理解 volatile
理解volatile其实还是有点儿难度的,它与Java的内存模型有关,所以在理解volatile之前需要先了解有关Java内存模型的概念,目前只做初步的介绍。
一、操作系统语义
计算机在运行程序时,每条指令都是在CPU中执行的,在执行过程中势必会涉及到数据的读写。
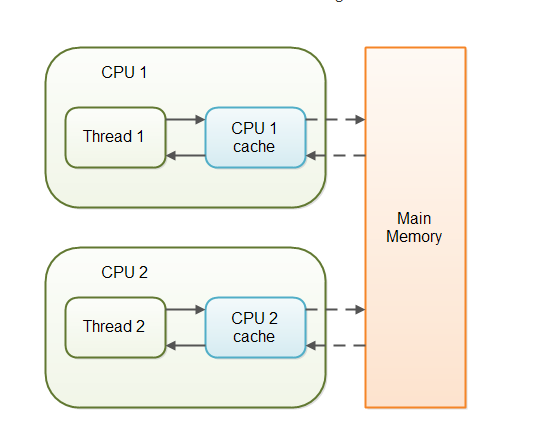
我们知道程序运行的数据是存储在主存中,这时就会有一个问题,读写主存中的数据没有CPU中执行指令的速度快,如果任何的交互都需要与主存打交道则会大大影响效率,所以就有了CPU高速缓存。
CPU高速缓存为某个CPU独有,只与在该CPU运行的线程有关。
1、产生数据一致性 / 内存不可见性问题
有了CPU高速缓存虽然解决了效率问题,但是它会带来一个新的问题:内存不可见性 ——> 数据一致性。
线程在运行的过程中会把主内存的数据拷贝一份到线程内部cache中,也就是working memory。这个时候多个线程访问同一个变量,其实就是访问自己的内部cache,不再与主存打交道,只有当运行结束后才会将数据刷新到主存中。
【举一个简单的例子】:
public class VariableTest {
public static boolean flag = false;
public static void main(String[] args) throws InterruptedException {
ThreadA threadA = new ThreadA();
ThreadB threadB = new ThreadB();
new Thread(threadA, "threadA").start();
Thread.sleep(1000l);//为了保证threadA比threadB先启动,sleep一下
new Thread(threadB, "threadB").start();
}
static class ThreadA extends Thread {
public void run() {
while (true) {
if (flag) {
System.out.println(Thread.currentThread().getName() + " : flag is " + flag);
break;
}
}
}
}
static class ThreadB extends Thread {
public void run() {
flag = true;
System.out.println(Thread.currentThread().getName() + " : flag is " + flag);
}
}
}
运行结果:(光标一直在闪)

上面例子出现问题的原因在于:
(1)线程A把变量flag(false)加载到自己的内部缓存cache中;线程B修改变量flag后,即使重新写入主内存,但是线程A不会重新从主内存加载变量flag,看到的还是自己cache中的变量flag。所以线程A是读取不到线程B更新后的值,然后一直死循环...
