剖析虚幻渲染体系(13)- RHI补充篇:现代图形API之奥义与指南
13.1 本篇概述
13.1.1 本篇内容
本篇是RHI篇章的补充篇,将详细且深入地阐述现代图形API的特点、原理、机制和优化技巧。更具体地,本篇主要阐述以下内容:
- 现代图形API的基础概念。
- 现代图形API的特性。
- 现代图形API的使用方式。
- 现代图形API的原理和机制。
- 现代图形API的优化建议。
此文所述的现代图形API指DirectX12、Vulkan、Metal等,而不包含DirectX11和Open GL(ES),但也不完全排除后者的内容。
由于UE的RHI封装以DirectX为主,所以此文也以DirectX作为主视角,Vulkan、Metal等作为辅视角。
13.1.2 概念总览
我们都知道,现存的API有很多种(下表),它们各具特点,自成体系,涉及了众多不同但又相似的概念。
| 图形API | 适用系统 | 着色语言 |
|---|---|---|
| DirectX | Windows、XBox | HLSL(High Level Shading Language) |
| Vulkan | 跨平台 | SPIR-V |
| Metal | iOS、MacOS | MSL(Metal Shading Language) |
| OpenGL | 跨平台 | GLSL(OpenGL Shading Language) |
| OpenGL ES | 移动端 | ES GLSL |
下面是它们涉及的概念和名词的对照表:
| DirectX | Vulkan | OpenGL(ES) | Metal |
|---|---|---|---|
| texture | image | texture and render buffer | texture |
| render target | color attachments | color attachments | color attachments or render target |
| command list | command buffer | part of context, display list, NV_command_list | command buffer |
| command list | secondary command buffer | - | parallel command encoder |
| command list bundle | - | light-weight display list | indirect command buffer |
| command allocator | command pool | part of context | command queue |
| command queue | queue | part of context | command queue |
| copy queue | transfer queue | glBlitFramebuffer() | blit command encoder |
| copy engine | transfer engine | - | blit engine |
| predication | conditional rendering | conditional rendering | - |
| depth / stencil view | depth / stencil attachment | depth attachment and stencil attachment | depth attachment and stencil attachment, depth render target and stencil render target |
| render target view, depth / stencil view, shader resource view, unordered access view | image view | texture view | texture view |
| typed buffer SRV, typed buffer UAV | buffer view, texel buffer | texture buffer | texture buffer |
| constant buffer views (CBV) | uniform buffer | uniform buffer | buffer in constant address space |
| rasterizer order view (ROV) | fragment shader interlock | GL_ARB_fragment_shader_interlock | raster order group |
| raw or structured buffer UAV | storage buffer | shader storage buffer | buffer in device address space |
| descriptor | descriptor | - | argument |
| descriptor heap | descriptor pool | - | heap |
| descriptor table | descriptor set | - | argument buffer |
| heap | device memory | - | placement heap |
| - | subpass | pixel local storage | programmable blending |
| split barrier | event | - | - |
| ID3D12Fence::SetEventOnCompletion | fence | fence, sync | completed handler, -[MTLComandBuffer waitUntilComplete] |
| resource barrier | pipeline barrier, memory barrier | texture barrier, memory barrier | texture barrier, memory barrier |
| fence | semaphore | fence, sync | fence, event |
| D3D12 fence | timeline semaphore | - | event |
| pixel shader | fragment shader | fragment shader | fragment shader or fragment function |
| hull shader | tessellation control shader | tessellation control shader | tessellation compute kernel |
| domain shader | tessellation evaluation shader | tessellation evaluation shader | post-tessellation vertex shader |
| collection of resources | fragmentbuffer | fragment object | - |
| pool | heap | - | - |
| heap type, CPU page property | memory type | automatically managerd, texture storage hint, buffer storage | storage mode, CPU cache mode |
| GPU virtual address | buffer device address | - | - |
| image layout, swizzle | image tiling | - | - |
| matching semantics | interface matching (in / out) | varying (removed in GLSL 4.20) | - |
| thread, lane | invocation | invocation | thread, lane |
| threadgroup | workgroup | workgroup | threadgroup |
| wave, wavefront | subgroup | subgroup | SIMD-group, quadgroup |
| slice | layer | - | slice |
| device | logical device | context | device |
| multi-adapter device | device group | implicit(E.g. SLICrossFire) | peer group |
| adapter, node | physical device | - | device |
| view instancing | multiview rendering | multiview rendering | vertex amplification |
| resource state | image layout | - | - |
| pipeline state | pipeline | stage and program or program pipeline | pipeline state |
| root signature | pipeline layout | - | - |
| root parameter | descriptor set layout binding, push descriptor | - | argument in shader parameter list |
| resulting ID3DBlob from D3DCompileFromFile | shader module | shader object | shader library |
| shading rate image | shading rate attachment | - | rasterization rate map |
| tile | sparse block | sparse block | sparse tile |
| reserved resource(D12), tiled resource(D11) | sparse image | sparse texture | sparse texture |
| window | surface | HDC, GLXDrawable, EGLSurface | layer |
| swapchain | swapchain | Pairt of HDC, GLXDrawable, EGLSurface | layer |
| - | swapchain image | default framebuffer | drawable texture |
| stream-out | transform feedback | transform feedback | - |
从上表可知,Vulkan和OpenGL(ES)比较相似,但多了很多概念。Metal作为后起之秀,很多概念和DirectX相同,但部分又和Vulkan相同,相当于是前辈们的混合体。
对于Vulkan,涉及的概念、层级和数据交互关系如下图所示:

Vulkan概念和层级架构图。涉及了Instance、PhysicalDevice、Device等层级,每个层级的各个概念或资源之间存在错综复杂的引用、组合、转换、交互等关系。

Metal资源和概念框架图。
13.1.3 现代图形API特点
对于传统图形API(DirectX11及更早、OpenGL、OpenGL ES),GPU编程开销很大,主要表现在:
- 状态校验(State validation):
- 确认API标记和数据合法。
- 编码API状态到硬件状态。
- 着色器编译(Shader compilation):
- 运行时生成着色器机器码。
- 状态和着色器之间的交互。
- 发送工作到GPU(Sending work to GPU):
- 管理资源生命周期。
- 批处理渲染命令。
对于以上开销大的操作,传统图形API和现图形代API的描述如下:
| 阶段 | 频率 | 传统图形API | 现代图形API |
|---|---|---|---|
| 应用程序构建 | 一次 | - | 着色器编译 |
| 内容加载 | 少次 | - | 状态校验 |
| 绘制调用 | 1000次每帧 | 状态校验,着色器编译,发送工作到GPU | 发送工作到GPU |
以上可知,传统API将开销较大的状态校验、着色器编译和发送工作到GPU全部放到了运行时,而现代图形API将着色器编译放到了应用程序构建期间,而状态校验移至内容加载之时,只保留发送工作到GPU在绘制调用期间,从而极大减轻了运行时的工作负担。
现代图形API(DirectX12、Vulkan、Metal)和传统图形API的描述对照表如下:
| 现代图形API | 传统图形API |
|---|---|
| 基于对象的状态,没有全局状态。 | 单一的全局状态机。 |
| 所有的状态概念都放置到命令缓冲区中。 | 状态被绑定到单个上下文。 |
| 可以多线程编码,并且受驱动和硬件支持。 | 渲染操作只能被顺序执行。 |
| 可以精确、显式地操控GPU的内存和同步。 | GPU的内存和同步细节通常被驱动程序隐藏起来。 |
| 驱动程序没有运行时错误检测,但存在针对开发人员的验证层。 | 广泛的运行时错误检测。 |
相比OpenGL(ES)等传统API,Vulkan支持多线程,轻量化驱动层,可以精确地管控GPU内存、同步等资源,避免运行时创建和消耗资源堆,避免运行时校验,避免CPU和GPU的同步点,基于命令队列的机制,没有全局状态等等(下图)。

Vulkan拥有更轻量的驱动层,使得应用程序能够拥有更大的自由度控制GPU,也有更多的硬件性能。
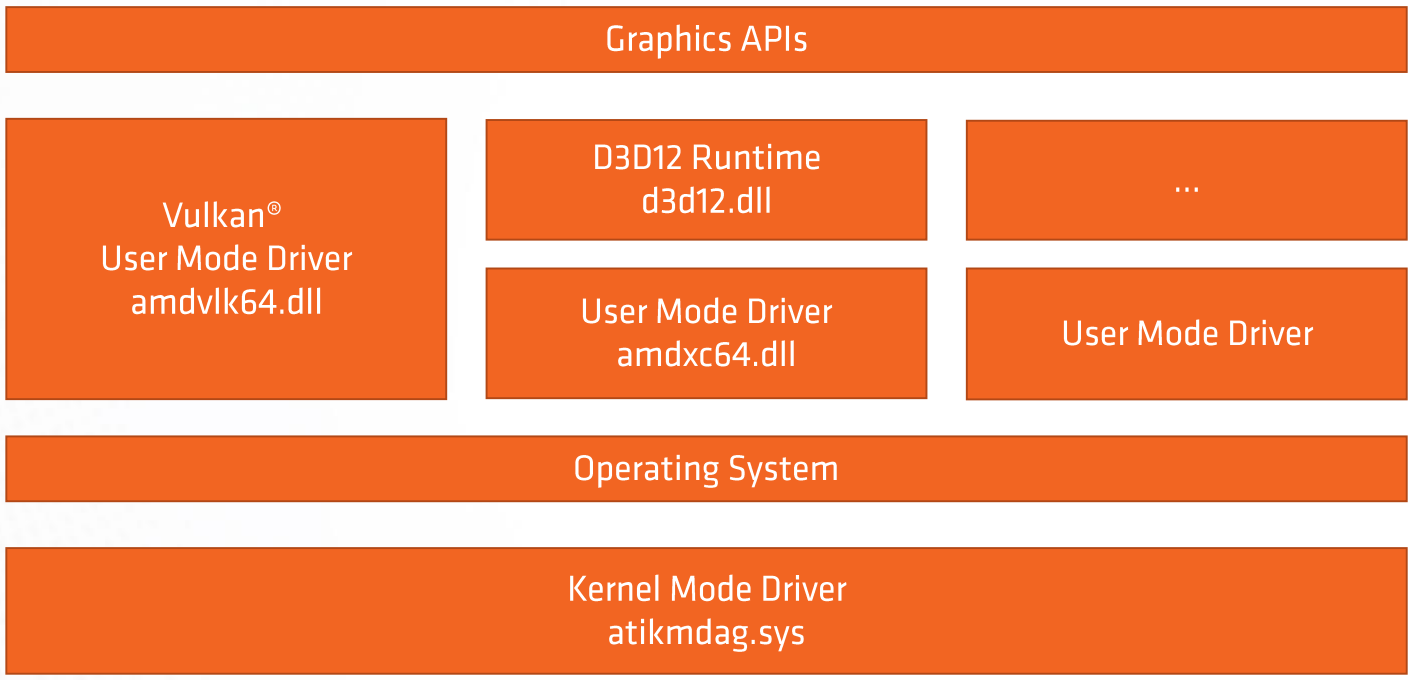
图形API、驱动层、操作系统、内核层架构图。
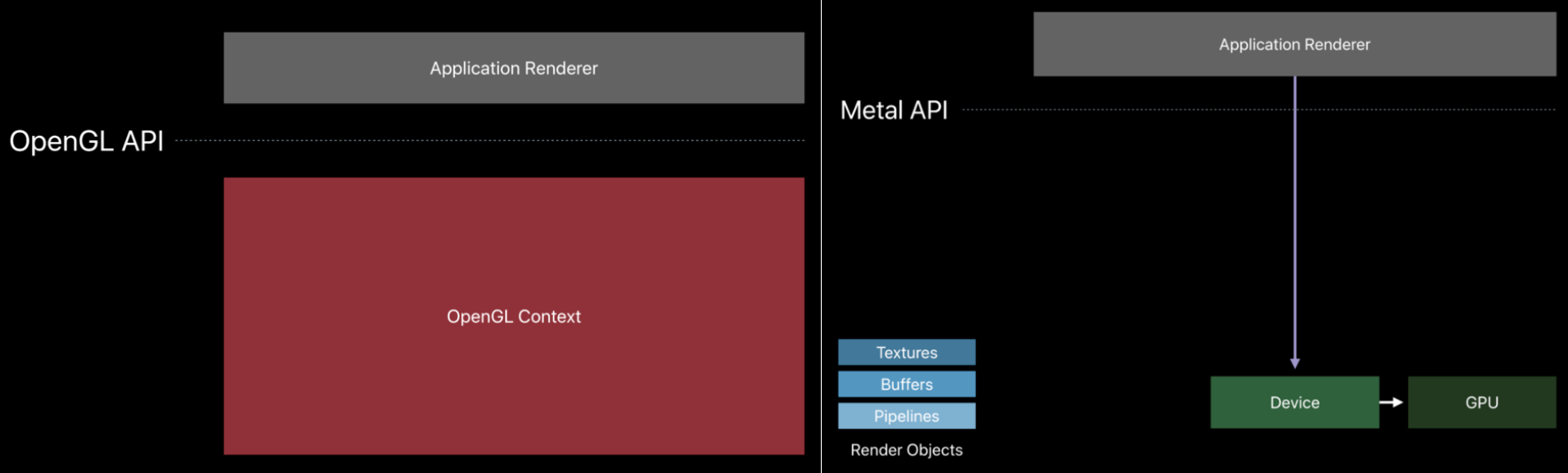
Metal(右)比OpenGL(左)拥有更轻量的驱动层。
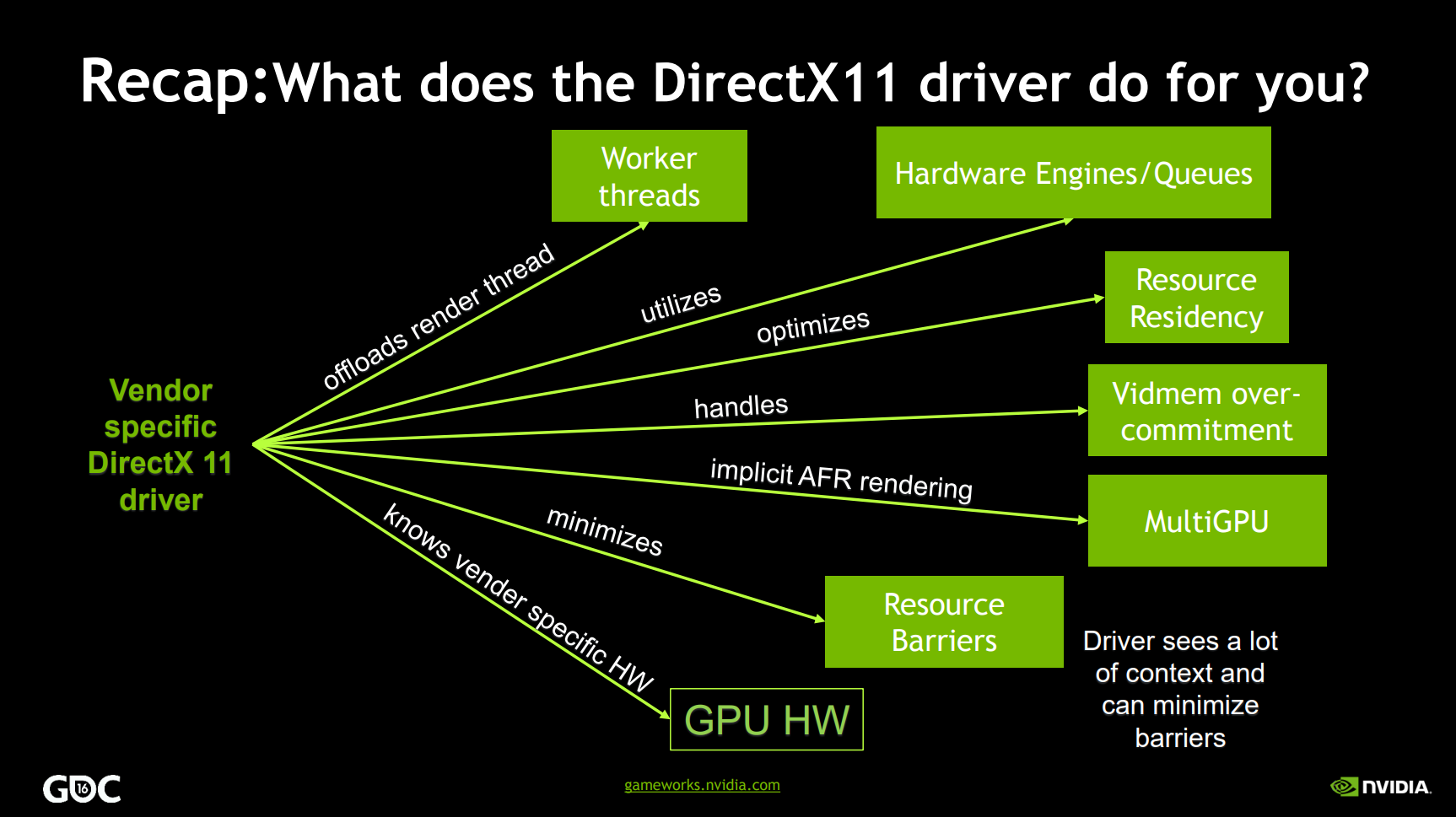
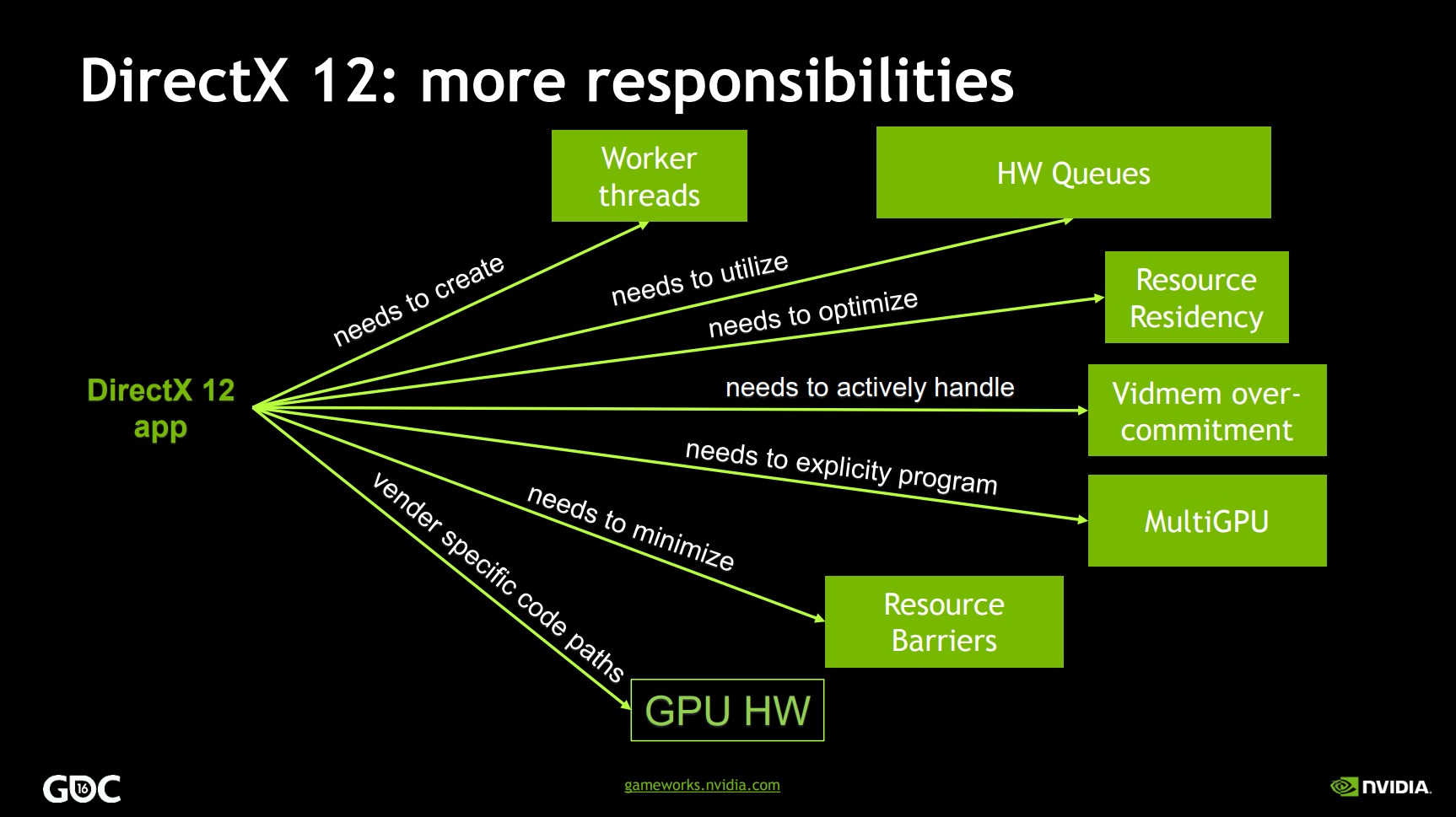
DirectX11驱动程序(上)和DirectX12应用程序(下)执行的工作对比图。
得益于Vulkan的先进设计理念,使得它的渲染性能更高,通常在CPU、GPU、带宽、能耗等指标都优于OpenGL。但如果是应用程序本身的CPU或者GPU负载高,则使用Vulkan的收益可能没有那么明显:

对于使用了传统API的渲染引擎,如果要迁移到现代图形API,潜在收益和工作量如下图所示:

从OpenGL(ES)迁移到现代图形API的成本和收益对比。横坐标是从OpenGL(ES)迁移其它图形API的工作量,纵坐标是潜在的性能收益。可见Vulkan和DirectX12的潜在收益比和工作量都高,而Metal次之。
部分GPU厂商(如NVidia)会共享OpenGL和Vulkan驱动,甚至在应用程序层,它们可以混合:
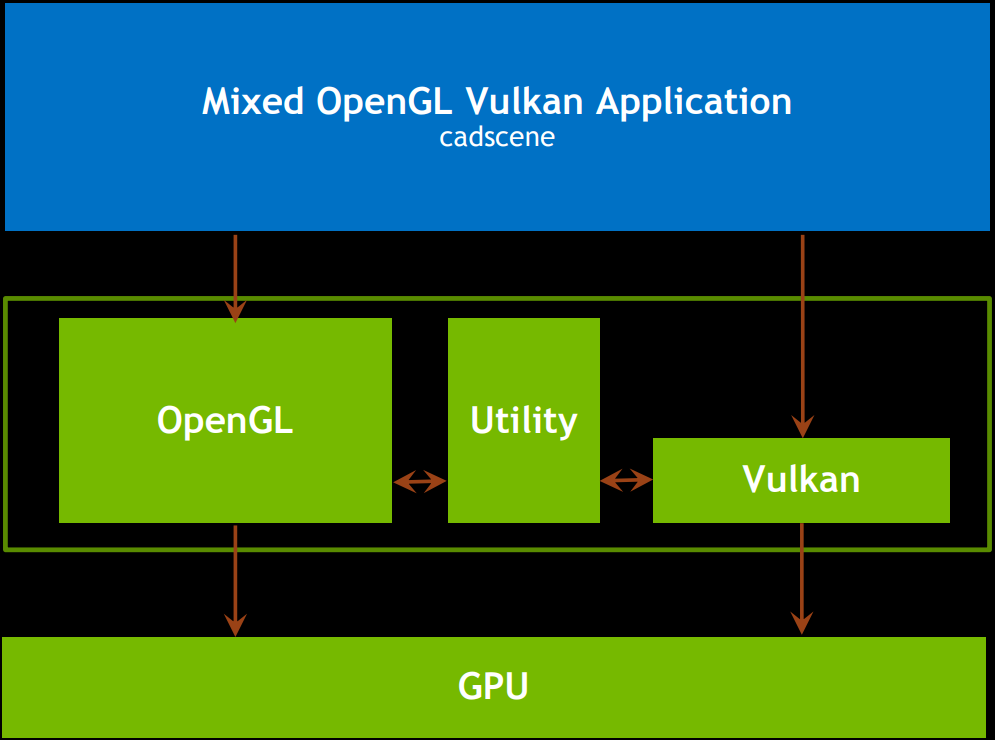
NV的OpenGL和Vulkan共享架构图。可以共享资源、工具箱,提升性能,提升可移植性,允许应用程序在最重要的地方增加Vulkan,获取了OpenGL即获取了Vulkan,减少驱动程序的开发工作量。
利用现代图形API,可以获得的潜在收益有:
- 更好地利用多核CPU。如多线程录制、多线程渲染、多队列、异步技术等。
- 更小的驱动层开销。
- 精确的内存和资源管理。
- 提供精确的多设备访问。
- 更多的Draw Call,更多的渲染细节。
- 更高的最小、最大、平均帧率。
- 更高效的GPU硬件使用。
- 更高效的集成GPU硬件使用。
- 降低系统功率。
- 允许新的架构设计,以前由于传统API的技术限制而认为是不可能的,如TBR。
13.2 设备上下文
13.2.1 启动流程
对大多数图形API而言,应用程序使用它们时都存在以下几个阶段:
- InitAPI:创建访问API内部工作所需的核心数据结构。
- LoadingAssets:创建数据结构需要加载的东西(如着色器),以描述图形管道,创建和填充命令缓冲区让GPU执行,并将资源发送到GPU的专用内存。
- UpdatingAssets:更新任何Uniform数据到着色器,执行应用程序级别的逻辑。
- Presentation:将命令缓冲区列表发送到命令队列,并呈现交换链。
- AppClosed:如果应用程序没有发送关闭命令,则重复LoadingAssets、UpdatingAssets、Presentation阶段,否则执行Destroy阶段。
- Destroy:等待GPU完成所有剩余工作,并销毁所有数据结构和句柄。
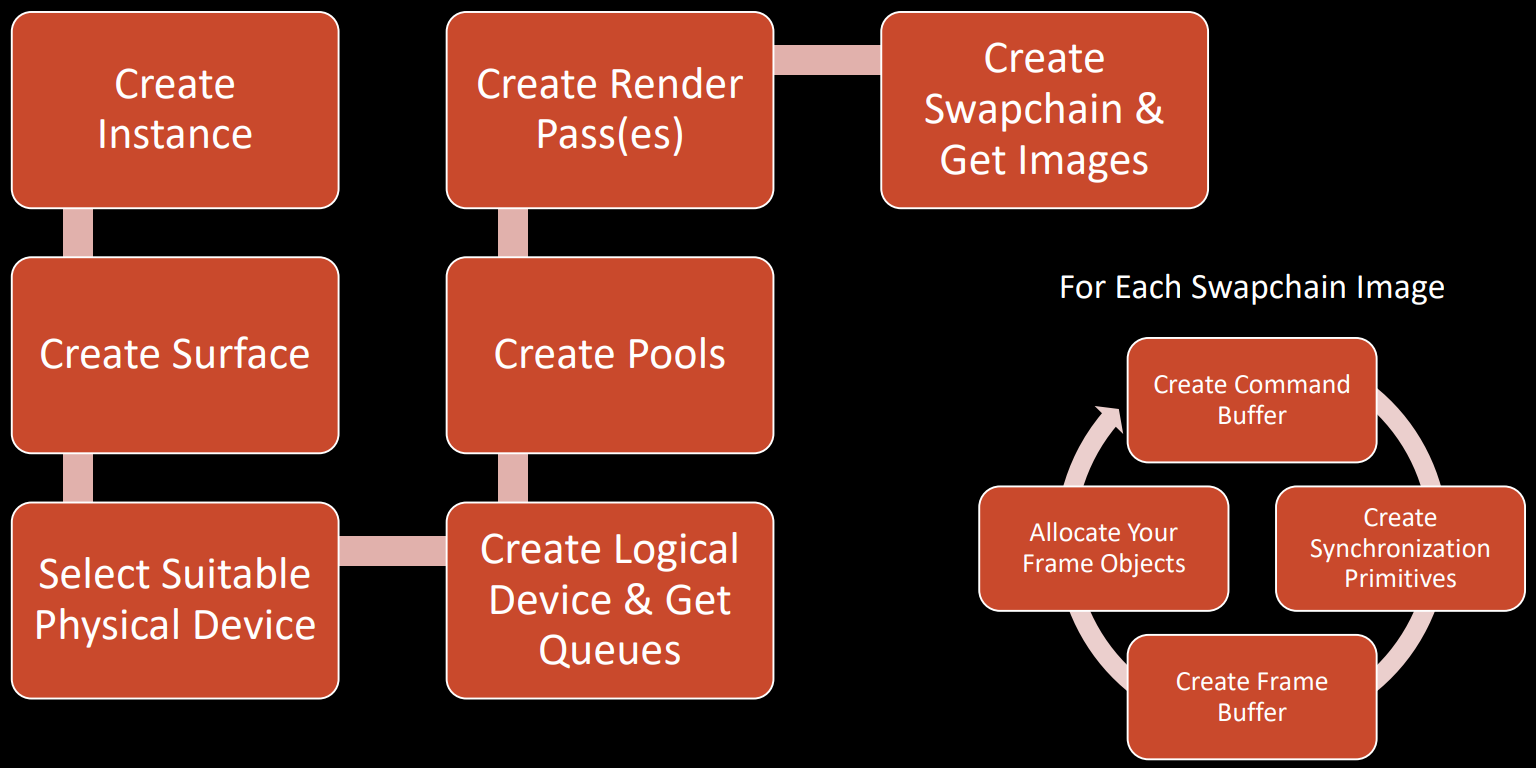
现代图形API启动流程。
后续章节将按照上面的步骤和阶段涉及的概念和机制进行阐述。
13.2.2 Device
初始化图形API阶段,涉及了Factory、Instance、Device等等概念,它们的概念在各个图形API的对照表如下:
| 概念 | UE | DirectX 12 | DirectX 11 | Vulkan | Metal | OpenGL |
|---|---|---|---|---|---|---|
| Entry Point | FDynamicRHI | IDXGIFactory4 | IDXGIFactory | vk::Instance | CAMetalLayer | Varies by OS |
| Physical Device | - | IDXGIAdapter1 | IDXGIAdapter | vk::PhysicalDevice | MTLDevice | glGetString(GL_VENDOR) |
| Logical Device | - | ID3D12Device | ID3D11Device | vk::Device | MTLDevice | - |
Entry Point(入口点)是应用程序的全局实例,通常一个应用程序只有一个入口点实例。用来保存全局数据、配置和状态。
Physical Device(物理设备)对应着硬件设备(显卡1、显卡2、集成显卡),可以查询重要的设备具体细节,如内存大小和特性支持。
Logical Device(逻辑设备)可以访问API的核心内部函数,比如创建纹理、缓冲区、队列、管道等图形数据结构,这种类型的数据结构在所有现代图形api中大部分是相同的,它们之间的变化很少。Vulkan和DirectX 12通过Logical Device创建内存数据结构来控制内存。
每个应用程序通常有且只有一个Entry Point,UE的Entry Point是FDynamicRHI的子类。每个Entry Point拥有1个或多个Physical Device,每个Physical Device拥有1个或多个Logical Device。
13.2.3 Swapchain
应用程序的后缓存和交换链根据不同的系统或图形API有所不同,涉及了以下概念:
| 概念 | UE | DirectX 12 | DirectX 11 | Vulkan | Metal | OpenGL |
|---|---|---|---|---|---|---|
| Window Surface | FRHIRenderTargetView | ID3D12Resource | ID3D11Texture2D | vk::Surface | CAMetalLayer | Varies by OS |
| Swapchain | - | IDXGISwapChain3 | IDXGISwapChain | vk::Swapchain | CAMetalDrawable | Varies by OS |
| Frame Buffer | FRHIRenderTargetView | ID3D12Resource | ID3D11RenderTargetView | vk::Framebuffer | MTLRenderPassDescriptor | GLuint |
在DirectX上,由于只有Windows / Xbox作为API的目标,最接近Surface(表面)的东西是从交换链接收到的纹理返回缓冲区。交换链接收窗口句柄,从那里DirectX驱动程序内部会创建一个Surface。对于Vulkan,需要以下几个步骤创建可呈现的窗口表面:
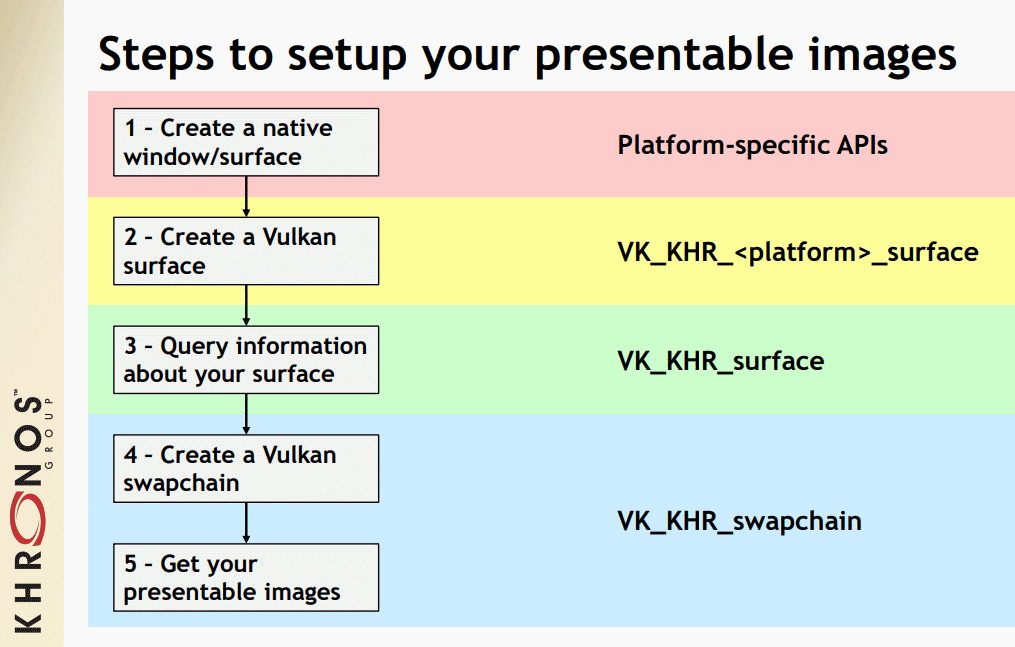
Vulkan WSI的步骤示意图。
由于MacOS和iOS窗口具有分层结构(hierarchical structure),其中应用程序包含一个视图(View),视图可以包含一个层(layer),在Metal中最接近Surface的东西是layer或包裹它的view。
Metal和OpenGL缺少交换链的概念,而把交换链留给了操作系统的窗口API。
DirectX 12和11没有明确的数据结构表明Frame Buffer,最接近的是Render Target View。
Swapchain(交换链)包含单缓冲、双缓冲、三缓冲,分别应对不同的情况。应用程序必须做显式的缓冲区旋转:
DirectX:IDXGISwapChain3::GetCurrentBackBufferIndex()
下面是对Swapchain的使用建议:
- 如果应用程序总是比vsync运行得慢,那么在交换链中使用1个Surface。
- 如果应用程序总是比vsync运行得快,那么在交换链中使用2个Surface,可以减少内存消耗。
- 如果应用程序有时比vsync运行得慢,那么在交换链中使用3个Surface,可以给应用程序提供最佳性能。
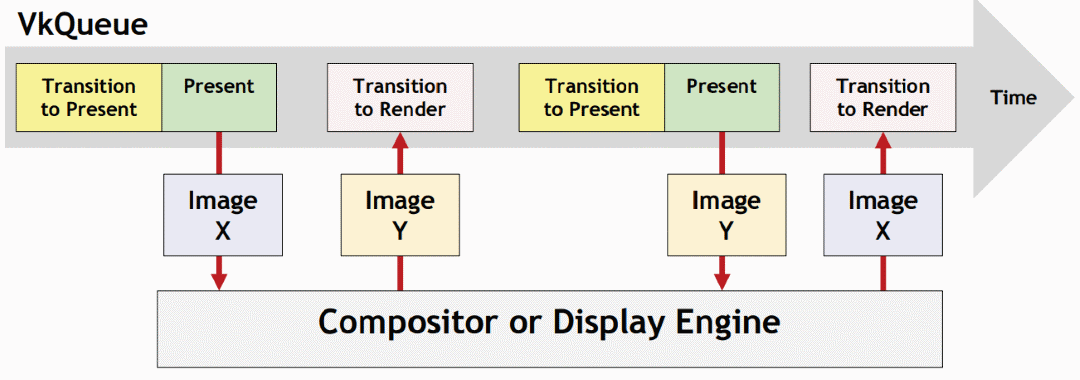
Vulkan交换链运行示意图。
13.3 管线资源
现代图形渲染管线涉及了复杂的流程、概念、资源、引用和数据流关系。(下图)

Vulkan渲染管线关系图。
13.3.1 Command
现代图形API的Command(命令)包含应用程序向GPU交互的所有操作,涉及了以下几种概念:
| 概念 | UE | DirectX 12 | DirectX 11 | Vulkan | Metal | OpenGL |
|---|---|---|---|---|---|---|
| Command Queue | - | ID3D12CommandQueue | ID3D11DeviceContext | vk::Queue | MTLCommandQueue | - |
| Command Allocator | - | ID3D12CommandAllocator | ID3D11DeviceContext | vk::CommandPool | MTLCommandQueue | - |
| Command Buffer | FRHICommandList | ID3D12GraphicsCommandList | ID3D11DeviceContext | vk::CommandBuffer | MTLRenderCommandEncoder | - |
| Command List | FRHICommandList | ID3D12CommandList[] | ID3D11CommandList | vk::SubmitInfo | MTLCommandBuffer | - |
Command Queue允许我们将任务加入队列给GPU执行。GPU是一种异步计算设备,需要让它一直处于繁忙状态,同时控制何时将项目添加到队列中。
Command Allocator允许创建Command Buffer,可以定义想要GPU执行的函数。Command Allocator数量上的建议是:
如果有数百个Command Allocator,是错误的做法。Command Allocator只会增加,意味着:
- 不能从分配器中回收内存。回收分配器将把它们增加到最坏情况下的大小。
- 最好将它们分配到命令列表中。
- 尽可能按大小分配池。
- 确保重用分配器/命令列表,不要每帧重新创建。
Command Buffer是一个异步计算单元,可以描述GPU执行的过程(例如绘制调用),将数据从CPU-GPU可访问的内存复制到GPU的专用内存,并动态设置图形管道的各个方面,比如当前的scissor。Vulkan的Command Buffer为了达到重用和精确的控制,有着复杂的状态和转换(即有限状态机):
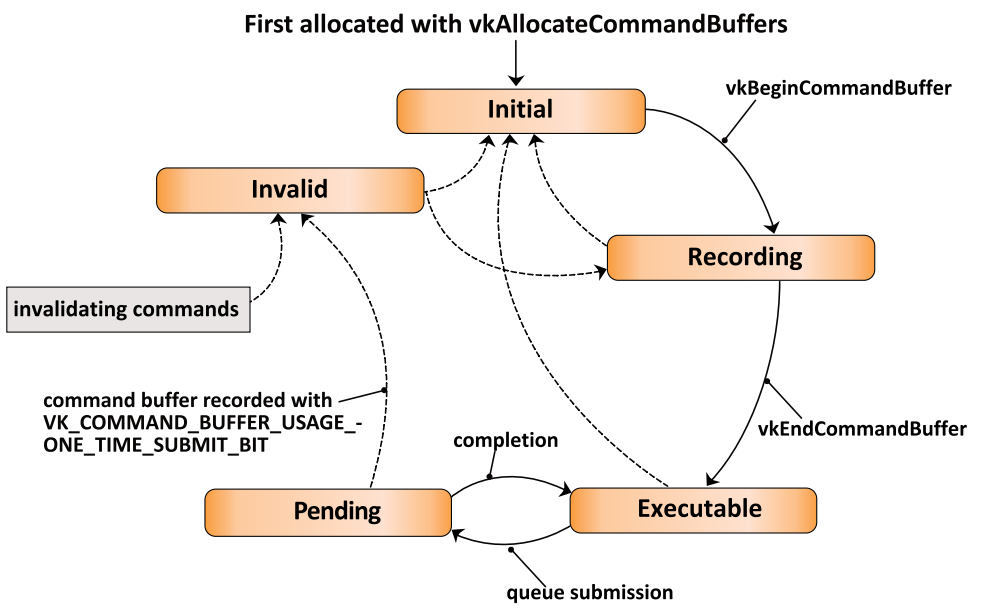
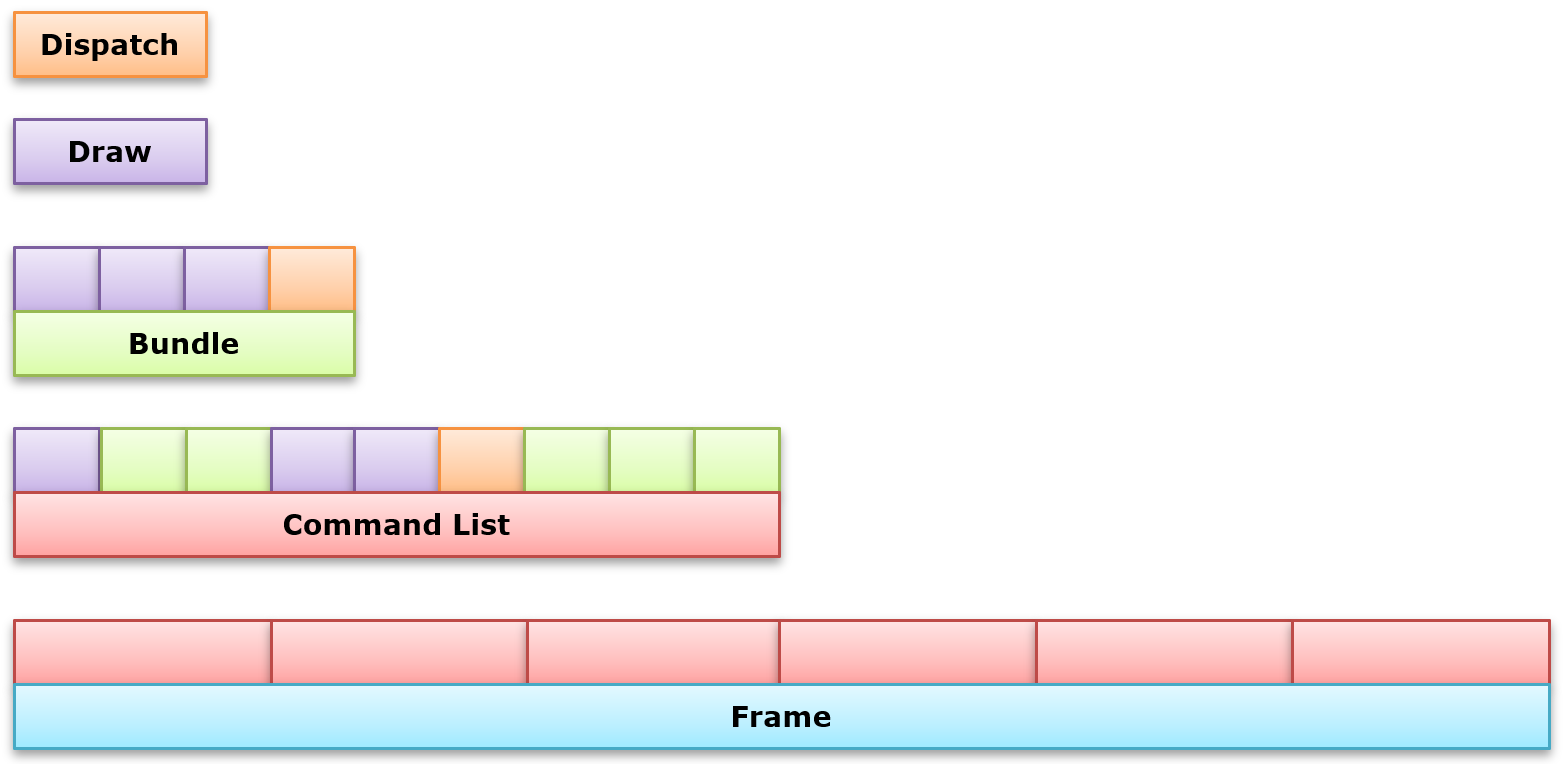
Command List是一组被批量推送到GPU的Command Buffer。这样做是为了让GPU一直处于繁忙状态,从而减少CPU和GPU之间的同步。每个Command List严格地按照顺序执行。Command List可以调用次级Command List(Bundle、Secondary Command List)。这两级的Command List都可以被调用多次,但需要等待上一次提交完成。
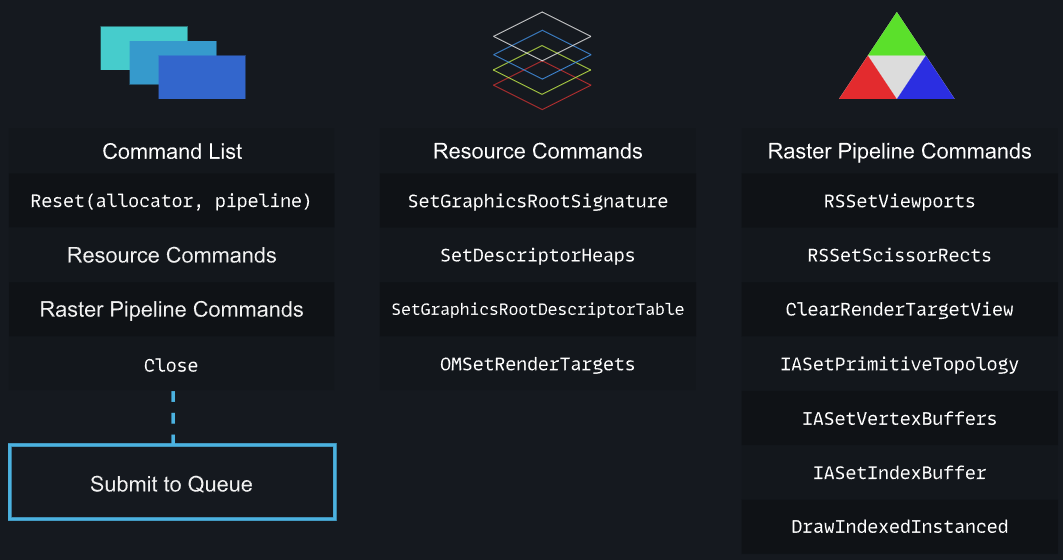
下图是DX12的命令相关的概念构成的层级结构关系图:
对于相似的Command List或Allocator,尽量复用之:

当重置Command List或Allocator时,尽量保持它们引用的资源不变(没有销毁或新的分配)。
但如果数据很不相似,则销毁之,销毁之前必须释放内存。
为了更好的性能,在Command方面的建议如下:
-
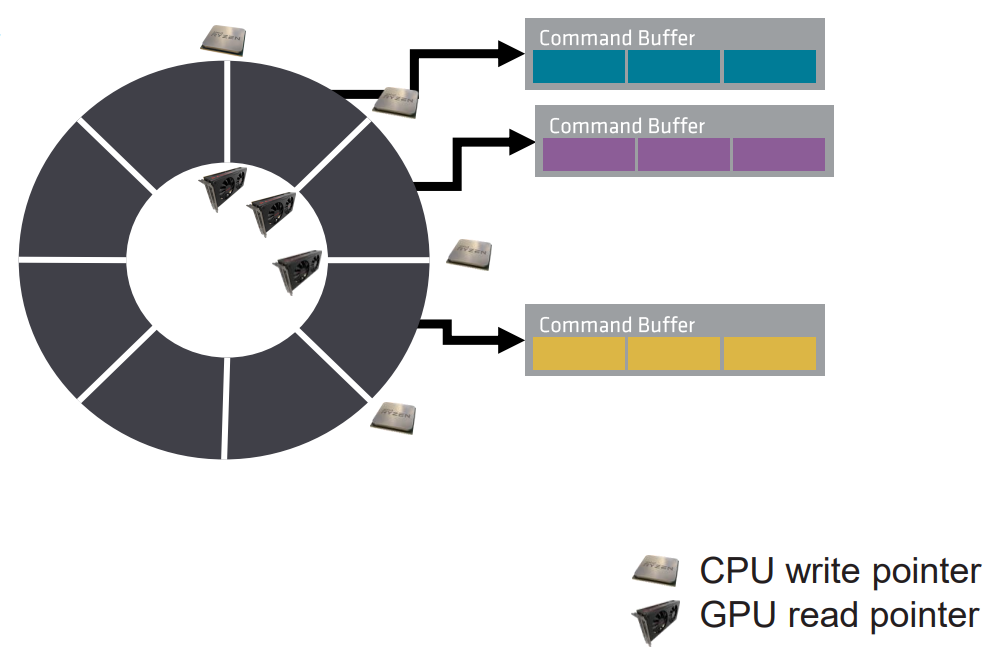
对Command Buffer使用双缓冲、三缓冲。在CPU上填充下一个,而前一个仍然在GPU上执行。
![]()
-
拆分一帧到多个Command Buffer。更有规律的GPU工作提交,命令越早提交越少延时。
![]()
-
限制Command Buffer数量。比如每帧15~30个。
-
将多个Command Buffer批处理到一个提交调用中,限制提交次数。比如每帧每个队列5个。
-
控制Command Buffer的粒度。提交大量的工作,避免多次小量的工作。
-
记录帧的一部分,每帧提交一次。
-
在多个线程上并行记录多个Command Buffer。
![]()
-
大多数对象和数据(包含但不限于Descriptor、CB等内存数据)在GPU上使用时不会被图形API执行引用计数或版本控制。确保它们在GPU使用时保持生命周期和不被修改。可以和Command Buffer的双缓冲、三缓冲一起使用。
![]()
-
使用Ring Buffer存储动态数据。
![]()




