

动手学深度学习-第4章多层感知机
最简单的深度网络称为多层感知机。多层感知机由多层神经元组成, 每一层与它的上一层相连,从中接收输入; 同时每一层也与它的下一层相连,影响当前层的神经元。
4.1多层感知机
仿射变换中的线性是一个很强的假设.很容易找出违反单调性的例子.处理这一问题的一种方法是对我们的数据进行预处理, 使线性变得更合理
**对于深度神经网络,我们使用观测数据来联合学习隐藏层表示和应用于该表示的线性预测器。 **
可以通过在网络中加入一个或多个隐藏层来克服线性模型的限制, 使其能处理更普遍的函数关系类型。
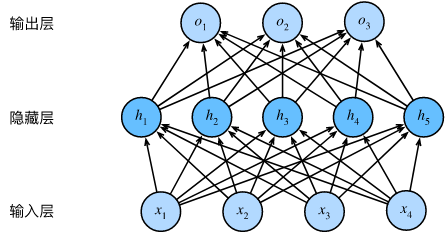
为了发挥多层架构的潜力, 我们还需要一个额外的关键要素: 在仿射变换之后对每个隐藏单元应用非线性的激活函数(activation function)\(\sigma\)。 激活函数的输出(例如,\(\sigma(\cdot)\))被称为活性值(activations)。 一般来说,有了激活函数,就不可能再将我们的多层感知机退化成线性模型:
\(\begin{split}\begin{aligned}
\mathbf{H} & = \sigma(\mathbf{X} \mathbf{W}^{(1)} + \mathbf{b}^{(1)}), \\
\mathbf{O} & = \mathbf{H}\mathbf{W}^{(2)} + \mathbf{b}^{(2)}.\\
\end{aligned}\end{split}\)
多层感知机是通用近似器。 即使是网络只有一个隐藏层,给定足够的神经元和正确的权重, 我们可以对任意函数建模
激活函数(activation function)通过计算加权和并加上偏置来确定神经元是否应该被激活, 它们将输入信号转换为输出的可微运算。
-
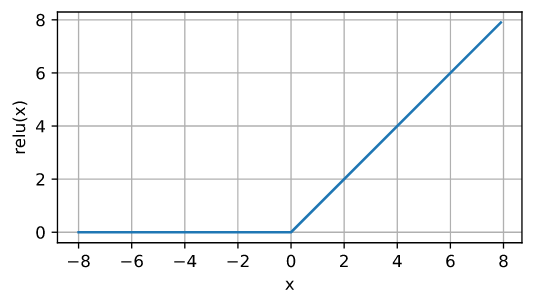
ReLU函数
修正线性单元(Rectified linear unit,ReLU),给定元素x,ReLU函数被定义为该元素与0的最大值:
\(\operatorname{ReLU}(x) = \max(x, 0).\)
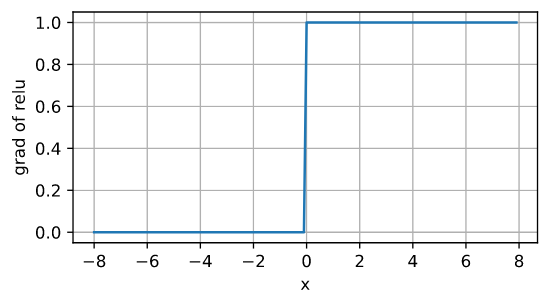
导数图像
-
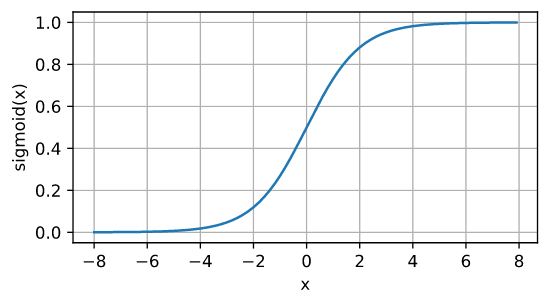
sigmoid函数
sigmoid通常称为挤压函数(squashing function): 它将范围(-inf, inf)中的任意输入压缩到区间(0, 1)中的某个值:
$\operatorname{sigmoid}(x)= \frac{1}{1+\exp(-x)}. $
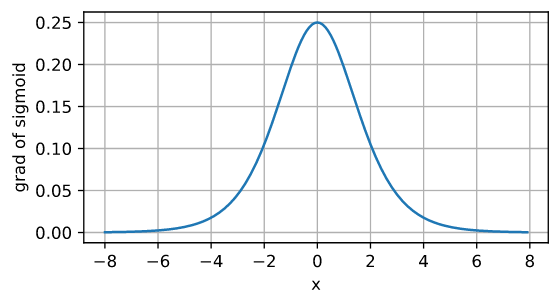
sigmoid函数的导数为下面的公式:
\(\frac{d}{dx} \operatorname{sigmoid}(x) = \frac{\exp(-x)}{(1 + \exp(-x))^2} = \operatorname{sigmoid}(x)\left(1-\operatorname{sigmoid}(x)\right).\)
- tanh函数
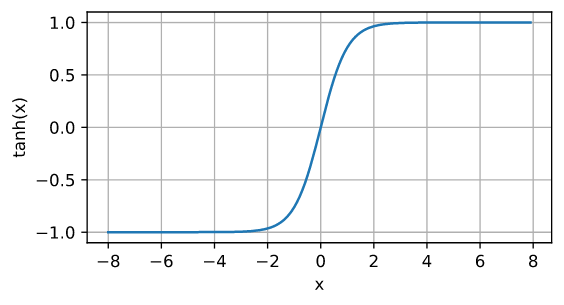
tanh(双曲正切)函数也能将其输入压缩转换到区间(-1, 1)上
$\operatorname{tanh}(x)=\frac{1-\exp(-2x)}{1+\exp(-2x)} $
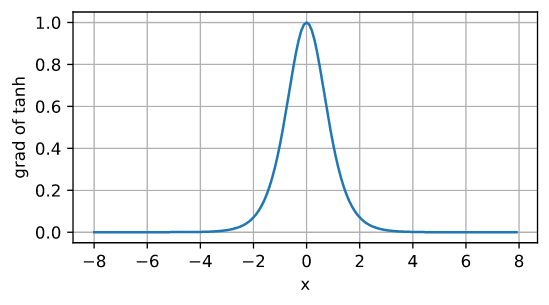
tanh函数的导数是:
\(\frac{d}{dx} \operatorname{tanh}(x) = 1 - \operatorname{tanh}^2(x).\)
4.2多层感知机算法实现知机
点击查看代码
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法
return (H@W2 + b2)
loss = nn.CrossEntropyLoss(reduction='none')
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
d2l.predict_ch3(net, test_iter)
在所有其他参数保持不变的情况下,更改超参数num_hiddens的值,并查看此超参数的变化对结果有何影响。确定此超参数的最佳值。
为了确定最佳的num_hiddens值,可以进行如下步骤:
初始化其它超参数;
定义神经网络模型,在其中指定num_hiddens的值,然后进行训练;
使用训练好的模型进行预测,并获取预测精度;
重复步骤2和步骤3,使用不同的num_hiddens值,以确定最佳值。
