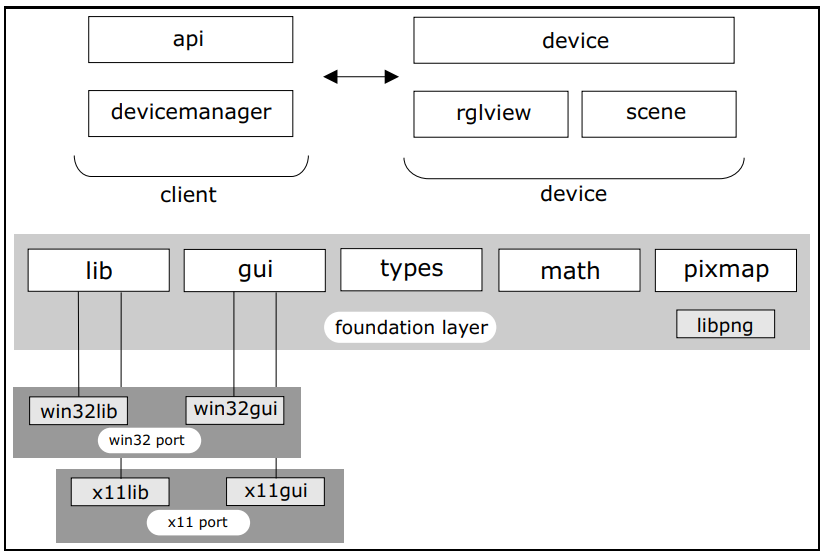
简要概述了架构中涉及的软件模块,基础层代表平台抽象,包括五项核心服务。
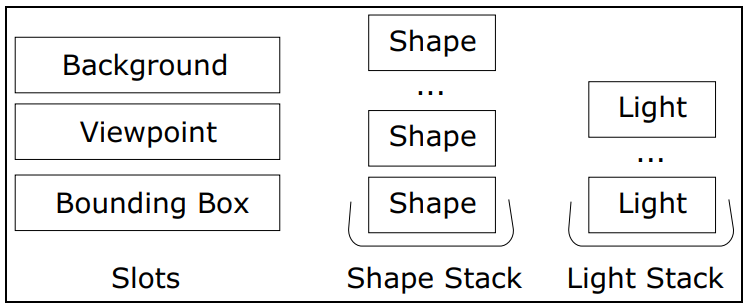
场景描述存储在复合对象模型中,渲染引擎以非常频繁的速率对其进行计算。下图的逻辑数据模型使用堆栈语义同时管理多个形状和灯光,管理三个额外的对象槽,一次保存一个对象,插槽对象被替换,而堆栈对象可以立即弹出或可选地清除。
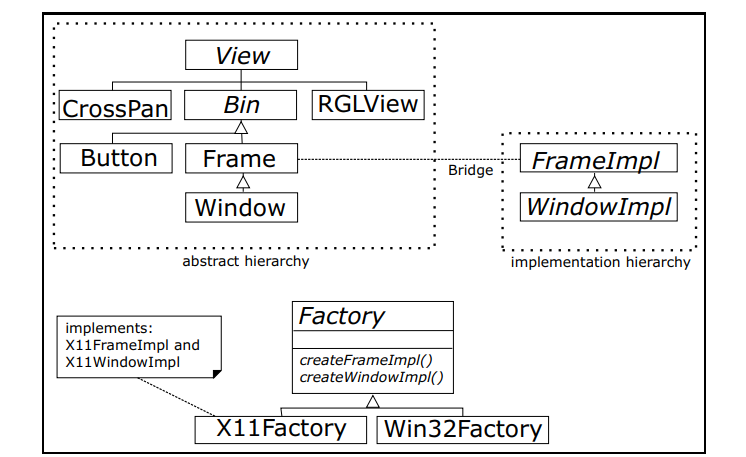
对于GUI层,采用了抽象层和实现层相分离,使用工厂模式创建具体的设备实例,以达到封装不同绘制库的目的:
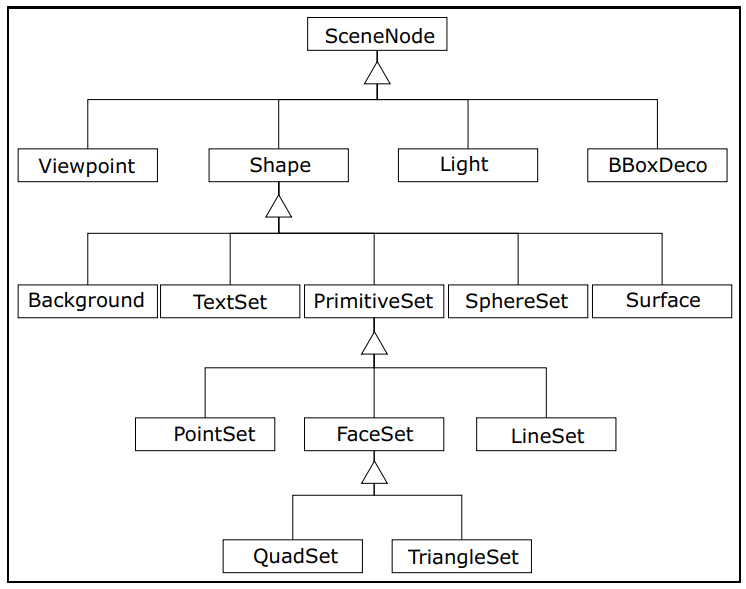
渲染引擎和数据模型已使用下图中描绘的类层次结构实现,渲染是使用多态性执行,外观信息在由Shape和BBoxDeco类聚合的Material类中实现,名为Scene的中心类管理数据模型并实现整体渲染策略。
2004年,Beyond Finite State Machines Managing Complex, Intermixing Behavior Hierarchies提出了基于行为的代理的架构。
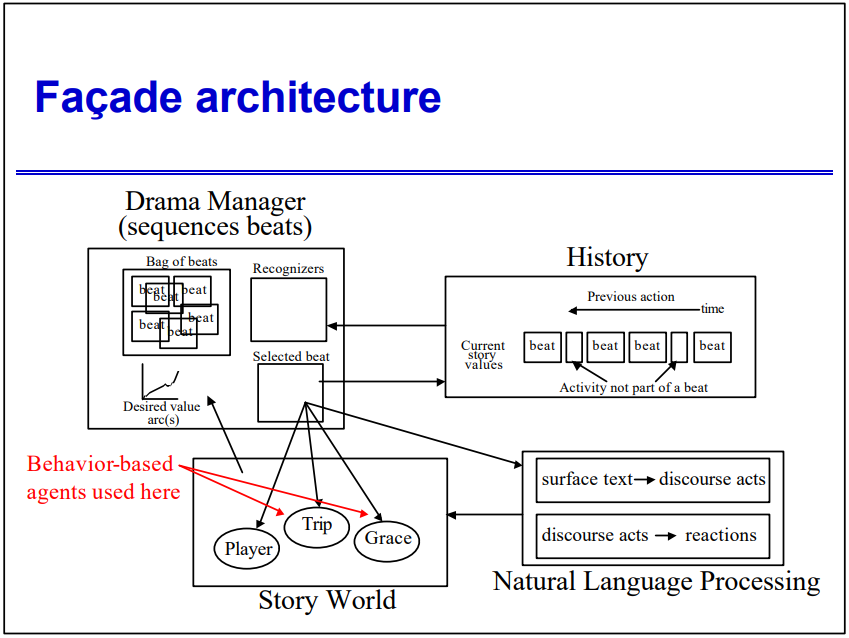
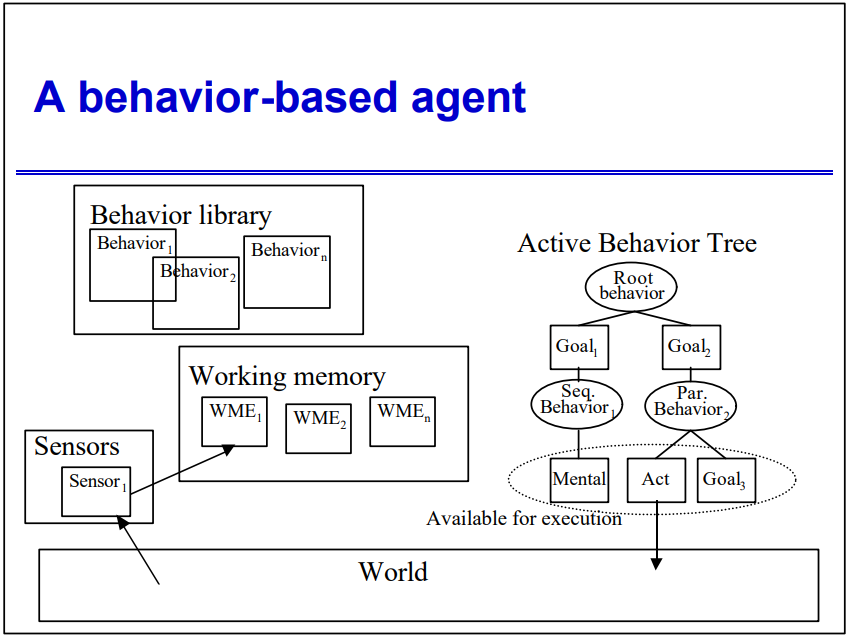
基于行为的代理的架构图。
对比FSM,基于行为的编码支持混合(可以同时处于多个“状态”),层次结构比平面FSM更具表现力,目标和行为之间的动态耦合,可以看作是行为树的初代雏形。
Game Mobility Requires Code Portability则阐述了针对版本众多的移动平台编写更易于跨平台的代码及使用的技术。该文从项目目录组织、文件夹结构、框架设计、编码风格、宏定义、重视编译器警告等方面提供建议或示范。其框架设计使用钩子(hook)及有限状态机创建事件驱动的应用程序设计,并使用这些挂钩来驱动应用程序的核心。实现的伪代码如下:
static boolean EventHandler( ... Parameters ... )
{
switch ( eventCode )
{
case EVT_APP_START:
ClearScreen( curApp )
MemInit( curApp ); // Initialize memory manager
GameStart( curApp );
GamePostfix( curApp );
break;
case EVT_APP_STOP:
GameEnd( curApp );
MemExit( curApp ); // Exit the memory manager
break;
case EVT_APP_EVENT: // Special treatment may be
GameEvent( curApp ); // required here depending on
break; // the actual platform
case EVT_APP_SUSPEND:
SuspendGame( curApp );
break;
case EVT_APP_RESUME:
ResumeGame(curApp );
break;
case EVT_KEY_PRESS:
keyPressed(curApp, parameter );
break;
case EVT_KEY_RELEASE:
keyReleased( curApp, parameter );
break;
}
}
以上是驱动游戏引擎的平台无关代码的挂钩,通过这个接口,抽象了核心平台依赖,可以为当时几乎所有环境创建此内核,并且可以轻松扩展以添加功能,例如手写笔。
对于内存管理,主张确保重载new、delete和new[]、delete[]和添加添加调试工具,例如边界检查、泄漏检测和其它统计信息。
void *operator new( size_t size );
void operator delete( void *ptr );
void *operator new[]( size_t size );
void operator delete[]( void *ptr );
在GUI上,通过拼接来动态创建各种尺寸的背景:

此外,为了更好的跨平台可移植性,该文建议注意以下事项:
- 记录代码并使用合理且不言自明的变量和函数名称。
- 尽量使用断言。不仅可以检测程序逻辑中的错误,还可以揭示手机和平台之间的移植问题,例如不正确的字节顺序、对齐问题、损坏的数据等。
- 有意识地寻找和隔离平台和设备依赖关系。
- 如果数据结构发生变化,确保在所有配置中进行正确的调整,永远不要让代码开放或容易出现错误。
- 尽可能针对多设备编写代码。
- 完成应用程序后,锁定游戏引擎代码,以免将来被破坏。可以使用版本控制系统来做到这一点,或者将文件设为只读。
- 正确记录构建应用程序所需的步骤。
- 记录实现新手机版本所需的步骤。
- 永远不要在代码中使用#ifdef。最不便携的解决方案,本质上是一种hack,通常会在以前运行良好的版本和构建中引入错误。
- 移植时,尽量少修改代码。更改的代码越少,引入新错误的机会就越小!
Adding Spherical Harmonic Lighting to the Sushi Engine分享了Sushi引擎添加球面谐波(Spherical Harmonic)作为光照的技术和经验。已知渲染方程如下所示:

假设模型是刚体、不移动且光源是远处的球体,约束V和H项后,积分变成了恒定量。在此情况下,可以预计算这些项(Pre-Computed Radiance Transfer,PRT)并保存到所有的P点。其中传输函数(transfer function)的公式和图例如下:
传输函数编码了在P点有多少光可见和有多少光被反射,存储时使用球面谐波(Spherical Harmonic,SH),积分入射光时只剩下两个向量的点积。具体做法是:
- 离线阶段,预计算漫反射辐射率传输,按逐顶点或逐纹素保存结构。
- 运行阶段,引擎投射光源到SH。
- 像素和顶点着色器用漫反射传输函数积分入射光,以计算全局漫反射。
实现的工作流如下图:

文中给出了详细的实现细节和步骤,这里就不详述,有兴趣的同学可以看原论文。

下图是Sushi引擎的PRT效果图:

Speed up the 3D Application Production Pipeline则阐述了RenderWare引擎的架构、渲染管线和支持的特性。RenderWare包含3个组件:游戏框架、工作区、管理器。它们的关系如下图:
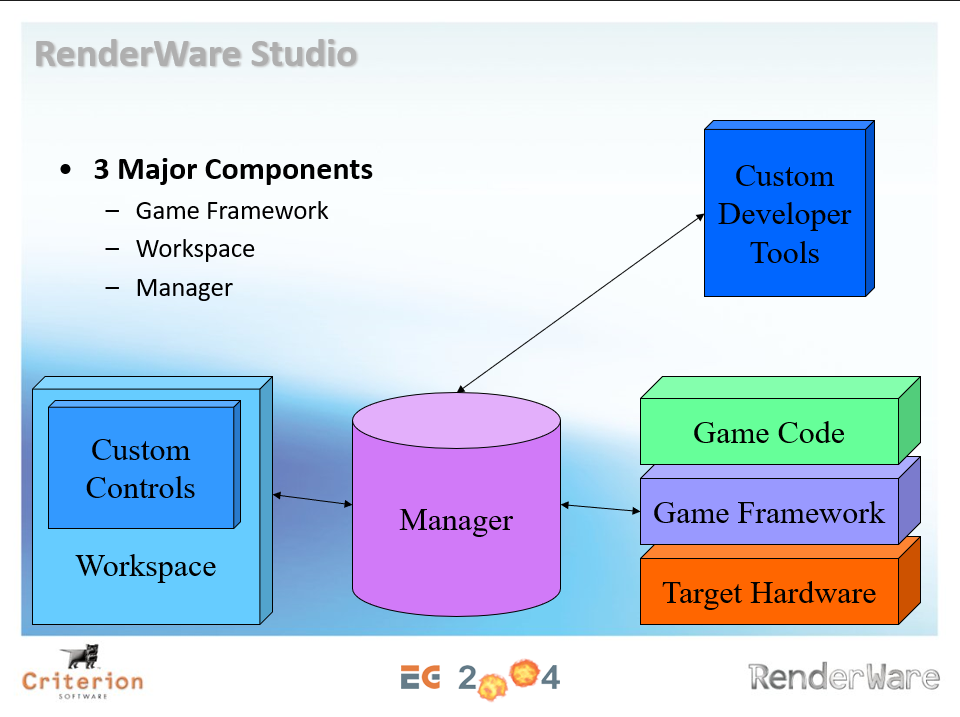
RenderWare的图形架构如下图,通过插件、套件和部分引擎API和应用程序交互,达到可扩展、解耦的目的。
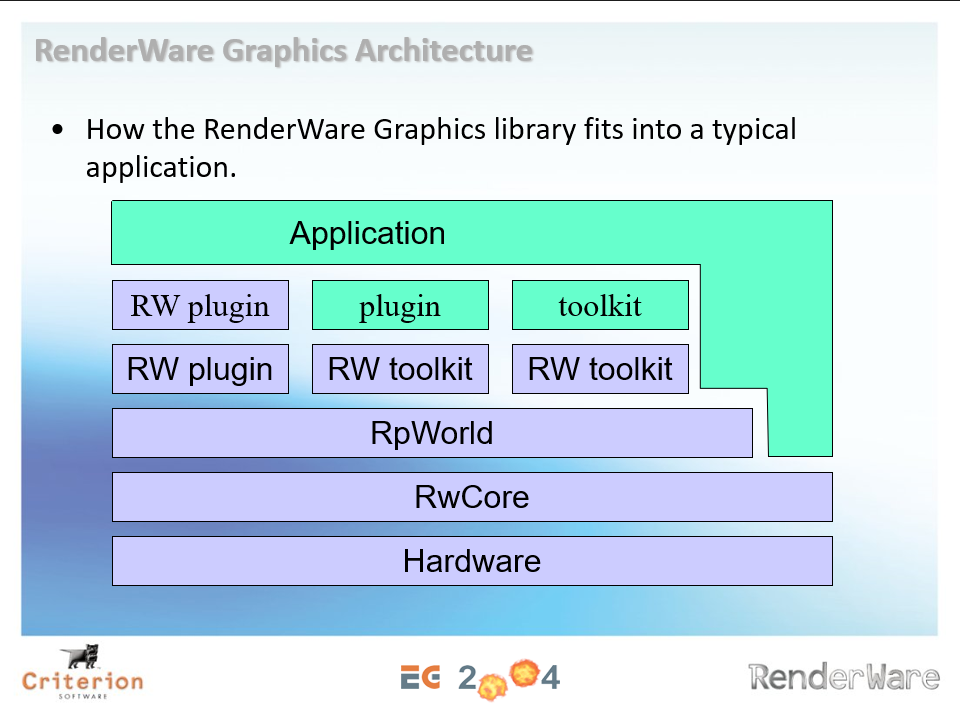
RenderWare的渲染管线普通(General)、特殊案例(Special-cased)、平台优化(Platform-optimized)、自定义管线(Custom-built pipelines)4中类型。普通模式支持静态网格、蒙皮网格和多纹理,特殊案例支持复制、粒子、优化的光照设置、简化的权重蒙皮、贝塞尔批处理图元、光照贴图等,平台优化只要为DX9和XBOX优化顶点/像素着色器,超过150个用于PS2的手 VU流水线,手动优化的 GameCube组装器管道,可用时进行硬件蒙皮。
在图形方面,RenderWare支持带有API的DMA管理器、纹理缓存管理、管线构建套件、PDS管线传输系统、动态顶点缓冲区管理、渲染状态缓存、原生几何体/纹理实例化等。另外还支持场景管理、平台优化的文件系统、流式加载、异步加载、粒子系统、文件打包、智能管线选择等功能。

RenderWare渲染效果图。(2004)
An explanation of Doom 3’s repository-style architecture提到Doom 3的架构图,可知Doom 3包含了场景图、游戏逻辑框架、物理和碰撞、骨骼蒙皮、低级渲染、资源管理、第三方库、核心系统等模块。其中核心系统包含断言、数学库、内存管理(Zone Memory)、自定义数据结构。(下图)
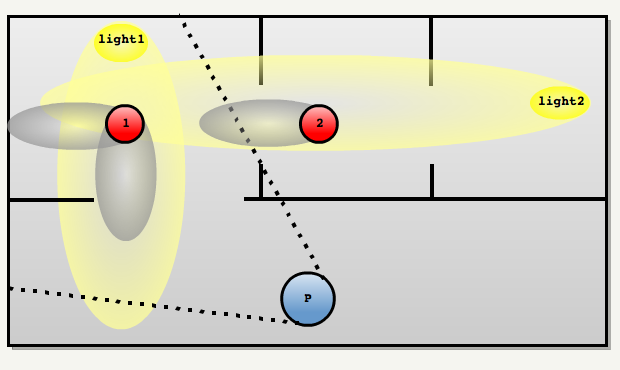
Doom 3的引擎模块架构和依赖图。(2004)
Doom 3的低级渲染(LLR)是所有游戏引擎中最大、最复杂的组件之一,应用于3D图形时极为重要,低级渲染包含引擎的所有原始渲染工具,处理游戏中存在的许多预处理任务。LLR负责底层数据结构,负责游戏操作,以及预处理关卡设计。关卡是二维设计的,因此不能有多层的关卡,游戏将楼层划分为 2 个单独的级别。
在资源管理方面,Doom 3使用了一个名为DeePsea的资源管理器,包含支持3D对象建模、对象碰撞解决等的包,游戏信息/数据包存储在称为WAD的特殊文件中,IWAD(内部 WAD)或 PWAD(补丁 WAD),包含相关数据的WAD被组装成块,例如:名为“BLOCKMAP”的IWAD块存储指示地图中的任何两个对象是否相互接触的信息。
在渲染特效方面,Doom 3已经支持光照贴图、HDR照明、PRT照明、粒子和贴花系统、后期效果、环境映射等。

上:Doom 3的光照对比图;下:Doom 3的特效系统。
Doom 3的场景图(Scene Graph)包含场景/区域中的所有渲染模型和纹理,与前台组件交互确保后台所需的一切都上传到GPU内存,处理剔除并将命令发送到后台。
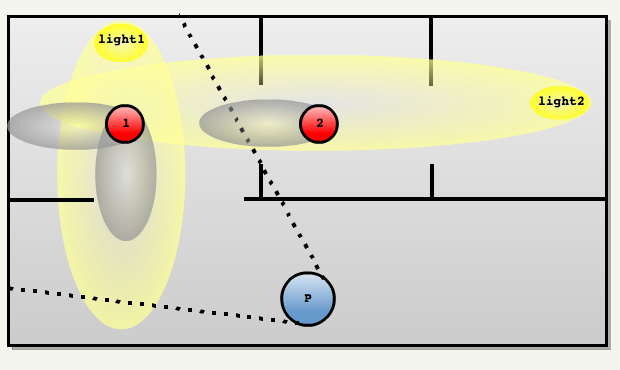
Doom 3场景图中的光源裁剪示意图。
有了以上技术的支持,使得同期的场景效果出现明显的改善:

2004年的游戏室内场景截图。
Development of a 3D Game Engine - OpenCommons提到了2000中后期的引擎设计思路,此引擎被称为Spark Engine。Spark Engine的游戏引擎主要逻辑的伪代码如下:
OnDraw()
Frustum cull check
If inside or intersects, call Draw()
Draw()
If Node, call OnDraw() for children
If Mesh, add to render queue to be processed
If set to skip, call Render() immediately
Render() (Mesh only)
Apply render states (checked against renderer’s enforced states)
Apply material
Update material definitions (sets shader constants)
Evoke device draw call
对于场景渲染器,它是引擎的渲染工具和桥梁,是在绘制过程中传递给每个空间的对象,并提供将对象实际渲染到屏幕的功能。场景渲染器被设计成完全独立的,每个渲染器都拥有一个摄像头,因此也拥有一个视口——它可以是整个屏幕,也可以是其中的一小部分。允许多个渲染器在不同的上下文中同时处于活动状态,例如,一个分屏游戏,两个玩家使用自己的相机渲染相同的场景图,场景图数据完全独立于渲染器。除了包含与图形设备交互和启动绘图调用的功能,渲染器提供了一些额外的功能来提高渲染性能。渲染器通过两种方式完成此操作:
-
渲染状态缓存。渲染器跟踪应用到图形设备的最后渲染状态,以减少状态切换。切换状态可能很昂贵,因此减少冗余是渲染器采用的有用策略。
-
渲染队列。渲染器拥有一个渲染队列来管理一组桶,使得开发人员可以控制渲染对象的顺序。默认情况下,引擎支持四个桶:Pre-Bucket、Opaque、Transparent 和Post-Bucket,它们按此顺序呈现。控制渲染几何图形的顺序很有用,可以允许正确绘制透明物体。下图用一个透明和不透明的立方体展示了此技术特点,左边的图片有正确排列的立方体,而右边的图片没有:
![]()

渲染状态会影响在顶点和像素流经渲染管道时几何图形的处理方式。在微软游戏开发套件XNA中,状态被定义为引擎使用的枚举。与XNA不同,引擎将这些枚举分组为单独的类,这些类可以直接附加到诸如Spatial的类,场景图允许渲染状态被继承和结合。引擎在定义渲染状态时也采用了稍微不同的方法,引擎渲染状态是指与几何数据相关的所有信息,包括材质颜色信息、纹理和光照。渲染状态分为两大类:
- 全局渲染状态。包含来自XNA的枚举,类似于渲染状态的典型定义,例如alpha混合、三角形剔除、深度缓冲等。这些状态被定义为全局状态,因为它们的信息独立于Spatial类的任何属性。因此,这些状态本质上只不过是包装器提供与XNA中的渲染状态枚举接口的组件化形式。
- 数据渲染状态。是为引擎的材质系统提供着色、纹理和照明信息的特殊用途类。将数据与材质和着色器分离允许灵活性和重用——数据渲染状态所持有的纹理和灯光对象不对应于任何一个着色器。引擎的TextureState可以保存任意数量的纹理,这些纹理可以被不同的材质解释。例如,一些着色器可能只使用第一个纹理作为漫反射颜色,其它着色器可能将第二个和第三个纹理用于法线和高光贴图。
所有Spark Engine渲染状态都继承自一个名为AbstractRenderState的抽象类。以下是引擎当前支持的渲染状态:
- BlendState:控制透明度选项的 alpha 和颜色混合。
- CullState:控制三角形剔除,例如逆时针、顺时针或无剔除。
- FillState:控制应如何填充对象,无论是线框、实体还是点。
- FogState:控制固定功能的DirectX9.0c的雾功能。
- ZBufferState:控制深度缓冲。
- MaterialState:用于控制对象统一材质颜色的数据渲染状态,例如作为漫反射、环境反射、发射和镜面反射颜色。
- TextureState:应用于对象的纹理的数据渲染状态,还管理纹理过滤和包装模式的采样器状态。
- LightState:灯光对象的数据渲染状态,跟踪依附于空间的光源列表。
对于材质系统,材质定义了对象应该如何着色和着色的属性,每个被渲染的对象都需要有一个关联的材质,与XNA的Effect API直接相关。 材质系统是一个简单但非常灵活的系统,旨在解决直接使用Effect API的几个缺点, 绘制调用中效果的典型调用过程伪代码如下:
Load the shader effect file
Set shader constants
Call Effect.Begin()
For each EffectPass do
Call EffectPass.Begin()
Draw geometry
Call EffectPass.End()
Call Effect.End()
Spark Engine还支持点光源、聚光灯、定向光等光源类型,抽象各种类型的光源的结构体如下:
//Light struct that represents a Point, Spot, or Directional
//light. Point lights are with a 180 degree inner/outer angle,
//and directional lights have their position's w = 1.0.
struct Light {
//Color properties
float3 Ambient;
float3 Diffuse;
float3 Specular;
//Attenuation properties
bool Attenuate;
float Constant;
float Linear;
float Quadratic;
//Positional (in world space) properties
float4 Position; //Note: w = 1 means direction is used
float3 Direction;
float InnerAngle;
float OuterAngle;
};
它们的渲染效果如下:

Spark Engine光源渲染效果。从上到下依次是点光源、聚光灯、平行光。
此外,Spark Engine还支持不同着色阶段的光照、法线贴图、高光贴图、轮廓光、立方体环境图、地形编辑、光照图等效果。
Spark Engine的立方体环境图。
QUAKE III ARENA在网络同步方面,采用了CS架构,通过网络链接服务器,以便服务器同步各个客户端之间的操作:
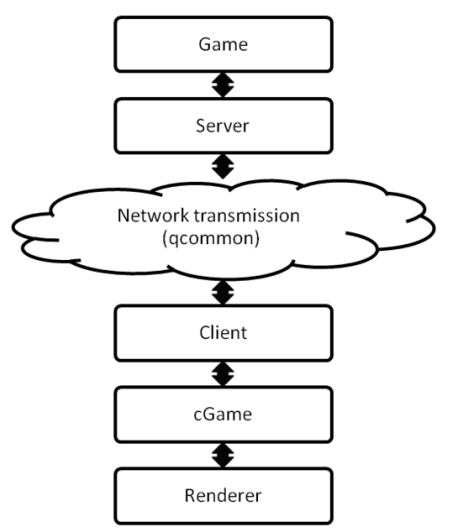
QUAKE III ARENA的游戏子系统包含游戏的服务器实现,还包含一些游戏服务器之间共享的库和客户。PMOVE模块是更新播放器的主要模块整个游戏的状态信息,采取的输入是当前播放器状态 (player_state_t),以及从客户端接收到的用户操作(usercmd_t)。 一个新的生成的player_state_t代表当前玩家在游戏中的状态。(下图)
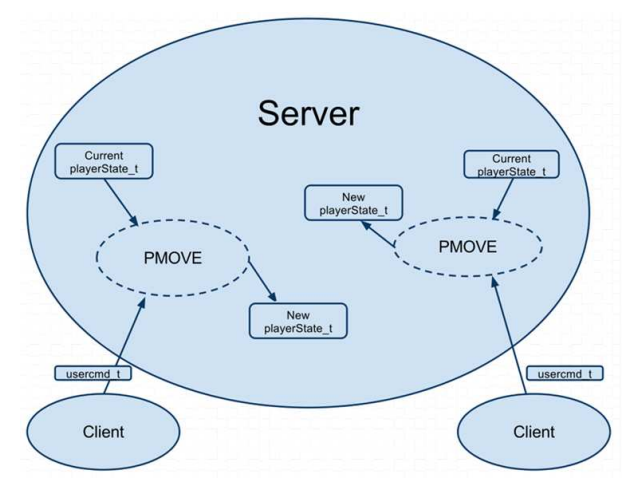
上图是QUAKE III ARENA的客户端同步到服务器的通讯模型,下图则是服务器通讯到客户端的同步模型:
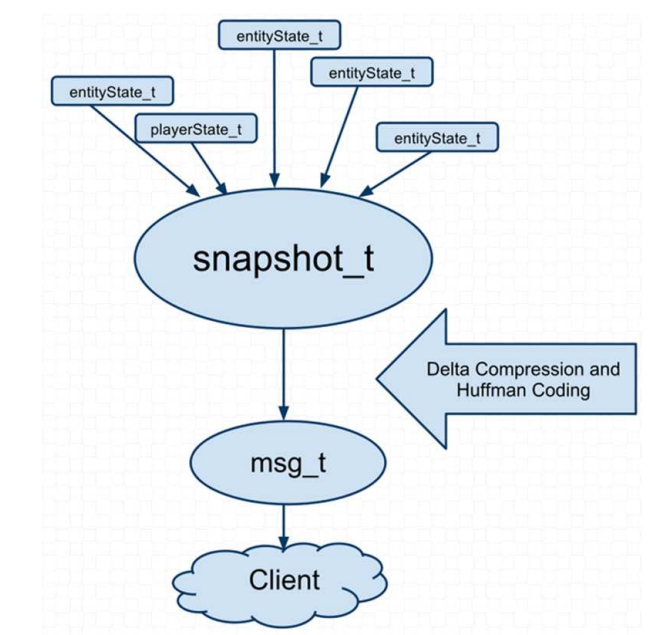
同期的ORGE引入了场景管理器、资源管理器、渲染及插件等模块,其架构图如下:

OGRE的根对象是入口点,必须是第一个创建的对象,必须是最后一个删除的对象,启用系统配置,有一个连续的渲染循环。场景管理器包含出现在屏幕上的所有内容和地形(高度图)、外部和内部场景的不同管理器。Entity是可以在场景中渲染的对象类型,包含任何由网格表示的东西(玩家、地面……),但灯光、广告牌、粒子、相机等对象不是实体。SceneNode(场景节点)跟踪连接到它的所有对象的位置和方向,实体仅在附加到 SceneNode 对象时才会在屏幕上呈现,场景节点的位置总是相对于它的父节点,场景管理器包含一个根节点,所有其他场景节点都连接到该根节点。最后的结构是场景图。ORGE的渲染主循环如下:
void Root::startRendering(void)
{
// ... Initialization ...
mQueuedEnd = false;
while( !mQueuedEnd )
{
//Pump messages in all registered RenderWindow windows
WindowEventUtilities::messagePump();
if (!renderOneFrame())
break;
}
}
bool Root::renderOneFrame(void)
{
if(!_fireFrameStarted())
return false;
if (!_updateAllRenderTargets()) // includes _fireFrameRenderingQueued()
return false;
return _fireFrameEnded();
}
ORE的资源管理策略如下:
-
每个资源有4种状态:
- Unknown:Ogre不知道该资源,它的文件名被存储了,但 Ogre 不知道如何处理它。
- Declared:标记为创建。Ogre知道它是什么类型的资源,以及在创建它时如何处理它。
- Created:Ogre创建了资源的一个空实例,并将其添加到相关的管理器中。
- Loaded:创建的实例已完全加载,访问资源文件的阶段。
-
Ogre的原生ResourceManagers是在Root::Root中创建的
-
通过调用指定资源位置
-
手动声明资源。
-
脚本解析自动声明资源。
-
满足某些条件的资源才会被设置为加载的。
2006年的UE3支持了64位HDR色彩、逐像素光照、高级动态光影(动态模板缓冲阴影体积、软阴影、预计算阴影、大数量的预计算光)、材质系统、体积雾、支持物理和环境交互的粒子系统,以及其它诸多渲染特性(如法线贴图、参数化的 Phong 光照; 自定义艺术家控制每个材料照明模型,包括各向异性效果; 虚拟位移映射; 光衰减功能; 预先计算的阴影掩模; 定向光照贴图; 以及使用球谐图预先计算的凹凸粒度自阴影等等)。这些特性的加持,使得UE3的渲染画质有了显著的提升。(下图)


UE3的部分渲染特性。从左上到右下依次是带有自阴影的角色动态软阴影、动态软阴影、逐像素光影、法线贴图的半透明对象扭曲和衰减帧缓冲区、云体动态阴影、体积雾、64位HDR色彩、法线贴图漫反射和镜面反射照明与模糊阴影的相互作用。

UE3的角色和场景物体渲染效果。
到了CryEngine3,因为引入了更多新兴的技术,使得渲染画面又上了一个台阶(下图)。

CryEngine 3的游戏画面截图。
2006年,A realtime immersive application with realistic lighting: The Parthenon和The Parthenon Demo: Preprocessing and Rea-Time Rendering Techniques for Large Datasets描述了一个交互式系统的设计和实现,该系统能够实时再现Siggraph 2004上展示的短片“帕台农神庙”中的关键序列之一,该演示程序旨在在特定的沉浸式现实系统上运行,使用户能够以接近电影级的视觉质量感知虚拟环境。

实时演示的屏幕截图。时间从黎明流逝到黄昏,阴影在建筑物上移动,场景的整体色调根据天空照明而变化。这些照片是从不同的位置拍摄的,每次都更靠近建筑物。
该文讨论了与数据集大小和所需照明计算的复杂性相关的一些技术问题。为了解决这些问题,提出了使扫描的3D模型更适合实时渲染应用程序的方法,并且描述了基于直接和间接光之间的分离和广泛的预计算的照明算法。其中直接光和非直接光的公式如下:
该文还展示了如何使用现有渲染引擎预先计算光照不变量,以及如何使用现代GPU实现这些着色算法。由此产生的技术已被证明是准确的(在渲染结果方面)并且对于实时应用程序来说是负担得起的(在时间方面)。此外,由于算法执行仅限于硬件着色器,如何将这种计算集成到现有的应用程序框架中。由于演示中使用的技术非常通用,因此可以将相同类型的计算集成到其它现有的可视化系统中。

实时着色示例:注意阴影如何在几何体上精确移动(上图和左下图),以及HDR照明计算如何允许调整曝光以更好地感知阴影下的细节(右图)。

漫射照明预计算。左侧是用于照明的球面谐波基,正负值以红色和绿色编码。在右侧,通过使用谐波作为天穹光源照亮场景,可以看到对象的每个部分受该谐波影响的程度。
在现代GPU的硬件着色器上完成所有计算后,扩展现有渲染引擎以适应额外的数据和着色器管理是可行的。通过这种方式,甚至可以为大型3D数据集可视化工具添加逼真的照明。
该文还提及了渐进式缓冲区(Progressive Buffer)的技术,需要对模型进行预处理,将模型拆分为Cluster,参数化Cluster和样本纹理。详细见小节14.3.4.4 Progressive Buffer。
论文还探讨了阴影图、PCF软阴影、SH预计算、实例化、天空渲染(天空环境光、直接光)、遮挡剔除等技术。

SH估算。使用三阶球谐函数 (SH) 为每一帧导出和记录HDR照明信息,用于提供漫反射照明信息以渲染场景。

天空环境光渲染。每顶点弯曲法线用于查找SH表示,使用笛卡尔SH评估,12条指令用于3阶,用于衰减环境光的环境光遮蔽纹理(半分辨率)。

天空直接光渲染。从天空盒中提取每帧太阳的颜色、强度和位置,凹凸贴图只需要作为细节纹理。

PCF在4样本下优化前后的效果对比。

遮挡查询几何剔除。绘制的每个Cluster都经过遮挡查询测试,以查看为当前帧绘制了多少像素。如果绘制了任何像素,则将体素标记为下一帧绘制,如果没有可见像素,下一帧启用廉价的“探测”,用颜色和禁用Z写入来渲染四边形,以代替体素。
2006年,Practical Parallax Occlusion Mapping For Highly Detailed Surface Rendering讲到了视差遮挡映射的技术,以提升物体表面的细节和可信度。

平行视差遮挡映射(左)和法线映射(右)对比图。
视差遮挡映射依赖法线贴图、高度(位移)图两种资源,它们的计算都在切线空间中完成,因此可以应用于任意曲面。(下图)
 )
)
在计算视差效果时,可以通过应用高度图并使用几何法线和视图矢量偏移高度图中的每个像素来计算表面的运动视差效果,通过高度场追踪光线以找到表面上最近的可见点。算法的核心思想是跟踪当前在高度图中反向渲染的像素,以确定高度图中的哪个纹素将产生渲染的像素位置,如果实际上一直在使用实际的位移几何体。输入网格提供了用于向下移动曲面的参考平面,高度场被归一化以进行正确的射线高度场交叉计算(0表示参考多边形表面值,1表示凹陷)。
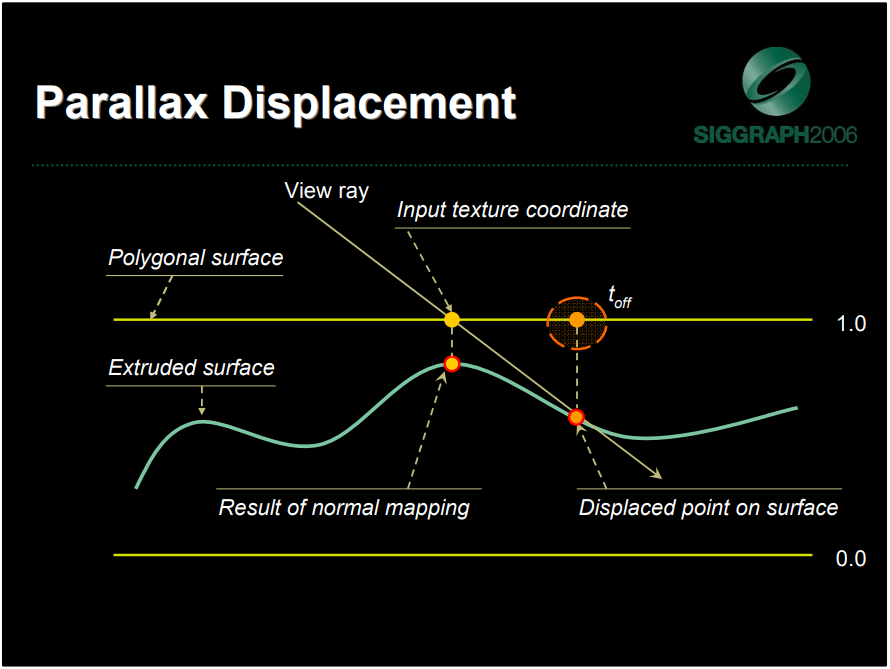
在实现的过程中,有逐顶点和逐像素两种方式,可以采用高度图轮廓追踪(Height Field Profile Tracing),选择合适的射线相交检测、动态的采用率,可以实现自阴影、软阴影等效果。在计算光照时,使用计算的纹理坐标偏移量来采样所需的贴图(反照率、法线、细节等),给定这些参数和可见性信息,可以根据需要应用任何照明模型(例如Phong),计算反射/折射,非常灵活。
此外,还可以采用自适应LOD系统,计算当前mip map级别。对于最远的LOD级别,使用法线贴图(阈值级别)进行渲染,随着表面接近观察者,提高采样率,作为当前Mip贴图级别的函数。在阈值LOD级别之间的过渡区域,在法线贴图和全视差遮挡贴图之间进行混合。
Rendering Gooey Materials with Multiple Layers涉及了多层材质的渲染。多层材质主要用于渲染半透明、体积材质、参合介质、多种介质的渲染,涉及分层组合(层间遮挡、以Alpha格式存储不透明度)、深度视差(层深或厚度引起的视差)、光源扩散(光在层之间散射)等技术。该文抛弃了传统的多纹理混合的技术,采用了全新的组合技术,包含法线贴图、半透明遮罩、平行视差、图像过滤等。

多层材质渲染案例:心脏。
总之,该文开创了多层材质渲染的先例,具有计算效率高,视觉效果佳(体积的深度视差、次表面散射的纹理模糊)等特点。
Real-time Atmospheric Effects in Games讲述了天空光渲染、全局体积雾及它们的组合效果:

此文还探讨了软粒子和云体的实现:

禁用(左)和启用(右)软粒子的对比图。
云体渲染使用了逐像素深度,且实现了云体对地形的遮挡阴影效果:

云体阴影效果。云阴影在单个全屏通道中投射,使用深度恢复世界空间位置,变换为阴影图空间。
此外,该文还介绍到逐像素深度可用于河流等水体渲染,以呈现水下深度不同而具体不同颜色的效果:

Shading in Valve’s Source Engine讲述了2006年的Source Engine使用的着色技术,包含用于世界光照的辐射法线贴图(Radiosity Normal Mapping)和高光计算,用于模型光照的辐照度体积(Irradiance Volume)、半兰伯特(Half-Lambert)、冯氏光照(Phong),用于HDR渲染的色调映射、自动曝光以及色彩校正。
使用辐射度量的光照更加真实,比直接光更高的宽容度,避免恶劣的照明情况,减少对内容制作光源的微观管理,因为不能像电影一样逐个调整灯光。


仅直接光(上)和辐射度光(下)的对比图。
Source Engine着色的关键在于创建了Radiosity Normal Mapping来有效地解决辐射度和法线映射,在新的基(novel basis)上表达了完整的光照环境,以便有效地对任意数量的灯光执行漫反射凹凸映射。
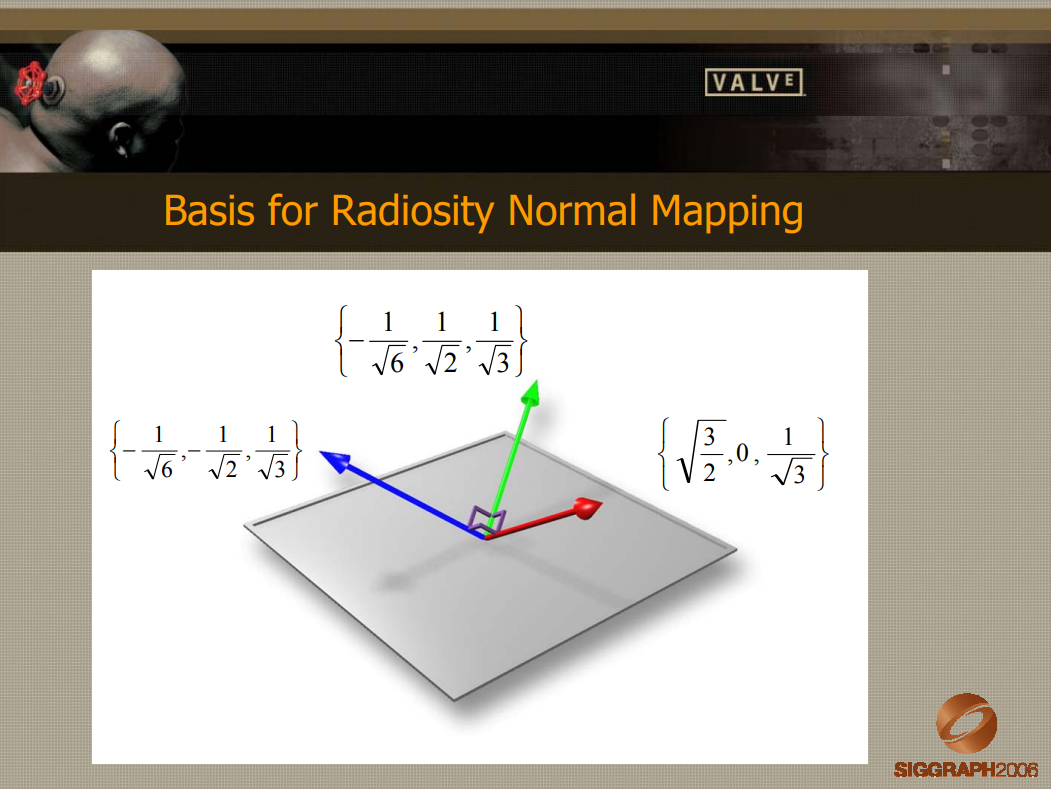
辐射度法线映射的基。
计算光照图的值时,传统的光照传输预处理计算光照贴图值只会计算单个颜色值,在辐射法线映射中,计算基础中每个向量的光值,使得光照贴图存储量增加了三倍,但Source引擎研发人员认为它提升了质量和灵活性,值得承担额外的开销。
对三种光照贴图颜色进行采样,并根据变换后的向量在它们之间进行混合:
float3 dp;
dp.x = saturate( dot( normal, bumpBasis[0] ) );
dp.y = saturate( dot( normal, bumpBasis[1] ) );
dp.z = saturate( dot( normal, bumpBasis[2] ) );
dp *= dp;
diffuseLighting = dp.x * lightmapColor1 + dp.y * lightmapColor2 + dp.z * lightmapColor3;

可变照度密度可视化。
Source Engine在模型光照使用的半兰伯特时,通常在端接器处将N·L截取为零,半兰伯特将-1到1余弦项(红色曲线)缩放1/2,偏差1/2和正方形以将光一直拉到周围(蓝色曲线)。

对于非直接光照,Source引擎采用环境立方体基(Ambient Cube Basis),六个RGB波瓣存储在着色器常量中,比前两个球谐函数更简洁的基础(九种 RGB 颜色):

环境立方体基实现细节。

环境立方体与球谐函数的比较。

其它游戏(上)和采用半兰伯特、环境立方体(下)的对比。
Source引擎的光照计算树如下:

Ambient Aperture Lighting阐述了用可视孔径(Visibility aperture)、区域光源和软硬阴影,并应用于地形渲染。所谓环境孔径光照,是指使用孔径来近似可见度函数的着色模型,预先计算的可见性,动态球面光源和点光源,支持硬和软阴影,类似于地平线映射,但允许区域光源,“环境”来自这样一个事实,即使用修改后的环境遮挡计算来找到平均可见度的孔径。
环境孔径照明分两个阶段工作:
- 预计算阶段。逐顶点或逐像素在网格上的每个点计算可见性函数,使用球冠存储可见性函数,球形帽存储一个平均的、连续的可见区域,球冠是被平面截断的球体的一部分(半球本身就是球冠)。
- 渲染阶段。球形帽用作孔径,孔径用于限制入射光,使其仅从可见(未遮挡)方向进入,面光源投射到半球上并夹在光圈上,决定了有多少光通过孔径。
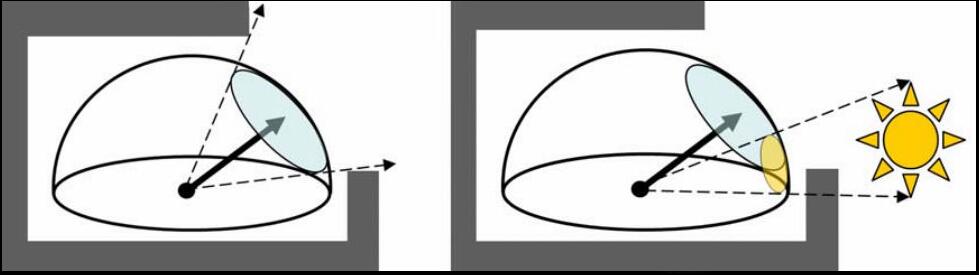
孔径照明示意图。
使用光圈进行渲染的过程如下:
- 将球面光源投射到半球上。
- 投影面光源覆盖半球的某些区域。投影球体形成一个球冠,就像孔径一样。
- 找到投射光的球冠和孔径的球冠的交点。
- 一旦找到相交区域,就知道通过孔径的光源部分。
精确光影(上)和孔径近似结果(下)对比图。
Fast Approximations for lighting of Dynamic Scenes主要阐述了游戏Small world采用了体积进行光照近似的计算,并例举了几个具体的应用案例,如辐照度切片( Irradiance slices)、有符号距离函数(Signed Distance Functions)及视图对齐的辐照度体积。
辐照度切片的目标是混合来自动态平面光源的柔和和锐利阴影,而无需预先计算。平行于光源将世界切片,在每个切片存储一个纹理:
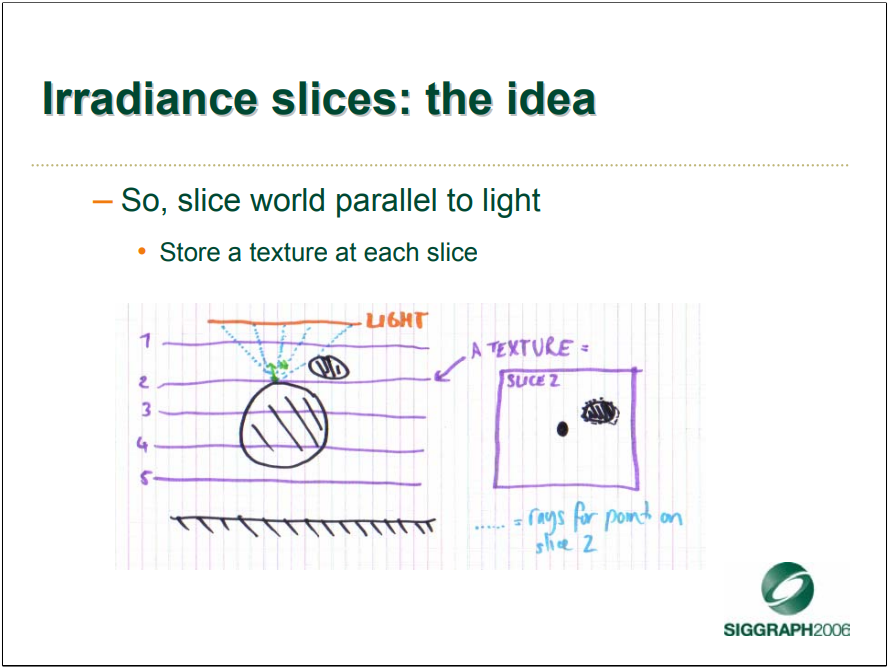
从最靠近光线的地方开始,依次追踪来自每个平面的光线。如果光线到达前一个平面,则停止跟踪,并在前一个平面返回结果:

对于SDF,使用它来测量表面曲率,以便获得近似的AO,如折痕和凹陷内的区域接收到的天光较少,表面曲率是一个很好的开始。

SDF计算AO示意图。
辐照度体积(Irradiance Volume)是当时很多游戏用来存储(和采样)流过场景中任何点的光,通常它们是世界对齐的,并以粗分辨率预先计算,存储在任何方向流动的辐照度,通常使用球谐函数压缩。

视图对齐的辐照度体积不同于世界对齐的辐照度体积,它是视图对齐的。在动态场景中,无法预先计算辐照体积,因此,基于潜在的大量光源发射器,使用GPU以低分辨率每帧动态重新计算它。在屏幕空间中计是有意义的,在文中示例,针对约束的小世界,因此使用少量切片 (16),与屏幕平行,它们在后投影空间中均匀分布,即在“w”中均匀分布(1/z)。

视图对齐的辐照度体积的渲染效果图。
总之,该文使用小场景的体积表示呈现了3种新技术以获得漂亮的外观。第一个是在场景中重复缩放和模糊切片可以产生令人信服的半影效果;第二个是GPU更新的体积纹理用于快速计算来自“天窗”的遮挡信息,以提供带有一些反射光效果的漂亮AO外观;第三个是屏幕对齐的“辐照度体积”梯度用于快速计算来自大量移动光源的照明。
An Analysis of Game Loop Architectures谈到了游戏循环架构的设计、实现等内容,目的是隐藏复杂性、覆盖面小、最高级别的游戏架构。该文给出定义游戏循环的伪代码:
GameLoop()
{
Startup();
while (!done)
{
GetInput();
Sim();
Render();
}
Shutdown();
}
游戏循环至少有一个执行线程,包括启动阶段、处理输入/输出的循环阶段、关闭阶段等。该文还定义了游戏循环架构,陈述了从1940年代到2000年代的演变节点:

游戏循环的复杂性可以由下图描述。设计游戏循环时,最初也是最基础的首先考虑时间问题。然后开始使用多个游戏循环并增加系统复杂性,此时必须处理循环耦合。最后需要考虑转移到具有多个CPU的平台,即并发,这时的复杂度将大大提升。有趣的是,还可以将“复杂性”视为时间箭头,或“处理器数量”箭头,随着游戏引擎的发展,可以将其视为单线程单CPU,然后是多线程单CPU,然后是多线程多CPU。也可以视为历史时间线或经过多次迭代演变的游戏引擎,沿着边缘移动,游戏变得更加复杂,并且使用了更多的处理器。此图是累积的,不解决耦合和时间就无法解决并发问题。
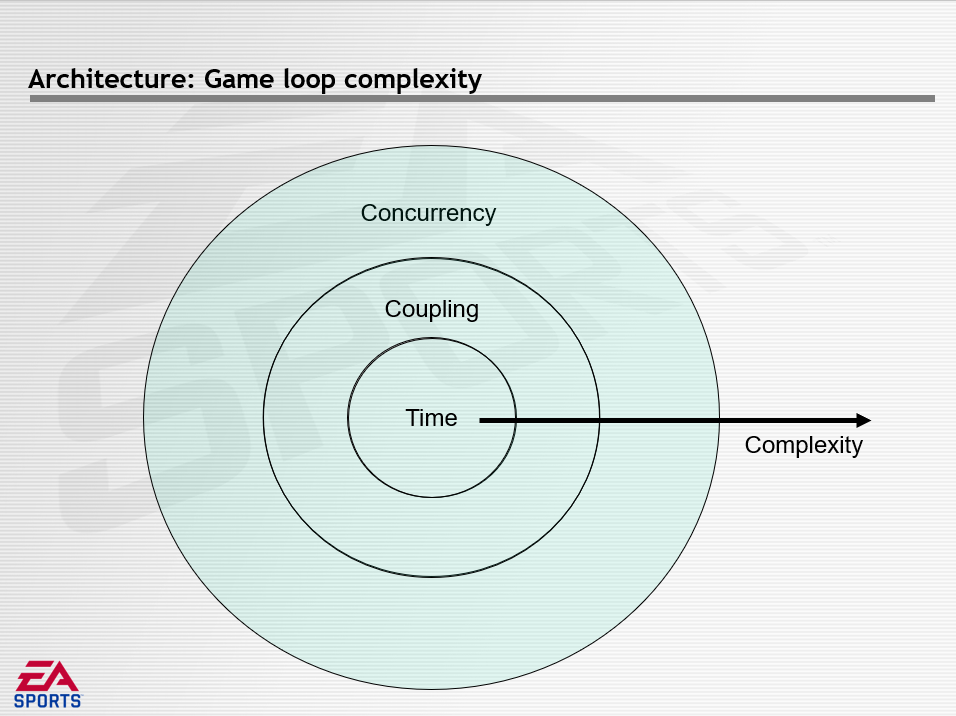
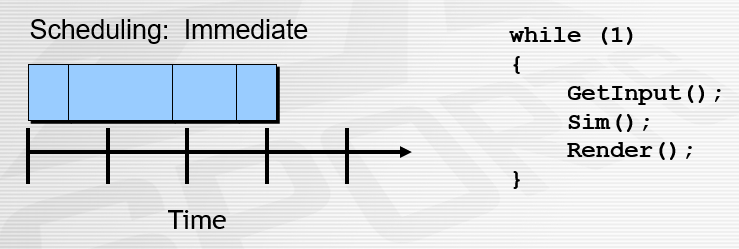
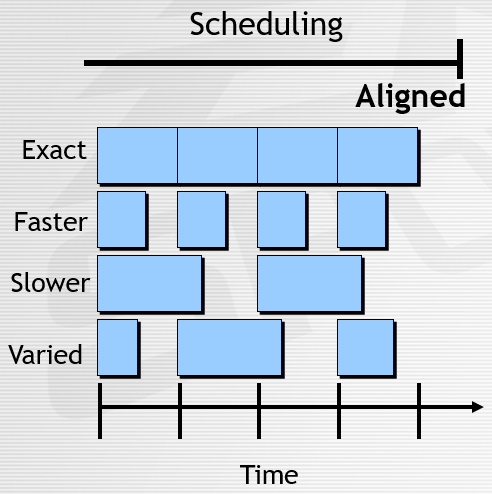
对于最内圈的时间,为了实时流畅运行,可以使用频率驱动的游戏循环,将时间划分为离散的迭代,尝试运行足够快和足够流畅。这样的结果是每个Loop迭代都是一个时间片。面临的挑战是如何保持具有可变执行时间的循环频率,影响的因素性能、宽容度、决策和简单性。而实现的架构决策有调度(Scheduling)和时间步长(Time Step)两种方式。调度控制循环迭代何时开始。

调度模型:即时、最佳匹配、对齐。
对于即时的调度模式,尽可能块地运行,利于是性能和简洁性,不利于宽容度,缺少决策性。即时的调度模式又可细分为精确、快速、缓慢、可变等方式:

即时调度模式常见于早期的冒险游戏,其用例和伪代码如下:
对于最佳匹配的调度模式,描述时间的平均性,尝试维持帧率、在准确的时间开始以及跟上帧率。利于性能和宽容度,不利于简洁性,不具备决策性。

对齐的调度模型描述了垂直同步,利于简单,不利于性能和宽容度,缺少决策性。
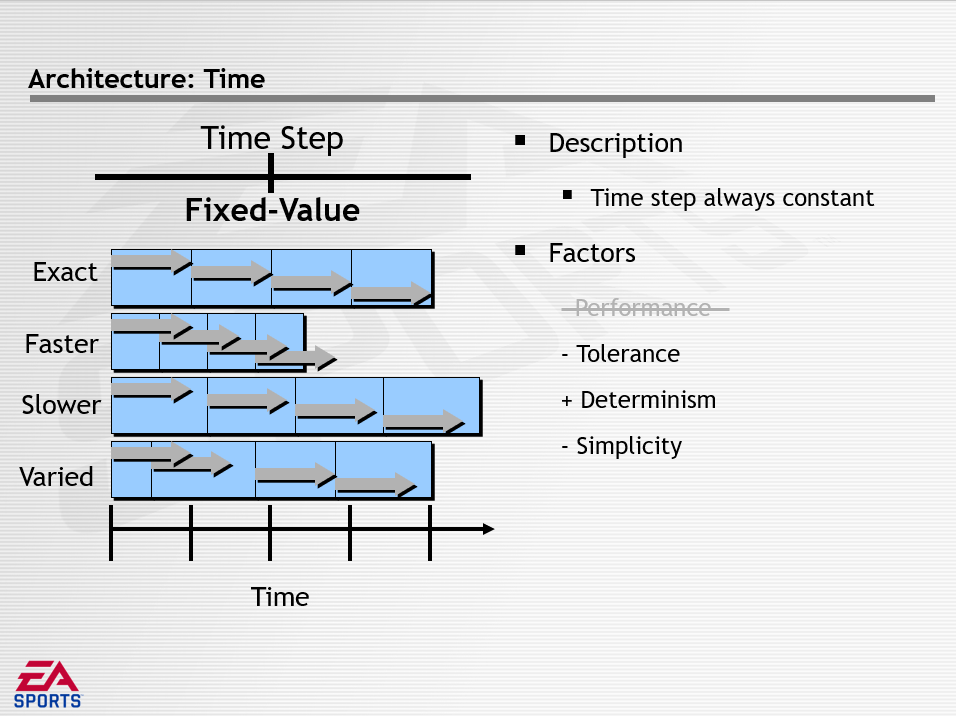
对于时间步长(Time Step)的时间架构,分为无(None)、固定值(Fixed-Value)、实时(Real-Time)三种模式,它们的特点分别如下所示:

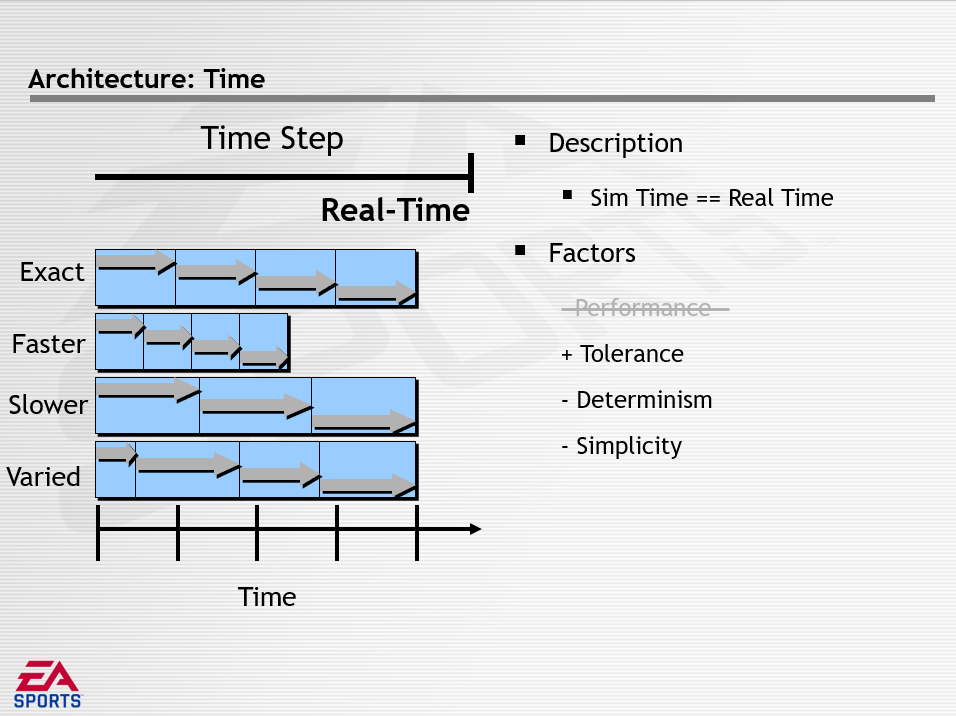
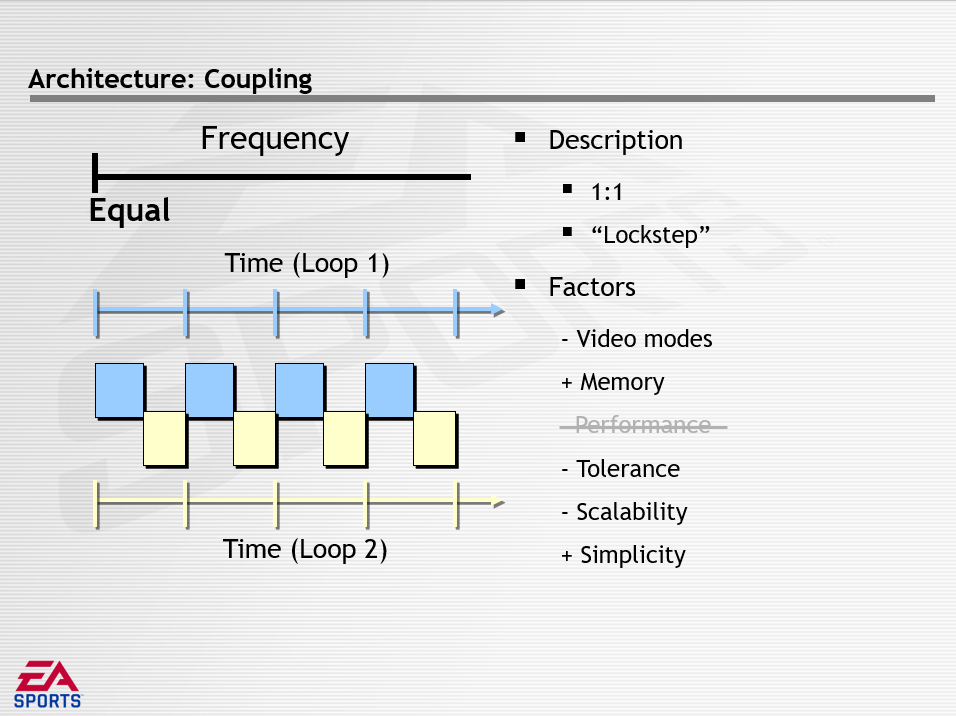
上面分析完最内圈的时间,接着分析中间圈的耦合性。耦合性的问题是支持不同频率的系统,可以通过多个游戏循环解决,将获得循环耦合,即每对循环之间的依赖关系。耦合性面临的挑战如何将代码和数据拆分为多个循环,影响的因素有性能、宽容、简单、视频模式、内存、可扩展性等。架构决策分为频率耦合和数据耦合。
其中频率描述一个循环在多大程度上依赖于另一个循环的频率,分为相等(Equal)、多次(Multi)、解耦(Decoupled)三种方式,它们的特点如下所示:
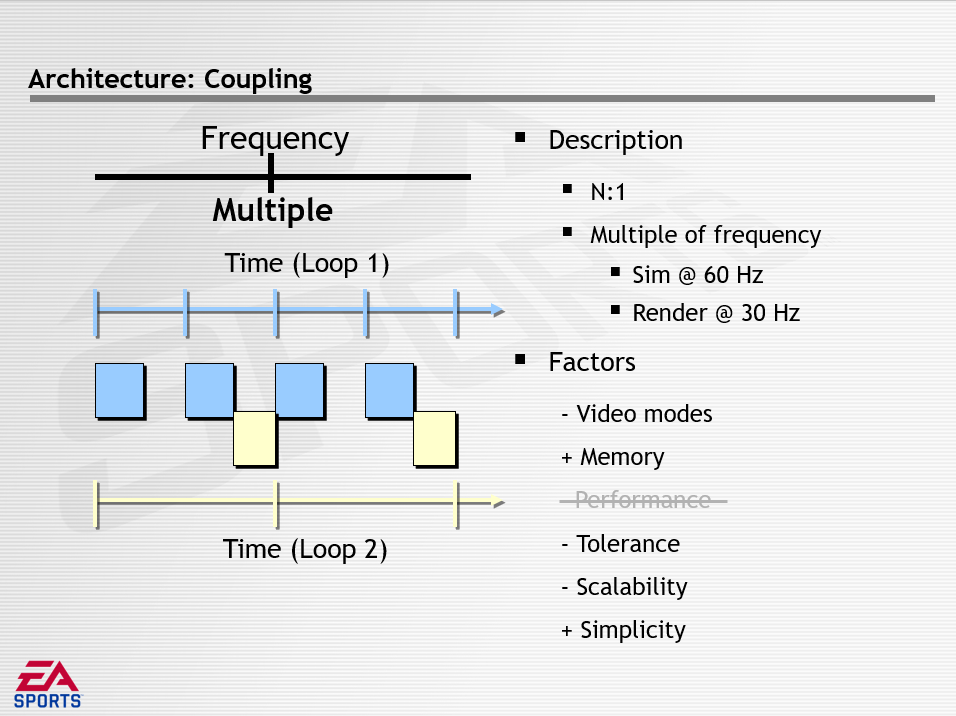
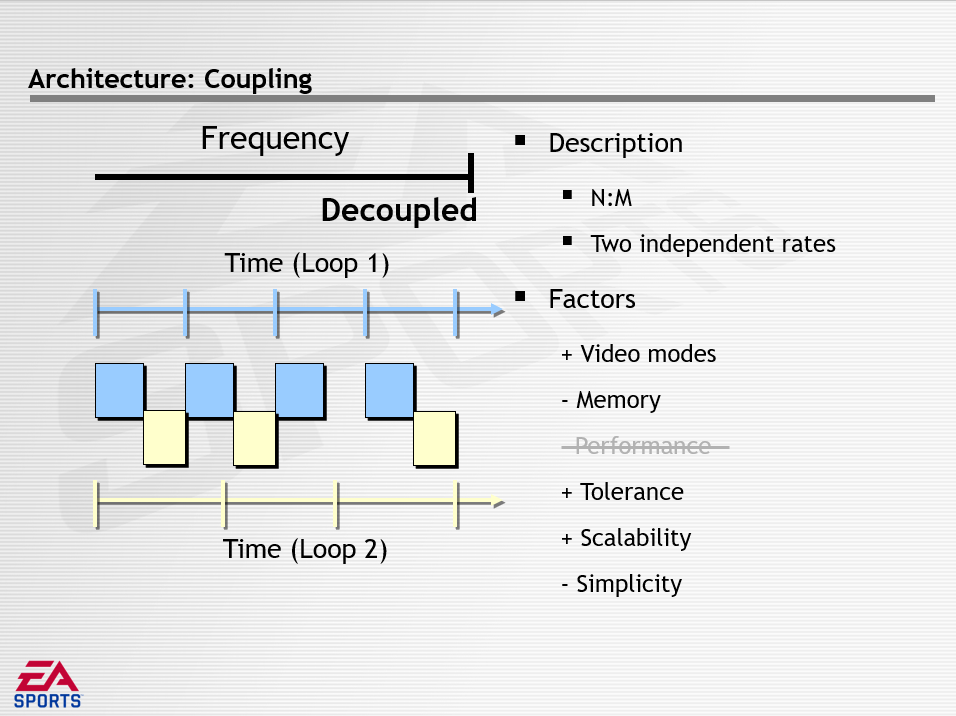
数据解耦描述了共享数据的数量和方法,分为紧密(Tight)、松散(Loose)、无(None),它们的特点如下所示:
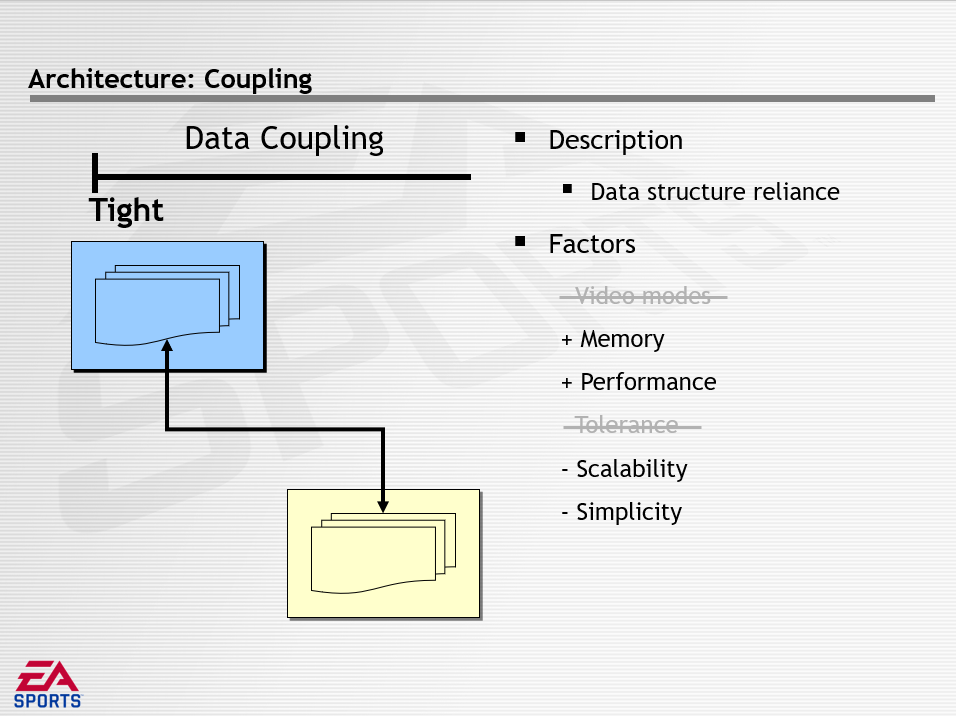
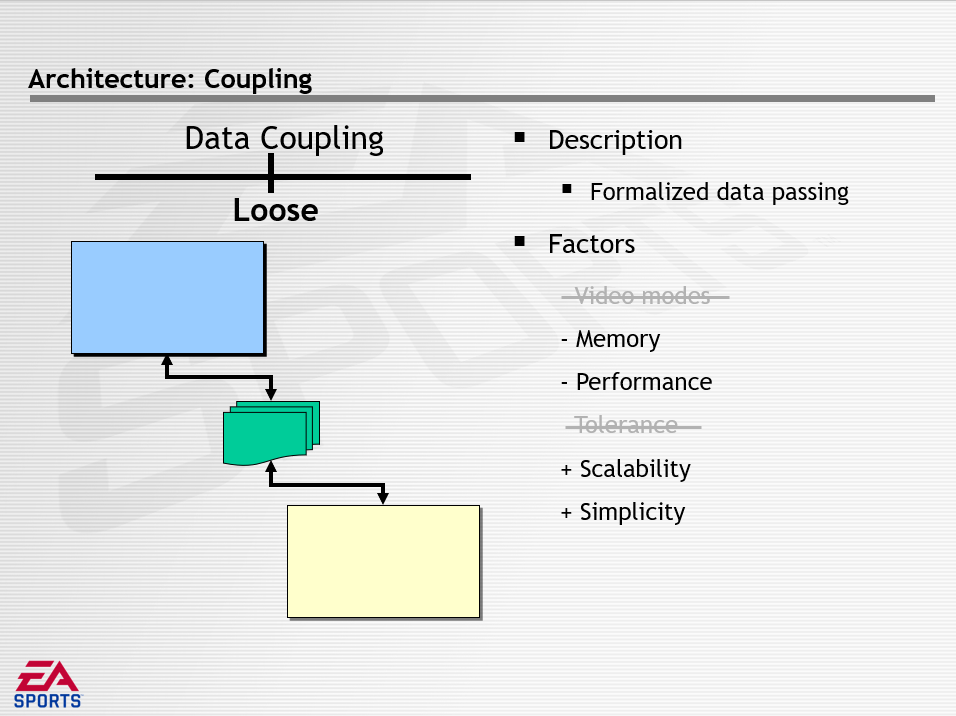
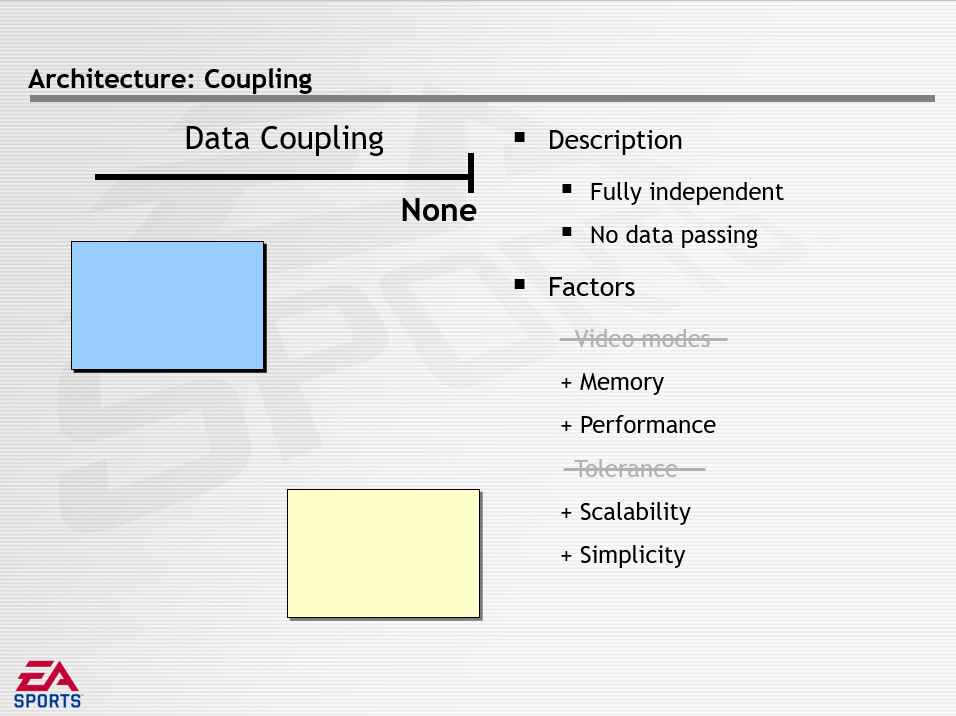
游戏循环的最外圈是并发,存在的问题是硬件制造商需要极端的性能,可通过硬件包含多个CPU来解决,结果是游戏循环和CPU之间的映射而形成并发。面试的挑战是如何管理同时执行,影响的因素有性能、简单、可扩展性。架构决策有低级并发(Low-Level Concurrency)和高级并发(High-Level Concurrency)。
低级并发是在游戏循环内并发,包含无(None)、指令(Instruction)、函数(Function)三种模式。低级并发广泛覆盖,最容易过渡到下一代架构,从小处着手并成长,开放式MP,自下而上的方法,可以延时执行。
高级并发是跨越一对游戏循环的并行,包含序列(Sequential)、交叉(Interleaved)、平行(Parallel)三种模式,它们的描述如下:
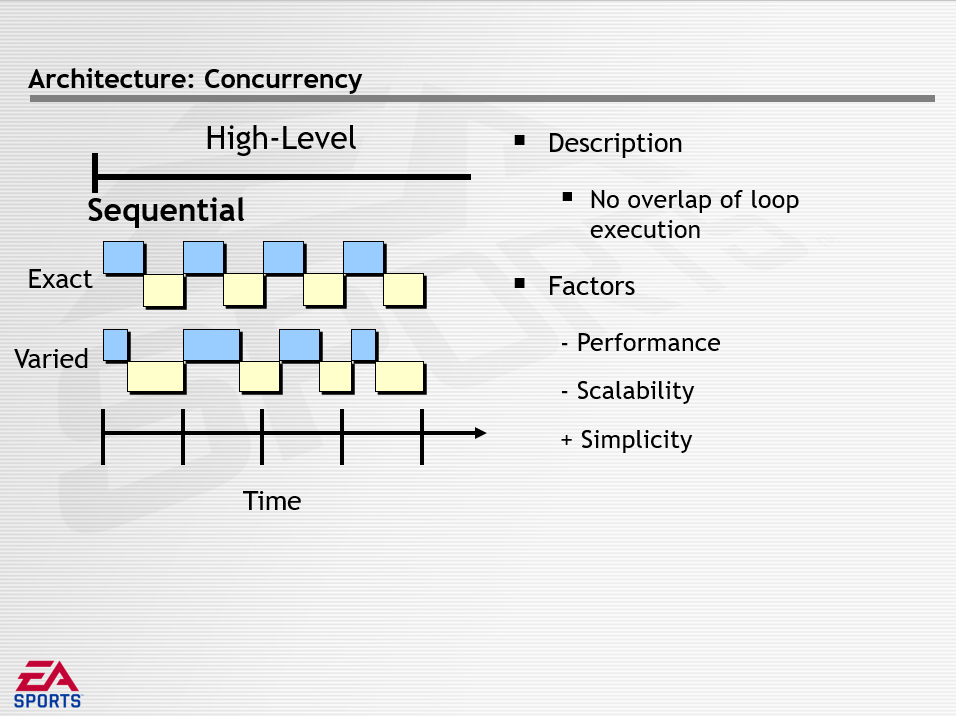
下图是游戏Madden在数据解耦方面采用的具体策略:

Ritual™ Entertainment: Next-Gen Effects on Direct3D® 10详细地讲述了DirectX10的新特点及使用它来实现新效果的案例。文中提到DirectX10的特点是:
- 一致性(如控制台)。有保证的基本功能集供您定位,跨所有芯片组的严格定义的行为。
- 更高的性能上。通过设计显着提高小批量性能,使用更强大的几何引擎卸载CPU。
- 更好的视觉效果。提高灵活性和可编程性,新的硬件功能。
DirectX10改进了硬件渲染管线,包含纹理阵列、几何着色器、流输出、资源视图、输入汇编器、通用着色器核心 (SM 4.0)、整数/位指令、比较过滤、常量缓冲区、状态对象、用于HDR、法线/凹凸贴图内容的新压缩格式、更多纹理、RT、指令、寄存器、级间通信、预测渲染、阿尔法覆盖率、多样本回读等等。
在软件栈上,特性有流线型和分层运行时、干净一致的API、强大的调试层、精益的核心、具有新语言功能的新HLSL编译器、新效果系统,以及基于新的 Windows Vista™ 显示驱动程序模型构建。
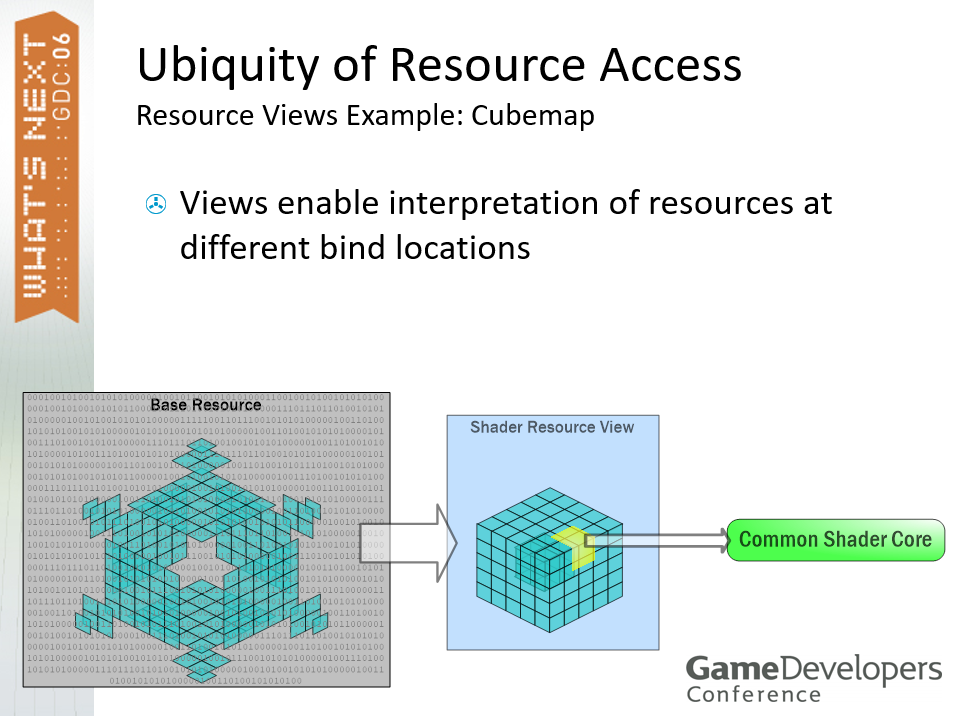
无处不在的资源访问资源视图示例:Cubemap,视图可以描述不同绑定位置的资源。

视图可以重新解释资源数据的格式。
不同于DirectX9,DirectX10可以通过几何着色器访问所有的图元信息(点、线、三角形):


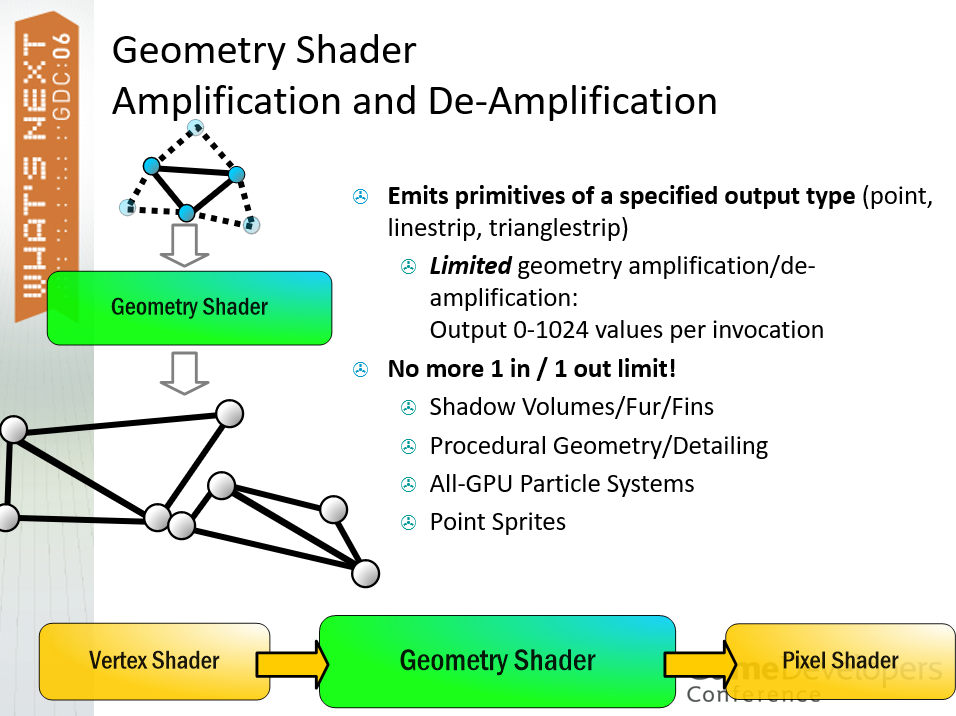
通过几何着色器(GS),可以实现全GPU材质系统,按逐图元材质选择和设置,可以计算边长和皱纹模型、平面方程、轮廓边,将重心设置为超过插值器的数量。可以构建指定输出类型的图元(点、线带、三角形带),有限的几何放大/去放大:每次调用输出 0-1024 个值,不再有 1进1出的限制,可以实现阴影体积/毛皮/翅膀、程序几何/细节、全GPU粒子系统、点精灵等。
GS还可以触发系统解释值(System-Interpreted Value),例如图元的RenderTargetArrayIndex,为体积渲染选择切片,为渲染到立方体贴图选择一个面,但MRT仍然在PS中指定。
另外,VS或GS支持流输出(Stream Output),将VS/GS结果流式传输到内存中的一个或多个缓冲区,DrawAuto() 无需App/CPU干预即可绘制动态数量的GS数据。可用于迭代、程序几何处理、全GPU粒子系统等。(下图)
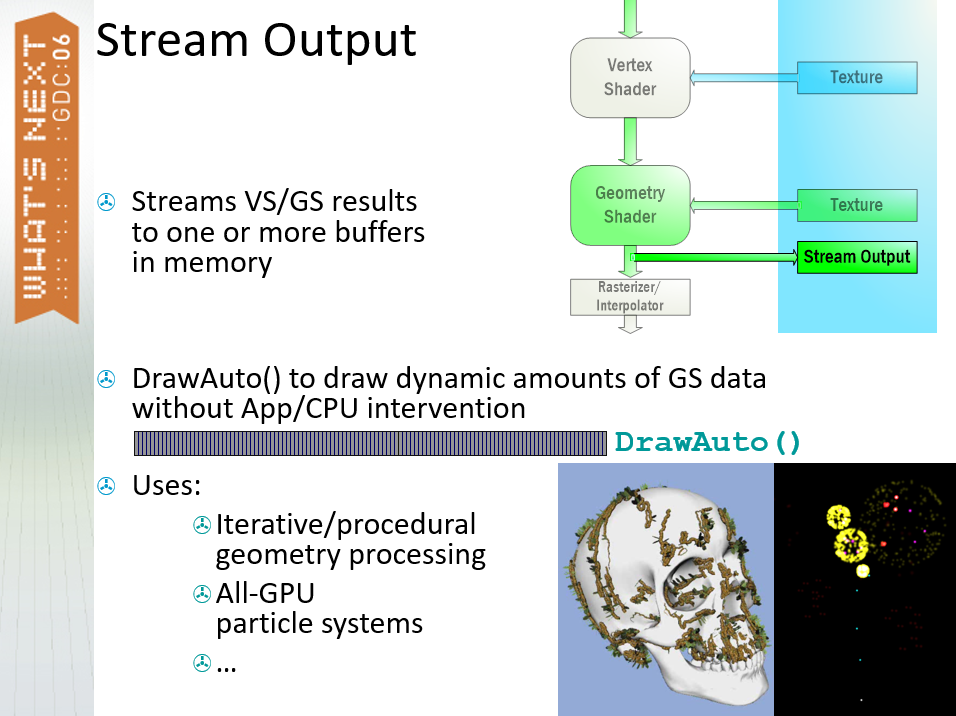
Feeding the Monster: Advanced Data Packaging for Consoles针对主机平台阐述了资源加载问题、LIP解决方案、C++对象打包等内容。文中提到,为了满足下一代数据需求,加载将需要更频繁,光驱性能不会随着内存/CPU功率的增加而扩展,因此加载性能必须是最佳状态,且必须消除除原始磁盘传输之外的任何处理。
常规的加载数据策略是使用加载画面(Loading Screen),但它具有破坏性的、技术无趣、不可跳过的过场动画也不是更好,因此它不适合当时的需求。还有一种策略是后台加载(Background Loading),在线程或其它处理器中使用阻塞I/O,游戏资产在游戏过程中加载,玩家沉浸感得以保留。但当时的要求是不能比加载屏幕慢很多、必须低于CPU开销、不得阻止其它IO,因此后台加载的加载性能必须是最佳的,必须消除除原始磁盘传输之外的任何处理。
对下一代加载技术的要求是:必须以接近硬件传输限制的速度加载大量资产,必须以很少的CPU成本实现后台加载,数据资产必须在不造成内存碎片的情况下流入和淘汰。
加载时间包含释放内存空间(卸货、碎片整理)、搜索时间、读取时间、分配、解析、重定位(指针、哈希 ID 查找)、注册(例如物理系统)等。减少加载时间的策略有:
-
始终加载压缩文件。使用N:1压缩将加载N倍快,双缓冲隐藏解压时间,大量处理能力可用于在下一代游戏机上进行解压。
-
利用光盘功能。将经常访问的数据存储在光盘的外部,将音乐流存储在中间(防止完全搜索),在中心附近存储一次性数据(视频、过场动画、引擎可执行文件),小心层切换(0.1秒消耗)。
-
使用轻量级设计模式。如几何实例化、动画分享。
-
优先选取程序化技术。如参数化曲面、纹理(火、烟、水)。
-
始终离线准备数据。消除引擎中的文本或中间格式解析,浪费在转换或解释数据上的引擎时间,加载本机硬件和中间件格式,直接加载C++对象。
文中还提到加载C++对象的原因,有更自然的数据处理方式、无需解析或解释资产、创建快、指针重定位、哈希ID转换、对象注册等。加载C++对象需要非常智能的封装系统:成员指针、虚拟表、基类、对齐问题、字节顺序(Endianness)。而加载非C++对象时,必须是读入内存后可以使用的格式(如纹理/法线贴图、Havok结构体、音频、脚本字节码),实现和使用都很简单。
文中提到了一种新的加载技术叫就地加载(Load-In-Place,LIP),是游戏资产打包和加载解决方案,用于定义、存储和加载本机C++对象的框架,具备动态存储,即一个自我碎片整理的游戏资产容器。
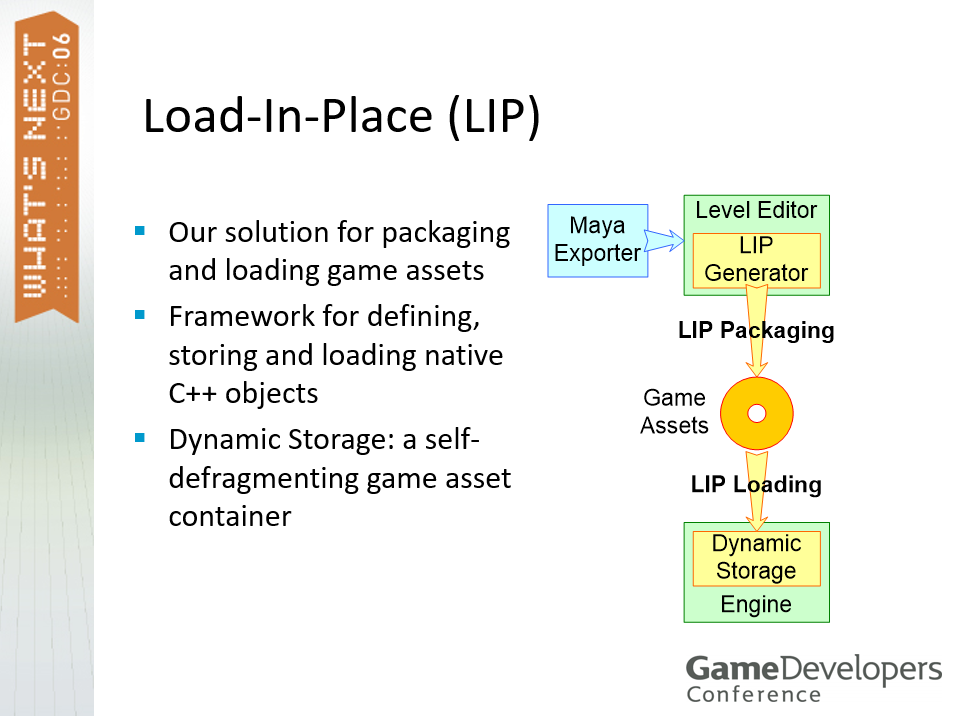
LIP加载技术。
LIP技术涉及到了LIP条目(item),1个LIP条目对应1个游戏资产,1个LIP条目对应唯一哈希ID(64 位),其中的32位用于类型ID和属性,另外32位用于散列资产名称(CRC-32)。LIP条目是最小的数据单位,用于查询、碎片整理移动、卸载,支持C++对象和二进制块。LIP条目样例包括联合动画、人物模型、环境模型部分、碰撞地板部分、游戏对象(英雄、敌人、触发器等)、脚本、粒子发射器、纹理等等。
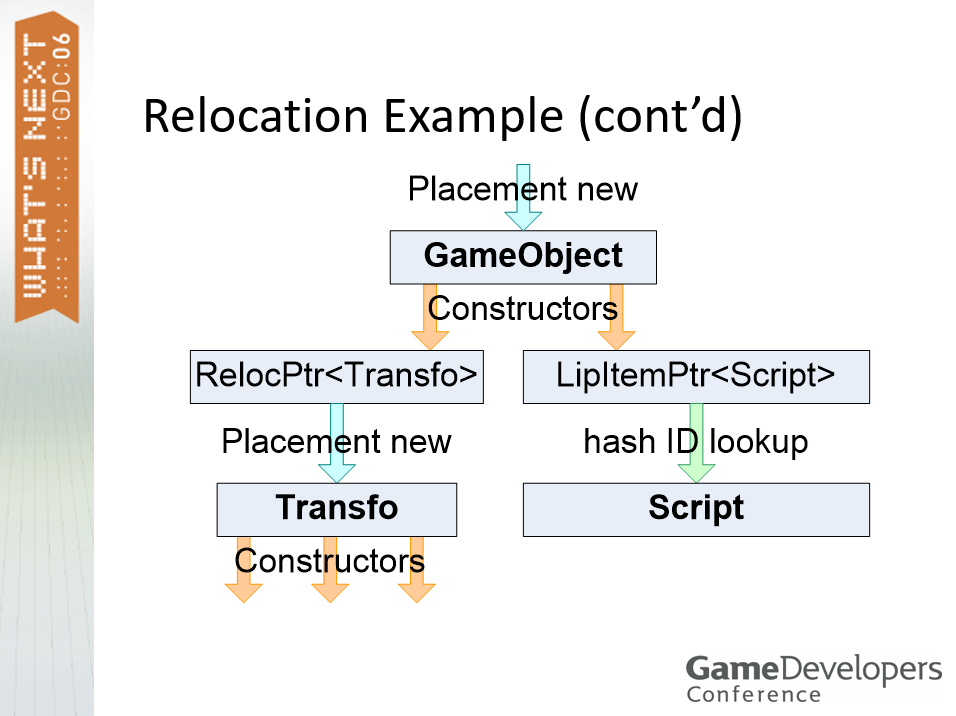
基于C++的LIP条目可以由任意数量的C++对象和数组组成,在光盘上,所有内部指针都保持相对于LIP条目块,指针重定位从重定位构造函数上的新位置开始,内部指针通过构造函数链接自动重定位。
为了顺利从磁盘加载C++的LIP条目,需要重载new操作符(语法:new(<address>) <type>;),调用构造函数但不分配内存,初始化虚拟表,为主类重定位构造函数上的每个LIP项调用一次。然后重定位构造函数,所有类和结构都需要:可以由LIP框架加载、包含需要重定位的成员,支持3种构造函数(加载重定位构造函数、移动重定位构造函数(碎片整理)、动态构造函数(可选,可以是虚拟的),但不支持默认构造函数。对于对象成员重定位,内部指针必须指向LIP项目块内并转换成绝对指针,外部引用(仅限LIP条目)存储为LIP条目哈希ID并转换为全局资产表条目中指向所引用LIP条目的指针,LIP框架为所有指针类型提供了带有适当构造函数的封装类。重定位示例代码:
// --- GameObject定义 ----
class GameObject {
public:
GameObject(const LoadContext& ctx);
GameObject(const MoveContext& ctx);
GameObject(HASHID id, Script* pScript);
protected:
lip::RelocPtr<Transfo> mpLocation;
lip::LipItemPtr<Script> mpScript;
};
// --- GameObject实现 ----
GameObject::GameObject(const LoadContext& ctx) :
mpLocation(ctx),
mpScript(ctx) {}
GameObject::GameObject(const MoveContext& ctx) :
mpLocation(ctx),
mpScript(ctx) {}
GameObject::GameObject(HASHID id, Script* pScript) :
mpLocation(new Transfo),
mpScript(pScript) { SetHashId(id); }
// --- 重装new操作符 ----
template<typename LipItemT>
void PlacementNew(lip::LoadContext& loadCtx)
{
new(loadCtx.pvBaseAddr) LipItemT(loadCtx);
}
// 加载示例
loadCtx.pvBaseAddr = pvLoadMemory;
PlacementNew<GameObject>(loadCtx);
基于C++的LIP条目构建的步骤和流程图例如下:
LIP还存在加载单元(Load Unit),它是LIP条目组,可以加载的最小数据单位,1个加载单元对应1个加载命令,文件数量最小化,1 个独立于语言的文件(如模型、动画、脚本、环境……)及N个语言相关的文件(字体、游戏内文字、纹理、音频……),加载单元文件通常被压缩。加载单元还涉及加载单元表,每个LIP条目在表中都有一个条目,包含哈希ID、LIP条目的偏移量。
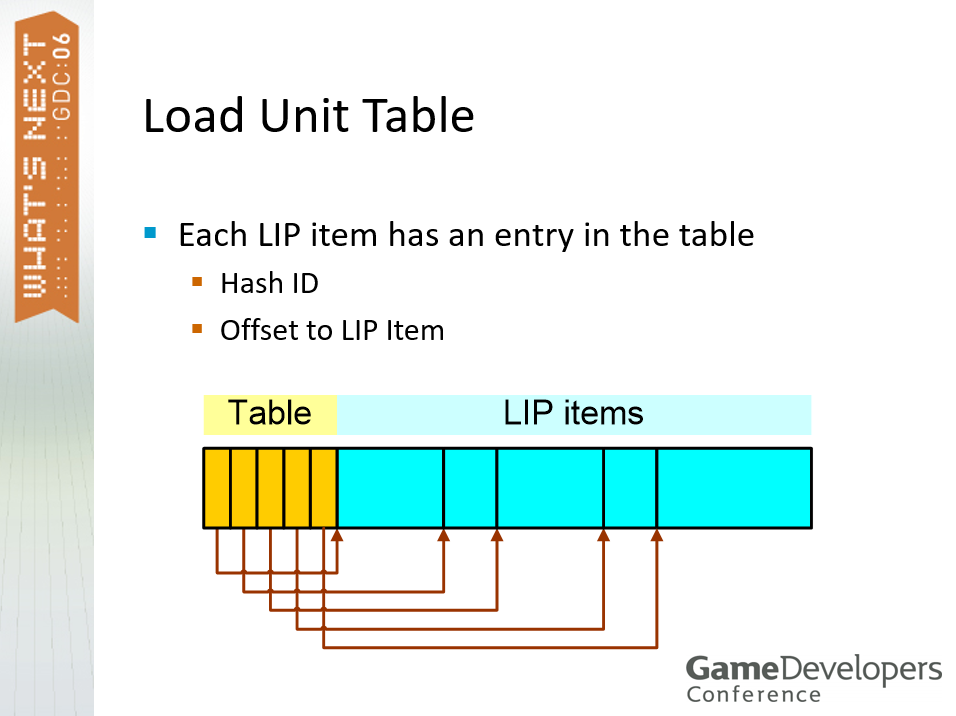
文中采用了动态加载,它的加载过程如下:
- 读取加载单元文件并解压缩到可用存储内存。
- 加载单元表偏移被重新定位。
- 加载单元表条目合并到全局资产表中。
- 为每个LIP条目调用一个新的展示位置。
- 某些LIP条目类型可能需要第二次初始化通过(例如注册)。
动态加载的卸货过程如下:
- 每个LIP条目都可以单独移除。
- 一个加载单元的所有LIP条目可以一起移除。
- 在C++ LIP条目上调用析构函数。
- 动态存储算法稍后会对新的碎片进行整理。
LIP条目可以被锁定,锁定的条目无法被移动或卸载。
此外,LIP还可以用于基于网络的资产编辑,LIP条目可以在游戏过程中从关卡中迁移出来或迁移进去,资产规模的变化无关紧要。另外,LIP也可以用于Maya导出用于存储中间艺术资产,比解析XML效率高得多。
该文还探讨了编辑器所需的数据以及实现方式、虚函数表数据对齐、引擎所需的信息及用于重定位的各类智能指针等内容。
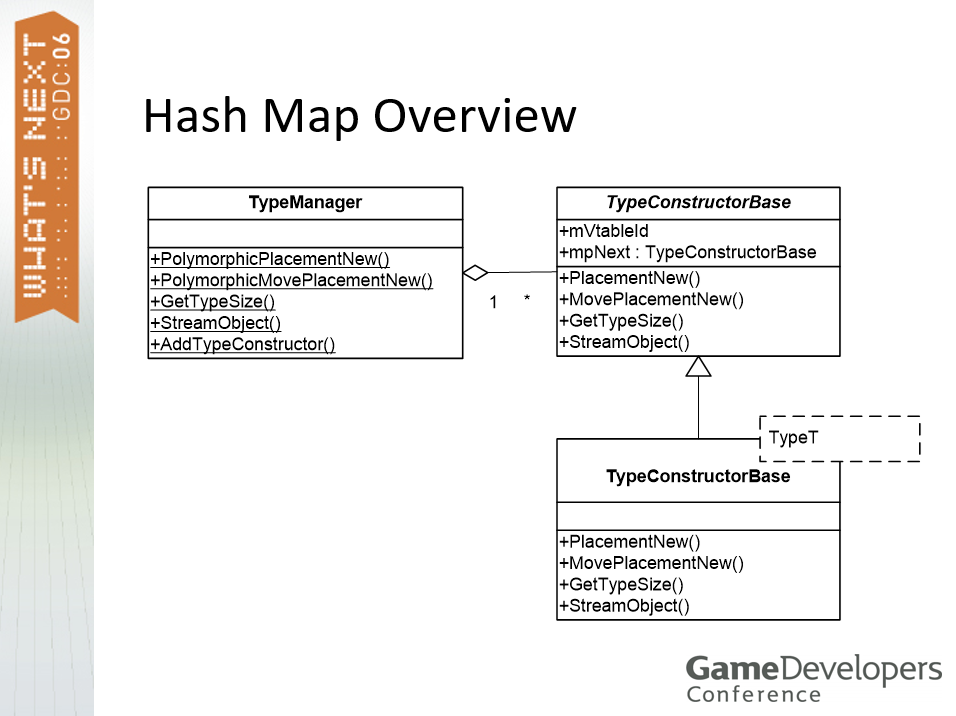
引擎所需的信息之一:类型哈希表。
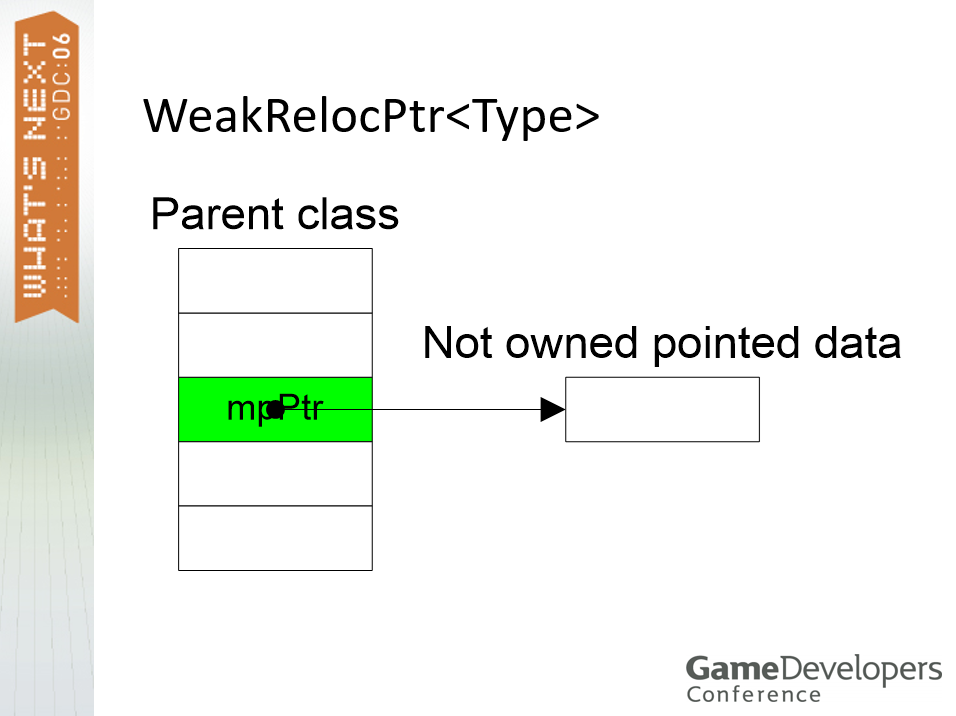
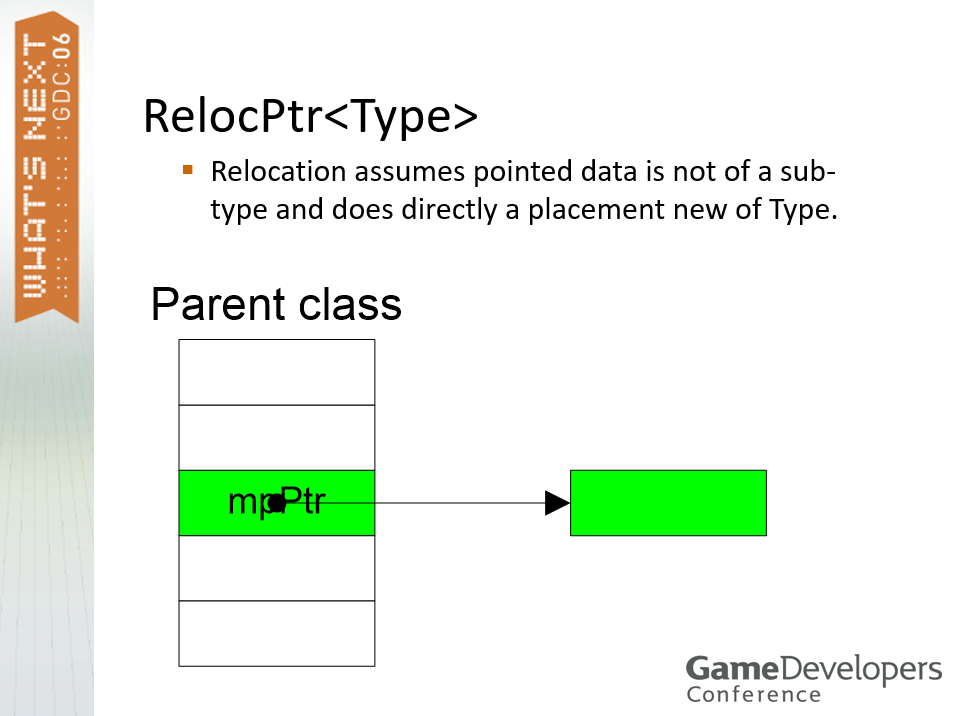
用于重定位的各类智能指针:弱引用、强引用智能指针。
Best Practices in Game Development讲述了游戏架构的演变、软件的限制、游戏架构的趋势等内容。
软件限制包含物理定律、软件法则、算法的挑战、发布的难度、设计的问题、组织的重要性、经济学的影响、政治的影响、人类想象力的极限等。大多数超高效组织通过可执行文件的增量和迭代发布来发展他们的架构。
游戏架构中的力量,当时处于一个由以下因素驱动的拐点:
- 新控制台的诞生。戏剧性的技术转变。
- 新的游戏类型。开发工作室必须学习新的编程模型,购买新的开发工具,从单线程、线性、执行模型转变为多线程、并行、执行模型。
文中提到影响软件的因素很多,如下所示:

并指出架构软件是不同的,没有等效的物理定律,不同的透明度,具体复杂性(状态空间的组合爆炸、非连续行为、系统性问题),需求和技术流失,复制和分发成本低。软件工程的整个历史是不断上升的抽象层次之一,在计算机语言、平台、处理、架构、工具、赋能等方面都在不断演化:

架构化的理由有在多产项目中围绕发展可执行架构的流程中心,结构良好的系统充满模式,可以抗风险,简单有弹性。下图是文中提出的几种软件架构元模型:
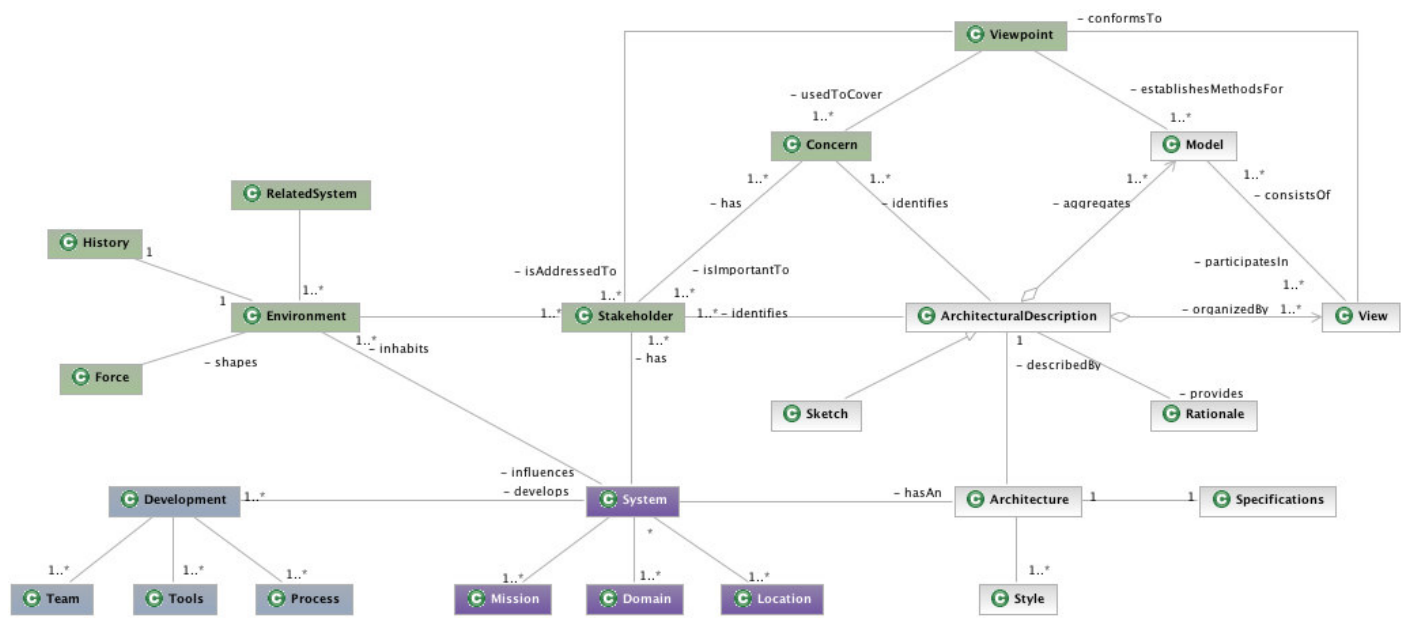
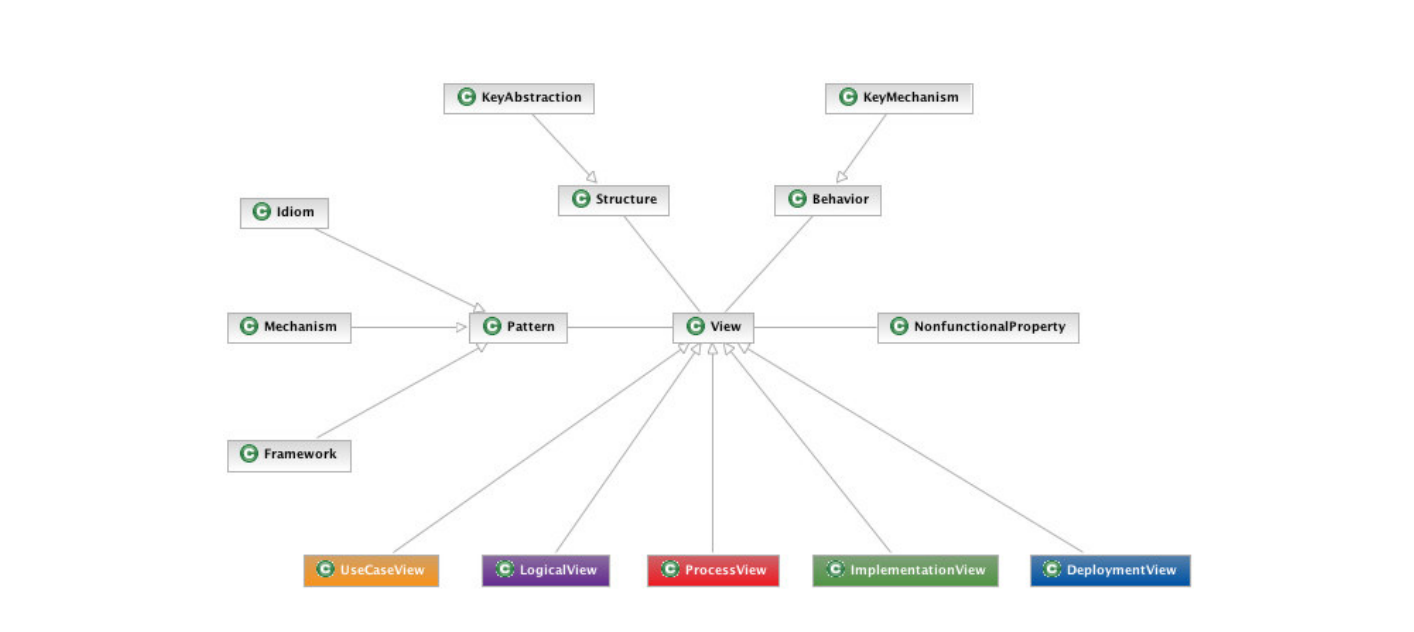
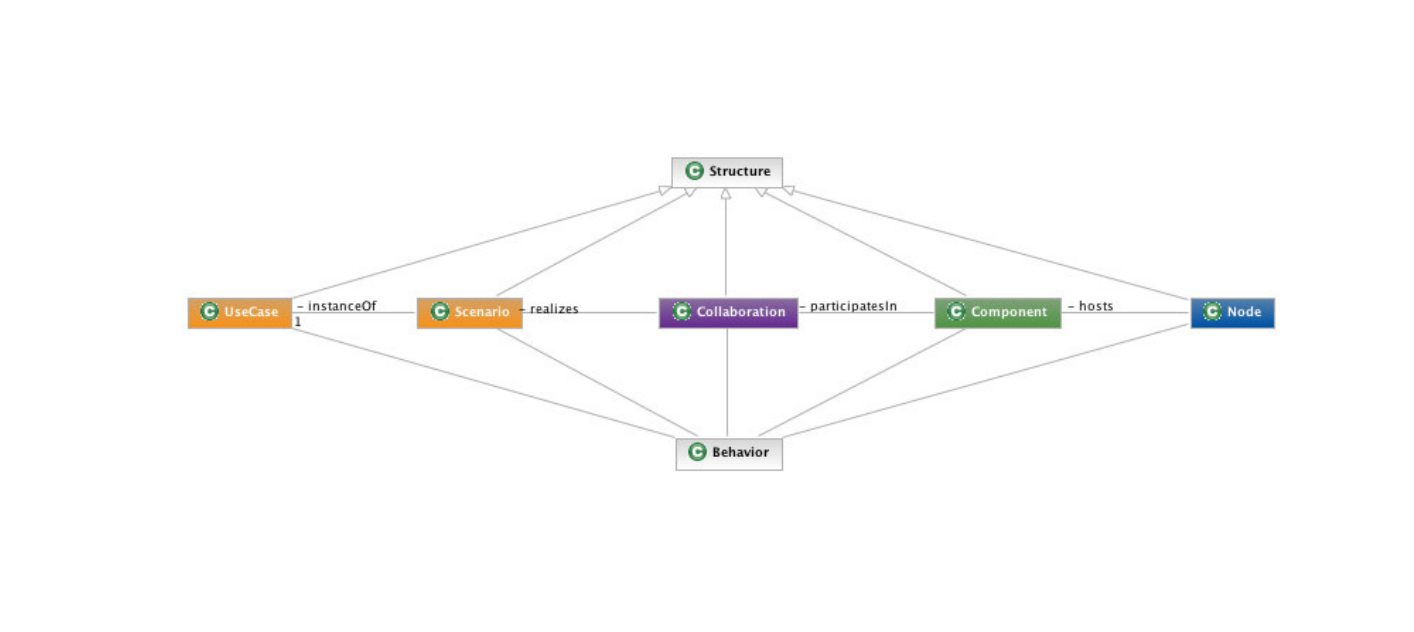
跨功能机制涉及一些结构和行为横切组件(如安全、并发、缓存、持久性),这些元素通常表现为散布在整个系统中的小代码片段,很难使用传统方法进行本地化。文中也提到了4+1视图的软件架构模型,下面是ABIO的部署视图和逻辑视图:
文中还谈及了提高软件经济学的效率问题,给出了如下的公式:
其中:
- 复杂度代表人工生成的代码量。
- 过程代表方法、符号、成熟度。
- 团队代表技能、经验、动机。
- 工具代表处理自动化。
可以用下图的二维平面来衡量之,其中横坐标是从松散到严律,纵坐标是从瀑布型到迭代型,它们各有不同的特点:

通用技术栈如下图:

2007年是DirectX 10发布之后的一年,已经有不少文献阐述利用它的新渲染管线和特性以优化渲染性能和实现一些新的视觉效果,Introduction to Direct3D 10 Course便是其中之一。该文谈及在应用程序中使用DX10以最大限度地提高性能的最佳实践。每当需要创建或更新数据时,管道都会以某种方式停止,通过控制需要将数据发送到管道的频率,可以最大限度地减少每次状态更新、资源创建或不断修改的开销。将工作移出到最外层循环,也可以显著提升效率:
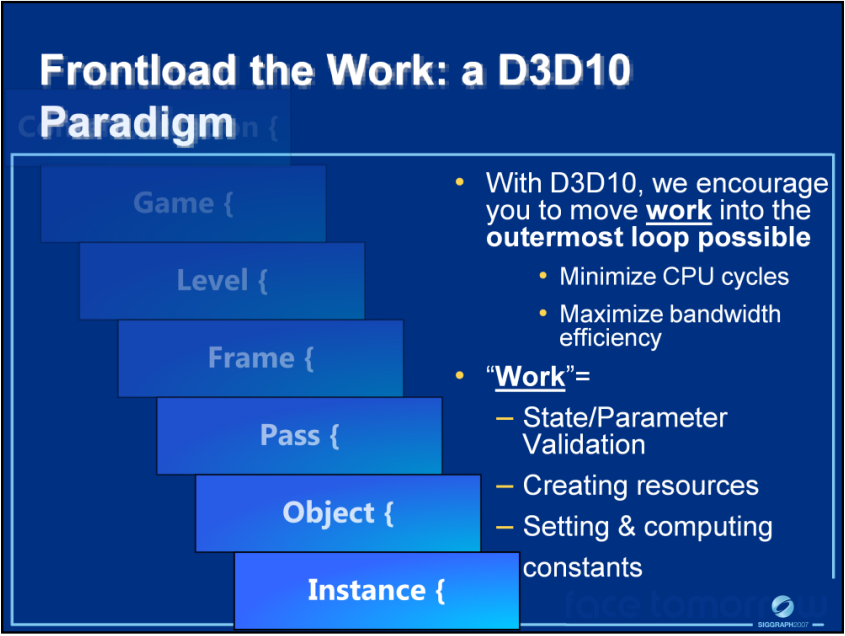


下图是当时盛行的FX架构:

该文还建议使用依赖图来追踪资源的依赖性及资源的更新,利用资源的依赖关系,可以消除重复的内存实例和数据:
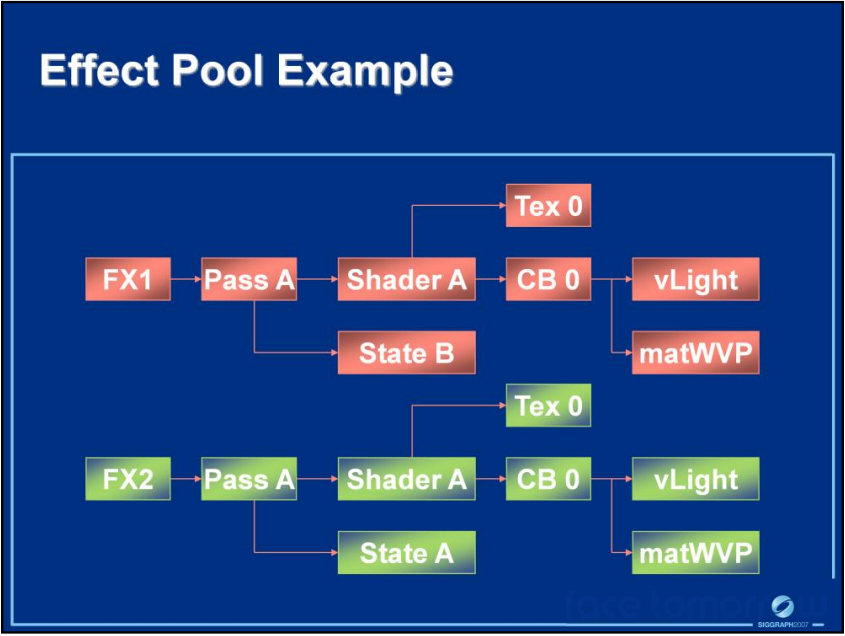
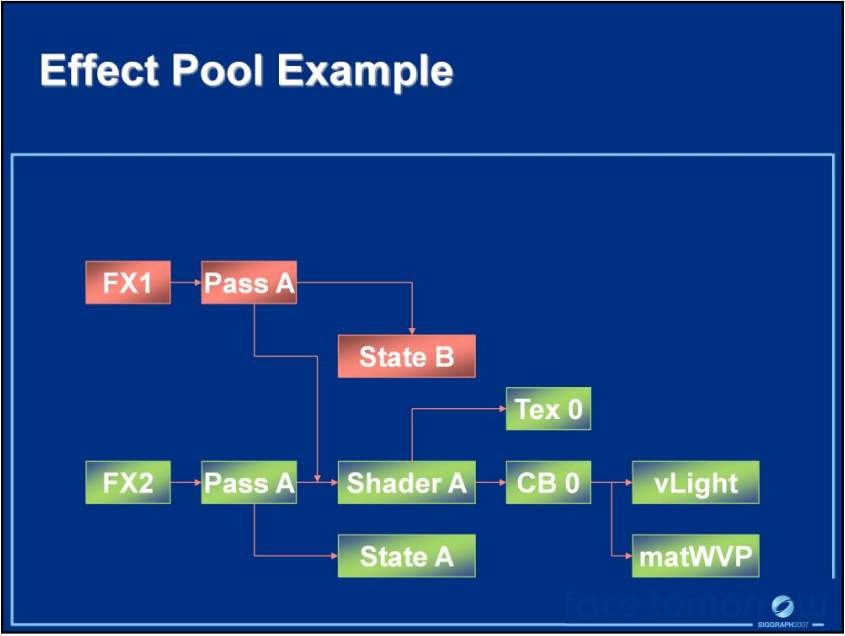
对于固定常量,建议首先按CPU频率组织,可以最小化API调用,减少CPU到GPU的带宽。其次按所需的着色器标记组织,最小化材质依赖,塞入4096大小的float4缓冲区:
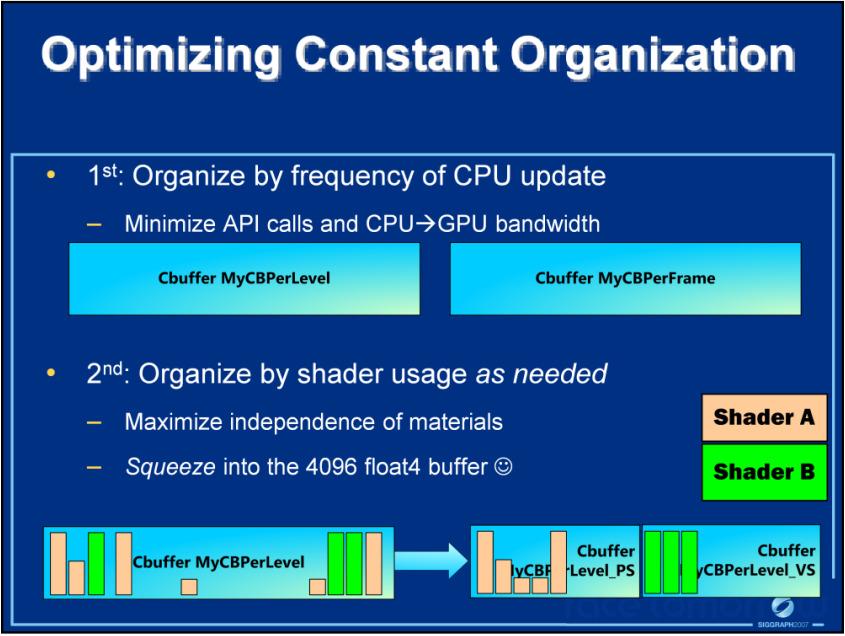
打包常量时,也有很多细节需要注意:

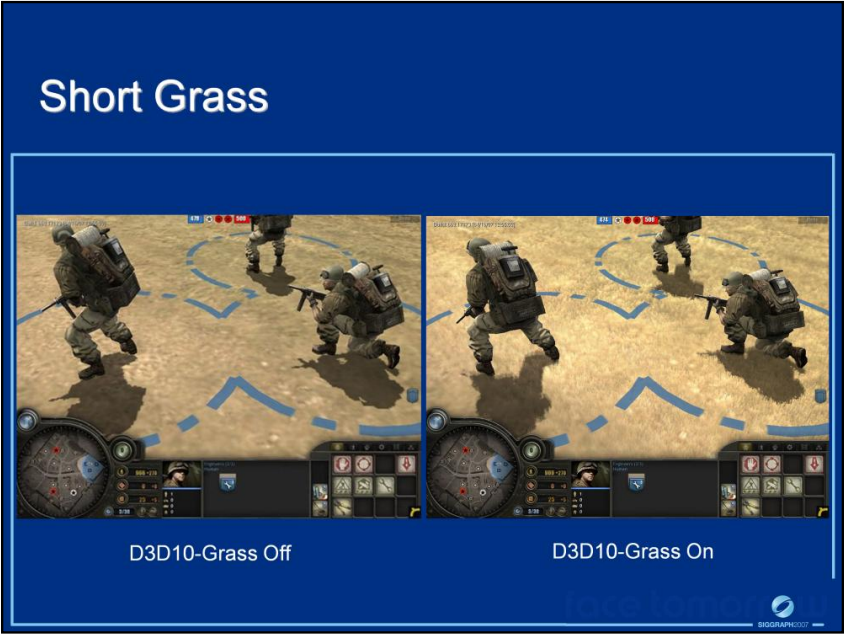
利用DX10,可以实现更好的草、沙石等效果:

与此同时,大量的实时全局光照计算也慢慢被发掘,并引入到各种渲染引擎中,Practical Global Illumination with Irradiance Caching便是最好的证明。该文献实则是实时光线追踪的一系列文章,涉及随机光线追踪、辐照度缓存算法、辐射率中的辐照度缓存、光子映射、光泽反射、时间一致性、辐照度分解以及相关的软件和硬件实现等内容。其中辐射率中的辐照度缓存算法步骤如下:
-
环境常量的计算。
- 所谓的“环境项”近似于无穷级数的余数。
- 顶级间接辐照度的平均值是一个很好的近似值。
- 可以使用移动平均线,因为辐照度缓存会随着时间的推移而被填充。
- 高估环境项比低估更糟糕。
-
半球自适应超级采样。
- 为了最大限度地提高间接辐照度积分的准确性。
- 基于邻域检测方差对高方差区域进行超采样,采样直到误差在投影半球上一致或达到采样限制。
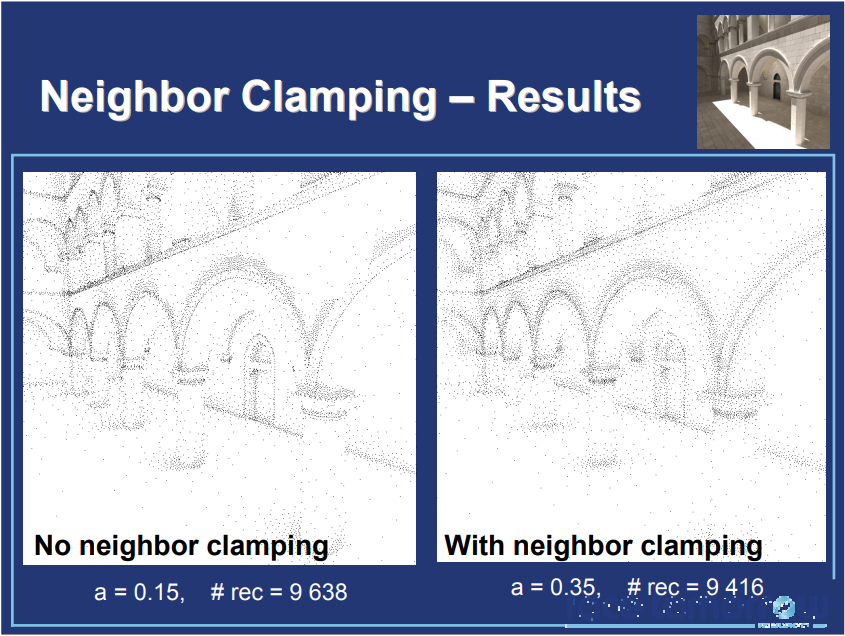
-
最大和最小记录间距。
-
如果没有最小记录间距,内角会被解析到像素级别。
-
应用最小间距,准确度在一定的场景比例下逐渐下降。
-
最大值间距是最小间距的64倍,似乎是正确的。
![]()
![]()
-
-
记录间距的梯度限制。
-
渐变不控制间距,除非
||gradient||*spacing > 1。 -
然后,为了避免负值并提高准确性,可以减少间距。
-
如果已经达到最小间距,反而减少梯度。
![]()
-
-
使用旋转梯度的凹凸贴图。
-
凹凸不平的表面减少了记录共享。
-
忽略凹凸贴图,我们可以对刚刚计算的辐照度应用旋转梯度。
-
促进了最佳的重复使用和间距,也避免了样品泄漏的问题。
![]()
-
-
排除表面/材质的选项。
- 用户选择的材质(以及他们修改的表面)可能会被间接排除在外。
- 这可以节省数小时在草地等领域中毫无意义的相互反射计算。
- 如果只包含少数材质,则可以指定包含列表。
- 最好有第二种类型的相互反射计算可用。
-
为多处理器记录共享数据。
- 除了为后续视图重用记录外,辐照度缓存文件还可用于在多个进程之间共享记录。
- 同步:锁定→读取→写入→解锁。
- 其它进程的记录被读入,然后这个进程的新记录被写出。
- NFS锁管理器并不总是可靠的。

