
网络
1、HTTP头部都有哪些信息?HTTP从1到2和3都有哪些改进?
通用标头、实体标头、请求标头、响应标头
HTTP1.0 HTTP 1.1主要区别
长连接
HTTP 1.0需要使用keep-alive参数来告知服务器端要建立一个长连接,而HTTP1.1默认支持长连接。
HTTP是基于TCP/IP协议的,创建一个TCP连接是需要经过三次握手的,有一定的开销,如果每次通讯都要重新建立连接的话,对性能有影响。因此最好能维持一个长连接,可以用个长连接来发多个请求。
节约带宽
HTTP 1.1支持只发送header信息(不带任何body信息),如果服务器认为客户端有权限请求服务器,则返回100,否则返回401。客户端如果接受到100,才开始把请求body发送到服务器。
这样当服务器返回401的时候,客户端就可以不用发送请求body了,节约了带宽。
支持文件断点续传
另外HTTP还支持传送内容的一部分。这样当客户端已经有一部分的资源后,只需要跟服务器请求另外的部分资源即可。这是支持文件断点续传的基础。
HOST域
现在可以web server例如tomat,设置虚拟站点是非常常见的,也即是说,web server上的多个虚拟站点可以共享同一个ip和端口。
HTTP1.0是没有host域的,HTTP1.1才支持这个参数。
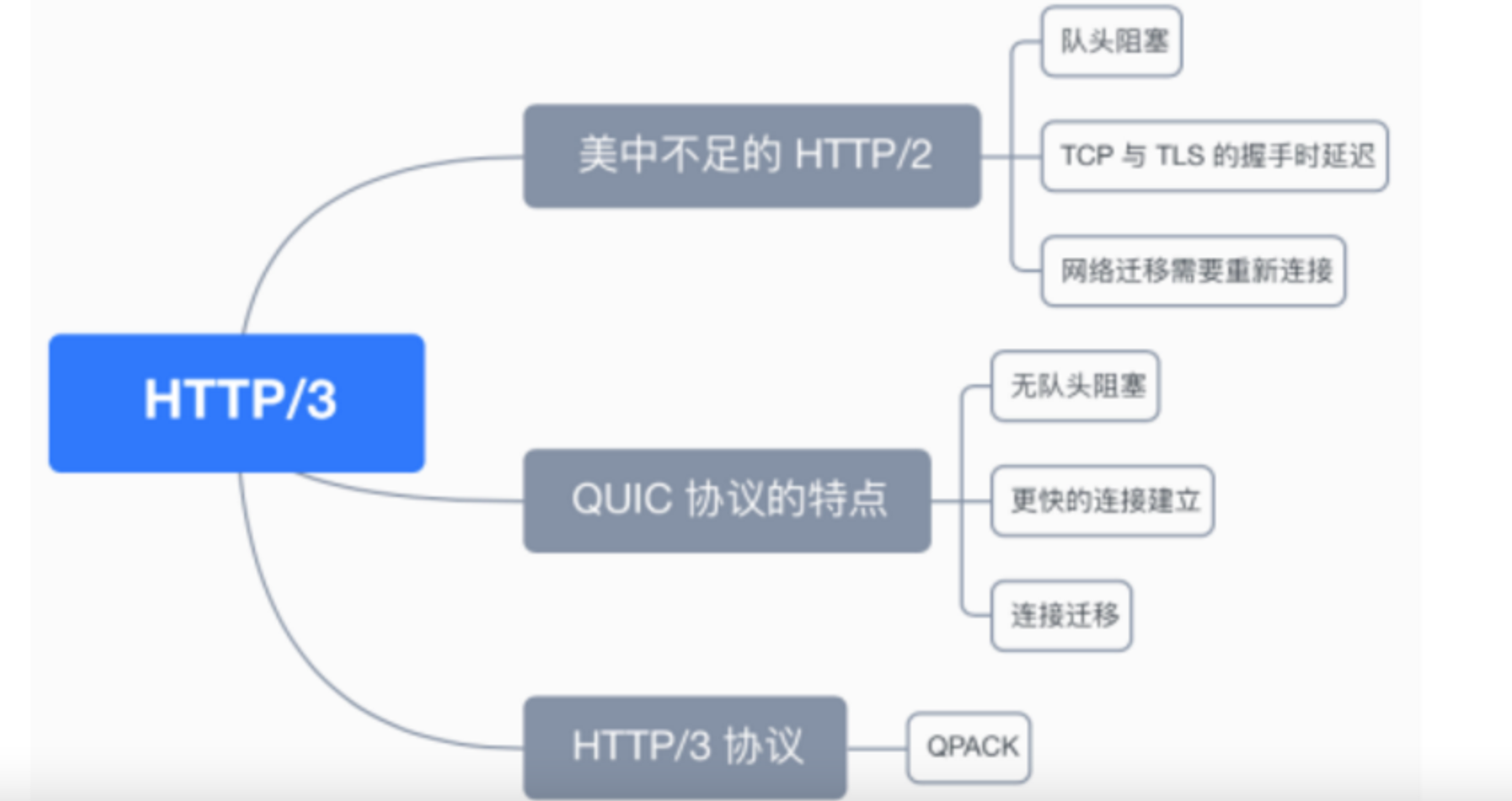
- 新的二进制格式:HTTP1.1 基于文本格式传输数据;HTTP2.0采用二进制格式传输数据,解析更高效。
- 多路复用:在一个连接里,允许同时发送多个请求或响应,并且这些请求或响应能够并行的传输而不被阻塞,避免 HTTP1.1 出现的”队头堵塞”问题。
- 头部压缩,HTTP1.1的header带有大量信息,而且每次都要重复发送;HTTP2.0 把header从数据中分离,并封装成头帧和数据帧,使用特定算法压缩头帧,有效减少头信息大小。并且HTTP2.0在客户端和服务器端记录了之前发送的键值对,对于相同的数据,不会重复发送。比如请求a发送了所有的头信息字段,请求b则只需要发送差异数据,这样可以减少冗余数据,降低开销。
- 服务端推送:HTTP2.0允许服务器向客户端推送资源,无需客户端发送请求到服务器获取。
HTTP3:
2、HTTP 与 HTTPS的区别?HTTPS如何![]()

HTTP报文结构
请求头:
第一层:【请求方法】【请求地址】【HTTP版本】
第二层:【请求头】
第三层:【请求内容】
应答头:
第一层:【HTTP版本】【状态码】【状态解释】
第二层:【应答头】
第三层:【应答内容】
HTTP请求方法
请求方法:HTTP请求的本质是对服务器资源进行操作的过程(增删改查+系统功能),通过定义不同方法实现不同操作是清晰并且是必要的。
GET:最常用的方法,常用于请求服务器发送某个资源
PUT:和GET相反,向服务器写入资源
POST:向服务器写入数据
DELETE:请求服务器删除请求URL所指定的资源
HEAD:和GET类似,但服务器在响应中只返回首部
TRACE:观察请求报文到达服务器的最终样子
HTTP状态码
200~299 成功状态码
300~399 重定向状态码
400~499 客户端错误状态码
500~599 服务端错误状态码
200:OK 请求没问题,实体的主体部分包含了所请求的资源
204:No Content 响应报文中包含若干首部和一个状态行,但没有实体的主体部分 (返回没问题,但是应答没有具体内容)
304:Not Modified 所请求的资源未修改,服务器返回此状态码时,不会返回任何资源 (表示没有修改,原本从服务器获取改成从本地获取了)
从客户端角度排查问题
400:Bad Request 客户端请求的语法错误,服务器无法理解
401:Unauthorized 请求客户端在获取对资源的访问权之前,对自己进行认证
403:Forbidden 请求被服务器拒绝了
404:Not Found 用于说明服务器无法找到所请求的URL
从服务端角度排查问题
500:Internal Server Error 服务器内部错误,无法完成请求
502:Bad Gateway 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应
503: Service Unavailable 用来说明服务器现在无法为该请求提供服务(服务器宕机了)
504:Gateway Timeout 网关或代理的服务器,未及时从远端服务器获取请求(网关超时了)
GET和POST请求区别?
