剖析虚幻渲染体系(12)- 移动端专题Part 3(渲染优化)
12.6 移动端渲染优化
前面几章详尽地剖析了移动端GPU架构的特性和机理,那么就可以指导我们抽象出一些准则,从而获得高性能的渲染代码和应用程序。
为了获得流畅、高效、良好体验,每个应用程序都必须重视性能优化,并贯穿始终。应用程序的性能优化分为以下三角循环:
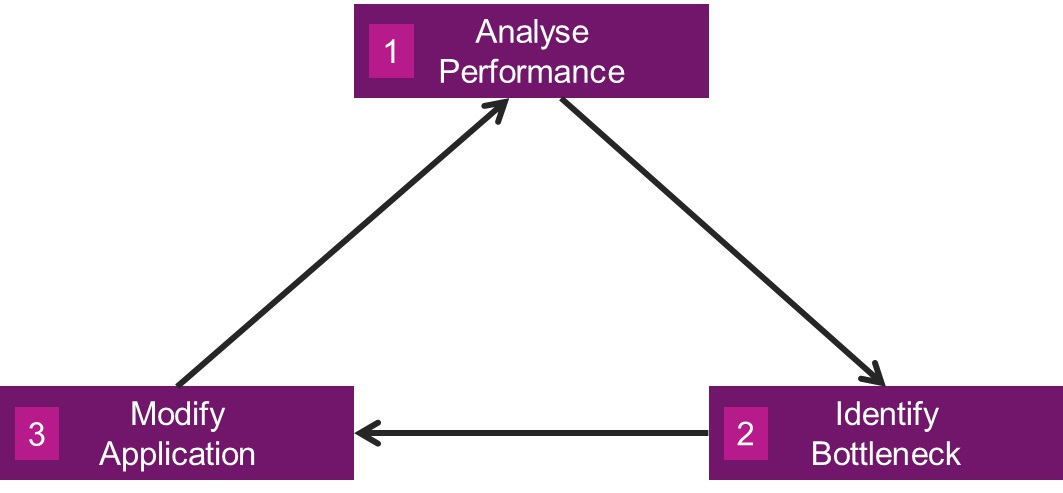
第一步,分析应用程序的整体性能。
第二步,利用工具定位出性能瓶颈。
第三步,修改应用程序。回到第一步递归分析。
这个三角循环什么时候停止呢?那就是应用程序的性能已经达到了项目之初指定的标准(如高中低画质不低于多少帧,DC、三角面数小于多少等),并且已经知道应用程序已经达到了效率极限,再往下便到了投入产出比很小的牛角尖。
本篇会涉及以下概念:
| 名称 | 别名 | 描述 |
|---|---|---|
| USC (Unified Shading Cluster) | Shading Cluster, Shading Unit, Execution Unit | 图形核心的半自主部分,通常可以执行整个工作组。其他大型部件如纹理单位(Texture Unit)可以在USC之间共享。 |
| Core | Processor, Graphics Core | 图形核心的一个几乎完全自主的部分。通常情况下,是USC的集合以及可能支持的硬件,如纹理单元。 |
| Task | Thread Group, Warp, Wavefront | USC执行的线程的原生分组,PowerVR Rogue内核由32个线程组成。 |
| shared | Shared variables | 存储于Shared memory的变量。 |
| const / uniform | const / uniform变量, uniform块, uniform缓冲区 | 存储于Constant memory的变量、块、缓冲区。 |
补充一下PowerVR Rogue硬件架构和数据流交互图,如下所示:

PowerVR Rogue的Unified Shading Cluster(USC)如下所示:

另外,补充一下本章大量涉及的片元(fragment)的概念:
片元(fragment)是GPU内部的几何体光栅化后形成的最小表示单元,它经过一系列片元操作(alpha测试,深度测试,模板测试等)后,才可能最终写入渲染纹理成为像素(pixel)。所以,片元不是像素,但有概率成为像素。
不过在D3D或UE内部,没有片元的概念,像素包含了片元。
12.6.1 渲染管线优化
12.6.1.1 使用新特性
- Variable Rate Shading
Variable Rate Shading(VRS,可变率着色)允许像素着色器一次着色一个或多个像素,这样一个着色计算可以代表一个像素或一组像素。VRS是反锯齿技术的逆解。抗锯齿技术通过平滑高变化的内容,更频繁地采样每个像素,以避免走样(aliasing)和锯齿(jagged)边缘。然而,如果要渲染的表面没有高的颜色变化或将在随后的通道上被模糊(例如,运动模糊),在每个像素都一个着色计算的操作通常是低效的。
VRS允许开发者指定着色率,其中只对一个像素执行一个着色器计算,结果操作应用于指定的像素组配置。如果使用得当,应该不会导致视觉质量下降,同时显著减轻GPU渲染的负担,从而节省功耗并提高性能。

VRS示意图。画面根据颜色变化频率采用不同的着色率,变化高的采用高着色率(如汽车),反之用低着色率(如左下和右下路面)。
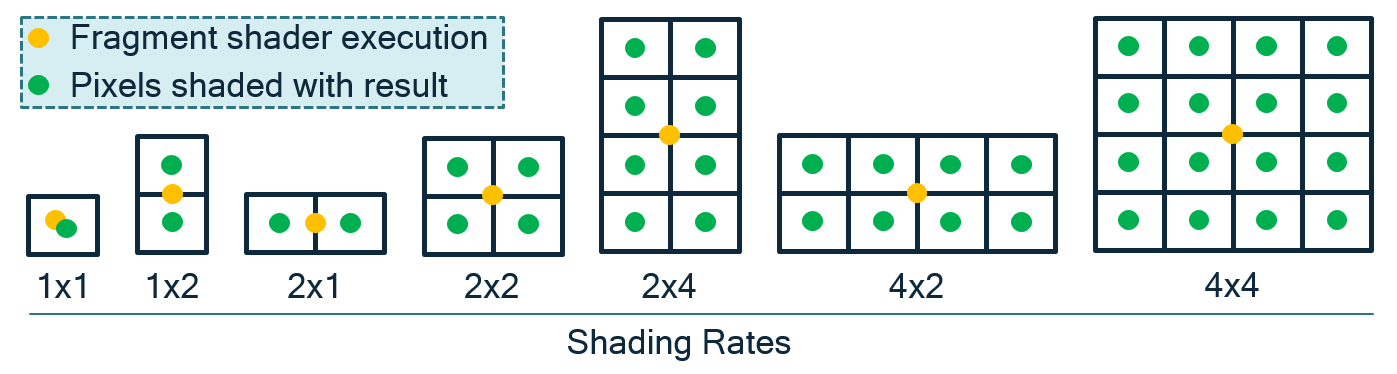
VRS支持的常见着色率和运行机制。其中黄点是着色坐标,绿点是直接复用黄点的着色结果。
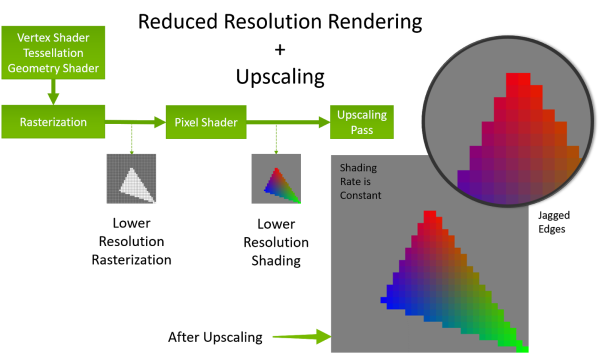
VRS在渲染管线的工作机制。VRS在光栅化阶段采用指定着色率执行光栅化,进入PS之后再放大。
UE可以给每个材质设定1个着色率,在材质属性模板中:
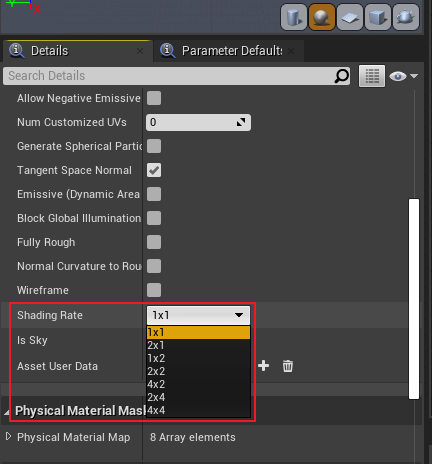
VRS优化的核心思想在于减少计算次数并复用周边计算点的结果,从而达到提升渲染效率的目的。适合使用VRS的情形:
- 颜色变化率低的物体。
- 处于运动模糊区域的物体。
- 景深范围之外的物体。
使用移动端的VRS需要依赖不同图形API的扩展:
// ------ OpenGLES ------
// Qualcomm
QCOM_shading_rate
GL_SHADING_RATE_1X1_PIXELS_QCOM
GL_SHADING_RATE_1X2_PIXELS_QCOM
......
// Arm / Imagination Tech
(不支持)
// ------ Vulkan ------
VK_KHR_fragment_shading_rate
- 使用Vulkan代替OpenGL。
相比OpenGL等传统API,Vulkan支持多线程,轻量化驱动层,可以精确地管控GPU内存、同步等资源,避免运行时校验,基于命令队列的机制,没有全局状态等等(下图)。

得益于Vulkan的先进设计理念,使得它的渲染性能更高,通常在CPU、GPU、带宽、能耗等指标都优于OpenGL。但如果是应用程序本身的CPU或者GPU负载高,则使用Vulkan的收益可能没有那么明显:

- 使用遮挡剔除。
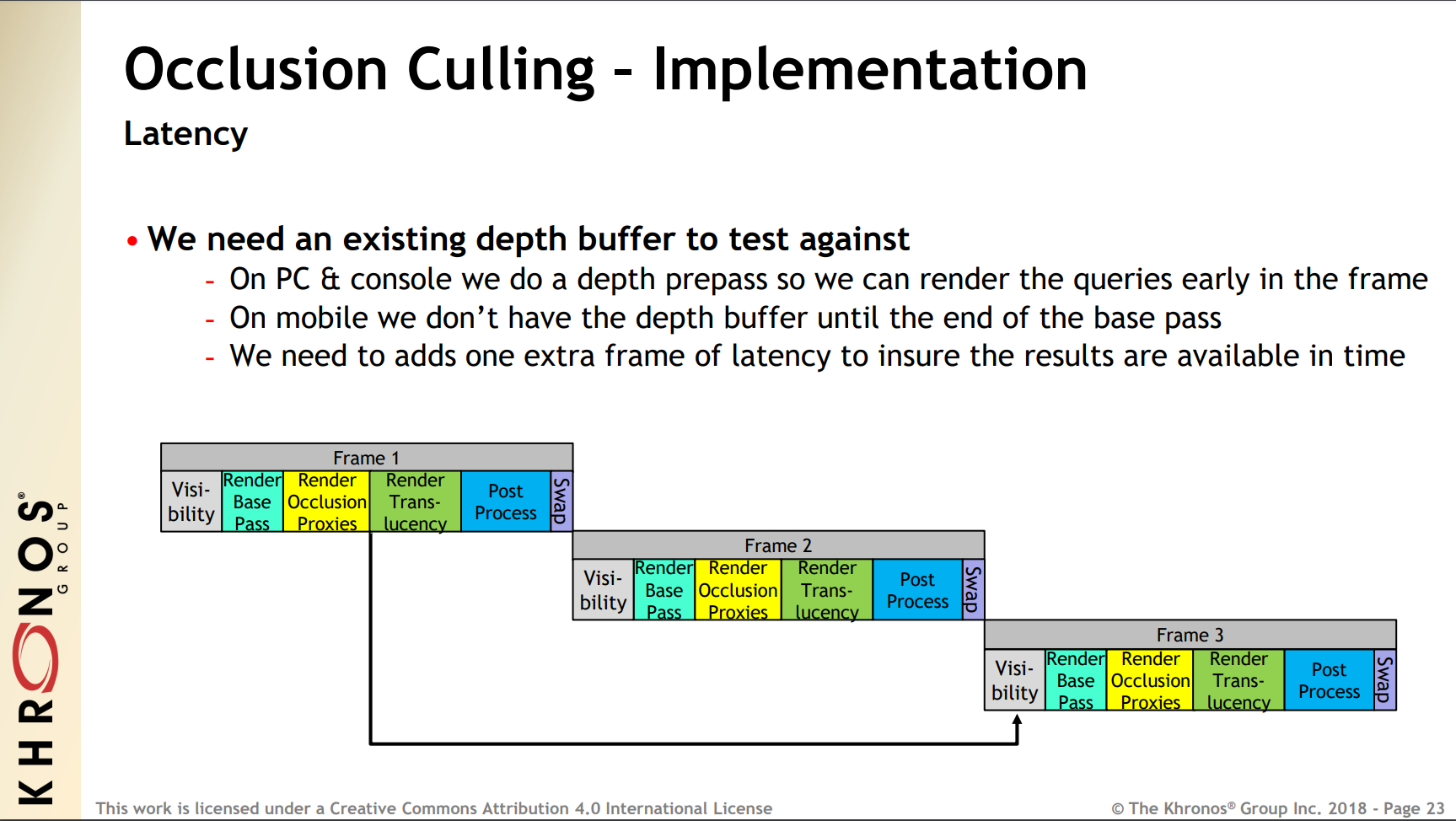
遮挡剔除可以提前剔除掉被遮挡的物体或者远处占屏幕很小的物体,避免进入GPU管线,占用带宽和计算资源。UE在移动端的遮挡剔除延迟了两帧(因为BasePass结束之后才有深度缓冲,需要再增加一帧延迟确保结果可用):
然后是在RHI线程等待遮挡查询的结果,遮挡查询的结果是在渲染线程使用,由于延迟了两帧,所以渲染线程在计算可见性时不需要等待:
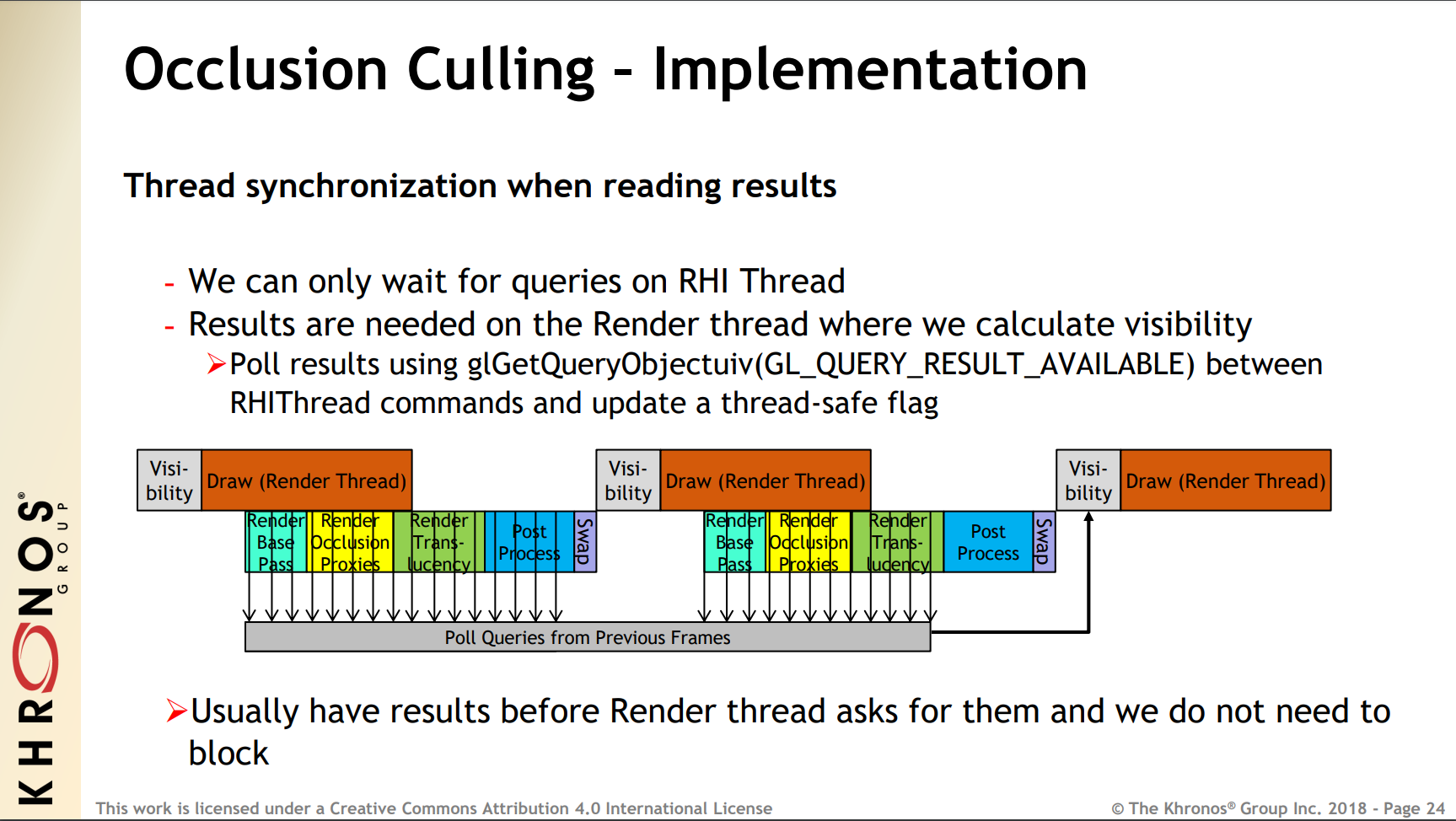
使用遮挡剔除时,需要遵循以下建议:
1、只在需要时返回查询结果,不要等待它,因为同步等待是非常低效的。
2、对于遮挡,只在必要时使用精确计数选项。OpenGL ES使用GL_ANY_SAMPLES_PASSED,、Vulkan使用VK_QUERY_CONTROL_PRECISE_BIT = false,除非确实需要知道遮挡的数量。
3、不要修改正在绘制调用中引用的资源。
4、不要将GL_MAP_INVALIDATE_BUFFER /GL_MAP_INVALIDATE_RANGE与glMapBufferRange()一起使用,因为这些标志在某些版本的驱动会触发创建一个不必要的资源拷贝。
12.6.1.2 管线优化
- 曲面细分期间消除子像素。
曲面细分增加细节级别,并可以通过允许其他游戏子系统在低分辨率的网格表示上操作来减少内存带宽和CPU周期。然而,高级别的曲面细分可以产生子像素三角形,这导致光栅化利用率降低。利用距离、屏幕空间大小或其他自适应度量来计算避免子像素三角形的曲面细分因子是很重要的。
- 曲面细分期间开启背面剔除。
图元的背面剔除可以防止冗余的像素进入像素着色器中,从而提升性能。
- 删除未使用的render target或shader资源。
操作更多的RT或shader资源,会增加带宽,降低性能。故而尽量删除未引用的资源。
- 避免GMEM加载。
在每个Pass渲染之前,需要调用图形API明确清理RT。
OpenGL ES: glClear()
Vulkan: LOAD_OP_CLEAR / LOAD_OP_DONT_CARE
- 使用subpass或PLS。
Vulkan的subpass(或OpenGL ES的PLS)可以让多个pass的数据持续保存在GMEM(Tile缓冲区)中,避免数据反复从GMEM和全局内存之间传输,从而降低带宽和延时。
- 使用PSO缓存。运行时创建PSO对象比较消耗CPU性能,如果在离线阶段收集、编译材质使用的Shader并保存成二进制文件,以便下次运行时调用时直接读取Cache文件并转成PSO对象,可以降低CPU负载。下图是UE的PSO缓存机制图示:
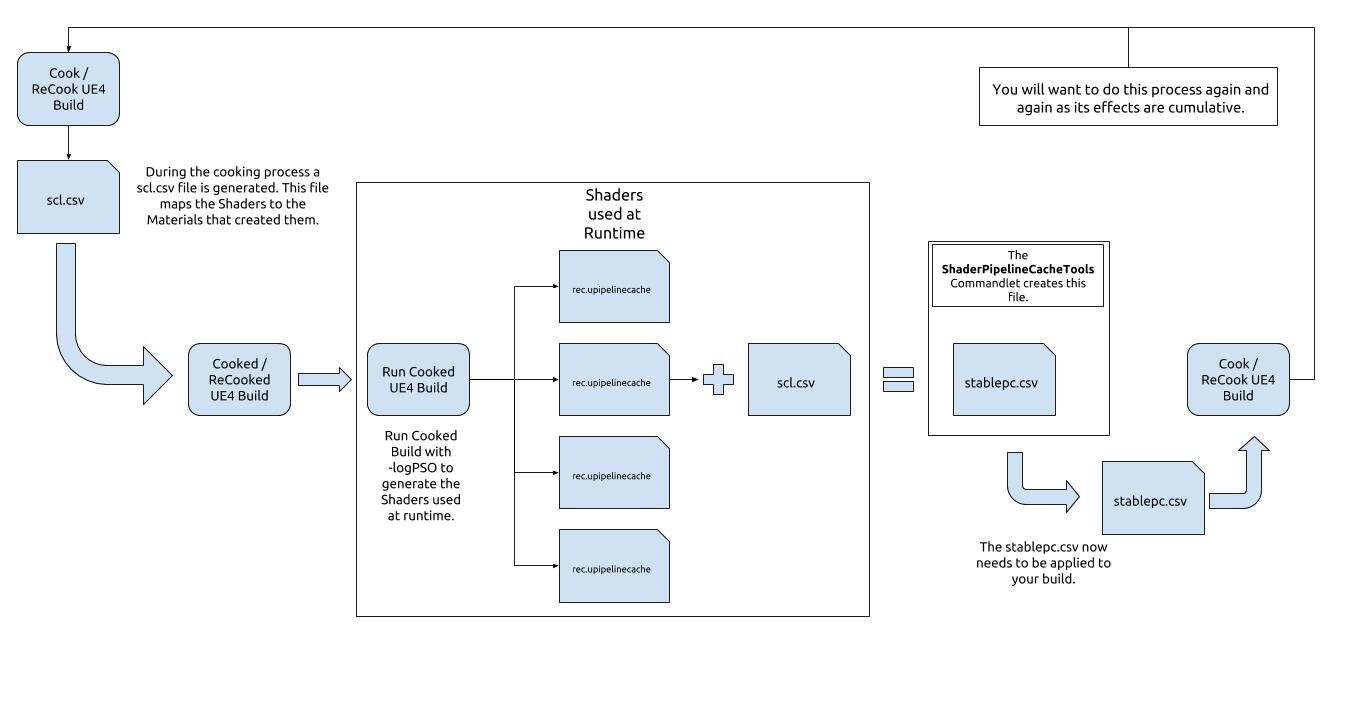
更多详情请参看UE官方文档:PSO Caching。
- 使用仅深度(Z-only)渲染。
GPU有一种特殊的模式,可以以两倍于正常模式的速率写入Z-only像素,例如应用程序渲染阴影图。
有两种方式可以让GPU进入此模式:
1、图形API明确指示,硬件才能进入这个特殊的渲染模式。
2、应用程序通过特定的渲染状态提示驱动程序。比如:使用一个空的片元着色器和禁用Frame Buffer(帧缓冲区)写掩码。
一些渲染程序或引擎(如UE)会使用专用的PrePass来渲染深度,以充分利用Early-Z计算。不过对于移动端GPU需要谨慎对待,应以实际测试为准。
- 使用间接索引(indirect indexed)的绘制接口。
间接绘制调用将开销从CPU转移到GPU,从而减少CPU和GPU的带宽。例如,在加载时缓存绘制调用参数,以便在缓冲对象存储中渲染网格。这些缓存数据可以作为glDrawArraysIndirect 或glDrawElementsIndirect的输入参数。
需要OpenGL ES 3.1才支持。
- Draw Call优化。
- 合并几何物体,同时合并它们的材质。
- 使用批处理,即便不是CPU受限,也可以减少能耗。
- 使用实例化(instance)。
- 使用非直接索引绘制。
- 避免多次绘制小量物体。
- 根据高中低画质设定合理的Draw Call数量。
使用批处理时,要注意顶点总数限制,不能超过索引的表达范围(通常最大是65k)。另外,如果合并或批处理之后的物体包围盒过大,反而会造成性能下降,因为无法有效使用Frustum Cullinig、遮挡剔除等技术进行剔除。
另外,需要注意提交的几何物体具有相邻性,尽量落在同一个Tile内,以减少覆盖的Tile数量,降低带宽,提升缓存命中率:


