在linux上安装spark详细步骤
在linux上安装spark ,前提要部署了hadoop,并且安装了scala.
对应版本
>>提君博客原创 http://www.cnblogs.com/tijun/ <<
| 名称 | 版本 |
| JDK | 1.8.0 |
| hadoop | 2.6.0 |
| scala | 2.11.0 |
| spark | 2.2.0 |
第一步,下载 https://spark.apache.org/downloads.html
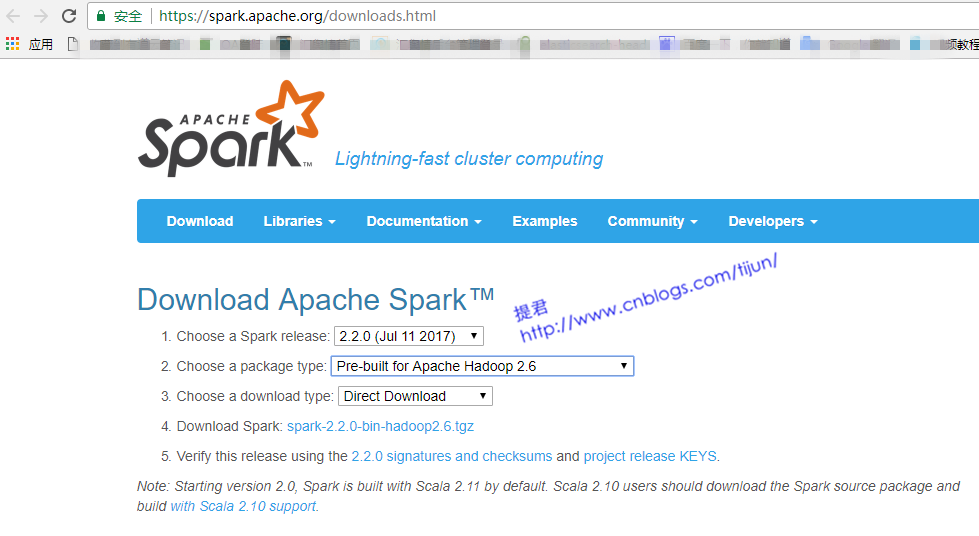
第二步,解压
tar -zxvf spark-2.2.0-bin-hadoop2.6.tgz
第三步,配置环境变量
vi /etc/profile #SPARK_HOME export SPARK_HOME=/home/hadoop/spark-2.2.0-bin-hadoop2.6 export PATH=$SPARK_HOME/bin:$PATH
第四步,spark配置,
>>提君博客原创 http://www.cnblogs.com/tijun/ <<
spark-env.sh
JAVA_HOME=/home/hadoop/jdk1.8.0_144 SCALA_HOME=/home/hadoop/scala-2.11.0 HADOOP_HOME=/home/hadoop/hadoop260 HADOOP_CONF_DIR=/home/hadoop/hadoop260/etc/hadoop SPARK_MASTER_IP=ltt1.bg.cn SPARK_MASTER_PORT=7077 SPARK_MASTER_WEBUI_PORT=8080 SPARK_WORKER_CORES=1 SPARK_WORKER_MEMORY=2g #spark里许多用到内存的地方默认1g 2g 这里最好设置大与1g SPARK_WORKER_PORT=7078 SPARK_WORKER_WEBUI_PORT=8081 SPARK_WORKER_INSTANCES=1
spark-defaults.conf
spark.master spark://ltt1.bg.cn:7077
slaves
ltt3.bg.cn
ltt4.bg.cn
ltt5.bg.cn
-----------------------------
如果整合hive,hive用到mysql数据库的话,需要将mysql数据库连接驱动jmysql-connector-java-5.1.7-bin.jar放到$SPARK_HOME/jars目录下
------------------------------
