
Hadoop综合大作业
本次作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
Hadoop综合大作业 要求:
1.将爬虫大作业产生的csv文件上传到HDFS
2.对CSV文件进行预处理生成无标题文本文件
3.把hdfs中的文本文件最终导入到数据仓库Hive中
4.在Hive中查看并分析数据
5.用Hive对爬虫大作业产生的进行数据分析,写一篇博客描述你的分析过程和分析结果。(10条以上的查询分析)
数据预处理:
对爬取的CSV文件进行处理和清洗,删除空白和没用的数据
清理重复的数据和无效数据

大数据分析:
1.将爬虫大作业产生的csv文件上传到HDFS
先用命令创建文件夹,并进入其文件夹位置。
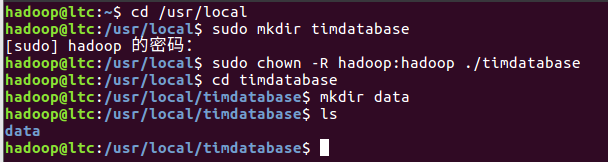
将文件复制到新创文件夹中,并查看前五条数据,测试是否上传成功。
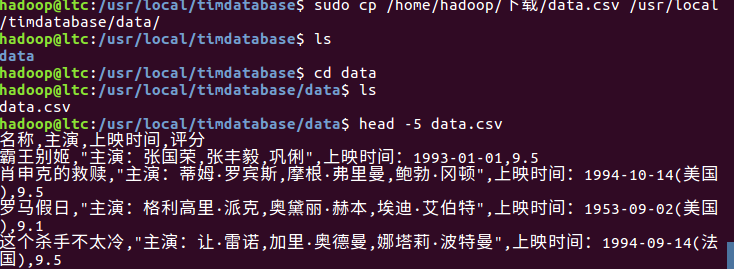
为了更好的显示效果,我们先对数据进行文本预处理。
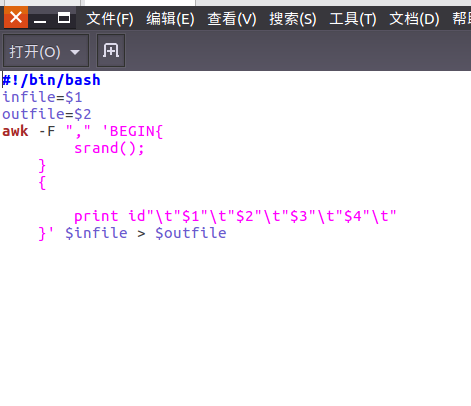
预处理后用命令使其生效并测试是否成功。
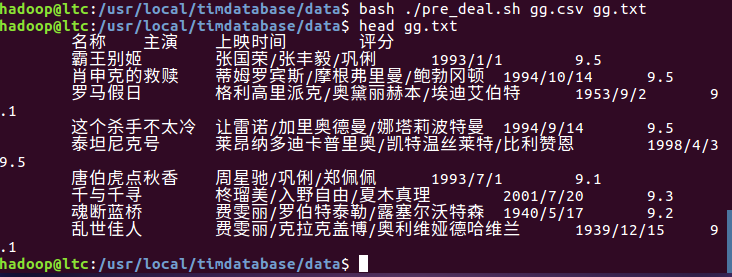
启动数据库服务,并进入hive路径

