

k8s各组件作用和pod通信原理
https://www.cnblogs.com/cyh00001/p/16488539.html

kube-apiserver kube-apiserver负责和etcd交互, 提供了k8s各类资源对象的增删改查及watch等HTTP Rest接口,
这些对象包括pods、services、replication controllers等,API Server 为REST操作提供服务, 并为集群的共享状态提供前端,所有其他组件都通过该前端进行交互。同时也是外部的唯一入口 kube-scheduler kubernetes调度器是一个控制面进程,负责将Pods指派到节点上。
通过调度算法为待调度Pod列表的每个Pod从可用Node列表中选择一个最适合的Node,并将信息写入etcd中。
node节点上的kubelet通过API Server监听到kubernetes Scheduler 产生的Pod绑定信息,然后获取对应的Pod清单,下载Image,并启动容器。 策略: LeastRequestedPriority:优先从备选节点列表中选择资源消耗最小的节点(CPU+内存) CalculateNodeLabelPriority:优先选择含有指定Label的节点 BalanceResourceAllocation:优先从备选节点列表中选择各项资源使用率最均衡的节点 kube-controller-manager kube-controller-manager:Controller Manager还包括一些子控制器(副本控制器、节点控制器、命名空间控制器和服务账号控制器等),
控制器作为集群内部的管理控制中心,负责集群内部的Node、Pod副本、服务端点(Endpoint)、命名空间(Namespace)、
服务账号(ServiceAccount)、资源定额(ResourceQuota)的管理,当某个Node意外宕机时,
Controller Manager会及时发现并执行自动化修复流程,确保集群中的pod副本始终处于预期的工作状态。 controller-manager控制器每间隔5秒钟检查一次节点的状态。 如果controller-manager控制器没有收到自节点的心跳,则将该node节点标记为不可达。 controller-manager将在标记为无法访问之前等待40秒。 如果该node节点被标记为无法访问后5分钟还没有恢复,controller-manager会删除当前node节点的所有pod并在其它可用节点重建这些pod。 pod高可用机制: node monitor period:节点监视周期,5s node monitor grace period:节点监视器宽限期,40s pod eviction timeout:pod驱逐超时时间,5m Kubelet kubelet是运行在每个worker节点的代理组件,它会监视已分配给节点的pod,具体功能如下: 向master汇报node节点的状态信息 接受指令并在Pod中创建docker容器 准备Pod所需的数据卷 返回pod的运行状态 在node节点执行容器健康检查 coredns pod向coredns提供服务名,coredns负责进行域名解析,解析为ip返回pod,pod在用ip去和msater交互。 tiger: 服务名是固定的,但是cluster ip 是不断变化的。如果跨namespace 访问,则可以直接通过curl servicename.namesapce这样访问 单个node内的pod通信机制: 主机网卡etho0,docker0网桥,pod内虚拟网卡veth0的作用: 主机网卡eth0是用来跨node节点pod通信用的。 