
多模态大模型工作梳理(施工中....)
本文是对于近年来一些多模态大模型工作的相关总结,重点是这些模型的演化路线,各自做了什么改进。
CLIP
论文链接:https://arxiv.org/abs/2103.00020
以往的图像模型都是采用有监督的预训练,需要在人工标注的数据集上进行学习,这限制了图像模型预训练的数据规模。
CLIP采用了自然语言信号来监督图像模型的学习。人工标注的数据集很贵,但是图片-文本pair对在网上随处都是。因此,作者从网上爬取了一个新的数据集,其中包含4亿对 (图像,文本) 对,用于对比学习。
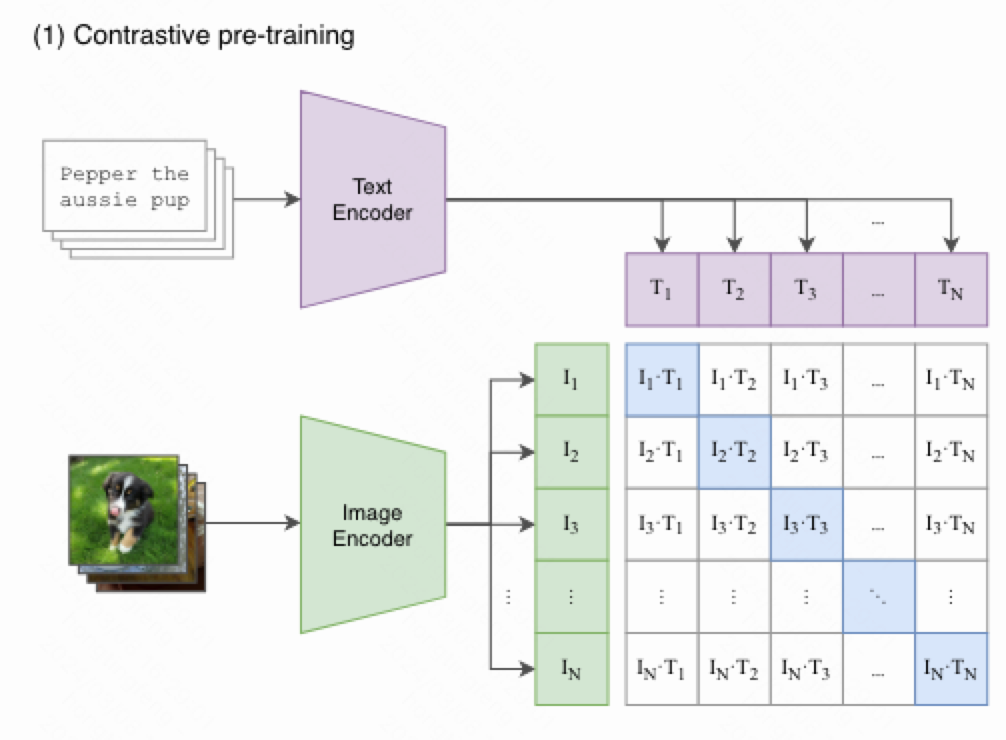
CLIP采用了一个图像编码器和一个文本编码器,两者都生成一个向量,通过拉近相同pair对的距离,拉远不同pair对的距离,来进行对比学习。所用的损失为InfoNCE Loss,也是Moco中采用的损失。
Í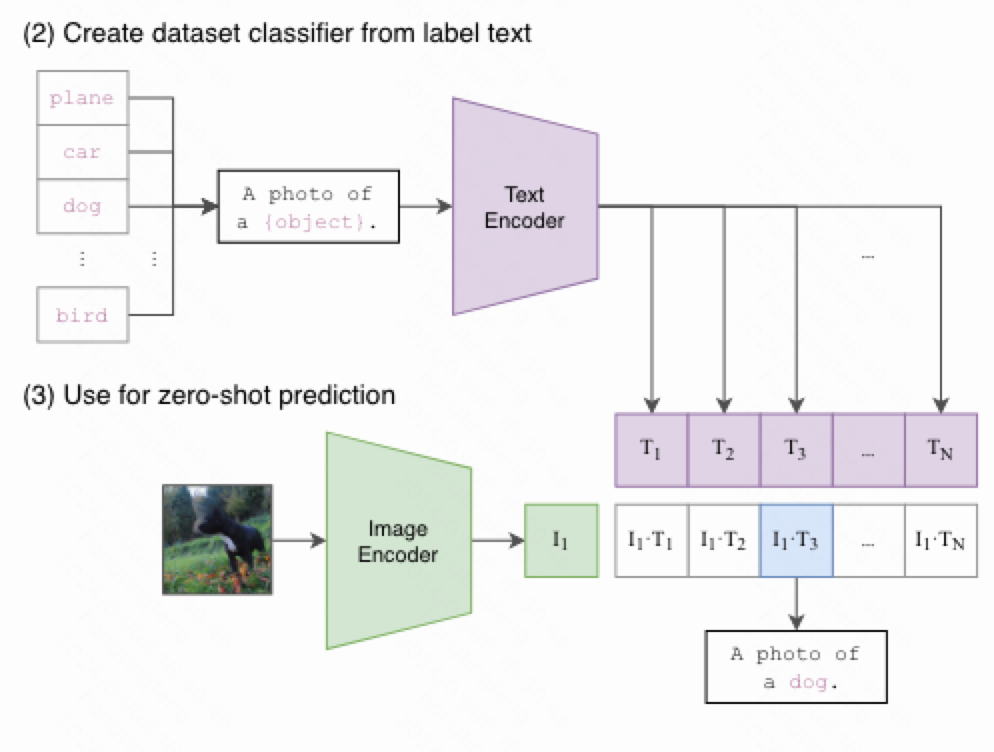
CLIP的预测不依赖于softmax,因此预测训练中没有出现过的标签。通过将类别标签拓展为多个文本,通过文本编码器后和图像向量进行比较,相似度最高者即为预测结果。
由于采用了以往难以企及的大规模预训练,CLIP有着强大的Zero-shot能力。
SLIP
论文地址:https://arxiv.org/abs/2112.12750
SLIP在CLIP的基础上,引入了更多的模态内部的自监督信号。
SLIP中,一张图片经过三种数据增强形成三张图片:
- 图片1和文本做对比学习。
- 图片2和图片3做对比学习。