上:良好的几何物体提交顺序;下:错误的几何物体提交顺序。
- 禁用Alpha Test / Discard。
Alpha Test会打乱TBR的正常流程,造成渲染管线Stall,在PowerVR尤为明显(Alpha Test阶段会写回深度到HSR阶段)。
因为TB(D)R在渲染不透明物体时普遍开启了Early-Z技术和特殊的隐藏面消除技术(HSR、FPK),在此阶段会开启深度测试,并写入通过了深度测试的片元深度。但是,如果开启了Alpha Test或Shader中使用了Discard,无法在Early-Z/隐藏面消除技术阶段就确定该片元的深度是否有效,必须等执行完PS、Alpha Test等阶段才行:
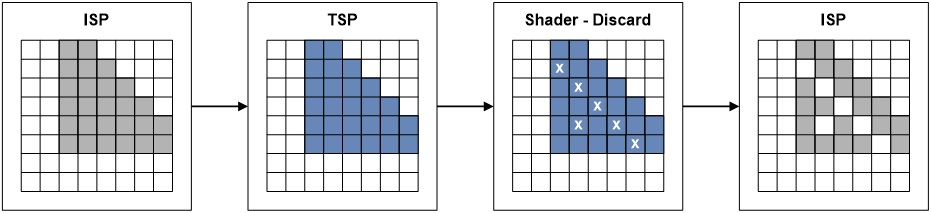
这样就无法充分发挥HSR技术的优势,从而降低渲染性能。
可以使用Alpha Blend代替Alpha Test。如果确实需要Alpha Test,则物体的渲染顺序需尊照此顺序:Opaque -> Alpha-tested -> Blended。
- 尽量减少Alpha Blend。
原因是延迟渲染器,比如PowerVR GPU,在片元着色器处理它之前计算片元的可见性,防止输出图像中的不可见片元被不必要地处理。如果需要透明对象,请尽量减少透明对象的数量。
由于Alpha Blend不能写入深度,不能充分利用HSR/FPK,会引发Overdraw,提升带宽和数据传输量。
如果确实需要,有以下优化建议:
1、优先使用unorm格式,而不是浮点数。(注意:此条来自Arm Mali的建议,其它GPU可能不一样,以实测为主)
2、如果是不透明物体,应禁用Blend和alpht to coverage。
3、不要在携带MSAA数据的浮点frame buffer上使用混合。
4、避免过高的OverDraw。监控每像素基础上生成的混合层数量,即使是简单的着色器,混合层数量高会因为片元数量多而快速消耗时钟周期。
5、考虑将大型UI元素分成不透明和透明部分。然后可以分别绘制不透明部分和透明部分,允许Early-ZS或FPK/HSR删除不透明部分下面的OverDraw。
6、不要仅仅在片元着色器中将alpha设置为1.0来禁用混合。
- 充分利用Early-Z和FPK/HSR剔除被遮挡的像素。
为了充分利用Early-Z,物体绘制顺序应该如下所示:
1、绘制不透明物体。从前向后绘制。
2、绘制镂空(Masked)物体。从前向后绘制。
3、绘制半透明物体。从后向前绘制。
对于广泛支持TBR架构的移动端GPU,不建议开启Prepass绘制专用的深度,否则反而会增加带宽和Draw Call。
另外,在绘制不透明物体时,尽量做到以下几点:
1、禁用discard语句。
2、禁用Alpha to Coverage。
3、禁止在片元着色器中修改深度。
若是违反以上任意一条,便会使Early-Z失效,强制使用Late-Z,从而降低渲染效率。
- 充分开启裁剪和测试。
裁剪技术包含遮挡剔除、视锥体裁剪、Scissor、距离裁剪、LOD等等。
测试包含背面测试、深度测试、模板测试等,但禁用透明度测试。
- 禁用Z-Prepass。
移动端GPU基于TBR结构通常内置了像素级的剔除,无需再专门绘制一次深度。UE在移动端默认禁用了Z-Prepass。
- 最小化模板缓冲的更新。
1、如果值相同,则使用KEEP而不是REPLACE。
2、有些渲染器(如UE)使用光照绘制Pass对(pair):第一个Pass用于创建模板缓冲,第二个Pass用于给未蒙版的片元着色。可以在第二个Pass重置模板值,以便为下一个光照配对做好准备,这样可以避免单独的模板清理操作。
UE的移动端场景渲染器在绘制光照时正是使用了此种模板清理优化方式。
-
正确调用图形API。
-
除非达到了目标性能,否则不要以导致GPU空闲的方式使用API。
-
不要过早等待渲染管线中的围栏(fence)和查询(query)对象的查询结果。
-
调用glMapBufferRange()时使用GL_MAP_UNSYNCHRONIZED标记开启异步,防止渲染管线卡顿。
-
避免同步方式调用以下接口:
- glFlush()。但是,某些GPU(如PowerVR)由于使用了双缓冲机制,不会卡调用线程。
- glFinish()
- glReadPixels()
- glWaitSync()
- glClientWaitSync()
- eglClientWaitSync()
- 没有GL_MAP_UNSYNCHRONIZED标记的glMapBufferRange()
避免不必要地调用以上接口,调用次数越少越好。
-
避免使用glFlush()来分割渲染通道,因为驱动程序(Mali)会在需要时自动刷新。
-
尽可能执行Clear。在绘制前或渲染通道开始时,使用glClear/glDiscardFramebufferEXT/glInvalidateFramebuffer执行渲染纹理的清理,防止GPU读取上一帧的数据到Tile缓冲区中,节省带宽。Vulkan则使用loadOp。
-
尽可能使用glColorMask屏蔽不需要写入的颜色通道。
-
如果违反以上建议,有可能导致以下结果:
1、如果管道被耗尽,GPU在产生气泡期间部分空闲,导致性能损失。
2、根据与系统动态电压和频率缩放电源管理逻辑的相互作用,可能会有一些性能不稳定。
- 优化Command Buffer。
1、要获得最佳性能,请设置ONE_TIME_SUBMIT_BIT标志。不要设置SIMULTANEOUS_USE_BIT,除非确实需要。
2、构建每帧命令缓冲区,而不是使用同步命令缓冲区。
3、如果替代方法是每次在应用程序逻辑中重放相同的命令序列,则使用SIMULTANEOUS_USE_BIT。它比应用程序手动重放命令更有效,但比一次性提交缓冲区更低效。
4、不要使用设置了RESET_COMMAND_BUFFER_BIT的命令池,会增加内存管理开销,因为驱动程序无法为池中的所有命令缓冲区使用单个大型分配器。
5、使用secondary command buffer来允许多线程渲染通道的构造。
6、最小化每帧secondary command buffer的调用次数。
- 优化描述符集和布局(descriptor sets and layouts)。
1、尽可能多地打包描述符集绑定空间。
2、更新已经分配但不再引用的描述符集,而不是重置描述符池和重新分配新的描述符集。
3、重用预分配的描述符集,避免更新相同的信息。
4、使用VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER_DYNAMIC或VK_DESCRIPTOR_TYPE_STORAGE_BUFFER_DYNAMIC绑定相同的UBO或SSBO,但不同的偏移量。 另一种选择是构建更多的描述符集。
5、不要在描述符集中留下空白,会浪费空间,阻断访问连续性。
6、不要留下未使用的条目(entry),因为复制和合并依旧有消耗。
7、不要在性能关键的代码路径上从描述符池(descriptor pool)分配描述符集。
8、如果不打算更改绑定偏移量,就不要使用DYNAMIC_OFFSET UBOs/SSBOs,因为处理动态偏移量会有很小的额外成本。低效的描述符集和布局未优化的Vulkan描述符集和布局的负面影响可能会增加绘制调用的CPU消耗。
- 避免渲染管线气泡(空闲)。
以下几种情况会产生渲染管线气泡:
1、Command Buffer提交不够频繁。不经常提交命令缓冲区会减少GPU处理队列中的工作量,限制潜在的编排机会。
2、数据依赖。假设有渲染通道M和N,M在稍后的阶段。当N在管道中被M更早地使用时,数据依赖就产生了。数据依赖会导致延迟,在此期间必须做足够的工作来隐藏结果生成中的延迟。
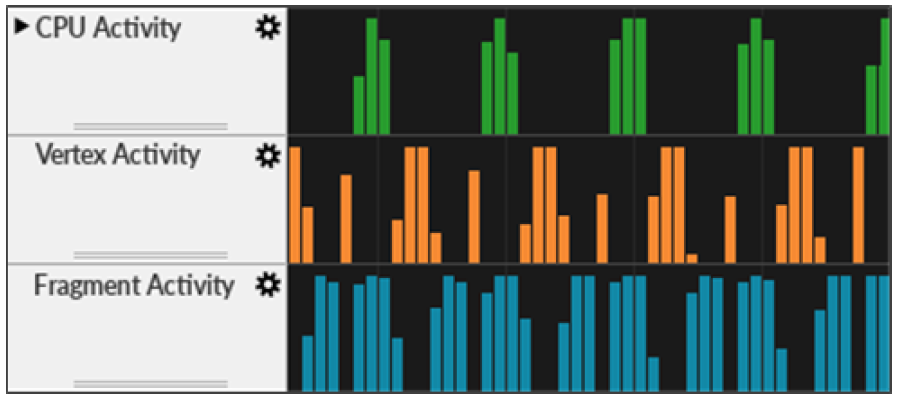
渲染管线气泡示意图。图中显示CPU、VS、PS都存在气泡。
以下建议可以减少管线气泡:
1、频繁地提交Command Buffer。例如,为帧中的每个主要渲染通道之后,但渲染通道期间不宜提交。
2、如果某些情况导致了气泡,尝试填充气泡技术。例如,通过在两个渲染通道之间插入独立的工作负载。
3、考虑在比使用依赖数据的阶段更早的管道阶段生成依赖数据。例如,计算(compute)阶段适合为顶点着色阶段生成输入数据。而片元阶段是不合适的,因为它的执行晚于顶点着色阶段管道,否则会造成卡顿和延时。
4、考虑在管道中的更后阶段处理依赖数据。例如,片元着色使用来自其他片元着色的输出比计算着色使用片元着色更好。
5、使用栅栏异步地将GPU的数据读回CPU。千万不用同步地调用从GPU读取数据到CPU的接口,否则整个渲染管线将可能发生严重停滞。
此外,以下建议可以优化渲染管线:
1、不要在管道的任何地方不必要地等待GPU数据。
2、不要等到帧结束才提交所有的渲染通道。
3、在没有足够的中间工作来隐藏延迟的情况下,不要在管道中创建任何逆向(backwards)的数据依赖。
4、不要使用vkQueueWaitIdle()或vkDeviceWaitIdle()。
- 正确使用管线同步。
现代图形API(如Vulkan)拥有非常细粒度的管线阶段:
typedef enum VkPipelineStageFlagBits
{
VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT = 0x00000001,
// Vertex Stages
VK_PIPELINE_STAGE_DRAW_INDIRECT_BIT = 0x00000002,
VK_PIPELINE_STAGE_VERTEX_INPUT_BIT = 0x00000004,
VK_PIPELINE_STAGE_VERTEX_SHADER_BIT = 0x00000008,
VK_PIPELINE_STAGE_TESSELLATION_CONTROL_SHADER_BIT = 0x00000010,
VK_PIPELINE_STAGE_TESSELLATION_EVALUATION_SHADER_BIT = 0x00000020,
VK_PIPELINE_STAGE_GEOMETRY_SHADER_BIT = 0x00000040,
// Fragment Stages
VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT = 0x00000080,
VK_PIPELINE_STAGE_EARLY_FRAGMENT_TESTS_BIT = 0x00000100,
VK_PIPELINE_STAGE_LATE_FRAGMENT_TESTS_BIT = 0x00000200,
VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT = 0x00000400,
// Compute Stages
VK_PIPELINE_STAGE_COMPUTE_SHADER_BIT = 0x00000800,
VK_PIPELINE_STAGE_TRANSFER_BIT = 0x00001000,
VK_PIPELINE_STAGE_BOTTOM_OF_PIPE_BIT = 0x00002000,
VK_PIPELINE_STAGE_HOST_BIT = 0x00004000,
VK_PIPELINE_STAGE_ALL_GRAPHICS_BIT = 0x00008000,
VK_PIPELINE_STAGE_ALL_COMMANDS_BIT = 0x00010000,
(......)
} VkPipelineStageFlagBits;
现代图形API(如Vulkan)也包含了众多同步对象:
1、Subpass依赖、Pipeline Barrier、Event等,用于单个Queue内的精细粒度同步。
2、Semaphore(信号)用于跨Queue的较重度的依赖关系。
管线依赖存在两个变量:srcStage和dstStage。srcStage标明必须等待的管线阶段(pipeline stage),dstStage标明在处理开始之前必须等待同步的管线阶段。
为了更好的并行效率和更少的管线气泡,srcStage越早越好,而dstStage越迟越好。如果srcStage是VK_PIPELINE_STAGE_BOTTOM_OF_PIPE_BIT时,将获得最差的性能。
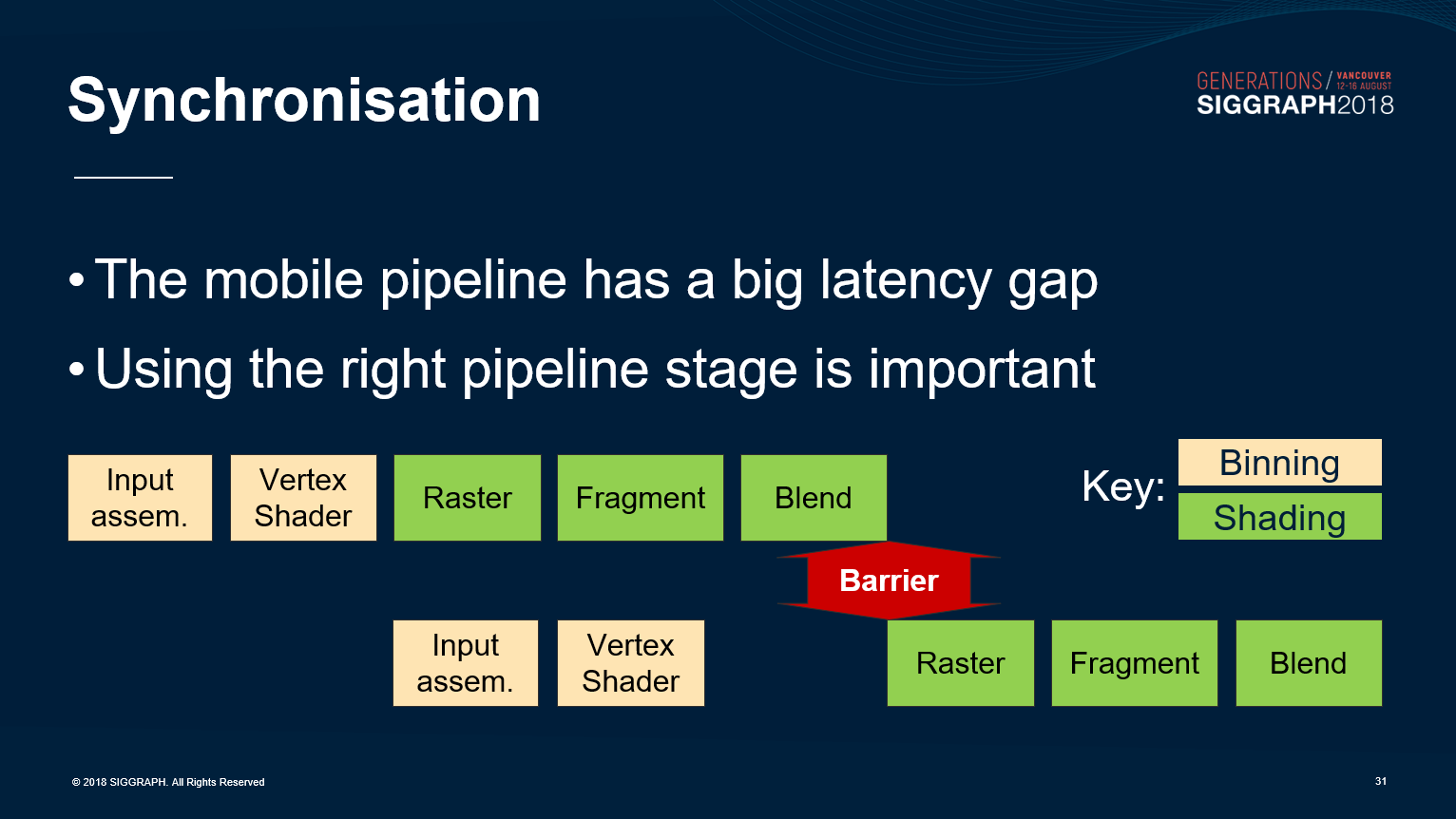
Semaphore可以使用pWaitDstStages指定具体的阶段。
更具体地说,遵循以下准则,可以获得更好的渲染效率:
1、srcStageMask被设置得越早越好。
2、dstStageMask被设置得越晚越好。
3、检查依赖关系是向前的(比如srcStageMask是顶点或计算,dstStageMask是片元)还是向后的(如srcStageMask是片元,dstStageMask是顶点或计算)。 尽量减少使用向后依赖关系。
4、如果确实需要向后依赖,则在生成和消费资源之间添加足够的延迟,以便隐藏向后依赖引起的调度气泡。
5、使用srcStageMask = ALL_GRAPHICS_BIT 和 dstStageMask = FRAGMENT_SHADER_BIT 彼此同步两个渲染通道。
6、零拷贝(Zero-copy)算法是最有效的,因此尽量减少TRANSFER拷贝操作的使用。密切关注TRANSFER副本对硬件流水线的影响。
7、只在需要时使用队列内屏障(intra-queue barrier),并在屏障之间尽可能多地安排工作。
8、不要让硬件处于空闲状态。
9、不要忘记重叠顶点/计算和片元之间的处理。
10、不要使用下面的srcStageMask到dstStageMask同步组合,因为它们会完全耗尽管道:
BOTTOM_OF_PIPE_BIT to TOP_OF_PIPE_BIT
ALL_GRAPHICS_BIT to ALL_GRAPHICS_BIT
ALL_COMMANDS_BIT to ALL_COMMANDS_BIT
11、如果合并管道屏障,请注意不要引入错误的依赖项。确保不打破顶点/片元重叠,并创建一个不必要的气泡。
12、不要使用VkEvent信号并立即等待该事件,用vkCmdPipelineBarrier()。
13、不要在单个Queue中使用VkSemaphore进行依赖管理。
14、不要让渲染管线留有太大的空闲(否则降低性能),也不要让渲染管线留有太小的空闲(否则可能产生错误)。
- 正确处理管线资源。
OpenGL ES为应用开发人员提供了一个同步呈现模型,即使底层的执行可能是异步的,必须反映数据资源在绘制调用时的状态。如果一个应用程序修改了一个资源,而一个挂起的draw调用仍在引用它,那么驱动程序必须采取规避操作来确保正确性。
驱动程序处理这些资源的同步行为时因GPU厂商而异,例如Mali驱动程序避免了阻塞和等待资源引用计数达到零,因为这样做会耗尽管道并导致性能低下。Mali GPU会创建一个全新版本的资源,资源的旧版本或幽灵(Ghost)版本将一直保留,直到挂起的绘制调用完成,其引用计数降至零。其它一些驱动程序(如PowerVR)会卡住本帧的渲染管线,延迟到下一帧处理,引发性能下降。
这种行为开销大,需要为新资源分配内存,并在完成时清理空资源。如果更新不是完全替换,还需要从旧的资源缓冲区复制到新的资源缓冲区。
为了优化资源,需要遵循以下建议:
1、避免修改已入队的draw call引用的资源,可以使用N-buffered资源,并通过管道进行动态资源更新。
2、使用GL_MAP_UNSYNCHRONIZED标记,以允许使用glMapBufferRange()来补齐缓冲区中仍被动态绘制调用引用的未引用区域。不要将GL_MAP_INVALIDATE_BUFFER /GL_MAP_INVALIDATE_RANGE与glMapBufferRange()一起使用,因为这些标志在某些版本的驱动会触发创建一个不必要的资源拷贝。
- 高效地上传纹理资源。
上传纹理资源到到图形硬件时,对于非压缩纹理,按线性的扫描线上传,对于压缩的纹理,将会逐块上传。
部分GPU内部(如PowerVR)使用独特的布局来改善内存访问局部性和提高缓存效率。数据的重新格式化是由专用硬件在芯片上完成的,因此非常快。如果能遵循以下步骤更能提升性能:
1、在非性能关键时期上传纹理,如初始化。有助于避免与纹理加载相关的帧率下降。
2、避免上传帧期间(mid-frame)的纹理数据到已经用于该帧的纹理对象。
3、在纹理上传完成后执行一个预热(warm-up)步骤。依然是有助于避免与纹理加载相关的帧率下降。
前面提到的预热(warm-up)步骤可以确保纹理立即完全上传。默认情况下,glTexImage2D不会立即执行上传所需的所有处理,纹理是在第一次使用时完全上传的。可以通过在屏幕上画出一系列三角形或用有问题的纹理对象进行绑定处理来强制上传。
12.6.1.3 带宽优化
- 注意数据的存放位置。如:RAM、VRAM、Tile Buffer、GPU Cache,减少不必要的数据传输。
- 关注数据的访问类型。如:是只读还是只写操作,是否需要原子操作,是否需要缓存一致性。
- 关注缓存数据的可行性,硬件可以缓存数据以供GPU后续操作快速访问。可以通过以下几点提升缓存命中率:
- 提高传输速度,确保客户端顶点数据缓冲区被用于尽可能少的绘制调用。理想情况下,应用程序永远不应该使用它们。
- 减少GPU在执行调度或绘制调用时需要访问的数据量。这样可以让尽量多的数据放到缓存行,提升命中率。
- 使用纹理压缩格式。优先ASTC,其次是ETC、PVRTC、BC等压缩格式。GPU的硬件通常都支持这类压缩格式,可以快速地编解码它们,并且可以一次性读取更多的纹素内容到GPU的缓存行,提升缓存命中率。
- 使用位数更少的像素格式。如RGB565比RGB888少8位,ASTC_6X6代替ASTC_4x4等。Adreno支持的像素格式参见Spec Sheets。
- 使用半精度(如FP16)取代高精度(FP32)数据。如模型顶点和索引数据,并且可以使用SOA(Structure of Array)数据布局,而不用AOS。
- 降分辨率渲染,后期再放大。可以减少带宽、计算量,减少设备热发热量。
- 尽量减少绘制次数。绘制数量的减少可以减少CPU和GPU之间、GPU内部的带宽和消耗。
- 确保数据存储在On-Chip内。
利用PLS、Subpass的特性,可以实现移动端的延迟渲染、粒子软混合等。下表是PowerVR GX6250在实现延迟渲染时,使用不同的位数和性能的关系:
| 配置 | 时间/帧(ms) |
|---|---|
| 96bit + D32 | 20 |
| 128bit + D32 | 21 |
| 160bit + D32 | 23 |
| 192bit + D32 | 24 |
| 224bit + D32 | 28 |
| 256bit + D32 | 29 |
| 288bit + D32 | 39 |
以上可知,当位数大于256,超过GX6250的最大位数,数据无法完全存储在On-Chip内,会外溢到全局内存,导致每帧时间暴增10ms,增幅为34.5%。
因此,对每像素的数据进行精心的组装、优化和压缩,保持数据能够完全容纳于On-Chip内,可有效提升性能,节省带宽。
- 避免多余的副本。
确保使用相同内存的硬件组件(CPU、图形核心、摄像机接口和视频解码器等)都访问相同的数据,而不需要进行任何中间复制。
- 使用正确的标记创建Buffer、纹理等内存。部分Mali GPU(如Bifrost)执行以下几个标记组合:
1、DEVICE_LOCAL_BIT | HOST_VISIBLE_BIT | HOST_COHERENT_BIT
2、DEVICE_LOCAL_BIT | HOST_VISIBLE_BIT | HOST_CACHED_BIT
3、DEVICE_LOCAL_BIT | HOST_VISIBLE_BIT | HOST_COHERENT_BIT | HOST_CACHED_BIT
4、DEVICE_LOCAL_BIT | LAZILY_ALLOCATED_BIT
其中HOST_VISIBLE_BIT | HOST_COHERENT_BIT | HOST_CACHED_BIT的内存类型说明如下:
1、提供CPU上的缓存存储,与内存的GPU视图一致,无需手动同步。
2、如果芯片组支持CPU与GPU之间的硬件一致性协议,则该GPU支持此标记组合。
3、由于硬件的一致性,它避免了手动同步操作的开销。当可用时,缓存的、一致的内存优先于缓存的、不一致的内存类型。
4、必须用于CPU上的应用软件映射和读取的资源。
5、硬件一致性的功耗很小,所以不能用于CPU上只写的资源。对于只写资源,通过使用Not Cached,一致内存类型绕过CPU缓存。
关于LAZILY_ALLOCATED内存类型说明:
1、是一种特殊的内存类型,最初只支持GPU虚拟地址空间,而不是物理内存页面。如果访问内存,则根据需要分配物理页。
2、必须与使用VK_IMAGE_USAGE_TRANSIENT_ATTACHMENT_BIT创建的瞬态attachment一起使用。瞬态Image的目的是用作帧缓冲attachment,只存在于一个单一的渲染过程中,可以避免使用物理内存。
3、不能将数据写回全局内存。
以下是Vulkan内存标记的使用建议:
1、对于不可变资源,使用HOST_VISIBLE | HOST_COHERENT内存。
2、对于CPU上只写的资源,使用HOST_VISIBLE | HOST_COHERENT内存。
3、使用memcpy()将更新写入HOST_VISIBLE | HOST_COHERENT内存,或者按顺序写入以获得CPU write-combine单元的最佳效率。
4、使用HOST_VISIBLE | HOST_COHERENT | HOST_CACHED内存用于将资源读回CPU,如果此组合不可以,则使用HOST_VISIBLE | HOST_CACHED。
5、使用LAZILY_ALLOCATED内存用于仅在单个渲染过程中存在的临时帧缓冲区附件。
6、只将LAZILY_ALLOCATED内存用于TRANSIENT_ATTACHMENT帧缓冲区附件。
7、映射和取消映射缓冲区消耗CPU性能。因此要持久地映射经常被访问的缓冲区,例如:统一缓冲区、数据缓冲区或动态顶点数据缓冲区。
- 尽量使用零拷贝(Zero-Copy)路径。
如下图所示,通过使用EglImage实现Camera和OpenCL共享Original Image Data,OpenCL和OpenGL ES共享Final Image Data,从而达到零拷贝:

- 将内存访问分组。
编译器使用几种启发式方法,可以识别内核中的内存访问模式,这些模式可以组合成读或写操作的突发传输。为了让编译器更好实现这种优化,内存访问应该尽可能紧密地组合在一起。
例如,将读放在内核的开头,写放在内核的结尾,可以获得最佳的效率。对更大的数据类型(如向量)的访问也会尽可能地编译为单个传输,加载1个float4比加载4个单独的float值更好。
- 合理使用Shared/Local内存。
可以在Shader初期(如初始化),将常访问的数据先读取到Shared/Local内存,提升访问速度。
- 以行优先(Row-Major)的顺序访问内存。
GPU通常会预读取行相邻的数据到GPU缓存中,如果着色器算法以行优先的方式访问,可以提升Cache命中率,降低带宽。
- GPU特定带宽优化。
Mali的Transaction elimination只有在以下情形适用:
1、采样数据为1。
2、mimap级别为1。
3、image使用了COLOR_ATTACHMENT_BIT。
4、image没有使用TRANSIENT_ATTACHMENT_BIT。
5、使用单一颜色附件。(Mali-G51 GPU及之后没有此限制)
6、有效的tile尺寸是16x16像素,像素数据存储决定了有效的tile尺寸。
Mali GPU还支持AFBC纹理,可以减少显存和带宽。
12.6.2 资源优化
12.6.2.1 纹理优化
- 使用压缩格式。
ASTC由于出色的压缩率,更接近原图的画质,适应更多平台而成为首选的纹理压缩格式。因此,只要可能,尽量使用ASTC。除非部分古老的设备,无法支持ASTC,才考虑使用ETC、PVRTC等纹理压缩格式。详见12.4.14 Adaptive Scalable Texture Compression。
- 尽量使用Mipmaps。
纹理Mipmaps提供提升内存占用来达到降低采样纹理时的数据量,从而降低带宽,提升缓冲命中率,同时还能提升画质效果。鱼和熊掌皆可得,何乐而不为?具体地说表现在以下方面:
1、极大地提高纹理缓存效率来提高图形渲染性能,特别是在强烈缩小的情况下,纹理数据更有可能装在Tile Memory。
2、通过减少不使用mipmapping的纹理采样不足而引起的走样来提高图像质量。
但是,使用Mipmaps会提升33%的内存占用。以下情况需要避免使用:
1、过滤不能被合理地应用,例如对于包含非图像数据的纹理(索引或深度纹理)。
2、永远不会缩小的纹理,比如UI元素,其中texel总是一对一地映射到像素。
- 使用打包的图集。
打包图集之后,有可能合批渲染或实例化渲染,减少CPU和GPU的带宽。
- 尺寸保持2的N次方。
尽管目前的图形API都已经支持非2N的次方尺寸(NPOT)的纹理,但有充分的理由建议保持纹理尺寸在2的N次方(POT):
1、在大多数情况下,POT纹理应该比NPOT纹理更受青睐,因为这为硬件和驱动程序的优化工作提供了最好的机会。(例如纹理压缩、Mimaps生成、缓存行对齐等)
2、2D应用程序应该不会因为使用NPOT纹理而出现性能损失(除非可能在上传时)。2D应用程序可以是浏览器或其他呈现UI元素的应用程序,其中NPOT纹理以一对一的texel到pixel映射显示。
3、保证长和宽都是32像素倍数的纹理,以便纹理上传可以让硬件优化。
- 最小化纹理尺寸。
- 最小化纹理位深。
- 最小化纹理组件数量。
- 利用纹理通道打包多张贴图。例如将材质的粗糙度、高光度、金属度、AO等贴图打包到同一张纹理的RGBA通道上。
12.6.2.2 顶点优化
- 使用分离位置的交错的顶点布局。原因详见12.4.11 Index-Driven Vertex Shading。
- 使用合适的顶点和索引存储格式。降低数据精度可以降低内存、带宽,提高计算单元运算量。目前主流移动端GPU支持的顶点格式有:
GL_BYTE
GL_UNSIGNED_BYTE
GL_SHORT
GL_UNSIGNED_SHORT
GL_FIXED
GL_FLOAT
GL_HALF_FLOAT
GL_INT_2_10_10_10_REV
GL_UNSIGNED_INT_2_10_10_10_REV
-
考虑几何物体实例化。现代移动端GPU普遍支持实例化渲染,通过提交少量的几何数据可以绘制多次,来降低带宽。每个实例允许拥有自己的数据,如颜色、变换矩阵、光照等。常用于树、草、建筑物、群兵等物体。
-
图元类型使用三角形。现代GPU设计便是处理三角形,如果是四边形之类的很可能会降低效率。
-
减少索引数组大小。如使用条带(strip)格式代替简单列表格式,使用原始的有效索引代替退化三角形。
-
对于转换后缓存( post-transform cache),局部地优化索引。
-
避免使用低空间一致性的索引缓冲区。会降低缓存命中率。
-
使用实例属性来解决任何统一的缓冲区大小限制。 例如,16KB的统一缓冲区。
-
每个实例使用2的N次方个顶点。
-
优先使用gl_InstanceID到统一缓冲区或着色器存储缓冲区的索引查找,而不是逐实例属性数据。
12.6.2.3 网格优化
- 使用LOD。
使用网格的LOD可以提升渲染性能和降低带宽。相反,不使用LOD,会造成性能瓶颈。
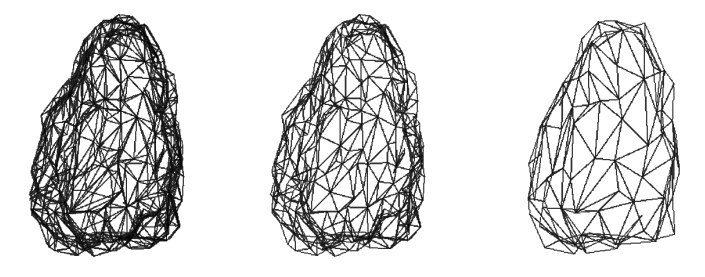
同个网格不同LOD的线框模式。
以下是浪费计算和内存资源的例子:
1、使用大量多边形的对象不会覆盖屏幕上的一个小区域,比如一个遥远的背景对象。
2、使用多边形的细节,将永远不会看到由于相机的角度或裁剪(如物体在视野锥之外)。
3、为对象使用大量的图元。实际上可以用更少的图元来绘制,还能保证视觉效果不损失。
-
简化模型,合并顶点。通过合并相邻很近的顶点,可以有效减少网格顶点数量,利用网格简化技术,可以生成良好的LOD数据。
-
离线合并靠在一起的小网格。如沙石、植被等。
-
单个网格的顶点数不能超过65k。主要是移动端的顶点索引精度是16位,最大值是65535。
-
删除看不见的图元。例如箱子内部的三角形。
-
使用简单的几何物体,配合法线贴图、凹凸贴图增加细节。
-
避免小面积的三角形。
Quad的绘制机制,会导致小面积的三角形极大提升OverDraw。在PowerVR硬件上,对于覆盖低于32个像素的三角形,会影响光栅化的效率,导致性能瓶颈。
提交许多小三角形可能会导致硬件在顶点阶段花费大量时间处理它们,此阶段主要影响因素是三角形的数量而不是大小。尤其会导致平铺加速器( tile accelerator,TA)固定功能硬件的瓶颈。数量众多的小三角形将导致对位于系统内存中的参数缓冲区(parameter buffer)的访问次数增加,增加内存带宽占用。
- 保证网格内每个图元至少能创建10~20个像素。
- 使用几乎等边的三角形。可以使面积与边长的比例最大化,减少生成的片元Quad的数量。
- 避免细长的三角形。
和小三角形类似,细长三角形(下图红色所示)也会产生更多无效的像素,占用更高的GPU资源,提高Overdraw。

- 避免使用扇形或类似的几何布局。三角形扇形的中心点具有较高的三角形密度,以致每个三角形具有非常低的像素覆盖率。可以考虑Tile轴对齐的切割,但会引入更多三角形。(下图)

扇形(图左)进行Tile轴对齐的切割后产生的三角形数量(图右)。
12.6.3 Shader优化
12.6.3.1 语句优化
- 使用适当的数据类型。
在代码中使用最合适的数据类型可以使编译器和驱动程序优化代码,包括shader指令的配对。使用vec4数据类型而不是float可能会阻止编译器执行优化。
int4 ResultOfA(int4 a)
{
return a + 1; // int4和int相加, 只需要1条指令.
}
int4 ResultOfA(int4 a)
{
return a + 1.0; // int4和float相加, 需要3条指令: int4 -> float4 -> 相加 -> int4
}
- 减少类型转换。
uniform sampler2D ColorTexture;
in vec2 TexC;
vec3 light(in vec3 amb, in vec3 diff)
{
// 纹理采样返回vec4, 会隐性转换成vec3, 多出1条指令.
vec3 Color = texture(ColorTexture, TexC);
Color *= diff + amb;
return Color;
}
// 以下代码中, 输入参数/临时变量/返回值都是vec4, 没有隐性类型转换, 比上面代码少1条指令.
uniform sampler2D ColorTexture;
in vec2 TexC;
vec4 light(in vec4 amb, in vec4 diff)
{
vec4 Color = texture(Color, TexC);
Color *= diff + amb;
return Color;
}
- 打包标量常数。
将标量常数填充到由四个通道组成的向量中,大大提高了硬件获取效率。在GPU骨骼动画系统中,可增加蒙皮的骨骼数量。
float scale, bias; // 两个float值.
vec4 a = Pos * scale + bias; // 需要两条指令.
vec2 scaleNbias; // 将两个float值打包成一个vec2
vec4 a = Pos * scaleNbias.x + scaleNbias.y; // 一条指令(mad)完成.
- 使用标量操作。
要小心标量操作向量化,因为相同的向量化输出需要更多的时间周期。例如:
highp vec4 v1, v2;
highp float x, y;
// Bad!!
v2 = (v1 * x) * y; // vector*scalar接着vector*scalar总共8个标量muladd.
// Good!!
v2 = v1 * (x * y); // scalar*scalar接着vector*scalar总共5个标量muladd.
12.6.3.2 状态优化
- 尽量使用const。
如果正确使用,const关键字可以提供显著的性能提升。例如,在main()块之外声明一个const数组的着色器比没有的性能要好得多。
另一个例子是使用const值引用数组成员。如果值是const,GPU可以提前知道数字不会改变,并且数据可以在运行着色器之前被预读取,从而降低Stall。
- 保持着色器指令数量合理。
过长的着色器通常比较低效,比如需要在一个着色器中包含相对于纹理获取数量的许多指令槽,可以考虑将算法分成几个部分。
由算法的一部分生成的值可以存储到纹理中,然后通过采样纹理来获取。然而,这种方法在内存带宽方面代价昂贵。以下情形也会降低纹理采样效率:
1、使用三线性、各向异性过滤、宽纹理格式、3D和立方体贴图纹理、纹理投影;
2、使用不同Lod梯度的纹理查找;
3、跨像素Quad的梯度计算。
- 最小化shader指令数。
现代shader编译器通常会执行特定的指令优化,但它不是自动有效的。很多时候需要人工介入,分析着色器,尽可能减少指令,即使是节省一条指令也值得。
- 避免使用全能着色器(uber-shader)。
uber-shader使用静态分支组合多个着色器到一个单一的着色器。如果试图减少状态更改和批处理绘制调用,那么是有意义的。然而,通常会增加GPR数量,从而影响性能。
- 高效地采样纹理。
纹理采样(过滤)的方式很多,性能和效果通常成反比:

纹理的部分过滤类型及对应效果图。
要做到高效地采样纹理,必须遵循以下规则:
1、避免随机访问,保持采样在同一个2x2像素Quad内,命中率高,着色器更有效率。
2、避免使用3D纹理。由于需要执行复杂的过滤来计算结果值,从体积纹理中获取数据通常比较昂贵。
3、限制Shader纹理采样数量。在一个着色器中使用四个采样器是可以接受的,但采样更多的纹理可能会导致性能瓶颈。
4、压缩所有纹理。这允许更好的内存使用,转化为渲染管道中更少的纹理停顿。
5、考虑开启Mipmaps。Mipmaps有助于合并纹理获取,并有助于以增加内存占用为代价的提高性能。同时还能降低带宽,提升缓存命中率。
6、尽量使用简单的纹理过滤。性能从高到低(效果从低到高)的采样方式:最近点(nearest)、双线性(bilinear)、立方(cubic)、三线性(tri-linear)、各向异性(anisotropic)。越复杂的采样方式,会读取越多的数据,从而提升内存访问带宽,降低缓存命中率,造成更大的延迟。需要格外注意这一点。
7、优先使用texelFetch / texture(),通常会比纹理采样效率更高(但需要工具分析验证)。
8、谨慎对待预计算纹理LUT。实时渲染中,很常将复杂计算的结果编码到纹理中,并将其用作查找表(如IBL的辐照度图,皮肤次表面散射预积分图)。这种方式只会在着色器是瓶颈时提升性能。如果函数参数和查找表中的纹理坐标在相邻片元之间相差很大,那么缓存效率就会受到影响。应该执行性能概要分析,以确定此法是否有实际上的提升。
9、使用mediump sampler代替highp sampler,后者的速度是前者的一半。
10、各向异性过滤(Anisotropic Filtering,AF)优化建议:
(1)先使用2x各向异性,评估它是否满足质量要求。较高的样本数量可以提高质量,但也会带来效益递减,并且往往与性能成本不相称。
(2)考虑使用2x双线性各向异性,而非三线性各向同性。在各向异性高的区域,2x双线性算法速度更快,图像质量更好。注意,通过切换到双线性过滤,可以在mipmap级别之间的过度点上看到接缝。
(3)只对受益最大的对象使用各向异性和三线性滤波。注意,8x三线性各向异性的消耗是简单双线性过滤的16倍!
- 尽量避免依赖纹理读取(Dependent texture read)。
依赖纹理读取是一种特殊的纹理读取,其中纹理坐标依赖于着色器中的一些计算(而不是某种规律变化)。由于这个计算的值不能提前知道,它不可能预取纹理数据,因此在着色器处理降低缓存命中率,引发卡顿。
顶点着色纹理查找总是被视作依赖纹理读取,就像片元着色中基于zw通道变化的纹理读取。在一些驱动程序和平台版本中,如果给定带有无效w的Vec3或Vec4,则Texture2DProj()也可以作为依赖纹理读取。
与依赖纹理读取相关的成本在某种程度上可以通过硬件线程调度来抵消,特别是着色器涉及大量的数学计算。这个过程涉及到线程调度程序暂停当前线程并在另一个线程中交换到USC上的处理。这个交换的线程将尽可能多地处理,一旦纹理获取完成,原始线程将被交换回(下图)。