创建一个数据库dbpy,和数据表lagou_py。在测试十条数据。
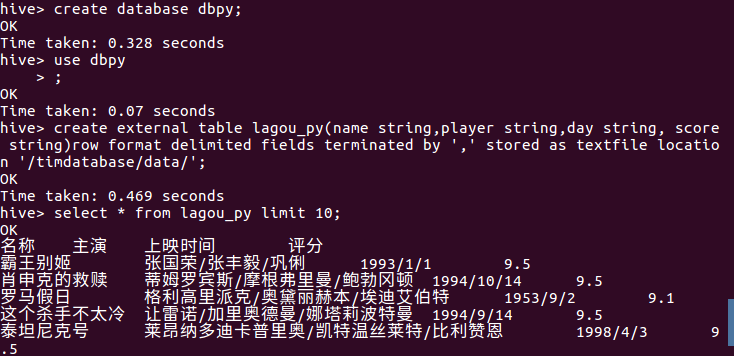
用hive对数据进行分析
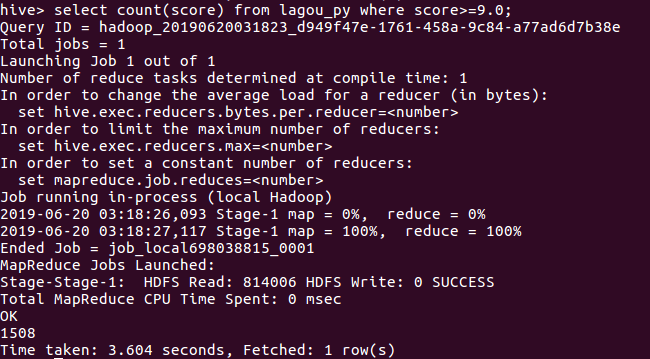
1.查看评分在9.0以上的电影数量,得到结果为1508部。可以看出其网站电影质量比较高。
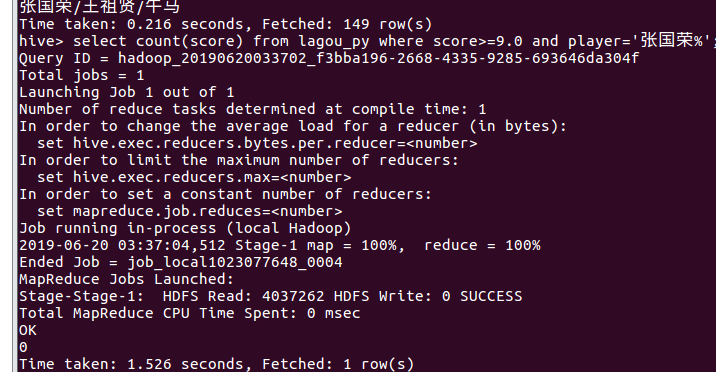
2.查看由张国荣主演的电影。


3.查看由张国荣主演的评分大于9.0的电影,其结果为0
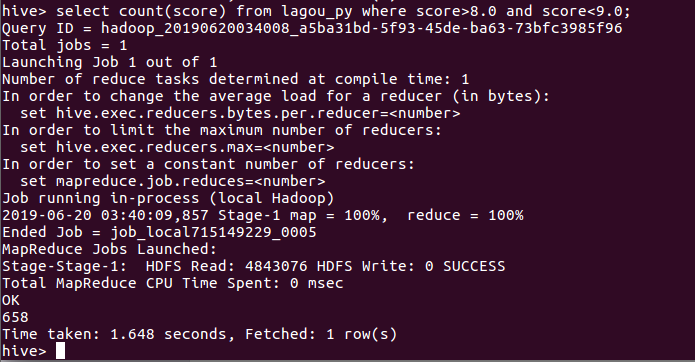
4查看评分在8.0-9.0的电影数量其结果为658部
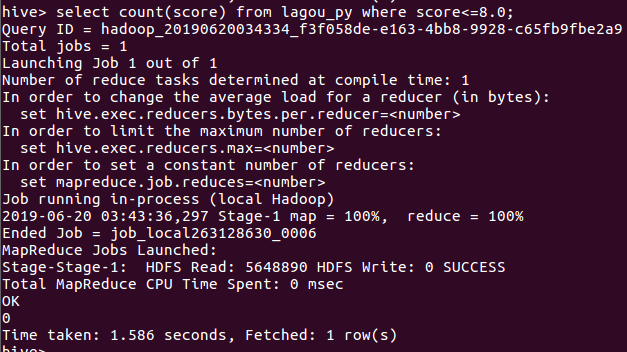
5.查询分数<8.0的电影数量,其结果为0
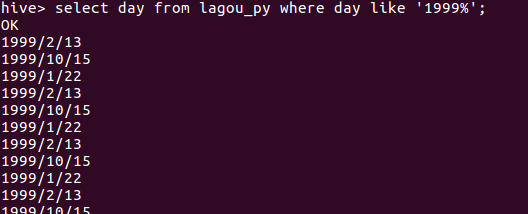
6.查询1999年所拍的电影数量。

7.查看评分在9.5以上的电影。


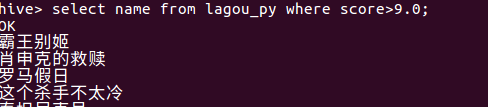
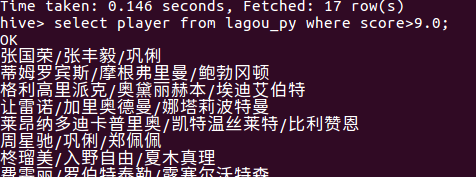
8.查询评分在9.0以上的电影名称,方便给观众推荐
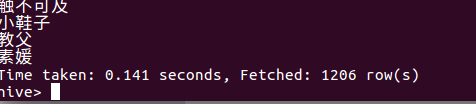
查询评分9.0以上的电影的主演。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号