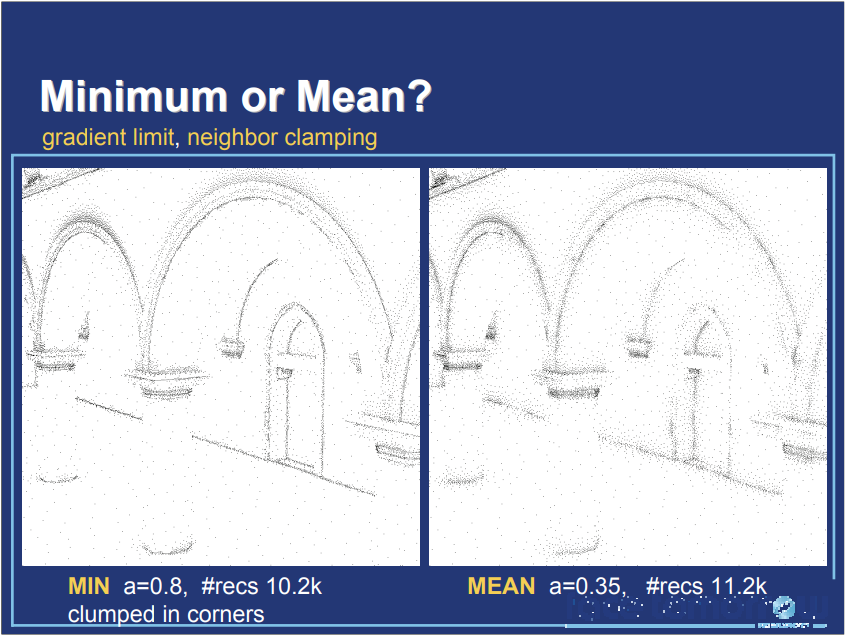

如果光照变化率高且记录不足会导致插值瑕疵,而自适应辐射率缓存可以解决之。


特别是,将间接照明的空间采样密度调整为实际的局部照明条件,与辐照度缓存形成对比,其中采样密度仅基于场景几何进行调整。对比旧的方法,新的方法可以提升渲染效果:

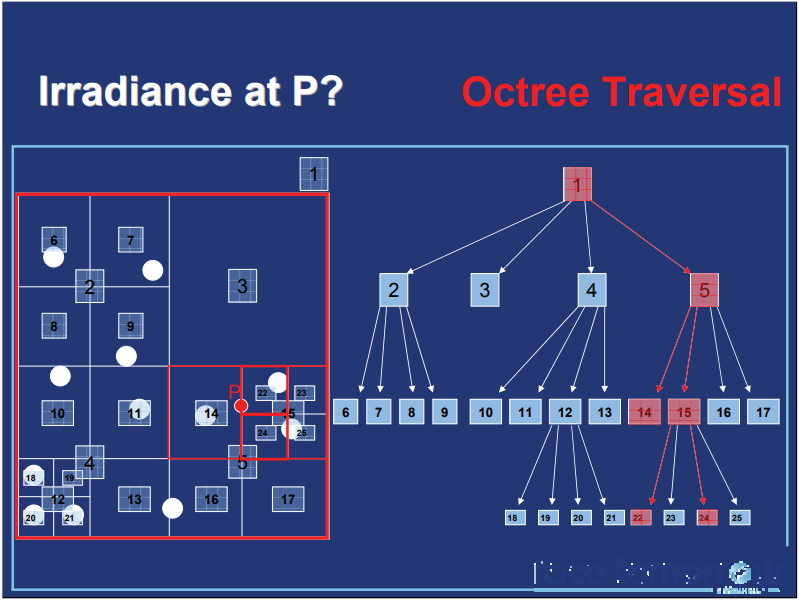
文中还谈及了GPU的实现细节,例如八叉树存储和遍历过程:
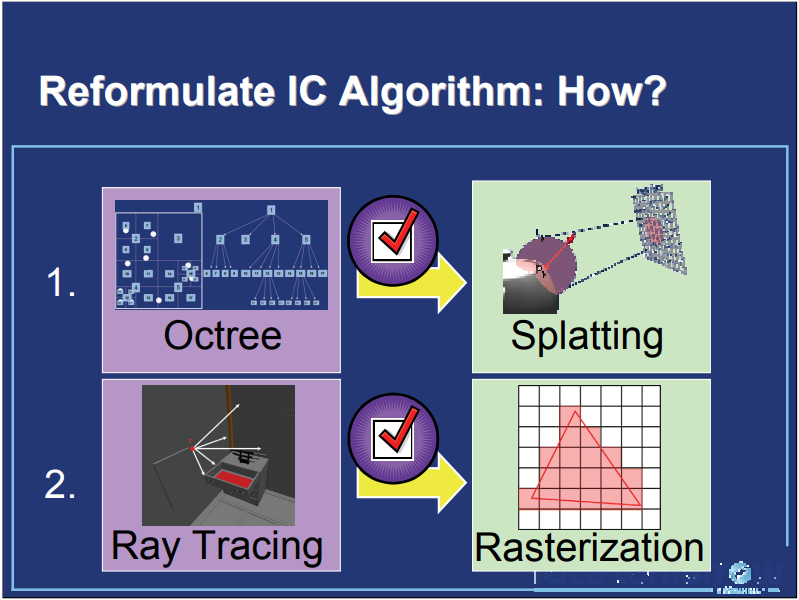
为了更好地在GPU上实现IC(Irradiance Cache),文章重新定制了算法,步骤如下:
该系列文献还给出了其它的技术分析、实现细节以及和其它方法的对比,非常值得点击原文查看。
Advanced Real-Time Rendering in 3D Graphics and Games也讲解了大量的渲染技术,包含地形渲染、曲面细分、CryEngine 2的架构设计和照明技术、GPU粒子、自阴影等等。文中提到了Valve的Source引擎利用距离场改进Alpha-Tested的材质效果:

64x64纹理编码的矢量效果。(a)是简单的双线性过滤 ;(b)是 alpha测试;(c) 是距离场技术 。
距离场的生成需要依赖高分辨率的输入纹理:

(a) 高分辨率 (4096×4096) 二进制输入用于计算 (b) 低分辨率 (64×64) 距离场。
利用生成的距离场信息,可以渲染出高质量的抗锯齿的镂空材质,甚至支持软硬边、发光、描边、软阴影、锐角等效果。在Valve发行的游戏《军团要塞2》中,采用了风格化的着色模型,其具体步骤如下图所示:


子文献Animated Wrinkle Maps讲述了利用多张法线图映射到不同的表情,以便通过插值获得表情间的法线,更加精确、自然地匹配人脸面部表情的效果。
 )
)
Ruby的面部纹理(从左到右):反照率贴图、切线空间法线贴图、脸部拉伸后的切线空间皱纹贴图 1、脸部压缩后的切线空间皱纹贴图 2。

八个皱纹蒙版分布在两个纹理的颜色和 Alpha 通道(白色代表 Alpha 通道的内容)。 [左] 左眉(红色)、右眉(绿色)、中眉(蓝色)和嘴唇(Alpha)的面具。 [右] 左脸颊(红色)、右脸颊(绿色)、左上脸颊(蓝色)和右上脸颊(alpha)的蒙版。还使用了此处未显示的下巴面罩。
值得一提的是,这种技术在许多年后,被Unreal Engine用在了数字人的表情渲染上,详情参考笔者的另一篇文章:剖析Unreal Engine超真实人类的渲染技术Part 1 - 概述和皮肤渲染。
子章节Terrain Rendering in Frostbite Using Procedural Shader Splatting讲述了Frosbite引擎利用过程化着色器溅射改进引擎的地形渲染。引擎团队提出了一种灵活的称为Procedural Shader Splatting的地形渲染框架和技术,其中基于图形的表面着色器控制地形纹理合成和分布,以允许单独专门化地形材质以平衡性能、内存、视觉质量和工作流程。该技术使引擎能够支持针对地面破坏的动态高度场修改,同时保持远距离和近距离的高视觉质量以及低内存使用率。灌木丛的程序实例已集成到系统中,使用地形材质分布和着色器是一种非常强大的工具和简单的方法,可以在内存和内容创建中以低成本添加视觉细节。

Frosbite引擎的地形渲染效果。
Frostbite Rendering Architecture and Real-time Procedural Shading & Texturing Techniques讲述了2007年的Frostbite引擎渲染架构、渲染技术及相关应用。用Frostbite研制的主机游戏Battlefield: Bad Company支持的特性有大型可破坏景观、可破坏的建筑物和物体、可破坏树叶的大森林、机动车(吉普车、坦克、船只和直升机)、动态天空、动态照明和阴影等。此阶段的Frostbite的渲染架构图如下:
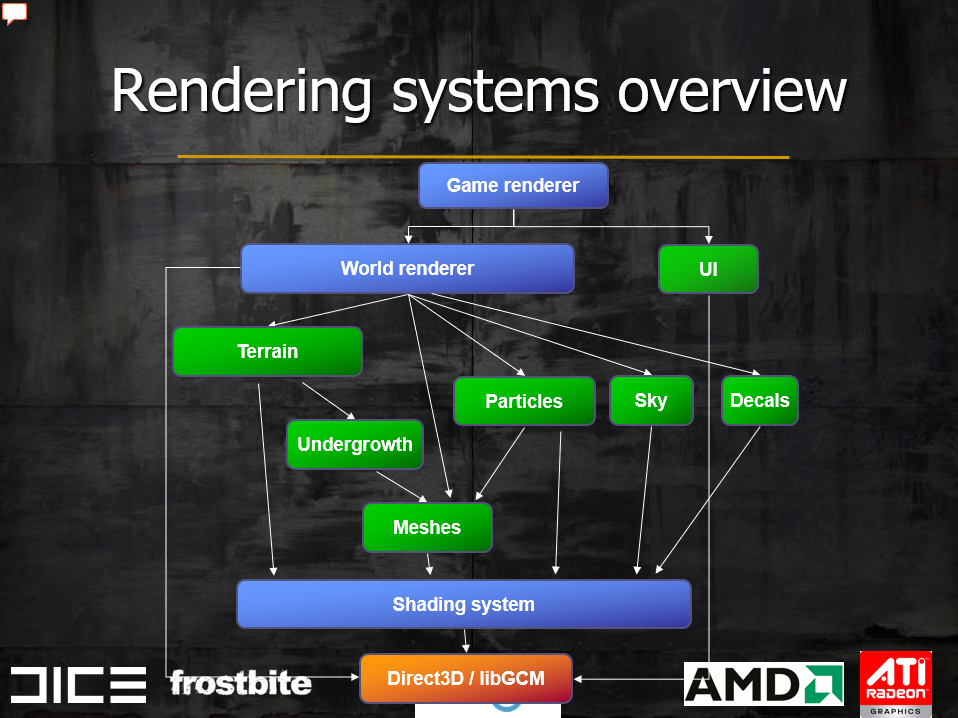
上图的蓝色是主要系统,绿色是渲染子系统。着色系统的特点是与平台无关的高级渲染API,简化和概括渲染、着色和照明,轻松快速地进行高质量着色,处理与GPU和平台API的大部分通信。
着色系统还支持多种图像API和高级着色状态,高级着色状态与图像API无关,方便上层的用户和系统使用,减少重复代码。高级着色状态的用例有光源(数量、颜色、类型、阴影)、几何处理(蒙皮、实例化)、效果(雾、光照散射)、表面着色(VS、PS)等。总之,高级着色状态更易于使用,对用户来说更高效,在系统之间共享和重用功能,隐藏和管理着色器排列的地狱模式,通用并集中到着色器管道,平台可能以不同的方式实现状态(取决于功能),多通道照明而不是单通道。
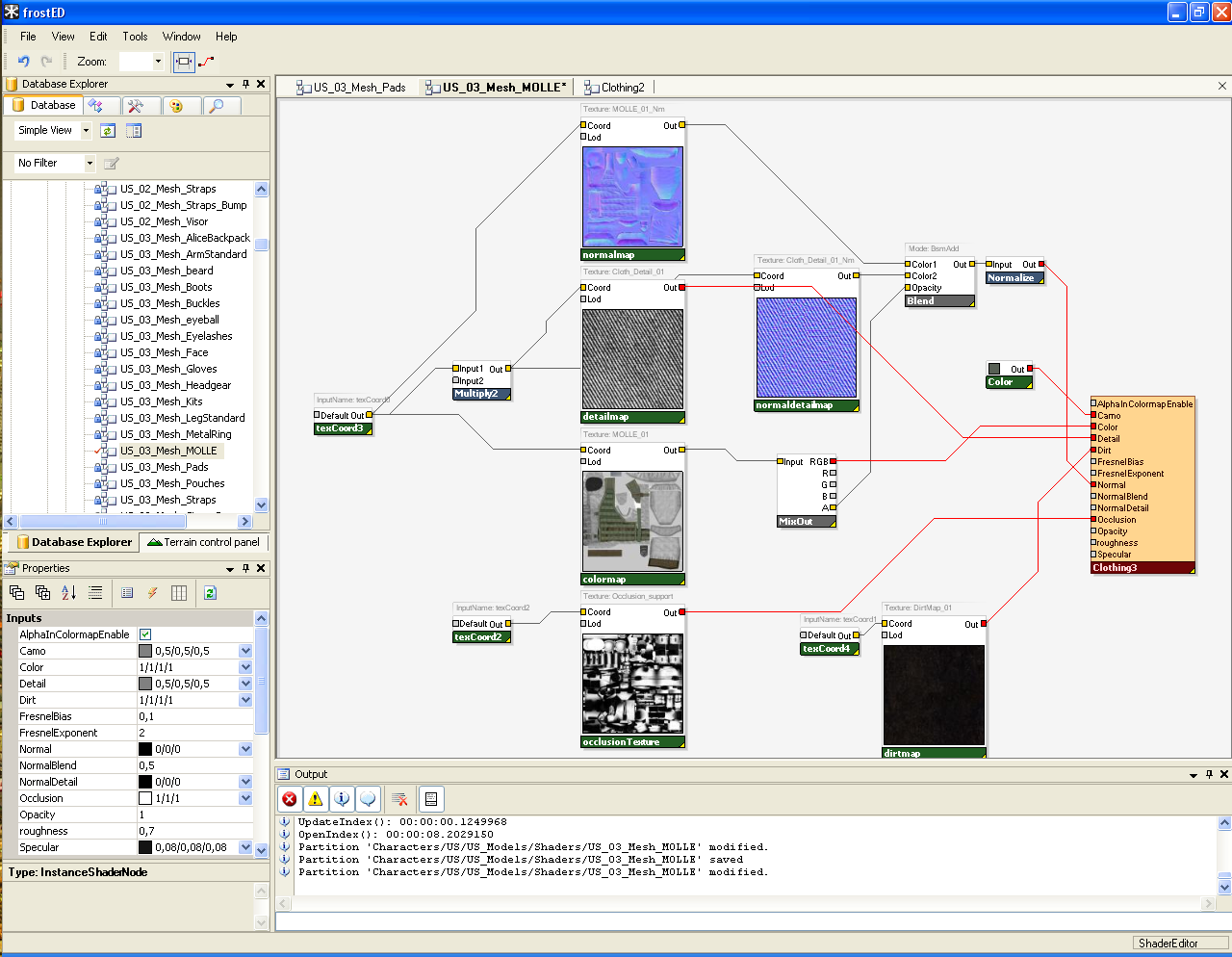
早期Frostbite的着色可视化编辑器。
Frostbite着色系统管线如下:
- 大型复杂离线预处理系统。系统报告想要的状态组合。
- 为运行时生成着色解决方案。每种着色状态组合的解决方案,示例:具有流实例化、表面着色器、光散射并受室外光源和阴影影响的网格以及用于Xbox 360的2个点光源。
- 生成HLSL顶点和像素着色器。
- 解决方案包含完整的状态设置。如通道、着色器、常量、参数、纹理等。
Frostbite着色系统运行时步骤如下:
- 用户压入渲染块到队列。几何和高级状态组合。
- 查找状态组合的解决方案。在管道离线阶段创建。
- 渲染块由后端发送给D3D/GCM。
- 渲染块已排序(类别和深度)。
- 后端设置特定于平台的状态和着色器。由该解决方案的管道确定,轻量且静默。
- 绘制。
Frostbite的世界渲染器(World renderer)负责渲染3d世界,管理世界视图和渲染子系统(例如地形、网格和后处理),可以根据启用的功能将视图拆分为多个子视图(用于阴影贴图渲染的仅深度阴影视图、动态环境贴图的简化视图)。世界渲染器分为3个阶段:
- 剔除(cull)。为每个视图收集可见实体和光/影/实体交互,从所有可见实体复制渲染所需的实体数据,多线程需要,因为数据在渲染时可能会更改(不好)。
- 构建(build)。可见实体被传递给它们各自的实体渲染器,实体渲染器与子系统通信(比如网格渲染器),子系统构建渲染块和状态(在着色系统中按视图入队)。
- 渲染(render)。为每个视图刷新着色系统中的队列渲染块以进行实际渲染,对视图应用后处理:Bloom、色调映射、DOF、色彩校正等。
它们都在不同的线程上运行(下图),需要多核的控制台和PC,以双缓冲和级联方式运行(简化同步和流程)。

室外光源采用基于混合图像的现象学模型,漫射太阳和天空光具有分析性(3 个方向:太阳、天空、地面)并且非常易于控制,来自天空的镜面反射是基于图像的(动态立方体贴图),mipmap用作可变粗糙度,来自太阳的镜面反射可用于精确分析。统一镜面粗糙度,单个 [0,1] 粗糙度值控制立方体贴图mipmap偏差(天空)和分析镜面反射指数(太阳),可能因像素而异。

同年的CryEngine 2利用DirectX 10支持了以下特性:
- 支持不同的场景环境,各有特点。

CryEngine 2渲染的丛林、外星人室内、冰雪等不同类型的场景。
- 电影级质量渲染,不影响恐怖谷。
- 动态光影。预计算光照对于许多提高性能和质量的算法至关重要,拥有动态光照和阴影使我们无法使用这些算法中的大多数,因为它们通常依赖于静态属性。
- 支持多GPU和多CPU (MGPU & MCPU)。多线程和多显卡的开发要复杂得多,而且通常很难不破坏其它配置。
- 支持4km × 4km的大场景。
- 针对从着色器模型2.0到4.0 (DirectX10)的GPU。
- 高动态范围。在《孤岛惊魂》中使用HDR取得了不错的效果,而对于逼真的外观,可以在没有LDR限制的情况下开发游戏。
- 动态环境(易碎)。最酷的功能之一,但实现并不容易。
在光影方面,CryEngine 2放弃了模板阴影,选择具有高质量的软阴影的阴影图,并且阴影图可以调整以获得更好的性能或质量。在直接光照方面,采用了动态遮挡图、具有屏幕空间随机查找的阴影贴图、具有光源空间随机查找的阴影贴图、阴影遮蔽纹理、延迟阴影遮蔽生成、点光源的展开阴影贴图、方差阴影贴图(VSM)等技术。

CryEngine 2不同结果质量的阴影贴图示例。从左到右:无 PCF、PCF、8个样本、8个样本+模糊、PCF+8个样本、PCF+8个样本+模糊。

CryEngine 2具有随机查找的阴影贴图示例。左上:无抖动1个样本,右上:屏幕空间噪声8个样本,左下:世界空间噪声8个样本,右下:调整设置的世界空间噪声8个样本。

CryEngine 2给定场景的阴影遮罩纹理示例:左图:使用太阳(作为阴影投射器)和两个阴影投射灯的最终渲染,右图:RGB 通道中具有三个灯光的光罩纹理。

CryEngine 2给定场景的阴影遮罩纹理示例 - 红色、绿色和蓝色通道存储 3个单独灯光的阴影遮蔽。

CryEngine 2将方差阴影贴图应用于场景的示例。上图:未使用方差阴影贴图(注意硬法线阴影),下图:使用方差阴影贴图(注意两种阴影类型如何组合)。
在非直接光方面,CryEngine 2采用了3D传输采样(3D Transport Sampler)、实时环境图、SSAO等技术,在当时,这些都是新兴的具有开创性的渲染技术。
其中3D传输采样可以计算分布在多台机器上的全局光照数据(出于性能原因),计算全局光照使用的是光子映射(Photon Mapping),它可以轻松集成并快速提供良好的结果。

CryEngine2单个光源的实时环境图。

CryEngine 2的SSAO可视化和应用到场景的对比图。
此外,CryEngine 2根据不同的情形对水体、地形、网格等物体执行了细致的LOD技术,采用了溶解、FFT、方形水面扇、屏幕空间曲面细分(下图)等技术。

CryEngine 2的屏幕空间曲面细分线框图。

左:没有边缘衰减的屏幕空间曲面细分(注意左边没有被水覆盖的区域),右:有边缘衰减的屏幕空间曲面细分。
CryEngine 2作为下一代引擎,选择以上技术主要是因为质量、生产时间、性能和可扩展性,并且在游戏《孤岛危机》获得成功的验证,成为当时令人瞩目的主流引擎之一。
Collaborative Soft Object Manipulation for Game Engine-Based Virtual Reality Surgery Simulators提及的游戏引擎一种抽象架构:
该文分析了UE、id Tech、Source Engine等引擎的特点,然后给与了一种引擎选择的评估策略,以模拟虚拟手术。

操作用户(上)和观察用户看到的可变形心脏模型(下)。
The Delta3D Gaming and Simulation Engine: An Open Source Approach to Serious Games阐述了开源3D引擎Delta3D在项目开发的经验和教训,通过构建一个基于游戏的开源模拟引擎,提高产品的成功概率。其中Delta3D的架构如同下图所示:
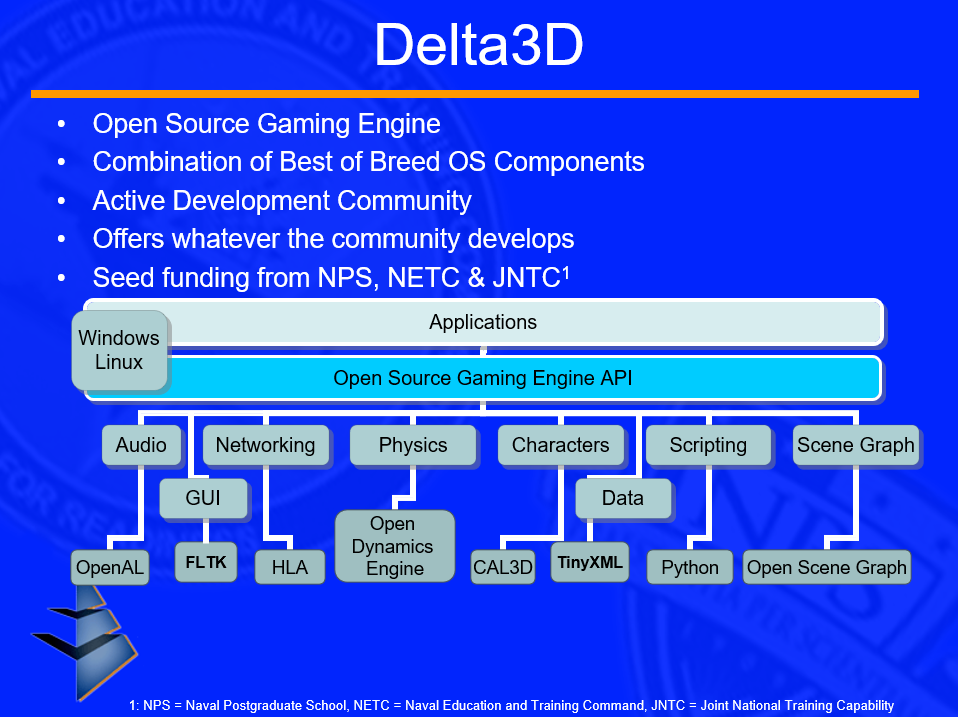
Delta3D支持的特性见下图:

它的渲染效果如下图所示:

Software Requirement Specification Common Infrastructure Team提到了一种可交互的游戏引擎的架构图:
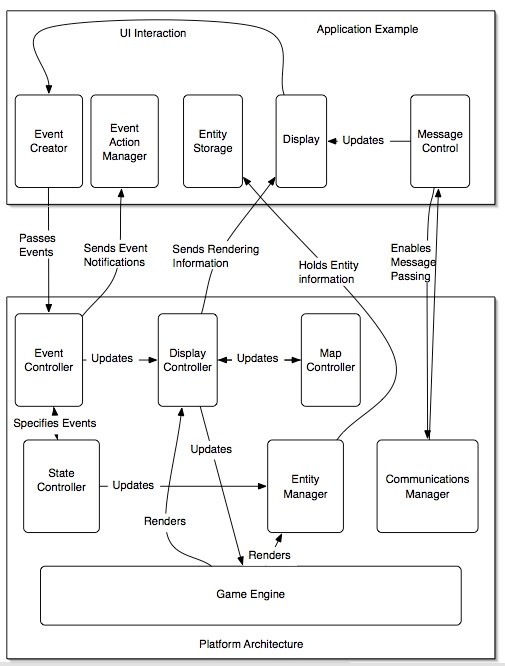
应用程序、平台框架和游戏引擎所需的最常见元素,并促进了消息传递、状态维护和实体注册等操作。
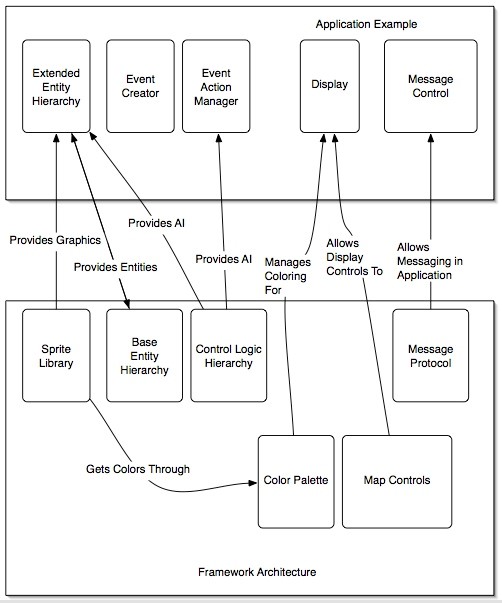
框架常见的功能,以促进应用程序开发。该框架还提供平台的一些接口,以加快应用程序级别的开发。

游戏世界由许多处理状态变化、游戏逻辑和渲染的子模块组成。来自GUI的事件被发送到游戏控制器,它会提醒其余的子模块根据需要改变行为。
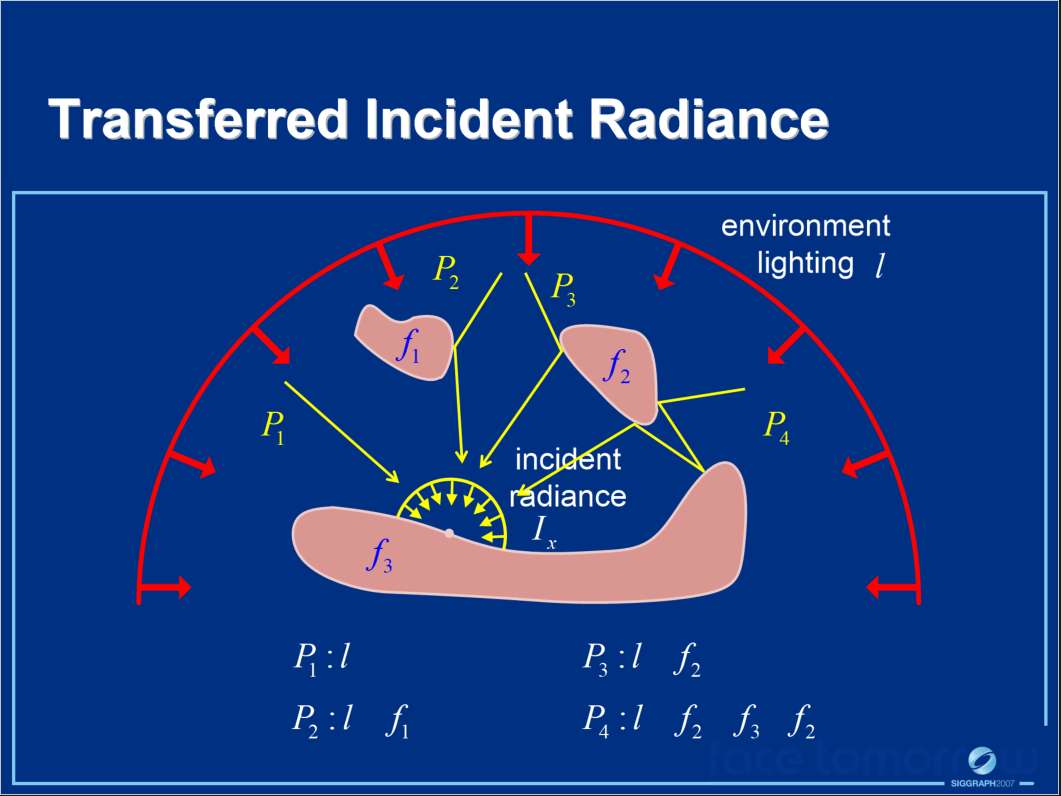
在光照渲染方面,Interactive Relighting with Dynamic BRDFs在PRT和动态BRDF基础上提出了新的BRDF积分方式。具体做法是将传输的入射辐射预先计算为场景中照明和BRDF的函数,以便考虑动态BRDF的全局照明效果。为了克服辐射传输和BRDF之间的非线性关系问题,采用了一种基于预计算传输张量的技术。另外,还通过张量近似表示表面点的BRDF空间,能够在改变三个场景条件中的任何一个时获得快速着色。使用传输的入射辐射和BRDF张量基础,可以使用动态BRDF及其相应的全局照明效果有效地执行场景的运行时渲染。

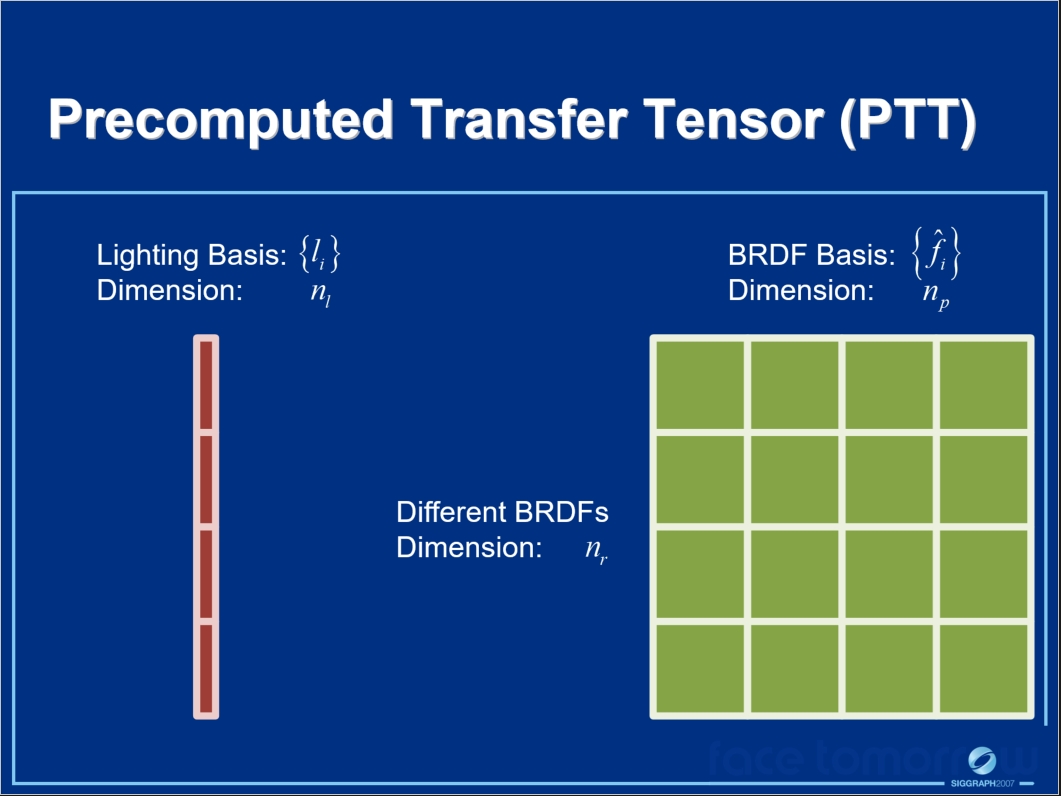
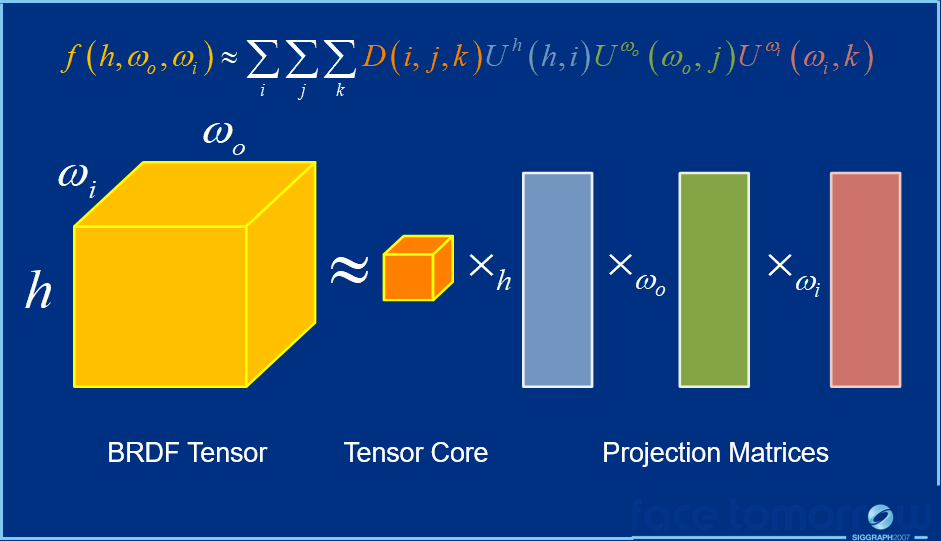
上图中:
- \(I_x(l, \omega_i)\)是传输的入射辐射,被预先计算为照明和BRDF(预计算传输张量)的函数。
- \(f(\omega_o, \omega_i)\)是BRDF空间,由用于快速着色的张量近似表示。
- \(B_x(\omega_o)\)是运行时渲染,根据传输的入射辐射和BRDF张量基计算的。
其中\(I_x(l, \omega_i)\)转变为预计算传输张量(PTT)的过程如下面系列图所示:

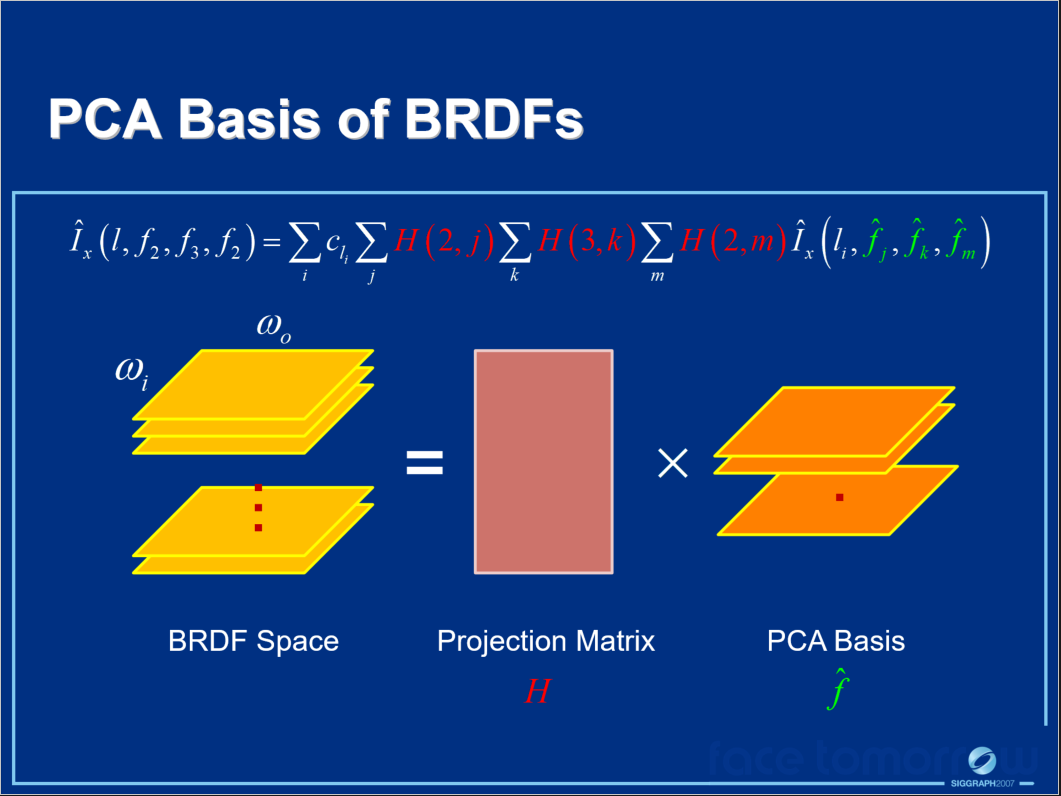
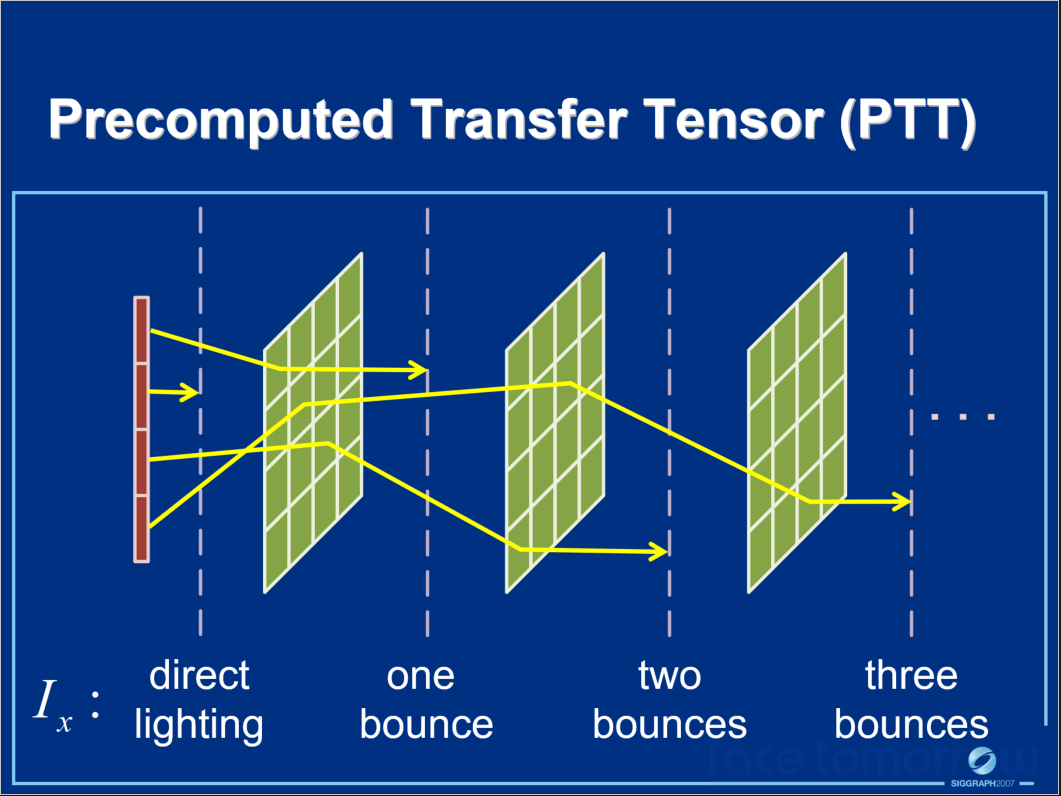
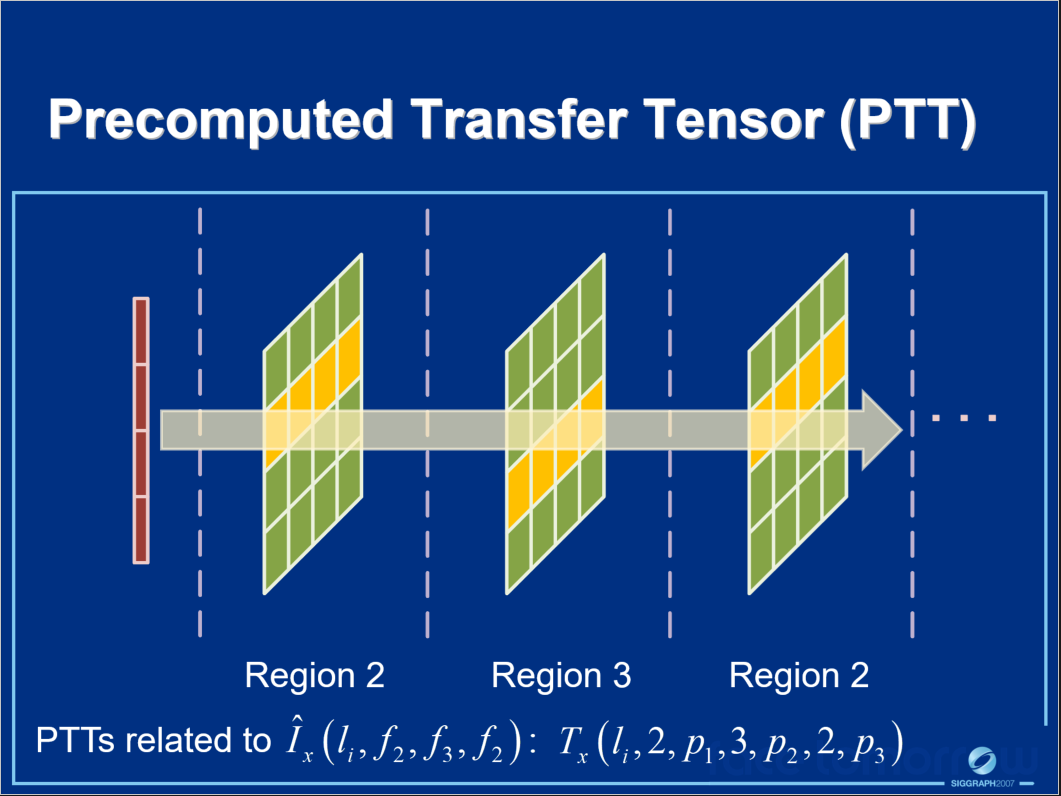
不同光路的传输辐射在PTT中单独处理,PTT是光照和BRDF的线性函数,PTT可以在运行时快速组合以获得整体转移的入射辐射。\(f(\omega_o, \omega_i)\)由张量近似的过程如下系列图所示:

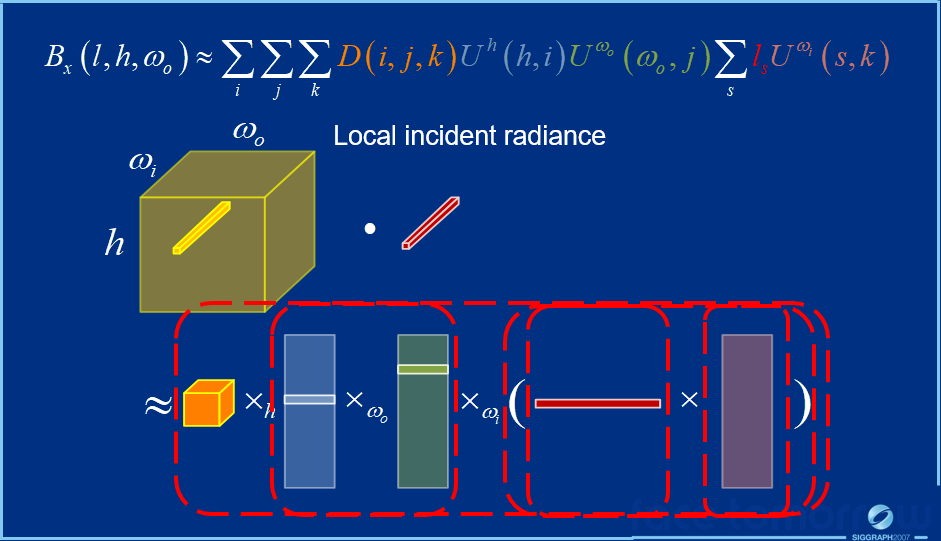
最终合成的运行时渲染方程如下:

算法的总体流程如下:
渲染效果图如下:

文中还给出了渲染时的具体实现细节和性能分析,限于篇幅,此处不再阐述,有兴趣的同学可以阅读原文。
时间来到了2008年,Advances in Real-Time Rendering in 3D Graphics and Games (SIGGRAPH 2008 Course)大量阐述了当年实时渲染领域最新的研究成果、渲染技术和实际应用,包含Halo 3的光照和材质、StarCraft II渲染、虚拟纹理、GPU并行模拟、硬件级wavelet等。
Halo 3支持Cook Torrance BRDF、球谐光照图和漫反射、多种镜面高光(解析高光、环境图高光、区域高光)等特性。

Halo 3使用二次SH的谐波光照图纹理。

Halo 3用于区域高光的预积分纹理。从左到右:C(0,2,3,6)、D(0,2,3,6)和CD(7,8)。横轴表示视图变化,纵轴表示粗糙度变化。

Halo 3的渲染画面截图。
Advanced Virtual Texture Topics表明虚拟纹理是一个mipmap纹理,用作缓存,以允许模拟更高分辨率的纹理以进行实时渲染,同时仅部分驻留在纹理内存中。通过最近几代商品GPU上可用的高效像素着色器功能已经可以实现此功能。文中讨论了由于虚拟纹理的使用、内容创建问题、结果、性能和图像质量而对引擎设计的技术影响,还介绍了几个实际应用案例,以突出挑战并提供解决方案。虚拟纹理涉及纹理过滤、块压缩、浮点精度、磁盘流、UV边界、mipmap生成、LOD选择等技术细节。
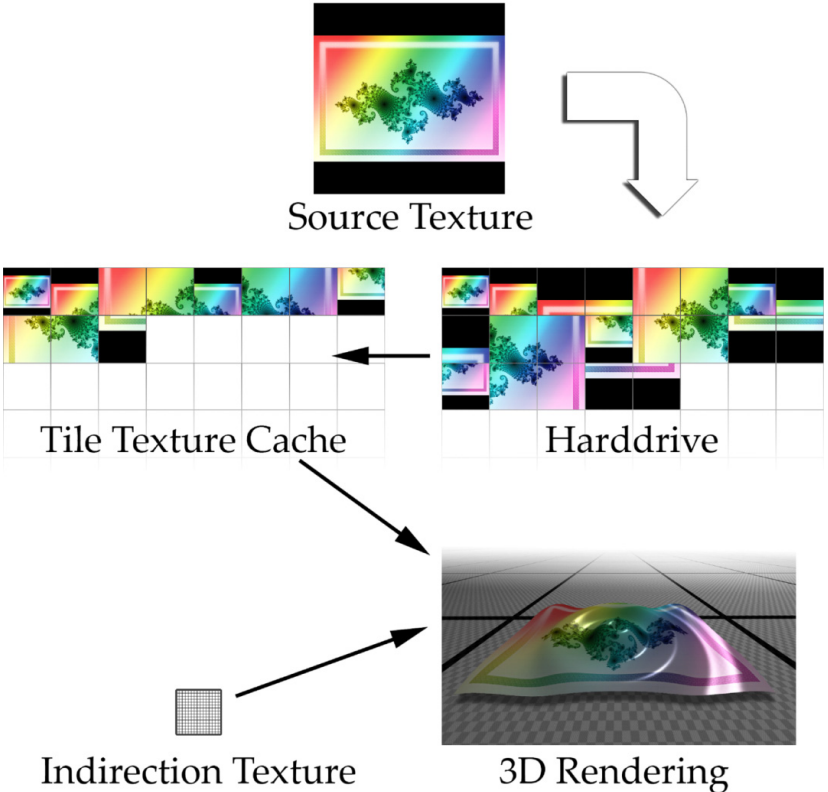
虚拟纹理法的典型使用场景.

使用虚拟纹理受益的场景示例 - 游戏Crysis中的贴花(道路、轮胎痕迹、泥土)在地形材料混合之上使用。
March of the Froblins: Simulation and rendering massive crowds of intelligent and detailed creatures on GPU由AMD呈现,文中专门开发了演示程序Froblin,用展示大规模蒙皮角色的模拟、渲染及AI。

Froblin演示画面。

Froblin动态寻路可视化。

Froblin的动画纹理布局。变换存储为3x4矩阵,使用了一个纹理数组,其中水平和垂直维度对应关键帧和骨骼索引,切片编号用于索引动画序列。沿着纹理的一个轴改变时间可以使用纹理过滤硬件在关键帧之间进行插值。注意,根据权重对每个顶点的骨骼影响进行排序,并使用动态分支来避免获取零权重的骨骼,可以显著提升性能,因为大多数顶点不具有超过两个骨骼影响。
// 用于获取、插入和混合骨骼动画的着色器代码
float fTexWidth;
float fTexHeight;
float fCycleLengths[MAX_SLICE_COUNT];
Texture2DArray<float4> tBones;
sampler sBones; // should use CLAMP addressing and linear filtering
void SampleBone( uint nIndex, float fU, uint nSlice, out float4 vRow1, out float4 vRow2, out float4 vRow3 )
{
// compute vertical texture coordinate based on bone index
float fV = (nIndices[0]) * (3.0f / fTexHeight);
// compute offsets to texel centers in each row
float fV0 = fV + ( 0.5f / fTexHeight );
float fV1 = fV + ( 1.5f / fTexHeight );
float fV2 = fV + ( 2.5f / fTexHeight );
// fetch an interpolated value for each matrix row, and scale by bone weight
vRow1 = fWeight * tBones.SampleLevel( sBones, float3( fU, fV0, nSlice ), 0 );
vRow2 = fWeight * tBones.SampleLevel( sBones, float3( fU, fV1, nSlice ), 0 );
vRow3 = fWeight * tBones.SampleLevel( sBones, float3( fU, fV1, nSlice ), 0 );
}
float3x4 GetSkinningMatrix( float4 vWeights, uint4 nIndices, float fTime, uint nSlice )
{
// derive length of longest packed animation
float fKeyCount = fTexWidth;
float fMaxCycleLength = fKeyCount / SAMPLE_FREQUENCY;
// compute normalized time value within this cycle
// if out of range, this will automatically wrap
float fCycleLength = fCycleLengths[ nSlice ];
float fU = frac( fTime / fCycleLength );
// convert normalized time for this cycle into a texture coordinate for sampling.
// We need to scale by the ratio of this cycle's length to the longest,
// because the texture size is defined by the length of the longest cycle
fU *= (fCycleLength / fMaxCycleLength);
float4 vSum1, vSum2, vSum3;
float4 vRow1, vRow2, vRow3;
// first bone
SampleBone( nIndices[0], fU, nSlice, vSum1, vSum2, vSum3 );
vSum1 *= vWeights[0];
vSum2 *= vWeights[0];
vSum3 *= vWeights[0];
// second bone
SampleBone( nIndices[1], fU, nSlice, vRow1, vRow2, vRow3 );
vSum1 += vWeights[1] * vRow1;
vSum2 += vWeights[1] * vRow2;
vSum3 += vWeights[1] * vRow3;
// third bone
if( vWeights[2] != 0 )
{
SampleBone( nIndices[2], fU, nSlice, vRow1, vRow2, vRow3 );
vSum1 += vWeights[2] * vRow1;
vSum2 += vWeights[2] * vRow2;
vSum3 += vWeights[2] * vRow3;
}
// fourth bone
if( vWeights[3] != 0 )
{
SampleBone( nIndices[3], fU, nSlice, vRow1, vRow2, vRow3 );
vSum1 += vWeights[3] * vRow1;
vSum2 += vWeights[3] * vRow2;
vSum3 += vWeights[3] * vRow3;
}
return float3x4( vSum1, vSum2, vSum3);
}
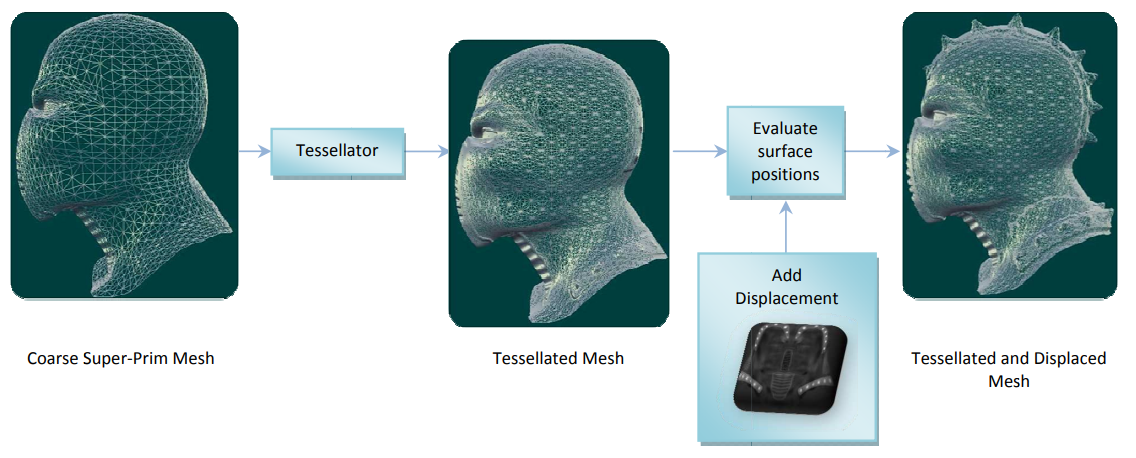
对角色模型采用了曲面细分,以便近景特写时添加角色细节。

左:启用了曲面细分,模型细节更丰富;右:未启用曲面细分,轮廓更粗糙。
下图是GPU的曲面细分管线:
压缩动画顶点的位布局如下图所示,位置的每个分量使用16位,切线使用两个8位球坐标,法线占用32位,每个UV坐标16位。 由于切线坐标系是正交的,剔除存储副法线(可由解压缩的法线和切线重新计算)。由于可以使用完整的32位字段,对法线使用类似DEC3N的压缩,比球坐标需要更少的ALU操作。如果需要额外的数据字段,8位球坐标可用于法线,其质量水平与DEC3N相当,在ATI Radeon™ HD 4870 GPU上对所有替代方案进行了试验,发现它们之间的性能或质量几乎没有实际差异。

压缩动画顶点的位布局。
因为角色是动态的,所以他们的阴影不能作为预处理被写入SHLM(球谐光照图),取而代之的是一种更传统的实时阴影方法,即并行阴影映射(parallel‐spit shadow mapping),用来渲染它们的阴影。理想情况下,希望阴影贴图只减弱太阳对光线贴图的影响,而不想在角色投射阴影的地方简单地暗化地形。可以通过在地形的像素着色器中将一个主导方向光从光照环境中分离出来。(下图)
人物在地形上的阴影。左半边在山的阴影下,右半边在阳光直射下。上:人物不正确地在地形的遮挡区域投下了双重阴影;下:使用阴影校正因子来防止双重阴影的影响。

动态角色(底部)和其他静态场景道具(顶部)通过从地形的SHLM取样来建立一个近似的光照环境进行着色。
Using wavelets with current and future hardware介绍了小波(wavelet)的概念、性质和用途。小波是由单个波形(称为母小波)的缩放和平移副本形成的数学函数。它们允许将函数分解为不同频率分量的叠加,可以单独对其进行操作(称为多分辨率分析)。一个函数可以通过使用小波变换变成小波形式,并且可以通过逆变换(类似于傅里叶变换)转换回原始函数。作为基函数的小波比标准傅里叶表示(及其在球面上的类似物,球谐函数)具有几个显著的优势,它们更擅长表示具有不连续性或急剧变化的函数、非周期性函数,并且在许多情况下具有局部支持,这允许对数据集进行有效的窗口修改。它们是分层细化的系统,因此可以稀疏地表示数据中低对比度的局部区域,同时,它们可以是正交的。小波变换可以是连续的或离散的,并且可以表示任何维度的数据。一般来说,我们会对离散的二维小波感兴趣,特别是二维非标准Haar。

非标准2D Haar的垂直、水平和对角小波。
小波在实时渲染方面有许多潜在的应用,以下是潜在的应用列表:
-
实时着色器纹理解压缩。表示任意标量数据(例如图像或球谐系数)的纹理可以有损地压缩成小波树,然后使用线性纹理紧凑地表示。给定像素或顶点着色器中的 (u, v),可以使用着色器内的展开遍历实时恢复该位置的原始纹理值。此外,可以在图像和滤波器内核之间分层执行任意滤波器操作(包括双线性滤波器内核)。
![]()
实时GPU纹理解压。子块纹理中的每个纹理元素都包含小波树的偏移量。
-
照明的实时双重和三重积(triple product)积分。小波可用于对照明积分的元素进行编码和压缩,选择正交的小波集(例如非标准的2D Haar)可以将双重积积分分解为点积运算的稀疏列表。可以通过描述如何通过一组简单(和小)的规则推导出三倍系数来将其扩展到三重积积分,小波还可用作BRDF解析表示的近似值。
![]()
(左)红色区域光和(右)格雷斯大教堂照明环境之间的实时GPU双重积积分。
![]()
同上的格雷斯大教堂连续三帧,但夸张化对比。
![]()
使用点采样进行BRDF积分近似的连续三帧的三重积积分,以及用于漫射照明的高频法线贴图。
-
静态阴影贴图。完全静态或主要静态的阴影贴图可以用小波表示,可能具有高度压缩,深度值的查询方式与上述纹理压缩相同。可以通过仅考虑其覆盖与变化区域相交的那些小波来合并阴影贴图的局部变化,证明了局部支持下建立基组的价值。
-
位移贴图压缩。类似地,位移贴图也可以进行小波压缩,小波压缩将明显压缩低变化区域,并将高变化区域表示为任意精度水平。此外,小波压缩是一种用于压缩非常大的位移贴图的有用方法,例如地形表示——通常会在周围散布一些高频变化的小区域,中间有平滑的低频数据。使用合理的压缩比,允许单个纹理(这里存储小波树而不是精确的位移值)跨越比当前图形硬件允许的最大纹理分辨率大得多的区域,并且可能允许更轻松的流式传输和LOD方法。
-
更容易的静态和动态纹理打包。 在任意网格上自动生成UV映射函数是一个棘手的问题,当需要额外的映射特性时更是如此,例如失真最小化,并尝试在图集边界上匹配纹素。除了这些要求之外,还希望最大化总纹理使用率,以便有效地使用可用内存。有一些程序可以生成良好的UV映射,但通常仍然存在生成纹理使用不佳的映射的情况。小波图像压缩将大量压缩多边形之间未使用的间隙,即使对于近乎无损的压缩也可以产生良好的结果。对于动态打包,可以采用在大块中分配新的纹理空间,而不必费心思有效地与现有图集执行分块,填充后,该块将被小波压缩。
-
几何表示。具有关联UV映射的可变形对象可以具有由表面上的小波表示的变形。一种可能的方法是允许对要使用的小波数量有一个固定的上限(也许是为了控制内存使用)。通过移除最古老的现有高频小波,可以为新的变形腾出空间——因此旧变形的宽广形状可以保持更长的时间,但会牺牲更精细的细节。此外,多分辨率表示可用于直接更新物体的质心和惯性矩,可能具有不同的精度水平。 这表明以单一多分辨率形式表示的数据更易于在具有不同精度要求的不同系统中使用。



StarCraft II: Effects & Techniques由暴雪呈现,讲述了2008年的星际争霸2的图形引擎的特性和技术。星际争霸2的图形引擎的设计目标有:
-
可扩展性优先。让游戏最大程度流畅地运行在不同的系统、图形API、硬件设备之中。
-
让GPU压力大于CPU。在提升游戏质量水平时,选择了更多地强调GPU而不是CPU。其中一个主要原因是,在星际争霸 II中,可以生成和管理潜在的数百个较小的基本单元。最多有8名玩家同时游戏,亦即一次在屏幕上最多显示大约500 个角色。因为建造的单位数量很大程度上在玩家的控制之下(以及由于所选种族的选择),所以平衡引擎负载使得CPU潜力在高单位数量和低单位单位中都得到充分利用计数情况变得繁琐。
![]()
玩家可以控制非常多的角色,因此平衡批次计数和顶点吞吐量是可靠性能的关键。
-
引擎的双重性质。存在两种模式:游戏模式和故事模式。在正常的游戏过程中(即游戏模式),会从相对较远的距离渲染场景,批量数量较多,并且关注动作而不是细节。在故事模式下,玩家通常会坐下来欣赏游戏丰富的故事、传说和视觉效果,通过对话与其他角色互动并观看动作展开,与游戏模式有完全不同且经常相反的限制; 故事模式通常拥有较少的批次数量、特写镜头和更沉思的感觉。
![]()
上:游戏模式;下:故事模式。


对于星际争霸 II,任何渲染的不透明模型都会将以下内容存储到绑定在其主渲染通道中的多个渲染目标中:
- 不受局部光照影响的颜色分量,例如自发光、环境贴图和前向光照颜色分量;
- 深度;
- 每像素法线;
- 环境光遮蔽术语,如果使用静态环境光遮蔽。 如果启用了屏幕空间环境光遮蔽,烘焙的环境光遮蔽纹理将被忽略;
- 无照明的漫反射材质颜色;
- 无照明的镜面材质颜色。
MRT提供了可用于各种效果的每像素值,例如:
- 照明、雾量、动态环境遮挡和智能位移、景深、投影、边缘检测和厚度测量的深度值。
- 动态环境光遮挡的法线。
- 用于照明的漫反射和镜面反射。
星际争霸 II支持以下特性:
-
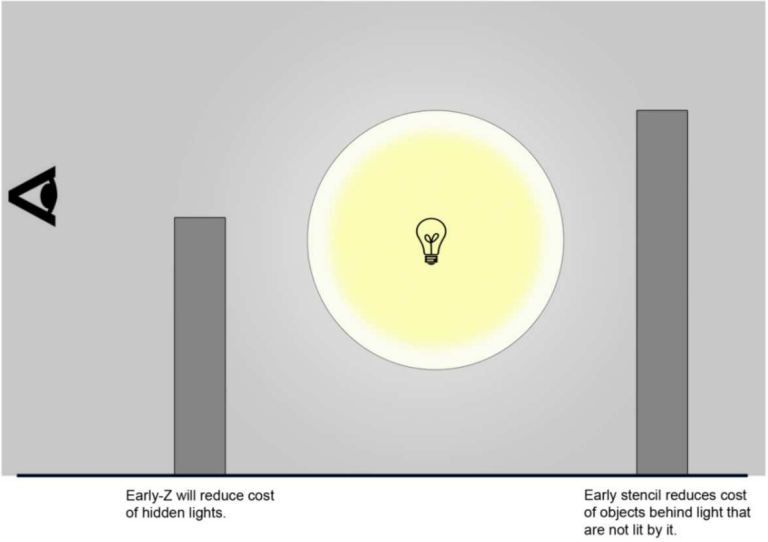
延迟光照。像素位置重建、模板、Early-Z 和 Early-Stencil等。
![]()
![]()
上:Early-ZS示意图;下:延迟光照效果。
-
屏幕空间环境光遮蔽。SSAO的主要思想是通过对屏幕空间中相邻像素的深度进行采样来近似可见表面上的点的遮挡函数,得到的解决方案将缺少来自当前隐藏在屏幕上的对象的遮挡线索,但由于环境遮挡往往是一种低频现象,因此近似值通常相当令人信服。
![]()
星际争霸2的SSAO效果。
-
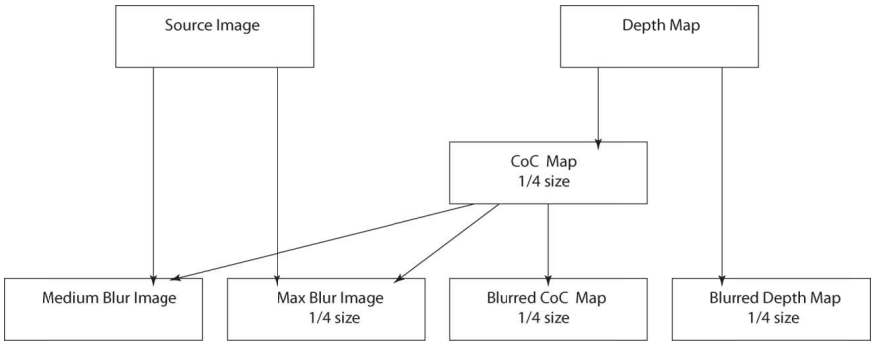
景深。利用弥散圆(Circle of Confusion)来模拟摄像机的焦距内清晰焦距外模拟的景深效果。
![]()
DOF的处理流程和步骤。
-
半透明阴影。使用额外的信息通道(第二张阴影贴图保存半透明阴影信息,额外的颜色缓冲区保存半透明阴影的颜色)来扩展阴影贴图的每像素信息,从而轻松地增强具有半透明阴影支持的阴影贴图。光线照射到前面的透明物上,并在连续照射到每个透明层时被过滤。
![]()
光源过滤过程示意图。


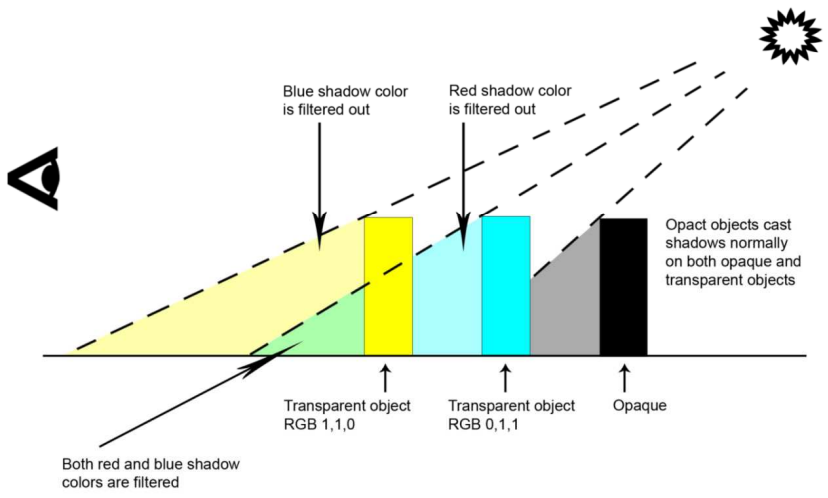
Lighting and Material of HALO 3详细地分享了Halo 3所使用的光照、材质模型、HDR渲染等方面的技术内容。该文先是对比了之前的一些光照表达方式:

利用DX SDK改进了UV的打包方式,提升利用率:

对光照图进行了二度优化:信号处理、纹理压缩。

场景渲染和物体渲染的步骤如下所示:


还可以对SH的存储和计算进行优化:

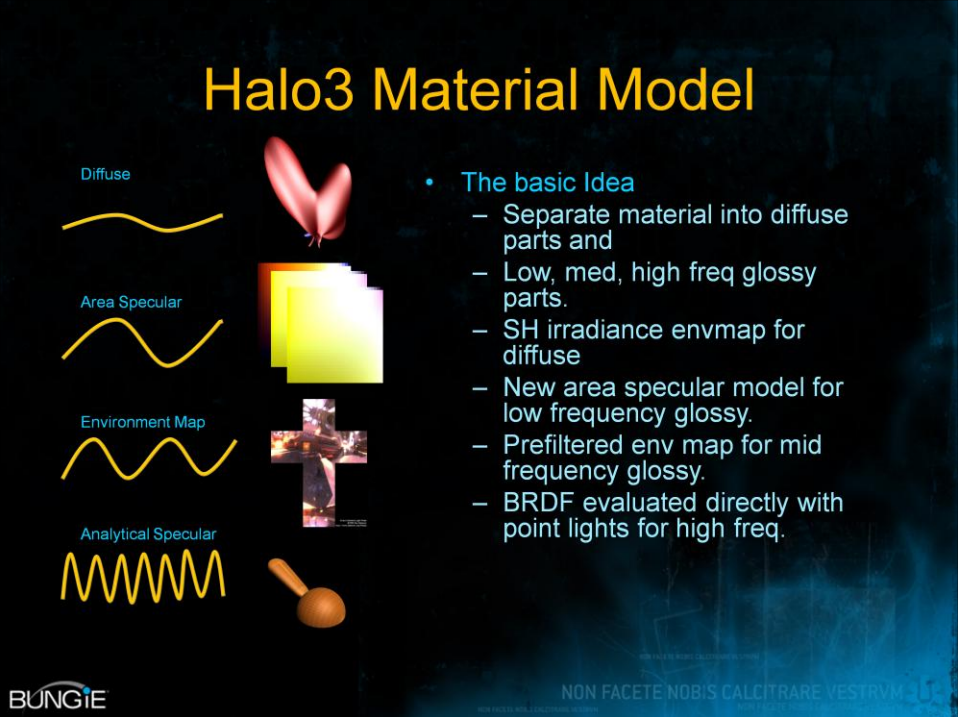
在材质方面,Halo 3不同当时的大多数游戏,已经支持更加PBR的Cook-Torrance的BRDF、复杂度更高的区域光,并且做到了更高的实时性和更小的存储量。

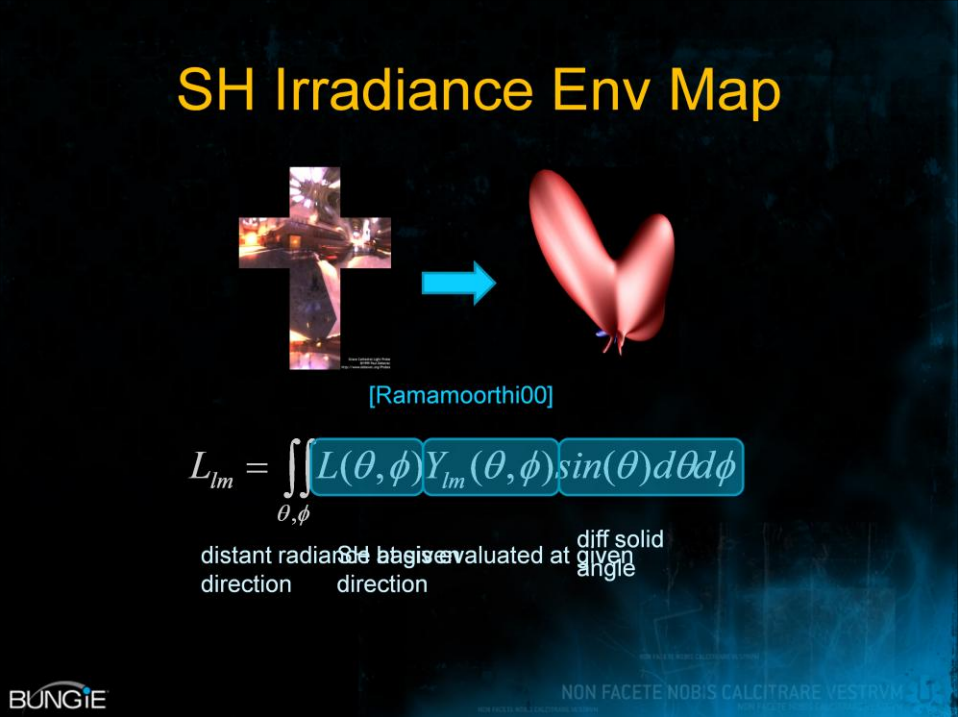
由此,Halo 3实现了漫反射+多种频率(低频、中频、高频)高光的光照模型,其中漫反射用SH辐照度,低频高光用新的区域高光模型,中频高光用预过滤的环境图,高频高光用直接解析评估的点光源。
预积分SH光照信息的推导过程和实现过程如下:



下图是组合了SH辐照度的漫反射 + 预过滤环境图中频高光 + 点光源解析的高频高光的效果图:

下图是Halo 3的HDR渲染管线:
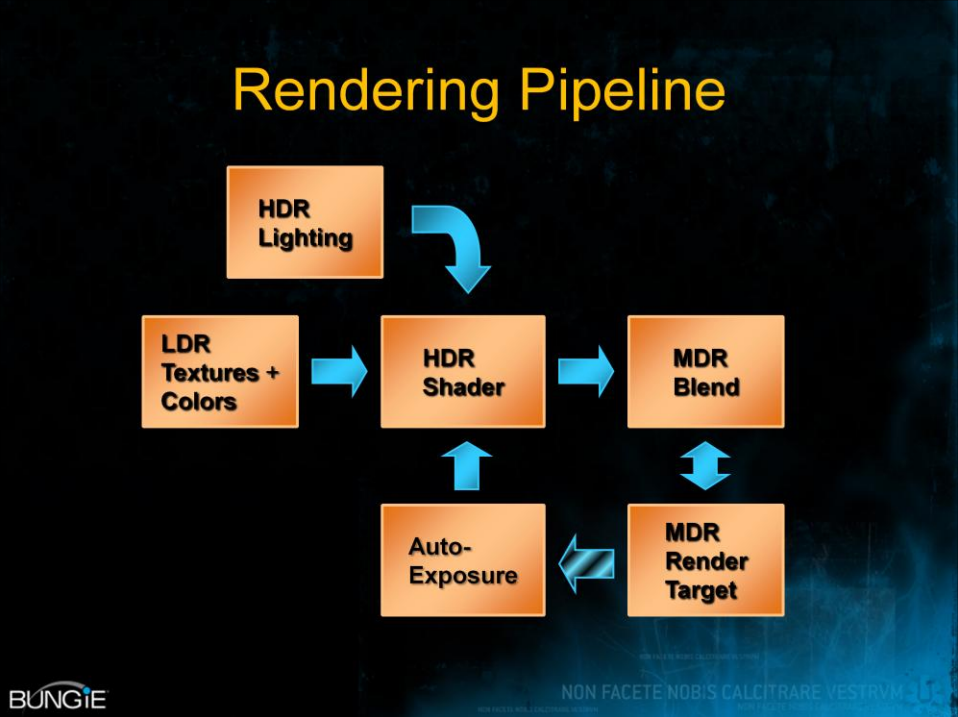
Halo 3的渲染目标需要考虑内存大小、渲染速度、硬件混合支持、动态范围、阶数(banding)等因素,动态范围和阶数可用于曝光范围。下图是XBox 360的渲染目标详情:

The Intersection of Game Engines & GPUs: Current & Future分享和讨论DICE在Frostbite引擎及游戏中当前和未来的图形用例以及对图形硬件的影响,具体包含引擎现状、着色器、并行、纹理、光线追踪、计算着色器等内容。Frostbite在很早的版本就开始使用基于图形节点的着色编辑器(下图),它的好处在于:
- 丰富的高级着色框架。被所有内容和系统使用。
- 艺术家友好。易于创建、调整和管理。
- 灵活。程序员和艺术家可以扩展和公开功能。
- 以数据为中心。封装资源,可变换到不同的着色平台。

基于图形节点的着色编辑器会生成很多着色器排列(Shader permutation),着色器排列是每个使用的特征/数据组合,包含HLSL顶点和像素着色器,如果有许多特性会引起排列爆炸(着色器图、照明、几何),需要平衡排列和特征的性能,如动态分支,存在在许多排列中。
在并行方面,Frostbite已经支持多线程命令录制,以便重复利用当时日渐增多的CPU核心。
Frostbite引擎考量了软件遮挡剔除和硬件遮挡剔除。软件遮挡剔除的方案是在 SPU/CPU上光栅化粗粒度的z-buffer,光栅化时使用低多边形遮挡网格、100m视距、最大10000个顶点/帧、手动保守方式,z-buffer是256x114浮点格式,专为PS3打造,已应用于上线的游戏中。然后在传递给所有其它系统之前根据z-buffer使用屏幕空间bbox测试剔除所有对象,可以节省大量工作。需要GPU光栅化和测试,但是遮挡查询引入开销和延迟,可以管理,不理想,条件渲染只对GPU有帮助,而不是CPU、帧内存或绘图调用。也期望低延迟额外GPU执行上下文,在GPU上完成光栅化和测试,与CPU同步;将整个剔除和渲染移至GPU,如场景图、剔除、系统、调度、最终目标。
Frostbite还探讨了实时光线追踪,更加关注性能,光栅化主光线,轻松集成到引擎中,只是切换某些效果和对象的另一种方法而不更换整个管道,高效的动态几何、程序和手动动画(树叶、角色)、破坏(树叶、建筑物、物体)。光追发射想要玻璃、金属度,对重要物体的正确反射,用于测试的简化版世界几何体和着色。
Software Instrumentation of Computer and Video Games阐述了软件分析工具对游戏和引擎的作用,并基于虚幻引擎提出并验证了由初级到高级逐渐完善的几种方案,可用来监控、控制、改善玩家的体验等。
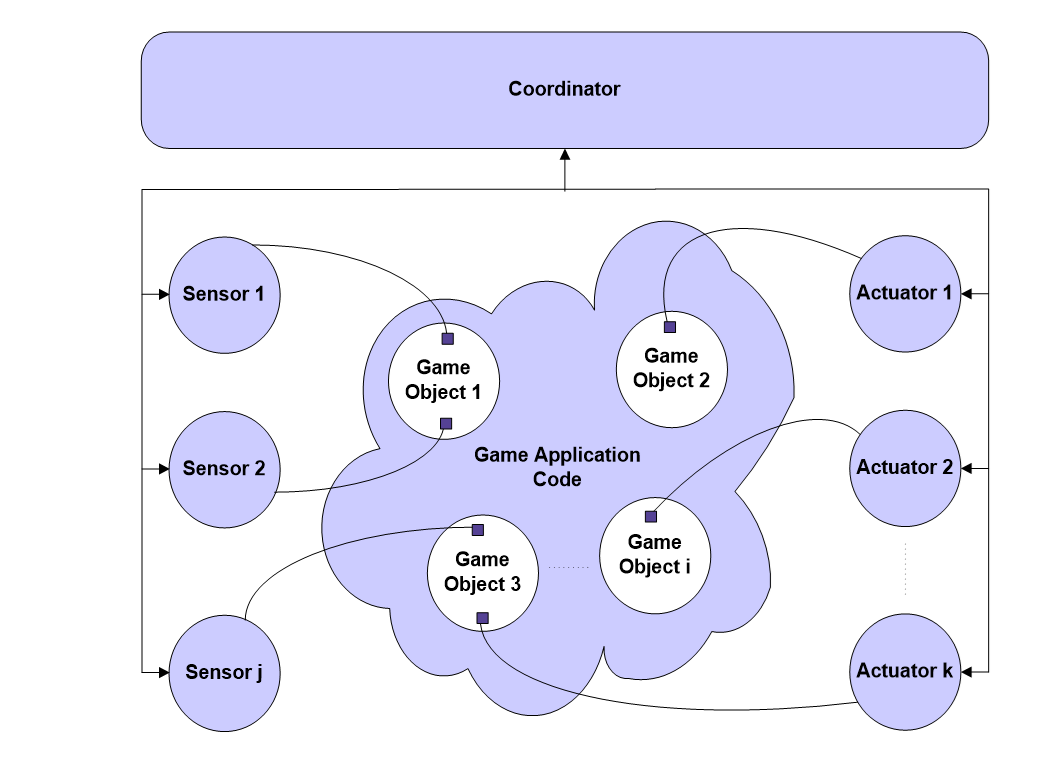
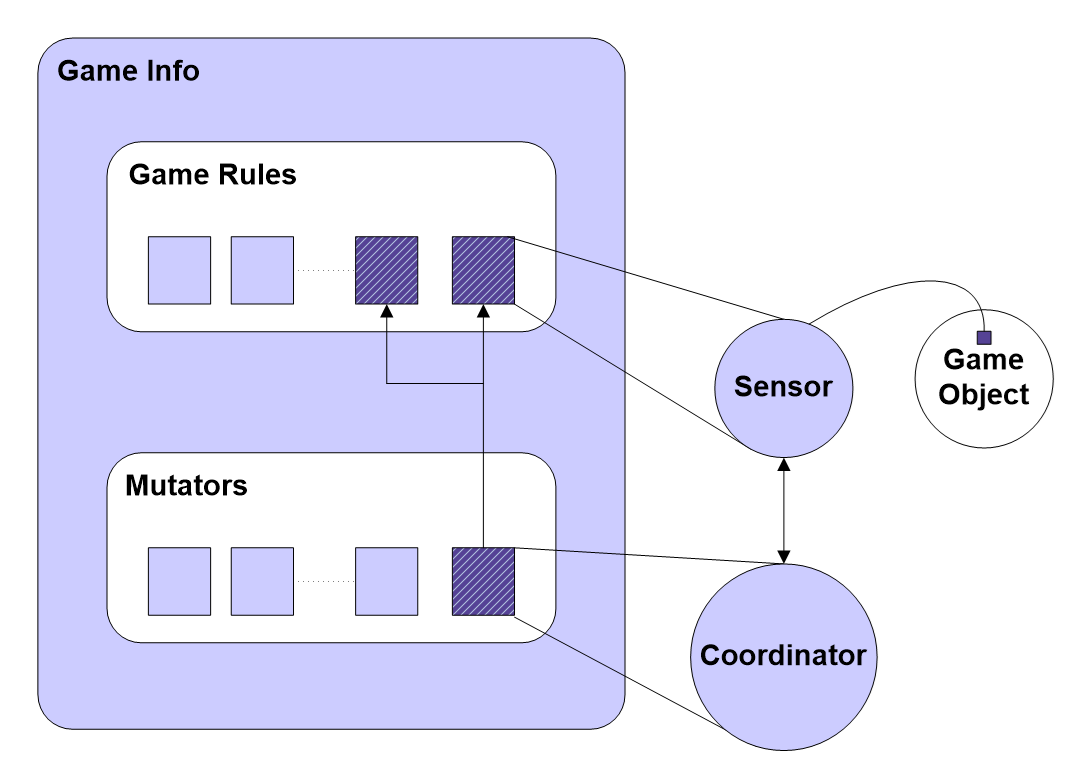
传感器(Sensor)用于收集对内容分析有用的各种数据:角色死亡、角色使用武器、车辆犯罪、使用攻击性语言、角色的性别和种族多样性以及各种其他游戏统计数据,数据可以在整个游戏过程中报告,也可以仅在游戏结束时作为摘要报告,传感器可以在运行时进行配置,以根据正在进行的内容分析的需要定制收集的数据。
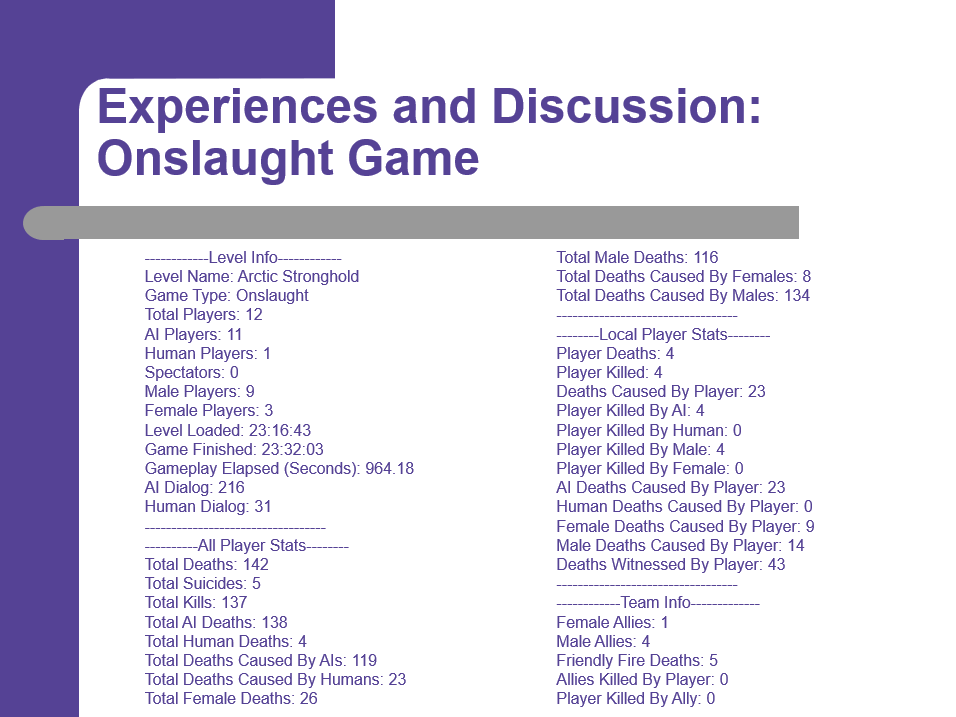
下图是分析器分析的部分数据和信息:
John Carmack Archive - Interviews详细记录了id公司创始人Carmack在id公司、Domm/Quake引擎、渲染技术及行业趋势等方面的探讨,其中包含了光线追踪、GPU、引擎架构、跨平台等方面的细节。
UnrealScript: A Domain-Specific Language讲述了UnrealScript的由来、目标、特点、案例等技术细节。UnrealScript是Unreal Engine早期版本的脚本语言,类Java风格,允许使用引擎快速开发游戏,允许轻松开发修改。
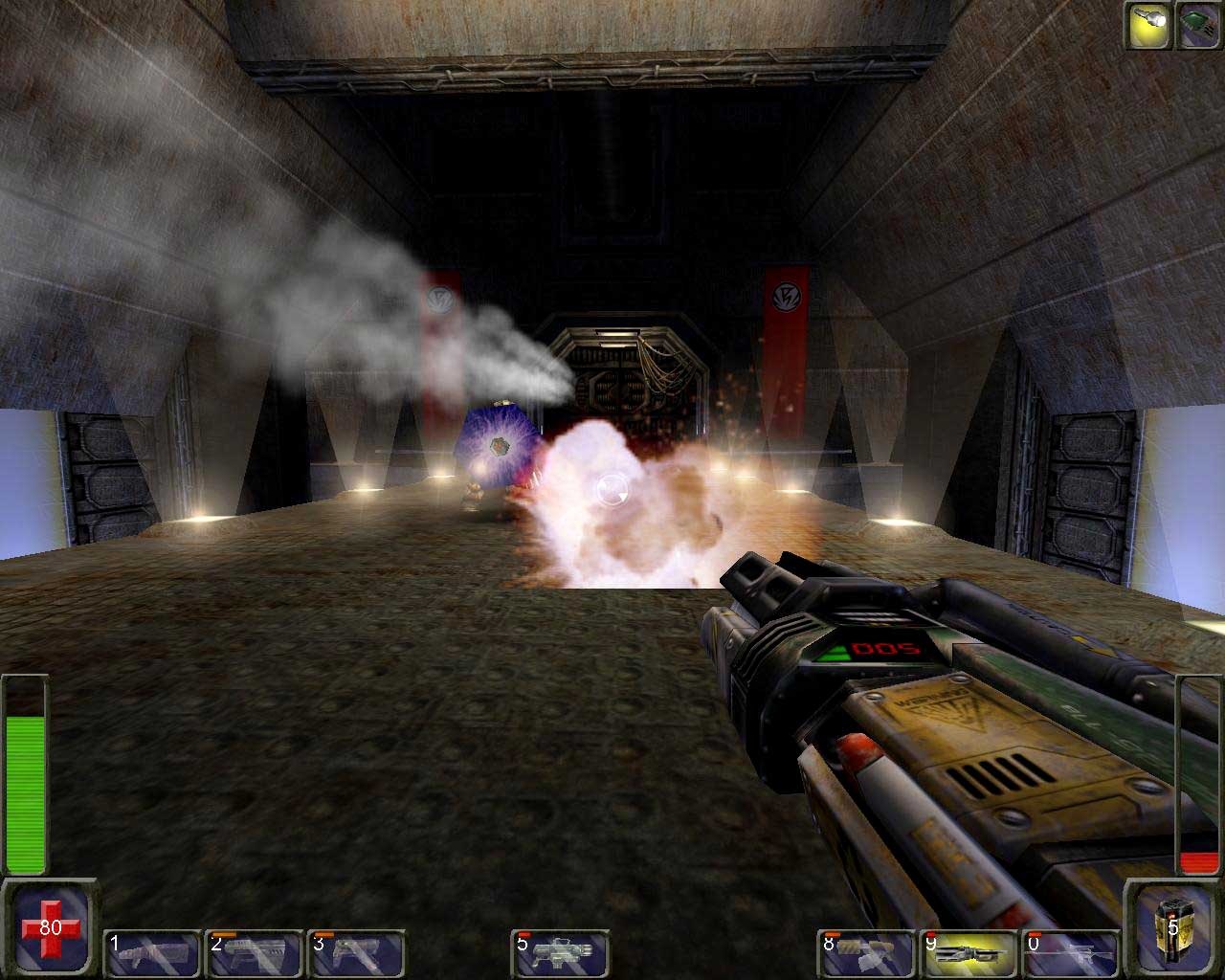
Operation: Na Pali的截图,Unreal Tournament的修改版(Unreal Engine 1 – 1999 年发布)。
UnrealScript的设计目标是直接支持游戏概念(Actor、事件、持续时间、网络),高度抽象(对象和交互,而不是位和像素),编程简单(OO、错误检查、GC、沙盒)。
UnrealScript看起来像Java,类Java语法(类、方法、继承),游戏特定功能(状态、网络),在框架中运行,游戏引擎向对象发送事件,对象为服务调用游戏引擎(库)。
// UnrealScript示例代码
function TranslatorHistoryList Add(string newmessage)
{
prev=Spawn (class,owner);
prev.next=self;
prev.message=newmessage;
return prev;
}
Unrealscript被编译成在运行时执行的字节码,没有JIT!
UnrealScript的Actor状态就是语言的一部分,支持网络、变量修改、错误检测等,编译为VM字节码(如Java),比C++慢20倍。但即使有100多个对象,CPU也只花费5%的时间来运行UnrealScript,图形、物理引擎完成大部分工作,因此UnrealScript不需要很快。
UnrealScript和C++的分工可由下图明确,主要是UI、游戏逻辑事件处理、动作和攻击、状态机、武器逻辑、碰撞回调等。

GC上采用了分代垃圾收集器,增加了世界中的actor有一个destroy()函数的复杂性,垃圾收集器还负责将指向已销毁actor的指针设置为NULL。
语言的灵活度如下图所示,从上往下灵活性提升,但维护工作也随之增加。

随着UE4的发布,UnrealScript被蓝图取代,消失在UE快速迭代发展的历史进程中。不过它的设计理念和使用的技术依然值得我们学习和探究。
Emergent Game Technologies: Gamebryo Element Engine涉及了跨平台、流处理等技术,并在Gamebryo Element Engine做了实践和验证。其中流处理提到了顶点动画+骨骼动画的应用案例:

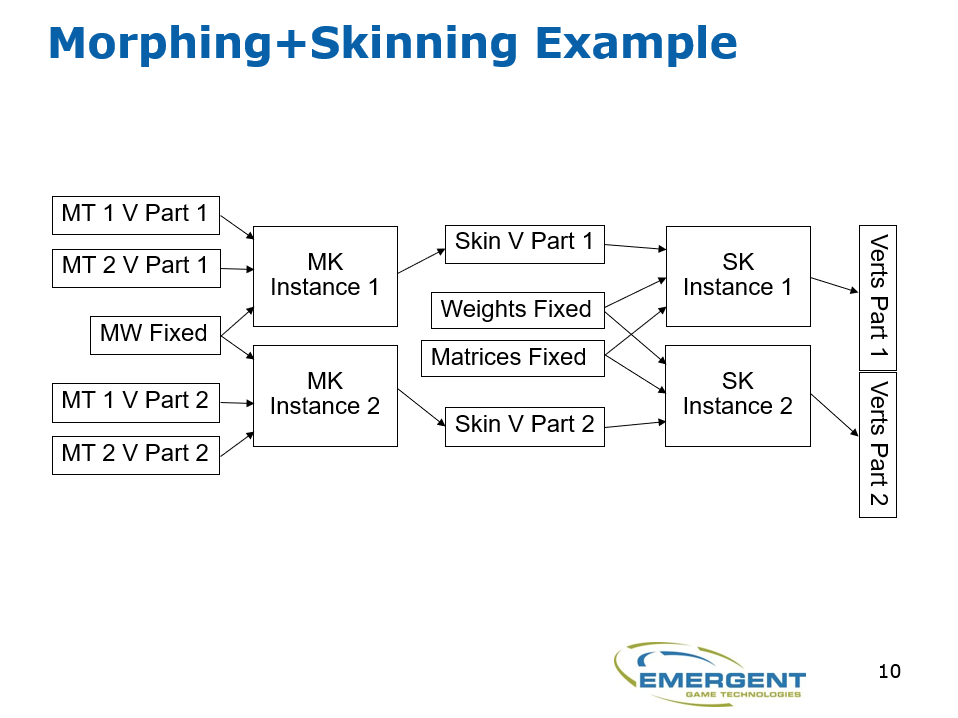
由流定义的任务依赖关系,将任务分类为执行阶段,使用其它任务结果的任务在后期运行,阶段N+1任务依赖于阶段N任务的输出,给定阶段的任务可以并发运行,一个阶段完成后,可以运行下一个阶段。

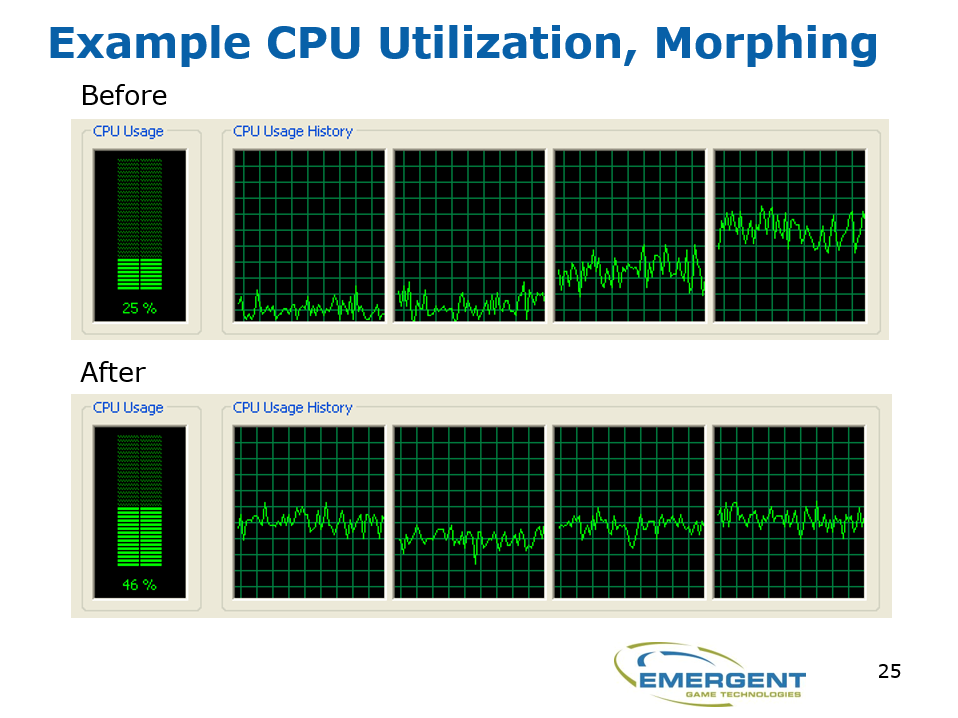
多线程化之后的cpu使用率对比,注意后者的cpu占用更均匀:
Creating believable crowds in ASSASSIN'S CREED描述了刺客信条的群体模拟、渲染、优化等技术。刺客信条采用了分层动画机制:
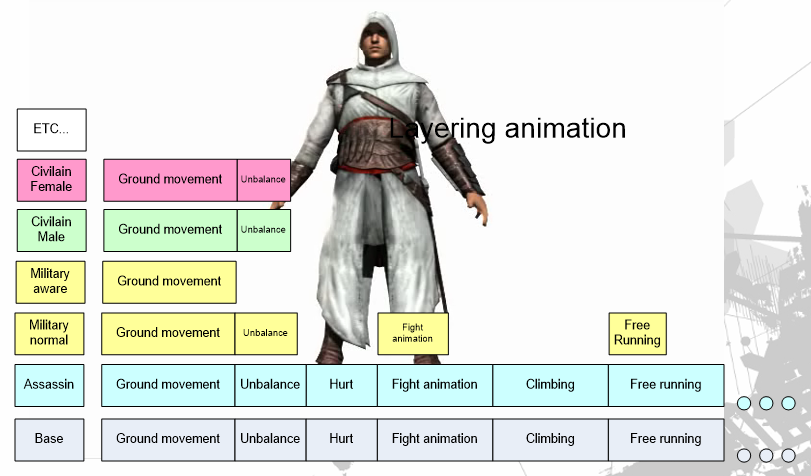
还拥有复杂的运动系统,更逼真的动画等于控件无响应,非常复杂意味着对其它系统的影响太大,于是进行了简化,保持最大的流动性。下图是简化后的移动系统图例:
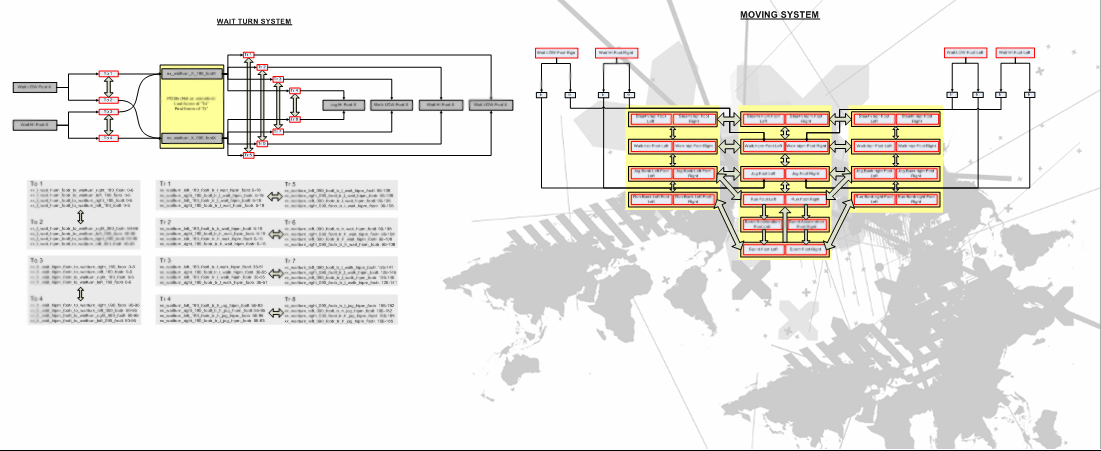
在运行模拟上,采用了并发,利用很多线程,在PC和360上运行良好,在PS3上尽可能多的SPU。
2000的中后期,由于游戏针对多平台发行成为主流,这也要求引擎具备强力的跨平台支持。How To Go From PC to Cross Platform Development Without Killing Your Studio阐述了Source引擎如何将游戏多平台化,加速生成过程,解决各种问题。文中提到,跨平台开发存在开发人员效率、人员分配、迭代、认证、用户体验、编程等方面的问题。为了解决这些问题,文章提出了混合处理资产的方案,即每晚将资产树编译成包,艺术家指定要在本地覆盖的单个资产,以获得两全其美的效果。Source引擎管道中的工具自动处理平台差异,而不是针对每个资产做不同平台的版本,从而加速资源的跨平台化。为了解决资产的增长快过内存容量的问题,Source引擎对资产执行引用跟踪、压缩、裁剪、维护等操作,以大幅减少资产的占用。对资产进行细致的定位可以获得更好的效果,反之差异明显(下图)。

上:未压缩和裁剪资产的渲染效果;下:由于资产处理不当,引发画面显著模糊。
资产压缩对纹理效果最显著,并且80%的问题由20%的纹理引起。Source引擎的工具可以方便地查看20%的这部分纹理:

针对资产加载时间长的问题,Source引擎对不同的加载操作执行了不同的优化:
| 问题 | 解决方案 |
|---|---|
| 查找 | 连续文件,精心布局 |
| 未对齐的读取 | 扇区对齐 |
| 缓冲访问 | 无缓冲的DMA I/O |
| 同步卡顿 | 异步加载 |
| 按需加载的小文件 | 大容量的单个文件 |
由于当时的主机游戏包体都存于DVD中,Source引擎采取了Zip文件格式、平衡了CPU或IO带宽的压缩、专用的线程异步加载等措施来提速DVD的数据加载。下图是Source引擎的资产加载架构图:
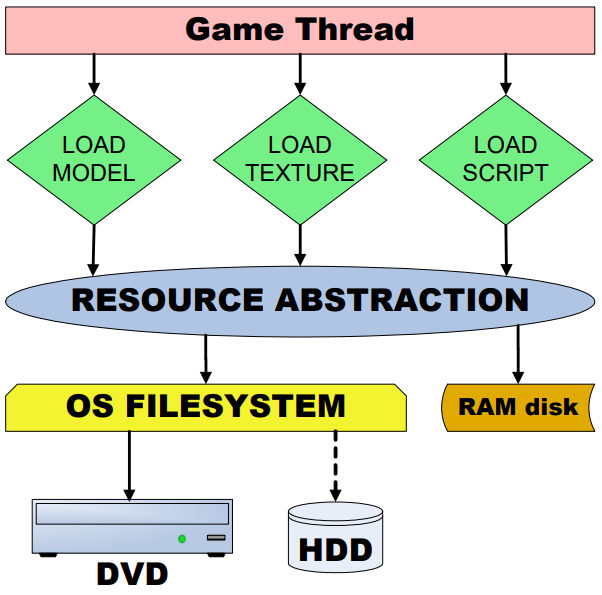
另外的一篇文献也给出了不同的资产架构图:
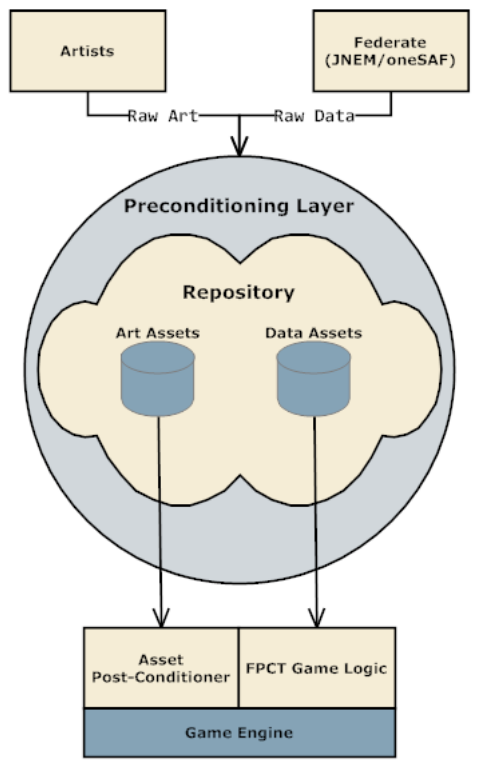
下面两图分别是Source引擎的同步加载和异步加载对比图:
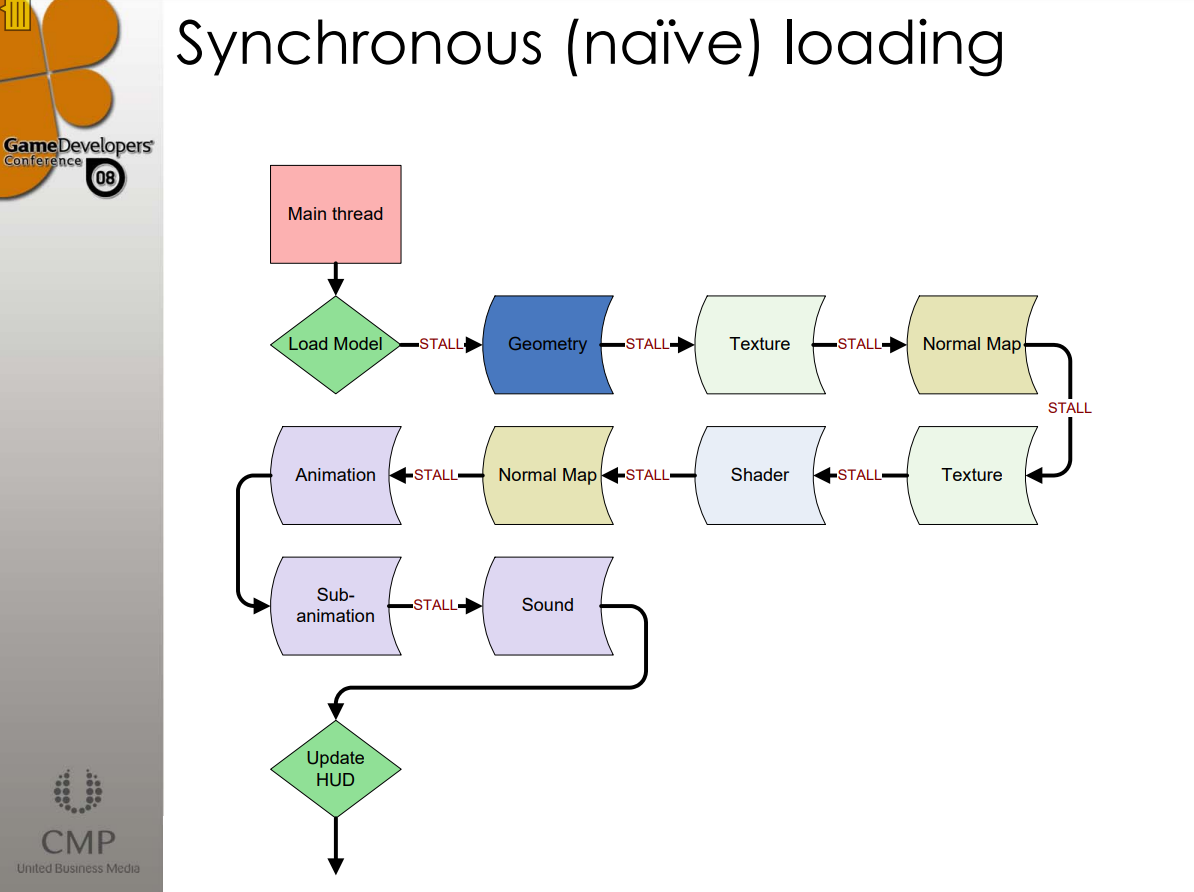
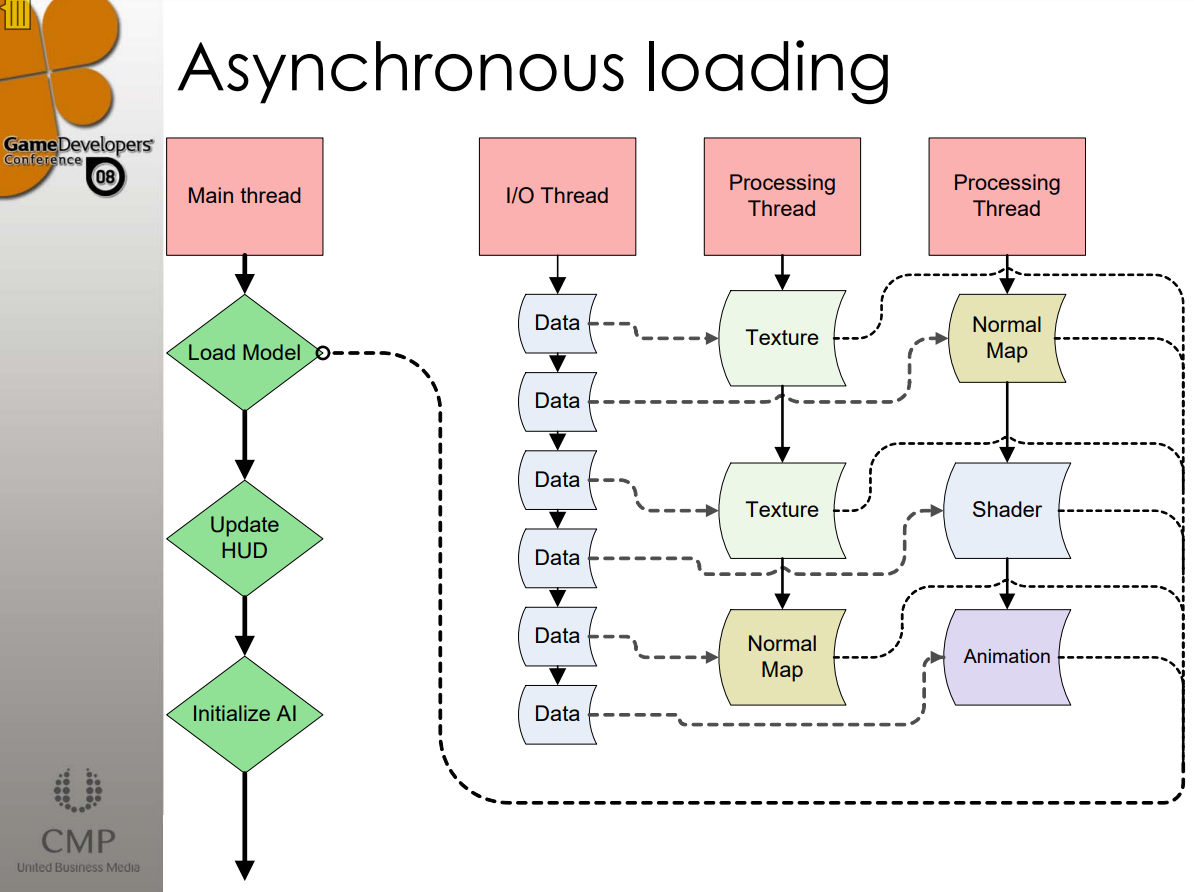
关键的加载技术有:
- I/O 线程执行无缓冲的DMA传输。
- 保持磁盘连续旋转。
- 无锁实现。
- 用CPU/SPU换取I/O带宽
- 返回虚拟值以同步负载。
对于大文件,采用流式加载:
- 始终存储每个动画和音频的前1/2秒。
- 在后台异步加载其余部分。
- 需要一个资源抽象层,它可以告知几个状态:有数据、正在获取数据、永远不会得到数据。
对于小文件,将所有小的临时(Ad Hoc)文件预编译成一个大blob,在单次操作中读取它,创建假文件系统,不必更改游戏代码。(下图)
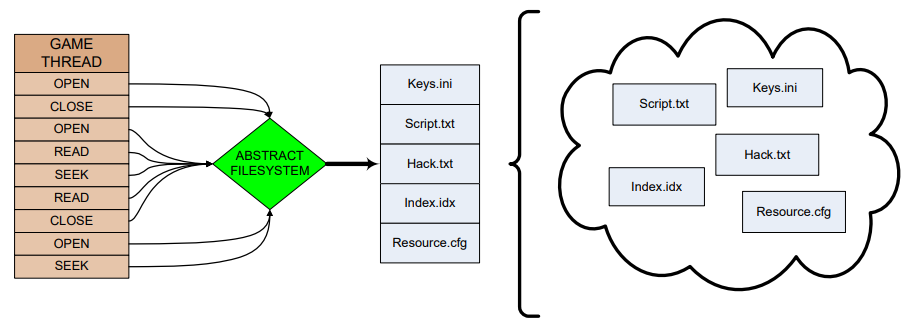
提前预处理每个关卡的资源引用,如果要建立一个pak,需要知道pak里面有什么,包括每一项资产,分析加载依赖关系,加载包体外的资源时触发崩溃。
在多线程处理上,Source引擎已经支持作业队列系统,可以由主线程生成作业,插入作业队列,然后计算线程去作业队列获取作业执行,并产生结果。
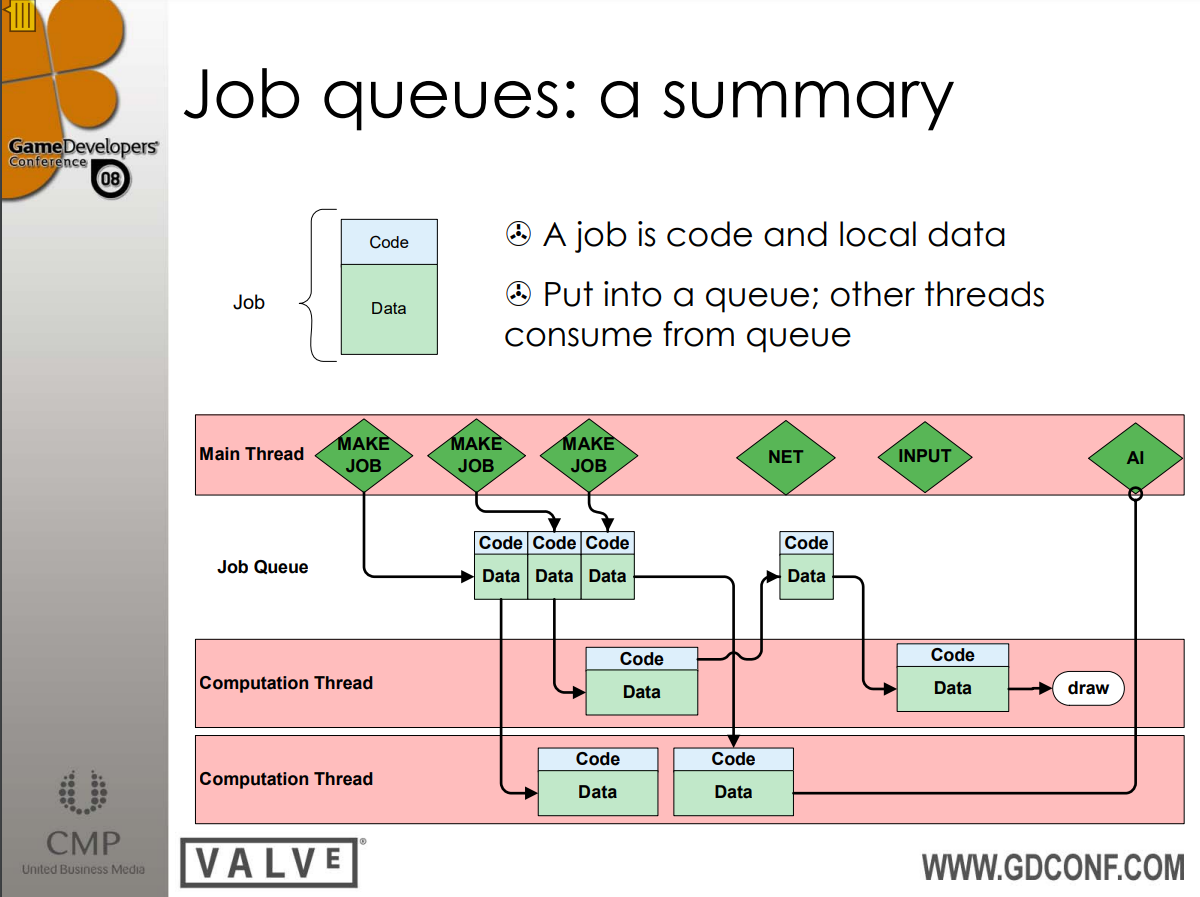
Source引擎的作业队列架构图。其中作业是代码和局部数据包,作业被放入作业队列,然后由其它线程从作业队列获取作业并消费。
图形也是跨平台经常出现问题的模块,例如电视和电脑显示器的像素和颜色空间不同导致色差:

着色器也造成平台差异的主要因素之一。Source引擎在PC和控制台都使用HLSL,但着色器编译器可能有点不同,最复杂的着色器会出现一些问题,并且GPU/CPU 功率平衡略有不同,Source团队在每晚离线编译所有内容以进行回归测试,以便减少和避免这些平台的差异。
考虑到当时的360、PS3都是采用有序的PowerPC CPU,在执行杂乱的代码时,效率上比x86慢许多。直接使用交叉编译代码的速度提高了25%-50%,仔细优化则可以接近x86的速度,若使用SIMD,则在PPC上比x86更胜一筹。
Source还注重渲染管线的特点和问题,比如PPC具有高延迟、高吞吐量,了解所有潜在的风险:寄存器依赖、加载命中存储、缓存未命中、微码、ERAT、TLB……注重分析器的内容,80%的性能来自于接触20%的代码。在编码中,尽量使用SIMD技术。使用适用于所有平台的抽象接口,推送原生向量类,用浮点数替换双精度数。以向量相加为例,代码如下:
FORCEINLINE Vector Add ( const Vector & a, const Vector & b )
{
#ifdef _X360
return __vaddfp( a, b );
#elif defined(_SSE)
return _mm_add_ps( a, b );
#else
return Vector( a.x + b.x, a.y + b.y, a.z + b.z, a.w + b.w );
#endif
}
Modern Graphics Engine Design提到场景管理包含了许多加速结构,诸如KD树、四叉树等,以便快速查询和剔除不可见的物体,减少Draw Call。但在当时,最常用的技术还是对物体进行排序,按具有最有利于连贯性的属性排序。另外,使用逐顶点数据对着色参数进行编码,减少设置顶点着色器常量的需要,减少切换顶点着色器的需要(例如索引调色板蒙皮),也可将每个顶点索引应用于其它事物(如照明、遮挡等)。
使用纹理编码着色参数,减少设置像素着色器常量的需要,减少切换像素着色器的需要,例如将光泽度放入法线贴图的alpha中,而不是通过SetPixelShaderConstant() 设置它。将4个光照遮挡项编码为光照贴图,并一次绘制所有4个带阴影的光源。
在光照计算上,存在三种技术:完全静态(预先计算每个顶点或光照贴图)、部分动态(灯光可以改变颜色和强度,但不能移动,将逐光遮挡项构建到顶点或纹理中)、完全动态(为阴影执行大量 CPU 光线投射,使用GPU辅助的阴影,如阴影贴图或阴影体积)。光照相关的特点和消耗情况如下表:
| 技术 | CPU消耗 | VS消耗 | PS消耗 | 备注 |
|---|---|---|---|---|
| 静态光照图 | 低,如果使用纹理页 | 低 | 低 | 任意数量的光源和阴影都无关 |
| 动态光照图 | 高,至少光源改变时 | 低 | 低 | 越多光源更新消耗越大 |
| 动态光照图(带阴影) | 限制级 | 低 | 低 | 对于CPU太多光线投射 |
| 遮挡映射 | 低,如果使用纹理页 | 低 | 中 | 限制灯光数量为4个左右 |
| 逐顶点遮挡 | 低 | 中 | 低 | 光源只能更改颜色 |
| 模板阴影(CPU) | 高,仅用于批次计数和轮廓 | 低 | 高 | 每个表面限制为3个光源 |
| 模板阴影(GPU) | 对批次尺寸中等 | 非常高 | 高 | 每个表面限制为3个光源 |
| 深度阴影图 | 低 | 中 | 中 | 锯齿瑕疵 |
| 基于SH的PRT | 低 | 中 | 低 | 仅无限的光源,没有动画 |
在着色器管理上,该文提出处理着色器有两种主要方法,取决于游戏类型。对于开放式 - 在关卡编辑器中由艺术家驱动,高度灵活,使用 HLSL / .FX 文件来管理复杂性,支持许多着色器类型的有点复杂,使用注释识别着色器参数,但如果不小心,可能会造成着色器爆炸,经常切换着色器也不利于减少绘制调用。另外一种是统一着色器模型——由引擎驱动能力或游戏需求,更少、更具体、优化的着色器,实用 C++ 编码来设置着色器,仍然可以使用 .fx 文件,但不需要那么多,着色器来自更有限的选择集,通过限制着色器更改导致的最大绘制调用数,有利于更高的帧速率,必须将着色器参数构建到几何和纹理中以获得速度优势。
在测试引擎中,将世界划分为一个个16x16x16米的3d格子(Cell),场景的角形被剪裁到格子,每个单元格都有一个顶点和一个索引缓冲区,碰撞三角形的AABBTree匹配渲染三角形的镶嵌,也是材质记录的向量(包含三角形的索引缓冲区范围和用于带材质的三角的AAB),还有移动实体列表(包含 AABox和对仅用于渲染的网格数据的引用)。
将世界分成大量格子的优势:
- 高效剔除。
- 可以共享相同的VB和IB而不超过65K的顶点或三角形限制。可以为IB使用16位索引,可以为AABB树使用16位索引,可以将树中的 AABB框压缩到16或8字节。
- 每个轴并且仍然具有良好的精度。
- 可以更快地拒绝其他单元格中的移动实体。
- 可以将照明限制为每个Tile仅7个光源。
用这种3d网格划分法,可以实现以下特性:
- 在一次绘制调用中绘制整个世界单元格。
- 多达7个光源。
- 漫反射和高光凹凸贴图。
- 柔和的阴影。
- 光泽映射,颜色偏移镜面反射。
- Masked的自发光。
- 存储在Dest Alpha中的水或雾深度。
- 雾、雾和水是部分alpha通道。基于dest alpha混合雾层颜色。
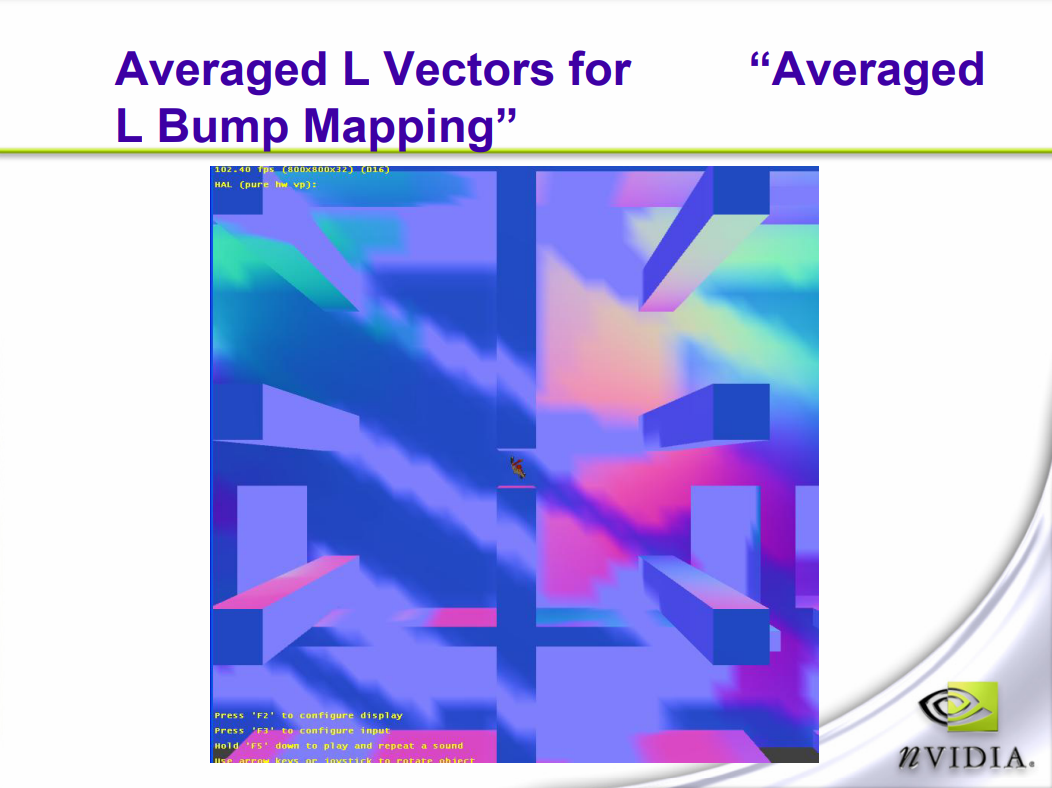
此外,测试引擎还提到了平均L凹凸映射(Averaged L Bump Mapping)的技术,以解决普通的凹凸映射在光源数量较多的情况下性能低下的问题。
“A bit more Deferred” - CryEngine 3中提到CryEngine 3在2009年引入的新技术,比如改进流式加载、多线程、改善光照、性能检测工具、追踪shader编译问题等。由于引入了Uber Sahder(全能着色器),编译所有可能的排列会产生内存、生产和性能等诸多问题,CryEngine3的解决方案有动态分支/分离成多个通道/减少组合并接受更少的功能和更少的性能、异步着色器编译、分布式作业系统编译着色器缓存等。
在延迟渲染上,CryEngine 3做了改进,不再使用CryEngine 2的延迟渲染,而是采用了Light Pre-Pass渲染,将通道分成3个:
1、前向渲染生成GBuffer数据(即几何通道)。
2、延迟光照(Phong)并累加到纹理。
3、用光照累加纹理前向着色。(不是延迟着色)
这种方式的优势是更少的带宽和内存占用,更加灵活的着色。对于光照累加纹理,存在6通道和4通道布局,后者效果有少许差异但更快:

CryEngine 3还将光照累加纹理用于IBL,以加速渲染。(下图)

左:漫反射RGB+高光RGB的高质量画面;右:漫反射RGB+高光强度的快速渲染画面。差异通常可以忽略不计(取决于环境)。
传统存储GBuffer的法线的方式和特点如下:
-
XYZ世界空间。如果采用8位,极端反射/镜面反射有问题;如果是10位,效果良好,但是镜面强度和PS3无法满足。
-
解决量化瑕疵的方法有细节法线贴图、噪声、抖动。
-
XY 视图空间(Z 重构)8/10/16 位,取反Z位(透视和法线映射)。但是
z = z_sign * sqrt(1-x*x-y*y)当z接近0时,精度变得很差。(下图)![]()
XY视图空间的法线存储精度问题。图中红色表示z接近0时存在问题。

针对以上的法线存储精度问题,CryEngine 3做了修正,对法线的z进行调整,并缩放xy分量:

这样做的好处是在重要的地方更精确(明亮的部分)、友好的帧缓冲混合、没有z重建问题,缺点是浪费面积、视图空间的法线占用的ALU比世界空间多。
CryEngine 3改进了SSAO的效果,利用法线计算出更加精确的AO:

左:改进前的SSAO;右:利用法线改进后的SSAO。
在光照方面,支持2D(矩形)和3D(凸面体)进行光源光栅化,其中3D方式可以利用Z缓冲区和更紧致的包围盒(更少的处理像素)。除了常规的光源类型,还支持交叉阴影图查找,它的优点是无需额外的内存、更少的带宽、在阴影遮蔽通道数量上没有限制。
在IBL光照上,远距离光采用光照探头,结合立方体贴图获得实时高效的HDR照明,从镜面立方体图获得漫反射立方体图,不同的Mip代表不同强度的镜面反射的效果,通过添加法线依赖和镜面光照改善环境光照条件下的阴影,光照探头可以在指定的水平位置生成,延迟光照允许混合局部光照探针,结合SSAO获得更好的效果。
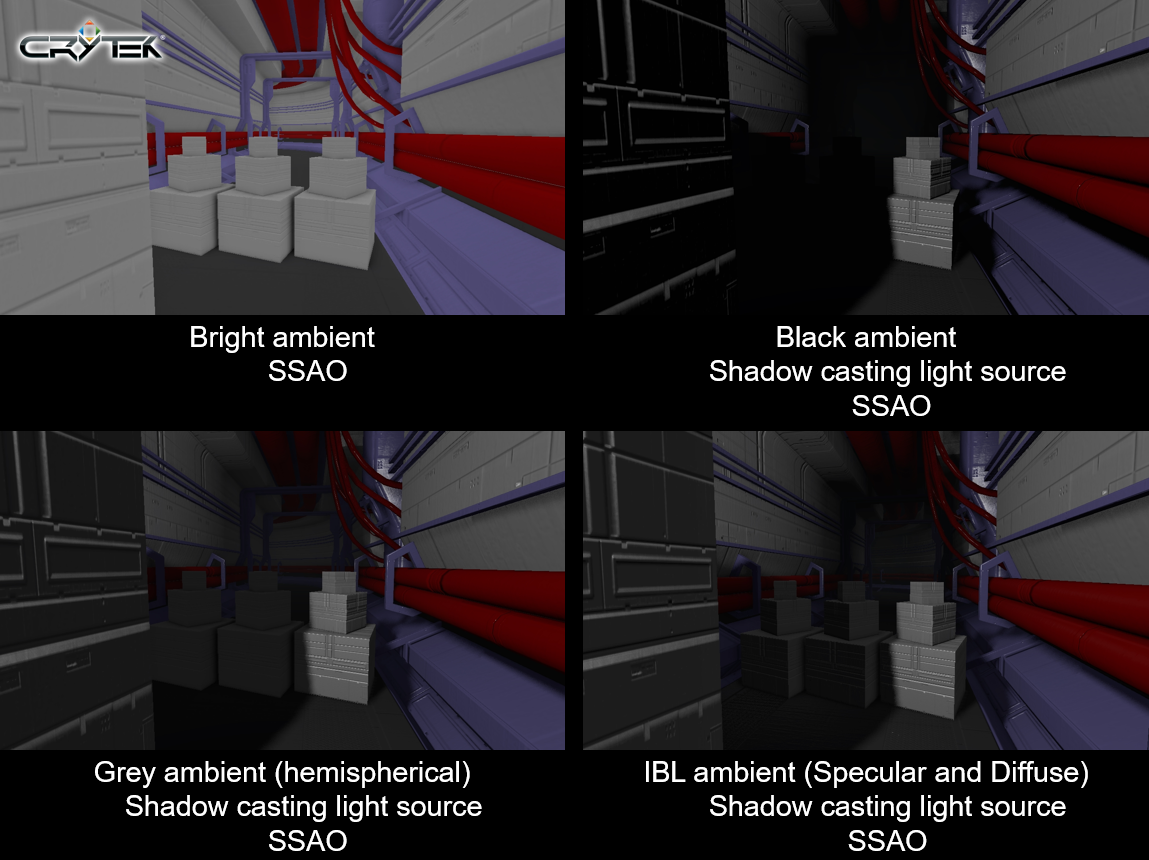
CryEngine 3的几种光照效果。从左上到右下依次是:亮环境+SSAO,暗环境+阴影投射光源+SSAO,灰环境(SH)+影投射光源+SSAO,IBL环境光(镜面+漫反射)+影投射光源+SSAO。
此外,CryEngine 3还尝试了实时动态全局光照的效果,在Xbox360、PS3和PC上快速实现,全动态(几何、材质和灯光),无预计算,达到静态和动态对象统一。

上:没有GI;下:开启了动态GI。
Hitting 60Hz with the Unreal Engine: Inside the Tech of Mortal Kombat vs DC Universe提到了使用Unreal Engine 3遇到的性能问题以及解决方案。性能开销主要有CPU和GPU方面,细分如下:
-
GPU开销
-
GPU固定开销
- 后期处理
- 通常是最大的固定成本。
- 将尽可能多的操作组合在一起以隐藏工作(即Bloom+DOF+Gamma+分辨率重定向)
- 尽可能多地切角和必要的特殊情况——例如, 我们根据情况使用 3 种不同 DOF 方法中的 1 种:普通玩法用经典模糊交叉淡入淡出,主菜单/电影用扩大泊松圆盘,Klose-Kombaty用一系列模糊平面。
- 后期处理
-
一般渲染开销
- 8bpc渲染目标,0..2的线性色阶。
- 我们以γ=1.0和γ=2.2的组合进行照明,取决于照明的内容,以节省成本。
- 不透明:使用MSAA。
- 半透明:MSAA后解析。
- 游戏的3D分辨率为1040x624,然后按比例放大以允许HUD以1280x720渲染。
-
多通道开销
- 通道的逐光源开销太高。
- 大多是预光照,所以选择了前向渲染。
- Z-Prepass典型的深度复杂度 < 1.5。
- 通过“细节环”从前到后对不透明对象进行松散分类,移除Z-prepass可节省约0.75毫秒。
- 如果可能,每个像素只处理一次。
-
照明开销
-
世界光照(静态)。使用Illuminate Labs的Beast进行预计算照明,并使用Turtle构建了一些动态的RNM,动态RNM在材质中或通过MITV进行动画处理。预计算光照是纹理和顶点RNM光照的混合,添加了一条快速路径以支持对远处物体的仅逐顶点漫反射RNM评估。
-
世界光照(动态)。高效点光源是通过混合按像素照明(地面)和按顶点(环境的其余部分)来完成的;考虑到最大负载,着色器使用三个仅漫反射点光源激活并注入材质;没有分支,始终评估所有三个光源,这些光源在3-deep FIFO中全局分配和管理。
-
角色光照。
-
自定义照明模型:SH系数集的辐照度。评估梯度以确定每个对象的SH集,仅使用前4 个系数(环境和方向项)对模型进行漫射,3 个高效点光源按顶点进行评估,并组合成最终的漫反射光照结果,通过 (E•N) 的功率缩放并乘以漫射照明来伪造规格。下图是角色高光效果:
![]()
-
通过使用 (E•N) 作为漫射照明和SH环境项之间的lerp因子来伪造皮肤透射。
-
边缘照明:衰减功率缩放 (1-E•N),然后通过硬阈值 (1-E•N) 进行mul,如果阈值提高到足够高(~0.7),最终看起来像chrome映射。角色网格采用批量渲染,下图是皮肤和金属的效果:
![]()
-
-
-
粒子开销。
-
-
CPU开销
- 粒子开销
- 布料和水体
- 渲染线程虚拟开销、状态缓存
- 通用渲染线程优化:大量工作以减少不必要的操作;渲染线程虚拟意味着大量的空闲;缓存尽可能多的状态以减少冗余的虚拟调用, 例如,将FMaterialRenderProxy的GetMaterial虚拟调用替换为缓存调用;从着色器处理内部移除大量不必要的对 GetXXX()(即GetPixelShader)状态的重复调用。
- 垃圾回收
- 从游戏中移除了所有实时调用GC,仅在退出模式时调用。
- 内存管理切换到UObjects/AActors的延迟(按帧)清理。
- 通过Rootset捕获的所有加载数据。
- 引入UResource类,一个引用计数UObject。
- 所有USurface派生类(即UMaterial、UTexture等)都通过UResource进行引用计数,以防止不必要的删除。
- 其它建议
- 预先预算性能!
- 鉴于Edge和360的统一着色器,几何问题比填充率更小。
- 预先确定有效的PostFx并硬连线大多数排列。
- 尽可能减少动态临界区内存分配,会大量卡住所有性能。
- 尽可能使用池分配器,并注意重新分配。
- 强制设计师和艺术家使用性能指标运行!