- 图片1和文本用了clip embedding层,图片2和图片3用了同一个用于图片的embedding层。
DeCLIP
论文地址:https://arxiv.org/abs/2110.05208
继续引入监督信息,以降低对数据规模的依赖。使用了以下三种监督信号:
- 图像-文本对比监督:即clip的监督方法。
- 自监督:
- 图像:使用simsiam的方法,一张图片增强得到两个图片view,用共享参数的encoder提取特征,计算并将提升余弦相似度,然后一边的encoder回传梯度,另一边停止梯度。
- 文本:使用Bert的MLM预训练。
- 最邻近监督学习(Nearest-Neighbor Supervision, NNS):维持一个文本特征队列,对于每一个图像的两个view,选取这个队列中与其最相近的文本特征作为正样本,队列中的其他特征作为负样本,做infonce。这样做是因为非一对的文本和图片并不一定是不匹配的,这样可以挖掘潜在的正样本。
ViLT
论文地址:
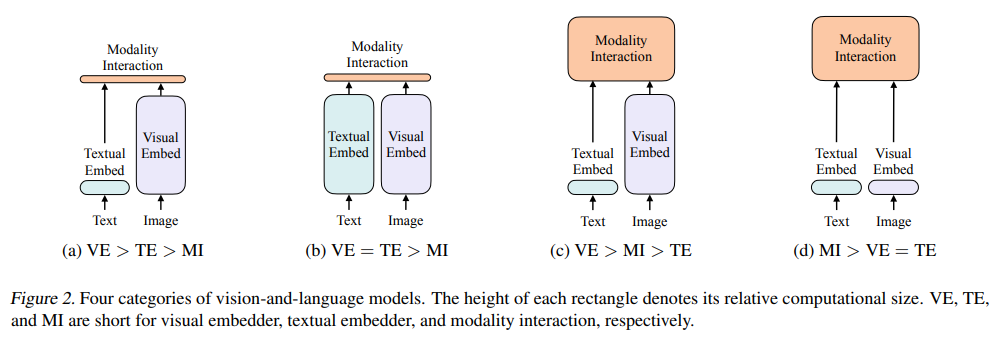
ViLP属于模型d,视觉和文本编码器都很轻量,这也是首个视觉编码器和文本编码器一样轻量的方法。且ViLT不采用目标检测器的同时,没有损失太多精度。
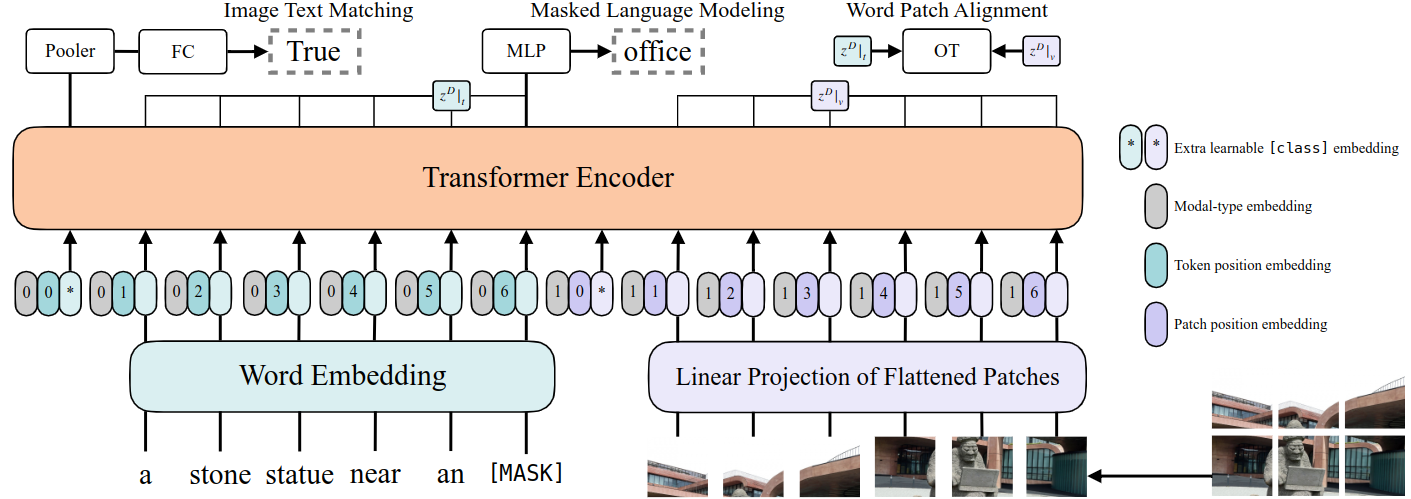
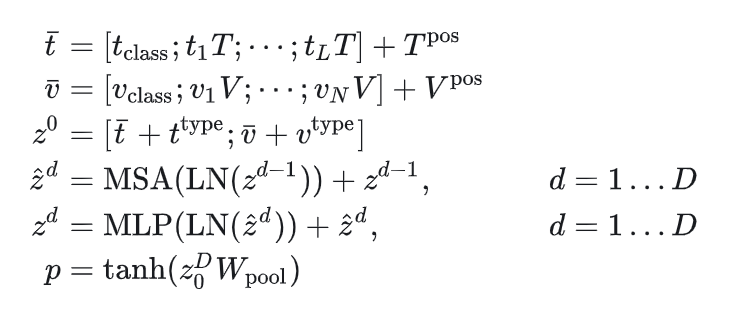
模型流程:
- 文本:使用word embedding对文本进行转换后与model type embedding进行拼接,并加上文本位置编码。
- 图像:分块后经过一个线性层进行embedding,与model type embedding进行拼接,并加上图像位置编码。