1. GET把参数包含在URL中,POST通过request body传递参数。
2. GET请求在URL中传送的参数是有长度限制的,而POST没有。
大多数浏览器通常都会限制url长度在2K个字节,而大多数服务器最多处理64K大小的url。
3. GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
4. GET请求只能进行url编码,而POST支持多种编码方式。
5. GET产生一个TCP数据包;POST产生两个TCP数据包。
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);
而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
6. GET在浏览器回退时是无害的,而POST会再次提交请求。
7. GET产生的URL地址可以被Bookmark,而POST不可以。
8. GET请求会被浏览器主动cache,而POST不会,除非手动设置。
9. GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
10. 对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
DNS域名解析:
第一步:检查浏览器缓存中是否缓存过该域名对应的IP地址
第二步:如果在浏览器缓存中没有找到IP,那么将继续查找本机系统是否缓存过IP
第三步:向本地域名解析服务系统发起域名解析的请求
第四步:采用迭代的方式,分别向根域名、顶级域名、权限域名解析服务器发起域名解析请求
第八步:服务器返回IP地址给本地服务器
第九步:本地域名服务器缓存解析结果
第十步:返回解析结果给用户,浏览器并缓存该域名对应的ip地址
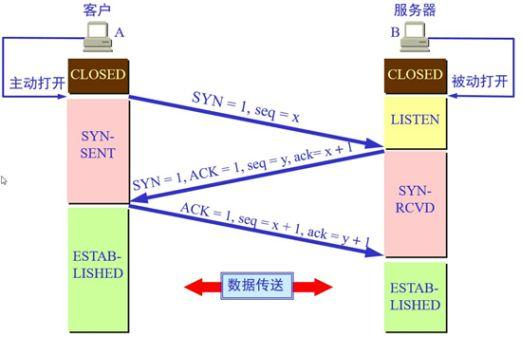

为什么要进行三次握手,两次握手难道不行么?
我们可以将三次握手中的客户端和服务器之间的握手过程比喻成A和B通信的过程:
在第一次通信过程中,A向B发送信息之后,B收到信息后可以确认自己的收信能力和A的发信能力没有问题。
在第二次通信中,B向A发送信息之后,A可以确认自己的发信能力和B的收信能力没有问题,但是B不知道自己的发信能力到底如何,所以就需要第三次通信。
在第三次通信中,A向B发送信息之后,B就可以确认自己的发信能力没有问题。
1.为什么建立连接协议是三次握手,而关闭连接却是四次握手呢?
这是因为服务端的LISTEN状态下的SOCKET当收到SYN报文的建连请求后,它可以把ACK和SYN(ACK起应答作用,而SYN起同步作用)放在一个报文里来发送。但关闭连接时,当收到对方的FIN报文通知时,它仅仅表示对方没有数据发送给你了;但未必你所有的数据都全部发送给对方了,所以你可以未必会马上会关闭SOCKET,也即你可能还需要发送一些数据给对方之后,再发送FIN报文给对方来表示你同意现在可以关闭连接了,所以它这里的ACK报文和FIN报文多数情况下都是分开发送的。
2.为什么TIME_WAIT状态还需要等2MSL后才能返回到CLOSED状态?
