
SegViT: Semantic Segmentation with Plain Vision Transformers
SegViT: Semantic Segmentation with Plain Vision Transformers
* Authors: [[Bowen Zhang]], [[Zhi Tian]], [[Quan Tang]], [[Xiangxiang Chu]], [[Xiaolin Wei]], [[Chunhua Shen]], [[Yifan Liu]]
初读印象
comment:: 提出了 "注意力到掩码"(Attention-to-Mask,ATM)模块,将一组可学习类标记与空间特征图之间的相似性映射转移到分割掩码中。
Why
- FCN:将1×1 卷积层通常应用于具有代表性的特征图,以获得像素级预测。感受野有限,空间位置之间的相关性很难在 FCN 中明确建模。
- ViT:采用了朴素的非层次结构,全程保持了特征图的分辨率。注意力机制的潜力尚未得到充分挖掘。
- 新的分类方法:将每个像素的分类过程分离开来。通过使用固定数量的可学习标记来重建结构,并将其作为权重用于特征图的转换,动态生成分类概率。这种模式使分类过程在全局范围内进行,减轻了解码器按像素进行分类的负担,从而使分类更精确,性能更高。对于这些方法来说,特征图仍然是以静态方式计算的,通常需要特征合并模块,如 FPN。
本文:与以往的按像素分类范式不同,学习一个有意义的类标记,然后找到与之相似度更高的局部patch。首次利用注意力图中的空间信息为每个类别生成掩码预测,这可以作为语义分割的新范例。
What
Mask-to-Attention
给定类嵌入
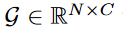 N为类别数。和encoder中第i层的输出