docker0网桥类似一个虚拟交换机,她是支持该节点上不同pod之间进行ip寻址和通讯的设备。 veth0则是pod1的虚拟网卡,是支持该pod内容器互通和对外访问的虚拟设备。docker0和veth0都是linux支持和创建的虚拟网络设备。 比如一个pod内有三个容器,则这三个容器就共享一个虚拟网卡veth0.内部的这些容器可以通过localhost访问,但他们不能使用同一个端口, 否则会有网络冲突。 每一个pod内还有pause容器,这个pause容器的唯一目的就是为pod建立共享的veth0的网络接口
跨节点node通信时,需要根据pod+pod ip去访问对方node+node ip,这个时候需要借助于CNI插件。
同节点pod通信因为都用的同一个docker0网桥,所以是可以直接通讯的,不存在跨网络段访问
同一个pod内部的容器互相通信,由于使用的是同一个linux network namespace也就是共用同一个网络协议栈,所以可以直接通过localhost去访问服务。
转:https://blog.yingchi.io/posts/2020/8/k8s-flannel.html
从底层网络来看,kubernetes 的网络通信可以分为三层去看待:
- Pod 内部容器通信;
- 同主机 Pod 间容器通信;
- 跨主机 Pod 间容器通信;
对于前两点,其网络通信原理其实不难理解。
- 对于 Pod 内部容器通信,由于 Pod 内部的容器处于同一个 Network Namespace 下(通过 Pause 容器实现),即共享同一网卡,因此可以直接通信。
- 对于同主机 Pod 间容器通信,Docker 会在每个主机上创建一个 Docker0 网桥,主机上面所有 Pod 内的容器全部接到网桥上,因此可以互通。
而对于第三点,跨主机 Pod 间容器通信,Docker 并没有给出很好的解决方案,而对于 Kubernetes 而言,
跨主机 Pod 间容器通信是非常重要的一项工作,但是有意思的是,Kubernetes 并没有自己去解决这个问题,
而是专注于容器编排问题,对于跨主机的容器通信则是交给了第三方实现,这就是 CNI 机制。
CNI,它的全称是 Container Network Interface,即容器网络的 API 接口。kubernetes 网络的发展方向是希望通过插件的方式来集成不同的网络方案,
CNI 就是这一努力的结果。CNI 只专注解决容器网络连接和容器销毁时的资源释放,提供一套框架,
所以 CNI 可以支持大量不同的网络模式,并且容易实现。平时比较常用的 CNI 实现有 Flannel、Calico、Weave 等。
CNI 插件通常有三种实现模式:
- Overlay:靠隧道打通,不依赖底层网络;
- 路由:靠路由打通,部分依赖底层网络;
- Underlay:靠底层网络打通,强依赖底层网络;
在选择 CNI 插件时是要根据自己实际的需求进行考量,比如考虑 NetworkPolicy 是否要支持 Pod 网络间的访问策略,
可以考虑 Calico、Weave;Pod 的创建速度,Overlay 或路由模式的 CNI 插件在创建 Pod 时比较快,Underlay 较慢;
网络性能,Overlay 性能相对较差,Underlay 及路由模式相对较快。
Flannel 工作原理
CNI 中经常见到的解决方案是 Flannel,由CoreOS推出,Flannel 采用的便是上面讲到的 Overlay 网络模式
Flannel的工作原理