- 文本和图像在向量维度上进行拼接,输入Transformer Encoder中。Transformer Encoder用ViT的预训练权重做初始化(可能是因为没有专门的图像提取器,而图像用transformer提是需要大量预训练的)。
模型预训练:
- Image Text Matching:Transformer的输出经过池化和线性层,来判断文本、图片是否为一对。
- MLM:Bert的预训练,采用了Whole Word Masking,避免只通过单词上下文进行预测。
ALBEF
论文地址:https://arxiv.org/abs/2107.07651
ALBEF的全名为ALign the image and text representations BEfore Fusing them,顾名思义,在多模态的特征融合之前先进行对齐。
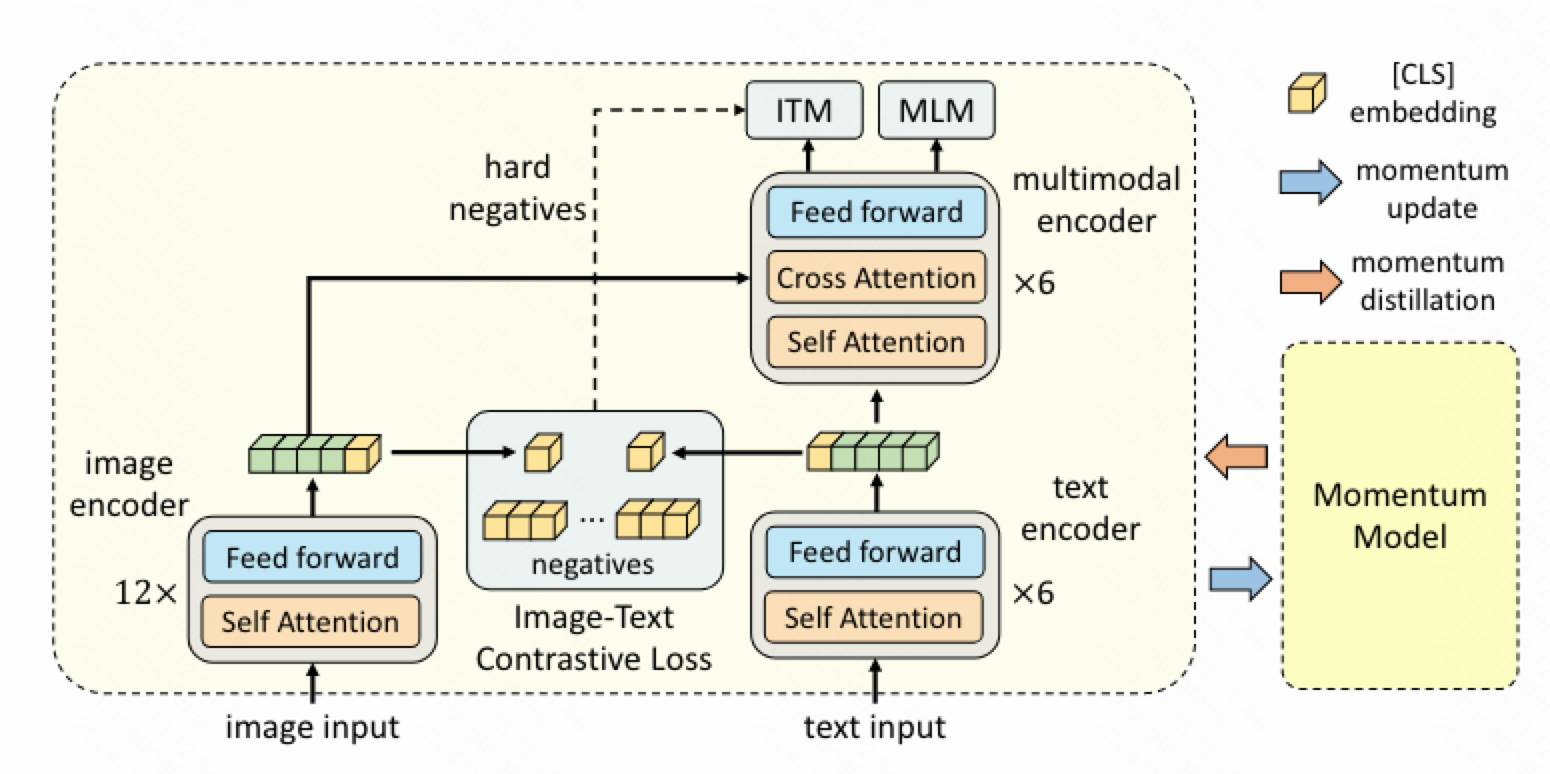
模型由三部分构成:
- 图像编码器:采用12层的ViT-base;
- 文本编码器: 采用Bert的前6层;
- 多模态编码器: 采用Bert的后6层,使用啦cross attention。
共有三个损失函数:
- image-text contrastive learning(ITC):图文对比损失,采用了Moco的feature queue,且图像和文本各维护一个feature queue,单模态的向量各自和另一个模态的队列做infonce;相当于有两个image encoder和两个text encoder,其中一个采用动量更新参数,并构建图像特征和文本特征,并存入队列中,从而增大对比损失时的负样本数量。
