【Java使用手册】-05 Scanning与Formatting
本文包括一部分内容:
- Oracle官网Java教程-Scanning and Formatting 和译文(译文属于个人理解);
part1. 教材及翻译
Scanning and Formatting
Programming I/O often involves translating to and from the neatly formatted data humans like to work with. To assist you with these chores, the Java platform provides two APIs. The scanner API breaks input into individual tokens associated with bits of data. The formatting API assembles data into nicely formatted, human-readable form.
译:扫描和格式化
编写 I/O 常常涉及到与人们喜欢使用的格式化整齐的数据之间的转换。为了帮助你完成这些任务,Java 平台提供了两个API。 scanner API 将输入分解为与数据为相关的单个标记。formatting API 将数据组装成格式化良好、可读的形式。
Scanning
Objects of type
Scannerare useful for breaking down formatted input into tokens and translating individual tokens according to their data type.译:扫描
Scanner类型的对象对于将格式化的输入分解为独立的标签字段和根据他们的数据类型转换单个标签非常有用。Breaking Input into Tokens
By default, a scanner uses white space to separate tokens. (White space characters include blanks, tabs, and line terminators. For the full list, refer to the documentation for
Character.isWhitespace.) To see how scanning works, let's look atScanXan, a program that reads the individual words inxanadu.txtand prints them out, one per line.译:将输入分解为符号
默认情况下,scanner 通过空白字符来分隔标记。(空白字符包括空格、制表符和行终结符。完整列表请参考文档
Character.isWhitespace)。要了解 scanner 是如何工作的,我们看下下面这个程序,它读取 xannadu.txt 的单个单词,并将它们输出,每行一个。import java.io.*; import java.util.Scanner; public class ScanXan { public static void main(String[] args) throws IOException { Scanner s = null; try { s = new Scanner(new BufferedReader(new FileReader("xanadu.txt"))); while (s.hasNext()) { System.out.println(s.next()); } } finally { if (s != null) { s.close(); } } } }Notice that
ScanXaninvokesScanner'sclosemethod when it is done with the scanner object. Even though a scanner is not a stream, you need to close it to indicate that you're done with its underlying stream.The output of
ScanXanlooks like this:译:
注意,当 scanner 处理完扫描对象时,它会调用 Scanner 的 close 方法。即使 scanner 不是一个流,你也需要关闭它,以表明你已经完成了对其底层流的处理。
程序的输出是这样的:
In Xanadu did Kubla Khan A stately pleasure-dome ...To use a different token separator, invoke
useDelimiter(), specifying a regular expression. For example, suppose you wanted the token separator to be a comma, optionally followed by white space. You would invoke,译:
要使用不同的分隔符,请调用 'useDelimiter()' 方法,指定正则表达式。例如,假设你希望标记分隔符是逗号,后面可以有空格。你可以向下面这样调用。
s.useDelimiter(",\\s*");Translating Individual Tokens
The
ScanXanexample treats all input tokens as simpleStringvalues.Scanneralso supports tokens for all of the Java language's primitive types (except forchar), as well asBigIntegerandBigDecimal. Also, numeric values can use thousands separators. Thus, in aUSlocale,Scannercorrectly reads the string "32,767" as representing an integer value.We have to mention the locale, because thousands separators and decimal symbols are locale specific. So, the following example would not work correctly in all locales if we didn't specify that the scanner should use the
USlocale. That's not something you usually have to worry about, because your input data usually comes from sources that use the same locale as you do. But this example is part of the Java Tutorial and gets distributed all over the world.The
ScanSumexample reads a list ofdoublevalues and adds them up. Here's the source:译:翻译独特的标记
上面例子将所有的输入标签视为简单的String值。Scanner 还支持 Java 语言所有的的原始类型的标记(char除外),包括 BigInteger 和 BigDecimal。此外,数值可以使用数千个分隔符。因此,在美国地区,Scanner 将字符串"32767"正确地读取为一个整数值。
我们必须提到区域设置,因为数以千计的分隔符和十进制符号都是特定于区域设置的。所以,如果我们没有指定 scanner 程序应该使用 US 语言环境,那么下面的示例将不能在所有的语言环境中正确工作。这不是你通常需要关注的问题,因为你的输入数据通常来自于和你是相同区域的数据源。但是,这个示例是 Java 教案的一部分,并在世界各地分发。
下面的 ScanSum 示例读取一些 double 类型的值并将它们相加。这是源码:
import java.io.FileReader; import java.io.BufferedReader; import java.io.IOException; import java.util.Scanner; import java.util.Locale; public class ScanSum { public static void main(String[] args) throws IOException { Scanner s = null; double sum = 0; try { s = new Scanner(new BufferedReader(new FileReader("usnumbers.txt"))); s.useLocale(Locale.US); while (s.hasNext()) { if (s.hasNextDouble()) { sum += s.nextDouble(); } else { s.next(); } } } finally { s.close(); } System.out.println(sum); } }And here's the sample input file,
