(十九) Pyppeteer模块的基本使用
引言
Selenium 在被使用的时候有个麻烦事,就是环境的相关配置,得安装好相关浏览器,比如 Chrome、Firefox 等等,然后还要到官方网站去下载对应的驱动,最重要的还需要安装对应的 Python Selenium 库,确实是不是很方便,另外如果要做大规模部署的话,环境配置的一些问题也是个头疼的事情。那么本节就介绍另一个类似的替代品,叫做 Pyppeteer。
Pyppeteer简介
注意,本节讲解的模块叫做 Pyppeteer,不是 Puppeteer。Puppeteer 是 Google 基于 Node.js 开发的一个工具,有了它我们可以通过 JavaScript 来控制 Chrome 浏览器的一些操作,当然也可以用作网络爬虫上,其 API 极其完善,功能非常强大。 而 Pyppeteer 又是什么呢?它实际上是 Puppeteer 的 Python 版本的实现,但他不是 Google 开发的,是一位来自于日本的工程师依据 Puppeteer 的一些功能开发出来的非官方版本。
在 Pyppetter 中,实际上它背后也是有一个类似 Chrome 浏览器的 Chromium 浏览器在执行一些动作进行网页渲染,首先说下 Chrome 浏览器和 Chromium 浏览器的渊源。
Chromium 是谷歌为了研发 Chrome 而启动的项目,是完全开源的。二者基于相同的源代码构建,Chrome 所有的新功能都会先在 Chromium 上实现,待验证
稳定后才会移植,因此 Chromium 的版本更新频率更高,也会包含很多新的功能,但作为一款独立的浏览器,Chromium 的用户群体要小众得多。两款浏览
器“同根同源”,它们有着同样的 Logo,但配色不同,Chrome 由蓝红绿黄四种颜色组成,而 Chromium 由不同深度的蓝色构成。
![]()

Pyppeteer 就是依赖于 Chromium 这个浏览器来运行的。那么有了 Pyppeteer 之后,我们就可以免去那些繁琐的环境配置等问题。如果第一次运行的时候,Chromium 浏览器没有安装,那么程序会帮我们自动安装和配置,就免去了繁琐的环境配置等工作。另外 Pyppeteer 是基于 Python 的新特性 async 实现的,所以它的一些执行也支持异步操作,效率相对于 Selenium 来说也提高了。
环境安装
由于 Pyppeteer 采用了 Python 的 async 机制,所以其运行要求的 Python 版本为 3.5 及以上
pip3 install pyppeteer
快速上手
例: 爬取http://quotes.toscrape.com/js/ 全部页面数据
import asyncio from pyppeteer import launch from lxml import etree async def main(): browser = await launch() # 新建一个browser对象 page = await browser.newPage() # 在浏览器中新建一个选项卡 await page.goto('http://quotes.toscrape.com/js/') # 在浏览器中输入URL,相当于selenium里面的get page_text = await page.content() # 使用.content()方法获取页面源码 tree = etree.HTML(page_text) div_list = tree.xpath('//div[@class="quote"]') print(len(div_list)) await browser.close() # 关闭浏览器 asyncio.get_event_loop().run_until_complete(main())
运行结果:10
解释:launch 方法会新建一个 Browser 对象,然后赋值给 browser,然后调用 newPage 方法相当于浏览器中新建了一个选项卡,同时新建了一个 Page 对象。然后 Page 对象调用了 goto 方法就相当于在浏览器中输入了这个 URL,浏览器跳转到了对应的页面进行加载,加载完成之后再调用 content 方法,返回当前浏览器页面的源代码。然后进一步地,我们用 pyquery 进行同样地解析,就可以得到 JavaScript 渲染的结果了。在这个过程中,我们没有配置 Chrome 浏览器,没有配置浏览器驱动,免去了一些繁琐的步骤,同样达到了 Selenium 的效果,还实现了异步抓取,爽歪歪!