- Masked Language Modeling(MLM): Bert的预训练。
- Image-Text Matching(ITM): 图像和文本的匹配损失函数。采用多模态编码器的[cls],后跟线性层和softmax,进行二分类判断图文是否一致。由于这个任务过于简单,所以采用了hard negatives:对于一个 mini-batch 中的每张图片,按照对比相似度分布(ITC那一步得到的)从同一 mini-batch 中抽取一个不与该图片成对的文本,作为 hard negative(与图片更相似的文本被抽取的机会更高)。同样地,也为每个文本抽取一个 hard negative。
采用动量模型进行蒸馏学习
在高噪声的训练数据集上,很有可能一段不与图像匹配的文本也很好地描述了图像内容,可能比 ground truth 描述地还要好。为了提升在噪声数据上的训练效率,ALBEF 采用了 Momentum Distillation(动量蒸馏)的方法生成 pseudo label(是一个 softmax score)。
ITC:

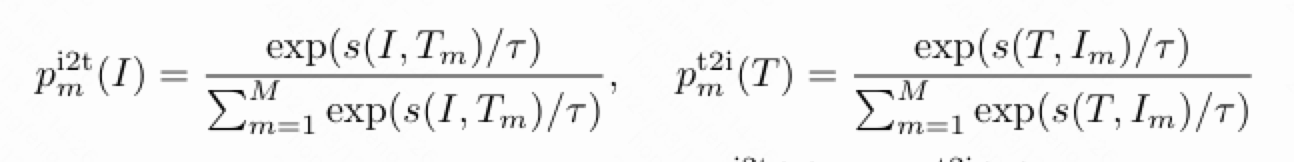
即附加一个对动量模型中ITC得到的softmax score的KL散度。
MLM:
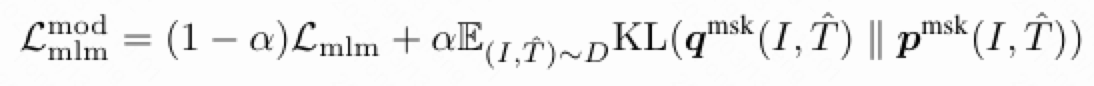
即在MLM部分,附加一个对动量模型的MLM中预测得到的softmax score的KL散度。
VLMo
VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