针对这些开销,除了以上建议,该文还提出了其它很多具有建设性的优化建议和改进技术,即便过去了许多年,也具有一定参考价值,值得一看。
在资产方面的跨平台,也有论文分享技术和经验,例如Practical techniques for managing Code and Assets in multiple cross platform titles。该论文从资产管线入手,目的是将数据导入游戏、版本控制/工作流程、将数据转换为优化的目标格式、针对特定平台进行优化、验证/错误检查、检查资产的错误/问题(骨骼数量、纹理纵横比、多边形数量、文件大小……)及管理同一项目的多个版本。他们的资产管道概述如下:
- 每个项目都有一组作业(每个源资产一个)。
- 所有作业设置和来源都存储在一个中心位置(对资产使用perforce)。
- 自定义用户界面。
- 与工作流程工具相关联(不同的权利/角色)。
- 艺术家/资产创建者在本地工作并在完成后提交他们的更改。
- 有引用这些转换器的转换器可执行文件和作业类型。
- 示例:纹理的不同作业类型(UI、环境、字符……)
- JobTypes是项目特定的。
- 作业类型可用于定义限制/约束。
- 作业类型定义强制/预设转换器的一些参数为常用设置。
- 每个项目在其目录结构中都有自己的转换器可执行文件副本。
- 自定义项目特定转换器。
- 控制用于项目的转换器的版本,最终能够归档项目所必需的。
- 大多数项目都有特定于该项目的特殊转换器。
- 地图/关卡数据转换器。
- 数据库包含待定(待构建)作业列表。
- 每个客户端都拉出待处理的作业,在本地构建它们并将结果推送到中央服务器上。
- 转换器可执行文件+作业设置+源资产必须始终在所有机器上创建相同的结果(与上下文无关)。
- 每个客户端都从服务器复制最新版本。
- 转换后的资源放入游戏构建文件夹(包含所有文件的平面文件夹)。
- 项目的每个版本都有一个游戏构建文件夹。
- 对于光盘版本,重新排序并打包这些文件。
- 项目的每个版本都有一个游戏构建文件夹。
- 大多数平台直接从这个目录加载。
- 其他人首先需要光盘仿真/ROM构建。
- 快速重新加载某些资产以支持快速迭代时间。
Next-Gen Asset Streaming Using Runtime Statistics探讨了面向下一代引擎特性的资产流式加载技术。它的核心思想在于利用运行时收集的统计信息,在构建管线中生成资源依赖图,然后用资源依赖图可以找到哪些需要加载哪些不需要加载。
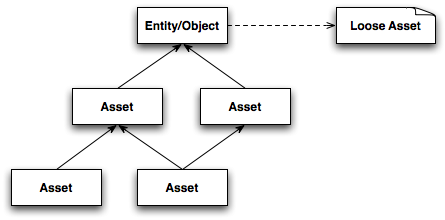
场景物体和资源的依赖图。虚线表示场景物体引用了运行时添加的依赖资源。

构建资源依赖图机制架构图。包含运行时异步收集信息发送给统计服务器,右统计服务器开启统计构建器构建的资源依赖信息。
该文还探讨了构建延迟、内存管理等问题。
The Next Mainstream Programming Language: A Game Developer’s Perspective是Tim Sweeney(Epic Games的CEO)在2009年分享的演讲,从游戏开发者的视角讲述了下一代主流编程语言。该文提及游戏开发的典型流程和技术(游戏模拟、数值计算、着色),以及当时的语言并发性和可靠性上存在哪些缺陷。用UE3研发的Gears of War(战争机器)的游戏逻辑达到25万行C++代码,而当时的UE3的引擎源码也是如此。(下图)

UE3研发的Gears of War的游戏画面。
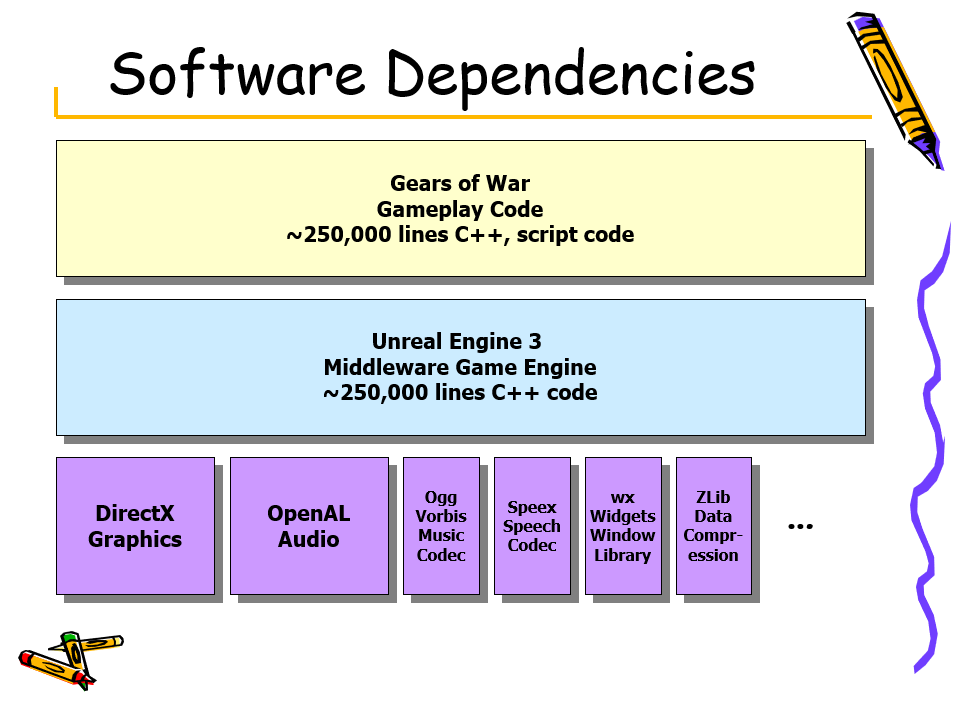
Gears of War、UE3、图形API及第三方库的架构图及代码量。
由于游戏的逻辑和渲染技术越来越复杂,当时的UE游戏存在三种类型的代码:游戏逻辑模拟、数值计算、着色。
对于游戏逻辑模拟,随着交互对象随着时间的推移对游戏世界的状态进行建模,面向对象的高级代码,用C++或脚本语言编写,命令式编程风格通常被垃圾收集。在规模上,每秒30-60次更新(帧),约1000个不同的游戏类别(包含命令式状态、成员函数,高动态),约10000个活跃的游戏对象,每次更新游戏对象时,通常会接触其它5-10个对象。
对于数值计算,包含算法(场景图遍历、物理模拟、碰撞检测、寻找路径、声音传播),低级高性能代码,用C++编写,带有SIMD内在函数,本质上是功能性的,使用大型常量数据结构将小型输入数据集转换为小型输出数据集。
对于着色,生成像素和顶点属性,用HLSL/CG着色语言编写,在GPU上运行,本质上是数据并行,控制流是编译期已知信息,令人尴尬的并行,当时的GPU是16-宽到48-宽。在规模上,游戏以30 FPS@1280x720p运行,约5000个可见物体,每帧渲染约1000万像素,每像素光照和阴影需要每个对象和每个光照多渲染通道,典型的像素着色器大约100条指令长,着色器FPU是4宽的SIMD,约500GFLOPS的计算能力。
这三种类型的代码信息对比表如下:
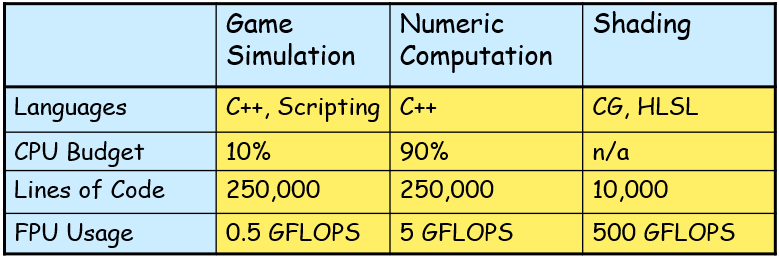
当时的UE3常面临的难题有:
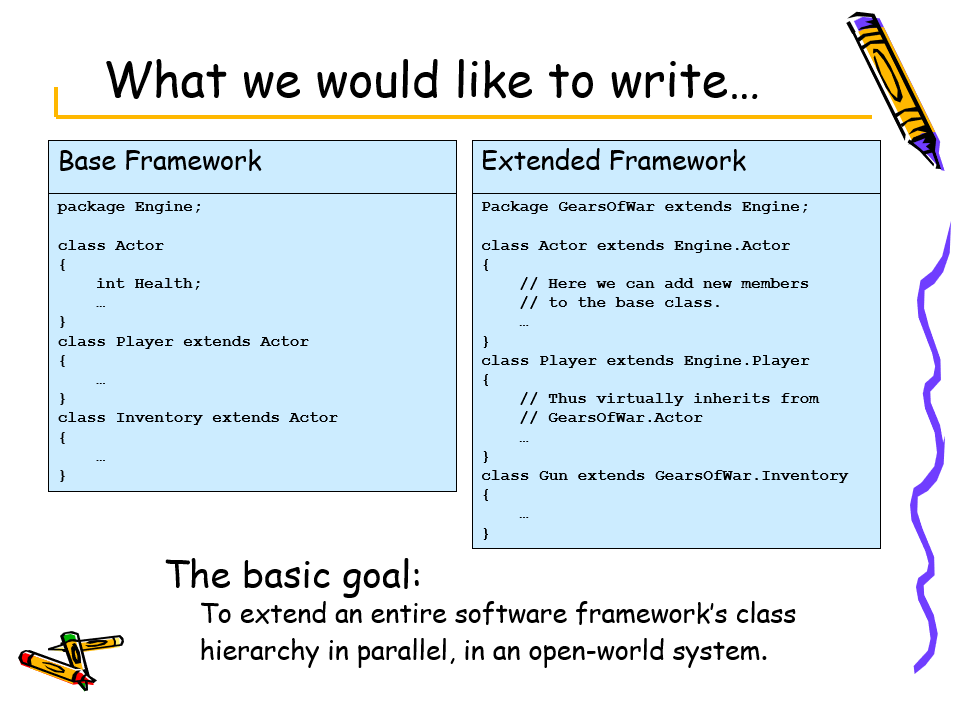
- 性能。当以60FPS更新10000个对象时,一切都是性能敏感的。
- 模块化。每个游戏大约10-20个中间件库非常重要。
- 可靠性。容易出错的语言/类型系统导致浪费精力去寻找琐碎的错误,显著影响生产力。
- 并发。硬件支持6-8个线程,但C++不具备并发性。
对于性能,UE认为生产力同样重要,乐意牺牲10%的性能来提高10%的生产力,并且从不使用汇编语言,没有一组简单的“热点”可以优化!在模块化上,基本目标是在开放世界系统中并行扩展整个软件框架的类层次结构。下图是基础框架和扩展架构的代码示意图:
在可靠性方面,对非法地址、越界访问等问题进行修正,以获得较为健壮的代码。(下图)
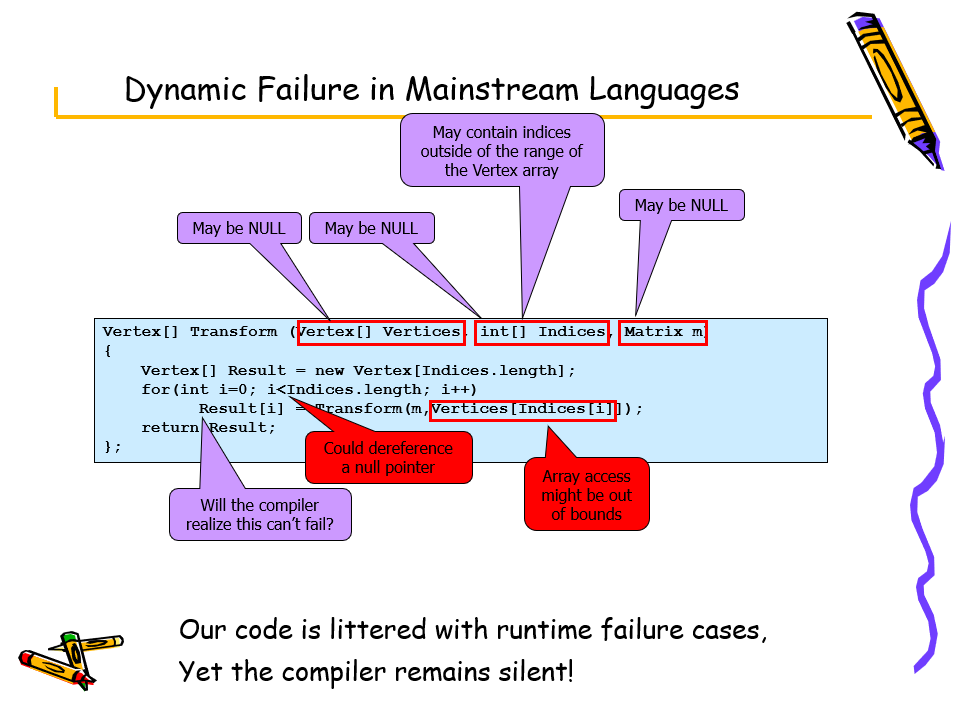
上:改进前的不可靠的代码;下:修正后的代码。
在并发方面,理想的情况是:任何线程都可以随时修改任何状态,所有同步都是显式的、手动的,没有正确性属性的编译时验证:无死锁、无竞争。要完全符合理想的情况实践上很难!UE3的措施是:
- 1 个主线程负责完成不能希望安全地进行多线程的所有工作。
- 1个重量级渲染线程。
- 4-6个辅助线程池。动态地分配给简单的任务给它们。
- 必须非常小心地编程!
但是以上方式会导致巨大的生产力负担,无法很好地适应线程数。
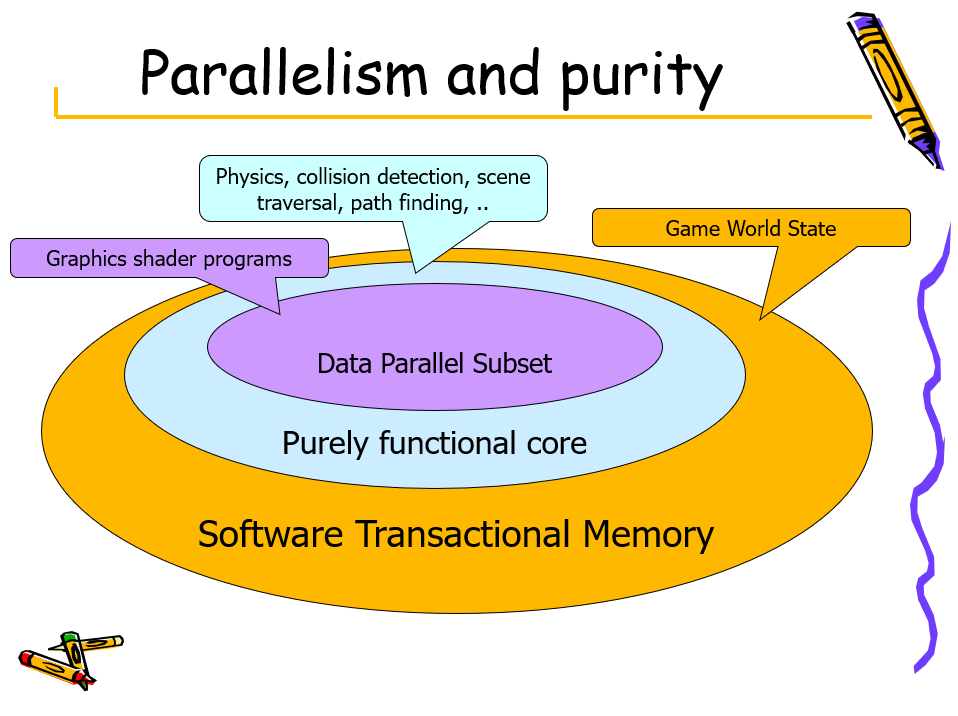
在着色并发上,UE3的新编程语言针对“令人尴尬的并行”着色器编程,它的构造自然映射到数据并行实现,使用静态控制流(通过掩码支持的条件)。
在数值计算并发上,本质上是纯函数算法,但支持在可变状态下本地运行,Haskell ST、STRef解决方案支持在引用透明代码中封装本地堆和可变性,这些是隐式并行程序的构建块,UE3中约80%的CPU工作可以通过这种方式并行化。
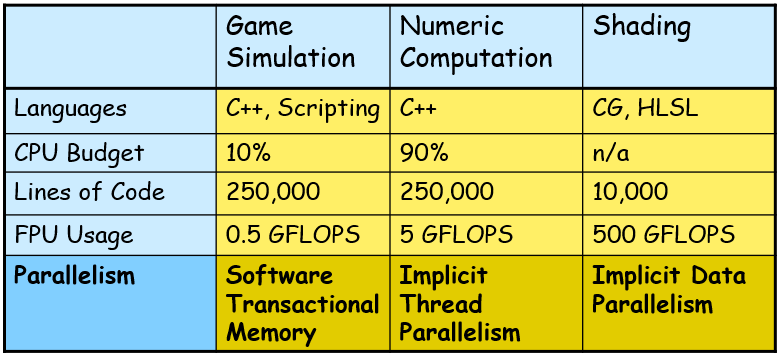
三种类型的代码的特点和并行方式如下表所示:
并行性和纯度的关系如下图所示:
Tim Sweeney还给出了游戏技术的简史:
Building a Dynamic Lighting Engine for Velvet Assassin描述了在游戏Velvet Assassin中构建了不使用光照图的完全动态光照。该游戏使用的引擎支持松散八叉树场景管理、物体三角形OBB树、带有阴影贴图的混合单通道/多通道照明、可见性入口、通过反射灯间接照明及针对Xbox 360特定优化。
OBB和ABB对比。
混合光照是多通道和单通道前向渲染器的混合体,每个主光一个通道,所有次级光源组合成一个通道。主光源采用了经典多通道(Doom 3风格),可以投射阴影,周围几何体的灯光查询。次级光源采用经典的单通道(Half Life 2风格),光源收集到一个通道中(基于计数的着色器变化),不能投射阴影,周围灯光的几何查询(最大数量)。

对于反弹光,给出从表面首次反射的间接光的外观,不得照亮其放置的表面,具有由轴确定的半球影响半径。
对每一帧:
- 让所有主光源都在视野中。
- 分发阴影贴图池。
- 为每个渲染阴影贴图:
- 渲染光截头体中包含的所有对象。
- 获取所有在视图中的对象。
- 渲染基础通道:
- 对于每个对象,为着色器收集最近的N次级光源(按重要性排序)。
- 为每个主光渲染附加通道:
- 对在视图中且在光截头体中的每个对象。
这就是为什么需要一个高效的空间:索引数据结构。
Valvet Assassin采纳了多线程渲染,第一个线程执行所有空间查询并编译一个“drawlist”,第二个线程设置着色器寄存器、渲染状态和提交批次,大多数场景有300到1200批次/帧。
Techniques for Improving Large World and Terrain Streaming谈到了MMO的大世界地图的需求、面临的挑战和新引入的技术。
文中提到加载所有游戏资源的粗略方法无法扩展到大型世界:加载时间过长,内存占用过大,需要合作编辑。需要引入一种新的技术,满足不要加载所有数据,根据需要动态加载和卸载数据,在运行时保持最低要求的数据集。
基础流式加载将所有对象实例保存在内存中,实例不需要大量内存(位置、旋转、比例、状态……),流入/流出所需资源,资源数据(网格、纹理等)需要更多。加载角色周围区域的资源,卸载不再可见的资源。基础流式加载存在的问题:需要将所有对象保存在内存中,对流媒体行为的控制很少,不规则和不可预测的流式传输,没有资源依赖就很难调度。
该文改进了流式加载的管线流程:
流式加载对工具的要求是:
-
合作编辑
- 多人应该能够一起编辑世界。
- 需要解决/防止编辑冲突。
- 将场景存储为多个图层文件。
- 图层可以由不同的人独立锁定和编辑。
- 与修订控制同步。
-
可流式传输的世界数据
- 没有单一的世界文件。
- 将大文件分解为单独的文件以进行编辑和流式传输。
- 艺术工具必须促进和支持网格实例的重用。
-
资源依赖
-
计算并存储世界上所有的资源依赖。
![]()
-
-
分组
- 更好地控制数据的方式:已编辑、已烘焙、流式传输。
-
地形分区
- 自动分组为二维网格。
- 分区提供了可管理的数据块来编辑、烘焙和流式传输。
- 地形数据可以是100MB。
- 仅将相关扇区保留在内存中。
- 流入,根据需要换出。
- 遥远扇区的较低细节近似值。
- 实时编辑和绘画。
- 支持合作编辑。
- 逐扇区锁定。
- 编辑器自动锁定并处理连续性。
-
区域
-
对象实例可以由关卡设计师在空间上分组到区域中。
-
每个区域都会生成一个单独的文件,当玩家接近时,可以动态流式传输。
-
允许生成/销毁对象组。
![]()
-
-
数据处理
-
编辑时的程序/原始数据。
-
运行时的烘焙数据。
![]()
-
地形分区
- 每个分区一个文件(One File Per Sector),包含:高度图、纹理混合贴图、烘焙n个最重要的纹理、植被概率图、预计算对象实例。
- LOD:预计算错误指标、世界空间法线贴图。
- 自定义索引列表。
-
区域
- 建立每个区域在导出时使用的资源列表。
- 编辑器知道使用了哪些资源(和依赖项)。
- 在运行时,资源列表将按顺序处理和加载。
- 根据依赖关系排序,因此加载不需要停止(例如,着色器库是加载网格的先决条件)。
![]()
-
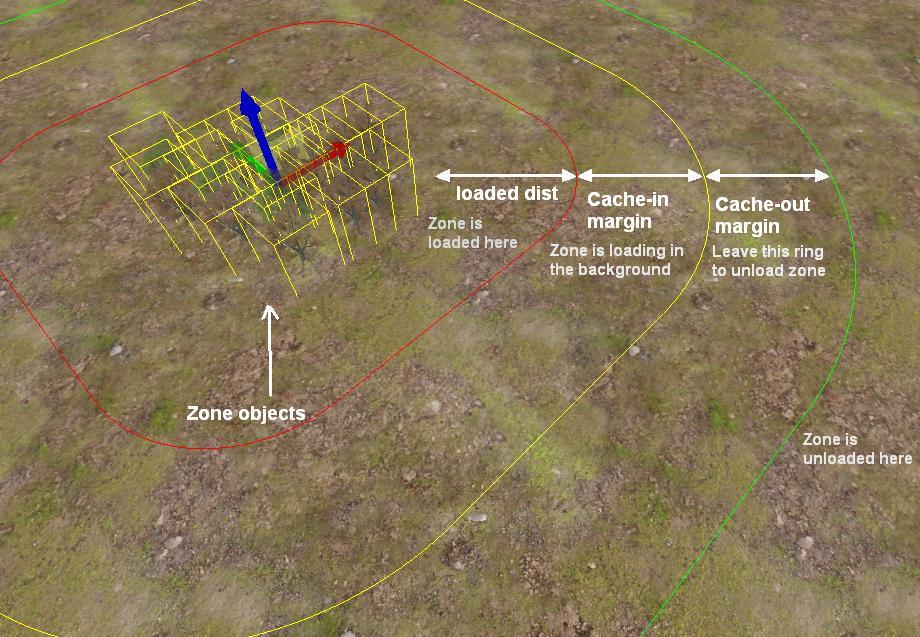
流式加载对运行时的要求是:
- 资源管理系统
- 动态加载/卸载。
- 引用计数。
- 内存使用信息。
- 资源依赖信息。
- 用于评估上次使用资源的时间戳。
- 可以卸载x秒未使用的资源。
- 硬内存和软内存限制。
- 用于纹理、网格等的不同资源池。
- 流式区域
- 流媒体区域。
- 所有资源的预缓存。
- 单独线程:从文件加载资源数据,可选数据转换/生成。
- 主线程:创建资源。
- 加载资源后,在区域中创建所有对象实例。速度很快,因为资源已经加载,可选择随时间分布(即从最大/最重要的对象开始)。
- 如果玩家直接传送到有待处理资源的区域怎么办?
- 选项 A:显示替换资源(例如非常低分辨率的纹理)。
- 选项 B:一旦相关资源可用,对象就会弹出。
- 选项 C:暂停游戏并从主线程加载剩余资源。
- 流式地形分区
- 使用较低细节的几何图形和纹理加载和渲染远处扇区。
- 流式传输高细节版本。
- 使用世界空间法线贴图来避免照明伪影/跳变。
Insomniac Physics描述了IG物理系统的演变、着色器、库着色器、自定义事件着色器等内容。该物体系统经历的数次迭代的示意图如下:

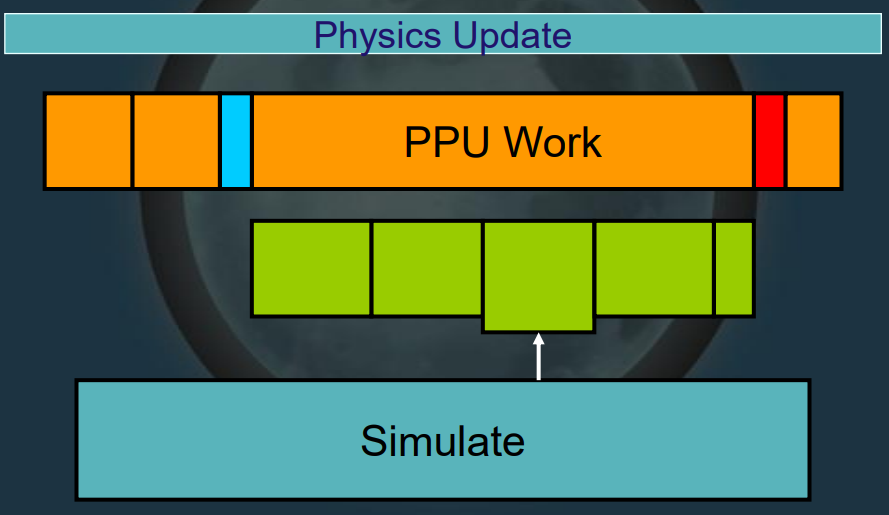


演变的依据和变化是多线程化、流程精细化、细粒度化、核心利用率提升。
State-Based Scripting in Uncharted 2: Among Thieves讲述了神秘海域2的脚本系统,包含扩展游戏对象模型、状态脚本语法、例研究、实现讨论、总结和建议。
使用脚本的主要好处:减轻工程团队的压力,代码变成数据——快速迭代,赋予内容创作者权力,Mod社区的关键推动者。
有两种游戏脚本语言:数据定义语言和运行时语言。运行时脚本语言通常:由虚拟机 (VM) 解释,简单小——低开销,可供设计师和其他“非程序员”使用,强大——一行代码就可以产生大的影响。顽皮狗大量使用数据定义和运行时脚本,两者都基于PLT Scheme(Lisp 变体)。类Lisp语言的主要优点:易于解析,数据定义和运行时代码可以自由混合,强大的宏系统——易于定义自定义语法,顽皮狗有着丰富的Lisp传统。数据定义语言有:自定义文本格式、Excel逗号分隔值 (.csv)、XML等等,运行时语言有Python、Lua、Pawn(小 C)、OCaml、F#等等,许多流行的引擎已经提供了脚本语言:Quake C, UnrealScript, C# (XNA)等等
每个游戏引擎都有某种游戏对象模型,定义游戏世界中的所有对象类型,通常(但不总是)用面向对象的语言编写,常用于扩展本机对象模型的脚本语言,有很多方法可以做到这一点。
UnrealScript与C++对象模型紧密集成,带有一些附加组件的单根类层次结构,UnrealScript (.uc) 中定义的类,C++头文件 (.h) 自动生成,用C++或完全用UnrealScript实现。

以属性为中心的设计用于Thief、Dungeon Siege、Age of Mythology、Deus Ex 2等,游戏对象只是一个唯一的id (UID),“装饰”有各种属性(健康、盔甲、武器等),属性封装数据+行为。
Uncharted Engine的对象模型,类层次结构较浅、单根,含大量附加组件。

Uncharted 2的状态脚本在许多方面类似于以属性为中心的模型,添加有限状态机 (FSM) 支持,与“属性”无关,粗粒度(每个对象一个脚本),更像是现有实体类型的脚本扩展或协调其它实体行动的“导演”。状态脚本包括属性和状态,状态通过运行时脚本代码定义对象的行为:对事件的反应,随时间推移的自然行为(更新事件),状态之间的过渡动作(开始/结束事件)。
实例化状态脚本时,附加到原生 (C++) 游戏对象:设计师扩展或修改原生C++对象类型定义全新的对象类型;附加到触发区域:凸体积、检测进入、退出和占用;作为独立对象放置:“director”协调其它对象的动作(例如 IGC);关联任务:任务即检查点,脚本管理关联的任务,安排AI更新,控制玩家目标。
下图是自定义对象类型(易碎标志)的案例:

虚拟机实现方面,由简单VM实现的类方案运行时语言,每个轨道编译成称为lambda的字节码块:
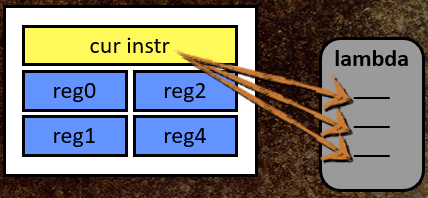
VM的内部状态包括指向当前lambda的指针(字节码程序)、当前指令的索引、临时和即时数据的寄存器库,其中寄存器是变体类型。
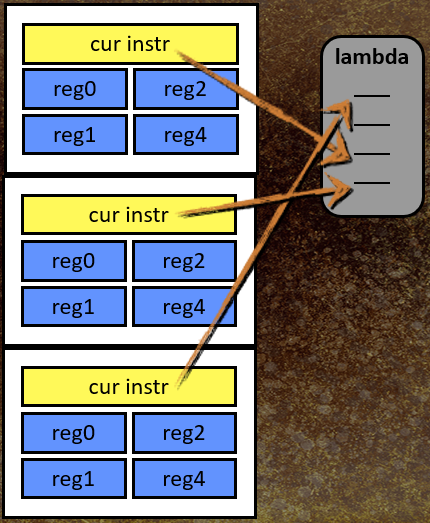
语言支持嵌套函数调用,因此需要调用堆栈,堆栈帧 = 寄存器组 + 程序计数器。
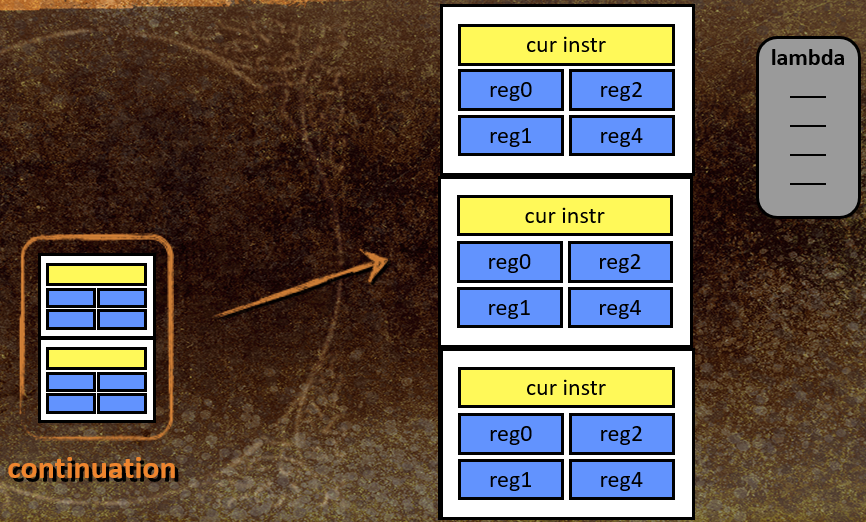
状态脚本代码可以等待(睡眠),通过称为延续(Continuation)的东西实现。
成功的脚本系统的主要特征:虚拟机集成到游戏引擎中,能够每帧运行代码(更新),能够响应事件和发送事件,能够引用游戏对象(通过句柄、唯一ID等),操纵游戏对象的能力,设计人员可以在脚本中定义新的对象类型。
许多不同的引擎脚本架构:脚本驱动引擎(引擎只是一个由脚本调用的库),引擎驱动脚本(简单的脚本事件处理程序、脚本化的属性或组件、脚本游戏对象类)。
Star Ocean 4 - Flexible Shader Managment and Post-processing分享了Aska游擎在RGP游戏STAR OCEAN:The Last Hope使用的着色器管理和后处理技术。其中完全灵活的着色器是指管理艺术家可以在Maya中创建材质,使用Hypershade界面,根据艺术家设置自动生成着色器二进制文件。
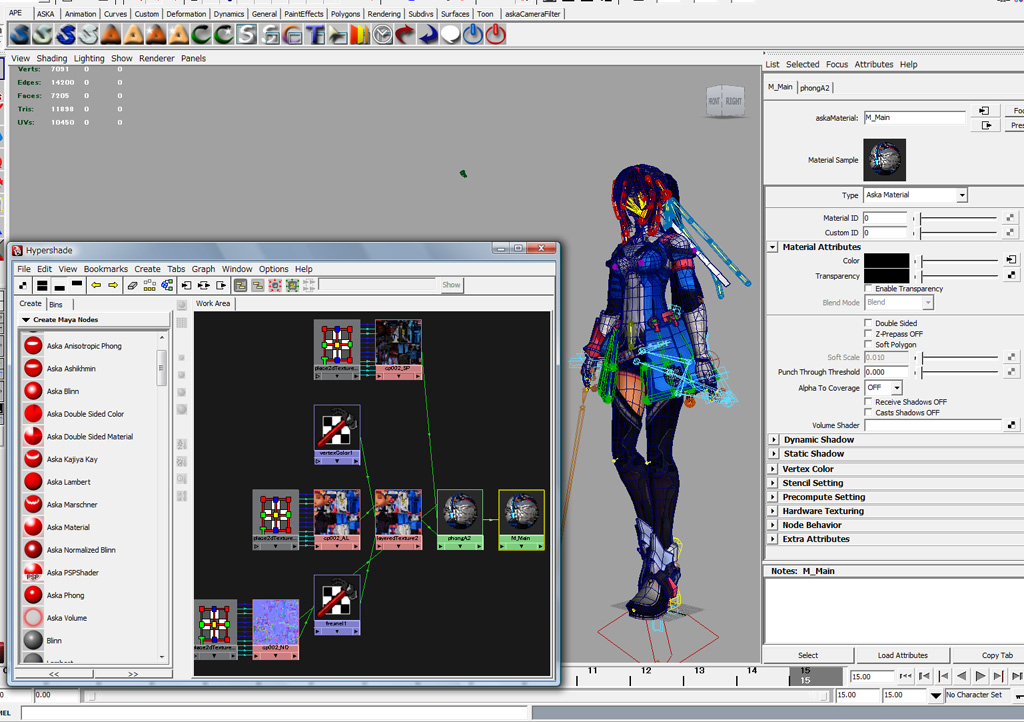
设计方针是艺术家在Maya中创建着色器,他们可以在没有程序员的情况下创建着色器,不受程序员限制,可以立即尝试新想法,需要培训艺术家,如何设置参数和构造着色器,物理知识(一点点)和模板。
运行时(开发期间)生成的着色器,其优点:不必在资源文件中包含着色器二进制文件,艺术家可以自由创建着色器,在运行时轻松支持着色器的变化,易于管理着色器二进制文件。其缺点:着色器变化的数量爆炸式增长,大型着色器二进制文件,必须创建可能的着色器变化,必须通关游戏中所有可能的内容。
可以细分着色器,实现具有特定功能的小型着色器节点,对应Maya中的Shader Node,艺术家可以自由连接每个输入和输出:UV、颜色、正常、Alpha…

使用照明结果对表面进行着色:Phong、各向异性Phong、Blinn-Phong、归一化Phong、Ashikhmin、Kajiya-Kay、Marschner(反照率贴图、高光贴图、光泽度(光泽度)贴图、菲涅耳图、偏移贴图、半透明、环境光遮蔽)。

着色编辑器还支持法线、UV、阴影、投射、计算及其它众多功能节点。

着色节点编辑器。
在后处理方面,Aska游擎支持色调映射(标准色调映射、胶片模拟(再现薄膜或 C-MOS 传感器的规格、再现胶片颗粒或数字噪声)、抖动)、镜头模拟(DOF、强光、基于物理的镜头结构、运动模糊(相机、对象)、彩色滤光片(对比、亮度、单调、色调曲线、色温)、其他效果(户外光散射、光轴模拟、屏幕空间环境光遮蔽)等。
着色文件采用了缓存机制,将编译好的着色器存储在devkit上的着色器缓存文件中,缓存组件(着色键、常数表、着色器二进制),假设此文件包含游戏中使用的所有可能的着色器组合。
着色器缓存是在QA期间创建,随着项目接近尾声,缓存文件的大小增加,一开始估计10M,但实际上超出了10M。解决尺寸问题的方案是在运行时解压缩每个着色器二进制文件,将着色器缓存分离到L1和L2,支持多个着色器缓存文件,创建了一个工具来管理Windows中的着色器文件,平衡实现的性能与尺寸控制参数。
但是,尽管付出了很多努力,尺寸还是超过50M,超过30000种缓存组合,即便拆分了缓存文件,但它们仍然超出了可接受的文件大小。开始分析着色器缓存文件的细节,发现是着色器适配器占用了大多数着色器组合。
什么是着色器适配器?
在运行时添加的着色器,如阴影、投影仪等等……这几种shader占据了80%,尤其是阴影,有一个着色器甚至支持一个对象的5个阴影。
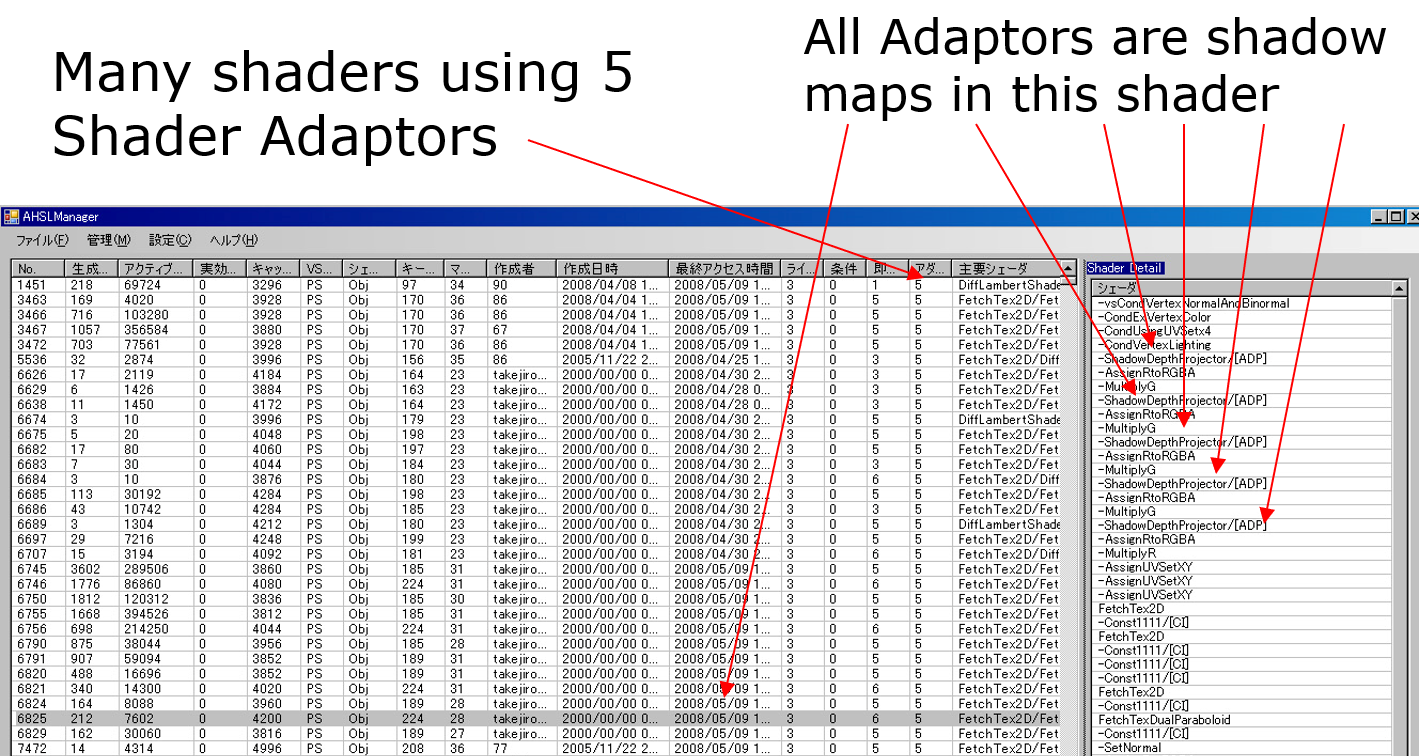
增加对着色器适配器(阴影)数量的限制,在生成期间或在工具中限制数量,尺寸显著减小,但导致外观问题,需要手动调整。支持非生成着色器的实现功能,在着色器适配器的情况下,使用的基础着色器,总比消失好。
缓存文件由QA团队创建,在修复与着色器相关的规范和资源时创建缓存文件,使用调试功能,通过玩游戏,合并由多个测试人员创建的文件,但由于对此系统不熟悉,这个过程比预期的要艰难得多,数周与数十名测试人员,一次又一次地完成。
以上着色系统的优点是:高灵活性,艺术家可以在没有程序员的情况下创建各种着色器,可以创建不合理的着色器组合,优化性能(着色器立即常数…),可以使用着色器编译器自动生成最佳着色器代码。
以上着色系统的缺点是:着色器缓存创建的成本,自动创建的限制,文件大小问题,缓存文件太大。因此,在创建资源的情况下应该意识到这一点,尝试减少着色器数量,创建着色器的困难,艺术家必须知道着色器的机制。
此外,Aska游擎还实现了基于物理的Bokeh DOF、镜头模拟、HDR渲染等效果。
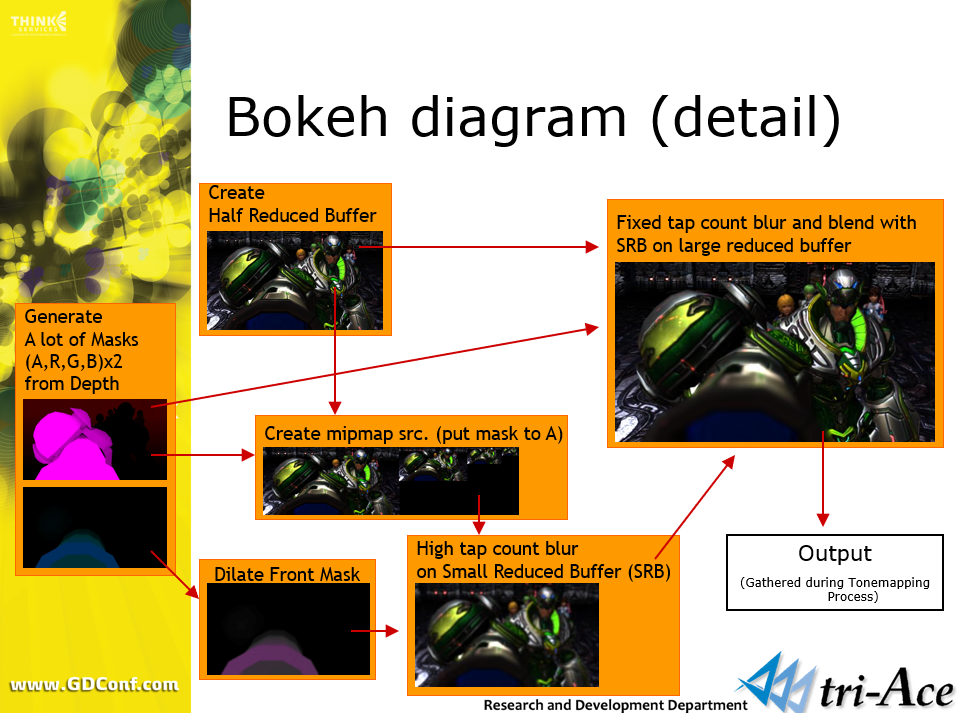
Bokeh景深渲染流程图。
对于色调映射,不使用特定算法,而是使用胶片或C-MOS传感器的规格来创建曲线表,曲线是基于对数基础压缩的:
float u = saturate(log2(vInCol.r+1)/2.32);
vOutCol.r = tex1D(s, u).r;
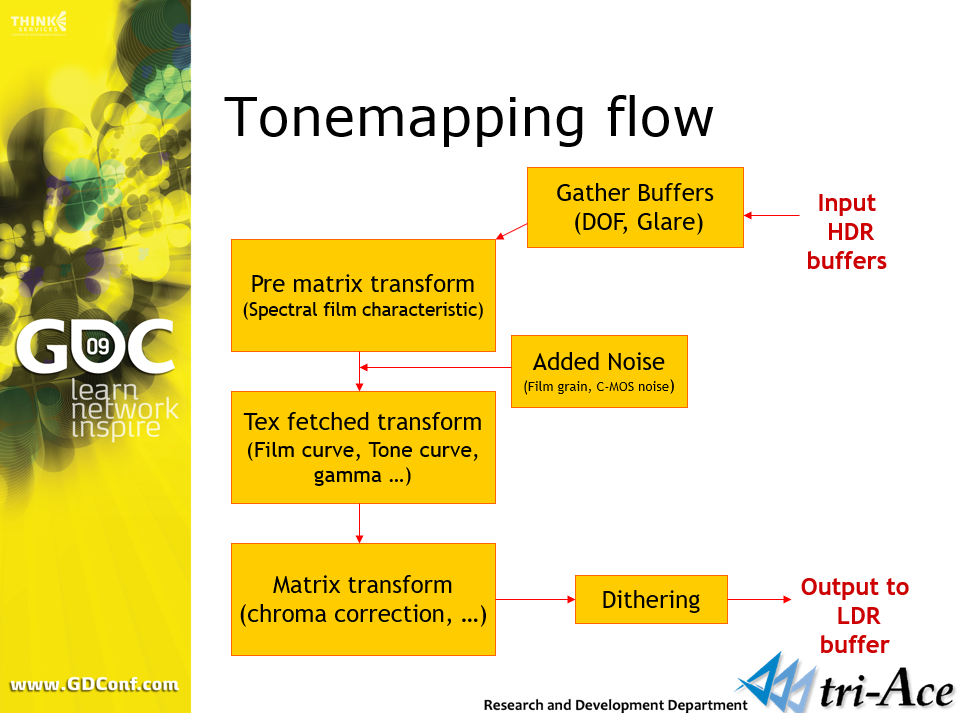
色调映射渲染流程图。

常见的色调曲面效果对比。

不同质量等级下的后处理效果对比。
Light Propagation Volumes in CryEngine 3分享了CryEngine 3的光照管线、核心思想、应用、改进、组合技术、主机优化等。
2009年的CryEngine 3已经支持众多主流平台,适合室外和室内的光照渲染,采用统一阴影贴图、SSAO、延迟光照等。

CryEngine 3采用了照明累积管线:应用全局/局部半球环境,将其替换为本地延迟光探测器(可选),全局照明,将间接项乘以SSAO以应用环境光遮蔽,在间接照明之上应用直接照明。
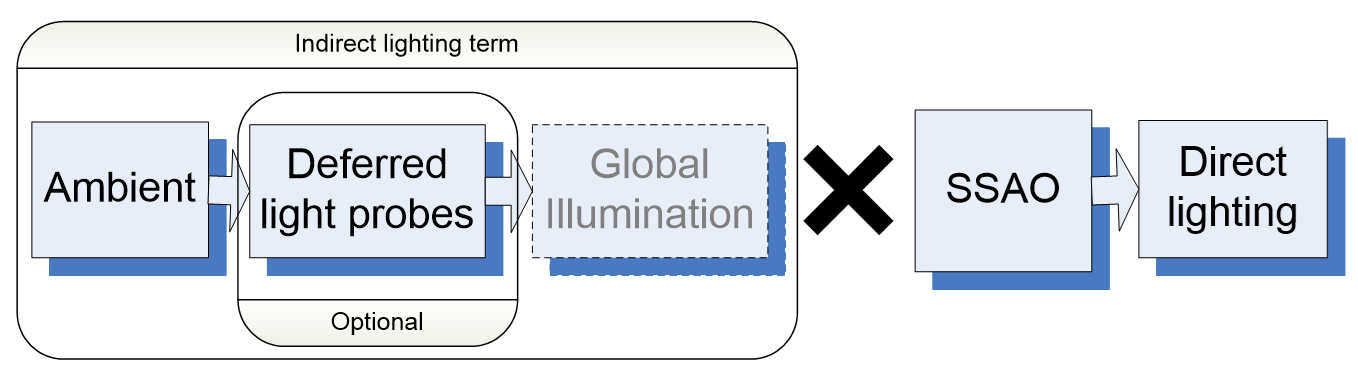
上图中的全局光照,CryEngine 3采用了光照传播体积(Light Propagation Volumes,LPV)。LPV的目标是将照明复杂性与屏幕覆盖率解耦(分辨率×过度绘制),Radiance缓存和存储技术,点光源的大规模照明,全局照明,参与媒体渲染(仍在进行中……),主机(Xbox 360、PlayStation 3)友好。
LPV最重要的步骤是在辐射体积中的传播光,从发射器的给定初始辐射分布开始,辐射传播的迭代过程,用于相邻单元的6点轴向模板(收集,GPU更高效,能量守恒),每次迭代都会增加结果,然后进一步传播。

6点轴向模板(6-points axial stencil)示意图。*

辐射传播过程示意图(以2D单个单元格的单次迭代为例)。
在上图中,不妨将初始辐射分布仅放置在发射器所在的单元格中(一种非常方便的情况,因为只需要为一个光源渲染一个像素),想要在网格上获得最终的辐射分布,建议的解决方案是迭代地传播辐射,每次迭代都会对每个单元应用一个6点轴向模板,意味着对于每个单元,通过收集方案传输来自相邻轴向单元的辐射。收集是GPU友好的,每次迭代的结果被收集到最终的辐射体积中,下一次迭代应用于前一次的结果。
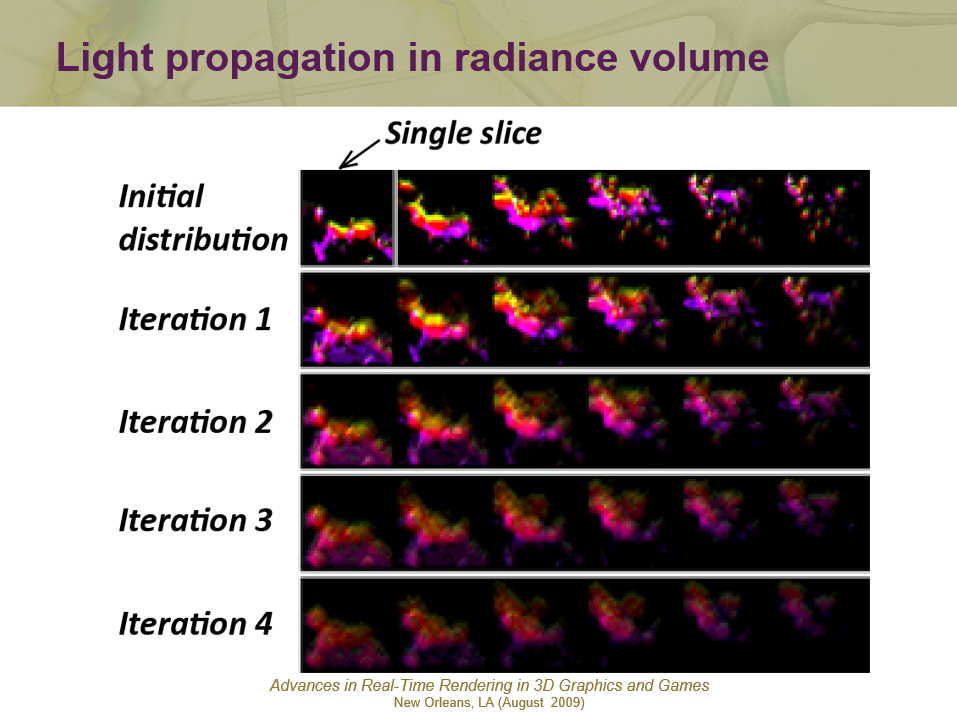
LPV多次迭代示意图。
上图是几个辐射传播迭代的结果。第一行是初始辐射分布,可以看到有很多光源,左上角的四边形是一片辐射纹理,所以3D辐射纹理在这张图片中展开。该过程是高度衰减的,意味着可以通过几次迭代来限制它(根据光源的初始强度,对于32x32x32辐射体积,8到16次),由此产生的辐射分布是所有这些辐射迭代的累积。
用LPV渲染时,按常规着色,类似于SH Irradiance Volumes,使用世界空间位置的简单3D纹理查找,与法线的余弦叶积分以获得辐照度,着色器中二阶SH的简单计算,透明物体和参与媒体的照明,延迟着色/照明,将体积的形状绘制到累积缓冲区中,支持几乎所有的延迟优化。
LPV还支持海量光源的照明,结合反射阴影图(Reflective Shadow Maps,RSM)后,可以获得全局光照的效果。其中反射阴影贴图带有MRT布局的阴影贴图:深度、法线和颜色,是高效的虚拟点光源(Virtual Point Light,VPL)生成器。

RSM携带的数据:法线(右上)、深度(左下)、颜色(右下)。
结合LPV和RSM的全局光照的渲染步骤如下:
- 将来自VPL的初始辐射注入辐射体积。
- 点渲染。
- 将每个点放入适当的单元格,使用顶点纹理获取/R2VB。
- 每个带有SH的VPL的近似初始辐射,着色器中的简单解析表达式。
- 传播辐射。
- 渲染具有传播辐射的场景。

LPV效果图。
VPL存在的问题是:VPL的注入涉及位置偏移,注入VLP的位置变为网格对齐,空间辐射近似的结果,非预期的辐射溢出,例如双面薄几何照明。
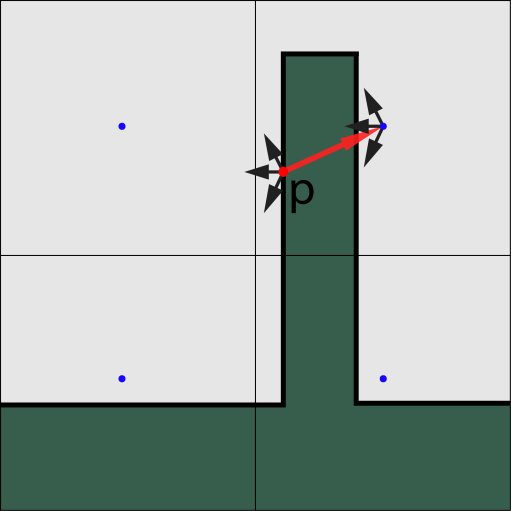
解决方案有:
- 将VPL朝法线或光源方向偏移半个格子。
- 通过各向异性双边滤波耦合,在最终渲染过程中。表面法线偏移的样本辐射,计算辐射梯度,将辐射度与辐射度梯度进行比较。
全局光照的级联光照传播体积描述如下:
- 一个网格尺寸有限,分辨率低。
- 辐射体积的多分辨率方法。类似于Cascaded Shadow Maps技术,在视野之外保留周围的辐射。
- 每个级联都是独立的。每个级联都有单独的RSM,通过相邻边缘传输辐射,按特定RSM的大小过滤对象。
- 辐射发射器的有效分层表示。

GI组合SSGI的步骤如下:
- 屏幕空间全局照明。
- SSGI的局限性:只有屏幕空间信息,近距离物体的巨大内核半径。
- LPV的局限性:局部解决方案,低分辨率空间近似。
- SSGI和LPV互相补充。
- 自定义混合。
[Lighting Research at Bungie](https://advances.realtimerendering.com/s2009/SIGGRAPH 2009 - Lighting Research at Bungie.pdf)介绍了Bungie公司研制的游戏Halo 3的实时光照和预计算全局光照。实时光照方面涉及天空和大气、天空光、概率阴影测试(Probabilistic Shadow Test)、方差阴影图(VSM)、指数阴影图(ESM)、CSM、EVSM等。预计算方面,在光子映射的基础上,改进了原先比较慢的部分,提出了新的渲染流程,获得很大的速度提升。
在大气渲染上,采用了Precomputed Atmospheric Scattering的方法,考虑单次和多次散射,在GPU上的预计算,从太空可见,支持光束。散射模型采用了Raleigh和Mie散射,预计算部分预包含透射比、内散射、辐照度,将预先计算的查找表存储为纹理,使用GPU生成纹理。(下图)

天空光方面,对于远处的山脉和物体采用了Precomputed Atmospheric Scattering的方法,使用单一颜色作为天空辐照度。近处的物体为了更好地逼近特写几何,使用CIE天空亮度分布,预先计算的辐照度进行缩放,每个方位角投影到SH,用多项式拟合系数,使用PRT渲染GI外观。



天空光的对比,从上到下:仅直接光、用SH近似、用PRT近似。
概率阴影测试(Probabilistic Shadow Test)在给定样本在阴影中的概率、当前接收器、遮挡器深度下,其公式如下:
其中:
- \(d_o\)是随机变量,表示遮挡体的深度分布函数。
- \(d_r\)是当前阴影接收者的深度。
对于基于方差的阴影测试(Variance-Based Shadow Test),二进制测试(Binary test)成为概率分布函数,即当前片段处于阴影中的概率。\(P_r(d_o \ge d_r)\)源自两个矩(moment):
使用切比雪夫(Chebyshev)不等式作为检验的上限:
在VSM基础上了,为了达到更好的效果,Bungie团队还尝试了ESM、EVSM以获得更精确的阴影效果。
对于预计算光照方面,传统的CPU光子映射管线存在两大瓶颈:
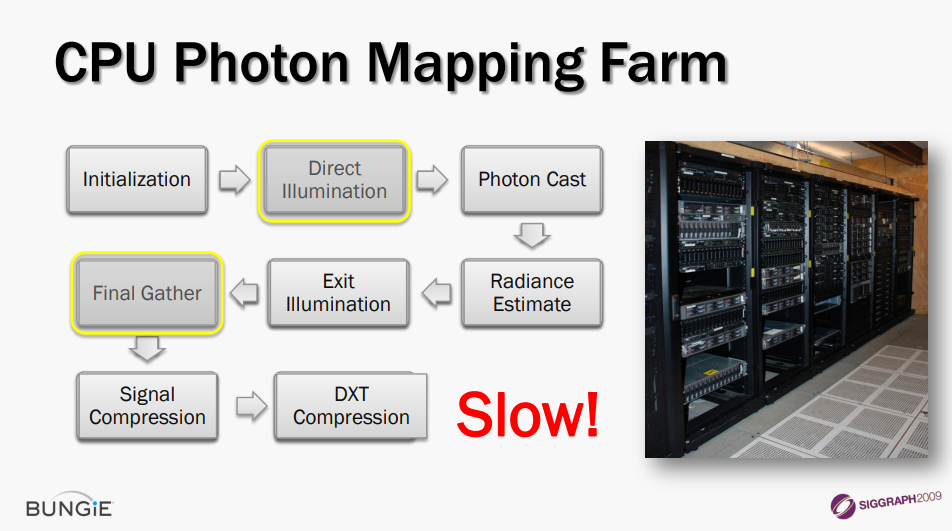
Bungie团队针对瓶颈部分做了优化,直接照明阶段使用GPU KD树的快速光线投射,最终收集阶段使用GPU KD树的快速光线投射,光子照明切割(Cut),间接照明的分簇样本点。
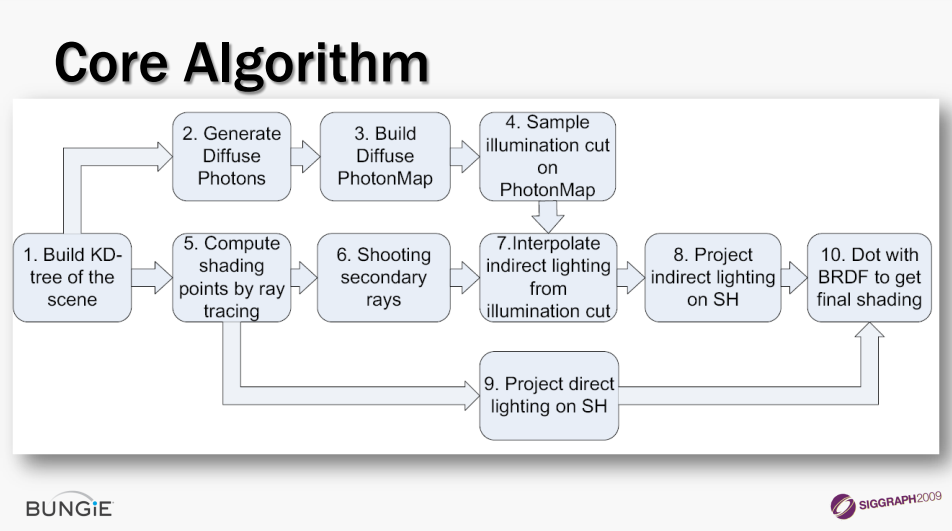
光子照明裁剪(Cut)类似于光源切割,估算光子树每个节点的辐照度,通过树计算“切割”,使用RBF基进行插值。