GPU的Context需要访问缓存或内存,会导致若干个时钟周期的延迟,此时调度器会激活第二组Context以利用ALU。

GPU越多Context可用就越可以提升运算单元的吞吐量,上图的18组Context的架构可以最大化地提升吞吐量。
虽然硬件会尽力隐藏内存延迟,但为了获得良好的性能,应该尽可能避免依赖纹理读取。应用程序尽量在片元着色器执行之前就计算出纹理坐标。
- 避免使用动态分支。
动态分支会延迟shader指令时间,但如果分支的条件是常量,则编译器就会在编译器进行优化。否则如果条件语句和uniform、可变变量相关,则无法优化。其它建议:
1、最小化空间相邻着色线程中的动态分支。
2、使用min(), max(), clamp(), mix(), saturate()等内置函数避免分支语句。
3、检查分支相对于计算的好处。例如,跳过距离相机阈值以上的像素进行光照计算,通常比直接进行计算会更快。
- 打包shader插值数据。
着色器插值需要GPR(General Purpose Register,通用寄存器)传递数据到像素着色器。GPR的数量有限,若占满,会导致Stall,所以尽量减少它们的使用。
能使用uniform的就不用varying。将值打包在一起,因为所有varying都有四个组件,不管它们是否被使用,比如将两个vec2纹理坐标放入一个vec4。也存在其它更有创意的打包和实时数据压缩。
- 减少着色器GRP的占用。
占用越多的GPR(General Purpose Register,通用寄存器)意味着计算量大,如果没有足够的可用寄存器时,可能会导致寄存器溢出,从而导致性能欠佳。以下一些措施可以减少GRP的占用:
1、使用更简单的着色器。
2、修改GLSL以减少哪怕是一条指令,有时也能减少一个GPR的占用。
3、不展开循环(unrolling loop)也可以节省GPRs,但取决于着色器编译器。
4、根据目标平台配置着色器,确保最终选择的解决方案是最高效的。
5、展开循环倾向于将纹理获取放到着色器顶部,导致需要更多的GPR来保存多个纹理坐标并同时获取结果。
6、最小化全局变量和局部变量的数量。减少局部变量的作用域。
7、最小化数据维度。比如能用2维的就不要用3维。
8、使用精度更小的数据类型。如FP16代替FP32。
- 在着色器上避免常量的数学运算。
自从着色器出现以来,几乎每一款发行的游戏都在着色器常量上花费了不必要的数学运算指令。需要在着色器中识别这些指令,将这些计算移到CPU上。在编译后的代码中识别着色器常量的数学运算可能更容易。
- 避免在像素着色器中使用discard等语句。
一些开发者认为,在像素着色器中手动丢弃(也称为杀死)像素可以提高性能。实际上没有那么简单,有以下原因:
1、如果线程中的一些像素被杀死,而同Quad的其他像素没有,着色器仍然执行。
2、依赖于编译器如何生成微代码(Microcode)。
3、某些硬件架构(如PowerVR)会禁用TBDR的优化,造成渲染管线的Stall和数据回写。
- 避免在像素着色器中修改深度。
理由类同上一条。
- 避免在VS里采样纹理。
虽然目前主流的GPU已经使用了统一着色器架构,VS和PS的执行性能相似。但是,还是得确保在VS对纹理操作是局部的,并且纹理使用压缩格式。
- 拆分特殊的绘制调用。
如果一个着色器瓶颈在于GPR和/或纹理缓存,拆分Draw Call到多个Pass反而可以增加性能。但结果难以预测,应以实际性能测试为准。
- 尽量使用低精度浮点数。
FP16的运算性能通常是FP32的两倍,所以shader中尽可能使用低精度浮点数。
precision mediump float;
#ifdef GL_FRAGMENT_PRECISION_HIGH
#define NEED_HIGHP highp
#else
#define NEED_HIGHP mediump
#endif
varying vec2 vSmallTexCoord;
varying NEED_HIGHP vec2 vLargeTexCoord;
UE也对浮点数做了封装,以便在不同平台和画质下自如低切换浮点数的精度。
- 尽量将PS运算迁移到VS。
通常情况下,顶点数量明显小于像素数量。通过将计算从像素着色器迁移到顶点着色器,可以减少GPU工作负载,有助于消除冗余计算。
例如,拆分光照计算的漫反射和高光反射,将漫反射迁移到VS,而高光反射保留在PS中,这样能获得效果和效率良好平衡的光照结果。
- 优化Uniform / Uniform Buffer。
1、保持Uniform数据尽可能地小。不超过128字节,以便在多数GPU良好地运行任意给定的着色器。
2、将Uniform改成OpenGL ES的带有#define的编译时常量,Vulkan的专用常量,或者着色源中的静态语法。
3、避免Uniform的向量或矩阵中存在常量,例如总是0或1的元素。
4、优先使用glUniform()设置uniform,而不是从buffer中加载。
5、不要动态地索引uniform数组。
6、不要过度使用实例化。使用gl_InstanceID访问Instanced uniform就是动态索引,无法使用寄存器映射的Uniform。
7、将Uniform的相关计算尽可能地移到CPU的应用层。
8、尽量使用uniform buffer代替着色器存储缓冲区(shader storage buffer)。只要uniform buffer空间充足,就尽量使用之。如果uniform buffer对象在GLSL中静态索引,并且足够小,驱动程序或编译器可以将它们映射到用于默认统一块全局变量的相同硬件常量RAM中。
- 保持UBO占用尽可能地小。
如果UBO小于8k,则可以放进常量存储器,将获得更高的性能。否则,会存储在全局内存,存取时间周期显著增加。
- 选择更优的着色算法。
选择更优的有效的算法比低级别(指令级)的优化更重要。因为前者更能显著地提升性能。
- 选择合适的坐标空间。
顶点着色器的一个常见错误是在模型空间、世界空间、视图空间和剪辑空间之间执行不必要的转换。如果模型世界转换是刚体转换(只包含旋转、平移、镜像、光照或类似),那么可以直接在模型空间中进行计算。
避免将每个顶点的位置转换为世界或视图空间,更好的做法是将uniforms(如光的位置和方向)转换到模型空间,因为它是一个逐网格的操作,计算量更少。在必须使用特定空间的情况下(例如立方体映射反射),最好整个Shader都使用这个空间,避免在同一个shader中使用多个坐标空间。
- 优化插值(Varying)变量。
减少插值变量数量,减少插值变量的维度,删除无用(片元着色器未使用)的插值变量,紧凑地打包它们,尽可能使用中低精度数据类型。
- 优化原子(Atomic)。
原子操作在许多计算算法和一些片元算法中比较常见。通过一些微小的修改,原子操作允许许多算法在高度并行的GPU上实现,否则将是串行的。
原子的关键性能问题是争用(contention)。原子操作来自不同的着色器核心。要达到相同的高速缓存行(cache line),需要数据一致性访问L2高速缓存。
通过将原子操作保持在单个着色器核心来避免争用,当着色器核心在L1中控制必要的缓存行时,原子是最高效的。以下是具体的优化建议:
1、考虑在算法设计中使用原子时如何避免争用。
2、考虑将原子间距设置为64个字节,以避免多个原子在同一高速缓存行上竞争。
3、考虑是否可以通过累积到共享内存原子中来分摊争用。然后,让其中的一个线程在工作组的末尾推送全局原子操作。
- 充分利用指令缓存(Instruction cache)。
着色器核心指令缓存是一个经常被忽略的影响性能的因素。由于并发运行的线程数量众多,因此足够重视指令缓存对性能的重要性。优化建议如下:
1、使用较短的着色器与更多的线程,而不是更长的色器与少量的线程。较短的着色器指令在缓存中更有可能被命中。
2、使用没有动态分支的着色器。动态分支会减少时间局部性,增加缓存压力。
3、不要过于激进地展开循环(unroll loop),尽管一些展开可能有所帮助。
4、不要从相同的源代码生成重复的着色程序或二进制文件。
5、小心同个tile内存在多个可见的片元着色(即Overdraw)。所有未被Early-ZS或FPK/HSR剔除的片元着色器,必须加载和执行,增加缓存压力。
12.6.3.3 汇编级优化
建议Shader低级别优化只在性能异常敏感的地方或者优化后期才关注和执行,否则可能事倍功半。
对于GPU指令集,很多指令可以在1个时钟周期完成,但有些指令则需要多个周期。下图是PowerVR的部分可以在1个时钟周期完成的指令:
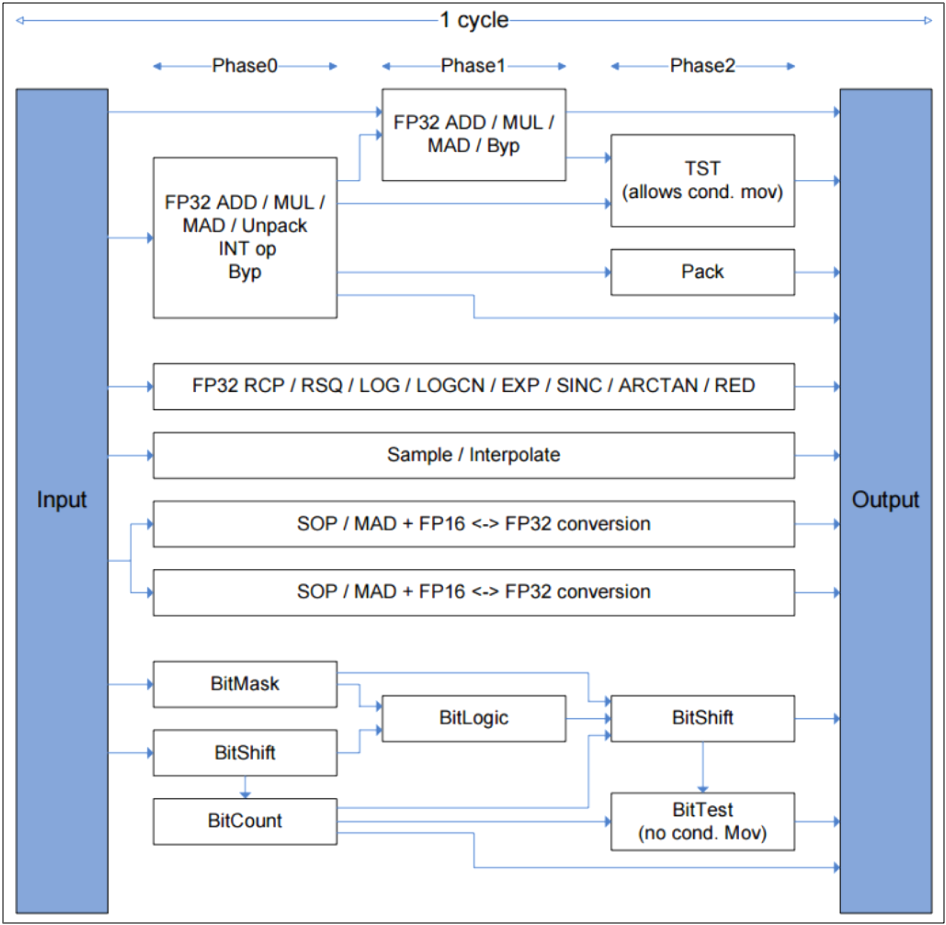
对于峰值性能的测量,若以PowerVR 500MHz G6400为例,则常见指令的峰值性能数据如下:
| 数据类型 | 操作 | 单指令操作数 | 单指令时钟 | 理论吞吐量 |
|---|---|---|---|---|
| 16-bit float | Sum-Of-Products | 6 | 1 | (0.5 × 4 × 16 × 6) ÷ 1 = 192 GFLOPS |
| float | Multiply-and-Add | 4 | 1 | (0.5 × 4 × 16 × 4) ÷ 1 = 128 GFLOPS |
| float | Multiply | 2 | 1 | (0.5 × 4 × 16 × 2) ÷ 1 = 64 GFLOPS |
| float | Add | 2 | 1 | (0.5 × 4 × 16 × 2) ÷ 1 = 64 GFLOPS |
| float | DivideA | 1 | 4 | (0.5 × 4 × 16 × 1) ÷ 4 = 8 GFLOPS |
| float | DivideB | 1 | 2 | (0.5 × 4 × 16 × 1) ÷ 2 = 16 GFLOPS |
| int | Multiply-and-Add | 2 | 1 | (0.5 × 4 × 16 × 2) ÷ 1 = 64 GILOPS |
| int | Multiply | 1 | 1 | (0.5 × 4 × 16 × 1) ÷ 1 = 32 GILOPS |
| int | Add | 1 | 1 | (0.5 × 4 × 16 × 1) ÷ 1 = 32 GILOPS |
| int | Divide | 1 | 30 | (0.5 × 4 × 16 × 1) ÷ 30 = 1.07 GILOPS |
性能估计以理论上的峰值来计算,实际上由于各种依赖、降频、上下文切换等原因,可能实际峰值达不到。
默认情况下,编译器将浮点除法实现为两个范围缩减,然后是倒数和乘法指令,需要4个循环。
另外,重点提一下整数除法,效率极低,应该避免,可以先转成float再除。
更多指令的消耗情况可参见Complex Operations。
下面是常见的低级别优化措施(以PowerVR为例,其它GPU类似但不完全相同,应以实测为准)。
1、为了充分利用USC核心,必须始终以乘-加(MAD)形式编写数学表达式。例如,更改以下表达式以使用MAD表单可以减少50%的周期成本:
fragColor.x = (t.x + t.y) * (t.x - t.y); // 2 cycles
{sop, sop, sopmov}
{sop, sop}
-->
fragColor.x = t.x * t.x + (-t.y * t.y); // 1 cycle
{sop, sop}
2、通常最好以倒数形式写除法,因为倒数形式直接由指令RCP支持。完成数学表达式的简化可以进一步提高性能。
fragColor.x = (t.x * t.y + t.z) / t.x; // 3 cycles
{sop, sop, sopmov}
{frcp}
{sop, sop}
-->
fragColor.x = t.y + t.z * (1.0 / t.x); // 2 cycles
{frcp}
{sop, sop}
3、sign(x)的结果可能是以下几种:
if (x > 0)
{
return 1;
}
else if(x < 0)
{
return -1;
}
else
{
return 0;
}
但利用sign来获取符号并非最优选择:
fragColor.x = sign(t.x) * t.y; // 3 cycles
{mov, pck, tstgez, mov}
{mov, pck, tstgez, mov}
{sop, sop}
-->
fragColor.x = (t.x >= 0.0 ? 1.0 : -1.0) * t.y; // 2 cycles
{mov, pck, tstgez, mov}
{sop, sop}
4、使用inversesqrt代替sqrt:
fragColor.x = sqrt(t.x) > 0.5 ? 0.5 : 1.0; // 3 cycles
{frsq}
{frcp}
{mov, mov, pck, tstg, mov}
-->
fragColor.x = (t.x * inversesqrt(t.x)) > 0.5 ? 0.5 : 1.0; // 2 cycles
{frsq}
{fmul, pck, tstg, mov}
5、normalize的取反优化:
fragColor.xyz = normalize(-t.xyz); // 7 cycles
{mov, mov, mov}
{fmul, mov}
{fmad, mov}
{fmad, mov}
{frsq}
{fmul, fmul, mov, mov}
{fmul, mov}
-->
fragColor.xyz = -normalize(t.xyz); // 6 cycles
{fmul, mov}
{fmad, mov}
{fmad, mov}
{frsq}
{fmul, fmul, mov, mov}
{fmul, mov}
6、abs、dot、neg、clamp、saturate等优化:
// abs
fragColor.x = abs(t.x * t.y); // 2 cycles
{sop, sop}
{mov, mov, mov}
-->
fragColor.x = abs(t.x) * abs(t.y); // 1 cycle
{sop, sop}
// dot
fragColor.x = -dot(t.xyz, t.yzx); // 3 cycles
{sop, sop, sopmov}
{sop, sop}
{mov, mov, mov}
-->
fragColor.x = dot(-t.xyz, t.yzx); // 2 cycles
{sop, sop, sopmov}
{sop, sop}
// clamp
fragColor.x = 1.0 - clamp(t.x, 0.0, 1.0); // 2 cycles
{sop, sop, sopmov}
{sop, sop}
-->
fragColor.x = clamp(1.0 - t.x, 0.0, 1.0); // 1 cycle
{sop, sop}
// min / clamp
fragColor.x = min(dot(t, t), 1.0) > 0.5 ? t.x : t.y; // 5 cycles
{sop, sop, sopmov}
{sop, sop}
{mov, fmad, tstg, mov}
{mov, mov, pck, tstg, mov}
{mov, mov, tstz, mov}
-->
fragColor.x = clamp(dot(t, t), 0.0, 1.0) > 0.5 ? t.x : t.y; // 4 cycles
{sop, sop, sopmov}
{sop, sop}
{fmad, mov, pck, tstg, mov}
{mov, mov, tstz, mov}
7、Exp、Log、Pow:
// exp2
fragColor.x = exp2(t.x); // one cycle
{fexp}
// exp
float exp( float x )
{
return exp2(x * 1.442695); // 2 cycles
{sop, sop}
{fexp}
}
// log2
fragColor.x = log2(t.x); // 1 cycle
{flog}
// log
float log( float x )
{
return log2(x * 0.693147); // 2 cycles
{sop, sop}
{flog}
}
// pow
float pow( float x, float y )
{
return exp2(log2(x) * y); // 3 cycles
{flog}
{sop, sop}
{fexp}
}
执行效率从高到低:exp2 = log2 > exp = log > pow。
8、Sin、Cos、Sinh、Cosh:
// sin
fragColor.x = sin(t.x); // 4 cycles
{fred}
{fred}
{fsinc}
{fmul, mov} // plus conditional
// cos
fragColor.x = cos(t.x); // 4 cycles
{fred}
{fred}
{fsinc}
{fmul, mov} // plus conditional
// cosh
fragColor.x = cosh(t.x); // 3 cycles
{fmul, fmul, mov, mov}
{fexp}
{sop, sop}
// sinh
fragColor.x = sinh(t.x); // 3 cycles
{fmul, fmul, mov, mov}
{fexp}
{sop, sop}
执行效率从高到低:sinh = cosh > sin = cos。
9、Asin, Acos, Atan, Degrees, and Radians:
fragColor.x = asin(t.x); // 67 cycles
fragColor.x = acos(t.x); // 79 cycles
fragColor.x = atan(t.x); // 12 cycles (许多判断条件)
fragColor.x = degrees(t.x); // 1 cycle
{sop, sop}
fragColor.x = radians(t.x); // 1 cycle
{sop, sop}
从上可知,acos和asin效率极其低,高达79个时钟周期;其次是atan,12个时间周期;最快的是degrees和radians,1个时钟周期。
10、向量和矩阵:
fragColor = t * m1; // 4x4 matrix, 8 cycles
{mov}
{wdf}
{sop, sop, sopmov}
{sop, sop, sopmov}
{sop, sop}
{sop, sop, sopmov}
{sop, sop, sopmov}
{sop, sop}
fragColor.xyz = t.xyz * m2; // 3x3 matrix, 4 cycles
{sop, sop, sopmov}
{sop, sop}
{sop, sop, sopmov}
{sop, sop}
向量和矩阵的维度的数量越少效率越高,所以尽量缩减它们的维度。
11、标量、向量运算:
fragColor.x = length(t-v); // 7 cycles
fragColor.y = distance(v, t);
{sopmad, sopmad, sopmad, sopmad}
{sop, sop, sopmov}
{sopmad, sopmad, sopmad, sopmad}
{sop, sop, sopmov}
{sop, sop}
{frsq}
{frcp}
-->
fragColor.x = length(t-v); // 9 cycles
fragColor.y = distance(t, v);
{mov}
{wdf}
{sopmad, sopmad, sopmad, sopmad}
{sop, sop, sopmov}
{sop, sop, sopmov}
{sop, sop}
{frsq}
{frcp}
{mov}
fragColor.xyz = normalize(t.xyz); // 6 cycles
{fmul, mov}
{fmad, mov}
{fmad, mov}
{frsq}
{fmul, fmul, mov, mov}
{fmul, mov}
-->
fragColor.xyz = inversesqrt( dot(t.xyz, t.xyz) ) * t.xyz; // 5 cycles
{sop, sop, sopmov}
{sop, sop}
{frsq}
{sop, sop}
{sop, sop}
fragColor.xyz = 50.0 * normalize(t.xyz); // 7 cycles
{fmul, mov}
{fmad, mov}
{fmad, mov}
{frsq}
{fmul, fmul, mov, mov}
{fmul, fmul, mov, mov}
{sop, sop}
-->
fragColor.xyz = (50.0 * inversesqrt( dot(t.xyz, t.xyz) )) * t.xyz; // 6 cycles
{sop, sop, sopmov}
{sop, sop}
{frsq}
{sop, sop, sopmov}
{sop, sop}
{sop, sop}
以下是GLSL部分内置函数的展开形式:
vec3 cross( vec3 a, vec3 b )
{
return vec3( a.y * b.z - b.y * a.z,
a.z * b.x - b.z * a.x,
a.x * b.y - b.y * a.y );
}
float distance( vec3 a, vec3 b )
{
vec3 tmp = a – b;
return sqrt( dot(tmp, tmp) );
}
float dot( vec3 a, vec3 b )
{
return a.x * b.x + a.y * b.y + a.z * b.z;
}
vec3 faceforward( vec3 n, vec3 I, vec3 Nref )
{
if( dot( Nref, I ) < 0 )
{
return n;
}
else
{
return –n:
}
}
float length( vec3 v )
{
return sqrt( dot(v, v) );
}
vec3 normalize( vec3 v )
{
return v / sqrt( dot(v, v) );
}
vec3 reflect( vec3 N, vec3 I )
{
return I - 2.0 * dot(N, I) * N;
}
vec3 refract( vec3 n, vec3 I, float eta )
{
float k = 1.0 - eta * eta * (1.0 - dot(N, I) * dot(N, I));
if (k < 0.0)
return 0.0;
else
return eta * I - (eta * dot(N, I) + sqrt(k)) * N;
}
12、分组运算。
将标量和向量一次分组,可以提升效率:
fragColor.xyz = t.xyz * t.x * t.y * t.wzx * t.z * t.w; // 7 cycles
{sop, sop, sopmov}
{sop, sop, sopmov}
{sop, sop}
{sop, sop, sopmov}
{sop, sop}
{sop, sop, sopmov}
{sop, sop}
-->
fragColor.xyz = (t.x * t.y * t.z * t.w) * (t.xyz * t.wzx); // 4 cycles
{sop, sop, sopmov}
{sop, sop, sopmov}
{sop, sop}
{sop, sop}
以上汇编指令以PowerVR GPU为案例,其它的类似但可能不完全一样,需要视具体平台执行优化。
12.6.4 综合优化
12.6.4.1 光影优化
前向渲染适合简单的只有少量动态光源的场景。
传统延迟渲染适合很多动态光源(特别是小范围的局部光源)的场景。但是,受限于Tile内缓冲区的带宽位数,不能存储过多的几何表面信息。
基于Compute Shader的光照技术(如tiled deferred、cluster deferred、forward+)由于MRT的数据极可能超出Tile内缓冲区,会向全局内存写入数据,造成极大的访问周期和延迟。不建议用于移动端。
阴影技术有很多,但最适合TBR硬件架构的阴影技术当属模板阴影(stencil shadowing)。因为TBR的GPU硬件非常擅长处理模板缓冲区,数据存储在Tile内存中,不需要写入系统内存。如果硬阴影是可接受的,应该优先使用模板阴影算法。
需要将结果写入片外存储器的技术(如阴影图),通常比完全在Tile内存储器中计算的技术性能更差。
如果要使用SSAO技术,为了防止频繁随机高跨度地访问深度缓冲,最好使用HZB(层级Z-Buffer)来加速。
如果需要使用SSR技术,提前为场景颜色的Frame Buffer做下采样(使用OpenGL ES接口glFramebufferTexture2DDownsampleIMG)。
优先使用模板裁剪光照算法,而不是传统的分块、分簇光照。
对移动端的光照进行特殊优化,例如Filament对光照的可见性函数进行了简化:
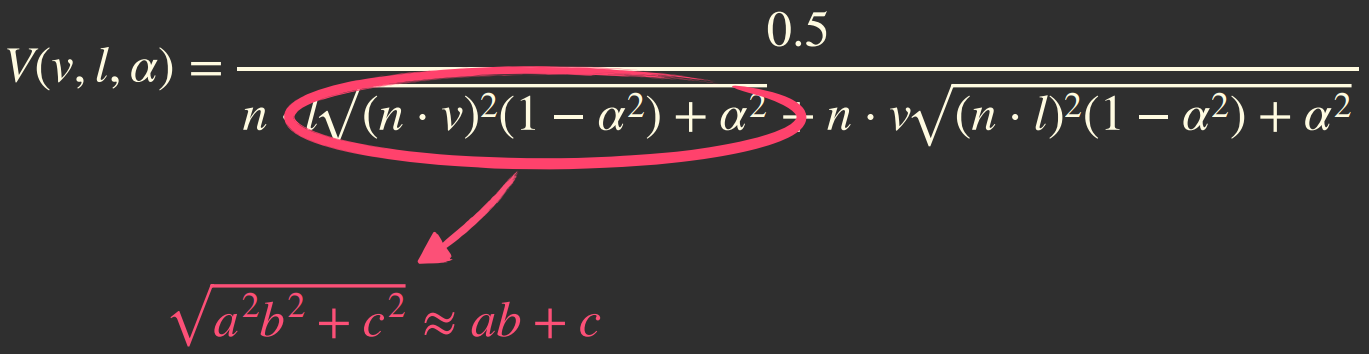
简化后的可见性公式如下所示:

对应的实现代码:
float V_SmithGGXCorrelated_Fast(float roughness, float NoV, float NoL)
{
// Hammon 2017, "PBR Diffuse Lighting for GGX+Smith Microsurfaces"
return 0.5 / mix(2.0 * NoL * NoV, NoL + NoV, roughness);
}
对IBL光照部分,Filament摒弃了Diffuse Map,直接采纳Specular Map(粗糙度为1时的Mimap level)来模拟:

但是Specular Map只有5级,最小的尺寸是16x16:

Mimap级别映射到粗糙度如下:
| Mipmap级别 | 粗糙度 |
|---|---|
| 0 | 0.000 |
| 1 | 0.018 |
| 2 | 0.086 |
| 3 | 0.250 |
| 4 | 1.000 |
存储IBL的纹理时没有使用RGBM格式(因为质量不达标),而是采用R11G11B10F的格式,重组成RGBA8888,以PNG格式存储。
对于金属物体,为了解决传统PBR光照的能量不守恒问题,Filament采用了Lagarde & Golubev的方案:

传统PBR在计算金属材质时存在能量不守恒问题。上排是不守恒的图例,越黑标明丢失的能量越多,下排是Filment修复后的图例(要非常仔细才能看清)。

Filament修复金属光照不守恒的BRDF公式。
实现的代码如下:
// 传统的IBL计算代码
const float V = Visibility(…) * NoL * (VoH / NoH);
const float F = pow5(1.0f - VoH);
r.x += V * (1.0f - F);
r.y += V * F;
// Filament修复后的代码
const float V = Visibility(…) * NoL * (VoH / NoH);
const float F = pow5(1.0f - VoH);
r.x += V * F;
r.y += V;
在AO方面,Filament模拟了多反弹(Multi-bounce)效果:


Filament的多反弹AO效果对比图。上:关闭多反弹;下:开启多反弹,注意眼睛和耳朵明亮了少许。
AO多反弹的模拟代码如下:
vec3 gtaoMultiBounce(float visibility, const vec3 albedo)
{
// Jimenez et al. 2016,
// “Practical Realtime Strategies for Accurate Indirect Occlusion"
vec3 a = 2.0404 * albedo - 0.3324;
vec3 b = -4.7951 * albedo + 0.6417;
vec3 c = 2.7552 * albedo + 0.6903;
return max(vec3(visibility), ((visibility * a + b) * visibility + c) * visibility);
}
diffuseLobe *= gtaoMultiBounce(ao, diffuseColor);
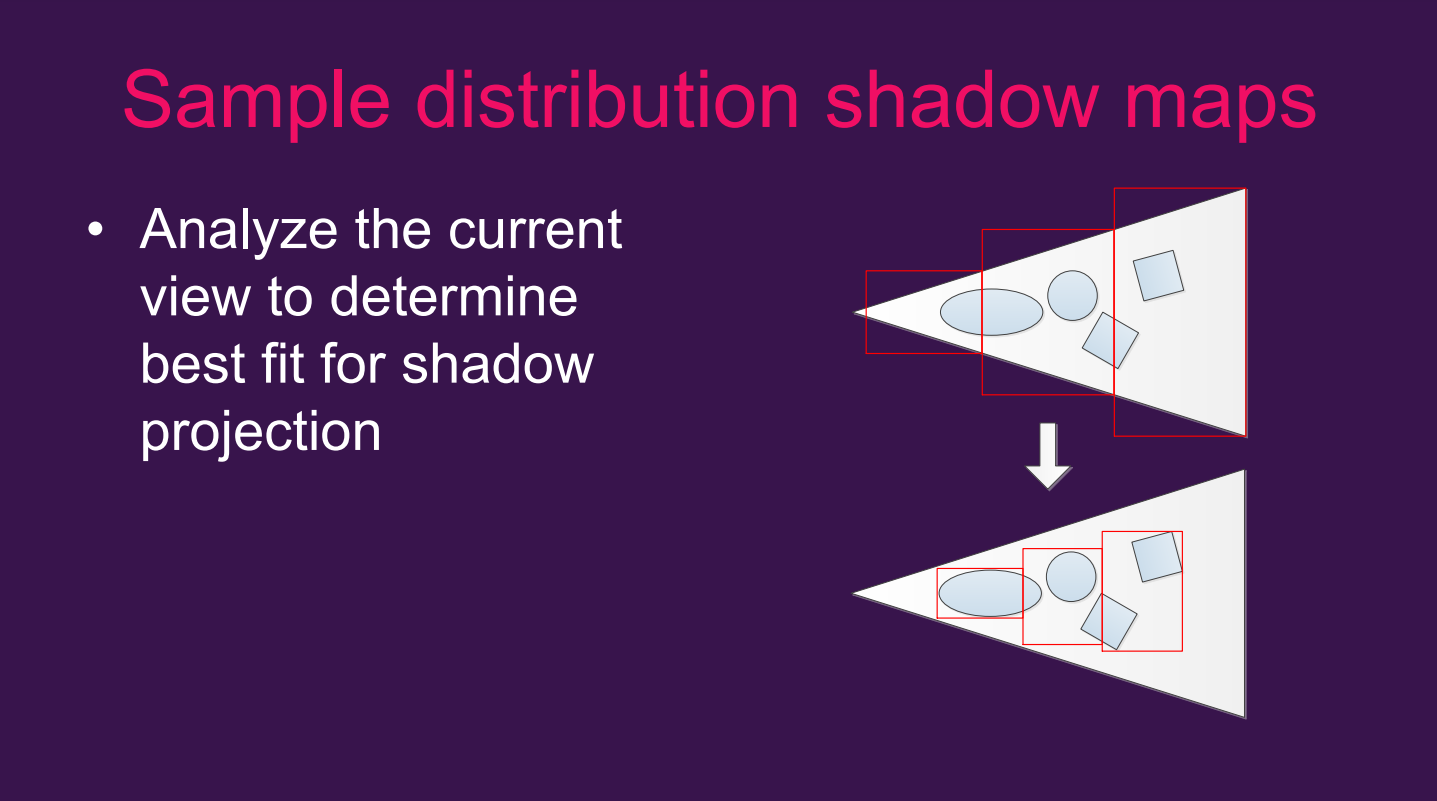
阴影方面也存在不少优化技术。例如,下图是Sample distribution shadow map(SDSM,样本分布阴影图)技术展示通过计算物体包围盒代替视锥体包围盒来减少阴影图的尺寸:
SDSM还通过构造HZB并使用上一帧的HZB来避免GPU卡顿,利用CS生成级联子阴影图的距离,生成的HZB可以用于快速裁剪级联子阴影图。通过这些优化措施,SDSM可以均衡每个级联的图元数量,可以均衡阴影图分辨率和输出分辨率,可以用更小的分辨率获得和非SDSM方法的类似阴影效果。以下是SDSM和非SDSM的效果对比图:


上:普通CSM阴影;下:SDSM阴影。
在性能方面,SDSM的表现也要胜出一筹:
如果在低端设备,可以尝试使用圆团(Blob)阴影代替阴影图:

左:阴影图;右:Blob阴影。
在高级光照方面,可以尝试Forward+、Light Prepass等光照渲染技术。以下是各种光照技术在移动GPU的对比图:
此外,可以尝试使用MatCap技术来实现IBL效果,可以获得性能和效果良好的平衡:
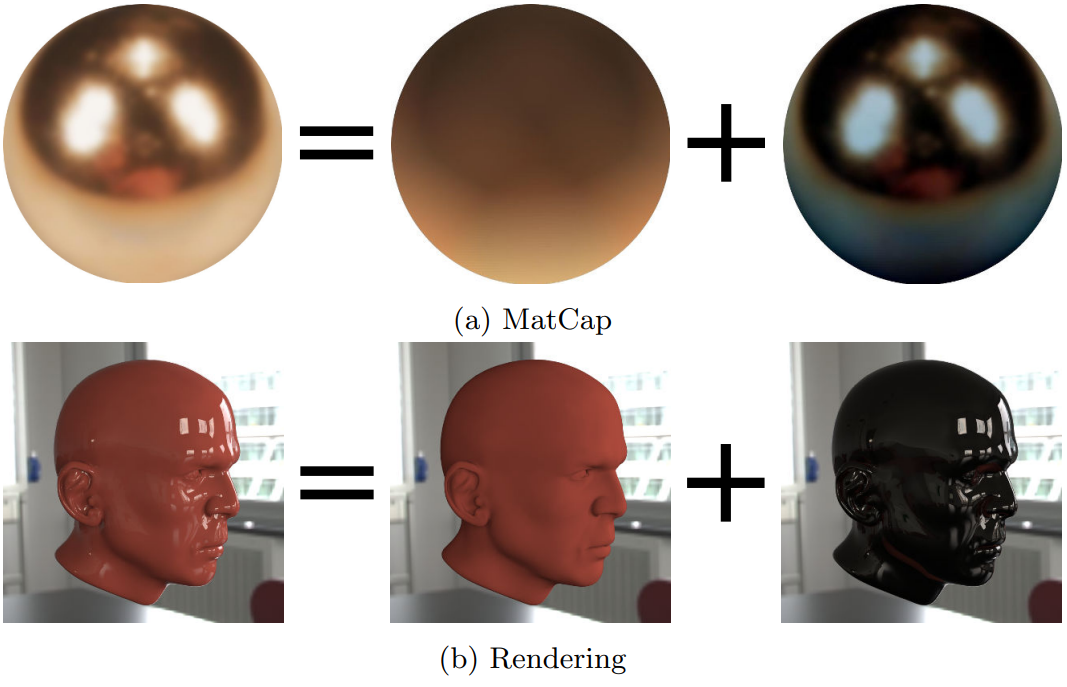
利用MatCap技术实现的渲染效果。
12.6.4.2 后处理优化
后处理效果会占用更大的带宽,所以非必须,尽量关闭所有后处理效果。
如果确实需要后处理,常见的优化手段如下:
1、将多个后处理效果合并成一个Shader完成。
2、降分辨率计算后处理效果。
3、尽量将后处理的数据访问保持在Tile内。
4、尽量不访问周边像素数据。如果需要,尽量保持局部性和时效性,提升缓存命中率。
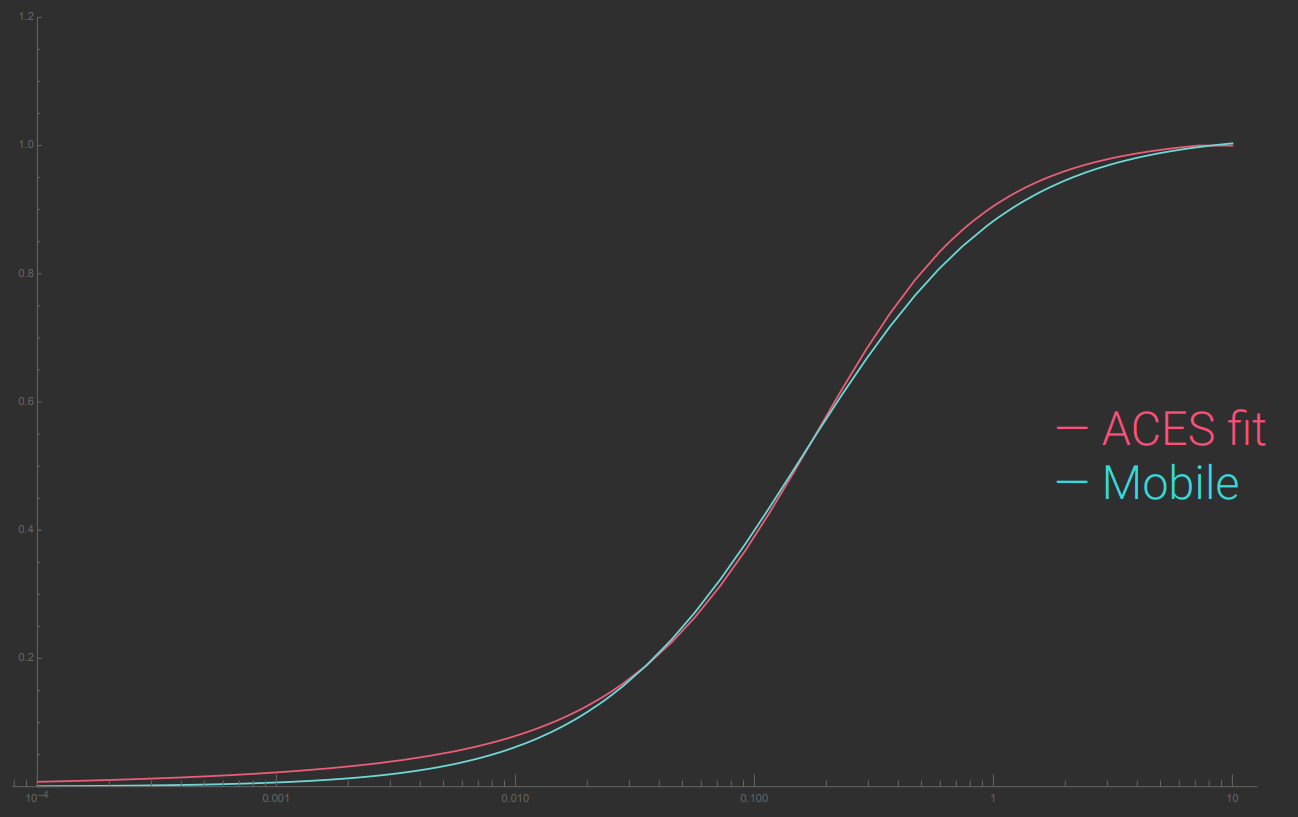
5、专用的算法优化。如将高斯模糊拆分成横向模糊+竖向模糊(分离卷积核)。Filament对针对移动端的色调映射做了优化:
// 原始的ACES色调映射。
vec3 Tonemap_ACES(const vec3 x)
{
// Narkowicz 2015, "ACES Filmic Tone Mapping Curve”
const float a = 2.51;
const float b = 0.03;
const float c = 2.43;
const float d = 0.59;
const float e = 0.14;
return (x * (a * x + b)) / (x * (c * x + d) + e);
}
// 移动端版本的色调映射
vec3 Tonemap_Mobile(const vec3 x)
{
// Transfer function baked in,
// don’t use with sRGB OETF!
return x / (x + 0.155) * 1.019;
}
而简化后的色调映射曲线非常接近:
Arm对常用的后处理效果在不同的质量等级下给出了技术参考:

12.6.4.3 精灵渲染优化
优化精灵渲染的常见手段有:控制精灵的数量,控制精灵在屏幕的面积,减少空白区域。
现代GPU对图元数量的增加没有那么敏感,而对开启了Alpha Blend的精灵(Sprite)空白区域的增加,反而更加敏感,因为会浪费很多无效的片元着色处理。避免空白区域浪费的一种有效手段是增加绘制精灵的几何体复杂性,通过增加几何复杂度来减少透明性的浪费,可以显著提高性能。
以往在用精灵模拟粒子特效时,会用一个四边形绘制一个圆形,此时四边形周边都是空白区域,浪费比例达到惊人的22%。如果将4边形增加到12边形,那么浪费的片元处理数量就可以减少到3%。它们的公式和结果对比如下:

4边形和12边形在浪费的片元处理数量比例对比图。图左是4边形,浪费比例为21.4%;图右是12边形,浪费比例为2.9%。
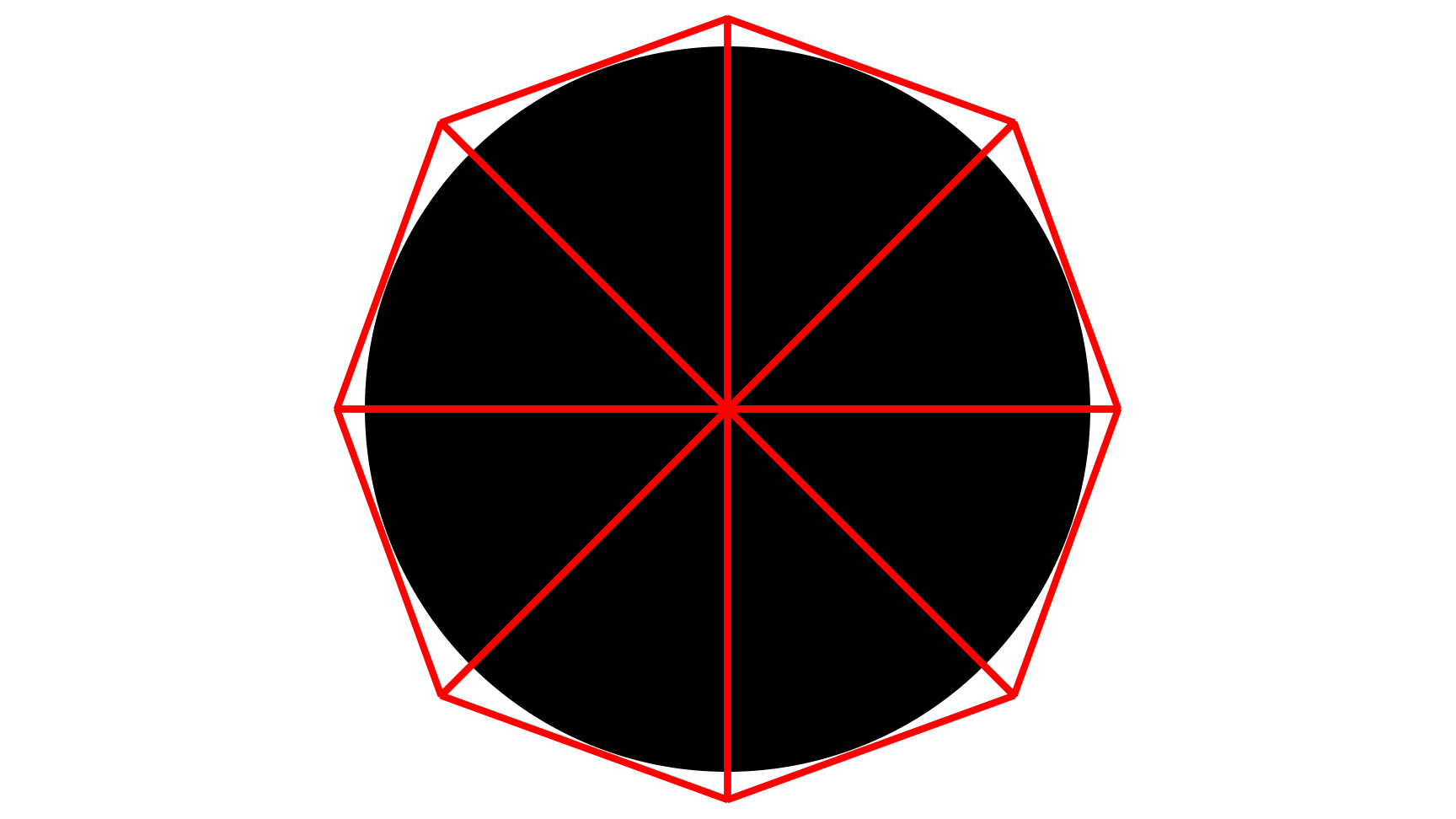
使用8边形绘制圆形半透明物体的图例。
另外,可以将将不透明和半透明对象(如UI元素)分割成单独的绘制提交。绘制提交顺序建议如下:
1、不透明的场景精灵元素。
2、半透明的场景精灵元素。
3、半透明的UI元素。
对于粒子特效,远处的粒子清晰度无关紧要,可以使用更简单的纹理过滤方式(如最近点)。
12.6.4.4 均衡GPU工作负载
对于GPU密集型的应用程序,瓶颈常常会发生在GPU侧,而发生的原因是GPU各部件的工作负载不均衡,导致了性能瓶颈。
通过合理分摊GPU各部件的工作负载,可以有效消除瓶颈,充分发挥GPU的功效,提升渲染性能。以下是可区分工作负载的GPU资源:
1、ALU(逻辑运算单元)
2、Texturing Load(纹理加载)
3、ISP Load(图像综合处理器加载)
4、Renderer Active(渲染器活动)
5、Tiler Active(分块器活动)
通过GPU厂商提供的Profiler(如Snapdragon Profiler、PVRMonitor),可以有效监控它们的动态。下面是均衡工作负载的优化描述:
1、使用预计算并将结果存储在查找表(LUT),可以将ALU的工作转移到Texturing Load。
2、使用程序纹理函数代替纹理获取,可以将Texturing Load的工作转移到ALU。
3、使用深度和模板测试减少着色器调用,从而减少纹理负载或ALU的工作量。
4、基于ALU的Alpha test可以用来交换深度prepass和深度测试,会增加draw call和几何开销,但可以显著降低ALU工作量和寄存器压力。
5、Alpha test和噪声函数结合使用来实现LOD过渡效果,会极大提升ALU工作量。在这种情况下,可以执行模板prepass来转移ALU工作量到ISP。
6、高保真画质可以提供更复杂的着色器、更高的分辨率纹理、增加多边形数量来提高。当渲染达到瓶颈时,更好的做法是增加多边形数量,而不是增加片元着色器的复杂度。
12.6.4.5 Compute Shader优化
在Compute Shader(计算着色器,CS)之前,有多种方法可以在OpenGL ES中暴露令人尴尬的并行计算:
1、光栅化一个四边形,并在像素着色器中执行任意计算,然后可以将结果写入纹理中。
2、使用变换反馈在顶点着色器中执行任意计算。
这些方法都存在诸多限制,比如着色器不能感知其它着色器,写入数据的目标是限制死的(VS只能写入gl_Position和变量寄存器中,PS只能写入指定的RenderTarget中)。
而Compute Shader没有上述的限制,可以指定任意的输入、输出数据源,并且不用跑传统的渲染管线,可以方便、高效、灵活地运行自定义的计算。
每个Compute Shader派发任务时,可以指定Work Group的数量,以及每个Work Group的线程数量。