论文地址:https://arxiv.org/abs/2111.02358
双塔结构:如CLIP,模态交互较为简单,适用于多模态检索任务。
单塔结构:如ViLP和ALBEF,会融合模态信息,适用于多模态分类。
VLMo是一种统一的多模态模型,将多个模态的编码器统一到了一起,即mixture of modality experts。VLMo的transformer中,多头自注意力的参数都是相同的,即模态间共享;每个模态都有一个属于自己的FFN。VLMo中使用了三种:图像、文本和图像文本混合。
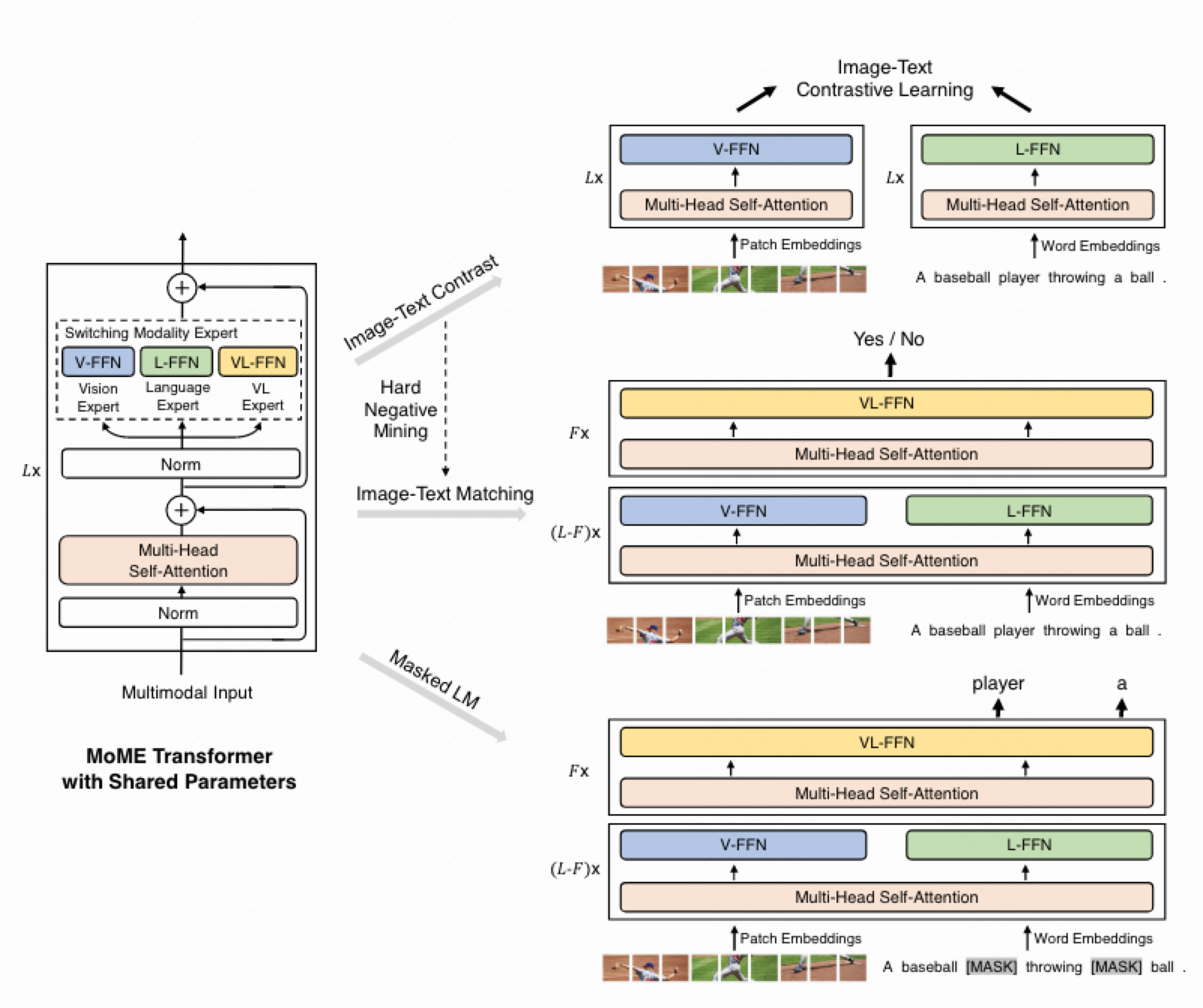
如上图所示,VLMo可以适配双塔和单塔的任务:
- ITC:图像给V-FFN,文本给L-FFN,最后两者做对比学习。
- ITM:前几个Block图像和文本分开做,后几个Block把两者拼接起来并给VL-FFN。
- MLM:同ITM。
图像和文本的表征:

图像:附加一个[cls],patch后展平经过线性层,加上位置编码和图像标记。
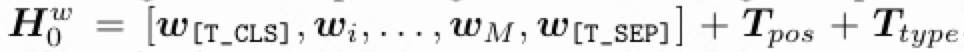
文本:附加一个[cls]和[sep],单词转为词根,经过线性层,加上位置编码和文本标记。
联合:沿着向量方向拼接文本和图像表征。
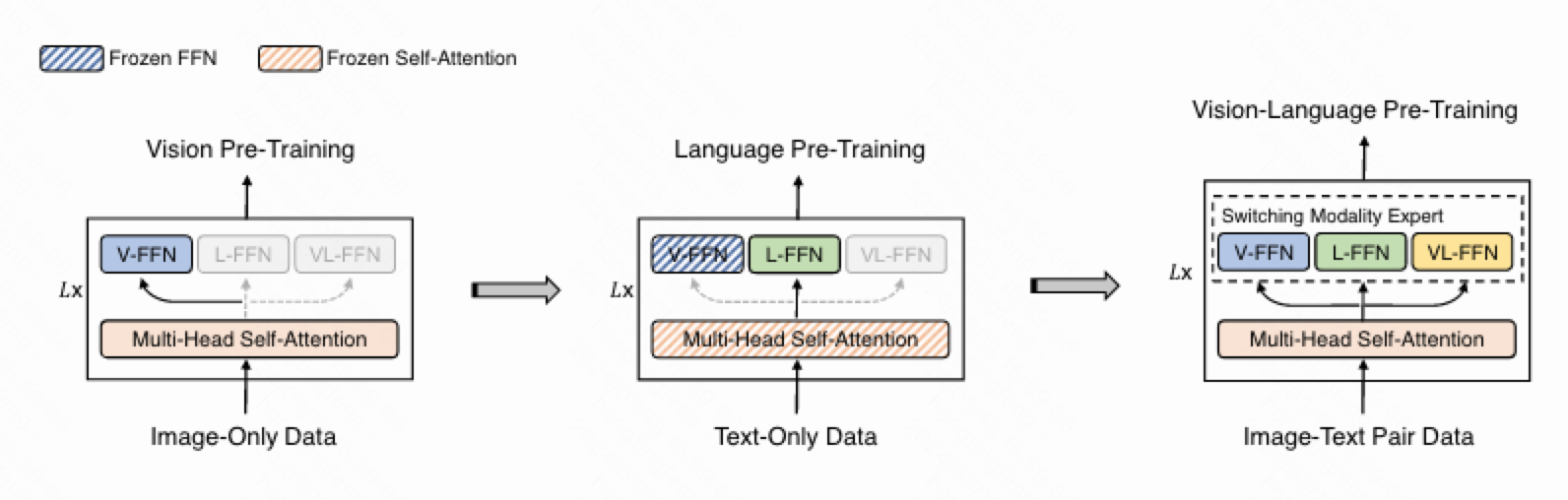
VLMo的预训练也采用了以上三个任务,但是ITC没使用moco,只使用mini-batch内的负样本。同时采用了分阶段预训练,首先利用 BEIT中的大规模纯图self-attention自我注意模块的参数,并在大量纯文本数据上通过掩码语言建模训练语言专家(L-FFN)。最后,对整个模型进行视觉语言预训练,即ITC、ITM和MLM。
