
框架类(mybatis&spring mvc&dubbo&MQ)
redis
BGSAVE:https://draveness.me/whys-the-design-redis-bgsave-fork/
二、spring mvc
- Springmvc原理
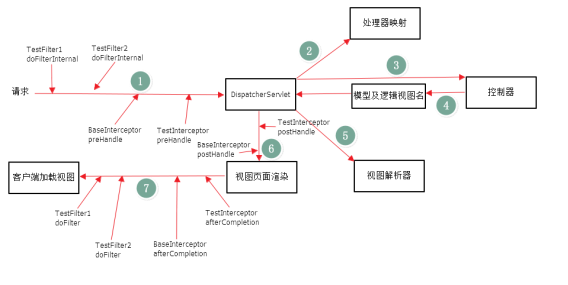
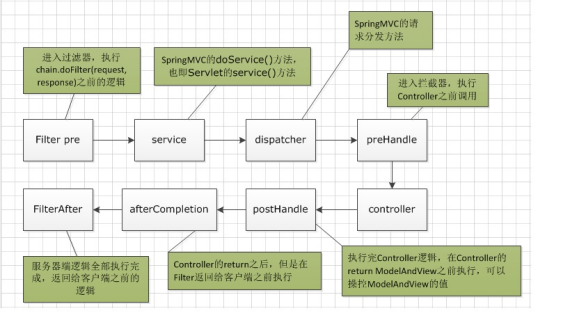
(1) 客户端发送一个http请求到服务端,web服务端对http进行解析,如果匹配到dispatcherServelet的请求映射路径,web将请求转交给dispatcheservelet
(2) Dispatchservelet根据请求的信息以及handlermapping中配置的信息找到处理请求的处理器
(3) Dispathservelet根据handlermapping找到对应的handler,再由具体的handleradapter对handler进行具体的调度
(4) Handler处理完后由具体的ModelAndView()对象返回给dispatchserverlet
(5) 通过viewResoler将逻辑视图转为真正的view
(6) Dispacher通过model解析出ModelAndView()中的参数进行解析最终展现出完整的view并返回给客户端

- 拦截器和过滤器
过滤器依赖servlet容器实现。在实现上基于函数回调,可以对几乎所有的请求进行过滤,但过滤实例只能在容器初始化时调用
拦截器,依赖web框架,在实现上基于JAVA反射机制,缺点是只能对controller进行拦截,不能直接对访问静态资源的请求进行拦截。
拦截器可以在方法前后,异常前后等调用。过滤器只能在请求前和请求后各调用一次;拦截器是被包裹在过滤器中的
过滤器和拦截器的执行顺序如下
springboot启动流程主要分为三个部分:
第一部分进行SpringApplication的初始化模块,配置一些基本的环境变量、资源、构造器、监听器,
第二部分实现了应用具体的启动方案,包括启动流程的监听模块、加载配置环境模块、及核心的创建上下文环境模块,
第三部分是自动化配置模块,该模块作为springboot自动配置核心,在后面的分析中会详细讨论。在下面的启动程序中我们会串联起结构中的主要功能。
具体如下:
每个SpringBoot程序都有一个主入口,也就是main方法,main里面调用SpringApplication.run()启动整个spring-boot程序,该方法所在类需要使用@SpringBootApplication注解,以及@ImportResource注解(if need),
@SpringBootApplication包括三个注解,功能如下:
@EnableAutoConfiguration:SpringBoot根据应用所声明的依赖来对Spring框架进行自动配置
@SpringBootConfiguration(内部为@Configuration):被标注的类等于在spring的XML配置文件中(applicationContext.xml),装配所有bean事务,提供了一个spring的上下文环境
@ComponentScan:组件扫描,可自动发现和装配Bean,默认扫描SpringApplication的run方法里的Booter.class所在的包路径下文件,所以最好将该启动类放到根包路径下
三、mybatis
- mybatis缓存和代理机制。mybatis和hibernate的比较
http://blog.csdn.net/lu930124/article/details/50991899
l mybatis提供了一级缓存和二级缓存,用来提高查询性能。
一级缓存是SQLSession级别的缓存,Mybatis默认开启一级缓存,是基于hashmap的本地缓存。不同的SQLSession之间的缓存数据区域互不影响。同一个SQLSession执行两次相同的sql查询语句,第二次直接从缓存中拿数据。执行insert、update和delete会清除缓存。
二级缓存是mapper级别的缓存,同样是基于hashmap进行存储,多个SQLSession可以共享二级缓存,其作用域是 mapper 的同一个 namespace。不同的 SqlSession 两次执行相同的 namespace 下的 sql 语句,会执行相同的 sql,第二次查询只会查询第一次查询时读取数据库后写到缓存的数据,不会再去数据库查询。
二级缓存是mapper级别的缓存,多个SQLSession共享
如下图
代理模式,即只需要程序员编写Mapper接口(相当于DAO),由mybatis框架根据接口定义创建接口的动态代理对象,代理对象的方法体同DAO接口实现类方法。
Mapper接口开发需要遵循以下规范:
1、 Mapper.xml文件中的namespace与mapper接口的类路径相同。
2、 Mapper接口方法名和Mapper.xml中定义的每个statement的id相同
3、 Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql 的parameterType的类型相同
4、 Mapper接口方法的输出参数类型和mapper.xml中定义的每个sql的resultType的类型相同
写mapper.xml文件,然后写mapper.java的接口文件,然后加载mapper.xml文件。mybatis官方推荐使用mapper代理方法开发mapper接口,程序员不用编写mapper接口实现类,使用mapper代理方法时,输入参数可以使用pojo包装对象或map对象,保证dao的通用性。就是代理到mapper.xml文件吧?