上:每次派发Compute Shader的Work Group示意图;下:每个Work Group有若干条线程,这些线程有一个Shared Memory。
Compute Shader运行的伪代码如下:
for (int w = 0; w < NUM_WORK_GROUPS; w++)
{
// 保证并行运行。
parallel_for (int i = 0; i < THREADS_IN_WORK_GROUP; i++)
{
execute_compute_thread(w, i);
}
}
对workgroup尺寸,建议如下:
1、使用64作为工作组的基准(baseline)大小。每个工作组使用的线程不要超过64个。
2、使用4的倍数作为工作组的大小。
3、在更大的工作组之前尝试更小的工作组尺寸,特别是在使用barrier或shared memory的情况下。
4、在处理图像或纹理时,使用方形执行维度(例如8x8)来利用最优的2D缓存局域性。
5、如果一个工作组要完成每个工作组的工作,考虑将工作拆分成两个通道。这样做可以避免barrier和内核中大多数线程产生空闲间隙。小尺寸工作组的barrier也会产生性能成本。
6、Compute Shader的性能并不总是直观的,所以要持续不断测量性能。
对Shared memory,建议如下:
1、使用共享内存以便在工作组中的线程之间共享重要或复杂的计算。
2、保持共享内存尽可能小,因为这样可以减少数据缓存的急剧变化。
3、降低精度和数据宽度以减少所需的共享内存的大小。
4、需要设置barrier来同步访问共享数据。从桌面开发中移植过来的着色器代码有时会因为GPU特定的假设而忽略一些barrier。但这种假设在移动GPU上使用是不安全的。
5、与插入barrier相比,分割算法到多个着色器上计算更高效。
6、对于障碍,较小的工作组更低消耗。
7、不要将数据从全局内存复制到共享内存,会降低缓存命中率。
8、不要使用共享内存来实现代码。例如:
if (localInvocationID == 0)
{
common_setup();
}
barrier();
(.....) // 逐线程的shader逻辑
barrier();
if (localInvocationID == 0)
{
result_reduction();
}
上面的代码中common_setup和result_reduction只需要一个线程,工作组内的其它线程将在等待,产生Stall和空闲。
将上面的代码分拆成三个着色器更佳,因为common_setup和result_reduction只需更少的线程。
然而尴尬的是UE的CS代码中大量使用了这种合并的代码,如TAA、SSGI等等。
对Image(或Texture)的处理建议如下:
1、当使用变化插值时,纹理坐标将使用固定功能硬件(fixed function hardware)进行插值。反过来,释放着色器周期以获得更有用的工作负载。
2、写入内存可以使用Tile-Writeback硬件与shader代码并行完成。
3、不需要范围检查imageStore()坐标。当使用不完全细分一帧的工作组时,可能会出现问题。
4、可以进行帧缓冲压缩和传输消除(transaction elimination,仅Mali GPU)。
下面是使用compute进行图像处理的一些优点:
1、可以利用相邻像素之间的共享数据集,可以避免一些算法的额外传输。
2、在每个线程中使用更大的工作集更容易,从而避免了一些算法的额外传输。
3、对于像FFT(快速傅里叶变换)这样需要多个片元渲染通道的复杂算法,通常可以合并到单个计算分派(dispatch)中。
12.6.4.6 多核并行
多核已经是目前移动端SoC的主流CPU的标配(多数CPU已经达到8核或更多),如何利用多核的并行能力提升渲染效果,是个非常庞大且具有挑战性的任务。
首先充分利用现代图形API(DirectX12、Vulkan、Metal)允许多核创建、执行Command Buffer的特性,以提升并行效率:
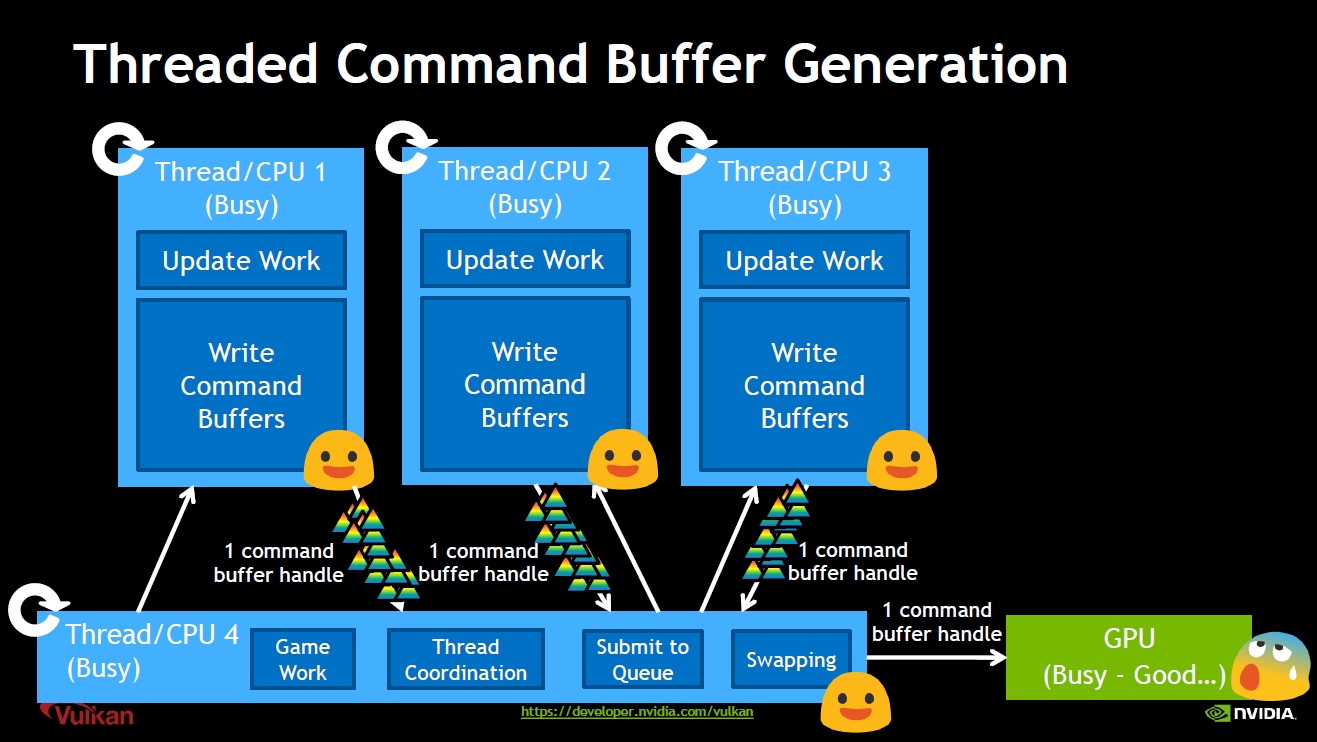
Vulkan图形API并行生成Command Buffer示意图。
Filament的作业系统并行渲染图示如下:
filamente作业系统简化图例。每个块代表一个新的父作业,它本身可以生成N个作业。这个系统中的每个循环都是多线程的,并且是作业化的。
UE则使用TaskGraph进行并行化的渲染。此方面的更多技术可以参看:剖析虚幻渲染体系(02)- 多线程渲染。
12.6.4.7 其它综合优化
- 系统集成优化
大多数移动平台使用垂直同步信号显示,以防止屏幕撕裂缓冲区交换。如果GPU渲染的速度比垂直同步周期慢,那么一个只包含两个缓冲区的交换链很容易使GPU卡顿。优化交换链(swap chain)的建议:
1、如果应用程序总是比vsync运行得慢,那么就不要在交换链中使用两个表面(Surface)。
1、如果应用程序总是比vsync运行得快,那么在交换链中使用两个表面,可以减少内存消耗。
2、如果应用程序有时比vsync运行得慢,那么在交换链中使用三个表面,可以给应用程序提供最佳性能。
- 高效地使用MRT
MRT(Multiple Render Target)已在移动端普遍地支持,常见的使用案例是延迟渲染,在几何Pass阶段需要MRT来存储表面的几何信息(基础色、法线、深度、材质)。
TBDR可以利用Tile缓冲区(如PLS、Subpass),保持MRT数据在高速缓存上,从而提升内存数据访问速度,减少延迟。
为了在大多数移动端GPU上良好地工作,MRT的每像素数据尺寸尽量控制在128位(16字节)内+一个深度模板缓冲,在一些更新的GPU上,可以增加到256位(32字节)+一个深度模板缓冲。如果超出,Tile内缓冲区不足,GPU会强制将数据保存在全局内存,大大降低数据操作速度。
除了内存事务和性能考虑之外,当渲染目标在系统内存中溢出时,并不是所有渲染目标格式都会在系统内存总线上以全速(full rate)支持。因此,根据GPU中可用的格式和纹理处理单元(TPU),传输速率可能会进一步降低。对于PowerVR GPU而言,以下格式和速率关系如下:
1、RGBA8可以全速读取。
2、RGB10A2可以接近全速读取。
3、RG11B10只能半速读取。
4、RGBA16F只能半速读取。
5、RGBA32F只能1/4全速读取(没有双线性过滤)。
- 选择适合的HDR像素格式
对于HDR,有几种格式可以供选择,考量的因素包含内存带宽、精度(质量)、alpha支持等。对于硬件本身支持的HDR纹理格式,可以使用RGB10A2或RGBA16F,但会增加带宽。这些纹理提供了质量、性能(过滤)和内存带宽使用之间的良好平衡。
RGBM和RGBdiv8纹理格式都要求开发者在着色器中实现编码和解码功能,需要额外的USC周期,因为它们不被硬件支持。如果应用程序受到USC限制,就不应该使用这些格式。它们的优势在内存带宽非常低,与RGBA8的带宽成本相同。 如果应用程序受到内存带宽的限制,那么研究这些格式可能会很有用。其中RGBM和HDR Color之间编解码代码如下:
// 将HDR颜色编码成RGBM.
float4 RGBMEncode( float3 color )
{
float4 rgbm;
color *= 1.0 / 6.0;
// 将HDR颜色的系数编码到Alpha通道中.
rgbm.a = saturate( max( max( color.r, color.g ), max( color.b, 1e-6 ) ) );
rgbm.a = ceil( rgbm.a * 255.0 ) / 255.0;
rgbm.rgb = color / rgbm.a;
return rgbm;
}
// 解码RGBM成HDR颜色.
float3 RGBMDecode( float4 rgbm )
{
return 6.0 * rgbm.rgb * rgbm.a;
}
常见的HDR格式详细描述如下表:
| 纹理格式 | 带宽消耗 | USC消耗 | 过滤 | 精度 | Alpha |
|---|---|---|---|---|---|
| RGB10A2 | 1x RGBA8 | 无 | 硬件加速,比RGBA8稍慢 | RGB通道更高的精度,以alpha精度为代价 | 只有四个值 |
| RGBA16F | 2x RGBA8 | 无 | 硬件加速,0.5x RGBA8 | 远高于RGBA8的精度 | 支持 |
| RG11B10F | 2x RGBA8 | 无 | 硬件加速,0.5x RGBA8 | 等同RGBA16F | 不支持 |
| RGBA32F | 4x RGBA8 | 无 | 硬件加速,0.25x RGBA8,仅支持最近点 | 远高于RGBA16F的精度 | 支持 |
| RGBM (RGBA8) | 1x RGBA8 | 编码/解码数据 | 硬件不支持此格式过滤 | RGB值范围比RGBA8高 | 不支持 |
| RGBdiv8(RGBA8) | 1x RGBA8 | 比RGBM稍复杂 | 硬件不支持此格式过滤 | 同上 | 不支持 |
可以优先考虑打包的32位格式(RGB10_A2、RGB9_E5),来代替FP16或FP32。
- 选择合适的抗锯齿
MSAA适用于前向渲染,TAA适应于延迟渲染。除此之外,还有众多形态分析抗锯齿技术,效率从高到低依次是:FXAA、CMAA、MLAA、SMAA。
因此根据项目情况选择适合的抗锯齿,也可以根据高中低画质选择不同的抗锯齿技术。
使用MSAA时,优先使用4x,效果和效率达到较好的平衡。使用Tile内的MSAA解析,避免使用glBlitFramebuffer()等接口显式解析。
监控、分析和对比开启、关闭抗锯齿技术的性能。
Filament针对高光部分执行了特殊的抗锯齿过滤算法(修改粗糙度):
float normalFiltering(float perceptualRoughness, const vec3 worldNormal)
{
// Kaplanyan 2016, "Stable specular highlights"
// Tokuyoshi 2017, "Error Reduction and Simplification for Shading Anti-Aliasing"
// Tokuyoshi and Kaplanyan 2019, "Improved Geometric Specular Antialiasing"
vec3 du = dFdx(worldNormal);
vec3 dv = dFdy(worldNormal);
float variance = specularAntiAliasingVariance * (dot(du, du) + dot(dv, dv));
float roughness = perceptualRoughnessToRoughness(perceptualRoughness);
float kernelRoughness = min(2.0 * variance, specularAntiAliasingThreshold);
float squareRoughness = saturate(roughness * roughness + kernelRoughness);
return roughnessToPerceptualRoughness(sqrt(squareRoughness));
}
materialRoughness = normalFiltering(materialRoughness, getWorldGeometricNormalVector());
- 尽可能将计算提前
通过将它们移到管道中需要处理的实例较少的较早位置,可以减少计算的总数。计算链如下:
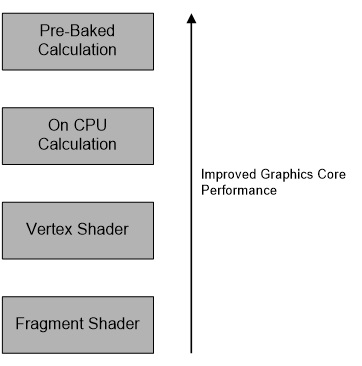
效率从高到低依次是:预计算、CPU应用层计算、顶点着色器、像素着色器。
以光照计算为例,渲染效率从高到低:光照图、IBL、逐顶点光照、逐像素光照。
但效率高意味着可控性差,需在效率和效果中取得平衡。
- 杂项优化
注意电量消耗和设备温度,防止CPU或GPU降频导致性能下降。
考虑降分辨率或帧率,或者根据某些策略动态调整。
提前加载IO负载大的数据,并且缓存起来。尽可能预计算消耗大的任务。
隐藏UI界面后面的物体。(下图)

划分质量等级,制定好参数规格,按等级选择不同消耗的技术。
考虑动态网格合批(UE没有此功能,需要自己实现)。
降分辨率渲染半透明物体,之后再放大混合到场景颜色中。(下图)


此外,还需要注意多线程同步、遮挡剔除查询、屏障、渲染通道、创建GPU资源和上传、静态静态、内存占用和泄漏、显存占用、VS和PS性能比例等等方面的消耗和优化。
下面是A Year in a FortniteFornite在移动端所做的部分优化图例:
Fornite在优化(缓存)描述符表之后的性能对比图。上:优化前;下:优化后。
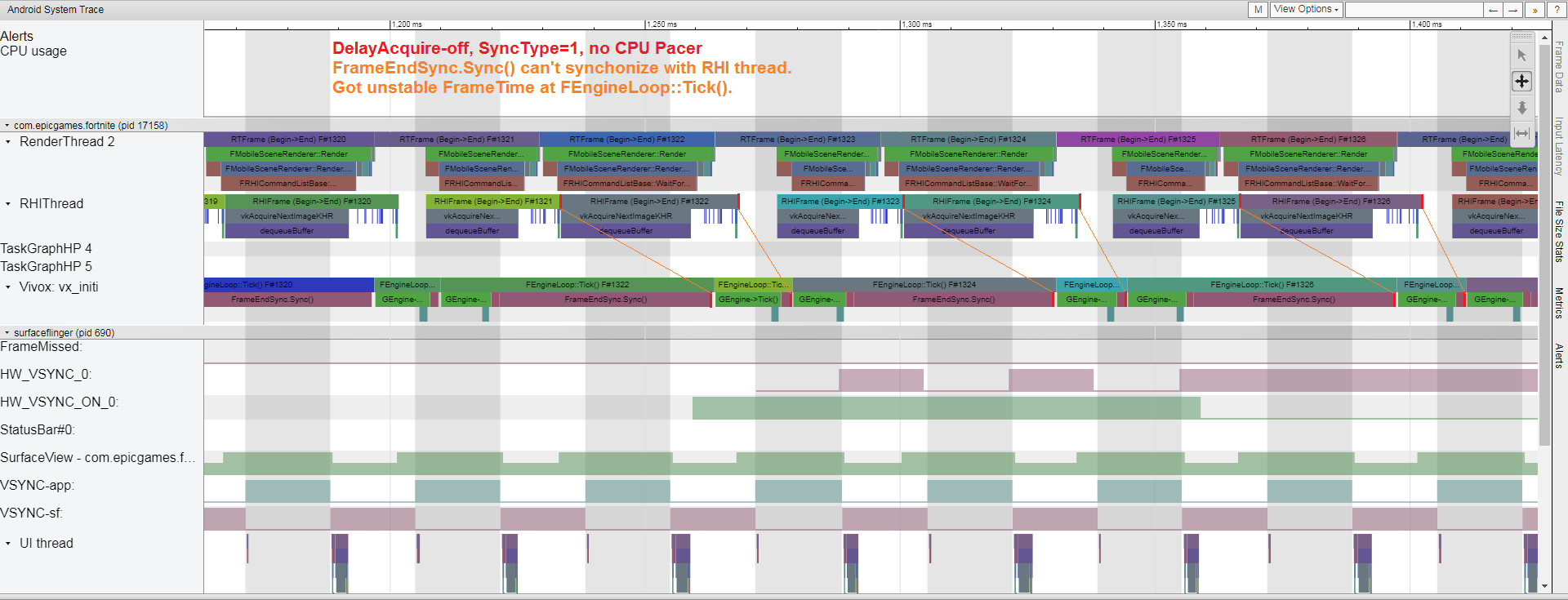

Fornite在优化同步消耗的前后对比图。上:优化前;下:优化后。
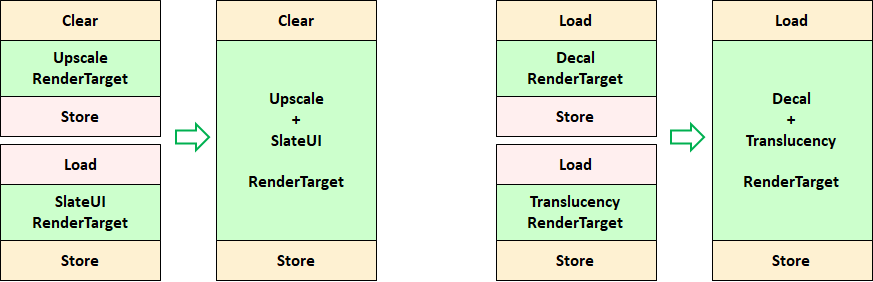
Fornite在优化渲染通道的前后对比图。左:优化前;右:优化后。
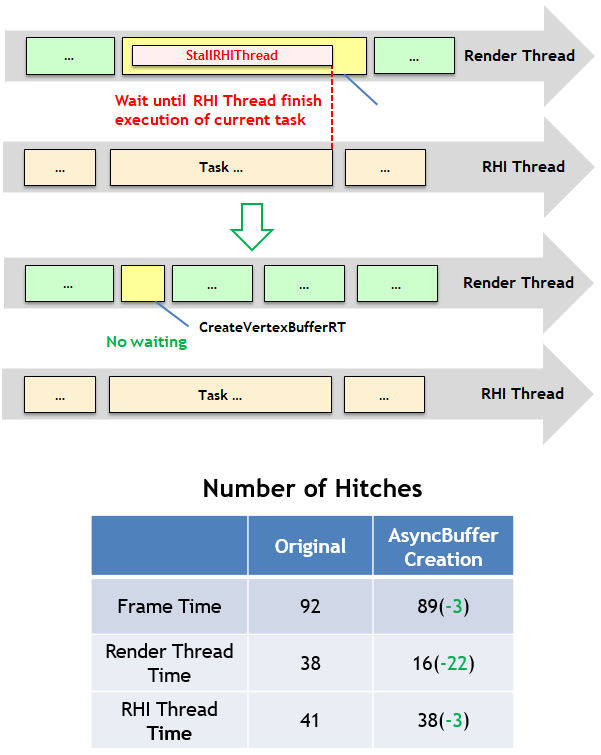
Fornite在异步创建顶点和索引缓冲之后的效果对比图。
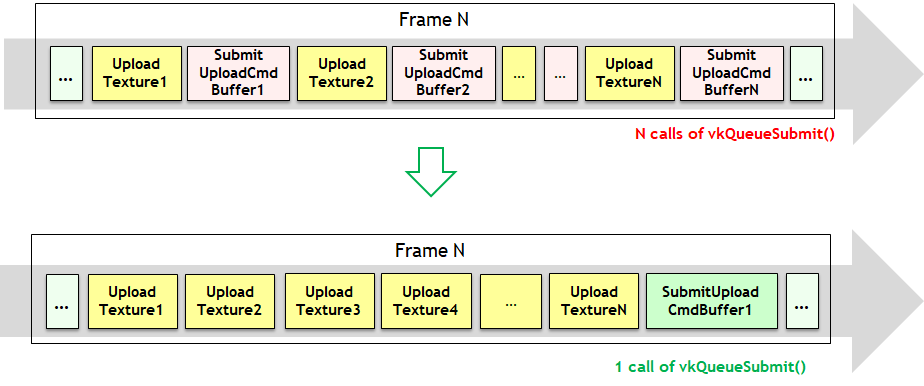
Fornite对纹理上传进行优化(分散打包到一起)的效果对比图。
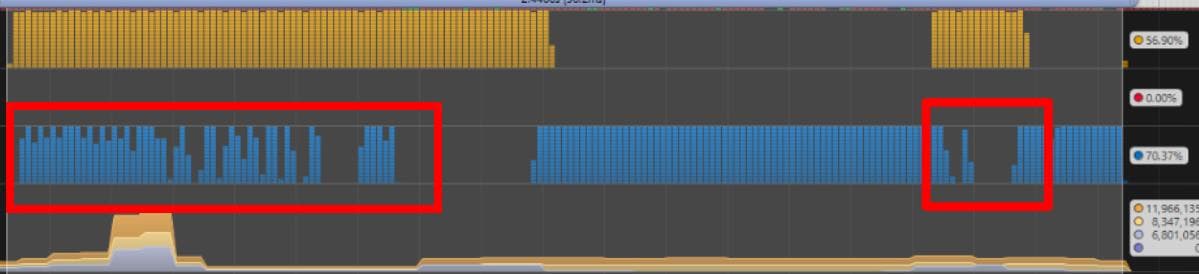