(2)除了cache的原因,重排序后的指令在多线程执行时也有可能导致内存不可见,由于指令顺序的调整,线程A读取某个变量的时候线程B可能还没有进行写入操作呢,虽然代码顺序上写操作是在前面的。
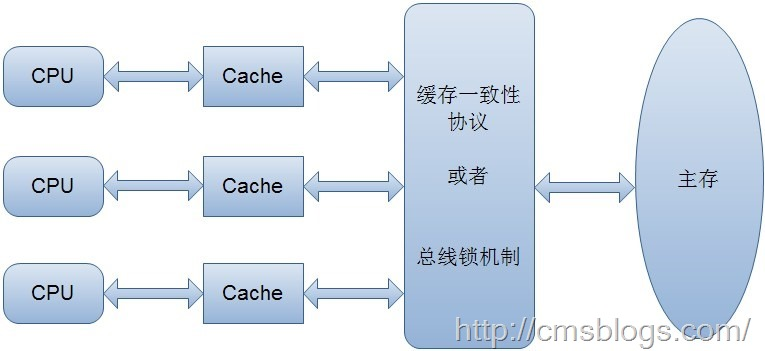
2、解决缓存一致性方案
- 通过在总线加LOCK#锁的方式
- 通过缓存一致性协议
但是方案1存在一个问题:它是采用一种独占的方式来实现的,即总线加LOCK#锁的话,只能有一个CPU能够运行,其他CPU都得阻塞,效率较为低下。
第二种方案:缓存一致性协议(MESI协议)确保每个缓存中使用的共享变量的副本是一致的。
核心思想如下:当某个CPU在写数据时,如果发现操作的变量是共享变量,则会通知其他CPU告知该变量的缓存行是无效的,因此其他CPU在读取该变量时,发现其无效会重新从主存中加载数据。
二、Java内存模型
1、共享变量
共享变量是指:可以同时被多个线程访问的变量,共享变量是被存放在堆里面,所有的方法内的临时变量都不是共享变量。
2、有序性 (happens-before原则)
一个线程观察其他线程中的指令执行顺序,由于指令重排序,该观察结果一般杂乱无序
重排序:是指为了提高指令运行的性能,在编译时或者运行时对指令执行顺序进行调整的机制。重排序分为编译重排序和运行时重排序。
编译重排序是指:编译器在编译源代码的时候就对代码执行顺序进行分析,在遵循as-if-serial的原则前提下对源码的执行顺序进行调整。
运行时重排序:是指为了提高执行的运行速度,系统对机器的执行指令的执行顺序进行调整。
【as-if-serial原则】是指在单线程环境下,无论怎么重排序,代码的执行结果都是确定的。
3、可见性(synchronized,volatile)
内存的可见性是指线程之间的可见性,一个线程的修改状态对另外一个线程是可见的,用通俗的话说,就是假如一个线程A修改一个共享变量flag之后,则线程B去读取,一定能读取到最新修改的flag。
(看上边示例)
Java提供了volatile来保证可见性。
当一个变量被volatile修饰后,表示着线程本地内存无效,当一个线程修改共享变量后他会立即被更新到主内存中,当其他线程读取共享变量时,它会直接从主内存中读取。
当然,synchronize和锁都可以保证可见性。
4、原子性(atomic,synchronized)
原子性:提供互斥访问,同一时刻只能有一个线程对数据进行操作。 即一个操作或者多个操作 要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。就像数据库里面的事务一样,他们是一个团队,同生共死。
在单线程环境下我们可以认为整个步骤都是原子性操作,但是在多线程环境下则不同,Java只保证了基本数据类型的变量和赋值操作才是原子性的。
要想在多线程环境下保证原子性,则可以通过锁、synchronized来确保。
// 一个很经典的例子就是银行账户转账问题:
比如从账户A向账户B转1000元,那么必然包括2个操作:从账户A减去1000元,往账户B加上1000元。试想一下,如果这2个操作不具备原子性,会造成什么样的后果。
假如从账户A减去1000元之后,操作突然中止(B此时并没有收到)。
然后A又从B取出了500元,取出500元之后,再执行 往账户B加上1000元 的操作。这样就会导致账户A虽然减去了1000元,但是账户B没有收到这个转过来的1000元(少了500)。
所以这2个操作必须要具备原子性(不可分割的最小操作单位)才能保证不出现一些意外的问题。
三、volatile原理
(1)使用volatile的变量依然会被读到线程内部cache中,只不过当B线程修改了flag后,会将flag写回主内存,同时会通过 CPU 总线嗅探机制通知到A线程去同步内存中flag的值,并且禁止指令重排序,可以保证内存的可见性和数据的一致性。
(2)线程读取数据的时候直接读写内存,同时volatile不会对变量加锁,因此性能会比synchronized好。
volatile相对于synchronized稍微轻量些,在某些场合它可以替代synchronized,但是又不能完全取代synchronized,只有在某些场合才能够使用volatile。
使用它必须满足如下两个条件:
// 1、对变量的写操作不依赖当前值;
// 2、该变量没有包含在具有其他变量的不变式中
volatile经常用于两个两个场景:状态标记、double check(单例模式)
参考: https://zhuanlan.zhihu.com/p/138819184

 浙公网安备 33010602011771号
浙公网安备 33010602011771号