Theory and Practice of Game Object Component Architecture阐述了面向组件和面向对象的特点和区别及实现方法。
游戏对象(GameObject)是任何在游戏世界中具有代表性的事物(如角色、道具、车辆、导弹、相机、触发体积、灯光等),需要标准本体,要求明晰、均匀,功能、事物和工具移动性,代码重用和维护(例如使用模块化/继承减少重复)。
早期的引擎常以集成来实现不同类型的游戏对象,随着物体种类增加,多重继承是解决问题的一种方法, 但它不能很好地扩展,也没有解决最终的挑战:设计/要求的变化。(下图)
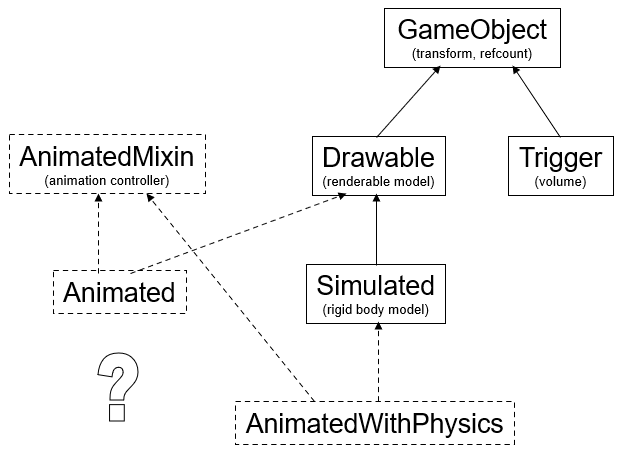
这种继承主导的方法不是每组关系都可以用有向无环图来描述,类层次结构很难改变,功能向父类迁移,在兄弟类型特化需要消耗额外的内存。对复杂的应用程序,将引起很多错综复杂的类继承树:
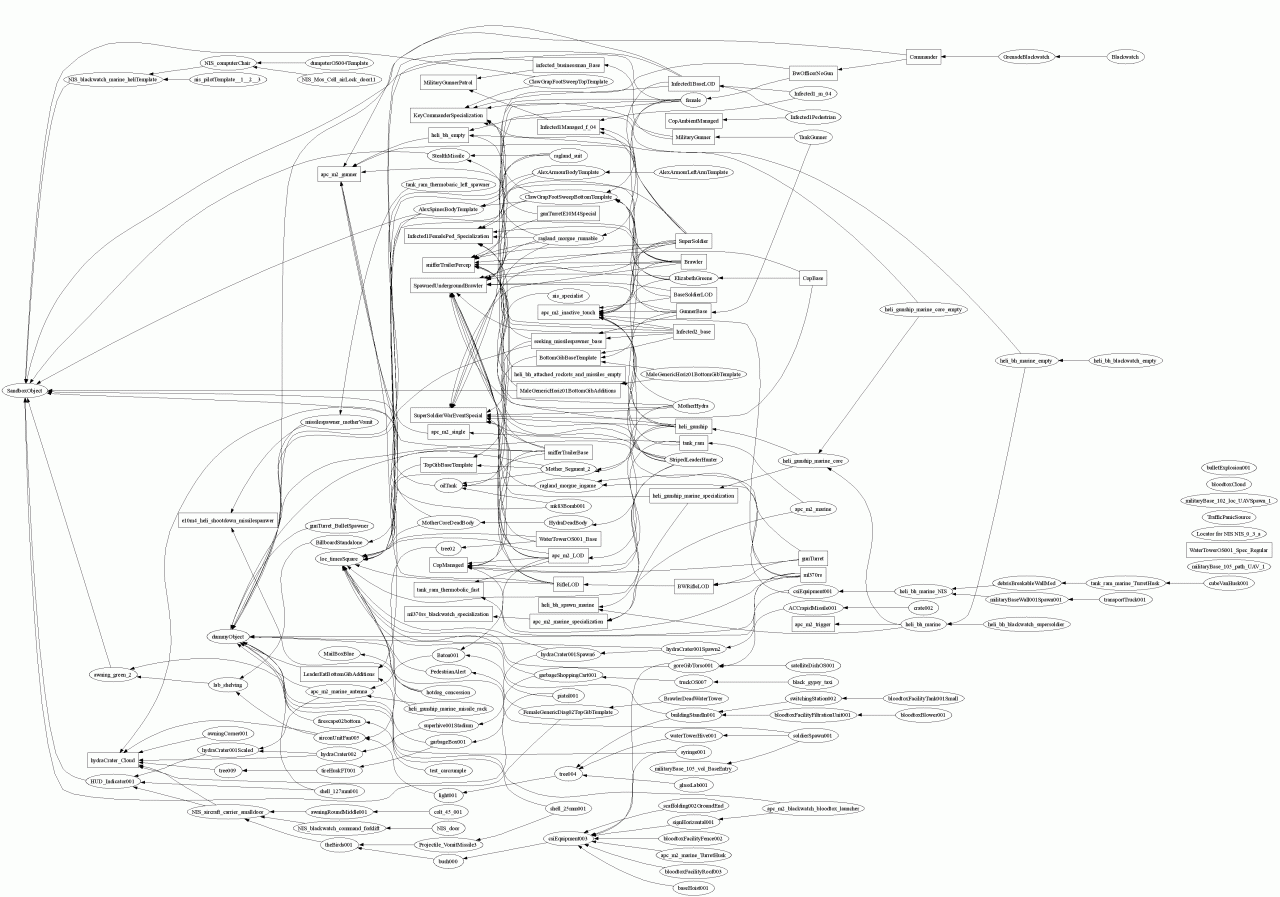
基于组件的方法与面向方面的编程相关但不相同,一个类是一个容器:属性(数据)和行为(逻辑),属性即键值对列表,行为即带有 OnUpdate() 和 OnMessage() 等响应函数的对象。
面向对象和面向组件的对比。
该文还提到了数据驱动的创建,文本或二进制,从管道加载,并发加载,延迟实例化,专用工具,数据驱动的继承等。
TOD_BeginObject GameObject 1 "hotdog_concession"
{
behaviours
{
PhysicsBehaviour 1
{
physicsObject "hotdog_concession"
} ,
RenderBehaviour 1
{
drawableSource "hotdog_concession"
} ,
HealthBehaviour 1
{
health 2.000000
} ,
GrabbableBehaviour 1
{
grabbableClass "2hnd"
}
}
}
TOD_EndObject
数据驱动的创建优势:赋予新属性很容易,创建新类型的实体很容易,行为是可移植和可重用的,与游戏对象对话的代码与类型无关,一切都经过包装和设计,可以相互交互。简而言之:可以编写通用代码。
数据驱动的创建劣势:必须编写通用代码,游戏对象是无类型且不透明的,如果对象具有可附加行为,则附加到它,代码必须同等对待所有对象,不能查询数据和属性,例如:
if object has AttachableBehaviour // 无法访问属性
then attach to it
Rendering Technology at Black Rock Studio分享了Alpha组合基础、地面植被、树木渲染、屏幕空间透明度遮蔽等技术。
文中提到了Alpha Test由一位值确定片元是否可见,可与z缓冲区一起使用,可能导致锯齿。而Alpha To Coverage将alpha转换为像素的覆盖掩码,覆盖掩码与MSAA覆盖掩码进行“与”运算,与alpha测试结合使用时提供更柔和的边缘,可与z缓冲区一起使用,但是由此产生的alpha渐变并不总是看起来很好。(下图)


Alpha Test(上)和Alpha To Coverage(下)导致的瑕疵。
该文针对以上问题提出了全新的处理流程,以获得更柔顺自然的地表覆盖物混合效果。新的渲染流程分为3个阶段:
- 密度图。离线生成,用来放置地表覆盖物的2D映射图。
- 分块缓存。相机移动时,计算地表覆盖物的类型、位置、尺寸等。
- 顶点缓冲。逐帧生成,编码了类型、位置、尺寸的精灵顶点。

在渲染时,在相机周围的固定区域渲染草,区域划分为8平方米的400个分块,每平方米包含4个屏幕对齐的精灵,所以每个图块包含256 个精灵,每个精灵信息都被编码为一个4维向量,分块缓存在内存中。根据相机的位置确定需要渲染的分块,然后查询密度图获取地板覆盖物的数据,每帧生成顶点缓冲区,分块信息从分块缓存中复制,CPU需要为每个可见的分块复制16KB。
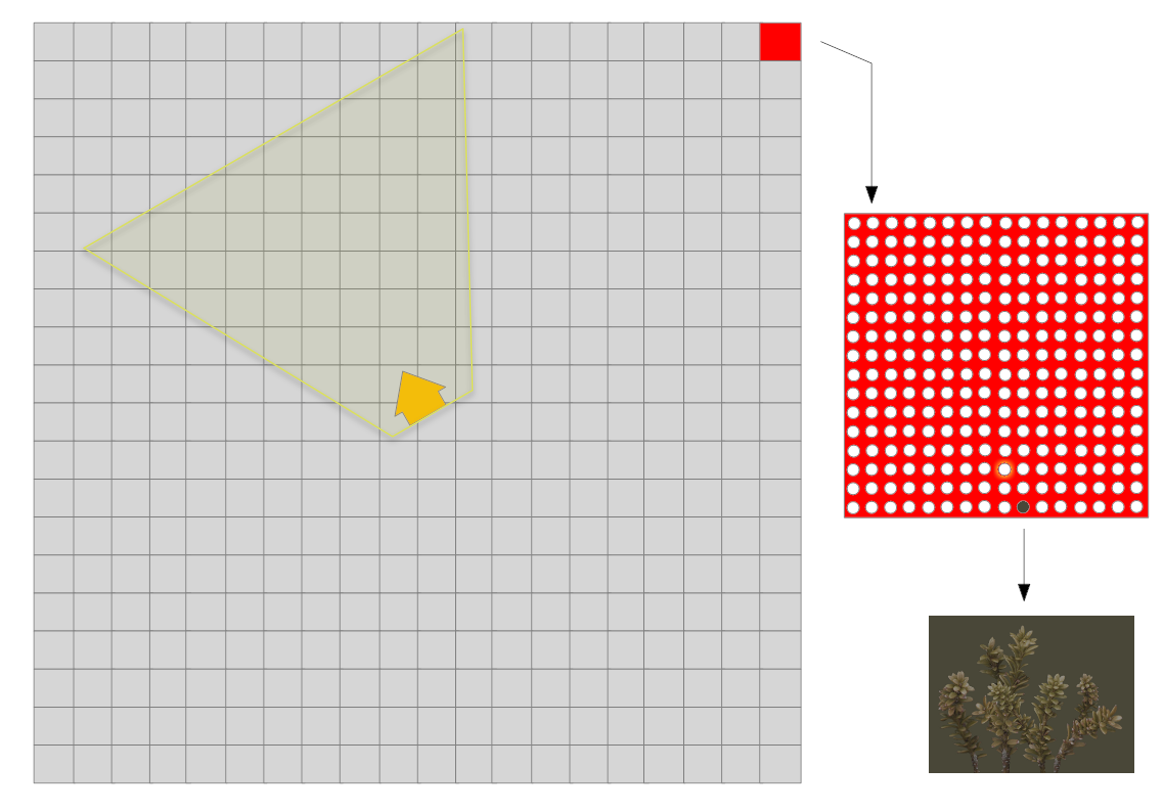
渲染相机附近分块的地板覆盖物的图例。

几种混合效果对比图。
Alpha混合需要几何排序,但是规则的几何放置使排序更容易,包含两级粒度:从后到前渲染分块和精灵在每个分块中排序。每个分块内的排序是预先计算的,预先计算了16个摄像机方向的渲染顺序(下图),并选择与当前最接近的相机方向的顺序。为了提高性能,将精灵分组为 32个“单元”,共8个,并且仅在单元级别进行排序。

预计算的分块排序,总共16个方向,图中只选取了其中的4个方向。
这种混合的好处是高品质阿尔法混合地面覆盖,低成本CPU排序,艺术家友好的工作流程。缺点是较高的过绘制,对GPU来说意味着较高的开销。
该文还提出了屏幕空间Alpha蒙版流程以更好地绘制树木等物体:
绘制树的Alpha模板时,使用解析的深度,禁止Z写入,渲染出树的alpha值。
sampler alphaTexture : register(s0);
struct PSInput
{
float2 vTex : TEXCOORD0;
};
float4 main( PSInput In ) : COLOR
{
return tex2D( alphaTexture , In.vTex ).aaaa;
}

输出Alpha蒙版时,存在两种方式:source + destination和max(source, destination)。

ADD给出不透明的结果,MAX提供更多细节和更柔和的轮廓,幸运的是,可以一次创建两者!用于写入渲染目标的颜色和alpha分量的不同混合模式,在最终组合过程中平均两个值。组合的PS代码如下:
sampler maskImage: register(s0);
sampler treeImage: register(s1);
sampler worldImage: register(s2);
float4 main( float2 vTexCoord : TEXCOORD ) : COLOR
{
float4 vTreeTexel = tex2D( treeImage, vTexCoord.xy );
float4 vWorldTexel = tex2D( worldImage, vTexCoord.xy );
float4 vMaskTexel = tex2D( maskImage, vTexCoord.xy );
float lerpValue = (vMaskTexel.r +vMmaskTexel.a) * 0.5f;
return lerp( vWorldTexel, vTreeTexel, lerpValue );
}
最终效果对比如下:

该文还分享了延迟着色的实践经验。Split/Second通道使用延迟着色渲染器,将光照与几何图形解耦,在渲染主场景时,照明所需的信息被写入几何缓冲区 (G-Buffer),场景的照明被推迟到在后处理阶段发生的照明通道。MRT的布局如下:

针对延迟着色的MSAA进行了优化。全屏抗锯齿的变化,FSAA将场景渲染到比要求更高的分辨率,平均值下降到所需的分辨率,严重影响性能。MSAA的每个像素只运行一次像素着色器,为多边形覆盖的每个片元设置片元颜色,但不能使用硬件对片元进行平均,因为G-Buffer不适合插值,意味着必须手动混合每个片元。
通过观察,发现85%的像素位于多边形内部,意味着它们的所有片元都是相同的,能否快速识别出其它15%的不同之处?需要识别的片元如下图红色所示:

可以使用一个试图识别多边形边缘的硬件特性:质心采样(Centroid sampling),质心采样避免了在多边形边界之外采样的顶点属性。
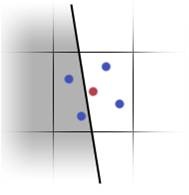
质心采样将用于确定颜色的位置调整为多边形覆盖的所有采样点的中心,因此,如果质心移动,那么就在多边形边缘。

幸运的是,在像素着色器中可以获取质心样本的值,如果它不为零,就可以知道三角形不会覆盖像素的所有样本。
struct PSInput
{
float4 vPos : TEXCOORD0;
// 质心采样的坐标!TEXCOORD1_CENTROID是系统属性值
float4 vPosCentroid : TEXCOORD1_CENTROID;
};
float4 main( PSInput In ) : COLOR
{
// 对比质心和像素位置的差异,如果完全一样,说明质心没有移动,像素完全在三角形内。
float2 vEdge = In.vPosCentroid.xy - In.vPos.xy;
// 笔者注,为了防止误差,应改成:float fEdge = (abs(vEdge.x) + abs(vEdge.y) <= 0.001f) ? 0.0f : 1.0f;
float fEdge = (vEdge.x + vEdge.y == 0.0f) ? 0.0f : 1.0f;
// 对于延迟着色,通常会将这个值打包到G-Buffer中的一位。
return float4( fEdge );
}
为了避免阴影瑕疵,使用百分比渐进过滤,PCF从阴影贴图中获取多个样本,对每个影子接收器执行深度测试,然后平均结果。可以将屏幕分成3个区域:绝对处于阴影中的区域、绝对不在阴影中的区域、可能在阴影中或不在阴影中的区域。实际上,只需要将PCF应用于这些区域中的最后一个(可能在阴影中或不在阴影中的区域)。虽然不可以准确地计算出来,但可以近似,生成一个掩码来显示必须执行PCF的位置。
第1个Pass输出1/4屏幕尺寸的阴影图,第2个Pass是屏幕尺寸的1/16,使用保守光栅化扩展边缘。


1/4尺寸的阴影图和使用保守算法扩展边缘的1/16阴影图。
该文还分享了辐照度体积的实践、效果及性能的优化。
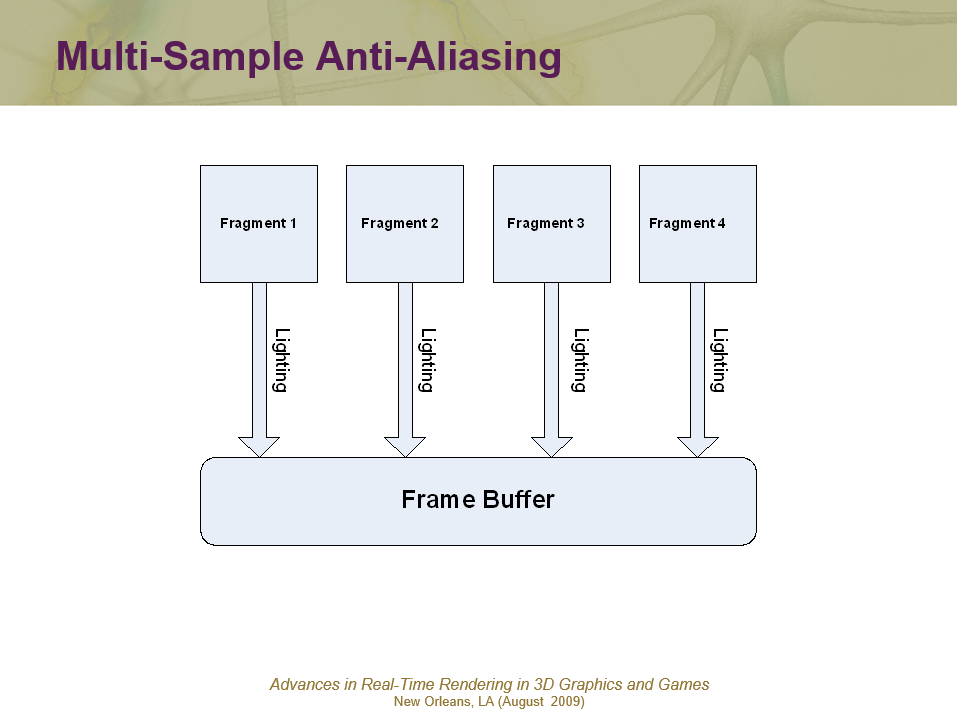
14.3.3.2 并行处理
在2000年初,已经有文献(Designing the Framework of a Parallel Game Engine)阐述如何将引擎并行化处理的技术和实现。其中,该文献提及了无锁步(Free Step)和锁步(Lock Step)两种执行模式。(下图)
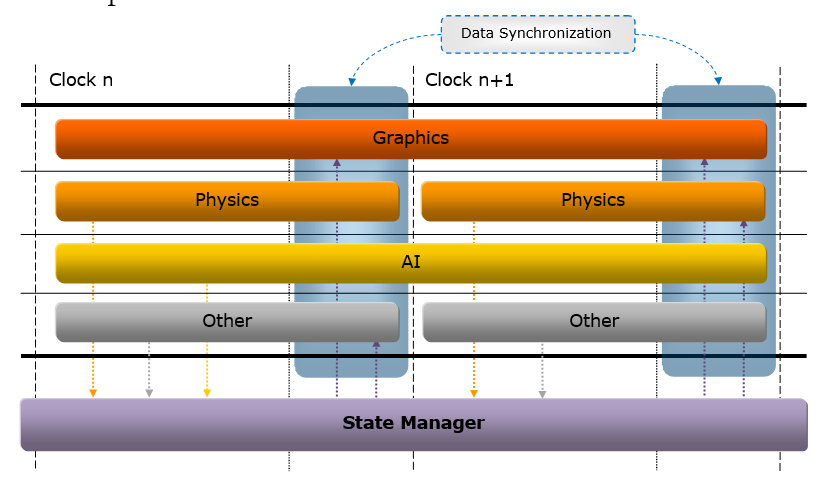
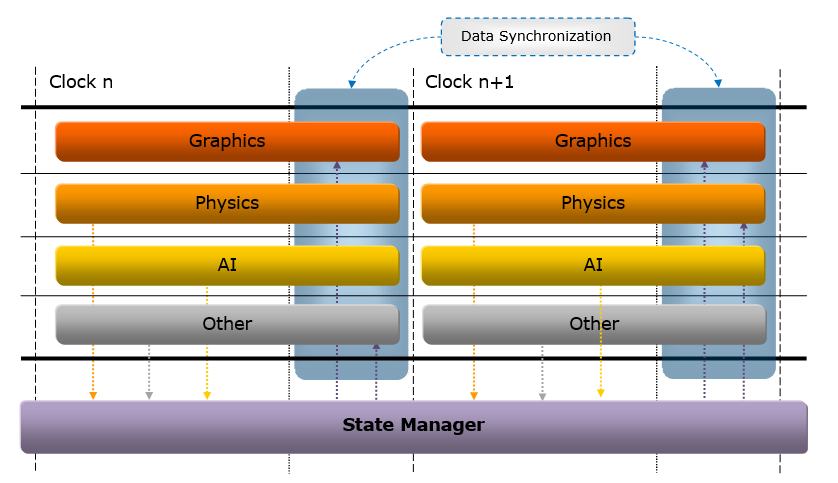
上:Free Step模式;下:Lock Step模式。
Free Step执行模式允许系统在完成计算所需的时间内运行。 Free Step可能会产生误导,因为系统并非随时可以自由完成,而是可以自由选择需要执行的时钟数。使用这种方法,向状态管理器简单地通知状态更改不足以完成任务,还需要将数据与状态更改通知一起传递,因为当需要数据的系统准备好进行更新时,已修改共享数据的系统可能仍在执行。此模式需要使用更多内存和更多副本,因此可能不是所有情况下最理想的模式。
Lock Step执行模式要求所有系统在一个时钟内完成它们的执行。实现起来更简单,并且不需要通过通知传递数据,因为对另一个系统所做的更改感兴趣的系统可以简单地向另一个系统查询该值(当然在执行结束时)。Lock Step还可以通过在多个步中交错计算来实现伪Free Step操作模式。 这样做的一个用途是让AI在第一个时钟内计算其初始“大视图”目标,而不是仅仅为下一个时钟重复目标计算,它现在可以根据初始目标提出一个更集中的目标。
该文献还提到了线程池的技术,将任务分拆成若干个粒度较小的子任务,由任务管理器调度,分派到线程池的线程中执行。(下图)
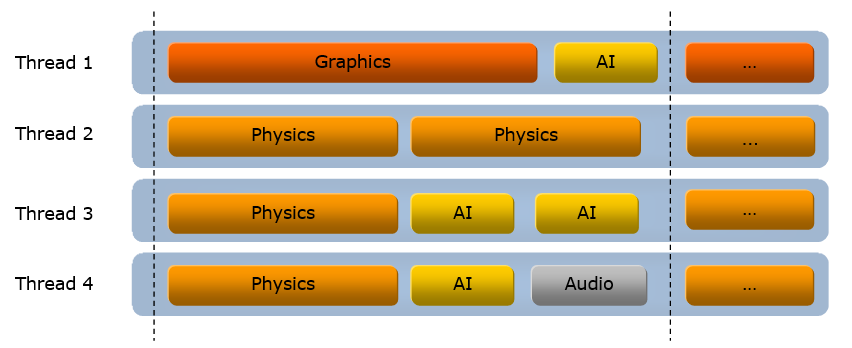
并行化引擎涉及到系统的核心概念,系统和场景、任务、物体的关系如下图所示:

游戏引擎主循环的步骤如下:
- 调用平台管理器来处理在当前平台上操作所需的所有窗口消息和/或其它平台特定项目。
- 将执行转移到调度程序,调度程序在继续之前等待时钟时间到期。
- 对于Free Step模式,调度程序检查哪些系统任务在前一个时钟完成了执行。 所有已完成(即准备执行)的任务都会发给任务管理器。
- 调度程序现在将确定哪些任务将在当前时钟完成并等待这些任务完成。
- 对于Lock Step模式,调度程序发出所有任务并等待它们完成每个时钟步长。
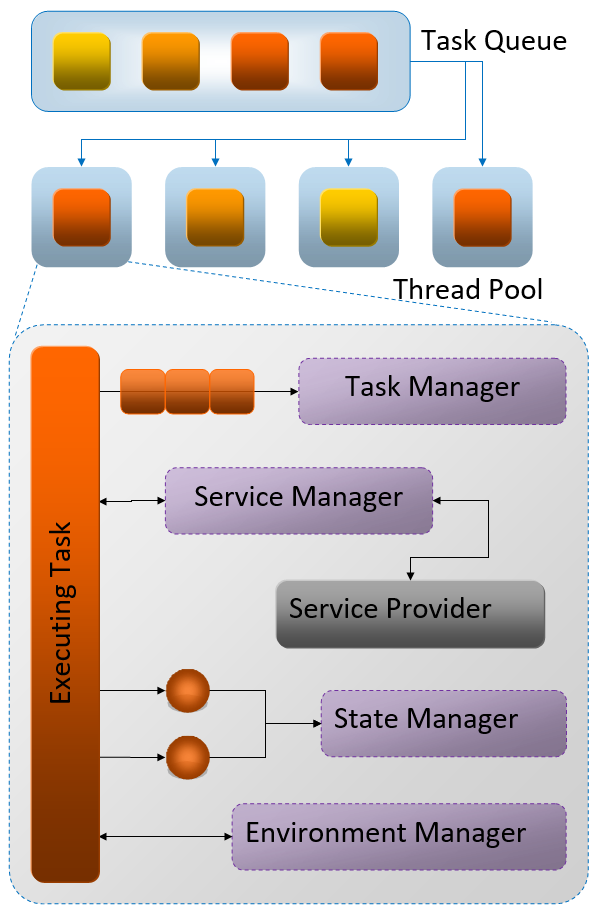
在执行任务时,调度器会从任务队列获取任务,分发到线程池中执行。其中执行的任务涉及到了任务管理器、服务管理器、状态管理器、环境管理器等诸多概念(详见下图,当今的多线程并行系统已经简化了它们)。
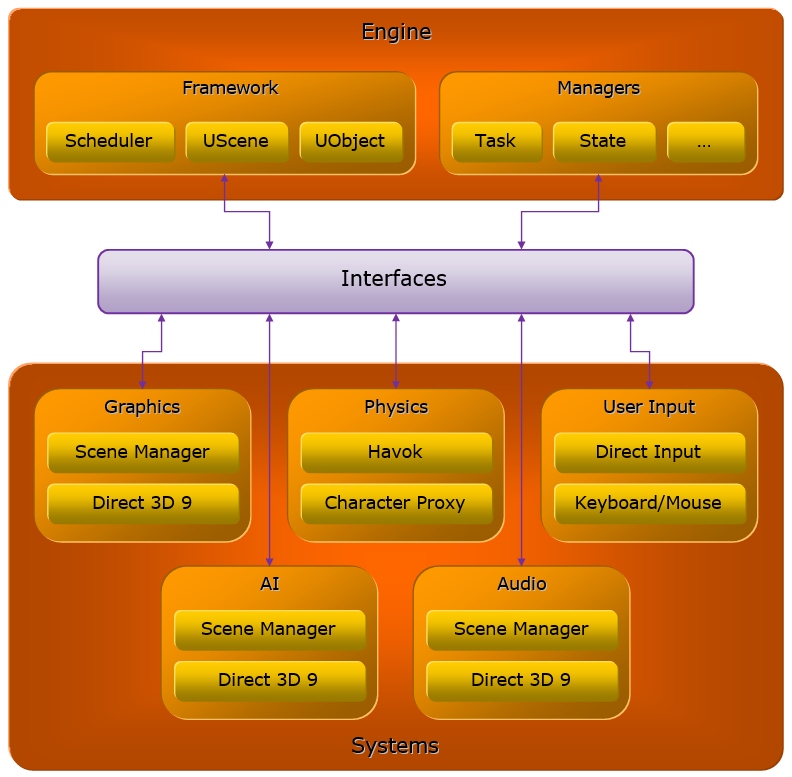
该文献抽象出的引擎架构分成了引擎层和系统层,它们通过接口层通讯和交互。各个层又涉及到了诸多概念和子系统,见下图:
引擎和系统的引用和交互关系如下图,其中全局场景(Universal Scene)拥有几何、图形、物理系统场景代表,每个场景代表有着和全局场景对应的物体代表,这些场景代表各自会产生许多任务,以便任务管理器调度与执行。

2004年的Challenges in programming multiprocessor platforms阐述了多处理的各种技术,其中该文涉及以下的概念:
- 硬件处理器布置
- 异构:多个不同的处理器
- 同构:同一处理器的倍数
- 软件安排
- 非对称:运行不同的代码库
- 对称:运行相同的代码
- 工作单元
- 应用程序:要解决的问题,由产品要求定义。
- 任务:程序员在应用程序中工作的有界表示,在设计时定义。
- 线程:在应用程序中实现任务的机制,在软件实现期间使用。
在软件设计时,可编程性至关重要,运行多个动态应用程序时增加复杂性,软件的工具/可见性越来越难,关注验证及可重复性,设计和测试开发环境变得越来越复杂。另外,可重用性是不争的事实,需要解决方案的可移植性,还需要功能的分层抽象。
经典的单指令上下文(单处理器)无法使用当前方法进行扩展,无法从指令级并行性中提取更多信息,处理器引擎需要从应用程序员那里获得帮助,让开发人员使用多指令上下文来表示他们的应用程序。
来自高MHz的高性能正在达到台式机和嵌入式的热量或能量的极限,英特尔取消P4支持多核,ARM发布多处理器内核,IBM表示无法从流程缩减中扩展。因此,微架构必须进化。
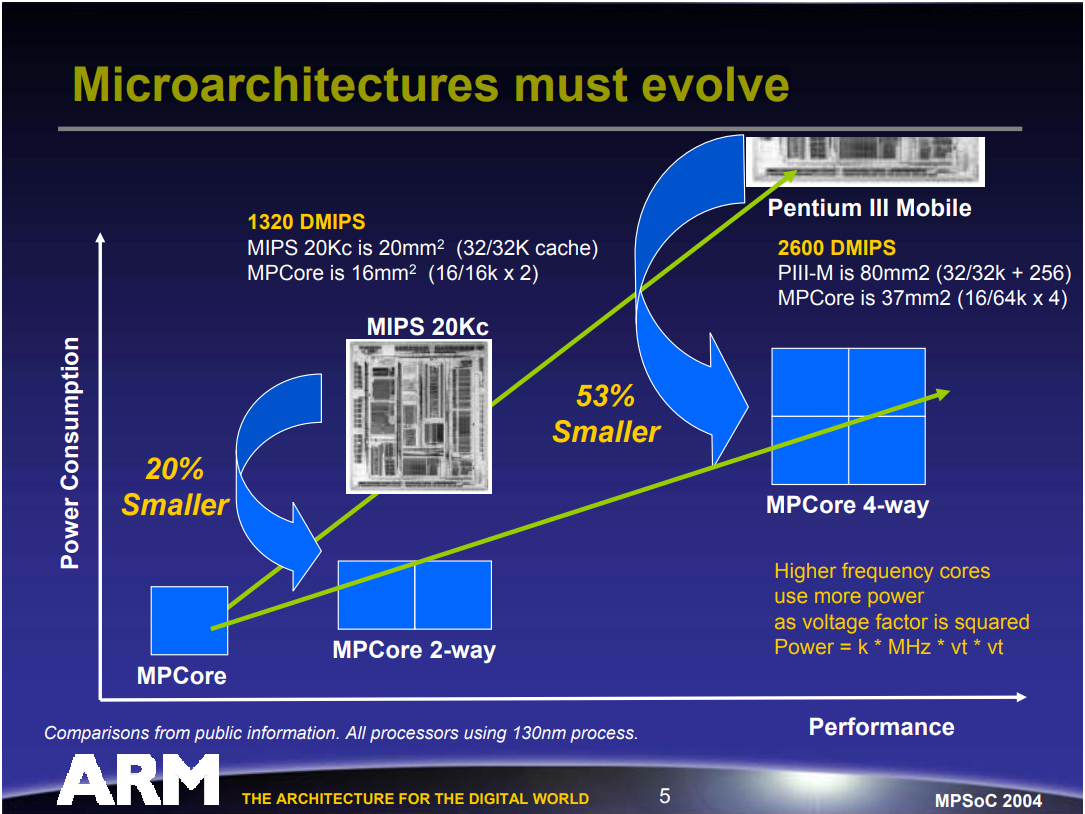
CPU核数和能量消耗关系图。
经典的异构不对称CPU架构如下:
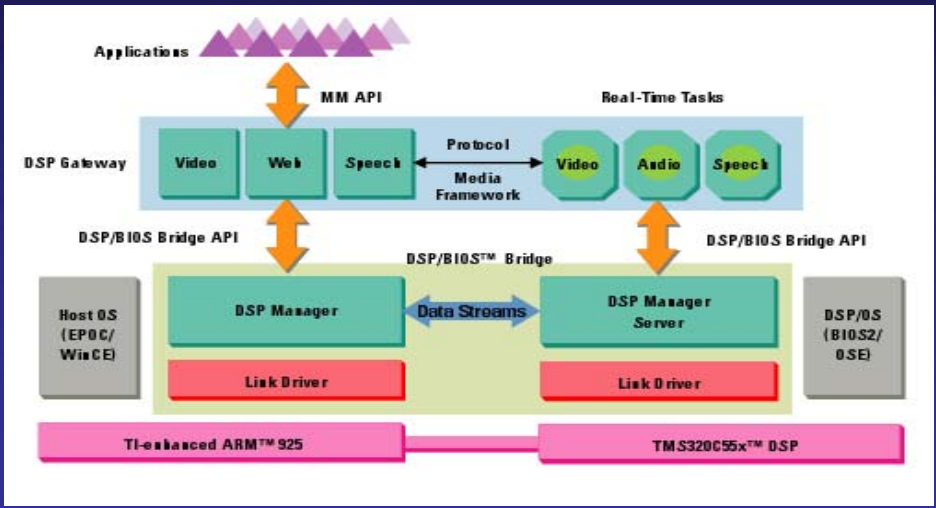
T.I. OMAP双核处理器架构。
同构不对称CPU架构。
非对称多处理 (AMP)使程序员能够同时运行多个应用程序的软件模型,在异构和同构处理器之间使用基于消息的互连,以各种形式提供。当应用程序可以跨处理器静态分区时,提供高效的解决方案,允许将任务的影响与其他任务隔离开来,提供一种将现有代码扩展到MPSoC的简单机制。

AM使用案例。左边是主CPU,右边是从属CPU。
AMP的挑战包括:程序员需要拆分应用程序并将子应用程序静态分配给处理器,可能跨越不同的微架构,如果不了解应用程序,将非常困难;管理开放平台的动态工作负载的复杂性打破了这种模式,难以确保处理器的有效利用,动态特性会使特定处理器过载,难以提供单任务可扩展性;所有供应商的解决方案都不同,导致工具支持的碎片化,如果需要更改,则需要重写/重新架构。
对称多处理 (SMP)使程序员能够利用多种指令上下文架构的软件模型(假设由各种硬件架构提供的公共内存和外设),具有一致互连的非对称MP、一致缓存的对称MP、公共缓存的多线程单处理器。SMP还提供通用模型以提高标准,程序员使用线程来表示他们的任务,操作系统在处理器上调度线程,被视为下一代主要的编程模型,在单处理器设计之间仍可移植。
多任务应用程序示例。
当时有几种实现选项:
- 单处理器。事件驱动,合作时间切片,异步工作分派,抢占式时间切片多线程。
- 多处理器。与单处理器相同,操作系统还能够通过CPU共享线程,降低上下文切换的成本,提高系统级响应。
- 在这两种情况下,最简单的方法是简单地将应用程序任务映射到线程,允许使用现有的代码实现。
多线程涉及的机制有:
- Fork-Exec:按需创建线程。任务有明确的开始和结束条件,任务是长期存在的,足以隐藏创建/杀死线程的成本,有助于将现有代码迁移到多任务应用程序,每个任务可能有多个同步点,不正确的分区会破坏性能。
- 工作池:将工作移交给工作池。应用程序有明确定义的“工作单元”,等待工作的任务池,任务同步最好限于工作单元的拆分/合并,需要确保工作项不是序列相关的。
// Fork-Exec伪代码
main()
{
while( !Shutdown )
{
work = WaitForWork();
CreateThread(WorkerTask, work);
}
}
WorkerTask(work)
{
DoWork(work);
}
// Worker Pooling伪代码
main()
{
For(i=0; i< numCPU * 2; i++)
{
CreatThread(WorkerTask, workQueue);
}
While( !Shutdown )
{
work = WaitForWork();
PostWork(workQueue, work);
}
}
WorkerTask(workQueue)
{
while( !Shutdown )
{
work = WaitforWork(workQueue);
DoWork(work);
}
}
多任务处理效果很好,直到单个任务需要比单个处理器更高的性能。如果任务很容易由多个子任务表示,则不是一个重要问题。子任务可能会很复杂的情况包含:由单一线性算法表示,特别是如果已经在代码中设置;算法是一系列相互依赖的操作。幸运的是,在软件代码块或循环级别寻找并行性可以简化这些问题,跨处理器拆分循环的迭代,在处理器上放置单独的代码段。
对称MP的挑战有:
- 难以将一项任务的影响与其他任务隔离开来,所有任务共享相同的处理器,OS API通常提供亲和力和任务级别优先级。
- 程序员需要注意不要滥用通用内存系统,通过需要太多同步点,通过导致数据需要在处理器之间不断迁移。
- 硬件必须解决处理子系统的瓶颈,围绕确保内存一致性,围绕处理器之间的同步。
ARM MPCore混合多处理器。
总之,嵌入式开放平台MPSoC不能简单地复制桌面微架构,无法承受传统一致性的成本(慢速系统总线和通信的SoC组件),需要将低功耗置于峰值性能之上。解决方案必须由开放平台开发团队编程,允许迁移现有代码库,使用“大众市场”模型,也可以提供高水平的处理效率。
Real World Multithreading in PC Games Case Studies也提及了多线程的并行技术。文中提到了超线程和普通线程的对比:

超线程拥有两个逻辑线程,可以并发地处理资源,从而提升资源利用率,提高吞吐量。

多处理器(左)和超线程(右)硬件结构对比图。
为什么游戏很难线程化?可从技术和商业两方面解答。技术方面,在阶段之间共享单个数据集的顺序管道模型,高度优化的密集代码最大限度地减少了HT的好处,线程经常涉及重大的高级设计更改。商业方面,多线程编程经验少,支持HT(如SSE)的系统的市场份额有限,以及消费者不知道HT。
但是,游戏应该线程化,依然可以从技术和商业两方面解答。技术方面,并行是CPU架构的未来->易于扩展(HT、多核等),在等待显卡/驱动程序时做其它事情,良好的MT设计可扩展,并防止重复重写。商业方面,在竞争环境中脱颖而出,所有PC平台都将支持多线程,并行编程教育将在多个平台(PC、控制台、服务器等)上获得回报,MT可扩展更多 -> 延长产品寿命。
游戏管线模型,游戏更新和渲染存在时序依赖和数据依赖。
多线程策略有两种:
-
任务并行。同时处理不相交的任务。对整个3D图形管线进行多线程化,例如线程1处理N帧,线程2处理N+1帧。有利于GPU密集型 游戏,由于存在依赖,较难实现,但不是不可能。
![]()
-
数据并行。同时处理不相交的数据。可以在辅助线程上执行音频处理、网络(包括 VoIP)、粒子系统和其它图形效果、物理学、人工智能、内容(推测)加载和拆包等任务。多线程程序内容创建,如几何、纹理、环境等。适合CPU密集型游戏,易于实现。
![]()


下图是论文提出的线程管理器,以便管理所有真实线程的生命周期:

下图是文中给出的程序化天空盒的多线程实现案例:

该文还探讨了文件异步加载、天气系统渲染、粒子系统渲染的多线程化。
Exploiting Scalable Multi-Core Performance in Large Systems阐述了Intel CPU的发展趋势以及多线程的架构分析、线程使用、调试和性能分析等。

Intel线程技术的四个方面。
文中谈及了线程之间的数据竞争和死锁,给出了势力及详细的解决步骤,包含汇编级分析。

Intel CPU在数据竞争的汇编级分析。

死锁示例。
当时的Intel线程分析工具的技术模型如下:

文中还给出了多线程锁的优化、单线程和多线程安全的读写锁,以及在串行区域禁用锁的代码示例(下图)。

High-Performance Physics Solver Design for Next Generation Consoles阐述了当前时单元处理器模型,以及如何并行地处理物理模拟。下面俩图分别是文中提及的流式积分过程以及利用并发DMA和处理来隐藏传输时间:

下面两图是刚体管道并行化的对比图:
为了减少带宽,提升运行效率,可以批处理作业:
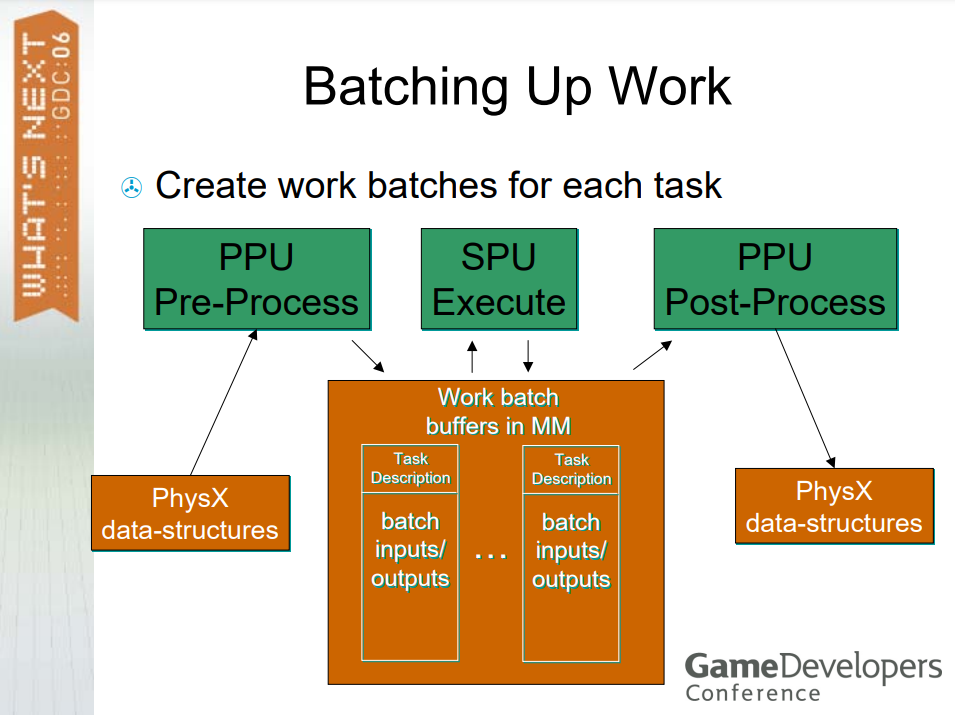
下图是多SPU的并行示意图和性能对比:

另外,文中还给出了高级和低级并行化,下图是低级并行化:
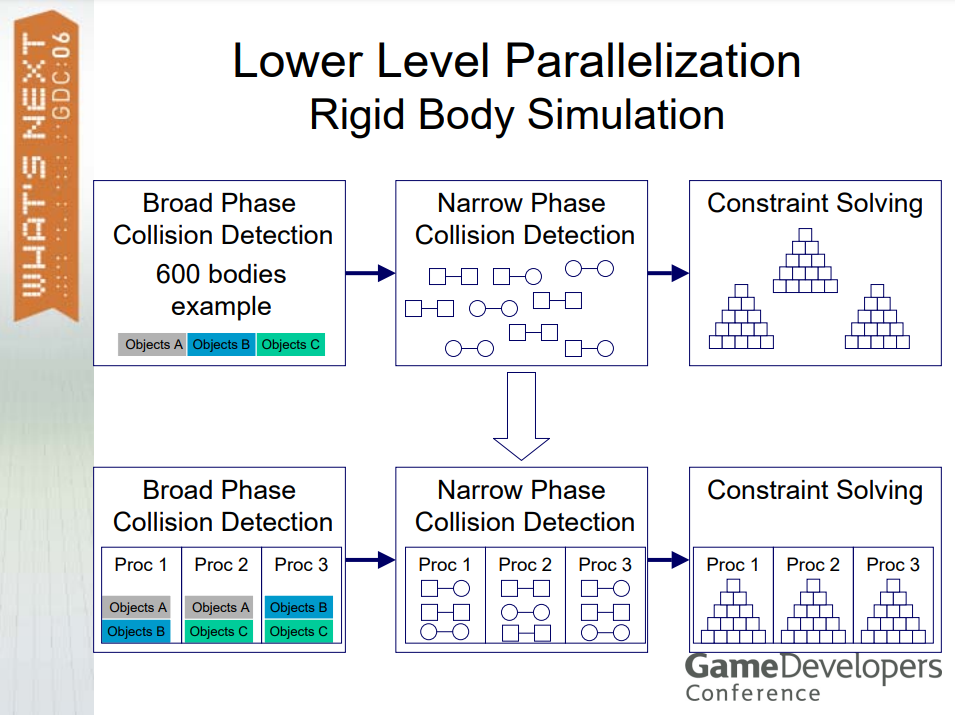
2007年,CPU和GPU的速度提升越来越快,CPU以1.4倍年增长率,而GPU以1.7倍(像素)到2.3倍(顶点)的年增长率。例如,3.0GHz Intel Core2 Duo(Woodcrest Xeon 5160)的计算峰值达到48GFLOPS,内存带宽峰值达到21GB/s,而英伟达GeForce 8800 GTX的计算峰值达到330GFLOPS,内存带宽峰值达到55.2GB/s。
上:CPU和GPU从2001到2007年的速度提升;下:GeForce 8800 GTX的统一着色器架构图。
速度的提升使得应用层有更多的机会执行更多通用的计算,文献General-Purpose Computation on Graphics Hardware便是其中的典型代表。GPU的通用计算包含大型矩阵/向量运算 (BLAS)、蛋白质折叠(分子动力学)、财务建模、FFT(SETI,信号处理)、光线追踪、物理模拟(布料、流体、碰撞……)、序列匹配(隐马尔可夫模型)、语音/图像识别(隐马尔可夫模型、神经网络)、数据库、排序/搜索、医学成像(图像分割、处理),还有很多很多……
文中涉及的内容涵盖GPU架构、数据并行算法、搜索和排序、GPGPU语言、CUDA、CTM、性能分析、GPGPU光栅化、光线追踪、几何计算、物理模拟等内容,可谓内容全面,将GPU的技术内幕和应用细节剖析得鞭辟入里。
当时的GPGPU计算量大,适合大规模并行,为独立操作设计的图形管道,可容忍较长的延迟,深度的前向反馈管道,可以容忍缺乏准确性,擅长并行、算术密集、流内存问题。新功能很好地映射到GPGPU,可以直接访问新 API 中的计算单元,新增的统一着色器可以简化3D渲染管线,提升计算单元的利用率。
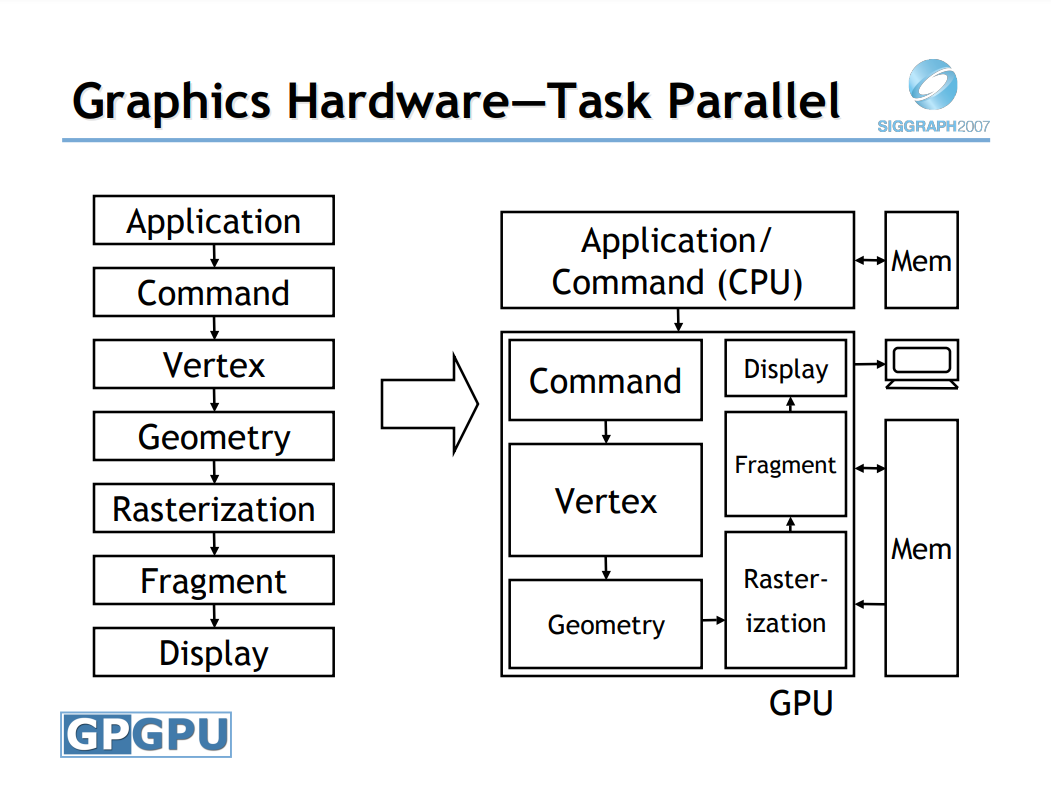
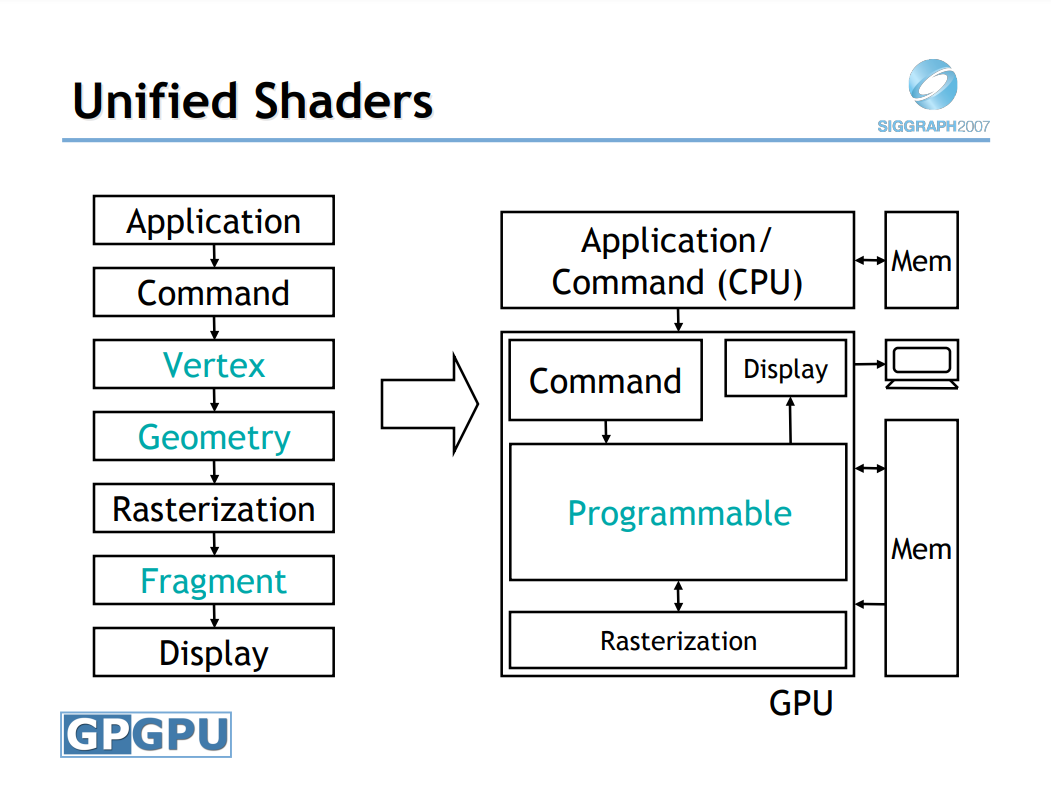
上:任务并行GPU架构;下:统一着色器GPU架构。

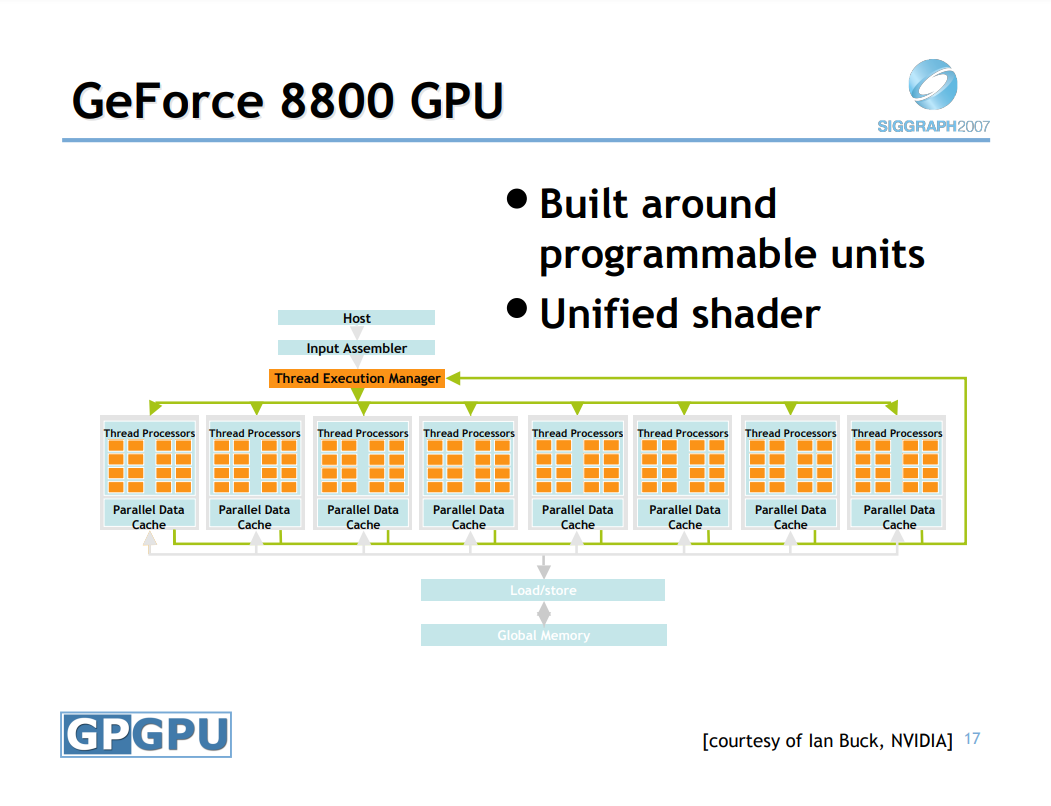
上:Geforce 6800的3D渲染管线,非统一着色器架构;下:Geforce 8800的统一着色器架构。
GPU是各项的混合体,包含历史的、固定功能的能力和新的、灵活的、可编程的功能。固定功能是已知的访问模式、行为,由专用硬件加速。可编程的是未知的访问模式,通用性好。而GPU内存模型必须兼顾两者,结果是充足的专用功能和限制灵活性可能会提高性能。
2007年CPU和GPU的内存架构模型。
GPU的数据结构分类:
- 密集阵列。地址转换:n维到m维。
- 稀疏数组。静态稀疏数组(如稀疏矩阵)、动态稀疏数组(如页表)。
- 自适应数据结构。静态自适应数据结构(如k-d树)、动态自适应数据结构(如自适应多分辨率网格)。
- 不可索引的结构(如堆栈)。
GPU比CPU在内存访问上更受限制,仅在计算之前分配/释放内存,与CPU之间是显式的传输。GPU由CPU控制,无法发起传输、访问磁盘等,因此,GPU更擅长访问数据结构,CPU更擅长构建数据结构,随着CPU-GPU带宽的提高,考虑在其“自然”处理器上执行数据结构任务。
GPU在计算(内核)期间只能有限地内存访问,包括寄存器(每个片段/线程)的读写、本地内存(线程间共享)、全局内存(计算期间只读,计算结束时只写,即预计算地址)以及全局内存(允许一般分散/收集,即读/写,见下图)。
通用计算的典型用例很多,比如合并元素、流数据压缩、扫描、排序等等。



GPGPU通用计算用例。从上到下依次是2D数据合并、流数据压缩、平衡树扫描、双调归并排序。
另外,GPGPU还可用于分组计算:
在GPU并行排序的管线和性能对比如下所示:
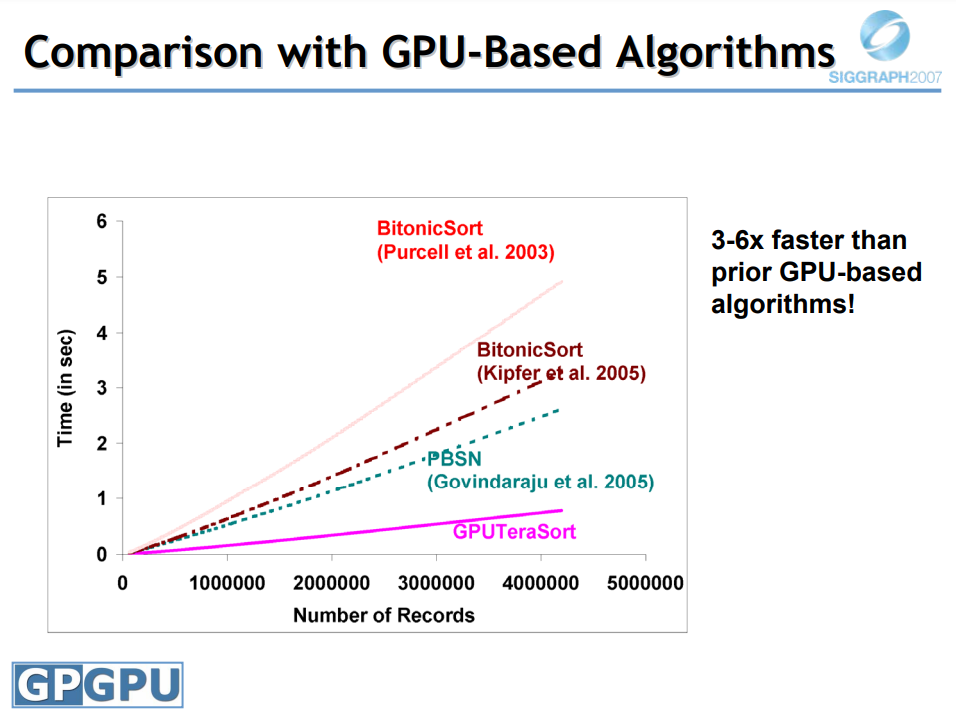
GPU缓存模型的特点是小型数据缓存,以更好地隐藏内存延迟,供应商不披露缓存信息——这对于GPU上的科学计算至关重要。可以设计简单的模型,确定缓存参数(块和缓存大小),提高排序、FFT和SGEMM的性能。缓存高效的算法性能如下图所示:

GPU缓存效率算法性能图例。观测的时间比理论峰值要稍高一些。
下图是CPU、GPGPU、CUDA的缓存模型对比图:

由斯坦福大学研发的开源工具GPUBench可以GPU内存访问的延时细节,如延时是否可隐藏以及访问模式是否会影响延时。具体测量方法是尝试不同数量的纹理提取和不同的访问模式(缓存命中:每次提取到相同的纹素,顺序:每次取指都会将地址加1,随机:随机纹理的相关查找),增加着色器的ALU操作,ALU操作必须依赖以避免优化。下面是不同的访问模式在ATI、NVidia几种GPU的数据获取消耗:


对于Early-Z的测试,通过设置Z缓冲区和比较函数以屏蔽计算,改变块的连贯性,更改块的大小,设置要绘制的不同数量的像素。在NVIDIA 7900 GTX的测试结果如下:
以上显示随机访问的效率最低,4x4块的一致性访问效率最佳。
对于着色器分支,采用测试语句if{ do a little }; else { LOTS of math},并且改变块的连贯性,更改块的大小,有不同数量的像素执行繁重的数学分支。测试结果显示如下:
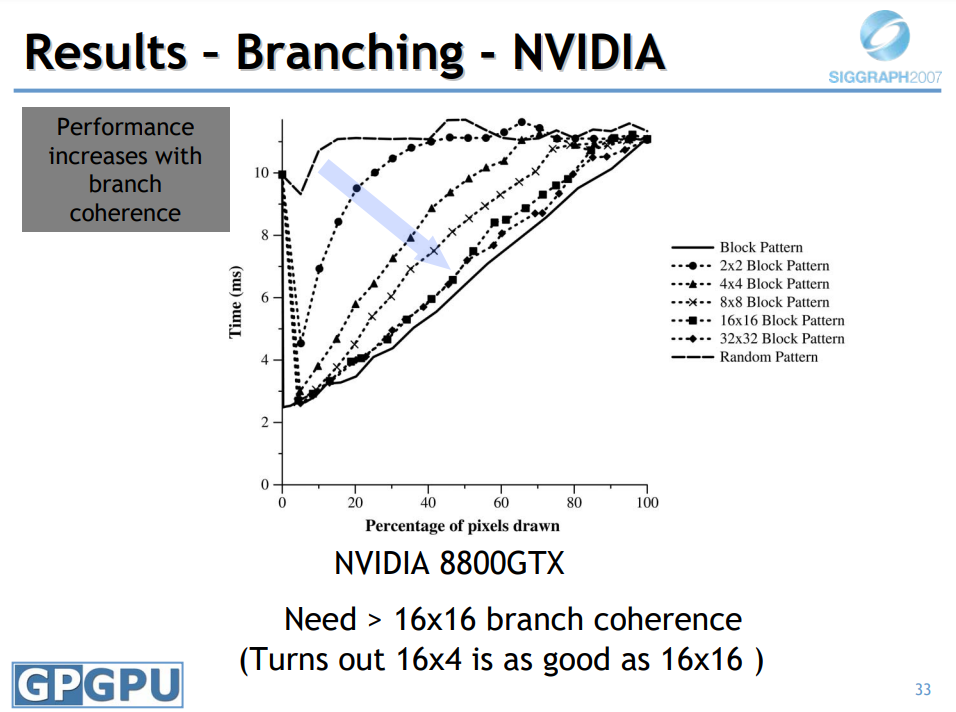
由此可知完全一致的访问拥有最好的性能,随机访问最差。
通用计算还适用于动态总面积表(Dynamic Summed Area Table)。动态总面积表的算法概述:生成动态纹理、反射贴图等,使用数据并行GPGPU计算生成SAT,在传统渲染过程中使用 SAT 数据结构。
SAT可用于光泽反射(模糊度取决于反射物体的距离)和景深(模糊度取决于与眼睛的距离)。

此外,还可用于分辨率匹配的阴影图计算:
Saints Row Scheduler探讨了多线程调度器的概念、架构和性能等主题。文种定义了调度器(Scheduler),认为它是控制流程的机制,类似于函数调用或线程调度,用于管理跨多个线程的独立可调度实体或“作业”的调度,存在很多很多有效的设计,但通常特定于平台/硬件。而作业(Job)是独立可调度的实体,没有顺序或数据,依赖于其它“准备好的”工作,通常是非阻塞的,无需等待I/O、D3D设备、其他异步事件,相当于一个函数指针/数据块对。将应用程序的处理分解为作业是使应用程序多处理器就绪的大部分工作。
调度器设计的准则是尽可能简单尽可能直观,可按应用程序配置,尽可能灵活,高性能/低开销,允许精细的作业粒度,优雅地处理抢先事件的机制。通用哲学是保持电线(wire)悬空,创建和使用构建块,避免高级语言结构。
Saints Row源自单线程应用程序,后有六个硬件线程。初始线程布局:标准模拟/渲染拆分、帧时间变化,约20到50ms,通常约33ms、音频驱动程序每5毫秒使用约2.3毫秒、流式传输活动时,使用整个线程、音频每约30毫秒执行一次。
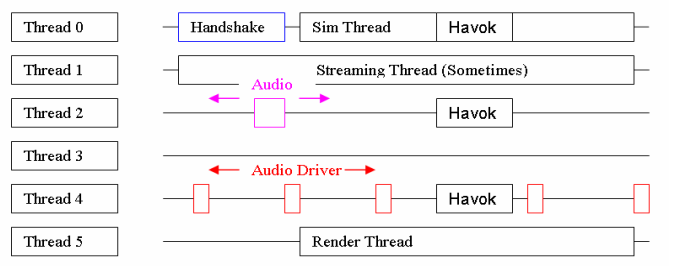
但这样的设计架构存在诸多问题,例如:
- 从其中一个主线程调度大量作业可以独占作业线程, “先到先得”顺序的后果。
- 部分线程减少了带宽:带有DSP/音频驱动程序的线程4仅约65%、线程1可以专用于流式传输、音频和流媒体都是抢先的。
- 组合和预通渲染两个冗长且持续的操作。
- Havok问题,使用自己的线程实用程序,必须为每个线程分配线程内存,经常串行。
Saints Row改进了调度器设计,采用先到先得的顺序,使用FIFO作业Q会产生“自然”的作业处理顺序。存在的问题是从一个主线程调度一大块作业可能会阻塞作业线程,更精细的作业粒度和为工作添加优先级都无济于事。解决方案是添加额外的FIFO作业Q和“作业偏差”,作业线程偏向于提供模拟类型或渲染类型的作业,动态可配置——可以动态更改偏差算法和线程/作业类型,确保每个主线程都有一些工作线程时间。
处理线程的特殊情况:
-
在Sim(模拟)和Render作业之间拆分作业线程。
- Sim在不流式传输时得到0、2 和1。
- Havok仅在0、1和2上运行。
- Render得到3、5和音频处理后剩下的4。
- 在帧的渲染密集部分也得到1和2。
-
组合和PrePass:
- 在主渲染线程上运行prepass,钉住组合通道作业到线程3。
- 最优先的工作。
- 线程3可自由供其它处理线程使用。
-
Havok:
- 带有自己的线程实用程序。无动态控制,每个执行Havok处理的线程都需要Havok线程内存,串行执行约一半的处理。
- 解决方案:
- 将三个线程专用于Havok,仅为这些线程分配线程内存。
- 从调度程序调用Havok时间步长。允许线程控制,在每帧的基础上添加或删除线程,性能与Havok线程实用程序相同。
- 自己分解并分解串行部分。
最终的线程布局是Havok移至前3个线程,固定到线程3的组合通道,在大部分帧期间允许渲染作业,在密集的模拟处理期间允许模拟工作,实际的模拟窗口更复杂,作业可以在主线程空闲时间进行调度。

对应用程序而言,当拆分作业时,最佳作业大小是调度程序开销的功能,设置一些“可接受”的标准,例如“5%或更少的开销”,然后测量每个作业的调度时间,对于Saints Row,最佳大小约为250-500微秒,如果作业需要更长的时间是不可取的。

Saints Row在PIX的时间线显示CPU使用率在90%左右。
Saints Row调度器内部的技术细节补充:
- 由临界区或自旋锁提供所有保护。
- 六个作业线程位于每个硬件线程上。
- 将作业插入作业Q会激活任何空闲的匹配作业线程。事件,而不是信号量,以实现灵活性。
- 作业生成线程可能会挂起并等待调度事件。挂起线程指定可以在他的硬件线程上运行的作业类型。
- 完成后,作业会触发事件(事件触发器)或安排更多作业(调度触发器)。
在性能方面,如果是单作业队列,将作业块移动到作业队列更有效,更灵活地逐个移动。由于线程争用,作业队列是一个重要的开销来源。如果使用临界区保护,可能应该阻塞队列。可以尝试无锁,无锁结构(堆栈、队列)的性能明显优于临界区保护结构,后进先出—— SLists、GPGems 6 堆栈,非常平坦的,先进先出——Michael的浮动节点、Fober的重新插入,谨慎使用。
Dragged Kicking and Screaming: Source Multicore介绍了Source引擎在多核面临的决策、如何利用多核,并提供了算法和范式。
Source引擎多核化的目标是将在Valve的业务中集成多核,无需重新编译即可扩展到内核,提升游戏帧率,将核心应用于新游戏逻辑。当时面临的挑战是游戏需要最大的CPU利用率,游戏本质上是串联的,之前存在着数十年单线程优化经验,已为单线程编写的数百万行代码。多核的策略包含线程模型和线程框架。线程模型又有细粒度线程、粗粒度线程和混合线程三种类型。
在线程安全方面,Source引擎采用高效的线程安全,无同步(“无需等待”),每个线程都有执行操作所需的所有数据的私有副本:处理独立问题的线程、用线程私有数据替换全局变量、重新定向到管道。