usnumbers.txt译:下面是简单的输入文件
8.5 32,767 3.14159 1,000,000.1The output string is "1032778.74159". The period will be a different character in some locales, because
System.outis aPrintStreamobject, and that class doesn't provide a way to override the default locale. We could override the locale for the whole program — or we could just use formatting, as described in the next topic, Formatting.译:
输出字符串为"1032778.74159"。在某些地区,句点是不同的字符,因为 System.out 是一个 PrintStream 对象,并且该类不提供重写默认区域设置的方法。我们可以覆写整个程序的区域——或者我们可以只使用格式化,如下一个主题,formatting所述。
Formatting
Stream objects that implement formatting are instances of either
PrintWriter, a character stream class, orPrintStream, a byte stream class.
Note: The only
PrintStreamobjects you are likely to need areSystem.outandSystem.err. (See I/O from the Command Line for more on these objects.) When you need to create a formatted output stream, instantiatePrintWriter, notPrintStream.
Like all byte and character stream objects, instances of
PrintStreamandPrintWriterimplement a standard set ofwritemethods for simple byte and character output. In addition, bothPrintStreamandPrintWriterimplement the same set of methods for converting internal data into formatted output. Two levels of formatting are provided:
printlnformat individual values in a standard way.formatformats almost any number of values based on a format string, with many options for precise formatting.译:格式化
实现格式化的流对象,要么是
PrintWriter(字符流的类)的实例,要么是PrintStream(字节流的类)的实例。注意:你可能会用到的唯一一个 PrintStream 对象是
System.out和System.err。(有关这些对象的更多信息,请参看 I/O from the Command Line )。当你需要创建一个格式化的输出流,实例化 PrintWriter,而不是 PrintStream。像所有的字节流、字符流一样,
PrintStream和PrintWriter的实例实现了一组标准的write方法,用于简单的字节和字符输出。此外,PrintStream和PrintWriter都实现了同样的一组方法,用于将内部数据转换为格式化输出。下面提供了两种级别的格式化:
println以标准方式格式化单个值。format基于格式字符串来格式化几乎任意数量的值,有许多选项用于精确格式化。The
printlnMethodsInvoking
printlnoutputs a single value after converting the value using the appropriatetoStringmethod. We can see this in theRootexample:译:
println方法在适当使用
toString方法转换值后,调用println输出单个值。我们可以在Root例子中看到这一点。public class Root { public static void main(String[] args) { int i = 2; double r = Math.sqrt(i); System.out.print("The square root of "); System.out.print(i); System.out.print(" is "); System.out.print(r); System.out.println("."); i = 5; r = Math.sqrt(i); System.out.println("The square root of " + i + " is " + r + "."); } }Here is the output of
Root:译:
下面是
Root程序的输出结果:The square root of 2 is 1.4142135623730951. The square root of 5 is 2.23606797749979.The
iandrvariables are formatted twice: the first time using code in an overload oftoString. You can format any value this way, but you don't have much control over the results.译:
i和r变量被格式化了两次:第一次使用toString。可以用这种方法格式化任何值,但是对结果没有太多的控制权。The
formatMethodThe
formatmethod formats multiple arguments based on a format string. The format string consists of static text embedded with format specifiers; except for the format specifiers, the format string is output unchanged.Format strings support many features. In this tutorial, we'll just cover some basics. For a complete description, see
format string syntaxin the API specification.The
Root2example formats two values with a singleformatinvocation:译:
format方法
format方法基于格式字符串对多个参数进行格式化。格式字符串由嵌入格式说明符的静态文本组成;除了格式说明符之外,格式字符串的输出不会改变。格式字符串支持许多特性。在本教程中,我们只介绍一些基本知识。有关完整的描述,请参阅API说明中的
format string syntax(格式字符串语法)。public class Root2 { public static void main(String[] args) { int i = 2; double r = Math.sqrt(i); System.out.format("The square root of %d is %f.%n", i, r); } }Here is the output:
译:
下面这是输出结果:
The square root of 2 is 1.414214.Like the three used in this example, all format specifiers begin with a
%and end with a 1- or 2-character conversion that specifies the kind of formatted output being generated. The three conversions used here are:
dformats an integer value as a decimal value.fformats a floating point value as a decimal value.noutputs a platform-specific line terminator.Here are some other conversions:
xformats an integer as a hexadecimal value.sformats any value as a string.tBformats an integer as a locale-specific month name.There are many other conversions.