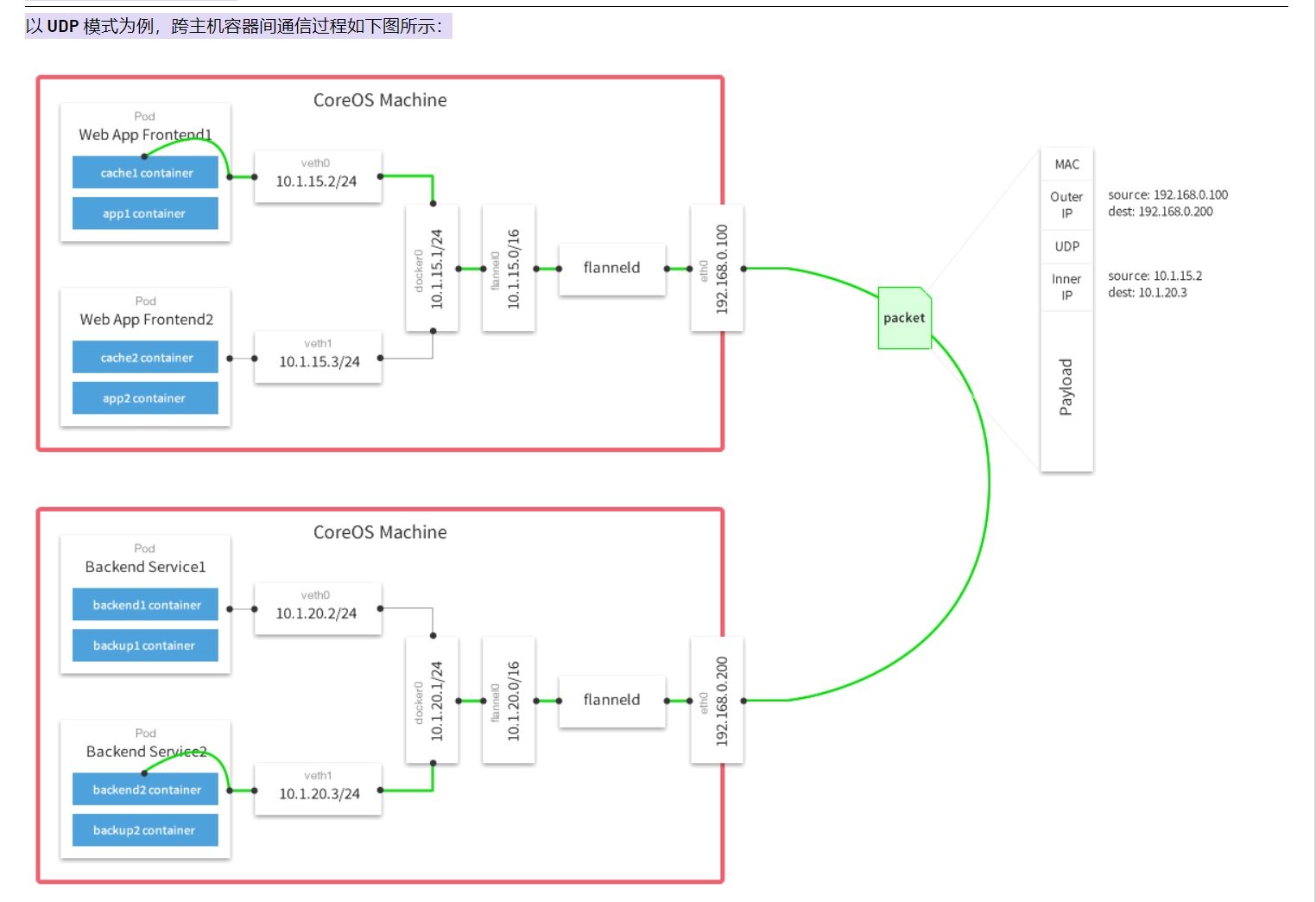
Flannel 实质上就是一种 Overlay 网络,也就是将 TCP 数据包装在另一种网络包里面进行路由转发和通信,目前已经支持 UDP、VxLAN、AWS VPC 和 GCE 路由等数据转发方式。
Flannel会在每一个宿主机上运行名为 flanneld 代理,其负责为宿主机预先分配一个子网,并为 Pod 分配IP地址。
Flannel 使用Kubernetes 或 etcd 来存储网络配置、分配的子网和主机公共IP等信息。数据包则通过 VXLAN、UDP 或 host-gw 这些类型的后端机制进行转发。
Flannel 规定宿主机下各个Pod属于同一个子网,不同宿主机下的Pod属于不同的子网。
Flannel 工作模式
支持3种实现:UDP、VxLAN、host-gw,
- UDP 模式:使用设备 flannel.0 进行封包解包,不是内核原生支持,频繁地内核态用户态切换,性能非常差;
- VxLAN 模式:使用 flannel.1 进行封包解包,内核原生支持,性能较强;
- host-gw 模式:无需 flannel.1 这样的中间设备,直接宿主机当作子网的下一跳地址,性能最强;
host-gw的性能损失大约在10%左右,而其他所有基于VxLAN“隧道”机制的网络方案,性能损失在20%~30%左右。

转:https://blog.yingchi.io/posts/2020/4/docker-k8s-network-3.html
Kubernetes & Docker 网络原理(三)
Service 通信
kube-proxy 运行机制
为了支持集群的水平扩展、高可用性,Kubernetes抽象出了Service的概念。Service是对一组Pod的抽象,它会根据访问策略(如负载均衡策略)来访问这组Pod。 Kubernetes在创建服务时会为服务分配一个虚拟的IP地址,客户端通过访问这个虚拟的IP地址来访问服务,服务则负责将请求转发到后端的Pod上。起到一个类似于反向代理的作用,但是它和普通的反向代理还是有一些不同:首先,它的Service 的 IP 地址,也就是所谓的 ClusterIP 是虚拟的,想从外面访问还需要一些技巧;其次,它的部署和启停是由Kubernetes统一自动管理的。
Service 和 Pod 一样,其实仅仅是一个抽象的概念,背后的运作机制是依赖于 kube-proxy 组件实现的。
在 Kubernetes 集群的每个 Node 上都会运行一个 kube-proxy 服务进程,我们可以把这个进程看作 Service 的透明代理兼负载均衡器,其核心功能是将到某个 Service 的访问请求转发到后端的多个 Pod 实例上。此外,Service的Cluster IP与 NodePort 等概念是 kube-proxy 服务通过iptables的NAT转换实现的,kube-proxy 在运行过程中动态创建与 Service 相关的 iptables 规则,这些规则实现了将访问服务(Cluster IP或NodePort)的请求负载分发到后端 Pod 的功能。由于 iptables 机制针对的是本地的 kube-proxy 端口,所以在每个 Node 上都要运行 kube-proxy 组件,这样一来,在 Kubernetes 集群内部,我们可以在任意 Node 上发起对 Service 的访问请求。综上所述,由于 kube-proxy 的作用,在 Service 的调用过程中客户端无须关心后端有几个 Pod,中间过程的通信、负载均衡及故障恢复都是透明的。