Source引擎的无锁的数据线程安全模型:空间分区。其中上图是客户端和服务器共享同一份数据,下图是空间分区,达到无锁的线程安全的目标。
此外,Source引擎用更好的同步工具、技术分析数据访问,例如使用读/写锁的符号表,使用排队函数调用来解耦。Source引擎还采用了混合线程技术,为作业使用适当的方法,例如一些系统在核心执行(例如声音),一些系统以粗粒度的方式在内部拆分。跨核心细粒度拆分昂贵的迭代,当核心空闲时入队一些作业以让它处于忙碌状态。需要强大的技术,最大化核心利用率。
Source的渲染架构和流程如下图:
存在的问题是按视图构建的场景限制了机会,任意对象类型的顺序和任意的代码执行,可以采用模拟和渲染交错,亦即惰性计算优化。迭代变换(如骨骼动画),并行化惰性计算触发器,将骨骼设置重构为每个视图单遍,将所有视图重构为单遍,其他CPU密集型阶段的模式相同。修改后的管道如下:
- 为多个场景并行构建场景渲染列表(例如世界及其在水中的倒影)。
- 重叠图形模拟。
- 并行计算所有场景中所有角色的角色骨骼变换。
- 允许多个线程并行绘制。
- 在另一个内核上序列化绘图操作。
实现混合线程,让程序员解决游戏开发问题,而不是线程问题,使所有程序员能够利用内核。对多数程序员而言,操作系统太过低级别,编译器扩展 (OpenMP)又太不透明,只能使用量身定制的工具:正确的抽象。量身定制的工具包括游戏线程基础设施,定制工作管理系统,使得程序员可以专注于保持核心忙碌。线程池:N-1个线程用于N个内核,支持混合线程:函数线程、数组并行、入队和立即执行。量身定制的工具的目标是使系统易于使用且不易混乱,例如编译器生成的函子(functor),使用模板打包函数和数据,调用点看起来很相似,像串行一样地调用队列化函数,节省时间,减少错误,鼓励实验。下面是Source引擎的几种多线程调用方式:
// 一次性推送到另一个核心
if ( !IsEngineThreaded() )
_Host_RunFrame_Server( numticks );
else
ThreadExecute( _Host_RunFrame_Server, numticks );
// 并行循环
void ProcessPSystem( CParticleEffect *pEffect );
ParallelProcess( particlesToSimulate.Base(), particlesToSimulate.Count(), ProcessPSystem );
// 入队一堆工作项,等待它们完成
BeginExecuteParallel();
ExecuteParallel( g_pParticleSystem, &CParticleSystem::Update, time );
ExecuteParallel( &UpdateRopes, time );
EndExecuteParallel();
对于争用,如果无法消除对共享资源的争用怎么办?例如,分配器被大量使用,多个固定大小的块池,每个池具有自定义自旋锁互斥锁,互斥限制规模,不想采用逐线程的分配器。可以尝试无锁的算法:无论调度或状态如何,都没有线程可以阻塞系统,在所有服务和数据结构的底层,依赖于原子写入指令:比较和交换。
// c++
bool CompareAndSwap(int *pDest, int newValue, int oldValue)
{
Lock( pDest );
bool success = false;
if ( *pDest == oldValue )
{
*pDest = newValue;
success = true;
}
Unlock( pDest );
return success;
}
// asm
bool CompareAndSwap(int *pDest, int newValue, int oldValue)
{
__asm
{
mov eax,oldValue
mov ecx,pDest
mov edx,newValue
lock cmpxchg [ecx],edx
mov eax,0
setz al
}
}
在分配器中使用无锁算法,用每个池的无锁列表替换互斥锁和传统的每个池的空闲列表,需要依赖Windows API或XDK SList等系统API。下面是无锁列表的插入示例代码:
void Push( SListNode_t *pNode )
{
SListHead_t oldHead, newHead;
for (;;)
{
oldHead.value64 = m_Head.value64;
newHead.value.iDepth = oldHead.value.iDepth + 1;
newHead.value.iSequence = oldHead.value.iSequence + 1;
newHead.value.Next = pNode;
pNode->pNext = oldHead.value.pNext;
if ( ThreadInterlockedAssignIf64( &m_Head.value64, newHead.value64, oldHead.value64 ) )
{
return;
}
}
}
无锁列表特别有用在为每个线程提供上下文不切实际时保留上下文结构池,有效地收集并行过程的结果以供以后处理,使用Push() 构建要操作的数据列表,然后使用Detach()(也称为“Flush”)在单个操作中获取另一个线程中的数据。Source的无锁算法细节如下:
- 线程池工作分配队列。源自Half Life 2异步I/O队列,专为一个生产者一个消费者而设计,带有互斥锁的简单优先队列,任意优先级,所有线程的一个队列。
- 解决方案:使用无锁队列,对固定优先级的接口进行返工,每个优先级一个队列,除了共享队列之外,每个核心一个队列,使用原子操作获取“门票”,实际完成的工作可能会有所不同。
- 锁允许一个稳定的现实。
- 无锁允许现实改变指令。
- 利用推理而不是锁定来了解系统的一部分是稳定的。
- 避免等待总是更好。
Source研发人员还呼吁行业建立或获得强大的工具和新技术,采用无锁机制将工作和数据移入和移出无等待代码,准备在多个核心上分解特征,使用可访问的解决方案来授权所有程序员,而不仅仅是系统程序员,根据游戏问题支持更高级别的线程。
Snakes! On a seamless living world阐述了名为Stackless的Python库模拟多线程的一种架构和技术。Stackless具有最少线程管理的 1000 个小任务,超快速上下文切换,强大的异常处理,管理小任务等。它的技术架构如下:
它拥有独立的调度器和事件过滤器:
Threading Successes of Popular PC Games and Engines谈到了游戏引擎多线程化的实际案例,提出了一些多线程化的模型:

操作队列使数据保持本地化,并降低带宽。将数据保存在一个地方,但在其上排队操作,在完美世界中,读取是即时、免费且一致的:
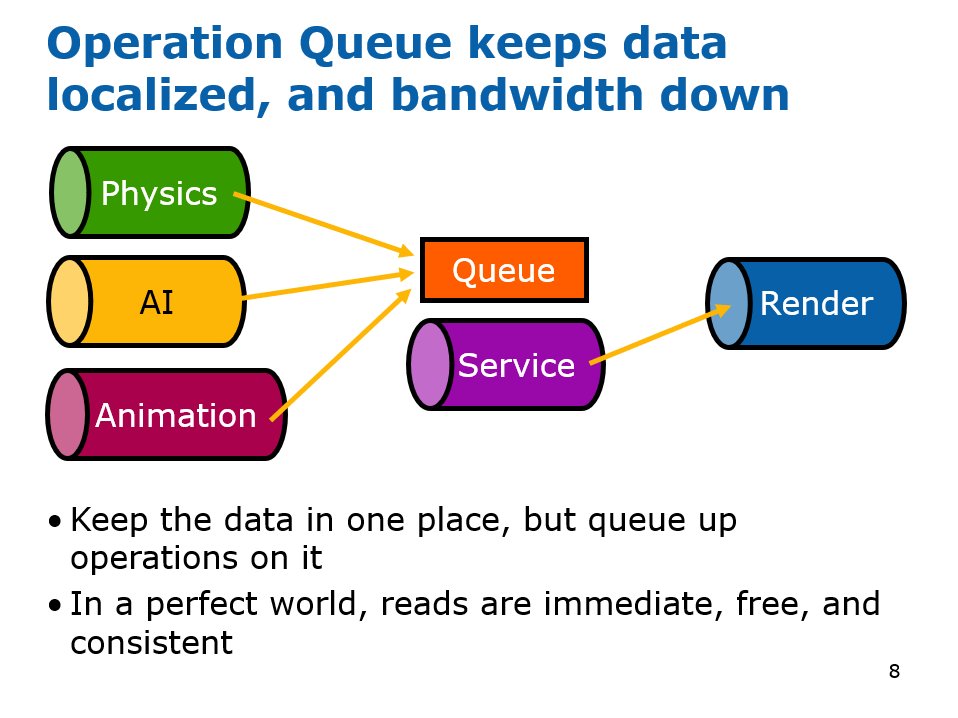
当时的游戏多核化时,需要关注:
- 线程性能。帧率,加载时间,与时间切片相比,更容易平滑帧速率,很常见
- 线程功能。许多可能的CPU密集型效果。
- 使用线程中间件。做任何事情,并扩大规模,很常见,但是它们一起工作的效果未知。
THQ/Gas Powered Games Supreme Commander and Supreme Commander: Forged Alliance也阐述了类似的多线程模型:

以上架构可以很好地适应负载,渲染负载通常会占主导地位,重新渲染以保持帧速率,模拟重的地图将尝试以模拟为主。下图是模拟线程和渲染线程的执行过程图:

内存管理器可以提供额外的提升,如果在线程游戏中不小心管理内存,内存使用可能会破坏缓存 ,内存分配/释放可能很慢。疑似内存管理有问题,例如执行很多小分配,构建代码可以轻松切换内存管理器。自定义内存管理器优于默认的malloc/free,可能会导致一些调试问题。
对游戏引擎进行多线程化时,尽量从一开始就进行线程架构设计,多线程化以前的单线程代码,尽可能解耦线程。不要害怕多线程化单线程代码。
Namco Bandai, EA Partner For Hellgate: London提及了几种并行化作业的技术和案例。他们第一次尝试是采用fork-and-join方法,主线程将在双核上完成一半的工作,专用线程将完成另一半,没有数据复制, 内存是一致的。
第二次尝试:异步更新、同步渲染。异步更新不会阻塞主线程,内存不再一致,当有新位置可用时(可能每一帧),天气粒子会重新绘制。更棘手,但看起来像一个赢家。
所做的代码更改是定义了一个回调来更新天气粒子,使用了现有的作业任务池,创建顶点缓冲区来保存天气粒子,粒子系统被标记为常规或异步。异步系统分为“善良双胞胎”和“邪恶双胞胎”:在绘制过程中,善良双胞胎从最后一帧绘制邪恶双胞胎的粒子,然后为邪恶双胞胎捕获绘制状态;在更新期间,邪恶双胞胎在回调中处理并填充顶点缓冲区。
他们总结到,线程化特性有很大的潜力,每个额外的核心都会在池中提供一个额外的线程,每个额外的线程相当于一个额外的功能。
Project “Smoke” N-core engine experiment分享了项目Smoke的多线程化的经验。该文提及的游戏引擎的一种多线程架构如下:
也认同了2007年关于游戏会多线程化的趋势和走向:
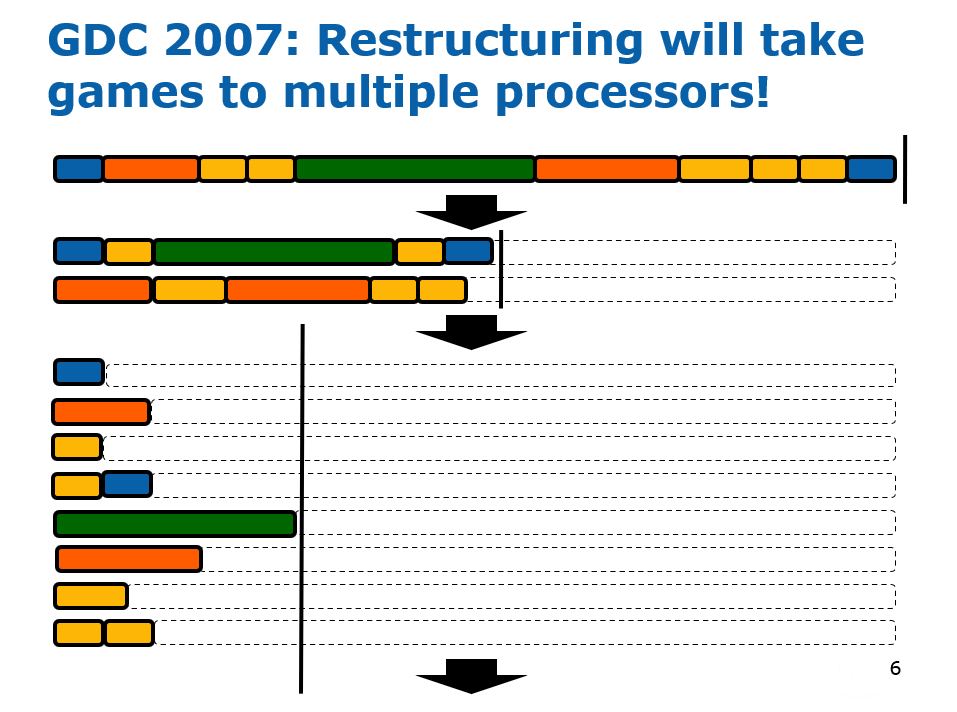
系统订阅更改消息机制如下:
任务的划分、步骤、执行和消息传统如下系列图:
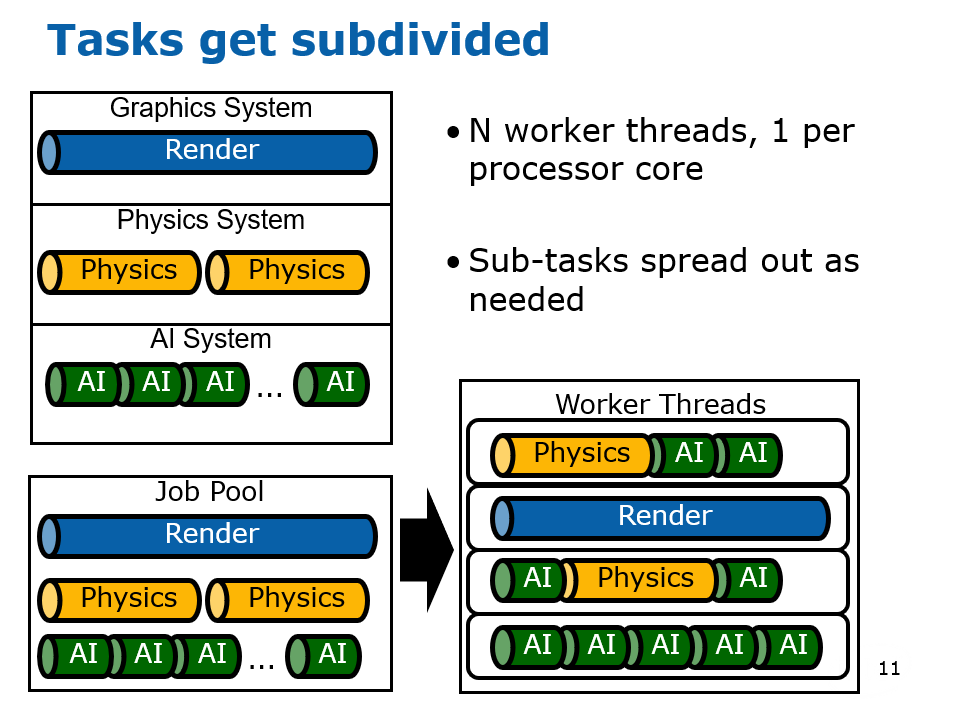
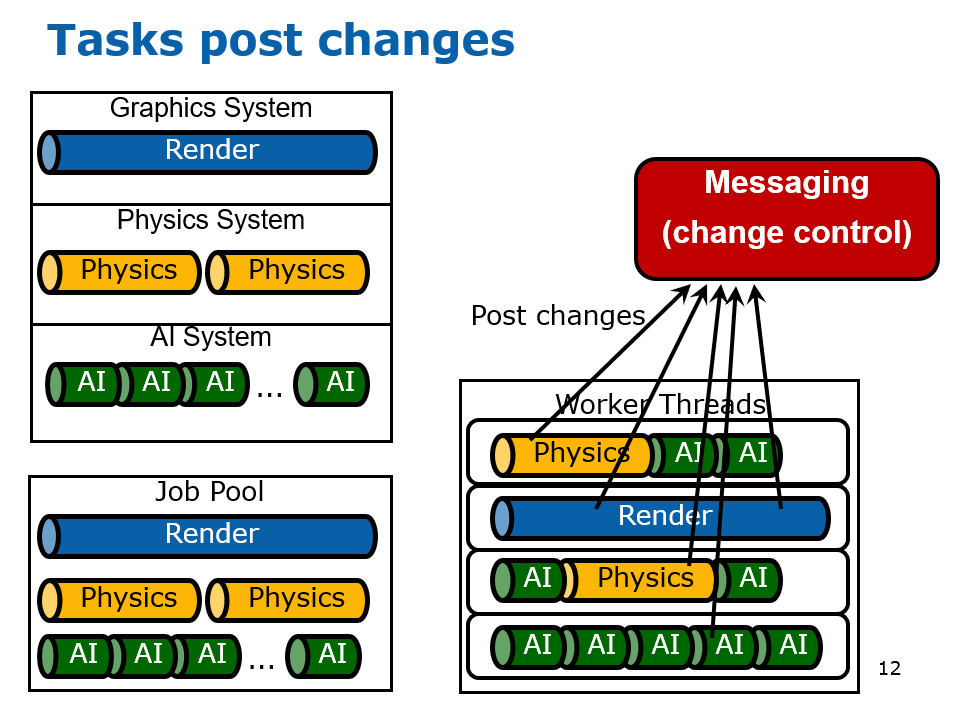
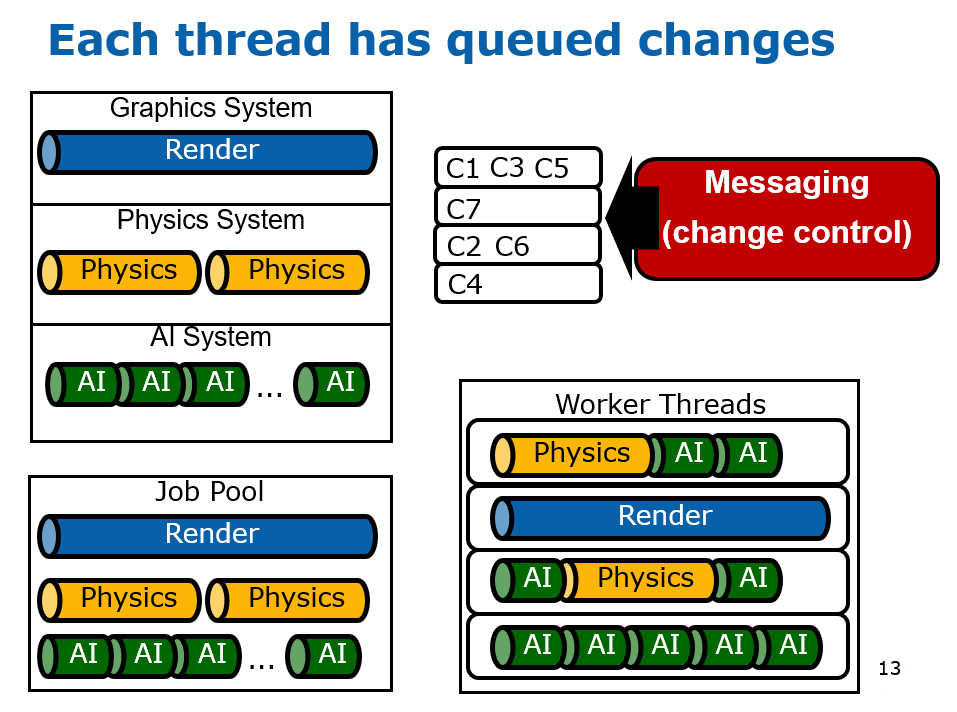
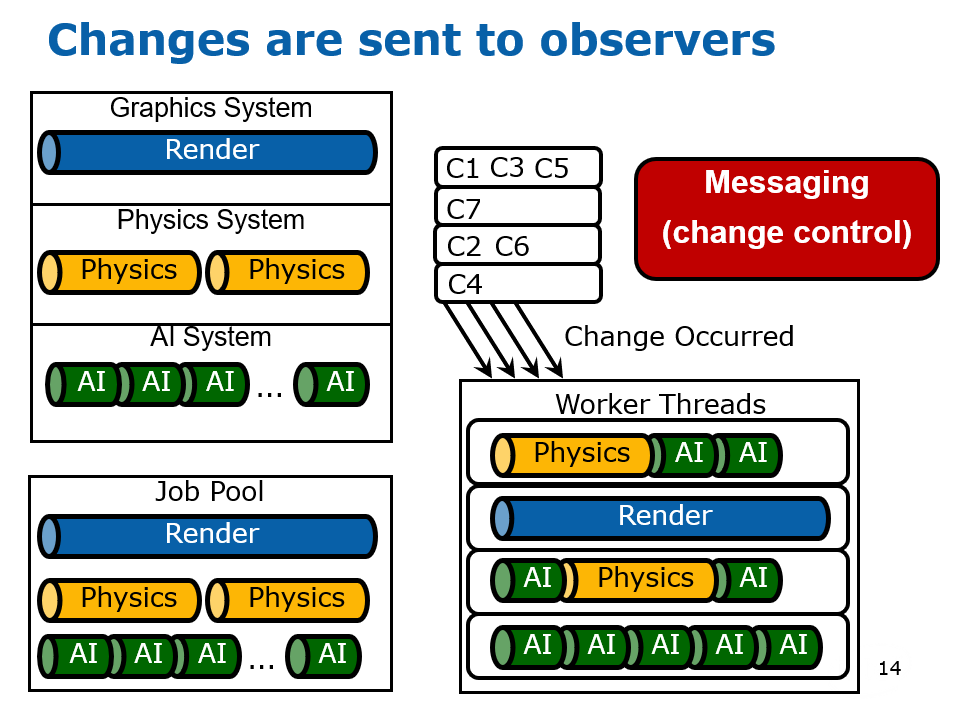
New Dog, Old Tricks: Running Halo 3 Without a Hard Drive谈到了高级IO设计、加载内容、加载过程等技术。该文谈及到了Halo 3为了解决加载冲突,加入了缓存的资源访问状态:
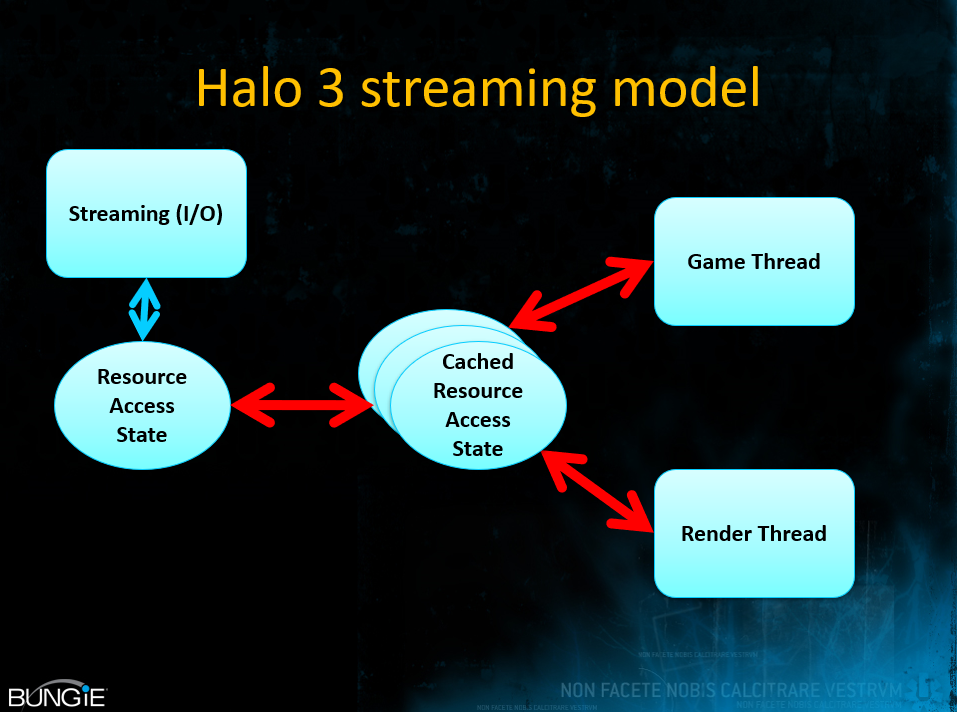
资源访问状态如下所示:

该文还详细探讨了区域集过渡的策略和方法:
资源加载由资源调度器控制,每个优先级生成一个所需的集合,按优先级顺序处理,发出I/O或无法成功时停止处理:
地图则通过优化后的地图布局和共享地图布局重新链接地图文件,从而获得优化后的地图:
2009年,Parallel Graphics in Frostbite – Current & Future阐述了Frostbite在CPU和GPU方面的并行技术,以及如何引入到渲染系统中。在当时,主流的PC已经达到2到8个硬件线程,PS3有2个硬件线程和6个SPU,而Xbox 360也有6个硬件线程。

2009年前后的CELL处理器外观图。
为了充分利用这些硬件线程,Frostbite引入作业系统,将系统划分为作业,带有显式输入和输出的异步函数调用,通常完全独立的无状态函数作业依赖创建作业图,所有核心都消耗作业。
构建大型的CPU作业图时,采用了合批,混合CPU和SPU作业,以降低GPU作业的延时。其中作业依赖性决定执行顺序、同步点、负载均衡、例如有效并行度。
对于渲染,Frostbite大量地将渲染系统划分为作业,渲染作业主要包含地形几何处理、灌木生成、贴花投影、粒子模拟、视锥裁剪、遮挡裁剪、遮挡光栅化、命令缓冲生成、PS3上的三角形裁剪等。大多数渲染作业将转移到GPU,主要是单向数据流的作业。
并行记录命令缓冲区时,将绘图调用和状态并行调度到多个命令缓冲区,使用核心相同的线性扩展,每帧1500-4000次绘制调用,减少延迟并提高性能。在DX11上实现并行命令记录,是减少CPU开销和延迟的杀手级功能,大约90%的渲染调度工作时间在D3D/驱动程序中。实现步骤大致如下:
1、为每个核心创建一个DX11的延迟设备上下文,与动态资源(cbuffer/vbuffer)一起用于延迟上下文。
2、渲染器有想要为帧的每个渲染“层”执行的所有绘制调用的列表。
3、将每一层的绘制调用拆分为大约256 个块(chunk),并且与延迟上下文并行调度,每个块生成一个命令列表。
4、渲染到即时上下文并执行命令列表。
当时的目标是当获得完整的DX11驱动程序支持时,接近线性扩展到八核(现在到 IHV)。
对于遮挡剔除,不可见的物体仍然必须更新逻辑和动画、生成命令缓冲区、需要在CPU和GPU上两端处理,部分物体难以实现全剔除,例如可破坏的建筑物、动态遮挡、难以预先计算、GPU遮挡查询的渲染可能很繁重。
面对以上的遮挡剔除问题,Frostbite的解决方案是使用软件遮挡光栅化。分为两大步骤:
- 在SPU/CPU上光栅化粗糙的zbuffer。256x114浮点,非常适合SPU LS(局部缓存),但可能是16位,低多边形遮挡网格,手动设置保守,100米的视距,最大10000个顶点/帧,并行SPU顶点和光栅作业,消耗在几毫秒。
- 然后根据zbuffer剔除所有对象。在传递给所有其它系统之前,以获得较大的性能提升,屏幕空间边界框测试。

来自《Battlefield: Bad Company》PS3 的图片和粗糙z-buffer。
除了软件遮挡剔除,Frostbite还支持GPU遮挡剔除。理想情况下需要GPU光栅化和测试,但是遮挡查询引入开销和延迟(可以管理,但远非理想),条件渲染只对 GPU 有帮助(不是 CPU、帧内存或绘图调用)。当时待探索的目标有两个:
-
低延迟额外GPU执行上下文。在它所属的 GPU 上完成光栅化和测试,与CPU锁步,需要在几毫秒内读回数据,在所有硬件上需要LRB上是可能的。
-
将整个剔除和渲染移至GPU。世界代表,剔除、系统、派遣,也是最终目标。
在延迟光照方面,Frostbite还采用了屏幕空间的分块分类(Screen-space tile classification),具体步骤如下:
-
将屏幕分成小块并确定有多少和哪些光源与每个小块相交。
-
仅对每个小块中的像素应用可见光源。在单个着色器中使用多个光源降低带宽和设置成本。
对屏幕进行分块之后,可以方便地和计算着色器协调工作,从而一次性完成工作。此方法已用于顽皮狗的Uncharted(下图)和SCEE PhyreEngine。

来自“The Technology of Uncharted”的屏幕空间分块技术,GDC'08。
在屏幕空间分块的基础上,便可以实现基于CS的延迟着色。使用 DX11 CS 进行延迟着色,在Frostbite 2中的实验性地实现,未经生产测试或优化,需要计算着色器5.0,假设没有阴影。
新的混合图形/计算着色管道:
- 图形管道光栅化GBuffer,用于不透明表面。
- 计算管道使用GBuffer,剔除光源,计算光照,并组合着色结果。
计算着色器的步骤有:
- 加载GBuffer和深度。
- 计算线程组/分块中的最小和最大Z。
- 确定每个分块的可见光源。
- 对于每个像素,累积来自可见光的光照。
- 结合光照和阴影反照率/参数。
每个步骤又有较多的细节,详情可以参看论文或4.2.3.2 Tiled-Based Deferred Rendering(TBDR)。利用此技术可以支持场景的海量光源照明:

基于CS延迟着色的优缺点如下:
-
优点:
- 恒定和绝对最小带宽。
- 仅读取GBuffer和深度一次!
- 不需要中间光缓冲器。
- 使用HDR、MSAA和颜色镜面反射会占用大量内存。
- 扩展到大量的大重叠光源!
- 细粒度剔除 (16x16)。
- 仅ALU成本,良好的未来扩展性。
- 可能对积累VPL(虚拟点光源)有用。
- 恒定和绝对最小带宽。
-
缺点:
-
需要支持DX11以上的硬件。
- CS 4.0/4.1由于原子性和分散的组共享写入而变得困难。
-
剔除小光源的开销。
- 可以使用标准光体渲染来累积它们。
- 或单独的CS用于tile-classific。
-
潜在性能。
- MSAA纹理加载/UAV 写入可能比标准PS慢。
-
无法输出到MSAA纹理。
- DX11 CS UAV限制。
-
总之,良好的并行化模型是良好游戏引擎性能的关键,混合任务和数据并行CPU和SPU作业的作业图非常适合Frostbite,其中SPU-jobs 做繁重的工作。通过充分利用DX11进行高效的互操作性,Frostbite开启了混合计算/图形管道的全新尝试和技术里程。此外,Frostbite还期望一个用户定义的流式传输管道模型,富有表现力和可扩展的带有队列的混合管道,专注于数据流和模式,而不是进行顺序内存传递。
Parallelizing the Physics Pipeline : Physics Simulations on the GPU则讲述了如何利用GPU进行并行化模拟物理的技术,包含刚体、流体、粒子等的物理参数、行为及碰撞。步骤概览如下:
- 粒子值的计算。对于每个粒子:读取刚体的值并写入粒子值。
- 网格生成。
- 碰撞检测和反应。对于每个粒子:从网格中读取邻居,写入计算的力(弹簧和阻尼器)。
- 更新动量。对于每个刚体:总结粒子的力并更新动量。
- 更新位置和四元数。对于每个刚体:读取动量,更新之。
上述步骤中涉及了格子生成、GPU树形结构遍历及动态生成等技术。下图描述了如何在GPU中用历史标记遍历树状结构的优化技术及和堆栈的性能对比图:

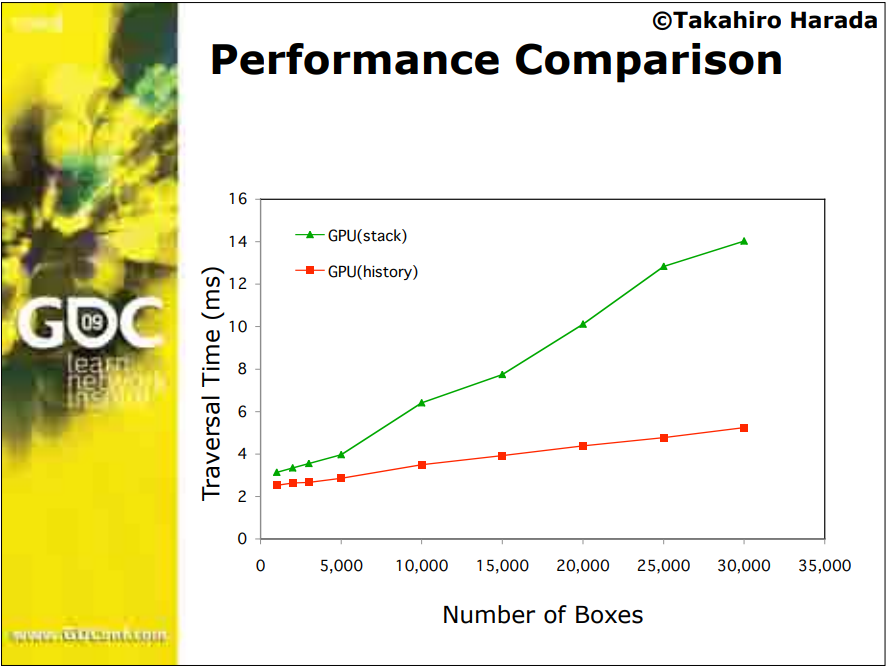
该文还提到了并行更新问题:如果一个刚体碰撞到另一个刚体,没问题;如果一个刚体与多个刚体发生碰撞,则无法并行更新。解决方案是合批,不同时更新所有内容,将它们分成几批,按顺序更新批次,以便并行更新批量碰撞。在GPU创建合批相比CPU并非易事,需要结合当时GPU的特点按照特定的策略并行地创建批次:

此外,该文还探讨了多GPU协调执行物理模拟的策略和实践:

上:设计多GPU并行模拟物理效果;下:不同GPU数量的性能对比。
id Tech 5 Challenges - From Texture Virtualization to Massive Parallelization阐述了id Tech 5的GPU虚拟纹理、用虚拟纹理并行化作业系统、将作业迁移到 (GP) GPU等。虚拟纹理技术概览如下图:
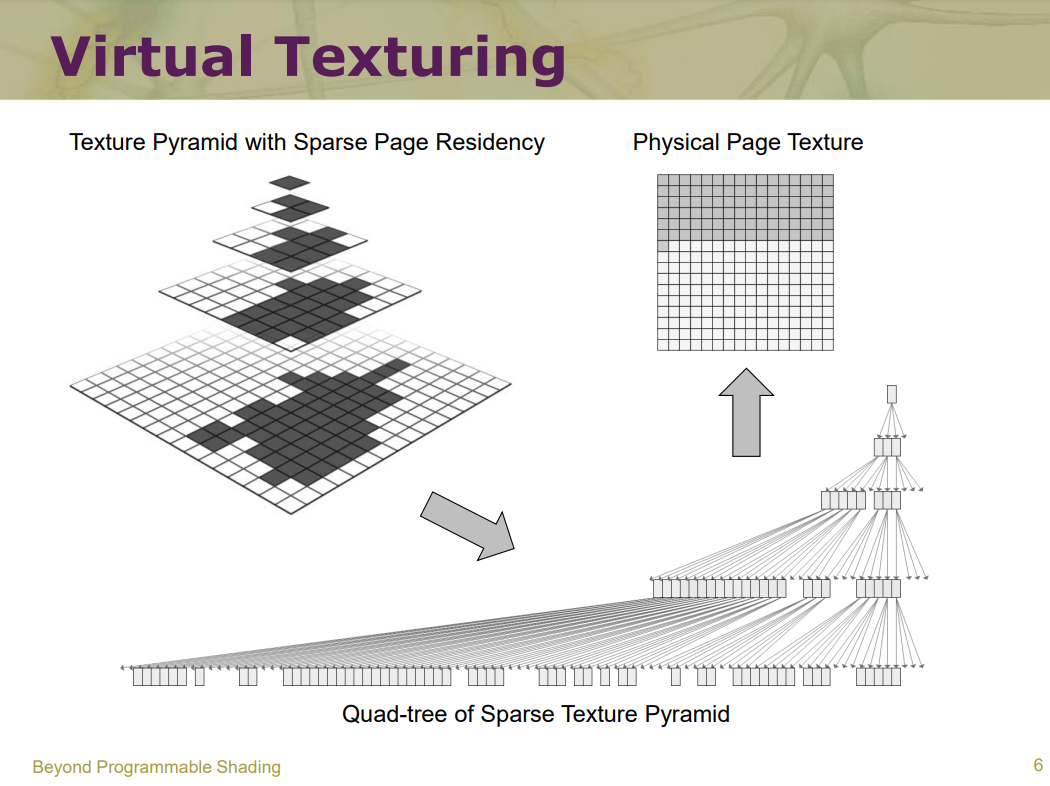
虚拟纹理可视化:

回馈信息分析告知需要哪些页面,由于是实时应用程序,所以不允许阻止。缓存处理命中、调度未命中以在后台加载,独立于磁盘缓存管理的常驻页面,物理页面组织为每个虚拟纹理的四叉树,免费、LRU 和锁定页面的链表。虚拟纹理的回馈分析时,生成相当于带优先级的广度优先四叉树顺序:

具有依赖关系的计算密集型复杂系统,但id希望在所有不同平台上并行运行。虚拟纹理的管线如下所示:

id Tech 5的作业处理系统强调简单性是可扩展性的关键,作业有明确的输入和输出,独立无状态、无停顿、始终完成,添加到作业列表的作业,具有多个作业列表,工作作业完全独立,通过“信号”和“同步”令牌简单同步列表中的作业。

但是,同步意味着等待,等待破坏了并行性。架构决策:作业处理需要1帧延迟才能完成,作业结果迟到一帧,需要一些算法操作(例如 叶子),排除一些算法(例如透明度排序的屏幕空间分箱),但总的来说,不是一个糟糕的妥协。
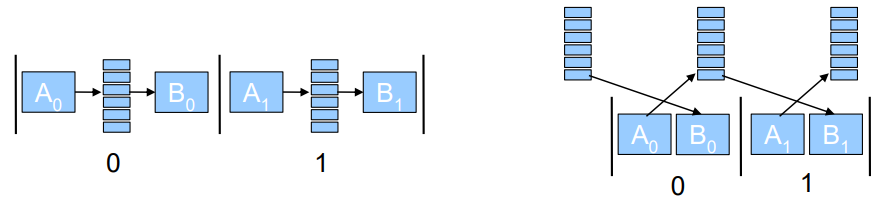
id Tech 5作业化的子系统包含碰撞检测、动画混合、避障、虚拟纹理、透明度处理(树叶、颗粒)、布料模拟、水面模拟、细节模型生成(岩石、鹅卵石等)等。
对于(GP) GPU 上的作业,没有足够的工作来填补SIMD / SIMT通道,不同工作的代码路径分歧太大,作业作为工作单元很有用(延迟容忍和小内存占用),需要利用工作中的数据并行性。将作业拆分为许多细粒度的线程,输入中的数据依赖性,输出数据的收敛,细粒度线程的内存访问很重要。
A Novel Multithreaded Rendering System based on a Deferred Approach介绍了为多线程渲染而设计的渲染系统的架构,遵循延迟渲染方法的架构实现在双核机器上显示了65%的提升。
游戏通常有25%到40%的帧时间用在D3D运行时和驱动程序,如果在渲染场景时引擎可以处理其它事情,那么开销就不会成为问题。但是,由于图形系统需要共享数据在其工作时保持不变,其它引擎系统会被阻塞,因此,如果图形系统是单线程的,则应用程序会浪费大量的CPU功率。该文讨论的系统架构旨在利用所有CPU内核创建命令缓冲区,以尽快将共享数据的所有权归还给其它系统,一旦创建了缓冲区,update系统就可以再次运行,而只有一个图形线程仍将命令缓冲区提交给GPU。下图说明了所描述的流程:

该文还对渲染状态进行了封装,以在不同平台进行差异化实现:
图形管理器是抽象层的中心类,负责初始化线程池,并随后为它们提供来自应用程序的工作。对于创建的每个线程,都会实例化并分配一个上下文,这种所有权贯穿线程的整个生命周期。更改上下文的所有权是不可能的,因为不同的线程可能永远不会调用相同的上下文。(下图)

下图显示了渲染引擎使用多线程图形管理器与常见的单线程解决方案获得的每秒帧数。单线程结果由标题为ST的绿色条显示,多线程的由标题为MT的红色条表示。横坐标表示物体数量,竖坐标表示帧数。
上图显示,在物体数量少的情况下,多线程的帧数反而有轻微的下降,但随着物体数量增加,多线程的优势凸显,当物体达到2006个时,多线程的帧数是单线程的1.7倍。
Regressions in RT Rendering: LittleBigPlanet Post Mortem分享了游戏LittleBigPlanet使用的技术,包含顶点动画、配置检测、Cluster、阴影、接触AO、精灵光源、耶稣光、双层透明、DOF、运动模糊、水体、流体等技术。
Cluster是无网格(mesh-less)算法:最小二乘法将新的刚性矩阵拟合到变形的顶点云:
- 移除质心 - 给出平移分量。
- \((\text{P} - \text{COM}) \ \times \ (\text{P}_{\text{rest}} - \text{COM}_{\text{rest}})\) 的二元矩阵和。
- 乘以静止姿势中预先计算的矩阵的逆。
- 正交化得到的最佳拟合矩阵以提供仿射变换,并可选择通过归一化来保留体积。
- 与原始刚体矩阵混合,根据需要制作出柔软/刚硬的形状。
更多细节参见:Meshless Deformations Based on Shape Matching。
LittleBigPlanet为角色添加了一个AO光,可以分析计算建模为5个球体(2个脚、2 条腿、1个腹股沟)的角色的遮挡,具体推导见:sphere ambient occlusion - 2006。

接触AO的原理(上)及开启前后的效果对比(下)。

精灵光源效果。

双层半透明效果。

水体网格。
Zen of Multicore Rendering分享了当时多核控制台硬件的有效渲染技术的编译和实践。
该文提到,多核时代的处理能力相比上一代:70倍三角形吞吐量、450倍像素填充率、390倍纹理速率、110倍带宽、16倍显存。
填充率是通过完全异步的乱序VPU(矢量处理单元)计算来实现的,在Larrabee上,每个核心有4个硬件线程,每个线程都乱序,但是对于一个线程的执行,顶点和像素是同步的。所以基本上有256个乱序进程,每个都由一组大约16个同步的像素或顶点组成,在任何时候都在运行中。预期着色器触发器将增长最多,速度不是来自更高的时钟频率,来自大量低功耗内核的速度,内存预计不会赶上着色器flops。ALU或VPU增加300倍,未来受纹理获取限制而不是ALU,同构计算让ALU或VPU忙于缓存一致的本地数据。
多核的影响或应用有动态几何的遮挡、动态可见性计算、空间变化的BRDF、高频照明、高品质分辨率、删除剩余的妥协等。实用技巧包含定向光照贴图基础、区域谐波、屏幕空间环境遮挡、阴影贴图等。其中动态辐照亮度的计算流程如下:

上图的小波辐射缓存(Wavelet radiance cache)包含3个步骤:Haar wavelet基、可见性、辐射分解。对于Haar wavelet基,球面谐波不是可用于辐射传输的唯一基,辐射度和区域光的总和也可以用Haar小波表示。Haar小波的辐射可见的三重积分足够快,可以在GPU上实时运行。
Haar Wavelet。
对于2D Haar小波和可见性,可见性函数 V(x, theta) 也是一个二元函数,将可见性乘以小波辐射是在空间和物理上打开和关闭小波方程的一部分。小波辐射度和可见度乘积的积分也简化了运行时间方程,在某些方面,球谐函数是定向光照图中基的频率校正分布,带状谐波正确地采样和存储辐射贡献,而不偏向于一个方向。
可以利用多核的不仅仅是阴影,还有完整的辐射照明模型,每个通道不是一盏灯,在tfetchCube中有效地采样稀疏小波数据。在计算辐射度的过程中,需要使用主成分分析(Principal Components Analysis,PCA)来降维简化计算,下图是PCA之后的复杂输入数据,PCA所做的是提取正交变量及其结果分布:

14.3.3.3 移动生态
游戏开发者杂志Game Developer - October 2005中出现了基于手机的游戏开发教程(下图)。该杂志提到,在手机游戏中创建炫酷的3D效果比想象中容易。在索尼爱立信开发者世界,可以找到加快移 JavaTM 3D开发速度所需的一切,从技术文档到响应式技术支持,还有Mascot Capsule v3 和 JSR-184 (m3g) 的移动插件,可以让开发者使用最喜欢的工具(如3D Studio Max、Maya 和 Lightwave)。

随着OpenGL ES的发展及移动设备的完善,移动生态初见苗头,而The Mobile 3D Ecosystem正是详细全面地阐述了2007年移动平台的技术和生态。该系列文中紧紧围绕着OpenGL ES 1.x和2.0展开讨论,描述了它的特点和应用。该文说到2007年将达到30亿移动用户,
到2009年,无线宽带用户将超过10亿,到2010年,60亿人口中的90%将拥有移动网络。
移动设备的特点是功率是最终瓶颈,通常不插在墙上,只有电池,电池不遵循摩尔定律,每年仅5-10%的容量提升。Gene定律(Gene’s law)表明随着时间的推移,集成电路的功耗呈指数级下降,意味着电池将持续更长时间。自1994年以来,运行IC所需的功率每2年下降10倍,但是2年前的性能还不够,需要提高速度,并尽可能省电。另外的制约因素则是散热和显示屏。


2005年之后的常见移动设备(上)和画面演变(下)。
当年的移动端图形API的架构图如下:
OpenGL ES 1.0的特点是保留OpenGL结构,消除不需要(冗余/昂贵/未使用)的功能,保持紧凑和高效,小于50KB的占用空间,无需硬件 FPU。另外,它推动创新,允许扩展,协调它们,与其它移动3D API (M3G / JSR-184) 保持一致,被Symbian OS、S60、Brew、PS3 / Cell architecture等系统支持。此时的渲染管线如下:
OpenGL ES 1.1新增了缓冲区对象、更好的纹理(大于2个纹理单位、组合 (+,-,interp)、dot3 凹凸、自动mipmap生成)、用户裁剪平面、点精灵(粒子作为点而不是四边形,随着距离减小尺寸)、状态查询(启用状态保存/恢复,适用于中间件)。下面是部分移动GPU的参数和特性:



当时的移动设备类型和平台繁多,表现在:
- CPU的速度和可用内存各不相同。电流范围30Mhz到600MHz,ARM7至ARM11,无FPU。
- 不同的分辨率。QCIF (176x144) 到VGA (640x480),在高端设备上抗锯齿,每通道颜色深度4-8 位 (12-32 bpp)。
- 可移植性问题。不同的CPU、操作系统、Java VM、C编译器……
GPU的图形功能包含:
- 通用多媒体硬件。纯软件渲染器(全部使用 CPU 和整数 ALU 完成),软件 + DSP / WMMX / FPU / VFPU,多媒体加速器。
- 专用3D硬件。软件T&L+硬件三角形设置/光栅化、全硬件加速。
- 性能:50K – 2M tris、1M – 100M像素/秒。
OpenGL ES可以充当硬件抽象层,提供编程接口(API)和不同设备的相同功能集以及统一的渲染模型(但无法保证性能)。

OpenGL ES 1.x渲染效果。
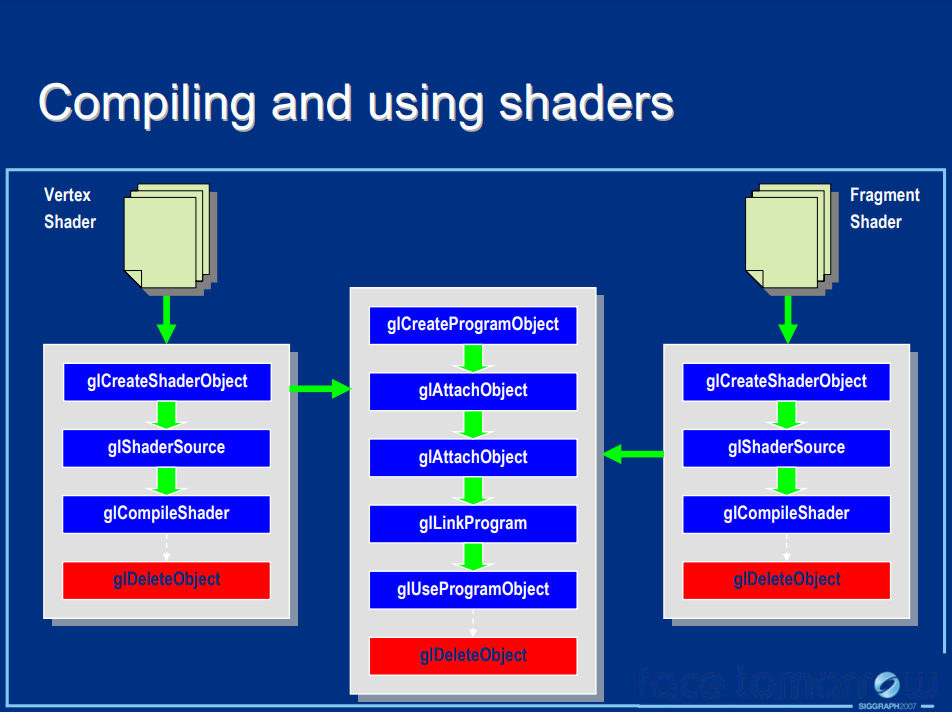
OpenGL ES使用Shader步骤。

移动游戏Playman Winter Games – Mr. Goodliving的2d和3d画面截图。
下面两个显示了当时的普通游戏开发过程和使用M3G框架的移动游戏开发过程:
下图是M3G框架在高中低端设备的架构图:

OpenGL ES 2.0发布初期,游戏开发者面临的难题是需要在新硬件之前开发他们的游戏引擎,OpenGL ES 2.0可能需要手持开发者显着改变他们的引擎,基于着色器的API将更多负担转移到应用程序,通过可编程性实现更大的灵活性。但可以通过OpenGL ES 2.0 Emulator和Render Monkey(下图)模拟渲染效果。
当时AMD的Sushi引擎率先支持了Open ES 2.0的集成,面临的主要挑战是设计一个引擎以针对具有不同功能集的多个API,设计基于着色器的引擎,平台兼容性,手持平台功能差异很大,各类限制使便携性成为挑战。
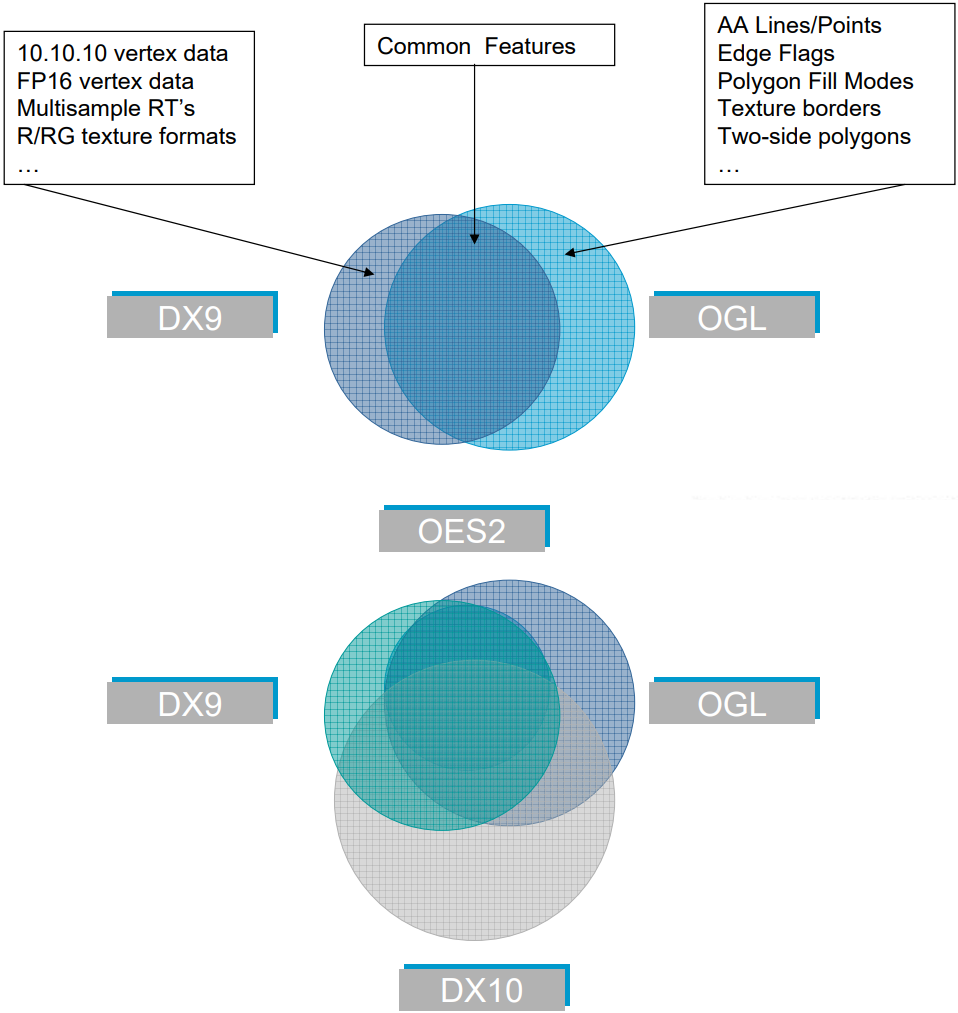
上:2005年,Sushi对DX9功能集进行了抽象,使用扩展来支持OpenGL中缺少的功能;下:2007年,图像API多了几种,选择不再那么容易,特别是如果将游戏机添加到组合中……
当时的Sushi引擎抽象API由需求驱动:必须使用所有API的最新功能,公开最小公分母不是一种选择,在每个API上运行相同的演示不是必需的,让内容驱动功能集而不是API抽象。API抽象之后看起来很像DX10:资源、视图、几何着色器、流输出、所有最新和最强大的功能......每个API实现都支持这些特征的一个子集。API抽象还存在回退(fallback)路径:引擎基于使用Lua的脚本系统,Lua脚本提供后备渲染路径。对Sushi来说,权衡高端功能与内容可移植性是良好的折衷。
手持平台有很多限制:没有标准模板库、没有C++异常、手动清理堆栈、不完整的标准库、有限的内存占用、无浮点单元等。Sushi为了保障平台可移植性,采用了标准抽象层(数学、I/O、内存、窗口等)、自定义模板类(列表、向量、映射表等)、限制使用C++(没有异常和STL)。
14.3.4 渲染技术
本节将阐述20000时代诞生的部分重要渲染技术。
14.3.4.1 Spherical Harmonic
- SH基础
Spherical Harmonic(SH)译为球面谐波、球谐、球谐函数,定义了球体\(S\)上的正交基,类似于一维圆上的傅立叶变换。
球体\(S\)如果使用卡迪尔坐标系和球面坐标系的参数化公式分别如下所示:
球面基函数定义为:
其中\(l\)是阶数(band index,另称波段索引),\(m\)是阶数内的索引(\(-l \le m \le l\)),\(P_{\ell }^{m}\)是相关的勒让德(Legendre)多项式。假设\(K_l^m\)是如下形式的归一化常数:
上述定义构成复基,通过简单的变换得到一个实数基:
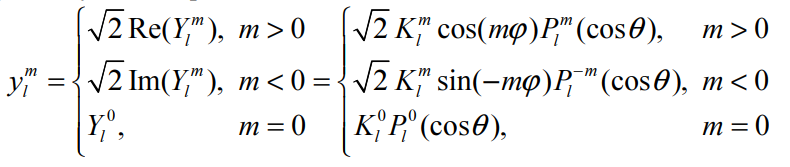
将\(K_l^m\)代入\(Y_{\ell }^{m}(\theta ,\varphi )\)之后,可得:
下图是\(l=6\)时(前7阶)的SH正交基的可视化:

还存在半球谐函数:

- SH投影和重建
因为SH基是标准正交的,定义在球体\(S\)上的标量函数\(f\)可以通过积分投影到它的系数中:
有些论文用其它类似的形式和起点不一样的\(i\)的投影公式(但本质是一样的,只是表现形式不同):
这些系数提供了\(n\)阶重建函数:
随着阶数\(n\)的增加,它越来越接近\(f\),低频信号只需几个SH频段即可准确表示,较高频率的信号通过低阶投影进行阶限(bandlimited,即平滑无走样)。投影到\(n\)阶涉及\(n^2\)个系数,根据投影系数和基函数的单索引向量重写$\overset{\frown} {f} $通常很方便,通过:
其中\(i=l\ (l+1)+m+1\)。这个公式很明显,在\(s\)处对重构函数的评估表示\(n^2\)分量系数向量\(f_i\)与评估基函数\(y_i(s)\)的向量的简单点积。

SH投影例子。取一个由两个面光源组成的函数,SH将它们投影到4个band=16个系数中。

对于低频信号(图中是低频光源),可以重建信号,仅使用这些系数来找到原始信号(光源)的低频近似值。

SH信号重建就是简单地线性组合各个SH基函数和对应系数的乘积。
- SH性质
SH投影的一个关键特性是它的旋转不变性, 也就是说,给定\(g(s)=f(Q(s))\),其中\(Q\)是\(S\)上的任意旋转,然后满足:
类似于一维傅立叶变换的平移不变性。实际上,此属性意味着当来自\(f\)的样本在一组旋转的样本点处收集时,SH投影不会导致走样失真。
SH投影具有旋转不变性。
SH基的正交性提供了有用的性质,即给定\(S\)上的任意两个函数\(a\)和\(b\),它们的投影满足:
换句话说,阶限(bandlimited)函数乘积的积分简化为它们的投影系数的点积。
将圆对称核函数\(h(z)\)与函数\(f\)的卷积表示为\(h*f\)。注意,\(h\)必须是圆对称的(因此可以定义为\(z\)而不是\(s\)的简单函数),以便将结果定义在\(S\)而不是高维旋转组\(SO(3)\)上。卷积的投影满足:
换句话说,投影卷积的系数是单独投影函数的简单缩放乘积。注意,因为\(h\)是关于\(z\)的圆对称,所以它的投影系数仅在\(m=0\)时是非零的。卷积特性提供了一种使用半球余弦核对环境贴图进行卷积的快速方法,定义为\(h(z)=max(z, 0)\),以获得辐照度贴图,其中\(h_l^0\)由解析给出公式。卷积特性还可用于生成具有较窄内核的预过滤环境图。
一对球面函数\(c(s)=a(s)b(s)\)其中\(a\)已知和\(b\)未知的乘积的投影可以看作是投影系数\(b_j\)通过矩阵\(\widehat{a}\)的线性变换:
其中对重复的\(j\)和\(k\)索引隐含求和。注意\(\widehat{a}\)是一个对称矩阵,\(\widehat{a}\)的分量可以通过使用从著名的Clebsch-Gordan系列推导出的递归对基函数的三重积进行积分来计算。它也可以使用数值积分来计算,而无需事先对函数\(a\)进行SH投影。请注意,乘积的\(n\)阶投影涉及两个因子函数的系数,最高可达\(2n-1\)阶。
球谐函数是球面上的一个带符号的正交函数系统,由函数表示在球坐标系中,可由球面坐标或隐式的卡迪尔坐标表示。

SH函数是基函数,基函数是可用于产生函数近似值的信号片段:
我们可以使用这些系数来重建原始信号的近似值:
对于SH光照,主要使用直接作用于系数本身的操作。
SH函数是正交基函数,是具有特殊性质的函数族,就像不重叠彼此足迹的函数,有点像傅里叶变换将函数分解为分量正弦波的方式。
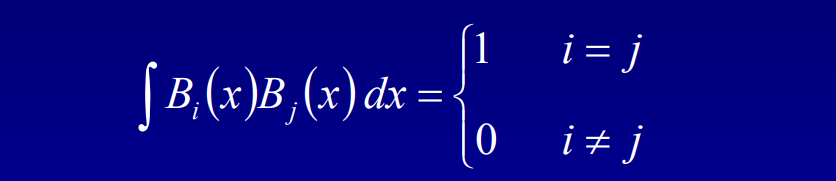
- SH光照
SH是一种有效的方法来捕获和显示一个对象的表面上的全局照明解决方案,常用于带动态光照的静态模型,渲染速度非常快,与光源的数量和大小无关,免费的高动态范围光照,是漫反射照明的临时替代品。
我们已知光照渲染方程如下:
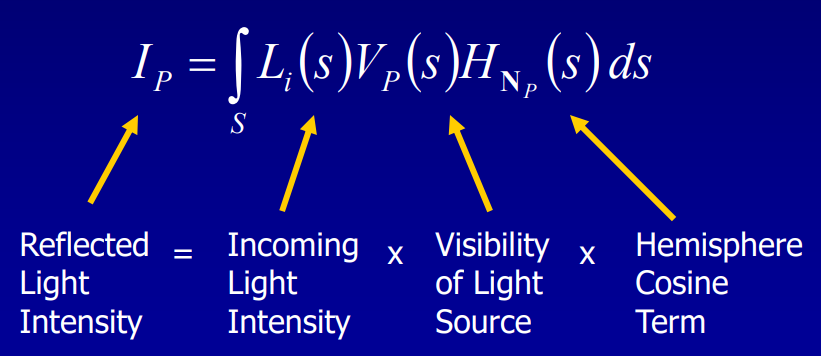
假设有以下带有光源、遮挡物的场景:

作为球面信号来照明,则是如下情形:

H(s)和V(s)可以合并成传输函数T(s):
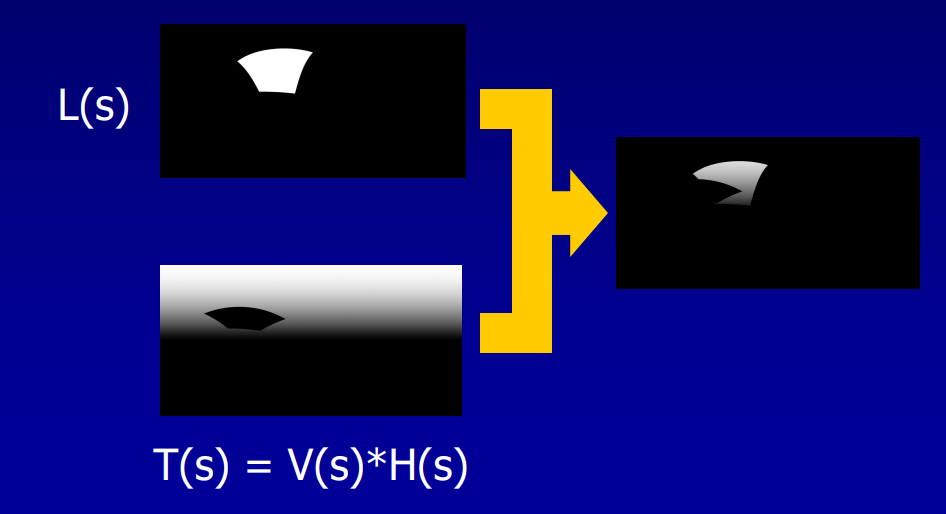
如果将光源和传输函数都表示为SH系数的向量,则光照积分如下:
可以通过系数之间的点积计算:
意味着:照明计算与光源的数量或大小无关,软阴影比硬边缘阴影开销更小,传输函数可以离线计算。对于复杂的照明函数,可以用HDR光照探头代替之,而不需要额外的成本:

对于次级光照(间接光),我们还可以利用被照亮的点来捕捉漫反射到漫反射的颜色溢出:

漫反射GI的优点:SH系数是在全局照明解决方案中传输能量的完美方式,计算直接光照后,自传输不需要额外的光线追踪。漫反射GI的缺点:假设所有远处的点都有相同的照明函数(例如,物体的一半以上没有阴影)。

由于SH假设光源在无限远处,所以光源不能进入p点和阻挡器之间。
为了SH投影一个光照函数,先计算球面上随机点的SH函数,再求和照明函数和SH值的乘积:

如果能保证样本均匀分布,就可以将权重移到总和之外:
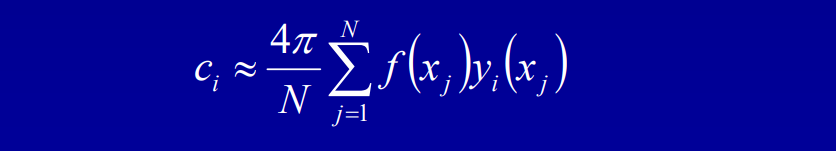
渲染方程的简化漫反射版本:
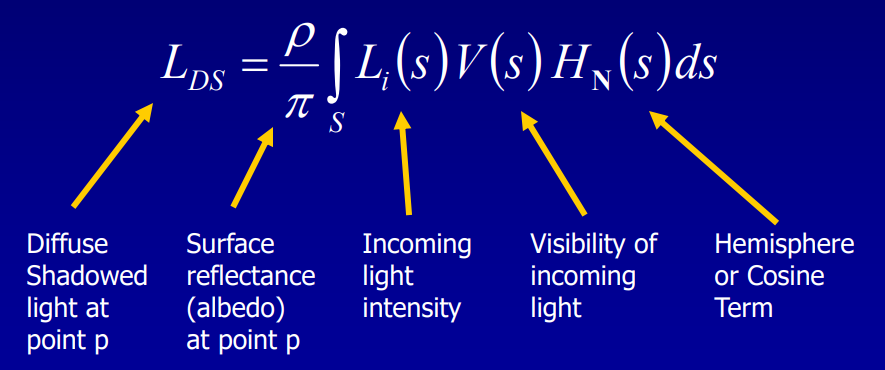
余弦项对于物理校正渲染必不可少,可来自能量传输公式:
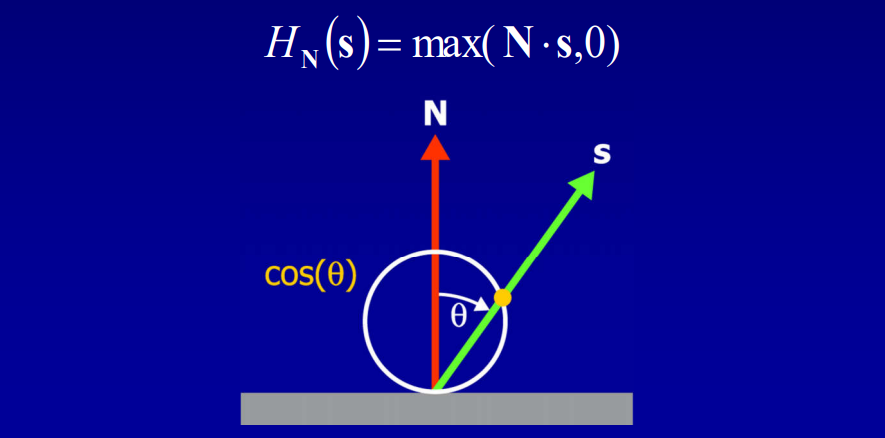
将渲染方程转换成两部分,就得到了要进行SH投影的传输函数,传输函数将反射率、表面法线和阴影编码为一个函数,无需为每个顶点存储表面法线:
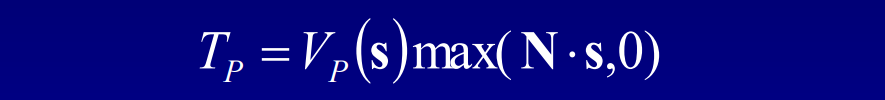
下面的代码是一个SH预处理器,一个简单的光线追踪器,用于计算模型中每个顶点的SH系数:
for(int i=0; i<n_samples; ++i)
{
double H = DotProduct(sample[i].vec, normal);
if(H > 0.0)
{
if(!self_shadow(pos,sample[i].vec))
{
for(int j=0; j<n_coeff; ++j)
{
value = H * sample[i].coeff[j];
result[j] += albedo * value;
}
}
}
}
const double factor = 4.0*PI / n_samples;
for(i=0; i<n_coeff; ++i)
coeff[i] = result[i] * factor;
上面的光照追踪存在一个问题,阴影测试通常会从模型内部发射光线,注意单边射线-三角形相交,首选不带孔洞的歧管模型(manifold model):