13.3.2 Render Pass
| 概念 | UE | DirectX 12 | DirectX 11 | Vulkan | Metal | OpenGL |
|---|---|---|---|---|---|---|
| Render Pass | FRHIRenderPassInfo | BeginRenderPass, EndRenderPass | - | VkRenderPass | MTLRenderPassDescriptor | - |
| SubPass | FRHIRenderPassInfo | - | - | VkSubpassDescription | Programmable Blending | PLS |
绘制命令必须记录在Render Pass实例中,每个Render Pass实例定义了一组输入、输出图像资源,以便在渲染期间使用。
DirectX 12录制命令队列示意图。其中命令包含了资源、光栅化等类型。
现代移动GPU已经普遍支持TBR架构,为了更好地利用此架构特性,让Render Pass期间的数据保持在Tile缓存区内,便诞生了Subpass技术。利用Subpass技术可以显著降低带宽,提升渲染效率。更多请阅读12.4.13 subpass和10.4.4.2 Subpass渲染。
Vulkan Render Pass内涉及的各类概念、资源及交互关系。
在OpenGL,采用Pixel Local Storage的技术来模拟Subpass。Metal则使用Programmable Blending(PB)来模拟Subpass机制(下图)。
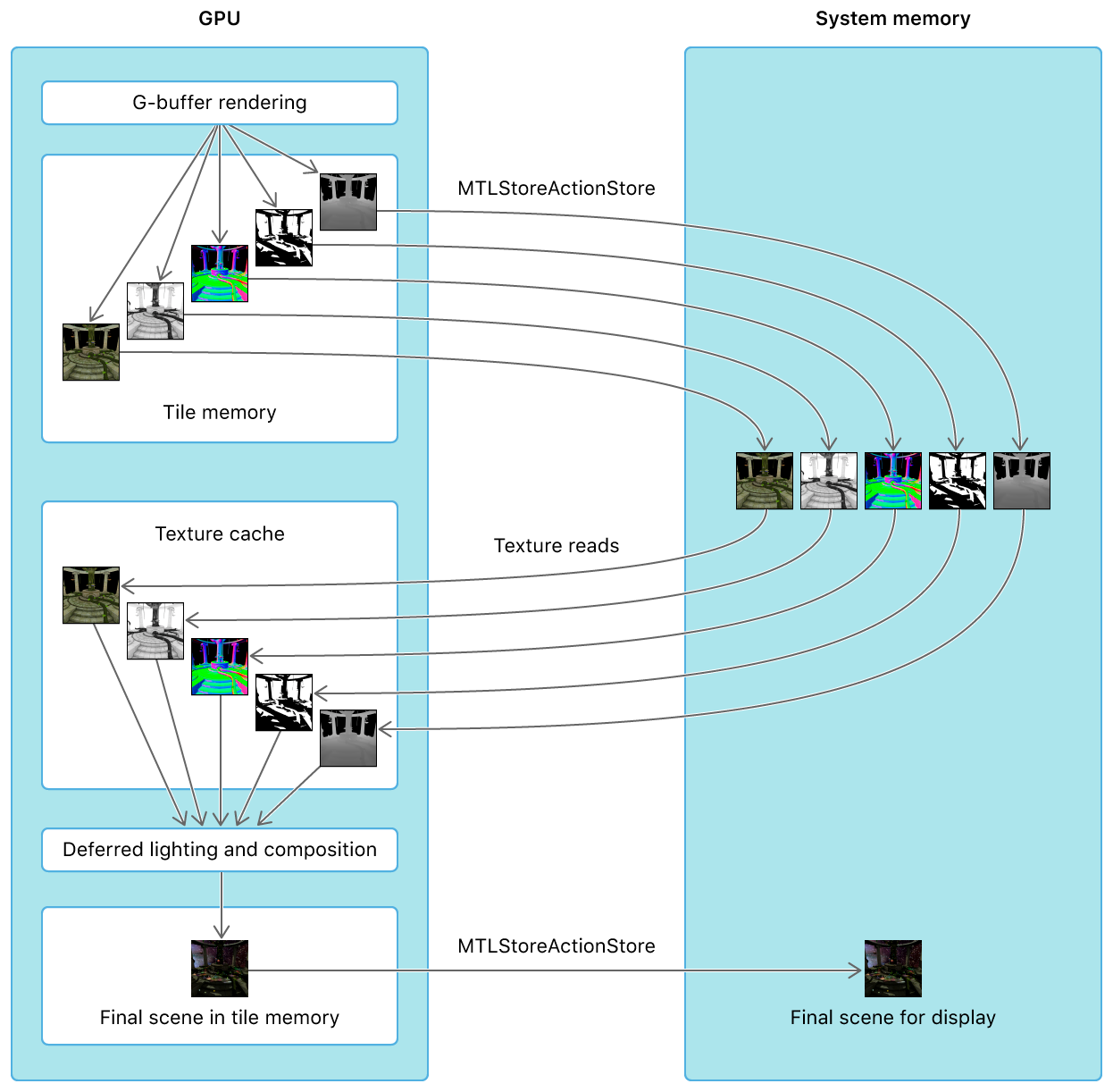
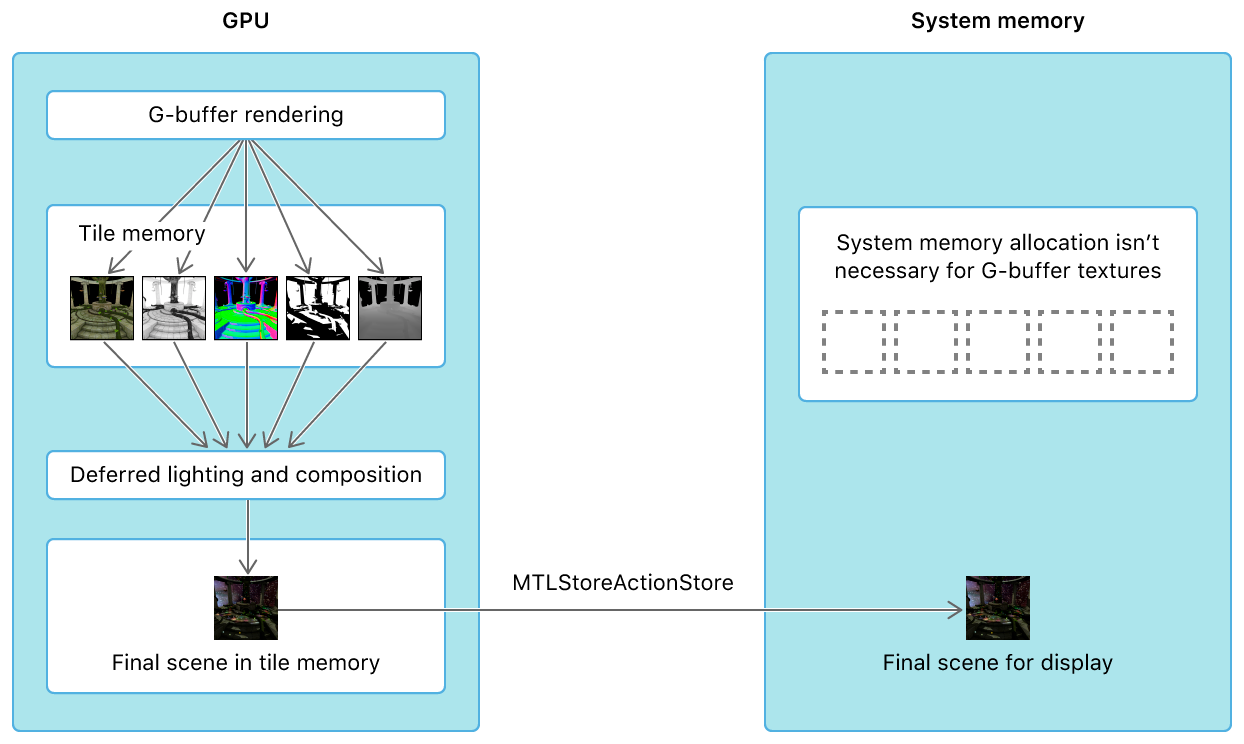
上:传统的多Pass渲染延迟光照,多个GBuffer纹理会在GBuffer Pass和Lighting Pass期间来回传输于Tile Memeory和System Memory之间;下:利用Metal的PB技术,使得GBuffer数据在GBuffer Pass和Lighting Pass期间一直保持在Tile Memroy内。
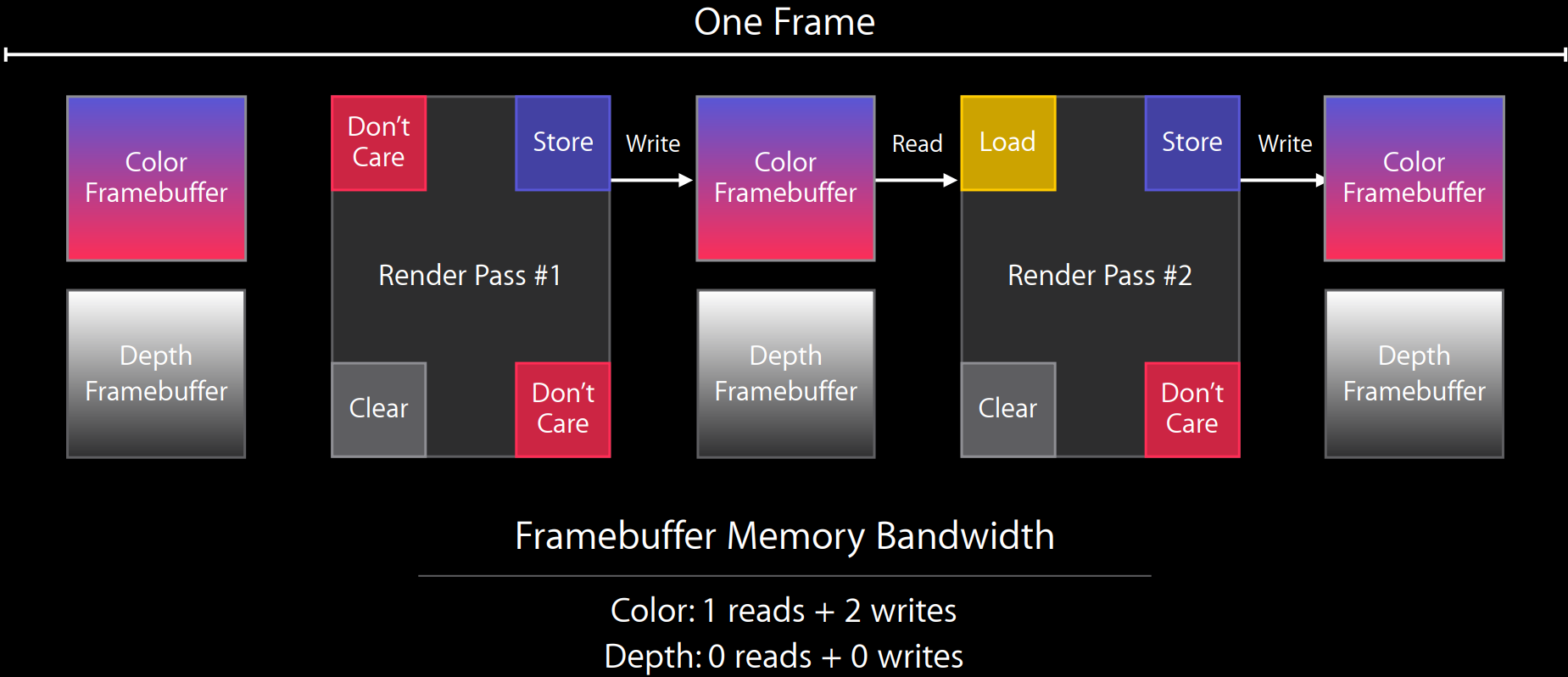
Metal利用Render Pass的Store和Load标记精确地控制Framebuffer在Tile内,从而极大地降低读取和写入带宽。
创建和使用一个Render Pass的伪代码如下:
Start a render pass
// 以下代码会循环若干次
Bind all the resources
Descriptor set(s)
Vertex and Index buffers
Pipeline state
Modify dynamic state
Draw
End render pass
Vulkan的Render Pass使用建议:
- 即使是几个subpass组成一个小的Render Pass,也是好做法。
- Depth pre-pass, G-buffer render, lighting, post-process
- 依赖不是必定需要的。
- 多个阴影贴图通道产生多个输出。
- 把要做的任务重叠到Render Pass中。
- 优先使用load op clear而不是vkCmdClearAttachment。
- 优先使用渲染通道附件的最终布局,而不是明确的Barrier。
- 充分利用“don’t care”。
- 使用解析附件执行MSAA解析。
更多Render Pass相关的说明请阅读:12.4.13 subpass和10.4.4.2 Subpass渲染。
13.3.3 Texture, Shader
| 概念 | UE | DirectX 12 | DirectX 11 | Vulkan | Metal | OpenGL |
|---|---|---|---|---|---|---|
| Texture | FRHITexture | ID3D12Resource | ID3D11Texture2D | vk::Image & vk::ImageView | MTLTexture | GLuint |
| Shader | FRHIShader | ID3DBlob | ID3D11VertexShader, ID3D11PixelShader | vk::ShaderModule | MTLLibrary | GLuint |
大多数现代图形api都有绑定数据结构,以便将Uniform Buffer和纹理连接到需要这些数据的图形管道。Metal的独特之处在于,可以在命令编码器中使用setVertexBuffer绑定Uniform,比Vulkan、DirectX 12和OpenGL更容易构建。
13.3.4 Shader Binding
| 概念 | UE | DirectX 12 | DirectX 11 | Vulkan | Metal | OpenGL |
|---|---|---|---|---|---|---|
| Shader Binding | FRHIUniformBuffer | ID3D12RootSignature | ID3D11DeviceContext::VSSetConstantBuffers(...) | vk::PipelineLayout & vk::DescriptorSet | [MTLRenderCommandEncoder setVertexBuffer: uniformBuffer] | GLint |
| Pipeline State | FGraphicsPipelineStateInitializer | ID3D12PipelineState | Various State Calls | vk::Pipeline | MTLRenderPipelineState | Various State Calls |
| Descriptor | - | D3D12_ROOT_DESCRIPTOR | - | VkDescriptorBufferInfo, VkDescriptorImageInfo | argument | - |
| Descriptor Heap | - | ID3D12DescriptorHeap | - | VkDescriptorPoolCreateInfo | heap | - |
| Descriptor Table | - | D3D12_ROOT_DESCRIPTOR_TABLE | - | VkDescriptorSetLayoutCreateInfo | argument buffer | - |
| Root Parameter | - | D3D12_ROOT_PARAMETER | - | VkDescriptorSetLayoutBinding | argument in shader parameter list | - |
| Root Signature | - | ID3D12RootSignature | - | VkPipelineLayoutCreateInfo | - | - |
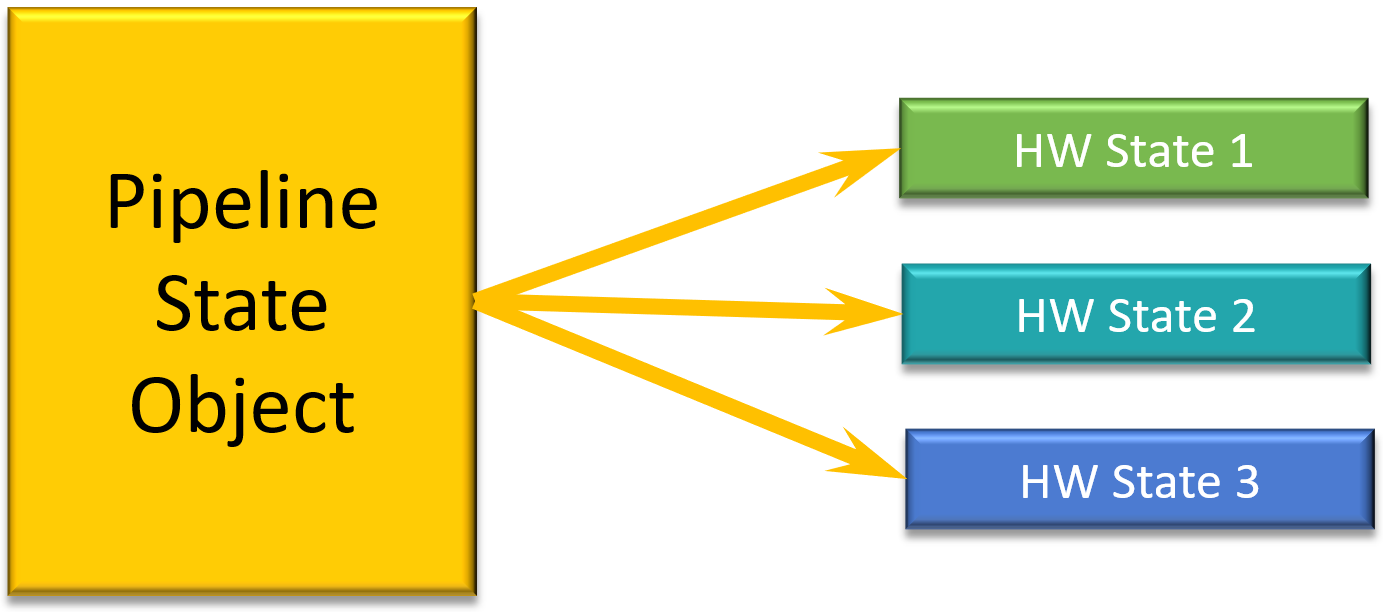
Pipeline State(管线状态)是在执行光栅绘制调用、计算调度或射线跟踪调度时将要执行的内容的总体描述。DirectX 11和OpenGL没有专门的图形管道对象,而是在执行绘制调用之间使用调用来设置管道状态。
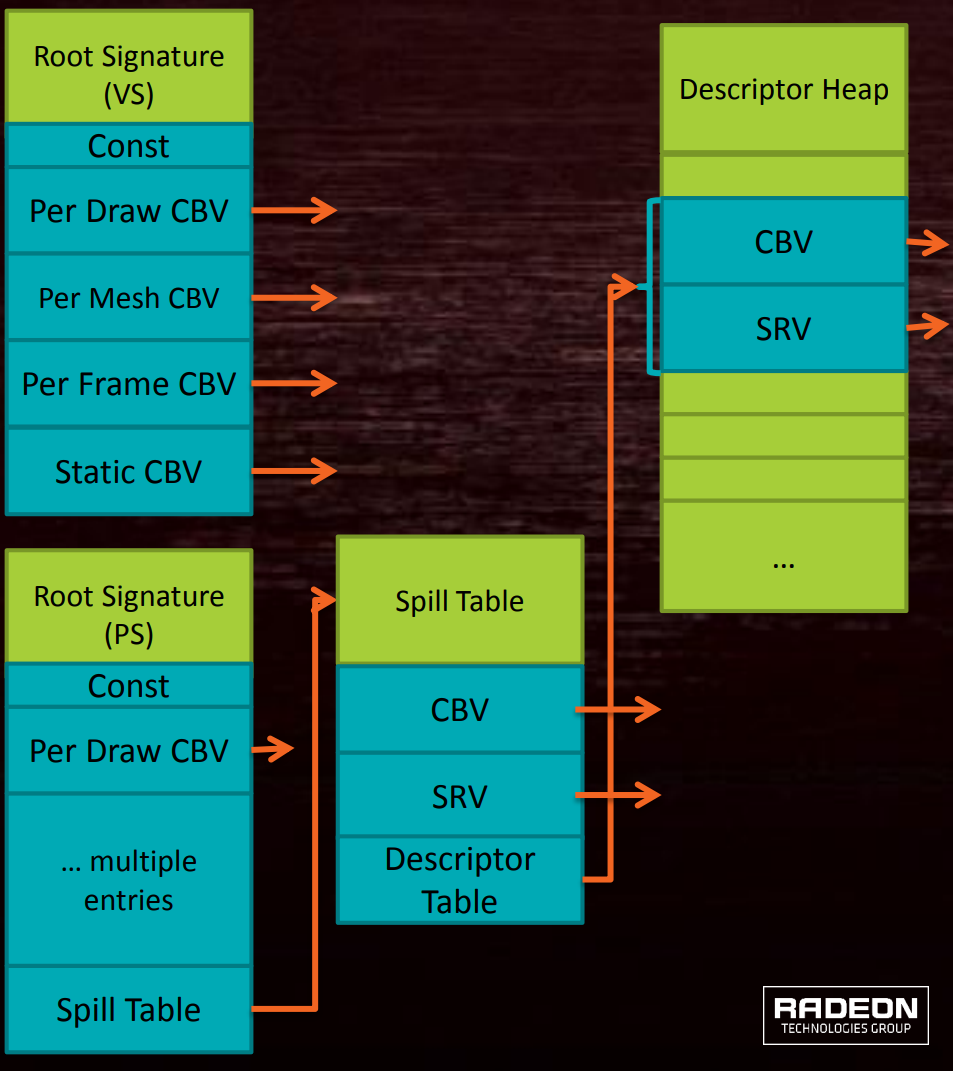
Root Signature(根签名)是定义着色器可以访问哪些类型的资源的对象,比如常量缓冲区、结构化缓冲区、采样器、纹理、结构化缓冲区等等(下图)。
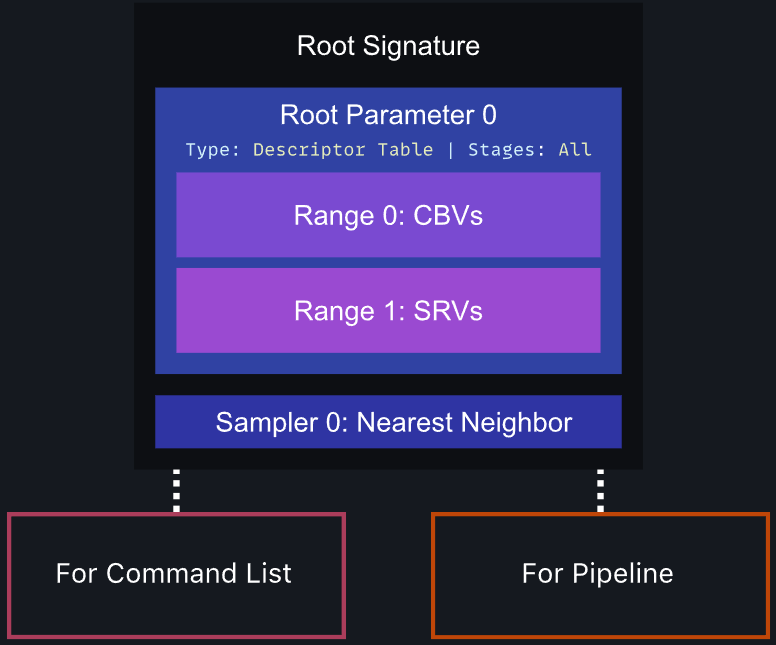
具体地说,Root Signature可以设置3种类型的资源和数据:Descriptor Table、Descriptor、Constant Data。
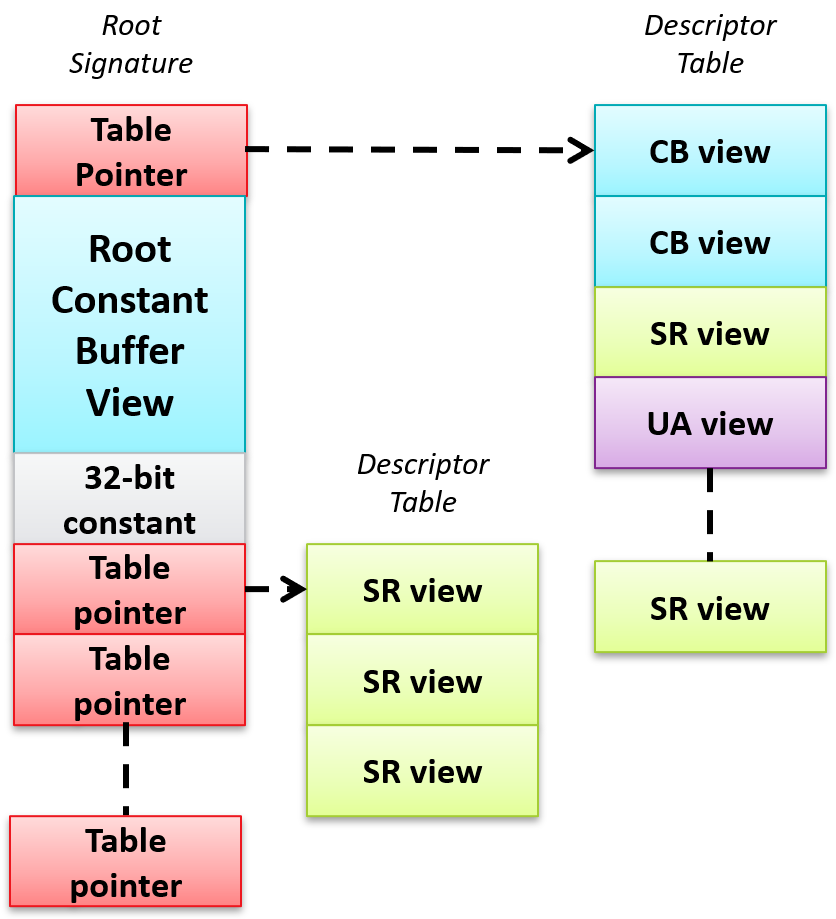
DirectX 12根签名数据结构示意图。
这三种资源在CPU和GPU的消耗刚好相反,需权衡它们的使用:

Root Signature3种类型(Descriptor Table、Descriptor、Constant Data)在GPU内存获取消耗依次降低,但CPU消耗依次提升。
更具体地说,改变Table的指针消耗非常小(只是改变指针,没有同步开销),但改变Table的内容比较困难(处于使用中的Table内容无法被修改,没有自动重命名机制)。
因此,需要尽量控制Root Signature的大小,有效控制Shader可见范围,只在必要时才更新Root Signature数据。
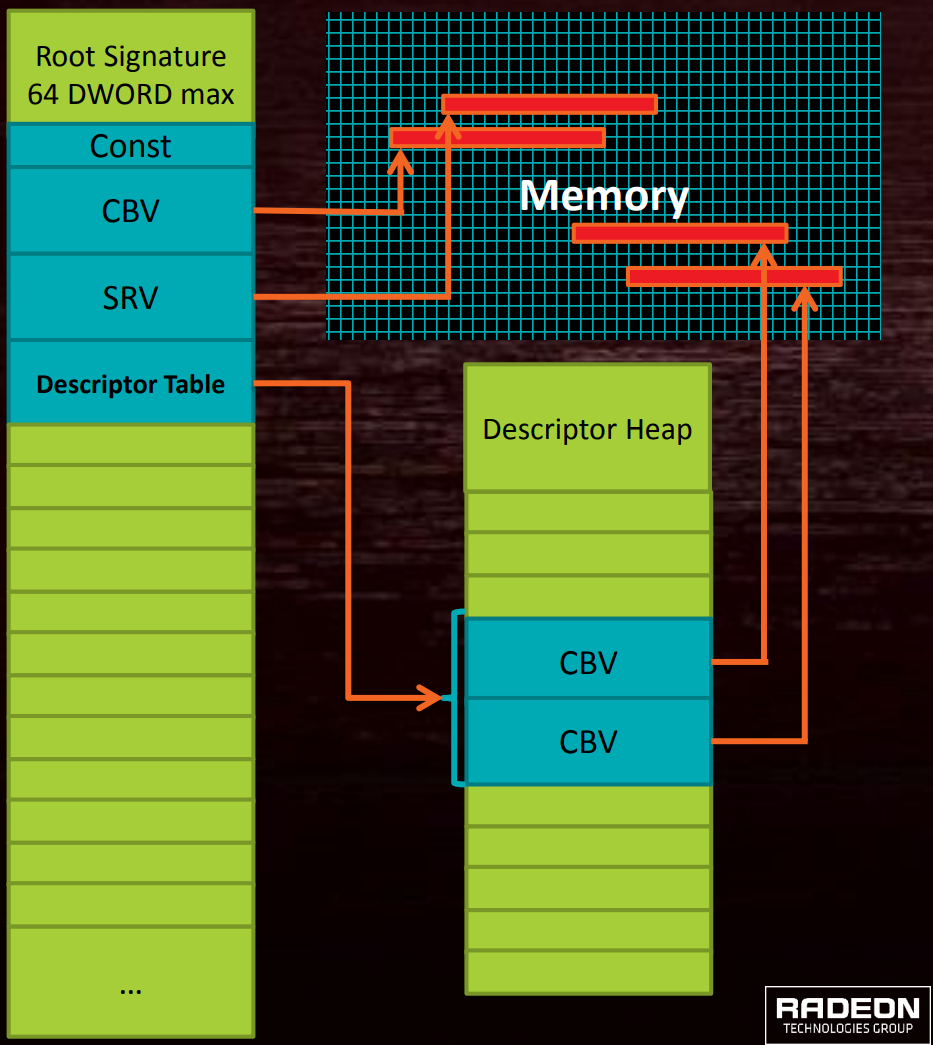
Root Signature在DirectX 12上最大可达64 DWORD,可以包含数据(会占用很大存储空间)、Descriptor(2 DWORD)、指向Descriptor Table的指针(下图)。
Descriptor(描述符)是一小块数据,用来描述一个着色器资源(如缓冲区、缓冲区视图、图像视图、采样器或组合图像采样器)的参数,只是不透明数据(没有OS生命周期管理),是硬件代表的视图。
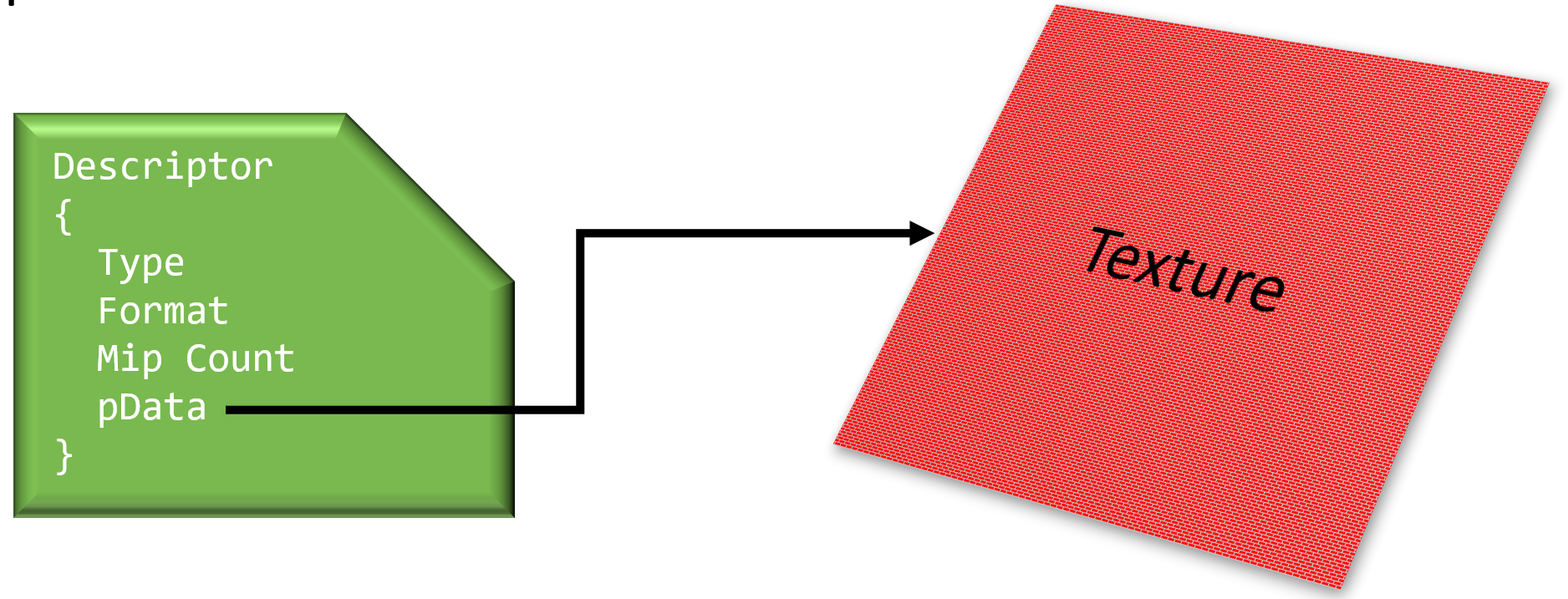
Descriptor的数据图例。
Descriptor被组织成Descriptor Table(描述符表),这些Descriptor Table在命令记录期间被绑定,以便在随后的绘图命令中使用。
每个Descriptor Table中内容的编排由Descriptor Table中的Layout(布局)决定,该布局决定哪些Descriptor可以存储在其中,管道可以使用的Descriptor Table或Root Parameter(根参数)的序列在Root Signature中指定。每个管道对象使用的Descriptor Table和Root Parameter有数量限制。
Descriptor Heap(描述符堆)是处理内存分配的对象,用于存储着色器引用的对象的描述。

Root Signature、Root Parameter、Descriptor Table、Descriptor Heap的关系。其中Root Signature存储着若干个Root Parameter实例,每个Root Parameter可以是Descriptor Table、UAV、SRV等对象,Root Parameter的内存内容存在了Descriptor Heap中。
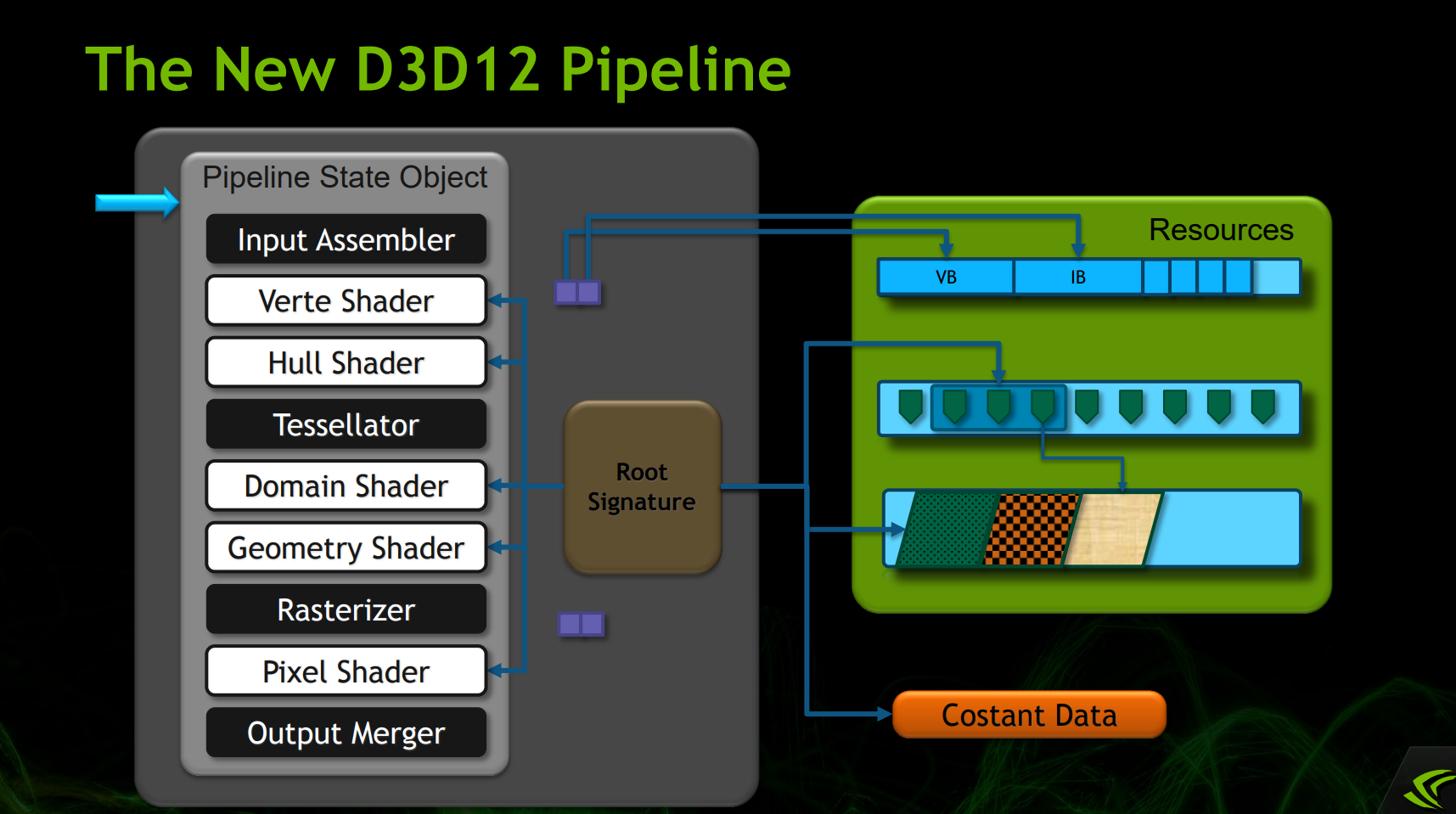
DX12的根签名在GPU内部的交互示意图。其中Root Signature在所有Shader Stage中是共享的。
下面举个Vulkan Descriptor Set的使用示例。已知有以下3个Descriptor Set A、B、C:
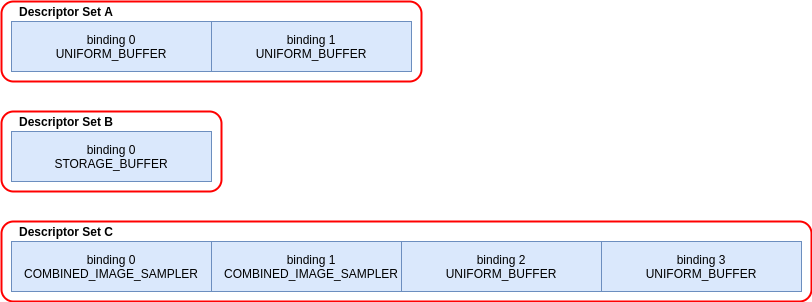
通过以下C++代码绑定它们:
vkBeginCommandBuffer();
// ...
vkCmdBindPipeline(); // Binds shader
// 绑定Descriptor Set B和C, 其中C在序号0, B在序号2. A没有被绑定.
vkCmdBindDescriptorSets(firstSet = 0, pDescriptorSets = &descriptor_set_c);
vkCmdBindDescriptorSets(firstSet = 2, pDescriptorSets = &descriptor_set_b);
vkCmdDraw(); // or dispatch
// ...
vkEndCommandBuffer();
则经过上述代码绑定之后,Shader资源的绑定序号如下图所示:

对应的GLSL代码如下:
layout(set = 0, binding = 0) uniform sampler2D myTextureSampler;
layout(set = 0, binding = 2) uniform uniformBuffer0 {
float someData;
} ubo_0;
layout(set = 0, binding = 3) uniform uniformBuffer1 {
float moreData;
} ubo_1;
layout(set = 2, binding = 0) buffer storageBuffer {
float myResults;
} ssbo;
对于复杂的渲染场景,应用程序可以修改只有变化了的资源集,并且要保持资源绑定的更改越少越好。下面是渲染伪代码:
foreach (scene) {
vkCmdBindDescriptorSet(0, 3, {sceneResources,modelResources,drawResources});
foreach (model) {
vkCmdBindDescriptorSet(1, 2, {modelResources,drawResources});
foreach (draw) {
vkCmdBindDescriptorSet(2, 1, {drawResources});
vkDraw();
}
}
}
对应的shader伪代码:
layout(set=0,binding=0) uniform { ... } sceneData;
layout(set=1,binding=0) uniform { ... } modelData;
layout(set=2,binding=0) uniform { ... } drawData;
void main() { }

Vulkan绑定Descriptor流程图。
下图是另一个Vulkan的VkDescriptorSetLayoutBinding案例:
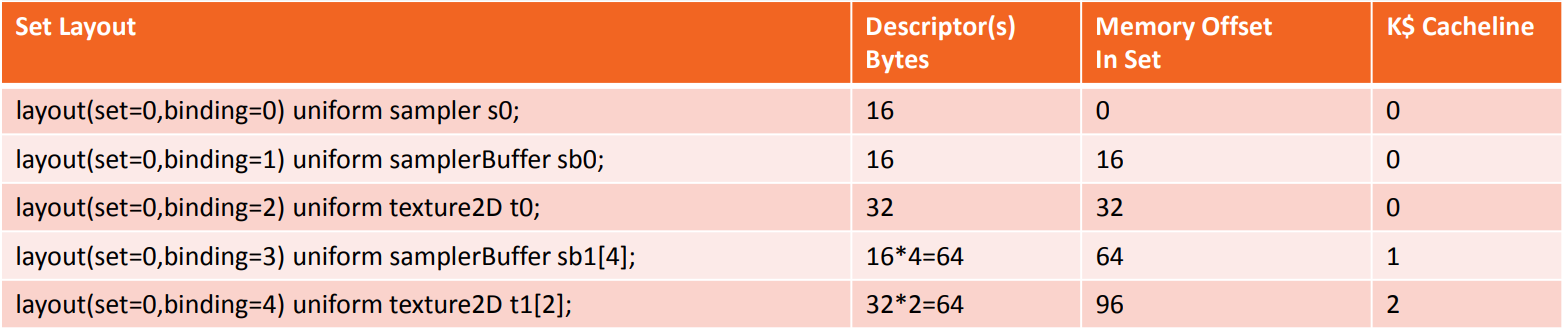
关于着色器绑定的使用,建议如下:
-
Root Signature最好存储在单个Descriptor Heap中,使用RingBuffer数据结构,使用静态的Sampler(最多2032个)。
-
不要超过Root Signature的尺寸。
- Root Signature内的CBV和常量应该最可能每个Draw Call都改变。
- 大部分在CB内的常量数据不应该是根常量。
-
只把小的、频繁使用的每次绘制都会改变的常量,直接放到Root Signature。
-
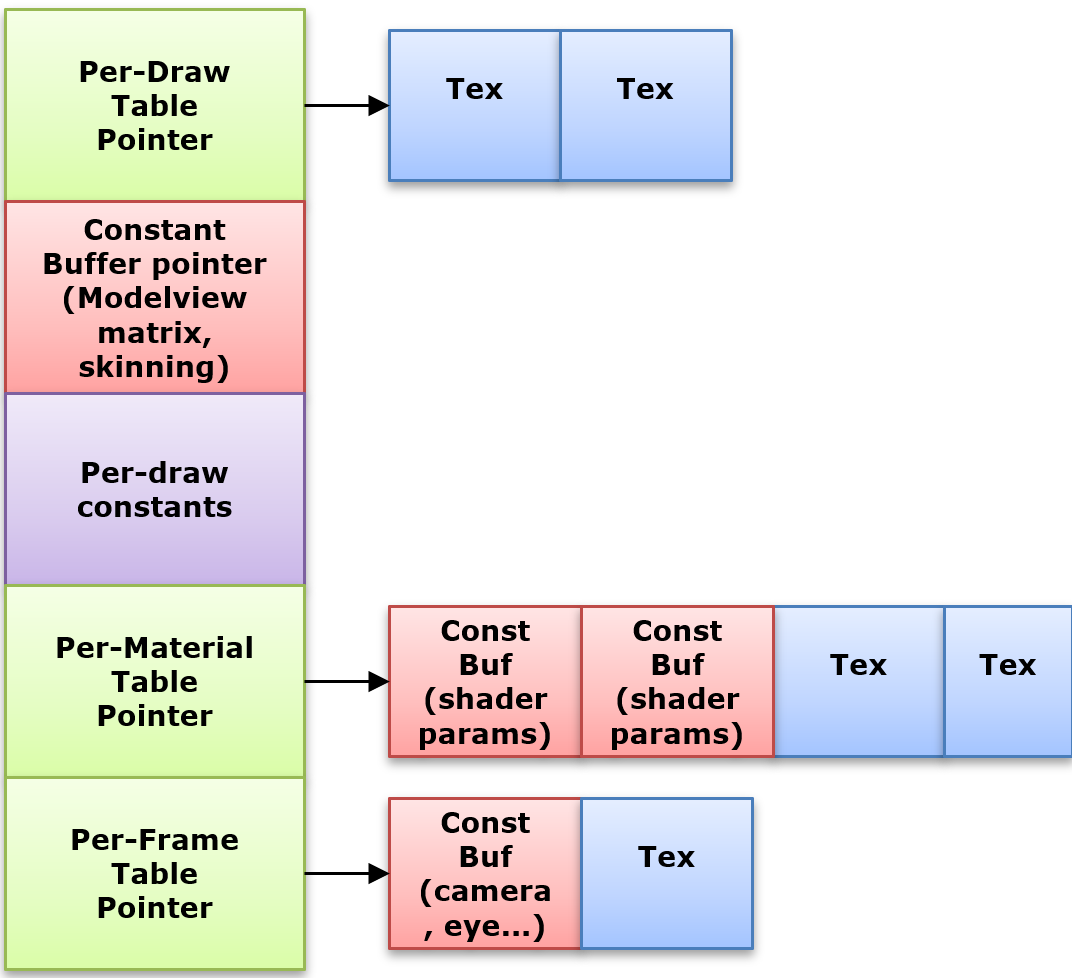
按照更新频率拆分Descriptor Table,最频繁更新的放在最前面(仅DirectX 12,Vulkan相反,Metal未知)。
-
Per-Draw,Per-Material,Per-Light,Per-Frame。
![]()
-
通过将最频繁改变的数据放置到根签名前面,来提供更新频率提示给驱动程序。
![]()
-
-
在启动时复制Root Signature到SGPR。
- 在编译器就确定好布局。
- 只需要为每个着色阶段拷贝。
- 如果占用太多SGPR,Root Signature会被拆分到Local Memory(下图),应避免这种情况!!
![]()
-
尽可能地使用静态表,可以提升性能。
-
保持RST(根签名表)尽可能地小。可以使用多个RST。
-
目标是每个Draw Call只改变一个Slot。
-
将资源可见性限制到最小的阶段集。
- 如果没必要,不要使用D3D12_SHADER_VISIBILITY_ALL。
- 尽量使用DENY_xxx_SHADER_ROOT_ACCESS。
-
要小心,RST没有边界检测。
-
在更改根签名之后,不要让资源绑定未定义。
-
AMD特有建议:
- 只有常量和CBV的逐Draw Call改变应该在RST内。
- 如果每次绘制改变超过一个CBV,那么最好将CBV放在Table中。
-
NV特有建议:
- 将所有常量和CBV放在RST中。
- RST中的常量和CBV确实会加速着色器。
- 根常量不需要创建CBV,意味着更少的CPU工作。
- 将所有常量和CBV放在RST中。
-
尽量缓存并重用DescriptorSet。
![]()


Fortnite缓存并复用DescriptorSet图例。
13.3.5 Heap, Buffer
| 概念 | UE | DirectX 12 | DirectX 11 | Vulkan | Metal | OpenGL |
|---|---|---|---|---|---|---|
| Heap | FRHIResource | ID3D12Resource, ID3D12Heap | - | Vk::MemoryHeap | MTLBuffer | - |
| Buffer | FRHIIndexBuffer, FRHIVertexBuffer | ID3D12Resource | ID3D11Buffer | vk::Buffer & vk::BufferView | MTLBuffer | GLuint |
Heap(堆)是包含GPU内存的对象,可以用来上传资源(如顶点缓冲、纹理)到GPU的专用内存。
Buffer(缓冲区)主要用于上传顶点索引、顶点属性、常量缓冲区等数据到GPU。
13.3.6 Fence, Barrier, Semaphore
| 概念 | UE | DirectX 12 | DirectX 11 | Vulkan | Metal | OpenGL |
|---|---|---|---|---|---|---|
| Fence | FRHIGPUFence | ID3D12Fence | ID3D11Fence | vk::Fence | MTLFence | glFenceSync |
| Barrier | FRDGBarrierBatch | D3D12_RESOURCE_BARRIER | - | vkCmdPipelineBarrier | MTLFence | glMemoryBarrier |
| Semaphore | - | HANDLE | HANDLE | vk::Semaphore | dispatch_semaphore_t | Varies by OS |
| Event | FEvent | - | - | Vk::Event | MTLEvent, MTLSharedEvent | Varies by OS |
Fence(栅栏)是用于同步CPU和GPU的对象。CPU或GPU都可以被指示在栅栏处等待,以便另一个可以赶上。可以用来管理资源分配和回收,使管理总体图形内存使用更容易。
Barrier(屏障)是更细粒度的同步形式,用在Command Buffer内。
Semaphore(信号量)是用于引入操作之间依赖关系的对象,例如在向设备队列提交命令缓冲区之前,在获取交换链中的下一个图像之前等待。Vulkan的独特之处在于,信号量是API的一部分,而DirectX和Metal将其委托给OS调用。
Event(事件)和Barrier类似,用来同步Command Buffer内的操作。对DirectX和OpenGL而言,需要依赖操作系统的API来实现Event。在UE内部,FEvent用来同步线程之间的信号。
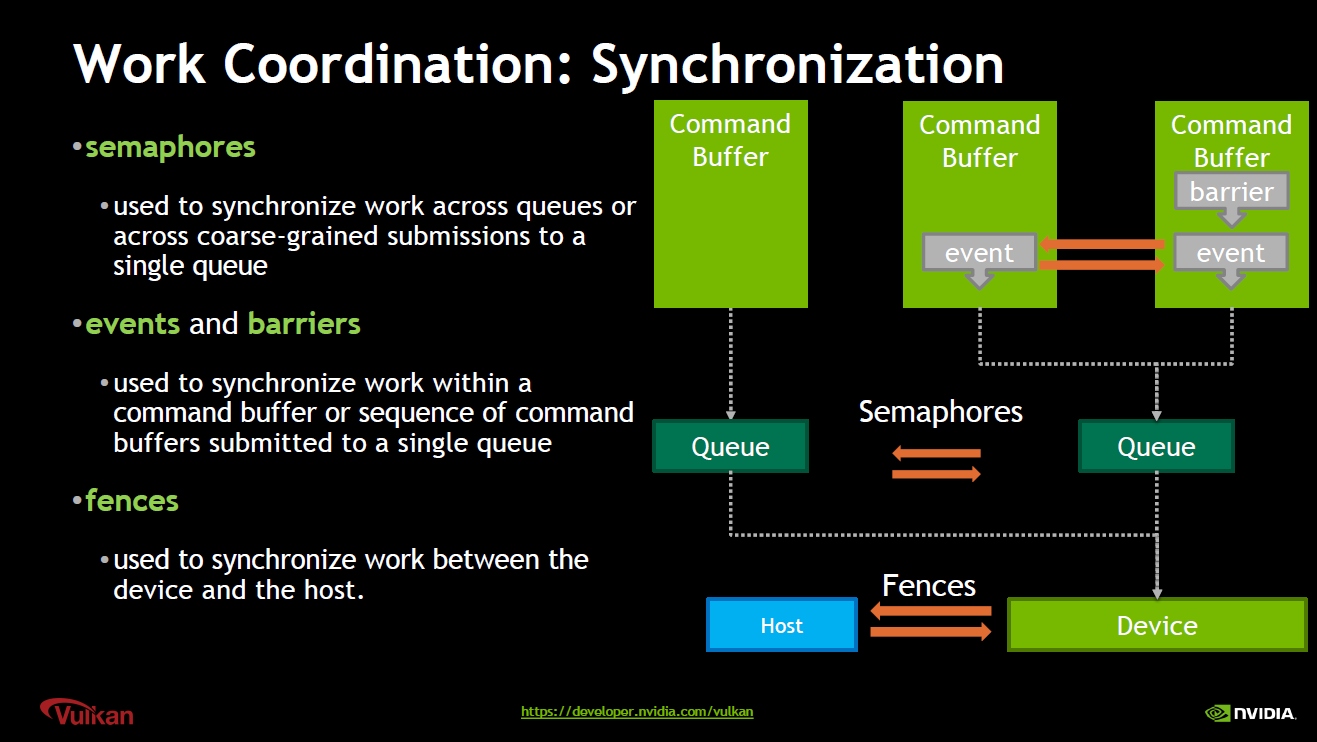
Vulkan同步机制:semaphore(信号)用于同步Queue;Fence(栅栏)用于同步GPU和CPU;Event(事件)和Barrier(屏障)用于同步Command Buffer。