详细用法
开启浏览器,调用 launch 方法即可,相关参数介绍:
ignoreHTTPSErrors (bool): 是否要忽略 HTTPS 的错误,默认是 False。
headless (bool): 是否启用 Headless 模式,即无界面模式,如果 devtools 这个参数是 True 的话,那么该参数就会被设置为 False,否则为 True,即默认是开启无界面模式的。
executablePath (str): 可执行文件的路径,如果指定之后就不需要使用默认的 Chromium 了,可以指定为已有的 Chrome 或 Chromium。
args (List[str]): 在执行过程中可以传入的额外参数。
devtools (bool): 是否为每一个页面自动开启调试工具,默认是 False。如果这个参数设置为 True,那么 headless 参数就会无效,会被强制设置为 False。
关闭提示条:”Chrome 正受到自动测试软件的控制”,这个提示条有点烦,那咋关闭呢?这时候就需要用到 args 参数了,禁用操作如下:
browser = await launch(headless=False, args=['--disable-infobars'])
处理页面显示问题:访问淘宝首页
import asyncio from pyppeteer import launch async def main(): browser = await launch(headless=False) page = await browser.newPage() await page.goto('https://www.taobao.com') await asyncio.sleep(10) asyncio.get_event_loop().run_until_complete(main())
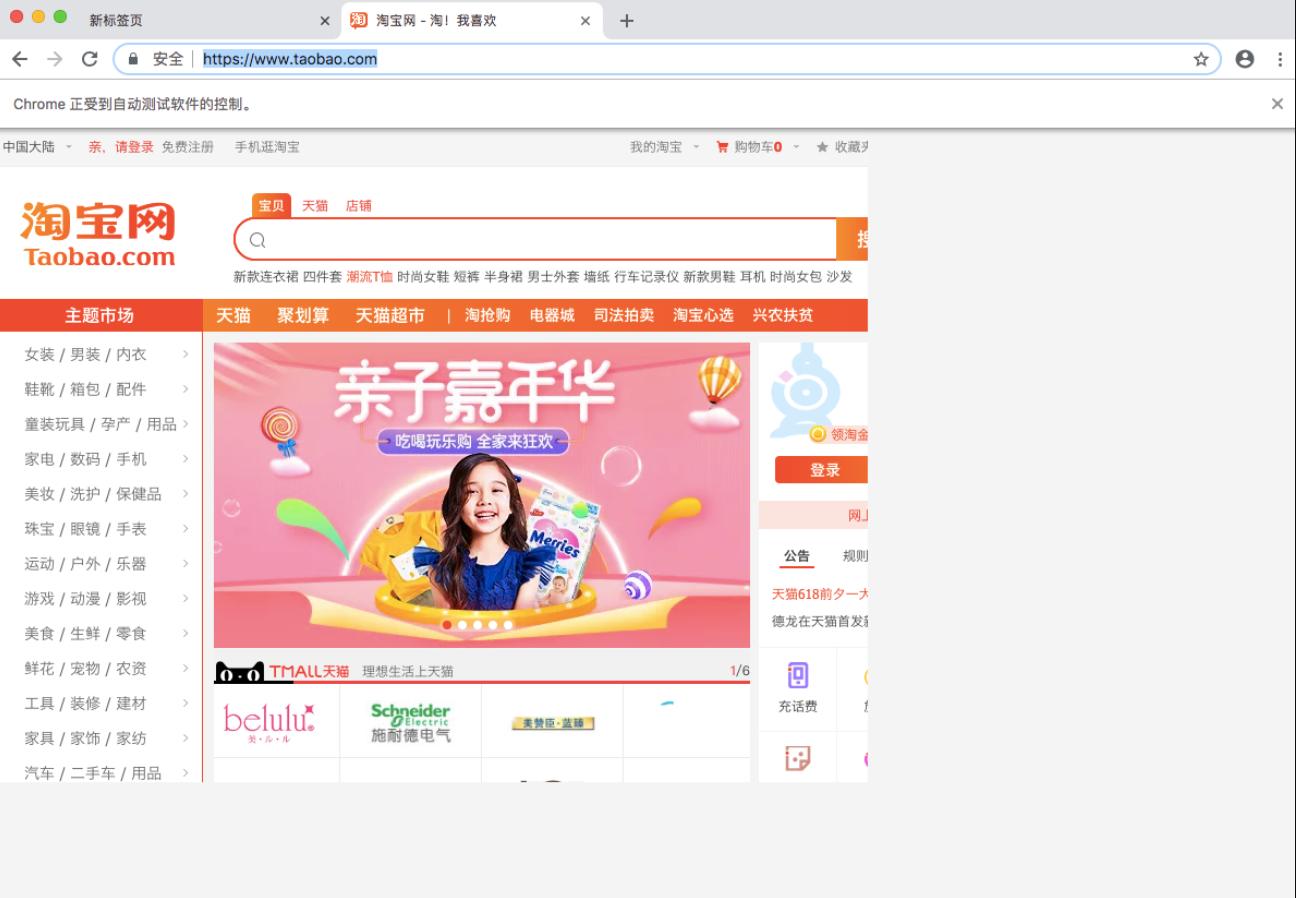
发现页面显示出现了问题,需要手动调用setViewport方法设置显示页面的长宽像素。设置如下:
import asyncio from pyppeteer import launch width, height = 1366, 768 async def main(): browser = await launch(headless=False) page = await browser.newPage() await page.setViewport({'width': width, 'height': height}) await page.goto('https://www.taobao.com') await asyncio.sleep(3) asyncio.get_event_loop().run_until_complete(main())
执行js程序:拖动滚轮。调用evaluate方法。
import asyncio from pyppeteer import launch width, height = 1366, 768 async def main(): browser = await launch(headless=False) page = await browser.newPage() await page.setViewport({'width': width, 'height': height}) await page.goto('https://movie.douban.com/typerank?type_name=%E5%8A%A8%E4%BD%9C&type=5&interval_id=100:90&action=') await asyncio.sleep(3)
# evaluate可以返回js程序的返回值 dimensions = await page.evaluate('window.scrollTo(0,document.body.scrollHeight)') await asyncio.sleep(3) print(dimensions) await browser.close() asyncio.get_event_loop().run_until_complete(main())
规避webdriver检测