N为类别数。和encoder中第i层的输出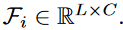
。
先使用线性映射得到QKV
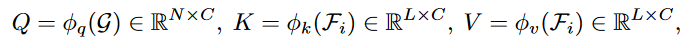 计算标记序列和输出序列的相似度:
计算标记序列和输出序列的相似度: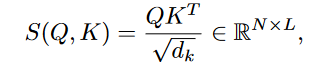
预测结果由相似度中的掩码得到。
 更新后的类嵌入为Attention的结果:
更新后的类嵌入为Attention的结果: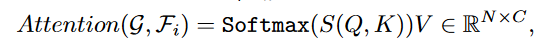
SegViT结构
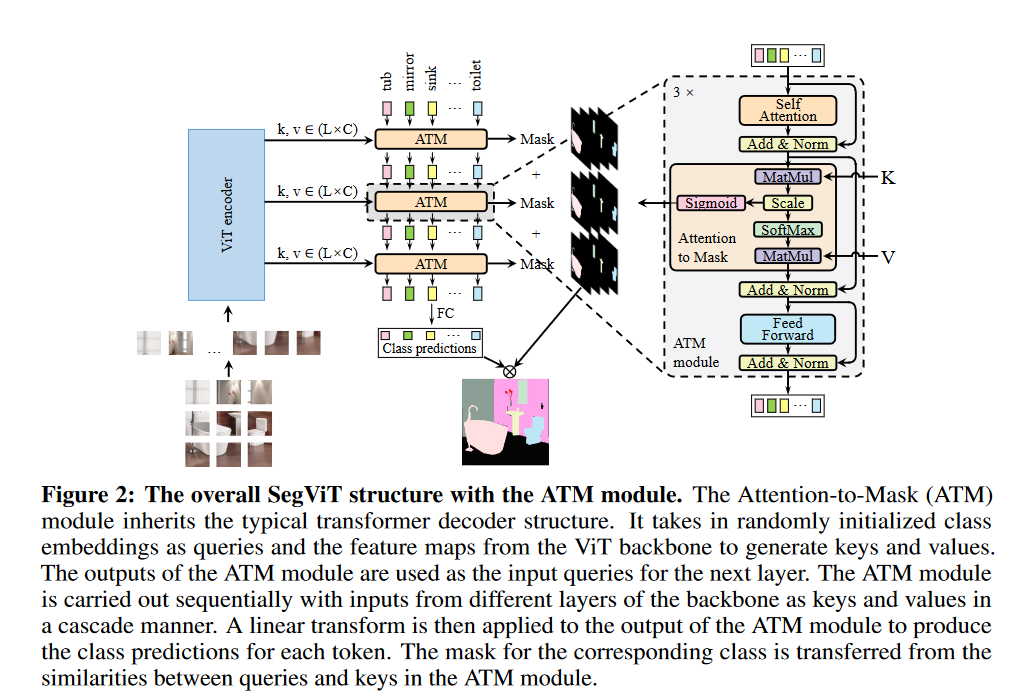 ATM在整个网络中使用了3次。第一个ATM的类嵌入是随机初始化的,后面ATM的类嵌入是前一个ATM输出的Attention的结果:
ATM在整个网络中使用了3次。第一个ATM的类嵌入是随机初始化的,后面ATM的类嵌入是前一个ATM输出的Attention的结果: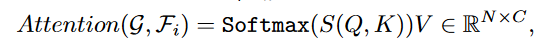
每一层的损失函数
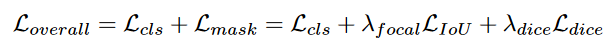
收缩结构
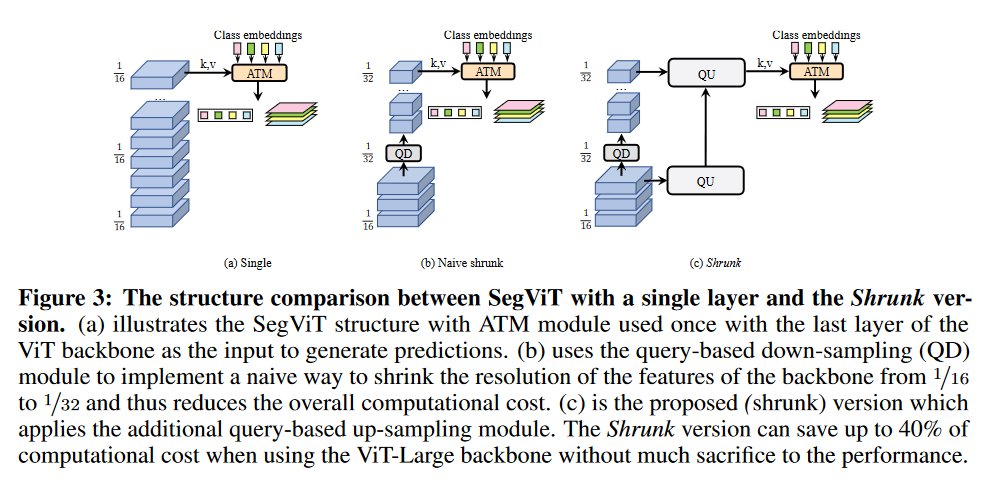
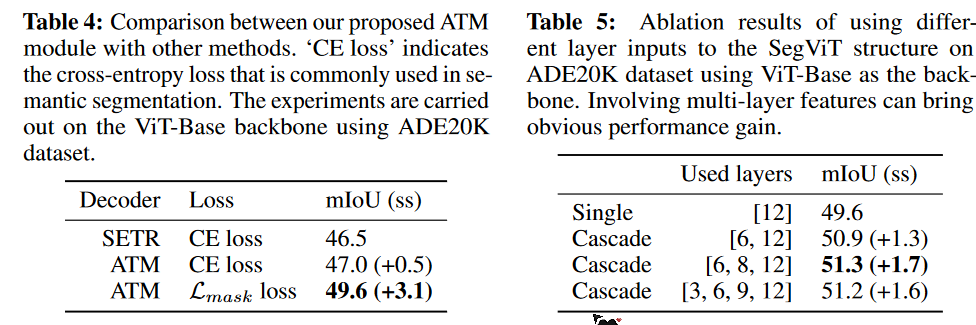
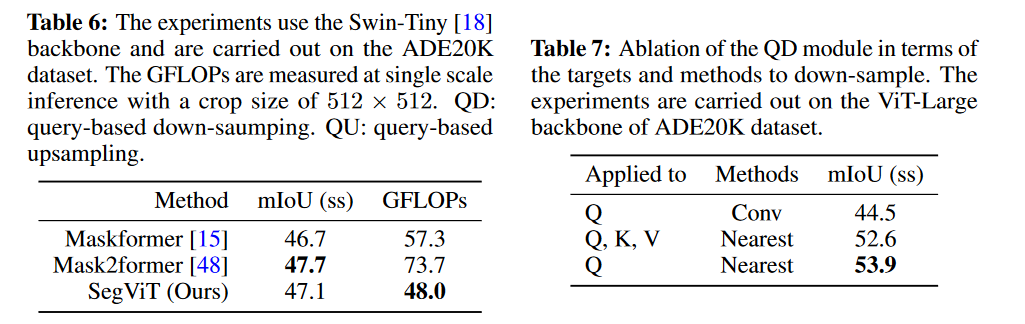
How


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话