Note:
Except for
%%and%n, all format specifiers must match an argument. If they don't, an exception is thrown.In the Java programming language, the
\nescape always generates the linefeed character (\u000A). Don't use\nunless you specifically want a linefeed character. To get the correct line separator for the local platform, use%n.
In addition to the conversion, a format specifier can contain several additional elements that further customize the formatted output. Here's an example,
Format, that uses every possible kind of element.译:
和本例中使用的三个格式说明符一样,所有的格式说明符都以%开头,以1或2个字符的转换结束。这些转换指定要生成的格式化输出的类型。这里使用的三种转换是:
- d 将整数值格式化为十进制值。
- f 将浮点数值格式化为十进制值。
- n 输出特定平台的行终止符。
下面是一些其他的转换:
- x 将整数值格式化为十六进制值。
- s 将任何值格式化为字符串。
- tB 将整数值格式化为特定区域设置的月份名。
还有很多其他的转换。
注意:
除了%% 和%n 之外,所有的格式说明符必须匹配一个参数。如果没有,则抛出异常。
在 Java 编程语言中,
\n转移总是生成换行字符(\u000A)。不要使用\n除非你特别想要一个换行符。要为本地平台获取正确的分隔符,请使用%n。除了转换之外,一个格式说明符可以包含几个额外的元素,这些元素可以进一步定制格式化的输出。下面是一个例子,
Format,它使用了所有可能的元素。public class Format { public static void main(String[] args) { System.out.format("%f, %1$+020.10f %n", Math.PI); } }Here's the output:
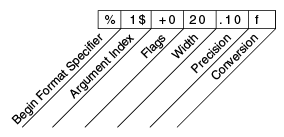
3.141593, +00000003.1415926536The additional elements are all optional. The following figure shows how the longer specifier breaks down into elements.
译:
其他元素都是可选的。下图显示了较长的说明符如何分解为元素。
Elements of a Format Specifier.
The elements must appear in the order shown. Working from the right, the optional elements are:
- Precision. For floating point values, this is the mathematical precision of the formatted value. For
sand other general conversions, this is the maximum width of the formatted value; the value is right-truncated if necessary.- Width. The minimum width of the formatted value; the value is padded if necessary. By default the value is left-padded with blanks.
- Flags specify additional formatting options. In the
Formatexample, the+flag specifies that the number should always be formatted with a sign, and the0flag specifies that0is the padding character. Other flags include-(pad on the right) and,(format number with locale-specific thousands separators). Note that some flags cannot be used with certain other flags or with certain conversions.- The Argument Index allows you to explicitly match a designated argument. You can also specify
<to match the same argument as the previous specifier. Thus the example could have said:System.out.format("%f, %<+020.10f %n", Math.PI);译:
格式说明符的元素:
元素必须按照显示的顺序出现。从右边开始,可选的元素是:
- Precision 精度。对于浮点值,这是格式化值的数学精度。对于s和其他通用转换,这是格式化值的最大宽度;如果需要,该值将被右截断。
- Width 宽度。格式化值的最小宽度;如果需要,该值将被填充。缺省情况下,该值用空格左填充。
- Flags 标志。指定其他格式选项。在格式示例中,+标志指定数字应该总是用符号格式化,0标志指定0是填充字符。其他标志包括-(右边的衬垫)和,(带有特定于区域设置的数千个分隔符的格式号)。注意,某些标记不能与某些其他标记或某些转换一起使用。
- The Argument Index 参数索引。允许您显式匹配指定的参数。还可以指定<来匹配前面的说明符所指定的参数。因此这个例子可以说:
System.out.format("%f, %<+020.10f %n", Math.PI);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号