import asyncio from pyppeteer import launch async def main(): browser = await launch(headless=False, args=['--disable-infobars']) page = await browser.newPage() await page.goto('https://login.taobao.com/member/login.jhtml?redirectURL=https://www.taobao.com/') await page.evaluate( '''() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }''') await asyncio.sleep(10) asyncio.get_event_loop().run_until_complete(main())
UA伪装
await self.page.setUserAgent('xxx')
节点交互
import asyncio from pyppeteer import launch async def main(): # headless参数设为False,则变成有头模式 browser = await launch(headless=False) page = await browser.newPage() # 设置页面视图大小 await page.setViewport(viewport={'width': 1280, 'height': 800}) await page.goto('https://www.baidu.com/') # 节点交互 await page.type('#kw','周杰伦',{'delay': 1000}) await asyncio.sleep(3) await page.click('#su') await asyncio.sleep(3) # 使用选择器选中标签进行点击 alist = await page.querySelectorAll('.s_tab_inner > a') a = alist[3] await a.click() await asyncio.sleep(3) await browser.close() asyncio.get_event_loop().run_until_complete(main())
综合练习
爬取头条和网易的新闻标题
import asyncio from pyppeteer import launch from lxml import etree async def main(): # headless参数设为False,则变成有头模式 browser = await launch(headless=False) page1 = await browser.newPage() # 设置页面视图大小 await page1.setViewport(viewport={'width': 1280, 'height': 800}) await page1.goto('https://www.toutiao.com/') await page1.evaluate('window.scrollTo(0,document.body.scrollHeight)') await asyncio.sleep(2) # 打印页面文本 page_text = await page1.content() page2 = await browser.newPage() await page2.setViewport(viewport={'width': 1280, 'height': 800}) await page2.goto('https://news.163.com/domestic/') await page2.evaluate('window.scrollTo(0,document.body.scrollHeight)') page_text1 = await page2.content() await browser.close() return {'wangyi':page_text1,'toutiao':page_text} def parse(task): content_dic = task.result() wangyi = content_dic['wangyi'] toutiao = content_dic['toutiao'] tree = etree.HTML(toutiao) a_list = tree.xpath('//div[@class="title-box"]/a') print("头条新闻爬取数量: ", len(a_list)) for a in a_list: title = a.xpath('./text()')[0] print('toutiao:',title) tree = etree.HTML(wangyi) div_list = tree.xpath('//div[@class="data_row news_article clearfix "]') print("网易新闻爬取数量: ", len(div_list)) for div in div_list: title = div.xpath('.//div[@class="news_title"]/h3/a/text()')[0] print('wangyi:',title) tasks = [] task1 = asyncio.ensure_future(main()) task1.add_done_callback(parse) tasks.append(task1) asyncio.get_event_loop().run_until_complete(asyncio.wait(tasks))
爬取结果:


头条新闻爬取数量: 28 toutiao: 港媒:黄之锋被裁定参选区议会提名无效 toutiao: 焯水用沸水or冷水?这些常识,很多人都错 toutiao: 滕昀轩出征第59届国际小姐全球总决赛 toutiao: 加州野火快速蔓延致20万人紧急疏散 全州进入紧急状态 toutiao: 黑道混混为追女生,7年画300本绘本,变身畅销作家 toutiao: 荷枪实弹!1500人清晨5点搬迁,竟出动2300多名公安武警 toutiao: 结婚前 女子突然发现未婚夫还有几场婚礼要办 toutiao: 乌克兰夫妇用LV限量皮箱装玉米“不知道它那么贵” toutiao: 苹果凌晨发布新耳机!灵感来自豌豆射手?网友评论笑疯 toutiao: 中美将提前签署部分贸易协议?外交部:工作层将持续抓紧磋商 toutiao: 报告称支付宝成国内第二大APP toutiao: 航母上生活用的淡水是哪来的 toutiao: 3名高级别干部被断崖式降级,有人被从中央委员降到调研员…… toutiao: 墨西哥警方发现毒贩窝点祭坛藏有大量人骨 toutiao: 小车内饰10年没有洗,5名洗车工奋战8小时,顾客:挺不好意思 toutiao: 央行重申违法!网红人民币蛋糕大众点评、饿了么仍有售 toutiao: 夫妇装修房子前买26桶油送邻居 留下致歉纸条:打扰了 toutiao: 韩国大白菜价格暴涨至34元1颗 网友:吃不起泡菜了 toutiao: 下班在家用电脑能做什么兼职补贴家用? toutiao: 韩国白菜价暴涨34元一颗!韩媒:简直是吃金菜 toutiao: 格力“招亲”人选敲定!15%股权转让,董小姐的绣球为何抛向TA? toutiao: 猪价上涨将终结?中科院院士饶子和发现非洲猪瘟病毒结构 toutiao: 广西一矿业公司发生冒顶事故已致2人遇难 toutiao: 本人一米六左右,想买个摩托车旅游,两万左右的有没有推荐下? toutiao: 欧盟同意英国“脱欧”再延期 toutiao: 女护士在明星睡过的床上打滚取乐?别穿着职业制服去追星 toutiao: 多多自走棋野兽战阵容搭配推荐 野兽战阵容如何搭配 toutiao: 如何利用短信营销提升转化率? 网易新闻爬取数量: 69 wangyi: 退休14年后 山西一厅级干部被开除党籍并入狱三年 wangyi: 美监管机构将禁止华为参与政府补贴项目 中方回应 wangyi: 何君尧被英大学剥夺名誉博士学位:英真实面目暴露 wangyi: 林郑月娥:从未与暴力示威者对话 坚定支持警方止暴 wangyi: 台媒:大陆游客每月少10万人次 业者损失51亿新台币 wangyi: 港警对特首说:我们不怕流汗流血 但别让我们流泪 wangyi: 湖南500余名处级干部家属被召集 现场通报典型案例 wangyi: 11个月战胜癌症重返蓝天 女飞行员升任军级 wangyi: 教育部:落实学校负责人陪餐制 严查不履行责任学校 wangyi: 广州海关通报侵权案情况 销毁14.17万件侵权货物 wangyi: 猪肉上涨对学校食堂影响如何?