第五步,将spark-2.2.0-bin-hadoop2.6 分发到各节点。启动
[hadoop@ltt1 sbin]$ ./start-all.sh starting org.apache.spark.deploy.master.Master, logging to /home/hadoop/spark-2.2.0-bin-hadoop2.6/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-ltt1.bg.cn.out ltt5.bg.cn: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/spark-2.2.0-bin-hadoop2.6/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-ltt5.bg.cn.out ltt4.bg.cn: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/spark-2.2.0-bin-hadoop2.6/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-ltt4.bg.cn.out ltt3.bg.cn: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/spark-2.2.0-bin-hadoop2.6/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-ltt3.bg.cn.out
最后查看进程
master节点
[hadoop@ltt1 sbin]$ jps 1346 NameNode 1539 JournalNode 1812 ResourceManager 1222 QuorumPeerMain 1706 DFSZKFailoverController 2588 Master 2655 Jps
worker节点
[hadoop@ltt5 ~]$ jps 1299 NodeManager 1655 Worker 1720 Jps 1192 DataNode
进入Spark的Web管理页面: http://ltt1.bg.cn:8080
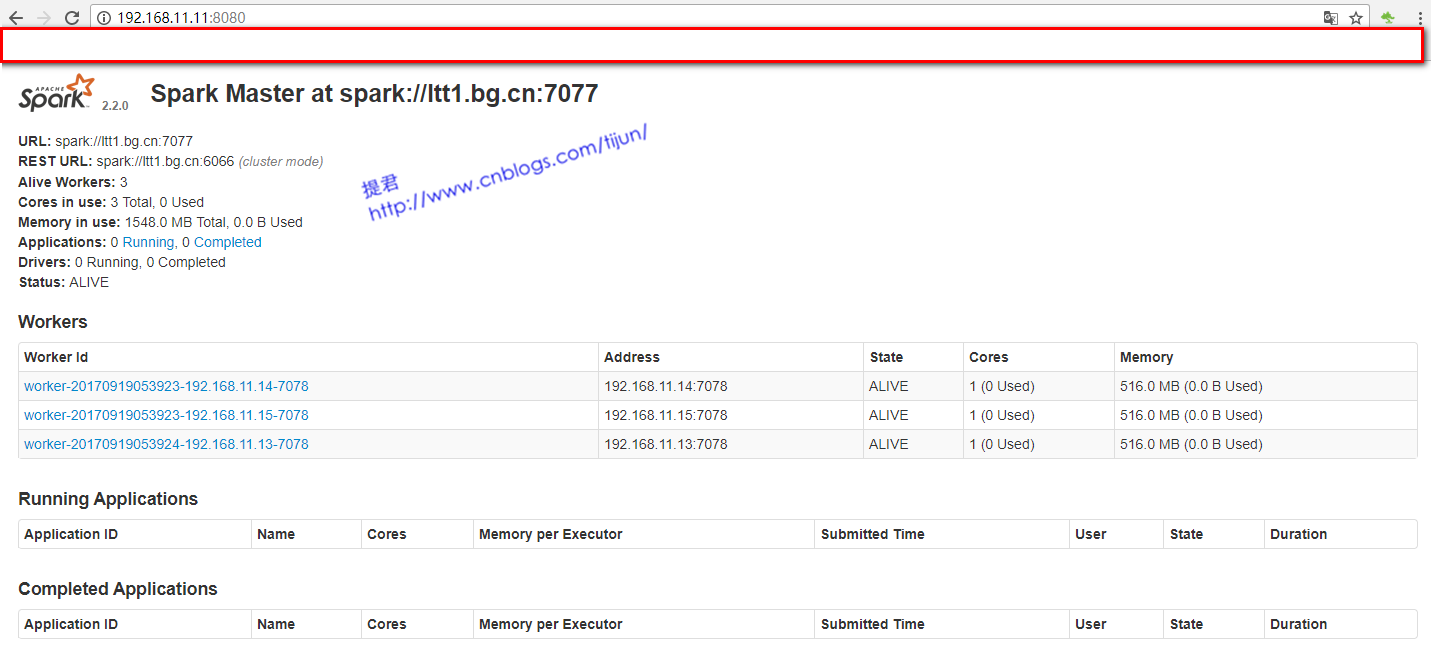
spark安装完成。
>>提君博客原创 http://www.cnblogs.com/tijun/ <<

 浙公网安备 33010602011771号
浙公网安备 33010602011771号