BLIP
论文地址:https://arxiv.org/pdf/2201.12086.pdf
BLIP主要的贡献为:
- 采用了统一的、混合了encoder-decoder架构完成理解任务和生成任务。
- 提出了Captioner-Filter对训练集进行过滤。
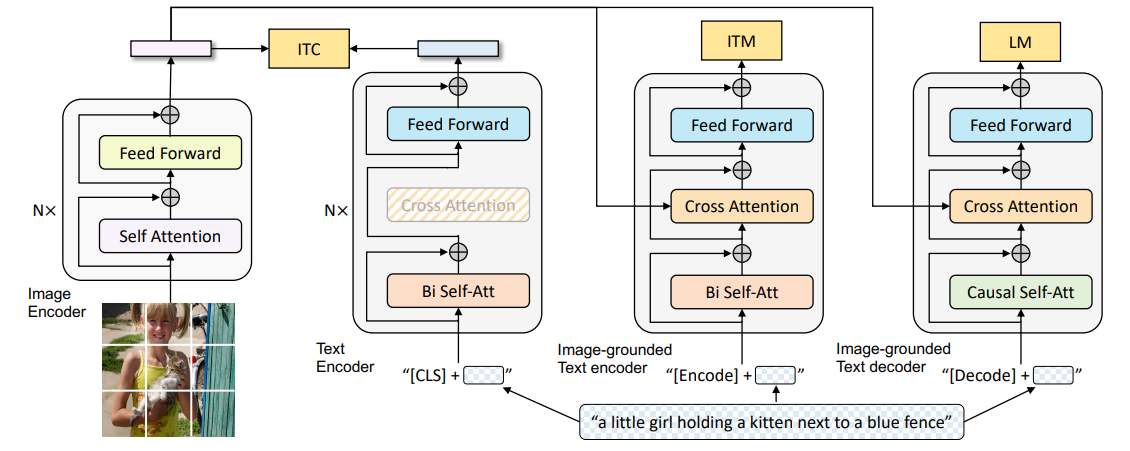
BLIP由三部分构成: - 图像编码器,ViT。
- Image-grounded text encoder:Bert的Bi Self-Att后加了一个Cross Att用于多模态交互。在ITC中提取文本特征时,不使用Cross Att,该种情况下,仅做文本编码器。在ITM任务中,使用Cross Att用于多模态融合。
3.Image-grounded text decoder: 将编码器的Bi Self-Att换成Causal Self-Att,其他部分不变。
BLIP的训练任务整体与ALBEF相似,都采用了moco、infonce和动量蒸馏,采用了ITC和ITM损失,但是将MLM换成了LM(Language Modeling)。
- ITC: 与ALBEF相同。
- ITM: 使用多模态编码器来进行模态交互,其他与ALBEF相同。
- LM:给定文本前缀和图片,预测下一个词是什么。
在进入三项任务前,文本前都会加上不同的标识符以做区分(见框架图)。
CapFit
为了提升对数据噪声的鲁棒性,BLIP采用Captioner、Filter的机制。BLIP先在全量数据上进行预训练,获得一个初步的预训练模型,后再在COCO上进行微调,并得到它的动量模型。