kube-proxy 运行模式
kube-proxy 的具体运行模式其实是随着 Kubernetes 版本的演进有着较大的变化的,整体上分为以下几个模式的演化:
- userspace (用户空间代理)模式
- iptables 模式
- IPVS 模式
userspace 模式
kube-proxy 最早的工作模式便是 userspace 用户空间代理模式,在这种模式下 kube-proxy 是承担着真实的 TCP/UDP 代理任务的,当 Pod 通过 Cluster IP 访问 Service 的时候,流量被 iptables 拦截后转发到节点的 kube-proxy 进程,服务的路由信息通过 watch API Server 进行获取,然后 kube-proxy 进程再与具体的 Pod 建立 TCP/UDP 连接,从而将请求发送给 Service 的后端 Pod 上,在这个过程中实现负载均衡。
iptables 模式
从 kubernetes 1.2 版本开始不再采用 userspace 用户空间代理模式,取而代之的是 iptables 模式,在 iptables 模式下 kube-proxy 不再担任直接的 proxy 作用,它的核心职责变为:一方面通过 watch API Server 实时获取 Service 与 Endpoint 的变更信息,然后动态地更新 iptables 规则,然后流量会根据 iptables 的 NAT 机制直接路由到目标 Pod,而不是再去单独建立连接。

与之前的 userspace 模式相比,iptables 模式完全工作在内核态,不需要切换到用户态的 kube-proxy,避免了内核态用户态的频繁切换使得性能相比之前有所提高。
但是 iptables 也存在着局限性,就是由于 iptables 客观因素,当 Kubernetes 集群规模扩大,Pod 数量大量增加之后,iptables 的规则数量会随之急剧增加,进而导致其转发性能的下降,甚至会出现规则丢失的情况(故障非常难以重现和排查),因此 iptables 模式也有待于改进。
IPVS 模式
IPVS 模式即 IP Virtual Server 模式,在 Kubernetes 1.11中 IPVS 模式升级为 GA,IPVS 虽然和 iptables 都是基于 Netfilter 实现,但是定位有着本质不同,iptables 设计为防火墙使用,而 IPVS 用于高性能负载均衡,而且从规则的存储角度,IPVS 采用的是 Hash Table 结构,因此理论上讲更适合在不影响性能的情况下大规模地扩展,同时 IPVS 支持比 iptables 更复杂的负载均衡算法(最小负载/最小连接数/加权等),支持服务器健康检查和连接重试等功能,另外还可以动态修改 ipset 集合。

在 IPVS 模式下,并不是就直接抛弃 iptables 了,虽然 IPVS 在性能上肯定是要优于 iptables 的,但同时也有许多功能 IPVS 相比 iptables 是缺失的,比如包过滤、地址伪装、SNAT 等功能,因此在一些场景下是需要 IPVS 与 iptables 配合工作的,比如 NodePort 实现。同时在 IPVS 模式下,kube-proxy 使用的是 iptables 的扩展 ipset,而不是直接通过 iptables 生成规则链。iptables 规则链是线性的数据结构,而 ipset 是带索引的数据结构,因此当规则很多时,可以高效地匹配查找。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY