
分布式并行计算MapReduce
该作业要求来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319
一、用自己的话阐明Hadoop平台上HDFS和MapReduce的功能、工作原理和工作过程。
Hdfs的功能:高度容错性、支持大规模数据集、支持流式读取数据、简单的一致性模型、移动计算而非移动数据、异构软硬件平台间的可移植性
MapReduce的功能:数据划分和计算任务调度、数据/代码互定位、系统优化、出错检测和恢复、HDFS工作原理及流程
hdfs的工作流程:
- hdfs集群分为两大角色:NameNode,DataNode (Secondary NameNode)
- NameNode负责管理整个文件的元数据(命名空间信息,块信息) 相当于Master
- DataNode负责管理用户的文件数据块 相当于Salve
- 文件会按照固定的大小(block=128M)切成若干块后分布式存储在若干个datanode节点上
- 每一个文件块有多个副本(默认是三个),存在不同的datanode上
- DataNode会定期向NameNode汇报自身所保存的文件block信息,而namenode则会负责保持文件副本数量
- hdfs的内部工作机制会对客户的保持透明,客户端请求方法hdfs都是通过向namenode申请来进行访问
- SecondaryNameNode有两个作用,一是镜像备份,二是日志与镜像的定期合并
MapReduce的工作流程:
1、输入文件分片,每一片都由一个MapTask来处理
2、Map输出的中间结果会先放在内存缓冲区中,这个缓冲区的大小默认是100M,当缓冲区中的内容达到80%时(80M)会将缓冲区的内容写到磁盘上。也就是说,一个map会输出一个或者多个这样的文件,如果一个map输出的全部内容没有超过限制,那么最终也会发生这个写磁盘的操作,只不过是写几次的问题。
3、从缓冲区写到磁盘的时候,会进行分区并排序,分区指的是某个key应该进入到哪个分区,同一分区中的key会进行排序,如果定义了Combiner的话,也会进行combine操作
4、如果一个map产生的中间结果存放到多个文件,那么这些文件最终会合并成一个文件,这个合并过程不会改变分区数量,只会减少文件数量。例如,假设分了3个区,4个文件,那么最终会合并成1个文件,3个区
5、以上只是一个map的输出,接下来进入reduce阶段
6、每个reducer对应一个ReduceTask,在真正开始reduce之前,先要从分区中抓取数据
7、相同的分区的数据会进入同一个reduce。这一步中会从所有map输出中抓取某一分区的数据,在抓取的过程中伴随着排序、合并。
8、reduce输出
二、HDFS上运行MapReduce
1)准备文本文件,放在本地/home/hadoop/wc

2)编写map函数和reduce函数,在本地运行测试通过

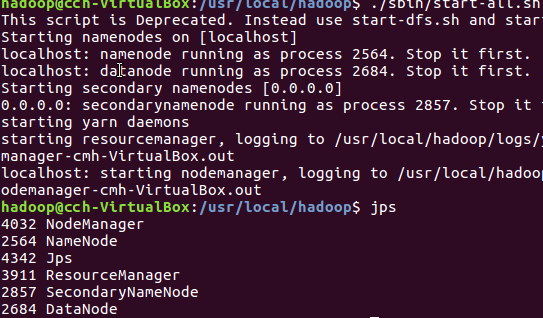
3)启动Hadoop:HDFS, JobTracker, TaskTracker
4)把文本文件上传到hdfs文件系统上 user/hadoop/input

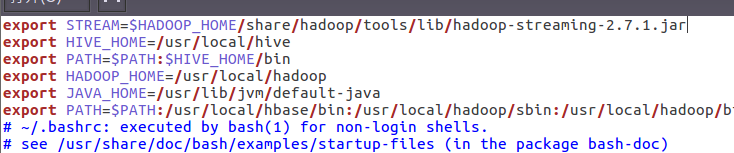
5)streaming的jar文件的路径写入环境变量,让环境变量生效
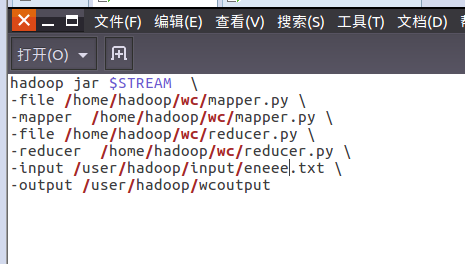
6)建立一个shell脚本文件:streaming接口运行的脚本,名称为run.sh
7)source run.sh来执行mapreduce

8)查看运行结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号