Vulkan semaphore在多个Queue之间的同步案例。
13.4 管线机制
13.4.1 Resource Management
对于现代的硬件架构而言,常见的内存模型如下所示:
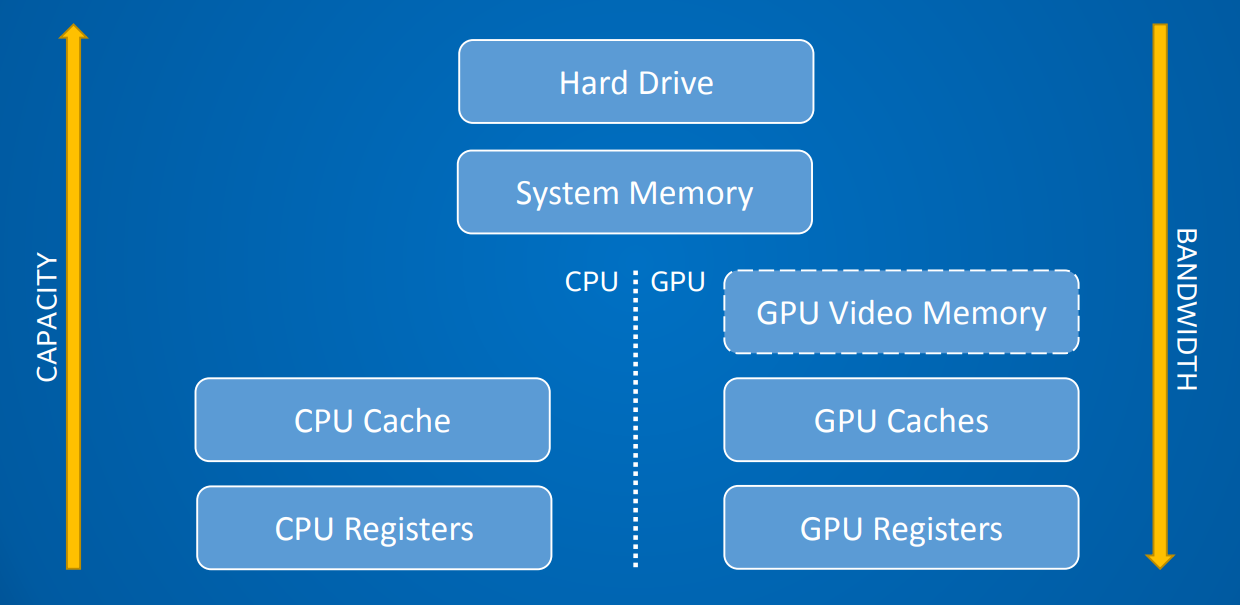
现代计算机内存模型架构图。从上往下,容量越来越小,但带宽越来越大。
对于DirectX 11等传统API而言,资源内存需要依赖操作系统来管理生命周期,内存填充遍布所有时间,大部分直接变成了显存,会导致溢出,回传到系统内存。这种情况在之前没有受到太多人关注,而且似乎我们都习惯了驱动程序在背后偷偷地做了很多额外的工作,即便它们并非我们想要的,并且可能会损耗性能。
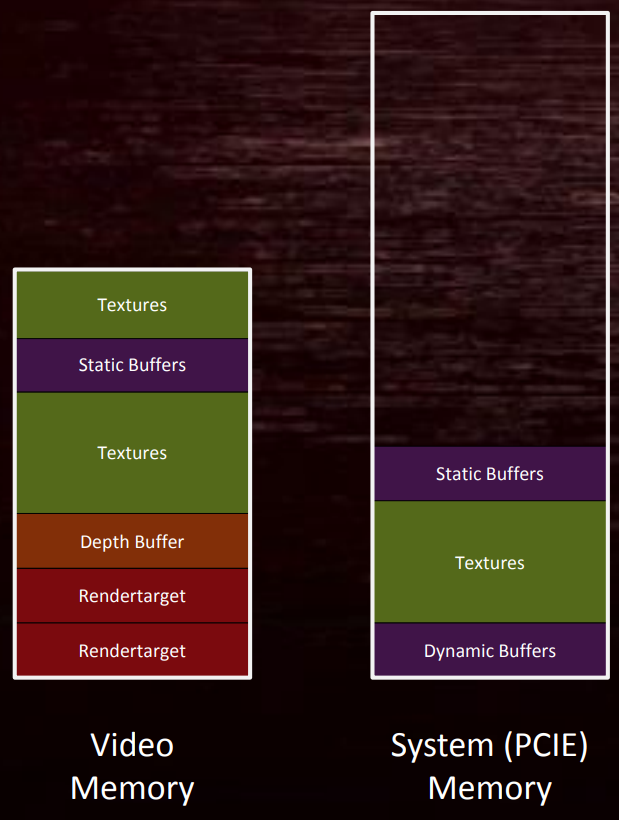
DirectX 11内存管理模型图例。部分资源同时存在于Video和System Memory中。若Video Memory已经耗尽,部分资源不得不迁移到System Memory。
相反,DirectX 12、Vulkan、Metal等现代图形API允许应用程序精确地控制资源的存储位置、状态、转换、生命周期、依赖关系,以及指定精确的数据格式和布局、是否开启压缩等等。现代图形API的驱动程序也不会做过多额外的内存管理工作,所有权都归应用程序掌控,因为应用程序更加知道资源该如何管理。
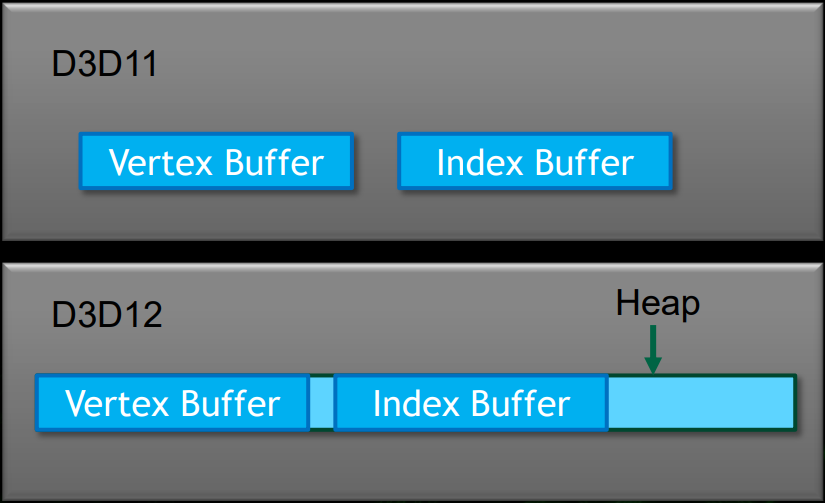
DX11和DX12的内存分配对比图。DX11基于专用的内存块,而DX12基于堆分配。
现代图形API中,几乎所有任务都是延迟执行的,所以要确保不要更改仍在处理队列中的数据和资源。开发者需要处理资源的生命周期、存储管理和资源冲突。
利用现代图形API管理资源内存,首选要考虑的是预留内存空间。
// DirectX 12通过以下接口实现查询和预留显存
IDXGIAdapter3::QueryVideoMemoryInfo()
IDXGIAdapter3::SetVideoMemoryReservation()
如果是前台应用程序,QueryVideoMemory会在空闲系统中启动大约一半的VRAM,如果更少,可能意味着另一个重量级应用已经在运行。
内存耗尽是一个最小规格问题(min spec issue),应用程序需要估量所需的内存空间,提供配置以修改预留内存的尺寸,并且需要根据硬件规格提供合理的选择值。
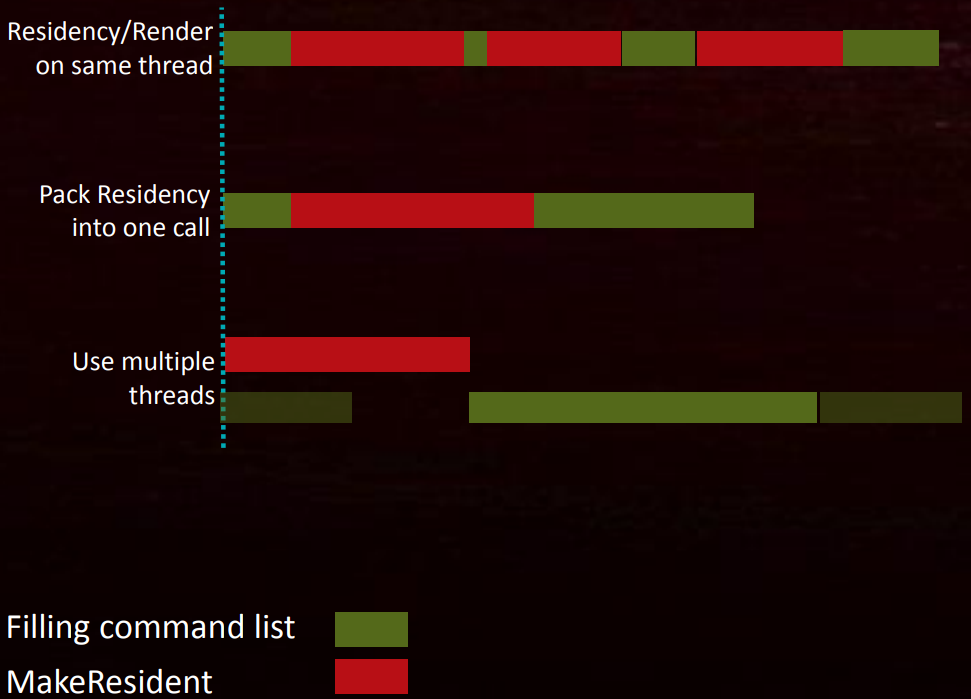
预留空间之后,DirectX 12可以通过MakeResident二次分配内存。需要注意的是,MakeResident是个同步操作,会卡住调用线程,直到内存分配完毕。它的使用建议如下:
-
对多次
MakeResident进行合批。 -
必须从渲染线程抽离,放到额外的专用线程中。分页操作将与渲染相交织。(下图)
![]()
-
确保在使用前就准备好资源,否则即便已经使用了专用的资源线程,依然会引发卡顿。
对此,可以使用提前执行策略(Run-ahead Strategie)。提前预测现在和之后可能会用到什么资源,在渲染线程之前运行几帧,更多缓冲区将获得更少的卡顿,但会引入延迟。

也可以不使用residency机制,而是预加载可能用于系统内存的资源,不要立即移动它们到显存。当资源被使用时,才复制到Video Memory,然后重写描述符或重新映射页面(下图)。当需要减少内存使用时,反向操作并收回显存副本。
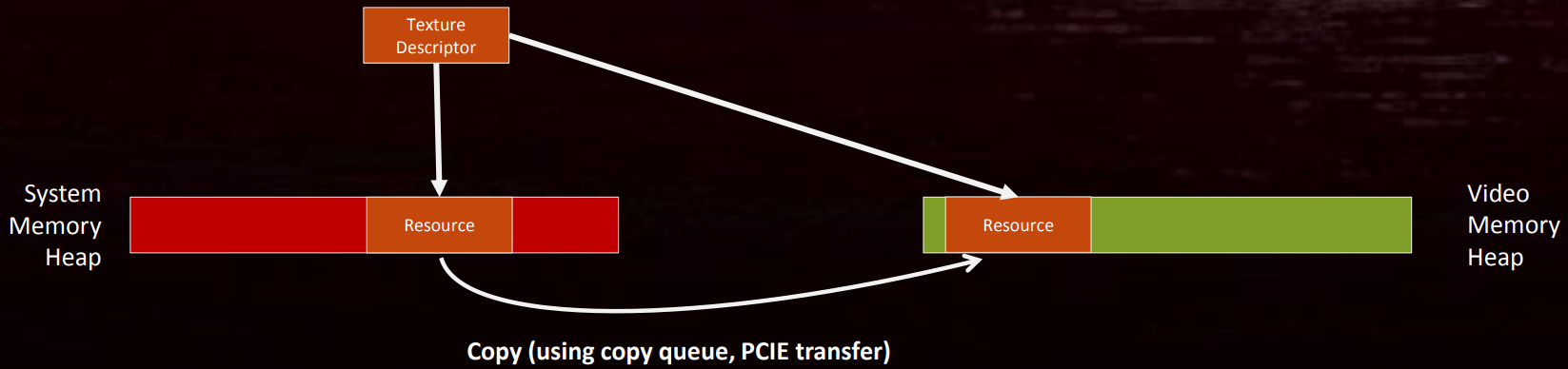
但是,这个方法对VR应用面临巨大挑战,会引发长时间延时的解决方案显然行不通。可以明智地使用系统内存,并在流(streaming)中具备良好的前瞻性。
另外,需要谨慎处理资源的冲突,需要用同步对象控制可能的资源冲突:
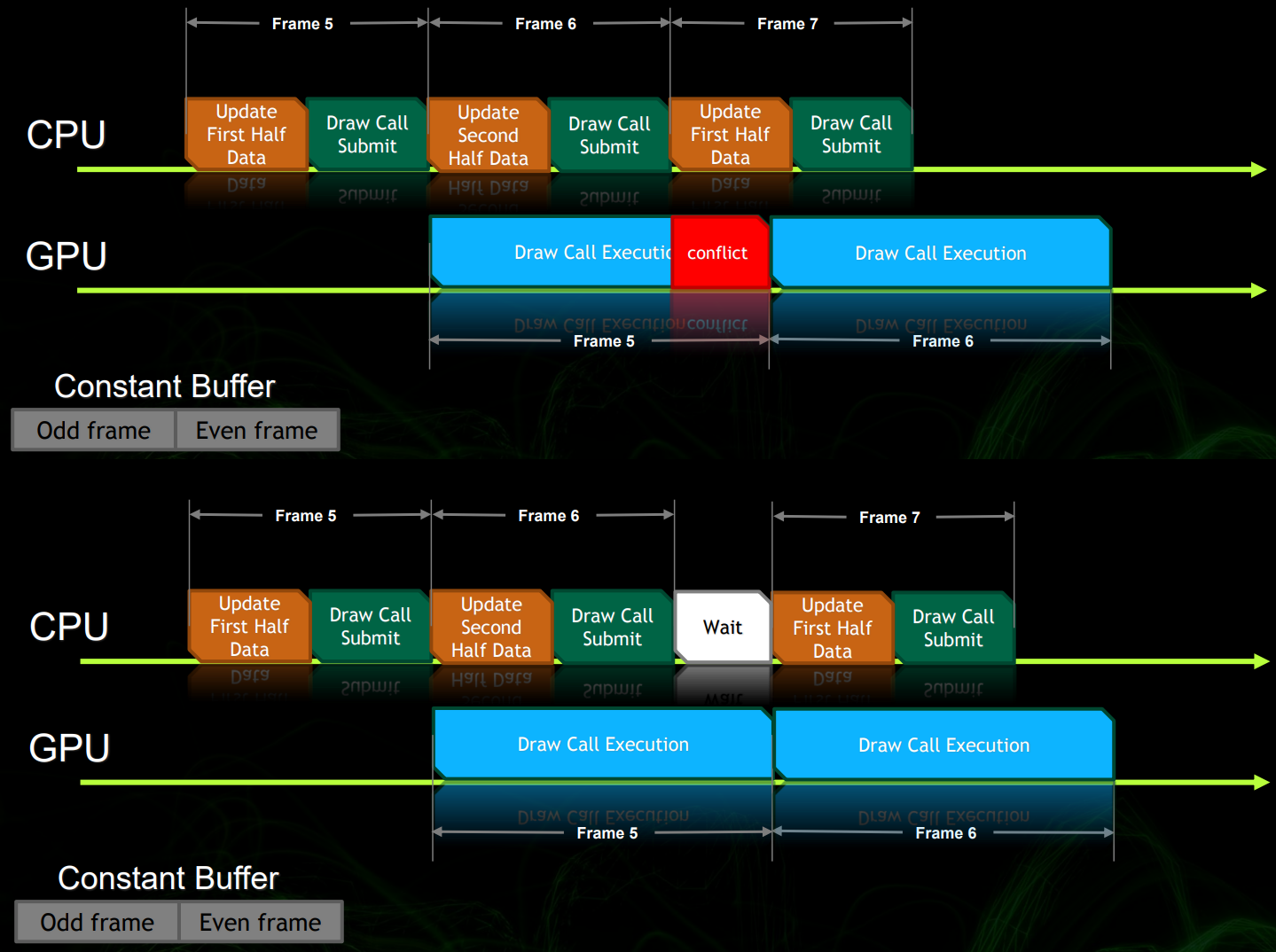
上:CPU在处理数据更新时和GPU处理绘制起了资源冲突;下:CPU需要显示加入同步等待,以便等待GPU处理完绘制调用之后,再执行数据更新。
常见的资源冲突情况:
- 阴影图。
- 延迟着色、光照。
- 实时反射和折射。
- ...
- 任何应用渲染目标作为后续渲染中贴图的情况。
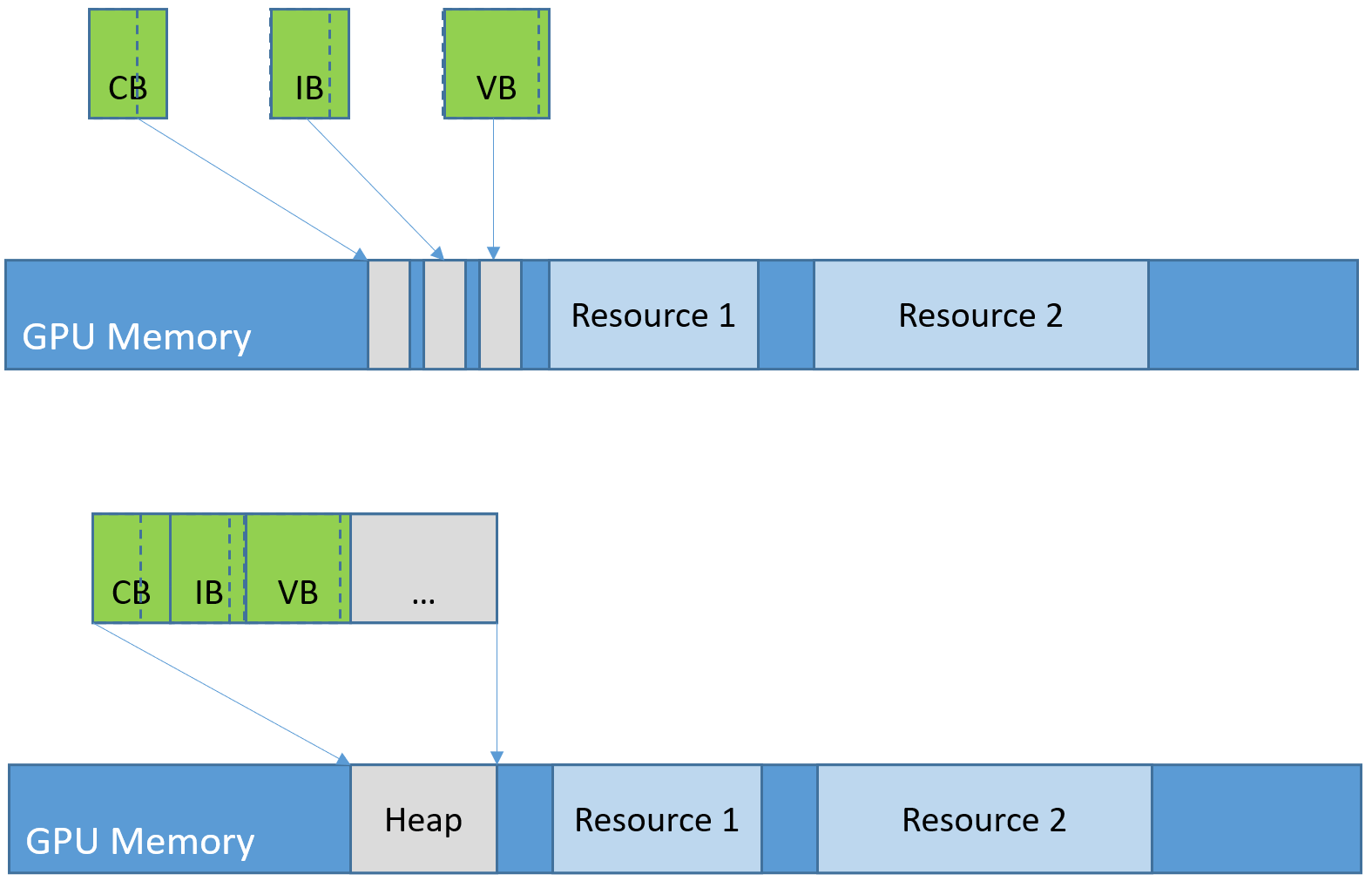
13.4.1.1 Resource Allocation
在 Direct3D 11 中,当使用D3D11_MAP_WRITE_DISCARD标识调用ID3D11DeviceContext::Map时,如果GPU仍然使用的缓冲区,runtime返回一个新内存区块的指针代替旧的缓冲数据。这让GPU能够在应用程序往新缓冲填充数据的同时仍然可以使用旧的数据,应用程序不需要额外的内存管理,旧的缓冲在GPU使用完后会自动销毁或重用。
D3D11等传统API在分配资源时,通常每块资源对应一个GPU VA(虚拟地址)和物理页面。
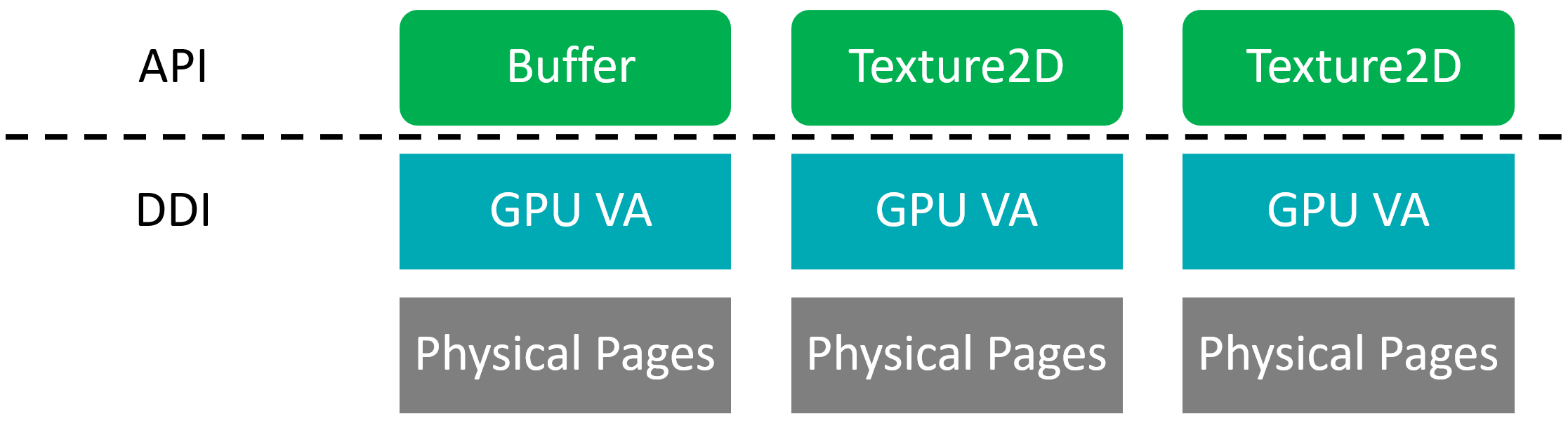
D3D11内存分配模型。
在 Direct3D 12 中,所有的动态更新(包括 constant buffer,dynamic vertex buffer,dynamic textures 等等)都由应用程序来控制。这些动态更新包括必要的 GPU fence 或 buffering,由应用程序来保证内存的可用性。
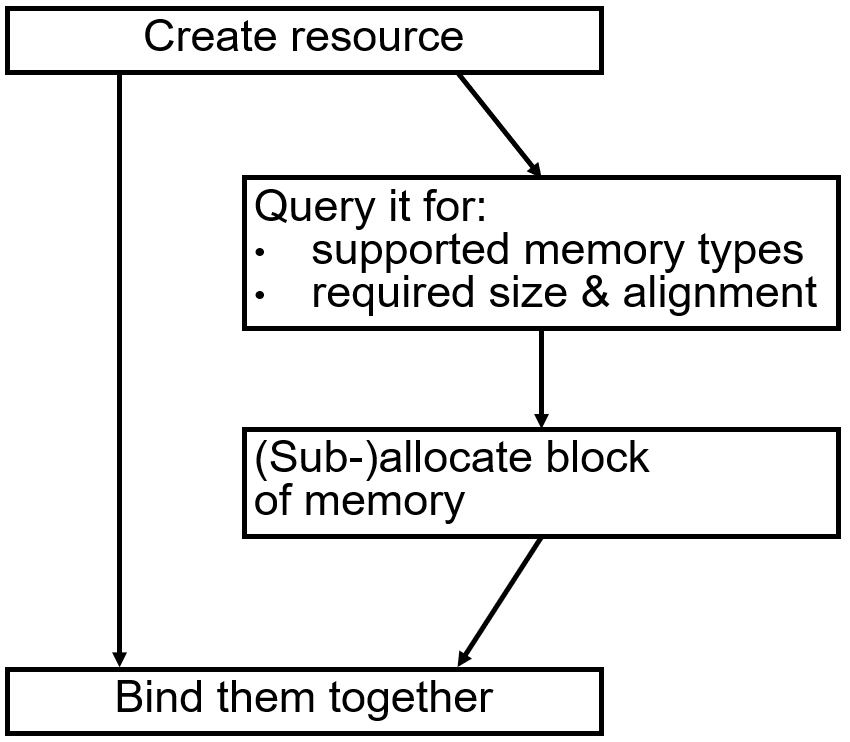
现代图形API需要应用程序控制资源的所有操作。
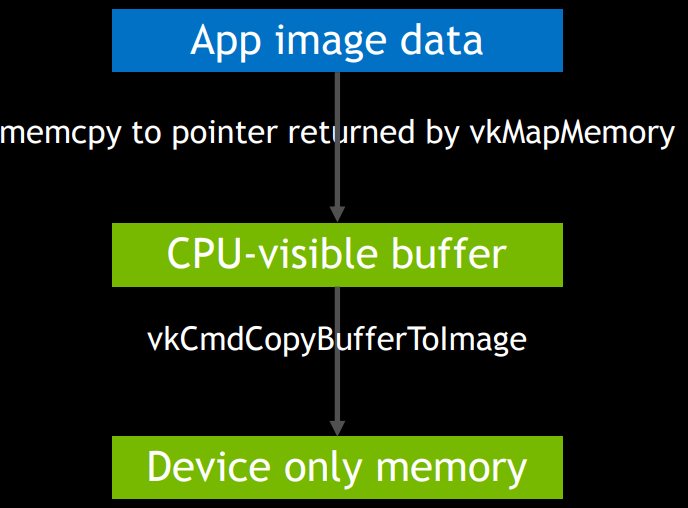
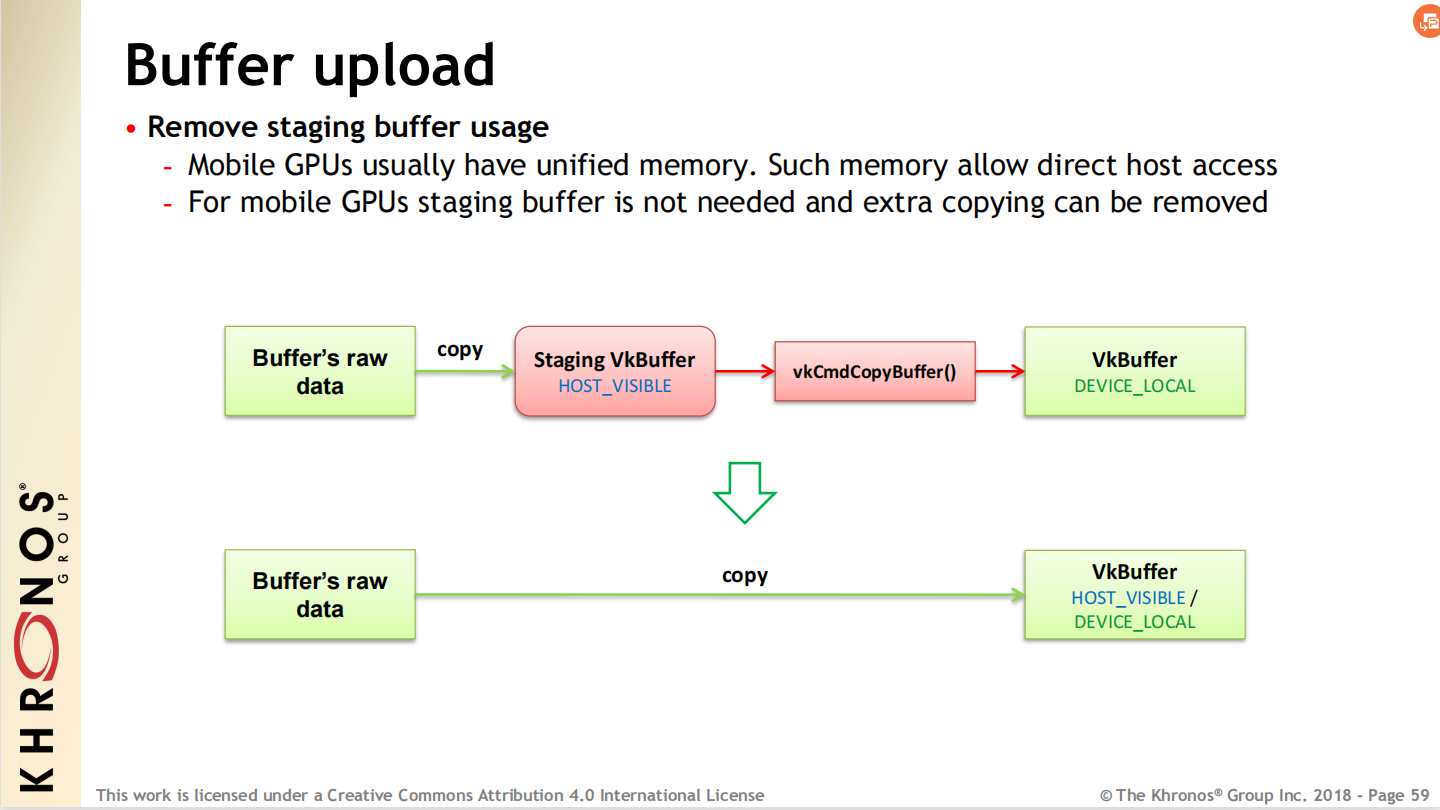
Vulkan创建资源步骤:先创建CPU可见的暂存缓冲区(staging buffer),再将数据从暂存缓冲区拷贝到显存中。
在D3D12等现代图形API中,资源的GPU VA和物理页面被分离开来,应用程序可以更好地分摊物理页面分配的开销,可以重用临时空置的内存,也可以调整场景不再使用的内存的用途。
D3D12内存分配模型。
不同的堆类型和分配的位置如下:
| Heap Type | Memory Location |
|---|---|
| Default | Video Memory |
| Upload | System Memory |
| Readback | System Memory |
下表是可能的拷贝操作的组合:
| Source | Destination |
|---|---|
| Upload | Default |
| Default | Default |
| Default | Readback |
| Upload | Readback |
不同的组合在不同类型的Queue的拷贝速度存在很大的差异:
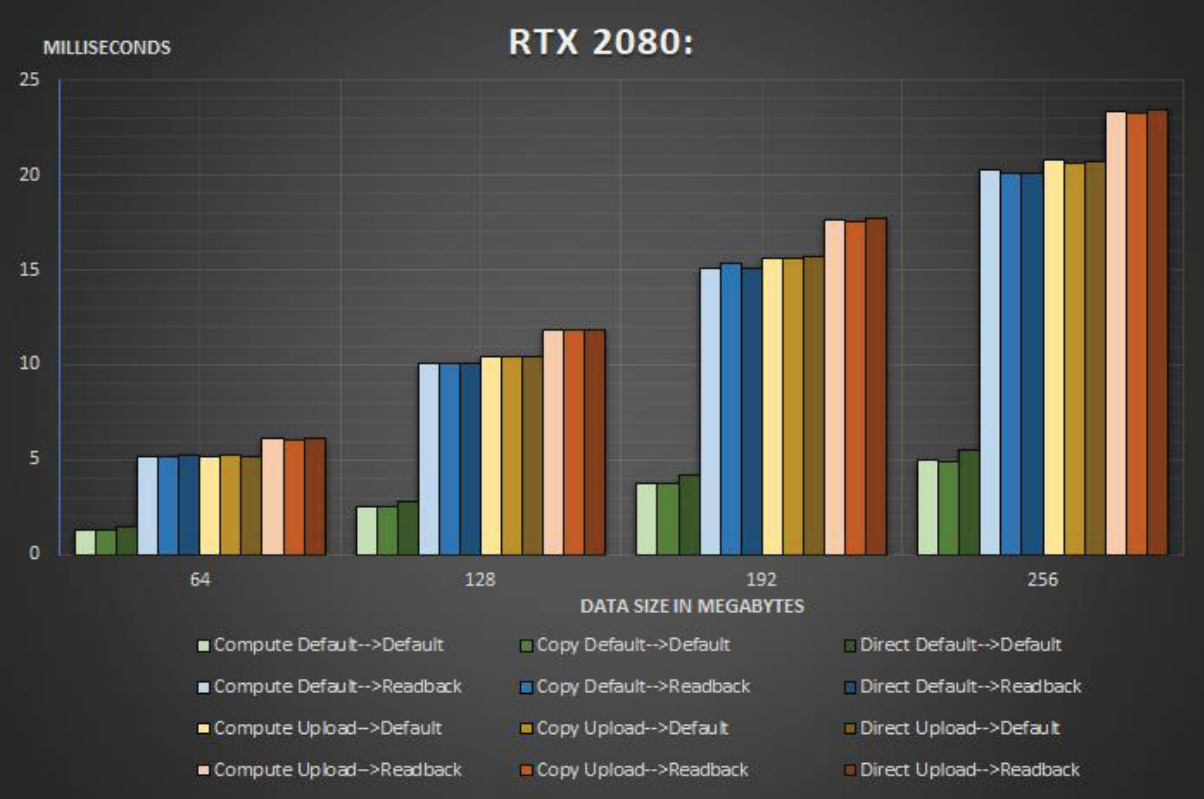
在RTX 2080上在堆类型之间复制64-256 MB数据时,命令队列之间的比较。
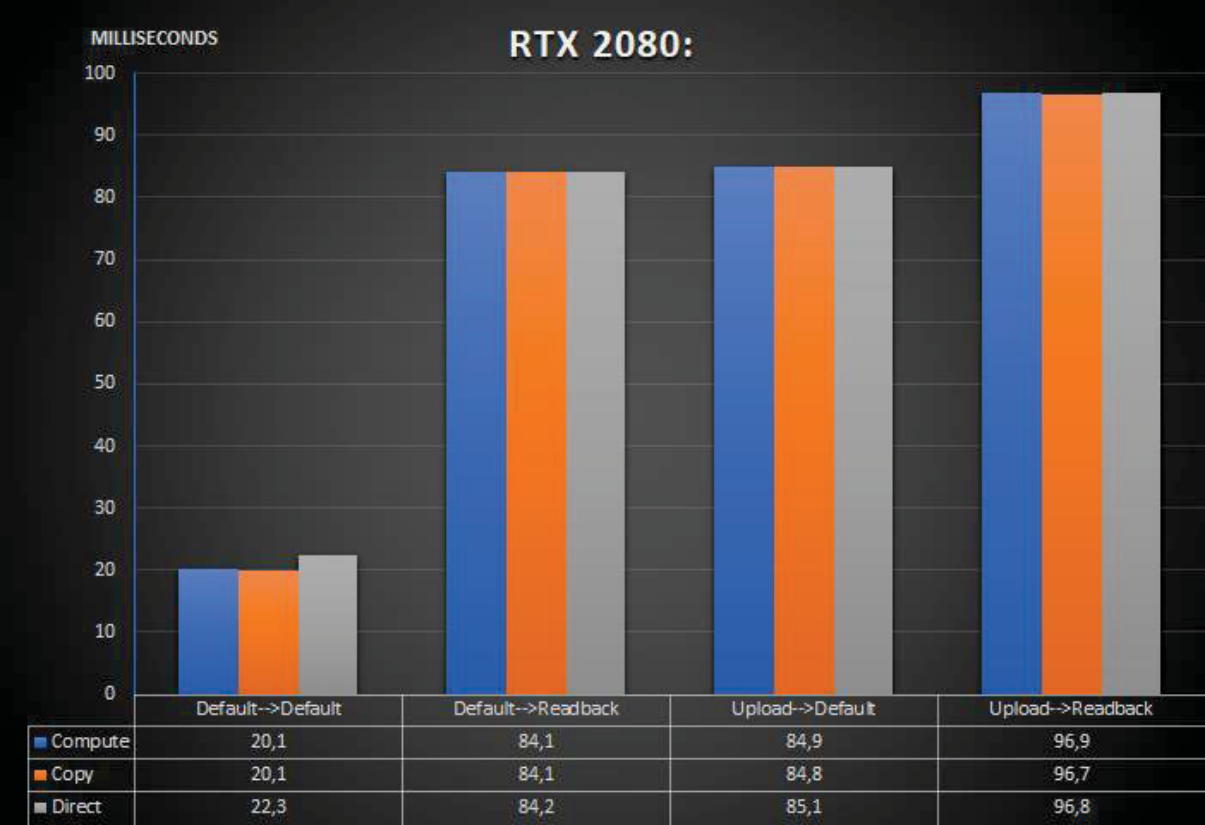
在RTX 2080上在堆类型之间复制数据时,跨所有命令队列的平均复制时间和数据大小之间的比较。
堆的类型和标记存在若干种,它们的用途和意义都有所不同:
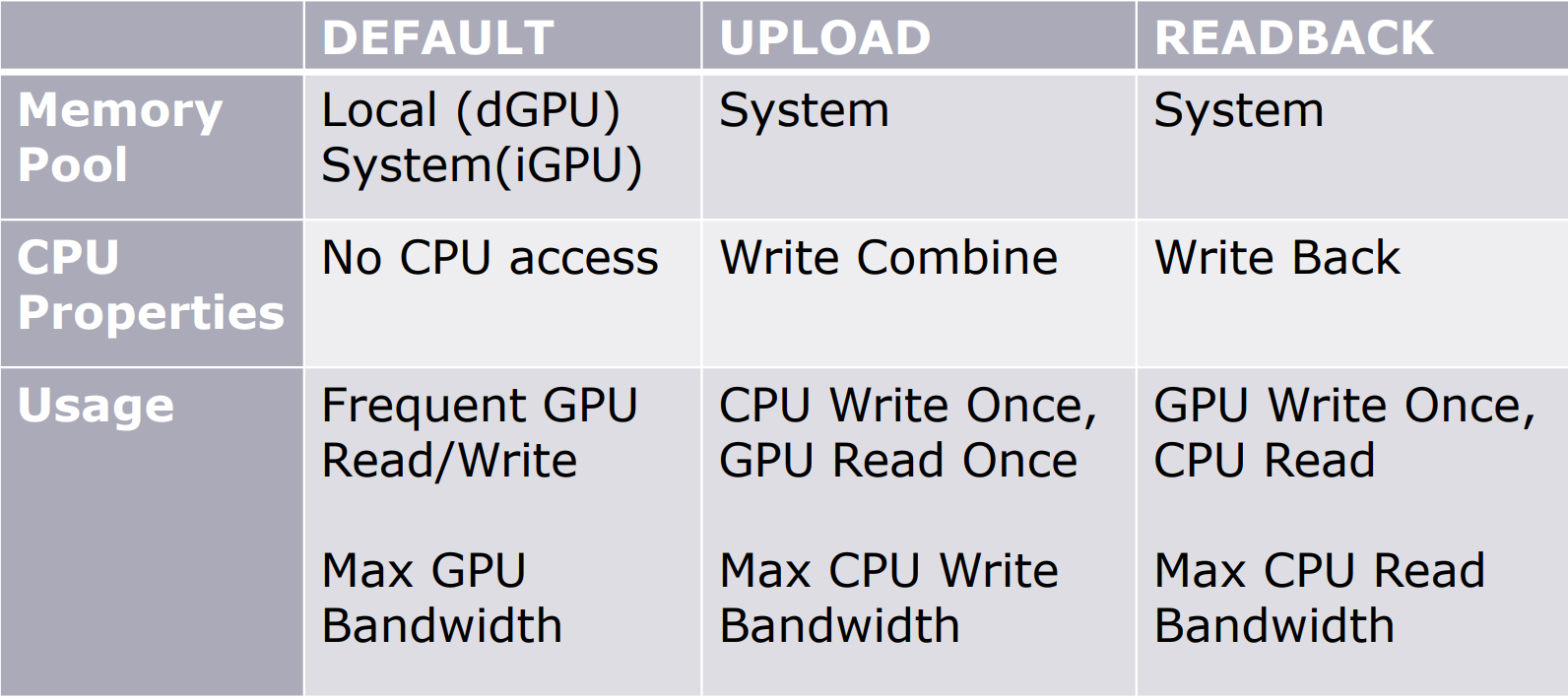
对于Resource Heap,相关属性的描述如下:

资源创建则有3种方式:
-
提交(Committed)。单块的资源,D3D11风格。
![]()
-
放置(Placed)。在已有堆中偏移。
![]()
-
预留(Reserved)。像Tiled资源一样映射到堆上。
![]()


这3种资源的选择描述如下:
| Heap Type | Desc |
|---|---|
| Committed | 需要逐资源驻留;不需要重叠(Aliasing)。 |
| Placed | 更快地创建和销毁;可以在堆中分组相似的驻留;需要和其它资源重叠;小块资源。 |
| Tiled / Reserved | 需要灵活的内存管理;可以容忍ResourceMap在CPU和GPU的开销。 |
下表是资源类型和VA、物理页面的支持关系:
| Heap Type | Physical Page | Virtual Address |
|---|---|---|
| Committed | Yes | Yes |
| Heap | Yes | No |
| Placed | No | Yes |
| Tiled / Reserved | No | Yes |
每种不同的GPU VA和物理页面的组合标记适用于不同的场景。下图是3种方式的分配机制示意图:
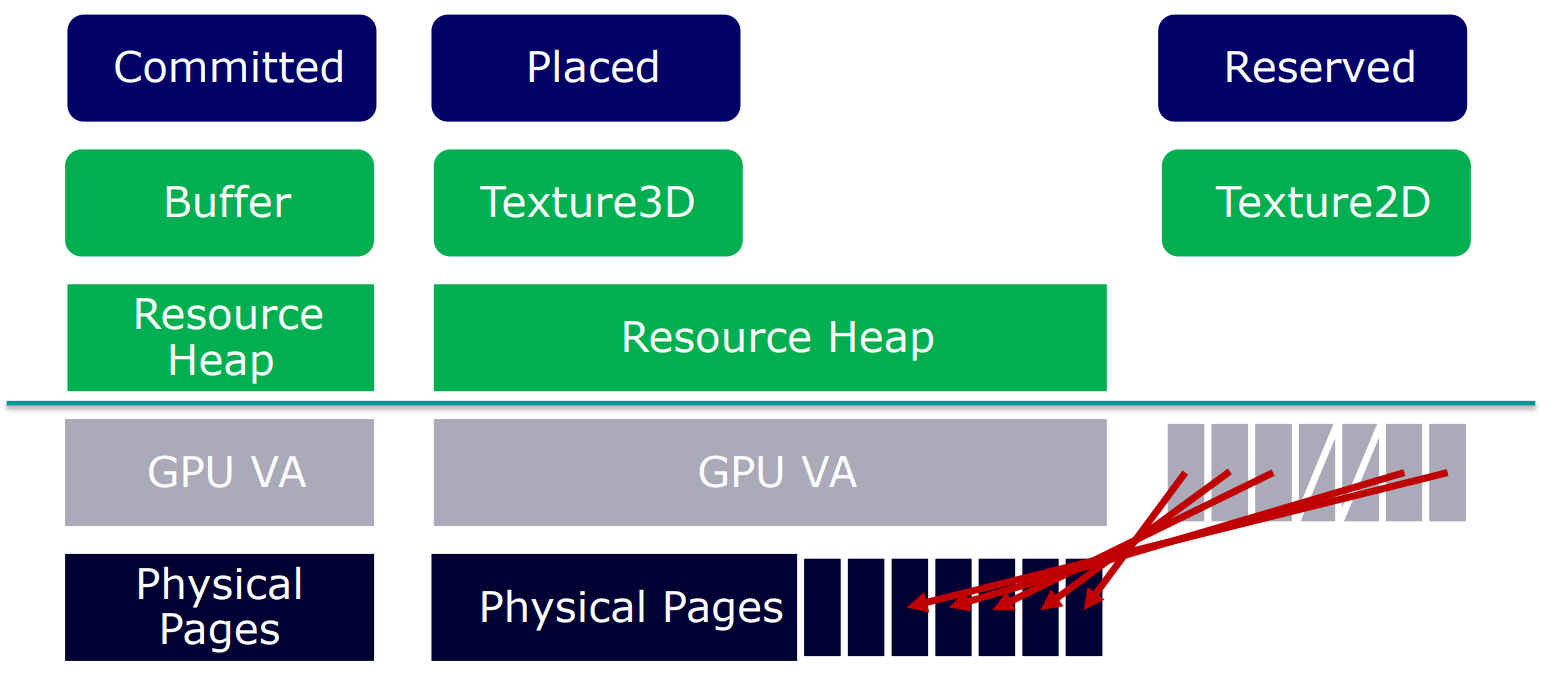
Committed资源使用建议:
-
用于RTV, DSV, UAV。
-
分配适合资源所需的最小尺寸的堆。
-
应用程序必须对每个资源调用MakeResident/Evict。
-
应用程序受操作系统分页逻辑的支配。
- 在“MakeResident”上,操作系统决定资源的放置位置。
- 同步调用,会卡住,直到它返回为止。
资源的整块分配和子分配(Suballocation)对比图如下:
面对如此多的类型和属性,我们可以根据需求来选择不同的用法和组合:
- 如果是涉及频繁的GPU读和写(如RT、DS、UAV):
- 分配显存:D3D12_HEAP_TYPE_DEFAULT / VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT。
- 最先分配。
- 如果是频繁的GPU读取,极少或只有一次CPU写入:
- 分配显存:D3D12_HEAP_TYPE_DEFAULT / VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT。
- 在系统内存分配staging copy buffer:D3D12_HEAP_TYPE_UPLOAD / VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT,将数据从staging copy buffer拷贝到显存。
- 放置在系统内存中作为备份(fallback)。
- 如果是频繁的CPU写入和GPU读取:
- 如果是Vulkan和AMD GPU,用DEVICE_LOCAL + HOST_VISIBLE内存,以便直接在CPU上写,在GPU上读。
- 否则,在系统内存和显存各自保留一份拷贝,然后进行传输。
- 如果是频繁的GPU写入和CPU读取:
- 使用缓存的系统内存:D3D12_HEAP_TYPE_READBACK / HOST_VISIBLE + HOST_CACHED。
更高效的Heap使用建议:
-
首选由upload heap填充的default heap。
-
从一个或多个提交的上传缓冲区(committed upload buffer)资源中构建一个环形缓冲区(ring buffer),并让每个缓冲区永久映射以供CPU访问。
![]()
-
在CPU侧,顺序地写入数据到每个buffer,按需对齐偏移。
-
指示GPU在每帧结束时发出增加的Fence值的信号。
-
在GPU没有达到Fence只之前,不要修改upload heap的数据。
-
-
在整个渲染过程种,重用上传堆用来存放发送到GPU的动态数据。
-
创建更大的堆。
- 大约10-100 MB。
- 子分配(Sub-allocate)用以存放placed resource。
![]()
-
逐Heap调用MakeResident/Evict,而不是逐资源。
-
需要应用程序跟踪分配。同样,应用程序需要跟踪每个堆中空闲/使用的内存范围。
-
谨慎使用MakeResident/Evict来分配或释放GPU内存。
- CPU + GPU的成本是显著的,所以批处理MakeResident和UpdateTileMappings。
- 如果有必要,将大量的工作负载分摊到多个帧。
- MakeResident是同步的。
- 不会返回,直到所有资源驻留完成。
- 批处理之。小批量是低效的,因为会产生大量的小型分页操作。
- 操作系统可能会开启计算来确定资源的位置,这将花费大量时间。调用线程会被卡住,直到它返回为止。
- 确保在工作线程,防止卡主线程。
- 需要处理MakeResident失败的情况。
- 通常意味着工作线程上没有足够的可用内存。
- 但即使有足够的内存(碎片)也会发生。
- Non-resident读取是个页面错误,很可能引起程序崩溃!!
- Evict的描述和行为如下:
- Evict可能不会立即采取任何行动。会被延迟到下一个MakeResident调用。
- 消耗比MakeResident小。
-
如果显存溢出,会导致性能急剧波动,需采取一系列措施解决或避免。
- 需关注内存密集型的应用程序,如浏览器。提供分辨率/质量设置让用户更改。
- 考虑1GB、2GB等不同硬件性能的配置。
- 如果显存已经没有可用内存了,可以在系统内存中创建溢出堆,并从显存堆中移动一些资源到系统内存。
- 应用程序比任何驱动程序/操作系统更有优势,可以知道什么资源是最重要的,从而将它们保留在显存中,而不重要的资源迁移出去。
![]()
-
也可以将非性能关键的资源移出显存,放到系统内存的溢出堆(overflow heap)。迁移最顶级的mip。
![]()
-
将资源移出显存步骤:
- 释放本地拷贝。
- 在转移到系统内存之前,了解资源的访问模式。
- 只读一次。
- 具有高局部性的可预测访问模式更佳。
-
迁移最顶级的mip,可以节省约70%的内存。
- 如果做得武断,视觉上有微小的差别。
- 如果做得明智,视觉上没有差别。
- 当纹理被放置在堆中的资源时,更容易实现。
-
重叠(或称为别名,Aliasing或Overlap)资源可以显著节省内存占用。
- 需要使用重叠屏障(Aliasing Barrier)。
- Committed RTV/DSV资源由驱动程序优先考虑。
- NV:当读取一致时,使用常量缓冲区而不是结构化缓冲区。例如,tiled lighting。
![]()
重叠资源示意图。其中GBuffer和Helper RT在时间上不重叠,可以分配在同一块内存上。
-
优化从哪种堆分配哪些资源可以提升2%以上的性能。包括调整分配资源的规则。
![]()
-
配合LRU资源管理策略大有裨益。
- 在资源最后一次使用后,将其保留在内存中一段时间。
- 只有资源使用驻留时才引进。
-
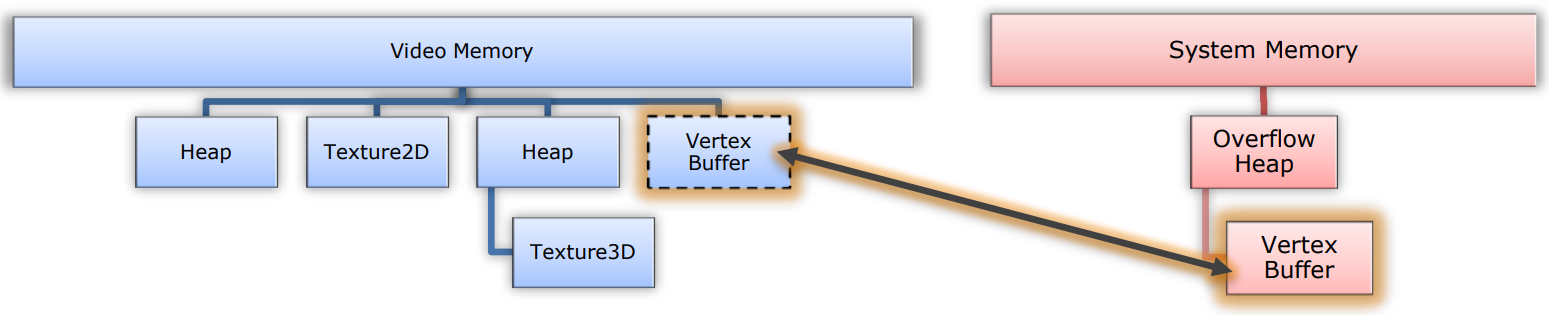
对于统一内存架构的设备,移除Staging Buffer。
![]()
-
对部分资源(如顶点缓存、索引缓冲)执行异步创建。
![]()



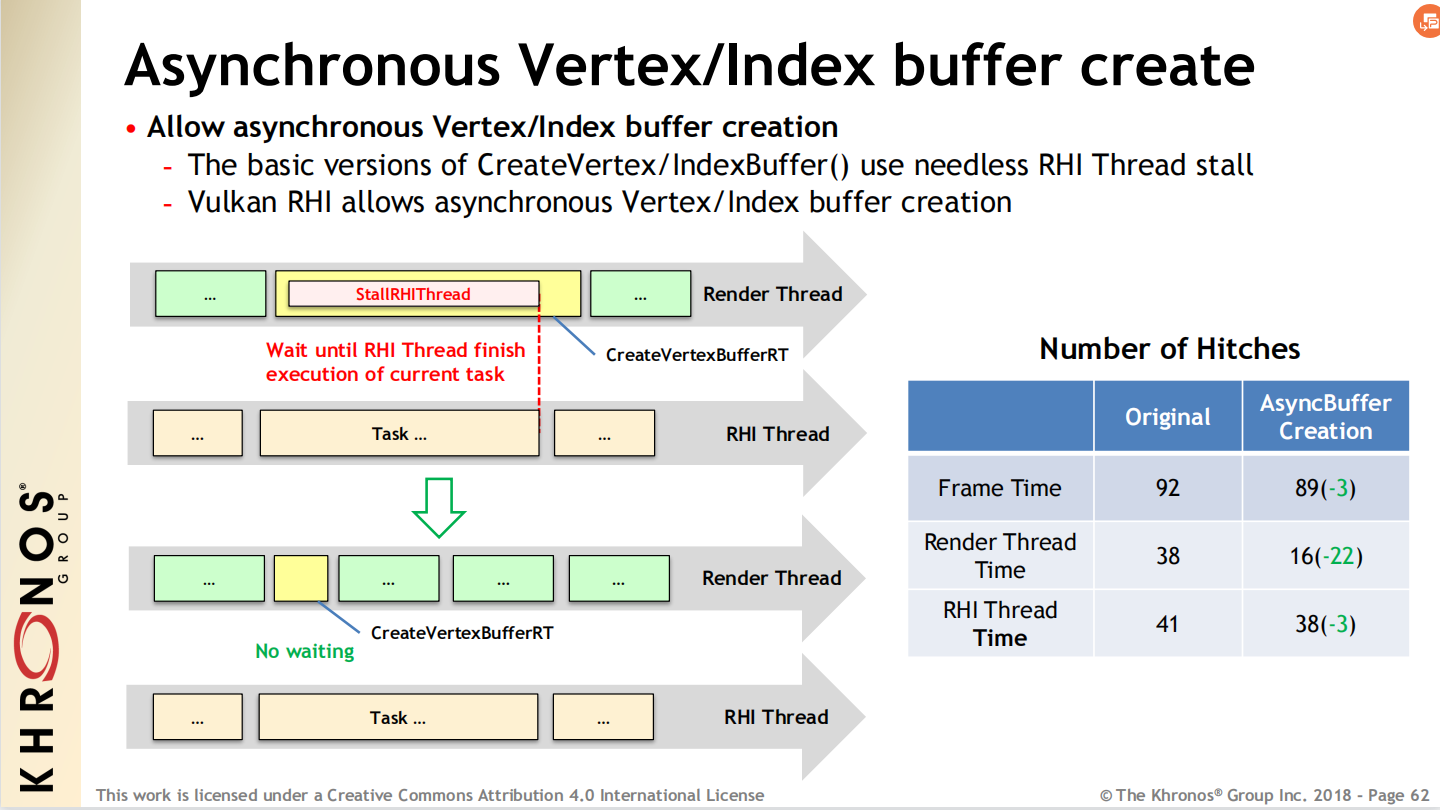
UE的Vulkan RHI允许异步创建顶点和索引缓冲,减少渲染线程的卡顿。
对于物理内存的重用,无论是reserved还是placed资源,必须遵循以下和D3D11的分块资源(Tiled Resource)相同的规则:
- 当物理内存被一个新的资源重用时,必须入队一个重叠屏障(aliasing barrier)。
- 首次使用或重新使用用作渲染资源或深度模板资源的物理内存时,应用程序必须使用清除或复制操作初始化资源内存。
D3D12在内存映射方面提供了显式的控制,可以每帧创建一个大buffer,暂存所有数据,对Const buffer没有专用的需求,转由应用程序按需构建。
对于高吞吐量的渲染,建议如下:
- 为了得到Draw Call的收益,必须安插相关处理到游戏逻辑种。
- 对于每个单位(如炮塔、导弹轨迹),CPU计算位置或颜色等数据必须尽快地上传到GPU。
以下是Ashes的CPU作业和GPU内存交互示意图:

13.4.1.2 Resource Update
对于现代图形API而言,资源更新的特点通常具有以下几点:
-
CPU和GPU共享相同的存储,没有隐式的拷贝。(只适用于耦合式的CPU-GPU架构,如Apple A7及之后的SoC)
-
自动的CPU和GPU缓冲一致性模型。
- CPU和GPU在命令缓冲区执行边界观察写操作。
- 不需要显式的CPU缓存管理。
-
可以显著提高性能,但应用程序开发者需要承担更多的同步责任。
-
资源结构(尺寸、层级、格式)由于会引发运行时编译和资源验证,产生很大的开销,因此不能被更改,但资源的内容可以被更改。(下图)
Metal中可以被更改和不能被更改的资源示意图。
-
更新数据缓冲时,CPU直接访问存储区,而不需要调用如同传统API的LockXXX接口。
-
更新纹理数据时,实现了私有存储区,可以快速有效地执行上传路径。
-
可以利用GPU的Copy Engine实现硬件加速的管线更新。
-
可以与其他纹理共享存储,为相同像素大小的纹理解释为不同的像素格式。
- 例如sRGB vs RGB,R32 vs RGBA8888。
-
可以与其他缓冲区共享纹理存储。
- 假设是行线性(row-linear)的像素数据。
-
将多个分散的纹理数据上传打包到同一个Command Buffer。
![]()
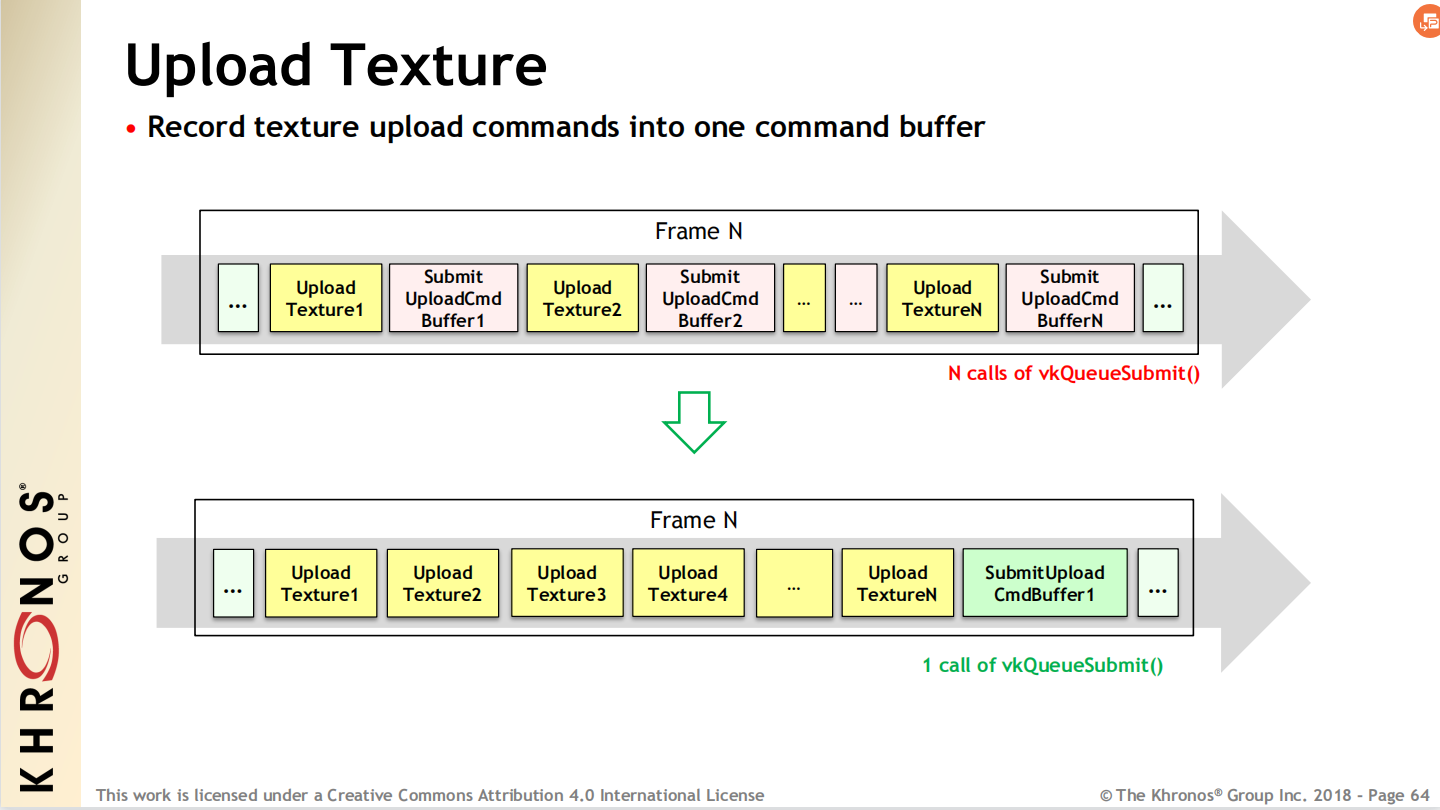
13.4.2 Pipeline State Object
在D3D11,拥有很多小的状态对象,导致GPU硬件不匹配开销:
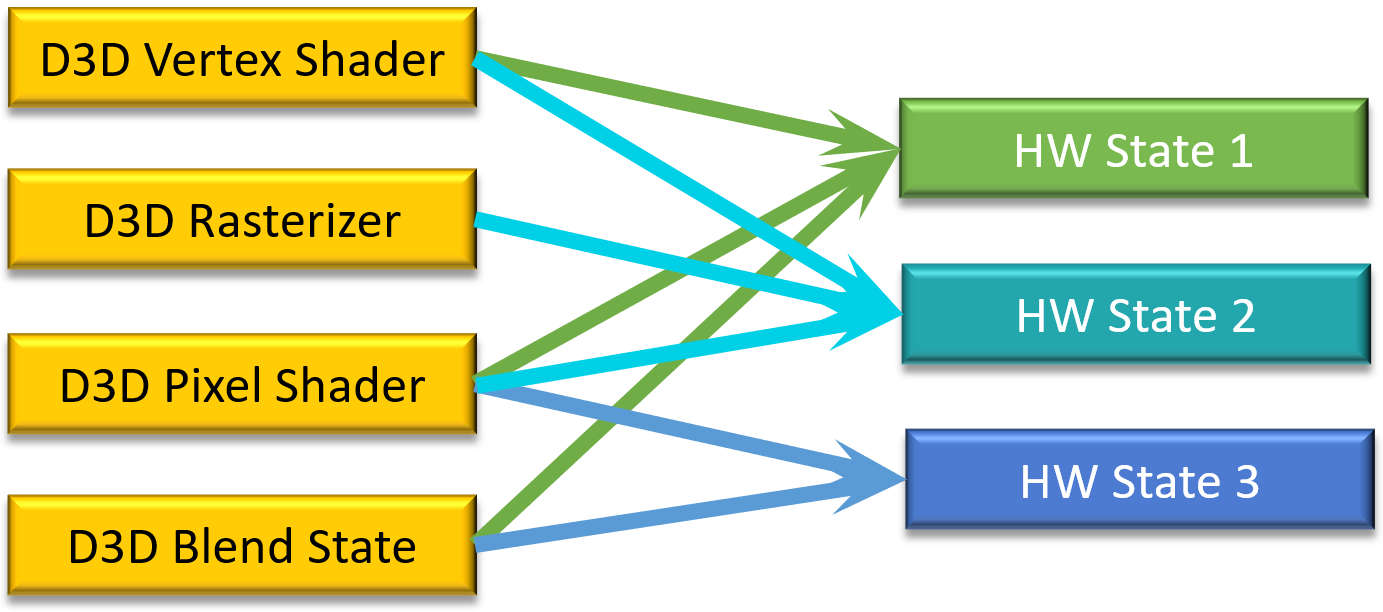 )
)
到了D3D12,将管线的状态分组到单个对象,直接拷贝PSO到硬件状态:
下面是D3D11和D3D12的渲染上下文的对比图:
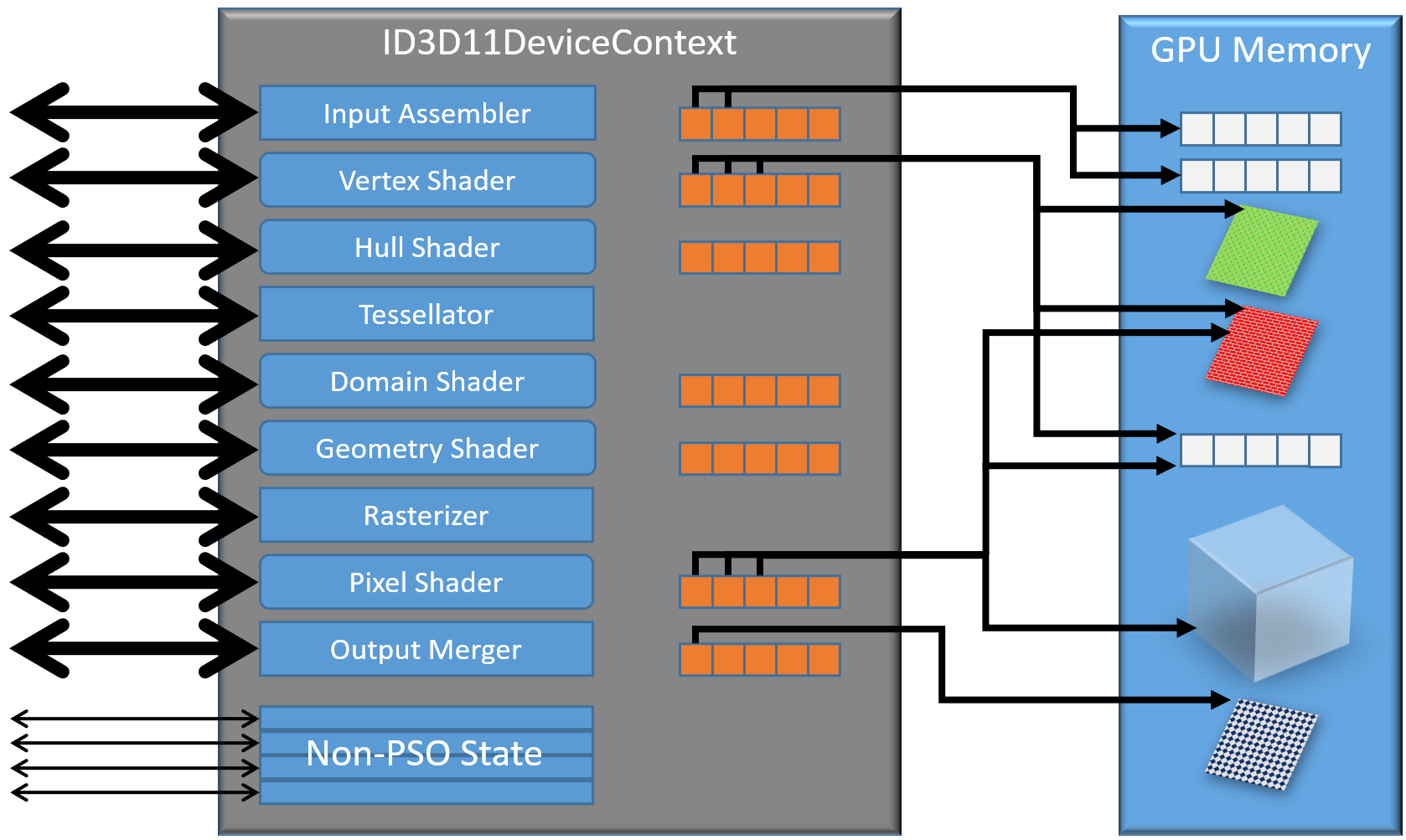
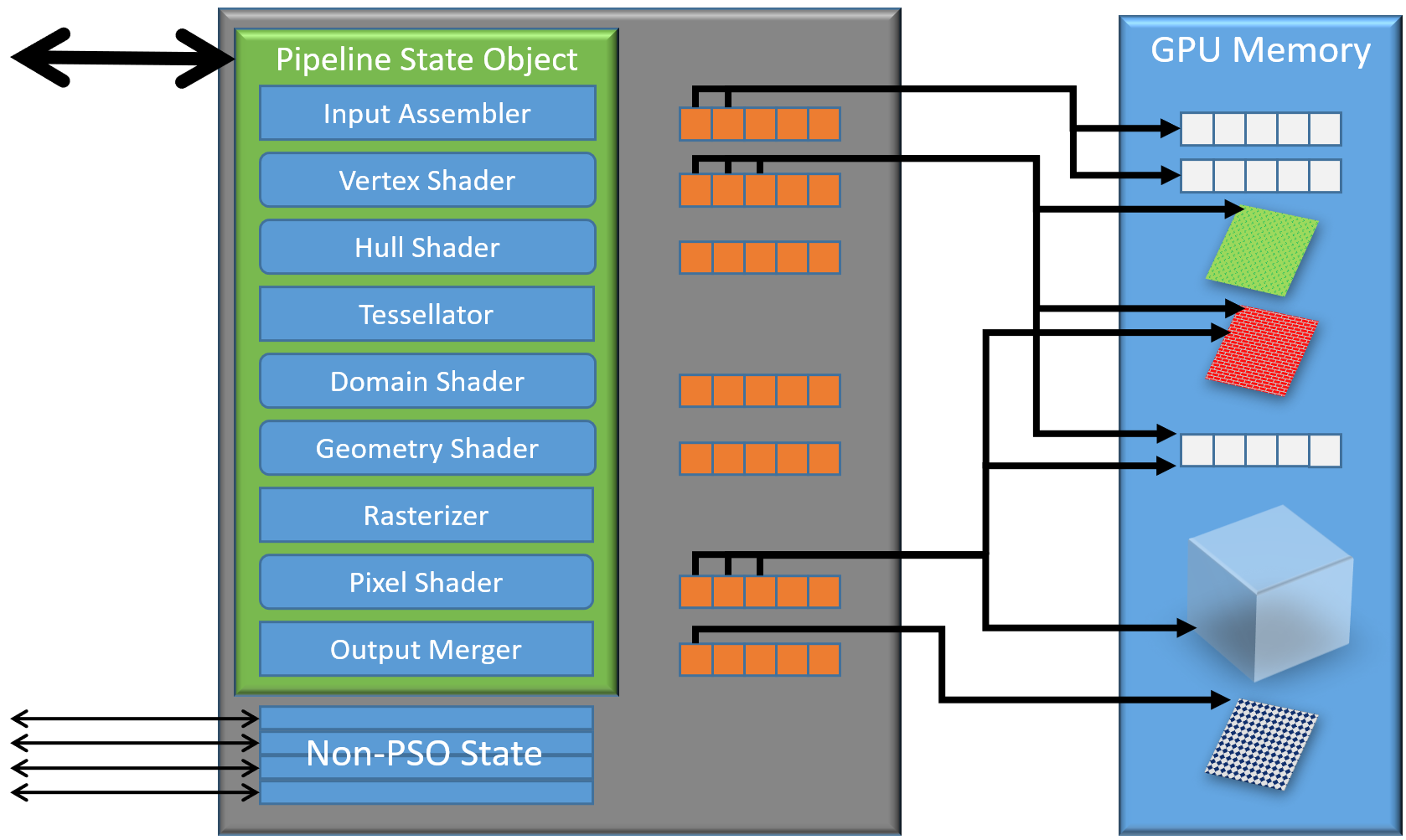
上:D3D11设备上下文;下:D3D12设备上下文。
Pipeline State(管线状态)通常拥有以下对象:
| Pipeline State | Description |
|---|---|
| DepthStencil | DepthStencil comparison functions and write masks |
| Sampler | Filter states, addressing modes, LOD state |
| Render Pipeline | Vertex and pixel shader functions, Vertex data layout, Multisample state, Blend state, Color write masks... |
Compute Shader涉及了以下Pipeline State:
| Pipeline State | Description |
|---|---|
| Compute State | Compute functions, workgroup configuration |
| Sampler | Filter states, addressing modes, LOD state |
更具体地,PSO涉及以下的状态(黑色和白色方块):

会影响编译的状态在对象创建后不能更改(如VS、PS、RT、像素格式、颜色写掩码、MSAA、混合状态、深度缓冲状态):

PSO的设计宗旨在于不在渲染过程中存在隐性的Shader编译和链接,在创建PSO之时就已经生成大部分硬件指令(编译进硬件寄存器)。由于PSO的shader输入是二进制的,对Shader Cache非常友好。下图是PSO在渲染管线的交互图:
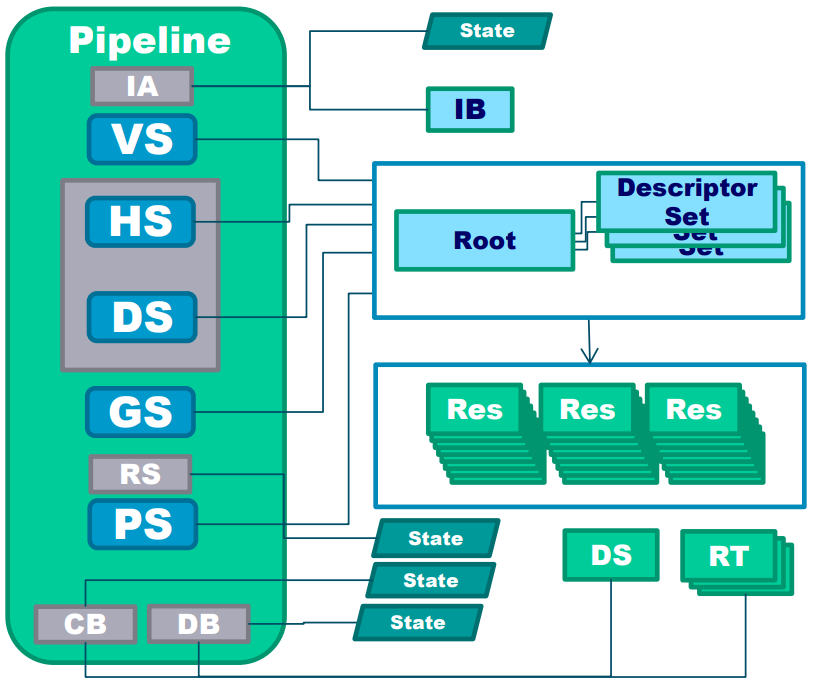
PSO配合根签名、描述符表之后的运行机制图例如下:
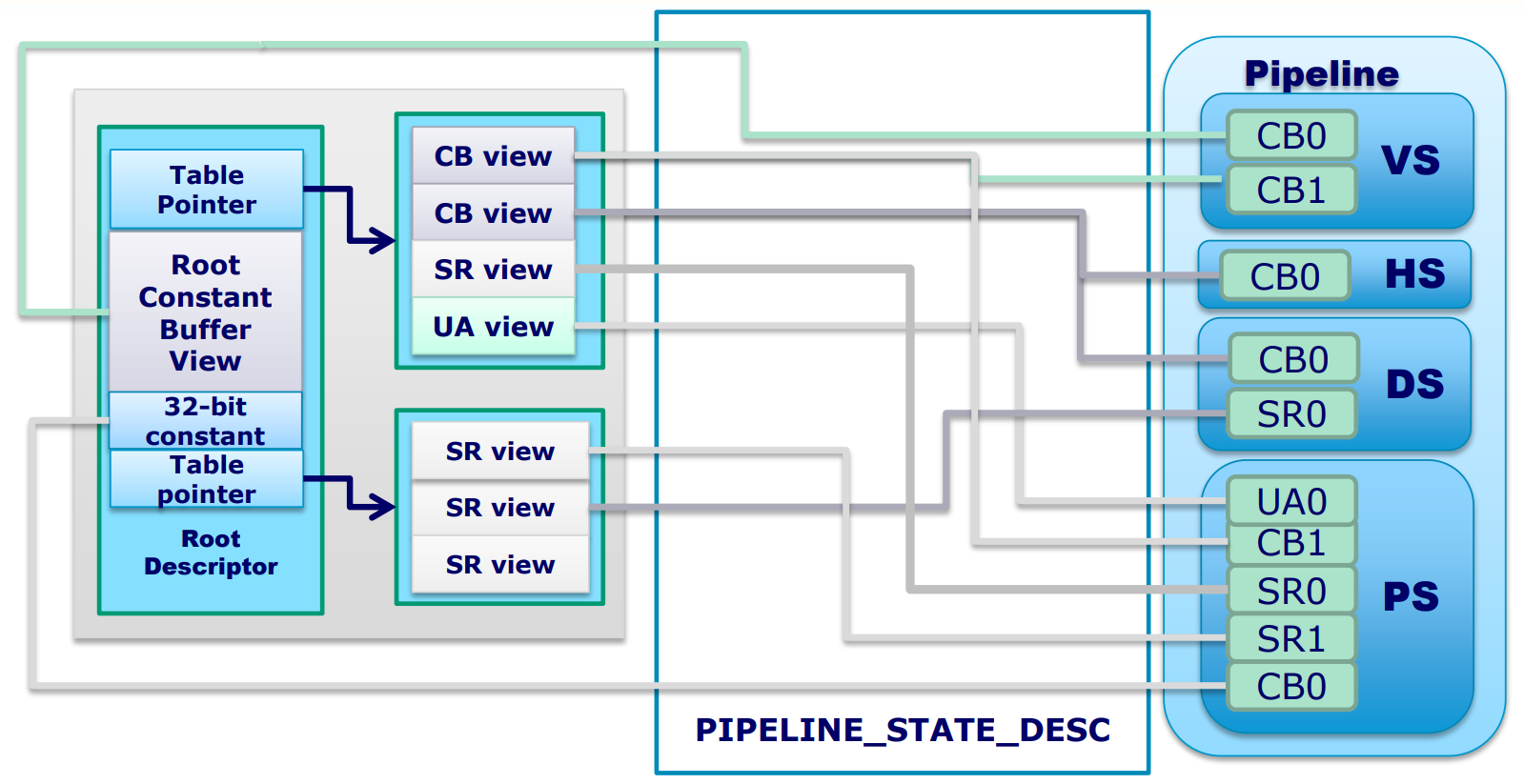
开发者仍然可以动态切换正在使用的PSO,硬件只需要直接拷贝最少的预计算状态到硬件寄存器,而不是实时计算硬件状态。通过使用PSO,Draw Call的开销显著减少,每帧可以有更多的Draw Call。但开发者需要注意:
-
需要在单独的线程中创建PSO。编译可能需要几百毫秒。
- Streaming线程也可以处理PSO。
- 收集状态和创建。
- 防止阻塞。
- 还可处理特化(specialization)。
- Streaming线程也可以处理PSO。
-
在同一个线程上编译类似的PSO。
- 例如,不同的混合状态但VS、PS相同的PSO。
- 如果状态不影响着色器,会重用着色器编译。
- 同时编译相同着色器的工作线程将等待第一次编译的结果,从而减少其它同时编译相同着色器的工作线程的等待时间。
-
对于无关紧要的变量,尽量使用相同的默认值。例如,如果深度测试被关闭,则以下数据无关紧要,尽量保持一样的默认值:
int DepthBias; float DepthBiasClamp; float SlopeScaledDepthBias; bool DepthClipEnable; -
在连续的Draw Call中,尽量保证PSO状态相似。(例如UE按照PS、VS等键值对绘制指令进行排序)
-
所有设置到Command Buffer的渲染状态组合到一个调用。
-
尽量减少组合爆炸。
- 尽早剔除未使用的排列。
- 在适当的地方考虑Uber Shader。
- 在D3D12中,将常量放到Root上。
- 在Vulkan中,特殊化(Specialization)常量。
-
如果在运行中构建PSO,请提前完成。
-
延迟的PSO更新。
-
编译越快越早,结果越好。
- 简单、通用、无消耗地初始着色器。
- 开始编译,得到更好的结果。
- 当编译结果准备好时,替换掉PSO。
-
通用、特化特别有用。
- 预编译通用的案例。
- 特殊情况下更优的路径是在低优先级线程上编译。
-
-
使用着色器和管线缓存。
-
应用程序可以分配和管理管道缓存对象。
-
与管道创建一起使用的管道缓存对象。如果管道状态已经存在于缓存中,则重用它。
-
应用程序可以将缓存保存到磁盘,以便下次运行时重用
-
使用Vulkan的设备UUID,甚至可以存储在云端。
-
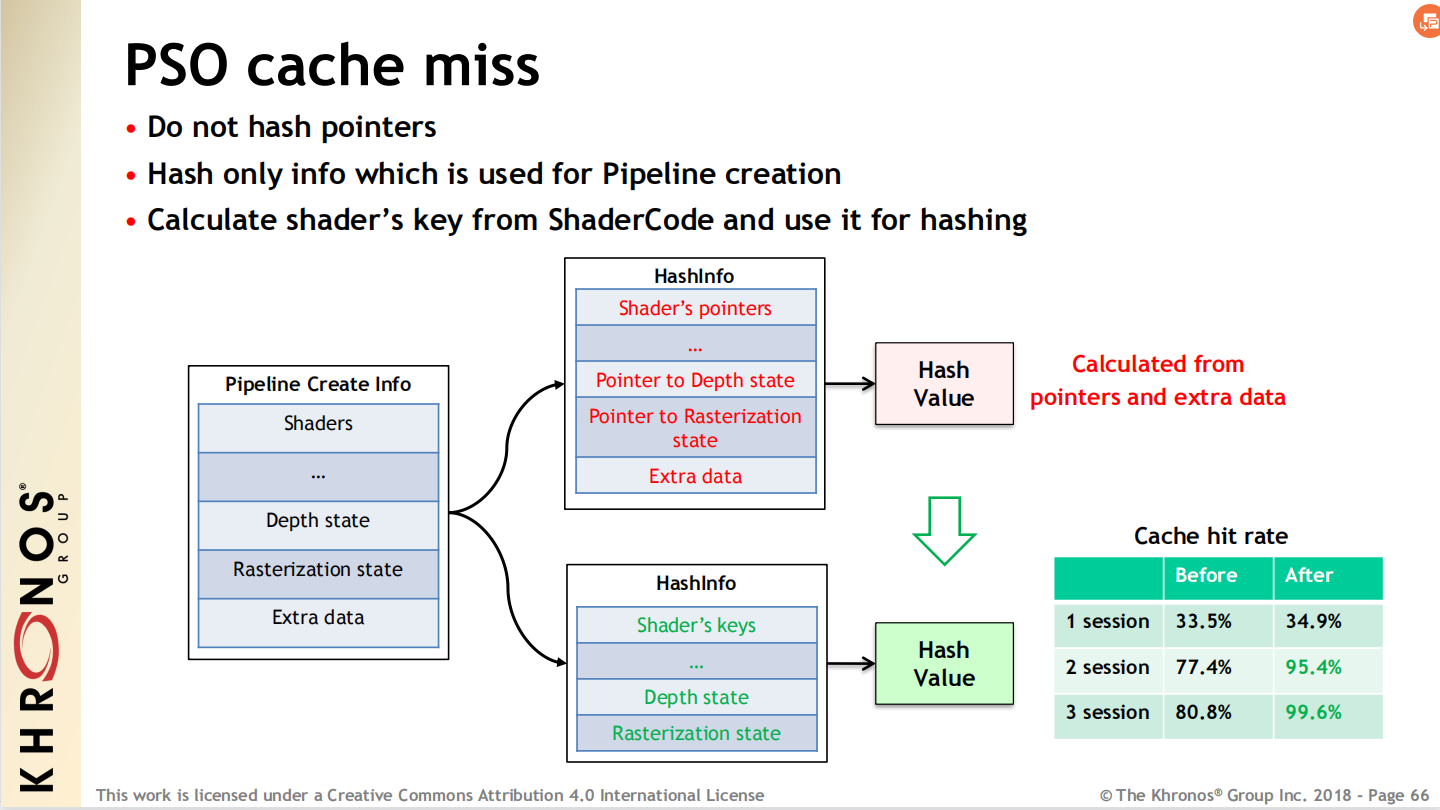
缓存的Hash值不要用指针,应当用着色器代码(Shader Code)。
![]()
-
-
对Draw Call按照PSO的相似性排序。
- 比如,可以按Tessellation/GS是否开启排序。
-
保持根签名尽可能地小。
- 按更新模式分组描述集。
-
按更新频率排序根条目。
- 变量频率最快的放最前面。
-
存储PSO和其他状态。
- 绝大多数像素着色器只有几个排列,可通过哈希访问排列。
- 为每个状态创建唯一的状态哈希。
- 将所有状态块放入具有惟一ID的池中。
- 使用块ID作为位来构造一个状态哈希。
- 从状态管理中删除采样器状态对象。
- UE采用16个固定采样器状态。
![]()
13.4.3 Synchronization
13.4.3.1 Barrier
现代图形API提供了种类较多的同步方式,诸如Fence、Barrier、Semaphore、Event、Atomic等。
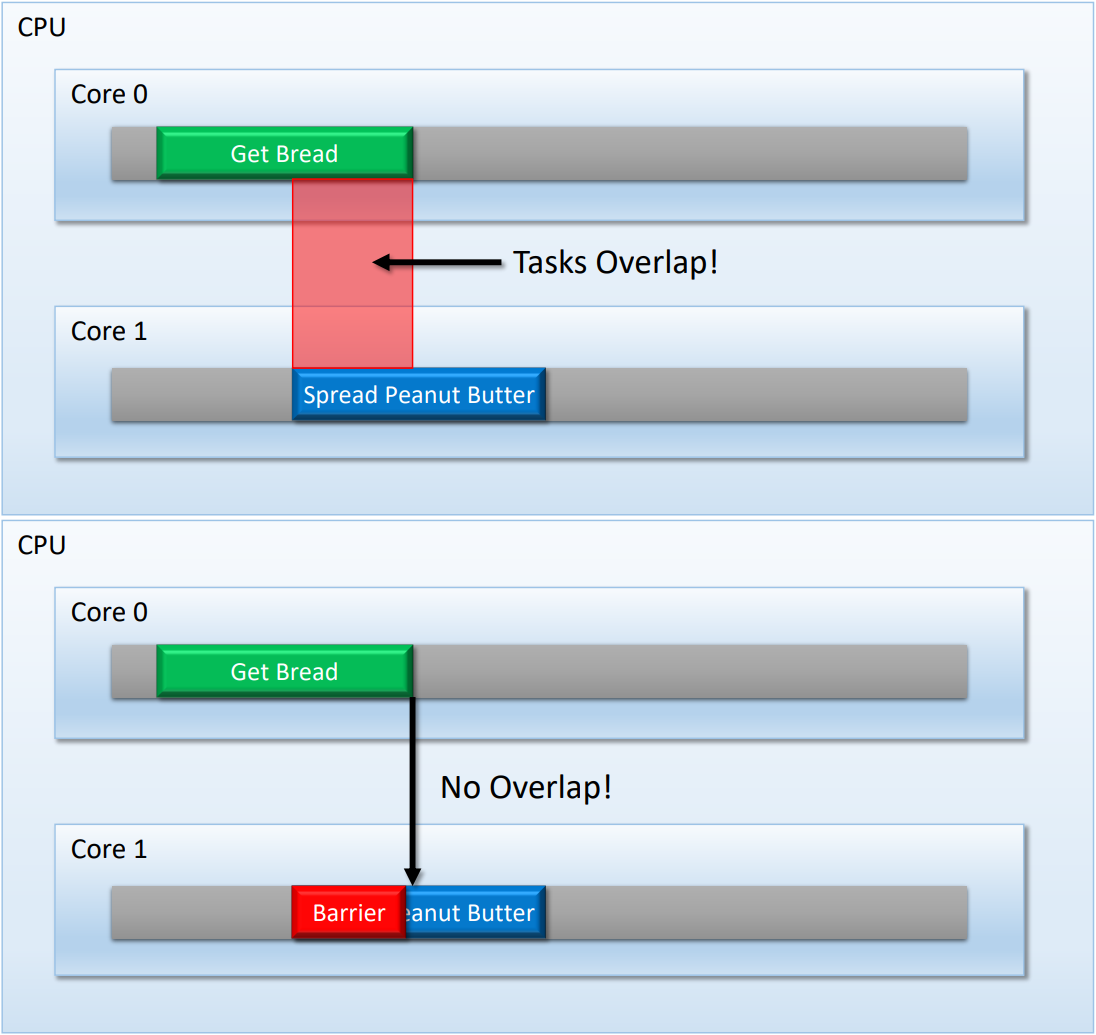
CPU Barrier使用案例。上:没有Barrier,CPU多核之间的依赖会因为Overlap而无法达成;下:通过Barrier解决Overlap,从而实现同步。
GPU拥有数量众多的处理线程,在没有Barrier的情况下,驱动程序和硬件会尽量让这些线程处理Overlap,以提升性能。但是,如果GPU线程之间存在依赖,就需要各类同步对象进行同步,确保依赖关系正常。这些同步对象的作用如下:
-
同步(Synchronisation)
确保严格和正确的工作顺序。常因GPU流水线的深度引发,比如UAV RAW/WAW屏障,避免着色器波(wave)重叠执行。
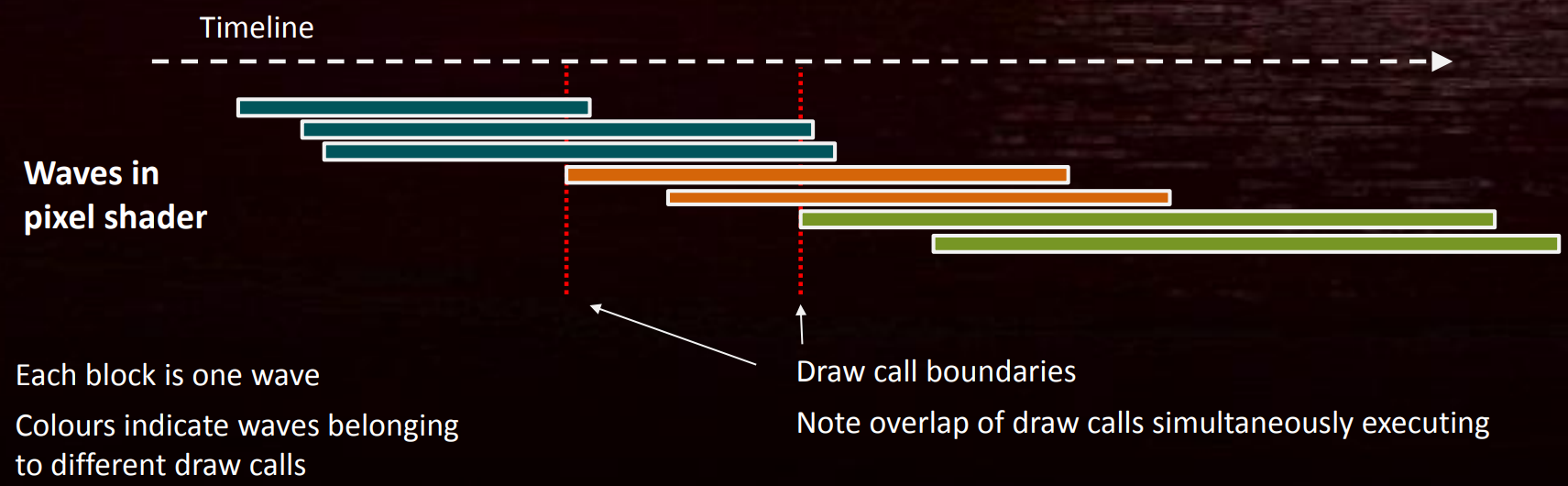
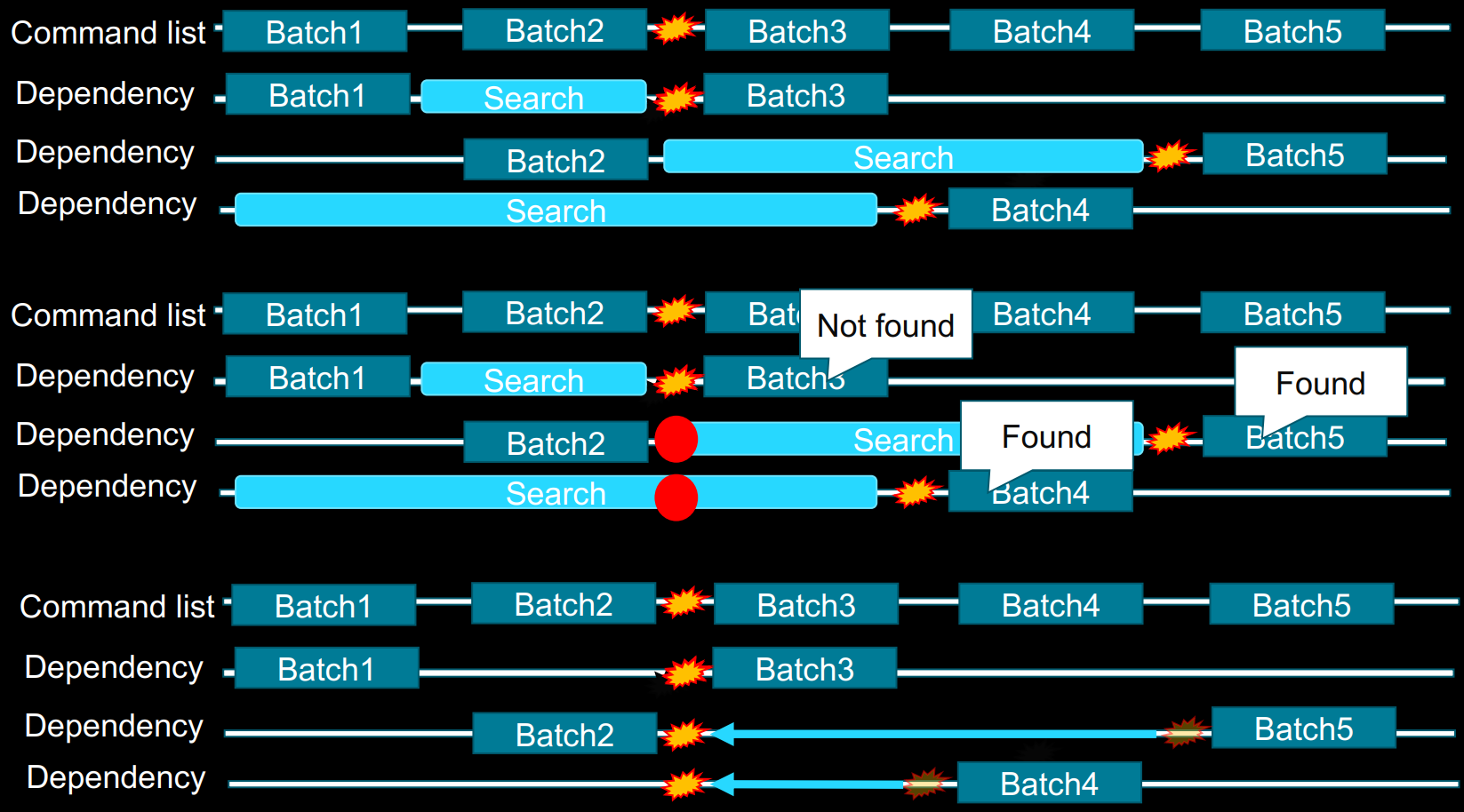
假设有以下3个Draw Call(DC),不同颜色属于不同的DC,每个DC会产生多个Wave:
![]()
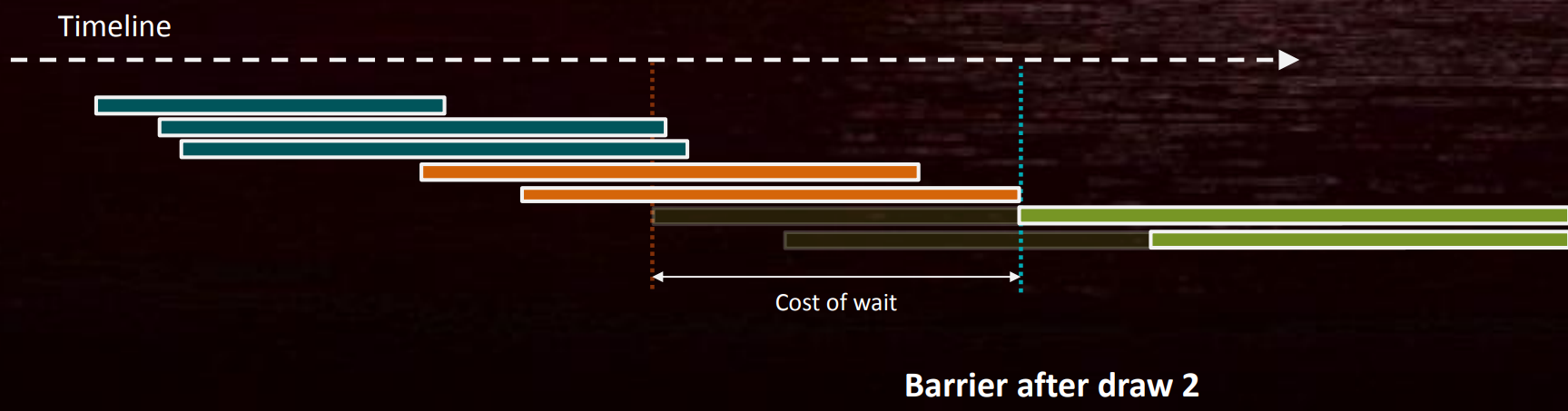
假设DC 3依赖DC1,如果在DC1完成之后增加一个Barrier,则DC2其实是多余的等待:
![]()
如果在DC2完成之后增加一个Barrier,则DC2依然存在冗余的等待:
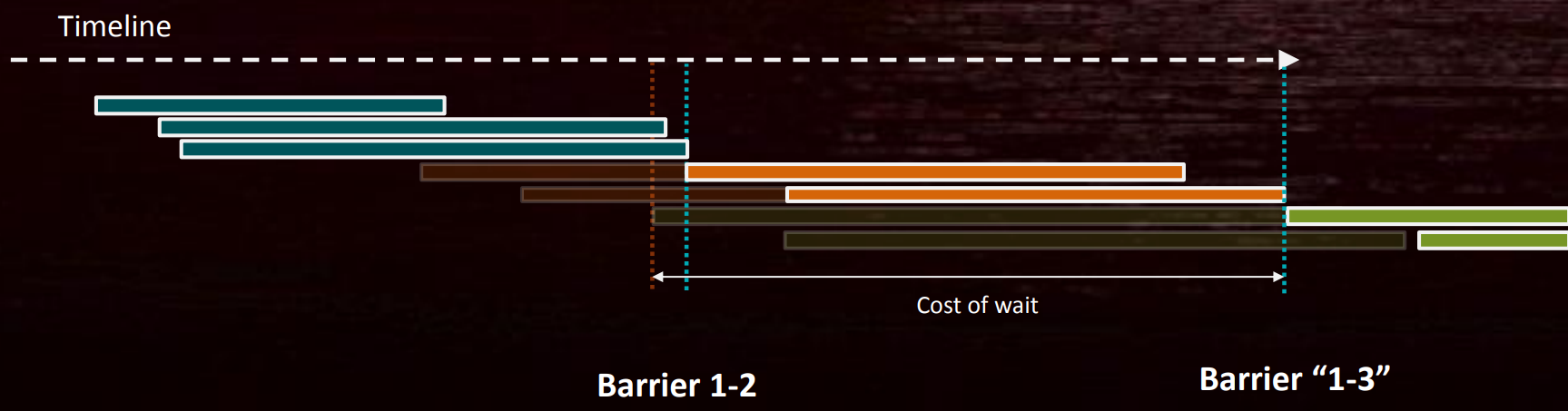
![]()
假设DC3和DC2依赖于DC1需要写入的不同资源,如果在DC1-2之间和DC1-3之间加入Barrier,则会引入更多的冗余等待:
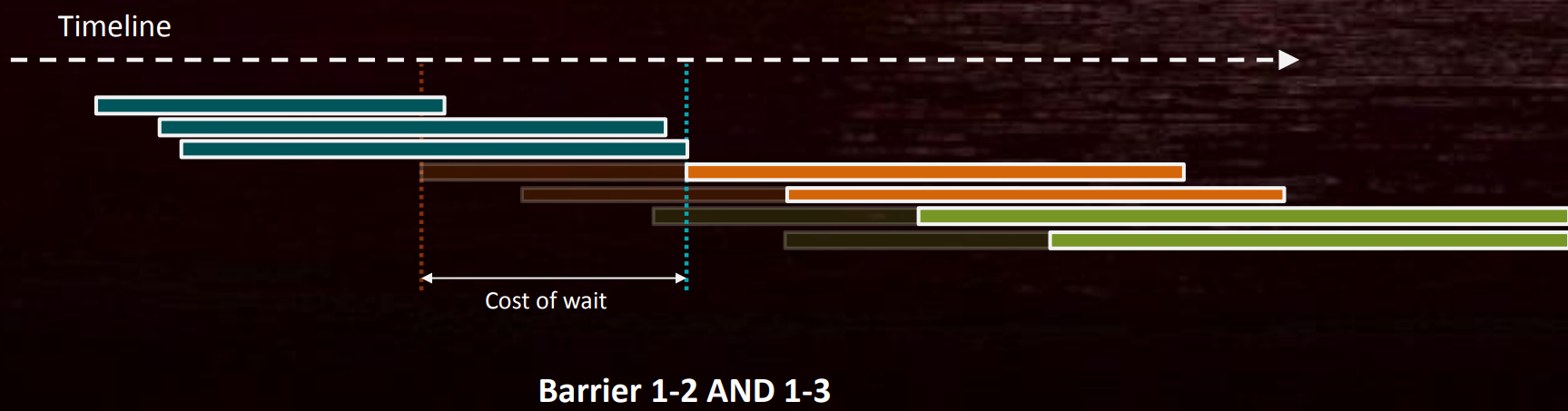
![]()
可以将原本的两个Barrier合并成一个,此时只有一个同步点,但依然会引起少量的冗余等待:
![]()
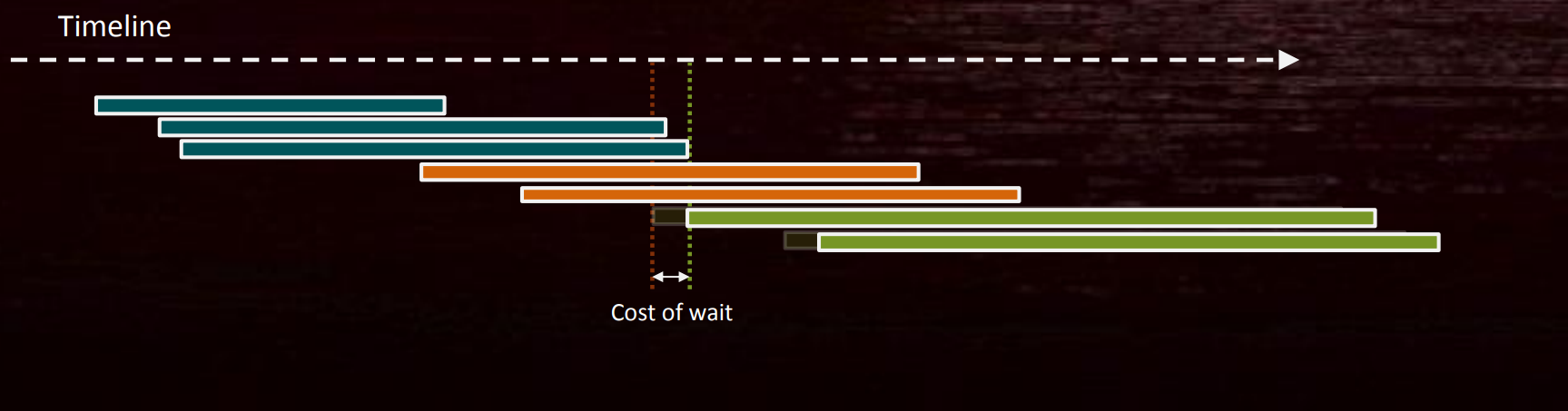
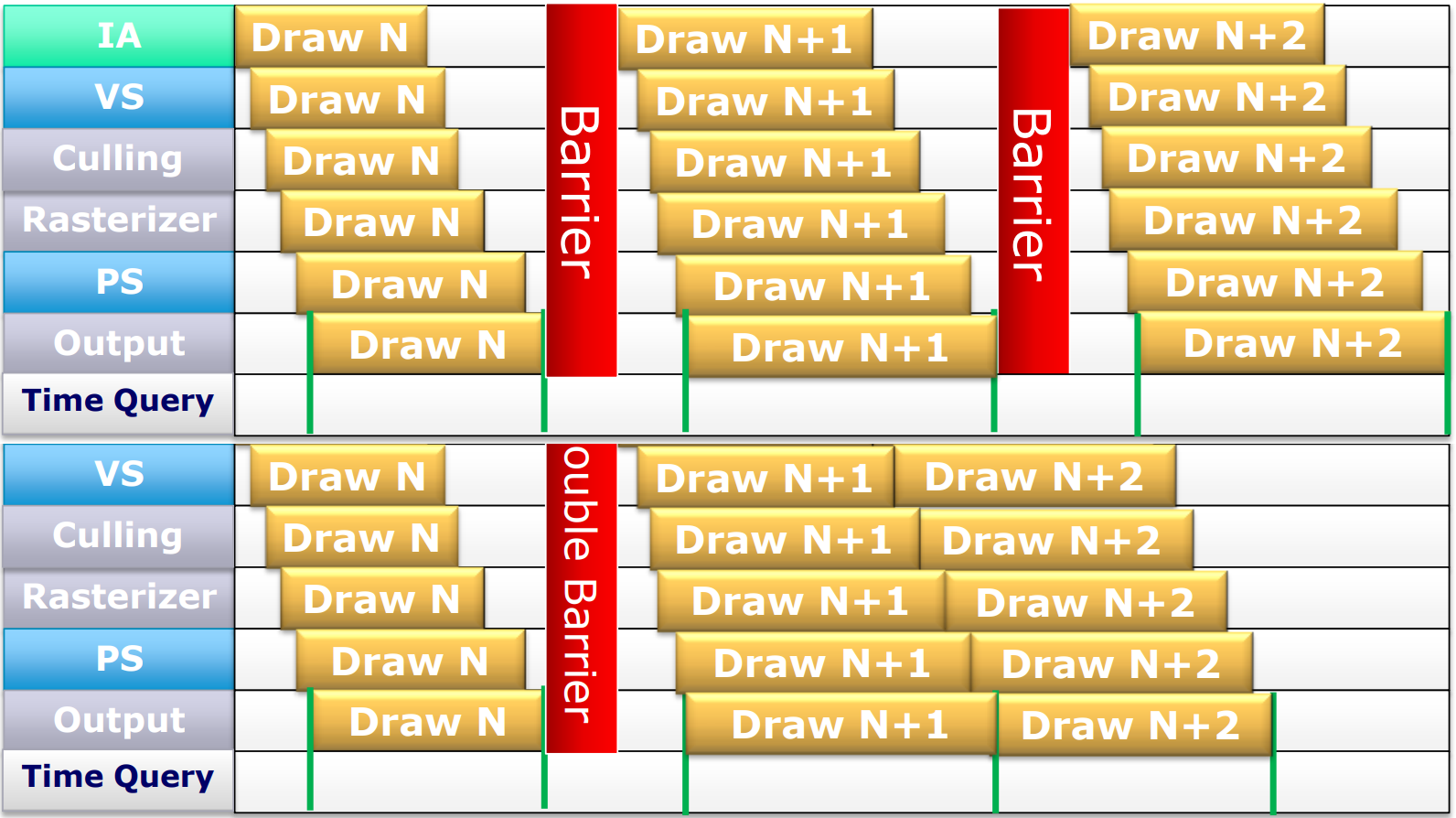
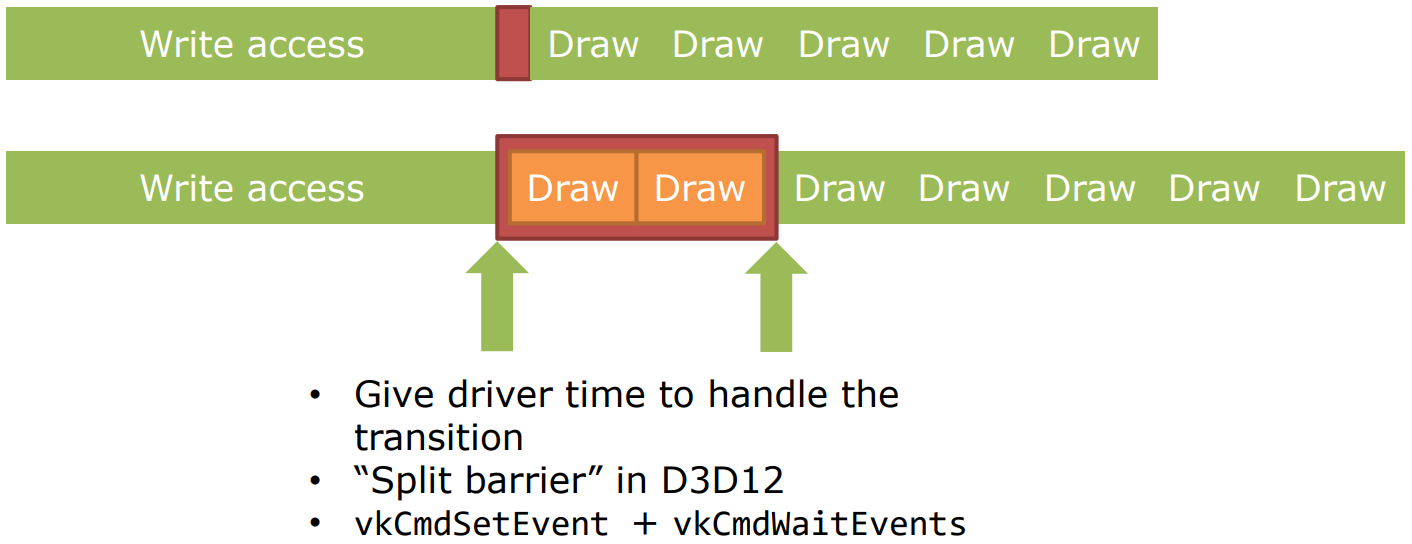
此时,可以拆分DC1和DC3之间的Barrier,DC1之后设为”Done“,在DC3之前设为”Make Ready“,此时DC2不受DC1影响,只有DC3需要等待DC1,这样的冗余等待将大大降低:
![]()
因此,拆分屏障(Split Barrier)可以减少同步等待的时间(前提是在上次使用结束和新使用开始之间有其它工作,如上例的DC2)。多个并发的Barrier也可以减少同步,并且尽量做到一次性清除多个Barrier。
如果Barrier丢失,将引发数据时序问题(timing issue)。
-
可见性(Visibility)
确保先前写入的数据对目标单元可见。
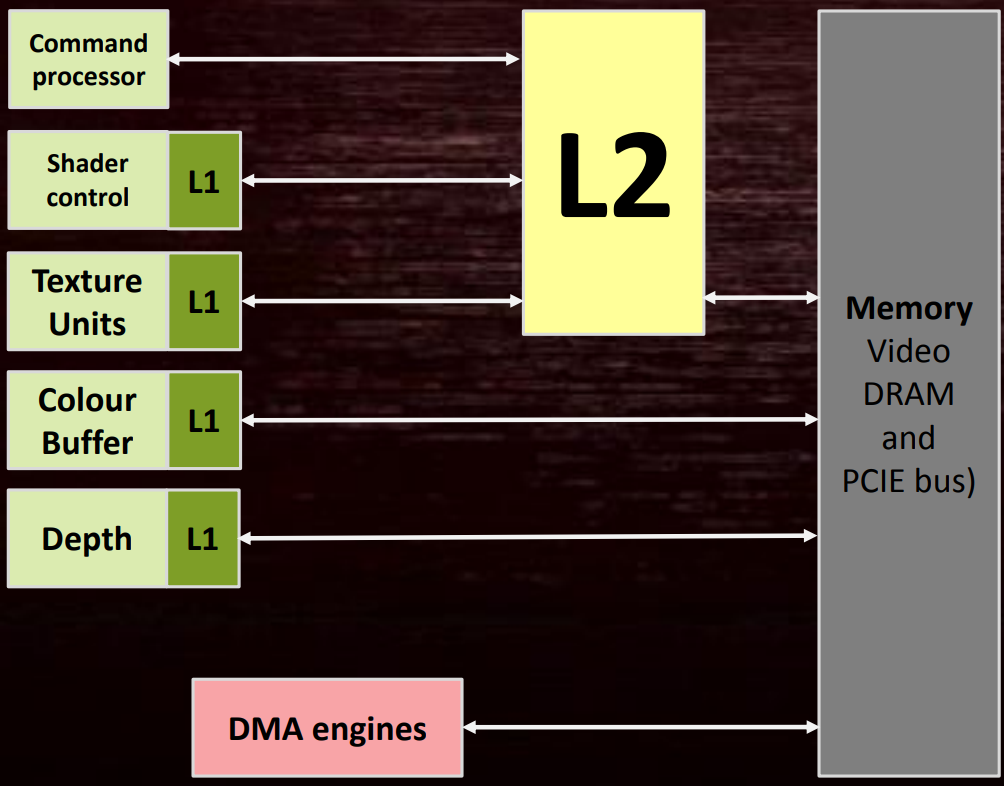
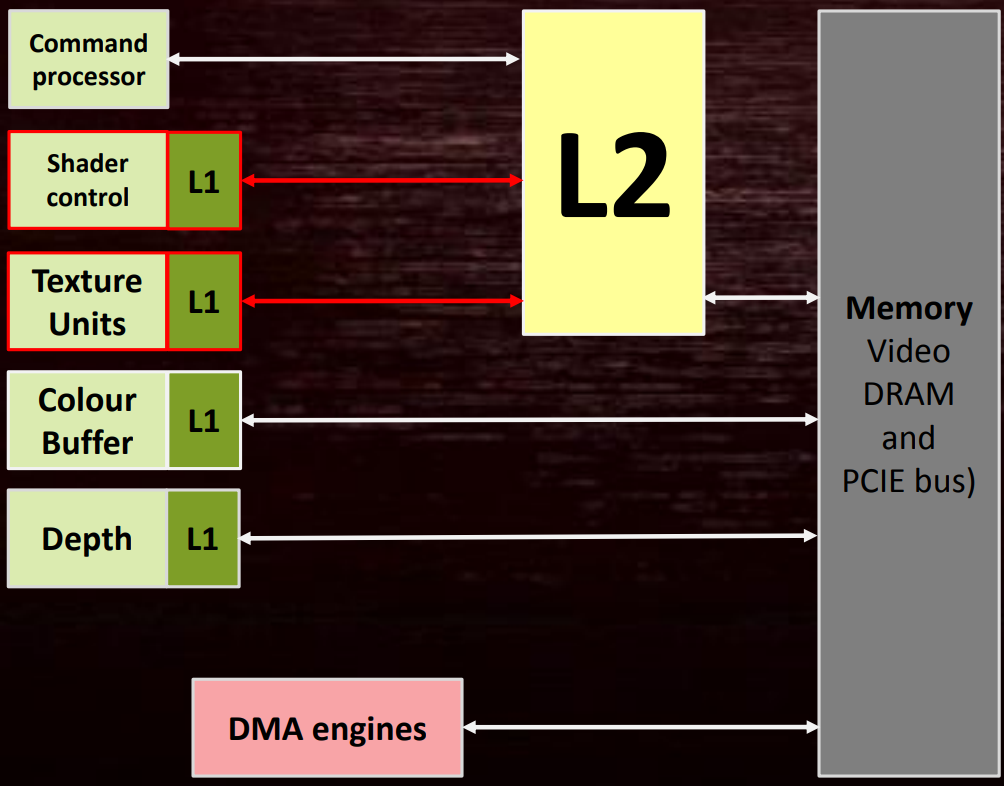
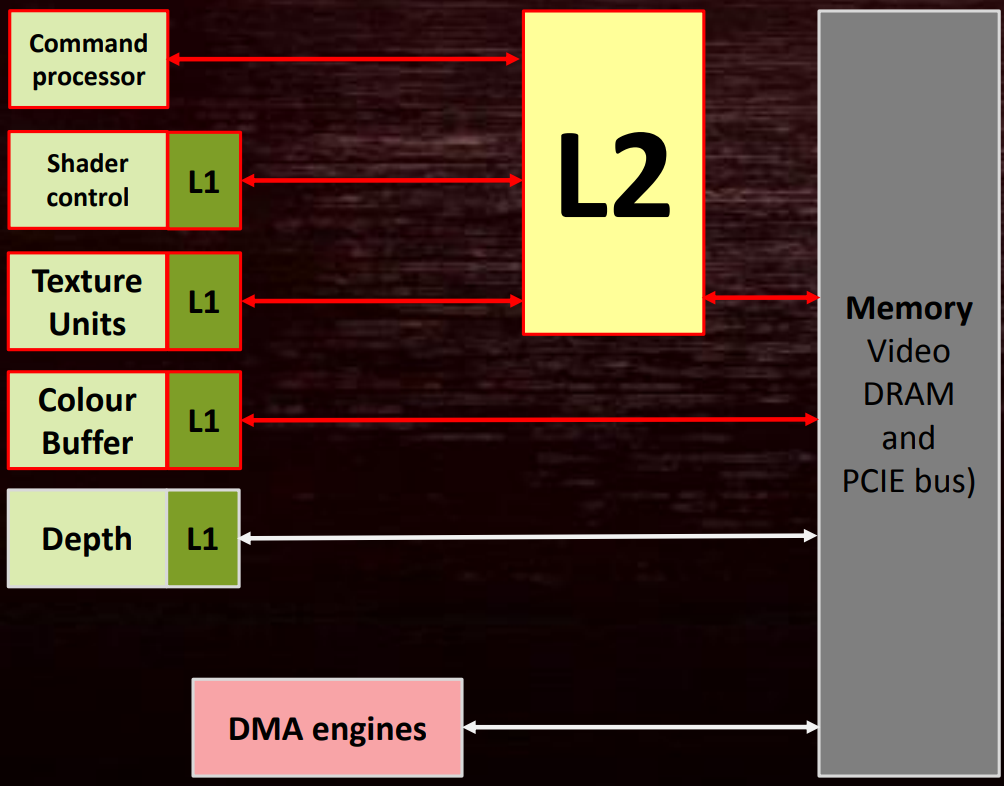
可见性涉及到GPU内部的多个元器件,如多个小的L1 Cache、大的L2 Cache(主要连接到着色器核心)。(下图)
![]()
举具体的例子加以说明。若要将缓冲区UAV转换成
SHADER_RESOURCE | CONSTANT_BUFFER标记,则会刷新纹理L1到L2,刷新Shader L1:![]()
若要将
RENDER_TARGET变成COMMON标记,则涉及很多操作:- 刷新Color L1。
- 刷新可能所有的L1。
- 刷新L2。
![]()
这种操作非常昂贵,占用更多时间和内存带宽,尽量避免此操作。此外,以下建议可以减少消耗:
- 合并多个Barrier成单个调用。联合多个Cache的刷新,减少冗余的刷新。
- 考量之前的资源状态,例如增加额外的RT->SRV覆盖RT->COMMON,反而没有任何开销!
- Split Barrier同样适应于可见性。注意,这也意味着要花额外的精力观察和消除Barrier。
-
格式转换(Format conversion)
确保数据的格式与目标单元兼容,最常见于解压(Decompression)。
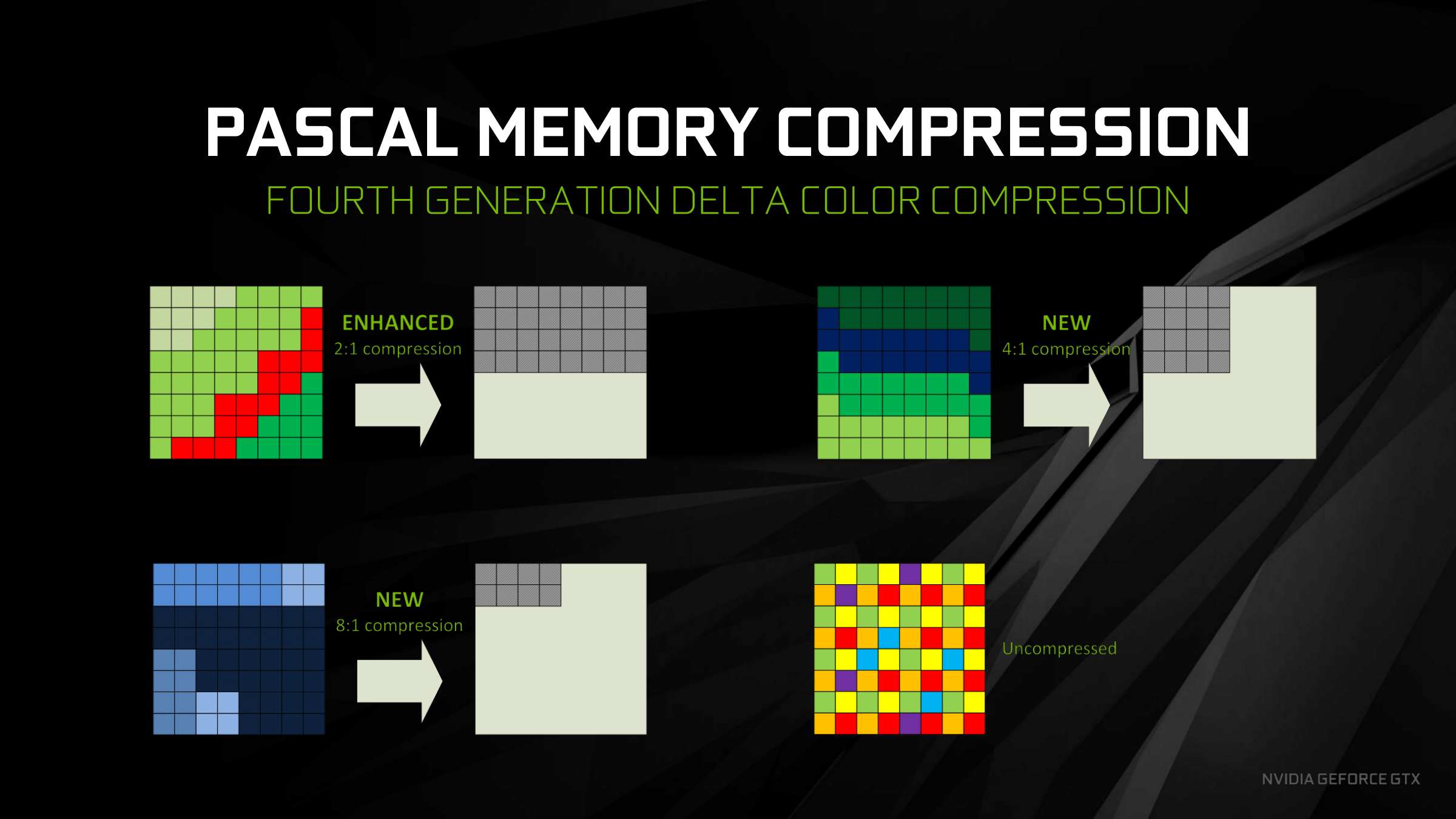
很多GPU硬件支持无损压缩,例如DCC(Delta Color Compression)、UBWC、AFBC等,以节省带宽。但是在读取这些压缩数据时可能会解压,UAV写入也会引起解压。
![]()
NV Pascal内存压缩图例。
![]()
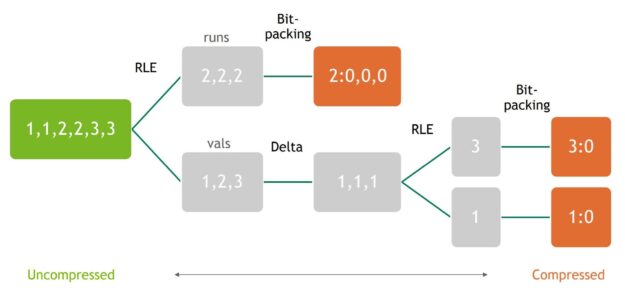
NV 的多级级联数据压缩技术。联合了RLE、Delta、Bit-packing等技术。
RT和DS表面在压缩时表现得更好,可以获得2倍速或更多的性能。
在最新的硬件上有两种不同的压缩方法:Full(全部)和Part(部分)。Full必须解压后才能读取RT或DS内容,Part也可以用于SRV。
如果需要解压,必须在某个地方承受性能卡顿。尽量避免需要解压的情况。
如果Barrier丢失,将引发数据意外损坏。
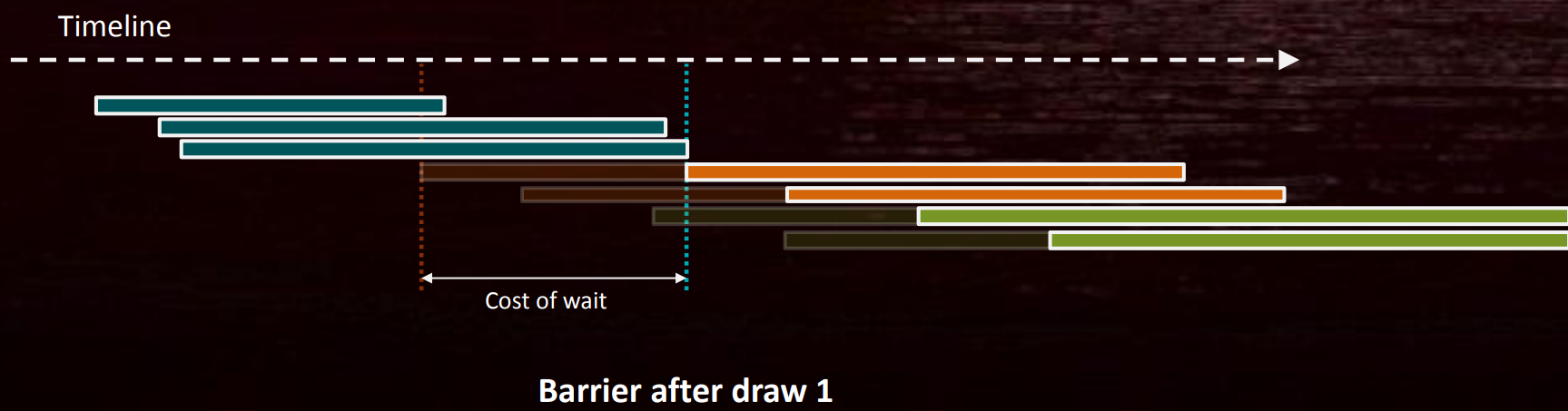
Barrier的GPU消耗常以时间戳(timestamp)来衡量,对于不需要解压的Barrier通常只需要微米(μs)级别的时间,需要耗费百分比级别的情况比较罕见,除非需要解压包含MSAA数据的表面。每个可写入的表面不应该超过2个Barrier。
每帧的表面(Surface)写入是个大问题,写入表面可能会因为Barrier丢失而损坏数据,每帧每个表面不要超过两个Barrier。
下面是一些负面的同步使用案例:
-
RT- > SRV -> Copy_source- > SRV -> RT。
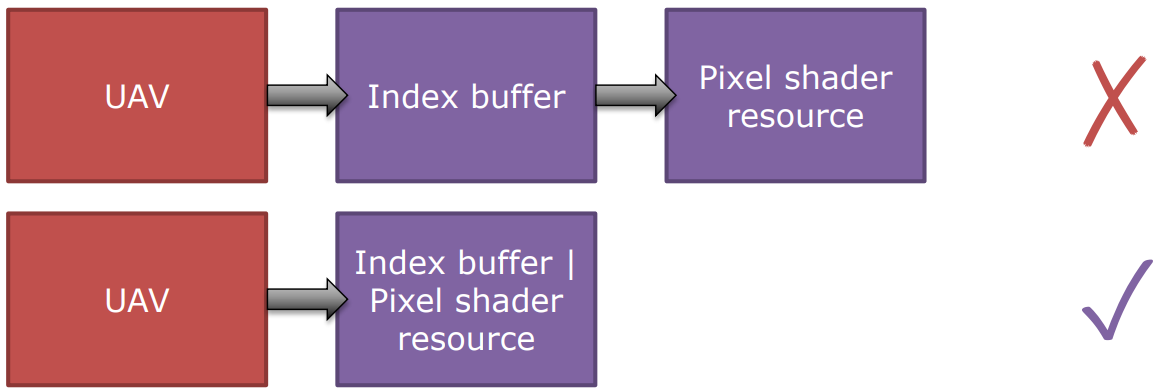
- 不要忘记,可以通过将OR操作组合多个标记。
- 永远不要有read到read(SRV -> Copy_source,Copy_source -> SRV)的Barrier。
- 资源的起始状态应放到正确的状态。
-
偶尔拷贝某个资源,但总是执行RT-> SRV|Copy。
- RT -> SR可能很低开销,但RT -> SRV|Copy可能很高开销。
- 资源的起始状态应放到正确的状态。
-
由于不知道资源的下一个状态是什么,所以总是在Command List后期转换所有资源到COMMON。
- 这样做的代价是巨大的!会导致所有表面强制解压!大多数Command List在启动前需要等待空闲。
-
只考虑正在使用的和/或在内部循环中的Barrier。
- 阻碍了Barrier合并。
-
负面的Barrier使用案例1:
void UploadTextures() { for(auto resource : resources) { pD3D12CmdList->Barrier(resource, Copy); pD3D12CmdList->CopyTexture(src, dest); pD3D12CmdList->Barrier(resource, SR); } }应改成:
void UploadTextures() { BarrierList list; // 所有纹理放在单个Barrier调用。 for(auto resource : resources) AddBarrier(list, resource, Copy) pD3D12CmdList->Barrier(list); list->clear(); // 拷贝纹理。 for(auto resource : resources) pD3D12CmdList-> CopyTexture(src, dest); // 另外一个合并的Barrier处理资源转换。 for(auto resource : resources) AddBarrier(list, resource, SR) pD3D12CmdList->Barrier(list); } -
负面的Barrier使用案例2:
for (auto& stage : stages) { for (auto& resource : resources) { if (resource.state & STATE_READ == 0) { ResourceBarrier (1, &resource.Barrier (STATE_READ)); } } }理想的绘制顺序如下:
![]()
但上述代码是逐材质逐Stage加入Barrier,会打乱理想的执行顺序,产生大量连续的空闲等待:
![]()


部分工具(RGP、PIX)会对Barrier展示详细信息或发出警告:

需要注意的是,图形API的Flush命令可以实现同步,但会强制GPU的Queue执行完,以使Shader Core不重叠,从而引发空闲,降低利用率:
DirectX 12和Vulkan的Barrier相当于图形API的Flush,等同于D3D12_RESOURCE_UAV_BARRIER,在draws/dispatche之间为transition/pipeline barrier添加一个线程flush,试着将非依赖的绘制/分派在Barrier之间分组。(这部分结论在未来的GPU可能不成立)
线程在内存访问时会引发卡顿,Cache刷新会引发空闲,有限着色器使用的任务包含:仅深度光栅化、On-Chip曲面细分和GS、DMA(直接内存访问)。为了减少卡顿和空闲,CPU端需要多个前端(front-end),并发的多线程(超线程),交错两个共享执行资源的指令流。
总之,GPU的Barrier涉及GPU线程同步、缓存刷新、数据转换(解压),描述了可见性和依赖。
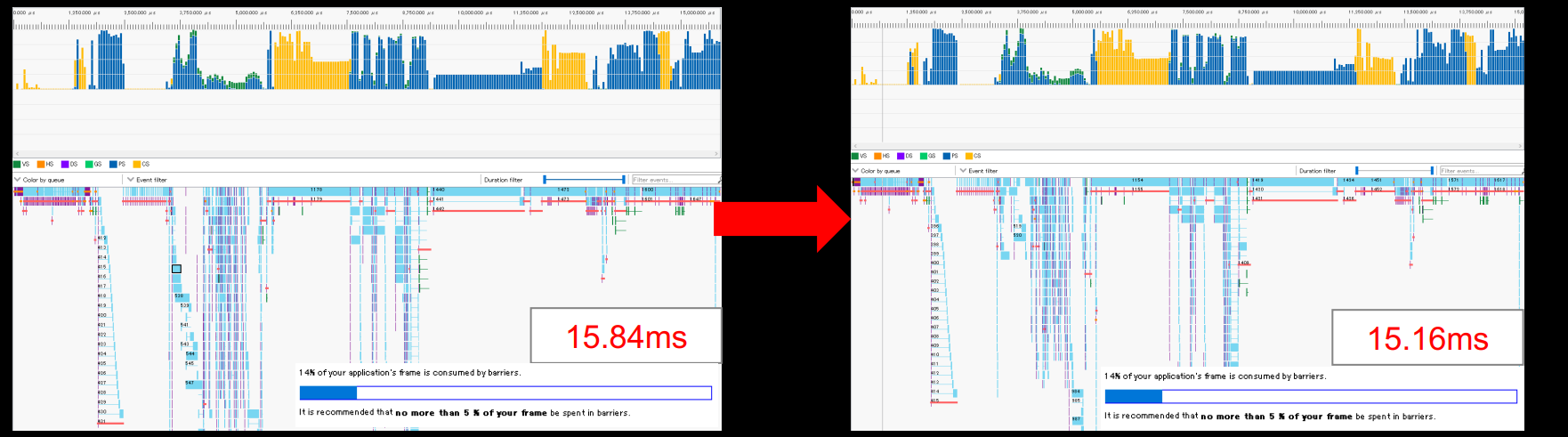
为了不让Barrier成为破坏性能的罪魁祸首,需要遵循以下的Barrier使用规则和建议:
-
尽可能地合批Barrier。
- 使用最小的使用标志集。避免多余的Flush。
- 避免read-to-read的Barrier。为所有后续读取获得处于正确状态的资源。
- 尽可能地使用split-barrier。
![]()
Barrier合批案例1。上:未合批的Barrier导致了更多的GPU空闲;下:合批之后的Barrier让GPU工作更紧凑,减少空闲。
![]()
Barrier合批案例2。上:未合批的Barrier导致了更大的GPU空闲;下:合批之后的Barrier让GPU工作更紧凑,减少空闲。
![]()
Barrier合批案例3。上:对不同时间点的Barrier向前搜寻前面资源的Barrier;中:找到这些Barrier的共同时间点;下:迁移后面Barrier到同一时间点,执行合批。
-
COPY_SOURCE可能比SHADER_RESOURCE的开销要大得多。
-
Barrier数量应该大约是所写表面数量的两倍。
-
Barrier会降低GPU利用率,更大的dispatch可以获得更好的利用率,更长时间的运行线程会导致更高的Flush消耗。
-
如果要写入资源,最好将Barrier插入到最后的那个Queue。
-
将transition放置在semaphore(信号量)附近。
-
需要明确指定源/目标队列。
-
如果还不能使用渲染通道,在任务边界上批处理Barrier,渲染通道是大多数障碍问题的最佳解决方案。
![]()
-
移动Barrier,让不依赖的工作可以重叠。
![]()
上:Barrier安插在两个不依赖的工作之间,导致中间产生大量的空闲;下:将Barrier移至两个任务末尾,让它们可以良好地重叠,减少空闲,降低整体执行时间。
-
避免跟踪每个资源的状态。
- 没有那么多资源来转换!
- 状态跟踪使得批处理变得困难。
- 不牢固。
-
避免转换所有的东西,因为Barrier是有消耗的!
- 成本通常随分辨率的变化而变化。
- 不同GPU代之间的消耗成本有所不同。
-
尽可能少的障碍——不要跟踪每个资源状态。
-
尽可能优先使用渲染通道。
-
明确所需的状态。
-
使用联合位来合并Barrier。
![]()
-
预留时间给驱动程序处理资源转换,使用Split Barrier等。
![]()
![]()
Split Barrier自动生成案例。上:生产者边界的Barrier;下:由于Depth在后面会被读取,结束写入,转成读取状态。
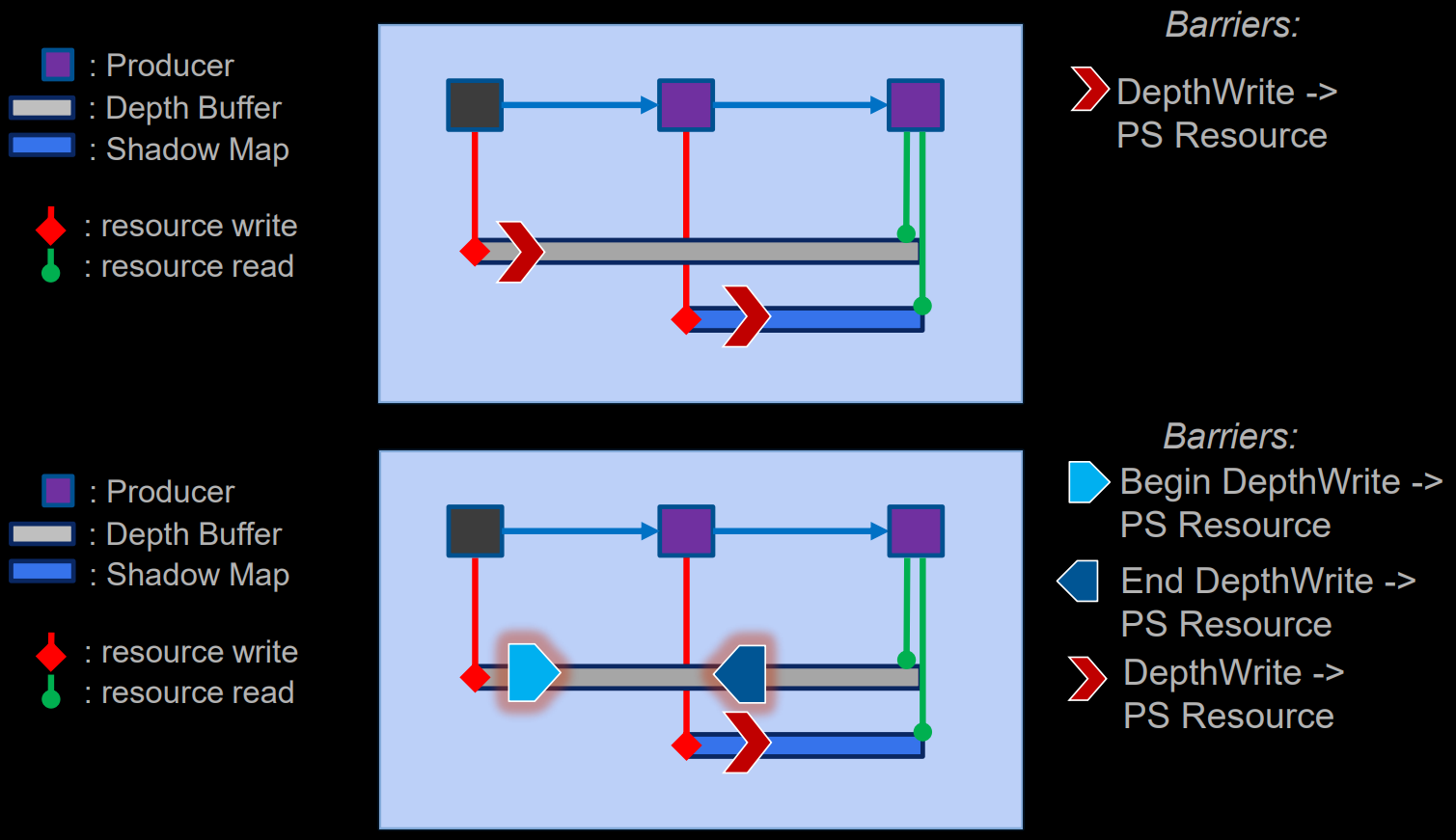
Barrier的实现方案有以下几种:
-
手工放置。
- 在简单引擎中非常友好。
- 但很快就变得复杂。
-
幕后自动生成。
- 逐资源追踪。
- 难以准确。
- 随需应变的过渡可能会导致批处理的缺乏,并经常在不理想的地方出现Barrier。
-
在D3D12上用渲染通道模拟。
- 更好的可移植性。
-
Frame Graph。
- 分析每个Pass,找出依赖关系。
- 然后可以确定每个资源内存重叠(aliasing)的范围。
- 比如,Frostbite的Frame Graph、UE的RDG。
- 所有的资源转换都由主渲染线程提交。主渲染线程也可以记录命令列表,并执行所有多线程同步。
![]()

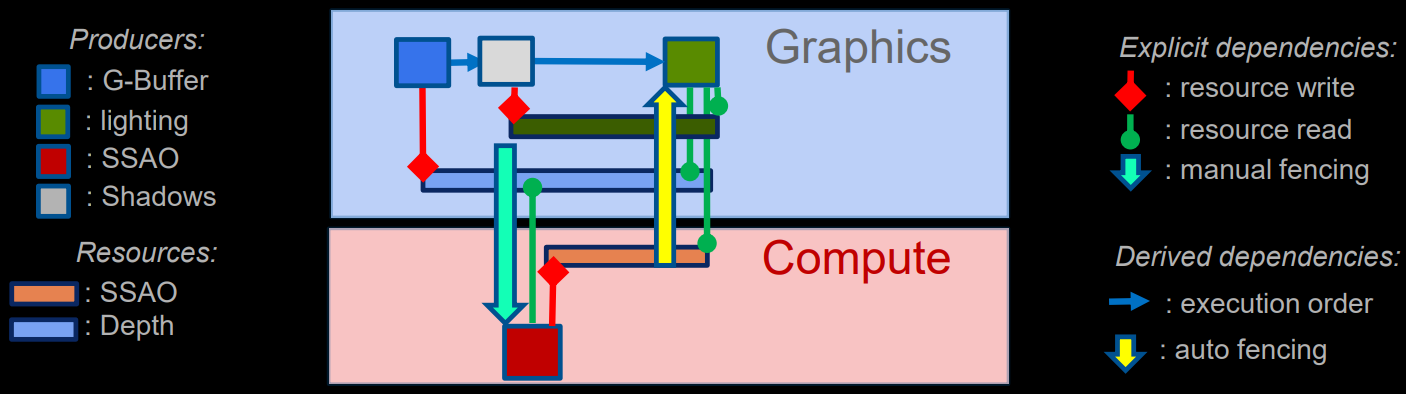
育碧的Anvil Next引擎实现了精确的自动化的资源跟踪和依赖管理,自动跟踪资源生命时间,以确定内存重用的选项(针对placed resource),自动跟踪资源访问同步,用户可以添加手动同步,以更好地匹配工作负载。(下图)
13.4.3.2 Fence
Fence(栅栏)是GPU的信号量,使用案例是确保GPU在驱逐(evict)前完成了资源处理。
可以每帧使用一个Fence,来保护逐帧(per-frame)的资源。尽量用单个Fence包含更多的资源。
Fence操作是在Command Queue上,而非Command List或Bundle。
每个Fence的CPU和GPU成本与ExecuteCommandLists差不多。不要期望Fence比逐ExecuteCommandLists调用更细的粒度触发信号。
Fence包含了隐式的acquire / release Barrier,也是Fence开销高的其中一个原因。
尝试使用Fence实现资源的细粒度重用,理想情况是最终使用一个SignalFence来同步所有资源重用。
下面是DX12的Barrier和Fence使用示例代码:
// ------ Barrier示例 ------
// 阴影贴图从一般状态切换到深度可写状态,得以将场景深度渲染至其中
pCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(pShadowTexture,
D3D12_RESOURCE_STATE_COMMON, D3D12_RESOURCE_STATE_DEPTH_WRITE));
// 阴影贴图将作为像素着色器的 Shader Resource 使用,场景渲染时,将对阴影贴图进行采样
pCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(pShadowTexture,
D3D12_RESOURCE_STATE_DEPTH_WRITE, D3D12_RESOURCE_STATE_PIXEL_SHADER_RESOURCE));
// 阴影贴图恢复到一般状态
pCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(pShadowTexture,
D3D12_RESOURCE_STATE_PIXEL_SHADER_RESOURCE, D3D12_RESOURCE_STATE_COMMON));
// ------ Fence示例 ------
// 创建一个Fence,其中fenceValue为初始值
ComPtr<ID3D12Fence> pFence;
pDevice->CreateFence(fenceValue, D3D12_FENCE_FLAG_NONE, IID_PPV_ARGS(&pFence)));
// 发送Fence信号。
pCommandQueue->Signal(pFence.Get(), fenceValue);
// Fence案例1:由CPU端查询Fence上的完成值(进度),如果比fenceValue小,则调用DoOtherWork
if (pFence->GetCompletedValue() < fenceValue)
{
DoOtherWork();
}
// Fence案例2:通过指定Fence上的值实现CPU和GPU同步
if (pFence->GetCompletedValue() < fenceValue)
{
pFence->SetEventOnCompletion(fenceValue, hEvent);
WaitForSingleObject(hEvent, INFINITE);
}
Fence和Semaphore会同步所有的GPU执行和内存访问,这就是为什么有时候什么都不等待或什么都不阻塞是可以的。
CPU和GPU同步模型可以考虑以下方式:
-
即发即弃(Fire-and-forget)。
- 工作开始时,通过围栏进行同步。但是,部分工作负载在帧与帧之间是不同的,会导致非预期的工作配对,从而影响整帧性能。
![]()
- 同样的情况,应用程序在ECL之间引入了CPU延时,CPU延迟传导到了GPU,导致非预期的工作配对,等等……
![]()
-
握手(Handshake)。
- 同步工作配对的开始和结束,确保配对确定性,可能会错过一些异步机会(HW可管理) 。
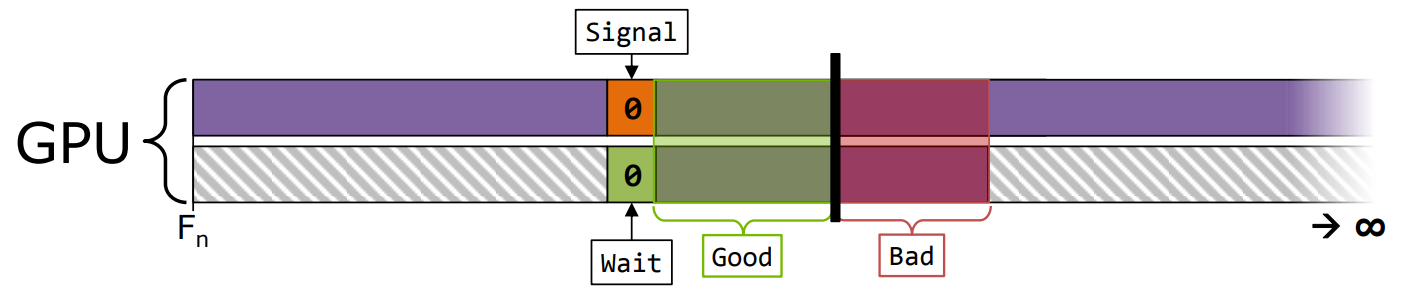
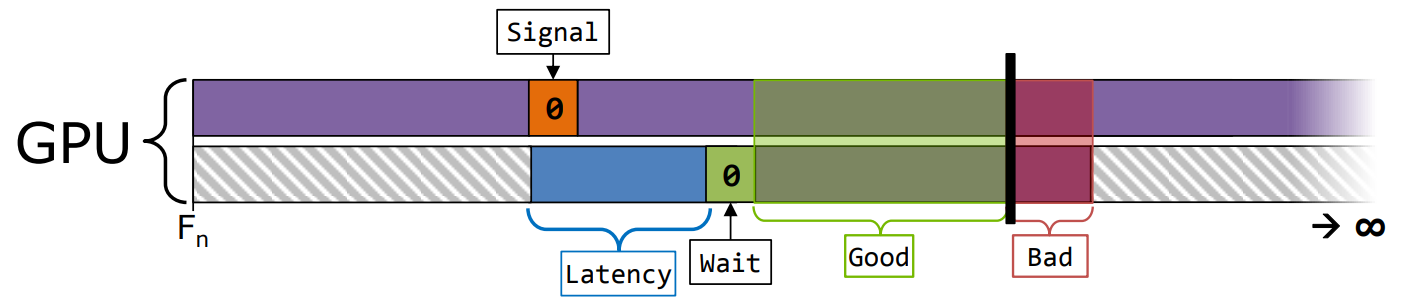
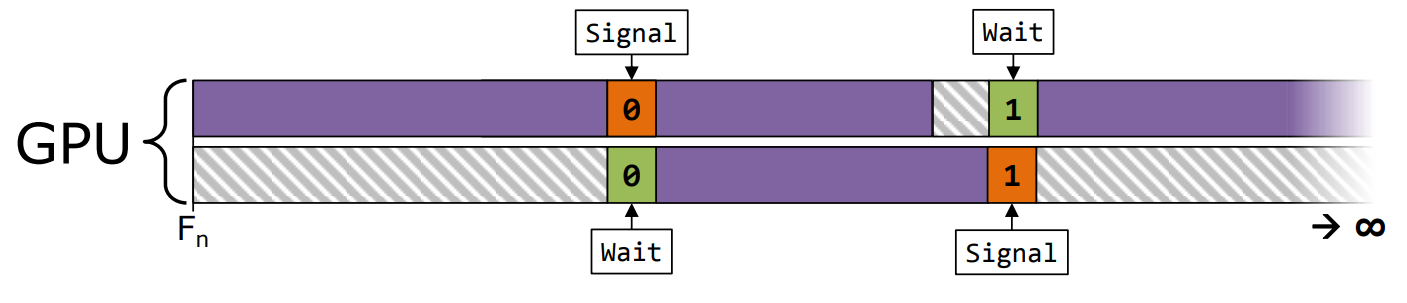
同时也要注意CPU可以通过ExecuteCommandLists(ECL)调度GPU,意味着CPU的空隙会传导到GPU上。
13.4.3.3 Pipeline Barrier
Pipeline Barrier在Vulkan用于解决命令之间的执行依赖(Execution Dependency)问题,以及内存依赖(Memory Dependency)问题。
大多数Vulkan命令以队列提交顺序启动,但可以以任何顺序执行,即使使用了相同管道阶段。
当两个命令相互依赖时,必须告诉Vulkan两个同步范围(synchronization scope):
- srcStageMask:Barrier之前会发生什么。
- dstStageMask:Barrier之后会发生什么。
当内存数据存在依赖时,必须告诉Vulkan两个访问范围(access scope):
- srcAccessMask:在Barrier之前发生的命令内存访问。Barrier执行的任何缓存清理(或刷新) 仅发生在此。
- dstAccessMask:在Barrier之后发生的命令内存访问。Barrier执行的任何缓存无效(cache invalidate) 仅发生在此。
下面举个具体的例子:
vkCmdCopyBuffer(cb, buffer_a, buffer_b, 1, ®ion); // buffer_a是拷贝源
vkCmdCopyBuffer(cb, buffer_c, buffer_a, 1, ®ion); // buffer_a是拷贝目标
上面的代码没有使用Pipline Barrier,会触发WAR(Write after read)冲突。可以添加Pipeline Barrier防止冲突:
vkCmdCopyBuffer(cb, buffer_a, buffer_b, 1, ®ion);
// 创建VkBufferMemoryBarrier
auto buffer_barrier = lvl_init_struct<VkBufferMemoryBarrier>();
buffer_barrier.srcAccessMask = VK_ACCESS_TRANSFER_READ_BIT;
buffer_barrier.dstAccessMask = VK_ACCESS_TRANSFER_WRITE_BIT;
buffer_barrier.buffer = buffer_a;
// 添加VkBufferMemoryBarrier
vkCmdPipelineBarrier(cb, VK_PIPELINE_STAGE_TRANSFER_BIT, VK_PIPELINE_STAGE_TRANSFER_BIT, 0, 0, nullptr, 1, &buffer_barrier, 0,nullptr);
// 拷贝数据。
vkCmdCopyBuffer(cb, buffer_c, buffer_a, 1, ®ion);
管线阶段位(pipeline stage bit)是有序的:
-
在vulkan规范中定义的逻辑顺序。
-
在srcStageMask,每个Stage位需要等待所有更早的Stage。
-
在dstStageMask,每个Stage位需要卡住所有更迟的Stage。
![]()
上:没有很好地设置管线阶段依赖位,导致并行率降低;下:良好地设置了管线阶段依赖位,提升了并行效率,降低整体执行时间。
![]()
上图的Vertex_Shader阶段会等待所有的灰色阶段,也会卡住所有的绿色阶段。
-
通常只需要设置正在同步的位。

内存访问掩码位是独立的:
- 需要设置所有正在同步的位。
- 但是,如果想使用需要的访问掩码,则必须显式地指定每个管道阶段。 (这是常见的错误来源)
假设有以下命令队列:
Command A
Barrier1
Command B
Barrier2
Command C
为了让A, B, C有序地执行,需要确保Barrier1.dstMask等同于或更早于Barrier2.srcMask。下表是不同情况的依赖关系:
| Barrier1.dstMask | Barrier2.srcMask | dependency chain? |
|---|---|---|
| DRAW_INDIRECT | DRAW_INDIRECT | Yes |
| DRAW_INDIRECT | COMPUTE_SHADER | No |
| COMPUTE_SHADER | DRAW_INDIRECT | Yes |
| BOTTOM_OF_PIPE or ALL_COMMANDS | DRAW_INDIRECT | Yes(可能很慢) |
下面是特殊的执行依赖的说明:
- srcStageMask = ALL_COMMANDS:会阻塞并等待所有阶段,强制等待直到GPU空闲,通常会损害性能。
- srcStageMask = NONE or TOP_OF_PIPE:不会等待任何东西,只能构建上一个Barrier携带了dstStageMask = ALL_COMMANDS标记的执行依赖链。
- dstStageMask = NONE or BOTTOM_OF_PIPE:没有任何东西等待此Barrier,用srcStageMask = ALL_COMMANDS构建一个执行依赖链。
下面是特殊的内存访问掩码的说明:
- NONE:没有内存访问,用于定义执行barrier。
- MEMORY_READ, MEMORY_WRITE:StageMask允许的任何内存访问。
- SHADER_READ:在sync2中扩开为(SAMPLER_READ | STORAGE_READ | UNIFORM_READ)。
- SHADER_WRITE:在sync2中扩展为STORAGE_WRITE(大于2^32) 。
更多Pipeline Barrier相关的说明请阅读:12.4.13 subpass。
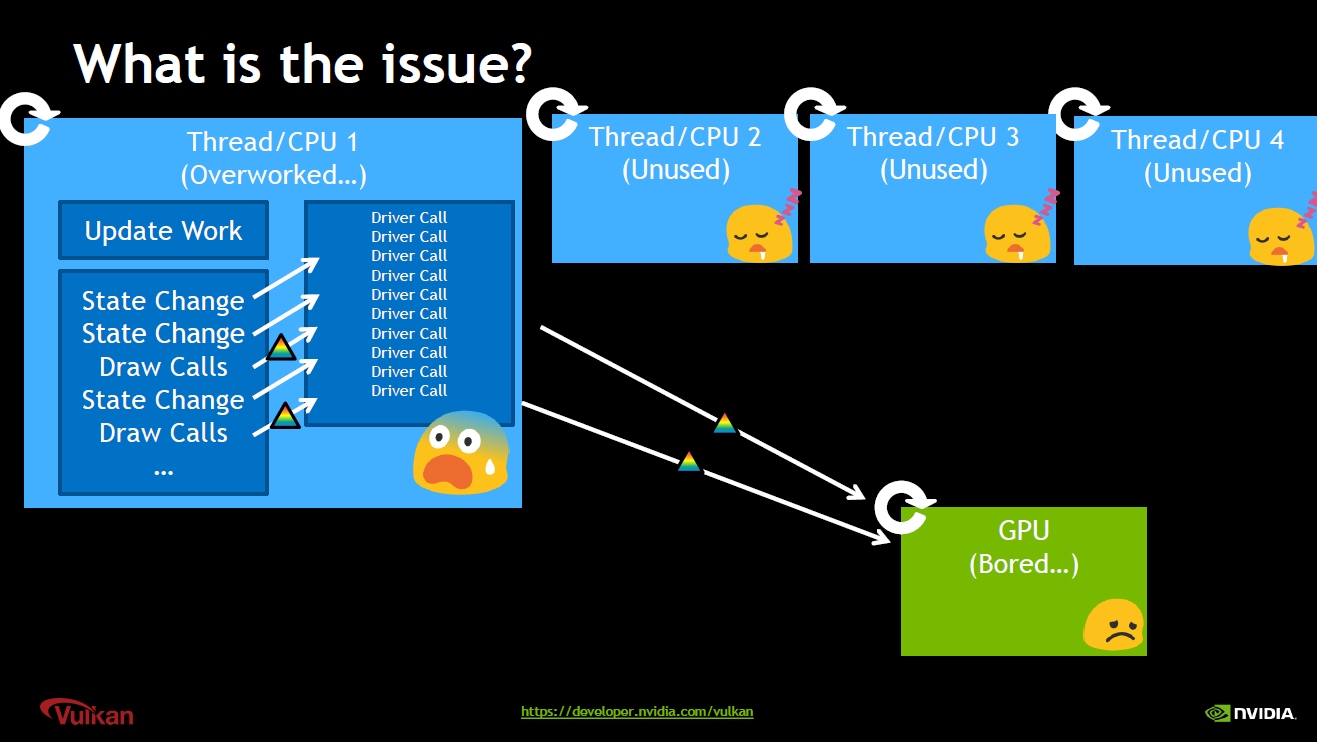
13.4.4 Parallel Command Recording
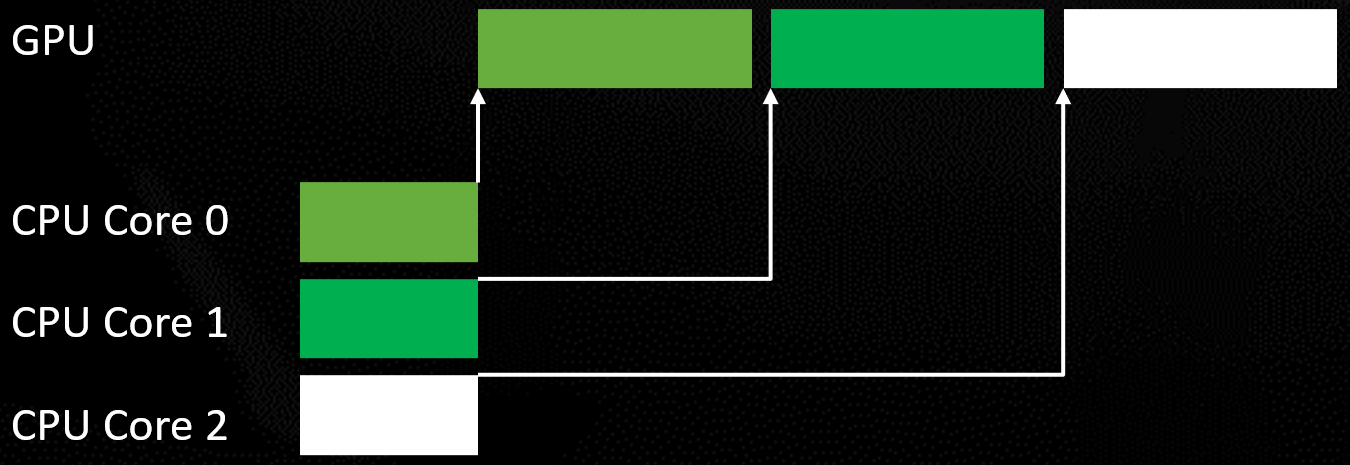
在现代图形API出现之前,由于无法在多个线程并行地录制渲染命令,使得渲染线程所在的CPU核极度忙碌,而其它核心处于空闲状态:
现代图形API(如Vulkan)从一开始就被创建为线程友好型,大量规范详细说明了线程安全性和调用的后果,并且所有的控制权和责任都落在应用程序上。
随着现代CPU核心数量愈来愈多,应用程序对多线程处理渲染的需求愈来愈强烈,最显著的就是希望能够从多个线程生成渲染工作,在多个线程中分摊验证和提交成本。具体的用例如下:
- 线程化的资源更新。
- CPU顶点数据或实例化数据动画(如形变动画)。
- CPU统一缓冲区数据更新。(如变化矩阵更新)。
- 并行的渲染状态创建。
- 着色器编译和状态验证。
- 线程化的渲染和绘制调用。
- 在多个线程中生成命令缓冲区。
Vulkan支持独立的工作描述和提交:
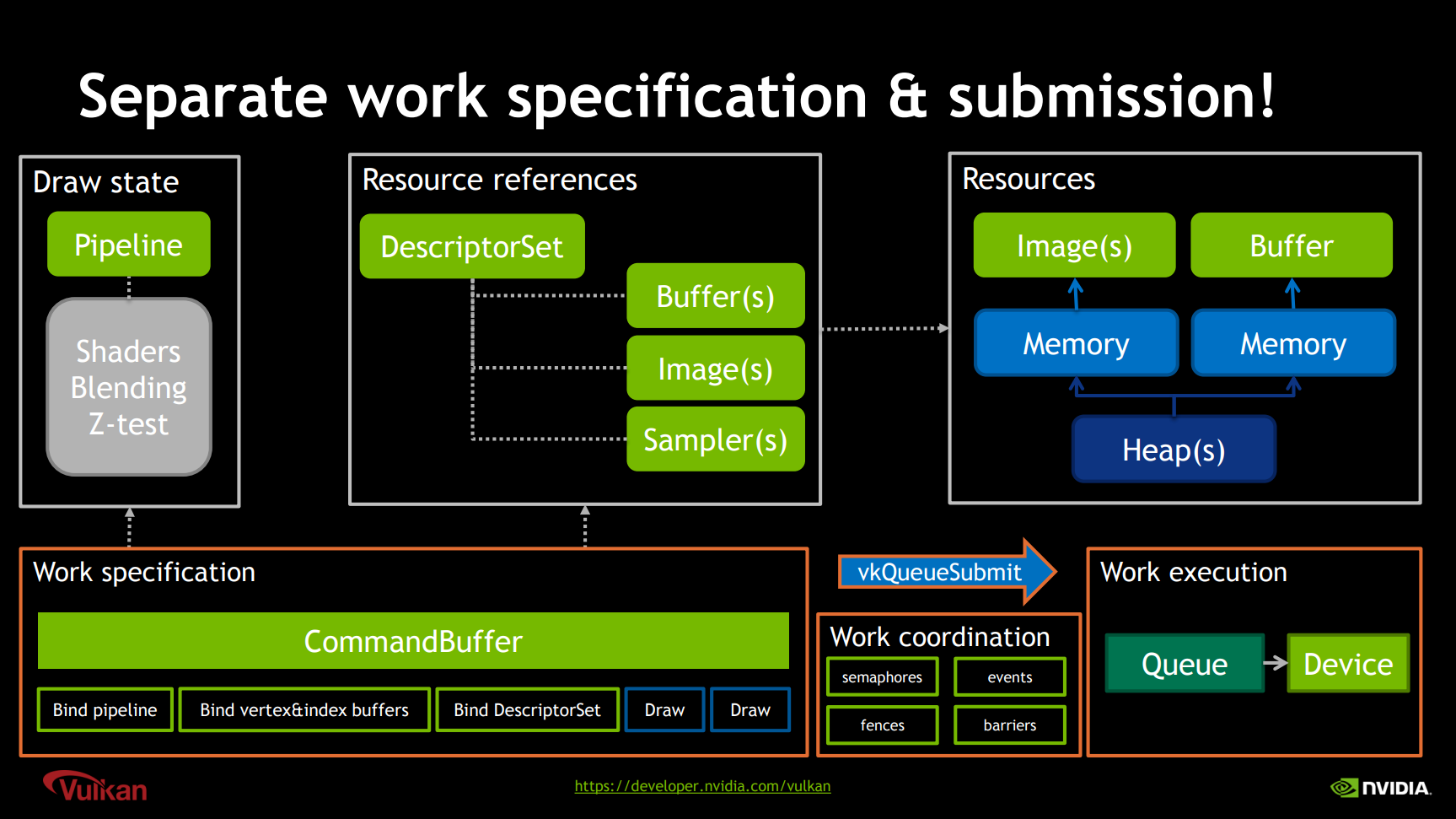
Vulkan资源、命令、绘制、提交等关系示意图。其中Work specification包含了绑定管线状态、顶点和索引缓冲、描述符集及绘制指令,涉及的资源有Command Buffer、绘制状态、资源引用,而资源引用又由描述符指定了资源实际的位置。Work specification通过vkQueueSubmit进行提交,提交时可以指定精确的同步操作。Queue最后在GPU内部被执行。
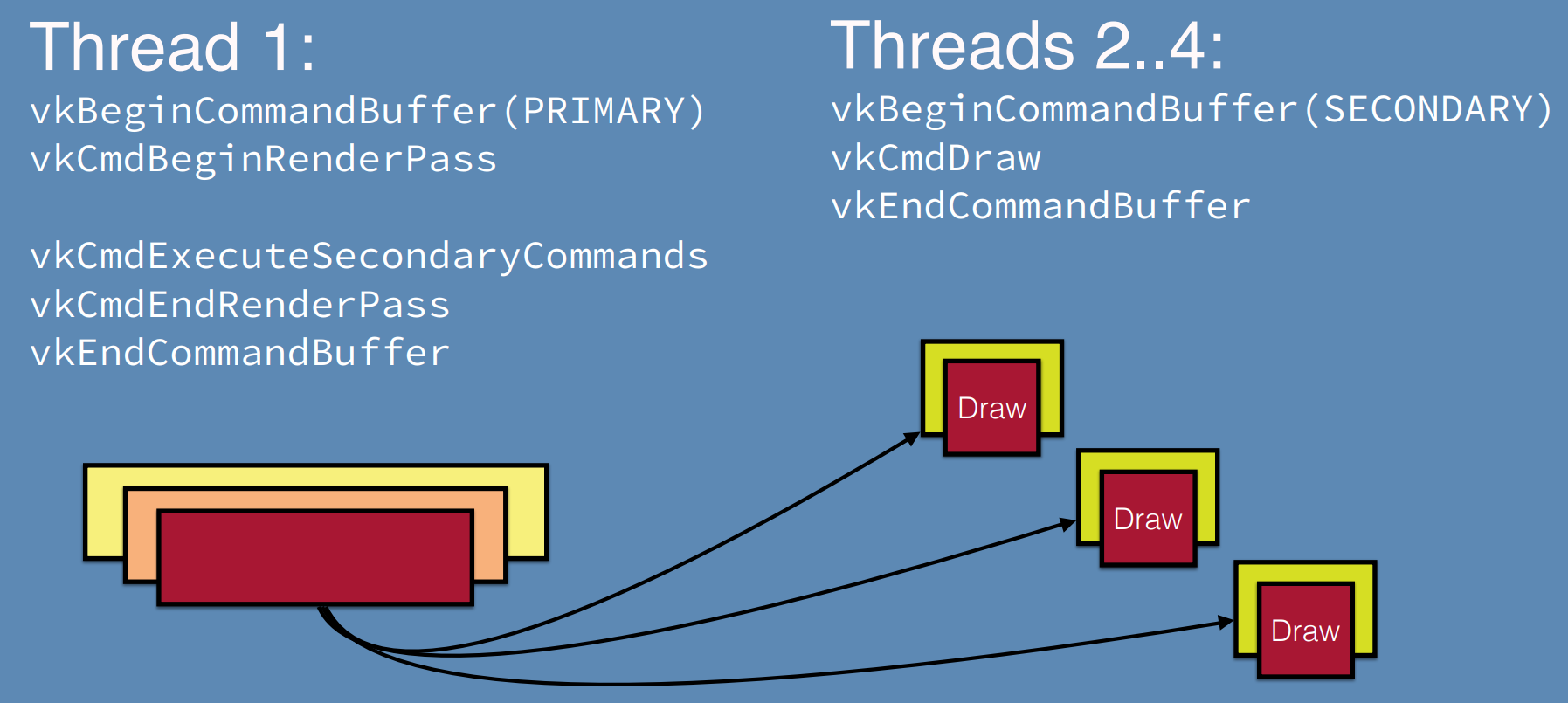
对于现代图形API的Command Buffer,所有的渲染都通过Command Buffer执行,可以单次使用多次提交,驱动程序可以相应地优化缓冲区,存在主要和次级Command Buffer,允许静态工作被重用。更重要的是,没有状态是跨命令缓冲区继承的!
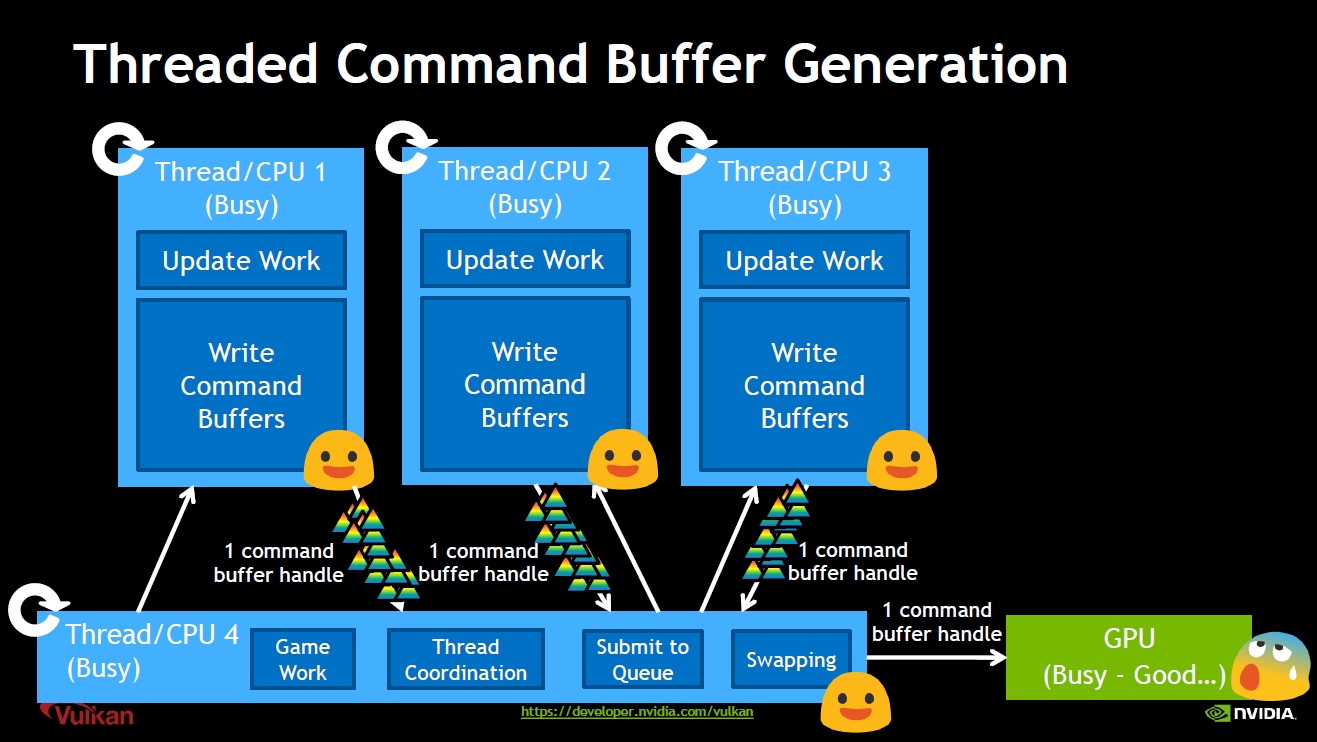
Vulkan多核并行地生成Command Buffer示意图。
Vulkan并行Pass调用和图例。
如果想要重用Vulkan的Command Buffer,应用程序可以利用Fence等确保被重用的Command Buffer不在使用状态,确保线程安全:

Metal也允许应用程序显式地构造和提交很多轻量级的Command Buffer。这些缓冲区可以并行地在多个线程中录制(下图),并且执行顺序可以由应用程序指定。这种方式非常高效,且确保执行性能可伸缩。
Metal并行录制命令缓冲区示意图。
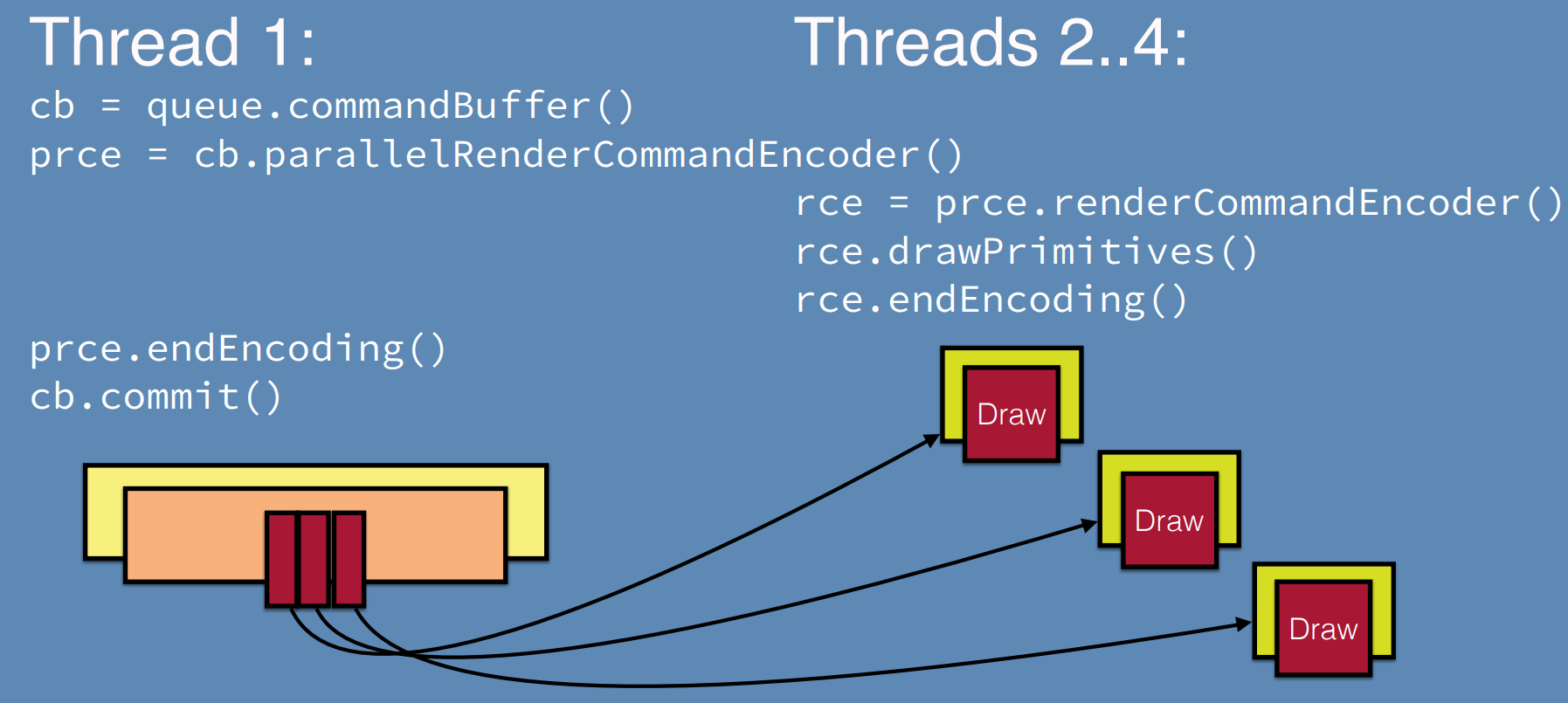
Metal并行Pass调用和图例。
和Vulkan、Metal类似,DirectX 12也拥有多线程录制渲染命令机制:
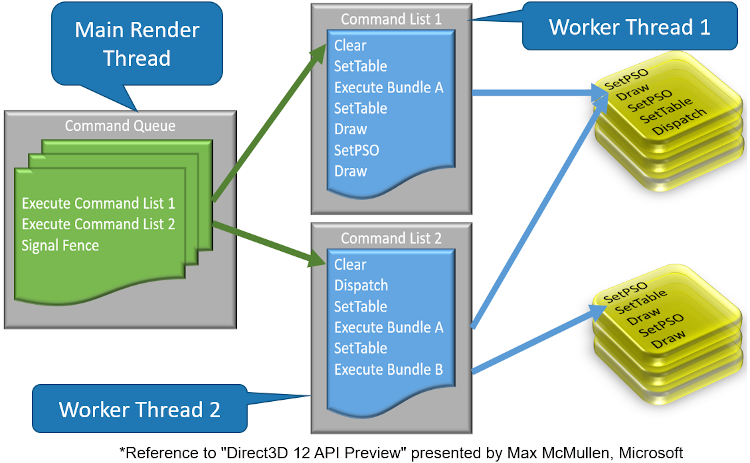
DX12多线程录制模型。注意图中的Bundle A被执行了两次。
除了Command Buffer可以被并行创建和重用,Command Allocator(Pool)也可以被多线程并行地创建,并且不同线程的Command Buffer必须被不同的Command Allocator(Pool)实例创建(否则需要额外的同步操作):

因此,良好的设计方案下,每个线程需要有多个命令缓冲区,并且线程每帧可能有多个独立的缓冲区,以便快速重置和重用不再使用的Command Allocator(Pool):

使用多个Command Queue提交绘制指令可能在GPU并行地执行,但依赖于OS调度、驱动层、GPU架构和状态、Queue和Command List的类型,和CPU线程相似。

多个Command队列提升GPU核心利用率示意图。
另外,需要指出的是,D3D12的Command Queue不等于硬件的Queue,硬件的Queue可能有很多,也可能只有1个,操作系统/调度器会扁平化并行提交,利用Fence让依赖对调度器可见。通过GPUView/PIX/RGP/Nsight等工具可以查看具体详情!
Vulkan的Queue又有着很大不同,显式绑定到公开的队列,但仍然不能保证是一个硬件队列。Vulkan的Queue Family类似于D3D12 Engine。
多核CPU面临并行操作和缓存一致性问题。对GPU而言也类似,Command Processor等同于Task Scheduler,Shader Core等同于Worker Core。
当其它命令队列被提交时,新的命令队列可以并行地构建,在提交和呈现期间不要有空闲。可以重用命令列表,但应用程序需要负责停止并发使用。
不要拆分工作到太多的命令队列。每帧可以拟定合理的任务数量,比如15-30个命令队列,5-10个ExecuteCommandLists个调用。
每个ExecuteCommandLists都有固定的CPU开销,所以在这个调用后面触发一个刷新,并且合批命令队列,减少调用次数。尽量让每个ExecuteCommandLists可以让GPU运行200μs,最好达到500μs。提交足够的工作可以隐藏OS调度器(scheduler)的延时,因为小量工作的ExecuteCommandLists执行时间会快于OS调度器提交新的工作。
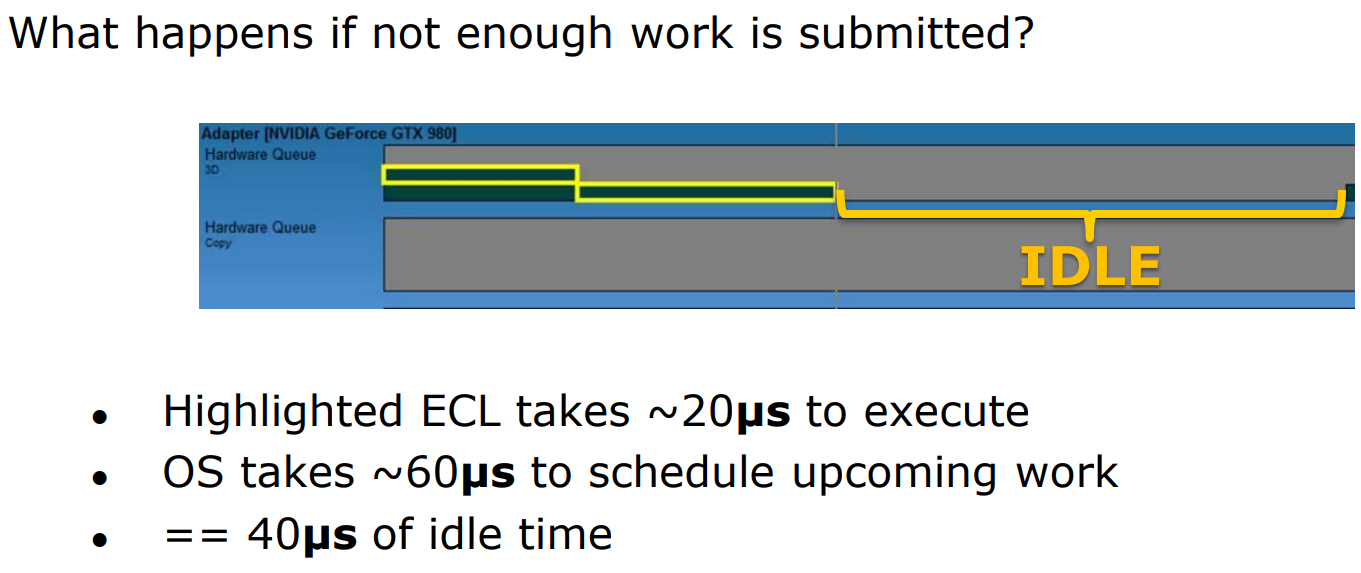
小量的命令队列提交导致了大量空闲的案例。
Bundle是个在帧间更早提交工作的好方法。但在GPU上中,Bundle并没有本质上更快,所以要谨慎地对待。充分利用从调用命令列表继承状态(但协调继承状态可能需要CPU或GPU成本),可以带来不错的CPU效率提升。对NV来言,每个Dispatch拥有5个以上相同的绘制,则使用Bundle;AMD则建议只有CPU侧是瓶颈时才使用Bundle。
13.4.5 Multi Queue
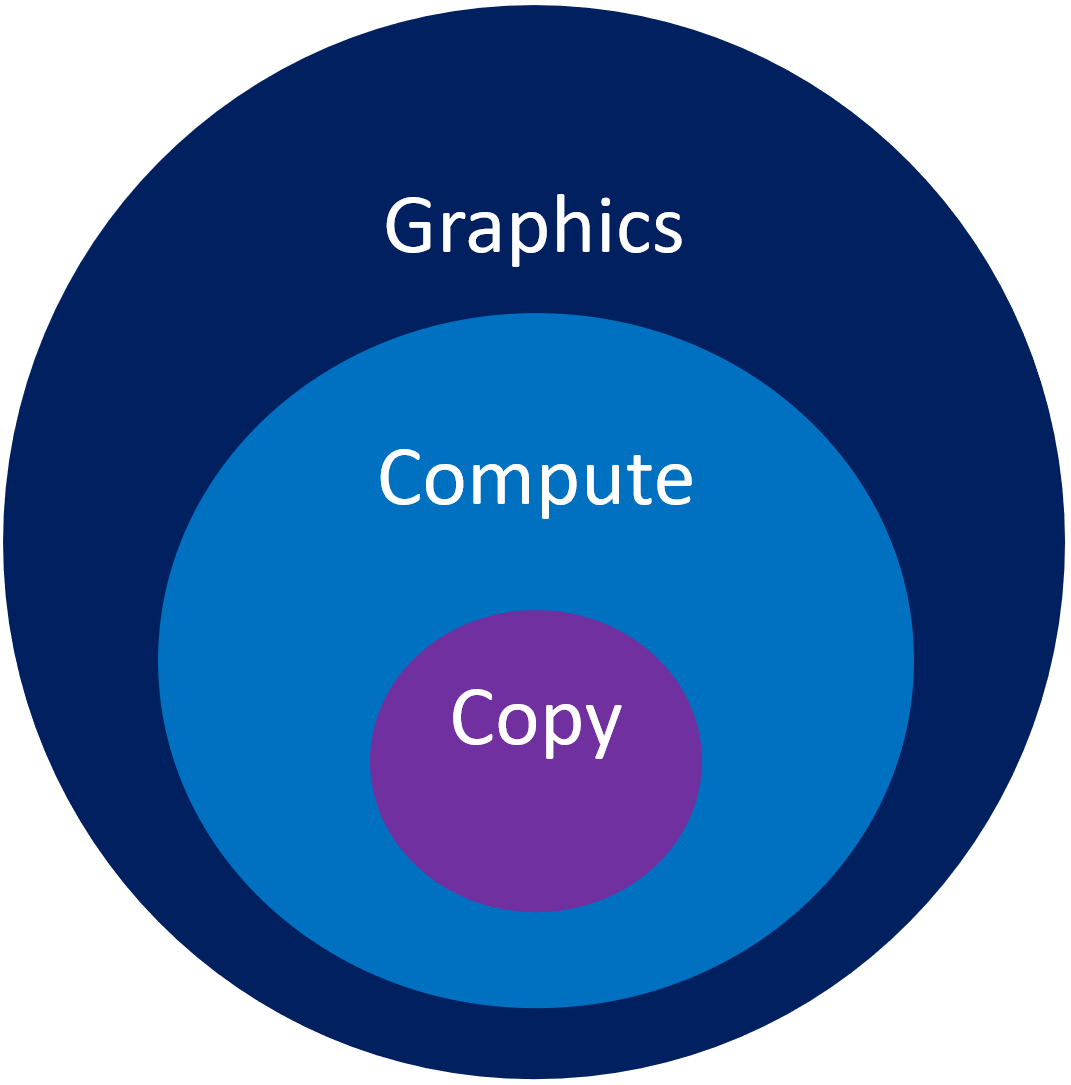
现代图形API都支持3种队列:Copy Queue、Compute Queue、Graphics Queue。Graphics Queue可以驱动Compute Queue,Compute Queue可以驱动Copy Queue。(下图)
Copy Queue通常用来拷贝数据,非常适合PCIe的数据传输(有硬件支持的优化),不会占用着色器资源。常用于纹理、数据在CPU和GPU之间传输,加速Mimap生成,填充常量缓冲区等等。开启异步数据拷贝和传输,和Graphic、Compute Engine并行地执行。
Compute Queue通常用来local到local(即GPU显存内部)的资源,也可以用于和Graphics Queue异步运行的计算任务。可以驱动Copy Engine。Compute Shader涉及了以下Pipeline State:
| Pipeline State | Description |
|---|---|
| Compute State | Compute functions, workgroup configuration |
| Sampler | Filter states, addressing modes, LOD state |
Graphics Queue可以执行任何任务,绘制通常是最大的工作负载。可以驱动Compute Engine和Copy Engine。
在硬件层面,GPU有3种引擎:复制引擎(Copy Engine)、计算引擎(Compute Engine)和3D引擎(3D Engine),它们也可以并行地执行,并且通过栅栏(Fence)、信号(Signal)或屏障(Barrier)来等待和同步。

DirectX12中的CPU线程、命令列表、命令队列、GPU引擎之间的运行机制示意图。
在录制阶段,就需要指明Queue的类型,相同的类型支持多个Queue,在同一个Queue内,任务是有序地执行,但不同的Queue之间,在硬件Engine内可能是打乱的:
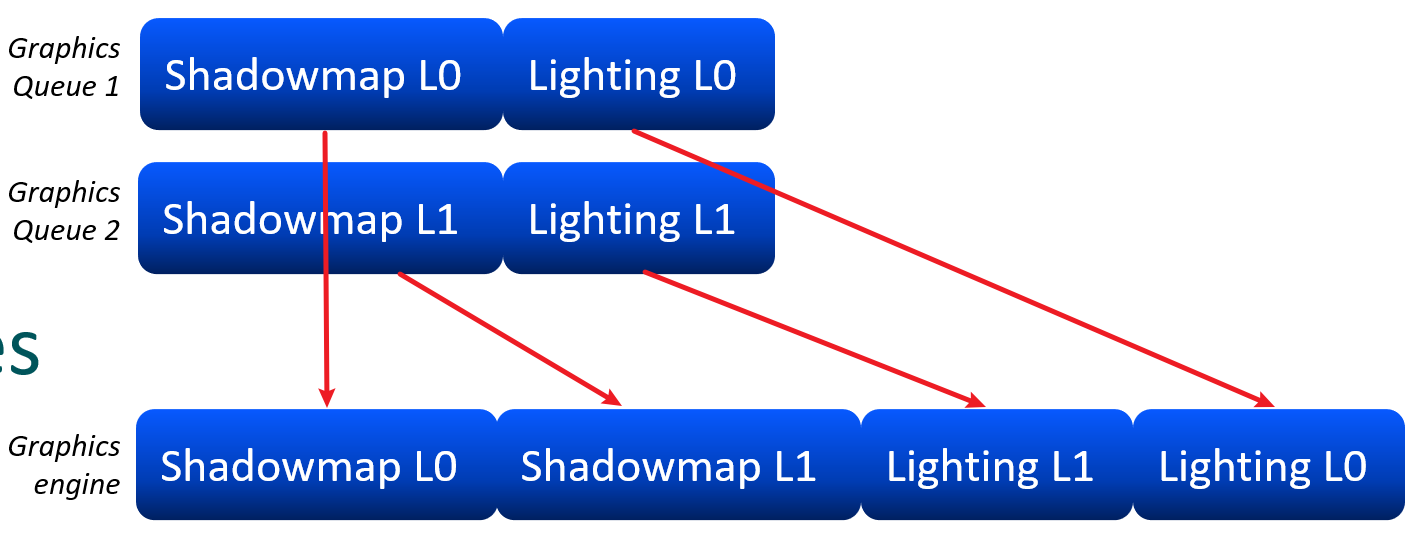
利用Async Quque的并行特性,可以提升额外的渲染效率。并行思路是将具有不同瓶颈的工作负载安排在一起,例如阴影图渲染通常受限于几何吞吐量,而Compute Shader通常受限于数据获取(可以使用LDS优化内存获取效率),极少受限于ALU。
但是,如果使用不当,Async Compute可能影响Graphics Queue的性能。例如,将Lighting和CS安排在一起就会引起同时竞争ALU的情况。需要时刻利用Profiler工具监控管线并行状态,揪出并行瓶颈并想方设法优化之。
对于渲染引擎,实现时最好构建基于作业的渲染器(如UE的TaskGraph和RDG),可有效处理屏障,也应该允许使用者手动指定哪些任务可以并行。作业不应该太小,需要保持每帧的Fence数量在个位数范围内,因为每个信号都会使前端(frontend)陷入停顿,并冲刷管道。
下图是渲染帧中各个阶段花费的时间的一个案例:

其中Lighting、Post Process和大多数阴影相关的工作都可以放到Compute Shader中。此外,为了防止帧的后处理等待同一帧的前面部分(裁剪、阴影、光照等),可以放到Compute Queue,和下一帧的前面阶段并行:
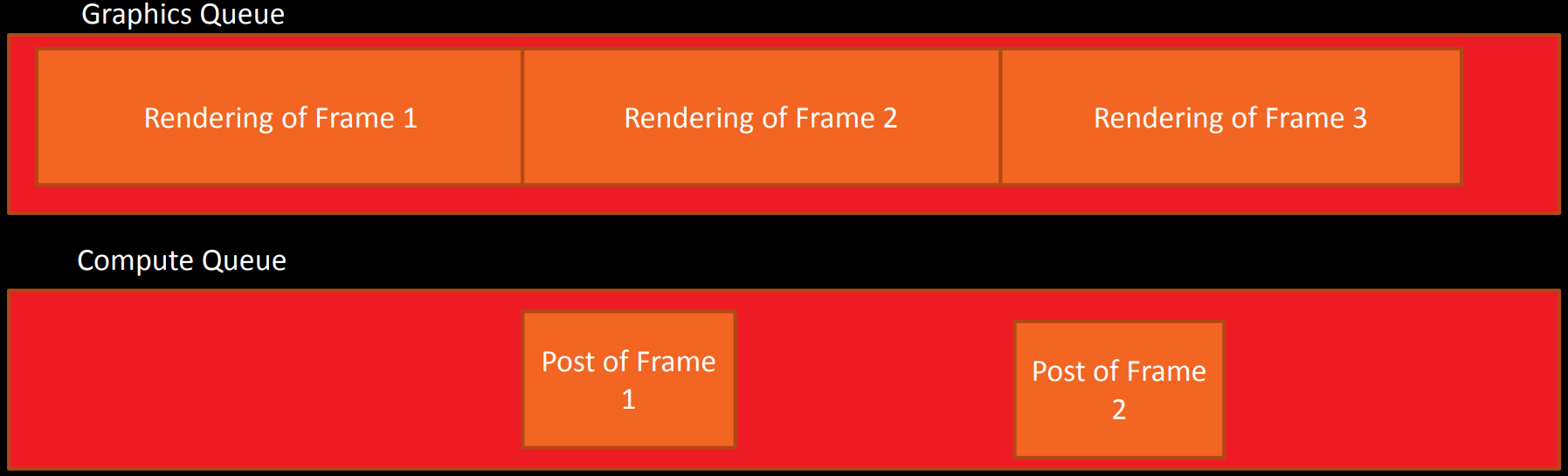
利用现代图形API,渲染引擎可以方便地实现帧和帧之间的重叠(Overlap)。基本思路是:
- 设置可排队帧的数量为3来代替2。
- 从图形队列创建一个单独的呈现队列。
- 在渲染结束的时候,不是立即呈现,而是发布一个计算任务,并向渲染器发送帧的post任务。
- 当帧的post任务完成后,发送一个信号给特殊的图形队列做实际的呈现。(下图)
但这种方式存在一些缺点:
- 实现复杂,会引入各种同步和等待。
- 帧会被拆分成多次进行提交。(尽量将命令缓冲区保持在1-2ms范围内)
- 最终会有1/ 2到1/3的额外延迟。
引入Async Compute之后,普遍可以提升15%左右的性能:
对于Workgroup的优化,从PS迁移到CS的传统建议如下:
-
迁移PS到Workgroup尺寸为(8, 8, 1)的CS。
- 1 wave/V$以获得空间局部性(但可能比PS更糟糕)。
- AMD的GCN在移动到下一个CU之前以逐CU(1 V$ / CU)运行一个Workgroup。
-
线程(lane,threa)到8x8的映射是线性块(linear block)。
- 实际可能是(4x1)模式的纹理获取方块(quad)。
- 实际可能引发V$存储体冲突(bank conflict)。
- GCN以4个线程为一组进行采样。
以上是不好的配置,良好的Workgroup配置案例如下:
-
(512, 1, 1)的Workgroup被配置成(32, 16, 1)。
- 8 wave / V$获得局部性。
- 每个wave是8x8的Tile。(每个GPU厂商和GPU系列存在差异,这里指AMD的GCN架构)
- 8个wave被组织成4x2个8x8Tile的集合。(下图)
![]()
-
线程到8x8的tile映射是重组的块线性(swizzled block linear)。
- 良好的2x2模式的纹理获取方块。(上图)
-
专用的着色器优化。
- 高度依赖2D空间的局部性来获得缓存命中。
- 在wave执行时更少的依赖。
-
使用本地内存的一种常见技术是将输入分割成块,然后,当工作组对每个块进行处理时,可以将其移动到本地内存中。
![]()

下面是NV和AMD对PS和CS的性能描述和建议:
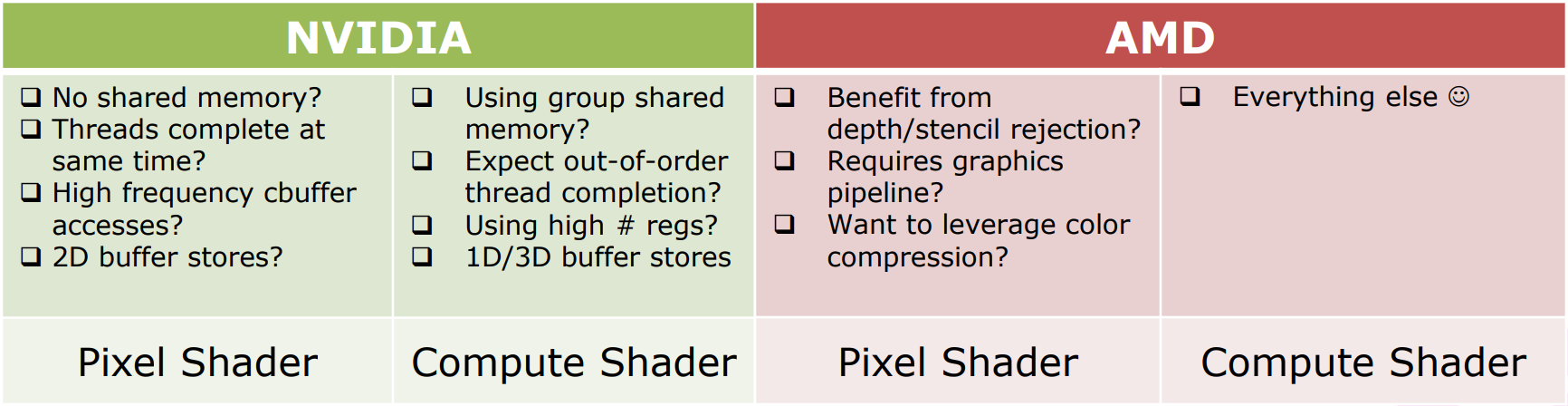
NV使用PS的建议:不需要共享内存、线程在相同时间完成、高频率的CB访问、2D缓冲存储;NV使用CS的建议:需要线程组共享内存、期望线程无序完成、高频率使用寄存器、1D或3D缓冲存储。
AMD使用PS的建议:从DS剔除中获益、需要图形渲染、需要利用颜色压缩;AMD使用CS的建议:PS建议之外的所有情况。
利用Async Compute和多类型Queue,可以将传统游戏引擎的顺序执行流程改造成并行的流程。


上:传统游戏引擎的线性渲染流程;下:利用GPU的多引擎并行地执行。
这样的并行方式,可以减少单帧的渲染时间,降低延时,从而提升Draw Call和渲染效果。
不过,在并行实现时,需要格外注意各个工作的瓶颈,常见的瓶颈有:数据传输、着色器吞吐量、几何数据处理,它们涉及的任务具体如下:

为了更好地并行效率,每个Engine的重叠部分尽量不要安排相同瓶颈的工作任务。
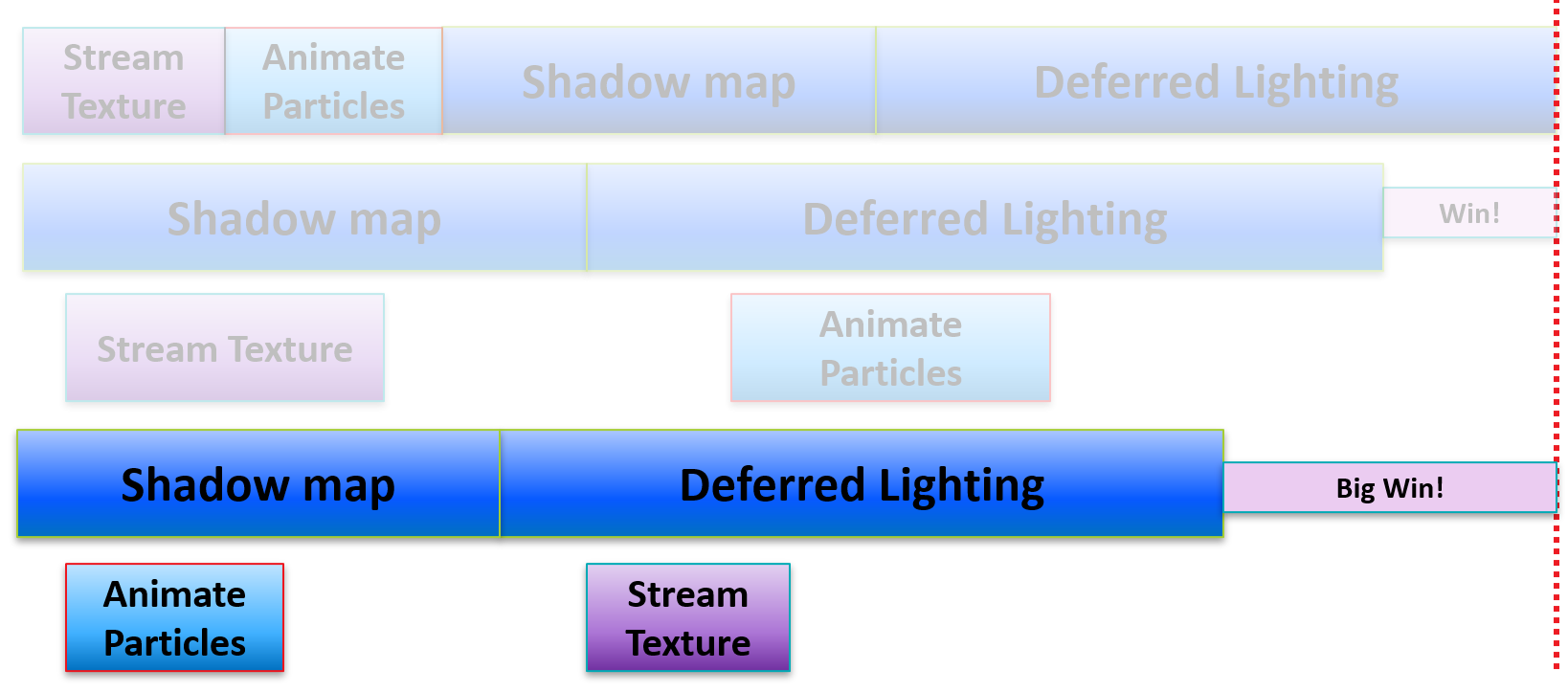
上:线性执行示意图;中:Shadow Map和Stream Texture、Deferred Lighting和Animate Particle瓶颈冲突,只能获得少量并行效率;下:避开瓶颈相同的任务,赢得较多的并行效率。
下图左边是良好的并行配对,右边则是不良的并行配对:

不受限制的调度为糟糕的技术配对创造了机会,好处在于实现简单,但坏处在于帧与帧具有不确定性和缺少配对控制:
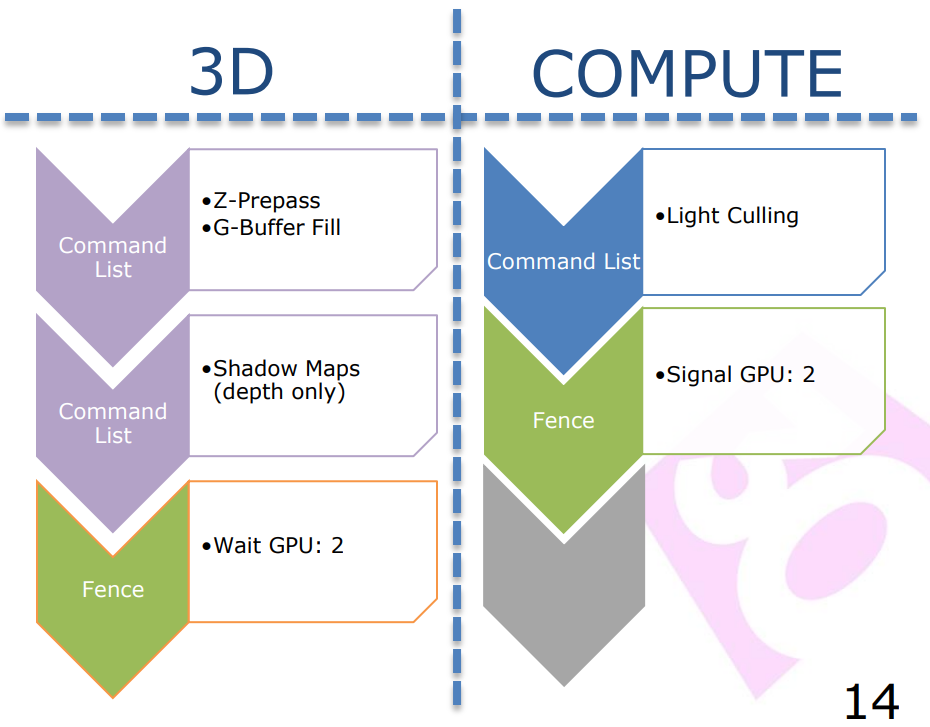
更佳的做法是,通过巧妙地使用Fence来显式地调度异步计算任务。好处是帧和帧之间的确定性,应用程序可以完全控制技术配对!坏处是实现稍微复杂一些:
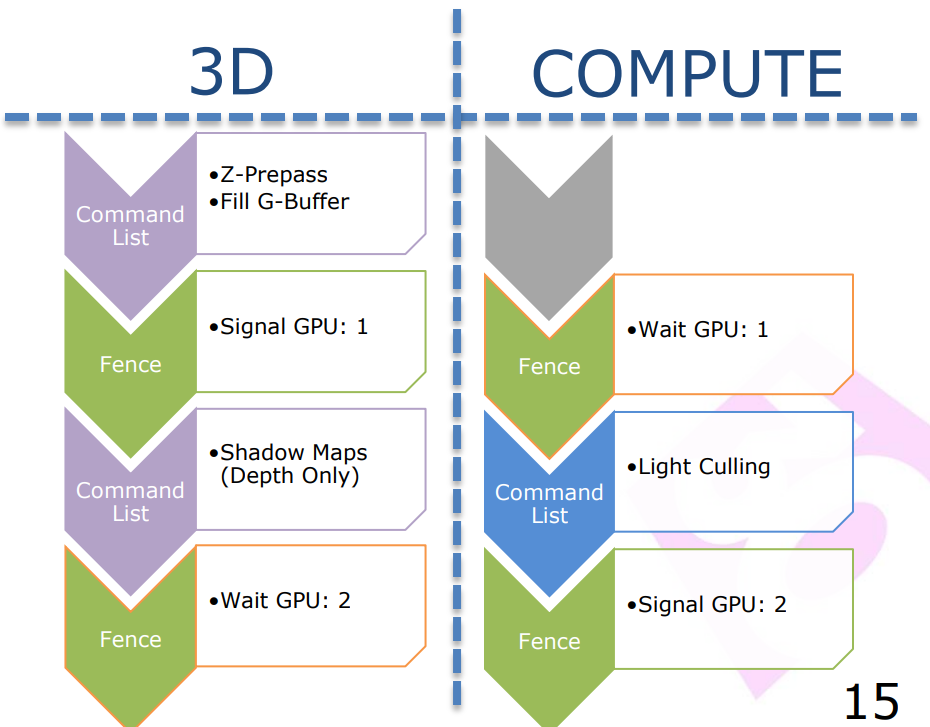
Copy Queue的特性、描述和使用建议如下:
-
专门设计用于通过PCIE进行复制的专用硬件。
-
独立于其他队列进行操作,让图形和计算队列可以自由地进行图形处理。
-
如果从系统内存复制到local(显存),使用复制队列。例如,Texture Streaming。
-
使用复制队列在PCIE上传输资源。使用多GPU进行异步传输是必不可少的。
-
避免在复制队列完成时自旋(spinning)。需提前做好传输计划。
-
注意复制深度+模板资源,复制仅深度可能触发慢路径(slow path)。(仅NV适应)
-
多GPU下,支持p2p传输。
-
确保GPU上有足够的工作来确保不会在复制队列上等待。
- 尽可能早地开始复制,理想情况下在本地内存中需要复制之前,先复制几帧。
-
显存内部的local到local的拷贝,分两种情况:
- 情况1:如果立即需要传输结果,使用Graphic Queue或Compute Queue。
- 情况2:如果不立即需要传输结果,使用Copy Queue。比如上传Buffer(constant、vertex、index buffer等),以及显存碎片整理(defragging)。
- 使用复制队列移动来执行显存碎片整理,比如占用每帧1%的带宽。让图形队列继续呈现,在Copy Queue不忙于Streaming的帧上执行。
![]()
Async Compute建议如下:
- 尽量少同步,理想情况下每帧只同步1-2次。每个同步点都有很大的开销。
- 将大型连续工作负载移到异步队列中。更多的机会重叠管道的drains / fills阶段。
- 更激进的做法:与下一帧重叠。
- 通常情况下,帧以光栅繁重的工作开始,以计算繁重的后处理结束。
- 可能增加延时!
13.4.6 其它管线技术
利用现代图形API支持光线追踪的特性,可以实现混合光线追踪阴影(Hybrid Raytraced Shadows):
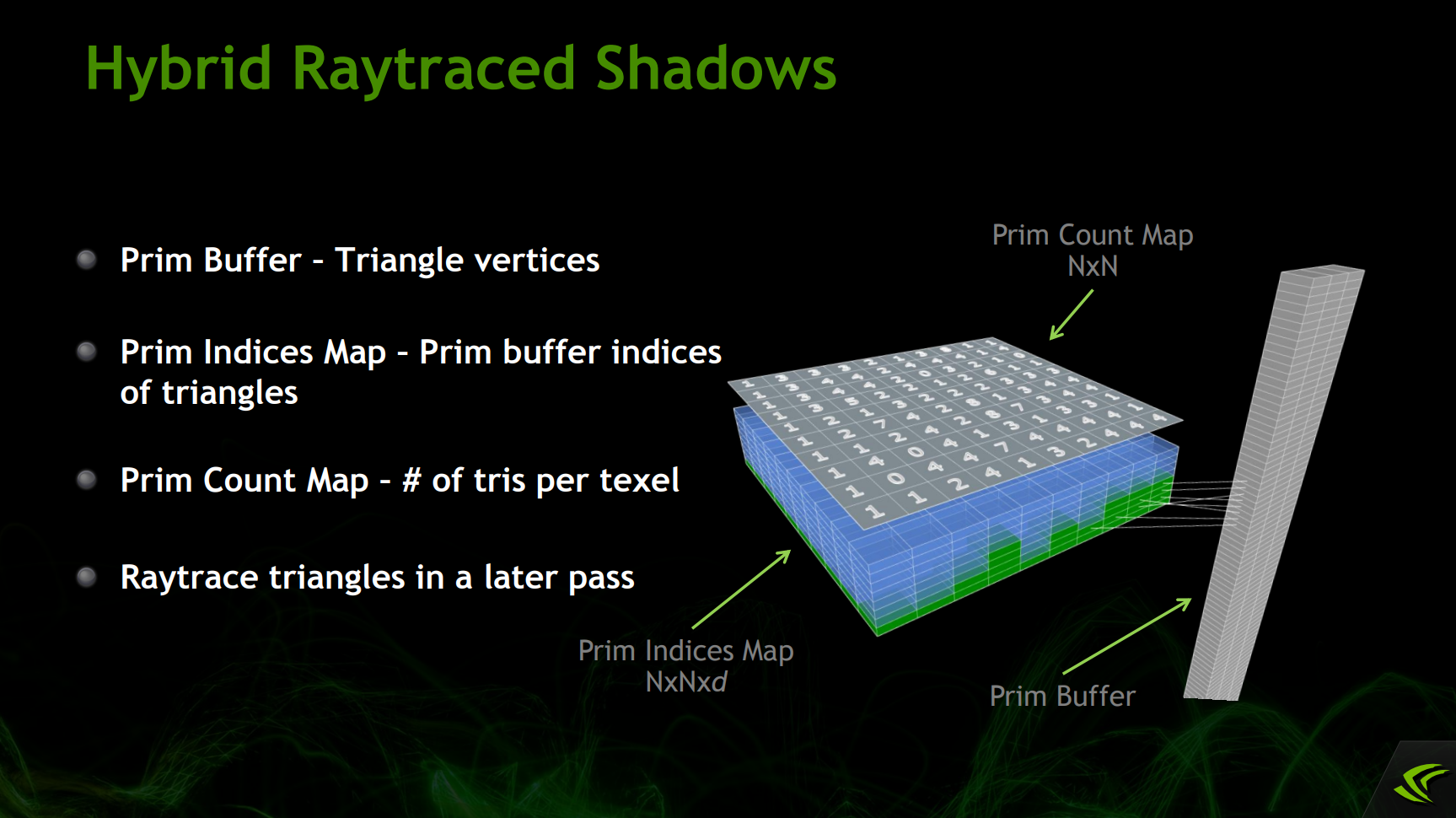
从而实现高质量的阴影效果:
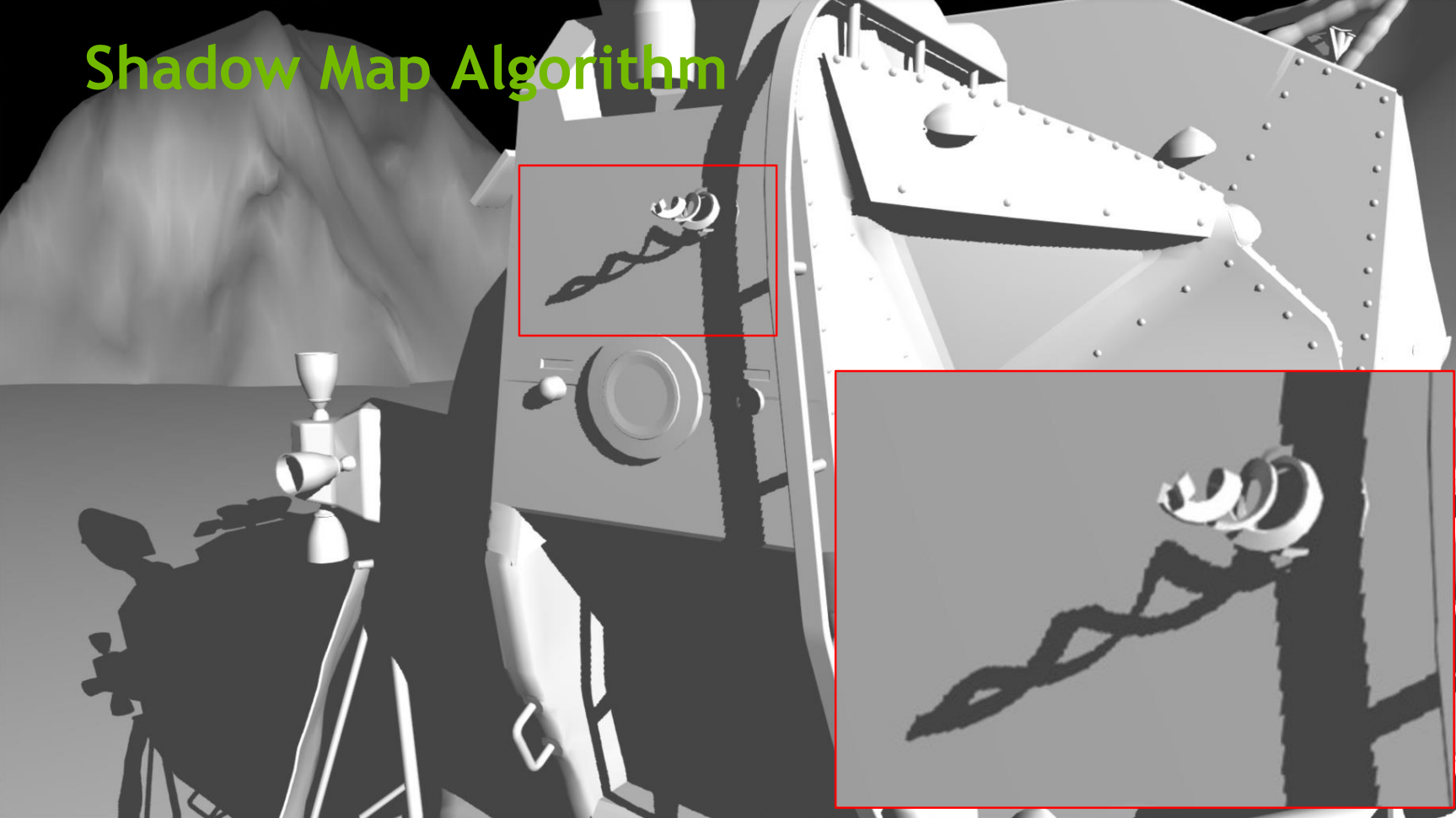

上:传统阴影图效果;下:混合光线追踪阴影效果。
值得一提的是,GPU管线的剔除会导致利用率降低,引起很多小的空闲区域:
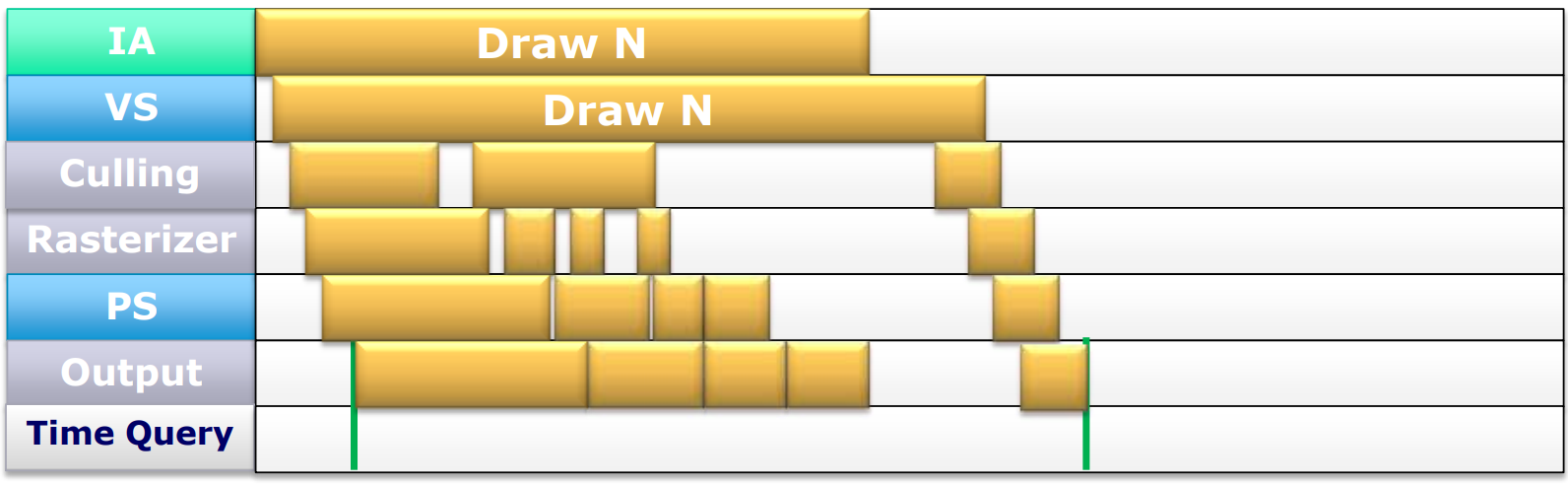
GPU利用率不足是导致延时的常见原因。
现代GPU为了降低带宽,在内部各部件之间广泛地使用了压缩格式,在采样时,会从显存中读取压缩的数据,然后在Shader Core中解压。(下图)
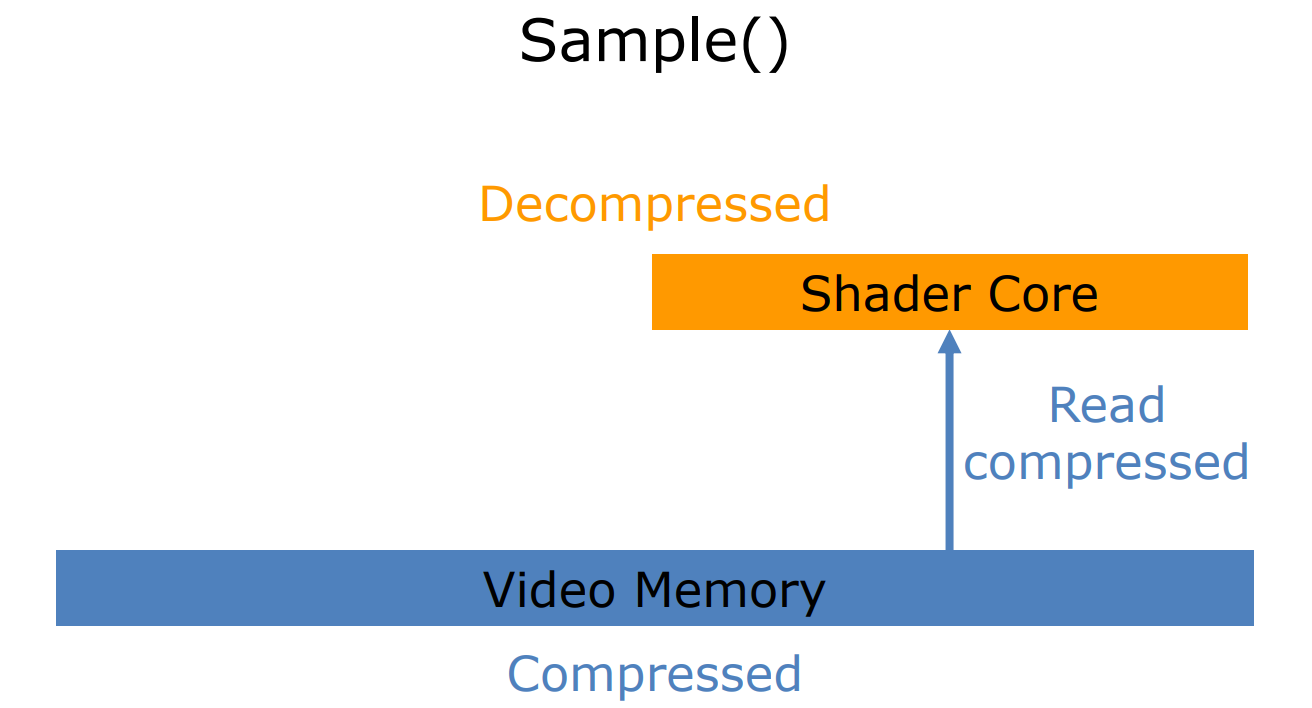
当需要导出(写入)数据时,会先压缩成颜色块,再写入压缩后的数据到显存。(下图)

GPU厂商工具通常可以观察纹理的格式和是否开启压缩:
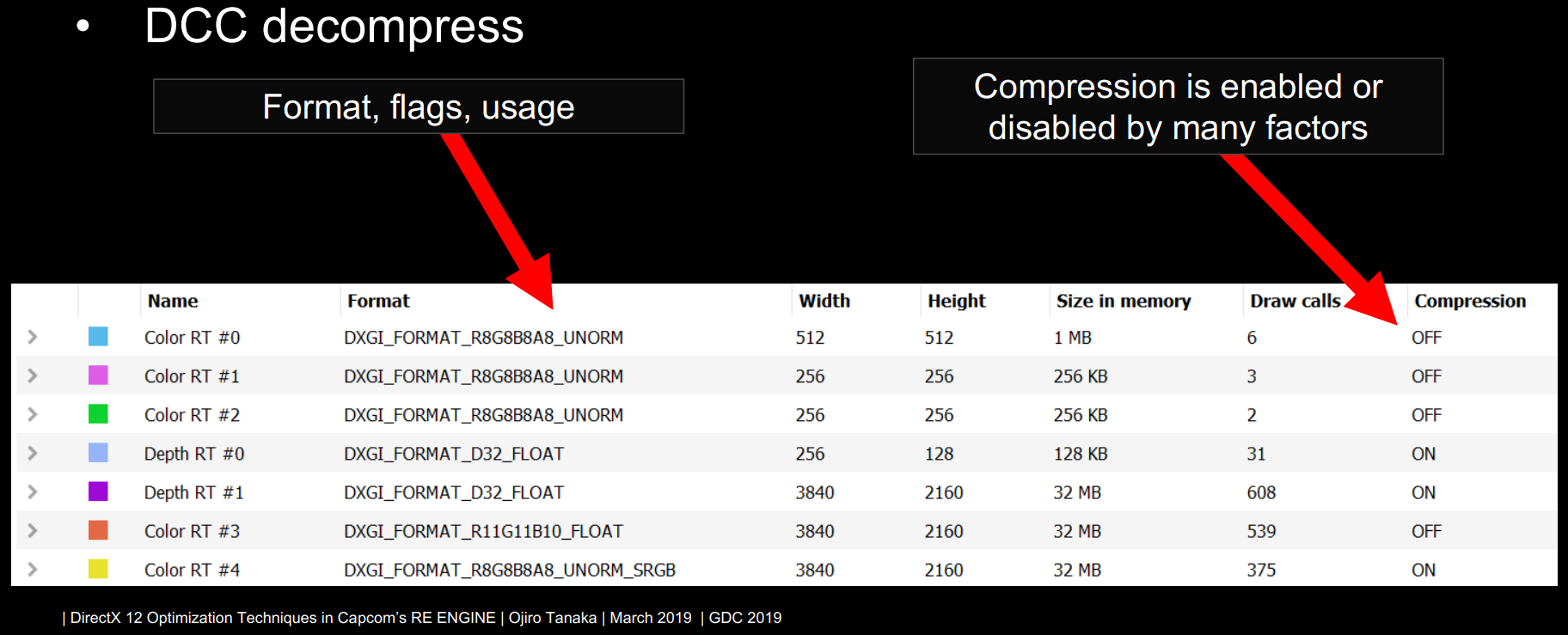
对于GPU内部的这种数据压缩,需要注意以下几点:
- 使用独占队列所有权。在共享所有权的情况下,驱动程序必须假定它使用在不能读写压缩的硬件块上。
- 显式地指明图像格式。UNKNOWN / MUTABLE会阻碍压缩,可以工作在VK_KHR_image_format_list。
- 只使用所需的图像用法。否则,资源最终可能会低于最佳压缩级别。
- 清理渲染或深度目标。会重置元数据,防止额外的带宽传输。
13.4.6.1 Wave
Wave在DirectX 12和Vulkan涉及的概念如下:
| DirectX 12 | Vulkan | Desc |
|---|---|---|
| Lane | Invocation | 在wave内执行的一个着色器调用(线程)。 |
| Wave | Subgroup | shader调用的集合,每个厂商调用的数量不同。 |

Lane和Wave结构示意图。
Wave[DX]执行模式:所有Lane同时执行,并且锁步(lock-step);Subgroup[VK]执行模型:Subgroup操作包含隐式屏障。
Wave机制的优势在于:
- 减少了barrier或interlock指令的使用。
- 更简单的着色器代码。
- 更易维护,容易编码。
- 对DFC一致性的更多控制。
- 有助于提高控制流(flow)一致性。
- 有助于提高内存访问一致性。
着色器标量化可以提高线程并行工作的速度,可用于照明,基于GPU的遮挡剔除,SSR等。
Wave指令集通过移除不必要的同步来提高标量运算的效率,支持DirectX 11和DirectX 12。它和Threadgroup、Dispatch处理不同的层级,所用的内存也不同(下图),因此需要使用正确层级的原子进行同步。

当使用Wave操作对纹理进行访问时,如果线程索引在一个计算着色器被组织在一个ROW_MAJOR模式,将匹配一个线性纹理,这种模式不能很好地保持邻域性,无法很多地命中缓存:
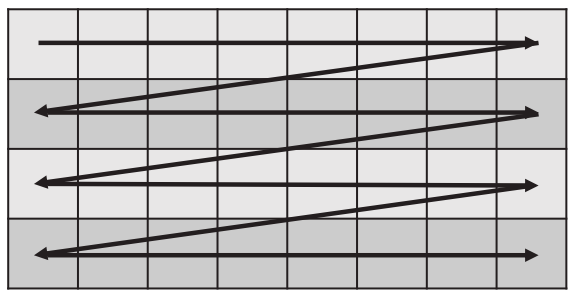
可以用标准重组(standard swizzle)来优化纹理访问,这种纹理布局的模式使得相邻像素被紧密地存储在内存中,提升缓存命中率:
下面是性能分析工具RGP抓取的以Wave为单位执行的VS、PS、CS图例:
支持Wave的GPU而言,数据是波形化的uniform(wave-uniform),但着色器编译器并不知道。一个典型的应用是,遍历光源,告诉编译器光源索引是wave-uniform,将数据从VGPR放入SGPR。
Capcom的RE引擎利用Wave操作,提升了约4.3%的性能:
关于Wave的更多技术细节请参阅:Wave Programming in D3D12 and Vulkan。
13.4.6.2 ExecuteIndirect
ExecuteIndirect机制允许组合若干个Draw、DrawIndexed、Dispatch到同一个调用里,更像是MultiExecuteIndirect()。在Draws/Dispatches之间,可以改变以下数据:
- 顶点缓冲、索引缓冲、图元数量等。
- 根签名、根常量。
- 根SRV和UAV。
下面是DX 12的ExecuteIndirect接口:

利用此接口,可以实现:
- 在一个ExecuteIndirect中绘制数千个不同的对象。为数百个对象节省了大量的CPU时间。
- 间接计算工作。为了获得理想的性能,可以使用NULL计数器缓冲参数。
- 图形绘制调用。为了获得理想的性能,保持计数器缓冲计数和ArgMaxCount调用差不多。
以下是DX11和DX12绘制树的对比:

此外,可以实现基于GPU的遮挡剔除。
13.4.6.3 Predication
Predication是DX12的特性,它完全与查询解耦,对缓冲区中某个位置的值的预测,GPU在执行SetPredication时读取buffer值。

支持Predication的API有:
- DrawInstanced
- DrawIndexedInstanced
- Dispatch
- CopyTextureRegion
- CopyBufferRegion
- CopyResource
- CopyTiles
- ResolveSubresource
- ClearDepthStencilView
- ClearRenderTargetView
- ClearUnorderedAccessViewUint
- ClearUnorderedAccessViewFloat
- ExecuteIndirect
使用案例就是基于异步CPU的遮挡剔除:一个CPU线程录制Command List,另外一个CPU线程执行软件(非硬件)遮挡查询并填充到Predication缓冲区。(下图)

13.4.6.4 UAV Overlap
首先要理解现代图形API如果没有依赖,可以并行地执行。
而UAV Barrier具体不明确的依赖,不清楚是读还是写,如果每个批处理写到一个单独的位置,它可以并行执行,前提是可以避免WAW(write-after-write)错误。
可以为每个compute shader的调度控制UAV同步,禁用UAV的同步使并行执行成为可能,在DirectX 11中,可以使用AGS和NVAPI引入等效函数。
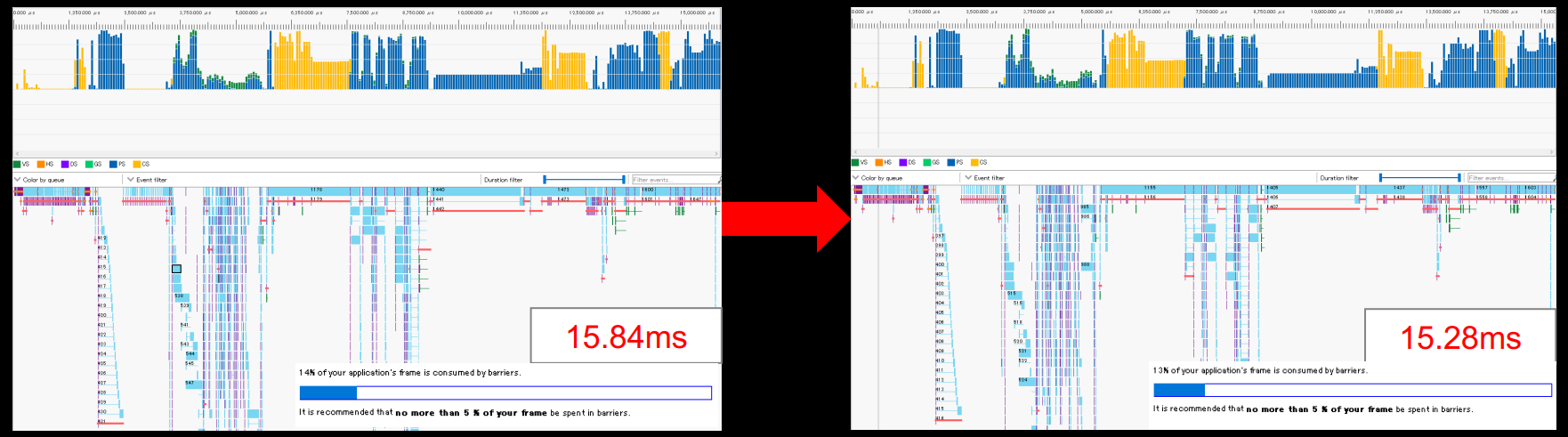
启用UAV Overlap机制,Capcom的RE引擎总体性能有些许的改善,大约提升了3.5%:
13.4.6.5 Multi GPU
现代图形API可显式、精确地控制多GPU,协同多GPU并行渲染,从而提升效率。主要体现在:
-
完全控制每个GPU上的内容。
-
在指定图形处理器上创建资源。
-
在特定的gpu上执行命令列表。
-
在GPU之间显式复制资源。完美的DirectX 12复制队列用例。
-
在GPU之间分配工作负载。不限于AFR(交叉帧渲染)。
![]()
多GPU协同工作示意图。

除了以上涉及的技术或特性,现代图形API还支持保守光栅化(Conservative Raster)、类型UAV加载(Typed UAV Loads)、光栅化有序视图(Rasterizer-Ordered Views )、模板引用输出(Stencil Reference Output)、UAV插槽、Sparse Resource等等特性。
13.5 综合应用
本章将阐述以下现代图形API的常见的综合性应用。
13.5.1 Rendering Hardware Interface
现代图形API有3种,包含Vulkan、DirectX、Metal,如果是渲染引擎,为了跑着多平台上,必然需要一个中间抽象层,来封装各个图形API的差异,以便在更上面的层提供统一的调用方式,提升开发效率,并且获得可扩展性和优化的可能性。
UE称这个封装层为RHI(Rendering Hardware Interface,渲染硬件接口),更具体地说,UE提供FDynamicRHI和其子类来封装各个平台的差异。下面是FDynamicRHI的继承结构图:
其中FDynamicRHI提供了统一的调用接口,具体的子类负责实现对应图形API平台的调用。
更多详情可参阅:剖析虚幻渲染体系(10)- RHI。
13.5.2 Multithreaded Rendering
摩尔定律的放缓,导致CPU厂商朝着多核CPU发展,作为图形API的制定者们,也在朝着充分利用多核CPU的方向发展。而现代图形API的重要改变点就是可以实现多核CPU的渲染。
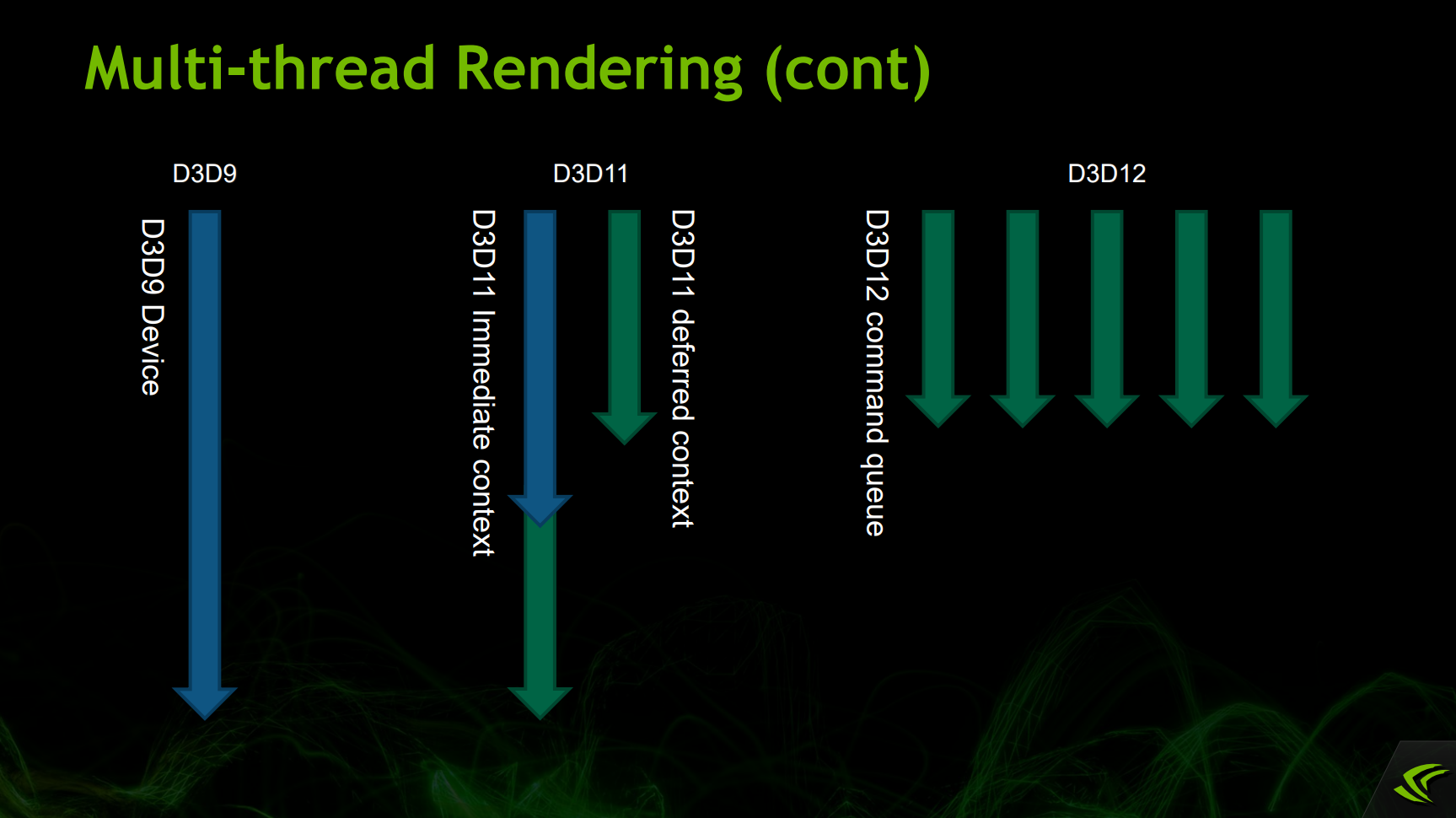
DX9、DX11、DX12的多线程模型对比示意图。

DX11、DX12的GPU执行模型对比示意图。
为了利用现代图形API实现多线程渲染,需要考虑CPU多线程和GPU多线程。CPU侧多线程需要考量:
- 多线程化的Command Buffer构建。
- 向队列提交不是线程安全的。
- 将帧拆分为大的渲染作业。
- 从主线程中分离着色器编译。
- 合批Command Buffer的提交。
- 在提交和呈现期间,不要阻塞线程。
- 可以并行的任务包括:
- Command List生成。需要用不同的command buffer。
- Descriptor Set创建。需要用不同的descriptor pool。
- Bundle生成。
- PSO创建。
- 资源创建。
- 动态数据生成。
GPU侧多线程需要考量硬件计算单元、核心、内存尺寸和带宽、ALU等性能,还要考虑CU、SIMD、Wave、线程数等指标。下表是Radeon Fury和Radeon Fury X的硬件参数:
| Radeon Fury X | Radeon Fury | |
|---|---|---|
| Compute Units(CU) | 64 | 56 |
| Core Frequency | 1050 Mhz | 1000 Mhz |
| Memory Size | 4 GB | 4 GB |
| Memory BW | 512 GB/s | 512 GB/s |
| ALU | 8.6 TFlops | 7.17 TFlops |
从上表可以得出Radeon Fury X的峰值线程数量是:
Radeon Fury X是多年前(2015年)的GPU产品,现在的GPU可以达到百万级别的线程数量。
为了减少卡顿和空闲,CPU端需要多个前端(front-end),使用并发的多线程(超线程),交错两个共享执行资源的指令流。下面是Bloom和DOF并行运行的图例:
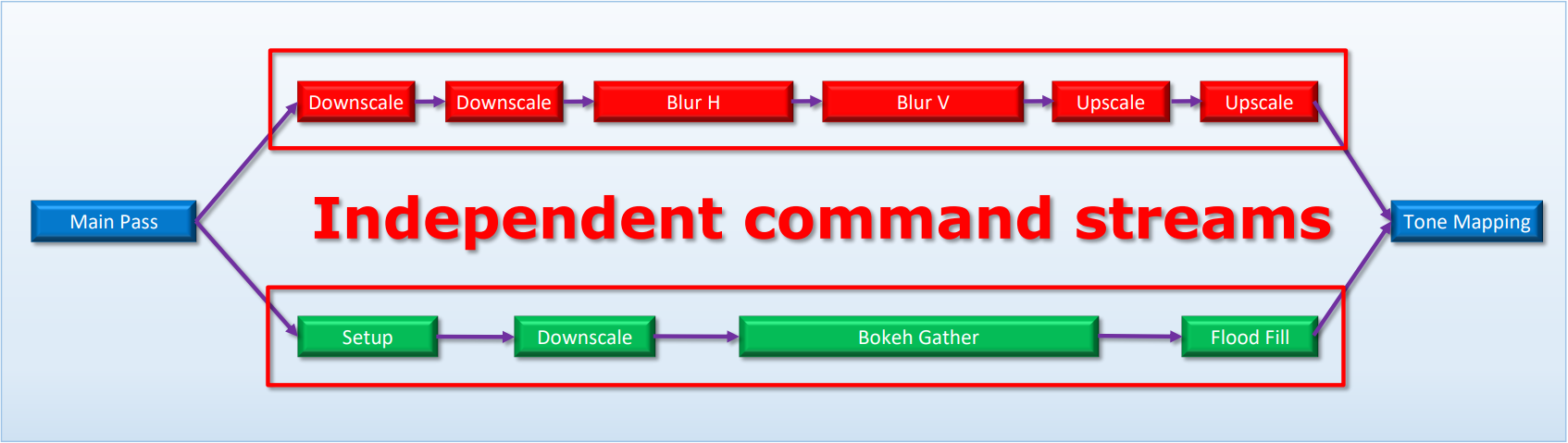
交错两个共享执行资源的指令流示例:Bloom和DOF。
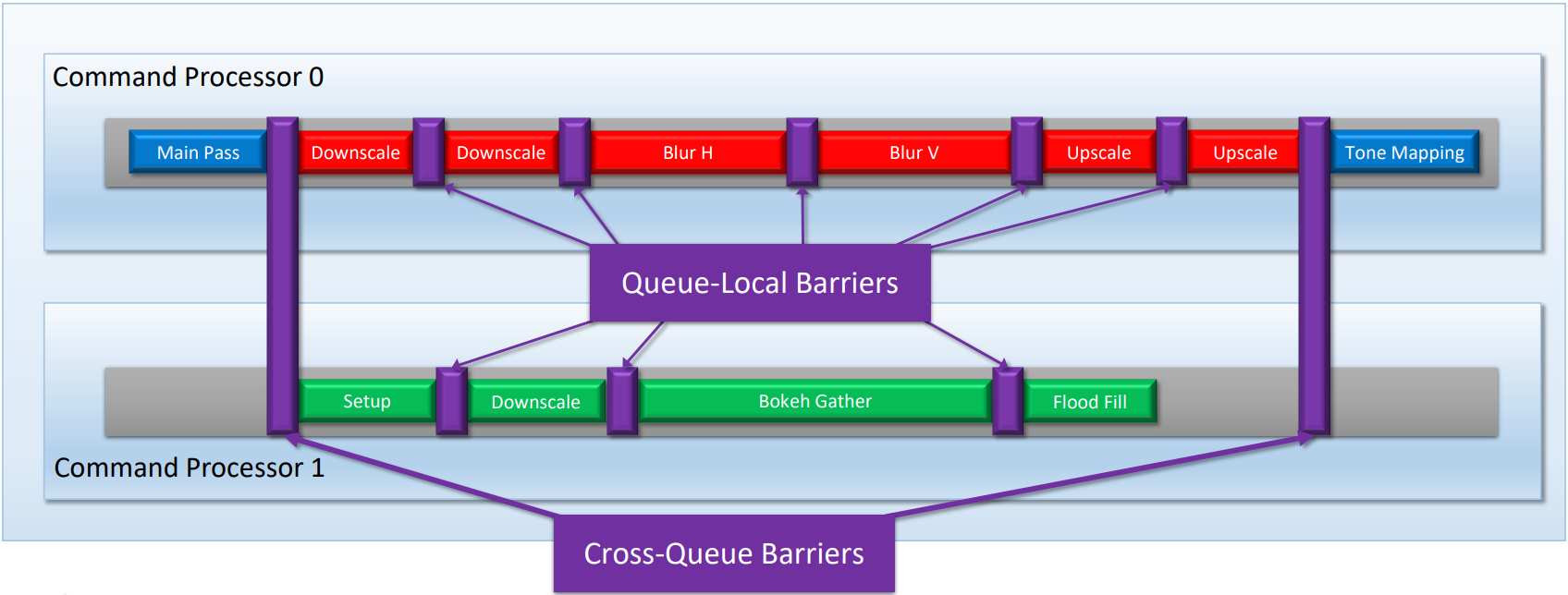
使用队列内Barrier和跨队列Barrier进行同步。
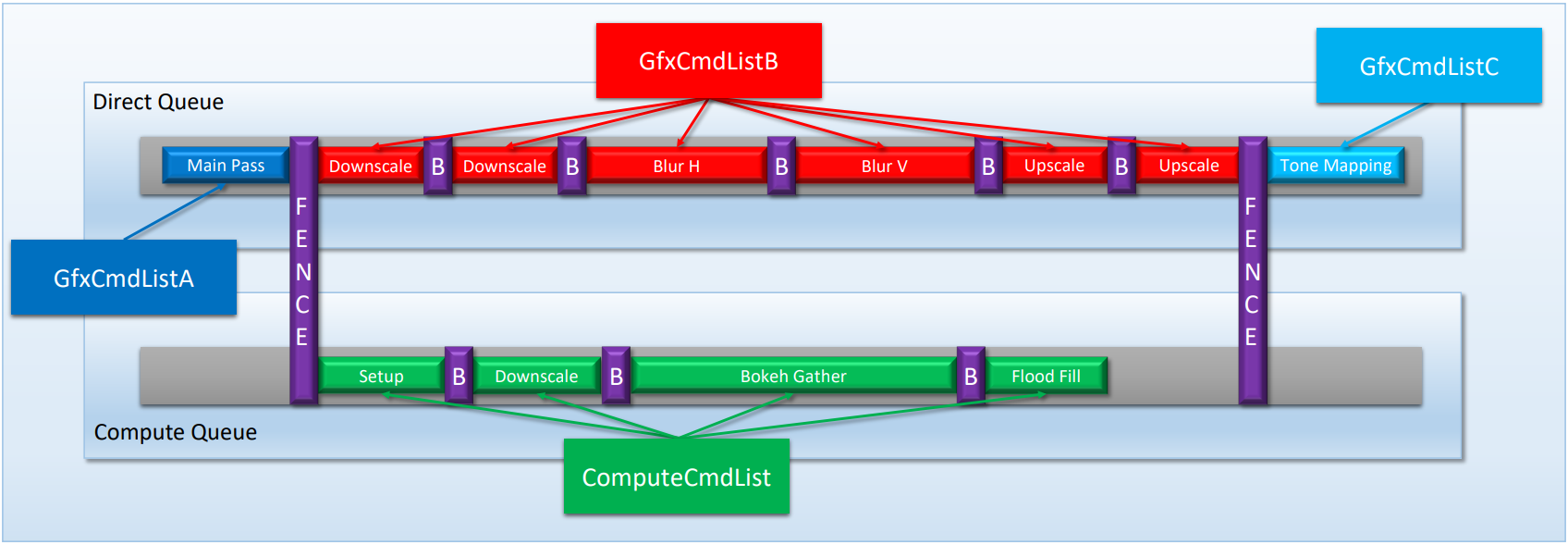
使用DirectX实现交错指令流的图例。
以下是使用DX12实现最简单的多线程渲染的伪代码:
// 主线程渲染函数。
void OnRender_MainThread()
{
// 通知每一个子渲染线程开始渲染
for workerId in workerIdList
{
SetEvent(BeginRendering_Events[workerId]);
}
// Pre Command List 用于渲染准备工作
// 重置 Pre Command List
pPreCommandList->Reset(...);
// 设置后台缓冲区从呈现状态到渲染目标的屏障
pPreCommandList->ResourceBarrier(1, (..., D3D12_RESOURCE_STATE_PRESENT, D3D12_RESOURCE_STATE_RENDER_TARGET));
// 清除后台缓冲区颜色
pPreCommandList->ClearRenderTargetView(...);
// 清除后台缓冲区深度/模板
pPreCommandList->ClearDepthStencilView(...);
// 其它 Pre Command List 上的操作
// ...
// 关闭 Pre Command List
pPreCommandList->Close();
// Post Command List 用于渲染后收尾工作
// 设置后台缓冲区从呈现状态到渲染目标的屏障
pPostCommandList->ResourceBarrier(1, (..., D3D12_RESOURCE_STATE_RENDER_TARGET, D3D12_RESOURCE_STATE_PRESENT));
// 其它 Post Command List 上的操作
// ...
// 关闭 Post Command List
pPostCommandList->Close();
// 等待所有工作线程完成任务 1
WaitForMultipleObjects(Task1_Events);
// 提交已完成渲染命令(Pre Command List 和所有工作线程上的用于任务 1 的 Command List)
pCommandQueue->ExecuteCommandLists(..., pPreCommandList + pCommandListsForTask1);
// 等待所有工作线程完成任务 2
WaitForMultipleObjects(Task2_Events);
// 提交已完成渲染命令(所有工作线程上的用于任务 2 的 Command List)
pCommandQueue->ExecuteCommandLists(..., pCommandListsForTask2);
// ...
// 等待所有工作线程完成任务 N
WaitForMultipleObjects(TaskN_Events);
// 提交已完成渲染命令(所有工作线程上的用于任务 N 的 Command List)
pCommandQueue->ExecuteCommandLists(..., pCommandListsForTaskN);
// 提交剩下的 Command List(pPostCommandList)
pCommandQueue->ExecuteCommandLists(..., pPostCommandList);
// 使用 SwapChain 呈现
pSwapChain->Present(...);
}
void OnRender_WorkerThread(workerId)
{
// 每一次循环代表子线程一帧渲染工作
while (running)
{
// 等待主线程开始一帧渲染事件通知
WaitForSingleObject(BeginRendering_Events[workerId]);
// 渲染子任务 1
{
pCommandList1->SetGraphicsRootSignature(...);
pCommandList1->IASetVertexBuffers(...);
pCommandList1->IASetIndexBuffer(...);
// ...
pCommandList1->DrawIndexedInstanced(...);
pCommandList1->Close();
// 通知主线程当前工作线程上的渲染子任务 1 完成
SetEvent(Task1_Events[workerId]);
}
// 渲染子任务 2
{
pCommandList2->SetGraphicsRootSignature(...);
pCommandList2->IASetVertexBuffers(...);
pCommandList2->IASetIndexBuffer(...);
// ...
pCommandList2->DrawIndexedInstanced(...);
pCommandList2->Close();
// 通知主线程当前工作线程上的渲染子任务 2 完成
SetEvent(Task2_Events[workerId]);
}
// 更多渲染子任务
// ...
// 渲染子任务 N
{
pCommandListN->SetGraphicsRootSignature(...);
pCommandListN->IASetVertexBuffers(...);
pCommandListN->IASetIndexBuffer(...);
// ...
pCommandListN->DrawIndexedInstanced(...);
pCommandListN->Close();
// 通知主线程当前工作线程上的渲染子任务 N 完成
SetEvent(TaskN_Events[workerId]);
}
}
}
以上代码成功地把任务分配给了子线程去处理,而主线程只关注如准备以及渲染后处理这样的工作。
子线程只需要适时通知主线程自己的工作情况,使用多个Command List可以无须打断地将一帧的渲染命令处理完成。同时,主线程也可以专心处理自己的工作,在合适的情况下,等待子线程完成阶段性工作,将子线程中相关的Command List使用Command Queue提交给 GPU。
当然只要能确保渲染顺序正确,子线程也可以通过 Command Queue 提交Command List上的命令。这里为了便于说明,把Command Queue提交Command List的操作,放在了主线程上。
在实现引擎的多线程渲染时,确保引擎能够覆盖所有的核心,以充分所有核心的运算性能,提升并行效率。配合Task Graph的多线程系统更好,一个线程提交所有命令队列,其它多个工作线程并行地构建命令队列。
另外,在现代3D游戏中,大量地使用了后期处理,可以将后期处理这样的任务放在主线程中,或者放在一个或多个子线程中。
任务良好调度的多线程渲染案例1。
任务良好调度的多线程渲染案例2。
下图是D3D11和D3D12的多线程性能对比图:
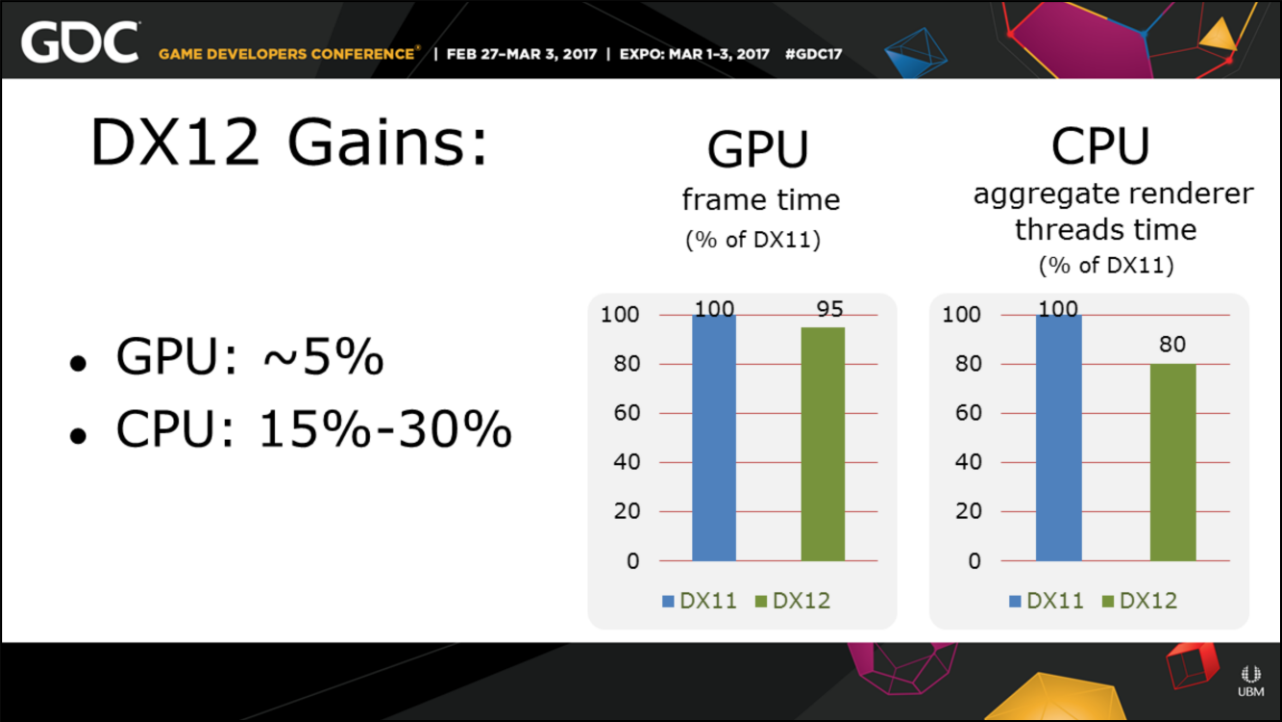
由此可知,D3D12的多线程效率更高,相比D3D11,整帧的时间减少了约31%,GPU时间减少了约50%。
在本月初(2021年12月)Epic Games召开的UOD 2021大会上,就职于腾讯光子的Leon Wei讲解了通过改造多线程渲染系统来并行化处理和提交OpenGL的API。
他的思路是先总结出目前UE的多线程渲染体系的总体机制:
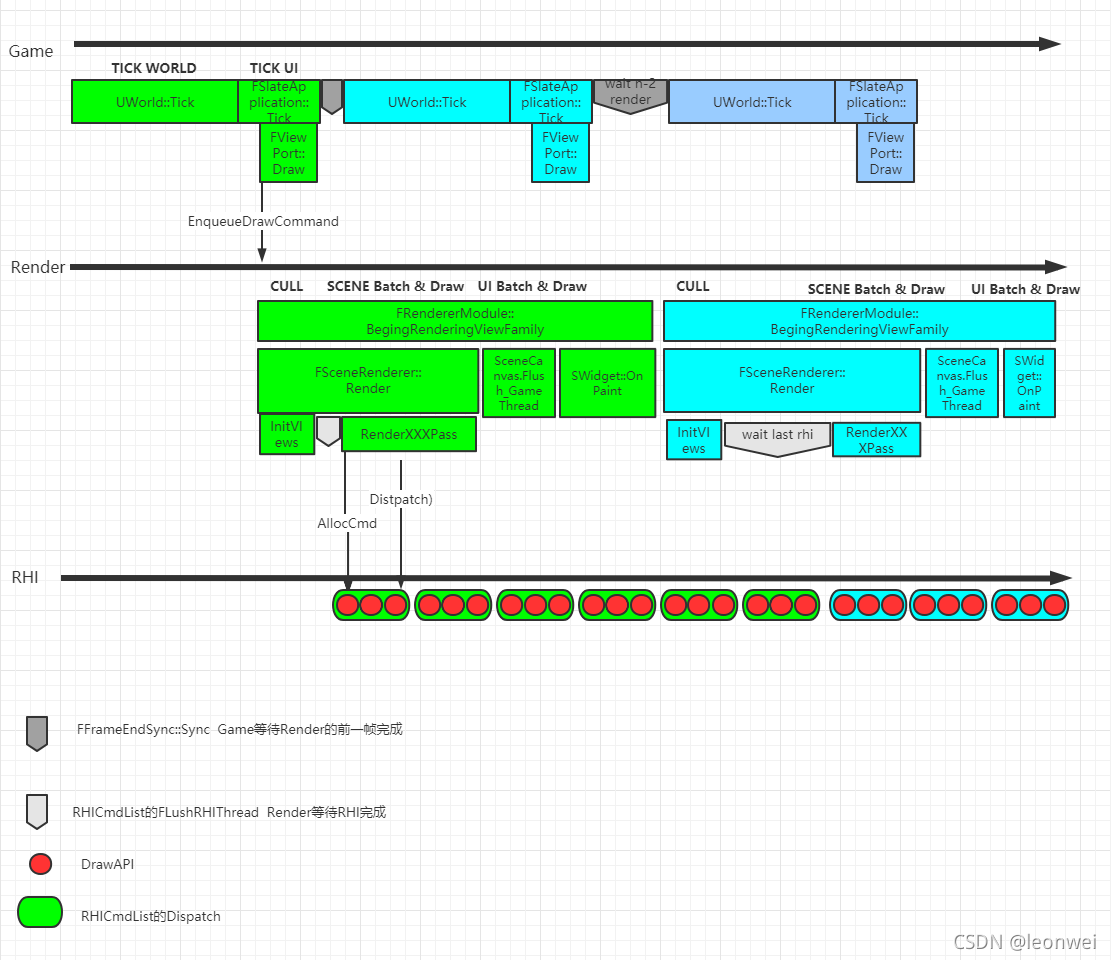
然后找出OpenGL调用中耗时较重的API:
glBufferData()
glBufferSubData()
glCompressedTexImage2D() / glCompressedTexImage3D()
glCompressedTexSubImage2D() / glCompressedTexSubImage3D()
glTexImage2D() / glTexImage3D()
glTexSubImage2D() / glTexSubImage3D()
glcompileshader / glshadersource
gllinkprogram
......
接着想办法将这些耗时严重的API从RHI主线程中抽离到其它辅助的RHI线程中:
上:耗时图形API调用在同一个RHI线程时会影响该线程的效率;下:将耗时API抽离到其它辅助线程,从而不卡RHI主线程。
下图是改造后的多RHI辅助线程的架构图:
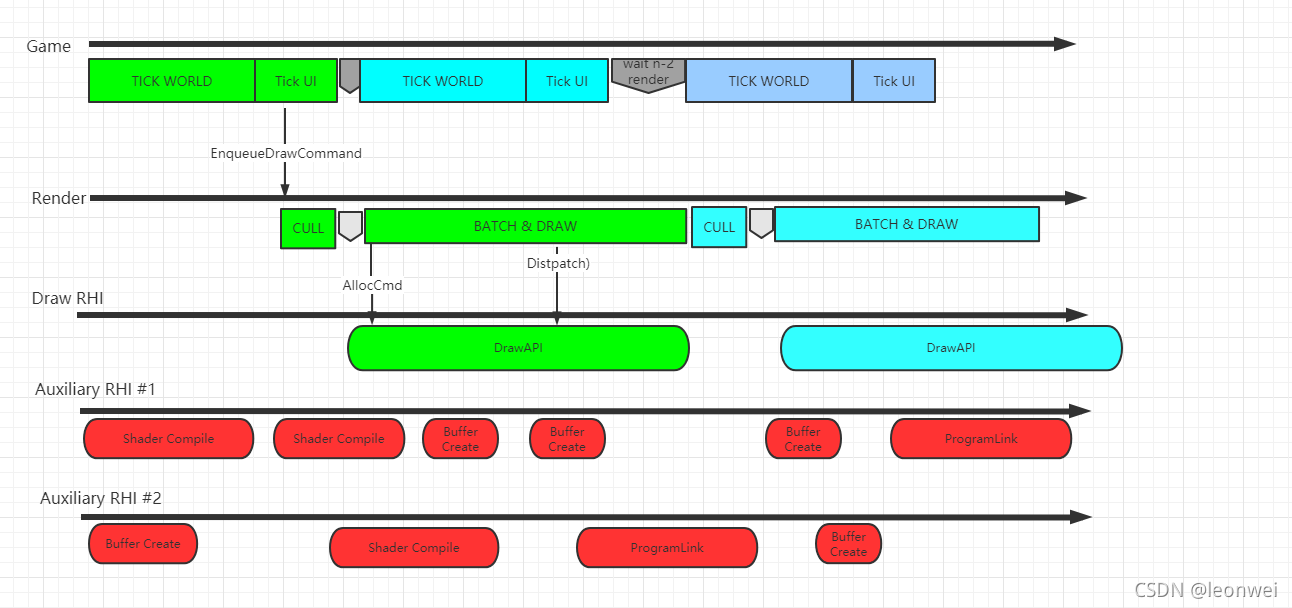
在新的多RHI架构中,需要额外处理多线程、资源之间的同步等工作。更多详情可访问Leon Wei本人的文章:基于UE4的多RHI线程实现。
13.5.3 Frame Graph
现代图形API提供了如此多的权限给应用程序,如果这一切都暴露给游戏应用层开发者,将是一种灾难。
游戏引擎作为基础且重要的中间层角色,非常有必要实现一种机制,可以良好地掌控现代图形API带来的遍历,并且尽量隐藏它的复杂性。此时,Frame Graph横空出世,正是为了解决这些问题。

Frame Graph旨在将引擎的各类渲染功能(Feature)、上层渲染逻辑(Renderer)和下层资源(Shader、RenderContext、图形API等)隔离开来,以便做进一步的解耦、优化。
育碧的Anvil引擎为了解决渲染管线的复杂度和依赖关系,构建了Producer System(生产系统)、Shader Inpute Groups(着色器输入组),精确地管理管线状态和资源。
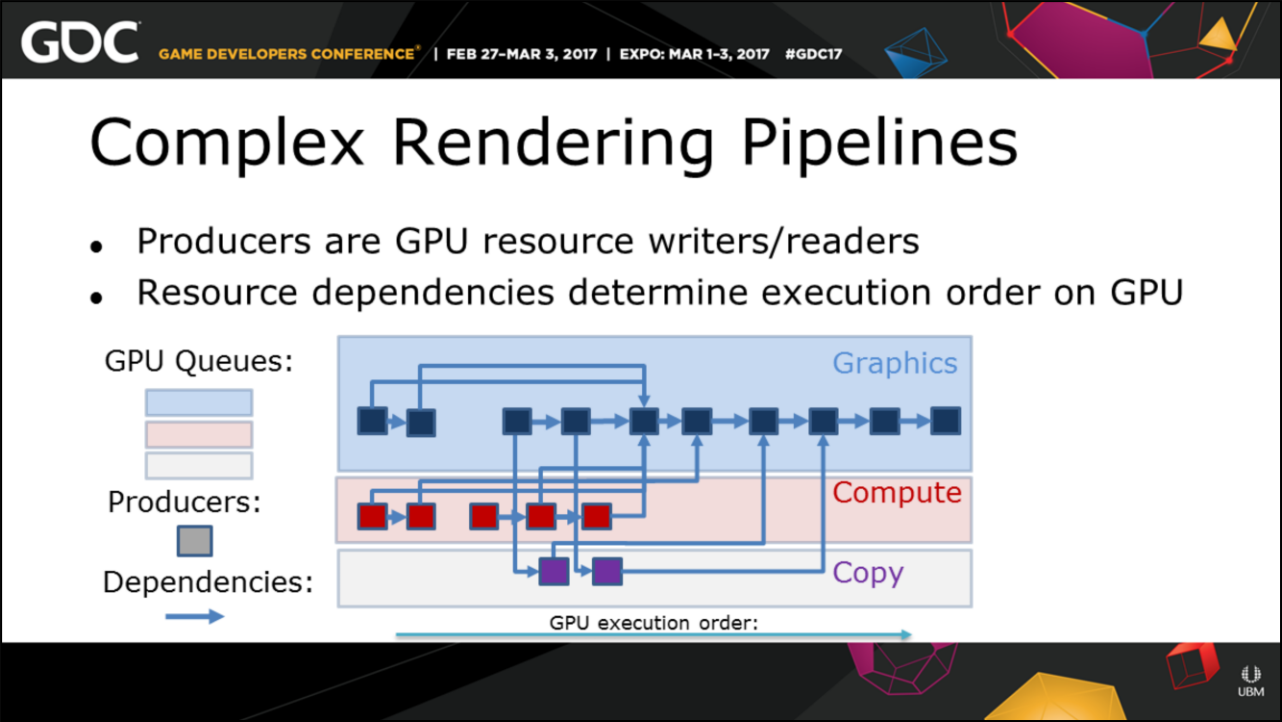
Anvil引擎内复杂的渲染管线示意图。
其中Anvil引擎的Producer System目标是实现资源依赖(资源生命周期、跨队列同步、资源状态转换、命令队列顺序执行和合并),精确地追踪资源依赖关系:

Anvil引擎追踪资源依赖和生命周期图例。
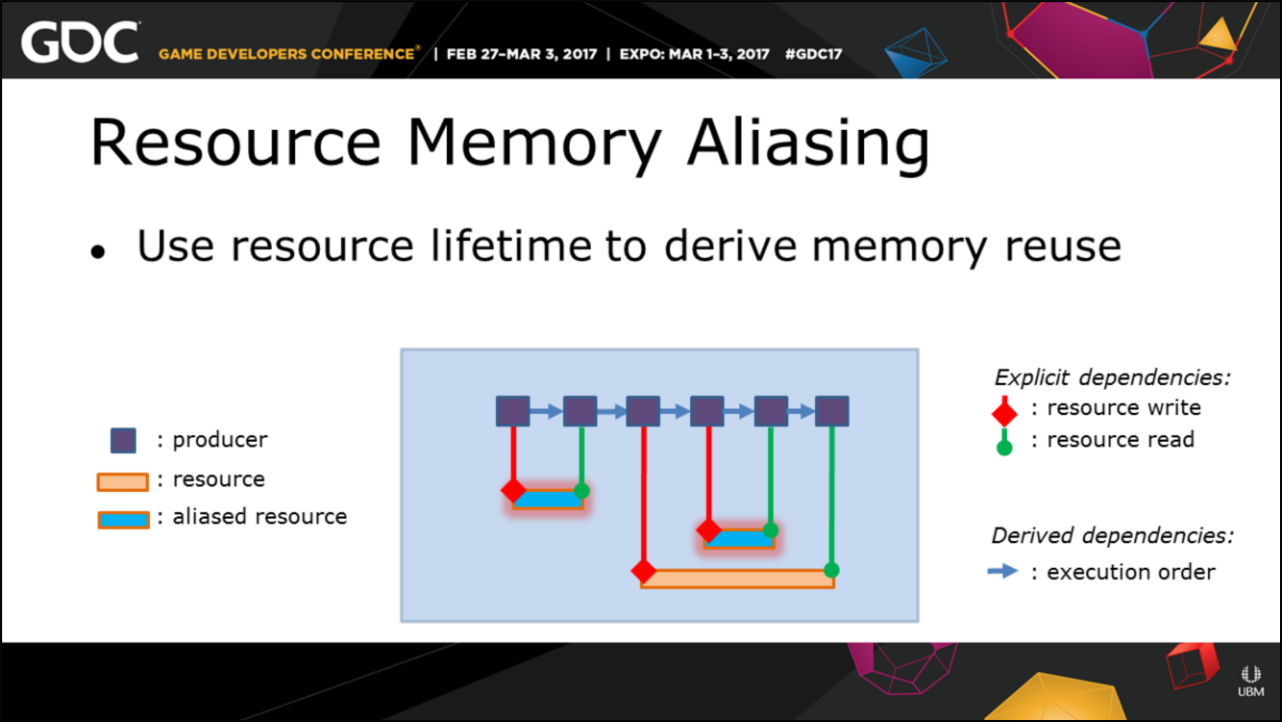
Anvil引擎实现内存重用图例。
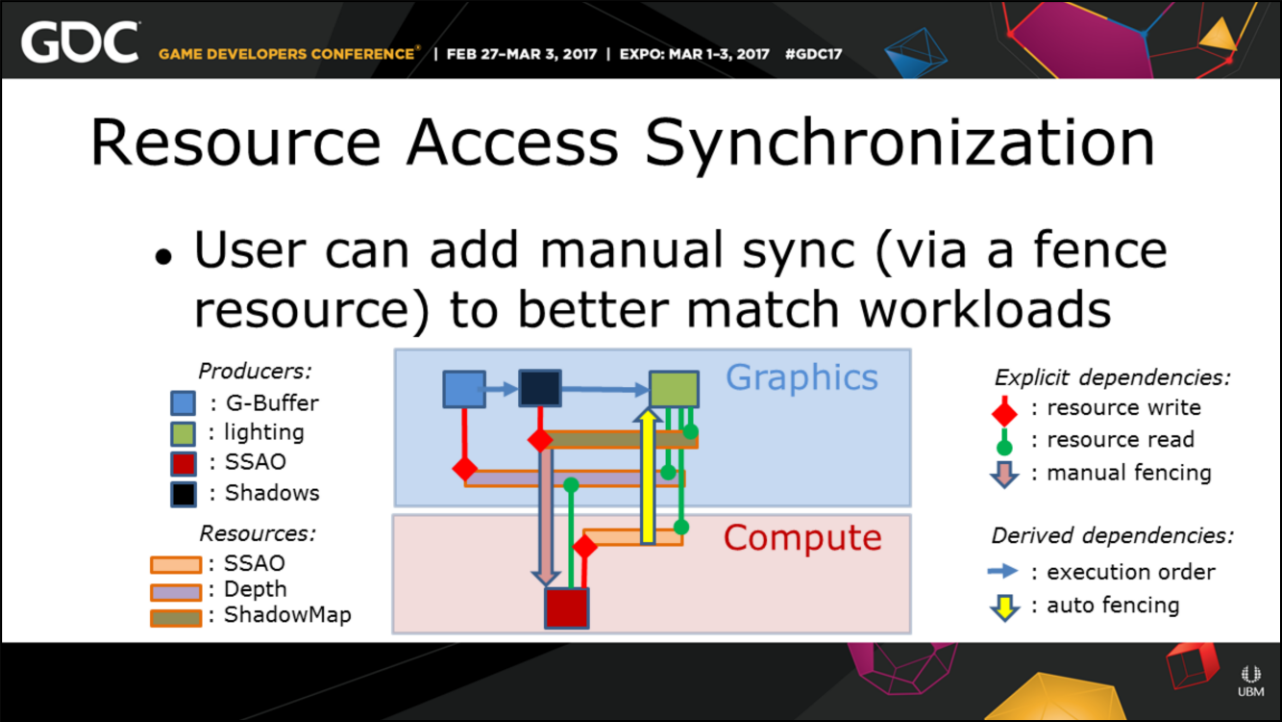
Anvil引擎实现资源同步图例。
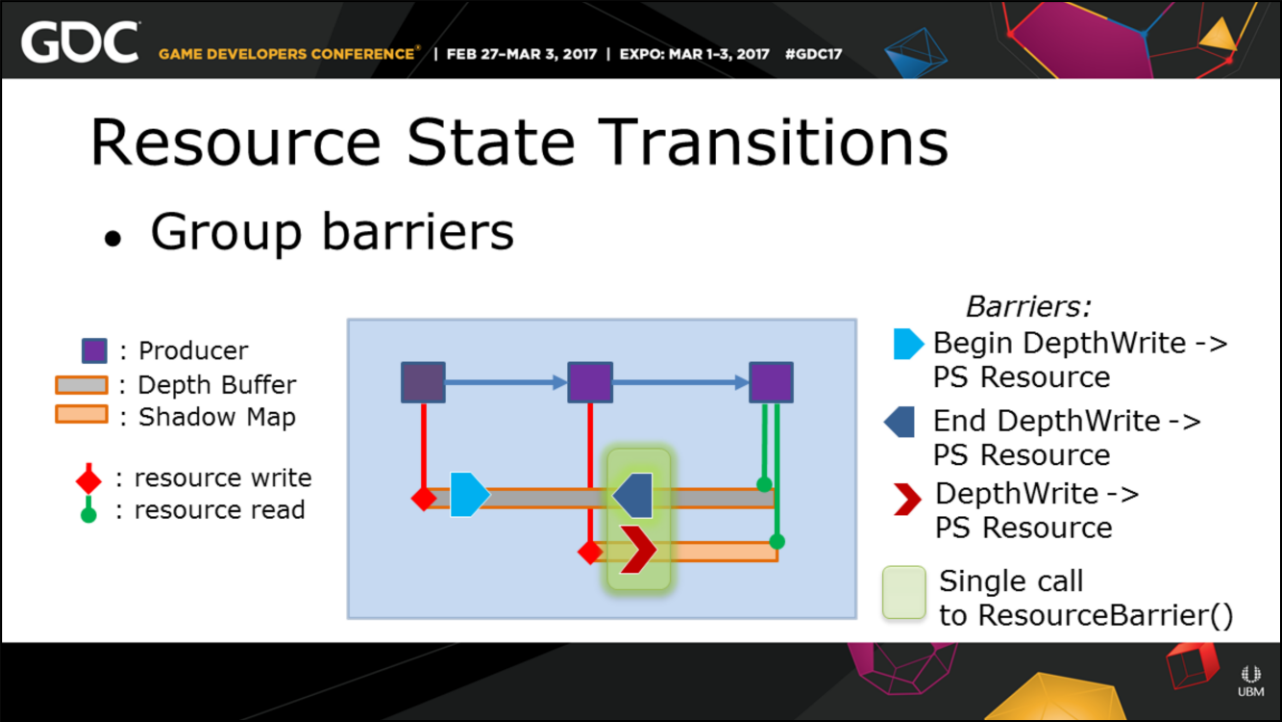
Anvil引擎实现和优化状态转换图例。
除此之外,Anvil可以自动生成调度图(Schedule Graph),可以察看GPU执行顺序、命令队列、生产者等信息:
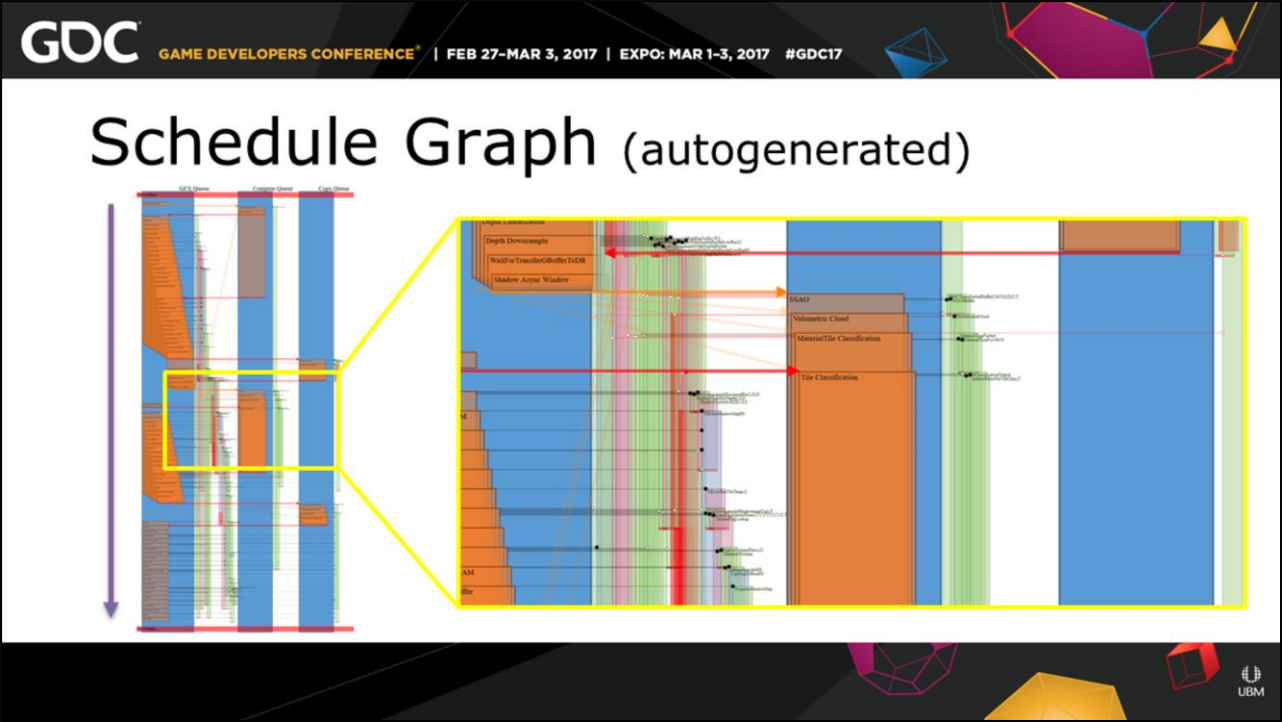
Anvil引擎生成的Schedule Graph。

Anvil引擎生成的Schedule Graph部分放大图。
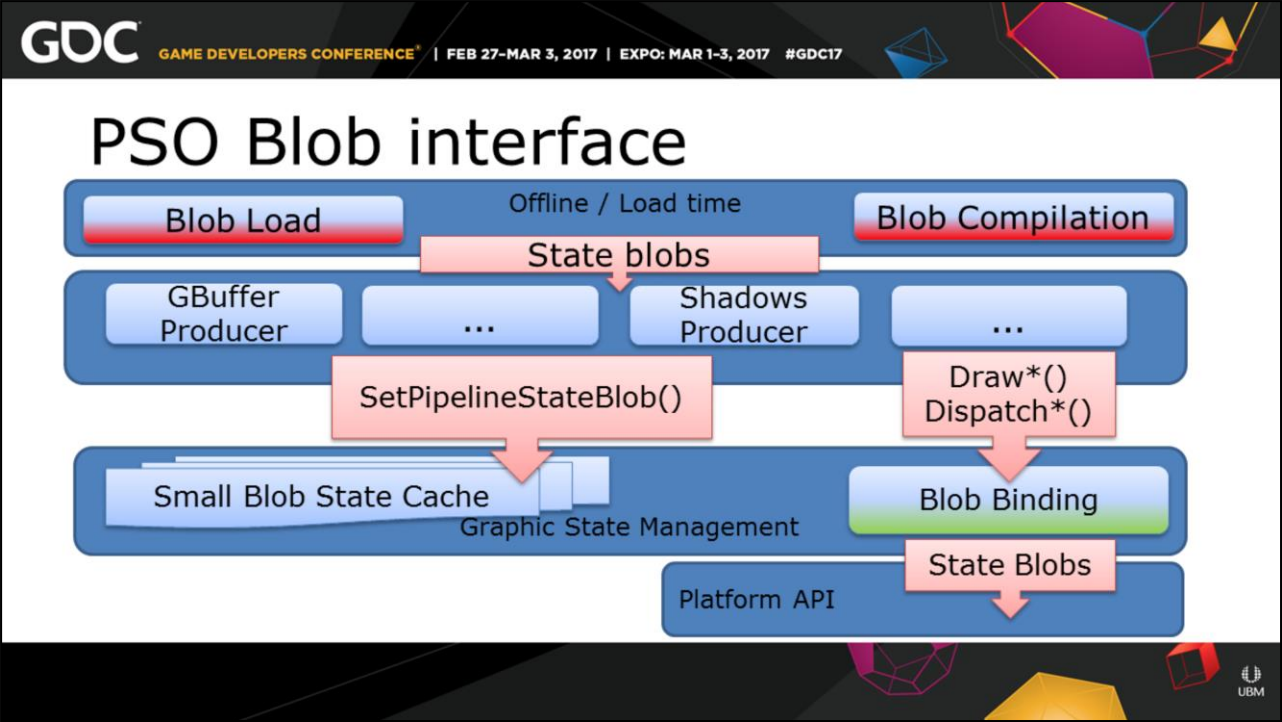
Anvil引擎的Shader Inpute Group是尽量在离线阶段收集并编译PSO:

对于PSO,尽量将耗时的状态提前到离线和加载时刻:
经过以上基于DX12等现代图形API的系统构建完成之后,Anvil的CPU平均可以获得15%-30%左右的提升,GPU则只有约5%:
另外,UE的RDG和Frostbite的Frame Graph都是基于渲染图的方式达成现代图形API的多线程渲染、资源管理、状态转换、同步操作等等。
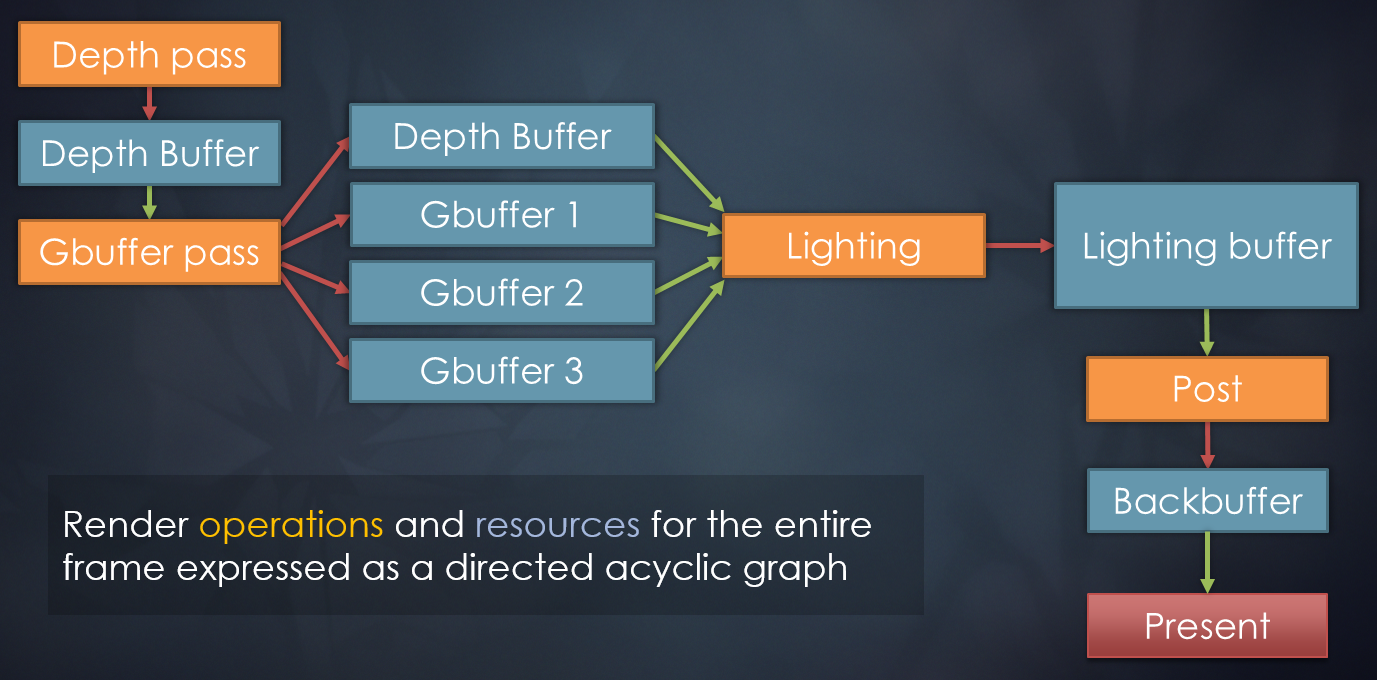
寒霜引擎采用帧图方式实现的延迟渲染的顺序和依赖图。
13.5.4 GPU-Driven Rendering Pipeline
下面对场景如何分解为工作项的高级概述。
- 首先进行粗粒度的视图剔除,然后幸存的集群通过各种测试进行三角形剔除。
- 在通道上运行一个快速压缩,以确保如果一个网格秒点完全被剔除(就像遮挡或截锥剔除的情况),以保证不会有零尺寸的绘制。
- 在管道的最后,有一组索引的绘制参数,使用DirectX 12的ExecuteIndirect(OpenGL需要AMD_mul _draw_indirect扩展,Xbox One需要ExecuteIndirect特殊扩展)执行GPU剔除。
- 通过间接参数切换PSO,意味着可以为整个场景只需要调用单个ExecuteIndirect,而不管状态或资源变化。

GPU-Driven管线的裁剪框架图。
GPU-Driven Rendering Pipeline执行过程还可以结合众多的裁剪技术(Frustum裁剪、Cluster裁剪、三角形裁剪、零面积图元裁剪、小面积图元裁剪、朝向裁剪、深度裁剪、分块深度裁剪、层级深度裁剪)和优化技术(非交叉数据结构、合批、压缩),以获得更高的渲染性能。
UE5的Nanite和Lumen将GPU-Driven Rendering Pipeline技术发挥得淋漓尽致,从而在PC端实现了影视级的实时渲染效果。
更多GPU-Driven Rendering Pipeline详情可参阅:
- Optimizing the Graphics Pipeline with Compute
- GPU-Driven Rendering Pipelines
- 剖析虚幻渲染体系(06)- UE5特辑Part 1(特性和Nanite)
- 剖析虚幻渲染体系(06)- UE5特辑Part 2(Lumen和其它)
13.5.5 Performance Monitor
AMD为DirectX12提供了性能检测工具,可以监控管线的很多数据(顶点缓存效率、裁剪率、过绘制等):

NV的官方开发人员测试了OpenGL、DX11、DX12的部分特性和API的性能,如下所示:
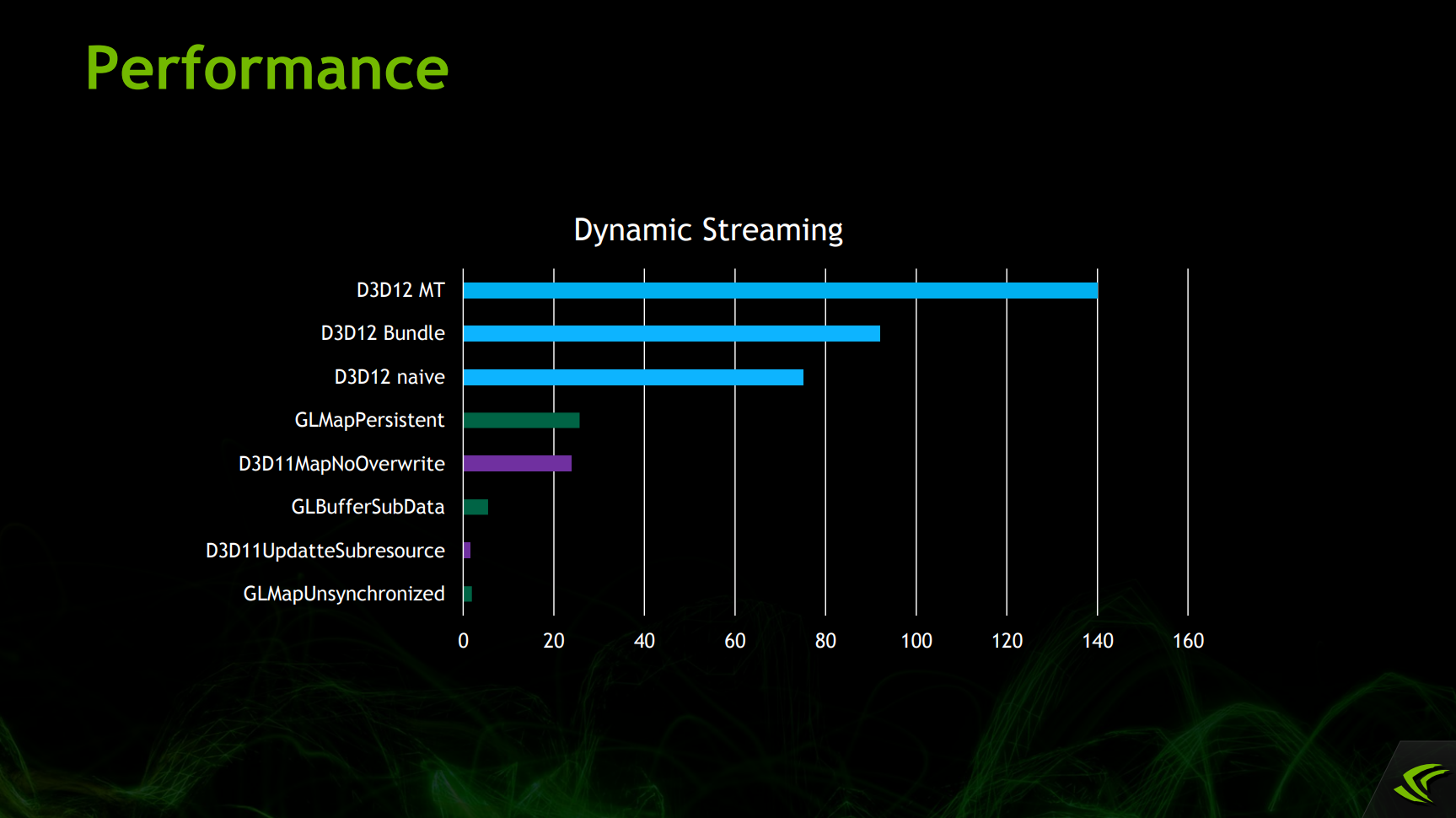
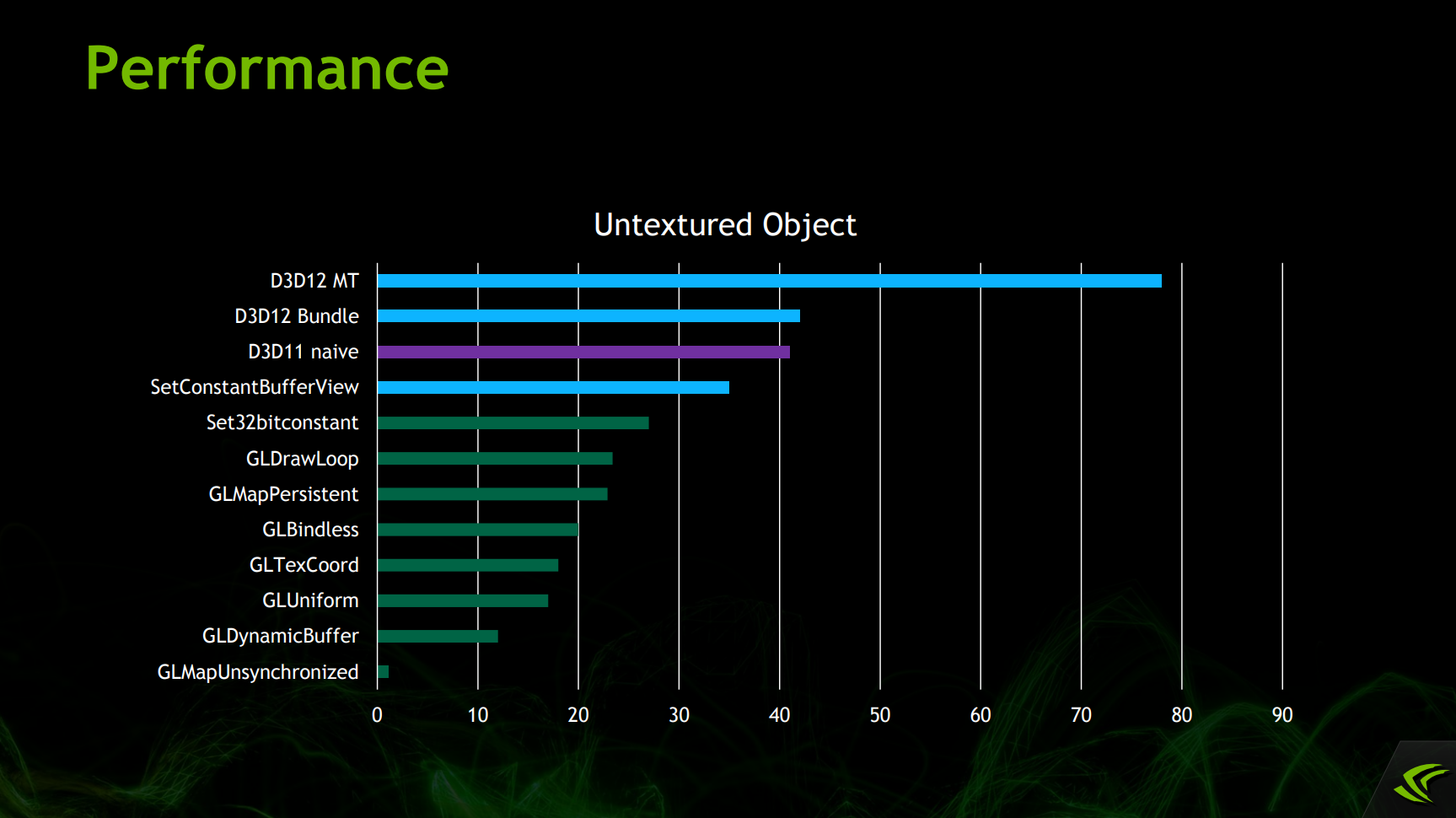
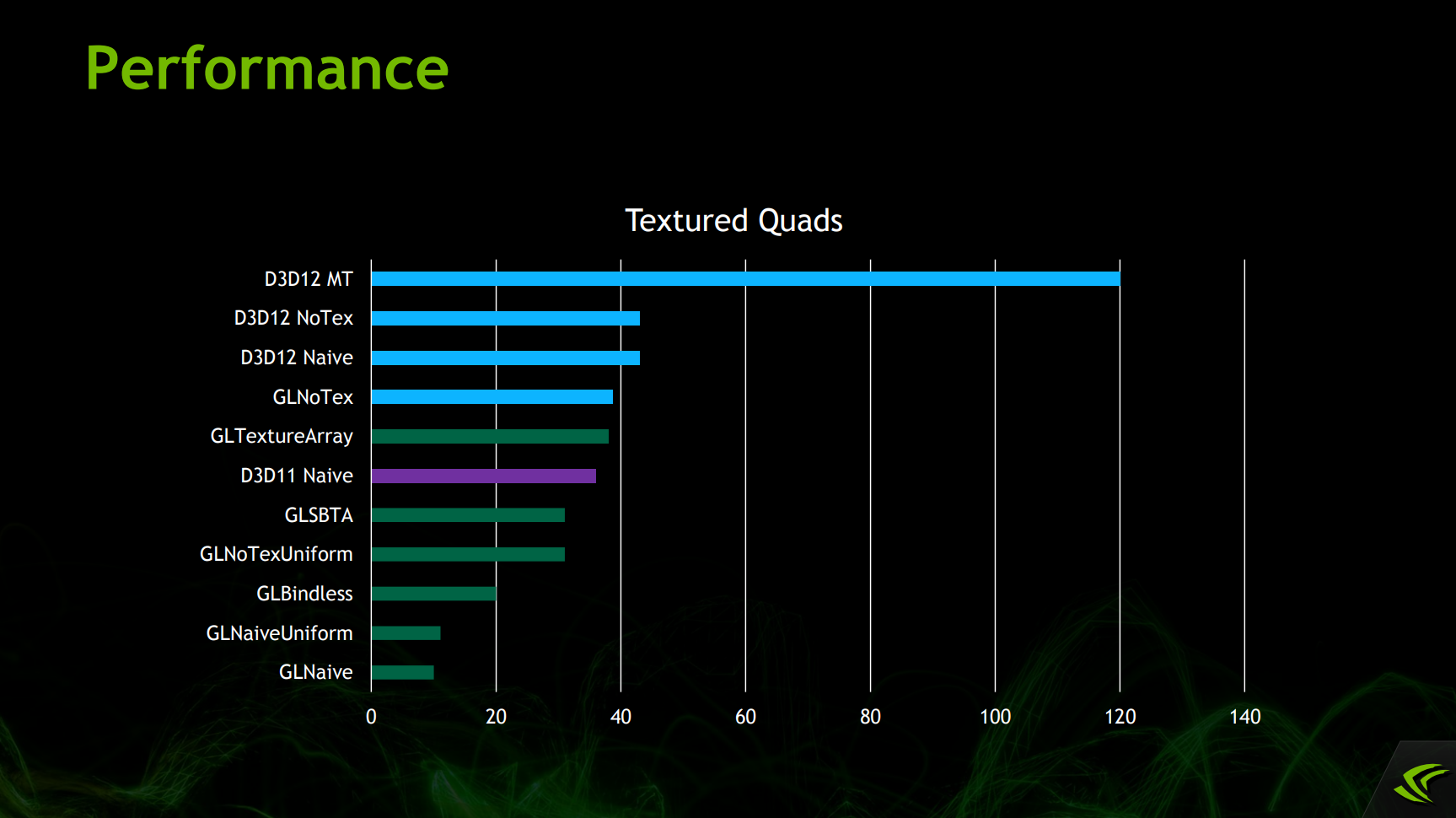
可见DX12的多线程、Bundle、原生API调用等性能远远领先其它传统图形API。
AMD也提供了相关的性能分析工具。对于渲染管线而言,常见的状态如下所示:
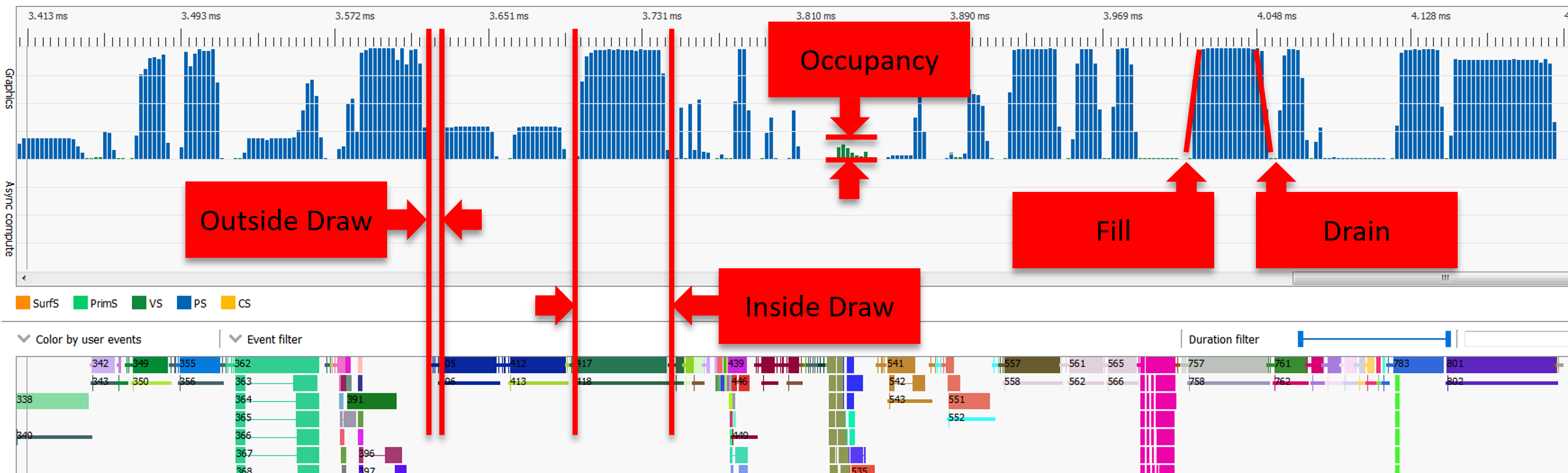
常见的管线状态:Inside Draw(绘制内)、Outside Draw(绘制外)、Occupancy(占用率)、Fill(填充)、Drain(疲态)。
Radeon GPU Profiler(RGP)可以查看Wave执行细节:

AMD内部工具甚至可以追踪Wave的生命周期、各个部件的指令状态和问题:
甚至可以估算平均延时和各级缓存命中率:

下图展示了Barrier和系列依赖+小量作业导致GPU大量的空闲:
下图展示的是简单几何体无法填满GPU和SIMULTANEOUS_USE_BIT命令缓冲区阻碍了并行引发的大量空闲:
下图展示的是多个Drain和Fill状态导致的GPU利用率降低:

下图则展示了冷缓存(Cold Cache)导致的GPU耗时增加:

但是,即便RGP显示管线的Wave占用率高,也可能会因为指令缓存丢失和大量空闲导致性能不高:

分析出了症状,就需要对症下药,采用各种各样的措施才能真正达到GPU的高性能。下图是常见Pass通过AMD分析工具的性能情况:

更多参见:ENGINE OPTIMIZATION HOT LAP。
GPUView也可以查看GPU(支持多个)的执行详情:
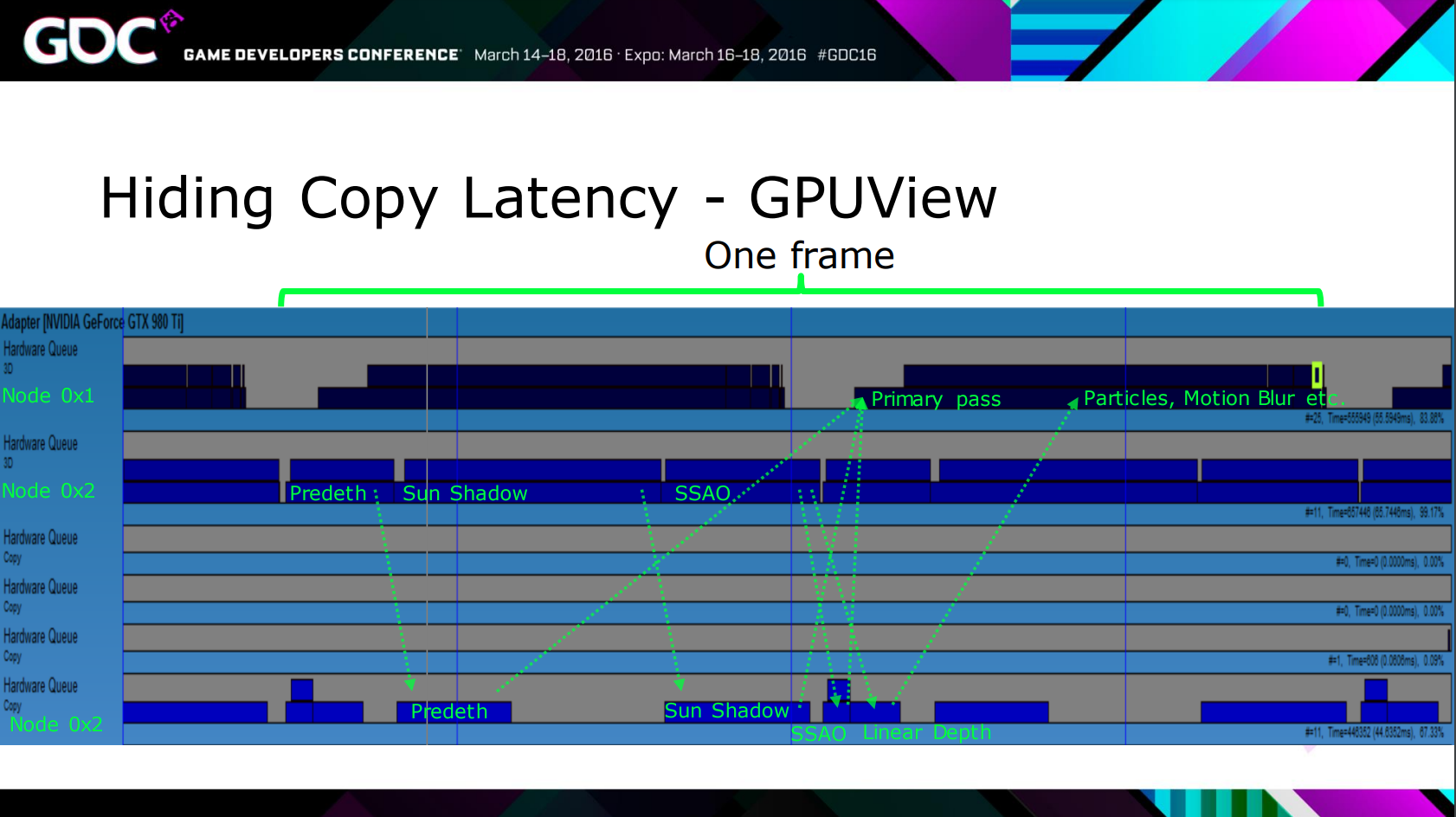
此外,Ensure Correct Vulkan Synchronization by Using Synchronization Validation详细地讲解了如何校验Vulkan的同步错误。

下图是Vulkan验证层的运行机制:
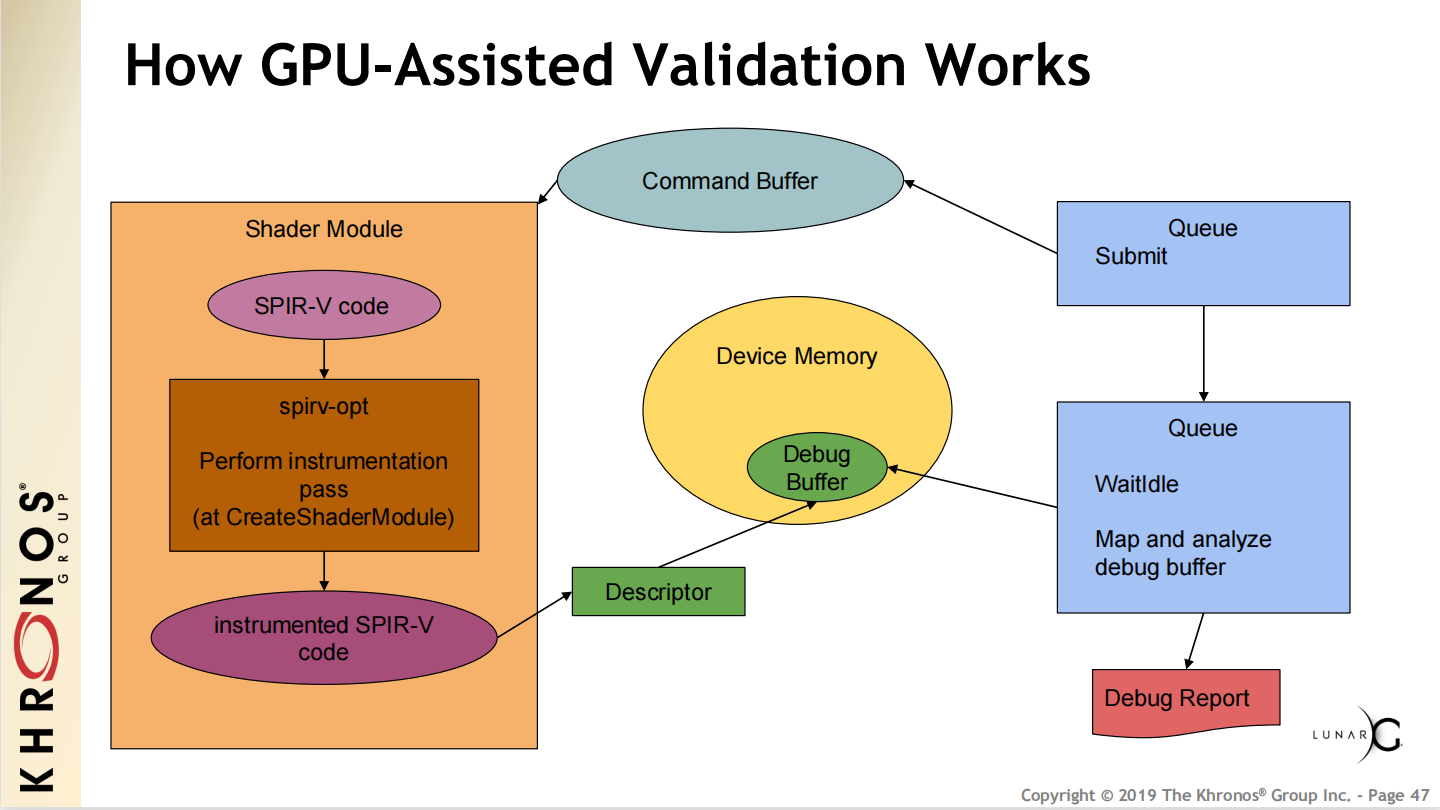
13.6 本篇总结
本篇主要阐述了现代图形API的特点、机制和使用建议,然后给出了部分应用案例。
13.6.1 Vulkan贡献者名单
笔者在查阅Vulkan资料时,无意间翻到Vulkan 1.2贡献者名单:Appendix I: Credits (Informative)。
粗略统计了一下他们所在的公司和行业,如下表:
| 公司 | 行业 | 人数 |
|---|---|---|
| OS | 26 | |
| AMD | CPU、GPU | 21 |
| Samsung Electronics | 设备 | 19 |
| NVIDIA | GPU | 18 |
| Intel | CPU、GPU | 18 |
| LunarG | 软件 | 16 |
| Qualcomm | GPU | 11 |
| Imagination Technologies | GPU | 11 |
| Arm | GPU | 10 |
| Khronos | 软件标准 | 7 |
| Oculus | VR | 6 |
| Codeplay | 软件 | 6 |
| Independent | 软件 | 6 |
| Unity Technologies | 游戏引擎 | 4 |
| Valve Software | 软件 | 4 |
| Epic Games | 游戏引擎 | 3 |
| Mediatek | 软件 | 3 |
| Igalia | 软件 | 3 |
| Mobica | 软件 | 3 |
| Red Hat | OS | 2 |
| Blizzard Entertainment | 游戏 | 1 |
| Huawei | 设备 | 1 |
从上表的数据可知总人数223,可以得出很多有意思的结论:
- Vulkan的标准主要由OS、GPU、CPU等公司提供,占比一半以上。
- Microsoft、Apple并未在列,因为他们有各自的图形API标准DirectX和Metal。
- 游戏行业仅有Unity、Epic Games、Blizzard等公司在列,占总人数(223)比例仅3.6%。
- 疑似华人总人数仅13,占总数比例仅5.8%。
- 国内企业只有华为在列,仅1人,占总人数比例仅0.45%。
总结起来就是国内的图形渲染技术离国外还有相当大的差距!吾辈当自强不息!
13.6.2 本篇思考
按惯例,本篇也布置一些小思考,以加深理解和掌握现代图形API:
- 现代图形API的特点有哪些?请详细列举。
- 现代图形API的同步方式有哪些?说说它们的特点和高效使用方式。
- 现代图形API的综合性应用有哪些?说说它们的实现过程。
特别说明
- 感谢所有参考文献的作者,部分图片来自参考文献和网络,侵删。
- 本系列文章为笔者原创,只发表在博客园上,欢迎分享本文链接,但未经同意,不允许转载!
- 系列文章,未完待续,完整目录请戳内容纲目。
- 系列文章,未完待续,完整目录请戳内容纲目。
- 系列文章,未完待续,完整目录请戳内容纲目。
参考文献
- Unreal Engine Source
- Rendering and Graphics
- Materials
- Graphics Programming
- Vulkan® 1.2.201 - A Specification
- Vulkan 1.1 Quick Reference
- Vulkan Tutorial
- Vulkan® Guide
- Vulkan Decoder Ring
- A Comparison of Modern Graphics APIs
- Raw Vulkan
- Raw Metal
- Raw DirectX 12
- DirectX 12 技术白皮书
- Raw DirectX 11
- Raw OpenGL
- Understanding Vulkan® Objects
- UE4/UE5的RHI(Vulkan为例)
- Direct3D 12 programming guide
- Direct3D 11 Programming guide
- Right on Queue: Advanced DirectX 12 Programming
- Metal API Overview
- Metal Programming Guide
- Metal Best Practices Guide
- Metal Shading Language Specification
- Working with Metal—Overview
- OpenGL 4.6 Core Specification
- OpenGL® ES 3.1 Reference Pages
- 移动游戏性能优化通用技法
- 游戏引擎随笔 0x11:现代图形 API 特性的统一:Attachment Fetch
- Using Next-Generation APIs on Mobile GPUs
- What's the main difference of pipeline process between Vulkan and DX12?
- Encoder results reuse
- Encoding Indirect Command Buffers on the CPU
- Rendering a Scene with Deferred Lighting in C++
- 基于UE4的多RHI线程实现
- Yet another blog explaining Vulkan synchronization
- ENGINE OPTIMIZATION HOT LAP
- Vulkan Multi-Threading
- An exploratory study of high performance graphics application programming interfaces
- Approaching Minimum Overhead with Direct3D12
- The NVIDIA Turing GPU Architecture Deep Dive: Prelude to GeForce RTX
- EXPLORING COMPRESSION IN THE GPU MEMORY HIERARCHY FOR GRAPHICS AND COMPUTE
- Optimizing Data Transfer Using Lossless Compression with NVIDIA nvcomp
- Breaking Down Barriers - An Intro to GPU Synchronization
- DirectX 12: A New Meaning for Efficiency and Performance
- DirectX12: A Resource Heap Type Copying Time Analysis
- Ensure Correct Vulkan Synchronization by Using Synchronization Validation
- Memory Management in Vulkan™ and DX12
- Practical DirectX 12 - Programming Model and Hardware Capabilities
- D3D12 & Vulkan Done Right
- GDC2017: Moving To DX12 Lessons Learned
- Getting The Best Out Of D3D 12
- DX12 & Vulkan Dawn of a New Generation of Graphics APIs
- Introduction to Direct 3D 12 by Ivan Nevraev
- Surfing the wave(front)s with Radeon™ GPU Profiler
- Vulkan on NVIDIA GPUs
- [Vulkan: Migrating from OpenGL ES](http://cdn.imgtec.com/sdk-documentation/Vulkan.Migrating from OpenGL ES.pdf)
- VULKAN FAST PATHS
- Real-Time Rendering
- An Overview of Next-Generation Graphics APIs
- Getting Explicit How hard is Vulkan Really?
- A sampling of UE4 rendering improvements Arne Schober
- Advanced Rendering with DirectX 11 and DirectX 12
- Porting your engine to Vulkan or DX12
- GDC 2016:D3D12 & Vulkan: Lessons learned
- GDC 2017:D3D12 & Vulkan: Lessons learned
- DirectX 12 Optimization Techniques in Capcom's RE ENGINE
- DirectX™ 12 Case Studies
- Efficient rendering in The Division 2
- Optimizing the Graphics Pipeline with Compute
- Deep Dive: Asynchronous Compute
- Explicit DirectX12 Multi GPU rendering
- Get the Most from Vulkan in Unity with Practical Examples from Infinite Dreams
- Wave Programming in D3D12 and Vulkan
- AMD GPU Performance Revealed
- CONCURRENCY MODEL IN EXPLICIT GRAPHICS APIS
- [AMD RYZEN™ PROCESSOR SOFTWARE OPTIMIZATION](https://gpuopen.com/wp-content/uploads/slides/GPUOpen_Let’sBuild2020_AMD Ryzen™ Processor Software Optimization.pdf)
- Optimizing for the RDNA Architecture
- Optimization with Radeon GPU Profiler A Vulkan Case
- High Zombie Throughput in Modern Graphics
- How we rethought driver abstraction
- Introduction to 3D Game Programming with DirectX® 12
- Triangles Are Precious - Let's Treat Them With Care
- FrameGraph: Extensible Rendering Architecture in Frostbite
- Advanced Graphics Techniques Tutorial Day: Practical DirectX 12 - Programming Model and Hardware Capabilities
- Programming GPU
- Efficient GPU Programming in Modern C++
- GPU-Driven Rendering Pipelines
- Understanding DirectX* Multithreaded Rendering Performance by Experiments
- Bringing Fortnite to Mobile with Vulkan and OpenGL ES
- DirectX 12: Advanced Graphics Performance
- DX12 Do's And Don'ts
- Vulkan Subgroup Tutorial
- Vulkan Best Practices for Mobile Developers
- API without Secrets: Introduction to Vulkan
- Advanced Graphics Tech: How to Thrive on the Bleeding Edge Whilst Avoiding Death by 1,000 Paper Cuts
- Ubisoft's Experience Developing with Vulkan
- VRS Tier 1 with DirectX 12 From Theory To Practice
- Vulkan in Rocksolid
- OPTIMISING A AAA VULKAN TITLE ON DESKTOP
- Making use of New Vulkan Features
- Vulkan: The State of the Union
- Microsoft Game Development Guide

 浙公网安备 33010602011771号
浙公网安备 33010602011771号