渲染画面结果如下:

在此基础上可以做得更好,即添加自传输。完整的渲染方程描述了照明表面如何相互照亮,产生颜色渗色:
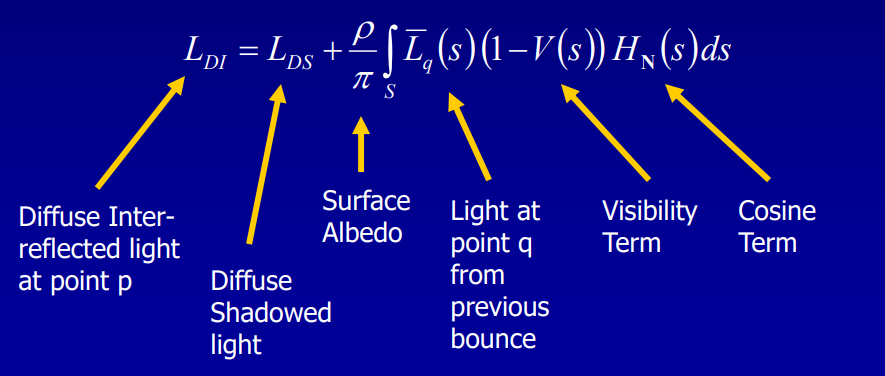
自传输图例如下,A点从B点接收与余弦项成正比的光照:
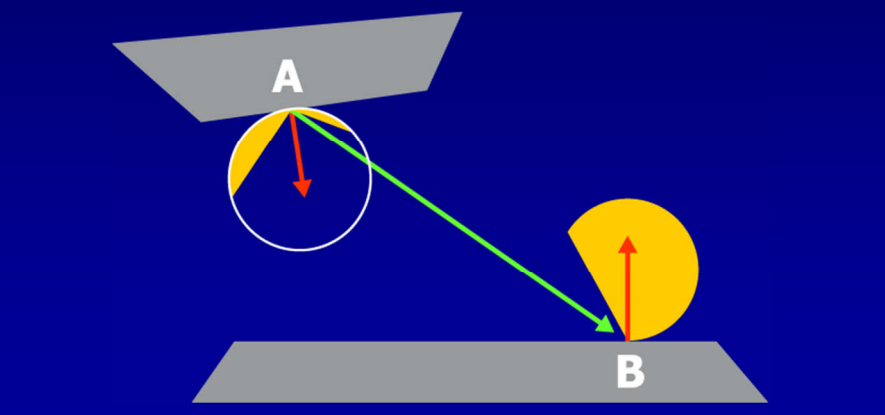
可以用图形表示为:
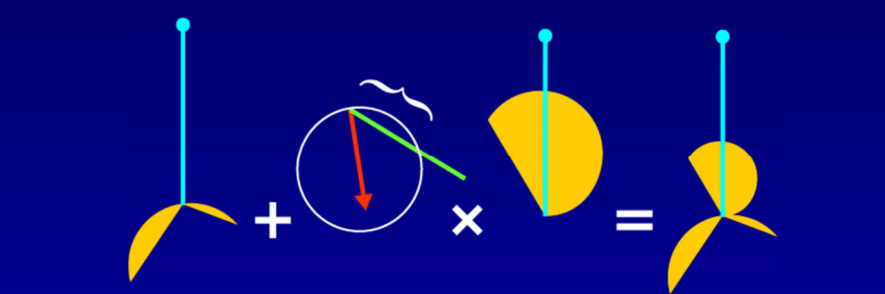
A点现在从上方接收光线,即使该方向在技术上是不可见的,使用SH照明,光照传输只是一系列乘法相加。渲染结果:

在运行时使用SH系数,根据实现的目标,有多种使用SH系数来重建图像的方法:单色灯或彩色灯,可重新着色的表面、固定颜色或自传输。
for(int j=0; j<n_coeff; ++j)
{
vertex[i].red += light[j] * vertex[i].sh_red[j];
vertex[i].green += light[j] * vertex[i].sh_green[j];
vertex[i].blue += light[j] * vertex[i].sh_blue[j];
}
照明函数的精度受阶数影响,更多系数可以编码更高频率的信号。
另外,可以使用SH照明作为照明计算的一部分,对天空球体使用SH光照并添加点光源和硬阴影来模拟太阳,对表面反射的漫反射部分使用SH光照。创建SH光源的方法有:
-
来自极坐标函数的数值。
-
光线追踪多边形模型或场景。
-
来自HDR光照探头或环境贴图。
-
直接来自解析解。例如圆盘光源的解决方案,角度t:
![]()

分析圆盘光源:在Maple或Mathematica中对球体上的此圆盘光函数进行符号积分,以找到解析表达式:

5阶圆盘灯的25个系数中只有4个非零,最后使用SH旋转来定位光源。
代理阴影是一种伪造物体间阴影的方法,如果场景中的每个物体都有自己的照明函数,可以使用分析“阻挡器”从另一个物体的方向减去光线。定义$b_t(s) $作为\(1-d_t(s)\)允许我们构建一个屏蔽SH系数的传输矩阵:
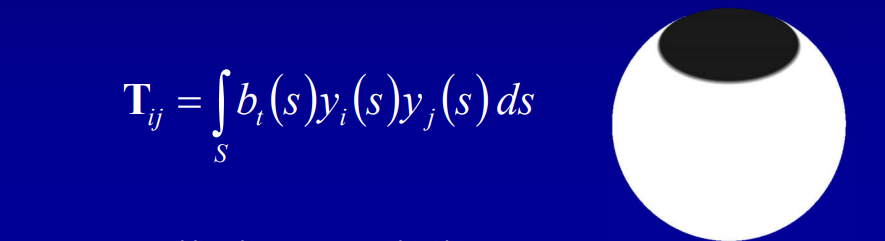
SH照明中的未解决问题:
- 更快的SH旋转方法。借鉴计算化学研究。
- SH照明非静态物体。当物体相对移动时,可见度函数V(s)会发生根本性的变化,如何编码?
- 利用SH向量的稀疏性。SH向量通常包含很少的非零系数。
- 高光镜面SH照明。一种编码和使用任意BRDF的优雅方式,对于一般情况还是太慢。
总之,SH光照是一种用于照明3D模型的新技术,为实时游戏带来面光源和全局照明,适用于任何可以进行Gouraud着色的平台,可用作静态场景中漫反射照明的替代品,2阶阴影仅使用4个系数。
另外,基于SH的PRT(Precomputed Radiance Transfer,预计算辐射传输)支持漫反射自传输、光泽反射自传输,计算过程见下图。
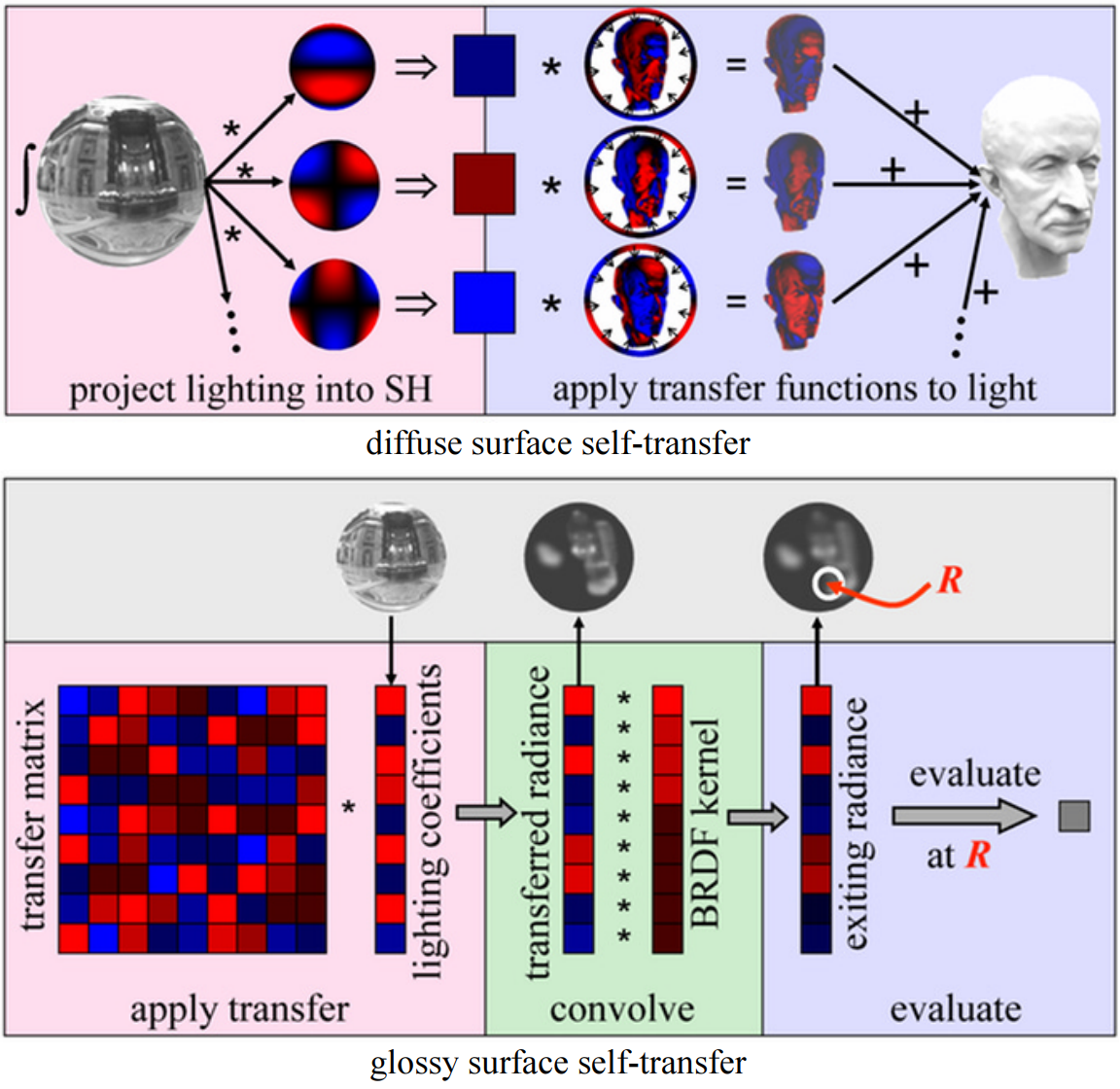
自传输运行时概览。红色表示SH系数的正值,蓝色表示SH系数的负值。对于漫反射表面(顶行),SH照明系数(左侧)乘以表面(中间)上的传输向量场以产生最终的结果(右)。表面上特定点的传输向量表示该表面如何响应该点的入射光,包括全局传输效应,如自阴影和自反射。对于光滑表面(底行),在模型上的每个点(而不是向量)都有一个矩阵,该矩阵将照明系数转换为表示传输辐射的球函数系数,结果与模型的BRDF核进行卷积,并在与视图相关的反射方向R处进行评估,以在模型上的某一点产生光照结果。
附完整的PRT实现代码:
// 3D向量
struct Vector3
{
float x;
float y;
float z;
};
// 球体
struct Spherical
{
float theta;
float phi;
}
// 样本
struct Sample
{
Spherical spherical_coord;
Vector3 cartesian_coord;
float* sh_functions;
};
// 采样器
struct Sampler
{
Sample* samples;
int number_of_samples;
};
// 获取样本
void GenerateSamples(Sampler* sampler, int N)
{
Sample* samples = new Sample [N*N];
sampler->samples = samples;
sampler->number_of_samples = N*N;
for (int i = 0; i < N; i++)
{
for (int j = 0; j < N; j++)
{
float a = ((float) i) + Random()) / (float) N;
float b = ((float) j) + Random()) / (float) N;
float theta = 2*acos(sqrt(1-a));
float phi = 2*PI*b;
float x = sin(theta)*cos(phi);
float y = sin(theta)*sin(phi);
float z = cos(theta);
int k = i*N + j;
sampler->samples[k].spherical_coord.theta = theta;
sampler->samples[k].spherical_coord.phi = phi;
sampler->samples[k].cartesian_coord.x = x;
sampler->samples[k].cartesian_coord.y = y;
sampler->samples[k].cartesian_coord.z = z;
sampler->samples[k].sh_functions = NULL;
}
}
};
// 获取随机数
float Random()
{
float random = (float) (rand() % 1000) / 1000.0f;
return(random);
}
// 勒让德多项式
float Legendre(int l, int m, float x)
{
float result;
if (l == m+1)
result = x*(2*m + 1)*Legendre(m, m);
else if (l == m)
result = pow(-1, m)*DoubleFactorial(2*m–1)*pow((1–x*x), m/2);
else
result = (x*(2*l–1)*Legendre(l-1, m) - (l+m–1)*Legendre(l-2, m))/(l-m);
return(result);
}
float DoubleFactorial(int n)
{
if (n <= 1)
return(1);
else
return(n * DoubleFactorial(n-2));
}
// 计算球谐函数
float SphericalHarmonic(int l, int m, float theta, float phi)
{
float result;
if (m > 0)
result = sqrt(2) * K(l, m) * cos(m*phi) * Legendre(l, m, cos(theta));
else if (m < 0)
result = sqrt(2) * K(l, m) * sin(-m*phi) * Legendre(l, -m, cos(theta));
else
result = K(l, m) * Legendre(l, 0, cos(theta));
return(result);
}
// 计算归一化系数K
float K(int l, int m)
{
float num = (2*l+1) * factorial(l-abs(m));
float denom = 4*PI * factorial(l+abs(m));
float result = sqrt(num/denom);
return(result);
}
// 预计算SH函数。
void PrecomputeSHFunctions(Sampler* sampler, int bands)
{
for (int i = 0; i < sampler->number_of_samples; i++)
{
float* sh_functions = new float [bands*bands];
sampler->samples[i].sh_functions = sh_functions;
float theta = sampler->samples[i].spherical_coord.theta;
float phi = sampler->samples[i].spherical_coord.phi;
for (int l = 0; l < bands; l++)
for (int m = -l; m <= l; m++)
{
int j = l*(l+1) + m;
sh_functions[j] = SphericalHarmonic(l, m, theta, phi);
}
}
}
}
// 颜色
struct Color
{
float r;
float g;
float b;
};
// 光照探针访问
void LightProbeAccess(Color* color, Image* image, Vector3 direction)
{
float d = sqrt(direction.x*direction.x + direction.y*direction.y);
float r = (d == 0) ? 0.0f : (1.0f/PI/2.0f) * acos(direction.z) / d;
float tex_coord [2];
tex_coord[0] = 0.5f + direction.x * r;
tex_coord[1] = 0.5f + direction.y * r;
int pixel_coord [2];
pixel_coord[0] = tex_coord[0] * image.width;
pixel_coord[1] = tex_coord[1] * image.height;
int pixel_index = pixel_coord[1]*image.width + pixel_coord[0];
color->r = image.pixel[pixel_index][0];
color->g = image.pixel[pixel_index][1];
color->b = image.pixel[pixel_index][2];
}
// 投影光照函数
void ProjectLightFunction(Color* coeffs, Sampler* sampler, Image* light, int bands)
{
for (int i = 0; i < bands*bands; i++)
{
coeffs[i].r = 0.0f;
coeffs[i].g = 0.0f;
coeffs[i].b = 0.0f;
}
for (int i = 0; i < sampler->number_of_samples; i++)
{
Vector3& direction = sampler->samples[i].cartesian_coord;
for (int j = 0; j < bands*bands; i++)
{
Color color;
LightProbeAccess(&color, light, &direction);
float sh_function = sampler->samples[i].sh_functions[j];
coeffs[j].r += (color.r * sh_function);
coeffs[j].g += (color.g * sh_function);
coeffs[j].b += (color.b * sh_function);
}
}
float weight = 4.0f*PI;
float scale = weight / sampler->number_of_samples;
for (int i = 0; i < bands*bands; i++)
{
coeffs[i].r *= scale;
coeffs[i].g *= scale;
coeffs[i].b *= scale;
}
}
// 三角形
struct Triangle
{
int a;
int b;
int c;
};
// 场景
struct Scene
{
Vector3* vertices;
Vector3* normals;
int* material;
Triangle* triangles;
Color* albedo;
int number_of_vertices;
};
// 投影无阴影的场景
void ProjectUnshadowed(Color** coeffs, Sampler* sampler, Scene* scene, int bands)
{
for (int i = 0; i < scene->number_of_vertices; i++)
{
for (int j = 0; j < bands*bands; j++)
{
coeffs[i][j].r = 0.0f;
coeffs[i][j].g = 0.0f;
coeffs[i][j].b = 0.0f;
}
}
for (int i = 0; i < scene->number_of_vertices; i++)
{
for (int j = 0; j < sampler->number_of_samples; j++)
{
Sample& sample = sampler->samples[j];
float cosine_term = dot(&scene->normals[i], &sample.cartesian_coord);
for (int k = 0; k < bands*bands; k++)
{
float sh_function = sample.sh_functions[k];
int materia_idx = scene->material[i];
Color& albedo = scene->albedo[materia_idx];
coeffs[i][k].r += (albedo.r * sh_function * cosine_term);
coeffs[i][k].g += (albedo.g * sh_function * cosine_term);
coeffs[i][k].b += (albedo.b * sh_function * cosine_term);
}
}
}
float weight = 4.0f*PI;
float scale = weight / sampler->number_of_samples;
for (int i = 0; i < scene->number_of_vertices; i++)
{
for (int j = 0; j < bands*bands; j++)
{
coeffs[i][j].r *= scale;
coeffs[i][j].g *= scale;
coeffs[i][j].b *= scale;
}
}
}
// 射线和三角形相交测试
bool RayIntersectsTriangle(Vector3* p, Vector3* d, Vector3* v0, Vector3* v1, Vector3* v2)
{
float e1 [3] = { v1->x – v0->x, v1->y – v0->y, v1->z – v0->z };
float e2 [3] = { v2->x – v0->x, v2->y – v0->y, v2->z – v0->z };
float h [3];
cross(h, d, e2);
float a = dot(e1, h);
if (a > -0.00001f && a < 0.00001f)
return(false);
float f = 1.0f / a;
float s [3] = { p->x – v0->x, p->y – v0->y, p->z – v0->z };
float u = f * dot(s, h);
if (u < 0.0f || u > 1.0f)
return(false);
float q [3];
cross(q, s, e1);
float v = f * dot(d, q);
if (v < 0.0f || u + v > 1.0f)
return(false);
float t = dot(e2, q)*f;
if (t < 0.0f)
return(false);
return(true);
}
// 可见性函数
bool Visibility(Scene* scene, int vertexidx, Vector3* direction)
{
bool visible (true);
Vector3& p = scene->vertices[vertexidx];
for (int i = 0; i < scene->number_of_triangles; i++)
{
Triangle& t = scene->triangles[i];
if ((vertexidx != t.a) && (vertexidx != t.b) && (vertexidx != t.c))
{
Vector3& v0 = scene->vertices[t.a];
Vector3& v1 = scene->vertices[t.b];
Vector3& v2 = scene->vertices[t.c];
visible = !RayIntersectsTriangle(&p, direction, &v0, &v1, &v2);
if (!visible)
break;
}
}
return(visible);
}
// 投影有阴影的场景
void ProjectShadowed(Color** coeffs, Sampler* sampler, Scene* scene, int bands)
{
...
for (int i = 0; i < scene->number_of_vertices; i++)
{
for (int j = 0; j < sampler->number_of_samples; j++)
{
Sample& sample = sampler->samples[j];
if (Visibility(scene, i, &sample.cartesian_coord))
{
float cosine_term = dot(&scene->normals[i], &sample.cartesian_coord);
for (int k = 0; k < bands*bands; k++)
{
float sh_function = sample.sh_functions[k];
int materia_idx = scene->material[i];
Color& albedo = scene->albedo[materia_idx];
coeffs[i][k].r += (albedo.r * sh_function * cosine_term);
coeffs[i][k].g += (albedo.g * sh_function * cosine_term);
coeffs[i][k].b += (albedo.b * sh_function * cosine_term);
}
}
}
}
...
}
// 渲染入口
void Render(Color* light, Color** coeffs, Scene* scene, int bands)
{
glBegin(GL_TRIANGLES);
for (int i = 0; i < scene->number_of_triangles; i++)
{
Triangle& t = &scene->triangles[i];
Vector3& v0 = scene->vertices[t.a];
Vector3& v1 = scene->vertices[t.b];
Vector3& v2 = scene->vertices[t.c];
Color c0 = { 0.0f, 0.0f, 0.0f };
Color c1 = { 0.0f, 0.0f, 0.0f };
Color c2 = { 0.0f, 0.0f, 0.0f };
for (int k = 0; k < bands*bands; k++)
{
c0.r += (light[k].r * coeffs[t->a][k].r);
c0.g += (light[k].g * coeffs[t->a][k].g);
c0.b += (light[k].b * coeffs[t->a][k].b);
c1.r += (light[k].r * coeffs[t->b][k].r);
c1.g += (light[k].g * coeffs[t->b][k].g);
c1.b += (light[k].b * coeffs[t->b][k].b);
c2.r += (light[k].r * coeffs[t->c][k].r);
c2.g += (light[k].g * coeffs[t->c][k].g);
c2.b += (light[k].b * coeffs[t->c][k].b);
}
glColor3f(c0.r, c0.g, c0.b);
glVertex3f(v0.x, v0.y, v0.z);
glColor3f(c1.r, c1.g, c1.b);
glVertex3f(v1.x, v1.y, v1.z);
glColor3f(c2.r, c2.g, c2.b);
glVertex3f(v2.x, v2.y, v2.z);
}
glEnd();
}
附PRT的shader代码:
// vertex shader
struct app2vertex
{
float4 f4Position : POSITION;
float4 f4Color : COLOR;
float3 vf3Transfer [N*N];
};
struct vertex2fragment
{
float4 f4ProjPos : POSITION;
float4 f4Color : COLOR;
};
vertex2fragment VertexShader
(
app2vertex IN,
uniform float3 vf3Light [N*N],
uniform float4x4 mxModelViewProj
)
{
vertex2fragment OUT;
OUT.f4ProjPos = mul(mxModelViewProj, IN.f4Position);
OUT.f4Color = float4(0.0f, 0.0f, 0.0f, 1.0f);
for (int i = 0; i < N*N; i++)
{
OUT.f4Color.r += (IN.vf3Transfer[i].r * vf3Light[i].r);
OUT.f4Color.g += (IN.vf3Transfer[i].g * vf3Light[i].g);
OUT.f4Color.b += (IN.vf3Transfer[i].b * vf3Light[i].b);
}
return(OUT);
}
// fragment shader
struct fragment2screen
{
float4 f4Color : COLOR;
};
vertex2fragment PixelShader( vertex2fragment IN )
{
fragment2screen OUT;
OUT.f4Color = IN.f4Color;
return(OUT);
}
14.3.4.2 Virtual Texture
Virtual Texture(VT,虚拟纹理)是一个mipmap纹理,用作缓存,模拟更高分辨率的纹理以进行实时渲染,同时仅部分驻留在纹理内存中。缓存是一种常见的技术,允许快速访问较大的数据集以驻留在较慢的内存中,此处描述的虚拟纹理使用传统的纹理映射缓存来自较慢内容设备的数据。下图显示了纹理存储的不同硬件设备如何以不同的速度/数量比进行分类。

硬件可以根据速度/数量比进行分类,容量从高到低依次是外围设备、内存、显存,但速度依次提升。GPU纹理查找操作仅限于一个纹理,且无法随机访问整个视频内存,因为受限于size3或高延迟。因此,图中的图表将“纹理”和“视频内存”列为单独的单元。
由于2000时代中后期的游戏场景、包体和纹理尺寸越来越大(8K),32位的内存地址无法完全容纳游戏的所有数据,并且加载完整的数据到内存或显存不切实际,因为IO带宽是最大的瓶颈。有限的物理内存可以通过使用硬盘驱动器的虚拟内存来补偿,不幸的是,这个选项对于实时渲染并不可行,因为传统的虚拟内存(作为操作系统和硬件功能)会阻塞,直到请求得到解决。如果没有可用的硬盘驱动器,这种情况会加剧,游戏机可能就是这种情况。为了解决这个问题并获得快速的关卡加载时间,现代引擎需要进行纹理流式传输。
在虚拟纹理中,只将纹理的相关部分保留在快速内存中,并从较慢的内存中异步请求丢失的部分(同时使用较低mip-map的内容作为后备),意味着需要将较低的mip-map保留在内存中,并且需要先加载这些部分。为了可以高效地查找纹理,将mip-map的纹理分割成合理大小的小块来实现连贯的内存访问。所有块(tile)使用固定大小,可以更轻松地管理缓存,并且可以更轻松地管理所有tile操作(如读取或复制),具有恒定的时间和内存特性。CryTek的实现不处理小于tile大小的mip-map,对地形渲染之类的应用程序,它们的纹理永远不会很远并且少量锯齿是可以接受的。可以通过简单地将多个mip-map打包到一个tile中来解决此问题,对于远处的物体,甚至可以回退到正常的mip-map纹理映射,但需要一个单独的系统来管理。
如下图所示,典型的虚拟纹理是在预处理时从某种源图像格式创建的,而不会对纹理大小施加API和图形硬件限制。数据存储在任何访问速度较低的设备上(如硬盘驱动器),可以删除虚拟纹理的未使用区域以节省内存。显存中的纹理(tile cache)由渲染3D视图所需的tile组成,还需要间接信息以有效地重建虚拟纹理布局,tile纹理缓存和间接纹理(indirection texture)都是动态的并且适应一个或多个视图。
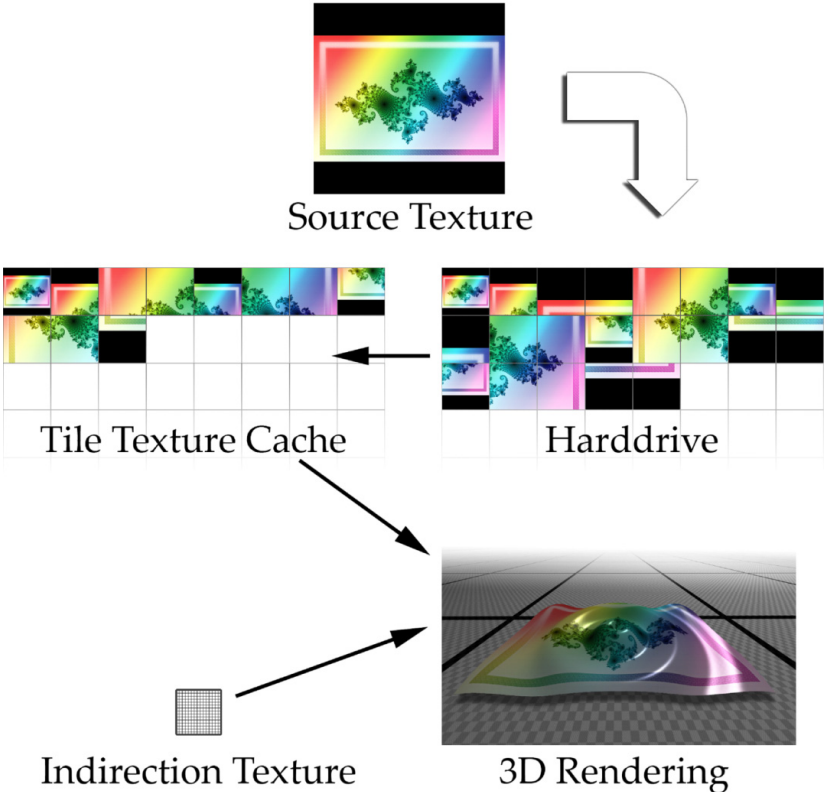
虚拟纹理的运行机制,包含了保存于慢速设备(如硬盘)的分成固定大小的纹理、位于显存的分块纹理缓存,以及关联了视图和分块纹理缓存的间接纹理。
CryTek使用四叉树来管理虚拟纹理,保证所有必需的操作都可以在恒定时间内实现。树的状态代表虚拟纹理当前使用的纹理tile,所有节点和叶子都与纹理tile相关联,在基本实现中,仅使用四叉树中的最高可用分辨率。当丢弃一些叶子时,较低分辨率的数据被存储为fallback,也可以用于逐渐过渡到更高分辨率的纹理tile,仅在叶子级别细化或粗化虚拟纹理。除了四叉树之外,还需要额外实现缓存策略(例如最近最少使用)。
像素着色器中的四叉树遍历被更高效的单个未过滤的纹理查找所取代,间接纹理在内存中可能非常小,并且由于连贯的纹理查找,对带宽也非常友好。单个纹理查找允许在恒定时间内使用简单的数学计算tile缓存中的纹理坐标。可以在像素着色器中使用以下HLSL代码为给定的虚拟纹理坐标计算关联的tile缓存纹理坐标:
float4 g_vIndir; // 非直接纹理边界:w, h, 1/w, 1/h
float4 g_Cache; // tile纹理缓存边界:w, h, 1/w, 1/h
float4 g_CacheMulTilesize; // tile纹理缓存边界*tilesize:w, h, 1/w, 1/h
// 采样器(最近点)
sampler IndirMap = sampler_state
{
Texture = <IndirTexture>;
MipFilter = POINT;
MinFilter = POINT;
MagFilter = POINT;
// MIPMAPLODBIAS = 7; // using mip-mapped indirection texture, 7 for 128x128
};
// 为给定的虚拟纹理坐标计算关联的tile缓存纹理坐标
float2 AdjustTexCoordforAT( float2 vTexIn )
{
float fHalf = 0.5f; // half texel for DX9, 0 for DX10
float2 TileIntFrac = vTexIn*g_vIndir.xy;
float2 TileFrac = frac(TileIntFrac)*g_vIndir.zw;
float2 TileInt = vTexIn - TileFrac;
float4 vTiledTextureData = tex2D(IndirMap,TileInt+fHalf*g_vIndir.zw);
float2 vScale = vTiledTextureData.bb;
float2 vOffset = vTiledTextureData.rg;
float2 vWithinTile = frac( TileIntFrac * vScale );
return vOffset + vWithinTile*g_CacheMulTilesize.zw + fHalf*g_Cache.zw;
}
如前所述,假设只有单个间接纹理并且tile缓存中的所有tile具有相同的大小,则可以计算虚拟纹理分辨率:
下面举几个例子:
注意,为了避免使用DXT等块状压缩纹理的双线性过滤瑕疵,需要额外的4像素边框。由于有损的DXT压缩,在压缩相邻tile时需要完全相同的块内容,否则可能会重建出错误的颜色值,从而导致可见的接缝。对于tile缓存纹理的更新,要求如下:
- 低延迟和高吞吐量。
- 带宽高效(仅复制所需部分)。
- 内存开销小。
- 更新不能有卡顿,且正确同步纹理状态。
- 当通过CPU更新内容时,不应从GPU内存复制到CPU内存(应使用丢弃)。
- 对于从tile缓存纹理进行快速纹理化,应该在适当的内存布局 (swizzled12) 和内存类型(显存)中。 注意,在某些硬件上压缩纹理以线性形式存储(没有swizzle)。
- 多个tile更新应该具有线性或更好的性能。
当时有3种方法可实现tile缓存纹理更新:
- 方法1:直接更新CPU。目标纹理需要在D3DPOOL_MANGED中,并通过LockRect() 函数更新纹理的一部分。这种方法会浪费主内存,并且很可能会延迟传输,直到绘制调用正在使用纹理。很简单,但不理想。
- 方法2:使用(小)中间tile纹理。此方法需要一个可锁定的中间纹理帽子以容纳一个tile(包括边框),使用LockRect()或StretchRect() 函数以复制内容。此法不适用于压缩纹理 (DXT),因为它们不能用作渲染目标格式,并且受图形API和硬件特性影响。
- 方法 3:使用(大)中间tile缓存纹理。此方法需要在D3DPOOL_SYSTEM中具有完整纹理缓存扩展的可锁定中间纹理。使用 LockRect(),中间纹理仅在需要时更新,随后的UpdateTexture()函数调用将数据传输到目标纹理,UpdateTexture()要求目的地位于D3DPOOL_DEFAULT中。
一旦新的tile更新到纹理缓存中,就可以更新间接纹理。间接纹理需要很少的内存,因此带宽不是问题,但使用多个间接纹理并对其进行更新通常会成为性能瓶颈,可以通过锁定或上传新纹理从CPU更新纹理。如果间接纹理使用渲染目标纹理格式,还可以考虑由CPU触发的GPU更新,通过绘制调用来完成更新,并且可以将简单的四边形渲染到纹理以有效地更新大区域。不应该有太多更新,因为tile缓存更新且两者相互依赖的情况应该很少见。
在CryTek的实现中,间接纹理仍然有一个通道,并且可以存储一个tile混合值。使用额外的着色器成本,允许通过缓慢混合tile来隐藏纹理tile替换。带过滤的混合值更佳,因为可以隐藏tile之间的接缝。
Tile资源的来源有:从磁盘流式传输、通过网络流式传输、程序内容生成。其中程序内容生成可以发生在CPU或GPU,典型代表是已在许多游戏的地形中使用的巨大纹理生成,地形细节通常由一些tile纹理组成,这些纹理以低得多的分辨率与插值信息混合,可以产生良好的效果,尤其是在与低分辨率纹理结合以增加变化并突破tile外观时。
Crysis使用地形材质混合(下图)来获得巨大地形的详细地面纹理,此法需要在像素级别混合多种材质。由于每个地形顶点都分配给一种材质(最多3个,因此在三角形内混合最多需要三个通道)。在离线过程中烘焙地表纹理允许更复杂的混合并保持渲染性能不变,也允许烘焙诸如道路或轮胎痕迹之类的细节。

使用虚拟纹理受益的场景示例:游戏Crysis中的贴花(道路、轮胎痕迹、泥土)在地形材料混合之上使用。
和CryTek略有不同,id Tech 5使用了稀疏纹理金字塔的四叉树(下图)来存储、管理、优化虚拟纹理。
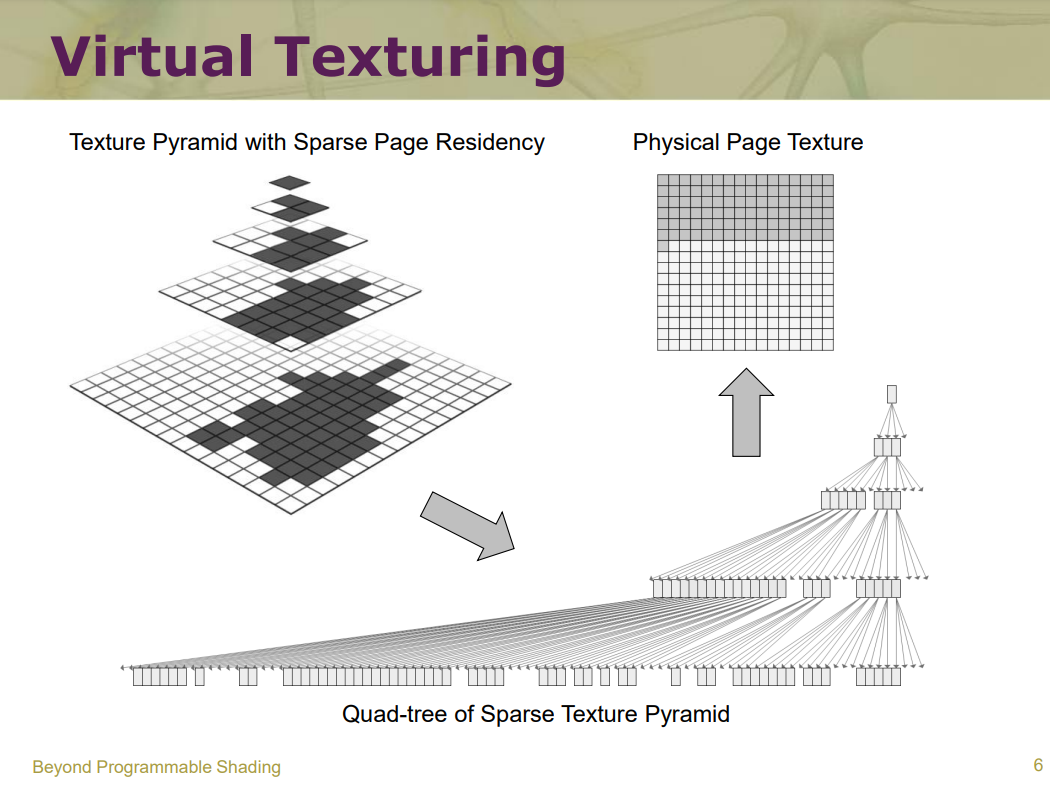
id Tech 5使用稀疏纹理金字塔的四叉树管理虚拟纹理。

虚拟纹理可视化。
id Tech 5在实现时关注了以下虚拟纹理的问题:
-
纹理过滤。不尝试过滤,尝试了无边界双线性过滤,带边框的双线性过滤效果很好,三线性滤波合理但仍然昂贵,可通过TXD (texgrad) 进行各向异性过滤,需要4-texel边框(最大aniso=4),带有隐式梯度的TEX也可以(在某些硬件上)。
![]()
-
由于物理内存超出而导致崩溃。有时需要的物理页面要多于拥有的,如果使用传统的虚拟内存,无法达成。使用虚拟纹理,可以全局调整回馈的LOD偏差,直到工作集适合。
![]()
-
高延迟下的LOD过渡。首次需要和可用性之间的延迟可能很高,特别是如果需要读取光盘,大于100毫秒的查找。放大的纹理更改LOD时会发生可见的跳变,如果使用三线性过滤,细节混合会很容易,但可以使用混合数据持续更新物理页面。
![]()
立即对粗糙页面进行上采样,然后在可用时融合更精细的数据。
![]()


对于虚拟纹理管理,回馈信息分析告知需要哪些页面,由于是实时应用程序,所以不允许阻止。缓存处理命中、调度未命中以在后台加载,独立于磁盘缓存管理的常驻页面,物理页面组织为每个虚拟纹理的四叉树,免费、LRU 和锁定页面的链表。虚拟纹理的回馈分析时,生成相当于带优先级的广度优先四叉树顺序:

虚拟内存的转码包含漫反射、镜面反射、凹凸和覆盖/alpha等数据,存储在凹凸纹理中的高光块缩放,通常达到2-6k的输入和40k的输出,Map、Unmap和Transcode都在可以直接写入纹理内存的平台上并行发生。下图是转码流水线到块或行级别以减少内存配置文件:
具有依赖关系的计算密集型复杂系统,但id希望在所有不同平台上并行运行。虚拟纹理的管线如下所示:
id Tech 5在id Tech 5中,作业化的子系统包含了虚拟纹理,以便重复利用多核优势,提升虚拟纹理的吞吐量。
14.3.4.3 Tone Reproduction
Tone Reproduction and Physically Based Spectral Rendering文献解决了渲染管道两端的两个相关关键问题领域,即在实际渲染过程中用于描述光的数据结构,以及以有价值的方式显示此类辐射强度的问题。
第一个子问题的兴趣来源于使用RGB颜色值来描述光强度和表面反射率是常见的行业惯例。虽然在不努力实现真正现实主义的方法的背景下是可行的,但如果要预测自然,则必须用更精确的物理技术代替这种方法。
第二个子问题是,虽然对渲染图像方法的研究为我们提供了更好更快的方法,但由于显示硬件的限制,我们不一定能看到它们的全部效果。标准计算机显示器的低动态范围需要某种形式的映射来生成感知准确的图像,色调再现操作试图复制真实世界亮度强度的效果。
该文献还回顾了关于光谱渲染和色调再现技术的工作,包括对光谱图像合成方法和准确色调再现的需求的调查,以及对物理正确渲染和关键色调映射算法的主要方法的讨论,未来将考虑光谱渲染和色调再现技术,以及显示硬件进步的影响。
虽然对创建图像方法的研究为我们提供了更好更快的方法,但由于显示限制,我们通常看不到这些技术的全部效果。为了准确的图像分析和与现实的比较,显示图像必须与原始图像尽可能接近。在需要预测成像的情况下,色调再现对于确保从模拟中得出的结论是正确的非常重要(下图)。
理想的色调再现处理过程。
该文还总结出了以往的色调再现方法的分类图:
色调再现方法图谱。横坐标是时间无关和时间相关,纵坐标是空间均匀和空间可变。
由此可知,目前广泛流行的色调映射技术早在几十年前就已有很多前人开始了相关的研究,为后续色调再现和色调映射的应用和普及奠定了基础。
14.3.4.4 Progressive Buffer
渐进式缓冲(Progressive Buffer,PB)用于渲染大型多边形模型的数据结构和系统,支持纹理、法线贴图,支持LOD之间的平滑过渡(无跳变)。Progressive Buffer需要对模型进行预处理,将模型拆分为Cluster,参数化Cluster和样本纹理,为不同的LOD创建多个(例如5个)静态顶点/索引缓冲区,每个缓冲区都有其父节点的1/4,通过从一个LOD一次简化每个图表(chart)来实现这一点,一直到下一个,简化了边界顶点到它的邻居,简化遵循边界约束并防止纹理翻转,还可以对每个缓冲区执行顶点缓存优化。

Progressive Buffer示例:从红色(最高分辨率)到绿色(最低分辨率)的五级细节颜色编码。
为了解决采样不足,对网格的Cluster需要进行纹理参数化,生成纹理坐标的分层算法。(下图)
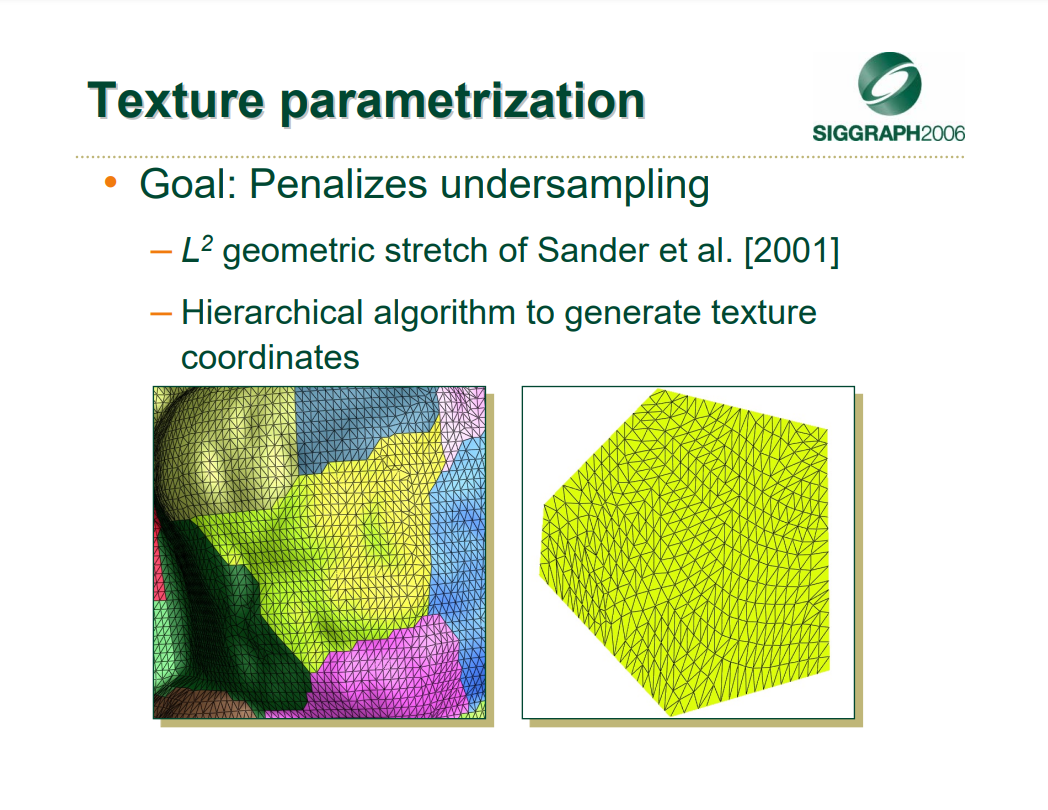
在处理粗糙Cluster时,需要对上一级的精细曲线边界进行直线化,以解决Cluster失真:


PB涉及的纹理打包计算,可参考Tetris packing [Levy 02]和Multi-Chart Geometry Images,为了尽量减少浪费的空间(下图黑色),一次放置一个图表(从大到小),选择最佳位置和旋转(最大限度地减少浪费的空间),对多个正方形尺寸重复上述操作,挑选最佳布局。

A:Tetris packing打包算法将图表一张一张插入,并在此过程中保持“水平”(蓝色),每个图表(绿色)都插入到最小化其底部水平线(粉红色)和当前水平线之间的“浪费空间”(黑色)的位置,然后使用当前图表的顶部水平线(红色)来更新水平线。B:样例模型(恐龙)数据集的结果。
PB的每个静态缓冲区将包含一个索引缓冲区和两个顶点缓冲区:
-
精细顶点缓冲区。表示当前LOD中的顶点。
-
粗糙顶点缓冲区。顶点与精细缓冲区对齐,这样每个顶点对应于下一个粗糙LOD中精细缓冲区的“父”顶点(注:需要顶点复制)。
![]()
PB的各级LOD层次图例如下:
运行时,静态缓冲区流式传输到顶点着色器(LOD根据Cluster到相机的中心距离确定),顶点着色器平滑地混合位置、法线和UV(混合权重基于到相机的顶点距离)。
结合下图加以说明缓冲区过渡。若降低LOD,橙色的\(PB_i\)过渡到对应的黄色,然后交换\(PB_i\)和\(PB_{i-1}\),黄色的\(PB_{i-1}\)过渡到对应的绿色。若增加LOD,则反向操作之。
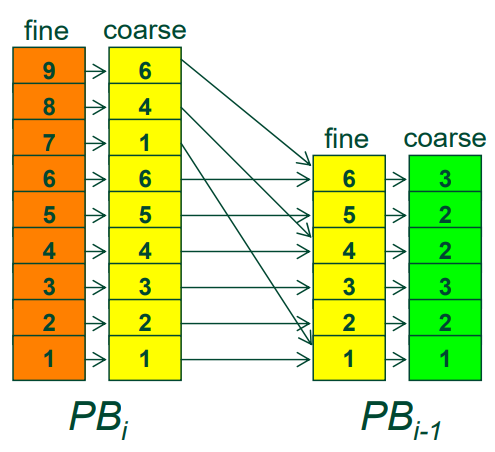
下图显示了LOD的选择机制和过程,以及涉及的各个概念和符号:
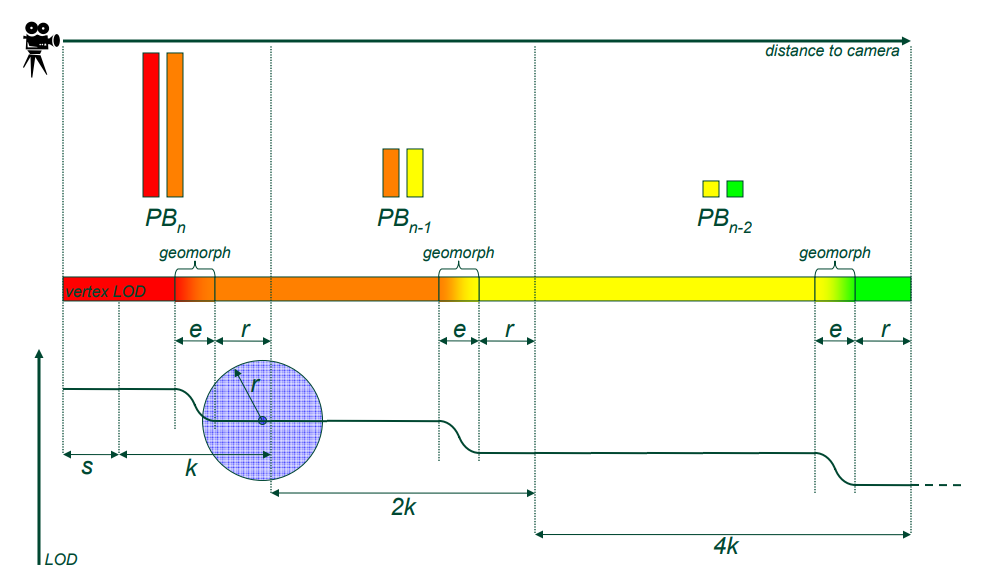
上图详细展示了PB的LOD选择的机制、原理和过程。其中横向坐标从左到右表示距摄像机的距离逐渐增加,纵坐标从下往上表示LOD的级别依次增加。\(S\)表示使用物体最高LOD的距离,\(r\)表示物体包围盒的半径,\(e\)表示几何过渡的距离,\(K\)表示每个LOD对应的距离范围(随着LOD的降低而翻倍,如K、2K、4K等等),中间的梯级往下的曲面表示了LOD之间的平滑过渡,隐藏了跳变。这种几何过渡方式和CSM比较类似。LOD的级数和权重计算如下图所示:
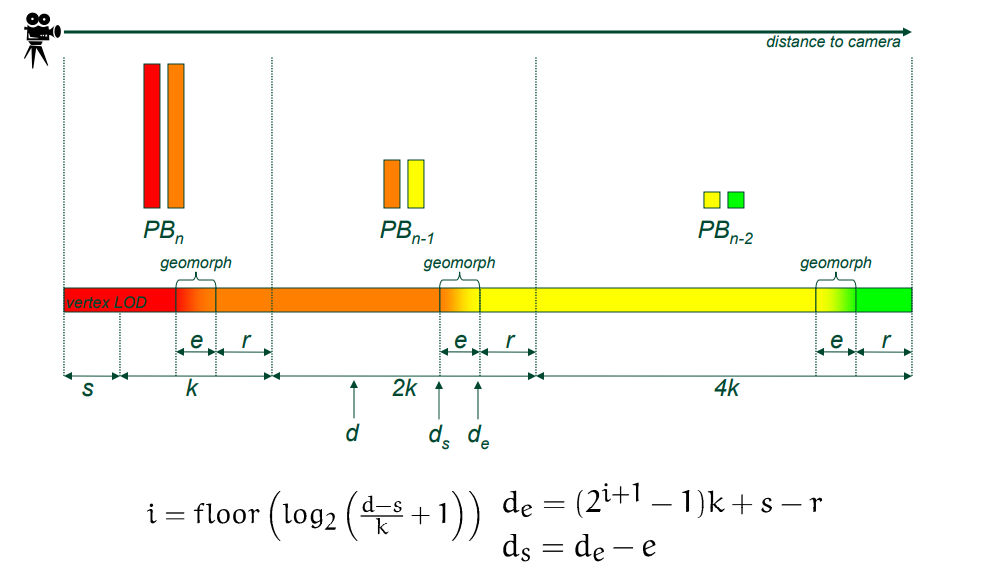
上图中,\(d\)表示物体和相机的距离,\(i\)表示LOD级数,\(d_e\)表示当前降低LOD的几何过渡的远端,\(d_s\)表示当前降低LOD的几何过渡的近端。
纹理的LOD类似于顶点LOD,每个细节层次也有纹理,每个较粗的LOD有前一个LOD的1/4的顶点数和1/4的纹素数。本质上,在粗化时删除了最高mip级别,并在细化时添加了一个mip级别。纹理像顶点一样混合:顶点变形权重传递给像素着色器,像素着色器执行两次提取(每个LOD一次),像素着色器根据插值权重混合生成的颜色。
粗糙缓冲区层次结构(Coarse buffer hierarchy,CBH)将所有Cluster的粗糙LOD存储在显存中的单个顶点/索引/纹理缓冲区中,当相邻Cluster远离相机时进行分组绘制调用。

处理CBH纹理时,最粗糙LOD的体素纹理被分组:

CBH纹理始终存储在显存中,调整了CBH缓冲区中的纹理坐标,从粗糙静态缓冲区切换到CBH缓冲区时没有可见的跳变。
数据结构的限制:顶点缓冲区大小加倍(但只有一小部分数据驻留在显存中),Cluster大小应大致相同(大型Cluster会限制最小LOD级数大小),比纯粹的分层算法有更多的绘图调用(不能在同一个绘图调用中切换纹理;粗略层次结构部分解决了这个问题),直线边界导致纹理拉伸。
PB受系统内存、显存、帧率(不太稳定)、最大级数大小等限制,\(k\)和\(s\)的值会相应地慢慢调整以保持在上述限制内(即自动LOD控制):

对于内存管理,使用单独的线程加载数据,并根据到相机的距离设置优先级如下:
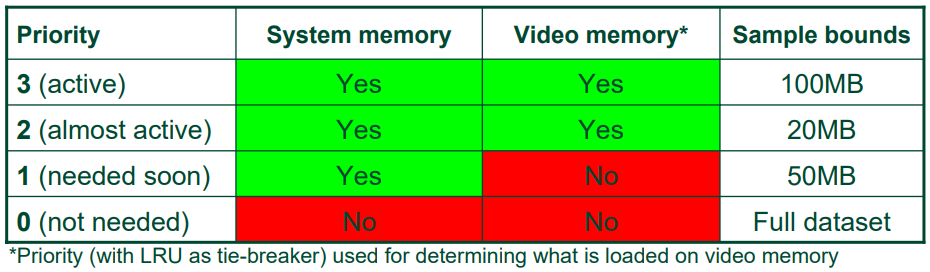
然后计算每个缓冲区的连续LOD,取整数部分,可以得到静态缓冲区,并为其分配优先级3:
如果连续LOD在另一个静态缓冲区LOD的指定阈值内,则相应地设置该缓冲区的优先级:

通过预取并保留大约20%的额外数据,而不是正在渲染的数据,可以确保拥有渲染所需的适当Cluster的LOD,如果没有预取,几个缓冲区可能会变得不可用。根据硬盘寻道时间、后台任务、其它CPU使用情况,可能会有很大差异。
下图的统计信息显示,可变LOD比固定LOD在FPS和内存方面具有更稳定的表现。
14.3.4.5 其它
2000时代涌现的技术枚不胜数,上面只是取其中的一小部分比较重要的加以说明。此外,诸如延迟着色及变种、SSAO、LPV等光影技术,以及各种后处理、多层材质、各类纹理映射等特殊渲染技术都已经出现并应用到了游戏引擎和发行的游戏中。例如,YARE引擎提到了很多基础渲染技术的实现,包含点光源、聚光灯、定向光,以及纹理映射、发现映射、平行映射(Parallax Mapping)、浮雕映射(Relief Mapping)、位移映射(Displacement Mapping)、渲染到立方体图(Render to Cubemap)、动态立方体图等,还有部分Bloom等后处理效果。

YARE引擎实现Bloom效果的通道。从左到右:原始图像、下采样图像、水平模糊图像、完全模糊图像、最终图像。
Half Life使用了纹理根据场景变化而变化的技术。图中以眼睛为例,可以看到五种不同的眼睛效果。
14.3.5 成长期总结
2000时代渲染引擎的发展总结起来如下:
- 视觉效果的提升。
- 图形API和硬件的发展。
- 多线程化,并发技术。
- 跨平台。
- 引擎功能愈来愈多、复杂,模块快速增长。
- 本篇未完待续。
特别说明
- 感谢所有参考文献的作者,部分图片来自参考文献和网络,侵删。
- 本系列文章为笔者原创,只发表在博客园上,欢迎分享本文链接,但未经同意,不允许转载!
- 系列文章,未完待续,完整目录请戳内容纲目。
- 系列文章,未完待续,完整目录请戳内容纲目。
- 系列文章,未完待续,完整目录请戳内容纲目。
参考文献
- Unreal Engine Source
- Rendering and Graphics
- Materials
- Graphics Programming
- Unreal Engine 2 Documentation
- Unreal Engine 3 Documentation
- Game engine
- List of game engines
- Game Engine Architecture
- Game Engine Architecture Third Edition
- Game Engine Architecture Course
- Welcome to CS1950u!
- Game Engine Fundamentals
- Designing the Framework of a Parallel Game Engine
- 深入GPU硬件架构及运行机制
- 由浅入深学习PBR的原理和实现
- Playstation 2 Architecture
- Procedural Rendering on Playstation® 2
- Independent Game Development
- CryEngine Sandbox Far Cry Edition
- Information Visualisation utilising 3D Computer Game Engines
- Using Commonsense Reasoning in Video Games
- GeForce 6 series
- List of game engines
- 3D Game Engine Architecture
- 《黑神话:悟空》12分钟UE5实机测试集锦
- Unreal Engine
- 虚幻引擎
- FROM ABSTRACT DATA MAPPING TO 3D PHOTOREALISM: UNDERSTANDING EMERGING INTERSECTIONS IN VISUALISATION PRACTICES AND TECHNIQUES
- Game Developer - October 2005
- Torque Tutorial #2
- Game Engine Tutorials:Chapter 1 - Introduction
- Unreal Engine 3 Technology
- Using the Source Engine for Serious Games
- Designing a Modern Rendering Engine
- Finding Next Gen – CryEngine 2
- CryENGINE 3 Game Development Beginner's Guide
- GPU overview Graphics and Game Engines
- 3dfx Interactive
- RIVA TNT
- DirectX
- Direct3D feature levels
- Feature levels in Direct3D
- High-Level Shader Language
- DirectX 3.0
- Microsoft Ships DirectX Version 3.0
- Microsoft Ships DirectX 5.0
- DirectX 5.0
- Microsoft's Official DirectX 6.0
- Multitexturing in DirectX 6
- Microsoft® DirectX® 7: What's New for Graphics
- GLFW
- OpenGL Related toolkits and APIs
- Nurien Mstar Online - (4minute - Huh) Bubble Item Mode
- GDM_April_2008(Game Developer)
- How To Go From PC to Cross Platform Development Without Killing Your Studio
- “A bit more Deferred” - CryEngine 3
- CryEngine
- Far Cry®
- CryENGINE 2
- Crysis 1 XBOX/PS3
- CryENGINE 3
- CryEngine Features
- The Matrix Awakens: An Unreal Engine 5 Experience
- Hitting 60Hz with the Unreal Engine: Inside the Tech of Mortal Kombat vs DC Universe
- Parallel Graphics in Frostbite – Current & Future
- Frostbite (game engine)
- EA Tech Blog
- irrlicht
- Practical techniques for managing Code and Assets in multiple cross platform titles
- Next-Gen Asset Streaming Using Runtime Statistics
- Light Pre-Pass Deferred Lighting: Latest Development
- The Next Mainstream Programming Language: A Game Developer’s Perspective
- An explanation of Doom 3’s repository-style architecture
- TerraForm3D Plasma Works 3D Engine & USGS Terrain Modeler
- Entity component system
- Entity Component Systems in Unity
- Entity Component System VS Entity Component
- Entities, components and systems
- Redefining Game Engine Architecture through Concurrency
- Tim Sweeney on the first version of the Unreal Editor
- Integrating Architecture Soar Workshop
- Ray Tracing for Games
- Modern Graphics Engine Design
- Ogre Golf
- Selecting the Best Open Source 3D Games Engines
- Theory, Design, and Preparation
- The Benefits of Multiple CPU Cores in Mobile Devices
- GAME ENGINES
- Development of a 3D Game Engine - OpenCommons
- Physically Based Shading Models for Film and Game Production
- Physically Based Shading at Disney
- Real Shading in Unreal Engine 4
- The Game Engine Space for Virtual Cultural Training
- Game Engines
- Quake III Arena Game Structures
- iOS and Android development with Unity3D
- The use cases that drive XNAT development
- Exploiting Game Engines For Fun & Profit
- GAME ENGINES: A 0-DAY’S TALE
- Comparison and evaluation of 3D mobile game engines
- Barotrauma
- Microsoft XNA
- Game Engines
- Game Engines-The Overview
- Multithreading for Gamedev Students
- A History of the Unity Game Engine
- A brief insight into BRTECH1
- Redefining Game Engine Architecture through Concurrency
- CRYENGINE 5.3 - Getting Started Guide
- The architecture and evolution of computer game engines
- Designing a Modern GPU Interface
- Game Engine Programming
- DX12 & Vulkan Dawn of a New Generation of Graphics APIs
- GPU-Driven Rendering Pipelines
- Limitation to Innovation in the North American Console Video Game Industry 2001-2013: A Critical Analysis
- The 4+1 View Model of Architecture
- Architectural Blueprints—The “4+1” View Model of Software Architecture
- Serious Games Architectures and Engines
- Game Engine Solutions
- Remote exploitation of the Valve Source game engine
- Game Engines - Computer Science
- High quality mobile VR with Unreal Engine and Oculus
- The Report by the written by Amanda Wong funded by the July 2017
- Entity Component Systems & Data Oriented Design
- A Taxonomy of Game Engines and the Tools that Drive the Industry
- Torque 3D Documentation
- Comparative Study on Game Engines
- MOBILE GAME DEVELOPMENT
- Evaluation of CPU and Memory performance between Object-oriented Design and Data-oriented Design in Mobile games
- Efficient generation and rendering of tube geometry in Unreal Engine
- Global Illumination Based on Surfels
- Radiance Caching for real-time Global Illumination
- BigWorld
- Ubisoft Anvil
- Destiny Game Engine: Tiger
- Multithreading the Entire Destiny Engine
- Lessons from the Core Engine Architecture of Destiny
- Destiny 2: Tiger Engine Changes
- Destiny
- Destiny 2
- RE Engine
- Rockstar Advanced Game Engine
- NVIDIA DLSS
- OpenGL
- OpenGL ES
- Tone Reproduction and Physically Based Spectral Rendering
- A Framework for an R to OpenGL Interface for Interactive 3D graphics
- Beyond Finite State Machines Managing Complex, Intermixing Behavior Hierarchies
- Game Mobility Requires Code Portability
- Challenges in programming multiprocessor platforms
- Adding Spherical Harmonic Lighting to the Sushi Engine
- Real World Multithreading in PC Games Case Studies
- Speed up the 3D Application Production Pipeline
- New 3D Graphics Rendering Engine Architecture for Direct Tessellation of Spline Surfaces
- A realtime immersive application with realistic lighting: The Parthenon
- The Parthenon Demo: Preprocessing and Rea-Time Rendering Techniques for Large Datasets
- Rendering Gooey Materials with Multiple Layers
- Practical Parallax Occlusion Mapping For Highly Detailed Surface Rendering
- Real-time Atmospheric Effects in Games
- Shading in Valve’s Source Engine slide
- Shading in Valve’s Source Engine
- Ambient Aperture Lighting
- Fast Approximations for lighting of Dynamic Scenes
- An Analysis of Game Loop Architectures
- Exploiting Scalable Multi-Core Performance in Large Systems
- Ritual™ Entertainment: Next-Gen Effects on Direct3D® 10
- Feeding the Monster: Advanced Data Packaging for Consoles
- Best Practices in Game Development
- High-Performance Physics Solver Design for Next Generation Consoles
- Collaborative Soft Object Manipulation for Game Engine-Based Virtual Reality Surgery Simulators
- Introduction to Direct3D 10 Course
- Practical Global Illumination with Irradiance Caching
- General-Purpose Computation on Graphics Hardware
- GPUBench
- The Mobile 3D Ecosystem
- Advanced Real-Time Rendering in 3D Graphics and Games
- Frostbite Rendering Architecture and Real-time Procedural Shading & Texturing Techniques
- Saints Row Scheduler
- PCI Express
- The Delta3D Gaming and Simulation Engine: An Open Source Approach to Serious Games
- Software Requirement Specification Common Infrastructure Team
- Dragged Kicking and Screaming: Source Multicore
- OpenGL ES 2.0 : Start Developing Now
- Interactive Relighting with Dynamic BRDFs
- Advances in Real-Time Rendering in 3D Graphics and Games (SIGGRAPH 2008 Course)
- Advanced Virtual Texture Topics
- March of the Froblins: Simulation and rendering massive crowds of intelligent and detailed creatures on GPU
- Using wavelets with current and future hardware
- StarCraft II: Effects & Techniques
- The Intersection of Game Engines & GPUs: Current & Future
- Software Instrumentation of Computer and Video Games
- John Carmack Archive - Interviews
- UnrealScript: A Domain-Specific Language
- GPU evolution: Will Graphics Morph Into Compute?
- Introduction to the Direct3D 11 Graphics Pipeline
- Lighting and Material of HALO 3
- Snakes! On a seamless living world
- Threading Successes of Popular PC Games and Engines
- THQ/Gas Powered Games Supreme Commander and Supreme Commander: Forged Alliance
- Emergent Game Technologies: Gamebryo Element Engine
- Namco Bandai, EA Partner For Hellgate: London
- Project “Smoke” N-core engine experiment
- New Dog, Old Tricks: Running Halo 3 Without a Hard Drive
- Creating believable crowds in ASSASSIN'S CREED
- id Tech 5 Challenges - From Texture Virtualization to Massive Parallelization
- Building a Dynamic Lighting Engine for Velvet Assassin
- Techniques for Improving Large World and Terrain Streaming
- A Novel Multithreaded Rendering System based on a Deferred Approach
- Regressions in RT Rendering: LittleBigPlanet Post Mortem
- Meshless Deformations Based on Shape Matching
- sphere ambient occlusion - 2006
- Insomniac Physics
- State-Based Scripting in Uncharted 2: Among Thieves
- Zen of Multicore Rendering
- Star Ocean 4 - Flexible Shader Managment and Post-processing
- Light Propagation Volumes in CryEngine 3
- [Lighting Research at Bungie](https://advances.realtimerendering.com/s2009/SIGGRAPH 2009 - Lighting Research at Bungie.pdf)
- Precomputed Atmospheric Scattering
- Theory and Practice of Game Object Component Architecture
- Rendering Technology at Black Rock Studio
- NVIDIA Developer Tools for Graphics and PhysX
- Animated Wrinkle Maps
- Terrain Rendering in Frostbite Using Procedural Shader Splatting
- Spherical Harmonic Lighting: The Gritty Details
- Precomputed Radiance Transfer for Real-Time Rendering in Dynamic, Low-Frequency Lighting Environments
- A Gentle Introduction to Precomputed Radiance Transfer
- Spherical harmonics
- Tetris packing [Levy 02]
- Multi-Chart Geometry Images

 浙公网安备 33010602011771号
浙公网安备 33010602011771号