Filter: 使用Image-grounded text encoder去过滤不匹配的图文对。
Captioner: 使用Image-grounded text decoder生成另一段标注,再用Filter去决定要不要留下这图文对。
最后用清洗过的数据集进行预训练。
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
论文地址:https://arxiv.org/abs/2301.12597
BLIP2使用了Q-Former(一个小型的Transformer,约180M)来对齐视觉特征和文本特征,使得可以直接使用那些预训练好的单模态模型(原先这两个模型是没对齐的),从而极大地减少了训练成本。
预训练阶段1:表征学习
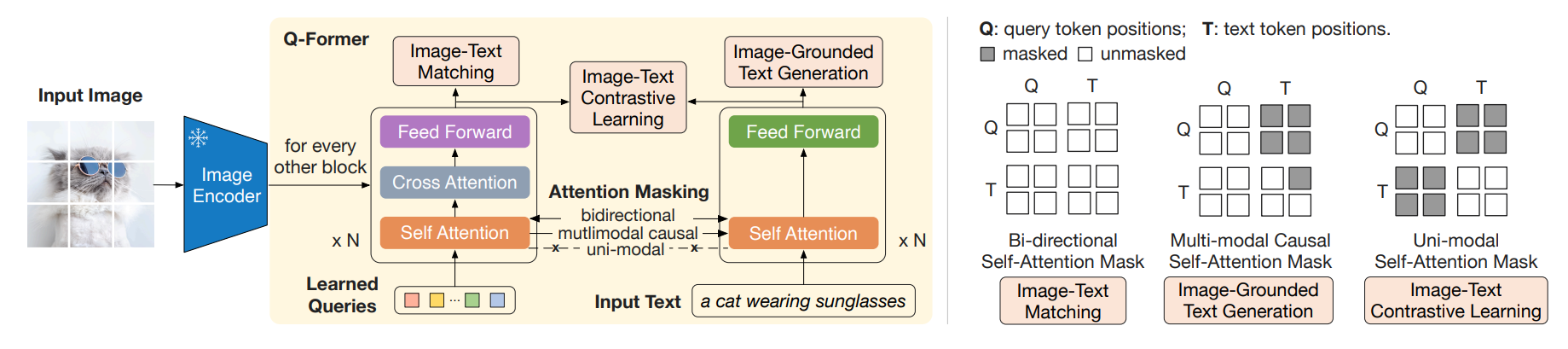
- 图像编码器,是冻结参数的。
- Q-Former:由两个Transformer组成,一个用于处理Query(一组可学习的token),另一组处理文本token。左边的Transformer的每一个偶数层都插入了一个随机初始化的CA,每一个SA都以image encoder的输出为图像侧的输入。左右两个Transformer都用Bert-Base作为初始化(除CA),且Self-Attention部分共享参数(这使得query token和text token也是互相可见的)。
文中说的是,Q-Former能够提取Image token中那些最和text相关的部分,且不管image token有多少个,都能得到最相关的那N个。这N个其实就是query token,因为query token作为query,是image token作为key和value聚合而成的。