下面是一个示例代码,用于探索num_hiddens的最佳值:
点击查看代码
import torch
import torchvision
import torchvision.transforms as transforms
# 加载训练集和测试集
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
trainset = torchvision.datasets.MNIST(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64,
shuffle=True, num_workers=2)
testset = torchvision.datasets.MNIST(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64,
shuffle=False, num_workers=2)
# 定义神经网络模型
class Net(torch.nn.Module):
def __init__(self, num_hiddens):
super(Net, self).__init__()
self.fc1 = torch.nn.Linear(28 * 28, num_hiddens)
self.fc2 = torch.nn.Linear(num_hiddens, 10)
def forward(self, x):
x = x.view(-1, 28 * 28)
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# 初始化超参数
lr = 0.1
num_epochs = 15
num_hiddens_list = [100, 200, 300, 400, 500]
# 训练模型,并测试不同的 num_hiddens 值
for num_hiddens in num_hiddens_list:
net = Net(num_hiddens)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
for epoch in range(num_epochs):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / len(trainloader)))
running_loss = 0.0
print('Finished Training')
# 测试模型
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
4.3多层感知机简洁算法实现知机
模块化设计使我们能够将与模型架构有关的内容独立出来
点击查看代码
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
4.4模型选择、欠拟合和过拟合
如果有足够多的神经元、层数和训练迭代周期, 模型最终可以在训练集上达到完美的精度,此时测试集的准确性却下降了。
影响模型泛化的因素:
- 可调整参数的数量。当可调整参数的数量(有时称为自由度)很大时,模型往往更容易过拟合。
- 参数采用的值。当权重的取值范围较大时,模型可能更容易过拟合。
- 训练样本的数量。即使模型很简单,也很容易过拟合只包含一两个样本的数据集。而过拟合一个有数百万个样本的数据集则需要一个极其灵活的模型。
4.5权重衰减
调整拟合多项式的阶数来限制模型的容量.
权重衰减(weight decay)是最广泛使用的正则化的技术之一, 它通常也被称为正则化。
\(L(\mathbf{w}, b) = \frac{1}{n}\sum_{i=1}^n \frac{1}{2}\left(\mathbf{w}^\top \mathbf{x}^{(i)} + b - y^{(i)}\right)^2.\)
对于\(\lambda = 0\),我们恢复了原来的损失函数。 对于\(\lambda > 0\),我们限制\(\| \mathbf{w} \|\)的大小。
\(L(\mathbf{w}, b) + \frac{\lambda}{2} \|\mathbf{w}\|^2,\)
正则化回归的小批量随机梯度下降更新如下式:
\(\begin{aligned}
\mathbf{w} & \leftarrow \left(1- \eta\lambda \right) \mathbf{w} - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \mathbf{x}^{(i)} \left(\mathbf{w}^\top \mathbf{x}^{(i)} + b - y^{(i)}\right).
\end{aligned}\)
- 正则化是处理过拟合的常用方法:在训练集的损失函数中加入惩罚项,以降低学习到的模型的复杂度。
- 保持模型简单的一个特别的选择是使用
- 惩罚的权重衰减。这会导致学习算法更新步骤中的权重衰减。
- 权重衰减功能在深度学习框架的优化器中提供。
- 在同一训练代码实现中,不同的参数集可以有不同的更新行为。
4.6消退法
期待“好”的预测模型能在未知的数据上有很好的表现: 经典泛化理论认为,为了缩小训练和测试性能之间的差距,应该以简单的模型为目标。
简单性的另一个角度是平滑性,即函数不应该对其输入的微小变化敏感。
暂退法在前向传播过程中,计算每一内部层的同时注入噪声:从表面上看是在训练过程中丢弃(drop out)一些神经元。 在整个训练过程的每一次迭代中,标准暂退法包括在计算下一层之前将当前层中的一些节点置零。
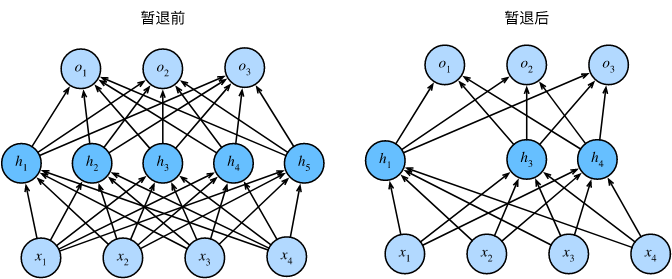
在测试时不用暂退法
点击查看代码
import torch
from torch import nn
from d2l import torch as d2l
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
# 在本情况中,所有元素都被丢弃
if dropout == 1:
return torch.zeros_like(X)
# 在本情况中,所有元素都被保留
if dropout == 0:
return X
mask = (torch.rand(X.shape) > dropout).float()
return mask * X / (1.0 - dropout)
- 暂退法在前向传播过程中,计算每一内部层的同时丢弃一些神经元。
- 暂退法可以避免过拟合,它通常与控制权重向量的维数和大小结合使用的。
- 暂退法将活性值
- 替换为具有期望值的随机变量。
- 暂退法仅在训练期间使用。
4.7前向传播、反向传播和计算图
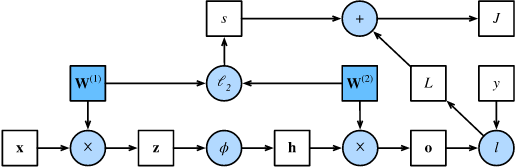
-
前向传播在神经网络定义的计算图中按顺序计算和存储中间变量,它的顺序是从输入层到输出层。 -
反向传播按相反的顺序(从输出层到输入层)计算和存储神经网络的中间变量和参数的梯度。 -
在训练深度学习模型时,前向传播和反向传播是相互依赖的。 -
训练比预测需要更多的内存。
4.8数值稳定性和模型初始化
初始化方案的选择在神经网络学习中起着举足轻重的作用, 它对保持数值稳定性至关重要。 此外,这些初始化方案的选择可以与非线性激活函数的选择有趣的结合在一起。 我们选择哪个函数以及如何初始化参数可以决定优化算法收敛的速度有多快。 糟糕选择可能会导致我们在训练时遇到梯度爆炸或梯度消失。
-
梯度爆炸(gradient exploding)问题: 参数更新过大,破坏了模型的稳定收敛;
-
是梯度消失(gradient vanishing)问题: 参数更新过小,在每次更新时几乎不会移动,导致模型无法学习。
1.梯度消失和梯度爆炸是深度网络中常见的问题。
2.需要用启发式的初始化方法来确保初始梯度既不太大也不太小。
3.ReLU激活函数缓解了梯度消失问题,这样可以加速收敛。
4.随机初始化是保证在进行优化前打破对称性的关键。
5.Xavier初始化表明,对于每一层,输出的方差不受输入数量的影响,任何梯度的方差不受输出数量的影响。
4.9环境和分布偏移
在许多情况下,训练集和测试集并不来自同一个分布。这就是所谓的分布偏移。
真实风险是从真实分布中抽取的所有数据的总体损失的预期。经验风险是训练数据的平均损失,用于近似真实风险。在实践中,我们进行经验风险最小化。
在相应的假设条件下,可以在测试时检测并纠正协变量偏移和标签偏移。在测试时,不考虑这种偏移可能会成为问题。
在某些情况下,环境可能会记住自动操作并以令人惊讶的方式做出响应。