The Challenges of Porting Traha to Vulkan对Pipeline Barrier进行优化的对比图。
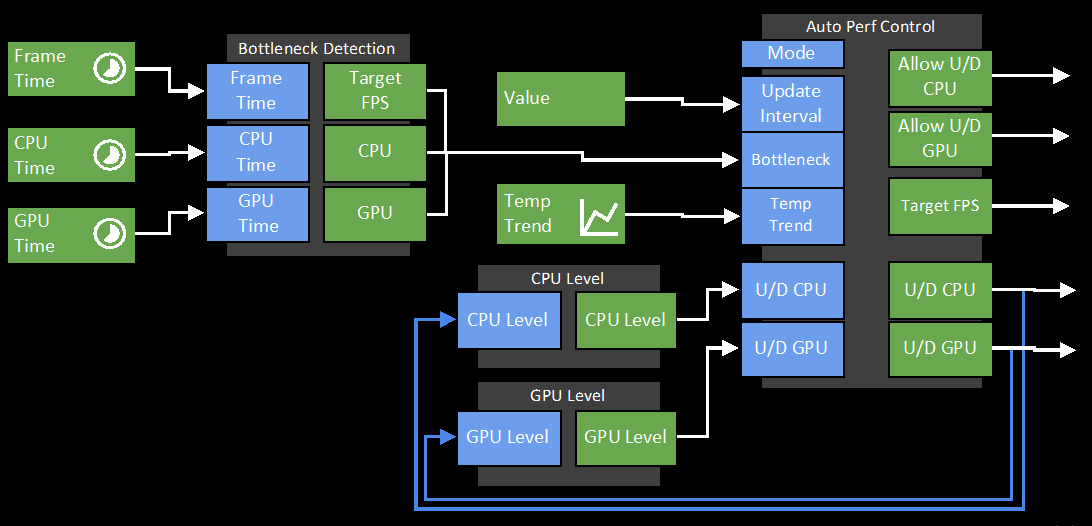
Adaptive Performance in Call of Duty Mobile对性能、能耗、温度等参数进行监控并自动动态调整的图例。
12.6.5 XR优化
XR的渲染通常有以下特点:
1、分辨率高。XR设备分辨率(1536x1536、2K、4K)比普通移动设备的(720p、1080p)要高。
2、刷新率更高。普通移动设备的刷新率通常在60Hz或更少(如30Hz),而XR设备为了体验更好,让用户不晕3D,必须保持60Hz以上甚至更高(72Hz、100Hz、120Hz)。
3、必须携带抗锯齿。如果不带抗锯齿技术,XR设备的渲染画质将出现严重的锯齿和闪烁(因为屏幕离眼睛更近)。
4、每帧需要渲染两遍(人都有两只眼睛嘛)。
以上的特殊设定,导致XR设备所需的带宽是普通移动设备的9倍以上。因此,加上电量和散热的限制,XR设备对性能异常苛刻,优化技术要求更加严苛。
下面是常见的XR渲染优化技术。
12.6.5.1 注视点渲染(Foveated Rendering)
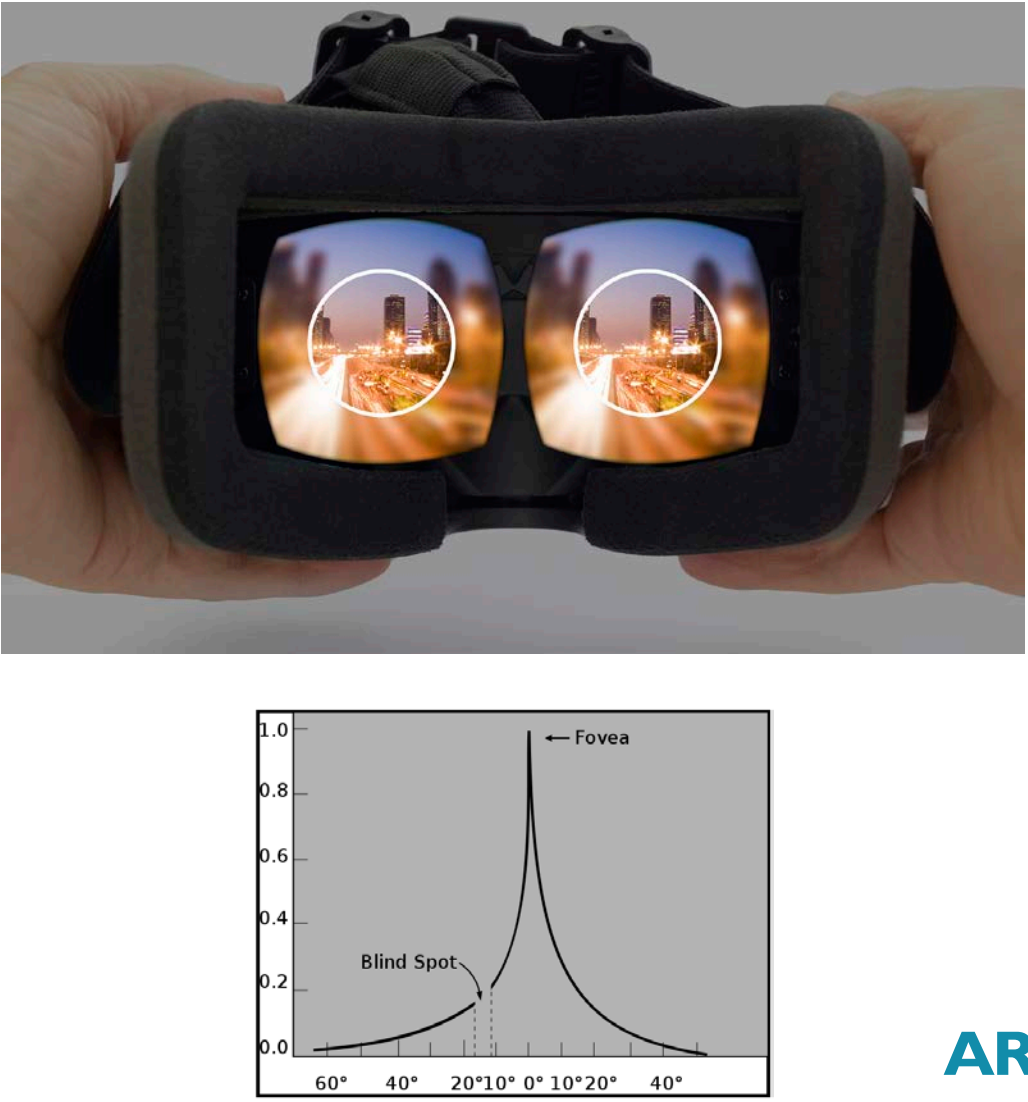
由于人眼对注视点的中心清晰度要求更高,离中心点越远,所需的清晰度递减:
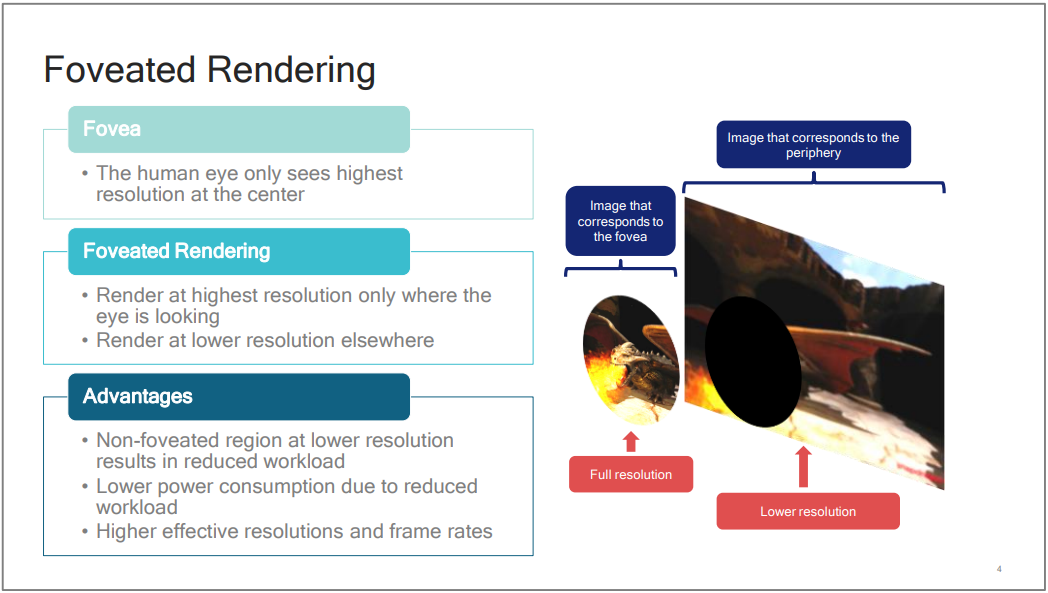
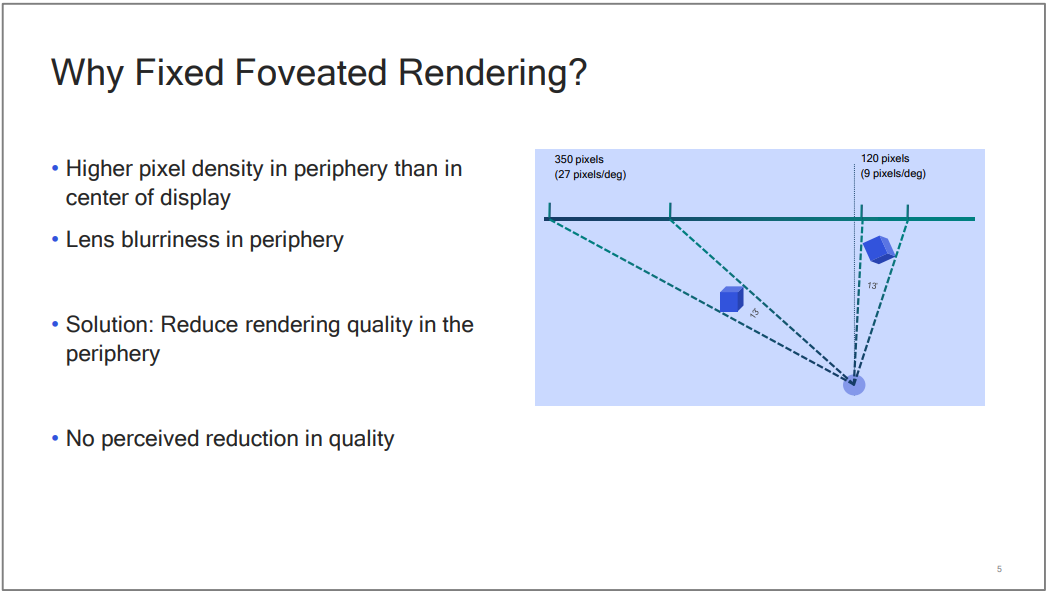
注视点渲染原理。原理是由于离眼睛注视点越近,相同的立体角覆盖的区域越少(需要越多的像素),反之越多(需要越少的像素)。
Qualcomm的XR专用芯片利用注视点渲染技术可以提升25%的性能,并且提升渲染分辨率:
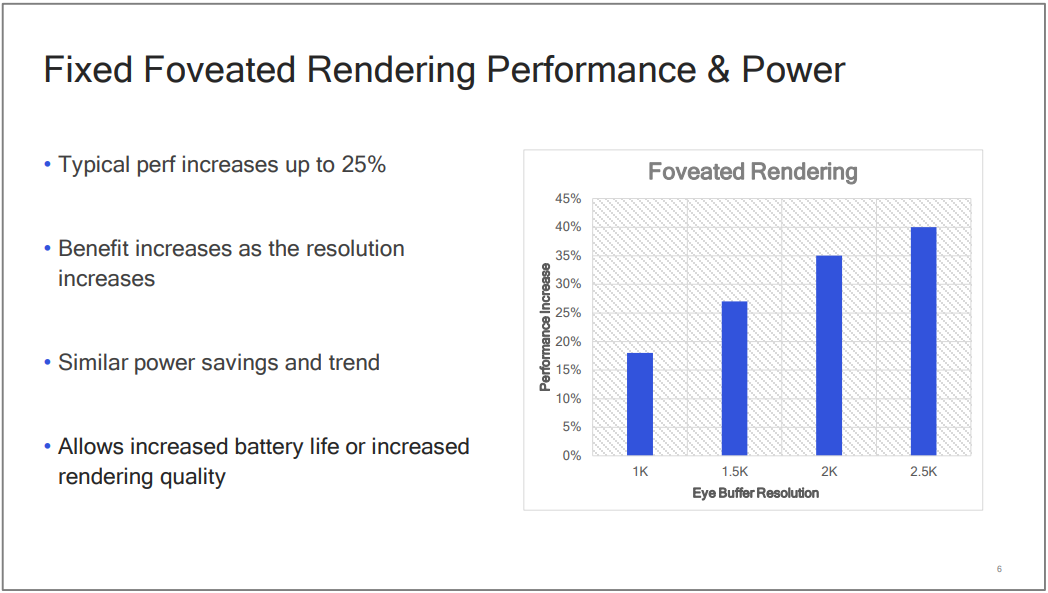
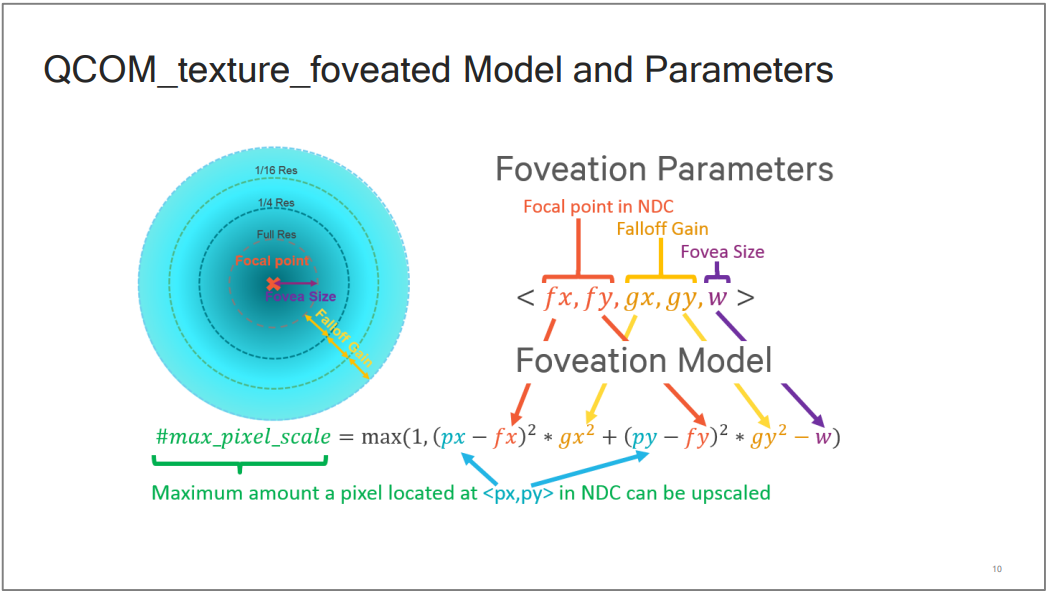
Qualcomm利用OpenGL ES或Vulkan的扩展,可以让开发人员使用详细的参数精确地控制注视点渲染的细节:
注视点渲染效果和偏离聚焦点的清晰度曲线如下所示:
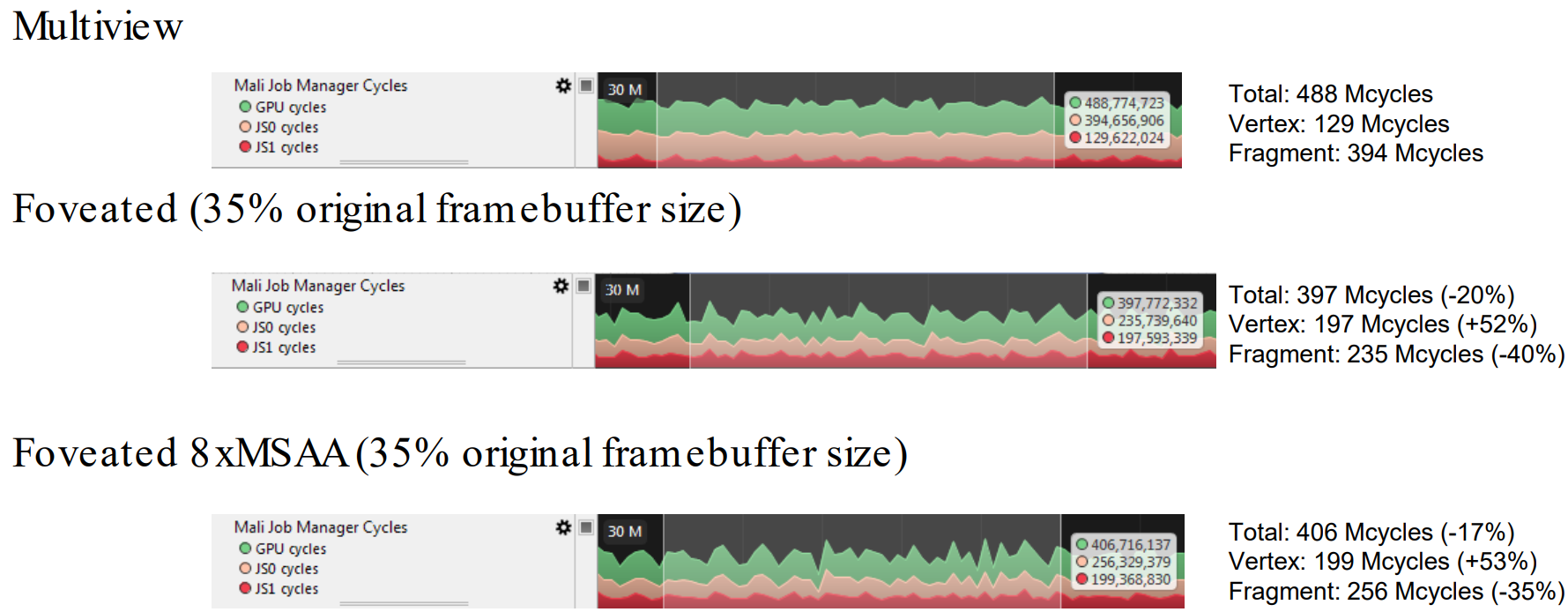
Mali使用注视点渲染技术之后总体上可以减少35%的帧缓存尺寸、20%的总消耗、40%的片元着色器消耗,但会增加52%的顶点着色器消耗:
12.6.5.2 多视图(Multiview)
Qualcomm的XR专用芯片实现了Advanced模式的多视图渲染:

用于优化VR等渲染的MultiView对比图。上:未采用MultiView模式的渲染,两个眼睛各自提交绘制指令;中:基础MultiView模式,复用提交指令,在GPU层复制多一份Command List;下:高级MultiView模式,可以复用DC、Command List、几何信息。
利用Multiview渲染技术,可以节省3349%的CPU时间,减少533%范围的能耗:

Mali GPU的Multiview实现和Qualcomm不太一样,在Fragment Shader之前都是共享同一份数据,而Fragment Shader之后则区分左右眼:
Vulkan在Multiview方面也提供了优化技术,表现在只记录两只眼睛不同的命令,提供了multiview关联的渲染通道,采用VIEW_LOCAL标记来提升Tile内利用率和缓存命中率:

其它平台或图形API实现Multiview时也有所不同:

12.6.5.3 立体渲染(Stereo Rendering)
立体渲染就是将两只眼睛合并成一个Pass执行渲染,从而减少Draw Call。首先需要做的是将两只眼睛的视锥体合并成一个:
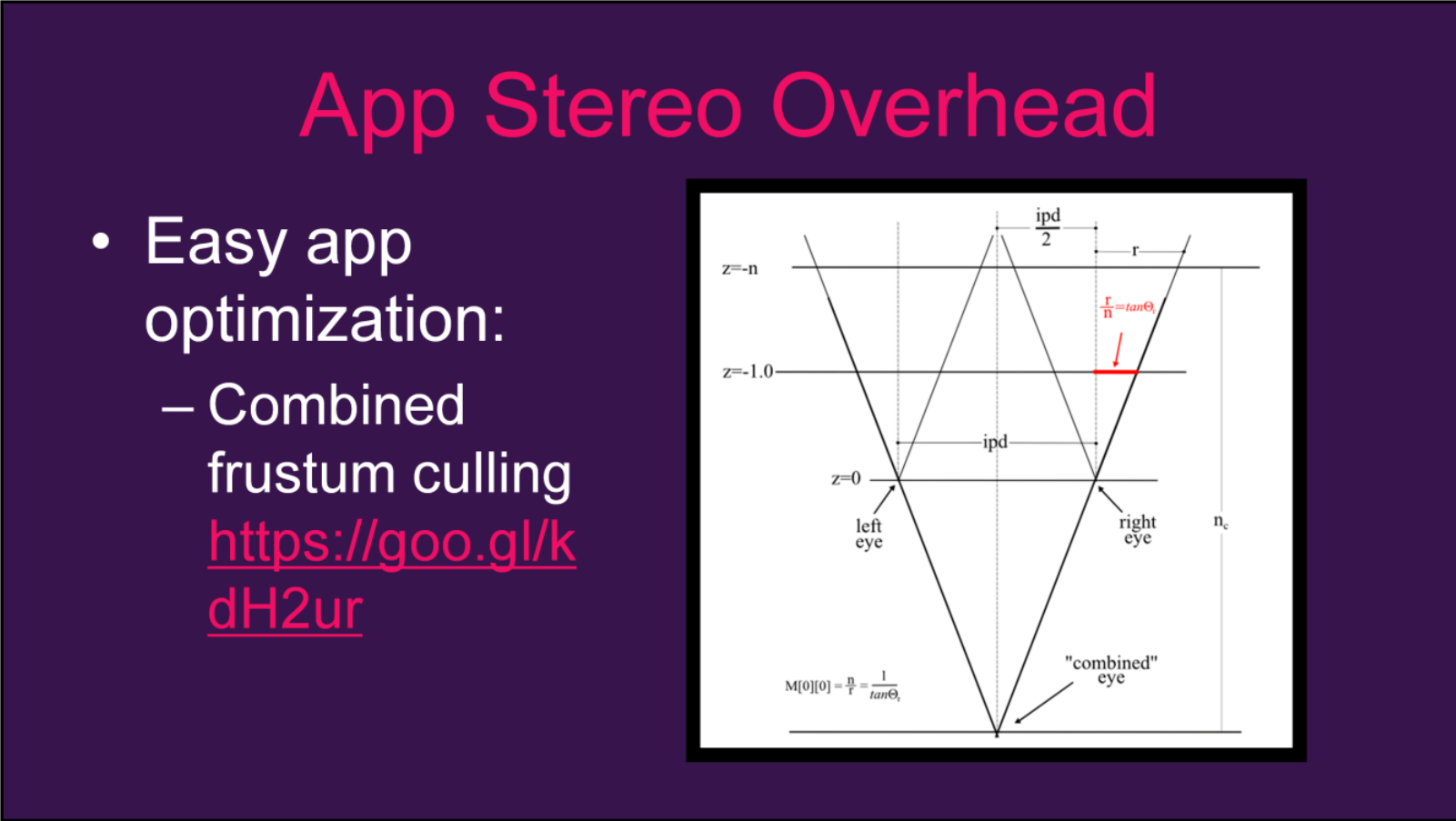
然后用合并的视锥体进入常规的渲染流程。根据摄像机的合并策略,可以分为平行、转位、移轴3种:

立体渲染的3种摄像机合并策略。左:平行;中:转位;右:移轴。
下图是平行方式的立体绘制效果(注意左右画面略有偏移):

12.6.5.4 隐藏延时
对XR设备来说,20ms是可以接受的最大延时,意味着逻辑数据(如设备姿态)获取到显示器呈现不能超过20ms。假设设备以60fps运行,如果有两帧的延迟,那么逻辑数据从第一帧到呈现的总时长将达到50ms!!(下图)
XR应用程序不同于普通简单的应用程序,为了利用多核优势,必然引入多线程渲染,因此在各个线程之间存在等待和延时。
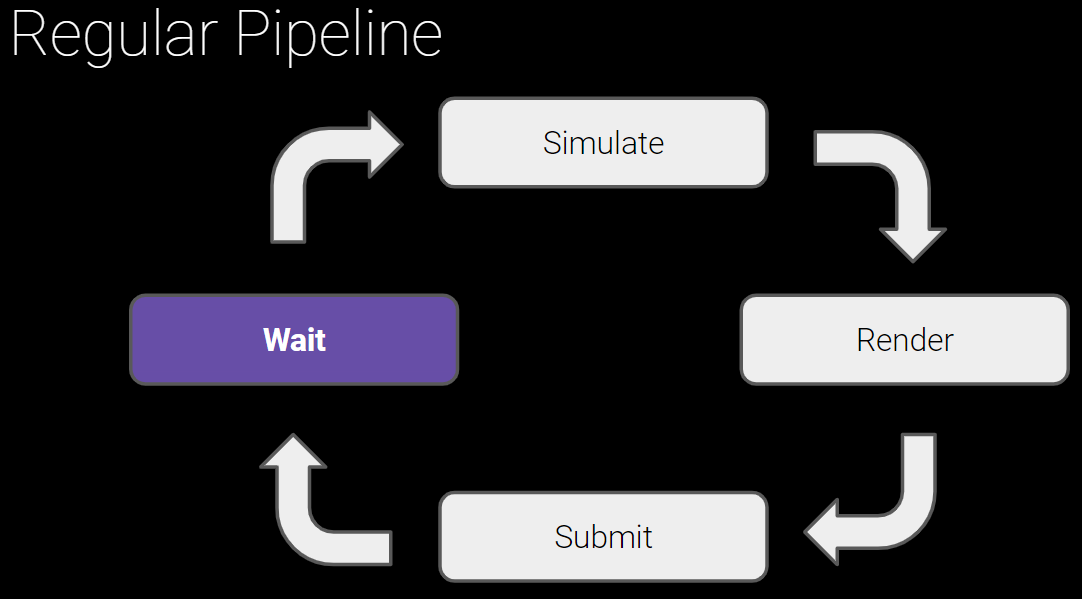
普通应用程序渲染流程图。
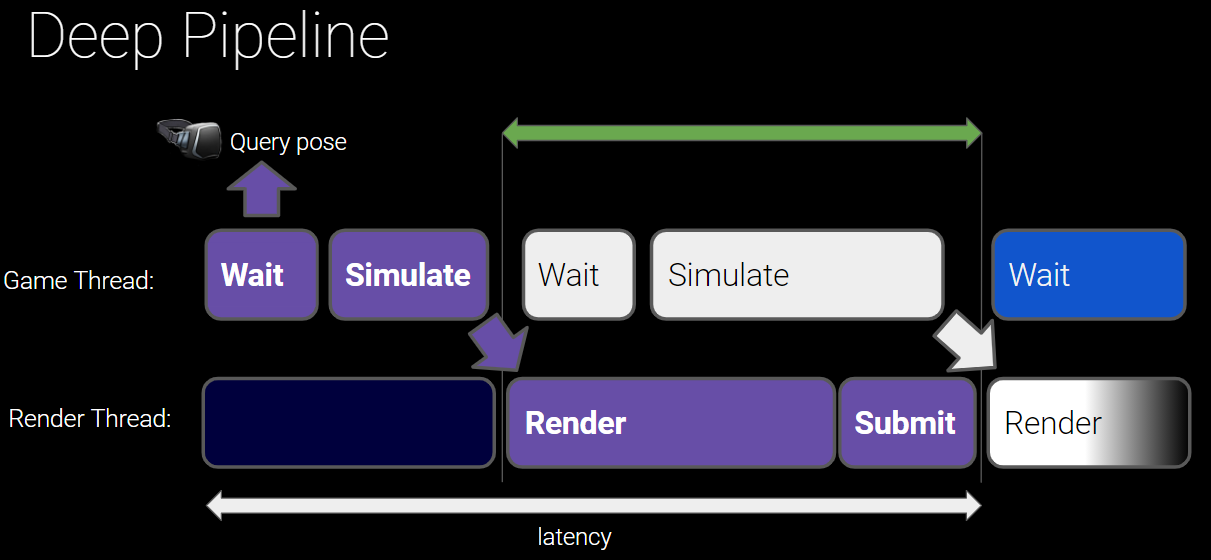
分离出游戏线程和渲染线程的模型,可以将逻辑模拟和渲染层分离,但会引发延时。
如果在游戏线程查询XR设备的姿态(Pose)等信息,会存在较大的延时,由此导致用户头晕和延滞感。解决这个问题也很简单,就是在渲染线程初期中再次查询姿态的信息,减少延时:
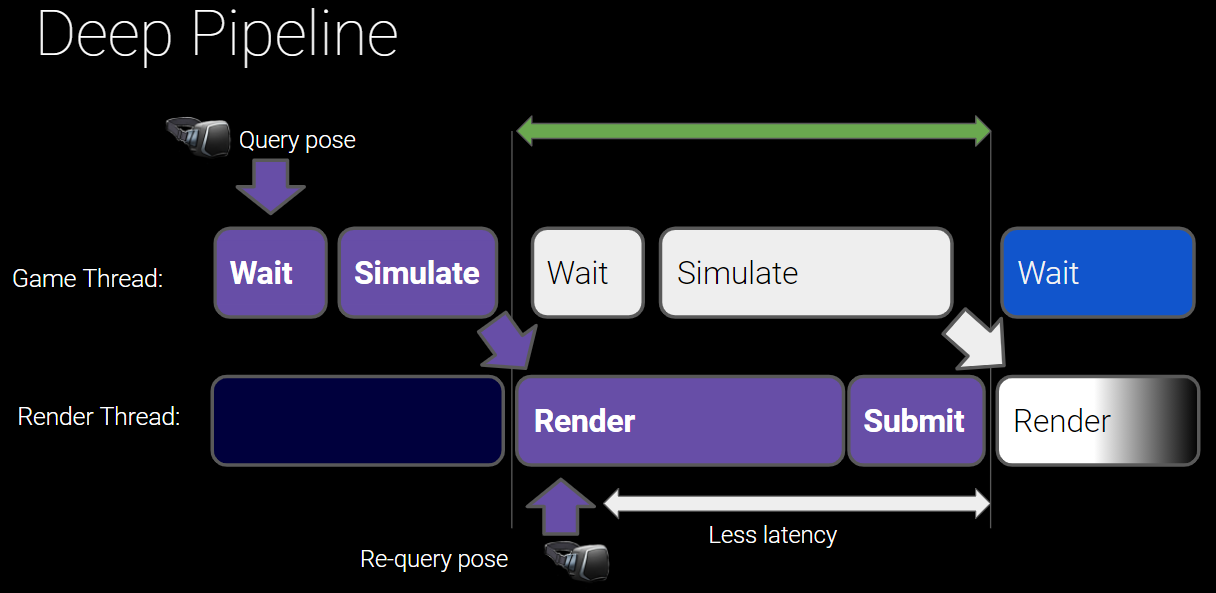
当然提高帧率,合理安排并行任务以缩短时长,采用单缓冲等措施也可以降低延时。
另外,Arm针对UE4在VR方面的应用尝试做优化,以使原本延迟3帧缩减到延迟1~2帧:

- 系统级优化。
例如Google的安卓系统工程师将安卓原本的三缓冲优化成了双缓冲,由此渲染延迟从3帧减少到1帧。
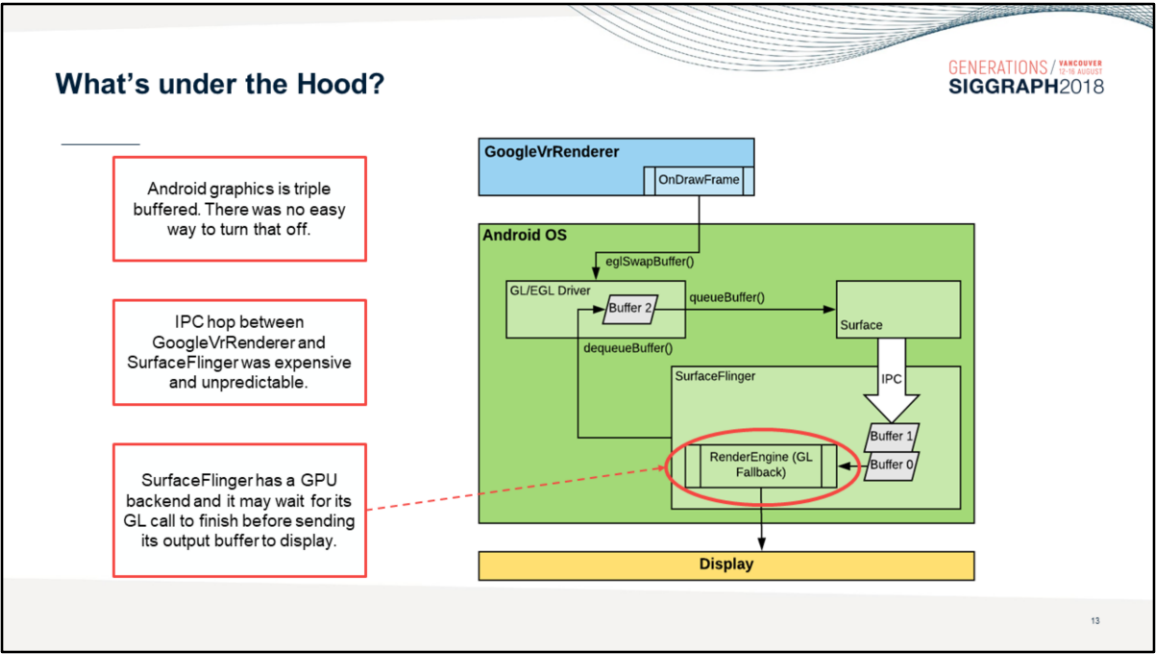
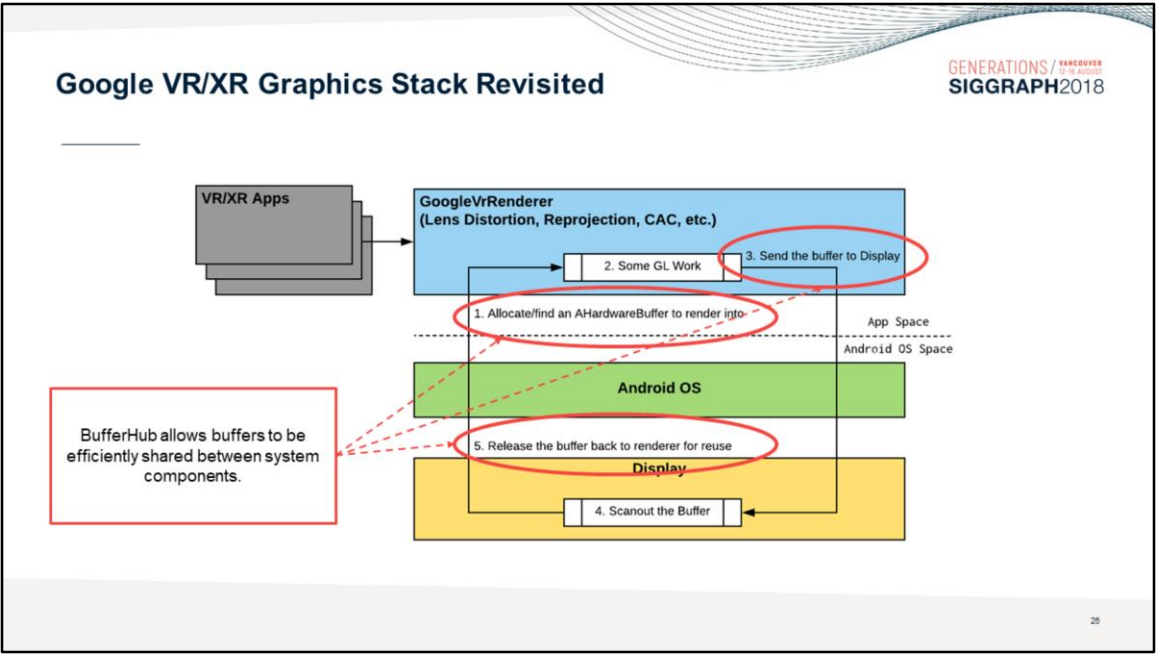
安卓优化渲染延迟对比图。上:没有优化;下:执行了优化。
12.6.5.5 制定技术规格
由于XR设备对比普通移动设备,可以制定出来的标准将更严苛。
以下是Oculus官方在技术规格方面给出的一些建议:
1、Draw Call
| 设备 | Draw Call数量 | 场景复杂度 |
|---|---|---|
| Quest 1 | 50~150 | 高 |
| Quest 1 | 150~250 | 中 |
| Quest 1 | 200~400 | 低 |
| Quest 2 | 80~200 | 高 |
| Quest 2 | 200~300 | 中 |
| Quest 2 | 400~600 | 低 |
2、三角面数
| 设备 | 三角面数 |
|---|---|
| Quest 1 | 35万~50万 |
| Quest 2 | 75万~100万 |
除了以上两个参数,还需要注意帧率、分辨率、内存、显存、卡顿、电量消耗、续航时间、设备温度等技术参数。

移动设备需要注意热量和能量的平衡。
12.6.5.6 其它XR优化
Optimized Rendering Techniques Based On Local Cubemaps提出了基于Local Cubemap优化的渲染技术,可以高效地实现动态软阴影、反射等效果:
Local Cubemap的概念和计算过程。
基于Local Cubemap的动态软阴影关键图例和实现。
基于Local Cubemap的动态反射关键图例和实现。
How Crytek Builds 3-Dimensional UI for VR提到了渲染VR内的字体有3种技术:渲染到纹理再映射到模型、距离场、3D建模,以及详细地对比了这几种方式的优缺点。
渲染到纹理对小字体不够优化,需要更高分辨率。


距离场字体拥有细腻的过度和良好的抗锯齿。但实现复杂,消耗较高。
3D网格字体。需要良好的抗锯齿技术支持,长远看也许是最好的选择。
12.6.6 调试工具
性能优化和调试分析工具息息相关,正所谓工欲善其事必先利其器。
除了RenderDoc、PIX、Visual Studio、XCode等软件或IDE提供了常规的性能分析之外,GPU厂商提供了更加专业和深入地分析自家硬件的分析工具。下面是常用的厂商和对应的分析工具表:
| GPU厂商 | GPU | 分析软件 |
|---|---|---|
| Qualcomm | Adreno | Snapdragon Profiler |
| Arm | Mali | Arm Mobile Studio |
| Imagination Tech | PowerVR | PowerVR Graphics Tools |
以Qualcomm的Snapdragon Profiler为例,它可以监控SoC的活动实况(Realtime)、追踪某段时间内的系统和驱动的工作负载(Trace)、分析某一帧的具体渲染状态、过程和资源(Snapshot)。
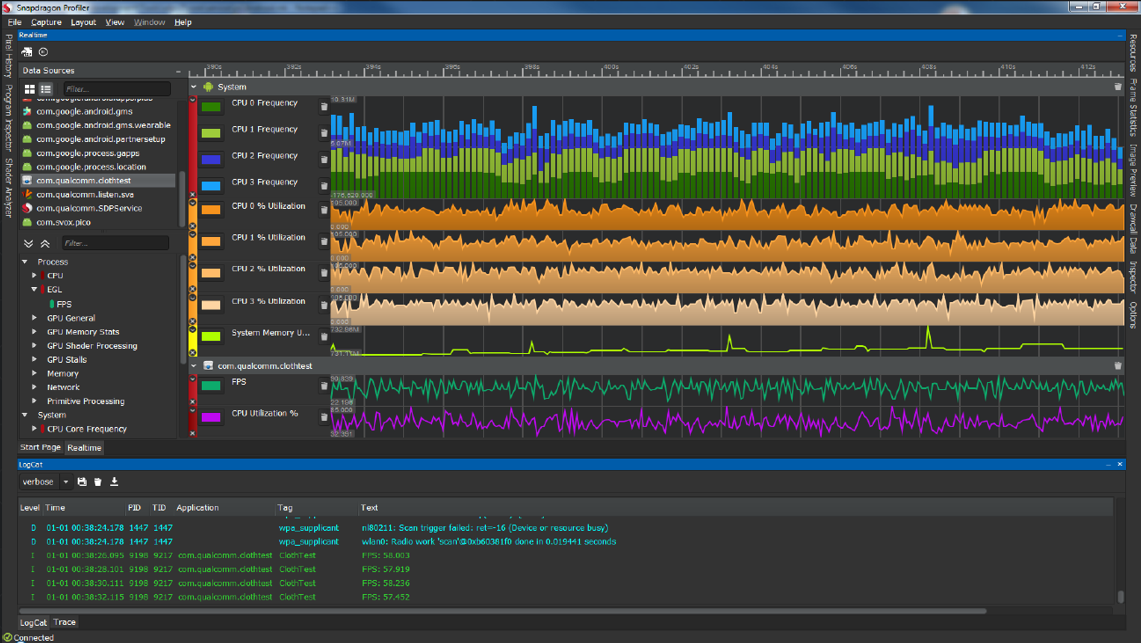
Snapdragon的Realtime页面。
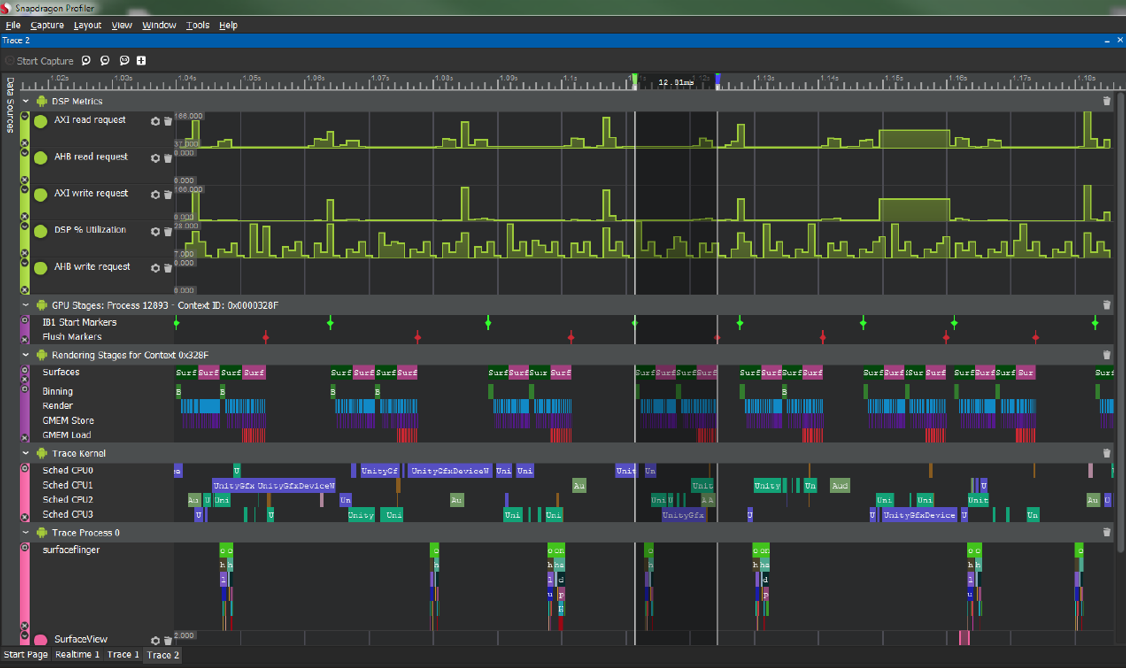
Snapdragon的Trace页面。
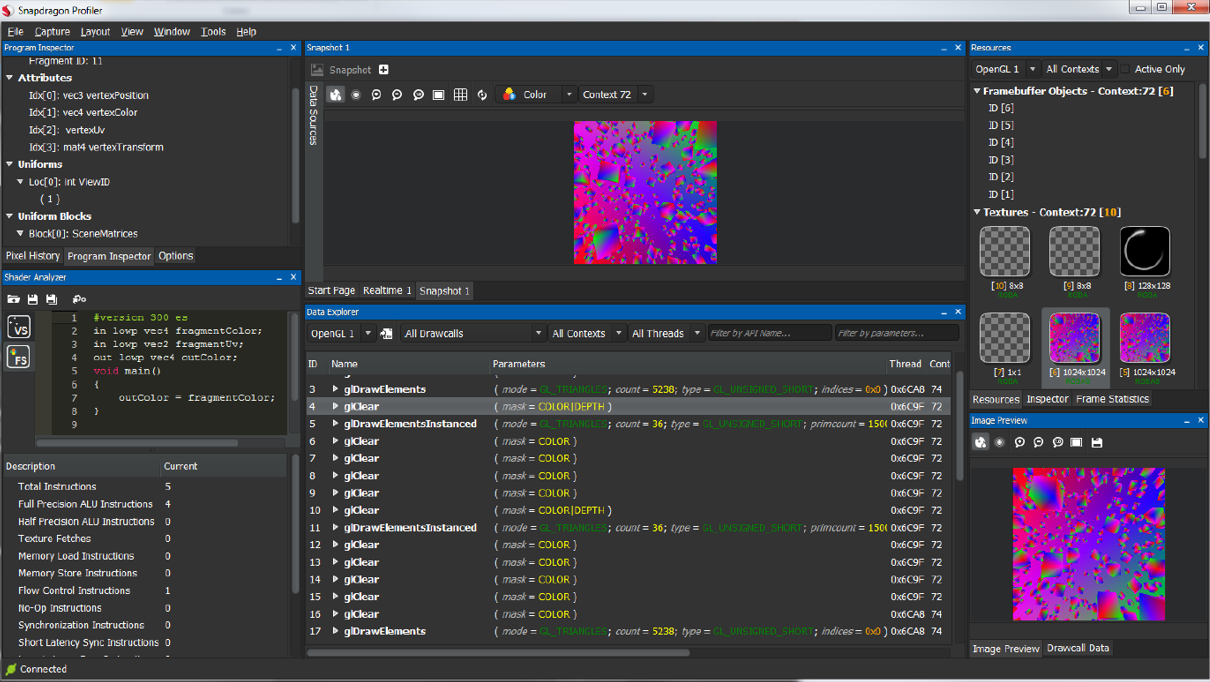
Snapdragon的Snapshot页面。
利用Snapdragon的强大监控功能,可以查看线程、驱动、GPU各部件消耗,查找性能瓶颈,优化卡顿、电量等。具体优化案例可以参见:Identify application bottlenecks。
12.7 本篇总结
本篇主要阐述了UE移动端的场景渲染器的主流程,前向和延迟渲染的过程,移动端的渲染特性和光照算法。后面两部分超脱UE,详细地阐述了当前移动端涉及的专用渲染技术,阐述了移动端GPU架构和运行机制,最后给出了详尽的渲染优化建议。
关于移动端游戏的优化,可以参阅笔者的另一篇文章移动游戏性能优化通用技法作为补充。
移动端专题分为三部分,总字数接近6万字,参考了100多篇各类文献、资料和论文,是参考文献最多的一篇。从组织、策划、研读论文到下笔撰写、修改、发表,总共耗费了一个多月。
当夜深人静本该就寝时,当周末本该轻松休闲时,笔者尚在奋笔疾书,虽然几近耗尽了所有业余时间,但成就感十足。希望对各位同学学习UE和移动端渲染有所帮助和参考,一起为国内图形渲染技术之崛起而努力。
12.7.1 本篇思考
按惯例,本篇也布置一些小思考,以助理解和加深UE及移动端渲染的掌握和理解:
- 请阐述UE移动端场景渲染器的主流程。
- 请阐述UE移动端的前向和延迟渲染主流程。
- 请阐述UE移动端光影的算法及所做的优化。
- 请阐述当前移动端专用的渲染技术,如TBR、Subpass等。
- 移动端的常见渲染优化技术有哪些?请例举一二。
团队招员
博主所在的团队正在用UE4开发一种全新的沉浸式体验的产品,急需各路贤士加入,共谋宏图大业。目前急招以下职位:
- UE逻辑开发。
- UE引擎程序。
- UE图形渲染。
- TA(技术向、美术向)。
要求:
- 扎实的技术基础。
- 高度的技术热情。
- 良好的自驱力。
- 良好的沟通协作能力。
- 有UE使用经验或移动端开发经验更佳。
有意向或想了解更多的请添加博主微信:81079389(注明博客园求职),或者发简历到博主邮箱:81079389#qq.com(#换成@)。
静待各路英雄豪杰相会。
特别说明
- 感谢所有参考文献的作者,部分图片来自参考文献和网络,侵删。
- 本系列文章为笔者原创,只发表在博客园上,欢迎分享本文链接,但未经同意,不允许转载!
- 系列文章,未完待续,完整目录请戳内容纲目。
- 系列文章,未完待续,完整目录请戳内容纲目。
- 系列文章,未完待续,完整目录请戳内容纲目。
参考文献
- Unreal Engine Source
- Rendering and Graphics
- Materials
- Graphics Programming
- Mobile Rendering
- Qualcomm® Adreno™ GPU
- PowerVR Developer Documentation
- PowerVR Performance Recommendations
- PowerVR Graphics Techniques
- Arm Mali GPU Best Practices Developer Guide
- Arm Mali GPU Graphics and Gaming Development
- Moving Mobile Graphics
- GDC Vault
- Siggraph Conference Content
- GameDev Best Practices
- Accelerating Mobile XR
- Frequently Asked Questions
- Google Developer Contributes Universal Bandwidth Compression To Freedreno Driver
- Using pipeline barriers efficiently
- Optimized pixel-projected reflections for planar reflectors
- UE4画面表现移动端较PC端差异及最小化差异的分享
- Deferred Shading in Unity URP
- 移动游戏性能优化通用技法
- 深入GPU硬件架构及运行机制
- Adaptive Performance in Call of Duty Mobile
- Jet Set Vulkan : Reflecting on the move to Vulkan
- Vulkan Best Practices - Memory limits with Vulkan on Mali GPUs
- A Year in a Fortnite
- The Challenges of Porting Traha to Vulkan
- L2M - Binding and Format Optimization
- Adreno Best Practices
- 移动设备GPU架构知识汇总
- Mali GPU Architectures
- Cyclic Redundancy Check
- Arm Guide for Unreal Engine
- Arm Virtual Reality
- Best Practices for VR on Unreal Engine
- Optimizing Assets for Mobile VR
- Arm® Guide for Unreal Engine 4 Optimizing Mobile Gaming Graphics
- Adaptive Scalable Texture Compression
- Tile-Based Rendering
- Understanding Render Passes
- Lighting for Mobile Platforms
- Frame Pacing for Mobile Devices
- ARM Mali GPU. Midgard Architecture
- ARM’s Mali Midgard Architecture Explored
- [Unite Seoul 2019] Mali GPU Architecture and Mobile Studio
- Killing Pixels - A New Optimization for Shading on ARM Mali GPUs
- Qualcomm's Quad-Core Snapdragon S4 (APQ8064/Adreno 320) Performance Preview
- Low Resolution Z Buffer support on Turnip
- Render Graph与现代图形API
- Hidden Surface Removal Efficiency
- Unreal Engine 4: Mobile Graphics on ARM CPU and GPU Architecture
- Low Latency Frame Syncing
- Qualcomm® Snapdragon™ Mobile Platform OpenCL General Programming and Optimization
- Qualcomm Announces Snapdragon 865 and 765(G): 5G For All in 2020, All The Details
- Introduction to PowerVR for Developers
- PowerVR Series5 Architecture Guide for Developers
- PowerVR Graphics - Latest Developments and Future Plans
- PowerVR virtualization: a critical feature for automotive GPUs
- PowerVR Performance Recommendations
- PowerVR Compute Development Recommendations
- PowerVR Low Level GLSL Optimisation
- Mobile GPU approaches to power efficiency
- Processing Architecture for Power Efficiency and Performance
- opengl: glFlush() vs. glFinish()
- Cramming Software onto Mobile GPUs
- Vulkan on Mobile Done Right
- Triple Buffering
- Asynchronous Shaders
- Why Talking About Render Graphs
- NVIDIA Variable Rate Shading
- Introduction to compute shaders
- Introduction to GPU Architecture
- An Introduction to Modern GPU Architecture
- Understanding GPU caches
- Transitioning from OpenGL to Vulkan
- Next Generation OpenGL Becomes Vulkan: Additional Details Released
- Bringing Fortnite to Mobile with Vulkan and OpenGL ES
- Appropriate use of render pass attachments
- Preparing Android for XR
- VkPipelineStageFlagBits(3) Manual Page
- RGBM color encoding
- The Mechanics of Robust Stencil Shadows
- Optimized Stencil Shadow Volumes
- PSO Caching
- High Quality, High Performance Graphics in Filament
- Analyzing Modern Rendering
- Advanced Real-time Shadowing
- Vulkan Multi-Threading
- Oculus Quest: Testing and Performance Analysis
- Making EVE: Gunjack
- Real-time 2D manipulation of plausible 3D appearance using shading and geometry buffers
- Profiling with Stereo Rendering
- Introduction to Stereo Rendering
- Multiview Rendering for VR
- Pipeline stall
- Improving Visual Rendering Quality in Mobile Virtual Reality on Unreal Engine
- Performance Guidelines for Mobile Devices
- Virtual Reality Presentations
- The future of mobile VR
- Optimized Rendering Techniques Based On Local Cubemaps
- Optimizing Assets for Mobile VR
- High Quality Mobile VR with Unreal Engine with Oculus
- Snapdragon Profiler
- Understanding and resolving Graphics Memory Loads
- Qualcomm® Snapdragon™ Profiler User Guide
- Identify application bottlenecks
- How Crytek Builds 3-Dimensional UI for VR

 浙公网安备 33010602011771号
浙公网安备 33010602011771号