阶段一也有ITC,ITM和ITG(Image-Grounded Text Generation,其实和BLIP的LM一样)三个训练任务,为了使得信息不泄露,三个任务中,Attention的Mask不同(BLIP2表征学习的右图)。具体而言,ITM中,使用的双向注意力,query token和text token互相可见。ITC中,query token和text token互相不可见,但各自内部是可见的。在ITG中,text token的待预测部分被masked。
预训练阶段1:图像生成文本学习
阶段1的Q-Former已经学习到了根据文本提取图片特征,阶段2的任务是把图片特征喂给冻结的LLM,根据图片特征生成文本,以进一步对齐图片-文本特征。
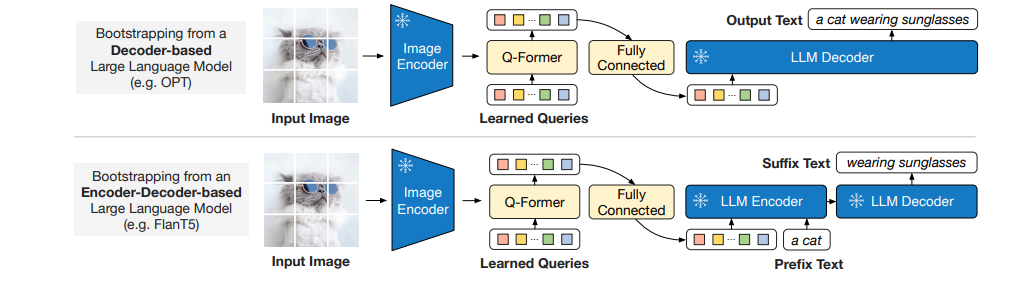
- 纯Decoder的LLM:将query token升维后喂给LLM,期望它生成文本。
- Encoder-Decoder的LLM:将query token和前缀text token升维后喂给LLM,期望它生成后缀。
BLIP2不用训练视觉模型,因此可以使用比较heavy的视觉模型。它在LLM上的训练不涉及LLM的更新,因此LLM不会出现灾难性遗忘的问题。
Coca
https://blog.csdn.net/lansebingxuan/article/details/131611916


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律