l Mybaits和hibernate的比较
相同点:都是ORM框架。
不同点:mybaits是通过mapper.xml维护映射关系,程序员手动编写的sql比hibernate的hql语句更加灵活,sql调优更容易,hibernate太重,sql调优麻烦;但是hibernate的hql的数据移植行好。:mybatis和hibernate都可以使用第三方缓存,而hibernate相比maybatis有更好的二级缓存机制
总结下来就是:
(1) mybatis是通过mapper.xml维护映射关系。Hibernate用hql语句,成本高,但是移植性好,那我们搞java的不太注重这个移植性问题了。Mybaits的sql调优更容易。
- Mybatis
是数据持久层框架。可以使用mybatis generator自动生成mapper和对应的配置文件。有2种基本用法:
(1) 使用注解
(2) 使用xml配置文件
基本使用是DAO层定义接口,接口的实现写在Mapper中和xml的配置文件名称相关,一一对应
四、dubbo
- Dubbo基本原理&rpc框架基本原理
Provider,服务提供方,生产者。
Consumer,服务消费方,消费者
Registry,服务注册与发现的注册中心
Monitor,监控中心,作用于服务治理
Container, 运行的服务器
调用关系说明:
0. 服务容器负责启动,加载,运行服务提供者。
1. 服务提供者在启动时,向注册中心注册自己提供的服务。
2. 服务消费者在启动时,向注册中心订阅自己所需的服务。
3. 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
4. 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
5. 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
- Zookeeper
Zookeeper是一个分布式应用协调服务。用来解决分布式系统中常见的一些数据管理问题,如统一命名服务、状态同步服务、集群管理、分布式应用配置。zookeeper维护的是一个类似文件系统的数据结构。客户端监听他关心的节点,当目录节点发生变化时,zookeeper会通知客户端。paxos算法实现,原理我不知道。
五、MQ
- 到家消息队列(dmq)
应用场景有,异步处理、应用解耦、流量削峰、日志处理、消息通讯。
主要组成有队列管理器、消息、队列、通道
Redis实现消息队列的原理是利用redis list中的lpush和rpop实现fifo消息队列。
(1) 消息顺序,消息队列一般是不支持消息顺序的,非要实现也可以,保证a消息ack后,再发b消息,但对吞吐量有影响,所以这种情况用rpc服务更合适
(2) 消息重复,这个一般是业务方自己进行幂等性处理,例如用数据库幂等表记录mq id,如果mq id存在则不处理,不存在和存入
(3) 事物消息,RocketMQ实现了事物消息
到家的消息队列原理

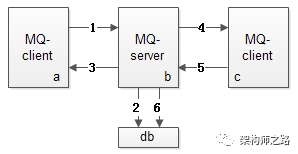
上图是一个MQ的核心架构图,基本可以分为三大块:
(1)发送方 -> 左侧粉色部分
(2)MQ核心集群 -> 中间蓝色部分,包括zk、db和后台管理等,mq核心集群对消息落地(落db)后对发送方callback,落地后发送给接收方,接收方收到后发送ack,mq serve收到ack将落地的消息进行删除。
发送方消息丢失,没有收到callback,则重发,mqserve这时候对接收方重发。下半场的消息必答会重发,接收方自己做幂等性处理。接收方最好不要对mq id做幂等,因为不知道
上半场是mq id,下半场是业务方自己去重,如orderid
(3)接收方 -> 右侧黄色部分
mq怎么防止消息丢失?