这是因为虽然双方都同意关闭连接了,而且握手的4个报文也都协调和发送完毕,按理可以直接回到CLOSED状态(就好比从SYN_SEND状态到ESTABLISH状态那样);但是因为我们必须要假想网络是不可靠的,你无法保证你最后发送的ACK报文会一定被对方收到,因此对方处于LAST_ACK状态下的SOCKET可能会因为超时未收到ACK报文,而重发FIN报文,所以这个TIME_WAIT状态的作用就是用来重发可能丢失的ACK报文。
HTTP 与 HTTPS 区别
1、http 明文传输,https 密文传输协议
2、默认端口 http:80 端口,https:443 端口
3、https 协议需要到 CA 申请证书,一般免费证书较少,因而需要一定费用
4、http 的连接很简单,是无状态的;HTTPS 协议是由 SSL/TLS+HTTP 协议构建的可进行加密传输、身份认证的网络协议,比 http 协议安全
https过程:
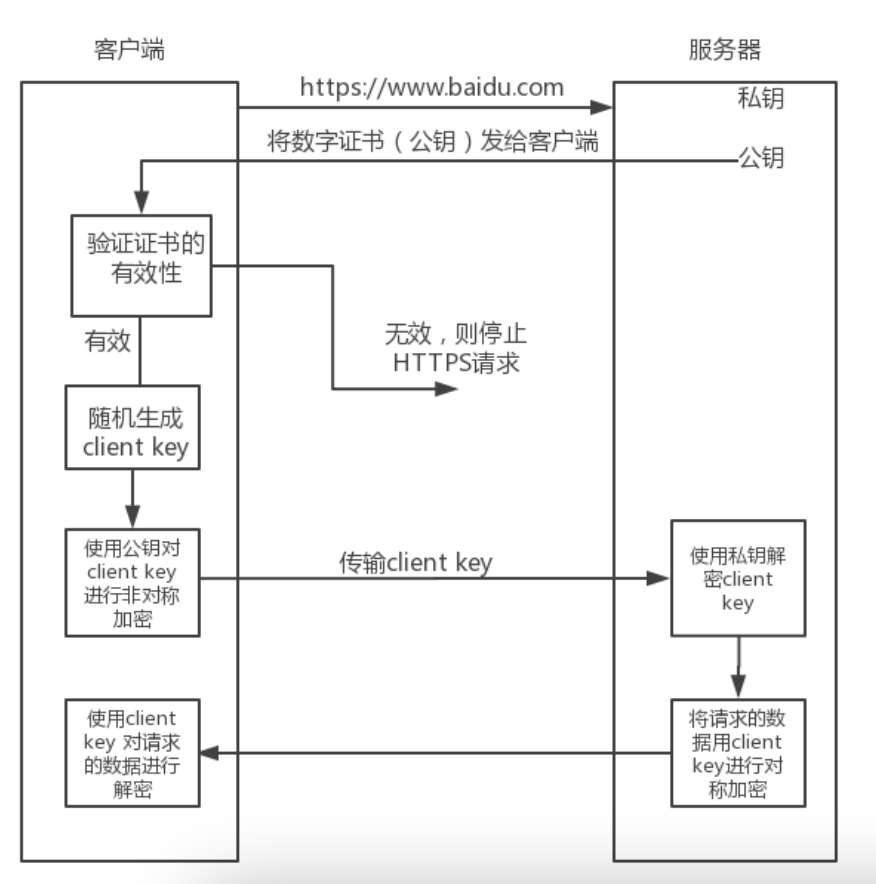
1、【浏览器】向服务器发送 https 请求
2、【服务器】向 CA 机构获取证书
3、【服务器】向浏览器发送数字证书(包含 public key)
4、【浏览器】用预置的 CA 列表验证证书,生成随机对称秘钥【key】,并使用公钥加密,如有问题会提示风险,
5、【浏览器】加密后的【key】,发送给【服务器】,作为接下来请求的秘钥
6、【服务器】用自己的 private key 解密得到对称秘钥 key
7、【浏览器】使用随机码 key 进行解密数据
8、【浏览器】【服务器】使用该秘钥进行通信
TCP确保传输可靠性的方式:
校验和
序列号/确认应答
超时重传
连接管理(三次握手、四次挥手)
流量控制(滑动窗口控制)
拥塞控制(慢启动、拥塞避免和快速恢复)
输入一个url后的流程:
应用层:
- 浏览器封装 HTTP 请求报文
- DNS 解析域名获得目标服务器地址
传输层:
- 建立连接
- 把应用层传过来的 HTTP 请求报文进行分割,并在各个报文上打上标记序号及端口号转发给网络层
网络层:
- 利用 ARP 协议根据 IP 地址获取作为通信目的地的 MAC 地址后转发给链路层
服务端在链路层收到数据,按序往上层发送,一直到应用层接收到浏览器发送来的 HTTP 请求报文,
然后处理该请求并返回 HTTP 响应报文,浏览器接收到响应报文之后解析渲染界面。
最后 TCP 断开连接。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号