市场监管总局回应 wangyi: 前港督:香港是中国的 我们不能告诉特区政府该做啥 wangyi: 陕西榆林人大常委会原副主任被双开:三观严重扭曲 wangyi: 林郑月娥:香港或进入技术经济衰退 全年或负增长 wangyi: 选举主任:黄之锋不符合候选人资格 选举提名无效 wangyi: 蔡当局选前大手笔 或将"债留子孙3500亿元新台币" wangyi: 人民日报:挺身制暴是香港社会共同的责任 wangyi: 人民日报:区块链技术创新不等于炒作虚拟货币 wangyi: 部分城市放松购房限制 经济日报:炒房没有捷径 wangyi: 稳外资政策增强外企信心“坚定看好中国投资前景” wangyi: 人民日报解读就业数据:下行压力加大影响就业吗? wangyi: 媒体:不止对中国"乱"提问 这些年CNN欠世界一堆账 wangyi: 新加坡第一夫人:香港人应找准在中国定位 wangyi: 前三季三大运营商营收均下滑 日均约赚4.03亿元 wangyi: 村支书受贿获刑:老板自愿送钱是看得起我 多有面子 wangyi: 董明珠来了"新老板":张磊狂砸400亿买下格力大股东 wangyi: 来了!四中全会这个“看点”你必须知道 wangyi: 山东辱母案新进展:讨债伤者起诉于欢索赔近20万 wangyi: 人民日报:外媒借"货车藏尸案"抹黑中国 用心险恶 wangyi: 教育部:"康复大学"依规不能冠以"中国"字样 wangyi: 人民日报谈网红带货:产品真的值得买吗? wangyi: "电筒主任"再回应质疑: 在干旱田里种菜当地很常见 wangyi: 央视再怼西方媒体:近期的热闻照出了一些人真面目 wangyi: 四中全会看点:处分刘士余 谁来递补中央委员空缺? wangyi: 持星条旗追打内地记者付国豪的香港暴徒 有新消息 wangyi: 四川一局长主动投案:100万退回了 我可以走了吗? wangyi: 香港大学校委会主席批举美国旗学生:非常可悲 可耻 wangyi: 村主任回应"深夜挑灯干农活":为了还原事实摆拍 wangyi: 为重案犯调监狱的湖北省监狱管理局原副局长判9年 wangyi: 紧邻香港的他们,立了怎样的集体一等功? wangyi: 女子为男友信用卡透支47万 对方却不承认这段关系 wangyi: 央视:未成年人立法 要不要降低刑事责任年龄? wangyi: 新任江苏省委常委郭元强已就任省委秘书长 wangyi: 香港警方:一周内206人被捕最小12岁 7名警员受伤 wangyi: 越南人移民英国大都从事美甲理发行业 年赚30万 wangyi: 杭州至德清城铁发招标公告 系2022年亚运会交通项目 wangyi: 香港反对派议员动议废除《禁蒙面法》 立法会否决 wangyi: 美海岸警卫队闯入黄海 中国万吨海警船近距离监视 wangyi: 西藏航空一航班备降贵阳 疑似风挡玻璃出现裂纹 wangyi: 英国39名遇难者是不是持假中国护照?外交部回应 wangyi: 中纪委连续点名3次的司长被查后 7人主动交代问题 wangyi: 安徽供销社原理事会主任钱斌被捕 受贿数额特别巨大 wangyi: 这名司长被中纪委点名3次 查处后7人主动交代问题 wangyi: 河北应急厅:兴华钢铁“10.24”致7死火灾涉嫌迟报 wangyi: 教育部确认:“康复大学”不冠以“中国”字样 wangyi: 陕西延长车载试验装置爆炸致8人死亡 5名伤者送医 wangyi: 韩国瑜公开表态:"台独"可能吗?战争没有赢家 wangyi: 中共第十九届中央委员会第四次全体会议在京召开 wangyi: 美国海岸警卫队闯入黄海 中国万吨海警船近距监视 wangyi: 中国书法家协会原副主席赵长青接受审查和调查 wangyi: 拒向黑暴低头 香港市民唱勇敢的中国人力挺建制派 wangyi: 人民日报:中共十九届四中全会值得期待 wangyi: 十九届四中全会的三大看点:不寻常的议题 wangyi: 四中全会连开4天 回顾历届四中全会看点 wangyi: 四中全会召开在即 一图带你了解中央全会 wangyi: 职工嫖娼受留用察看处分后正常上班 纪委严肃纠正 wangyi: 中央机关公开遴选选调318名公务员 今起开始报名 wangyi: "65后"副省长郭元强履新 曾经历三次干部公开选拔 wangyi: 他主动退百万贿赂以为能继续当局长 结果被"拿下"
作者:TigerLee
出处:http://www.cnblogs.com/tiger666/
本文版权归作者和博客园所有,欢迎转载。转载请在留言板处留言给我,且在文章标明原文链接,谢谢!
如果您觉得本篇博文对您有所收获,觉得我还算用心,请点击右下角的 [推荐],谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号