1、生产者丢失消息
(1)、可以选择使用MQ提供是事务功能,就是生产者在发送数据之前开启事务,然后发送消息,
如果消息没有成功被MQ接收到,那么生产者会受到异常报错,这时就可以回滚事务,然后尝试重新发送;
如果收到了消息,那么就可以提交事务。
(2)、可以开启confirm模式,在生产者哪里设置开启了confirm模式之后,每次写的消息都会分配一个唯一的id,
然后如何写入了MQ之中,rabbitmq会给你回传一个ack消息,告诉你这个消息发送OK了;
如果MQ没能处理这个消息,会回调你一个nack接口,告诉你这个消息失败了,你可以进行重试。
而且你可以结合这个机制知道自己在内存里维护每个消息的id,如果超过一定时间还没接收到这个消息的回调,那么你可以进行重发。
2、MQ自己弄丢了数据
设置消息持久化到磁盘。设置持久化有两个步骤:
(1)创建queue的时候将其设置为持久化的,这样就可以保证rabbitmq持久化queue的元数据,但是不会持久化queue里面的数据。
(2)发送消息的时候讲消息的deliveryMode设置为2,这样消息就会被设为持久化方式,此时rabbitmq就会将消息持久化到磁盘上。
必须要同时开启这两个才可以。
整个MQ挂了之后准备降级方案,生产者可先将消息缓存下来,再起一个定时任务扫描这些失败的消息,进行重发。
3、消费者弄丢数据
使用rabbitmq提供的ack机制,首先关闭rabbitmq的自动ack,
然后每次在确保处理完这个消息之后,在代码里手动调用ack。
这样就可以避免消息还没有处理完就ack。
采用定时对账、补偿的机制来提高消息的可靠性。
怎么解决消息重复消费?
要保证消息的幂等性,这个要结合业务的类型来进行处理。下面提供几个思路供参考:
(1)、可在内存中维护一个set,先查询这个消息在不在set里面,如果在表示已消费过,直接丢弃;
如果不在,则在消费后将其加入set当中。
(2)、如何要写数据库,可以拿唯一键先去数据库查询一下,如果不存在再写,如果存在直接更新或者丢弃消息。
(3)、如果是写redis那没有问题,每次都是set,天然的幂等性。
(4)、让生产者发送消息时,每条消息加一个全局的唯一id,然后消费时,将该id保存到redis里面,
消费时先去redis里面查一下有没有,没有再消费。
(5)、数据库操作可以设置唯一键,防止重复数据的插入,这样插入只会报错而不会插入重复数据。
如何处理大量积压的消息?
(1)通过增加消费者的服务节点数量来加快消息的消费。
(2)如果要快速处理积压的消息,可以创建一个新的Topic,并配置足够多的MessageQueue。
并紧急上线一组新的消费者,只负责搬运积压的消息,转储到新的Topic中,这个速度是可以很快的。
然后在新的Topic上,就可以通过增加消费者个数来提高消费速度了,之后再根据情况恢复成正常情况。
消息的发送顺序?
消费方同一个业务的消息放到同一个队列里,顺序消费。
六、ES
ES是一个基于Lucene构建的开源、分布式、RESTful的全文本搜索引擎。
1,es的工作过程实现是如何的?如何实现分布式的啊
Elasticsearch中通过分区实现分布式,数据写入的时候根据_routing规则将数据写入某一个Shard中,这样就能将海量数据分布在多个Shard以及多台机器上,已达到分布式的目标。
2,es在数据量很大的情况下(数十亿级别)如何提高查询效率啊?
3,es的查询是一个怎么的工作过程?底层的lucence介绍一下呗?倒排索引知道吗?
对于Search类请求,查询的时候是一起查询内存和磁盘上的Segment,最后将结果合并后返回。这种查询是近实时(Near Real Time)的。
对于Get类请求,查询的时候是先查询内存中的TransLog,如果找到就立即返回,如果没找到再查询磁盘上的TransLog,如果还没有则再去查询磁盘上的Segment。这种查询是实时(Real Time)的。
7、MAVEN
1、maven如何用git命令查看依赖树?
mvn dependency:tree
maven会根据传递依赖自动将jar引用的包下载下来,如果自动下载的jar包和已存在的jar相同,则可能发生版本冲突;
8、一致性hash算法
问题:hash(key)%N,如果直接对机器数量N取模来计算key路由的服务器机器,
当服务器挂掉,则存在大量数据缓存失效,可能会引起缓存雪崩。
方案:使用2^32(ip地址4个8位的组合)大小的环,使用hash(服务器ip)%2^32,将环划分成多个区域,
hash(key)%2^32将key落入到环上顺时针遇到的第一个服务器进行数据存取,当遇到扩缩容时,只有一小部分数据需要迁移。
问题:服务器将环划分不均匀,大部分热点数据key落在一台机器上
方案:每一台物理机器引入虚拟节点,将虚拟节点放到hash环上,
根据hash环找到物理机器,需要做虚拟节点与物理机器的映射,
虚拟节点的hash计算可以使用对应节点的ip加数字后缀的方式
方案:含有边界值的一致性hash
设定平均密度e,每个桶容量设为1+e
将每个缓存服务器视为一个含有一定容量的桶,顺时针查找第一个桶,若桶容量已超过阈值,则查找下一个桶,
所有桶都满了呢?
问题:可能存在同一个key两次访问到不同的服务器,
一致性hash主要解决的是增删节点时尽量减少数据迁移,还需要考虑业务是否允许集群中存在两个版本的缓存数据
一致性hash是分布式系统负载均衡的首选算法。
场景:缓存中间件redis集群
rpc框架Dubbo
LVS负载均衡调度器

 浙公网安备 33010602011771号
浙公网安备 33010602011771号