

某点网文章爬取
一、思路
分析网页结构【开发者工具F12】 >>> 确定选择器提取内容 >>> 下载保存
二、代码实现
# -*- coding:UTF-8 -*-
import os
import time
from concurrent.futures.thread import ThreadPoolExecutor
import requests
import urllib3
from bs4 import BeautifulSoup
# 禁用安全请求警告
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
file_path_base = 'G:/novel/lingdian' # 文件下载目录
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/77.0.3865.35 Safari/537.36 ", 'Referer': 'http://www.00kxs.com'}
chapter_content_array = []
# 从页面获取小说名称
def get_novel_name(novel_total_url):
response = requests.get(url=novel_total_url, headers=headers, verify=False)
response.encoding = 'gbk' # 'utf-8'
bf = BeautifulSoup(response.text, 'lxml')
title_content = bf.select('title')[0].text
title_content = str(title_content).split('_')[0]
if title_content.__contains__('完整'):
title_content = title_content[0:int(title_content.index('完整'))]
# 添加日期后缀
date_suffix = time.strftime('%Y%m%d', time.localtime(time.time()))
return title_content + '-' + date_suffix
# 从页面获取章节名称和url地址
def get_name2urls(novel_total_url):
response = requests.get(url=novel_total_url, headers=headers, verify=False)
response.encoding = 'gbk' # 'utf-8'
bf = BeautifulSoup(response.text, 'lxml')
name2urls = []
url_prefix = novel_total_url[0:int(novel_total_url.index('/html'))]
chapter_array = bf.select('.gochapter a')
if len(chapter_array) > 0:
all_url = novel_total_url + chapter_array[0].get('href')
response = requests.get(url=all_url, headers=headers, verify=False)
response.encoding = 'gbk' # 'utf-8'
bf = BeautifulSoup(response.text, 'lxml')
temp_index = 1
for tag_content in bf.select('.list_xm a'):
name2urls.append([str(tag_content.text).replace('?', '').replace('(求收藏推荐)', ''), url_prefix + tag_content.get('href'), temp_index])
temp_index += 1
else:
start_flag = False
temp_index = 1
for tag_content in bf.select('.chapter a'):
if start_flag:
name2urls.append([str(tag_content.text).replace('?', '').replace('(求收藏推荐)', ''), url_prefix + tag_content.get('href'), temp_index])
temp_index += 1
if str(tag_content).__contains__('第一章') or str(tag_content).__contains__('第1章'):
start_flag = True
name2urls.append([str(tag_content.text).replace('?', '').replace('(求收藏推荐)', ''), url_prefix + tag_content.get('href'), temp_index])
temp_index += 1
return name2urls
# 下载章节内容
def get_chapter_content(chapter_name2url):
chapter_name = chapter_name2url[0]
chapter_url = chapter_name2url[1]
chapter_index = chapter_name2url[2]
chapter_content = '【' + chapter_name + '】' + '\n'
try:
response = requests.get(url=chapter_url, headers=headers, verify=False)
response.encoding = 'gbk'
# print(response.text)
bf = BeautifulSoup(response.text, 'lxml')
print('第【' + str(chapter_index) + '】章' + '【' + chapter_name + '】内容提取中 >>>')
if len(bf.select('#novelcontent p')) > 0:
for tag_content in bf.select('#novelcontent p'):
if str(tag_content.text).__contains__('------'):
continue
chapter_content += tag_content.text + '\n'
else:
for tag_content in bf.select('#content p'):
if str(tag_content.text).__contains__('------'):
continue
chapter_content += tag_content.text + '\n'
chapter_content_array.append([chapter_index, chapter_content])
except Exception as error:
print('【' + chapter_name + '】内容获取失败 -> ' + str(error))
return [chapter_index, chapter_content]
# 下载操作 -> 使用章节内容对文件进行增量添加操作
def download(category_name, file_name, chapter_name, chapter_content):
if not os.path.exists(file_path_base):
os.makedirs(file_path_base)
dir_name = file_path_base + '/' + category_name
if not os.path.exists(dir_name):
os.makedirs(dir_name)
# 异常处理
try:
path = dir_name + '/' + file_name + '.txt'
with open(path, 'a', encoding='utf-8') as file:
file.write(chapter_content)
except Exception as error:
print('【' + chapter_name + '】写入失败 -> ' + str(error))
def start_crawl(novel_total_url):
total_start = time.perf_counter()
# 1、从总览页获取小说名称
novel_name = get_novel_name(novel_total_url)
# 2、从总览页获取章节名称和章节url
name2urls = get_name2urls(novel_total_url)
# 使用线程池提取章节内容
thread_pool = ThreadPoolExecutor(10)
for name2url_index in range(len(name2urls)):
thread_pool.submit(get_chapter_content, name2urls[name2url_index])
thread_pool.shutdown()
# 将多线程提取来的内容集合排序 -> 合成内容 -> 一次性写入本地文件
chapter_content_array.sort()
chapter_content_total = ''
for chapter_content in chapter_content_array:
chapter_content_total += chapter_content[1]
total_expend = time.perf_counter() - total_start
print('全部内容提取完成,总共耗时【' + ('%.1f' % total_expend) + '】秒')
write_start = time.perf_counter()
download('', novel_name, '第1章', chapter_content_total)
write_expend = time.perf_counter() - write_start
print('写入完成,总共耗时【' + ('%.1f' % write_expend) + '】秒')
if __name__ == '__main__':
novel_home_url = 'https://m.00ksw.com/html/62/62119/' # 斗罗
# novel_home_url = 'http://www.00kxs.com/html/3/3235/' # 透视
# novel_home_url = 'http://www.00kxs.com/html/56/56824/' #斗破
start_crawl(novel_home_url)
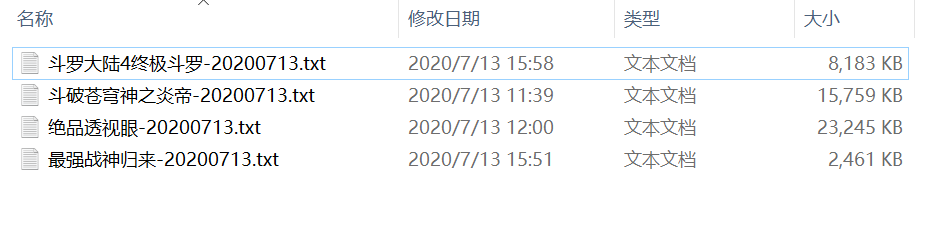
三、效果展示

四、打完收功~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号